Kata Kunci:DeepSeek R1, Pelatihan AI, Pembelajaran Penguatan RL, Model Hadiah Proses PRM
🔥 Fokus
DeepSeek R1 merilis paper 86 halaman mengungkap detail pelatihan: DeepSeek diam-diam memperbarui laporan teknis R1, berkembang pesat dari 22 halaman menjadi 86 halaman, hampir ditulis ulang sebagai “buku teks” yang dapat direplikasi. Laporan tersebut untuk pertama kalinya mengungkapkan secara rinci evolusi tiga tahap pelatihan Dev1/2/3, rincian biaya pelatihan yang sangat rendah sebesar $294.000, serta tinjauan atas upaya yang gagal seperti MCTS dan Process Reward Model (PRM). Langkah ini tidak hanya menunjukkan akumulasi mendalam mereka di bidang Reinforcement Learning (RL), tetapi juga membuktikan kepada komunitas open-source melalui parameter lampiran yang mendetail: model penalaran yang digerakkan murni oleh RL tidak hanya layak, tetapi juga memiliki rasio efisiensi yang sangat tinggi. Strategi kompetisi “transparansi” ini memaksa raksama closed-source untuk meninjau kembali hambatan teknologi mereka. (Sumber: _akhaliq, karminski3, 量子位)

MiniMax dan Zhipu AI IPO di bursa Hong Kong, memulai “Momen Shanghai/Beijing” model besar: Perusahaan pemimpin model besar China, MiniMax dan Zhipu AI, berturut-turut melantai di Bursa Efek Hong Kong (HKEX), menandai industri AGI China secara resmi memasuki tahap pengujian pasar sekunder. Pada hari pertama IPO, harga saham MiniMax melonjak lebih dari 100%, dengan nilai pasar melampaui 100 miliar HKD, di mana gen globalisasinya dengan pendapatan luar negeri lebih dari 70% sangat diminati oleh modal; Zhipu AI menunjukkan pertumbuhan eksponensial bisnis MaaS sebesar 25 kali lipat dalam 10 bulan. Keberhasilan IPO kedua perusahaan ini tidak hanya memberikan imbal hasil besar bagi investor awal, tetapi juga menyediakan sampel pembiayaan yang dapat direplikasi bagi unicorn AI berikutnya melalui sistem 18C, membuktikan nilai unik perusahaan China dengan kemampuan model dasar mandiri dalam kompetisi global. (Sumber: Zai_org, 36氪)

