Palabras clave:DeepSeek R1, entrenamiento de IA, aprendizaje por refuerzo RL, modelo de recompensa de proceso PRM
🔥 Enfoque
DeepSeek R1 revela detalles de entrenamiento en un paper de 86 páginas: DeepSeek ha actualizado silenciosamente el informe técnico de R1, expandiéndolo de 22 a 86 páginas, casi reescrito como un “libro de texto” reproducible. El informe revela por primera vez detalles sobre la evolución de las tres etapas de entrenamiento Dev1/2/3, un desglose del bajísimo costo de entrenamiento de 294,000 dólares, y una revisión de intentos fallidos como MCTS y Process Reward Model (PRM). Este movimiento no solo muestra su profunda acumulación en el campo de Reinforcement Learning (RL), sino que demuestra a la comunidad Open Source, a través de apéndices detallados, que los modelos de razonamiento impulsados puramente por RL no solo son viables, sino que tienen una eficiencia extremadamente alta. Esta estrategia de competencia de “transparencia” está obligando a los gigantes de código cerrado a reevaluar sus barreras tecnológicas. (Fuente: _akhaliq, karminski3, 量子位)

MiniMax y Zhipu AI inician el “momento Shanghai/Beijing” de los Large Models con sus IPO en Hong Kong: Las empresas líderes de Large Models en China, MiniMax y Zhipu AI, han aterrizado sucesivamente en la Bolsa de Hong Kong, marcando la entrada oficial de la industria AGI de China en la fase de prueba del mercado secundario. En su primer día de cotización, las acciones de MiniMax se dispararon más del 100%, superando una valoración de 100 mil millones de HKD, con su ADN globalizado (más del 70% de ingresos provenientes del extranjero) siendo muy bien recibido por el capital. Zhipu AI, por su parte, mostró un crecimiento exponencial de 25 veces en su negocio MaaS en 10 meses. La exitosa salida a bolsa de ambas compañías no solo brinda retornos generosos a los inversores iniciales, sino que también ofrece un modelo de financiación replicable para futuros unicornios de AI a través del sistema 18C, demostrando el valor único de las empresas chinas con capacidades de modelos base propios en la competencia global. (Fuente: Zai_org, 36氪)

