
Palavras-chave:Modelo de IA, Direção autônoma, Multimodal, GLM-4.7, Alpamayo, Qwen3-VL
🔥 Destaques
Zhipu AI abre oficialmente o capital na Bolsa de Hong Kong, iniciando a era dos IPOs de grandes modelos : Em 8 de janeiro de 2026, a Zhipu AI foi listada oficialmente na Bolsa de Valores de Hong Kong, tornando-se a primeira ação de grandes modelos do mundo, com a MiniMax logo atrás. Tang Jie revelou em uma carta interna que, após o lançamento do modelo flagship GLM-4.7, a receita anualizada (ARR) de MaaS cresceu 25 vezes em 10 meses, ultrapassando 500 milhões de RMB. Este evento marca a transição dos grandes modelos chineses da “perseguição tecnológica” para o “ciclo comercial fechado”, e o IPO abrirá canais para os modelos nacionais acessarem o mercado global, obtendo uma avaliação de valor internacional mais justa (Fonte: Zai_org)
Stanford lança SleepFM: prevendo mais de cem riscos de saúde através de uma noite de sono : Pesquisadores da Universidade de Stanford lançaram o modelo de AI multimodal SleepFM, treinado com base em mais de 585.000 horas de dados de sono. Ao analisar ondas cerebrais, frequência cardíaca e frequência respiratória, o modelo pode prever mais de 130 riscos de doenças, incluindo demência, doenças cardíacas e certos tipos de câncer, a partir de um registro de apenas uma noite. Este avanço demonstra o enorme potencial da AI na medicina preventiva, transformando dispositivos de monitoramento do sono em poderosas ferramentas de diagnóstico (Fonte: Reddit)

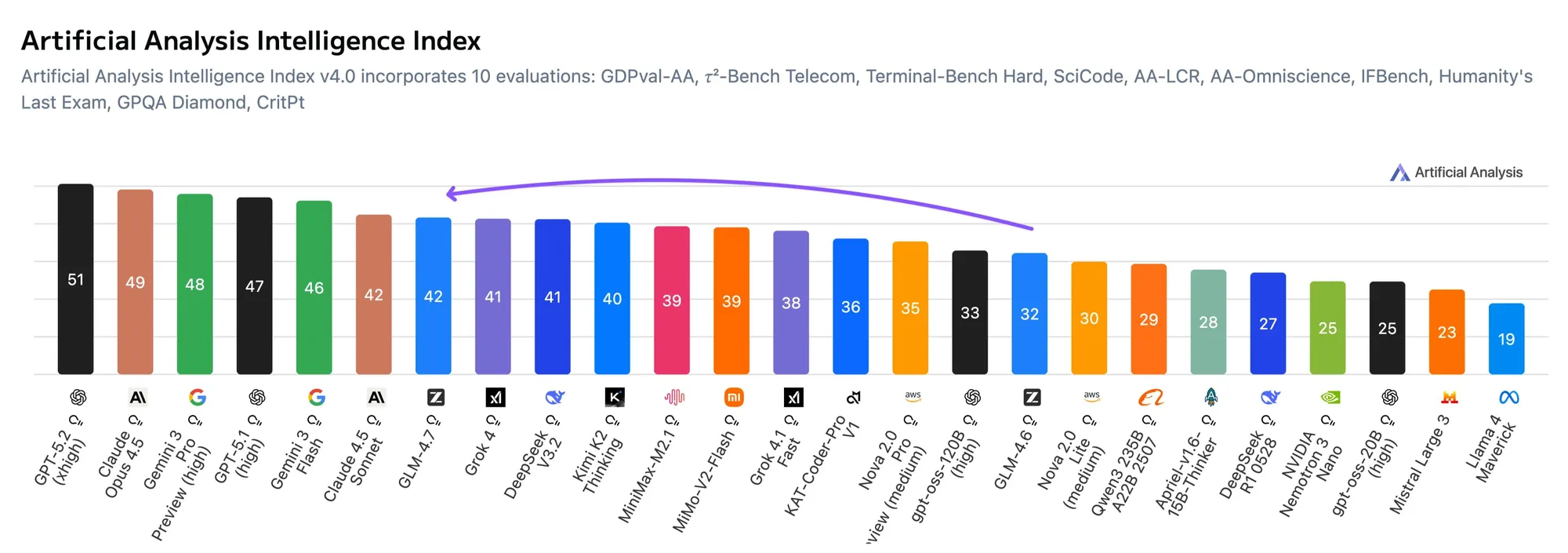
NVIDIA torna Alpamayo open-source: o primeiro modelo de direção autônoma com capacidades de raciocínio : A NVIDIA disponibilizou em código aberto o Alpamayo, o primeiro modelo de direção autônoma baseado em raciocínio Chain of Thought (CoT). Diferente dos sistemas tradicionais baseados apenas em reação, o Alpamayo pode realizar raciocínio lógico em cenários complexos ou raros, assim como um motorista humano. Combinando a “AI Factory” da arquitetura Vera Rubin, a NVIDIA está impulsionando a AI do domínio puramente digital para a Physical AI, abrangendo ferramentas de simulação e módulos de computação de borda, remodelando os padrões de direção autônoma de nível industrial (Fonte: TheTuringPost)
