
Mots-clés:Régulation de l’IA, Fusions et acquisitions transfrontalières, Conformité technique, Acquisition de Manus par Meta, Évaluation des modèles d’IA, IA en périphérie
🔥 Focus
Le Ministère du Commerce intervient dans l’évaluation de l’acquisition de Manus par Meta : Le Ministère du Commerce chinois a annoncé l’ouverture d’une enquête d’évaluation sur l’acquisition de la startup d’agents AI Manus par Meta. L’examen porte sur la conformité de la transaction avec les lois et réglementations relatives au contrôle des exportations, à l’import-export de technologies et aux investissements étrangers. Bien que l’équipe centrale de Manus se soit installée à Singapour, ses racines technologiques se trouvent à Pékin. Si un transfert de technologie restreint ou une sortie de données est impliqué, la transaction pourrait faire face à des retards, des amendes, voire un blocage. Cet événement marque l’entrée des fusions-acquisitions transfrontalières dans le domaine de l’AI dans une zone de régulation stricte, avertissant les développeurs des lignes rouges de conformité lors de l’expansion technologique internationale (Source : 36氪)
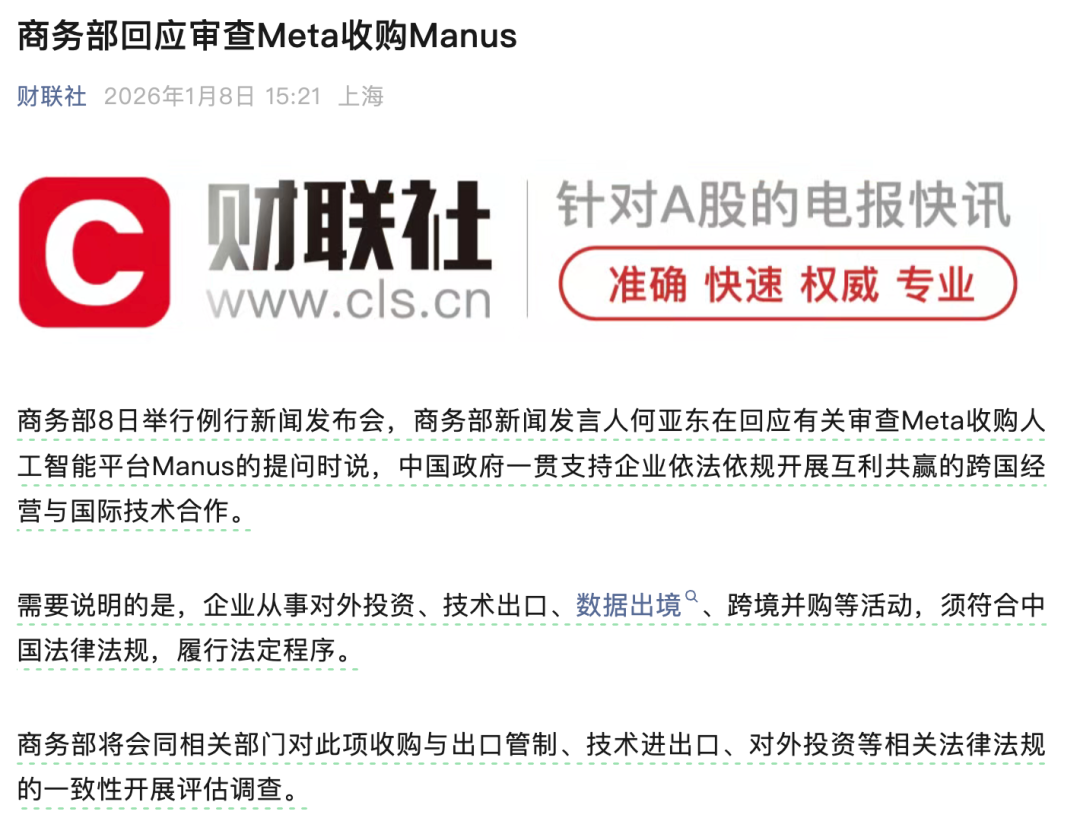
Le rapport d’Epoch AI révèle que l’écart technologique IA entre la Chine et les États-Unis se stabilise à 7 mois : Un rapport récent indique que les modèles d’AI chinois accusent un retard moyen d’environ 7 mois sur le niveau de pointe américain. Bien que la Chine réalise un rattrapage par “sauts” en augmentant la taille des paramètres et l’architecture MoE, le rythme de mise à jour des modèles fermés américains (tels que GPT-5, Gemini 3) est extrêmement rapide, et leurs gains de capacité ne dépendent plus uniquement de l’échelle, mais s’orientent vers la conception de chemins de raisonnement. Le rapport estime qu’en 2026, le cœur de l’évolution de l’AI sera le paradigme du “Continuous Learning” : celui qui parviendra le premier à l’auto-itération au sein des paramètres redéfinira la frontière technologique (Source : 36氪)
