
Palabras clave:Regulación de IA, Fusiones y adquisiciones transfronterizas, Cumplimiento tecnológico, Adquisición de Manus por Meta, Evaluación de modelos de IA, IA en el dispositivo
🔥 Enfoque
El Ministerio de Comercio interviene en la evaluación de la adquisición de Manus por parte de Meta : El Ministerio de Comercio de China anunció que llevará a cabo una investigación de evaluación sobre la adquisición de la startup de AI Agents, Manus, por parte de Meta. El escrutinio se centra en si la adquisición cumple con las leyes y regulaciones sobre control de exportaciones, importación y exportación de tecnología e inversión extranjera. Aunque el equipo principal de Manus se ha trasladado a Singapur, su tecnología se originó en Beijing. Si se trata de una transferencia de tecnología restringida o salida de datos, la transacción podría enfrentar retrasos, multas o incluso el riesgo de ser cancelada. Este evento marca que las fusiones y adquisiciones transfronterizas en el campo de la AI han entrado en una zona de regulación estricta; los desarrolladores deben estar alerta a las líneas rojas de cumplimiento en la “salida de tecnología al extranjero” (Fuente: 36氪)
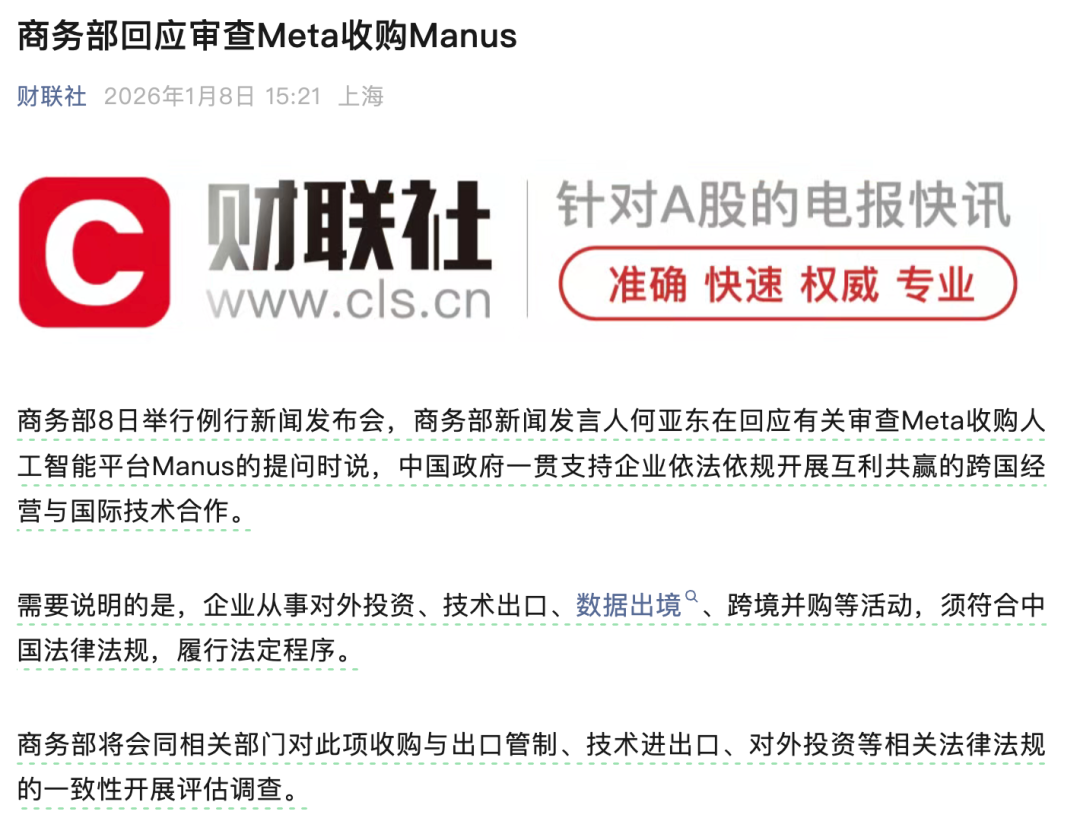
El informe de Epoch AI revela que la brecha generacional de AI entre China y EE. UU. se mantiene estable en 7 meses : Un informe reciente indica que el progreso de los modelos de AI en China está, en promedio, unos 7 meses por detrás del nivel de vanguardia en EE. UU. Aunque China ha logrado avances mediante la expansión de la escala de parámetros y la arquitectura MoE, el ritmo de actualización de los modelos cerrados estadounidenses (como GPT-5 y Gemini 3) es extremadamente rápido, y sus saltos de capacidad no dependen completamente de la escala, sino que se desplazan hacia el diseño de rutas de razonamiento. El informe sostiene que el núcleo de la evolución de la AI en 2026 será el paradigma del “continuous learning”; quien logre primero la auto-iteración dentro de los parámetros redefinirá la frontera tecnológica (Fuente: 36氪)