LMArena obtém US$ 150 milhões em financiamento, avaliação de AI torna-se infraestrutura central : A renomada arena de modelos de AI, LMArena, concluiu uma rodada de financiamento de US$ 150 milhões com uma avaliação de US$ 1,7 bilhão. Este enorme financiamento indica que, no momento em que modelos surgem incessantemente, sistemas de avaliação objetivos e confiáveis não são mais ferramentas auxiliares, mas sim a infraestrutura central do ecossistema de AI. A capitalização da capacidade de avaliação sinaliza que a indústria está mudando da “expansão cega” para a “orientação por qualidade”, ao mesmo tempo em que gera discussões amplas na comunidade sobre sua alta avaliação (Fonte: nearcyan)

🎯 Tendências
AI21 Labs lança série Jamba 2: arquitetura híbrida SSM-Transformer focada em nível empresarial : A AI21 lançou o Jamba 2 3B e o Jamba 2 Mini (52B parâmetros totais, 12B ativos). Esta série adota uma arquitetura híbrida SSM-Transformer com um contexto ultra-longo de 256K, apresentando excelente desempenho em benchmarks de seguimento de instruções como o IFEval. Sua principal vantagem reside no alto throughput e na eficiência de memória, sendo especialmente adequada para processar documentos longos e fluxos de trabalho de Agent empresariais que exigem alta confiabilidade (Fonte: Reddit)

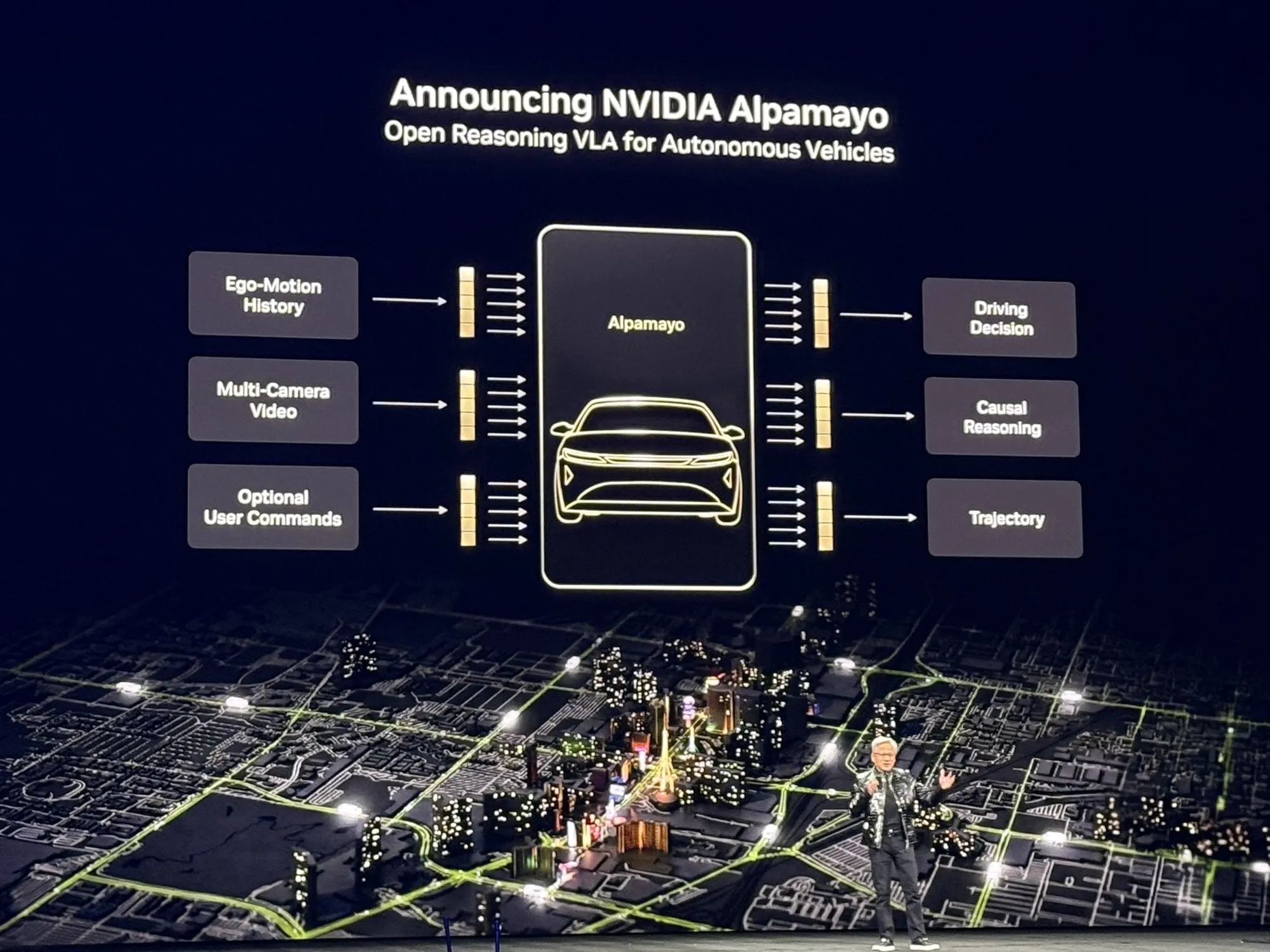
Alibaba torna open-source o modelo de recuperação multimodal Qwen3-VL: impulsionando o SOTA em compreensão cross-modal : O Alibaba lançou os modelos Qwen3-VL-Embedding e Reranker, que suportam entradas de modalidades mistas como texto, imagem e vídeo. O modelo apresenta desempenho excepcional em RAG multimodal, Visual Question Answering e busca cross-lingual, suportando mais de 30 idiomas. Esta arquitetura de recuperação em dois estágios (geração de vetores + pontuação refinada) melhora significativamente a precisão da recuperação de conteúdos visuais complexos, fornecendo suporte fundamental robusto para aplicações de AI multimodal (Fonte: Alibaba_Qwen)
