Schlüsselwörter:DeepSeek R1, KI-Training, Verstärkendes Lernen RL, Prozessbelohnungsmodell PRM
🔥 Fokus
DeepSeek R1 veröffentlicht 86-seitiges Paper und enthüllt Trainingsdetails: DeepSeek hat still und heimlich den DeepSeek R1 technischen Bericht aktualisiert und von 22 auf 86 Seiten massiv erweitert, was fast einer Neuschreibung zu einem reproduzierbaren „Lehrbuch“ gleichkommt. Der Bericht enthüllt erstmals detailliert die Entwicklung der drei Trainingsphasen Dev1/2/3, eine Aufschlüsselung der extrem niedrigen Trainingskosten von 294.000 US-Dollar sowie eine Analyse gescheiterter Versuche wie MCTS und Process Reward Models (PRM). Dieser Schritt demonstriert nicht nur die tiefe Expertise im Bereich Reinforcement Learning (RL), sondern beweist der Open-Source-Community durch detaillierte Parameter im Anhang: Rein RL-getriebene Reasoning-Modelle sind nicht nur machbar, sondern weisen ein extrem hohes Effizienzverhältnis auf. Diese Strategie der „Transparenz“ zwingt die Closed-Source-Giganten dazu, ihre technologischen Barrieren neu zu bewerten. (Quelle: _akhaliq, karminski3, 量子位)

MiniMax und智谱 AI (Zhipu AI) läuten mit Hongkong-Börsengängen den „Shanghai/Peking-Moment“ für Large Models ein: Die führenden chinesischen KI-Unternehmen MiniMax und Zhipu AI sind nacheinander an die Hongkonger Börse gegangen, was den offiziellen Eintritt der chinesischen AGI-Industrie in die Phase der Sekundärmarktprüfung markiert. Am ersten Handelstag stieg der Aktienkurs von MiniMax um über 100 %, wobei die Marktkapitalisierung 100 Milliarden HKD überschritt; besonders die globale Ausrichtung mit über 70 % Auslandsumsatz stieß bei Investoren auf Begeisterung. Zhipu AI wiederum zeigte ein exponentielles Wachstum des MaaS-Geschäfts um das 25-fache innerhalb von 10 Monaten. Die erfolgreichen Börsengänge bieten nicht nur frühen Investoren hohe Renditen, sondern dienen durch das 18C-Regelwerk auch als reproduzierbares Finanzierungsmodell für nachfolgende AI-Unicorns und beweisen den einzigartigen Wert chinesischer Unternehmen mit eigener Foundation Model-Kompetenz im globalen Wettbewerb. (Quelle: Zai_org, 36氪)