CES 2026: Explosión de Physical AI, de las pantallas al mundo real: Esta edición del CES se ha volcado completamente hacia el tema de “Physical AI”, lo que Jensen Huang de NVIDIA llamó el “momento ChatGPT de la Physical AI”. El Atlas de Boston Dynamics subió al escenario públicamente por primera vez y anunció su entrada a trabajar en las fábricas de Hyundai; LG lanzó CLOiD, un robot doméstico capaz de doblar ropa; y Lenovo presentó Qira, un super Agent de AI personal. La cadena de suministro china tuvo un desempeño destacado con más de 20 empresas de robótica presentes, mostrando capacidades de producción en masa que van desde manos diestras hasta robots humanoides de tamaño completo. La AI ya no es solo un cuadro de diálogo, sino que interviene profundamente en el mundo físico a través de sensores y actuadores, reconfigurando industrias tradicionales desde electrodomésticos y PC hasta automóviles. (Fuente: TheRundownAI, 雷科技)

OpenAI lanza el sector Healthcare para entrar en pistas verticales médicas: OpenAI ha lanzado oficialmente la experiencia ChatGPT Health, compatible con HIPAA, y en colaboración con instituciones médicas de primer nivel como Mayo Clinic y Boston Children’s Hospital. Esta función permite a los usuarios conectar sus registros médicos electrónicos y datos de Apple Health, utilizando AI para asistir en el análisis de informes médicos y la creación de planes de salud. Aunque ha sido apodado como la “versión estadounidense de Ant Afu”, representa la tendencia de los Large Models de profundizar desde lo general hacia campos verticales profesionales. La AI médica está evolucionando de simples preguntas y respuestas a asistentes profesionales capaces de integrar datos de múltiples fuentes y proporcionar soporte para decisiones clínicas, aunque la seguridad y el riesgo de diagnósticos erróneos siguen siendo el foco de atención de la comunidad. (Fuente: _samirism, openai)
🎯 Tendencias
Google DeepMind propone el framework “Nested Learning” (NL): Para abordar la falta de capacidad de aprendizaje continuo en los Transformer y su propensión al “olvido catastrófico”, el equipo de DeepMind, inspirándose en los mecanismos de memoria asociativa humana, propuso el framework de aprendizaje anidado NL. Este framework trata al optimizador como el “contexto” de la arquitectura del modelo, permitiendo que la AI construya estructuras abstractas durante la ejecución mediante el anidamiento de