NVIDIA lança Nemotron Speech ASR: reconhecimento de voz de ultra-baixa latência em open-source : A NVIDIA lançou o modelo Nemotron Speech ASR, projetado especificamente para Voice Agents, alcançando um tempo de conclusão de transcrição de 24ms e uma latência de interação de voz ponta a ponta inferior a 500ms. O modelo é totalmente open-source, incluindo pesos, código e dados de treinamento. Jensen Huang enfatizou na CES que os modelos open-source alcançarão totalmente os modelos fechados este ano, e a NVIDIA está impulsionando esse processo ao liberar ferramentas fundamentais de alto desempenho (Fonte: NerdyRodent)
DeepSeek atualiza o paper do R1: expandido significativamente de 22 para 86 páginas : A DeepSeek atualizou o paper do seu modelo histórico R1, adicionando uma grande quantidade de informações detalhadas sobre o treinamento e o design da arquitetura. Embora parte do conteúdo já tenha sido revelada em um paper anterior na Nature, esta atualização consolida ainda mais a liderança tecnológica da DeepSeek na comunidade open-source. A comunidade notou a estabilidade da lista de autores e a experiência contínua de otimização na arquitetura MLA (Fonte: teortaxesTex)

Google leva o Gmail para a era Gemini 3: criando um assistente de caixa de entrada proativo : O Google anunciou a integração total do Gemini 3 ao Gmail, transformando-o de uma simples ferramenta de e-mail em um assistente de caixa de entrada proativo. As novas funções incluem gerenciamento inteligente de agendas, resumo automático de cadeias de e-mails complexas e lembretes proativos baseados no contexto. Isso marca a transição dos grandes modelos de uma forma de “caixa de diálogo” para uma incorporação profunda nos fluxos de trabalho de produtividade, alcançando o gerenciamento inteligente de dados pessoais (Fonte: GoogleDeepMind)
🧰 Ferramentas
VideoRAG/Vimo: aplicação desktop open-source que suporta diálogos com vídeos ultra-longos : A equipe HKUDS da Universidade de Hong Kong lançou o VideoRAG e sua versão desktop Vimo, que suporta diálogos com vídeos de centenas de horas de duração. A ferramenta utiliza indexação de conhecimento baseada em grafos e codificação de contexto hierárquica para recuperar cenas de vídeo com precisão e responder a perguntas. Ela resolve os problemas de pressão de memória de vídeo e falhas de compreensão de modelos multimodais tradicionais ao lidar com vídeos longos, podendo rodar em uma única RTX 3090 (Fonte: GitHub)
