
Schlüsselwörter:KI-Modell, Autonomes Fahren, Multimodal, GLM-4.7, Alpamayo, Qwen3-VL
🔥 Fokus
Zhipu AI offiziell an der HKEX gelistet, Ära der Large Model IPOs beginnt : Am 8. Januar 2026 ging Zhipu AI offiziell an die HKEX, als weltweit erste Aktie eines Large Model-Unternehmens, gefolgt von MiniMax. Tang Jie verriet in einem internen Brief, dass nach der Veröffentlichung des Flaggschiff-Modells GLM-4.7 der jährliche MaaS-Umsatz (ARR) innerhalb von 10 Monaten um das 25-fache gestiegen ist und 500 Millionen RMB überschritten hat. Dieses Ereignis markiert den Übergang chinesischer Large Models vom „technologischen Aufholen“ zum „Business Loop“. Der IPO wird heimischen Modellen den Weg zum globalen Markt ebnen und eine fairere internationale Bewertung ermöglichen. (Quelle: Zai_org)
Stanford veröffentlicht SleepFM: Vorhersage von über 100 Gesundheitsrisiken durch eine Nacht Schlaf : Forscher der Stanford University stellten das multimodale AI-Modell SleepFM vor, das auf über 585.000 Stunden Schlafdaten trainiert wurde. Durch die Analyse von Gehirnwellen, Herzfrequenz und Atemfrequenz kann das Modell aus einer einzigen Nachtaufzeichnung Risiken für mehr als 130 Krankheiten vorhersagen, darunter Demenz, Herzkrankheiten und bestimmte Krebsarten. Dieser Durchbruch zeigt das enorme Potenzial von AI in der Präventivmedizin und verwandelt Schlafüberwachungsgeräte in leistungsstarke Diagnosetools. (Quelle: Reddit)

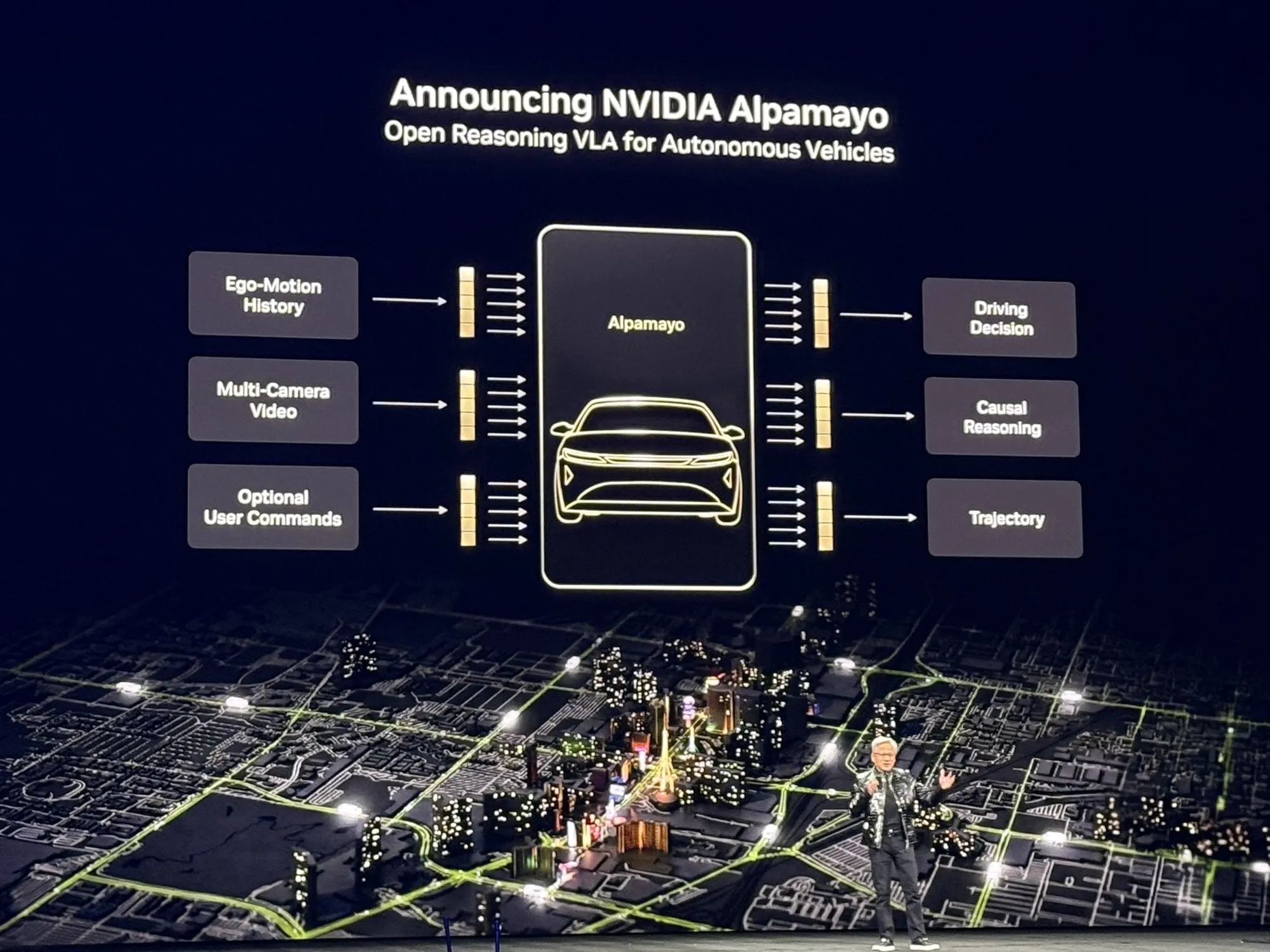
NVIDIA veröffentlicht Alpamayo als Open Source: Erstes autonomes Fahrmodell mit Reasoning-Fähigkeiten : NVIDIA hat Alpamayo quelloffen zur Verfügung gestellt, das erste autonome Fahrmodell, das auf Chain of Thought (CoT) Reasoning basiert. Im Gegensatz zu herkömmlichen Systemen, die nur reagieren, kann Alpamayo wie ein menschlicher Fahrer in komplexen oder seltenen Szenarien logisch denken. In Kombination mit der „AI Factory“ der Vera Rubin-Architektur treibt NVIDIA AI vom rein digitalen Bereich hin zu Physical AI, einschließlich Simulationswerkzeugen und Edge-Computing-Modulen, und definiert damit industrielle Standards für autonomes Fahren neu. (Quelle: TheTuringPost)
