
Mots-clés:Modèle d’IA, Conduite autonome, Multimodal, GLM-4.7, Alpamayo, Qwen3-VL
🔥 À la une
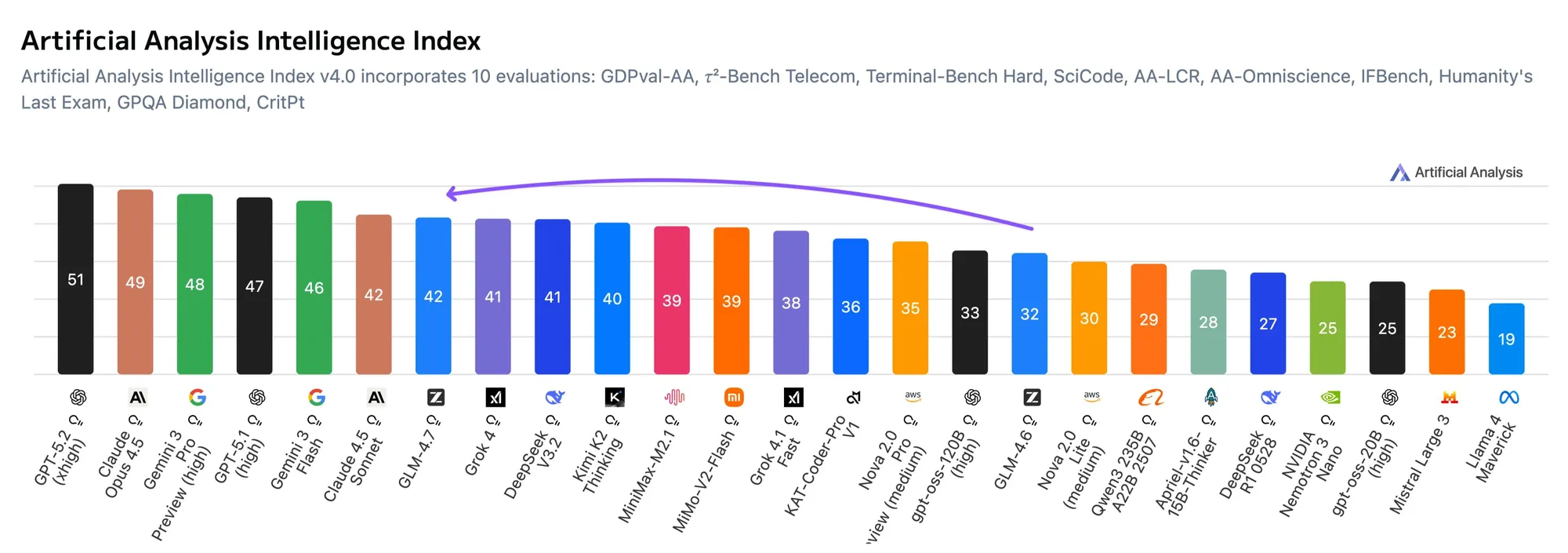
Zhipu AI entre officiellement à la Bourse de Hong Kong, ouvrant l’ère des IPO pour les grands modèles : Le 8 janvier 2026, Zhipu AI a été officiellement cotée à la HKEX, devenant la première action au monde dans le domaine des grands modèles, suivie de près par MiniMax. Tang Jie a révélé dans une lettre interne qu’après le lancement du modèle phare GLM-4.7, les revenus annuels récurrents (ARR) du MaaS ont été multipliés par 25 en 10 mois, dépassant les 500 millions de RMB. Cet événement marque la transition des grands modèles chinois du « rattrapage technique » vers une « boucle commerciale fermée ». L’IPO ouvrira la voie aux modèles nationaux vers le marché mondial et permettra d’obtenir une évaluation de valeur internationale plus équitable (Source : Zai_org)
Stanford publie SleepFM : prédire plus d’une centaine de risques pour la santé grâce à une nuit de sommeil : Des chercheurs de l’Université de Stanford ont lancé SleepFM, un modèle AI multimodal entraîné sur plus de 585 000 heures de données de sommeil. En analysant les ondes cérébrales, la fréquence cardiaque et le rythme respiratoire, ce modèle peut prédire plus de 130 risques de maladies, dont la démence, les maladies cardiaques et certains cancers, à partir d’un seul enregistrement nocturne. Cette percée démontre le potentiel immense de l’AI dans la médecine préventive, transformant les appareils de surveillance du sommeil en puissants outils de diagnostic (Source : Reddit)

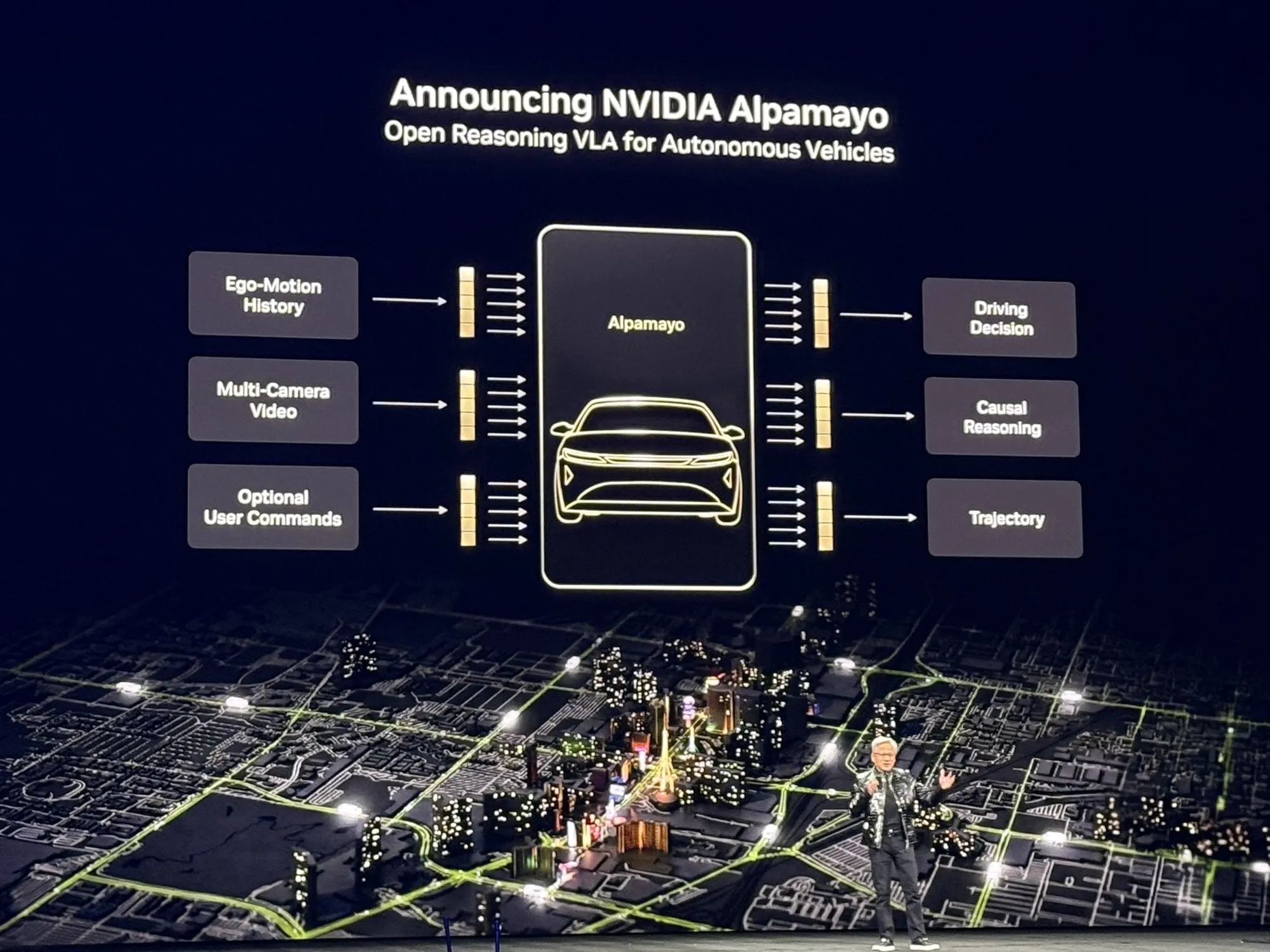
NVIDIA open-source Alpamayo : le premier modèle de conduite autonome doté de capacités de raisonnement : NVIDIA a rendu Alpamayo open-source, le premier modèle de conduite autonome basé sur le raisonnement Chain of Thought (CoT). Contrairement aux systèmes traditionnels purement réactifs, Alpamayo peut raisonner logiquement dans des scénarios complexes ou rares, à l’instar d’un conducteur humain. Combiné à l’architecture Vera Rubin de l’« AI Factory », NVIDIA pousse l’AI du domaine purement numérique vers l’AI physique, englobant des outils de simulation et des modules d’Edge Computing, redéfinissant ainsi les standards de la conduite autonome industrielle (Source : TheTuringPost)