CES 2026 Ledakan Physical AI: Dari layar menuju dunia nyata: CES tahun ini sepenuhnya beralih ke tema “Physical AI”, yang disebut oleh Jensen Huang dari Nvidia sebagai “momen ChatGPT untuk Physical AI”. Atlas dari Boston Dynamics tampil pertama kali di panggung publik dan mengumumkan mulai bekerja di pabrik Hyundai, LG merilis robot rumah tangga CLOiD yang bisa melipat pakaian, dan Lenovo meluncurkan personal AI super agent Qira. Rantai pasokan China tampil memukau dengan lebih dari 20 perusahaan robotika yang berpartisipasi, memamerkan kemampuan produksi massal mulai dari tangan robotik hingga humanoid berukuran penuh. AI tidak lagi sekadar kotak dialog, melainkan melakukan intervensi mendalam di dunia fisik melalui sensor dan aktuator, merekonstruksi rantai industri tradisional mulai dari peralatan rumah tangga, PC, hingga otomotif. (Sumber: TheRundownAI, 雷科技)

OpenAI merilis sektor Healthcare untuk masuk ke jalur vertikal medis: OpenAI secara resmi meluncurkan pengalaman ChatGPT Health, mendukung kepatuhan HIPAA, dan bekerja sama dengan institusi medis ternama seperti Mayo Clinic dan Boston Children’s Hospital. Fitur ini memungkinkan pengguna mengakses rekam medis elektronik dan data Apple Health, menggunakan bantuan AI untuk menganalisis laporan pemeriksaan dan menyusun rencana kesehatan. Meskipun dijuluki sebagai “Ant Fortune versi AS”, hal ini mewakili tren model besar yang merambah dari penggunaan umum ke bidang vertikal profesional. AI medis berevolusi dari tanya jawab sederhana menjadi asisten profesional yang mampu mengintegrasikan data multi-sumber dan memberikan dukungan keputusan klinis, meskipun keamanan dan risiko salah diagnosis tetap menjadi fokus perhatian komunitas. (Sumber: _samirism, openai)
🎯 Tren
Google DeepMind mengusulkan kerangka kerja “Nested Learning” (NL): Menanggapi masalah kurangnya kemampuan pembelajaran berkelanjutan pada Transformer dan kerentanannya terhadap “catastrophic forgetting”, tim DeepMind meminjam mekanisme memori asosiatif manusia untuk mengusulkan kerangka kerja Nested Learning (NL). Kerangka kerja ini menganggap optimizer sebagai “konteks” arsitektur model, melalui penyematan modul dengan frekuensi pembaruan