memU: infraestrutura de memória hierárquica para AI Agents : A NevaMind-AI lançou em código aberto o memU, um sistema de memória projetado para LLMs e Agents. Ele imita um sistema de arquivos, organizando dados brutos, itens de memória discretos e categorias agregadas em três camadas, suportando recuperação vetorial RAG e recuperação semântica de LLM. O sistema pode extrair automaticamente preferências, habilidades e fatos de diálogos, alcançando a auto-evolução da memória e melhorando significativamente a continuidade dos Agents em tarefas de longo prazo (Fonte: GitHub)

Maid: aplicativo open-source para rodar modelos de AI offline no celular : Maid é um App open-source que suporta a execução local de LLMs em dispositivos móveis, sendo especialmente adequado para cenários sem internet ou com requisitos de privacidade extremamente altos. Ele simplifica o processo de implantação de modelos em smartphones, permitindo que os usuários baixem modelos de diferentes tamanhos para conversar. Isso fornece uma solução móvel de baixo custo para computação de borda e popularização da AI (Fonte: Reddit)
Integração profunda entre Claude Code e Replit: novo paradigma de programação com Agents na nuvem : Desenvolvedores compartilharam experiências práticas da combinação do Claude Code com o Replit, enfatizando as vantagens dos editores na nuvem em resolver problemas de configuração de ambiente. Ao rodar o Claude Code dentro do Replit, é possível controlar múltiplos Agents simultaneamente a partir de um celular para o desenvolvimento. Este modelo de “geração é implantação” está mudando a lógica de entrega de software, permitindo que desenvolvedores não profissionais construam aplicações complexas rapidamente (Fonte: amasad)
📚 Aprendizado