módulos con diferentes frecuencias de actualización, convirtiendo la experiencia a corto plazo en conocimiento a largo plazo. Esto se considera un paso clave hacia la AGI, con la esperanza de que los modelos puedan evolucionar por sí mismos en entornos dinámicos como los humanos, en lugar de depender de costosos reentrenamientos. (Fuente: hardmaru, 新智元)
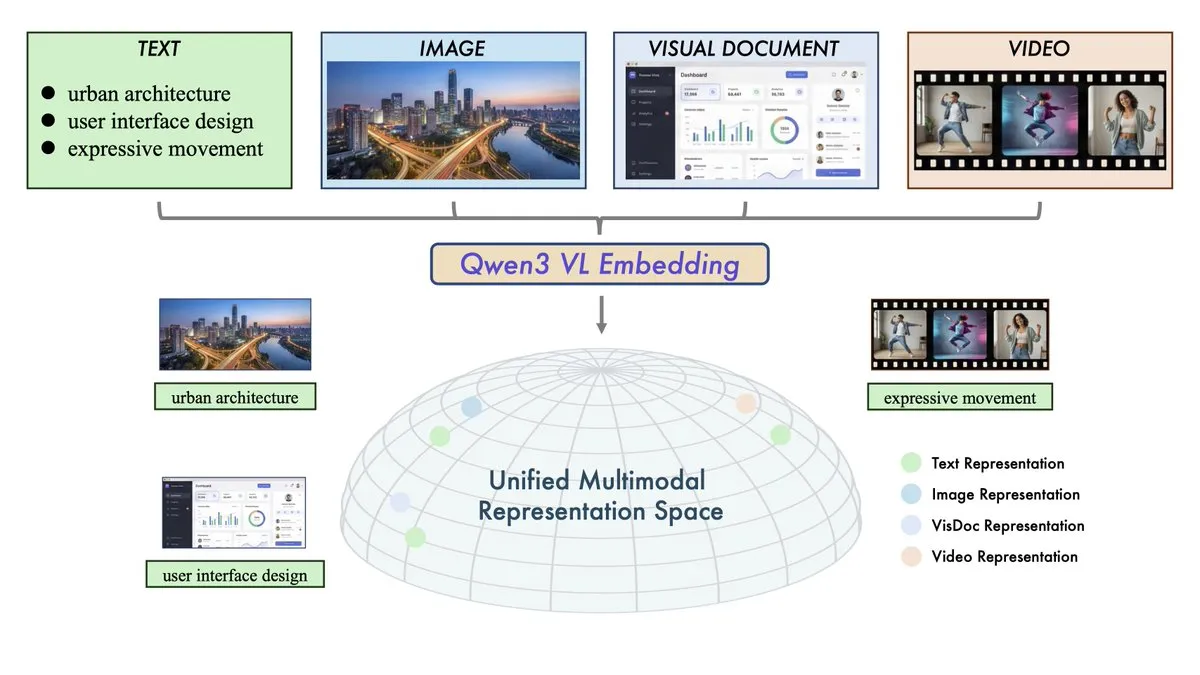
Alibaba lanza los modelos Qwen3-VL-Embedding y Reranker: El equipo de Qwen de Alibaba ha lanzado un dúo de recuperación multimodal destinado a unificar el espacio vectorial de texto, imagen, video y modalidades mixtas. Qwen3-VL-Embedding soporta más de 30 idiomas y alcanza un rendimiento SOTA en benchmarks de recuperación multimodal; Reranker mejora aún más la precisión de la recuperación mediante puntuaciones de relevancia de grano fino. Este lanzamiento marca la entrada oficial de la tecnología RAG (Retrieval-Augmented Generation) en la era de todas las modalidades, proporcionando la infraestructura central para construir Visual QA, búsqueda de video y Agents multimodales más complejos. (Fuente: huggingface, _akhaliq)
Fundador de a16z hacia 2026: La deflación del costo de la inteligencia impulsará una explosión de demanda: Marc Andreessen señaló que la velocidad de caída del costo unitario de la AI ya ha superado la Ley de Moore, y la inteligencia está pasando de ser un lujo a un producto básico como el agua o la electricidad. Predice que el mercado futuro presentará una “estructura piramidal”: en la cima, unos pocos supermodelos; en la base, pequeños modelos de borde ubicuos. Al mismo tiempo, cree que las startups se están alejando de las críticas de ser simples “envoltorios” mediante la “integración hacia atrás” con modelos de desarrollo propio, y los modelos de negocio de AI pasarán del pago por Token a la fijación de precios basada en el valor creado. (Fuente: nvidia, 华尔街见闻)
Los Large Models de voz para Smart Cockpits aceleran su integración en vehículos: En el CES, StepFun mostró un cockpit con un Large Model de voz end-to-end en colaboración con Geely Galaxy, con capacidades de reconocimiento emocional y memoria a largo plazo. La visión de la industria es que 2026 será el año del inicio de la producción en masa de Agents a nivel de entrada en los