
Keywords:AI model, autonomous driving, multimodal, GLM-4.7, Alpamayo, Qwen3-VL
🔥 Focus
Zhipu AI officially lists on HKEX, ushering in the LLM IPO era: On January 8, 2026, Zhipu AI officially debuted on the Hong Kong Stock Exchange, becoming the world’s first publicly traded LLM company, with MiniMax following closely behind. In an internal letter, Tang Jie revealed that after the release of the flagship GLM-4.7 model, MaaS annual recurring revenue (ARR) grew 25 times in 10 months, surpassing 500 million RMB. This event marks the shift of Chinese LLMs from “technological catch-up” to “commercial closed-loop.” The IPO will open a channel for domestic models to reach the global market and obtain a more equitable international valuation (Source: Zai_org)
Stanford releases SleepFM: Predicting over 100 health risks from a single night’s sleep: Stanford University researchers introduced SleepFM, a multimodal AI model trained on over 585,000 hours of sleep data. By analyzing brain waves, heart rate, and breathing frequency, the model can predict risks for more than 130 diseases, including dementia, heart disease, and certain cancers, from a single night’s recording. This breakthrough demonstrates AI’s massive potential in preventive medicine, transforming sleep monitoring devices into powerful diagnostic tools (Source: Reddit)

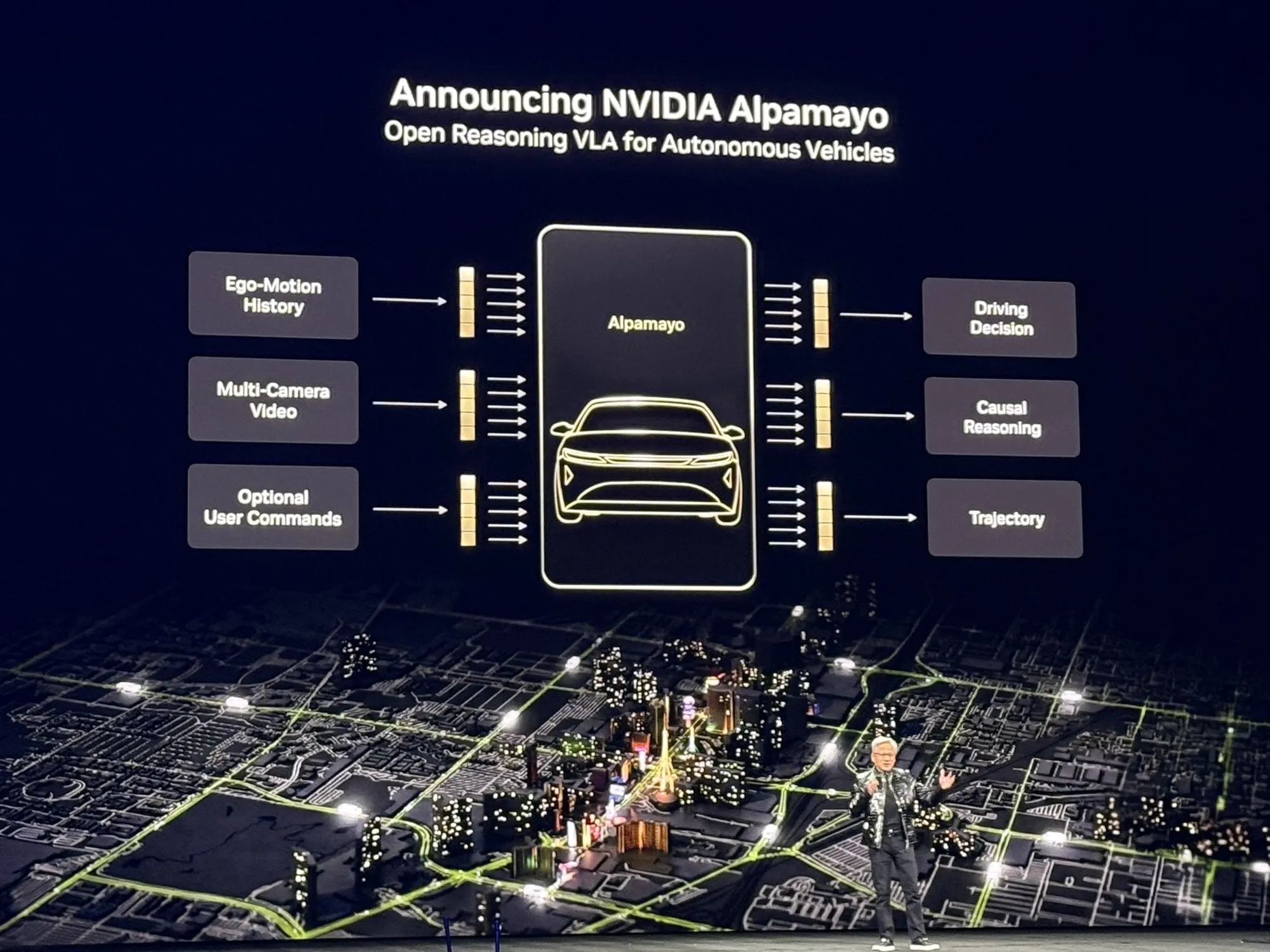
NVIDIA open-sources Alpamayo: The first autonomous driving model with reasoning capabilities: NVIDIA has open-sourced Alpamayo, the first autonomous driving model based on Chain-of-Thought (CoT) reasoning. Unlike traditional reactive systems, Alpamayo can think logically like a human driver in complex or rare scenarios. Combined with the “AI Factory” of the Vera Rubin architecture, NVIDIA is pushing AI from the purely digital realm into Physical AI, covering simulation tools and edge computing modules to reshape industrial-grade autonomous driving standards (Source: TheTuringPost)
