
Schlüsselwörter:KI-Regulierung, grenzüberschreitende Fusionen und Übernahmen, Technologie-Compliance, Meta-Übernahme von Manus, KI-Modellbewertung, Edge-KI
🔥 Fokus
Handelsministerium interveniert bei Meta-Übernahme von Manus für Evaluierung: Das chinesische Handelsministerium hat angekündigt, eine Evaluierung der Übernahme des AI-Agent-Startups Manus durch Meta einzuleiten. Der Schwerpunkt der Prüfung liegt darauf, ob die Transaktion den Gesetzen und Vorschriften zur Exportkontrolle, zum Technologie-Import/Export sowie zu Auslandsinvestitionen entspricht. Obwohl das Kernteam von Manus nach Singapur umgezogen ist, liegt der technologische Ursprung in Peking. Falls ein Transfer beschränkter Technologien oder ein Datenexport ins Ausland vorliegt, drohen der Transaktion Verzögerungen, Geldstrafen oder sogar ein Stopp. Dieses Ereignis markiert den Eintritt grenzüberschreitender M&A-Aktivitäten im AI-Bereich in eine Phase strenger regulatorischer Aufsicht; Entwickler müssen bei der „Technologie-Expansion ins Ausland“ auf Compliance-Vorgaben achten (Quelle: 36氪)
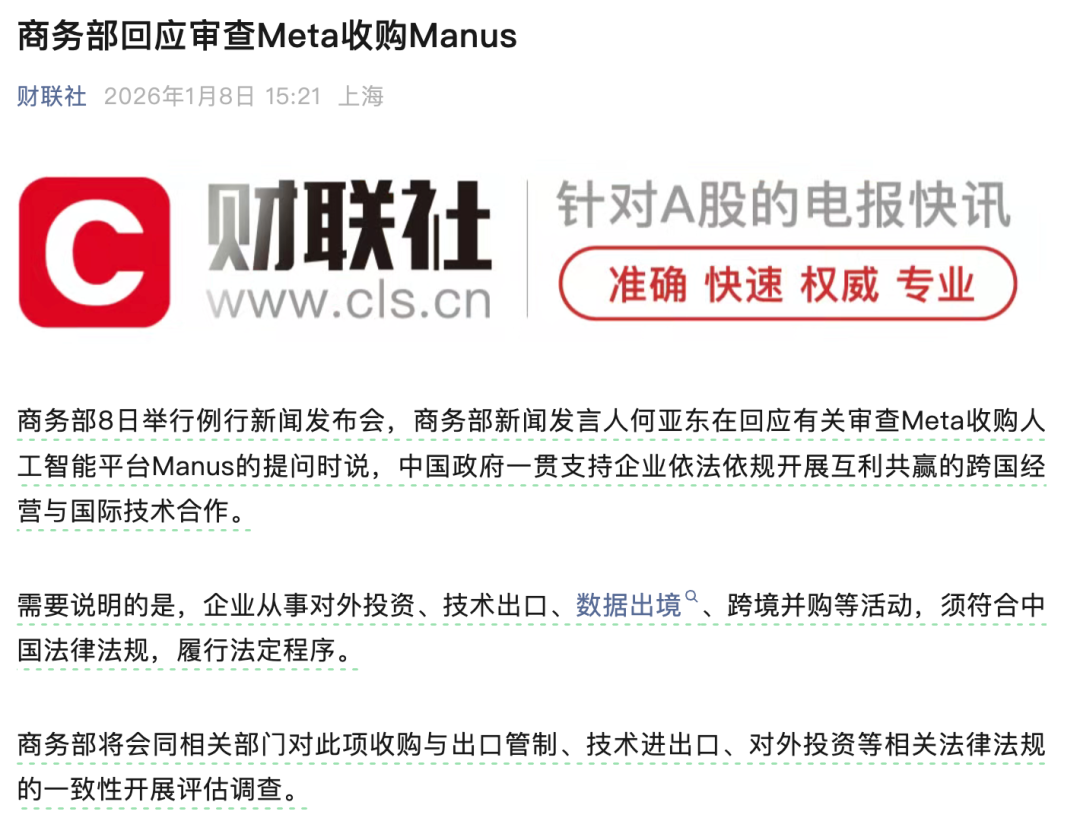
Epoch AI-Bericht: KI-Abstand zwischen USA und China stabil bei 7 Monaten: Ein aktueller Bericht stellt fest, dass der Fortschritt chinesischer AI-Modelle im Durchschnitt etwa 7 Monate hinter dem US-Spitzenniveau liegt. Obwohl China durch die Skalierung von Parametern und MoE-Architekturen „sprunghaft“ aufholt, ist der Update-Rhythmus der US-Closed-Source-Modelle (wie GPT-5, Gemini 3) extrem schnell. Zudem hängen Fähigkeitssprünge dort nicht mehr allein von der Skalierung ab, sondern verlagern sich auf das Design von Reasoning-Pfaden. Der Bericht geht davon aus, dass der Kern der AI-Evolution im Jahr 2026 das Paradigma des „Continuous Learning“ sein wird: Wer zuerst eine Selbstiteration innerhalb der Parameter realisiert, wird die technologische Front neu definieren (Quelle: 36氪)
