Palavras-chave:DeepSeek R1, Treinamento de IA, Aprendizagem por Reforço (RL), Modelo de Recompensa de Processo (PRM)
🔥 Destaques
DeepSeek R1 atualiza paper para 86 páginas revelando detalhes de treinamento: A DeepSeek atualizou silenciosamente o relatório técnico do R1, expandindo-o de 22 para 86 páginas, quase reescrevendo-o como um “livro didático” reproduzível. O relatório divulga pela primeira vez detalhes sobre a evolução das três fases de treinamento (Dev1/2/3), a decomposição do custo extremamente baixo de treinamento de US$ 294.000, e uma revisão de tentativas fracassadas como MCTS e Process Reward Model (PRM). Este movimento não apenas demonstra sua profunda experiência em Reinforcement Learning (RL), mas também prova à comunidade open source, através de apêndices detalhados de parâmetros, que modelos de raciocínio puramente movidos por RL são viáveis e possuem uma eficiência altíssima. Essa estratégia de competição baseada em “transparência” está forçando gigantes de código fechado a reavaliarem suas barreiras tecnológicas. (Fonte: _akhaliq, karminski3, 量子位)

MiniMax e Zhipu AI iniciam IPO em Hong Kong, marcando o “Momento Xangai/Pequim” dos grandes modelos: As empresas líderes em modelos de IA na China, MiniMax e Zhipu AI, estrearam sucessivamente na Bolsa de Valores de Hong Kong, sinalizando que a indústria de AGI da China entrou oficialmente na fase de teste do mercado secundário. No primeiro dia de listagem, as ações da MiniMax dispararam mais de 100%, com o valor de mercado ultrapassando 100 bilhões de dólares de Hong Kong; seu DNA globalizado, com mais de 70% da receita vinda do exterior, foi entusiasticamente recebido pelo capital. A Zhipu AI demonstrou um crescimento exponencial de 25 vezes em 10 meses no seu negócio de MaaS. O IPO bem-sucedido de ambas as empresas não apenas trouxe retornos generosos para investidores iniciais, mas também forneceu um modelo de financiamento replicável para futuros unicórnios de IA através do regime 18C, provando o valor único das empresas chinesas com capacidades de modelos de base proprietários na competição global. (Fonte: Zai_org, 36氪)

