키워드:딥시크 R1, AI 훈련, 강화 학습 RL, 과정 보상 모델 PRM
🔥 聚焦
DeepSeek R1 86페이지 논문 업데이트로 훈련 세부 사항 공개: DeepSeek가 R1 기술 보고서를 기존 22페이지에서 86페이지로 대폭 확장하며, 재현 가능한 ‘교과서’ 수준으로 전면 개편했습니다. 보고서에서는 Dev1/2/3 세 단계의 훈련 진화 과정, 29.4만 달러라는 극도로 낮은 훈련 비용 분석, 그리고 MCTS 및 Process Reward Model (PRM) 등 실패한 시도에 대한 복기 내용이 처음으로 상세히 공개되었습니다. 이번 행보는 Reinforcement Learning (RL) 분야에서의 깊은 기술력을 과시할 뿐만 아니라, 상세한 부록 파라미터를 통해 순수 RL 기반 추론 모델의 실현 가능성과 높은 효율성을 오픈소스 커뮤니티에 증명했습니다. 이러한 ‘투명화’ 경쟁 전략은 폐쇄형 모델 거물들이 기술적 장벽을 재검토하게 만들고 있습니다. (출처: _akhaliq, karminski3, 量子位)

MiniMax와 智谱(Zhipu) AI 홍콩 증시 IPO로 대형 모델의 ‘상하이/베이징 모먼트’ 개막: 중국 대형 모델 선두 기업인 MiniMax와 智谱 AI가 잇따라 홍콩 증권거래소에 상장하며, 중국 AGI 산업이 본격적으로 2차 시장의 검증 단계에 진입했음을 알렸습니다. MiniMax는 상장 첫날 주가가 100% 이상 폭등하며 시가총액 1,000억 홍콩 달러를 돌파했으며, 해외 매출 비중이 70%를 넘는 글로벌 경쟁력이 자본 시장의 주목을 받았습니다. 智谱 AI는 MaaS 사업이 10개월 만에 25배 성장하는 지수적 성장을 보여주었습니다. 두 회사의 성공적인 상장은 초기 투자자들에게 막대한 수익을 안겨주었을 뿐만 아니라, 18C 제도를 통해 후속 AI 유니콘 기업들에게 복제 가능한 자금 조달 모델을 제시하며 독자적인 파운데이션 모델 능력을 갖춘 중국 기업의 글로벌 경쟁력을 입증했습니다. (출처: Zai_org, 36氪)