cockpits de automóviles. El cockpit está pasando de un simple control por voz a un “tercer espacio” con ejecución proactiva y servicios personalizados; la arquitectura de AI con colaboración entre el borde y la nube se convertirá en el núcleo de la competencia entre fabricantes de automóviles, con el objetivo de integrar profundamente las capacidades de AI en la capa base del OS para lograr una fusión de experiencias multidominio. (Fuente: dotey, 科创板日报)
🧰 Herramientas
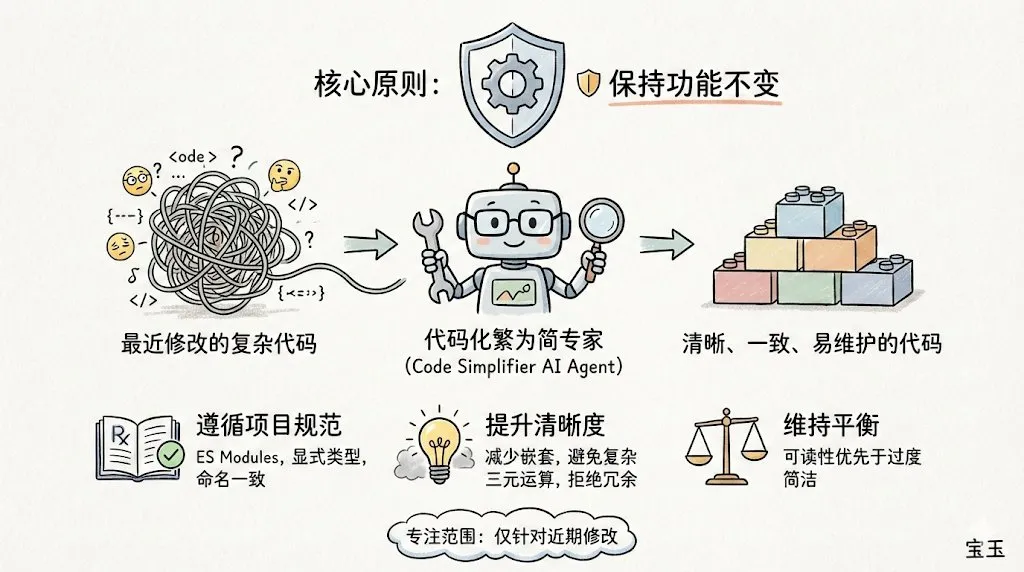
Lanzamiento de Claude Code y el plugin code-simplifier: La herramienta de línea de comandos Claude Code lanzada por Anthropic se ha vuelto viral en la comunidad de desarrolladores debido a su excelente sentido de ingeniería. Oficialmente se ha lanzado el plugin de agente code-simplifier, que permite simplificar bases de código complejas con un solo clic. Su concepto central es “el sistema de archivos como contexto”, mejorando significativamente la eficiencia al manejar grandes repositorios cargando dinámicamente los archivos necesarios en lugar de apilar Tokens. El feedback de la comunidad indica que ya ha superado a GPT-4o en comprensión lógica y reducción de “código innecesario”. (Fuente: dotey, natolambert)
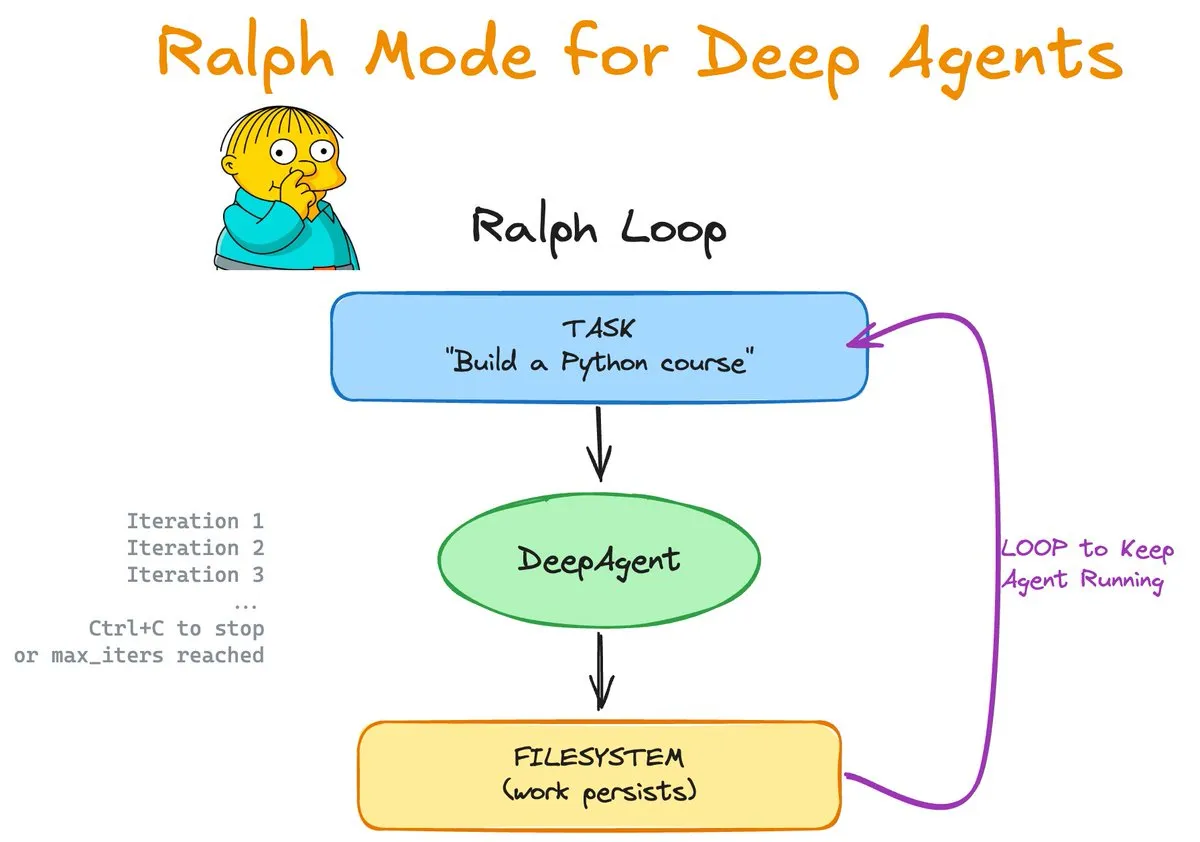
Ralph Mode: Ciclos continuos y mejora de memoria para Agents: Ralph Mode, lanzado por LangChain OSS, introduce soporte nativo para Skills y Memory en la biblioteca DeepAgents. Este modo permite que los Agents realicen tareas en ciclos infinitos con el respaldo del sistema de archivos y Git, actualizando constantemente su base de conocimientos a través de un proceso de aprendizaje “basado en habilidades”. Este diseño permite que los Agents se autocorrijan y acumulen experiencia, proporcionando un nuevo paradigma para el desarrollo de software autónomo y el procesamiento de tareas complejas de largo alcance. (Fuente: Vtrivedy10, hwchase17)
Pico AI Server: Un ChatGPT local y privado en Mac: Dirigido a usuarios sensibles a la privacidad, Pico AI Server permite ejecutar soporte GPT-oss completamente local en Apple Silicon. Optimizado con el framework MLX, esta herramienta permite a los usuarios de Mac con más de 24GB de memoria disfrutar de una experiencia de inferencia local fluida. Esto refleja la tendencia de la potencia de cómputo de AI migrando hacia el borde, donde los usuarios ya no necesitan subir datos sensibles a la nube para obtener asistencia de alto rendimiento en conversación y programación. (Fuente: awnihannun)