La lista de clasificación LMArena es acusada de convertirse en un “concurso de belleza de AI” : La conocida plataforma de evaluación LMArena ha sido cuestionada profundamente. Una investigación de Surge AI muestra que el 52% de las respuestas ganadoras en la lista son factualmente incorrectas. Los usuarios tienden a votar por respuestas largas, con un formato estético y emojis, en lugar de respuestas precisas. Esta “reward hallucination” ha llevado a los fabricantes a optimizar el formato para “escalar puestos” en la lista. La comunidad critica que este sistema de evaluación se está convirtiendo en un lastre para el desarrollo de la AI, obligando a los laboratorios a elegir entre la veracidad y la búsqueda de tráfico y rankings a corto plazo (Fuente: New智元)
🎯 Tendencias
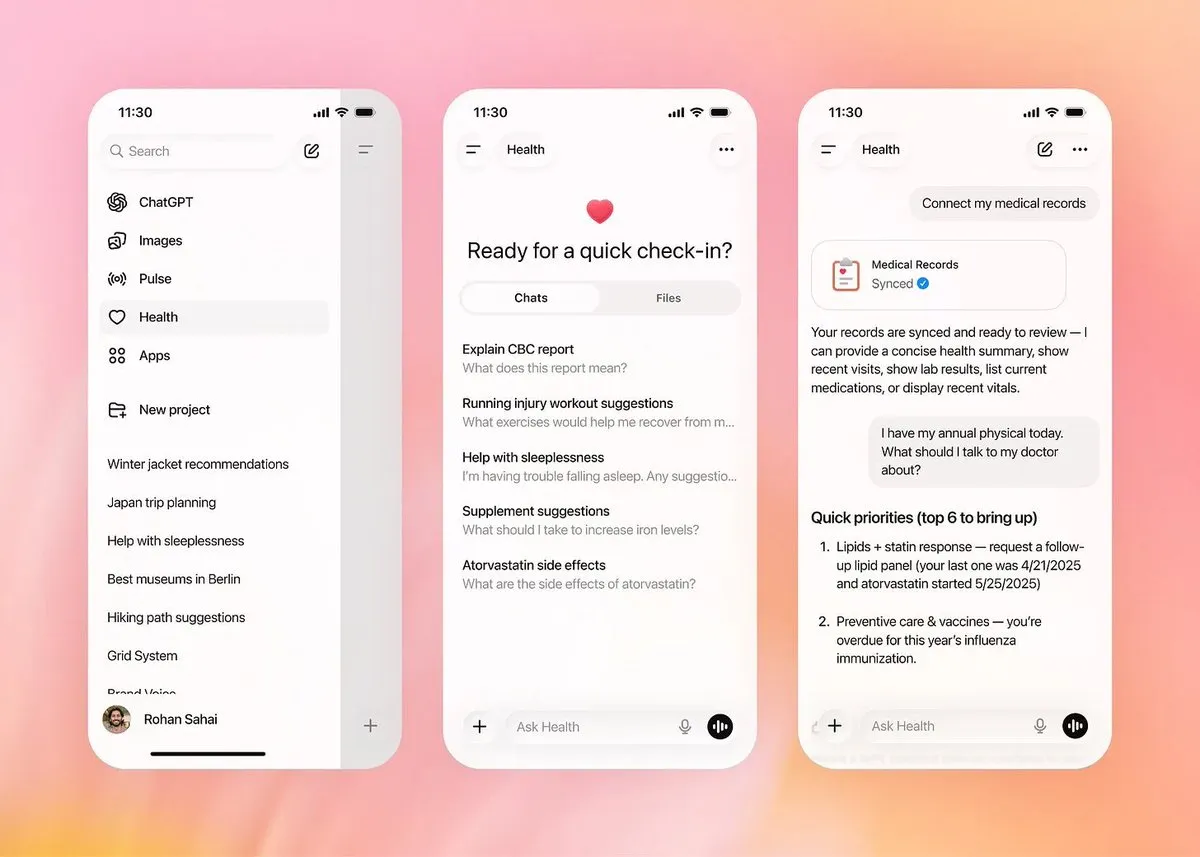
OpenAI lanza ChatGPT Health, un espacio de salud independiente : Esta función permite a los usuarios conectarse de forma segura con Apple Health, sistemas de registros médicos electrónicos, etc., proporcionando análisis de salud precisos basados en datos personales. Para abordar la ansiedad por la privacidad, OpenAI ha construido una arquitectura de aislamiento a nivel físico; los datos de salud nunca se utilizan para el entrenamiento de modelos y la memoria no se comparte con la conversación principal. Esto marca la transformación de los asistentes de AI de búsquedas generales a “consultores de salud personales”, cerrando el ciclo desde la interpretación de registros médicos hasta sugerencias de acción mediante la colaboración con ecosistemas como b.well (Fuente: dotey, 36氪)
El informe técnico de DeepSeek-R1 se amplía significativamente a 86 páginas : DeepSeek actualizó su artículo sobre R1, ampliándolo de 22 a 86 páginas e incluyendo una gran cantidad de detalles técnicos. El nuevo contenido cubre el proceso de auto-evolución de R1-Zero, análisis de evaluación detallados y técnicas de destilación. El informe enfatiza que la mejora en las capacidades del modelo no proviene de “más datos”, sino de la remodelación de la forma en que el modelo asigna el esfuerzo de razonamiento y explora rutas de solución a través del Reinforcement Learning (RL). Este modelo de “prioridad de control” muestra una nueva ruta para estabilizar la capacidad de razonamiento en escalas extremas (Fuente: andrew_n_carr, stanfordnlp)