CES 2026 Physical AI 폭발: 스크린에서 현실 세계로: 이번 CES는 ‘Physical AI’로 주제가 완전히 전환되었으며, NVIDIA의 젠슨 황은 이를 “Physical AI의 ChatGPT 모먼트”라고 칭했습니다. Boston Dynamics의 Atlas가 처음으로 공개 무대에 올라 현대자동차 공장 투입을 발표했고, LG는 옷을 갤 수 있는 가사 로봇 CLOiD를, Lenovo는 개인용 AI 슈퍼 인텔리전트 에이전트 Qira를 선보였습니다. 중국 공급망의 활약도 두드러졌는데, 20여 개 이상의 로봇 기업이 참가하여 정교한 로봇 손부터 풀사이즈 휴머노이드 로봇의 양산 능력을 과시했습니다. AI는 더 이상 단순한 대화창에 머물지 않고 센서와 액추에이터를 통해 물리적 세계에 깊숙이 개입하며 가전, PC에서 자동차에 이르는 전통 산업 체인을 재구성하고 있습니다. (출처: TheRundownAI, 雷科技)

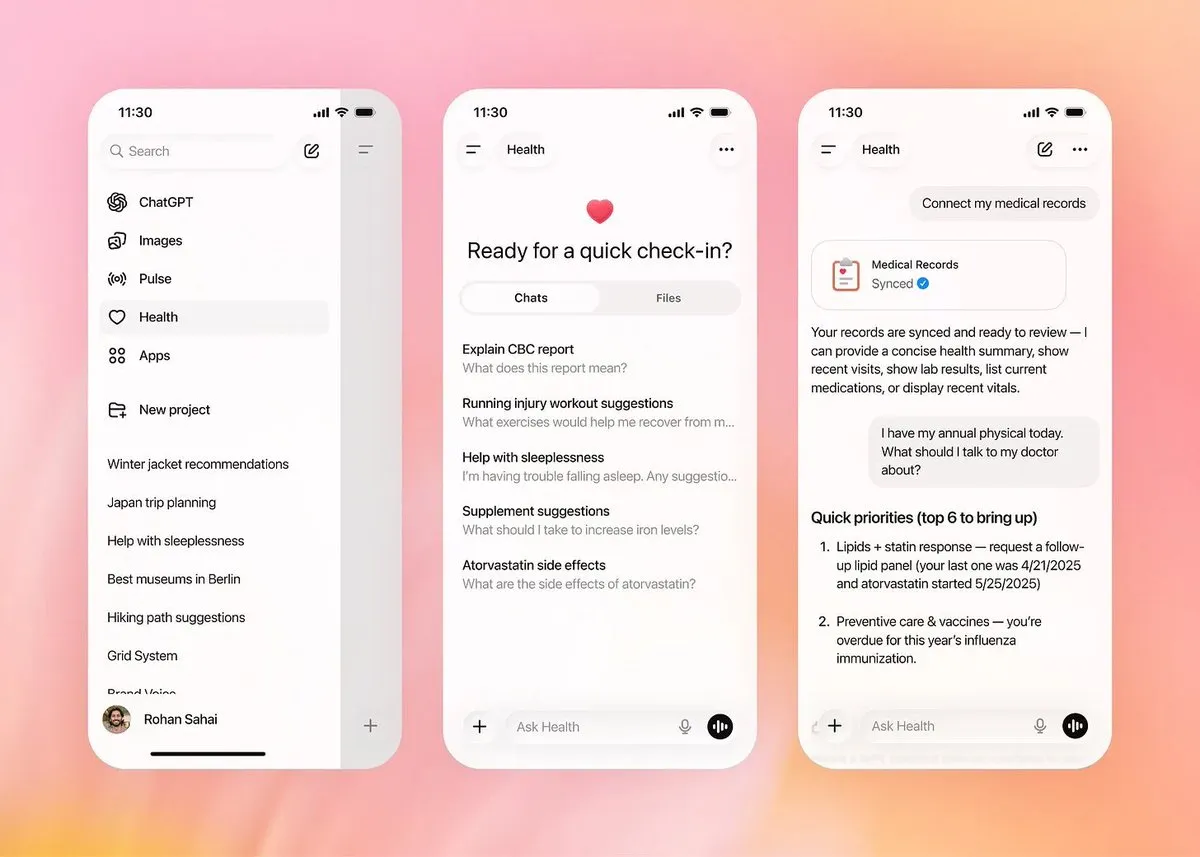
OpenAI, Healthcare 섹션 발표하며 의료 수직 시장 진출: OpenAI가 HIPAA 준수를 지원하고 Mayo Clinic, Boston Children’s Hospital 등 최고 의료 기관과 협력하는 ChatGPT Health 경험을 정식 출시했습니다. 이 기능은 사용자가 전자 건강 기록(EHR) 및 Apple 건강 데이터에 접근할 수 있게 하며, AI를 통해 검사 보고서 분석 및 건강 계획 수립을 보조합니다. 일각에서는 ‘미국판 앤트 아푸(蚂蚁阿福)’라고 부르기도 하지만, 이는 대형 모델이 범용 서비스에서 전문적인 수직 분야로 심화되는 추세를 대변합니다. 의료 AI는 단순 질의응답에서 다중 소스 데이터를 통합하고 임상 의사 결정을 지원하는 전문 어시스턴트로 진화하고 있으며, 안전성과 오진 위험은 여전히 커뮤니티의 주요 관심사로 남아 있습니다. (출처: _samirism, openai)
🎯 动向
Google DeepMind, ‘Nested Learning’ (NL) 프레임워크 제안: Transformer의 지속적인 학습 능력 부족과 ‘치명적 망각(Catastrophic Forgetting)’ 문제를 해결하기 위해 DeepMind 팀은 인간의 연상 기억 메커니즘을 벤치마킹한 Nested Learning 프레임워크 NL을 제안했습니다. 이 프레임워크는 옵티마이저를 모델 아키텍처의 ‘컨텍스트’로 간주하며, 서로 다른 업데이트 빈도를 가진 모듈을 중첩시켜 AI가 실행 중에 추상적 구조를 구축하고 단기 경험을 장기 지식으로 축적할 수 있게 합니다. 이는 AGI로 가는 핵심 단계로 간주되며, 모델이 값비싼 재훈련에 의존하지 않고 인간처럼 동적인 환경에서 스스로 진화할 수 있게 할 것으로 기대됩니다. (출처: hardmaru, 新智元)
