Mots-clés:DeepSeek R1, Entraînement IA, Apprentissage par renforcement RL, Modèle de récompense de processus PRM
🔥 À la une
DeepSeek R1 : un rapport de 86 pages révèle les détails de l’entraînement : DeepSeek a discrètement mis à jour son rapport technique R1, passant de 22 à 86 pages, le transformant presque en un « manuel » reproductible. Le rapport divulgue pour la première fois l’évolution des trois étapes d’entraînement Dev1/2/3, une décomposition du coût d’entraînement extrêmement bas de 294 000 dollars, ainsi qu’un retour d’expérience sur des tentatives infructueuses comme le MCTS et le Process Reward Model (PRM). Cette initiative démontre non seulement son expertise profonde en Reinforcement Learning (RL), mais prouve également à la communauté open source, via des paramètres détaillés en annexe, que les modèles de raisonnement purement pilotés par RL sont non seulement viables, mais aussi dotés d’un ratio efficacité/performance très élevé. Cette stratégie de compétition par la « transparence » force les géants du closed-source à réévaluer leurs barrières technologiques. (Source : _akhaliq, karminski3, 量子位)

MiniMax et Zhipu AI : l’entrée en bourse à Hong Kong marque le « moment Shanghai/Pékin » des grands modèles : Les leaders chinois de l’IA, MiniMax et Zhipu AI, ont successivement fait leur entrée à la bourse de Hong Kong (HKEX), marquant le passage de l’industrie AGI chinoise à l’étape de l’examen par le marché secondaire. Le premier jour de cotation, l’action de MiniMax a bondi de plus de 100 %, dépassant une capitalisation de 100 milliards de HKD, portée par son ADN mondial avec plus de 70 % de revenus provenant de l’étranger. Zhipu AI a quant à lui affiché une croissance exponentielle de son activité MaaS, multipliée par 25 en 10 mois. Le succès de ces introductions en bourse offre non seulement des rendements importants aux investisseurs précoces, mais fournit également un modèle de financement reproductible pour les futures licornes de l’IA via le régime 18C, prouvant la valeur unique des entreprises chinoises possédant des capacités de modèles de base autonomes dans la compétition mondiale. (Source : Zai_org, 36氪)