LMArena erhält 150 Millionen USD Finanzierung, AI-Evaluierung wird zur Kerninfrastruktur : Die bekannte AI-Modell-Arena LMArena hat eine Finanzierungsrunde über 150 Millionen USD bei einer Bewertung von 1,7 Milliarden USD abgeschlossen. Diese enorme Finanzierung zeigt, dass in einer Zeit, in der ständig neue Modelle erscheinen, objektive und vertrauenswürdige Evaluierungssysteme kein bloßes Hilfsmittel mehr sind, sondern die Kerninfrastruktur des AI-Ökosystems darstellen. Die Kapitalisierung der Evaluierungsfähigkeiten deutet darauf hin, dass sich die Branche von „blindem Kapazitätsausbau“ hin zu „Qualitätsorientierung“ bewegt, löst aber auch breite Diskussionen in der Community über die hohe Bewertung aus. (Quelle: nearcyan)

🎯 Trends
AI21 Labs veröffentlicht Jamba 2-Serie: Hybrid-SSM-Transformer-Architektur für Enterprise-Einsatz : AI21 hat Jamba2 3B und Jamba2 Mini (52B Gesamtparameter, 12B aktiv) vorgestellt. Die Serie nutzt eine Hybrid-SSM-Transformer-Architektur mit einem ultralangen Kontext von 256K und zeigt exzellente Leistungen in Benchmarks wie IFEval. Der Hauptvorteil liegt im hohen Durchsatz und der Speichereffizienz, was sie besonders geeignet für die Verarbeitung langer Dokumente und hochzuverlässige Enterprise Agent-Workflows macht. (Quelle: Reddit)

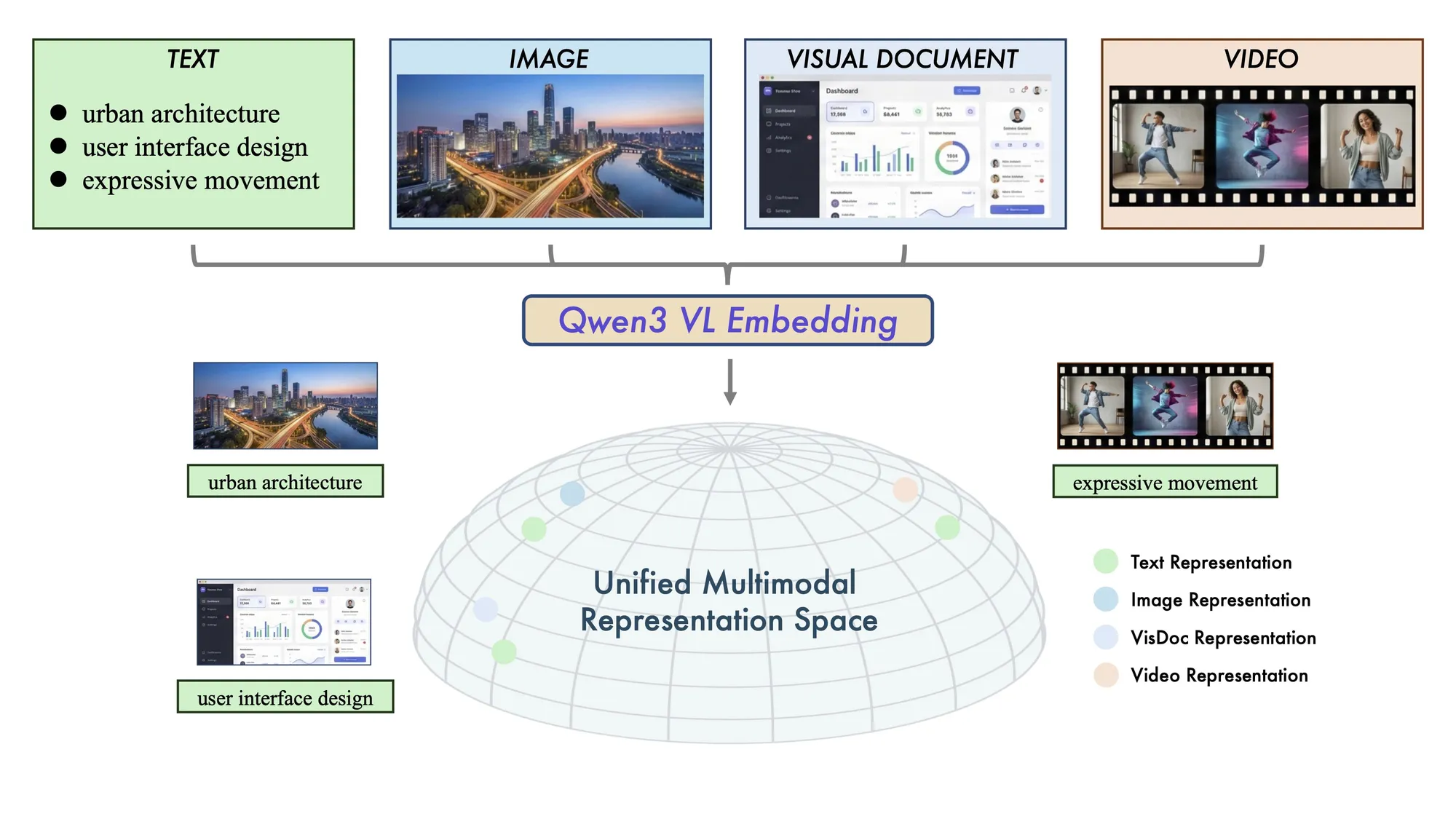
Alibaba veröffentlicht Qwen3-VL Multimodales Retrieval-Modell als Open Source: Fortschritt bei Cross-Modal Understanding SOTA : Alibaba hat die Modelle Qwen3-VL-Embedding und Reranker veröffentlicht, die gemischte Eingaben wie Text, Bilder und Videos unterstützen. Das Modell zeigt herausragende Leistungen in multimodalen RAG, Visual Question Answering und sprachübergreifender Suche und unterstützt über 30 Sprachen. Diese zweistufige Retrieval-Architektur (Vektorgenerierung + Fein-Scoring) verbessert die Präzision bei komplexen visuellen Inhalten erheblich und bietet eine starke Basis für multimodale AI-Anwendungen. (Quelle: Alibaba_Qwen)