MAGMA: arquitetura de memória de longo prazo para Agents baseada em estrutura multigrafo : Visando o problema de emaranhamento de informações no RAG tradicional durante o raciocínio de longo prazo, uma nova pesquisa propõe a arquitetura MAGMA. Ela armazena a memória em quatro grafos ortogonais: semântico, temporal, causal e de entidades, realizando a recuperação através de travessia de grafos guiada por políticas. Este método desacopla a representação da memória da lógica de recuperação, melhorando significativamente a precisão dos Agents ao lidar com relações causais complexas e sequências de eventos (Fonte: dair_ai)

Agentic Rubrics: método de verificação para SWE Agents sem execução de código : A verificação é a chave para o aprendizado por reforço. Pesquisadores propuseram as “Agentic Rubrics”, onde Agents especialistas geram checklists específicos para bases de código através de interação, pontuando diretamente os patches candidatos sem a necessidade de configurações de ambiente complexas ou execução de código. Nos testes do SWE-Bench, este método melhorou significativamente a eficiência e a taxa de precisão da verificação, fornecendo um sinal de feedback mais leve para o treinamento de Agents em larga escala (Fonte: arXiv)
Klear: arquitetura unificada para geração conjunta de áudio e vídeo : Para resolver problemas de dessincronização de áudio e vídeo e alinhamento labial ruim, o Klear introduz um design de torre única e blocos DiT unificados, combinados com uma estratégia de treinamento de máscara de modalidade aleatória. Ao construir um conjunto de dados de áudio e vídeo em larga escala com anotações densas, o Klear alcançou uma qualidade de geração extremamente alta mantendo a consistência semântica, com desempenho comparável ao Veo 3 do Google, fornecendo um novo caminho para a síntese multimodal (Fonte: arXiv)
Entropy-Adaptive Fine-Tuning (EAFT): resolvendo o esquecimento catastrófico em SFT : O paper aponta que o ajuste fino supervisionado (SFT) frequentemente causa “conflito de confiança” devido à imposição do modelo aos dados de supervisão externos. O EAFT utiliza a entropia ao nível de token como um mecanismo de gating para distinguir entre incerteza epistemológica e conflito de conhecimento, permitindo que o modelo aprenda amostras incertas enquanto inibe atualizações de gradiente de dados conflitantes. Experimentos provam que este método mitiga efetivamente a degradação da capacidade geral enquanto mantém o desempenho em tarefas downstream (Fonte: arXiv)