LMArena lève 150 millions de dollars, l’évaluation de l’AI devient une infrastructure centrale : La célèbre arène de modèles AI, LMArena, a bouclé une levée de fonds de 150 millions de dollars sur une valorisation de 1,7 milliard de dollars. Ce financement massif montre qu’à l’heure où les modèles prolifèrent, un système d’évaluation objectif et fiable n’est plus un outil auxiliaire, mais l’infrastructure centrale de l’écosystème AI. La capitalisation des capacités d’évaluation annonce un passage de l’industrie d’une « expansion aveugle » à une « approche axée sur la qualité », tout en suscitant de larges discussions au sein de la communauté sur sa valorisation élevée (Source : nearcyan)

🎯 Tendances
AI21 Labs lance la série Jamba 2 : l’architecture hybride SSM-Transformer au service des entreprises : AI21 a dévoilé Jamba2 3B et Jamba2 Mini (52B paramètres totaux, 12B actifs). Cette série utilise une architecture hybride SSM-Transformer avec un contexte ultra-long de 256K, affichant d’excellentes performances sur les benchmarks de suivi d’instructions comme IFEval. Ses principaux atouts résident dans son débit élevé et son efficacité mémorielle, particulièrement adaptés au traitement de documents longs et aux workflows d’Agent d’entreprise nécessitant une haute fiabilité (Source : Reddit)

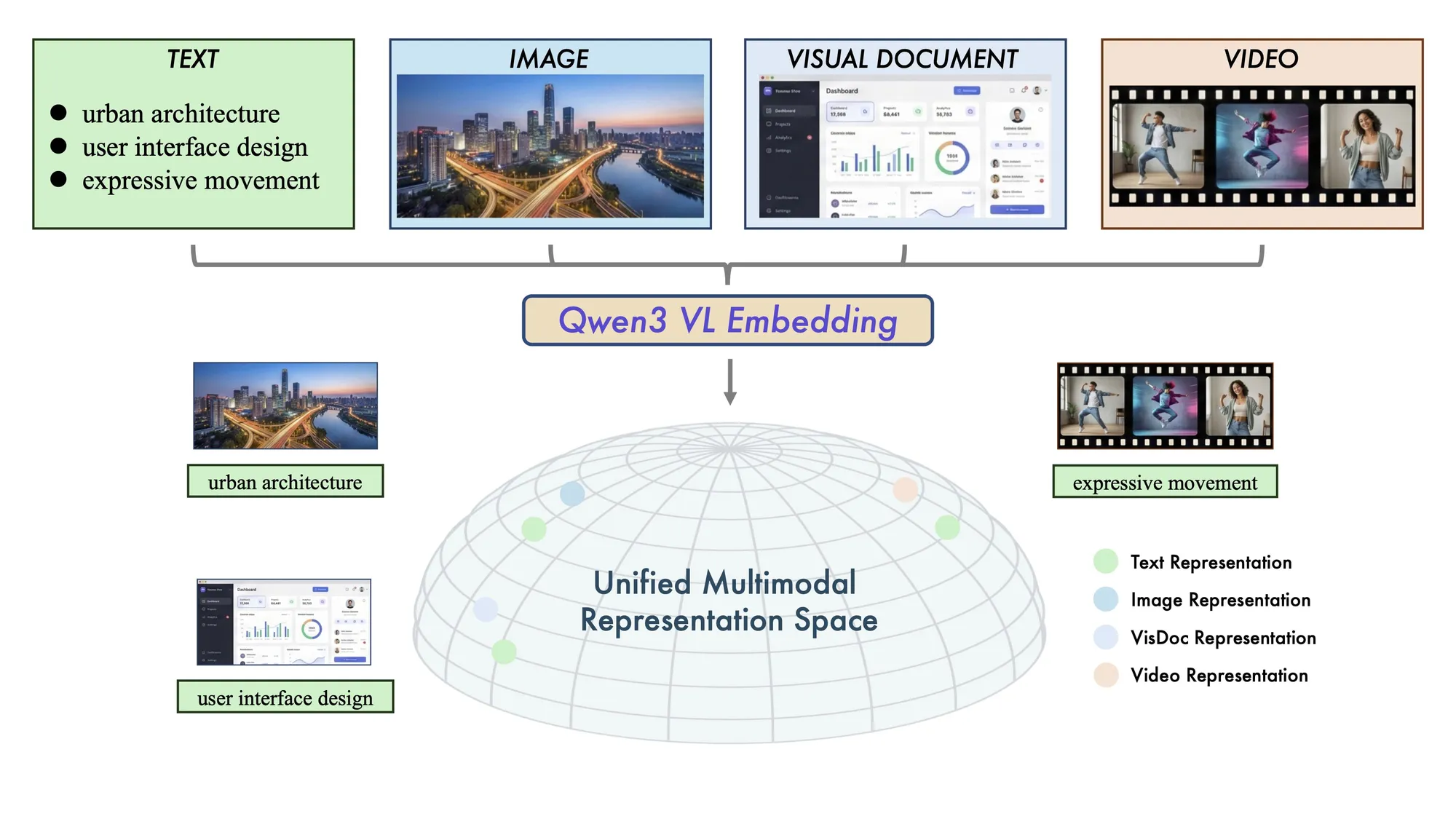
Alibaba open-source le modèle de recherche multimodale Qwen3-VL : faire progresser le SOTA de la compréhension transmodale : Alibaba a publié les modèles Qwen3-VL-Embedding et Reranker, prenant en charge des entrées multimodales mixtes (texte, image, vidéo). Ce modèle excelle dans le RAG multimodal, le Visual Question Answering et la recherche multilingue, supportant plus de 30 langues. Cette architecture de recherche en deux étapes (génération de vecteurs + scoring précis) améliore considérablement la précision de la recherche de contenus visuels complexes, offrant un support fondamental puissant pour les applications AI multimodales (Source : Alibaba_Qwen)