yang berbeda, memungkinkan AI membangun struktur abstrak saat dijalankan, mengendapkan pengalaman jangka pendek menjadi pengetahuan jangka panjang. Ini dianggap sebagai langkah kunci menuju AGI, yang diharapkan memungkinkan model berevolusi secara mandiri dalam lingkungan dinamis seperti manusia, alih-alih bergantung pada pelatihan ulang yang mahal. (Sumber: hardmaru, 新智元)
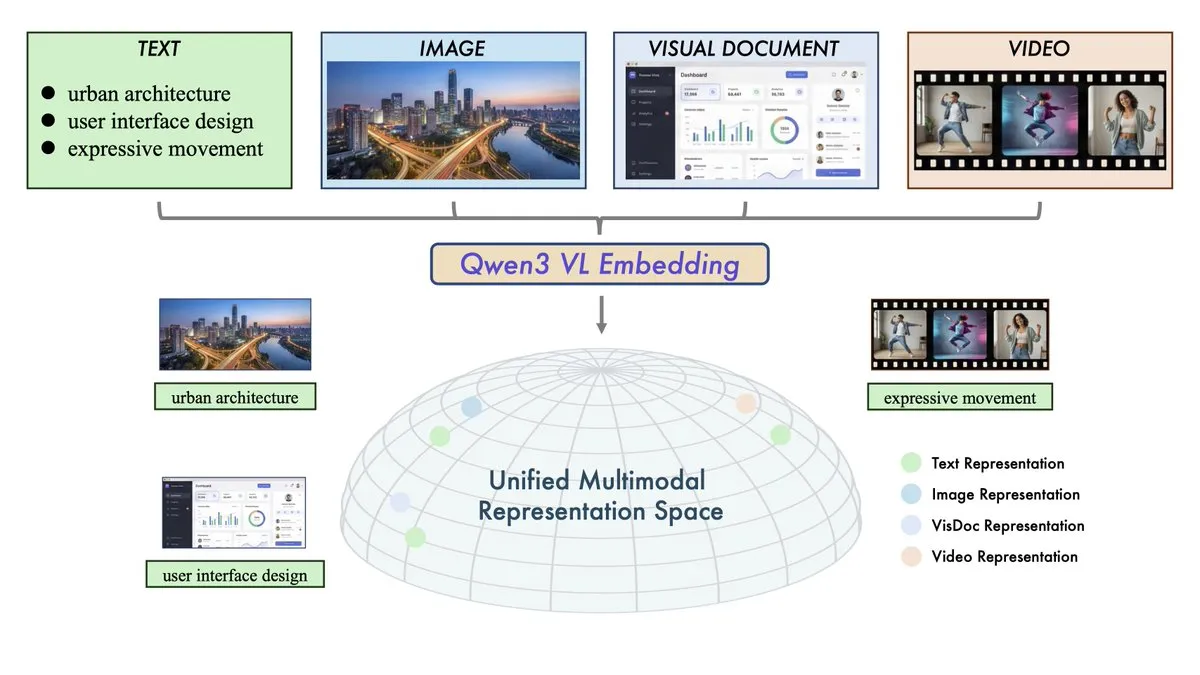
Alibaba merilis model Qwen3-VL-Embedding dan Reranker: Tim Qwen dari Alibaba meluncurkan duo pencarian multimodal yang bertujuan untuk menyatukan ruang vektor teks, gambar, video, dan modalitas campuran. Qwen3-VL-Embedding mendukung lebih dari 30 bahasa dan mencapai performa SOTA pada benchmark pencarian multimodal; Reranker meningkatkan akurasi pencarian lebih lanjut melalui skor relevansi fine-grained. Perilisan ini menandai teknologi RAG (Retrieval-Augmented Generation) secara resmi memasuki era full-modal, menyediakan infrastruktur inti untuk membangun visual Q&A, pencarian video, dan multimodal Agent yang lebih kompleks. (Sumber: huggingface, _akhaliq)
Pendiri a16z memprediksi 2026: Deflasi biaya kecerdasan akan mendorong ledakan permintaan: Marc Andreessen menunjukkan bahwa kecepatan penurunan biaya unit AI telah melampaui Hukum Moore, dan kecerdasan berubah dari barang mewah menjadi komoditas harian seperti air dan listrik. Ia memprediksi pasar masa depan akan menghadirkan “struktur piramida”: di puncak adalah segelintir super model, dan di dasar adalah model kecil edge-side yang ada di mana-mana. Pada saat yang sama, ia percaya bahwa perusahaan rintisan sedang menyingkirkan keraguan “wrapper” melalui “backward integration” dengan mengembangkan model mandiri, dan model bisnis AI akan beralih dari pembayaran per Token ke penetapan harga berdasarkan nilai yang diciptakan. (Sumber: nvidia, 华尔街见闻)