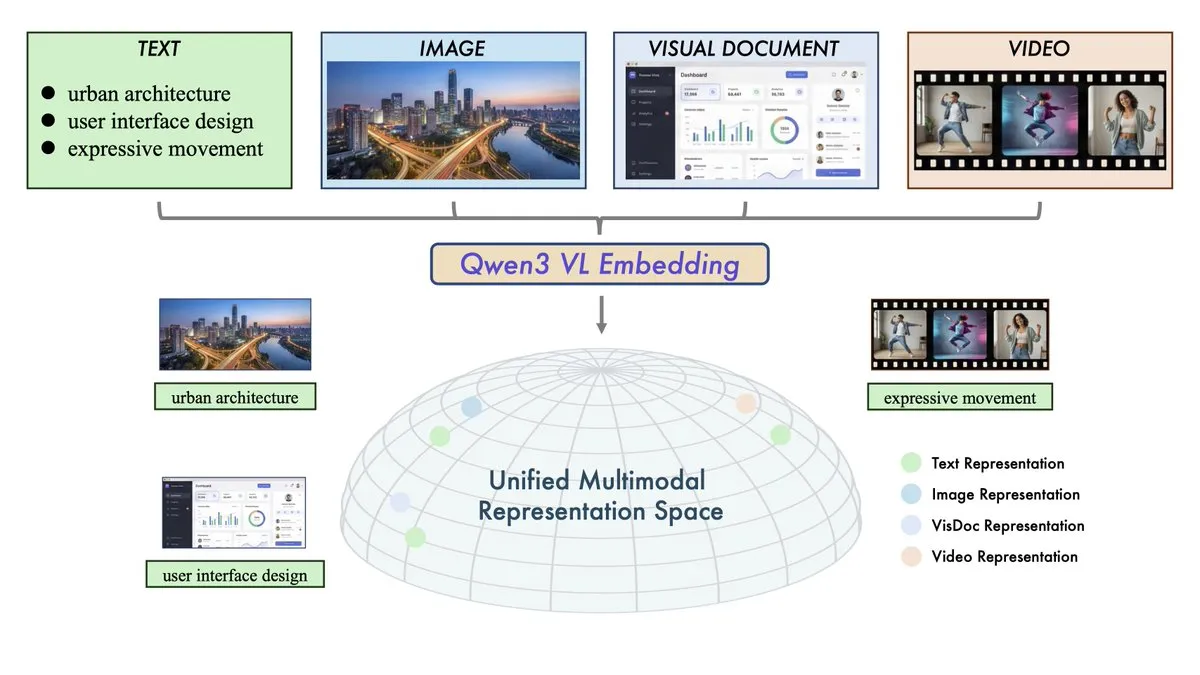
Alibaba, Qwen3-VL-Embedding 및 Reranker 모델 출시: Alibaba 톤이치엔원(Qwen) 팀이 텍스트, 이미지, 비디오 및 혼합 모달리티의 벡터 공간을 통합하는 멀티모달 검색 듀오를 출시했습니다. Qwen3-VL-Embedding은 30개 이상의 언어를 지원하며 멀티모달 검색 벤치마크에서 SOTA 성능을 달성했습니다. Reranker는 세밀한 관련성 점수 측정을 통해 검색 정확도를 더욱 높였습니다. 이번 출시는 RAG(Retrieval-Augmented Generation) 기술이 본격적으로 전체 모달리티 시대로 진입했음을 의미하며, 더 복잡한 시각적 질의응답, 비디오 검색 및 멀티모달 Agent 구축을 위한 핵심 인프라를 제공합니다. (출처: huggingface, _akhaliq)
a16z 창립자 2026년 전망: 지능 비용의 디플레이션이 수요 폭발 견인: Marc Andreessen은 AI의 단위 비용 하락 속도가 이미 무어의 법칙을 넘어섰으며, 지능이 사치품에서 수도나 전기 같은 생필품으로 변하고 있다고 지적했습니다. 그는 미래 시장이 ‘피라미드 구조’를 보일 것이라고 예측했습니다. 꼭대기에는 소수의 슈퍼 모델이, 바닥에는 어디에나 존재하는 에지 측 소형 모델이 위치할 것입니다. 또한 스타트업들이 ‘후방 통합’을 통해 자체 모델을 개발함으로써 ‘단순 래퍼(Wrapper)’라는 의구심에서 벗어날 것이며, AI 비즈니스 모델은 Token당 과금 방식에서 창출된 가치 기반 가격 책정 방식으로 전환될 것이라고 보았습니다. (출처: nvidia, 华尔街见闻)