LMArena secures $150M funding, AI evaluation becomes core infrastructure: The renowned AI model arena LMArena completed a $150 million funding round at a $1.7 billion valuation. This massive investment indicates that as models proliferate, objective and trustworthy evaluation systems are no longer just auxiliary tools but core infrastructure for the AI ecosystem. The capitalization of evaluation capabilities signals an industry shift from “blind expansion” to “quality-driven,” while also sparking widespread community discussion regarding its high valuation (Source: nearcyan)

🎯 Trends
AI21 Labs releases Jamba 2 series: Hybrid SSM-Transformer architecture targets enterprise-grade: AI21 introduced Jamba2 3B and Jamba2 Mini (52B total parameters, 12B active). This series utilizes a hybrid SSM-Transformer architecture with a 256K ultra-long context window, performing excellently on instruction-following benchmarks like IFEval. Its core advantages lie in high throughput and memory efficiency, making it particularly suitable for processing long documents and high-reliability enterprise Agent workflows (Source: Reddit)

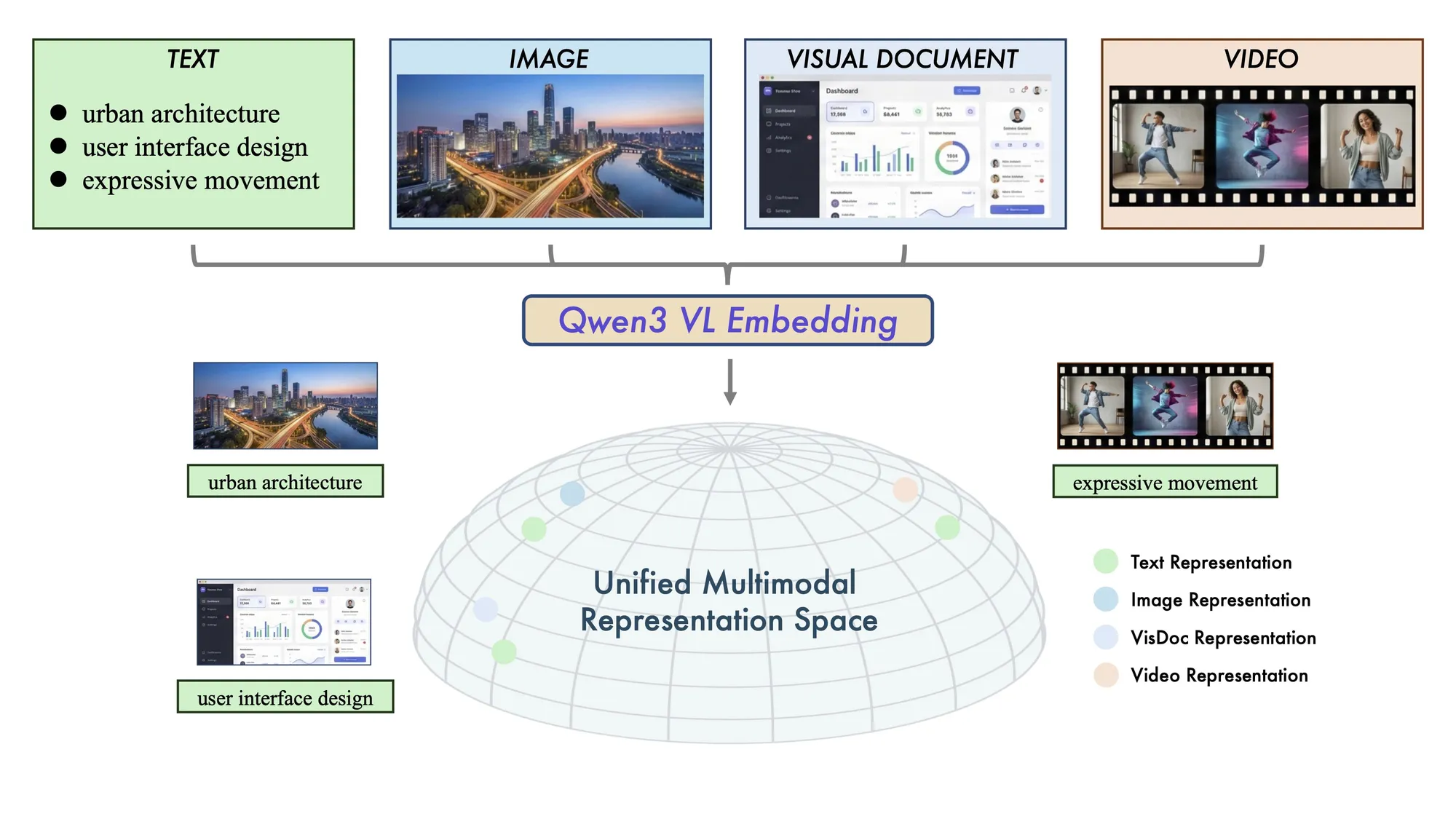
Alibaba open-sources Qwen3-VL multimodal retrieval models: Advancing cross-modal understanding SOTA: Alibaba released Qwen3-VL-Embedding and Reranker models, supporting mixed-modal inputs including text, images, and video. The models excel in multimodal RAG, visual QA, and cross-lingual search, supporting over 30 languages. This two-stage retrieval architecture (vector generation + fine-grained scoring) significantly improves retrieval accuracy for complex visual content, providing robust underlying support for multimodal AI applications (Source: Alibaba_Qwen)
NVIDIA releases Nemotron Speech ASR: Ultra-low latency open-source speech recognition: NVIDIA released the Nemotron Speech ASR model designed specifically for voice Agents, achieving a 24ms transcription completion time and sub-500ms end-to-end voice interaction latency. The model is fully open-source, including weights, code, and training data. Jensen Huang emphasized at CES that open-source models will fully catch up with closed-source models this year, and NVIDIA is driving this process by releasing high-performance underlying tools (Source: NerdyRodent)