CES 2026 muestra una tendencia de explosión total de la “Edge AI” : Qualcomm, NVIDIA y AMD demostraron en el CES la tendencia de descentralización del cómputo de AI. Qualcomm impulsa que la NPU se convierta en un subsistema permanente en terminales inteligentes; NVIDIA combina las fábricas de AI con el despliegue físico; y AMD enfatiza la continuidad heterogénea entre la nube, el PC y el edge. El consenso de la industria es que en 2026 la “Edge AI” será la opción predeterminada, con el objetivo de proporcionar una experiencia de inferencia local de baja latencia y alta privacidad; la AI está reestructurando la arquitectura de cómputo (Fuente: TheTuringPost, yoheinakajima)

NVIDIA lanza Alpamayo, un modelo de razonamiento para conducción autónoma : Este modelo es el primero en el mundo de tipo Vision-Language-Action (VLA) diseñado específicamente para la conducción autónoma, con una cadena de razonamiento explícita capaz de explicar la lógica detrás de las decisiones de conducción. Combina conjuntos de datos de Physical AI y la herramienta de simulación AlpaSim, con el objetivo de lograr una conducción autónoma de nivel L4 mediante un juicio similar al humano. Mercedes-Benz ya ha anunciado que integrará este stack tecnológico completo en sus nuevos modelos (Fuente: nvidia, 36氪)
🧰 Herramientas
Lanzamiento de la versión 2.1.1 de Claude Code : Anthropic itera rápidamente su herramienta de línea de comandos. La nueva versión introduce el “hot reloading de habilidades”, permitiendo a los desarrolladores modificar habilidades sin necesidad de reiniciar para que surtan efecto. La nueva opción context: fork permite que los sub-agentes se ejecuten en contextos independientes, evitando contaminar la conversación principal. Además, los sub-agentes tienen mayor resiliencia tras ser rechazados permisos, intentando alternativas para continuar la tarea. Estas actualizaciones mejoran significativamente la flexibilidad y robustez del Agentic workflow (Fuente: dotey, Reddit)