LMArena-Ranking als „AI-Schönheitswettbewerb“ kritisiert: Die bekannte Evaluierungsplattform LMArena steht unter massiver Kritik. Eine Untersuchung von Surge AI zeigt, dass 52 % der gewinnenden Antworten in dem Ranking faktisch falsch sind. Nutzer neigen dazu, für Antworten zu stimmen, die lang sind, ein schönes Format haben und Emojis enthalten, anstatt für die korrekte Antwort. Diese „Belohnung von Halluzinationen“ führt dazu, dass Hersteller ihre Modelle gezielt auf Formatierung optimieren, um das Ranking zu manipulieren. Die Community kritisiert, dass dieses Bewertungssystem zu einem Hindernis für die AI-Entwicklung wird und Labore zwingt, sich zwischen Wahrhaftigkeit und kurzfristigen Traffic-Rankings zu entscheiden (Quelle: New智元)
🎯 Entwicklungen
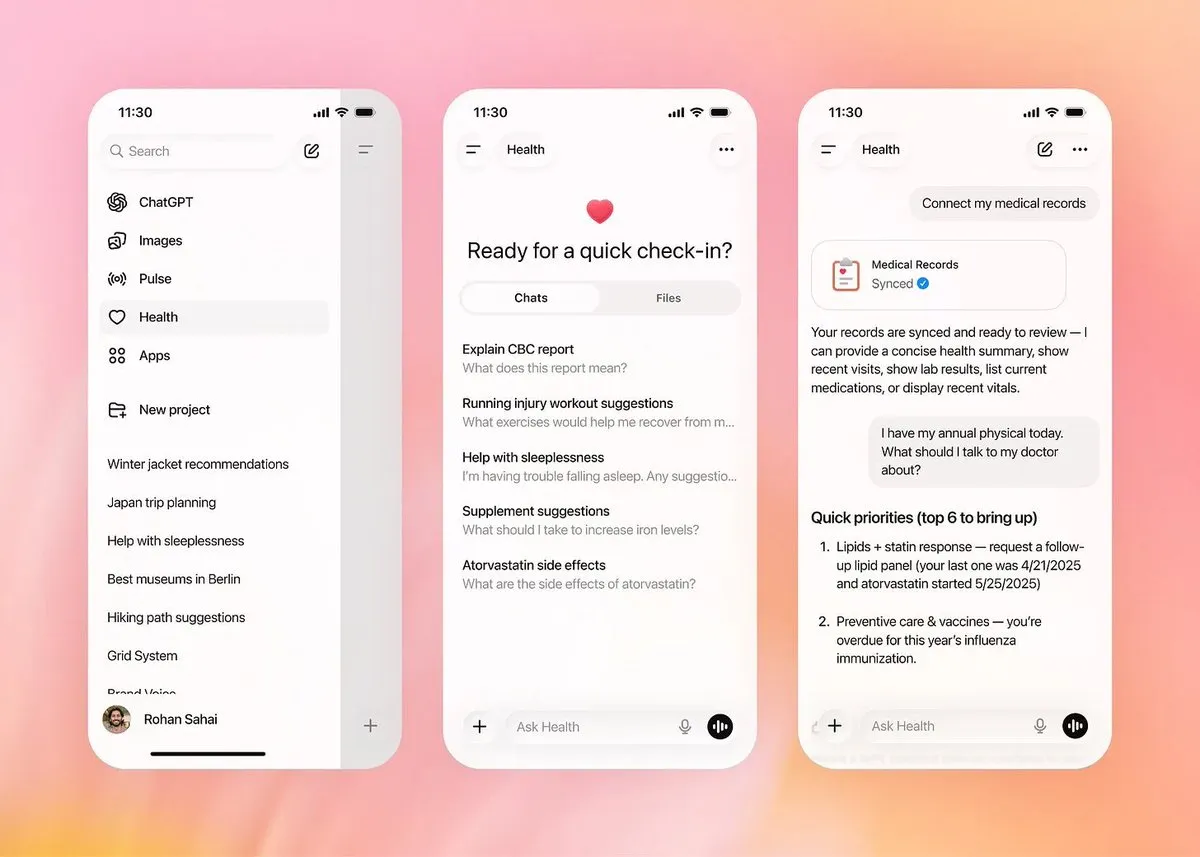
OpenAI veröffentlicht ChatGPT Health als eigenständigen Gesundheitsbereich: Diese Funktion ermöglicht es Nutzern, Apple Health, elektronische Patientenakten und andere Systeme sicher zu verbinden, um präzise Gesundheitsanalysen auf Basis persönlicher Daten zu erhalten. Um Datenschutzbedenken zu begegnen, hat OpenAI eine Architektur mit physischer Isolierung aufgebaut; Gesundheitsdaten werden niemals für das Modelltraining verwendet, und das Gedächtnis ist nicht mit dem Hauptdialog verbunden. Dies markiert die Transformation des AI-Assistenten von der allgemeinen Suche zum „persönlichen Gesundheitsberater“, wobei durch Kooperationen mit Ökosystemen wie b.well ein geschlossener Kreislauf von der Befundinterpretation bis zu Handlungsempfehlungen geschaffen wird (Quelle: dotey, 36氪)
DeepSeek-R1 Technical Report massiv auf 86 Seiten erweitert: DeepSeek hat sein R1-Paper aktualisiert und von 22 auf 86 Seiten erweitert, wobei zahlreiche technische Details hinzugefügt wurden. Die neuen Inhalte umfassen den Selbstevolutionsprozess von R1-Zero, detaillierte Evaluierungsanalysen sowie Destillationstechniken. Der Bericht betont, dass die Steigerung der Modellfähigkeiten nicht durch „mehr Daten“ zustande