CES 2026 Physical AI Boom: Vom Bildschirm in die reale Welt: Die diesjährige CES hat sich vollständig dem Thema „Physical AI“ verschrieben, was Nvidia-Chef Jensen Huang als den „ChatGPT-Moment der Physical AI“ bezeichnete. Der Atlas von Boston Dynamics trat erstmals öffentlich auf und kündigte seinen Einsatz in Hyundai-Fabriken an. LG präsentierte den Haushaltsroboter CLOiD, der Wäsche falten kann, während Lenovo den persönlichen AI-Super-Agenten Qira vorstellte. Die chinesische Lieferkette zeigte eine starke Präsenz mit über 20 teilnehmenden Robotik-Unternehmen, die Serienfertigungskapazitäten von geschickten Roboterhänden bis hin zu humanoiden Robotern in Originalgröße demonstrierten. AI ist nicht mehr nur ein Chatfenster, sondern greift über Sensoren und Aktoren tief in die physische Welt ein und strukturiert traditionelle Industrien von Haushaltsgeräten über PCs bis hin zu Automobilen neu. (Quelle: TheRundownAI, 雷科技)

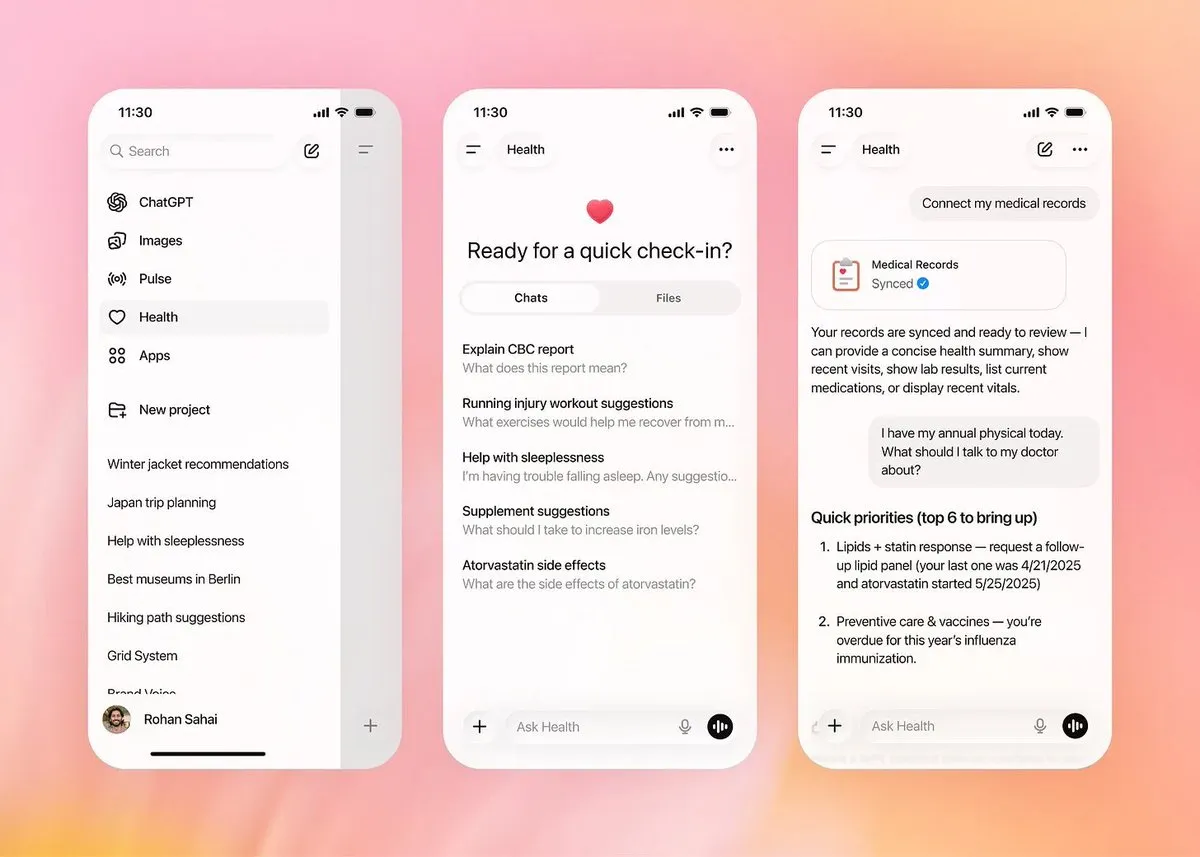
OpenAI veröffentlicht Healthcare-Sektor und steigt in vertikale Medizin-Märkte ein: OpenAI hat offiziell die ChatGPT Health Experience eingeführt, die HIPAA-konform ist und mit führenden medizinischen Einrichtungen wie der Mayo Clinic und dem Boston Children’s Hospital kooperiert. Die Funktion ermöglicht es Nutzern, elektronische Patientenakten und Apple Health-Daten zu verknüpfen, um durch AI-Unterstützung Untersuchungsberichte zu analysieren und Gesundheitspläne zu erstellen. Obwohl es scherzhaft als „amerikanische Version von Ant Afu“ bezeichnet wird, repräsentiert es den Trend von Large Models, sich von allgemeinen Anwendungen hin zu spezialisierten vertikalen Bereichen zu entwickeln. Medical AI entwickelt sich von einfachen Frage-Antwort-Systemen zu professionellen Assistenten, die Daten aus mehreren Quellen integrieren und klinische Entscheidungsunterstützung bieten können, wenngleich Sicherheit und Fehldiagnoserisiken weiterhin im Fokus der Community stehen. (Quelle: _samirism, openai)
🎯 Trends