NVIDIA veröffentlicht Nemotron Speech ASR: Open Source Spracherkennung mit extrem niedriger Latenz : NVIDIA hat das Nemotron Speech ASR-Modell veröffentlicht, das speziell für Voice Agents entwickelt wurde. Es erreicht eine Transkriptionszeit von 24 ms und eine End-to-End-Interaktionslatenz von unter 500 ms. Das Modell ist vollständig Open Source, einschließlich Gewichten, Code und Trainingsdaten. Jensen Huang betonte auf der CES, dass Open-Source-Modelle in diesem Jahr vollständig zu Closed-Source-Modellen aufschließen werden, und NVIDIA treibt diesen Prozess durch die Freigabe leistungsstarker Basis-Tools voran. (Quelle: NerdyRodent)
DeepSeek aktualisiert R1-Paper: Von 22 auf 86 Seiten massiv erweitert : DeepSeek hat das Paper zu seinem wegweisenden R1-Modell aktualisiert und umfangreiche tiefergehende Informationen zu Trainingsdetails und Architekturdesign hinzugefügt. Obwohl Teile bereits im Nature-Paper veröffentlicht wurden, festigt dieses Update die technologische Führungsposition von DeepSeek in der Open-Source-Community. Die Community bemerkte die Stabilität der Autorenliste sowie die kontinuierliche Optimierungserfahrung mit der MLA-Architektur. (Quelle: teortaxesTex)

Google bringt Gmail in die Gemini 3-Ära: Entwicklung zum proaktiven Posteingangs-Assistenten : Google kündigte die vollständige Integration von Gemini 3 in Gmail an, wodurch es sich von einem einfachen E-Mail-Tool zu einem proaktiven Assistenten wandelt. Zu den neuen Funktionen gehören die intelligente Verwaltung von Terminen, die automatische Zusammenfassung komplexer E-Mail-Ketten sowie proaktive Erinnerungen basierend auf dem Kontext. Dies markiert den Übergang von Large Models von einer reinen „Chatbox“ hin zu einer tiefen Einbettung in Produktivitäts-Workflows zur intelligenten Verwaltung persönlicher Daten. (Quelle: GoogleDeepMind)
🧰 Tools