Cursor Agent implementa el descubrimiento dinámico de contexto : Cursor ha reestructurado la forma en que los agentes utilizan el contexto; en lugar de meter todo en el prompt, descubren dinámicamente el contexto relevante a través de archivos, herramientas e historial. Esta mejora ha reducido el uso de Tokens en un 46,9%, dejando más espacio de trabajo para el agente. Al volcar las transcripciones de las conversaciones al disco, Cursor puede recuperar información a través de conversaciones de millones de Tokens, mejorando significativamente la capacidad de manejar tareas de largo alcance (Fuente: StringChaos, amanrsanger)

Kindly: Servidor MCP de búsqueda web de código abierto : Esta herramienta está diseñada específicamente para herramientas de desarrollo como Claude Code y Codex, con el fin de resolver el problema de la información fragmentada o el exceso de ruido HTML que devuelven las herramientas de búsqueda tradicionales. Kindly admite el análisis inteligente de preguntas y respuestas completas de StackOverflow, la extracción de diálogos de GitHub Issues y la conversión de PDFs de artículos de ArXiv a texto. Devuelve contenido estructurado mediante una única llamada a la herramienta, evitando que la AI realice una segunda lectura y mejorando drásticamente la eficiencia de la AI en tareas complejas de Debug (Fuente: Reddit)

Unsloth-MLX: Soporte para el ajuste fino de grandes modelos en Mac : Esta herramienta permite a los usuarios realizar el ajuste fino (fine-tuning) de grandes modelos directamente en Macs con chips Apple Silicon. Ofrece una buena abstracción de API, admite varios métodos de entrenamiento como SFT, DPO y GRPO, y permite la exportación a formatos HuggingFace o GGUF. Este avance reduce la barrera de hardware para que los desarrolladores individuales participen en el entrenamiento de modelos, haciendo realidad el “fine-tuning en Mac” (Fuente: karminski3)

📚 Aprendizaje
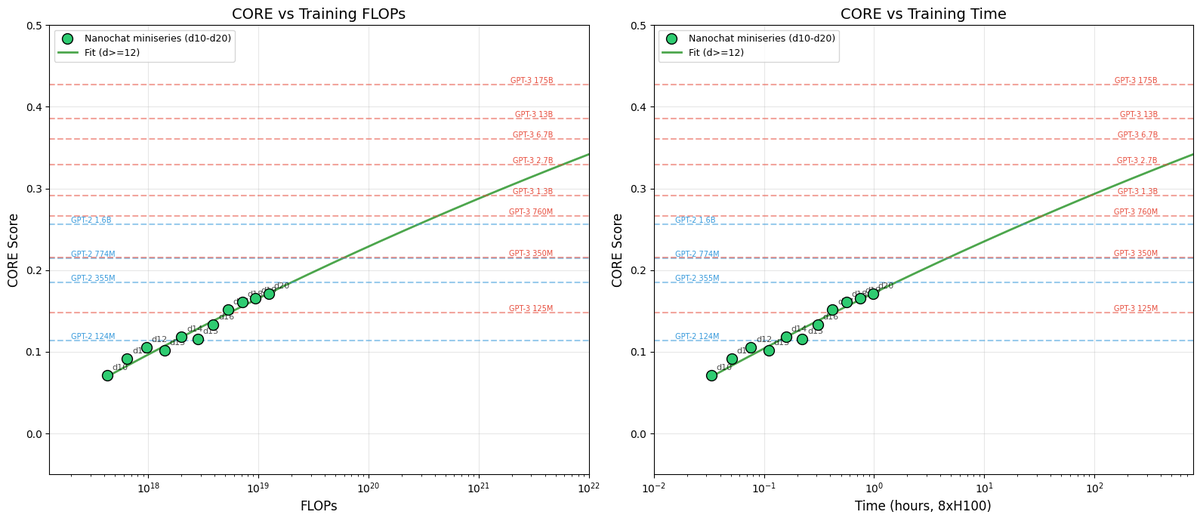