CES 2026: Explosão da Physical AI, das telas para o mundo real: Esta edição da CES voltou-se inteiramente para o tema “Physical AI”, que Jensen Huang, da NVIDIA, chamou de “o momento ChatGPT da Physical AI”. O Atlas da Boston Dynamics fez sua primeira aparição pública no palco e anunciou sua entrada em fábricas da Hyundai; a LG lançou o CLOiD, um robô doméstico capaz de dobrar roupas, enquanto a Lenovo apresentou o Qira, um super Agent de IA pessoal. A cadeia de suprimentos chinesa teve um desempenho notável, com mais de 20 empresas de robótica expondo, demonstrando capacidades de produção em massa que vão de mãos ágeis a robôs humanoides de tamanho real. A IA não é mais apenas uma caixa de diálogo, mas intervém profundamente no mundo físico através de sensores e atuadores, reconfigurando cadeias industriais tradicionais, de eletrodomésticos e PCs a automóveis. (Fonte: TheRundownAI, 雷科技)

OpenAI lança setor de Healthcare para entrar no segmento médico vertical: A OpenAI lançou oficialmente a experiência ChatGPT Health, com suporte à conformidade HIPAA e parcerias com instituições médicas de elite como a Mayo Clinic e o Boston Children’s Hospital. O recurso permite que os usuários acessem registros médicos eletrônicos e dados do Apple Health, utilizando a IA para auxiliar na análise de relatórios de exames e na formulação de planos de saúde. Embora apelidado de “versão americana do Ant Fortune”, ele representa a tendência de grandes modelos se aprofundarem de domínios genéricos para verticais profissionais. A IA médica está evoluindo de simples perguntas e respostas para assistentes profissionais capazes de integrar dados de múltiplas fontes e fornecer suporte à decisão clínica, embora a segurança e o risco de diagnósticos errados continuem sendo focos de atenção da comunidade. (Fonte: _samirism, openai)
🎯 Tendências
Google DeepMind propõe framework de “Nested Learning”: Visando o problema de que os Transformers carecem de capacidade de aprendizado contínuo e são propensos ao “esquecimento catastrófico”, a equipe da DeepMind, inspirada nos mecanismos de memória associativa humana, propôs o framework de Nested Learning (NL). Este framework trata o otimizador