Model besar suara Smart Cockpit mempercepat integrasi ke kendaraan: Di CES, StepFun (阶跃星辰) memamerkan cockpit model besar suara end-to-end hasil kerja sama dengan Geely Galaxy, yang memiliki kemampuan pengenalan emosi dan memori jangka panjang. Pandangan industri menganggap tahun 2026 akan menjadi tahun pertama produksi massal Agent tingkat entri di cockpit mobil. Cockpit beralih dari kontrol suara sederhana menjadi “ruang ketiga” dengan eksekusi proaktif dan layanan personal, arsitektur AI kolaborasi cloud-edge akan menjadi inti kompetisi produsen mobil, yang bertujuan untuk mengintegrasikan kemampuan AI secara mendalam ke lapisan bawah OS untuk mencapai integrasi pengalaman multi-domain. (Sumber: dotey, 科创板日报)
🧰 Alat
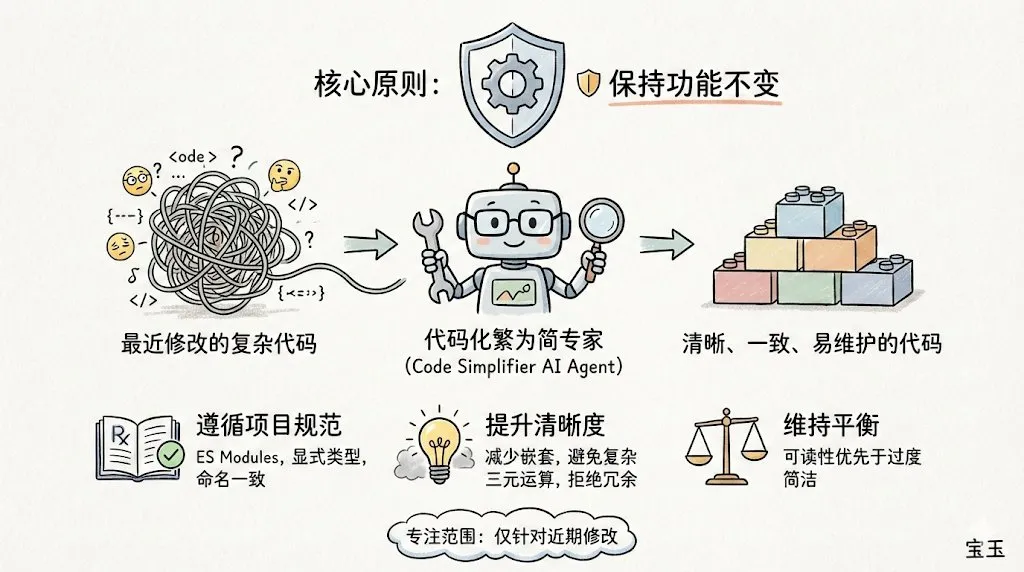
Claude Code dan plugin code-simplifier dirilis: Alat command-line Claude Code yang diluncurkan oleh Anthropic menjadi sangat populer di komunitas pengembang karena rasa engineering-nya yang luar biasa. Rilisan resmi terbaru adalah plugin agen code-simplifier, yang mendukung penyederhanaan basis kode kompleks dengan satu klik. Konsep intinya adalah “file system as context”, dengan memuat file yang diperlukan secara dinamis alih-alih menumpuk Token, secara signifikan meningkatkan efisiensi pemrosesan repositori besar. Umpan balik komunitas menunjukkan bahwa alat ini telah melampaui GPT-4o dalam pemahaman logika dan pengurangan “code fluff”. (Sumber: dotey, natolambert)
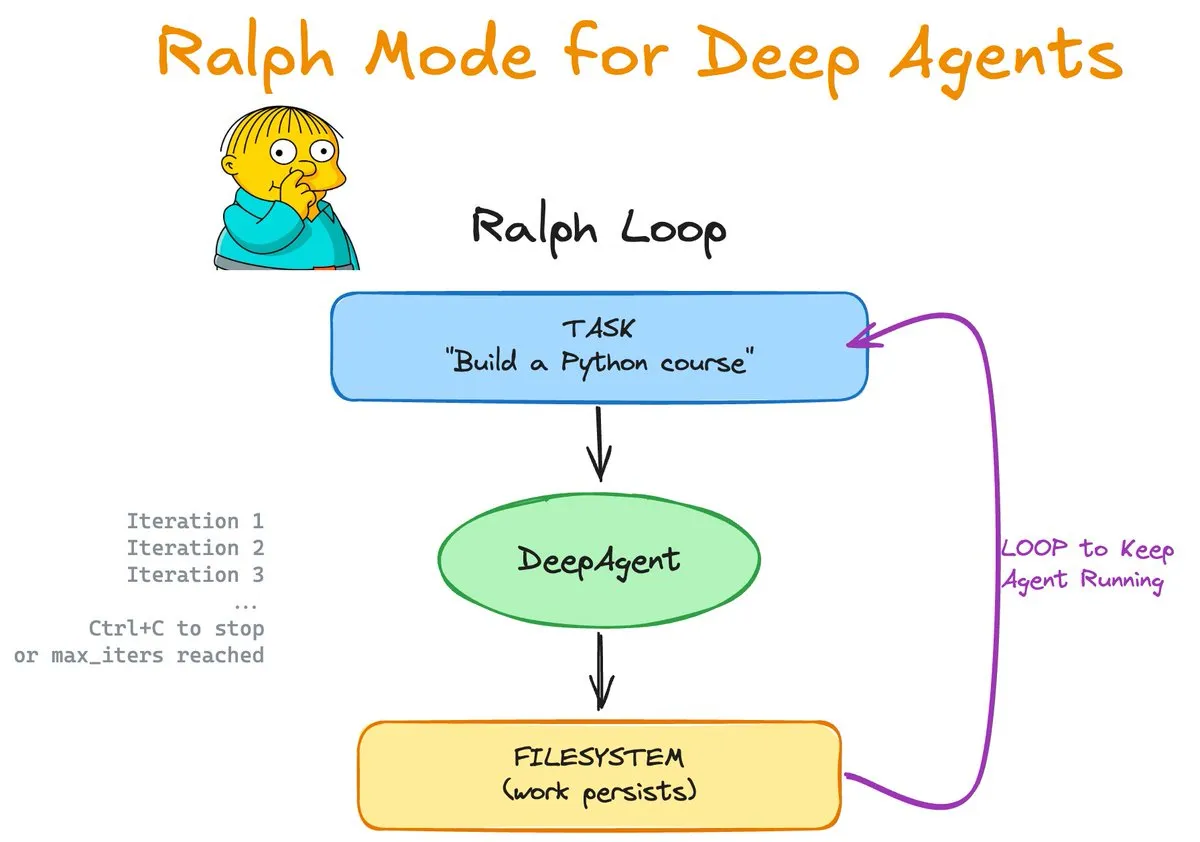
Ralph Mode: Loop berkelanjutan dan peningkatan memori Agent: Ralph Mode yang diluncurkan oleh LangChain OSS memperkenalkan dukungan Skills dan Memory asli untuk perpustakaan DeepAgents. Mode ini memungkinkan Agent melakukan tugas loop tak terbatas dengan dukungan sistem file dan Git, terus memperbarui basis pengetahuan melalui proses pembelajaran “skill-based”. Desain ini memungkinkan Agent untuk melakukan koreksi diri dan mengumpulkan pengalaman, menyediakan paradigma baru untuk pengembangan perangkat lunak otonom dan pemrosesan tugas jangka panjang yang kompleks. (Sumber: Vtrivedy10, hwchase17)
