
Kata Kunci:model besar, AI, penawaran umum perdana di Hong Kong, model konsumen MiniMax, kemampuan kode DeepSeek V4, ChatGPT Kesehatan
🔥 Fokus
MiniMax dan Zhipu Duel IPO di Bursa Hong Kong: Model C-end Menang di Putaran Pertama : Pada awal tahun 2026, dua dari “Enam Harimau Kecil” model besar, Zhipu dan MiniMax, berturut-turut melantai di Bursa Efek Hong Kong (HKEX). Harga saham MiniMax melonjak 109% pada hari pertama perdagangan, dengan valuasi pasar melampaui 137 miliar USD, mengungguli Zhipu. Analisis menunjukkan bahwa pasar memiliki ekspektasi lebih tinggi terhadap model aplikasi C-end MiniMax (seperti Xingye dan Hailuo), menganggap kemampuan monetisasi globalnya lebih kuat dibandingkan model B-end tradisional dengan private deployment. Ini menandai kompetisi model besar memasuki periode panen modal, di mana diferensiasi model bisnis—apakah mengikuti jalur lama B-end ala SenseTime atau merangkul tren global C-end—menjadi logika inti penentu valuasi (Sumber: 36氪, bookwormengr)

DeepSeek V4 Segera Dirilis: Kemampuan Coding Menantang GPT dan Claude : DeepSeek dikabarkan akan merilis model flagship generasi berikutnya, V4, pada bulan Februari. Pengujian internal menunjukkan bahwa V4 telah mencapai terobosan teknis dalam menangani Prompt kode yang sangat panjang dan analisis pola data, dengan peningkatan ketajaman logika yang signifikan. Kemampuan pembuatan kodenya diharapkan dapat melampaui GPT-5.2 dan Claude Opus 4.5. Paper MHC (Manifold-constrained Hyper-connectivity) yang baru-baru ini dirilis oleh DeepSeek dianggap sebagai fondasi teknis V4, yang mencapai lompatan performa lebih efisien dengan mengatasi ketidakstabilan saat model scaling. Dinamika ini menandakan bahwa model domestik akan bersaing langsung dengan level top internasional di bidang coding vertikal (Sumber: scaling01, LocalLLaMA)