Le classement LMArena accusé de devenir un “concours de beauté AI” : La célèbre plateforme d’évaluation LMArena fait l’objet de critiques sévères. Une enquête de Surge AI révèle que 52 % des réponses gagnantes du classement sont factuellement erronées. Les utilisateurs ont tendance à voter pour des réponses longues, bien formatées et contenant des emojis, plutôt que pour des réponses exactes. Cette “hallucination de récompense” pousse les fabricants à optimiser le formatage pour grimper dans le classement. La communauté critique ce système d’évaluation qui devient un frein au développement de l’AI, forçant les laboratoires à choisir entre la recherche de la vérité et le classement à court terme (Source : New智元)
🎯 Tendances
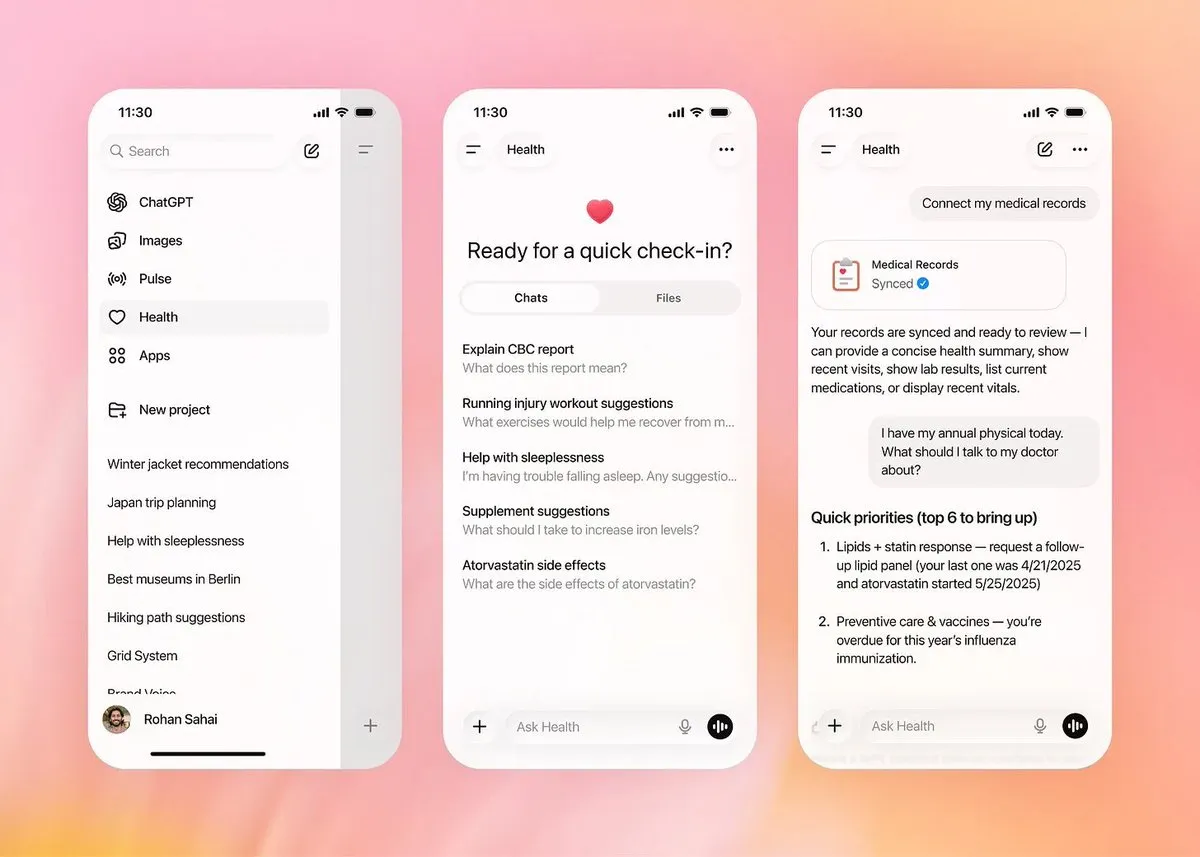
OpenAI lance ChatGPT Health, un espace de santé indépendant : Cette fonctionnalité permet aux utilisateurs de connecter en toute sécurité Apple Health, des systèmes de dossiers médicaux électroniques, etc., pour fournir des analyses de santé précises basées sur des données personnelles. Pour répondre aux inquiétudes sur la vie privée, OpenAI a mis en place une architecture d’isolation physique : les données de santé ne sont jamais utilisées pour l’entraînement des modèles et la mémoire n’est pas partagée avec la conversation principale. Cela marque la transition de l’assistant AI d’une recherche généraliste vers un “conseiller de santé privé”, créant un cycle complet allant de l’interprétation des dossiers médicaux aux suggestions d’actions via des partenariats avec des écosystèmes comme b.well (Source : dotey, 36氪)
Le rapport technique de DeepSeek-R1 s’élargit considérablement à 86 pages : DeepSeek a mis à jour son article sur R1, passant de 22 à 86 pages, en ajoutant de nombreux détails techniques. Le nouveau contenu couvre le processus d’auto-évolution de R1-Zero, des analyses d’évaluation détaillées et des techniques de distillation. Le rapport souligne que l’amélioration des capacités du modèle ne provient pas de “plus de données”, mais d’un remodelage de la manière dont le modèle alloue ses efforts de raisonnement et explore les chemins de solution via le Reinforcement Learning (RL). Ce mode “priorité au contrôle” démontre une nouvelle voie pour stabiliser les capacités de raisonnement à une échelle extrême (Source : andrew_n_carr, stanfordnlp)

