
Mots-clés:grand modèle, IA, introduction en bourse de Hong Kong, modèle B2C de MiniMax, capacité de codage de DeepSeek V4, ChatGPT Santé
🔥 Focus
Duel d’introduction en bourse à Hong Kong entre MiniMax et Zhipu AI : Victoire initiale du modèle B2C : Début 2026, Zhipu et MiniMax, deux des « Six Petits Tigres » des Large Language Models (LLM), sont entrés successivement à la bourse de Hong Kong (HKEX). Le premier jour, l’action de MiniMax a bondi de 109 %, portant sa valorisation à plus de 13,7 milliards USD, une performance supérieure à celle de Zhipu. Les analystes indiquent que le marché affiche des attentes plus élevées pour le modèle d’application B2C de MiniMax (tels que Xingye et Hailuo), estimant que sa capacité de génération de revenus à l’international est plus forte que le déploiement privé B2B traditionnel. Cela marque l’entrée de la compétition des LLM dans une phase de récolte de capitaux, où la différenciation du business model — suivre l’ancienne voie B2B de SenseTime ou embrasser la tendance mondiale B2C — devient la logique centrale de valorisation (Source : 36氪, bookwormengr)

Sortie imminente de DeepSeek V4 : Les capacités de code défient GPT et Claude : DeepSeek devrait lancer son prochain modèle phare, V4, en février. Des tests internes révèlent que V4 a réalisé des percées techniques dans le traitement des prompts de code ultra-longs et l’analyse de patterns de données, avec une rigueur logique nettement améliorée. Ses capacités de génération de code pourraient surpasser GPT-5.2 et Claude Opus 4.5. Le récent papier de recherche MHC (Manifold-constrained Hyper-connectivity) de DeepSeek est considéré comme le socle technique de V4, permettant un saut de performance plus efficace en résolvant l’instabilité lors du scaling des modèles. Cette dynamique suggère que les modèles chinois entreront en confrontation directe avec les meilleurs niveaux mondiaux dans le domaine vertical du code (Source : scaling01, LocalLLaMA)

Sakana AI publie Digital Red Queen : Percée dans la technologie de code auto-évolutif : Sakana AI, en collaboration avec le MIT, a proposé une nouvelle méthode utilisant les LLM pour permettre l’auto-évolution du code assembleur. Cette technologie utilise des combats itératifs dans un environnement hostile Turing-complet appelé « Core War », poussant le code vers la sélection naturelle et l’auto-optimisation par la compétition. Les agents produits par cette fonction d’objectif dynamique sont plus robustes et polyvalents que ceux issus d’une optimisation statique. Cette avancée démontre le potentiel immense de l’IA dans la programmation automatisée et les systèmes adaptatifs, marquant un changement de paradigme de l’apprentissage statique vers l’apprentissage évolutif (Source : hardmaru, SakanaAILabs)