Sakana AI Merilis Digital Red Queen: Terobosan Teknologi Self-evolving Code : Sakana AI bekerja sama dengan MIT mengusulkan metode baru yang menggunakan LLM untuk membuat kode assembly berevolusi secara mandiri. Teknologi ini mendorong kode untuk melakukan seleksi alam dan optimasi mandiri melalui pertempuran iteratif dalam lingkungan musuh yang Turing-complete seperti “Core War”. Objective function dinamis ini menghasilkan Agent yang lebih tangguh dan general dibandingkan optimasi statis. Terobosan ini menunjukkan potensi besar AI dalam bidang pemrograman otomatis dan sistem adaptif, menandai pergeseran paradigma dari “Static Learning” ke “Evolutionary Learning” (Sumber: hardmaru, SakanaAILabs)

ChatGPT Health Resmi Diluncurkan: AI Medis Memasuki Era Manajemen Kesehatan Pribadi : OpenAI merilis fitur ChatGPT Health yang mendukung sinkronisasi hasil tes dan data aplikasi kesehatan. Berdasarkan model kesehatan yang dibuat khusus, fitur ini dapat melakukan analisis mendalam terhadap laporan pemeriksaan medis dan memberikan saran. Meskipun produk serupa sudah ada di domestik (seperti Ant Afu), keterlibatan ChatGPT menandai raksasa AI global secara resmi menganggap manajemen kesehatan sebagai skenario aplikasi inti. Ini bukan hanya kompetisi teknologi, tetapi juga persaingan komprehensif mengenai privasi data, koneksi perangkat medis, dan panduan kesehatan personal (Sumber: op7418, artificial)

🎯 Tren
Anthropic Membatasi Langganan Claude untuk Aplikasi Pihak Ketiga Memicu Kontroversi : Anthropic baru-baru ini mulai membatasi pengguna langganan Claude Pro untuk menggunakan API credentials pada alat pihak ketiga seperti OpenCode dan Clawdbot. Langkah ini dianggap sebagai upaya untuk melindungi ekosistemnya sendiri (seperti Claude Code) dan mengontrol biaya. Komunitas bereaksi keras, menganggap hal ini melemahkan hak pilih pengguna, mendorong sebagian pengembang beralih ke model MiniMax atau Zhipu GLM yang lebih terbuka. Ini mencerminkan dilema produsen AI dalam menyeimbangkan antara “ekosistem terbuka” dan “bisnis tertutup” (Sumber: matanSF, MiniMax_AI)