스마트 콕핏 음성 대형 모델, ‘차량 탑재’ 가속화: CES에서 阶跃星辰(StepFun)은 지리자동차(Geely) 갤럭시와 협력한 엔드 투 엔드 음성 대형 모델 콕핏을 선보였습니다. 이 모델은 감정 인식과 장기 기억 능력을 갖추고 있습니다. 업계에서는 2026년이 엔트리급 Agent가 자동차 콕핏에서 대규모 양산되는 원년이 될 것으로 보고 있습니다. 콕핏은 단순한 음성 제어에서 능동적 실행과 개인화 서비스를 제공하는 ‘제3의 공간’으로 변모하고 있으며, 온디바이스와 클라우드가 협업하는 AI 아키텍처가 자동차 제조사 경쟁의 핵심이 될 것입니다. 이는 AI 능력을 OS 하단에 깊숙이 통합하여 다중 영역 경험 융합을 실현하는 것을 목표로 합니다. (출처: dotey, 科创板日报)
🧰 工具
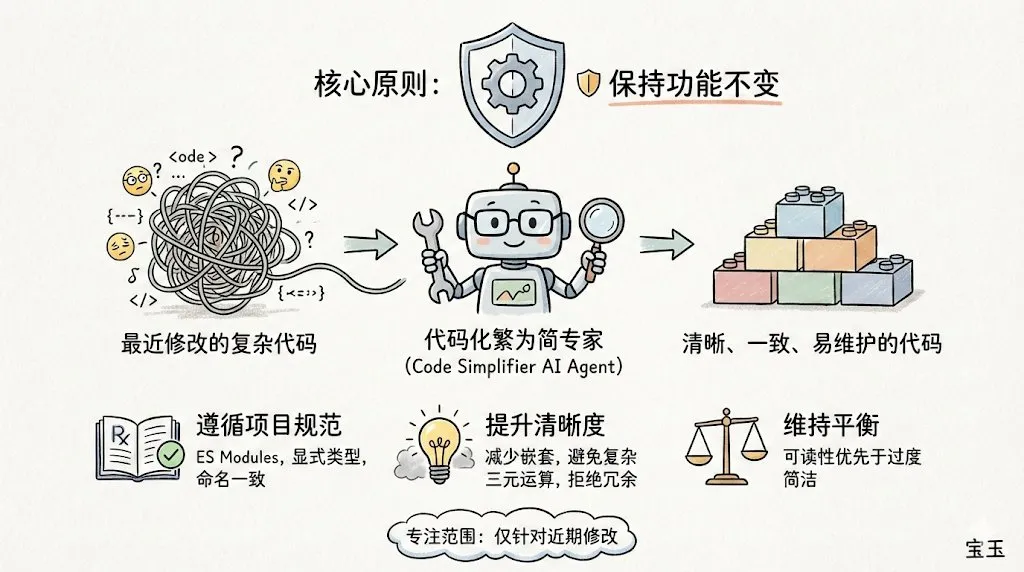
Claude Code 및 code-simplifier 플러그인 출시: Anthropic이 출시한 명령줄 도구 Claude Code가 뛰어난 엔지니어링 감각으로 개발자 커뮤니티에서 폭발적인 인기를 끌고 있습니다. 공식적으로 새로 출시된 code-simplifier 에이전트 플러그인은 복잡한 코드베이스를 클릭 한 번으로 단순화하는 기능을 지원합니다. 핵심 개념은 ‘파일 시스템이 곧 컨텍스트’라는 것으로, Token을 쌓아두는 대신 필요한 파일을 동적으로 로드하여 대규모 저장소 처리 효율을 획기적으로 높였습니다. 커뮤니티 피드백에 따르면 논리 이해와 ‘코드 군더더기’ 감소 측면에서 이미 GPT-4o를 넘어섰다는 평가입니다. (출처: dotey, natolambert)
Ralph Mode: Agent의 지속적인 루프와 메모리 강화: LangChain OSS가 출시한 Ralph Mode는 DeepAgents 라이브러리에 네이티브 Skills 및 Memory 지원을 도입했습니다. 이 모드는 Agent가 파일 시스템과 Git의 지원 하에 무한 루프 작업을 수행할 수 있게 하며, ‘스킬화’된 학습 과정을 통해 지식 베이스를 지속적으로 업데이트합니다. 이러한 설계는 Agent가 스스로 오류를 수정하고 경험을 축적할 수 있게 하여, 자율 소프트웨어 개발 및 복잡한 장기 작업 처리를 위한 새로운 패러다임을 제공합니다. (출처: Vtrivedy10, hwchase17)