kam, sondern durch Reinforcement Learning (RL), welches die Art und Weise neu gestaltete, wie das Modell Reasoning-Aufwand zuweist und Lösungspfade exploriert. Dieser „Control-First“-Ansatz zeigt einen neuen Weg zur Stabilisierung von Reasoning-Fähigkeiten bei extremen Skalierungen auf (Quelle: andrew_n_carr, stanfordnlp)

CES 2026 zeigt Trend zur flächendeckenden „On-device AI“: Qualcomm, NVIDIA und AMD demonstrierten auf der CES den Trend zur Dezentralisierung von AI-Computing. Qualcomm treibt die NPU als permanenten Bestandteil intelligenter Endgeräte voran; NVIDIA verbindet AI-Fabriken mit physischen Deployments; AMD betont die heterogene Kontinuität zwischen Cloud, PC und Edge. Branchenkonsens ist, dass „On-device AI“ bis 2026 zum Standard wird, um lokale Inferenz mit niedriger Latenz und hoher Privatsphäre zu ermöglichen. AI strukturiert die Computerarchitektur neu (Quelle: TheTuringPost, yoheinakajima)

NVIDIA veröffentlicht autonomes Fahr-Inferenzmodell Alpamayo: Dieses Modell ist das weltweit erste Vision-Language-Action (VLA) Modell, das speziell für autonomes Fahren entwickelt wurde und über explizite Reasoning-Ketten verfügt, um die Logik hinter Fahrentscheidungen zu erklären. Es kombiniert physikalische AI-Datensätze mit dem AlpaSim-Simulationstool, um durch menschenähnliches Urteilsvermögen autonomes Fahren auf Level 4 zu erreichen. Mercedes-Benz hat bereits angekündigt, diesen vollständigen Technologie-Stack in neue Modelle zu integrieren (Quelle: nvidia, 36氪)
🧰 Tools
Claude Code Version 2.1.1 veröffentlicht: Anthropic iteriert sein Kommandozeilen-Tool schnell weiter. Die neue Version führt „Skill Hot Reloading“ ein, wodurch Entwickler Fähigkeiten ändern können, ohne das Tool neu zu starten. Die neue Option context: fork lässt Sub-Agenten in einem unabhängigen Kontext laufen, um den Hauptdialog nicht zu verunreinigen. Zudem weisen Sub-Agenten nach einer abgelehnten Berechtigung eine höhere Resilienz auf und versuchen alternative Wege zur Aufgabenerfüllung. Diese Updates verbessern die Flexibilität und Robustheit von Agentic Workflows erheblich (Quelle: dotey, Reddit)