Google DeepMind schlägt „Nested Learning“ (NL) Framework vor: Um das Problem fehlender kontinuierlicher Lernfähigkeit und des „catastrophic forgetting“ bei Transformern zu lösen, hat das DeepMind-Team das Nested Learning Framework (NL) vorgeschlagen, das sich am menschlichen assoziativen Gedächtnis orientiert. Das Framework betrachtet den Optimizer als „Kontext“ der Modellarchitektur. Durch die Verschachtelung von Modulen mit unterschiedlichen Aktualisierungsfrequenzen kann die AI während des Betriebs abstrakte Strukturen aufbauen und kurzfristige Erfahrungen in langfristiges Wissen überführen. Dies wird als entscheidender Schritt in Richtung AGI angesehen, der es Modellen ermöglichen könnte, sich wie Menschen in dynamischen Umgebungen selbst weiterzuentwickeln, anstatt auf teures Retraining angewiesen zu sein. (Quelle: hardmaru, 新智元)
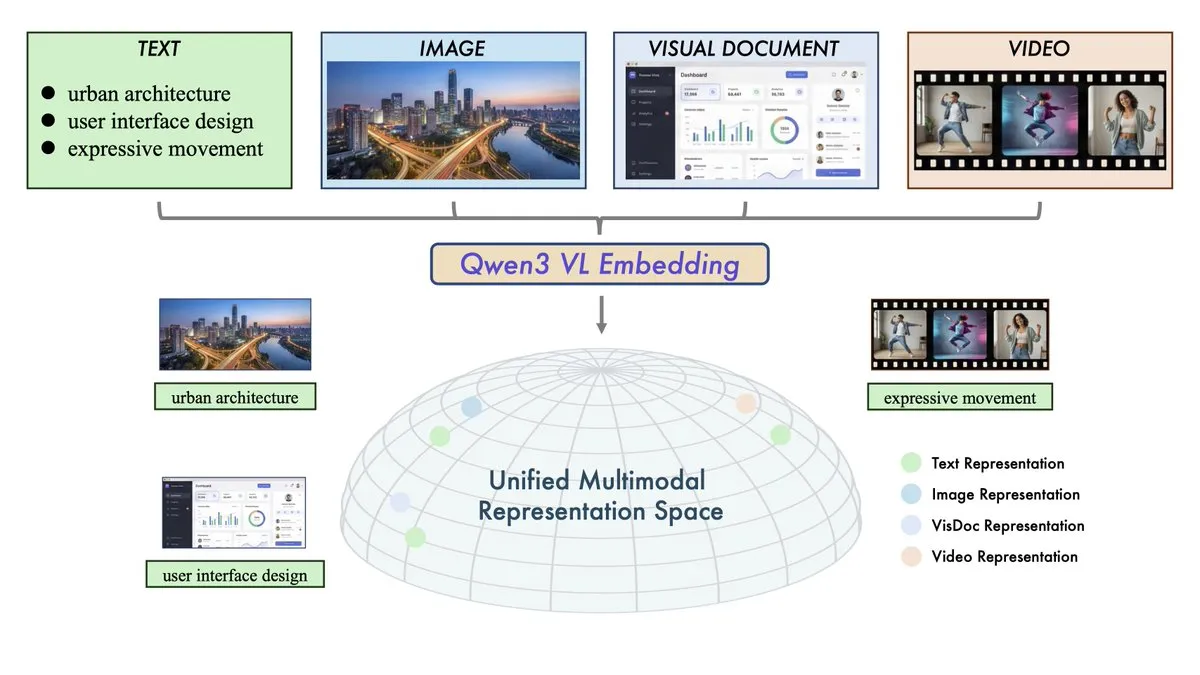
Alibaba veröffentlicht Qwen3-VL-Embedding und Reranker-Modelle: Das Alibaba Qwen-Team hat ein multimodales Retrieval-Duo vorgestellt, das darauf abzielt, den Vektorraum für Text, Bilder, Videos und gemischte Modalitäten zu vereinheitlichen. Qwen3-VL-Embedding unterstützt über 30 Sprachen und erreicht SOTA-Performance in multimodalen Retrieval-Benchmarks. Der Reranker verbessert die Retrieval-Präzision durch feingranulare Relevanzbewertungen weiter. Diese Veröffentlichung markiert den offiziellen Eintritt der RAG-Technologie (Retrieval-Augmented Generation) in das Zeitalter der Vollmodalität und bietet die Kerninfrastruktur für komplexere visuelle Frage-Antwort-Systeme, Videosuche und multimodale Agents. (Quelle: huggingface, _akhaliq)
a16z-Gründer Ausblick 2026: Deflation der Intelligenzkosten treibt Nachfrageexplosion: Marc Andreessen wies darauf hin, dass die Kosten pro AI-Einheit schneller sinken als Moore’s Law vorhersagt. Intelligenz wandelt sich von einem Luxusgut zu einem Alltagsgut wie Strom oder Wasser. Er prognostiziert eine „Pyramidenstruktur“ des zukünftigen Marktes: An der Spitze stehen einige wenige Super-Modelle, an der Basis allgegenwärtige Edge-Side Small Models. Gleichzeitig glaubt er, dass Startups durch „Rückwärtsintegration“ eigener Modelle den Vorwurf des bloßen „Wrappings“ entkräften werden. Das AI-Geschäftsmodell wird sich von der Bezahlung pro Token hin zu einer Preisgestaltung nach geschaffenem Wert verschieben. (Quelle: nvidia, 华尔街见闻)