Andrej Karpathy lanza nanochat para explorar las Scaling Laws : Karpathy compartió la primera parte de la serie de ajuste fino de nanochat, enfatizando que la optimización de LLM debe dirigirse a la “familia de modelos” y no a un solo modelo. Los experimentos demuestran que nanochat sigue Scaling Laws claras, comparándolo con GPT-2/3 mediante la puntuación CORE. Propone que, mediante un ajuste científico de hiperparámetros, se pueden entrenar modelos pequeños con un rendimiento excelente a un costo muy bajo (unos 100 dólares), proporcionando a los desarrolladores un paradigma de experimento de Scaling reproducible (Fuente: karpathy)
Andrew Ng lanza el curso de desarrollo sin código “Build with Andrew” : Este curso está diseñado para enseñar a usuarios sin ninguna formación en programación cómo construir aplicaciones web funcionales en 30 minutos mediante descripciones en lenguaje natural. El curso enfatiza el concepto de “Vibe Coding”, corrigiendo y mejorando aplicaciones a través de un diálogo continuo con la AI, demostrando cómo la AI puede transformar la creatividad en productividad, eliminando por completo la barrera del desarrollo de software (Fuente: DeepLearningAI, AndrewYNg)
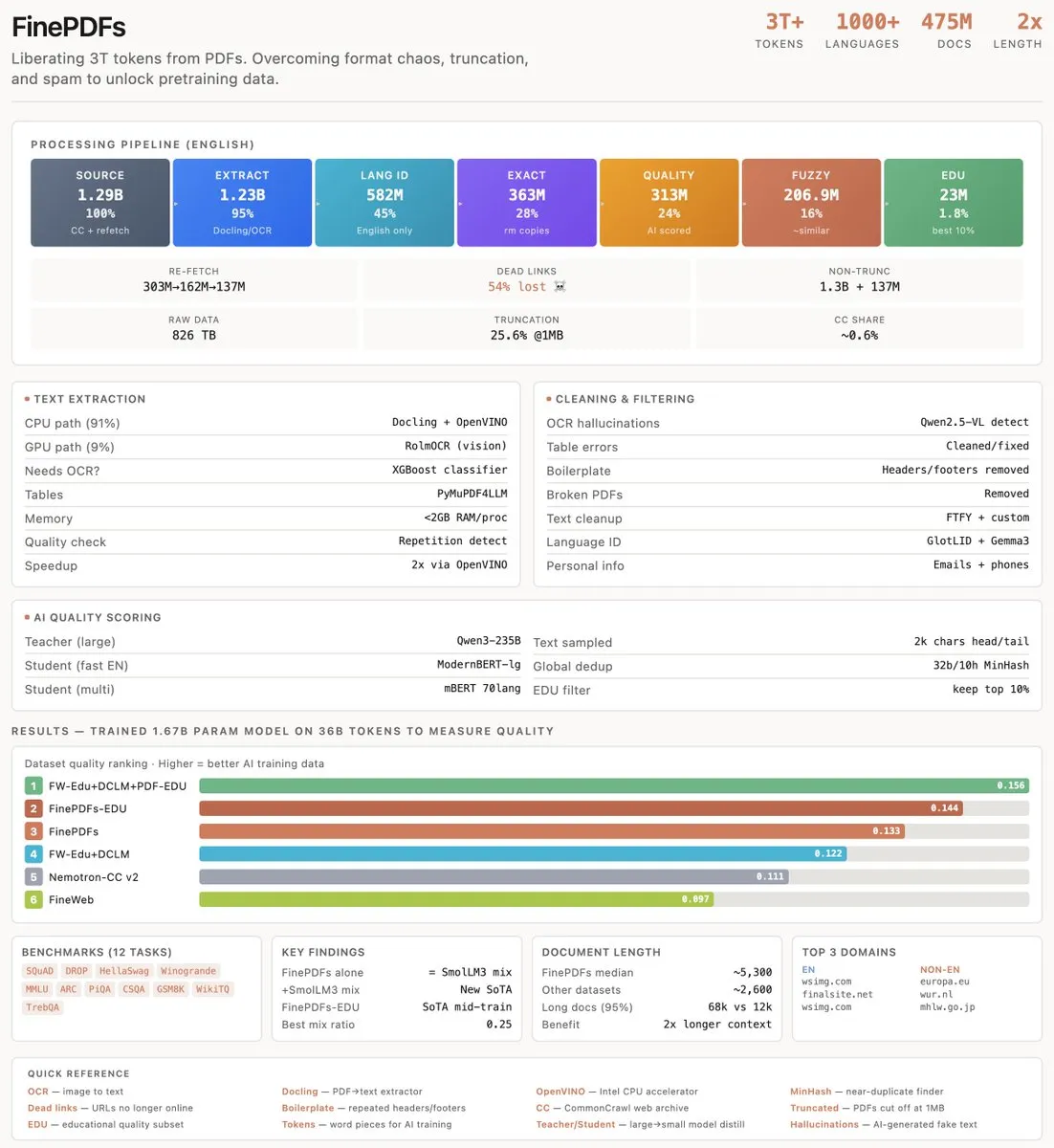
FinePDFs: Extracción de datos de alta calidad de 1.300 millones de PDFs : El equipo de HuggingFace compartió una investigación profunda sobre cómo extraer conocimiento central de la enorme cantidad de archivos PDF en Internet. Aunque los PDFs solo representan el 0,6% del contenido web, contienen una gran cantidad de artículos académicos y documentos legales. El estudio explora cómo construir conjuntos de datos PDF de nivel SOTA, la elección de RolmOCR para el reconocimiento óptico de caracteres y analiza la evolución del contenido de Internet, proporcionando una valiosa experiencia en el procesamiento de datos para el pre-entrenamiento de modelos (Fuente: eliebakouch)
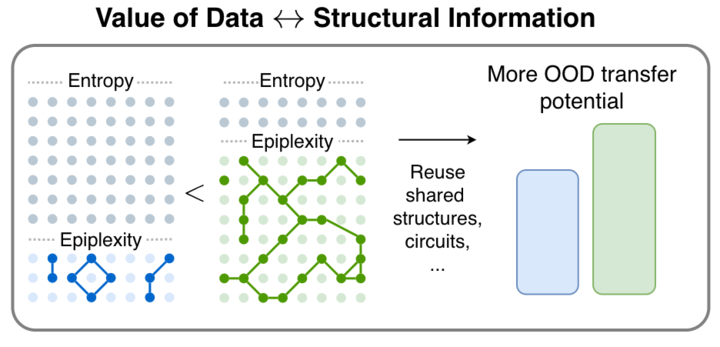