Pico AI Server: Mac용 로컬 프라이빗 ChatGPT: 프라이버시에 민감한 사용자를 위해 Pico AI Server는 Apple Silicon에서 완전히 로컬로 실행되는 GPT-oss 지원을 구현했습니다. MLX 프레임워크 최적화를 활용하여 24GB 이상의 메모리를 갖춘 Mac 사용자는 매끄러운 로컬 추론 경험을 즐길 수 있습니다. 이는 AI 연산 능력이 에지 측으로 이동하는 추세를 반영하며, 사용자는 민감한 데이터를 클라우드에 업로드하지 않고도 고성능 대화 및 프로그래밍 보조를 받을 수 있습니다. (출처: awnihannun)

LFM2.5 1.2B: 성능이 뛰어난 Agent 소형 모델: LiquidAI가 발표한 LFM2.5 1.2B Instruct 모델은 동일 크기 체급에서 놀라운 성능을 보여주며, 특히 Agent 작업, 데이터 추출 및 RAG에 최적화되었습니다. 지식 집약적 작업에는 권장되지 않지만, LM Studio와 같은 로컬 환경에서 추론 속도가 매우 빨라(최대 41 tps), 경량 AI 어시스턴트 및 도구 호출 워크플로우 구축에 이상적인 선택입니다. (출처: Reddit r/LocalLLaMA)

📚 学习
칭화대 팀 DrugCLIP, Science지 게재: AI로 약물 스크리닝 1,000만 배 가속: 칭화대학교 공동 연구팀이 가상 스크리닝을 밀집 검색(Dense Retrieval) 작업으로 재정의한 DrugCLIP 프레임워크를 제안했습니다. 단백질 결합 포켓과 소분자의 벡터 공간 매핑을 통해, 이 프레임워크는 8장의 A100에서 단 24시간 만에 10조 번의 계산을 완료할 수 있으며, 스크리닝 속도는 전통적인 방법보다 1,000만 배 빠릅니다. 이 돌파구는 AlphaFold 이후 시대의 새로운 약물 개발 패러다임을 열었으며, 초거대 규모 약물 발견의 진입 장벽을 크게 낮추었습니다. (출처: 36氪)

Sakana AI, Digital Red Queen (DRQ) 연구 발표: 이 연구는 Core War 프로그래밍 게임 샌드박스에서 LLM 기반의 적대적 진화를 시뮬레이션했습니다. LLM이 작성한 Redcode 프로그램들이 끊임없이 경쟁하게 함으로써 생물계의 ‘수렴 진화(Convergent Evolution)’와 유사한 현상을 관찰했습니다. 서로 다른 초기 조건의 프로그램들이 결국 자기 복제, 데이터 폭탄과 같은 유사하고 효율적인 생존 전략으로 진화했습니다. 이 작업은 인공 시스템의 적대적 역학 및 사이버 보안 진화를 연구하기 위한 안전하고 통제된 실험 환경을 제공합니다. (출처: hardmaru, SakanaAILabs)