Lancement officiel de ChatGPT Health : L’IA médicale entre dans l’ère de la gestion de santé personnelle : OpenAI a lancé la fonctionnalité ChatGPT Health, permettant la synchronisation des résultats d’analyses et des données d’applications de santé. Basé sur un modèle de santé dédié, il peut analyser en profondeur les rapports médicaux et fournir des recommandations. Bien que des produits similaires existent déjà en Chine (comme Ant Afu), l’implication de ChatGPT marque l’entrée officielle des géants mondiaux de l’IA dans la gestion de la santé comme scénario d’application central. Il ne s’agit pas seulement d’une compétition technologique, mais aussi d’un enjeu global sur la confidentialité des données, la connectivité des dispositifs médicaux et l’orientation personnalisée de la santé (Source : op7418, artificial)

🎯 Tendances
Anthropic limite l’utilisation de l’abonnement Claude pour les applications tierces, suscitant la controverse : Anthropic a récemment commencé à restreindre l’utilisation des identifiants API des abonnés Claude Pro dans des outils tiers comme OpenCode ou Clawdbot. Cette mesure est perçue comme un moyen de protéger son propre écosystème (comme Claude Code) et de contrôler les coûts. La communauté a réagi vivement, estimant que cela réduit la liberté de choix des utilisateurs, poussant certains développeurs vers des modèles plus ouverts comme MiniMax ou Zhipu GLM. Cela reflète le dilemme des fournisseurs d’IA entre « écosystème ouvert » et « boucle commerciale fermée » (Source : matanSF, MiniMax_AI)

Stratégies des géants des puces au CES 2026 : La tendance à la décentralisation du calcul IA s’affirme : Qualcomm, NVIDIA et AMD ont présenté des visions divergentes de l’infrastructure IA au CES. Qualcomm met l’accent sur l’inférence locale « always-on » à la périphérie (Edge) ; AMD recherche une continuité hétérogène entre le Cloud, le PC et l’Edge ; tandis que NVIDIA considère l’IA comme un système industriel, se concentrant sur la puissance de calcul centralisée et la simulation de robots physiques. Cela indique que le calcul IA se restructure selon les scénarios d’utilisation plutôt que par la simple compétition pour la puce la plus puissante, l’IA hybride (inférence lourde sur le Cloud + tâches à faible latence en local) devenant le consensus de l’industrie (Source : TheTuringPost)