CES 2026 : l’explosion de la Physical AI, des écrans au monde réel : Cette édition du CES s’est entièrement tournée vers le thème de la « Physical AI », Jensen Huang de NVIDIA l’ayant qualifiée de « moment ChatGPT pour la Physical AI ». L’Atlas de Boston Dynamics a fait sa première apparition publique sur scène en annonçant son intégration dans les usines Hyundai, LG a présenté CLOiD, un robot domestique capable de plier le linge, et Lenovo a lancé Qira, un super Agent personnel d’IA. La chaîne d’approvisionnement chinoise a brillé avec plus de 20 entreprises de robotique exposantes, démontrant des capacités de production de masse allant des mains agiles aux robots humanoïdes de taille réelle. L’IA n’est plus seulement une boîte de dialogue, mais intervient profondément dans le monde physique via des capteurs et des actionneurs, restructurant les industries traditionnelles de l’électroménager, du PC et de l’automobile. (Source : TheRundownAI, 雷科技)

OpenAI lance son segment Healthcare pour s’attaquer au marché vertical de la santé : OpenAI a officiellement lancé l’expérience ChatGPT Health, conforme à la norme HIPAA, en partenariat avec des institutions médicales de premier plan telles que la Mayo Clinic et le Boston Children’s Hospital. Cette fonctionnalité permet aux utilisateurs d’accéder à leurs dossiers médicaux électroniques et aux données Apple Health, utilisant l’IA pour aider à l’analyse des rapports d’examen et à l’élaboration de plans de santé. Bien que surnommé par certains le « Alipay Health américain », cela représente une tendance de fond : le passage des grands modèles du généraliste vers une expertise verticale profonde. L’IA médicale évolue d’un simple système de questions-réponses vers un assistant professionnel capable d’intégrer des données multisources et de fournir un soutien à la décision clinique, bien que la sécurité et les risques de diagnostic erroné restent au cœur des préoccupations de la communauté. (Source : _samirism, openai)
🎯 Tendances
Google DeepMind propose le cadre de « Nested Learning » (NL) : Pour résoudre le problème du manque de capacité d’apprentissage continu des Transformer et leur propension à l’« oubli catastrophique », l’équipe de DeepMind s’est inspirée des mécanismes de mémoire associative humaine pour proposer le cadre Nested Learning (NL). Ce cadre considère l’optimiseur comme le « contexte » de l’architecture du modèle, permettant à l’IA de construire des structures