VideoRAG/Vimo: Open-Source-Desktop-Anwendung für Dialoge mit ultralangen Videos : Das HKUDS-Team der Universität Hongkong hat VideoRAG und dessen Desktop-Version Vimo veröffentlicht, die Dialoge mit hunderten Stunden Videomaterial ermöglichen. Das Tool nutzt graphbasierte Wissensindizierung und hierarchische Kontextkodierung, um Szenen präzise zu finden und Fragen zu beantworten. Es löst Probleme mit VRAM-Druck und Verständnisbrüchen bei herkömmlichen multimodalen Modellen und läuft auf einer einzigen RTX 3090. (Quelle: GitHub)
memU: Hierarchische Speicherinfrastruktur für AI Agents : NevaMind-AI hat memU quelloffen veröffentlicht, ein Speichersystem für LLMs und Agents. Es imitiert ein Dateisystem und organisiert Rohdaten, diskrete Speichereinträge und aggregierte Kategorien in drei Ebenen, wobei RAG-Vektor-Retrieval und LLM-semantisches Retrieval unterstützt werden. Das System extrahiert automatisch Präferenzen, Fähigkeiten und Fakten aus Dialogen, ermöglicht eine Selbstentwicklung des Speichers und verbessert die Kohärenz von Agents bei Langzeitaufgaben erheblich. (Quelle: GitHub)

Maid: Open-Source-App zum Offline-Betrieb von AI-Modellen auf dem Smartphone : Maid ist eine Open-Source-App, die den lokalen Betrieb von LLMs auf Mobilgeräten ermöglicht, besonders geeignet für Szenarien ohne Internet oder mit extrem hohen Datenschutzanforderungen. Sie vereinfacht den Bereitstellungsprozess auf dem Smartphone, sodass Nutzer Modelle verschiedener Größen direkt herunterladen und nutzen können. Dies bietet eine niederschwellige mobile Lösung für Edge Computing und die Verbreitung von AI. (Quelle: Reddit)
Claude Code und Replit tief integriert: Neues Paradigma für Cloud-Agent-Programmierung : Entwickler teilten Praxiserfahrungen zur Kombination von Claude Code und Replit und betonten die Vorteile von Cloud-Editoren bei der Lösung von Konfigurationsproblemen. Durch den Betrieb von Claude Code innerhalb von Replit können mehrere Agents parallel vom Smartphone aus gesteuert werden. Dieses „Generation-as-Deployment“-Modell verändert die Software-Logik und ermöglicht es auch Nicht-Experten, schnell komplexe Anwendungen zu erstellen. (Quelle: amasad)