Atlas: orquestração de modelos heterogêneos e ferramentas para raciocínio complexo cross-domain : Com a diversificação de LLMs e ferramentas, escolher a melhor combinação tornou-se um desafio. O Atlas propõe um framework de caminho duplo: roteamento sem treinamento baseado em clustering para alinhamento dentro do domínio e roteamento de múltiplos passos baseado em aprendizado por reforço para generalização fora da distribuição. Este framework superou o GPT-4o em 15 benchmarks, demonstrando a poderosa capacidade de resolver problemas complexos através da orquestração de ferramentas multimodais especializadas (Fonte: arXiv)
💼 Negócios
Manus é adquirida pela Meta, com ARR ultrapassando US$ 125 milhões em 8 meses : A startup de Agents de execução de tarefas, Manus, revelou que seu ARR atingiu US$ 125 milhões pouco antes de ser adquirida pela Meta por US$ 2 bilhões. O produto alcançou a marca de cem milhões em apenas 8 meses após o lançamento, com um crescimento mensal superior a 20%. Isso reflete uma mudança na lógica comercial da AI: os usuários não pagam mais pela “capacidade”, mas sim pelos “resultados” e pela “entrega de tarefas” (Fonte: 36氪)
Boltz conclui rodada seed de US$ 28 milhões e firma parceria com a Pfizer : A startup de AI em biotecnologia Boltz anunciou a fundação da Boltz PBC e a obtenção de US$ 28 milhões em financiamento, lançando simultaneamente a plataforma Boltz Lab. A plataforma contém Agents especializados em design de pequenas moléculas e proteínas, e assinou um acordo de cooperação de vários anos com a gigante farmacêutica Pfizer. Isso marca a aceleração da comercialização de AI Agents em campos científicos rigorosos, como a pesquisa e desenvolvimento de medicamentos (Fonte: sarahcat21)
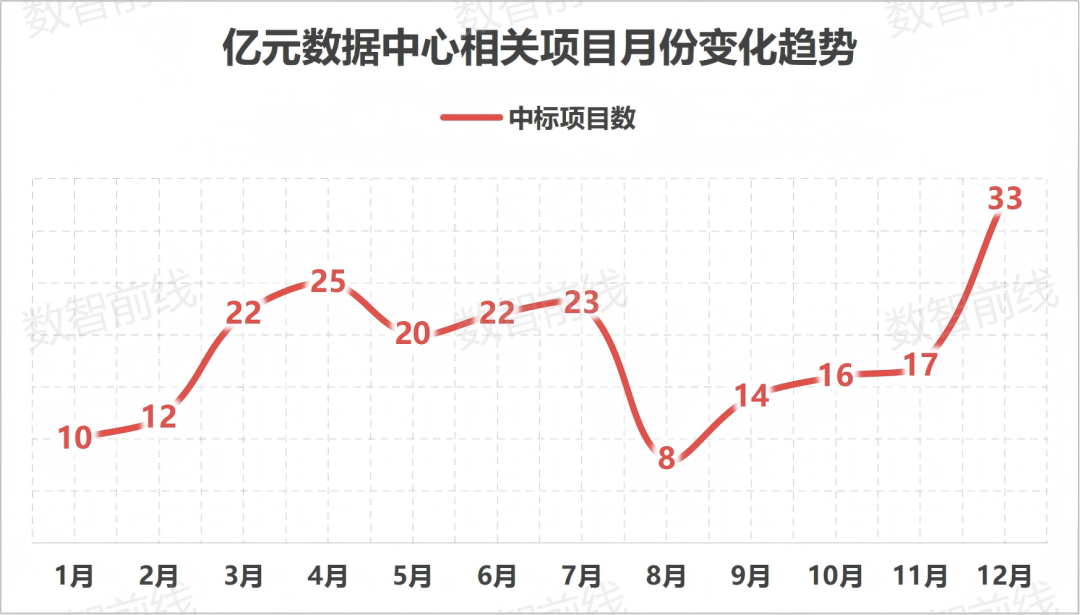