DeepSeek updates R1 paper: Expanded significantly from 22 to 86 pages: DeepSeek updated its landmark R1 model paper, adding extensive in-depth information on training details and architectural design. Although some content was previously disclosed in a Nature paper, this update further consolidates DeepSeek’s technical leadership in the open-source community. The community noted the stability of its author list and its continuous optimization experience with the MLA architecture (Source: teortaxesTex)

Google brings Gmail into the Gemini 3 era: Creating a proactive inbox assistant: Google announced the full integration of Gemini 3 into Gmail, transforming it from a simple email tool into a proactive inbox assistant. New features include intelligent life schedule management, automatic summarization of complex email threads, and context-based proactive reminders. This marks the deep embedding of LLMs from “chatboxes” into productivity workflows, enabling intelligent management of personal data (Source: GoogleDeepMind)
🧰 Tools
VideoRAG/Vimo: Open-source desktop app supporting dialogue with ultra-long videos: The HKUDS team from the University of Hong Kong released VideoRAG and its desktop version Vimo, supporting dialogue with videos spanning hundreds of hours. The tool uses graph-driven knowledge indexing and hierarchical context encoding to accurately retrieve video scenes and answer questions. It solves memory pressure and understanding gaps faced by traditional multimodal models when handling long videos, and can run on a single RTX 3090 (Source: GitHub)
memU: Hierarchical memory infrastructure for AI Agents: NevaMind-AI open-sourced memU, a memory system designed for LLMs and Agents. It mimics a file system, organizing raw data, discrete memory items, and aggregated categories into three layers, supporting both RAG vector retrieval and LLM semantic retrieval. The system automatically extracts preferences, skills, and facts from conversations to achieve self-evolving memory, significantly improving Agent coherence in long-term tasks (Source: GitHub)