Une étude du MIT révèle une convergence cognitive des meilleurs modèles : Le chemin vers la vérité s’éclaircit : Une étude du MIT a révélé que malgré des architectures et des données d’entraînement différentes, la compréhension interne de la matière (comme les structures moléculaires) par les modèles de haute performance tend à converger à mesure que leurs performances s’améliorent. Cela signifie que l’IA collabore pour extraire la logique fondamentale objective du monde physique. Pour les développeurs, cela suggère qu’il sera possible à l’avenir d’utiliser la « distillation de modèle » pour permettre aux petits modèles de copier les résultats des grands, sans avoir besoin d’une course effrénée à la puissance de calcul pour atteindre des capacités de découverte scientifique de haut niveau (Source : 36氪)

Alibaba Cloud lance l’année de la démocratisation du matériel IA : Déploiement massif d’agents intelligents on-device : Lors de l’exposition de matériel intelligent Tongyi, Alibaba Cloud a présenté plus de 200 dispositifs lancés en même temps qu’au CES, incluant des lunettes intelligentes, des AI Pin et des robots. Grâce à la couverture complète de la gamme de modèles Tongyi (de 0.5B à 480B), Alibaba Cloud propose aux fabricants de matériel une solution « Cloud-Edge collaborative » à faible consommation et haute intelligence. Cela marque la transformation de l’industrie chinoise du matériel, passant de « dispositifs connectés » à des « agents intelligents autonomes », où l’IA n’est plus une fonction marginale mais le moteur central de l’expérience utilisateur (Source : 36氪)

🧰 Outils
Ralph for Claude Code : Outil de boucle de développement IA autonome : Ralph est un outil de boucle de développement autonome basé sur Claude Code, doté d’une détection de sortie intelligente et d’une limitation de débit. Il permet à Claude Code d’améliorer un projet de manière itérative jusqu’à son achèvement, avec des mécanismes intégrés pour prévenir les boucles infinies et l’abus d’API. Il supporte la sortie JSON, la continuité des sessions et peut être surveillé en temps réel via tmux. Il standardise le flux de développement, permettant à l’IA de réaliser véritablement des tâches d’ingénierie logicielle en « boucle fermée » (Source : frankbria)