como o “contexto” da arquitetura do modelo, permitindo que a IA construa estruturas abstratas durante a execução através do aninhamento de módulos com diferentes frequências de atualização, transformando experiências de curto prazo em conhecimento de longo prazo. Isso é visto como um passo crucial em direção à AGI, permitindo que os modelos evoluam autonomamente em ambientes dinâmicos, em vez de dependerem de retreinamentos caros. (Fonte: hardmaru, 新智元)
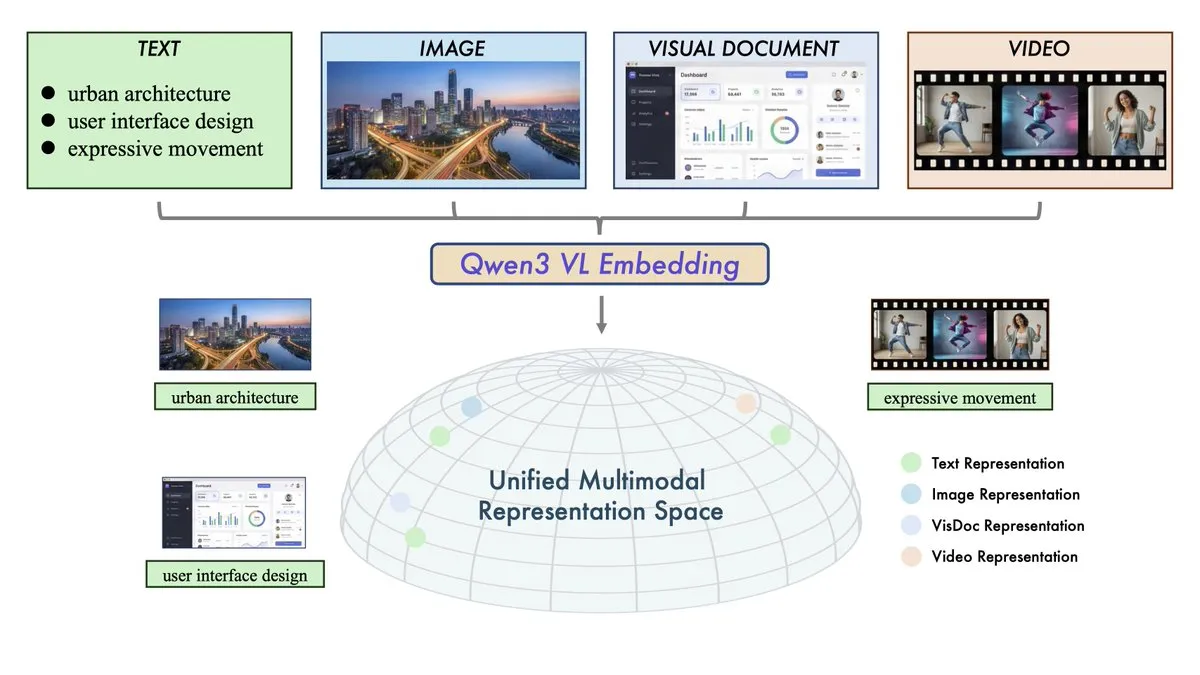
Alibaba lança modelos Qwen3-VL-Embedding e Reranker: A equipe Qwen da Alibaba lançou uma dupla de recuperação multimodal, visando unificar o espaço vetorial de texto, imagem, vídeo e modalidades mistas. O Qwen3-VL-Embedding suporta mais de 30 idiomas e atinge performance SOTA em benchmarks de recuperação multimodal; o Reranker melhora ainda mais a precisão da recuperação através de pontuação de relevância de grão fino. Este lançamento marca a entrada oficial da tecnologia RAG (Retrieval-Augmented Generation) na era de todas as modalidades, fornecendo infraestrutura central para a construção de Visual QA, busca de vídeo e Agents multimodais mais complexos. (Fonte: huggingface, _akhaliq)
Fundador da a16z prevê 2026: Deflação do custo de inteligência impulsionará explosão na demanda: Marc Andreessen apontou que a velocidade de queda do custo unitário da IA já superou a Lei de Moore, e a inteligência está deixando de ser um luxo para se tornar uma utilidade básica como água e eletricidade. Ele prevê que o mercado futuro apresentará uma “estrutura de pirâmide”: no topo, alguns supermodelos; na base, pequenos modelos onipresentes na borda (edge). Ao mesmo tempo, ele acredita que as startups estão se livrando das críticas de serem apenas “wrappers” através da “integração reversa” com modelos próprios, e o modelo de negócios de IA mudará do pagamento por Token para a precificação baseada no valor criado. (Fonte: nvidia, 华尔街见闻)