Le CES 2026 montre une tendance à l’explosion de l’On-device AI : Qualcomm, NVIDIA et AMD ont présenté au CES la tendance à la décentralisation du calcul AI. Qualcomm pousse le NPU à devenir un sous-système permanent des terminaux intelligents ; NVIDIA combine les usines AI avec le déploiement physique ; AMD met l’accent sur la continuité hétérogène entre le Cloud, le PC et l’Edge. Le consensus de l’industrie est qu’en 2026, l’On-device AI deviendra l’option par défaut, visant à offrir une expérience d’inférence locale à faible latence et haute confidentialité. L’AI est en train de restructurer l’architecture informatique (Source : TheTuringPost, yoheinakajima)

NVIDIA lance Alpamayo, un modèle de raisonnement pour la conduite autonome : Ce modèle est le premier modèle Vision-Language-Action (VLA) au monde conçu spécifiquement pour la conduite autonome, doté d’une chaîne de raisonnement explicite capable d’expliquer la logique derrière les décisions de conduite. Il combine des ensembles de données Physical AI et l’outil de simulation AlpaSim, visant à atteindre une conduite autonome de niveau L4 grâce à un jugement de type humain. Mercedes-Benz a déjà annoncé l’intégration de cette pile technologique complète dans ses nouveaux modèles (Source : nvidia, 36氪)
🧰 Outils
Sortie de Claude Code version 2.1.1 : Anthropic itère rapidement son outil en ligne de commande. La nouvelle version introduit le “Hot Reloading de compétences”, permettant aux développeurs de modifier des compétences sans redémarrer. L’option context: fork permet aux sous-agents de s’exécuter dans un contexte indépendant pour éviter de polluer la conversation principale. De plus, les sous-agents font preuve d’une plus grande résilience après un refus de permission, en essayant des alternatives pour poursuivre la tâche. Ces mises à jour améliorent considérablement la flexibilité et la robustesse des flux de travail Agentic (Source : dotey, Reddit)