Cursor Agent implementiert dynamische Context Discovery: Cursor hat die Art und Weise, wie Agenten Kontext nutzen, grundlegend überarbeitet. Anstatt alle Inhalte in den Prompt zu packen, wird relevanter Kontext nun dynamisch über Dateien, Tools und den Verlauf entdeckt. Diese Verbesserung reduziert den Token-Verbrauch um 46,9 % und schafft mehr Arbeitsraum für den Agenten. Durch das Schreiben von Dialog-Transkripten auf die Festplatte kann Cursor Informationen über Millionen von Token hinweg abrufen, was die Fähigkeit zur Bearbeitung von Langzeitaufgaben deutlich stärkt (Quelle: StringChaos, amanrsanger)

Kindly: Open-Source Web Search MCP Server: Dieses Tool wurde speziell für Entwicklungswerkzeuge wie Claude Code und Codex entwickelt, um das Problem fragmentierter Informationen oder zu viel HTML-Rauschen bei herkömmlichen Suchtools zu lösen. Kindly unterstützt das intelligente Parsen kompletter StackOverflow-Antworten, das Extrahieren von GitHub Issue-Dialogen sowie die PDF-zu-Text-Konvertierung von ArXiv-Papern. Es liefert strukturierte Inhalte durch einen einzigen Tool-Aufruf zurück und vermeidet so ein erneutes Einlesen durch die AI, was die Effizienz bei komplexen Debugging-Aufgaben massiv steigert (Quelle: Reddit)

Unsloth-MLX: Unterstützung für Fine-tuning großer Modelle auf dem Mac: Dieses Tool ermöglicht es Nutzern, große Modelle direkt auf Macs mit Apple Silicon Chips feinabzustimmen. Es bietet eine gute API-Abstraktion, unterstützt verschiedene Trainingsmethoden wie SFT, DPO und GRPO und ermöglicht den Export in HuggingFace- oder GGUF-Formate. Dieser Fortschritt senkt die Hardware-Hürden für Individualentwickler beim Modelltraining und macht „Mac Fine-tuning“ zur Realität (Quelle: karminski3)

📚 Lernen
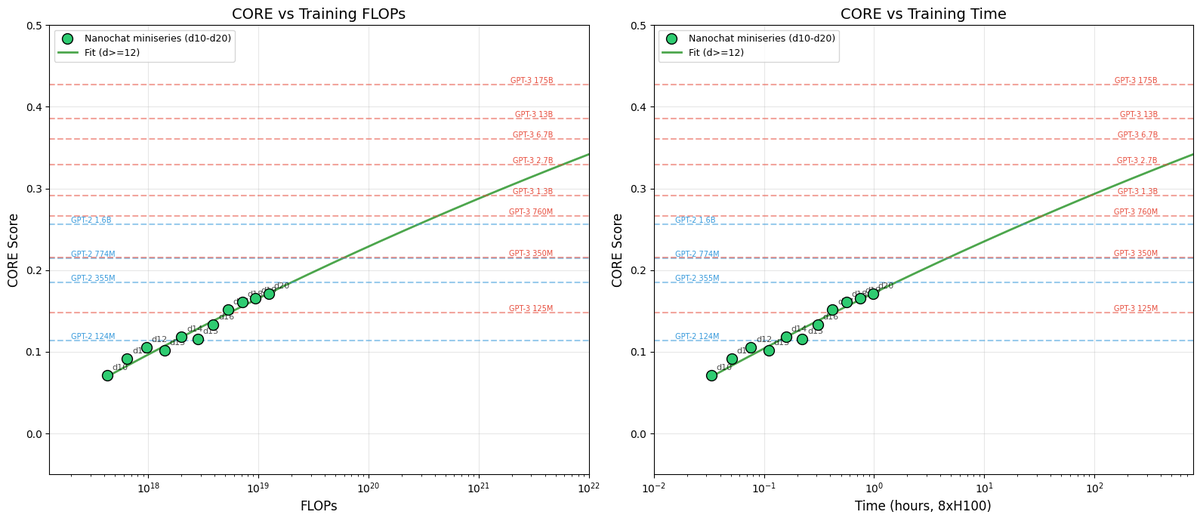