NVIDIA publie Nemotron Speech ASR : reconnaissance vocale à ultra-basse latence en open-source : NVIDIA a lancé le modèle Nemotron Speech ASR, conçu spécifiquement pour les Agents vocaux, atteignant un temps de transcription de 24ms et une latence d’interaction vocale de bout en bout inférieure à 500ms. Le modèle est entièrement open-source, incluant les poids, le code et les données d’entraînement. Jensen Huang a souligné au CES que les modèles open-source rattraperont pleinement les modèles propriétaires cette année, NVIDIA accélérant ce processus en libérant des outils de base haute performance (Source : NerdyRodent)
DeepSeek met à jour l’article R1 : passage massif de 22 à 86 pages : DeepSeek a mis à jour son article historique sur le modèle R1, ajoutant une quantité considérable d’informations approfondies sur les détails d’entraînement et la conception de l’architecture. Bien que certains contenus aient été révélés dans un précédent article de Nature, cette mise à jour consolide davantage le leadership technique de DeepSeek dans la communauté open-source. La communauté a noté la stabilité de la liste des auteurs et l’expérience d’optimisation continue sur l’architecture MLA (Source : teortaxesTex)

Google fait entrer Gmail dans l’ère Gemini 3 : créer un assistant de boîte de réception proactif : Google a annoncé l’intégration complète de Gemini 3 dans Gmail, transformant l’outil de messagerie simple en un assistant de boîte de réception proactif. Les nouvelles fonctionnalités incluent la gestion intelligente de l’emploi du temps, le résumé automatique de chaînes d’e-mails complexes et des rappels proactifs basés sur le contexte. Cela marque une étape où les grands modèles s’insèrent profondément dans les workflows de productivité, au-delà de la simple « boîte de dialogue », pour une gestion intelligente des données personnelles (Source : GoogleDeepMind)
🧰 Outils
VideoRAG/Vimo : application de bureau open-source pour le dialogue avec des vidéos ultra-longues : L’équipe HKUDS de l’Université de Hong Kong a publié VideoRAG et sa version de bureau Vimo, permettant de dialoguer avec des vidéos de plusieurs centaines d’heures. L’outil utilise un index de connaissances piloté par graphe et un codage contextuel hiérarchique pour localiser précisément les scènes vidéo et répondre aux questions. Il résout les problèmes de pression de mémoire vidéo et de rupture de compréhension des modèles multimodaux traditionnels face aux vidéos longues, et peut fonctionner sur une seule RTX 3090 (Source : GitHub)