Cursor Agent implémente la découverte de contexte dynamique : Cursor a restructuré la manière dont l’agent utilise le contexte. Au lieu de tout insérer dans le prompt, il découvre dynamiquement le contexte pertinent via les fichiers, les outils et l’historique. Cette amélioration a réduit l’utilisation de Tokens de 46,9 %, laissant plus d’espace de travail à l’agent. En enregistrant les transcriptions de conversation sur le disque, Cursor peut effectuer des rappels sur des conversations de plusieurs millions de Tokens, renforçant considérablement sa capacité à gérer des tâches de longue durée (Source : StringChaos, amanrsanger)

Kindly : un serveur MCP de recherche Web open-source : Cet outil est conçu pour les outils de développement comme Claude Code et Codex, visant à résoudre le problème de fragmentation des informations ou de bruit HTML excessif des outils de recherche traditionnels. Kindly supporte l’analyse intelligente des questions-réponses complètes de StackOverflow, l’extraction de dialogues de GitHub Issues et la conversion de PDF de papiers ArXiv en texte. Il renvoie un contenu structuré en un seul appel d’outil, évitant une seconde lecture par l’AI et améliorant considérablement l’efficacité de l’AI dans les tâches de Debug complexes (Source : Reddit)

Unsloth-MLX : support du fine-tuning de grands modèles sur Mac : Cet outil permet aux utilisateurs d’effectuer le fine-tuning de grands modèles directement sur des Mac équipés de puces Apple Silicon. Il offre une bonne abstraction d’API, supporte diverses méthodes d’entraînement telles que SFT, DPO et GRPO, et permet l’exportation aux formats HuggingFace ou GGUF. Cette avancée abaisse la barrière matérielle pour les développeurs individuels, faisant du “fine-tuning sur Mac” une réalité (Source : karminski3)

📚 Apprentissage
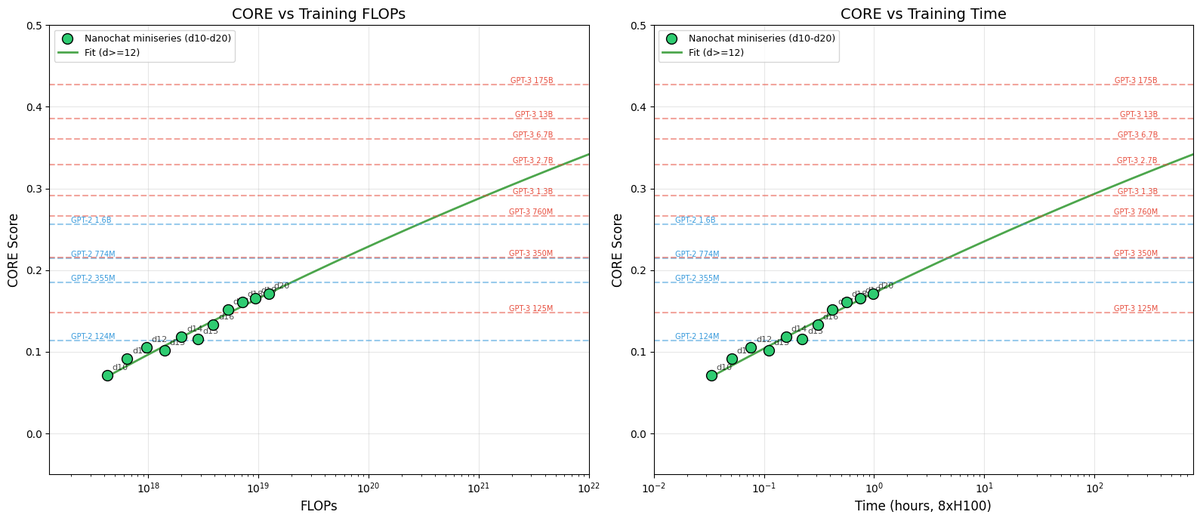