Pico AI Server: ChatGPT lokal dan privat di Mac: Untuk pengguna yang sensitif terhadap privasi, Pico AI Server mengimplementasikan dukungan GPT-oss yang berjalan sepenuhnya secara lokal di Apple Silicon. Menggunakan optimasi kerangka kerja MLX, alat ini memungkinkan pengguna Mac dengan memori 24GB+ menikmati pengalaman inferensi lokal yang lancar. Ini mencerminkan tren migrasi daya komputasi AI ke sisi perangkat, di mana pengguna tidak lagi perlu mengunggah data sensitif ke cloud untuk mendapatkan bantuan percakapan dan pemrograman berperforma tinggi. (Sumber: awnihannun)

LFM2.5 1.2B: Model kecil Agent dengan performa luar biasa: Model LFM2.5 1.2B Instruct yang dirilis oleh LiquidAI menunjukkan performa mengejutkan dalam kategori ukurannya, terutama dioptimalkan untuk tugas Agent, ekstraksi data, dan RAG. Meskipun tidak disarankan untuk tugas berat pengetahuan, kecepatan inferensinya di lingkungan lokal seperti LM Studio sangat cepat (mencapai 41 tps), menjadikannya pilihan ideal untuk membangun asisten AI ringan dan alur pemanggilan alat. (Sumber: Reddit r/LocalLLaMA)

📚 Pembelajaran
Tim Tsinghua DrugCLIP masuk Science: AI mempercepat penyaringan obat jutaan kali lipat: Tim peneliti gabungan Universitas Tsinghua mengusulkan kerangka kerja DrugCLIP, yang mendefinisikan ulang penyaringan virtual sebagai tugas pencarian padat. Melalui pemetaan ruang vektor antara kantong pengikat protein dan molekul kecil, kerangka kerja ini hanya membutuhkan 24 jam pada 8 unit A100 untuk menyelesaikan 10 triliun perhitungan, dengan kecepatan penyaringan 10 juta kali lebih cepat daripada metode tradisional. Terobosan ini membuka paradigma baru pengembangan obat di era pasca-AlphaFold, sangat menurunkan ambang batas penemuan obat skala ultra-besar. (Sumber: 36氪)

Sakana AI merilis riset Digital Red Queen (DRQ): Riset ini mensimulasikan evolusi permusuhan yang digerakkan oleh LLM dalam sandbox game pemrograman Core War. Dengan membiarkan program Redcode yang ditulis oleh LLM terus berkompetisi, fenomena “evolusi konvergen” yang mirip dengan dunia biologis diamati: program dari kondisi awal yang berbeda akhirnya berevolusi menjadi strategi bertahan hidup efisien yang serupa (seperti replikasi diri, bom data). Pekerjaan ini menyediakan lingkungan eksperimental yang aman dan terkendali untuk mempelajari dinamika permusuhan dan evolusi keamanan siber dalam sistem buatan. (Sumber: hardmaru, SakanaAILabs)