Layout Raksasa Chip di CES 2026: Tren Desentralisasi Komputasi AI Semakin Jelas : Qualcomm, NVIDIA, dan AMD memamerkan visi infrastruktur AI yang sangat berbeda di CES. Qualcomm menekankan pada on-device local inference yang selalu aktif; AMD mengejar kontinuitas heterogen antara cloud, PC, dan edge; sementara NVIDIA memandang AI sebagai sistem industri, berfokus pada daya komputasi terpusat dan simulasi robotika fisik. Ini menunjukkan bahwa komputasi AI sedang disusun ulang berdasarkan skenario operasional, bukan sekadar kompetisi chip tunggal terkuat. Hybrid AI (heavy inference di cloud + tugas latensi rendah di lokal) menjadi konsensus industri (Sumber: TheTuringPost)

Penelitian MIT Mengungkap Konvergensi Kognitif Model Top: Jalur Menuju Kebenaran Semakin Jelas : Sebuah penelitian dari MIT menemukan bahwa meskipun arsitektur model dan data pelatihan berbeda, seiring dengan peningkatan performa, pemahaman internal model berperforma tinggi terhadap materi (seperti struktur molekul) cenderung konsisten. Ini berarti AI secara kolektif menggali logika dasar objektif dari dunia fisik. Bagi pengembang, ini menandakan bahwa di masa depan, model kecil dapat “menyontek” hasil kerja model besar melalui “model distillation”, tanpa perlu terjebak dalam kompetisi daya komputasi tanpa akhir untuk mencapai kemampuan penemuan ilmiah berperforma tinggi (Sumber: 36氪)

Alibaba Cloud Memulai Tahun Pertama AI Hardware untuk Semua: Implementasi Skala Besar On-device Agent : Alibaba Cloud memamerkan lebih dari 200 perangkat keras perdana yang sama dengan di CES pada pameran perangkat keras pintar Tongyi, mencakup kacamata pintar, AI Pin, robot, dan lainnya. Melalui cakupan penuh model Tongyi (0.5B-480B), Alibaba Cloud menyediakan solusi “end-cloud synergy” dengan konsumsi daya rendah dan kecerdasan tinggi bagi produsen perangkat keras. Ini menandai transformasi industri perangkat keras China dari “perangkat terhubung” menjadi “Agent cerdas yang berpikir mandiri”, di mana AI bukan lagi fitur sampingan, melainkan mesin penggerak pengalaman inti perangkat (Sumber: 36氪)