memU : infrastructure de mémoire hiérarchique pour AI Agents : NevaMind-AI a rendu memU open-source, un système de mémoire conçu pour les LLM et les Agents. Imitant un système de fichiers, il organise les données brutes, les éléments de mémoire discrets et les catégories agrégées en trois couches, prenant en charge la recherche vectorielle RAG et la recherche sémantique LLM. Le système peut extraire automatiquement les préférences, compétences et faits des conversations, permettant une auto-évolution de la mémoire et améliorant considérablement la cohérence des Agents sur des tâches de longue durée (Source : GitHub)

Maid : application open-source pour exécuter des modèles AI hors ligne sur mobile : Maid est une application open-source permettant de faire tourner des LLM localement sur des appareils mobiles, idéale pour les situations sans connexion ou nécessitant une confidentialité extrême. Elle simplifie le processus de déploiement de modèles sur téléphone, permettant aux utilisateurs de télécharger directement des modèles de différentes tailles pour dialoguer. Cela offre une solution mobile à bas seuil pour l’Edge Computing et la démocratisation de l’AI (Source : Reddit)
Intégration profonde de Claude Code et Replit : un nouveau paradigme de programmation Agent dans le cloud : Des développeurs ont partagé leur expérience pratique de la combinaison de Claude Code et Replit, soulignant les avantages des éditeurs cloud pour résoudre les problèmes de configuration d’environnement. En exécutant Claude Code à l’intérieur de Replit, il est possible de contrôler parallèlement plusieurs Agents pour le développement depuis un mobile. Ce modèle « générer pour déployer » change la logique de livraison logicielle, permettant même aux non-professionnels de construire rapidement des applications complexes (Source : amasad)
📚 Apprentissage