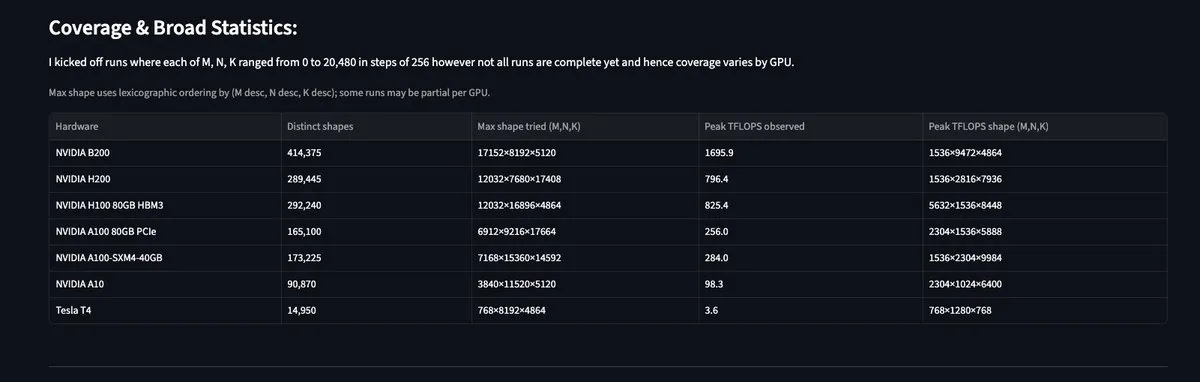
MAMF Explorer: GPU의 실제 Matrix Multiplication 성능 통찰: 개발자 Aflah가 출시한 MAMF Explorer 도구는 연구자들에게 제조사가 홍보하는 이론적 피크값이 아닌, 다양한 하드웨어에서 실제로 도달 가능한 피크 matmul FLOPS 데이터를 제공합니다. 이는 대규모 모델 훈련 및 추론의 연산 자원 할당 최적화에 매우 실용적인 가치를 지니며, 개발자가 Blackwell, H100 등 서로 다른 칩에서 실제 성능 병목 지점을 찾는 데 도움을 줍니다. (출처: StasBekman, charles_irl)
💼 商业
Anthropic 기업 가치 3,500억 달러 달성 전망, ARR 급성장: Anthropic이 100억 달러 규모의 자금 조달을 계획 중이며, 기업 가치가 반년 만에 두 배로 뛸 것이라는 소식이 전해졌습니다. 2025년 매출은 이미 9억 달러에 달했으며, 2026년에는 20억 달러 돌파를 목표로 하고 있습니다. OpenAI의 내부 갈등과 대조적으로 Anthropic은 높은 팀 안정성과 개발자 시장에서의 압도적인 성능(Claude Code 등)을 바탕으로 기업용 시장의 우선 선택지가 되고 있으며, IPO 속도에서도 이전 직장을 앞지를 가능성이 제기되고 있습니다. (출처: 36氪, srimuppidi)

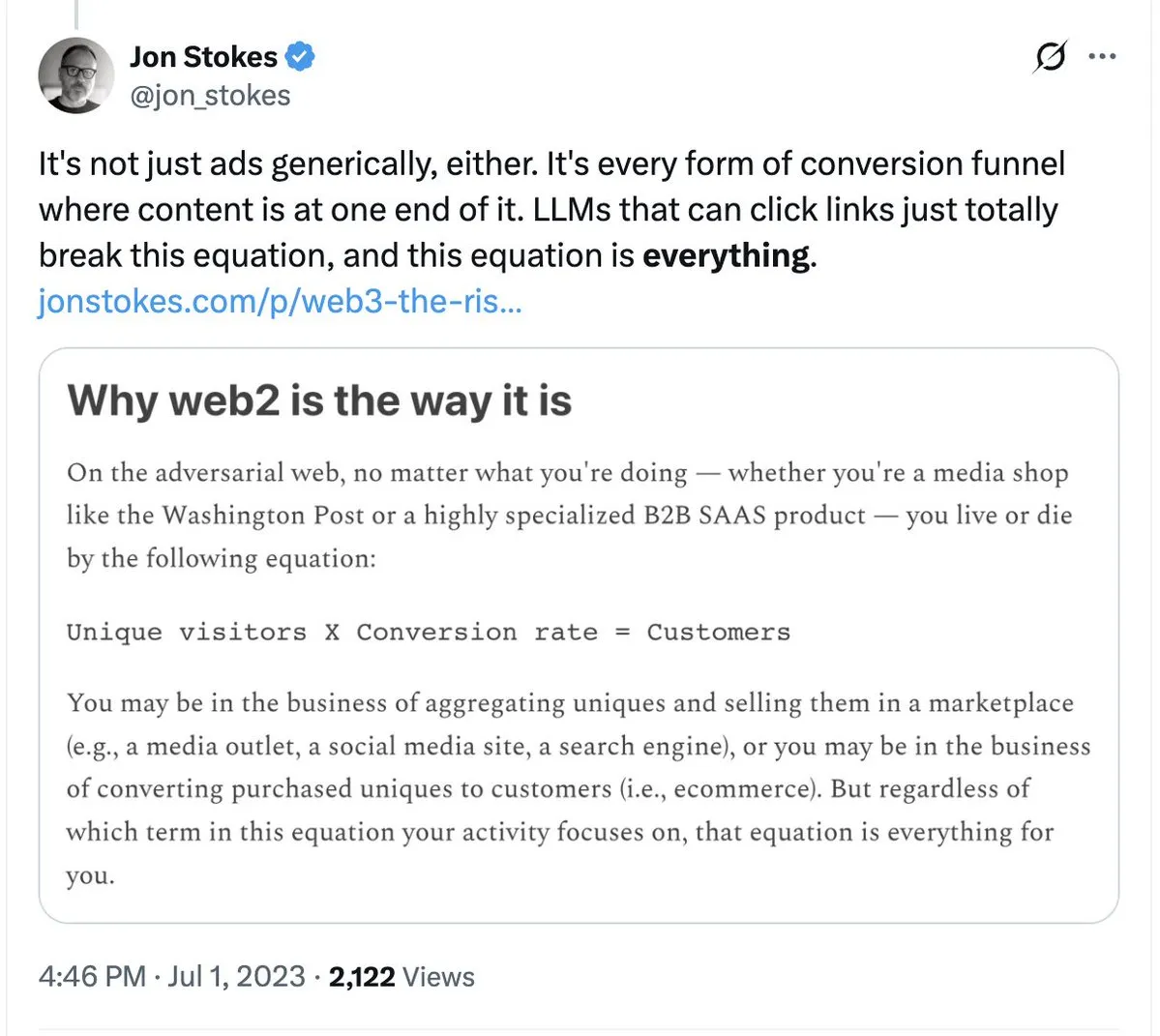
Tailwind 감원, AI가 전통적 SaaS 모델에 미치는 영향에 대한 반추: 유명 CSS 프레임워크인 Tailwind가 AI 프로그래밍 도구의 보급으로 인한 비즈니스 모델 붕괴를 이유로 인력의 75%를 감축한다고 발표했습니다. Tailwind의 사용량은 증가하고 있지만, 사용자들이 AI를 통해 코드를 생성하면서 유료 컴포넌트에 대한 의존도가 낮아졌기 때문입니다. 이 사건은 ‘인력/템플릿’ 가치에 의존하는 모든 소프트웨어 기업에 경종을 울립니다. AI가 클릭 한 번으로 솔루션을 생성할 수 있게 되면서 전통적인 지식 유료화 장벽이 무너지고 있습니다. (출처: jon_stokes, imjaredz)