📚 Learning
MAGMA: Multi-Graph-basierte Langzeitspeicher-Architektur für Agents : Um das Problem der Informationsverflechtung beim Long-Range Reasoning in herkömmlichen RAG-Systemen zu lösen, schlägt eine neue Studie die MAGMA-Architektur vor. Sie speichert Informationen in vier orthogonalen Graphen (Semantik, Zeit, Kausalität und Entität) und nutzt strategiegesteuerte Graph-Traversierung für das Retrieval. Diese Methode entkoppelt die Speicherrepräsentation von der Retrieval-Logik und verbessert die Genauigkeit von Agents bei komplexen kausalen Beziehungen und Ereignissequenzen erheblich. (Quelle: dair_ai)

Agentic Rubrics: SWE Agent-Validierungsmethode ohne Code-Ausführung : Validierung ist der Schlüssel zum Reinforcement Learning. Forscher schlagen „Agentic Rubrics“ vor, bei denen Experten-Agents durch Interaktion Codebase-spezifische Checklisten generieren, um Kandidaten-Patches direkt zu bewerten, ohne komplexe Umgebungen aufzubauen oder Code auszuführen. In SWE-Bench-Tests verbesserte diese Methode die Effizienz und Genauigkeit der Validierung erheblich und bietet ein leichteres Feedback-Signal für das Training von Agents in großem Maßstab. (Quelle: arXiv)
Klear: Einheitliche Architektur für gemeinsame Audio-Video-Generierung : Um Probleme mit asynchronem Audio-Video und schlechter Lippensynchronität zu lösen, führt Klear ein Single-Tower-Design und einheitliche DiT-Blöcke ein, kombiniert mit einer Trainingsstrategie für zufällige Modalitätsmaskierung. Durch den Aufbau eines großen Audio-Video-Datensatzes mit dichten Annotationen erreicht Klear eine extrem hohe Generierungsqualität bei gleichzeitiger semantischer Konsistenz, vergleichbar mit Googles Veo 3. (Quelle: arXiv)