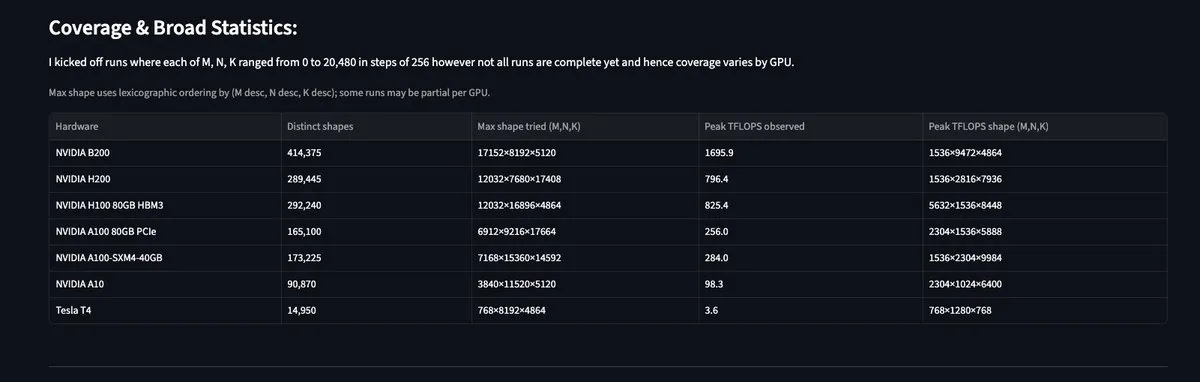
MAMF Explorer: Wawasan performa Matrix Multiplication GPU yang sebenarnya: Alat MAMF Explorer yang diluncurkan oleh pengembang Aflah menyediakan data puncak matmul FLOPS yang benar-benar dapat dicapai pada berbagai perangkat keras bagi para peneliti, alih-alih puncak teoritis yang dipromosikan produsen. Ini memiliki nilai praktis yang sangat tinggi untuk mengoptimalkan alokasi daya komputasi pelatihan dan inferensi model skala besar, membantu pengembang menemukan hambatan performa nyata pada berbagai chip seperti Blackwell, H100, dll. (Sumber: StasBekman, charles_irl)
💼 Bisnis
Valuasi Anthropic mungkin mencapai $350 miliar, ARR tumbuh pesat: Anthropic dikabarkan berencana menggalang dana $10 miliar, dengan valuasi berlipat ganda dalam setengah tahun. Pendapatannya pada tahun 2025 telah mencapai $900 juta, dan menetapkan target melampaui $2 miliar pada tahun 2026. Dibandingkan dengan konflik internal OpenAI, Anthropic menjadi pilihan utama di pasar korporat berkat stabilitas tim yang sangat tinggi dan “performa mematikan” di pasar pengembang (seperti Claude Code), bahkan dianggap mungkin melampaui mantan induknya dalam progres IPO. (Sumber: 36氪, srimuppidi)

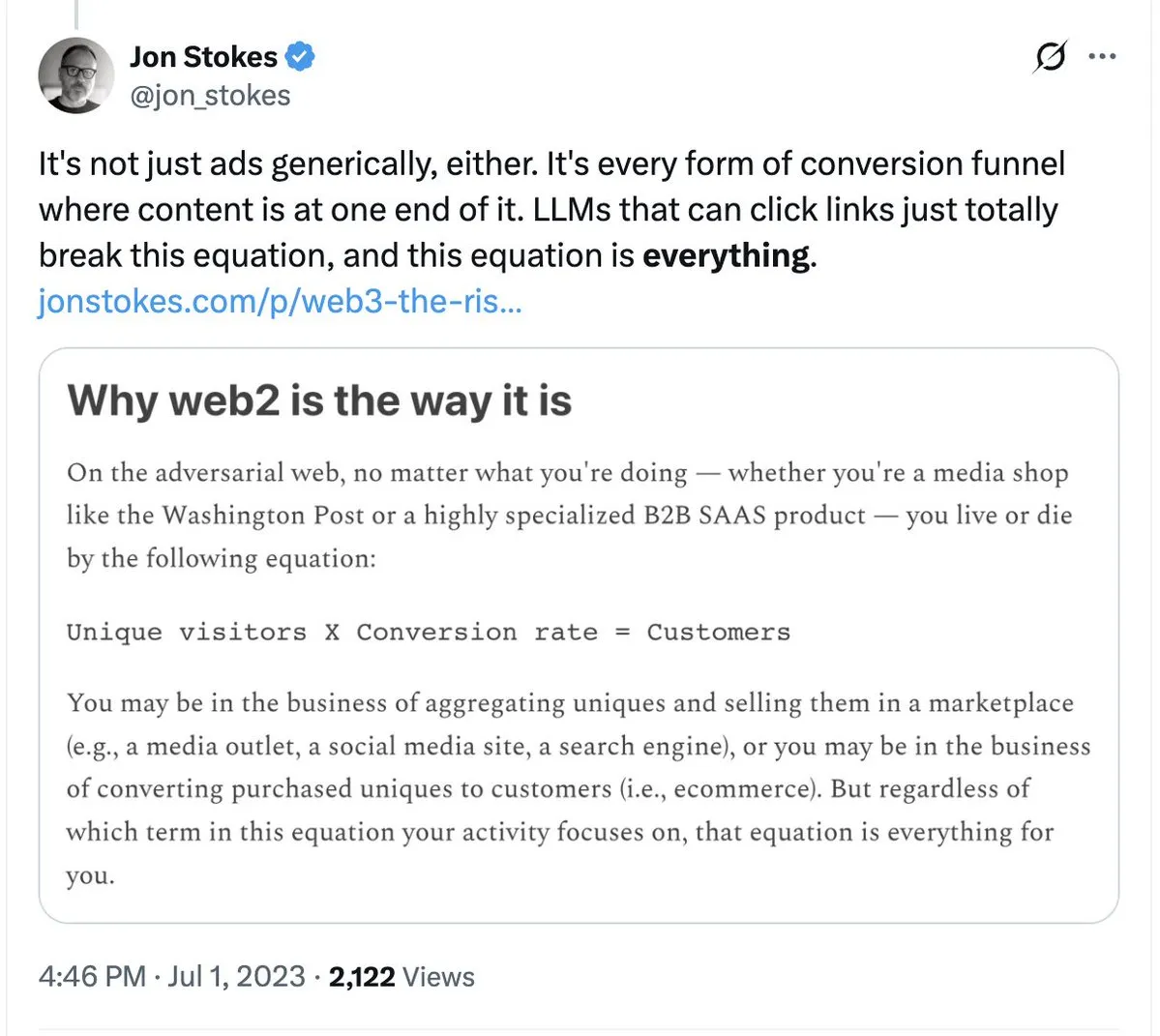
PHK Tailwind memicu refleksi dampak AI terhadap model SaaS tradisional: Kerangka kerja CSS terkenal Tailwind mengumumkan PHK sebesar 75%, dengan alasan popularitas alat pemrograman AI yang menyebabkan runtuhnya model bisnis mereka. Meskipun penggunaan Tailwind meningkat, kebutuhan pengguna untuk menghasilkan kode melalui AI telah mengurangi ketergantungan pada komponen berbayar mereka. Peristiwa ini menjadi peringatan bagi semua perusahaan perangkat lunak yang bergantung pada nilai “tenaga kerja/templat”: ketika AI mampu menghasilkan solusi implementasi dengan satu klik, hambatan pembayaran pengetahuan tradisional sedang runtuh. (Sumber: jon_stokes, imjaredz)