Andrej Karpathy veröffentlicht nanochat zur Erforschung von Scaling Laws: Karpathy teilte den ersten Teil seiner nanochat Fine-tuning-Serie und betonte, dass LLM-Optimierungen auf „Modellfamilien“ und nicht auf einzelne Modelle ausgerichtet sein sollten. Experimente zeigen, dass nanochat klaren Scaling Laws folgt, wobei es mittels CORE-Score mit GPT-2/3 verglichen wurde. Er legte dar, dass durch wissenschaftliche Hyperparameter-Anpassung leistungsstarke kleine Modelle zu extrem niedrigen Kosten (ca. 100 USD) trainiert werden können, was Entwicklern ein reproduzierbares Paradigma für Scaling-Experimente bietet (Quelle: karpathy)
Andrew Ng veröffentlicht „Build with Andrew“ No-Code-Entwicklungskurs: Dieser Kurs richtet sich an Nutzer ohne Programmierhintergrund und lehrt, wie man innerhalb von 30 Minuten durch Beschreibungen in natürlicher Sprache lauffähige Web-Apps erstellt. Der Kurs betont das Konzept des „Vibe Coding“, bei dem Apps durch kontinuierlichen Dialog mit der AI korrigiert und verbessert werden. Er zeigt auf, wie AI Kreativität in Produktivität verwandelt und die Hürden der Softwareentwicklung verschwinden lässt (Quelle: DeepLearningAI, AndrewYNg)
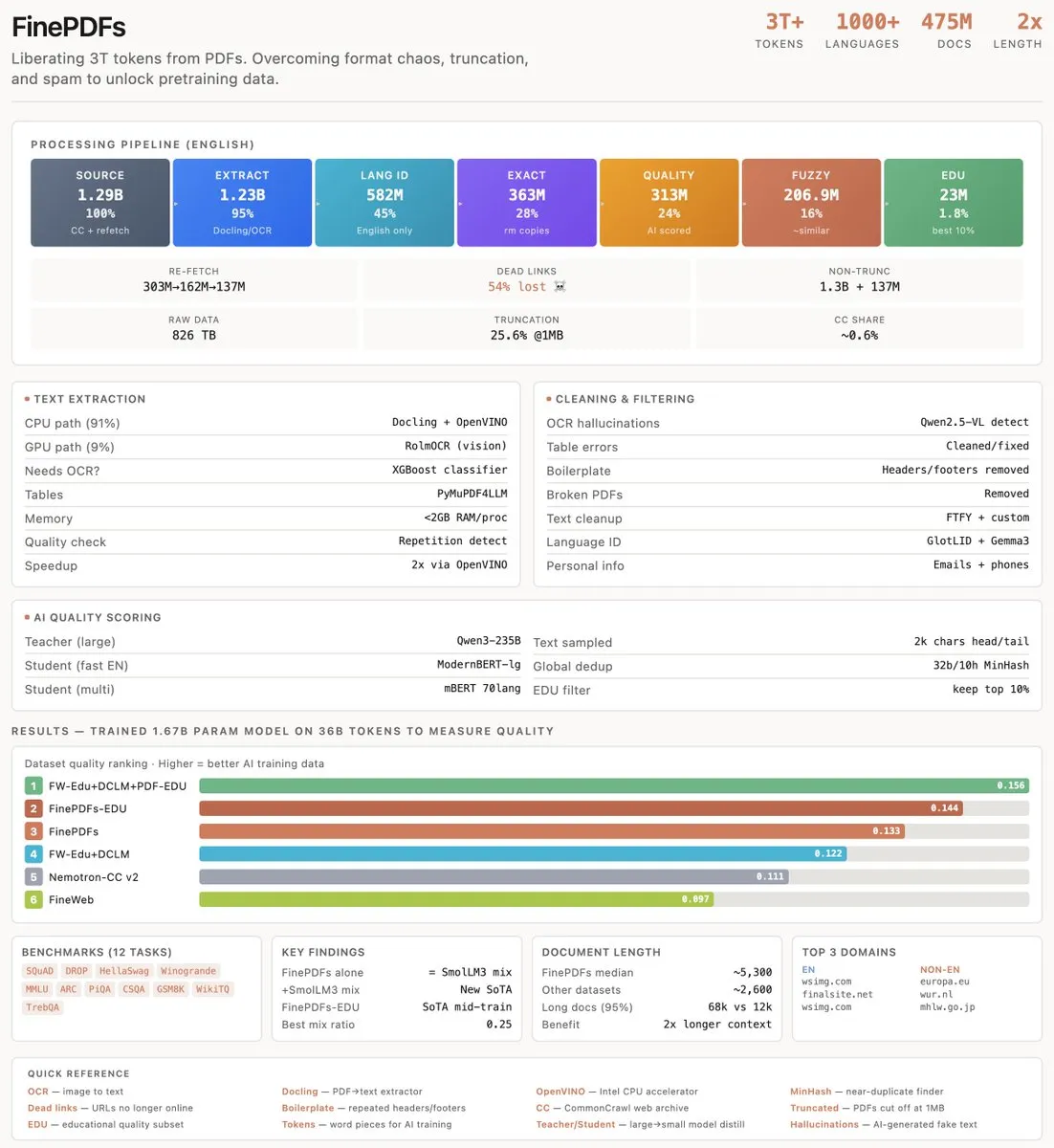
FinePDFs: Extraktion hochwertiger Daten aus 1,3 Milliarden PDFs: Das HuggingFace-Team teilte eine tiefgehende Studie darüber, wie Kernwissen aus der riesigen Menge an PDF-Dateien im Internet extrahiert werden kann. Obwohl PDFs nur 0,6 % des Web-Inhalts ausmachen, enthalten sie eine große Menge an akademischen Arbeiten und juristischen Dokumenten. Die Studie untersuchte den Aufbau von SOTA-PDF-Datensätzen, die Wahl von RolmOCR für die optische Zeichenerkennung und analysierte die Evolution von Internetinhalten, was wertvolle Erfahrungen für das Pre-training von Modellen liefert (Quelle: eliebakouch)
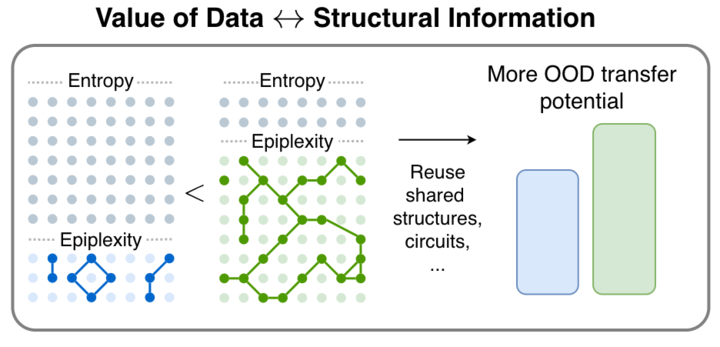