Maid: Open-source app for running AI models offline on mobile: Maid is an open-source app that supports running LLMs locally on mobile devices, particularly suitable for offline scenarios or those with high privacy requirements. It simplifies the mobile model deployment process, allowing users to directly download models of various sizes for dialogue. This provides a low-barrier mobile solution for edge computing and AI democratization (Source: Reddit)
Claude Code and Replit deep integration: A new paradigm for cloud Agent programming: Developers shared practical experiences combining Claude Code with Replit, emphasizing the advantages of cloud editors in solving environment configuration pain points. By running Claude Code within Replit, developers can parallelly control multiple Agents for development from a mobile device. This “generate-to-deploy” model is changing software delivery logic, allowing non-professional developers to build complex applications quickly (Source: amasad)
📚 Learning
MAGMA: Long-term memory architecture for Agents based on multi-graph structures: Addressing information entanglement issues in traditional RAG during long-term reasoning, new research proposes the MAGMA architecture. It stores memory in four orthogonal graphs: semantic, temporal, causal, and entity, retrieving information through policy-guided graph traversal. This method decouples memory representation from retrieval logic, significantly enhancing Agent accuracy when handling complex causal relationships and event sequences (Source: dair_ai)

Agentic Rubrics: SWE Agent verification method without code execution: Verification is key to reinforcement learning. Researchers proposed “Agentic Rubrics,” where expert Agents generate codebase-specific checklists through interaction to directly score candidate patches without complex environment setup or code execution. In SWE-Bench tests, this method significantly improved verification efficiency and accuracy, providing a lighter feedback signal for large-scale Agent training (Source: arXiv)