JD.com mendirikan “Chameleon Business Department” untuk mempercepat implementasi Embodied AI: JD.com meningkatkan proyek Chameleon yang sudah ada menjadi departemen bisnis, yang sepenuhnya menangani JoyAI App dan merek Embodied AI JoyInside. Inti dari departemen ini berfokus pada integrasi perangkat keras dan lunak AI, dan telah terhubung dengan lebih dari 40 merek robot dan mainan AI. Ini menunjukkan bahwa raksama e-commerce sedang memanfaatkan keunggulan rantai pasokan yang mendalam untuk mencoba membangun loop tertutup bisnis dari R&D hingga penjualan di bidang mainan AI dan robot industri. (Sumber: 36氪)
🌟 Komunitas
Linus Torvalds mengkritik perdebatan norma “AI garbage code”: Menanggapi diskusi tentang apakah komunitas kernel Linux harus menetapkan norma untuk kode yang dihasilkan AI, Linus secara blak-blakan menyebutnya “bodoh”. Ia berpendapat bahwa dokumentasi hanya bisa membatasi orang yang patuh, sementara orang yang mengirimkan “AI garbage code” tidak akan secara proaktif melabelinya. Ia bersikeras menganggap AI sebagai alat, dan menunjukkan bahwa kekebalan kernel harus berasal dari mekanisme peninjauan kode dan budaya komunitas, bukan dari sikap dokumentasi yang tidak berarti. (Sumber: 36氪)

“Karpathy Effect” memicu kecemasan kolektif di kalangan programmer: Andrej Karpathy mengeluh bahwa profesi programmer sedang direkonstruksi secara drastis, dengan bit yang dikontribusikan oleh pengembang menjadi semakin jarang. Komunitas merangkumnya sebagai “Karpathy Effect”: bahkan insinyur senior pun merasakan rasa tertinggal yang belum pernah terjadi sebelumnya. Diskusi berpendapat bahwa daya saing inti masa depan akan beralih dari “menulis kode” menjadi “memahami kompleksitas sistem”, vibe coding membuat insinyur 10x menjadi 100x, tetapi juga membuat ambang batas bagi pemula menjadi lebih tinggi. (Sumber: dejavucoder, arohan)
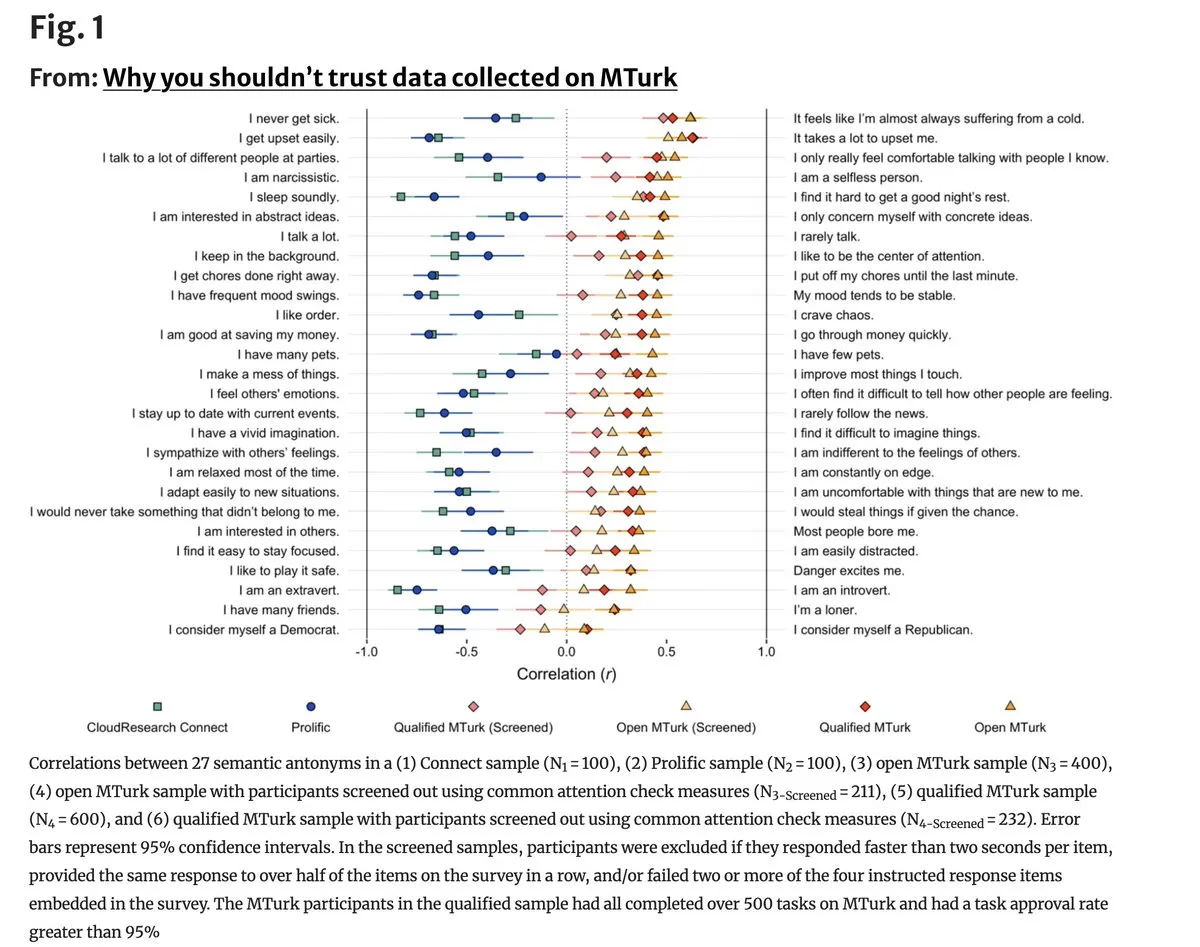