Grandes modelos de voz para cockpits inteligentes aceleram integração em veículos: Na CES, a StepFun demonstrou um cockpit com modelo de voz end-to-end em colaboração com a Geely Galaxy, apresentando reconhecimento emocional e capacidades de memória de longo prazo. A visão da indústria é que 2026 será o ano inaugural da produção em massa de Agents de nível de entrada em cockpits automotivos. O cockpit está deixando de ser um simples controle de voz para se tornar um “terceiro espaço” com execução proativa e serviços personalizados; a arquitetura de IA com colaboração nuvem-borda se tornará o núcleo da competição entre montadoras, visando integrar profundamente as capacidades de IA na camada base do OS para fusão de experiências multidomínio. (Fonte: dotey, 科创板日报)
🧰 Ferramentas
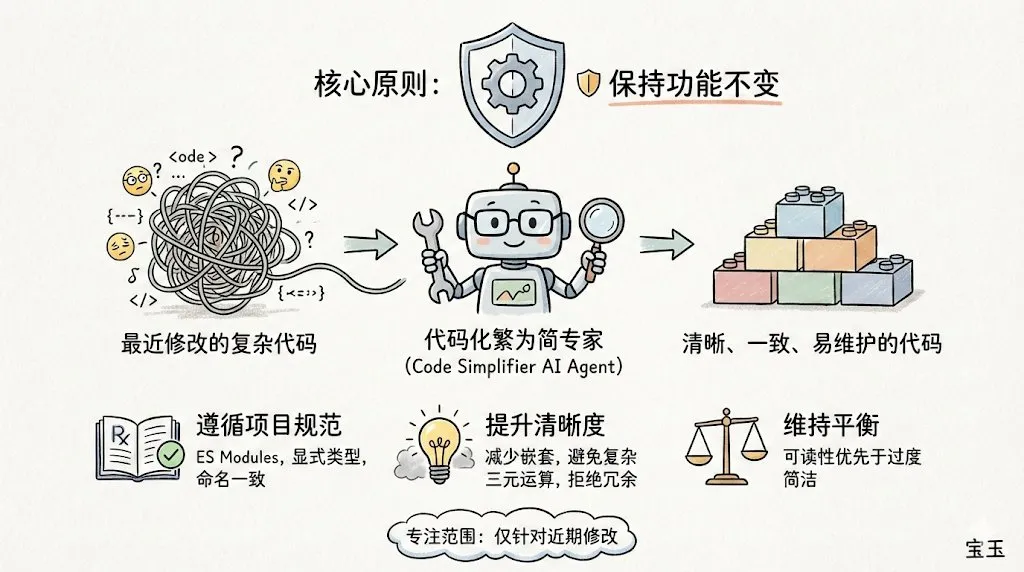
Lançamento do Claude Code e plugin code-simplifier: A ferramenta de linha de comando Claude Code, lançada pela Anthropic, explodiu na comunidade de desenvolvedores devido ao seu excelente senso de engenharia. A empresa lançou recentemente o plugin code-simplifier, que permite simplificar bases de código complexas com um clique. Seu conceito central é “sistema de arquivos como contexto”, carregando dinamicamente os arquivos necessários em vez de empilhar Tokens, o que melhora significativamente a eficiência ao lidar com grandes repositórios. O feedback da comunidade indica que ele já superou o GPT-4o em compreensão lógica e redução de “código prolixo”. (Fonte: dotey, natolambert)
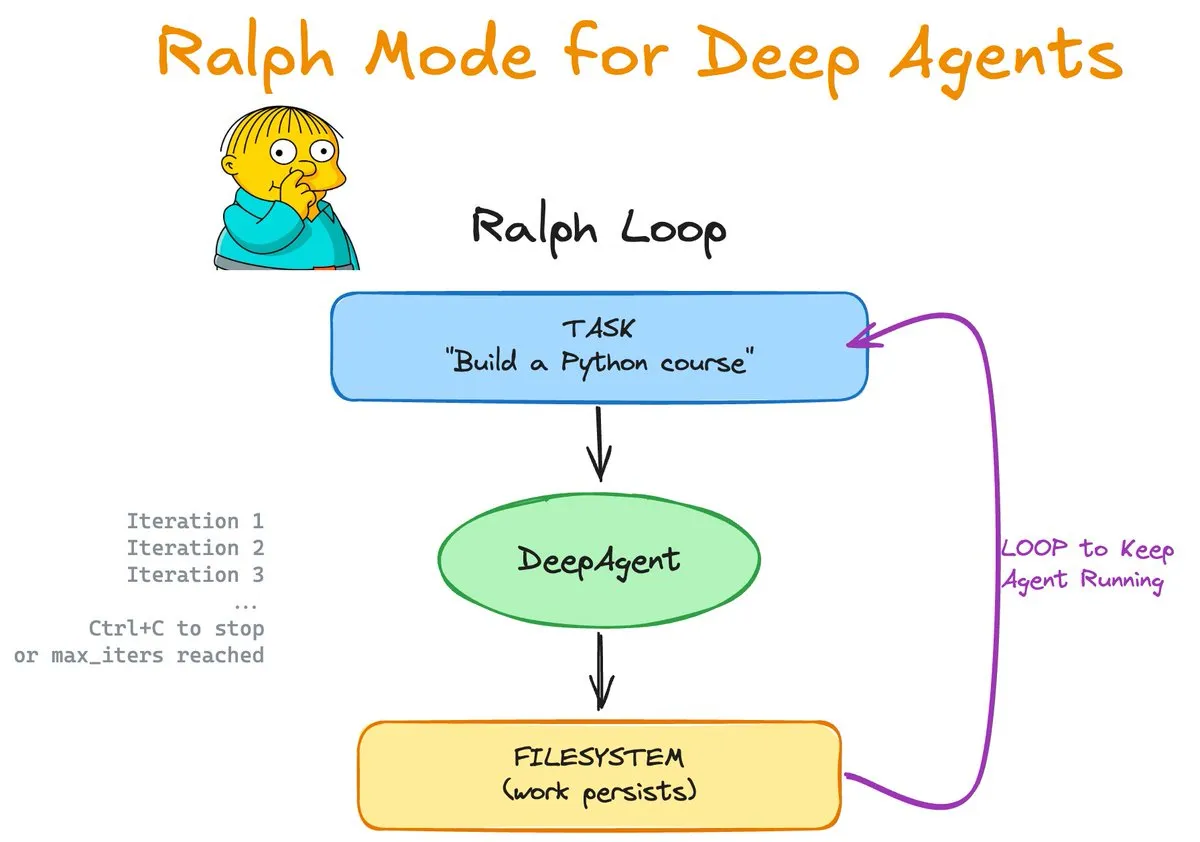
Ralph Mode: Ciclos contínuos e memória aprimorada para Agents: O Ralph Mode, lançado pela LangChain OSS, introduziu suporte nativo para Skills e Memory na biblioteca DeepAgents. Este modo permite que Agents realizem tarefas em ciclos infinitos com suporte do sistema de arquivos e Git, atualizando constantemente sua base de conhecimento através de um processo de aprendizado “skill-based”. Este design permite que o Agent se autocorrija e acumule experiência, fornecendo um novo paradigma para o desenvolvimento autônomo de software e processamento de tarefas complexas de longo prazo. (Fonte: Vtrivedy10, hwchase17)