abstraites pendant l’exécution et de transformer l’expérience à court terme en connaissances à long terme grâce à l’imbrication de modules à différentes fréquences de mise à jour. Ceci est considéré comme une étape cruciale vers l’AGI, permettant potentiellement aux modèles d’évoluer d’eux-mêmes dans des environnements dynamiques au lieu de dépendre d’un réentraînement coûteux. (Source : hardmaru, 新智元)
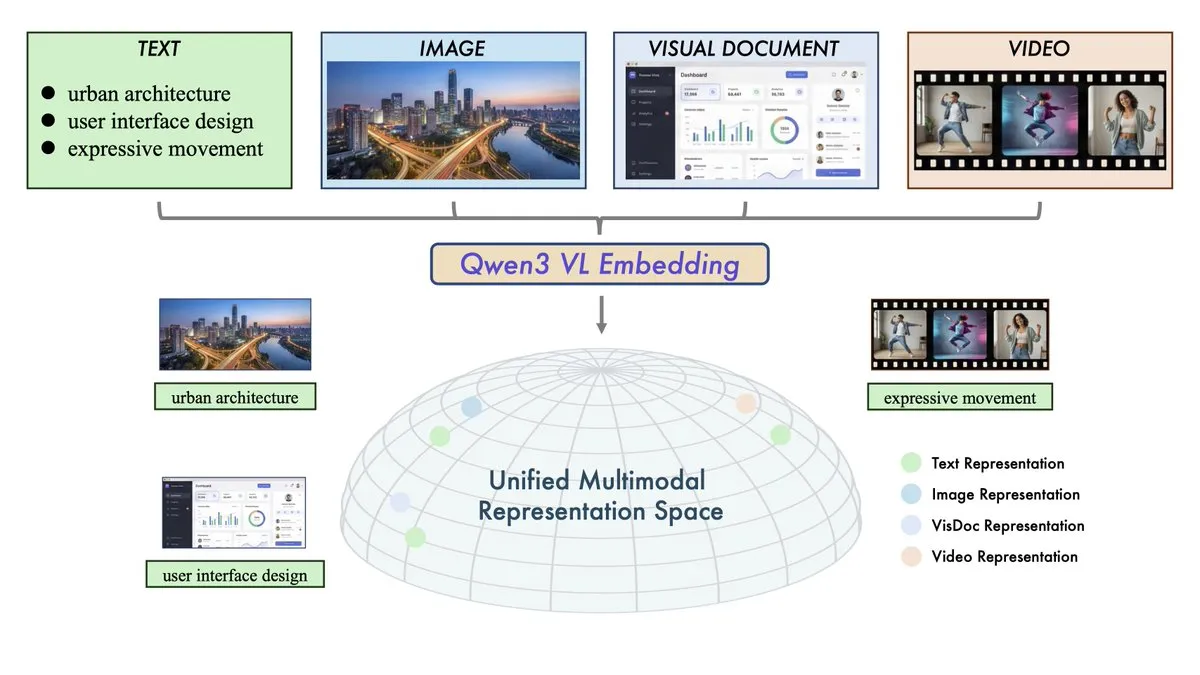
Alibaba publie les modèles Qwen3-VL-Embedding et Reranker : L’équipe Qwen d’Alibaba a lancé un duo de recherche multimodale visant à unifier l’espace vectoriel du texte, de l’image, de la vidéo et des modalités mixtes. Qwen3-VL-Embedding prend en charge plus de 30 langues et atteint des performances SOTA sur les benchmarks de recherche multimodale ; le Reranker améliore encore la précision de la recherche grâce à un score de pertinence à grain fin. Ce lancement marque l’entrée officielle de la technologie RAG (Retrieval-Augmented Generation) dans l’ère du tout-multimodal, fournissant l’infrastructure de base pour construire des systèmes de Visual QA, de recherche vidéo et des Agents multimodaux plus complexes. (Source : huggingface, _akhaliq)
Le fondateur d’a16z prévoit 2026 : la déflation du coût de l’intelligence stimulera l’explosion de la demande : Marc Andreessen souligne que la baisse du coût unitaire de l’IA a déjà dépassé la loi de Moore, l’intelligence passant d’un produit de luxe à une commodité comme l’eau ou l’électricité. Il prédit que le futur marché présentera une « structure pyramidale » : au sommet, quelques super-modèles, et à la base, des petits modèles omniprésents en périphérie (edge). Parallèlement, il estime que les startups se débarrassent des critiques de « simple surcouche » (wrapper) en développant leurs propres modèles par « intégration verticale inversée », et que le modèle économique de l’IA passera du paiement par Token à une tarification basée sur la valeur créée. (Source : nvidia, 华尔街见闻)