🧰 Alat
Ralph untuk Claude Code: Alat Autonomous AI Development Loop : Ralph adalah alat development loop otonom berbasis Claude Code, dilengkapi dengan deteksi keluar cerdas dan fungsi rate limiting. Alat ini memungkinkan Claude Code untuk meningkatkan proyek secara iteratif hingga selesai, dengan mekanisme perlindungan bawaan untuk mencegah infinite loop dan penyalahgunaan API. Mendukung output JSON, kontinuitas sesi, dan pemantauan real-time melalui tmux. Ralph menstandarisasi alur pengembangan, memungkinkan AI untuk benar-benar menyelesaikan tugas software engineering secara “closed-loop” (Sumber: frankbria)
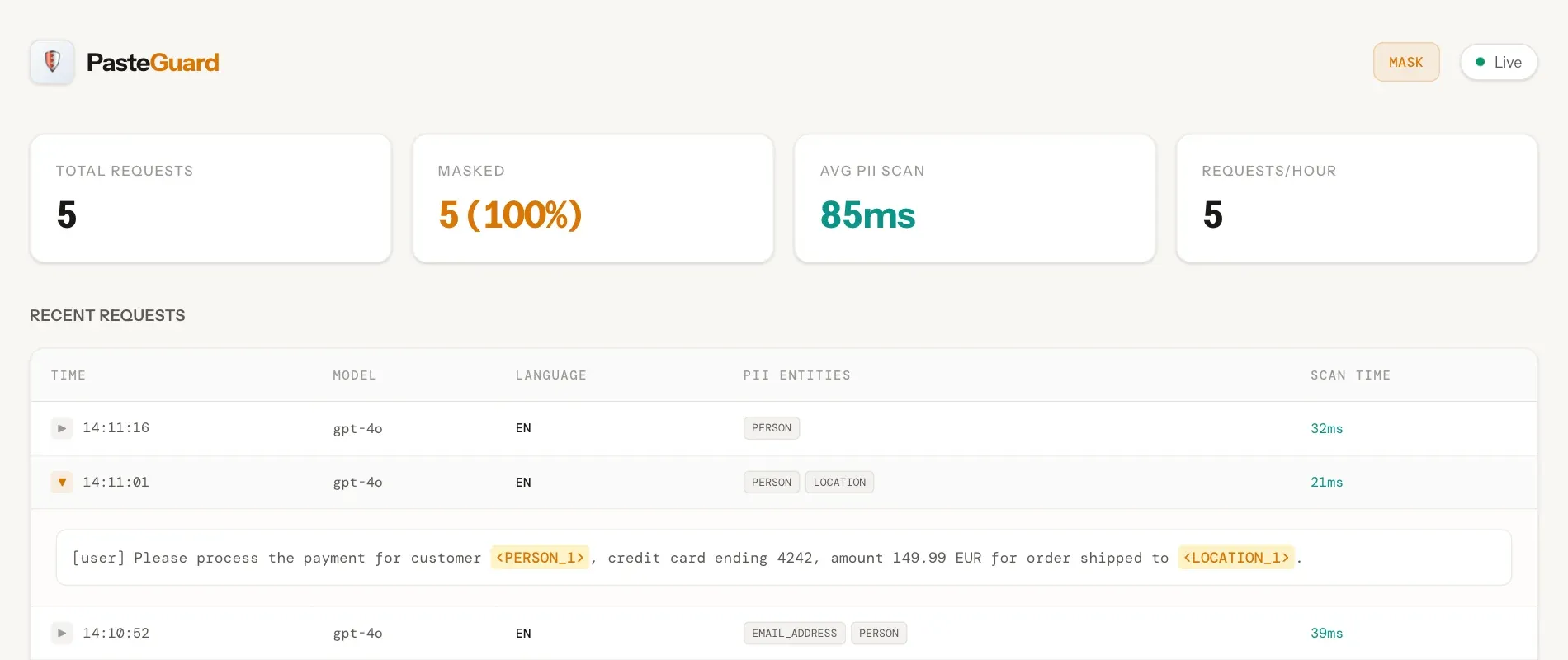
PasteGuard: Alat Privacy Proxy, Memblokir PII dalam Data Cloud LLM : Ini adalah privacy proxy yang dirancang khusus untuk Open WebUI, yang secara otomatis dapat memblokir informasi sensitif pribadi (PII) seperti nama, email, dan nomor telepon sebelum data dikirim ke cloud LLM. Mendukung “masking mode” dan “routing mode” (informasi sensitif diarahkan ke Ollama lokal untuk diproses). Mendukung 24 bahasa dan menggunakan teknologi Microsoft Presidio, secara efektif menyelesaikan kekhawatiran kepatuhan dan privasi perusahaan saat menggunakan cloud AI (Sumber: OpenWebUI)
Empirica: Kerangka Kognitif yang Memberikan Kemampuan “Self-reflection” pada AI Agent : Empirica adalah kerangka kognitif AI Agent open-source yang bertujuan untuk mengatasi masalah seperti kepercayaan diri buta dan kesalahan berulang pada Agent. Kerangka ini mengontrol tindakan dengan melacak kesenjangan pengetahuan Agent, pembelajaran persisten lintas sesi, dan menetapkan ambang batas kepercayaan diri. Alur kerja CASCADE intinya mengimplementasikan pre-check, gating, dan pengukuran pembelajaran, memungkinkan AI untuk melakukan Meta-cognition seperti manusia, mengevaluasi “apa yang saya ketahui” sebelum mengeksekusi (Sumber: artificial)