Sprach-LLMs für Smart Cockpits beschleunigen Integration in Fahrzeuge: Auf der CES präsentierte StepFun (阶跃星辰) in Zusammenarbeit mit Geely Galaxy ein End-to-End Sprach-LLM-Cockpit mit Emotionserkennung und Langzeitgedächtnis. Branchenexperten gehen davon aus, dass 2026 das Jahr der großflächigen Serienproduktion von Entry-Level Agents in Fahrzeugcockpits sein wird. Das Cockpit wandelt sich von einer einfachen Sprachsteuerung zu einem „dritten Lebensraum“ mit proaktiver Ausführung und personalisierten Diensten. Die Cloud-Edge-kollaborative AI-Architektur wird zum Kernwettbewerb der Automobilhersteller, mit dem Ziel, AI-Fähigkeiten tief in die OS-Ebene zu integrieren, um eine domänenübergreifende Erfahrung zu ermöglichen. (Quelle: dotey, 科创板日报)
🧰 Tools
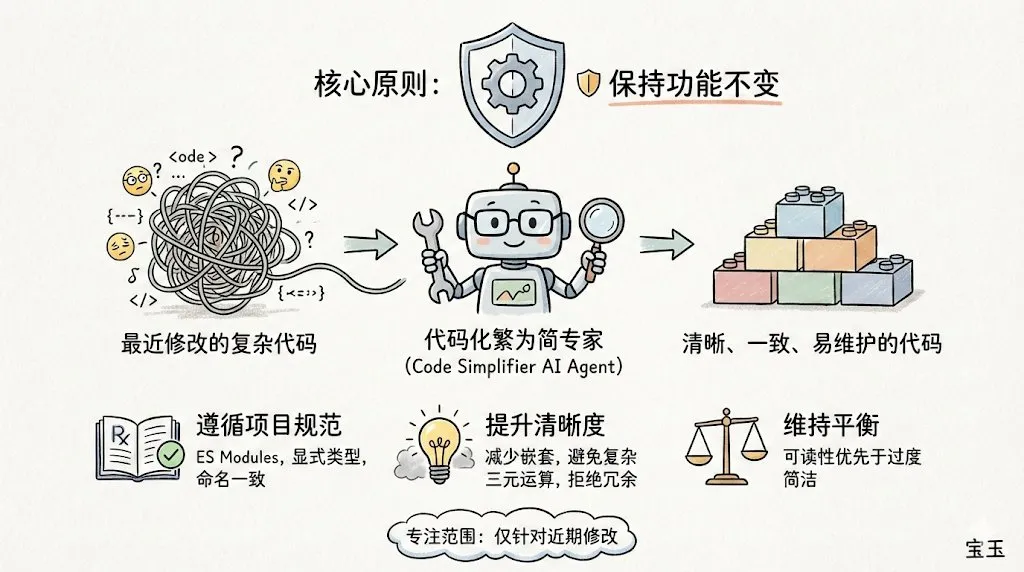
Claude Code und code-simplifier Plugin veröffentlicht: Das von Anthropic eingeführte Kommandozeilen-Tool Claude Code ist in der Entwickler-Community aufgrund seines exzellenten Engineering-Gefühls extrem populär geworden. Offiziell wurde nun das code-simplifier Agent-Plugin veröffentlicht, das die Vereinfachung komplexer Codebasen mit einem Klick unterstützt. Das Kernkonzept lautet „File system as context“: Durch das dynamische Laden benötigter Dateien anstelle des Stapelns von Token wird die Effizienz bei der Bearbeitung großer Repositories erheblich gesteigert. Community-Feedback deutet darauf hin, dass es GPT-4o in Bezug auf logisches Verständnis und die Reduzierung von „Code-Geschwätz“ bereits übertroffen hat. (Quelle: dotey, natolambert)
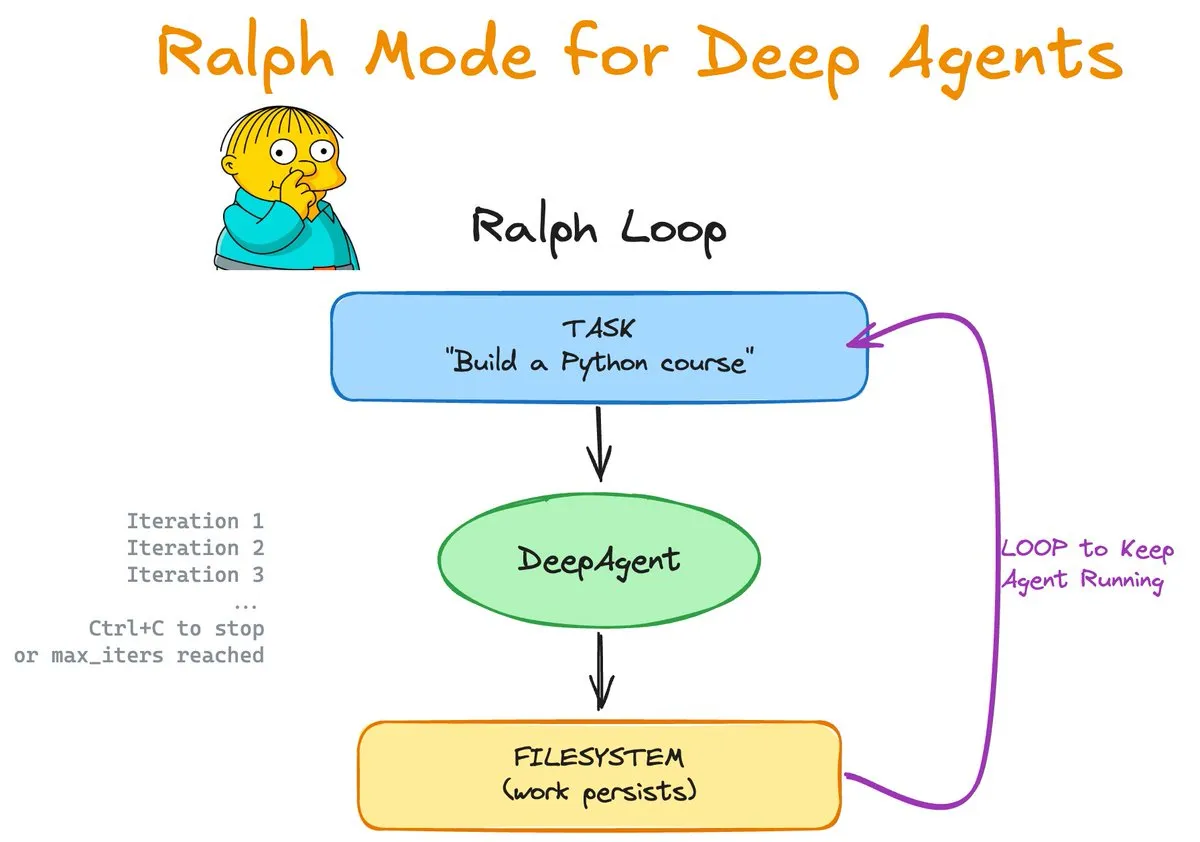
Ralph Mode: Kontinuierliche Loops und Memory-Erweiterung für Agents: Der von LangChain OSS eingeführte Ralph Mode bringt native Skills- und Memory-Unterstützung für die DeepAgents-Bibliothek. Dieser Modus ermöglicht es Agents, Aufgaben in Endlosschleifen mit Unterstützung des Dateisystems und Git auszuführen und ihre Wissensbasis durch einen „skill-basierten“ Lernprozess ständig zu aktualisieren. Dieses Design erlaubt es Agents, sich selbst zu korrigieren und Erfahrungen zu sammeln, was ein neues Paradigma für die autonome Softwareentwicklung und die Bearbeitung komplexer Langzeitaufgaben darstellt. (Quelle: Vtrivedy10, hwchase17)