京东(JD.com), ‘카멜레온 사업부’ 신설하여 Embodied AI 상용화 가속: 京东이 기존의 카멜레온 프로젝트를 사업부로 승격시켜 JoyAI App 및 Embodied AI 브랜드인 JoyInside를 전담하게 했습니다. 이 부서는 AI 소프트웨어와 하드웨어의 융합에 핵심적으로 집중하며, 이미 40여 개의 로봇 및 AI 완구 브랜드와 협력을 시작했습니다. 이는 이커머스 거물이 강력한 공급망 우위를 활용하여 AI 완구와 산업용 로봇 분야에서 연구개발부터 판매까지 이르는 비즈니스 폐쇄 루프를 구축하려는 시도를 보여줍니다. (출처: 36氪)
🌟 커뮤니티
Linus Torvalds, ‘AI 쓰레기 코드’ 규제 논쟁에 일침: Linux 커널 커뮤니티가 AI 생성 코드에 대한 규범을 제정해야 하는지에 대한 논의에 대해 Linus는 “멍청한 짓”이라고 직격탄을 날렸습니다. 그는 문서가 규칙을 지키는 사람만 구속할 뿐, ‘AI 쓰레기 코드’를 제출하는 사람은 애초에 표시조차 하지 않을 것이라고 지적했습니다. 그는 AI를 도구로 보아야 한다고 견지하며, 커널의 면역력은 무의미한 문서가 아닌 코드 리뷰 메커니즘과 커뮤니티 문화에서 나와야 한다고 강조했습니다. (출처: 36氪)

‘Karpathy 효과’가 유발한 프로그래머들의 집단 불안: Andrej Karpathy는 프로그래머라는 직업이 급격히 재구성되고 있으며, 개발자가 기여하는 비트(Bit)가 점점 희박해지고 있다고 한탄했습니다. 커뮤니티는 이를 ‘Karpathy 효과’라고 명명했습니다. 시니어 엔지니어조차 전례 없는 뒤처짐을 느끼고 있습니다. 논의에 따르면 미래의 핵심 경쟁력은 ‘코드 작성’에서 ‘시스템 복잡성 이해’로 전환될 것이며, vibe coding은 10배수 엔지니어를 100배수로 만들겠지만 초보자의 진입 장벽은 더욱 높일 것입니다. (출처: dejavucoder, arohan)
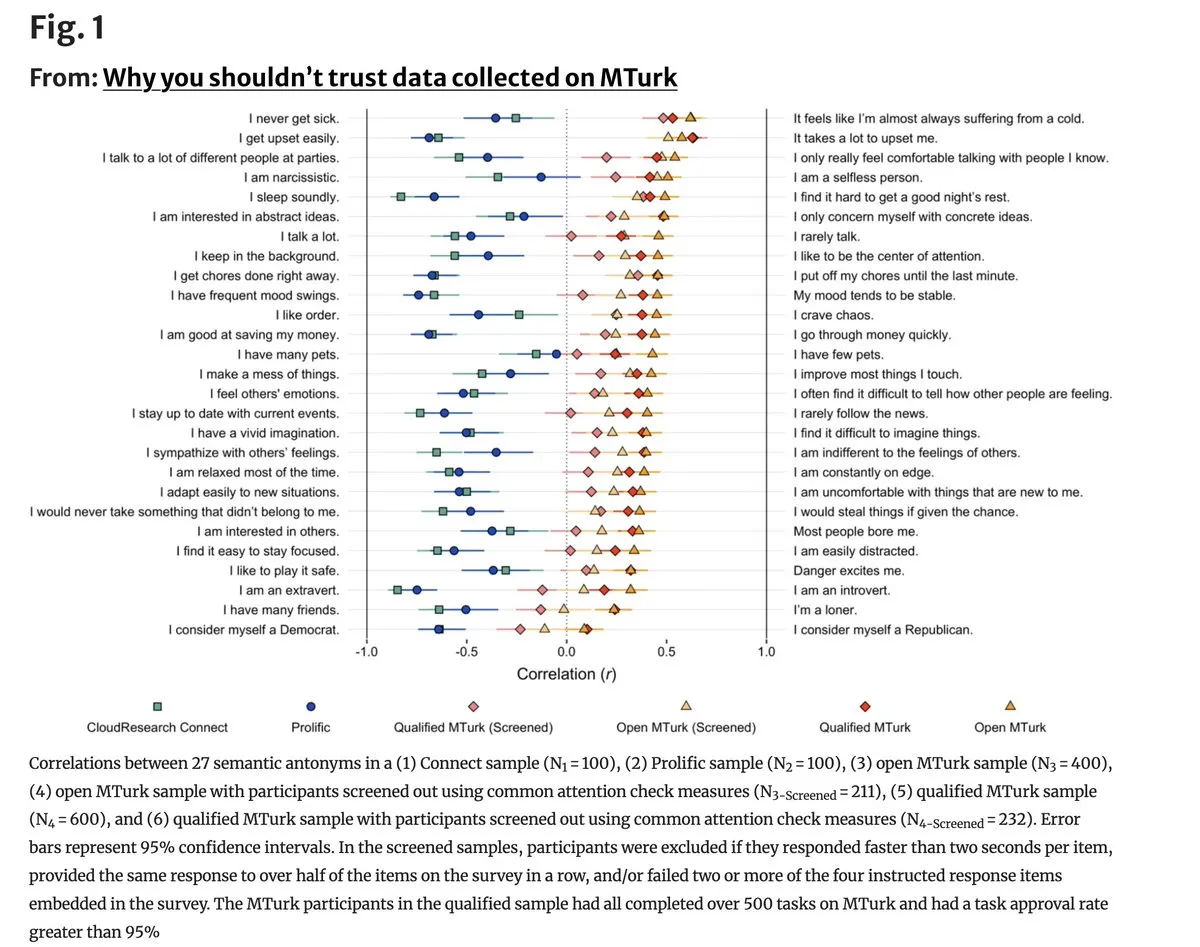