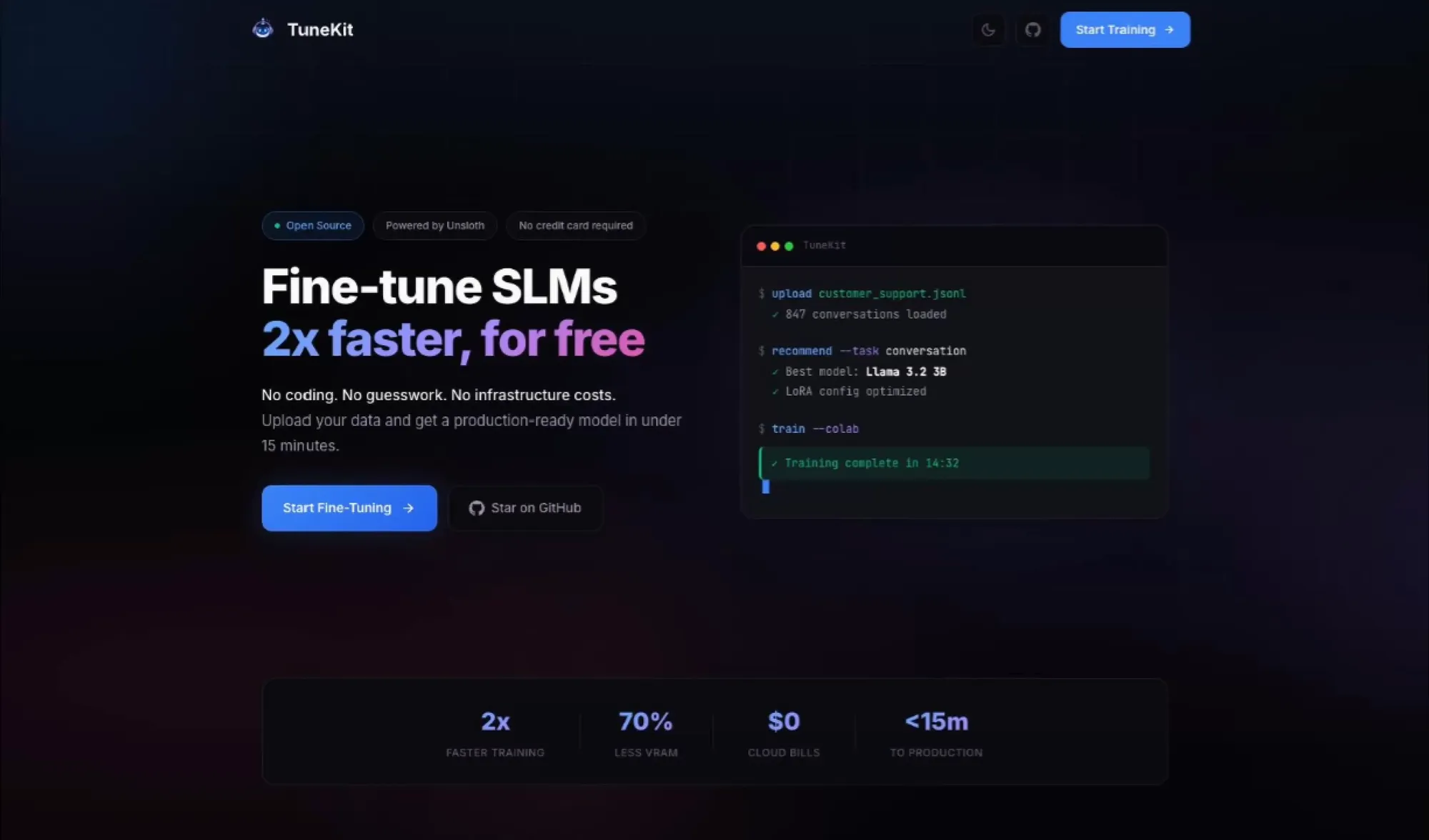
TuneKit: Alat Akselerasi Fine-tuning SLM : TuneKit bertujuan untuk menyederhanakan proses fine-tuning Small Language Model (SLM). Alat ini mendukung pelatihan gratis di Colab dan menggunakan Unsloth AI untuk mencapai akselerasi 2x lipat. Pengguna hanya perlu mengunggah data untuk mendapatkan notebook pelatihan tanpa perlu penulisan skrip yang rumit atau menyewa GPU mahal. Ini memberikan jalur optimasi SLM dengan hambatan rendah dan efisiensi tinggi bagi pengembang, terutama cocok untuk pengembangan model ringan pada skenario tertentu (Sumber: deeplearning)
📚 Pembelajaran
Roadmap Sistem AI Search dan RAG Modern 2026 : Roadmap ini merinci poin-poin kunci evolusi dari “vector database + Prompt” sederhana menuju sistem produksi yang kompleks, termasuk semantic + hybrid retrieval, explicit reranking layer, Agentic RAG (multi-step query decomposition), serta hallucination control. Roadmap ini menekankan pada desain sistem daripada kerangka kerja tunggal, memberikan panduan praktis bagi pengembang untuk membangun sistem AI search yang rendah latensi, rendah biaya, dan memiliki kontrol izin pada tahun 2026 (Sumber: artificial)

DeepLearning.AI Merilis Kursus Pengembangan AI Tanpa Dasar “Build with Andrew” : Kursus baru yang diluncurkan oleh Andrew Ng bertujuan agar orang non-teknis dapat belajar membangun aplikasi web menggunakan AI dalam waktu 30 menit. Kursus ini menekankan pada “Vibe Coding”, yaitu mendeskripsikan ide melalui bahasa alami, di mana AI akan menghasilkan kode dan melakukan iterasi. Ini menandai penghapusan total hambatan pengembangan perangkat lunak, di mana setiap orang dapat menjadi pengembang dan mengubah ide menjadi alat yang dapat dijalankan menggunakan AI (Sumber: DeepLearning.AI)