Klear: A unified architecture for joint audio-video generation: To address audio-video desynchronization and poor lip-syncing, Klear introduces a single-tower design and unified DiT blocks, paired with a random modality masking training strategy. By constructing a large-scale audio-video dataset with dense annotations, Klear achieves extremely high generation quality while maintaining semantic consistency, with performance comparable to Google’s Veo 3, offering a new path for multimodal synthesis (Source: arXiv)
Entropy-Adaptive Fine-Tuning (EAFT): Solving catastrophic forgetting in SFT: A paper points out that Supervised Fine-Tuning (SFT) often leads to “confidence conflict” by forcing models to fit external supervision. EAFT uses token-level entropy as a gating mechanism to distinguish between epistemic uncertainty and knowledge conflict, allowing the model to learn from uncertain samples while suppressing gradient updates for conflicting data. Experiments prove this method effectively mitigates general capability degradation while maintaining downstream task performance (Source: arXiv)
Atlas: Orchestrating heterogeneous models and tools for cross-domain complex reasoning: As LLMs and tools diversify, choosing the optimal combination becomes difficult. Atlas proposes a dual-path framework: training-free routing based on clustering for in-domain alignment, and multi-step routing based on reinforcement learning for out-of-distribution generalization. The framework outperformed GPT-4o across 15 benchmarks, demonstrating the power of orchestrating specialized multimodal tools to solve complex problems (Source: arXiv)
💼 Business
Manus acquired by Meta, ARR exceeds $125M in 8 months: Task-execution Agent startup Manus disclosed an ARR of $125 million shortly before being acquired by Meta for $2 billion. The product reached the hundred-million mark just 8 months after launch, with month-over-month growth exceeding 20%. This reflects a shift in AI business logic: users are no longer paying for “capability,” but for “results” and “task delivery” (Source: 36Kr)