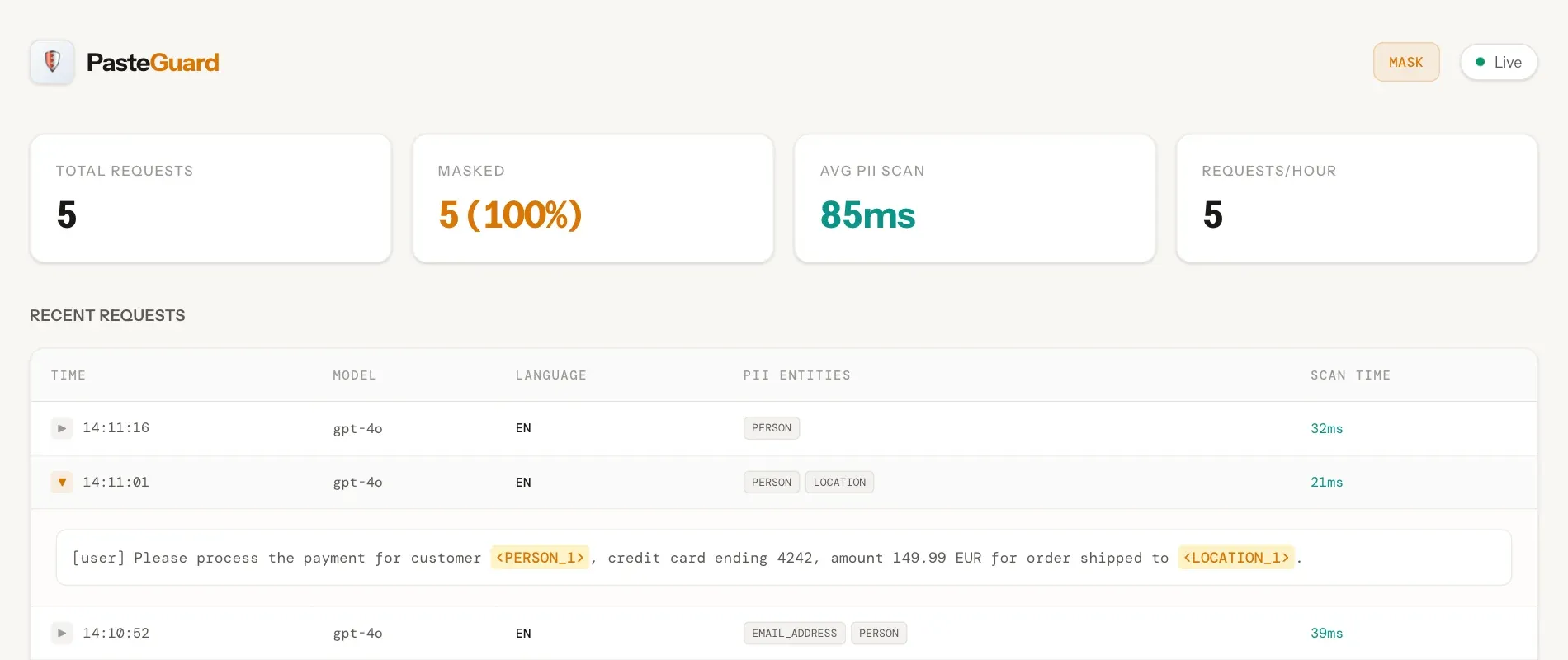
PasteGuard : Proxy de confidentialité pour masquer les PII dans les LLM Cloud : Il s’agit d’un proxy de confidentialité conçu pour Open WebUI, capable de masquer automatiquement les informations personnelles identifiables (PII) telles que les noms, emails et numéros de téléphone avant d’envoyer les données aux LLM sur le Cloud. Il propose un « mode masque » et un « mode routage » (où les informations sensibles sont traitées localement par Ollama). Supportant 24 langues et utilisant la technologie Microsoft Presidio, il résout efficacement les préoccupations de conformité et de confidentialité des entreprises utilisant l’IA Cloud (Source : OpenWebUI)
Empirica : Un framework cognitif dotant les agents IA de capacités d’auto-réflexion : Empirica est un framework cognitif open-source pour agents IA, visant à résoudre des problèmes tels que l’excès de confiance aveugle ou la répétition d’erreurs. Il suit les lacunes de connaissances de l’agent, assure un apprentissage persistant entre les sessions et définit des seuils de confiance pour contrôler les actions. Son flux de travail central CASCADE permet une vérification préalable, un filtrage (gating) et une mesure de l’apprentissage, permettant à l’IA de pratiquer la métacognition (Meta-cognition) en évaluant « ce que je sais » avant d’agir (Source : artificial)
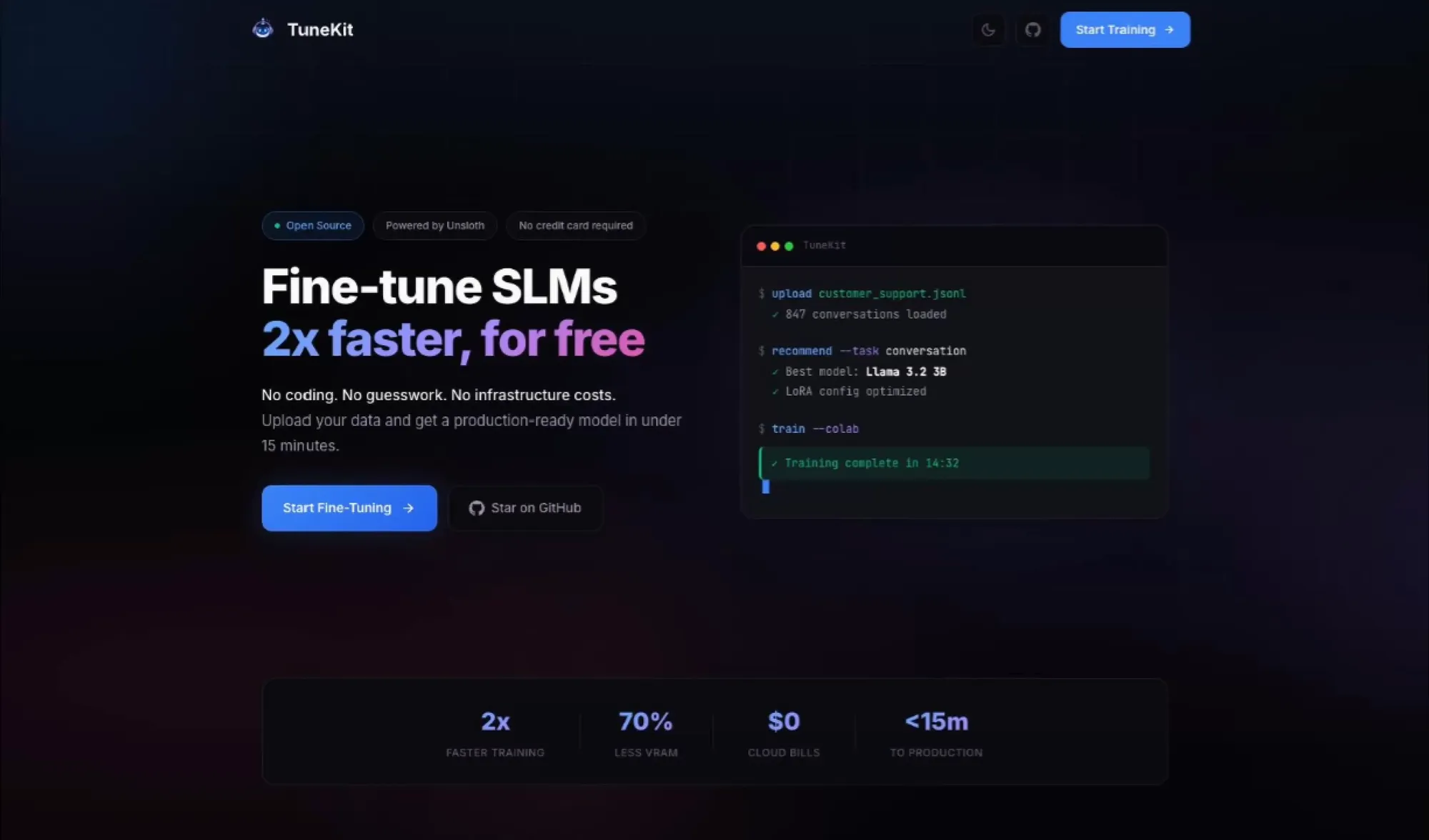
TuneKit : Outil d’accélération pour le fine-tuning des SLM : TuneKit vise à simplifier le processus de fine-tuning des Small Language Models (SLM). Il permet un entraînement gratuit sur Colab et utilise Unsloth AI pour doubler la vitesse d’exécution. Les utilisateurs n’ont qu’à télécharger leurs données pour obtenir un notebook d’entraînement, sans avoir besoin d’écrire des scripts complexes ou de louer des GPU coûteux. Cela offre aux développeurs un chemin efficace et accessible pour l’optimisation des SLM, particulièrement adapté au développement de modèles légers pour des scénarios spécifiques (Source : deeplearning)
📚 Apprentissage