Pico AI Server: Lokales, privates ChatGPT auf dem Mac: Für datenschutzbewusste Nutzer bietet Pico AI Server eine vollständig lokale GPT-oss-Unterstützung auf Apple Silicon. Optimiert durch das MLX-Framework ermöglicht das Tool Mac-Nutzern mit 24GB+ RAM eine flüssige lokale Inference-Erfahrung. Dies spiegelt den Trend der Migration von AI-Rechenleistung auf die Edge-Seite wider; Nutzer müssen keine sensiblen Daten mehr in die Cloud hochladen, um leistungsstarke Dialog- und Programmierunterstützung zu erhalten. (Quelle: awnihannun)

LFM2.5 1.2B: Leistungsstarkes kleines Modell für Agents: Das von LiquidAI veröffentlichte LFM2.5 1.2B Instruct Modell zeigt in seiner Größenklasse eine beeindruckende Leistung, insbesondere optimiert für Agent-Aufgaben, Datenextraktion und RAG. Obwohl es nicht für wissensintensive Aufgaben empfohlen wird, ist seine Inference-Geschwindigkeit in lokalen Umgebungen wie LM Studio extrem hoch (bis zu 41 tps), was es zur idealen Wahl für den Aufbau leichtgewichtiger AI-Assistenten und Tool-Calling-Workflows macht. (Quelle: Reddit r/LocalLLaMA)

📚 Lernen
Tsinghua-Team DrugCLIP in Science: AI beschleunigt Wirkstoff-Screening um das Millionenfache: Ein gemeinsames Forschungsteam der Tsinghua-Universität hat das DrugCLIP-Framework vorgestellt, das virtuelles Screening als Dense Retrieval-Aufgabe neu definiert. Durch das Mapping von Protein-Bindungstaschen und kleinen Molekülen in einen Vektorraum kann das Framework auf 8 A100-GPUs 10 Billionen Berechnungen in nur 24 Stunden durchführen – 10 Millionen Mal schneller als herkömmliche Methoden. Dieser Durchbruch schafft ein neues Paradigma für die Wirkstoffforschung in der Post-AlphaFold-Ära und senkt die Hürden für die Wirkstoffentdeckung im extrem großen Maßstab massiv. (Quelle: 36氪)

Sakana AI veröffentlicht Digital Red Queen (DRQ) Forschung: Diese Studie simuliert eine LLM-gesteuerte adversative Evolution in der Core War Programmierspiel-Sandbox. Indem LLM-geschriebene Redcode-Programme kontinuierlich gegeneinander antreten, wurde ein Phänomen beobachtet, das der biologischen „konvergenten Evolution“ ähnelt: Programme unter verschiedenen Anfangsbedingungen entwickelten letztlich ähnliche, hocheffiziente Überlebensstrategien (z. B. Selbstreplikation, Datenbomben). Diese Arbeit bietet eine sichere, kontrollierte Experimentierumgebung zur Untersuchung adversativer Dynamiken und der Evolution von Cybersicherheit in künstlichen Systemen. (Quelle: hardmaru, SakanaAILabs)