Entropy-Adaptive Fine-Tuning (EAFT): Lösung für katastrophales Vergessen in SFT : Das Paper zeigt auf, dass Supervised Fine-Tuning (SFT) oft zu „Konfidenzkonflikten“ führt, da das Modell gezwungen wird, externe Überwachung anzupassen. EAFT nutzt Token-Level-Entropie als Gating-Mechanismus, um zwischen epistemischer Unsicherheit und Wissenskonflikten zu unterscheiden. Dies erlaubt dem Modell, unsichere Samples zu lernen, während Gradienten-Updates bei konfliktbehafteten Daten unterdrückt werden. Experimente belegen, dass diese Methode die Degradierung allgemeiner Fähigkeiten effektiv mildert. (Quelle: arXiv)
Atlas: Orchestrierung heterogener Modelle und Tools für komplexes domänenübergreifendes Reasoning : Mit der Vielfalt an LLMs und Tools wird die Wahl der optimalen Kombination schwierig. Atlas schlägt ein Dual-Path-Framework vor: Cluster-basiertes, trainingsfreies Routing für In-Domain-Alignment und Reinforcement-Learning-basiertes Multi-Step-Routing für Out-of-Distribution-Generalisierung. Das Framework übertraf GPT-4o in 15 Benchmarks und demonstrierte die Stärke der Orchestrierung spezialisierter multimodaler Tools zur Lösung komplexer Probleme. (Quelle: arXiv)
💼 Business
Manus von Meta übernommen, ARR übersteigt 125 Millionen USD in 8 Monaten : Das Task-Execution-Agent-Startup Manus gab kurz vor der Übernahme durch Meta für 2 Milliarden USD bekannt, dass sein ARR 125 Millionen USD erreicht hat. Nur 8 Monate nach dem Start wurde die 100-Millionen-Marke überschritten, bei einem monatlichen Wachstum von über 20 %. Dies spiegelt den Wandel der AI-Geschäftslogik wider: Nutzer zahlen nicht mehr für „Fähigkeiten“, sondern für „Ergebnisse“ und „Task-Delivery“. (Quelle: 36氪)
Boltz schließt 28 Millionen USD Seed-Runde ab und kooperiert mit Pfizer : Das Biotech-AI-Startup Boltz gab die Gründung von Boltz PBC und eine Finanzierung von 28 Millionen USD bekannt, zeitgleich mit dem Start der Boltz Lab-Plattform. Die Plattform umfasst spezialisierte Agents für das Design kleiner Moleküle und Proteine und unterzeichnete eine mehrjährige Kooperation mit dem Pharmariesen Pfizer. Dies markiert die beschleunigte Kommerzialisierung von AI Agents in streng wissenschaftlichen Bereichen wie der Arzneimittelforschung. (Quelle: sarahcat21)