Les grands modèles vocaux pour cockpits intelligents s’accélèrent : Au CES, StepFun a présenté, en collaboration avec Geely Galaxy, un cockpit doté d’un grand modèle vocal end-to-end, capable de reconnaissance émotionnelle et doté d’une mémoire à long terme. Les experts du secteur estiment que 2026 sera l’année du déploiement massif des Agents comme point d’entrée dans les cockpits automobiles. Le cockpit passe d’un simple contrôle vocal à un « troisième espace » capable d’exécution proactive et de services personnalisés. L’architecture IA de collaboration cloud-edge deviendra le cœur de la compétition entre constructeurs, visant à intégrer profondément les capacités d’IA dans les couches basses de l’OS pour une fusion d’expériences multi-domaines. (Source : dotey, 科创板日报)
🧰 Outils
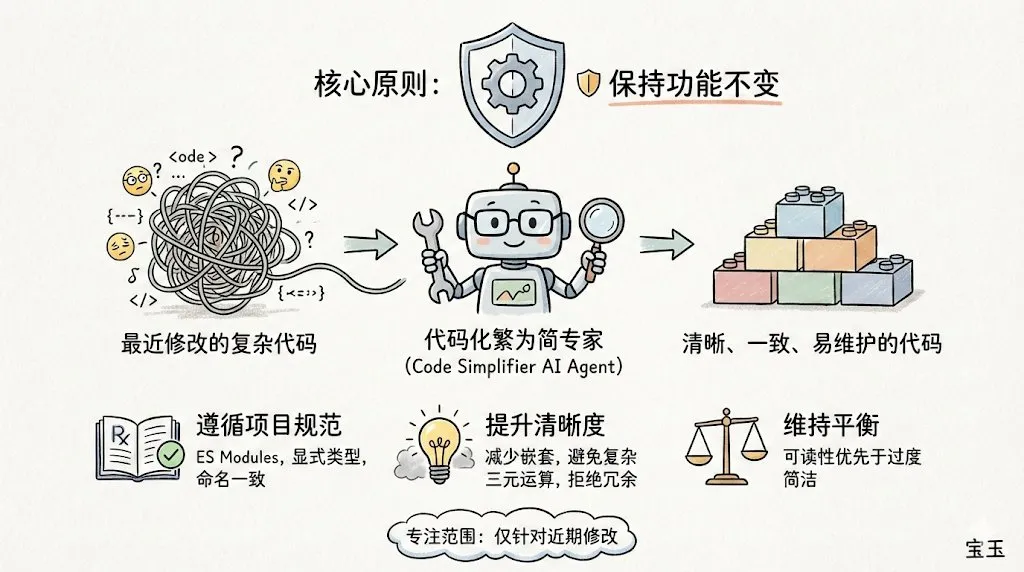
Lancement de Claude Code et du plugin code-simplifier : L’outil en ligne de commande Claude Code lancé par Anthropic a connu un immense succès dans la communauté des développeurs grâce à son excellente approche d’ingénierie. La dernière version officielle inclut le plugin agent code-simplifier, permettant de simplifier des bases de code complexes en un clic. Son concept central est « le système de fichiers comme contexte », améliorant considérablement l’efficacité du traitement des grands dépôts en chargeant dynamiquement les fichiers nécessaires au lieu d’empiler les Token. Les retours de la communauté indiquent qu’il surpasse GPT-4o en termes de compréhension logique et de réduction du « verbiage de code ». (Source : dotey, natolambert)
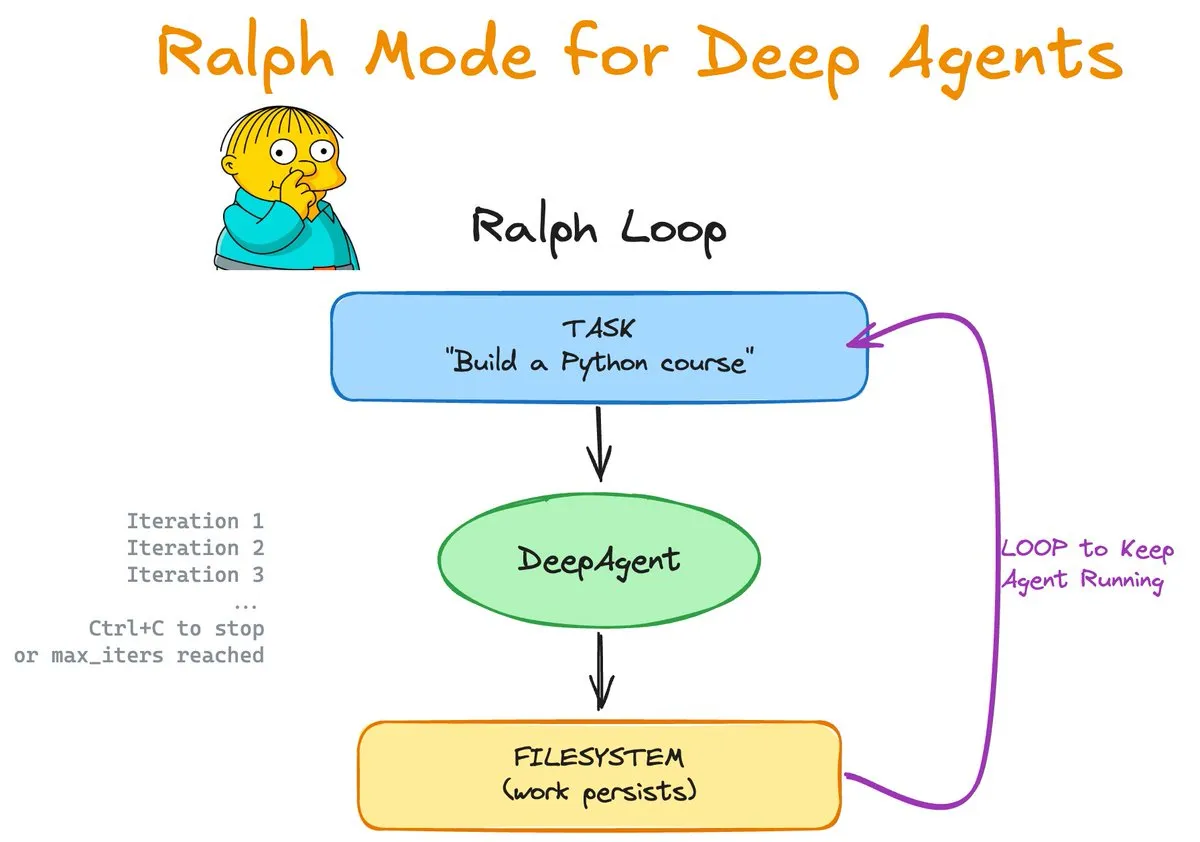
Ralph Mode : boucles continues et mémoire augmentée pour les Agents : Ralph Mode, lancé par LangChain OSS, introduit un support natif pour les Skills et la Memory dans la bibliothèque DeepAgents. Ce mode permet aux Agents d’effectuer des tâches en boucle infinie avec le support du système de fichiers et de Git, mettant constamment à jour leur base de connaissances via un processus d’apprentissage par « compétences ». Cette conception permet aux Agents de s’autocorriger et d’accumuler de l’expérience, offrant un nouveau paradigme pour le développement logiciel autonome et le traitement de tâches complexes de longue durée. (Source : Vtrivedy10, hwchase17)
Pico AI Server : un ChatGPT local et privé sur Mac : Pour les utilisateurs soucieux de leur vie privée, Pico AI Server permet de faire tourner des GPT-oss entièrement localement sur Apple Silicon. Optimisé grâce au framework MLX, cet outil permet aux utilisateurs de Mac disposant de 24 Go de RAM ou plus de bénéficier d’une expérience d’inférence locale fluide. Cela reflète la tendance de la migration de la puissance de calcul IA vers le edge, où les utilisateurs n’ont plus besoin de télécharger des données sensibles sur le cloud pour obtenir une assistance performante en conversation et en programmation. (Source : awnihannun)