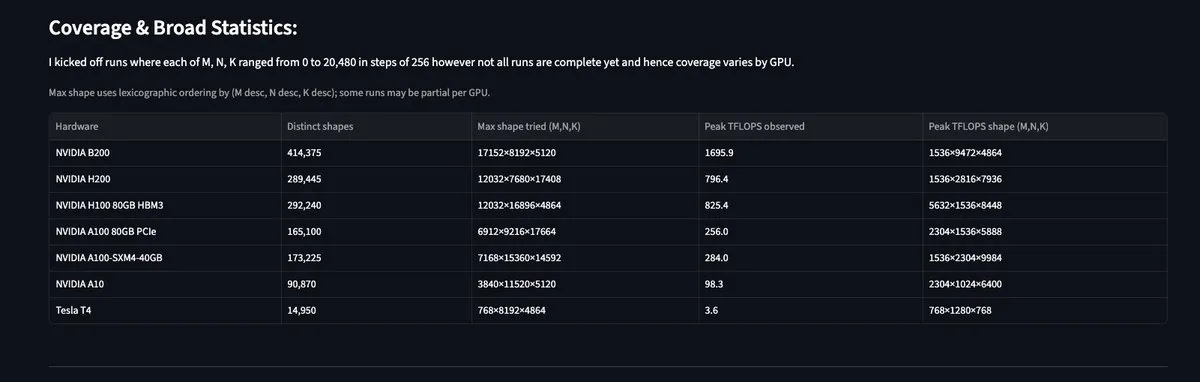
MAMF Explorer: Einblicke in die tatsächliche Matrix-Multiplikationsleistung von GPUs: Das vom Entwickler Aflah veröffentlichte MAMF Explorer Tool bietet Forschern Daten zu den tatsächlich erreichbaren Peak matmul FLOPS auf verschiedener Hardware, anstatt der theoretischen Spitzenwerte der Hersteller. Dies ist von hohem praktischem Wert für die Optimierung der Rechenressourcenverteilung beim Training und der Inference großer Modelle und hilft Entwicklern, echte Leistungsengpässe auf verschiedenen Chips wie Blackwell oder H100 zu finden. (Quelle: StasBekman, charles_irl)
💼 Business
Anthropic-Bewertung könnte 350 Mrd. USD erreichen, ARR wächst rasant: Berichten zufolge plant Anthropic eine Finanzierung über 10 Milliarden USD, wobei sich die Bewertung innerhalb eines halben Jahres verdoppelt hätte. Der Umsatz für 2025 hat bereits 900 Millionen USD erreicht, mit dem Ziel, 2026 die 2-Milliarden-Marke zu knacken. Im Vergleich zu den internen Konflikten bei OpenAI wird Anthropic aufgrund der hohen Teamstabilität und der „Performance-Dominanz“ im Entwicklermarkt (z. B. Claude Code) zur ersten Wahl im Enterprise-Markt; es wird sogar spekuliert, dass sie OpenAI beim IPO-Zeitplan überholen könnten. (Quelle: 36氪, srimuppidi)

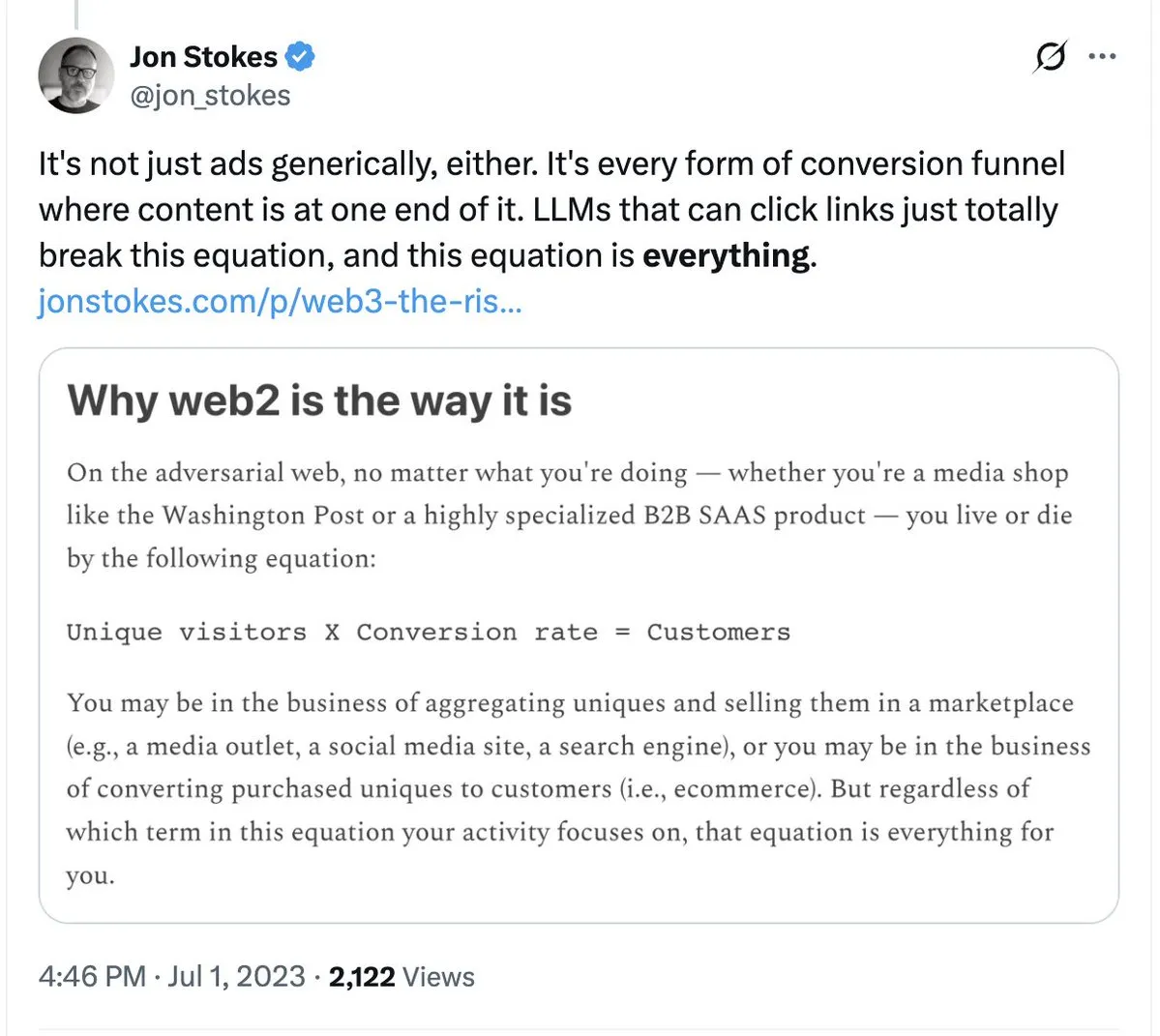
Tailwind-Entlassungen lösen Reflexion über AI-Auswirkungen auf traditionelle SaaS-Modelle aus: Das bekannte CSS-Framework Tailwind kündigte die Entlassung von 75 % seiner Belegschaft an, mit der Begründung, dass die Verbreitung von AI-Programmiertools sein Geschäftsmodell zerstört habe. Obwohl die Nutzung von Tailwind zunimmt, verringert der Bedarf der Nutzer an AI-generiertem Code die Abhängigkeit von kostenpflichtigen Komponenten. Dieses Ereignis warnt alle Softwareunternehmen, die auf dem Wert von „Arbeitskraft/Templates“ basieren: Wenn AI Implementierungslösungen mit einem Klick generieren kann, lösen sich traditionelle Barrieren für kostenpflichtiges Wissen auf. (Quelle: jon_stokes, imjaredz)