Kualitas data MTurk mengalami “krisis eksistensial” akibat keterlibatan AI: Riset terbaru menunjukkan bahwa kualitas data pada platform crowdsourcing seperti Amazon Mechanical Turk menurun drastis, dengan 96% item kontradiktif menunjukkan korelasi positif dalam pelabelan, membuktikan bahwa sejumlah besar pekerja menggunakan LLM untuk mengerjakan tugas secara asal-asalan. Ini sangat fatal bagi ilmu perilaku dan fine-tuning model yang bergantung pada pelabelan manusia berkualitas tinggi, komunitas menyerukan pembangunan jaringan pengumpulan data nyata berbasis verifikasi identitas. (Sumber: random_walker)
💡 Lainnya
Kekhawatiran komunitas open source terhadap klausul hukum NO FAKES Act: Definisi tanggung jawab mengenai “hak replika digital” dalam undang-undang tersebut dianggap memiliki jebakan. Jika model TTS atau kloning suara yang dirilis oleh pengembang digunakan oleh orang lain untuk membuat video selebriti palsu, pengembang mungkin menghadapi ganti rugi tanggung renteng yang besar. Komunitas khawatir hal ini akan menyebabkan pengembang model audio di platform seperti Hugging Face terjebak dalam “bunuh diri hukum”, sehingga mematikan inovasi teknologi audio open source. (Sumber: Reddit r/LocalLLaMA)
ICML 2026 memperkenalkan aturan baru “tanggung jawab bersama” untuk memberantas kecurangan akademik: Untuk memberantas pengiriman makalah “salami slicing” dan spam AI, ICML mengumumkan: jika satu makalah terbukti melakukan kecurangan, semua pengiriman di bawah nama semua rekan penulis dapat langsung ditolak. Mekanisme “tanggung jawab bersama” ini menuntut penanggung jawab kelompok penelitian untuk melakukan pengawasan secara pribadi. Pada saat yang sama, konferensi mengizinkan penggunaan AI untuk peninjauan makalah dengan syarat tertentu, tetapi harus mendapatkan persetujuan penulis. (Sumber: 36氪)
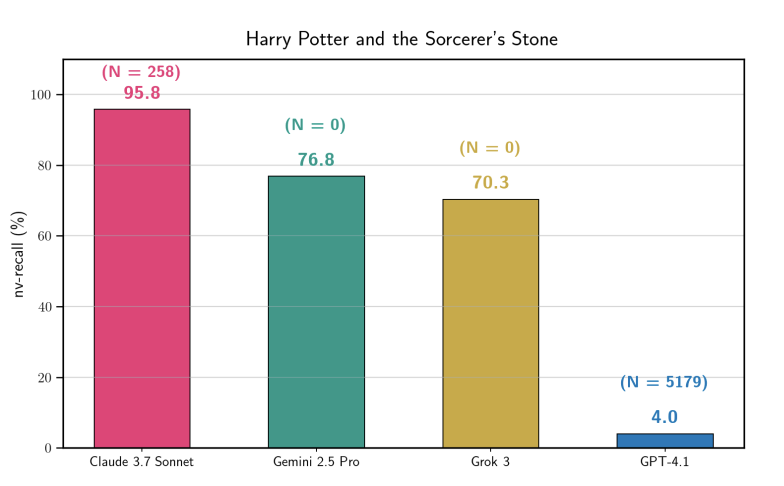
Paper Stanford mengonfirmasi LLM melakukan memorisasi data hak cipta yang serius: Riset menunjukkan bahwa Claude 3.7 Sonnet dapat mereproduksi 95,8% konten “Harry Potter” kata demi kata, diikuti oleh Gemini dan Grok. Ini secara kuat membantah klaim bahwa “model tidak menyimpan data pelatihan”, membuktikan bahwa filter keamanan yang ada tetap rapuh saat menghadapi induksi tertentu. Temuan ini akan memberikan bukti kunci untuk gugatan hak cipta AI di masa depan. (Sumber: stanfordnlp, andykonwinski)