LFM2.5 1.2B : un petit modèle performant pour les Agents : LiquidAI a publié le modèle LFM2.5 1.2B Instruct, qui affiche des performances impressionnantes pour sa taille, particulièrement optimisé pour les tâches d’Agent, l’extraction de données et le RAG. Bien qu’il ne soit pas recommandé pour des tâches nécessitant de vastes connaissances, sa vitesse d’inférence dans des environnements locaux comme LM Studio est extrêmement rapide (jusqu’à 41 tps), ce qui en fait un choix idéal pour construire des assistants IA légers et des flux d’appels d’outils (tool calling). (Source : Reddit r/LocalLLaMA)

📚 Apprentissage
L’équipe de Tsinghua publie DrugCLIP dans Science : l’IA accélère le criblage de médicaments par millions : Une équipe de recherche conjointe de l’Université Tsinghua a proposé le cadre DrugCLIP, qui redéfinit le criblage virtuel comme une tâche de recherche dense. En cartographiant les poches de liaison des protéines et les petites molécules dans un espace vectoriel, ce cadre peut réaliser 10 billions de calculs en seulement 24 heures sur 8 GPU A100, soit une vitesse de criblage 10 millions de fois supérieure aux méthodes traditionnelles. Cette percée ouvre un nouveau paradigme pour la R&D de médicaments dans l’ère post-AlphaFold, abaissant considérablement la barrière pour la découverte de médicaments à ultra-grande échelle. (Source : 36氪)

Sakana AI publie l’étude Digital Red Queen (DRQ) : Cette étude simule une évolution antagoniste pilotée par LLM dans un bac à sable de jeu de programmation Core War. En faisant s’affronter continuellement des programmes Redcode écrits par des LLM, les chercheurs ont observé un phénomène de « convergence évolutive » similaire au monde biologique : des programmes partant de conditions initiales différentes finissent par développer des stratégies de survie efficaces similaires (ex: auto-réplication, bombes de données). Ce travail fournit un environnement expérimental sûr et contrôlé pour étudier la dynamique antagoniste dans les systèmes artificiels et l’évolution de la cybersécurité. (Source : hardmaru, SakanaAILabs)