Pico AI Server: ChatGPT local e privado no Mac: Para usuários sensíveis à privacidade, o Pico AI Server implementou suporte a GPT-oss rodando inteiramente de forma local em Apple Silicon. Otimizada com o framework MLX, esta ferramenta permite que usuários de Mac com 24GB+ de memória desfrutem de uma experiência fluida de inferência local. Isso reflete a tendência de migração do poder computacional de IA para a borda, onde os usuários não precisam mais enviar dados sensíveis para a nuvem para obter assistência de alta performance em conversação e programação. (Fonte: awnihannun)

LFM2.5 1.2B: Pequeno modelo de alta performance para Agents: O modelo LFM2.5 1.2B Instruct lançado pela LiquidAI apresenta um desempenho impressionante para sua categoria de tamanho, sendo especialmente otimizado para tarefas de Agent, extração de dados e RAG. Embora não seja recomendado para tarefas pesadas de conhecimento, sua velocidade de inferência em ambientes locais como o LM Studio é extremamente rápida (até 41 tps), tornando-o uma escolha ideal para construir assistentes de IA leves e fluxos de chamada de ferramentas. (Fonte: Reddit r/LocalLLaMA)

📚 Aprendizado
Equipe da Tsinghua publica DrugCLIP na Science: IA acelera triagem de medicamentos em milhões de vezes: Uma equipe de pesquisa conjunta da Universidade de Tsinghua propôs o framework DrugCLIP, redefinindo a triagem virtual como uma tarefa de recuperação densa. Através do mapeamento do espaço vetorial entre bolsões de ligação de proteínas e pequenas moléculas, este framework pode completar 10 trilhões de cálculos em apenas 24 horas usando 8 GPUs A100, com uma velocidade de triagem 10 milhões de vezes mais rápida que os métodos tradicionais. Este avanço inaugura um novo paradigma de P&D de medicamentos na era pós-AlphaFold, reduzindo drasticamente a barreira para a descoberta de medicamentos em escala ultra-grande. (Fonte: 36氪)

Sakana AI lança pesquisa Digital Red Queen (DRQ): Este estudo simulou a evolução adversária impulsionada por LLM em um sandbox do jogo de programação Core War. Ao fazer com que programas Redcode escritos por LLMs competissem continuamente, observou-se um fenômeno de “evolução convergente” semelhante ao mundo biológico: programas sob diferentes condições iniciais acabaram evoluindo para estratégias de sobrevivência eficientes e similares (como autorreplicação e bombas de dados). Este trabalho fornece um ambiente experimental seguro e controlado para estudar a dinâmica adversária e a evolução da biossegurança em sistemas artificiais. (Fonte: hardmaru, SakanaAILabs)