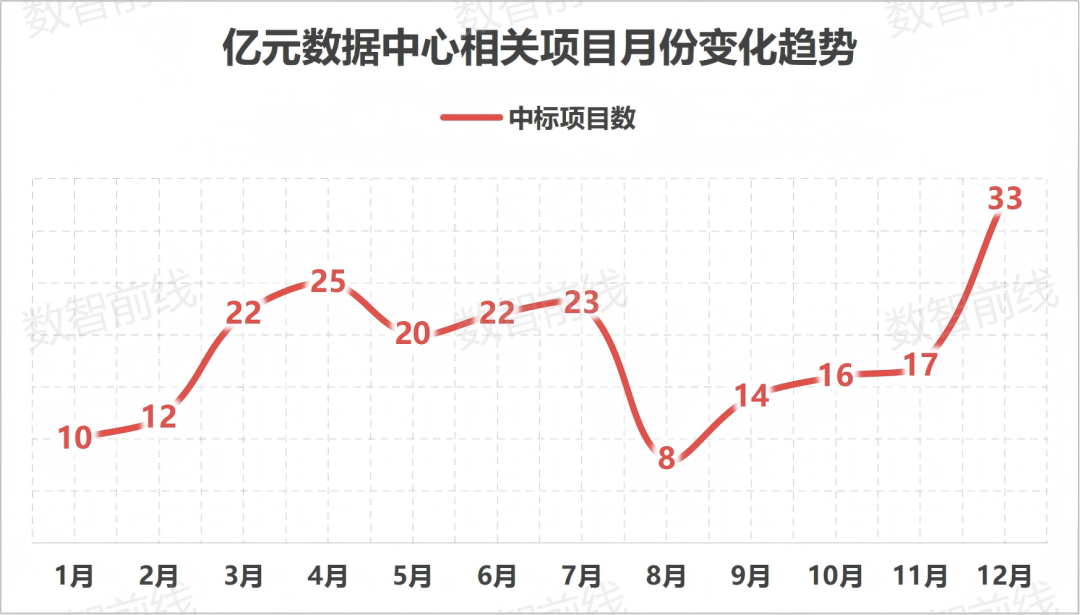
Chinas Rechenleistungsinfrastruktur erreicht „P-Level-Ära“, über 222 Großprojekte im Jahr 2025 : Der Bau von intelligenten Rechenzentren in China boomt weiter, wobei Netzbetreiber die Hauptakteure sind. Im Jahr 2025 gab es über 222 gewonnene Ausschreibungen mit einem Volumen von über 100 Millionen RMB; 10.000-Karten-Cluster werden zum Standard. Trends zeigen, dass der Bedarf an Inferenz-Rechenleistung schnell steigt und Flüssigkeitskühlung von einer Option zur Notwendigkeit wird. (Quelle: 36氪)
🌟 Community
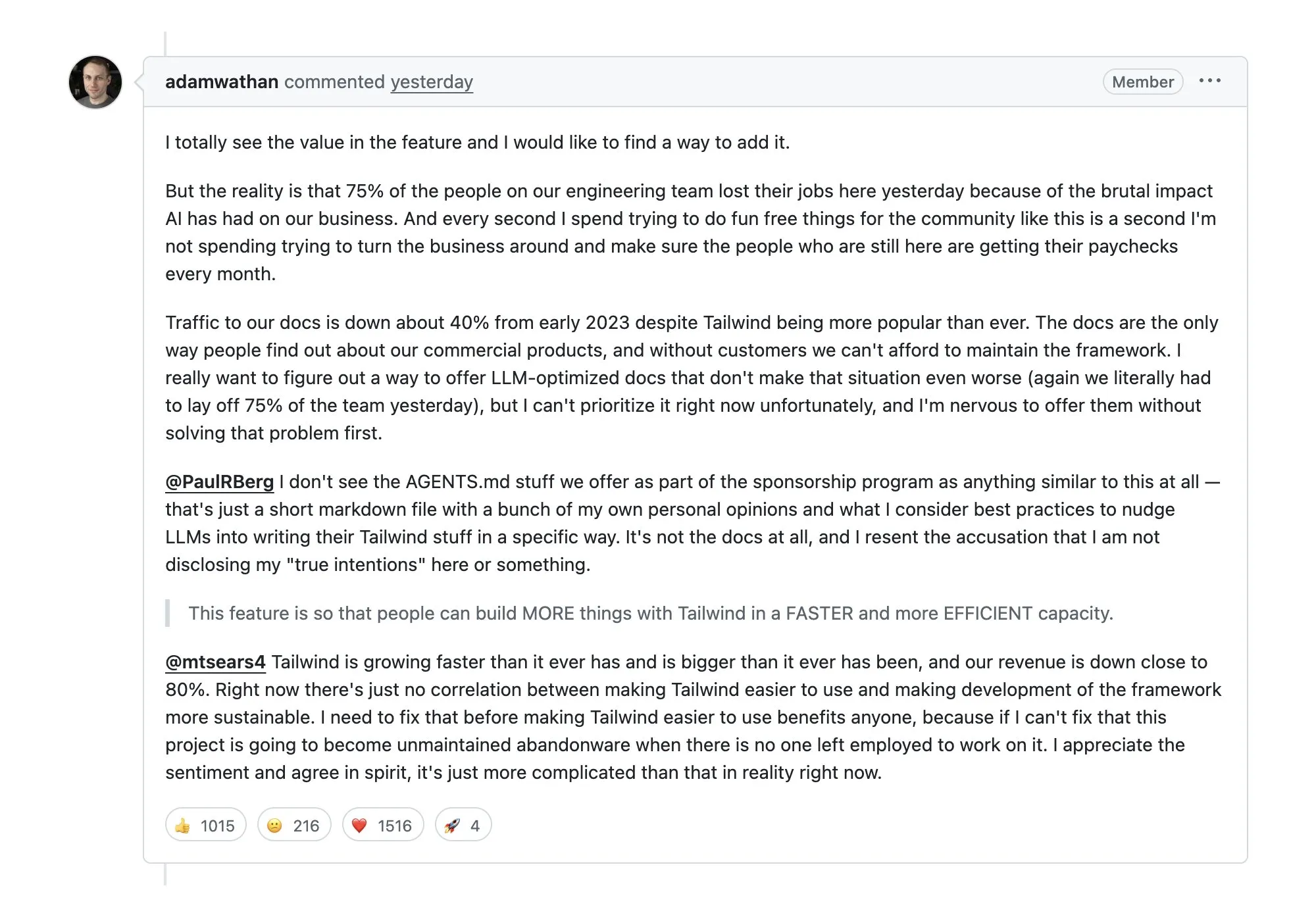
Tailwind entlässt 75 % der Belegschaft und löst Debatten aus: AI führt zu Rückgang bei Traffic und Umsatz : Das bekannte CSS-Framework Tailwind musste 75 % seiner Mitarbeiter entlassen, da AI Agents die Dokumentation massiv crawlen, was zu einem Rückgang des Website-Traffics um 40 % und sinkenden Umsätzen bei Bezahlprodukten führte. Dies löst tiefe Besorgnis über den „AI-Parasitismus“ im Open-Source-Ökosystem aus: Wie bleibt das Geschäftsmodell von Open-Source-Projekten bestehen, wenn AI direkt die Antworten liefert? (Quelle: aiamblichus)
1 Million Token Kontext ein Köder? Community diskutiert „Lost in the Middle“-Effekt : Entwicklertests ergaben, dass Modelle zwar Millionen-Kontexte versprechen, die Recall-Rate im mittleren Teil bei Datenmengen über 100.000 Token jedoch signifikant sinkt. Die Community empfiehlt eine zweistufige Strategie: erst Indizierung zur Lokalisierung, dann gezielte Eingabe. Dies zeigt, dass Datenhygiene und Retrieval-Strategien wichtiger sind als bloße Fenstergröße. (Quelle: Reddit)
Vibe Coding wird neuer Entwicklungstrend: Vom Code-Schreiben zum „Gefühls-Tuning“ : Die Community diskutiert leidenschaftlich über „Vibe Coding“, also die nicht-deterministische Entwicklung mittels natürlicher Sprache und Agents. Befürworter sehen darin eine Senkung der Hürden, Kritiker fürchten die Entstehung von unwartbarem „Code-Müll“. Institutionen wie Datawhale haben bereits Tutorials veröffentlicht, um Entwicklern beim Übergang von Demos zur AI-nativen Programmentwicklung zu helfen. (Quelle: dotey)