Boltz completes $28M seed round and partners with Pfizer: Biotech AI startup Boltz announced the formation of Boltz PBC and secured $28 million in funding, simultaneously launching the Boltz Lab platform. The platform includes specialized Agents for small molecule and protein design and has signed a multi-year partnership with pharmaceutical giant Pfizer. This marks the accelerated commercialization of AI Agents in rigorous scientific fields like drug discovery (Source: sarahcat21)
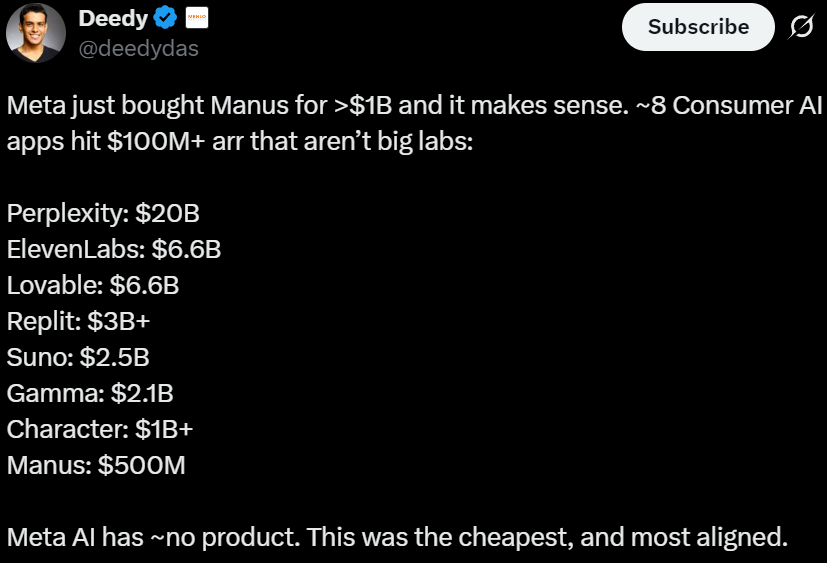
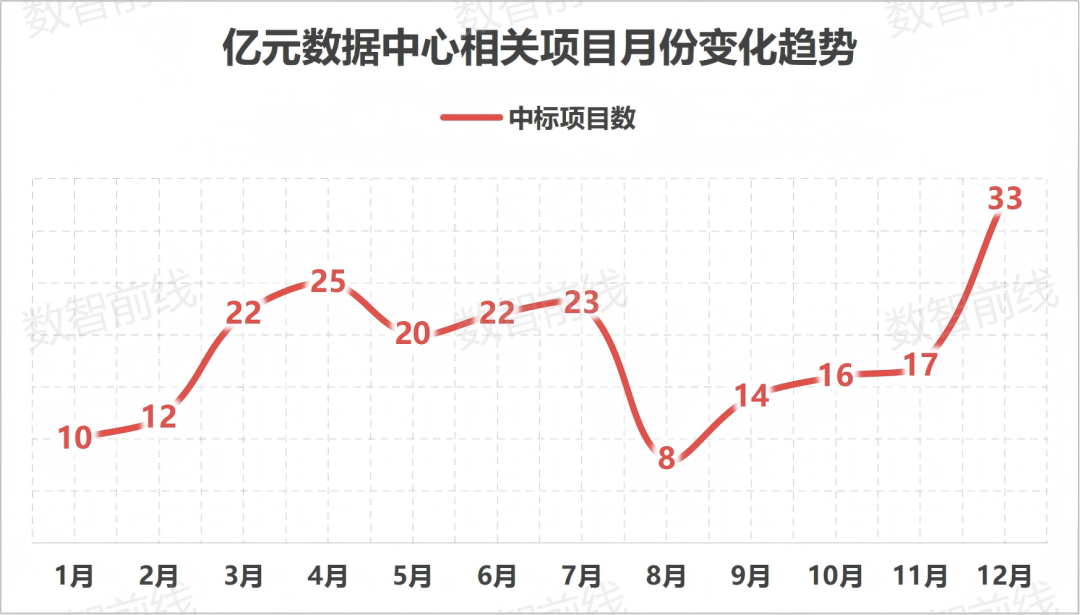
China’s computing infrastructure enters the “10,000P Era,” with over 222 projects exceeding 100M RMB in 2025: Domestic intelligent computing center construction remains hot, with telecom operators as the primary drivers. In 2025, there were over 222 winning bids for projects exceeding 100 million RMB, with 10,000-card clusters becoming standard. Trends show that inference computing demand is climbing rapidly, liquid cooling technology has moved from optional to mandatory, and the industry is solving utilization issues through a “use-driven construction” model (Source: 36Kr)
🌟 Community
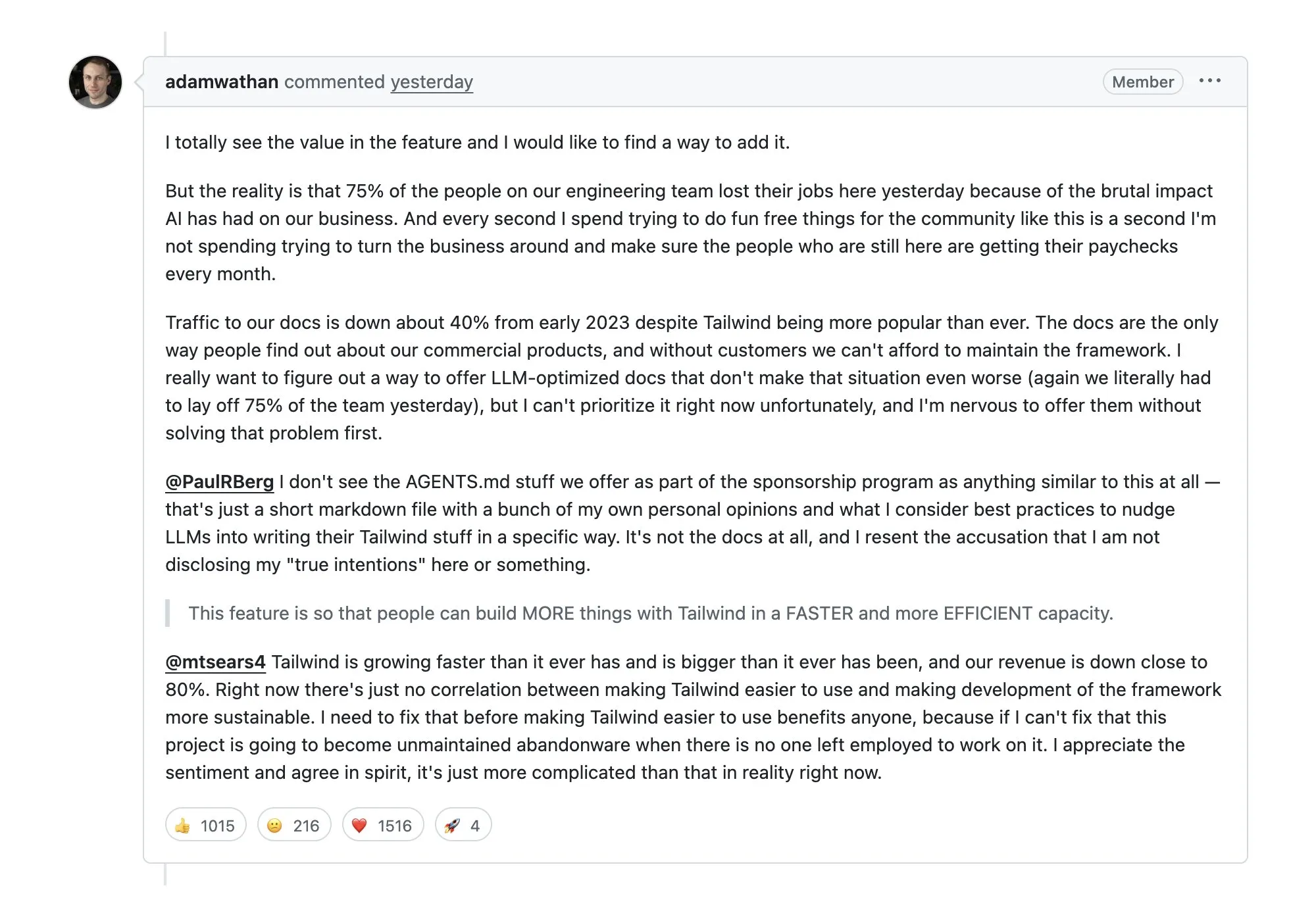
Tailwind layoffs of 75% spark debate: AI leads to drop in documentation traffic and revenue: Renowned CSS framework Tailwind was forced to lay off staff after AI Agents extensively scraped its documentation, leading to a 40% drop in website traffic and a sharp decline in paid product revenue. This has sparked deep concern in the community regarding “AI parasitism” in the open-source ecosystem: when AI directly provides answers, how can the business model of open-source projects be sustained? (Source: aiamblichus)
Is the 1 million token context a trap? Community discusses “Lost in the Middle” effect: Developer tests found that although models claim to support million-level contexts, recall rates for the middle portion drop significantly when processing data over 100,000 tokens. The community suggests a “two-step” strategy: index and locate first, then provide targeted input. This indicates that data hygiene and retrieval strategies are more important than simply chasing long windows (Source: Reddit)