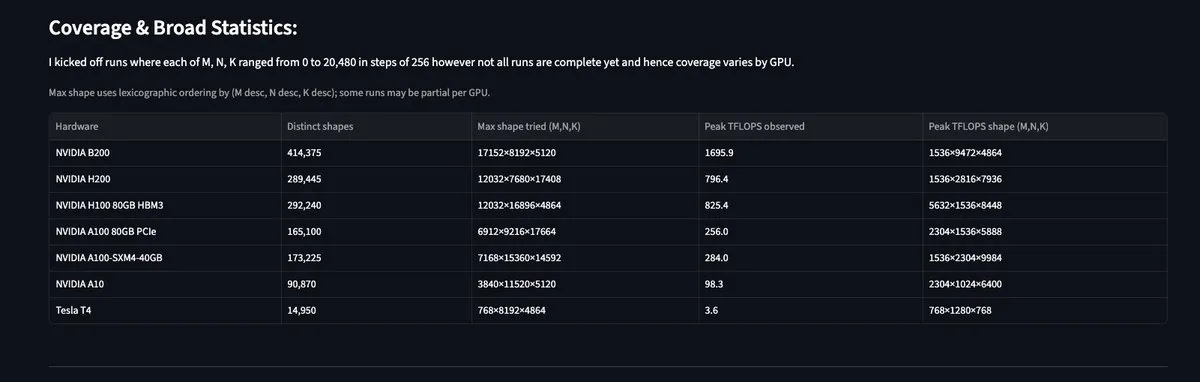
MAMF Explorer : analyser les performances réelles des multiplications de matrices sur GPU : L’outil MAMF Explorer, lancé par le développeur Aflah, fournit aux chercheurs des données sur les FLOPS de matmul crêtes réellement atteignables sur divers matériels, plutôt que les valeurs théoriques annoncées par les fabricants. C’est extrêmement utile pour optimiser l’allocation de puissance de calcul pour l’entraînement et l’inférence de modèles à grande échelle, aidant les développeurs à identifier les véritables goulots d’étranglement de performance sur différentes puces comme Blackwell ou H100. (Source : StasBekman, charles_irl)
💼 Business
La valorisation d’Anthropic pourrait atteindre 350 milliards de dollars, l’ARR en pleine croissance : Des rumeurs indiquent qu’Anthropic prévoit de lever 10 milliards de dollars, sa valorisation ayant doublé en six mois. Ses revenus pour 2025 ont déjà atteint 900 millions de dollars, avec un objectif de dépasser les 2 milliards en 2026. Contrairement aux tensions internes d’OpenAI, Anthropic, grâce à la grande stabilité de son équipe et à ses performances dominantes sur le marché des développeurs (comme Claude Code), devient le premier choix pour le marché des entreprises, certains pensant même qu’elle pourrait devancer son ancien employeur sur le chemin de l’IPO. (Source : 36氪, srimuppidi)

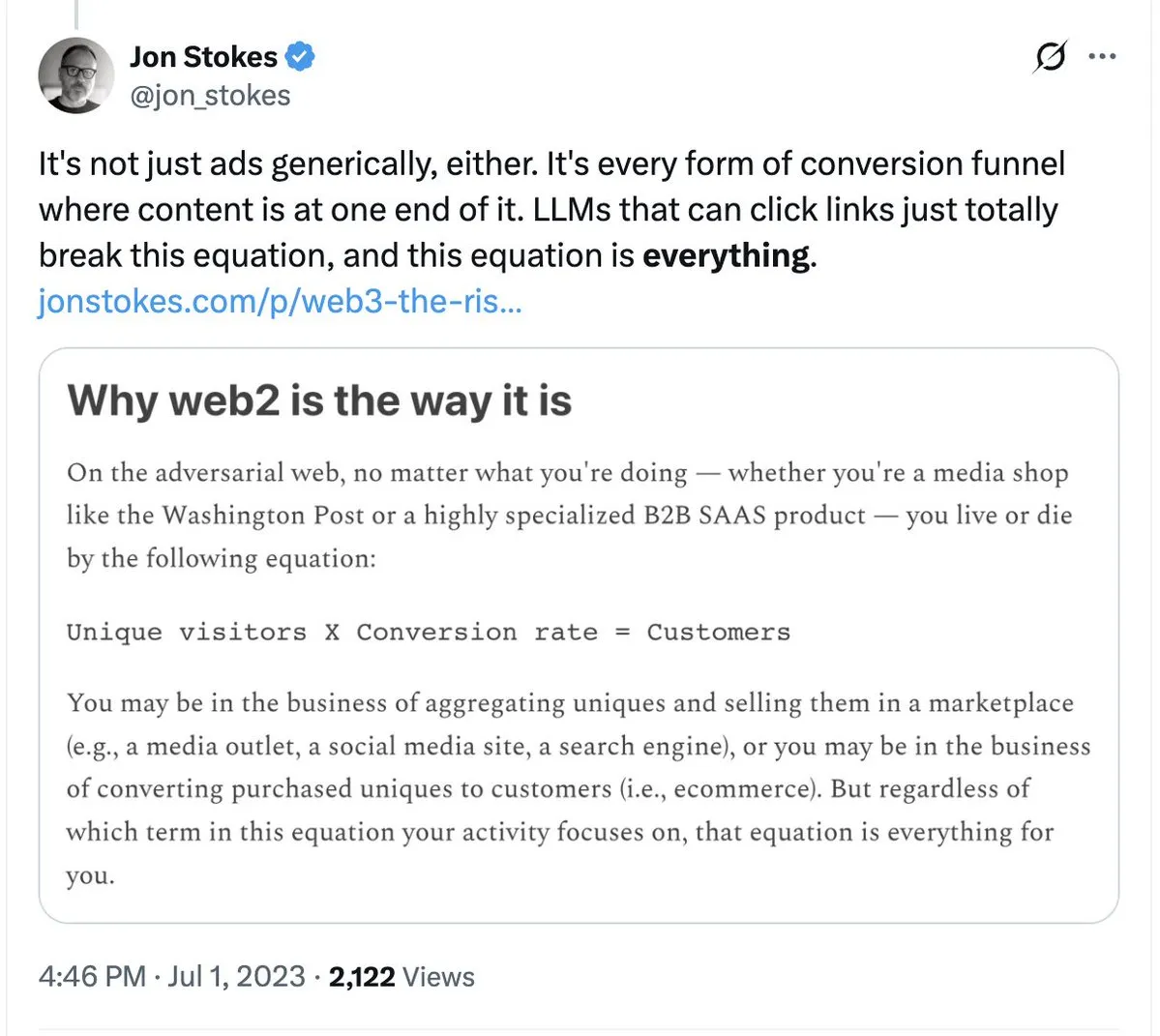
Les licenciements chez Tailwind font réfléchir sur l’impact de l’AI sur le modèle SaaS traditionnel : Le célèbre framework CSS Tailwind a annoncé le licenciement de 75 % de ses effectifs, justifiant cela par l’effondrement de son modèle économique dû à la popularité des outils de programmation IA. Bien que l’utilisation de Tailwind augmente, le besoin des utilisateurs de générer du code via l’IA a réduit leur dépendance vis-à-vis de ses composants payants. Cet événement est un avertissement pour toutes les entreprises de logiciels dépendant de la valeur « main-d’œuvre/modèles » : lorsque l’IA peut générer une solution en un clic, les barrières traditionnelles de la monétisation des connaissances s’effondrent. (Source : jon_stokes, imjaredz)