AI-Begleitung der Grenzen: Outsourcing von emotionalem Wert wirft ethische Fragen auf : Da der Markt für Begleit-AI die 100-Milliarden-Grenze überschreitet, beginnt die Gesellschaft, Risiken zu prüfen. Die von AI gebotene „konfliktarme, hochgradig kontrollierbare“ Interaktion könnte die Fähigkeit der Menschen schwächen, reale Beziehungen zu führen, und sogar „gemeinsame wahnhafte Bindungen“ auslösen. Experten foderen, dass AI als emotionale Ergänzung und nicht als Ersatz für menschliche Beziehungen dienen sollte. (Quelle: 36氪)
💡 Sonstiges
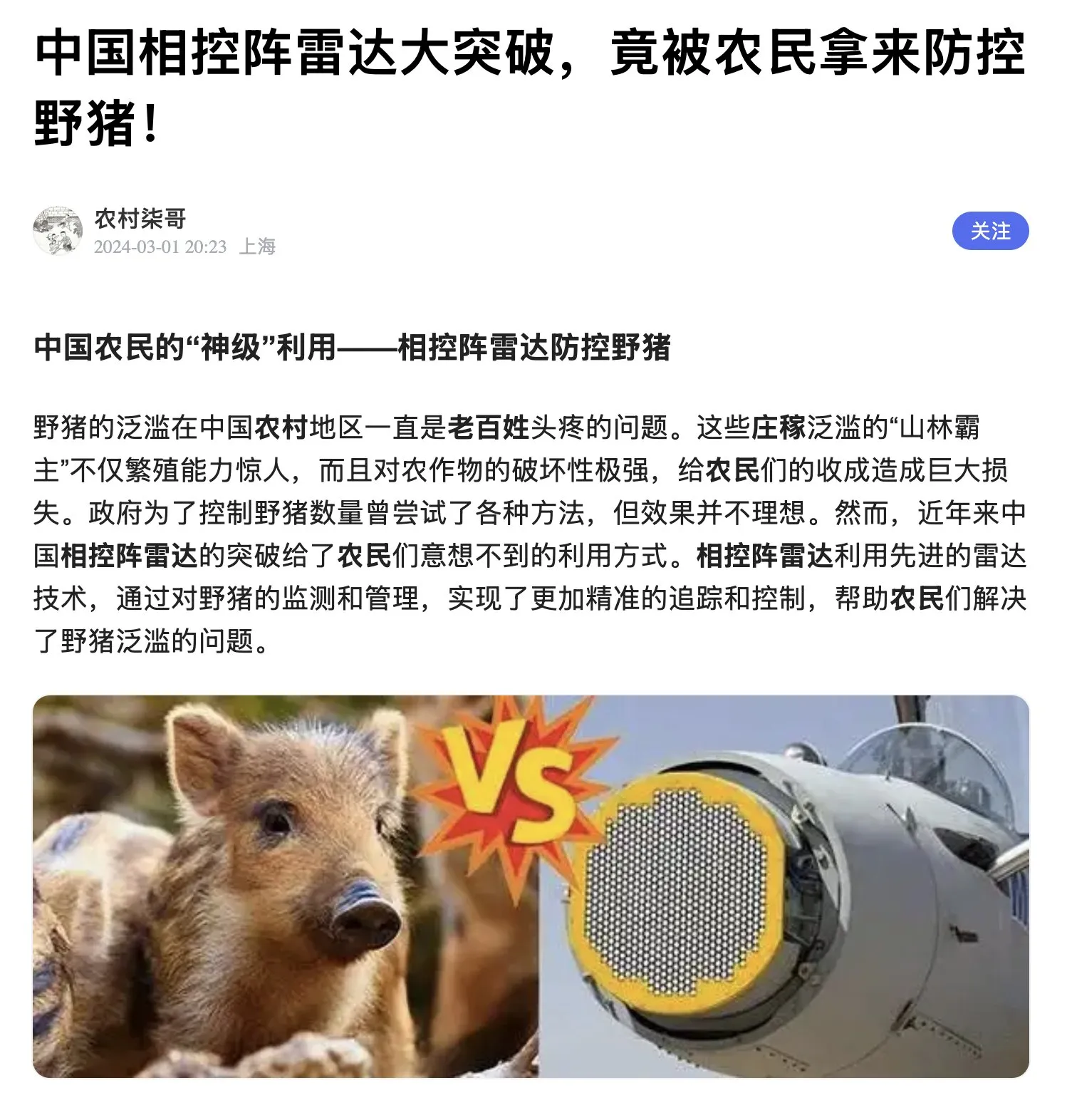
Chinesische Bauern nutzen AESA-Radar gegen Wildschweine : Mit der Kommerzialisierung der Phased-Array-Radartechnologie in China nutzen Bauern nun AESA-Radar in Kombination mit Drohnen, um Wildschwein-Einfälle zu erkennen. Dieser Fall zeigt den ungewöhnlichen Einsatz militärischer Hochtechnologie für zivile Probleme und spiegelt Chinas Produktionsvorteil bei GaN-Halbleitern wider. (Quelle: teortaxesTex)
Cerebras „Schokoladen“-Chip physisch enthüllt: Beeindruckende Dicke : Entwickler zeigten Fotos des Cerebras Wafer-Scale AI-Chips, dessen enorme Größe und Dicke für Aufsehen sorgten. Als weltweit größter Einzelchip repräsentiert er die physikalische Grenzerkundung von Hardware bei der Suche nach extremer Leistung. (Quelle: dylan522p)

Debian Datenschutz-Team tritt geschlossen zurück, GDPR-Compliance vor Herausforderungen : Das vor 7 Jahren gegründete Debian Datenschutz-Team ist wegen Überlastung geschlossen zurückgetreten, bisher gibt es keine Nachfolger. Dies offenbart die Anfälligkeit der Open-Source-Community gegenüber strengen Datenschutzregulierungen (wie GDPR); das Fehlen dieses „unsichtbaren Fundaments“ könnte die gesamte Linux-Ökosystemkette beeinträchtigen. (Quelle: 36氪)