MAGMA : architecture de mémoire à long terme pour Agent basée sur des structures multi-graphes : Pour remédier au problème d’enchevêtrement des informations dans le RAG traditionnel lors de raisonnements à long terme, une nouvelle étude propose l’architecture MAGMA. Elle stocke la mémoire dans quatre graphes orthogonaux : sémantique, temporel, causal et entité, effectuant la recherche via une traversée de graphe guidée par une stratégie. Cette méthode découple la représentation de la mémoire de la logique de recherche, améliorant nettement la précision des Agents face aux relations causales complexes et aux séquences d’événements (Source : dair_ai)

Agentic Rubrics : méthode de vérification pour SWE Agent sans exécution de code : La vérification est la clé de l’apprentissage par renforcement. Des chercheurs proposent les « Agentic Rubrics », où des Agents experts génèrent des listes de contrôle spécifiques à une base de code via interaction pour noter directement les correctifs candidats, sans installation d’environnement complexe ni exécution de code. Sur le benchmark SWE-Bench, cette méthode a considérablement amélioré l’efficacité et le taux de précision de la vérification, offrant un signal de retour plus léger pour l’entraînement d’Agents à grande échelle (Source : arXiv)
Klear : architecture unifiée pour la génération conjointe audio-vidéo : Pour résoudre les problèmes de désynchronisation audio-vidéo et de mauvais alignement labial, Klear introduit un design à tour unique et des blocs DiT unifiés, couplés à une stratégie d’entraînement par masque modal aléatoire. En construisant un vaste ensemble de données audio-vidéo avec des annotations denses, Klear atteint une qualité de génération extrêmement élevée tout en maintenant la cohérence sémantique, avec des performances comparables à Veo 3 de Google (Source : arXiv)
Fine-tuning adaptatif par entropie (EAFT) : résoudre l’oubli catastrophique dans le SFT : L’article souligne que le fine-tuning supervisé (SFT) provoque souvent des « conflits de confiance » en forçant le modèle à s’adapter à une supervision externe. EAFT utilise l’entropie au niveau du token comme mécanisme de porte pour distinguer l’incertitude épistémique du conflit de connaissances, permettant au modèle d’apprendre des échantillons incertains tout en inhibant les mises à jour de gradient des données conflictuelles. Les expériences prouvent que cette méthode atténue efficacement la dégradation des capacités générales tout en maintenant les performances sur les tâches aval (Source : arXiv)