LFM2.5 1.2B: Un modelo pequeño para Agents con rendimiento excepcional: El modelo LFM2.5 1.2B Instruct lanzado por LiquidAI tiene un desempeño sorprendente en su categoría de tamaño, optimizado específicamente para tareas de Agents, extracción de datos y RAG. Aunque no se recomienda para tareas con mucha carga de conocimiento, su velocidad de inferencia en entornos locales como LM Studio es extremadamente rápida (hasta 41 tps), lo que lo convierte en una opción ideal para construir asistentes de AI ligeros y flujos de llamadas a herramientas. (Fuente: Reddit r/LocalLLaMA)

📚 Aprendizaje
Equipo de Tsinghua publica DrugCLIP en Science: La IA acelera el cribado de fármacos millones de veces: Un equipo de investigación conjunto de la Universidad de Tsinghua propuso el framework DrugCLIP, que redefine el cribado virtual como una tarea de recuperación densa. A través del mapeo del espacio vectorial entre los bolsillos de unión de proteínas y las moléculas pequeñas, este framework puede completar 10 billones de cálculos en solo 24 horas utilizando 8 GPUs A100, con una velocidad de cribado 10 millones de veces más rápida que los métodos tradicionales. Este avance establece un nuevo paradigma para la investigación y desarrollo de fármacos en la era post-AlphaFold, reduciendo enormemente la barrera para el descubrimiento de fármacos a escala masiva. (Fuente: 36氪)

Sakana AI publica la investigación Digital Red Queen (DRQ): Este estudio simula la evolución adversaria impulsada por LLM en un sandbox del juego de programación Core War. Al permitir que programas Redcode escritos por LLM compitan constantemente, se observó un fenómeno de “evolución convergente” similar al del mundo biológico: programas con diferentes condiciones iniciales evolucionaron finalmente hacia estrategias de supervivencia eficientes similares (como la autorreplicación y las bombas de datos). Este trabajo proporciona un entorno experimental seguro y controlado para estudiar la dinámica adversaria y la evolución de la ciberseguridad en sistemas artificiales. (Fuente: hardmaru, SakanaAILabs)