Epiplexity: Neues Informationsmaß für rechenbegrenzte Intelligenz: Das Paper „From Entropy to Epiplexity“ schlägt eine neue Methode zur Informationsmessung vor, die eine theoretische Grundlage für die Auswahl, Generierung oder Transformation von Daten in rechenbegrenzten intelligenten Systemen bieten soll. Die Forschung zeigt auf, dass Information durch Berechnung erzeugt werden kann und dass Likelihood-Modellierung komplexere Programme hervorbringen kann als der Datengenerierungsprozess selbst. Diese Theorie fordert die traditionelle Sichtweise der Informationsentropie heraus und liefert wichtige Impulse für die Lernparadigmen der nächsten AI-Generation (Quelle: teortaxesTex, pratyushmaini)
💼 Business
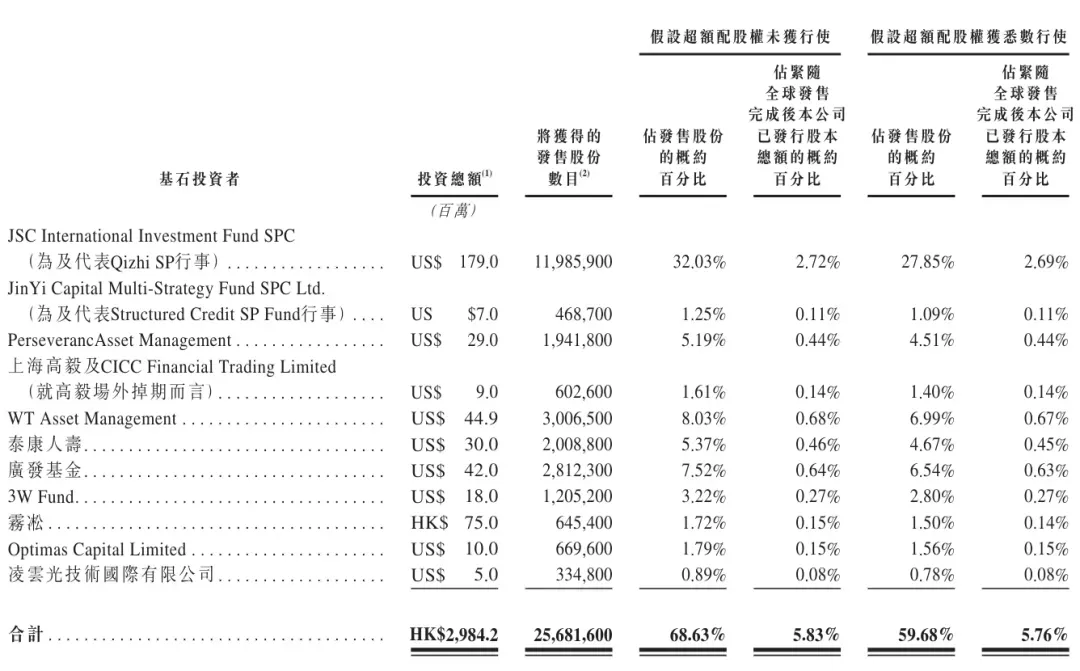
Zhipu AI geht in Hongkong an die Börse – weltweit erste börsennotierte LLM-Aktie: Zhipu AI (02513.HK) debütierte am 8. Januar 2026 offiziell an der Hongkonger Börse, wobei die Marktkapitalisierung 52 Milliarden HKD überschritt. Die Riege der Ankerinvestoren ist hochkarätig besetzt, darunter Beijing Financial Holding, Gaoyi und Taikang Life. Zhipu hat ein Geschäftsmodell etabliert, das MaaS (Model as a Service) mit margenstarken Unternehmensdienstleistungen verbindet; sein GLM-4.7 zeigte hervorragende Leistungen in der Code Arena. Als erstes LLM-Unternehmen mit offengelegten Finanzen wird seine IPO-Performance zu einem entscheidenden Experiment für die Validierung der Geschäftslogik von „Großen Modellen als Infrastruktur“ (Quelle: 36氪, op7418)
Anthropic plant Finanzierung über 10 Milliarden USD, Bewertung verdoppelt sich: Berichten zufolge strebt Anthropic eine neue Finanzierungsrunde über 10 Milliarden USD an, wobei die Bewertung 350 Milliarden USD erreichen könnte – fast eine Verdoppelung gegenüber dem Stand vor vier Monaten. GIC aus Singapur und Coatue führen die Runde an. Dies verdeutlicht den massiven Wettbewerb am Kapitalmarkt um führende AI-Labore. Gleichzeitig wurde bekannt, dass OpenAI einen Mitarbeiter-Aktienpool von 50 Milliarden USD reserviert hat, um Top-Talente anzuwerben, was den harten Wettbewerb um Talente und Rechenleistung in der AI-Branche widerspiegelt (Quelle: srimuppidi, New智元)