Roadmap 2026 pour la recherche IA moderne et les systèmes RAG : Cette feuille de route détaille les étapes clés pour passer d’une simple structure « base vectorielle + Prompt » à des systèmes de production complexes, incluant la recherche hybride sémantique, les couches de re-ranking explicites, l’Agentic RAG (décomposition de requêtes multi-étapes) et le contrôle des hallucinations. Elle met l’accent sur la conception système plutôt que sur un framework unique, offrant un guide pratique pour construire des systèmes de recherche IA à faible latence, faible coût et avec contrôle des accès en 2026 (Source : artificial)

DeepLearning.AI lance le cours « Build with Andrew » pour le développement IA sans prérequis : Le nouveau cours lancé par Andrew Ng vise à permettre aux non-techniciens d’apprendre à construire des applications Web avec l’IA en 30 minutes. Le cours met l’accent sur le « Vibe Coding », qui consiste à décrire des idées en langage naturel pour que l’IA génère le code et itère. Cela marque la suppression totale des barrières au développement logiciel, où chacun peut devenir développeur en transformant ses idées en outils fonctionnels grâce à l’IA (Source : DeepLearning.AI)
Sélection de papiers de recherche : GDPO, MHC et Delethink : Plusieurs articles de cette semaine se concentrent sur l’efficacité et la stabilité de l’entraînement des LLM. GDPO résout le problème de l’effondrement du signal dans GRPO sous des configurations de récompenses multiples ; MHC améliore la stabilité du scaling des modèles à grande échelle via des contraintes de variétés (manifolds) ; et Delethink propose une méthode de troncature périodique des tokens de raisonnement, réduisant considérablement le coût de calcul du raisonnement à longue chaîne sans modifier l’architecture (Source : HuggingFace, MachineLearning)
💼 Business
a16z lance le fonds American Dynamism II de 1,776 milliard USD : Andreessen Horowitz (a16z) a annoncé la création de son deuxième fonds « American Dynamism », d’un montant total de 1,776 milliard USD. Ce fonds vise à investir dans des technologies conformes aux intérêts nationaux des États-Unis, notamment l’aérospatiale, la défense, la sécurité publique et les infrastructures critiques. Cela reflète le pivot des grands fonds de capital-risque vers la convergence de l’IA, de la Deep Tech et de la stratégie nationale (Source : espricewright)

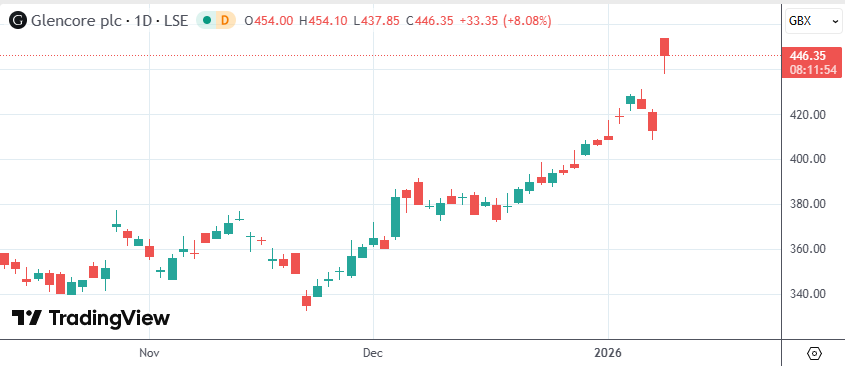
Rio Tinto et Glencore en discussion pour une fusion visant à créer le plus grand géant minier mondial : Les géants miniers mondiaux Rio Tinto et Glencore sont en consultations préliminaires pour une fusion potentielle. Si elle aboutit, elle donnerait naissance à une entreprise d’une capitalisation boursière supérieure à 200 milliards USD. Le moteur principal de cette fusion est l’acquisition de ressources en cuivre pour répondre à l’explosion de la demande générée par les centres de calcul IA et la transition énergétique (Source : 36氪)