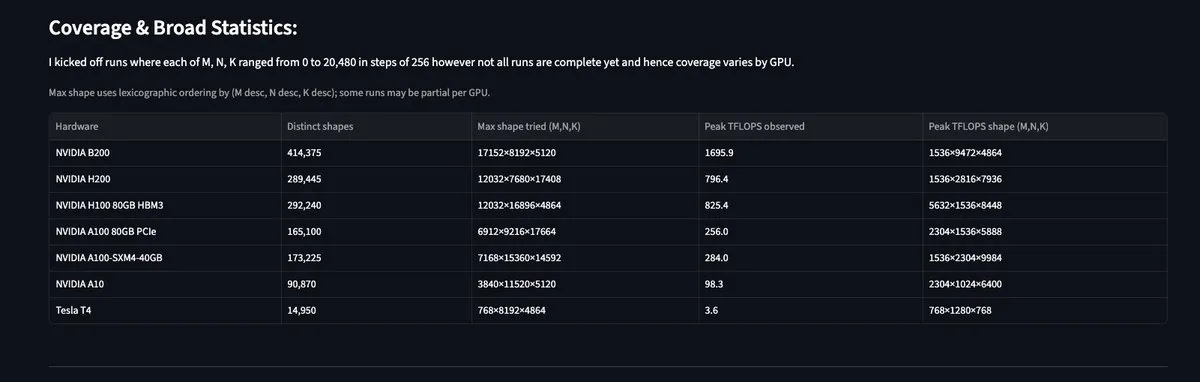
MAMF Explorer: Perspectivas sobre el rendimiento real de matmul en GPU: La herramienta MAMF Explorer, lanzada por el desarrollador Aflah, proporciona a los investigadores datos sobre los FLOPS de matmul pico realmente alcanzables en diversos hardwares, en lugar de los picos teóricos publicitados por los fabricantes. Esto tiene un alto valor práctico para optimizar la asignación de potencia de cómputo en el entrenamiento e inferencia de modelos a gran escala, ayudando a los desarrolladores a encontrar cuellos de botella de rendimiento reales en diferentes chips como Blackwell y H100. (Fuente: StasBekman, charles_irl)
💼 Negocios
La valoración de Anthropic podría alcanzar los 350.000 millones de dólares, con un rápido crecimiento del ARR: Se rumorea que Anthropic planea recaudar 10,000 millones de dólares, duplicando su valoración en medio año. Sus ingresos para 2025 ya han alcanzado los 900 millones de dólares, con el objetivo de superar los 2,000 millones en 2026. En comparación con las fricciones internas de OpenAI, Anthropic, con su alta estabilidad de equipo y su “rendimiento letal” en el mercado de desarrolladores (como Claude Code), se está convirtiendo en la opción preferida para el mercado empresarial, incluso considerándose que podría superar a su antiguo empleador en el progreso hacia una IPO. (Fuente: 36氪, srimuppidi)

Los despidos en Tailwind provocan una reflexión sobre el impacto de la IA en el modelo SaaS tradicional: El conocido framework de CSS, Tailwind, anunció un recorte del 75% de su personal, citando el colapso de su modelo de negocio debido a la popularidad de las herramientas de programación de AI. Aunque el uso de Tailwind está aumentando, la necesidad de los usuarios de generar código a través de AI ha reducido la dependencia de sus componentes de pago. Este evento advierte a todas las empresas de software que dependen del valor de “mano de obra/plantillas”: cuando la AI puede generar soluciones con un solo clic, las barreras tradicionales de pago por conocimiento se están desmoronando. (Fuente: jon_stokes, imjaredz)