Infraestrutura de computação da China entra na “Era dos 10.000P”, com mais de 222 projetos de nível de cem milhões em 2025 : A construção de centros de computação inteligente no mercado interno continua aquecida, com as operadoras tornando-se a força principal absoluta. Em 2025, houve mais de 222 projetos vencedores de licitação acima de cem milhões de RMB, com clusters de dez mil placas tornando-se o padrão. As tendências mostram que a demanda por poder computacional de inferência está subindo rapidamente, a tecnologia de resfriamento líquido passou de opcional para obrigatória, e a indústria está resolvendo problemas de taxa de utilização através do modelo “construção impulsionada pelo uso” (Fonte: 36氪)
🌟 Comunidade
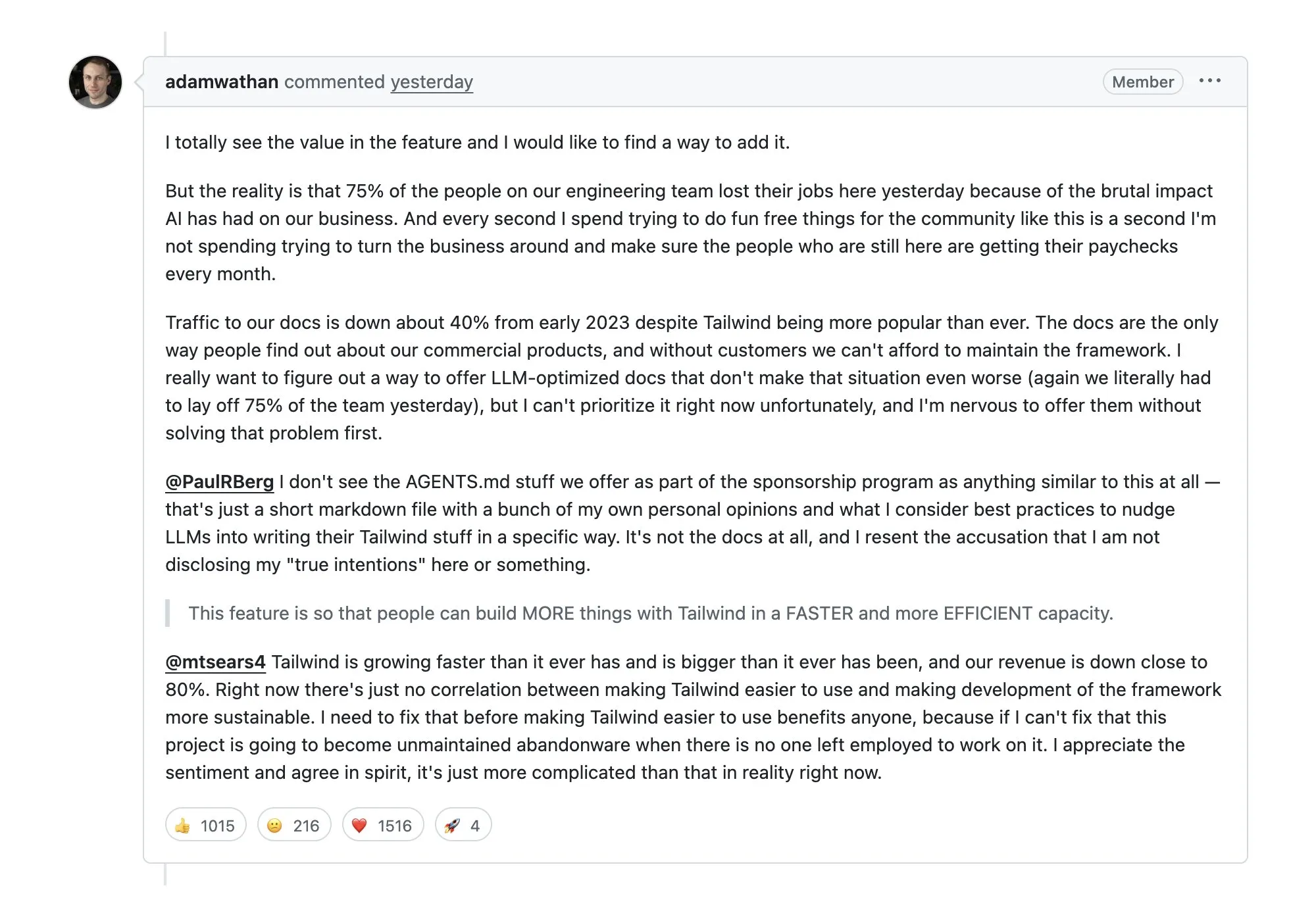
Demissões de 75% na Tailwind geram debate: AI causa queda no tráfego de documentação e na receita : O conhecido framework CSS Tailwind foi forçado a realizar demissões após o tráfego em seu site oficial cair 40% e a receita de produtos pagos despencar, devido à captura extensiva de sua documentação por AI Agents. Isso gerou uma profunda preocupação na comunidade sobre o “parasitismo da AI” no ecossistema open-source: quando a AI fornece respostas diretamente, como o modelo de negócios de projetos open-source pode ser mantido? (Fonte: aiamblichus)
Contexto de 1 milhão de tokens é uma armadilha? Comunidade discute o efeito “Lost in the Middle” : Testes de desenvolvedores descobriram que, embora os modelos afirmem suportar contextos de nível de milhões, a taxa de recall da parte central cai significativamente ao processar dados acima de 100.000 tokens. A comunidade sugere adotar uma estratégia de “dois passos”: primeiro indexar para localizar e depois inserir de forma direcionada. Isso indica que a higiene dos dados e as estratégias de recuperação são mais importantes do que a busca pura por janelas longas (Fonte: Reddit)
Vibe Coding torna-se nova tendência de desenvolvimento: de escrever código a “ajustar o feeling” : A comunidade está debatendo o “Vibe Coding”, ou seja, o uso de linguagem natural e Agents para desenvolvimento não determinístico. Os apoiadores acreditam que isso reduz as barreiras de entrada, enquanto os opositores temem a geração de uma grande quantidade de “lixo de código” impossível de manter. Instituições como a Datawhale já lançaram tutoriais sistemáticos relacionados para ajudar desenvolvedores a migrar de Demos para o desenvolvimento de programas AI-native (Fonte: dotey)