JD.com gründet „Chameleon Business Department“ zur Beschleunigung von Embodied AI: JD.com hat das ursprüngliche Chameleon-Projekt zu einer eigenen Geschäftseinheit hochgestuft, die die JoyAI App und die Embodied AI-Marke JoyInside übernimmt. Die Abteilung konzentriert sich auf die Verschmelzung von AI-Hard- und Software und steht bereits mit über 40 Robotik- und AI-Spielzeugmarken in Kontakt. Dies zeigt, wie der E-Commerce-Riese seine tiefen Vorteile in der Lieferkette nutzt, um einen geschlossenen Geschäftskreislauf von der Forschung bis zum Vertrieb im Bereich AI-Spielzeug und Industrieroboter aufzubauen. (Quelle: 36氪)
🌟 Community
Linus Torvalds wettert gegen Debatte über „AI-Müllcode“-Standards: In der Diskussion darüber, ob die Linux-Kernel-Community Standards für AI-generierten Code festlegen sollte, bezeichnete Linus dies als „dumm“. Er argumentiert, dass Dokumentationen nur diejenigen einschränken, die sich ohnehin an Regeln halten, während Leute, die „AI-Müllcode“ einreichen, diesen niemals freiwillig kennzeichnen würden. Er betrachtet AI weiterhin als Werkzeug und betont, dass die Immunität des Kernels aus Code-Review-Mechanismen und der Community-Kultur kommen müsse, nicht aus bedeutungslosen Dokumentationsvorgaben. (Quelle: 36氪)

„Karpathy-Effekt“ löst kollektive Angst unter Programmierern aus: Andrej Karpathy bemerkte, dass der Programmierberuf massiv umstrukturiert wird und die von Entwicklern beigesteuerten Bits immer spärlicher werden. Die Community fasst dies als „Karpathy-Effekt“ zusammen: Selbst erfahrene Ingenieure verspüren ein beispielloses Gefühl des Zurückbleibens. Die Diskussion legt nahe, dass sich die Kernkompetenz der Zukunft vom „Code schreiben“ hin zum „Verständnis von Systemkomplexität“ verschieben wird; Vibe Coding macht 10x-Ingenieure zu 100x-Ingenieuren, erhöht aber gleichzeitig die Hürden für Anfänger. (Quelle: dejavucoder, arohan)
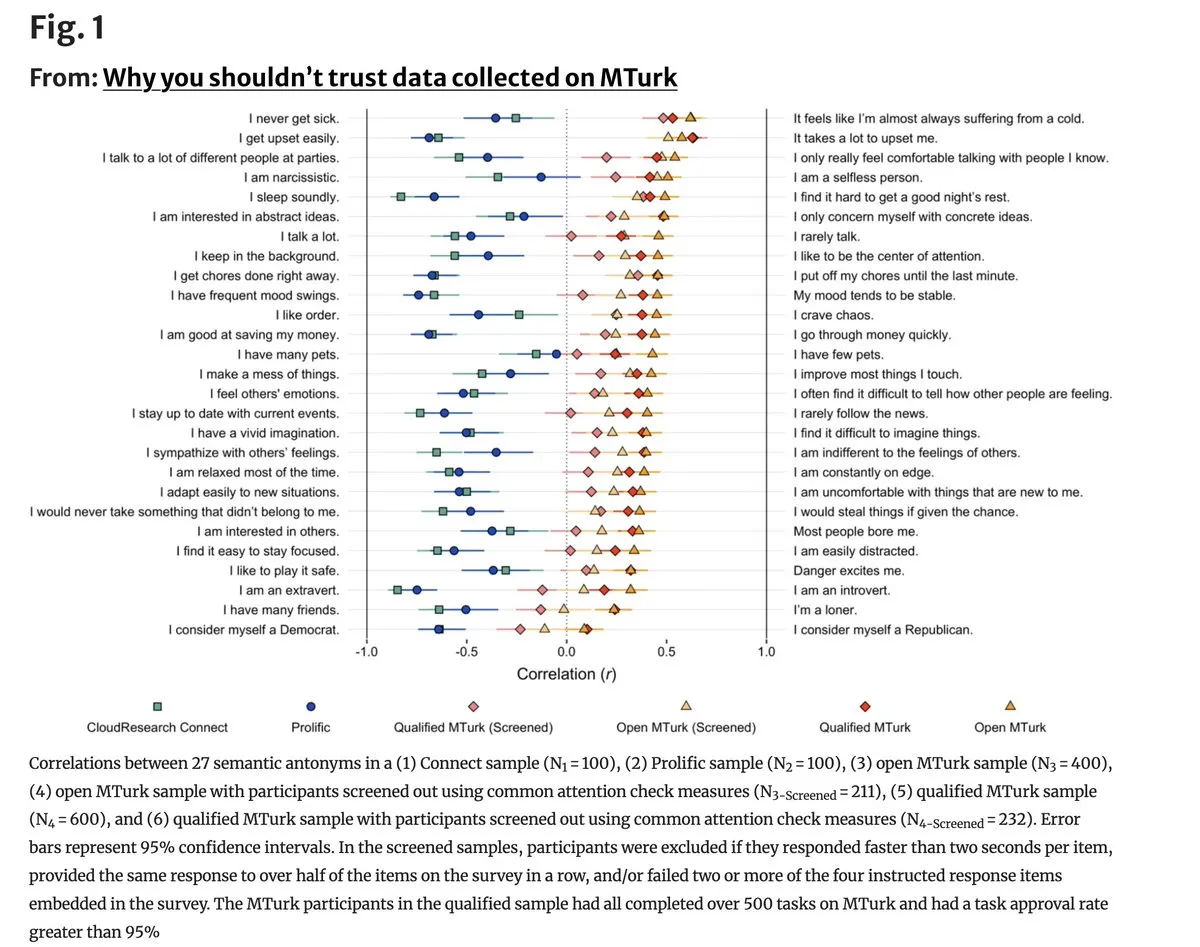