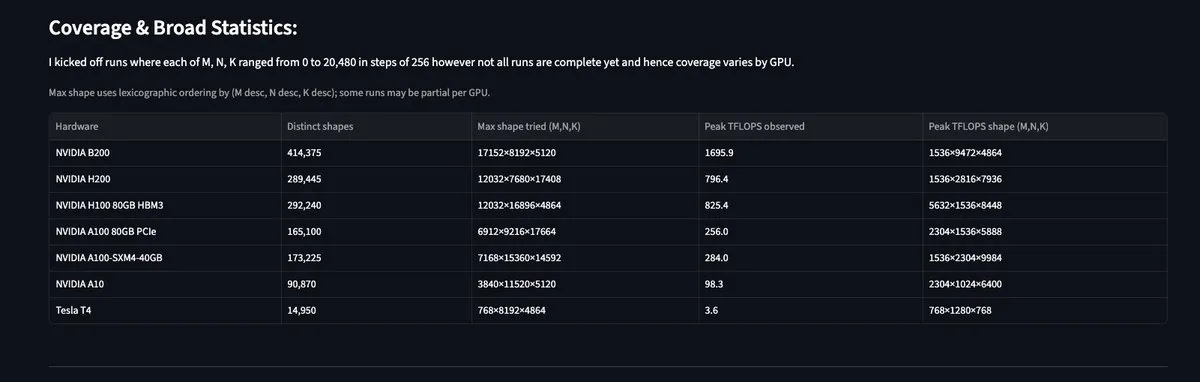
MAMF Explorer: Insights sobre a performance real de matmul em GPUs: A ferramenta MAMF Explorer, lançada pelo desenvolvedor Aflah, fornece aos pesquisadores dados sobre os picos de matmul FLOPS realmente alcançáveis em diversos hardwares, em vez dos picos teóricos anunciados pelos fabricantes. Isso tem um valor prático altíssimo para otimizar a alocação de poder computacional no treinamento e inferência de modelos de larga escala, ajudando desenvolvedores a encontrar gargalos reais de performance em diferentes chips como Blackwell e H100. (Fonte: StasBekman, charles_irl)
💼 Negócios
Valuation da Anthropic pode chegar a US$ 350 bilhões, com ARR em crescimento acelerado: Rumores indicam que a Anthropic planeja captar US$ 10 bilhões, com seu valuation dobrando em seis meses. Sua receita em 2025 já atingiu US$ 900 milhões, com uma meta de superar US$ 2 bilhões em 2026. Comparada ao conflito interno da OpenAI, a Anthropic, com sua altíssima estabilidade de equipe e “performance matadora” no mercado de desenvolvedores (como o Claude Code), está se tornando a primeira escolha no mercado corporativo, sendo inclusive considerada capaz de superar sua antiga casa no progresso para o IPO. (Fonte: 36氪, srimuppidi)

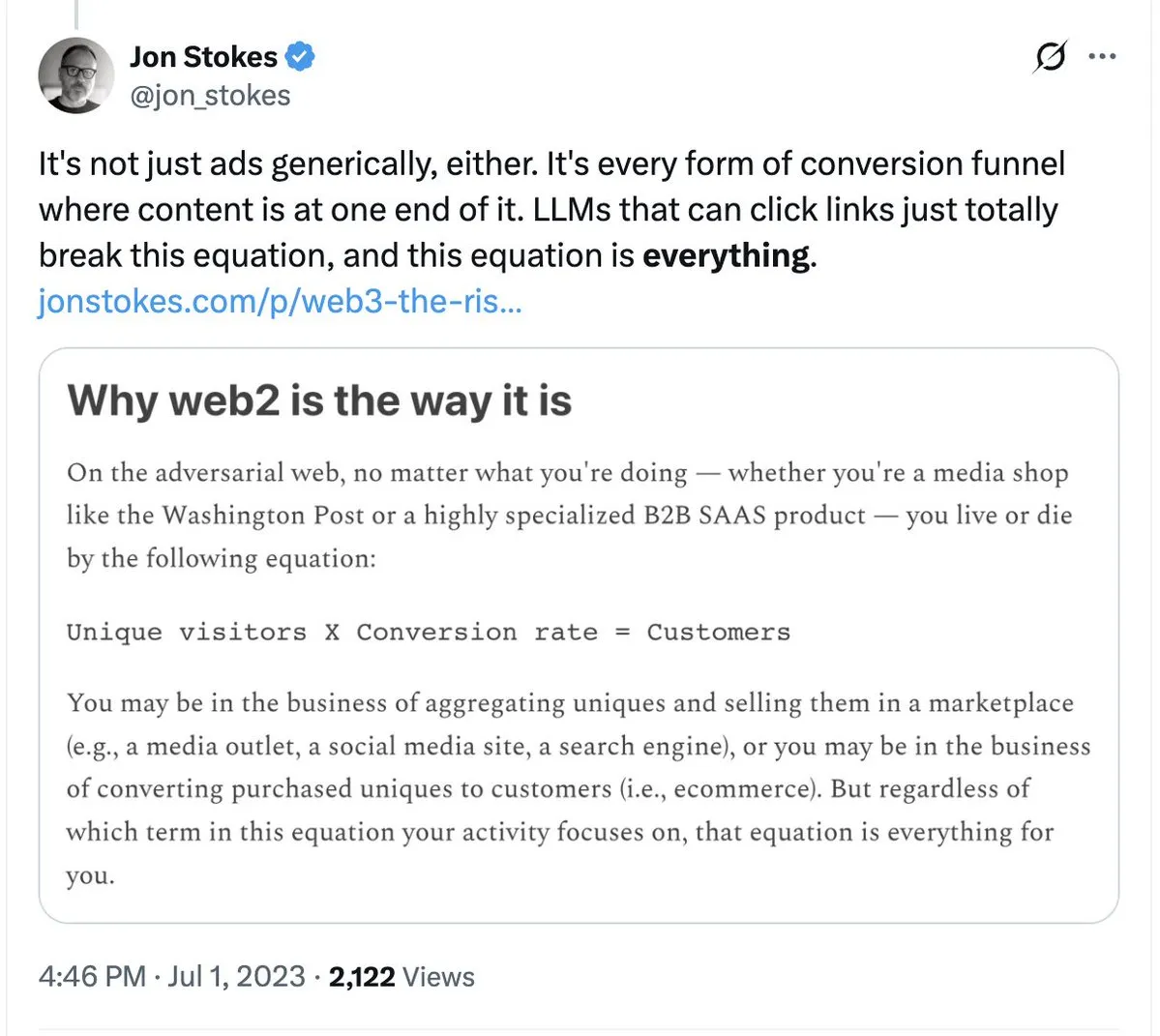
Demissões na Tailwind geram reflexão sobre impacto da IA no modelo SaaS tradicional: O conhecido framework CSS Tailwind anunciou a demissão de 75% de sua equipe, justificando que a popularização de ferramentas de programação com IA causou o colapso de seu modelo de negócios. Embora o uso do Tailwind esteja aumentando, a necessidade dos usuários de gerar código via IA reduziu a dependência de seus componentes pagos. Este evento serve de alerta para todas as empresas de software que dependem do valor de “mão de obra/templates”: quando a IA pode gerar soluções com um clique, as barreiras tradicionais de monetização de conhecimento estão se dissolvendo. (Fonte: jon_stokes, imjaredz)