Vibe Coding becomes a new development trend: From writing code to “tuning the feel”: The community is buzzing about “Vibe Coding”—using natural language and Agents for non-deterministic development. Supporters believe it lowers the barrier to entry, while opponents fear it will produce massive amounts of unmaintainable “code junk.” Organizations like Datawhale have released systematic tutorials to help developers transition from Demos to AI-native application development (Source: dotey)
The boundaries of AI companionship: Outsourcing emotional value raises ethical concerns: As the companion AI market surpasses 100 billion, society is beginning to scrutinize potential risks. The “low-conflict, high-control” interactions provided by AI may weaken human ability to handle real-world relationships, potentially leading to “shared delusional bonding.” Experts urge that AI should serve as an emotional supplement, not a replacement for human relationships (Source: 36Kr)
💡 Others
Chinese farmers use AESA radar to control wild boars: With Active Electronically Scanned Array (AESA) radar technology becoming “commoditized” and civilianized in China, farmers have begun using it alongside drones to detect wild boar intrusions. This case showcases the unique phenomenon of high-end military technology solving civilian pain points and reflects China’s production capacity advantage in GaN semiconductors (Source: teortaxesTex)
Cerebras “Chocolate” chip physical unit exposed: Incredible thickness: A developer shared a photo of the Cerebras wafer-scale AI chip, drawing attention for its massive size and surprising thickness. As the world’s largest single chip, it represents the exploration of physical limits in the pursuit of extreme computing performance (Source: dylan522p)

Debian Data Protection team resigns en masse, GDPR compliance faces challenges: The 7-year-old Debian Data Protection team resigned collectively due to limited bandwidth, with no current successors. This exposes the vulnerability of open-source communities in dealing with strict privacy regulations like GDPR; the lack of this “invisible foundation” could affect the entire Linux ecosystem (Source: 36Kr)