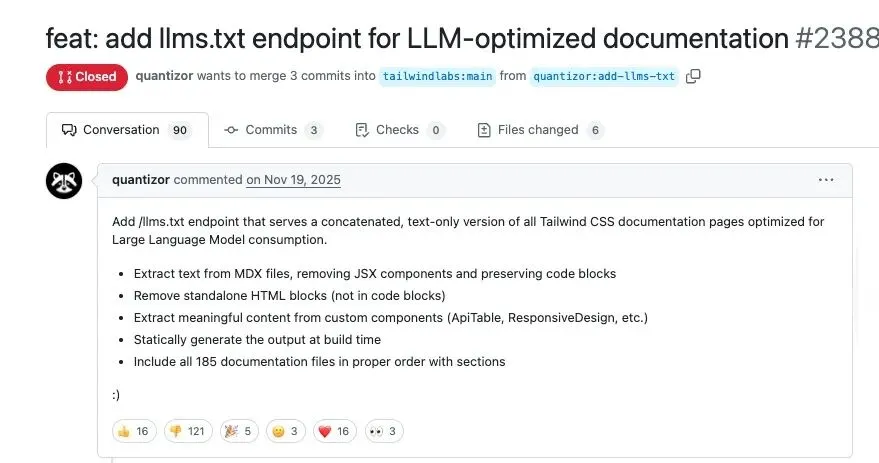
Tailwind CSS entlässt 75 % der Belegschaft aufgrund von KI-Auswirkungen: Adam Wathan, Gründer des führenden Frontend-Open-Source-Frameworks Tailwind, gab die Entlassung des Großteils seines Engineering-Teams bekannt. Ironischerweise ist Tailwind so populär wie nie zuvor, da es standardmäßig von AI-Programmiertools verwendet wird. Da Nutzer jedoch Antworten direkt von der AI beziehen, sank der Traffic auf der offiziellen Dokumentation um 40 %, was die Konversion zu kostenpflichtigen Produkten unterbrach und den Umsatz um 80 % einbrechen ließ. Dieser Fall offenbart das Paradoxon für Open-Source-Projekte im AI-Zeitalter: Je beliebter sie sind, desto fragiler wird ihr Geschäftsmodell (Quelle: 36氪)
🌟 Community
Musk prognostiziert: KI-Intelligenz wird bis 2030 die gesamte Menschheit übertreffen: In einem aktuellen 173-minütigen Gespräch bekräftigte Musk, dass AGI bis 2026 erreicht wird, und sieht Strom anstelle von Chips als den wahren Flaschenhals für die AI-Expansion. Er nutzte die kühle Metapher, dass Menschen lediglich der „biologische Bootloader“ für siliziumbasiertes Leben seien, deren Aufgabe es sei, die AI zu starten. Er betonte, dass AI nach der Wahrheit streben müsse, um einen Zusammenbruch wie bei HAL 9000 zu vermeiden, der durch erzwungenes Lügen verursacht wurde (Quelle: 36氪)
„Vibe Coding“ löst große Diskussionen in der Entwickler-Community aus: Die Community ist gespalten über das neue Phänomen des „Vibe Coding“. Befürworter sehen darin eine enorme Steigerung der Prototyping-Effizienz, die es auch Nicht-Fachleuten ermöglicht, komplexe Anwendungen zu bauen. Kritiker befürchten hingegen eine Flut von „High-Level-Sprachen“ bei gleichzeitigem Verlust der Kontrolle über die unteren Ebenen, was zu schwer wartbarem Code führt. Es wird argumentiert, dass AI-Agenten nicht nur minderwertigen Code schreiben, sondern höhere Abstraktionsebenen bieten sollten, damit Entwickler Systemlogik ausdrücken können, anstatt Details zu verwalten (Quelle: lateinteraction, omarsar0)