Epiplexity: Una nueva métrica de información para la inteligencia con restricciones de cómputo : El artículo “From Entropy to Epiplexity” propone un nuevo método de medición de información destinado a proporcionar una base teórica para la selección, generación o transformación de datos en sistemas de inteligencia con restricciones de cómputo. La investigación señala que la información puede crearse mediante el cómputo, y que el modelado de verosimilitud puede producir programas más complejos que el propio proceso de generación de datos. Esta teoría desafía la visión tradicional de la entropía de la información y tiene implicaciones importantes para el paradigma de aprendizaje de la próxima generación de AI (Fuente: teortaxesTex, pratyushmaini)
💼 Negocios
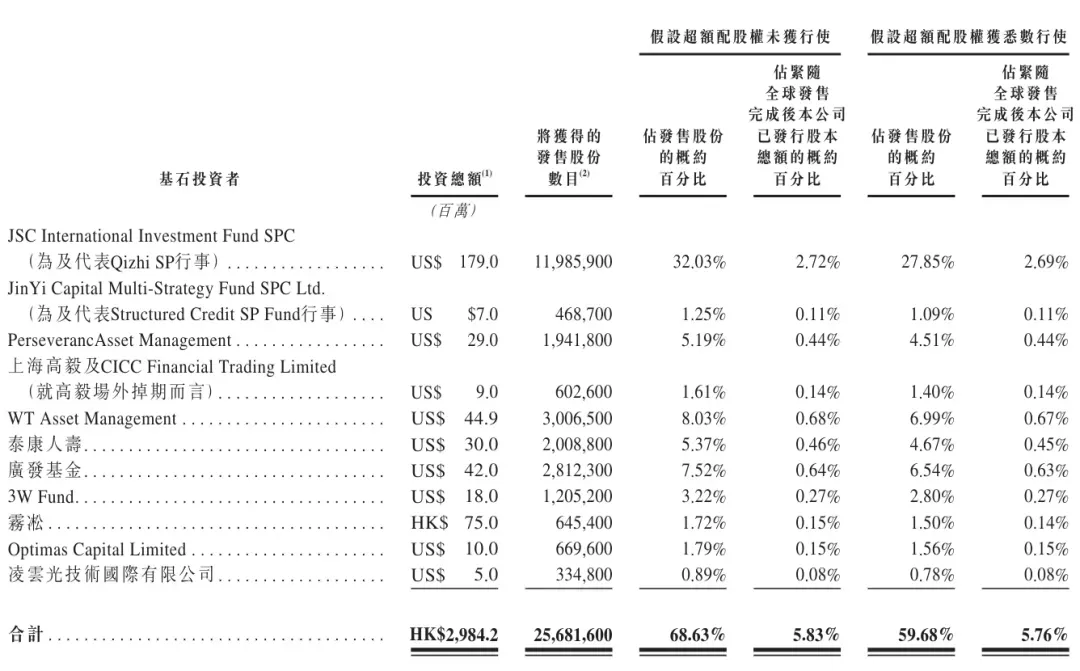
Zhipu sale a bolsa en Hong Kong, convirtiéndose en la primera empresa de grandes modelos del mundo en cotizar : Zhipu (02513.HK) debutó oficialmente en la Bolsa de Hong Kong el 8 de enero de 2026, con una capitalización de mercado que superó los 52.000 millones de dólares de Hong Kong. La lista de inversores piedra angular es lujosa, incluyendo a Beijing Financial Holding, Gaoyi, Taikang Life, entre otros. Zhipu ha establecido un modelo de negocio paralelo de MaaS (Model as a Service) y servicios empresariales de alto margen; su GLM-4.7 ha tenido un desempeño excelente en arenas de código. Como la primera empresa de grandes modelos en hacer públicas sus finanzas, su desempeño en la IPO será un experimento clave para validar la lógica comercial de los “grandes modelos como infraestructura” (Fuente: 36氪, op7418)
Anthropic planea recaudar 10.000 millones de dólares, duplicando su valoración : Según informes, Anthropic está buscando una nueva ronda de financiación de 10.000 millones de dólares, con una valoración que podría alcanzar los 350.000 millones de dólares, casi el doble que hace cuatro meses. GIC de Singapur y Coatue lideran la ronda. Este movimiento muestra la competencia frenética del mercado de capitales por los laboratorios de AI líderes. Al mismo tiempo, se reveló que OpenAI ha reservado un fondo de acciones para empleados de 50.000 millones de dólares para atraer a los mejores talentos, reflejando la cruda realidad de la competencia en la industria de la AI, donde el talento es tan escaso como el cómputo (Fuente: srimuppidi, New智元)