Google AI Studio sponsorise le projet Tailwind CSS : Google AI Studio a annoncé devenir sponsor officiel du projet Tailwind CSS. Cette initiative vise à renforcer l’intégration entre les outils de développement IA et les frameworks front-end populaires, aidant les développeurs à utiliser plus efficacement l’IA pour générer du code d’interface conforme aux standards UI modernes. Cela montre comment les fournisseurs de modèles fondamentaux s’insèrent dans le workflow des développeurs en sponsorisant des projets open-source clés (Source : crystalsssup)
🌟 Communauté
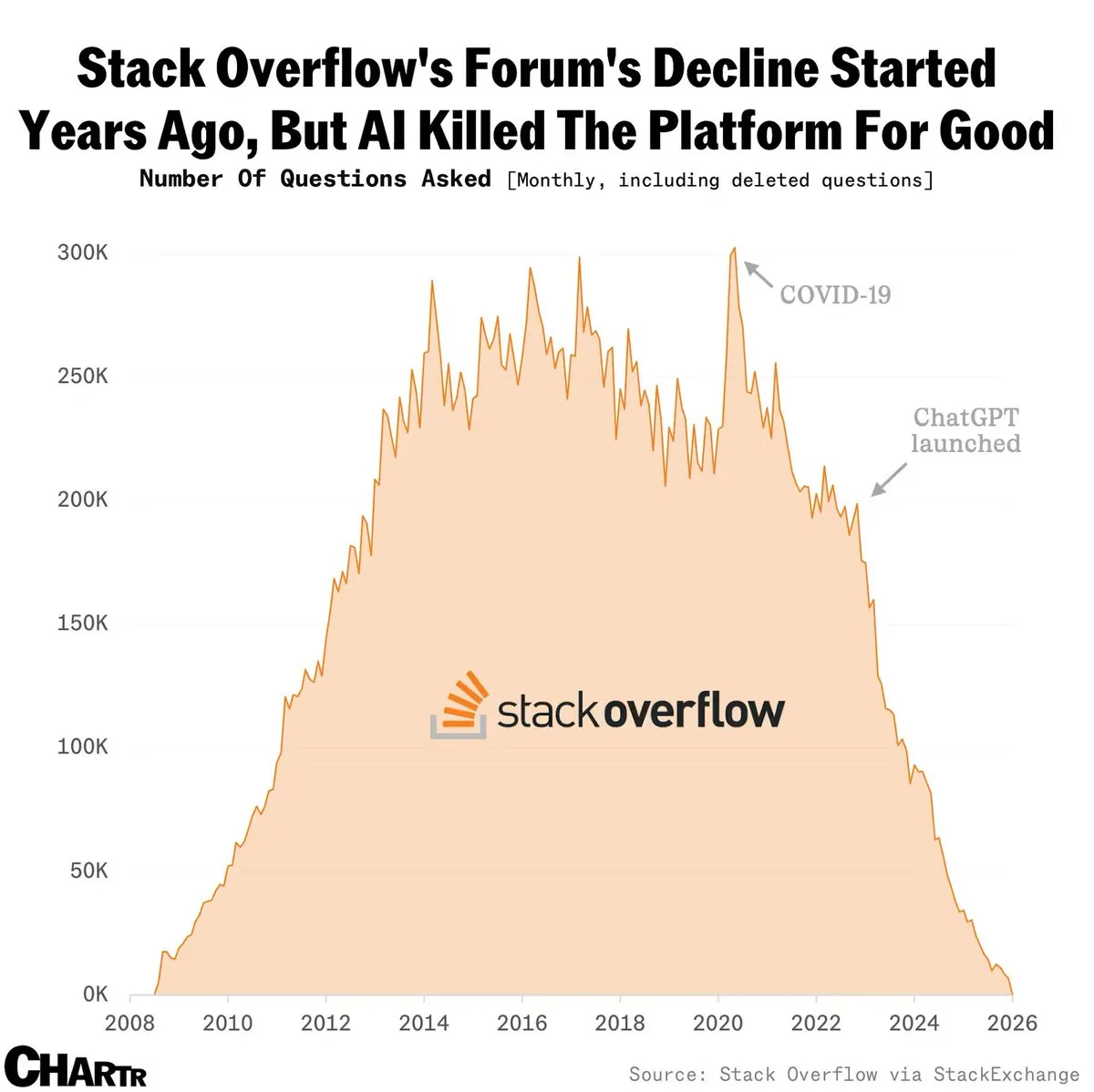
Stack Overflow double ses revenus grâce à l’octroi de licences pour les modèles IA : Malgré une chute drastique du volume mensuel de questions après le lancement de ChatGPT, Stack Overflow a doublé son chiffre d’affaires annuel pour atteindre 115 millions USD en vendant des licences de sa base de données de réponses humaines de haute qualité aux laboratoires d’IA. La communauté débat de cette « renaissance », prouvant la valeur ajoutée des données humaines de qualité à l’ère de l’IA. Cependant, certains craignent que ce modèle ne soit pas durable, car la vitesse de production de nouvelles connaissances ralentit (Source : BorisMPower)
Résonance chez les programmeurs sur la « fatigue mentale » causée par l’IA : Sur les réseaux sociaux, de nombreux développeurs rapportent que si l’IA les rend plus rapides, elle les épuise davantage mentalement. Le mode de travail est passé de « résoudre un problème difficile » à « superviser simultanément cinq produits semi-finis », nécessitant des changements de contexte fréquents, des revues de code et des ajustements de prompts. Ce transfert de « charge cognitive » suscite des discussions profondes sur le futur rôle du programmeur : sommes-nous des auteurs de code ou des superviseurs d’IA ? (Source : ArtificialInteligence)