JD.com cria “Chameleon Business Unit” para acelerar Embodied AI: A JD.com elevou o projeto original Chameleon a uma unidade de negócios, assumindo integralmente o JoyAI App e a marca de Embodied AI JoyInside. O núcleo deste departamento foca na integração de hardware e software de IA, já tendo estabelecido contato com mais de 40 marcas de robótica e brinquedos de IA. Isso mostra que a gigante do e-commerce está utilizando sua profunda vantagem na cadeia de suprimentos para tentar construir um ciclo comercial fechado, do P&D às vendas, nos setores de brinquedos de IA e robótica industrial. (Fonte: 36氪)
🌟 Comunidade
Linus Torvalds critica debate sobre normas para “AI junk code”: Em resposta às discussões na comunidade do kernel Linux sobre se deveriam ser estabelecidas normas para código gerado por IA, Linus chamou isso de “estupidez”. Ele acredita que documentos só restringem quem segue as regras, e quem submete “AI junk code” não irá rotulá-lo voluntariamente. Ele insiste em ver a IA como uma ferramenta e aponta que a imunidade do kernel deve vir dos mecanismos de revisão de código e da cultura da comunidade, e não de formalidades documentais sem sentido. (Fonte: 36氪)

“Efeito Karpathy” gera ansiedade coletiva entre programadores: Andrej Karpathy lamentou que a profissão de programador está sendo drasticamente reestruturada, com os bits contribuídos por desenvolvedores tornando-se cada vez mais escassos. A comunidade resumiu isso como o “Efeito Karpathy”: até engenheiros seniores sentem um senso de defasagem sem precedentes. As discussões sugerem que a competitividade central do futuro mudará de “escrever código” para “entender a complexidade do sistema”; o vibe coding está transformando engenheiros 10x em 100x, mas também tornando a barreira de entrada para iniciantes muito mais alta. (Fonte: dejavucoder, arohan)
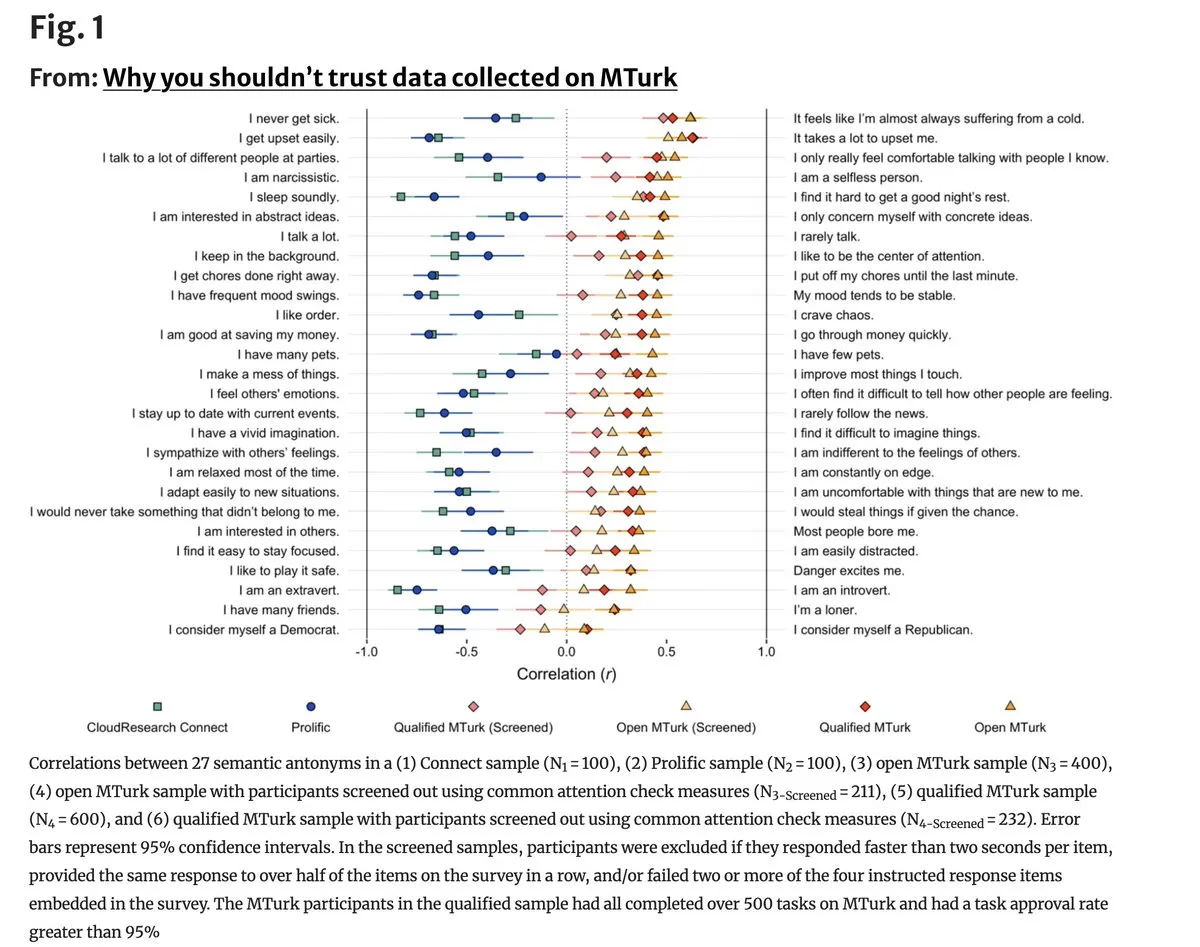