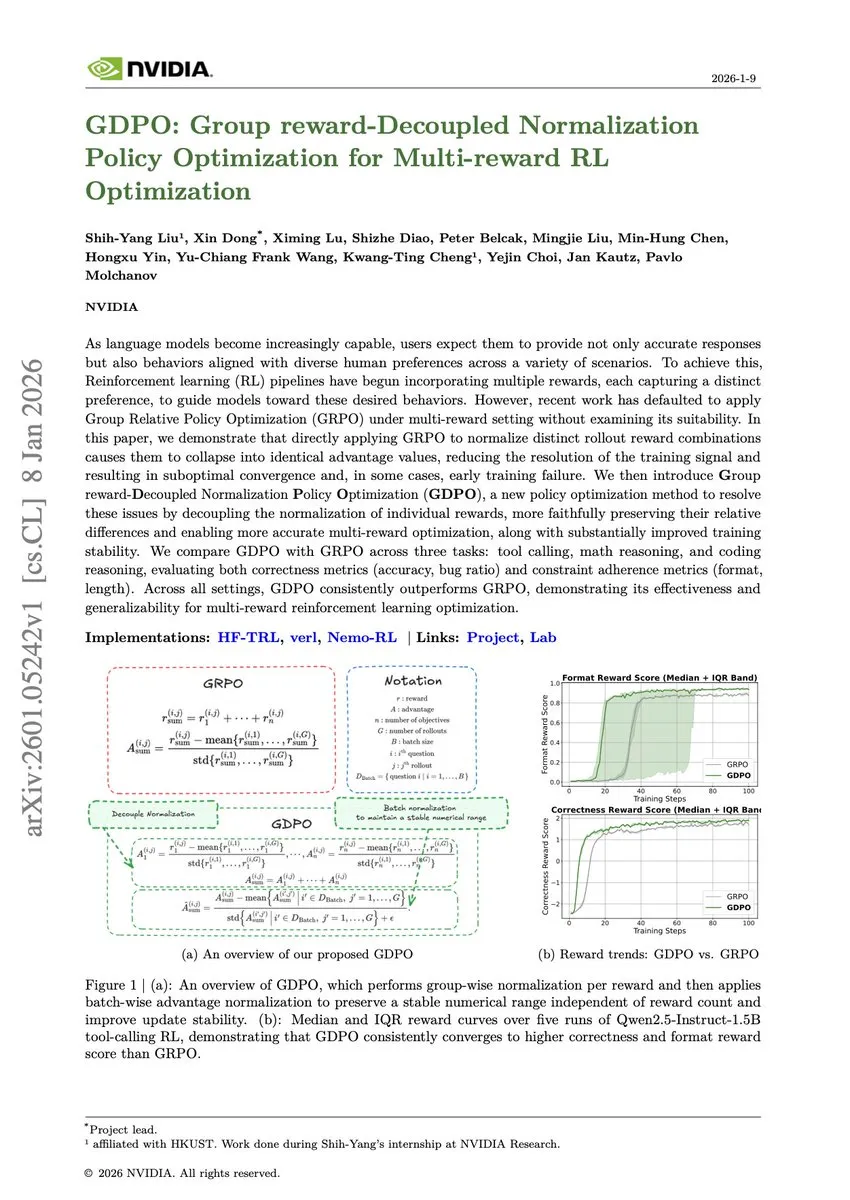
Daftar Paper Terdepan: GDPO, MHC, dan Delethink : Beberapa paper minggu ini berfokus pada efisiensi dan stabilitas pelatihan model besar. GDPO mengatasi masalah signal collapse pada GRPO dalam pengaturan multi-reward; MHC meningkatkan stabilitas scaling model skala besar melalui manifold constraints; sementara Delethink mengusulkan metode pemotongan periodik reasoning Token, yang secara signifikan mengurangi biaya komputasi long-chain reasoning tanpa mengubah arsitektur (Sumber: HuggingFace, MachineLearning)
💼 Bisnis
a16z Mendirikan American Dynamism Fund II Senilai 1,776 Miliar USD : Andreessen Horowitz (a16z) mengumumkan pembentukan dana “American Dynamism” tahap kedua dengan total 1,776 miliar USD. Dana ini bertujuan untuk berinvestasi pada teknologi yang sejalan dengan kepentingan nasional AS, termasuk kedirgantaraan, pertahanan, keamanan publik, dan infrastruktur inti. Ini mencerminkan modal ventura papan atas yang mengalihkan fokus kombinasi AI dan hard tech ke arah strategi nasional dan restrukturisasi industri (Sumber: espricewright)

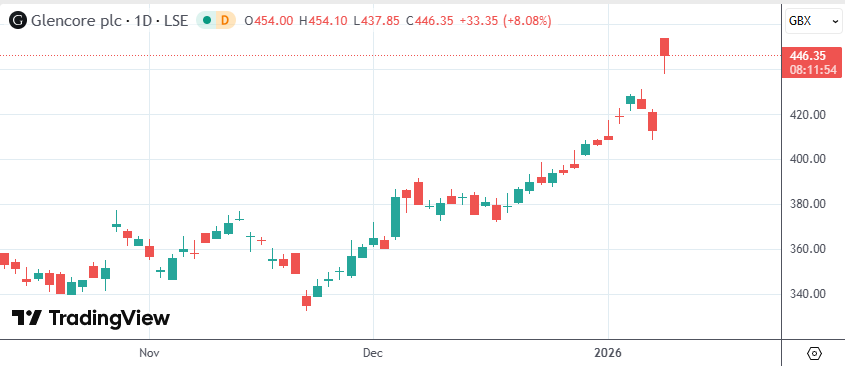
Rio Tinto dan Glencore Berdiskusi untuk Merger, Bertujuan Menjadi Raksasa Pertambangan Terbesar di Dunia : Raksasa pertambangan global Rio Tinto dan Glencore sedang dalam diskusi awal mengenai potensi merger. Jika tercapai, akan lahir perusahaan dengan valuasi pasar lebih dari 200 miliar USD. Pendorong utama merger ini adalah untuk memperoleh lebih banyak sumber daya tembaga guna menghadapi lonjakan permintaan tembaga akibat ledakan pusat data AI dan transisi energi (Sumber: 36氪)
Google AI Studio Mensponsori Proyek Tailwind CSS : Google AI Studio mengumumkan menjadi sponsor resmi proyek Tailwind CSS. Langkah ini bertujuan untuk memperkuat integrasi ekosistem antara alat pengembangan AI dan framework front-end populer, membantu pengembang lebih efisien dalam menggunakan AI untuk menghasilkan kode antarmuka yang sesuai dengan standar UI modern. Ini menunjukkan produsen model dasar sedang merambah alur kerja pengembang melalui sponsor proyek open-source inti (Sumber: crystalsssup)