JD.com crée le département « Chameleon » pour accélérer l’Embodied AI : JD.com a transformé son projet initial Chameleon en un département commercial à part entière, prenant en charge l’application JoyAI et la marque d’intelligence incarnée JoyInside. Ce département se concentre sur la fusion matérielle et logicielle de l’IA et a déjà établi des contacts avec plus de 40 marques de robotique et de jouets IA. Cela montre que les géants du e-commerce utilisent leurs solides avantages en matière de chaîne d’approvisionnement pour tenter de construire une boucle commerciale complète, de la R&D à la vente, dans les domaines des jouets IA et des robots industriels. (Source : 36氪)
🌟 Communauté
Linus Torvalds s’emporte contre le débat sur les normes du « code poubelle » généré par IA : Face aux discussions sur l’opportunité pour la communauté du noyau Linux d’établir des normes pour le code généré par IA, Linus a qualifié cela de « stupide ». Il estime que les documents ne peuvent contraindre que ceux qui respectent déjà les règles, et que ceux qui soumettent du « code poubelle IA » ne l’étiquetteront jamais d’eux-mêmes. Il maintient que l’IA doit être vue comme un outil et souligne que l’immunité du noyau doit provenir des mécanismes de revue de code et de la culture communautaire, et non de postures documentaires inutiles. (Source : 36氪)

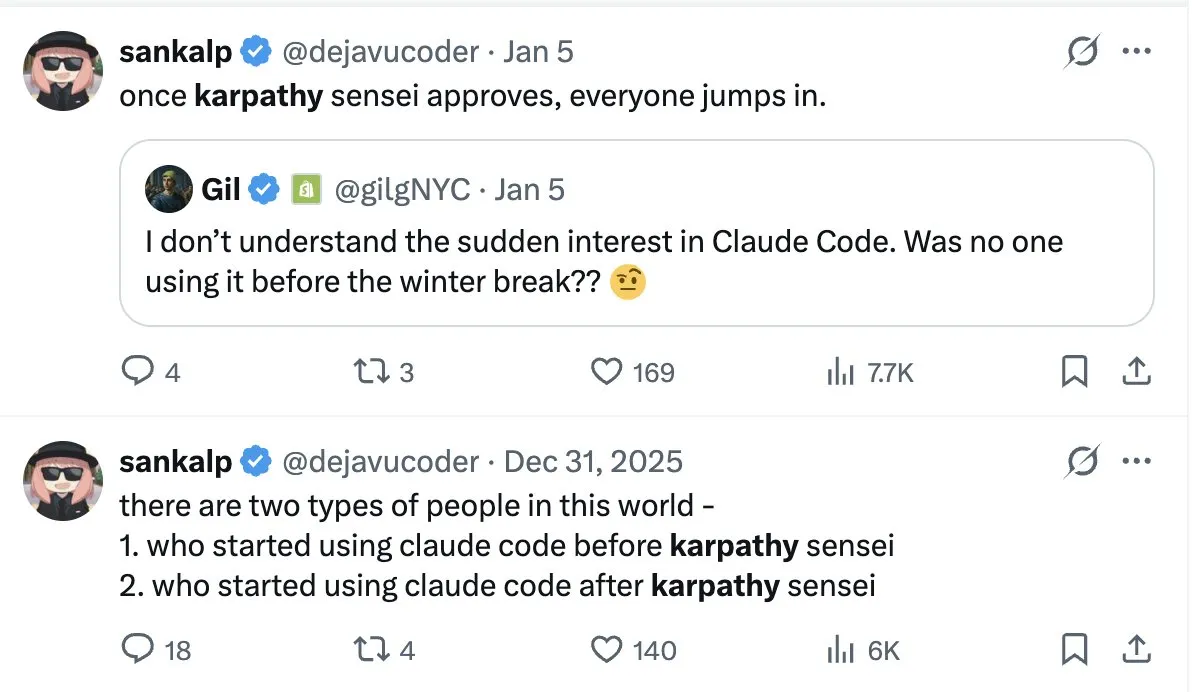
L’« effet Karpathy » provoque une anxiété collective chez les programmeurs : Andrej Karpathy a déploré que la profession de programmeur soit en train d’être radicalement restructurée, les bits contribués par les développeurs devenant de plus en plus rares. La communauté a résumé cela sous le nom d’« effet Karpathy » : même les ingénieurs seniors ressentent un sentiment de retard sans précédent. Les discussions suggèrent que la compétence clé du futur passera de « l’écriture de code » à la « compréhension de la complexité des systèmes », le vibe coding transformant les ingénieurs 10x en 100x, tout en rendant le seuil d’entrée pour les débutants beaucoup plus élevé. (Source : dejavucoder, arohan)
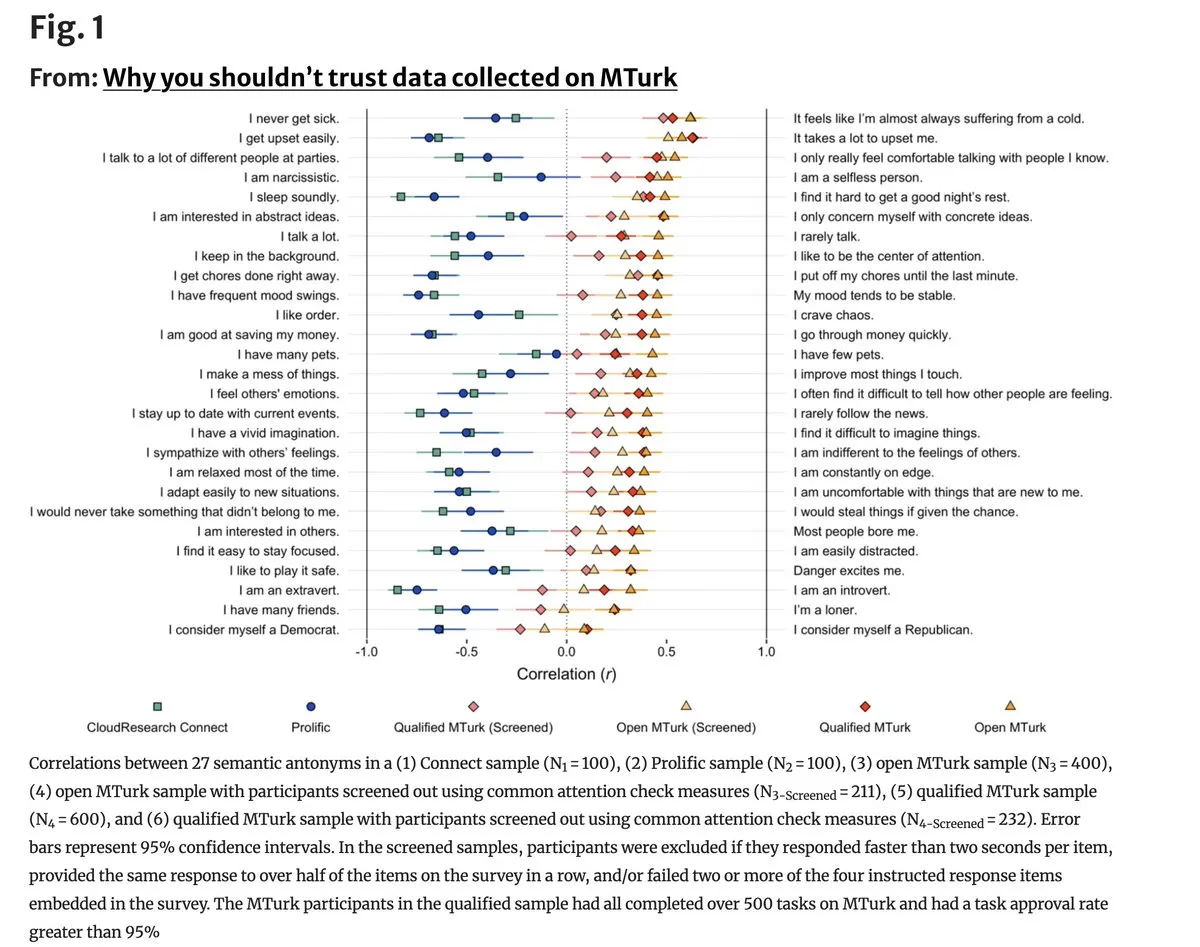