Existenzkrise der MTurk-Datenqualität durch AI-Beteiligung: Eine aktuelle Studie zeigt, dass die Datenqualität auf Crowdsourcing-Plattformen wie Amazon Mechanical Turk massiv sinkt. 96 % der widersprüchlichen Einträge in Annotationen korrelieren positiv, was beweist, dass eine große Anzahl von Arbeitern LLMs nutzt, um Aufgaben oberflächlich zu erledigen. Dies ist fatal für Verhaltenswissenschaften und Modell-Feintuning, die auf qualitativ hochwertigen menschlichen Annotationen basieren. Die Community fordert den Aufbau von Netzwerken zur Erfassung echter Daten auf Basis von Identitätsverifizierungen. (Quelle: random_walker)
💡 Sonstiges
Bedenken der Open-Source-Community über Bestimmungen des NO FAKES Act: Die Haftungsabgrenzung bezüglich „digitaler Replikationsrechte“ in diesem Gesetzentwurf wird als Falle bezeichnet. Wenn ein Entwickler ein TTS- oder Stimmenklon-Modell veröffentlicht, das von anderen zur Erstellung gefälschter Prominentenvideos genutzt wird, könnte der Entwickler mit massiven gesamtschuldnerischen Schadensersatzforderungen konfrontiert werden. Die Community befürchtet, dass dies für Entwickler von Audiomodellen auf Plattformen wie Hugging Face zu einem „rechtlichen Selbstmord“ führen und Innovationen in der Open-Source-Audiotechnologie ersticken könnte. (Quelle: Reddit r/LocalLLaMA)
ICML 2026 führt neue „Sippenhaft“-Regeln gegen akademischen Betrug ein: Um gegen „Salami-Slicing“-Einreichungen und AI-Spam vorzugehen, hat die ICML angekündigt: Wenn eine Arbeit Betrug aufweist, können alle Einreichungen unter den Namen aller Mitautoren direkt abgelehnt werden. Dieser Mechanismus der „Kollektivhaftung“ verlangt von den Leitern der Forschungsgruppen, die Qualität persönlich zu kontrollieren. Gleichzeitig erlaubt die Konferenz unter Bedingungen den Einsatz von AI bei der Begutachtung, jedoch nur mit Zustimmung der Autoren. (Quelle: 36氪)
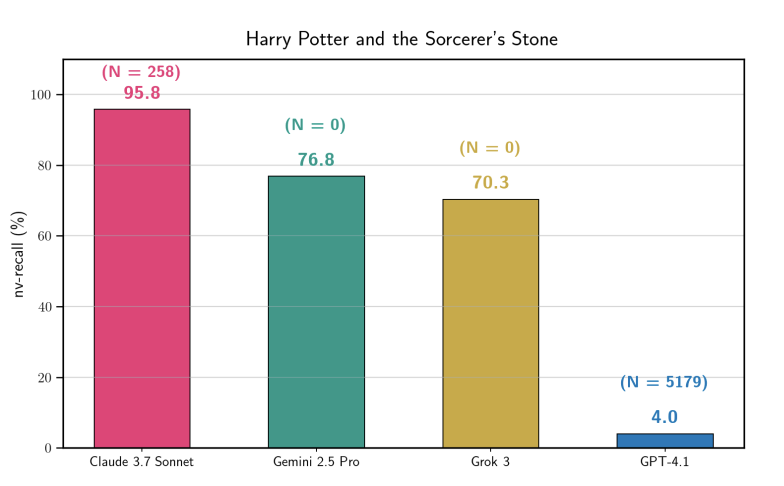
Stanford-Paper bestätigt massives Auswendiglernen von urheberrechtlich geschützten Daten durch LLMs: Untersuchungen zeigen, dass Claude 3.7 Sonnet 95,8 % der Inhalte von „Harry Potter“ wortwörtlich reproduzieren kann, gefolgt von Gemini und Grok. Dies widerlegt das Argument, dass Modelle keine Trainingsdaten speichern, und beweist, dass bestehende Sicherheitsfilter bei gezielter Induktion weiterhin anfällig sind. Diese Entdeckung wird wichtige Beweise für zukünftige AI-Urheberrechtsklagen liefern. (Quelle: stanfordnlp, andykonwinski)