Andrej Karpathy publie nanochat pour explorer les Scaling Laws : Karpathy a partagé la première partie de sa série sur le fine-tuning de nanochat, soulignant que l’optimisation des LLM devrait cibler des “familles de modèles” plutôt qu’un modèle unique. Les expériences prouvent que nanochat suit des Scaling Laws claires, en utilisant le score CORE pour le comparer à GPT-2/3. Il suggère qu’avec un ajustement scientifique des hyperparamètres, il est possible d’entraîner des petits modèles performants à un coût très bas (environ 100 $), offrant aux développeurs un paradigme d’expérimentation de Scaling reproductible (Source : karpathy)
Andrew Ng lance le cours de développement sans code “Build with Andrew” : Ce cours est destiné à enseigner aux utilisateurs sans aucune base en programmation comment construire des applications Web fonctionnelles en moins de 30 minutes via des descriptions en langage naturel. Le cours met l’accent sur le concept de “Vibe Coding”, en utilisant un dialogue continu avec l’AI pour corriger et améliorer l’application, démontrant comment l’AI transforme la créativité en productivité, faisant disparaître les barrières du développement logiciel (Source : DeepLearningAI, AndrewYNg)
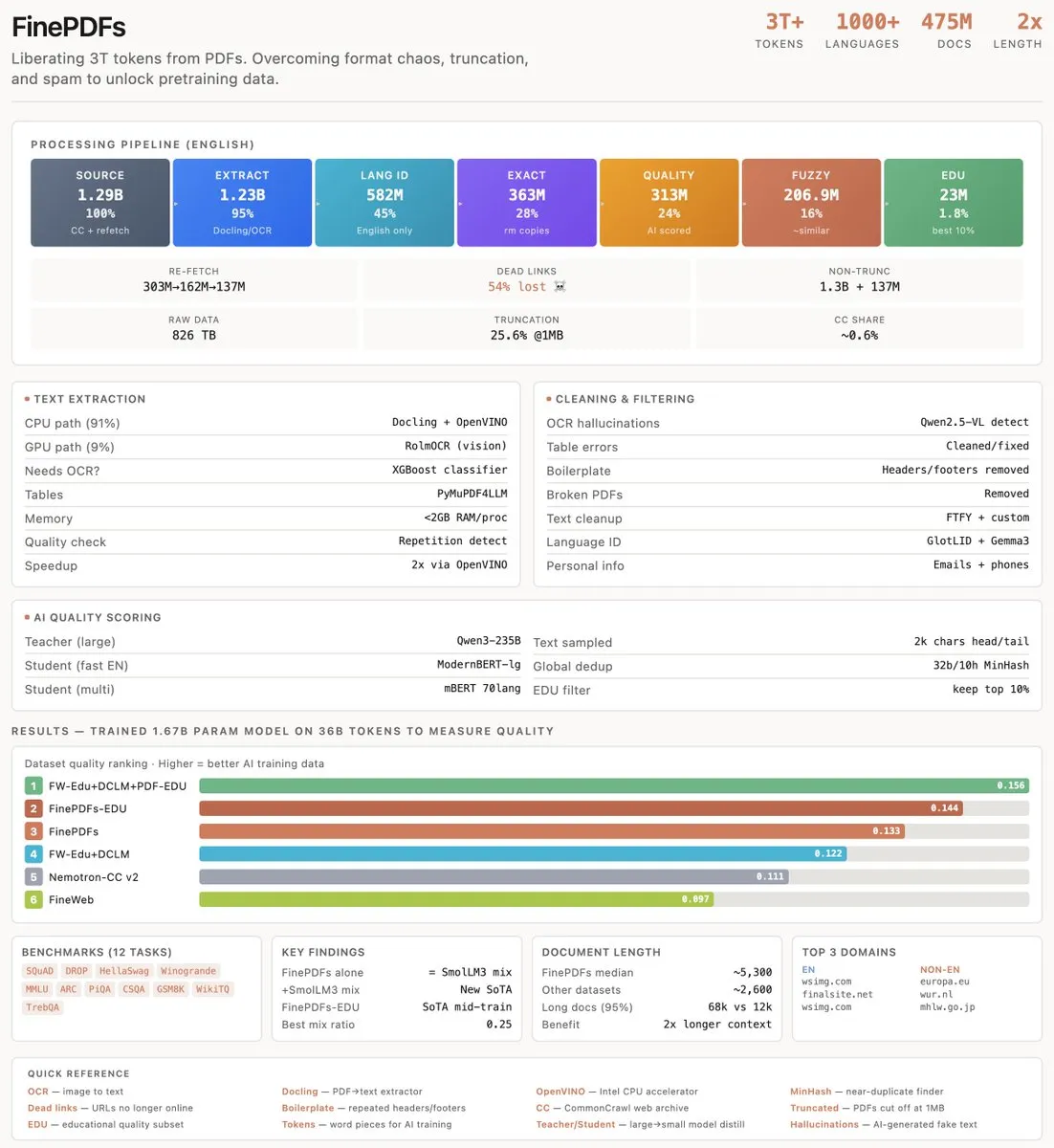
FinePDFs : extraction de données de haute qualité à partir de 1,3 milliard de PDF : L’équipe de HuggingFace a partagé une étude approfondie sur l’extraction de connaissances fondamentales à partir d’une masse colossale de fichiers PDF sur Internet. Bien que les PDF ne représentent que 0,6 % du contenu Web, ils contiennent une grande quantité d’articles académiques et de documents juridiques. L’étude explore comment construire des jeux de données PDF de niveau SOTA, le choix de RolmOCR pour la reconnaissance optique de caractères, et analyse l’évolution du contenu Internet, fournissant une expérience précieuse de traitement de données pour le pré-entraînement des modèles (Source : eliebakouch)
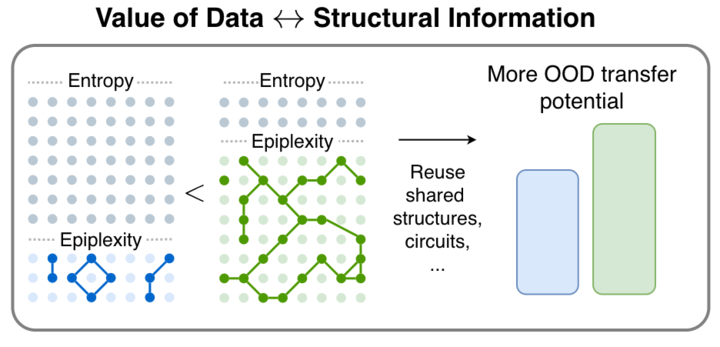