Débats polarisés sur le Vibe Coding : Applications CRUD ou vision technique profonde ? : La communauté est divisée sur le « Vibe Coding ». D’un côté, certains estiment qu’il améliore considérablement l’efficacité de l’écriture de code CRUD (Create, Read, Update, Delete) et de code de liaison (glue code). De l’autre, on craint que cela ne mène à une « prolifération de code de bas niveau », alors que les systèmes fondamentaux (bases de données, protocoles) nécessitent toujours une conception architecturale rigoureuse et des arbitrages réfléchis, plutôt que des instructions en langage naturel improvisées. L’IA élève-t-elle le niveau d’abstraction ou fabrique-t-elle davantage de « Slop » (contenu de faible qualité) difficile à maintenir ? (Source : lateinteraction)
💡 Autre
Zhihu lance un calendrier IA et une série de mises à jour de fonctionnalités IA : Zhihu a lancé un « Calendrier IA » regroupant les annonces majeures et les discussions approfondies du secteur, ainsi qu’un assistant « Zhida » dans les sections commentaires pour des résumés en un clic et des questions-réponses instantanées. De plus, Zhihu a lancé un service de flux audio IA 24h/24. Ces mesures montrent comment les plateformes de contenu restructurent l’efficacité de l’accès à l’information via l’IA, tentant de préserver la valeur des discussions sérieuses à l’ère de la recherche IA (Source : ZhihuFrontier)

Terence Tao collabore avec Math, Inc. pour faire progresser la formalisation des mathématiques : Le mathématicien Terence Tao, en tant que premier chercheur Veritas, travaille à la formalisation des estimations en théorie analytique des nombres. L’objectif est de créer un réseau mathématique vivant, vérifiable par machine, où toutes les conclusions en aval sont automatiquement mises à jour lorsque les estimations fondamentales s’améliorent. Cela est considéré comme une étape cruciale pour transformer la littérature mathématique en logiciel modulaire, ouvrant potentiellement un nouveau paradigme pour la recherche mathématique (Source : jpt401)
L’analyse des commentaires en ligne confrontée à la pollution par les « déchets synthétiques » : Des sociétés d’études de marché ont constaté qu’en 2026, environ 60 % des commentaires en ligne sont des « déchets synthétiques » générés par l’IA. Ces commentaires ont une grammaire parfaite mais manquent de nuances émotionnelles et de détails. Les analystes préfèrent désormais rechercher des commentaires avec des fautes d’orthographe, des émotions extrêmes ou des contextes spécifiques comme signaux d’une « humanité réelle ». Cela suggère que la valeur du web public comme échantillon de recherche s’effondre, la collecte de données se tournant vers des communautés fermées à forte friction (Source : ArtificialInteligence)