Atlas : orchestration de modèles hétérogènes et d’outils pour le raisonnement complexe multi-domaines : Avec la diversification des LLM et des outils, choisir la meilleure combinaison devient un défi. Atlas propose un framework à double voie : un routage sans entraînement basé sur le clustering pour l’alignement intra-domaine, et un routage multi-étapes basé sur l’apprentissage par renforcement pour la généralisation hors distribution. Ce framework a surpassé GPT-4o sur 15 benchmarks, démontrant la puissance de l’orchestration d’outils multimodaux spécialisés pour résoudre des problèmes complexes (Source : arXiv)
💼 Business
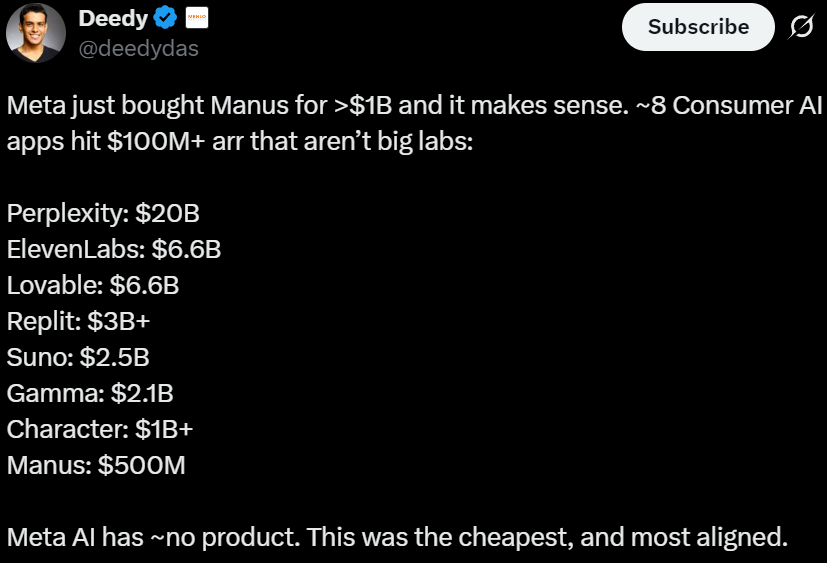
Manus rachetée par Meta, l’ARR dépasse 125 millions de dollars en 8 mois : La startup d’Agents d’exécution de tâches Manus, à la veille de son rachat par Meta pour 2 milliards de dollars, a révélé que son ARR a atteint 125 millions de dollars. Lancé il y a seulement 8 mois, le produit a déjà franchi la barre des 100 millions avec une croissance mensuelle supérieure à 20 %. Cela reflète un changement dans la logique commerciale de l’AI : les utilisateurs ne paient plus pour une « capacité », mais pour des « résultats » et la « livraison de tâches » (Source : 36Kr)
Boltz lève 28 millions de dollars en Seed et s’associe à Pfizer : La startup d’AI en biotechnologie Boltz a annoncé la création de Boltz PBC et une levée de fonds de 28 millions de dollars, lançant simultanément la plateforme Boltz Lab. La plateforme comprend des Agents spécialisés dans la conception de petites molécules et de protéines, et a signé un accord de collaboration pluriannuel avec le géant pharmaceutique Pfizer. Cela marque l’accélération de la commercialisation des AI Agents dans des domaines scientifiques rigoureux comme la R&D de médicaments (Source : sarahcat21)
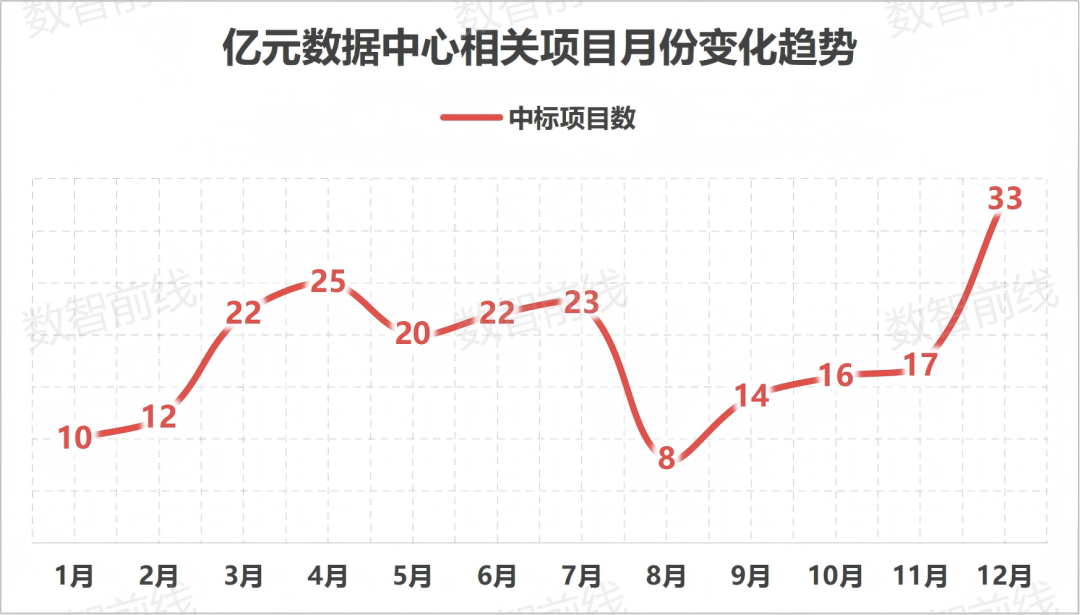