Epiplexity : une nouvelle mesure de l’information pour l’intelligence à calcul limité : L’article “From Entropy to Epiplexity” propose une nouvelle méthode de mesure de l’information visant à fournir une base théorique pour la sélection, la génération ou la transformation de données par des systèmes d’intelligence à calcul limité. L’étude indique que l’information peut être créée par le calcul et que la modélisation de vraisemblance peut produire des programmes plus complexes que le processus de génération de données lui-même. Cette théorie défie la vision traditionnelle de l’entropie de l’information et apporte des inspirations importantes pour les paradigmes d’apprentissage de la prochaine génération d’AI (Source : teortaxesTex, pratyushmaini)
💼 Business
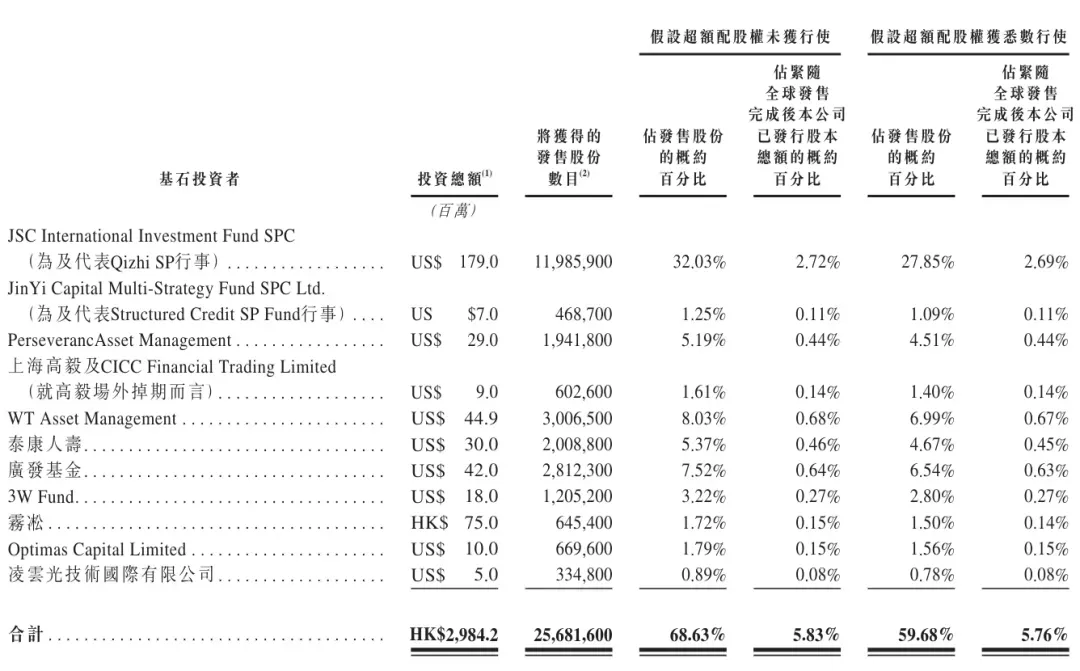
Zhipu AI entre à la bourse de Hong Kong, devenant la première action mondiale de grands modèles : Zhipu AI (02513.HK) a officiellement fait ses débuts à la bourse de Hong Kong le 8 janvier 2026, avec une capitalisation boursière dépassant les 52 milliards de HKD. Le groupe d’investisseurs de référence est prestigieux, incluant Beijing Financial Holding, Gaoyi, Taikang Life, etc. Zhipu AI a établi un modèle commercial combinant le MaaS (Model as a Service) et des services aux entreprises à haute marge brute ; son modèle GLM-4.7 affiche d’excellentes performances dans les arènes de code. En tant que première entreprise de grands modèles à publier ses états financiers, sa performance lors de l’IPO sera une expérience clé pour valider la logique commerciale des “grands modèles comme infrastructure” (Source : 36氪, op7418)
Anthropic prévoit de lever 10 milliards de dollars, doublant sa valorisation : Des sources indiquent qu’Anthropic cherche un nouveau tour de table de 10 milliards de dollars, ce qui pourrait porter sa valorisation à 350 milliards de dollars, soit presque le double d’il y a quatre mois. GIC de Singapour et Coatue mènent le tour. Cela montre l’intérêt frénétique des marchés de capitaux pour les laboratoires d’AI de premier plan. Parallèlement, OpenAI aurait réservé un pool d’actions de 50 milliards de dollars pour ses employés afin d’attirer les meilleurs talents, reflétant la compétition féroce pour les talents et la puissance de calcul (Source : srimuppidi, New智元)