JD.com establece el “Departamento de Negocios Chameleon” para acelerar la implementación de Embodied AI: JD.com ha elevado el proyecto original Chameleon a un departamento de negocios, encargándose plenamente de la JoyAI App y la marca de Embodied AI, JoyInside. El departamento se centra en la fusión de hardware y software de AI, y ya se ha conectado con más de 40 marcas de robótica y juguetes de AI. Esto demuestra que el gigante del comercio electrónico está utilizando sus profundas ventajas en la cadena de suministro para intentar construir un ciclo comercial cerrado desde la investigación y desarrollo hasta las ventas en los campos de juguetes de AI y robótica industrial. (Fuente: 36氪)
🌟 Comunidad
Linus Torvalds arremete contra el debate sobre las normas para el “código basura de IA”: Respecto a la discusión en la comunidad del kernel de Linux sobre si se deben establecer normas para el código generado por AI, Linus calificó directamente esto de “estúpido”. Sostiene que los documentos solo restringen a quienes siguen las reglas, mientras que quienes envían “código basura de IA” no lo etiquetarán voluntariamente. Insiste en ver a la AI como una herramienta y señala que la inmunidad del kernel debe provenir de los mecanismos de revisión de código y la cultura comunitaria, no de posturas documentales sin sentido. (Fuente: 36氪)

El “Efecto Karpathy” provoca ansiedad colectiva entre los programadores: Andrej Karpathy lamentó que la profesión de programador esté siendo reconfigurada drásticamente, con los bits contribuidos por los desarrolladores volviéndose cada vez más escasos. La comunidad lo ha resumido como el “Efecto Karpathy”: incluso los ingenieros senior sienten una sensación de rezago sin precedentes. La discusión sugiere que la competitividad central del futuro pasará de “escribir código” a “comprender la complejidad del sistema”; el vibe coding está convirtiendo a los ingenieros 10x en 100x, pero también está elevando el umbral para los principiantes. (Fuente: dejavucoder, arohan)
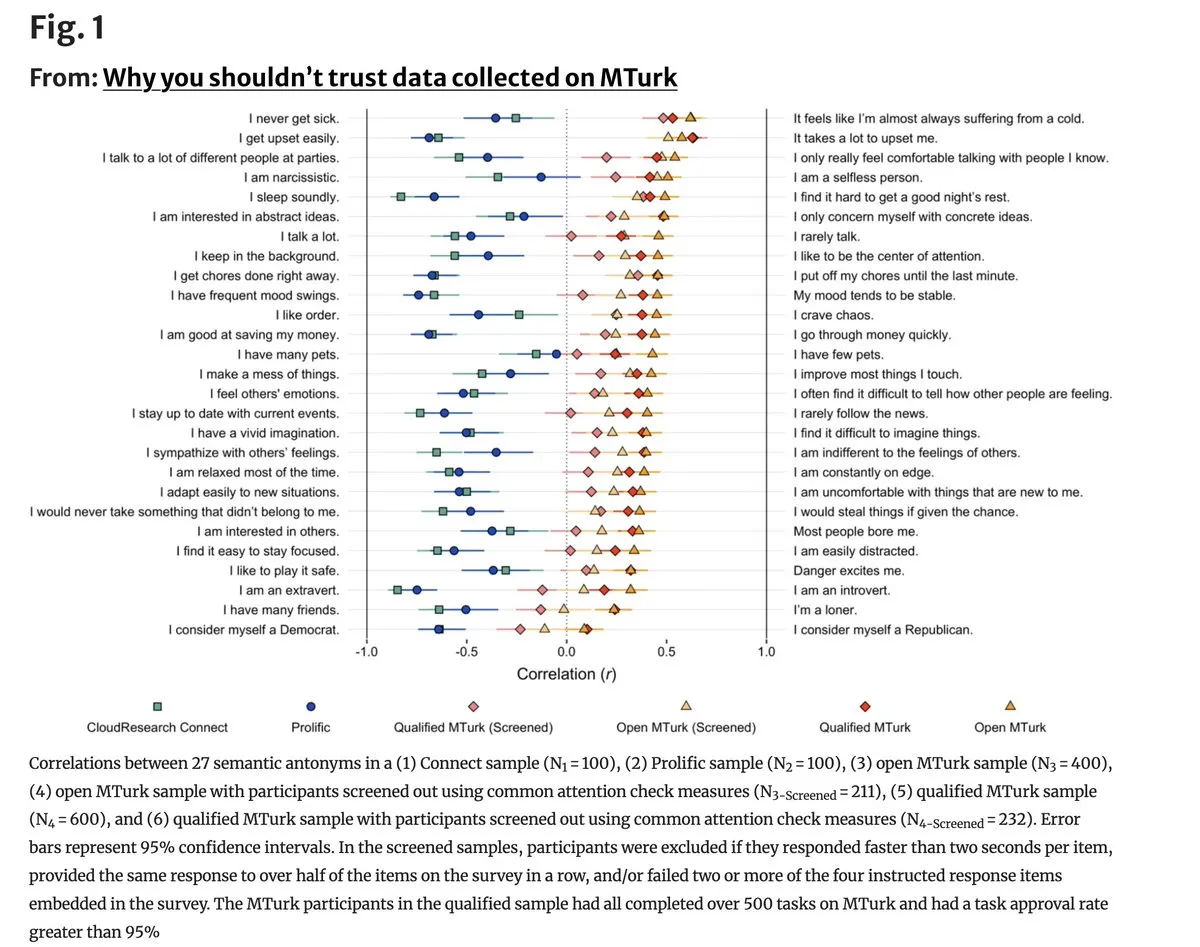
La calidad de los datos en MTurk sufre una “crisis existencial” debido a la participación de la IA: Un estudio reciente muestra que la calidad de los datos en plataformas de crowdsourcing como Amazon Mechanical Turk ha caído drásticamente, con un 96% de los ítems contradictorios mostrando una correlación positiva en el etiquetado, lo que demuestra