Qualidade de dados no MTurk enfrenta “crise existencial” devido à IA: Um novo estudo mostra que a qualidade dos dados em plataformas de crowdsourcing como o Amazon Mechanical Turk (MTurk) caiu severamente, com 96% dos itens contraditórios apresentando correlação positiva na rotulagem, provando que um grande número de trabalhadores está usando LLMs para realizar tarefas de forma superficial. Isso é fatal para as ciências comportamentais e o ajuste fino de modelos que dependem de rotulagem humana de alta qualidade; a comunidade está pedindo a criação de redes de coleta de dados reais baseadas em verificação de identidade. (Fonte: random_walker)
💡 Outros
Cláusulas do NO FAKES Act preocupam comunidade open source: A definição de responsabilidade sobre “direitos de réplica digital” no projeto de lei foi apontada como uma armadilha. Se um desenvolvedor lançar um modelo de TTS ou clonagem de voz que seja usado por terceiros para criar vídeos falsos de celebridades, o desenvolvedor pode enfrentar indenizações solidárias massivas. A comunidade teme que isso leve desenvolvedores de modelos de áudio em plataformas como Hugging Face ao “suicídio jurídico”, sufocando a inovação em tecnologias de áudio open source. (Fonte: Reddit r/LocalLLaMA)
ICML 2026 introduz novas regras contra fraude acadêmica: Para combater submissões do tipo “salami slicing” e o excesso de conteúdo gerado por IA, o ICML anunciou: se um paper apresentar comportamento fraudulento, todas as submissões sob os nomes de todos os coautores podem ser rejeitadas diretamente. Este mecanismo de “responsabilidade coletiva” exige que os líderes de grupos de pesquisa supervisionem pessoalmente os trabalhos. Ao mesmo tempo, a conferência permite o uso condicional de IA na revisão de papers, mas apenas com o consentimento dos autores. (Fonte: 36氪)
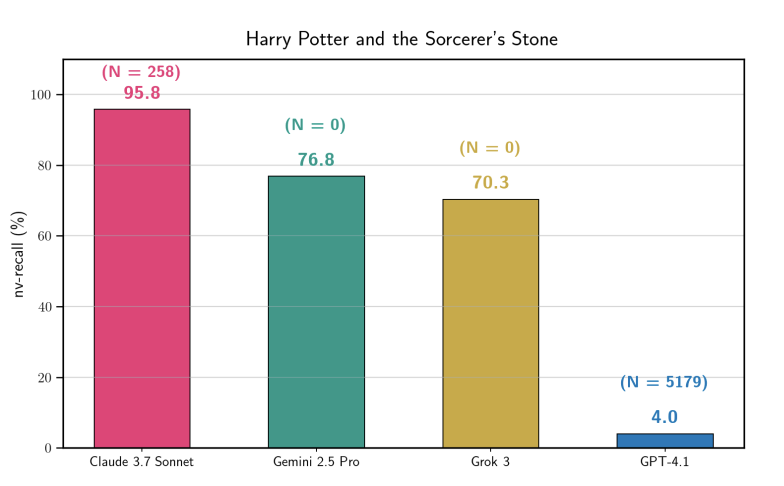
Paper de Stanford confirma que LLMs memorizam dados com copyright: O estudo mostra que o Claude 3.7 Sonnet pode reproduzir palavra por palavra 95,8% do conteúdo de “Harry Potter”, com Gemini e Grok logo atrás. Isso refuta fortemente a afirmação de que “modelos não armazenam dados de treinamento”, provando que os filtros de segurança existentes ainda são frágeis diante de induções específicas. Esta descoberta fornecerá evidências cruciais para futuros processos judiciais de direitos autorais de IA. (Fonte: stanfordnlp, andykonwinski)