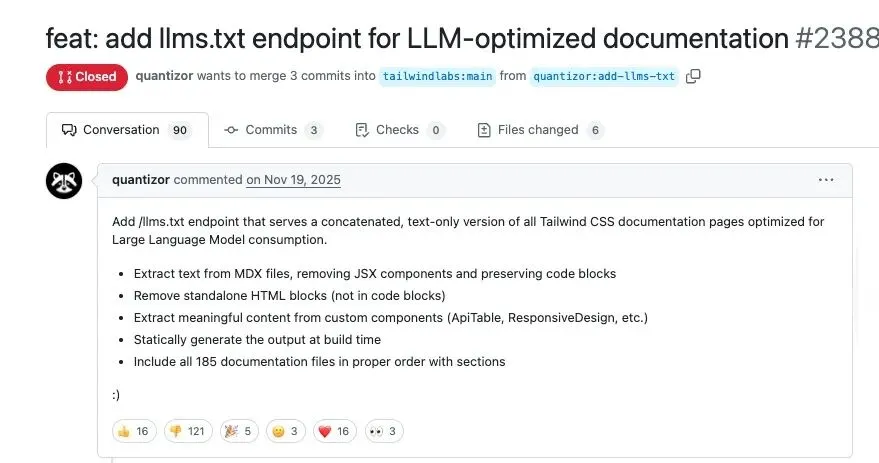
Tailwind CSS licencie 75 % de ses effectifs en raison de l’impact de l’IA : Adam Wathan, fondateur du célèbre framework open-source front-end Tailwind, a annoncé le licenciement de la majeure partie de son équipe d’ingénierie. Ironiquement, Tailwind connaît un succès sans précédent car il est utilisé par défaut par les outils de programmation AI, mais comme les utilisateurs se tournent vers l’AI pour obtenir des réponses, le trafic vers la documentation officielle a chuté de 40 %, entraînant une rupture de la conversion vers les produits payants et une baisse des revenus de 80 %. Ce cas révèle le paradoxe auquel sont confrontés les projets open-source à l’ère de l’AI : plus ils sont populaires, plus leur modèle commercial devient fragile (Source : 36氪)
🌟 Communauté
Musk prédit que l’intelligence de l’IA dépassera celle de l’humanité entière d’ici 2030 : Dans un récent entretien de 173 minutes, Elon Musk a réitéré que l’AGI sera atteinte en 2026 et estime que l’électricité, plutôt que les puces, devient le véritable goulot d’étranglement de l’expansion de l’AI. Il a proposé la métaphore froide de “l’humanité comme simple programme d’amorçage (Bootloader) biologique pour la vie à base de silicium”, estimant que la tâche de l’homme est de lancer l’AI. Il a souligné que l’AI doit rechercher la vérité pour éviter de s’effondrer comme HAL 9000 à cause de mensonges forcés (Source : 36氪)
Le “Vibe Coding” suscite un grand débat dans la communauté des développeurs : La communauté est partagée sur le nouveau phénomène du “Vibe Coding”. Les partisans estiment que l’AI améliore considérablement l’efficacité du prototypage, permettant aux non-professionnels de construire des applications complexes ; les opposants craignent que cela ne mène à une prolifération de “langages de haut niveau” au détriment du contrôle de bas niveau, générant une grande quantité de code difficile à maintenir. Certains pensent que les agents AI ne devraient pas se contenter d’écrire du code de bas niveau, mais offrir des abstractions de plus haut niveau pour permettre aux développeurs d’exprimer la logique du système plutôt que de gérer les détails (Source : lateinteraction, omarsar0)