L’infrastructure de calcul en Chine entre dans l’ère des « 10 000 P », plus de 222 projets dépassant les 100 millions de RMB en 2025 : La construction de centres de calcul intelligents reste intense en Chine, les opérateurs devenant les acteurs principaux. En 2025, plus de 222 projets adjugés dépassent les 100 millions de RMB, les clusters de 10 000 cartes devenant la norme. Les tendances montrent que la demande de puissance de calcul pour l’inférence grimpe rapidement, le refroidissement liquide passant d’option à nécessité, l’industrie cherchant à résoudre les problèmes de taux d’utilisation via un modèle « stimuler la construction par l’usage » (Source : 36Kr)
🌟 Communauté
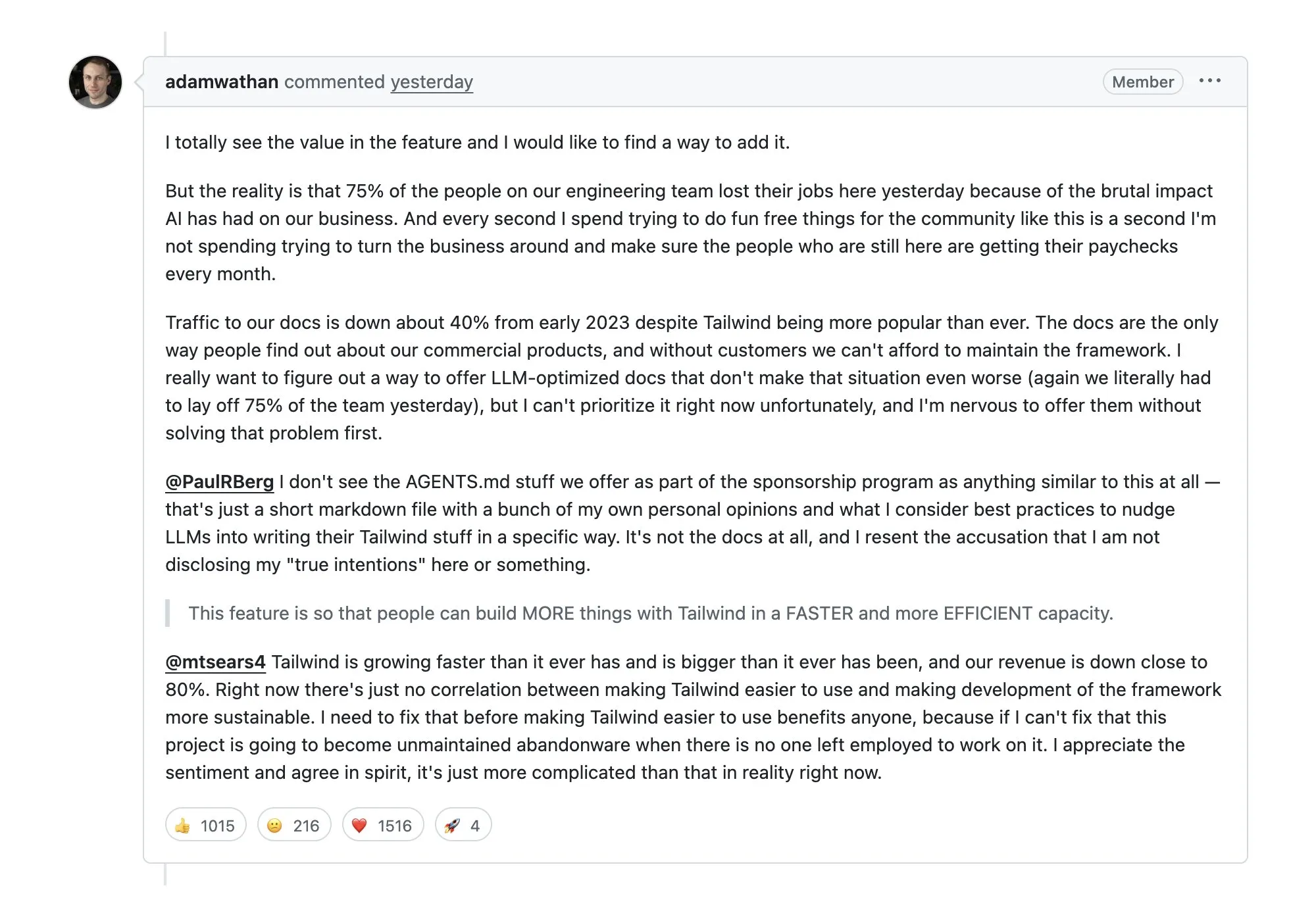
Le licenciement de 75% du personnel chez Tailwind suscite le débat : l’AI entraîne une baisse du trafic documentaire et des revenus : Le célèbre framework CSS Tailwind a été contraint de licencier massivement après que les AI Agents ont largement aspiré sa documentation, entraînant une chute de 40% du trafic sur son site officiel et une réduction drastique des revenus de ses produits payants. Cela soulève de profondes inquiétudes au sein de la communauté sur le « parasitisme de l’AI » envers l’écosystème open-source : quand l’AI fournit directement les réponses, comment le modèle commercial des projets open-source peut-il perdurer ? (Source : aiamblichus)
Le contexte de 1 million de tokens est-il un piège ? Discussion sur l’effet « Lost in the Middle » : Des tests de développeurs ont révélé que bien que les modèles prétendent supporter des millions de tokens de contexte, le taux de rappel des données situées au milieu chute considérablement au-delà de 100 000 tokens. La communauté suggère une stratégie en deux étapes : indexation pour localisation, puis entrée ciblée. Cela indique que l’hygiène des données et les stratégies de recherche sont plus cruciales que la simple poursuite de fenêtres de contexte géantes (Source : Reddit)
Le Vibe Coding devient une nouvelle tendance de développement : passer de l’écriture de code au « réglage du feeling » : La communauté débat du « Vibe Coding », qui consiste à utiliser le langage naturel et des Agents pour un développement non déterministe. Les partisans estiment que cela abaisse les barrières, tandis que les opposants craignent la production massive de « code poubelle » non maintenable. Des organisations comme Datawhale ont déjà publié des tutoriels pour aider les développeurs à passer des démos au développement de programmes AI-natifs (Source : dotey)