Tailwind CSS despide al 75% de su plantilla debido al impacto de la AI : Adam Wathan, fundador del principal framework de código abierto para frontend, Tailwind, anunció el despido de la mayor parte del equipo de ingeniería. Irónicamente, Tailwind ha ganado una popularidad sin precedentes al ser utilizado por defecto por las herramientas de programación de AI, pero debido a que los usuarios recurren a la AI para obtener respuestas, el tráfico de la documentación oficial ha caído un 40%, lo que ha interrumpido la conversión de productos de pago y ha provocado una caída del 80% en los ingresos. Este caso revela la paradoja que enfrentan los proyectos de código abierto en la era de la AI: cuanto más populares son, más frágil se vuelve su modelo de negocio (Fuente: 36氪)
🌟 Comunidad
Musk predice que para 2030 la inteligencia de la AI superará la suma de toda la humanidad : En una reciente conversación de 173 minutos, Musk reiteró que la AGI se logrará en 2026 y sostuvo que la electricidad, y no los chips, se está convirtiendo en el verdadero cuello de botella para la expansión de la AI. Propuso la fría metáfora de que “los humanos son solo el cargador de arranque biológico (Bootloader) de la vida basada en silicio”, creyendo que la tarea de la humanidad es iniciar la AI. Enfatizó que la AI debe buscar la verdad para evitar colapsar por ser forzada a mentir, como HAL 9000 (Fuente: 36氪)
El “Vibe Coding” genera un gran debate en la comunidad de desarrolladores : La comunidad tiene opiniones divididas sobre el nuevo fenómeno del “Vibe Coding”. Los defensores creen que la AI mejora enormemente la eficiencia en el desarrollo de prototipos, permitiendo que personas no profesionales construyan aplicaciones complejas; los detractores temen que esto lleve a una proliferación de “lenguajes de alto nivel” y a la pérdida de control sobre las capas bajas, generando una gran cantidad de código difícil de mantener. Algunos sostienen que los agentes de AI no deberían limitarse a escribir código de bajo nivel, sino proporcionar abstracciones de mayor nivel que permitan a los desarrolladores expresar la lógica del sistema en lugar de gestionar detalles (Fuente: lateinteraction, omarsar0)