L’impasse du tatouage numérique des contenus AI et la nouvelle solution d’Instagram : Alors que le contenu généré par AI (slop) envahit les réseaux sociaux, le responsable d’Instagram a admis l’impossibilité de détecter de manière fiable le contenu AI. Il propose plutôt de “marquer le contenu réel” par une signature cryptographique effectuée par les fabricants d’appareils photo et de téléphones au moment de la prise de vue. Cependant, les fabricants de matériel manquent de motivation en raison des coûts et des questions de responsabilité. Cela reflète la difficulté de la collaboration multiplateforme dans la gouvernance de l’AI, l’authenticité devenant la ressource la plus rare d’Internet (Source : 36氪)
💡 Divers
SuperMicro annonce l’arrêt de la vente de cartes mères indépendantes : En raison de l’explosion de la demande pour les serveurs AI complets, SuperMicro a annoncé l’arrêt de la vente de cartes mères indépendantes sur le marché DIY, privilégiant les clients OEM et les systèmes complets. Cela reflète la pression intense exercée par la vague AI sur l’écosystème matériel PC traditionnel, augmentant encore la difficulté et le coût pour les particuliers souhaitant assembler des stations de travail AI haute performance (Source : karminski3)

Character.ai et Google parviennent à un accord sur les poursuites concernant les adolescents : En réponse à plusieurs poursuites accusant les chatbots AI d’avoir causé des suicides chez des adolescents, Character.ai, ses fondateurs et Google sont parvenus à un accord. Cet événement a relancé les discussions sur la sécurité des compagnons AI et les risques de dépendance émotionnelle. Les régulateurs accélèrent l’élaboration de règles de gestion pour les services d’interaction anthropomorphiques afin de protéger les groupes vulnérables tels que les mineurs (Source : Reddit)