Les limites de la compagnie AI : l’externalisation de la valeur émotionnelle suscite des inquiétudes éthiques : Alors que le marché de l’AI de compagnie dépasse les 100 milliards, la société commence à examiner ses risques potentiels. Les interactions « à faible conflit et hautement contrôlables » offertes par l’AI pourraient affaiblir la capacité humaine à gérer les relations réelles, voire provoquer des « attachements délirants partagés ». Les experts appellent à ce que l’AI serve de complément émotionnel et non de substitut aux relations humaines (Source : 36Kr)
💡 Autres
Des agriculteurs chinois utilisent des radars à balayage électronique actif pour lutter contre les sangliers : Avec la démocratisation et la baisse des coûts de la technologie des radars à balayage électronique en Chine, des agriculteurs ont commencé à utiliser des radars AESA couplés à des drones pour détecter les intrusions de sangliers. Ce cas illustre l’application surprenante de technologies militaires de pointe pour résoudre des problèmes civils, reflétant également l’avantage de capacité de production de la Chine dans le domaine des semi-conducteurs GaN (Source : teortaxesTex)
Exposition physique de la puce « chocolat » de Cerebras : une épaisseur impressionnante : Un développeur a partagé des photos réelles de la puce AI à l’échelle du wafer de Cerebras, dont la taille gigantesque et l’épaisseur étonnante ont attiré l’attention. En tant que plus grande puce monolithique au monde, elle représente l’exploration des limites physiques du matériel de calcul dans la quête de performances extrêmes (Source : dylan522p)

Démission collective de l’équipe de protection des données de Debian, la conformité au RGPD (GDPR) menacée : L’équipe de protection des données de Debian, en place depuis 7 ans, a démissionné collectivement par manque de ressources, sans successeur actuel. Cela expose la vulnérabilité des communautés open-source face aux réglementations strictes sur la vie privée (comme le RGPD), l’absence de ces « fondations invisibles » pouvant affecter l’ensemble de la chaîne de l’écosystème Linux (Source : 36Kr)