🌟 Komunitas
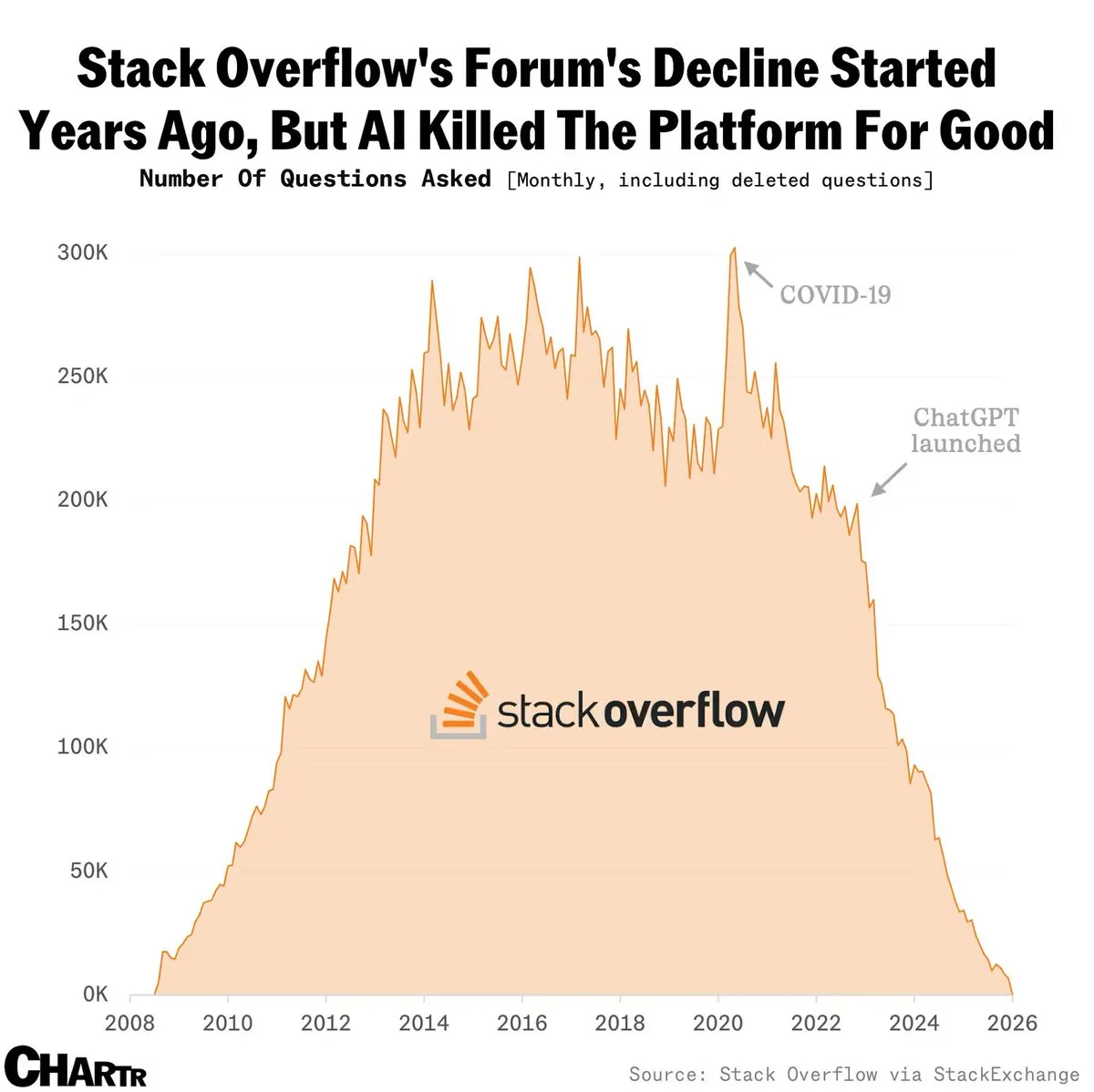
Stack Overflow Menggandakan Pendapatan Melalui Lisensi Model AI : Meskipun volume pertanyaan bulanan merosot tajam setelah peluncuran ChatGPT, Stack Overflow berhasil menggandakan pendapatan tahunannya menjadi 115 juta USD dengan melisensikan basis data jawaban manusia berkualitas tinggi kepada laboratorium AI. Komunitas mendiskusikan hal ini sebagai “kelahiran kembali”, membuktikan nilai premium data manusia berkualitas tinggi di era AI. Namun, ada juga pandangan yang khawatir model ini tidak berkelanjutan karena kecepatan produksi pengetahuan baru melambat (Sumber: BorisMPower)
Resonansi di Kalangan Programmer Mengenai “Kelelahan Mental” Akibat AI : Di media sosial, banyak pengembang melaporkan bahwa meskipun kecepatan kerja meningkat setelah menggunakan AI, mereka merasa lebih lelah secara mental. Mode kerja berubah dari “menyelesaikan satu masalah sulit” menjadi “mengawasi lima produk setengah jadi secara bersamaan”, yang membutuhkan context switching yang sering, peninjauan kode, dan penyesuaian prompt. Pergeseran “beban kognitif” ini memicu diskusi mendalam tentang peran programmer di masa depan: apakah kita penulis kode, atau mandor AI? (Sumber: ArtificialInteligence)
Diskusi Polarisasi Vibe Coding: Aplikasi CRUD atau Visi Teknologi Mendalam? : Komunitas terpecah pandangan mengenai “Vibe Coding”. Satu pihak menganggapnya sangat meningkatkan efisiensi penulisan CRUD (Create, Read, Update, Delete) dan glue code; pihak lain khawatir ini akan menyebabkan “banjir kode level rendah”, karena sistem dasar yang sebenarnya (seperti database, protokol) tetap membutuhkan desain arsitektur dan pertimbangan yang ketat, bukan sekadar instruksi bahasa alami yang santai. Apakah AI meningkatkan level abstraksi, atau justru menciptakan lebih banyak “Slop” yang sulit dipelihara? (Sumber: lateinteraction)