Limites da companhia de AI: terceirização de valor emocional gera preocupações éticas : Com o mercado de AI de companhia ultrapassando os cem bilhões, a sociedade começou a examinar seus riscos potenciais. As interações de “baixo conflito e alto controle” fornecidas pela AI podem enfraquecer a capacidade humana de lidar com relacionamentos reais, podendo até desencadear “vínculos de delírio compartilhado”. Especialistas pedem que a AI seja usada como um suplemento emocional, e não como um substituto para as relações humanas (Fonte: 36氪)
💡 Outros
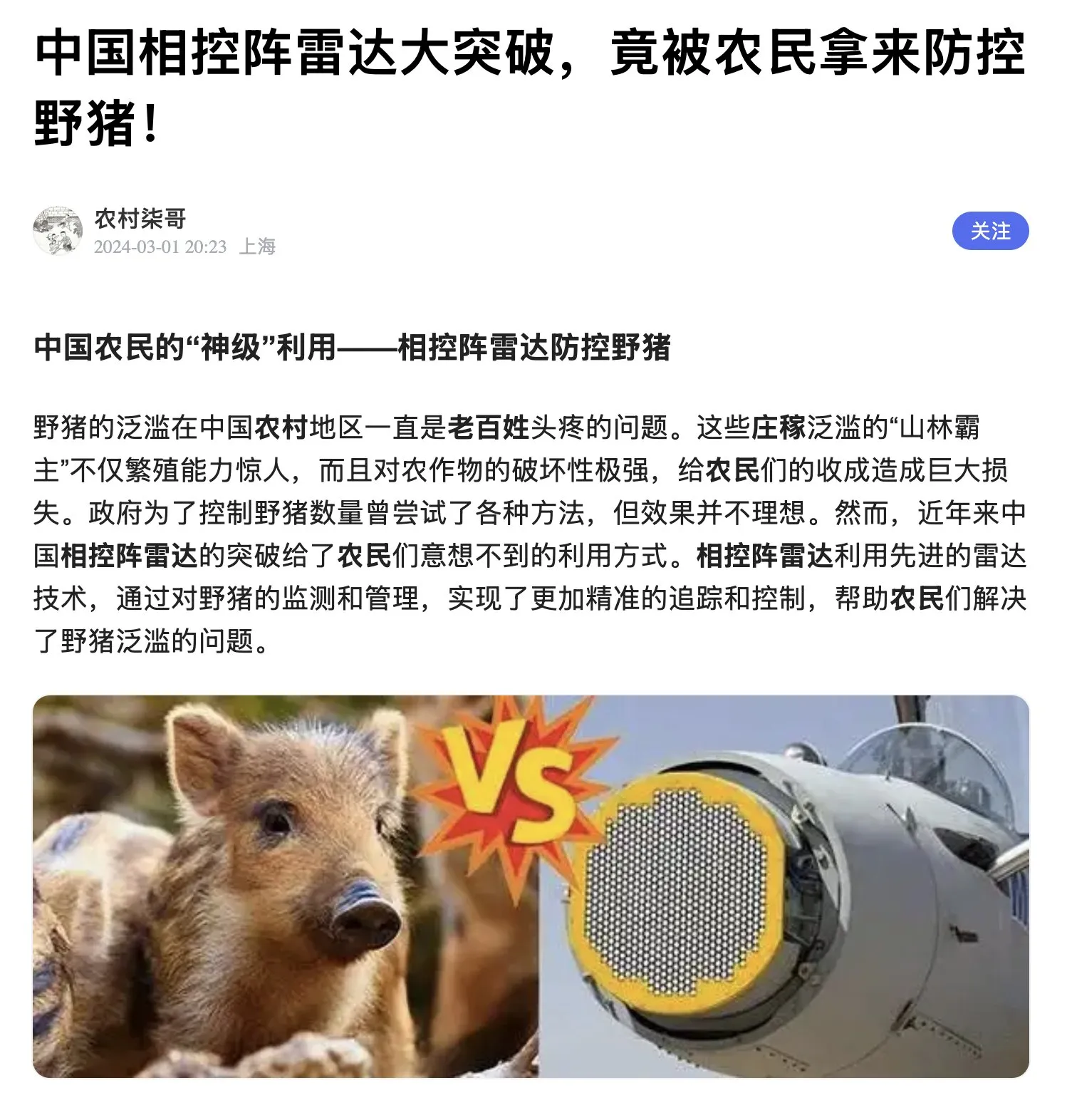
Agricultores chineses utilizam radar de varredura eletrônica ativa (AESA) para controlar javalis : Com a tecnologia de radar de varredura eletrônica tornando-se acessível e civil na China, agricultores começaram a usar radares AESA em conjunto com drones para detectar invasões de javalis. Este caso demonstra o cenário peculiar de tecnologias militares de ponta sendo aplicadas para resolver problemas civis, refletindo também a vantagem de capacidade de produção da China no campo de semicondutores GaN (Fonte: teortaxesTex)
Chip “Chocolate” da Cerebras é revelado fisicamente: espessura impressionante : Desenvolvedores compartilharam fotos reais do chip de AI em nível de wafer da Cerebras, cujo volume gigante e espessura impressionante atraíram a atenção. Como o maior chip monolítico do mundo, ele representa a exploração dos limites físicos do hardware de computação na busca por desempenho extremo (Fonte: dylan522p)

Equipe de proteção de dados do Debian renuncia em massa, conformidade com GDPR enfrenta desafios : A equipe de proteção de dados do Debian, fundada há 7 anos, renunciou coletivamente devido à energia limitada, e atualmente ninguém assumiu o cargo. Isso expõe a vulnerabilidade da comunidade open-source ao lidar com regulamentações de privacidade rigorosas (como o GDPR), e a ausência dessa “fundação invisível” pode afetar toda a cadeia do ecossistema Linux (Fonte: 36氪)