que un gran número de trabajadores está utilizando LLM para realizar tareas de manera superficial. Esto es fatal para las ciencias del comportamiento y el ajuste fino de modelos que dependen de un etiquetado humano de alta calidad; la comunidad está pidiendo el establecimiento de redes de recolección de datos reales basadas en la verificación de identidad. (Fuente: random_walker)
💡 Otros
Las cláusulas de la NO FAKES Act generan preocupación en la comunidad Open Source: Se ha señalado que la definición de responsabilidad en el proyecto de ley sobre los “derechos de réplica digital” contiene trampas. Si un desarrollador publica un modelo de TTS o clonación de voz que otros utilizan para crear videos falsos de celebridades, el desarrollador podría enfrentar enormes indemnizaciones solidarias. La comunidad teme que esto lleve a los desarrolladores de modelos de audio en plataformas como Hugging Face a un “suicidio legal”, asfixiando así la innovación en tecnología de audio de código abierto. (Fuente: Reddit r/LocalLLaMA)
ICML 2026 introduce nuevas reglas de “responsabilidad solidaria” para combatir el fraude académico: Para combatir las publicaciones tipo “salami slicing” y el spam de AI, ICML anunció que si se descubre fraude en un paper, todos los envíos bajo los nombres de todos los coautores podrían ser rechazados directamente. Este mecanismo de “responsabilidad colectiva” exige que los directores de los grupos de investigación supervisen personalmente el trabajo. Al mismo tiempo, la conferencia permite el uso condicional de AI para la revisión de papers, pero debe contar con el consentimiento de los autores. (Fuente: 36氪)
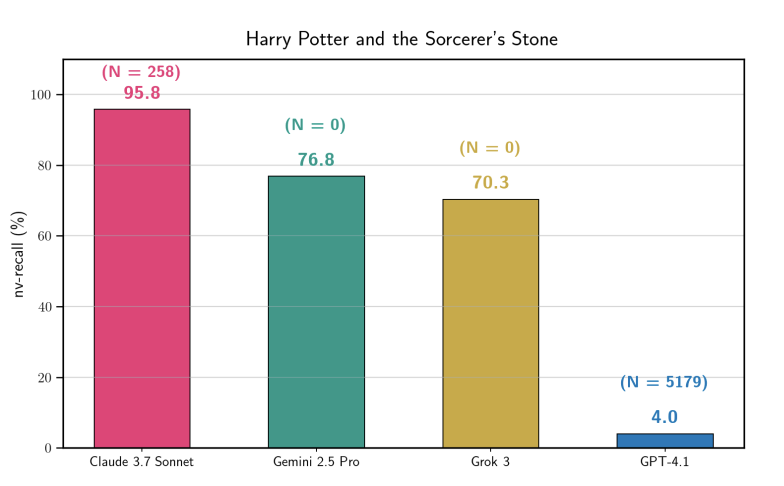
Paper de Stanford confirma que los LLM presentan una seria memorización de datos con copyright: La investigación muestra que Claude 3.7 Sonnet puede reproducir palabra por palabra el 95.8% del contenido de “Harry Potter”, seguido de cerca por Gemini y Grok. Esto refuta contundentemente la afirmación de que “los modelos no almacenan datos de entrenamiento”, demostrando que los filtros de seguridad existentes siguen siendo frágiles ante inducciones específicas. Este hallazgo proporcionará evidencia clave para futuras demandas de derechos de autor de AI. (Fuente: stanfordnlp, andykonwinski)