Crise existentielle pour la qualité des données sur MTurk à cause de l’IA : Une étude récente montre que la qualité des données sur les plateformes de crowdsourcing comme Amazon Mechanical Turk s’est gravement dégradée, 96 % des éléments contradictoires présentant une corrélation positive dans l’étiquetage, prouvant qu’un grand nombre de travailleurs utilisent des LLM pour bâcler leurs tâches. C’est fatal pour les sciences du comportement et le fine-tuning de modèles qui dépendent d’un étiquetage humain de haute qualité. La communauté appelle à la création de réseaux de collecte de données réelles basés sur la vérification d’identité. (Source : random_walker)
💡 Autres
Inquiétudes de la communauté open source concernant la loi NO FAKES Act : Les clauses de cette loi sur la responsabilité liée aux « droits de réplique numérique » sont perçues comme un piège. Si un développeur publie un modèle TTS ou de clonage de voix utilisé par un tiers pour créer de fausses vidéos de célébrités, le développeur pourrait faire face à des dommages-intérêts solidaires massifs. La communauté craint que cela ne pousse les développeurs de modèles audio sur des plateformes comme Hugging Face vers un « suicide juridique », étouffant ainsi l’innovation dans les technologies audio open source. (Source : Reddit r/LocalLLaMA)
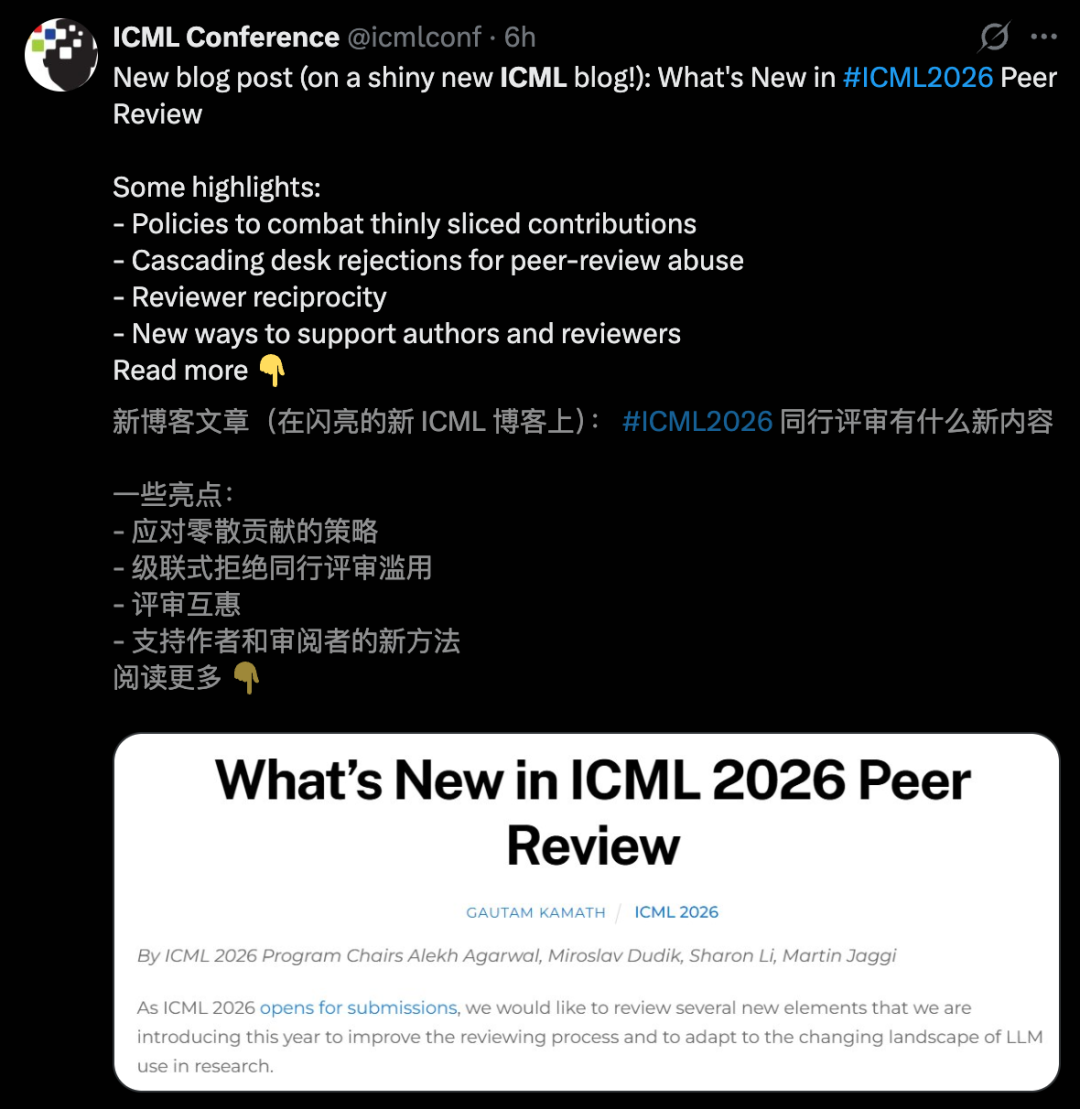
ICML 2026 introduit de nouvelles règles de responsabilité collective contre la fraude académique : Pour lutter contre les soumissions de type « salami slicing » et le spam généré par IA, l’ICML a annoncé que si une fraude est détectée dans un article, toutes les soumissions de tous les co-auteurs pourraient être directement rejetées. Ce mécanisme de responsabilité collective exige que les responsables de laboratoires vérifient personnellement chaque travail. Parallèlement, la conférence autorise l’utilisation conditionnelle de l’IA pour la relecture, sous réserve de l’accord des auteurs. (Source : 36氪)
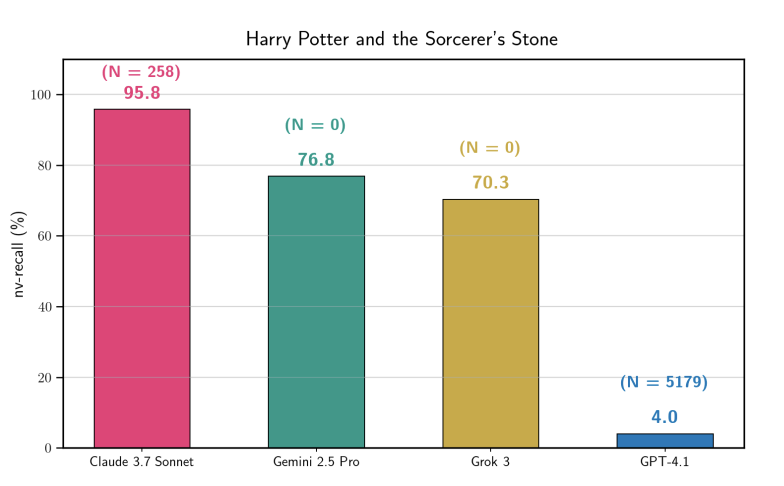
Une étude de Stanford confirme que les LLM mémorisent massivement des données sous copyright : L’étude montre que Claude 3.7 Sonnet peut reproduire mot pour mot 95,8 % du contenu de « Harry Potter », suivi de près par Gemini et Grok. Cela réfute l’idée que « les modèles ne stockent pas les données d’entraînement », prouvant que les filtres de sécurité actuels restent fragiles face à certaines incitations spécifiques. Cette découverte fournira des preuves cruciales pour les futurs litiges sur le droit d’auteur lié à l’IA. (Source : stanfordnlp, andykonwinski)