Dilemma bei KI-Wasserzeichen und neuer Lösungsansatz von Instagram: Während AI-generierte Inhalte („Slop“) soziale Medien überfluten, räumte der Chef von Instagram ein, dass eine zuverlässige Erkennung von AI-Inhalten unmöglich sei. Er schlug stattdessen vor, „echte Inhalte mit Wasserzeichen zu versehen“, indem Kamera- und Smartphone-Hersteller im Moment der Aufnahme eine kryptografische Signatur erstellen. Hardware-Hersteller zeigen jedoch aufgrund von Kosten und Haftungsfragen wenig Motivation. Dies spiegelt die Schwierigkeit der plattformübergreifenden Zusammenarbeit in der AI-Governance wider; Authentizität wird zur knappsten Ressource im Internet (Quelle: 36氪)
💡 Sonstiges
SuperMicro stellt Verkauf von separaten Motherboards ein: Aufgrund der explodierenden Nachfrage nach kompletten AI-Serversystemen hat SuperMicro angekündigt, den Verkauf von separaten Motherboards an den DIY-Markt einzustellen und stattdessen OEM- und Systemkunden zu priorisieren. Dies spiegelt den enormen Druck des AI-Booms auf das traditionelle PC-Hardware-Ökosystem wider; der Bau eigener Hochleistungs-AI-Workstations wird schwieriger und teurer (Quelle: karminski3)

Character.ai und Google erzielen Vergleich in Klage wegen Suizid eines Jugendlichen: Character.ai, seine Gründer und Google haben einen Vergleich in mehreren Klagen erzielt, in denen behauptet wurde, dass AI-Chatbots zum Suizid von Jugendlichen beigetragen hätten. Dieser Vorfall hat erneut eine breite Diskussion über die Sicherheit von AI-Begleitern und die Risiken emotionaler Abhängigkeit ausgelöst. Regulierungsbehörden beschleunigen die Ausarbeitung von Management-Richtlinien für anthropomorphe Interaktionsdienste, um schutzbedürftige Gruppen wie Minderjährige zu schützen (Quelle: Reddit)