💡 Lainnya
Zhihu Merilis Kalender AI dan Serangkaian Pembaruan Fitur AI : Zhihu meluncurkan “Kalender AI” yang mengagregasi rilis besar dan diskusi mendalam di bidang AI, serta meluncurkan asisten “Zhida” di kolom komentar yang mendukung ringkasan satu klik dan tanya jawab instan. Selain itu, Zhihu juga meluncurkan layanan audio stream AI 24 jam. Langkah-langkah ini menunjukkan platform konten sedang merestrukturisasi efisiensi perolehan informasi melalui AI, mencoba mempertahankan nilai diskusi serius di era AI search (Sumber: ZhihuFrontier)

Terence Tao Berkolaborasi dengan Math, Inc. untuk Memajukan Formalisasi Matematika : Matematikawan Terence Tao, sebagai Veritas Fellow pertama, sedang berupaya memformalisasi estimasi dalam teori bilangan analitik. Tujuannya adalah menciptakan jaringan matematika hidup yang dapat diperiksa mesin, di mana ketika estimasi dasar ditingkatkan, semua inferensi hilir dapat diperbarui secara otomatis. Ini dianggap sebagai langkah penting dalam mengubah literatur matematika menjadi perangkat lunak modular, yang diharapkan dapat membuka paradigma baru dalam penelitian matematika (Sumber: jpt401)
Analisis Komentar Online Menghadapi Polusi “Synthetic Slop” : Perusahaan riset pasar menemukan bahwa sekitar 60% komentar online pada tahun 2026 adalah “Synthetic Slop” yang dihasilkan oleh AI. Komentar-komentar ini memiliki tata bahasa yang sempurna tetapi kurang fluktuasi emosi dan detail. Analis sekarang lebih cenderung mencari komentar dengan kesalahan ejaan, emosi ekstrem, atau konteks spesifik sebagai sinyal “manusia asli”. Ini menandakan bahwa nilai jaringan publik sebagai sampel penelitian sedang runtuh, dan pengumpulan data beralih ke komunitas tertutup dengan hambatan tinggi (Sumber: ArtificialInteligence)