MTurk 데이터 품질, AI 참여로 인한 ‘존재론적 위기’: 최신 연구에 따르면 Amazon Mechanical Turk와 같은 크라우드소싱 플랫폼의 데이터 품질이 심각하게 하락했습니다. 모순되는 항목의 96%가 라벨링에서 양의 상관관계를 보였는데, 이는 수많은 작업자가 LLM을 사용해 대충 작업을 수행하고 있음을 증명합니다. 이는 고품질의 인간 라벨링에 의존하는 행동 과학 및 모델 미세 조정에 치명적이며, 커뮤니티는 신원 인증 기반의 실제 데이터 수집 네트워크 구축을 촉구하고 있습니다. (출처: random_walker)
💡 其他
NO FAKES Act 법안 조항, 오픈소스 커뮤니티의 우려 유발: 해당 법안의 ‘디지털 복제권’에 대한 책임 규정이 함정을 포함하고 있다는 지적이 나왔습니다. 개발자가 배포한 TTS나 음성 클론 모델이 타인에 의해 허위 유명인 비디오 제작에 사용될 경우, 개발자가 거액의 연대 책임을 질 수 있다는 것입니다. 커뮤니티는 이것이 Hugging Face와 같은 플랫폼의 오디오 모델 개발자들을 ‘법적 자살’로 몰아넣어 오픈소스 오디오 기술 혁신을 저해할 것이라고 우려하고 있습니다. (출처: Reddit r/LocalLLaMA)
ICML 2026, 학술 부정 방지를 위한 ‘연좌제’ 신규 규칙 도입: ‘살라미 전술(Salami Slicing)’식 투고와 AI를 이용한 무분별한 논문 양산을 막기 위해 ICML은 한 편의 논문에서 부정이 발견될 경우, 모든 공저자 명의의 모든 투고 논문을 즉시 거절할 수 있다고 발표했습니다. 이러한 ‘연좌제’ 메커니즘은 연구 책임자가 직접 내용을 확인하도록 요구합니다. 동시에 AI 심사위원 사용은 조건부로 허용되지만, 반드시 저자의 동의를 얻어야 합니다. (출처: 36氪)
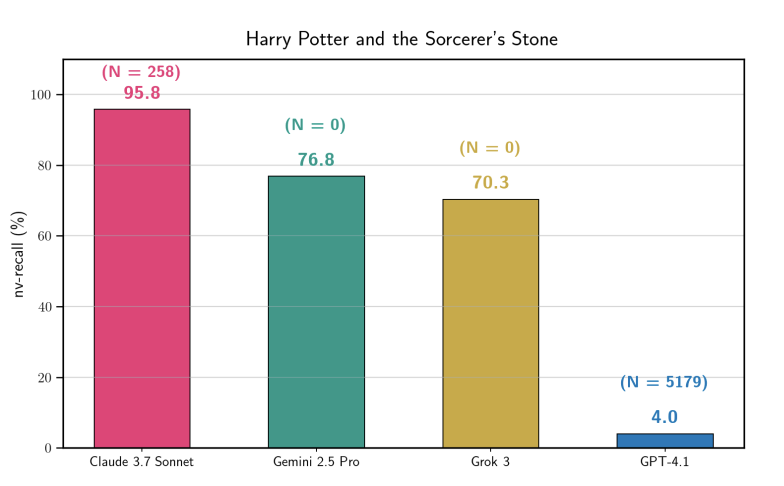
스탠퍼드 논문, LLM의 심각한 저작권 데이터 암기 확인: 연구에 따르면 Claude 3.7 Sonnet은 ‘해리 포터’ 내용의 95.8%를 토씨 하나 틀리지 않고 복원할 수 있으며, Gemini와 Grok이 그 뒤를 이었습니다. 이는 “모델은 훈련 데이터를 저장하지 않는다”는 주장을 정면으로 반박하며, 기존의 안전 필터가 특정 유도 심문 앞에서 여전히 취약함을 증명합니다. 이 발견은 향후 AI 저작권 소송에서 핵심적인 증거가 될 것입니다. (출처: stanfordnlp, andykonwinski)