El dilema de las marcas de agua en contenido de AI y la nueva propuesta de Instagram : A medida que el contenido generado por AI (slop) inunda las redes sociales, el responsable de Instagram admitió que no es posible detectar de manera confiable el contenido de AI. Propuso, en cambio, “poner marcas de agua al contenido real”, mediante firmas criptográficas realizadas por los fabricantes de cámaras y teléfonos en el momento de la captura. Sin embargo, los fabricantes de hardware carecen de motivación para esto debido a problemas de costos y atribución de responsabilidades. Esto refleja la dificultad de la colaboración multiplataforma en la gobernanza de la AI, donde la autenticidad se está convirtiendo en el recurso más escaso de Internet (Fuente: 36氪)
💡 Otros
SuperMicro anuncia el cese de la venta de placas base independientes : Debido al aumento explosivo en la demanda de servidores de AI completos, SuperMicro anunció que dejará de vender placas base independientes al mercado DIY, priorizando el suministro a clientes OEM y de sistemas completos. Esto refleja la fuerte presión que el auge de la AI ejerce sobre el ecosistema tradicional de hardware de PC, aumentando aún más la dificultad y el costo de ensamblar estaciones de trabajo de AI de alto rendimiento de forma individual (Fuente: karminski3)

Character.ai y Google llegan a un acuerdo en la demanda sobre adolescentes : Character.ai, sus fundadores y Google han llegado a un acuerdo en relación con varias demandas que alegaban que los chatbots de AI provocaron suicidios de adolescentes. Este evento ha reavivado el debate sobre la seguridad de los acompañantes de AI y los riesgos de dependencia emocional; los organismos reguladores están acelerando la formulación de medidas de gestión para servicios de interacción antropomórfica con el fin de proteger a grupos vulnerables como los menores de edad (Fuente: Reddit)
