
キーワード:大規模言語モデル, AI, 香港株式市場上場, MiniMax C向けビジネスモデル, DeepSeek V4のコーディング能力, ChatGPT Health
🔥 フォーカス
MiniMaxと智譜の香港市場上場対決:C向けモデルが初戦で勝利 : 2026年年初、大規模モデル「六小虎(Six Tigers)」の一角である智譜(Zhipu AI)とMiniMaxが相次いで香港証券取引所に上場した。MiniMaxの上場初日の株価は109%急騰し、時価総額は137億ドルを突破、智譜を上回るパフォーマンスを見せた。分析によると、市場はMiniMaxのC向けアプリケーションモデル(星野、海螺など)に対して高い期待を寄せており、その海外収益化能力が従来のB向けプライベートデプロイメントよりも強力であると判断している。これは大規模モデルの競争が資本回収期に入ったことを象徴しており、商湯(SenseTime)のようなB向け路線を歩むか、グローバルなC向けのトレンドを掴むかというビジネスモデルの差異が、時価総額を決定する核心的なロジックとなっている(ソース:36氪, bookwormengr)

DeepSeek V4がまもなくリリース:コード生成能力でGPTやClaudeに挑戦 : DeepSeekが2月に次世代フラッグシップモデルV4をリリースする予定であることがわかった。内部テストによると、V4は超長尺のコードPrompt処理とデータパターン解析において技術的ブレイクスルーを達成し、論理的厳密さが大幅に向上。コード生成能力はGPT-5.2やClaude Opus 4.5を超える可能性がある。DeepSeekが最近発表したMHC(Manifold-constrained Hyper-connectivity)論文がV4の技術基盤とされており、モデルのスケーリング時の不安定性を解決することで、より効率的な性能向上を実現した。この動向は、国産モデルが垂直的なコード領域において世界のトップレベルと正面から対峙することを予感させている(ソース:scaling01, LocalLLaMA)

Sakana AIがDigital Red Queenを発表:自己進化型コード技術の突破口 : Sakana AIはMITと共同で、LLMを利用してアセンブリコードを自己進化させる新しい手法を提案した。この技術は、「Core War(コア戦争)」というチューリング完全な敵対環境下で反復的な戦闘を行うことで、コードが競争を通じて自然選択と自己最適化を実現するように促すものである。この動的な目的関数から生み出されるエージェントは、静的な最適化よりも堅牢で汎用性が高い。このブレイクスルーは、自動プログラミングや自己適応システム分野におけるAIの巨大な可能性を示しており、「静的学習」から「進化学習」へのパラダイムシフトを象徴している(ソース:hardmaru, SakanaAILabs)

ChatGPT Healthが正式ローンチ:AI医療が個人健康管理の時代へ : OpenAIは、検査結果や健康アプリのデータの同期をサポートするChatGPT Health機能を発表した。特別に構築された健康モデルに基づき、健康診断レポートの深い分析とアドバイスの提供が可能となる。中国国内ではすでに類似製品(Ant Groupの阿福など)が存在するが、ChatGPTの参入は、グローバルなAI巨頭が健康管理を核心的なアプリケーションシナリオとして正式に位置づけたことを意味する。これは単なる技術競争ではなく、データプライバシー、医療機器との連携、そしてパーソナライズされた健康指導を巡る総合的な戦いである(ソース:op7418, artificial)

🎯 動向
AnthropicがサードパーティAppでのClaudeサブスクリプション利用を制限し論争に : Anthropicは最近、Claude ProのサブスクリプションユーザーがOpenCodeやClawdbotなどのサードパーティツールでAPI認証情報を使用することを制限し始めた。この動きは、自社のエコシステム(Claude Codeなど)の保護およびコスト抑制の手段と見なされている。コミュニティからは強い反発があり、ユーザーの選択権を損なうものだとして、一部の開発者がよりオープンなMiniMaxや智譜のGLMモデルへと移行する動きが出ている。これは、AIメーカーが「オープンなエコシステム」と「閉鎖的なビジネスループ」の間で揺れ動くバランスの難しさを反映している(ソース:matanSF, MiniMax_AI)

CES 2026におけるチップ巨頭の布陣:AIコンピューティングの分散化トレンドが鮮明に : Qualcomm、NVIDIA、AMDはCESにおいて、それぞれ異なるAIインフラのビジョンを提示した。Qualcommはエッジ側での常時稼働ローカル推論を強調し、AMDはクラウド、PC、エッジにわたるヘテロジニアスな連続性を追求、NVIDIAはAIを産業システムと捉え、集中型演算能力と物理ロボットのシミュレーションに注力している。これは、AIコンピューティングが単一の最強チップを競うのではなく、実行シナリオに応じて再編されていることを示しており、ハイブリッドAI(クラウドでの重い推論+ローカルでの低遅延タスク)が業界のコンセンサスとなっている(ソース:TheTuringPost)

MITの研究がトップモデルの認知収束を明らかに:真理への道筋が明確に : MITの研究によると、モデルのアーキテクチャや学習データが異なっていても、性能が向上するにつれて、高性能なモデルは物質(分子構造など)に対する内部的な理解が一致する傾向にあることがわかった。これは、AIが協力して物質世界の客観的な基底ロジックを掘り起こしていることを意味する。開発者にとっては、将来的に「モデル蒸留」を通じて小規模モデルに大規模モデルの「成果」を模倣させることが可能になり、際限のない演算能力競争に陥ることなく、高性能な科学的発見能力を実現できることを示唆している(ソース:36氪)

アリババクラウドがAIハードウェア普及元年を開始:エッジ側AIエージェントが大規模実装へ : アリババクラウド(Alibaba Cloud)は通義(Tongyi)インテリジェントハードウェア展示会において、スマートグラス、AI Pin、ロボットなど、CESで初公開されたものと同等のハードウェア200点以上を展示した。通義大規模モデルのフルサイズカバー(0.5B-480B)を通じて、アリババクラウドはハードウェアメーカーに低消費電力・高知能な「クラウド・エッジ協調」ソリューションを提供している。これは、中国のハードウェア産業が「ネット接続デバイス」から「独立思考型エージェント」へと集団的に転換したことを象徴しており、AIはもはや付随的な機能ではなく、デバイスの核心的な体験を駆動するエンジンとなっている(ソース:36氪)

🧰 ツール
Ralph for Claude Code:自律型AI開発ループツール : RalphはClaude Codeをベースとした自律型開発ループツールであり、インテリジェントな終了検知とレート制限機能を備えている。Claude Codeがプロジェクトを完了するまで反復的に改善することを可能にし、無限ループやAPIの乱用を防ぐ保護メカニズムを内蔵している。JSON出力、セッションの継続性をサポートし、tmuxを介したリアルタイム監視も可能。開発プロセスを標準化し、AIが真に「クローズドループ」でソフトウェアエンジニアリングのタスクを完了できるようにする(ソース:frankbria)
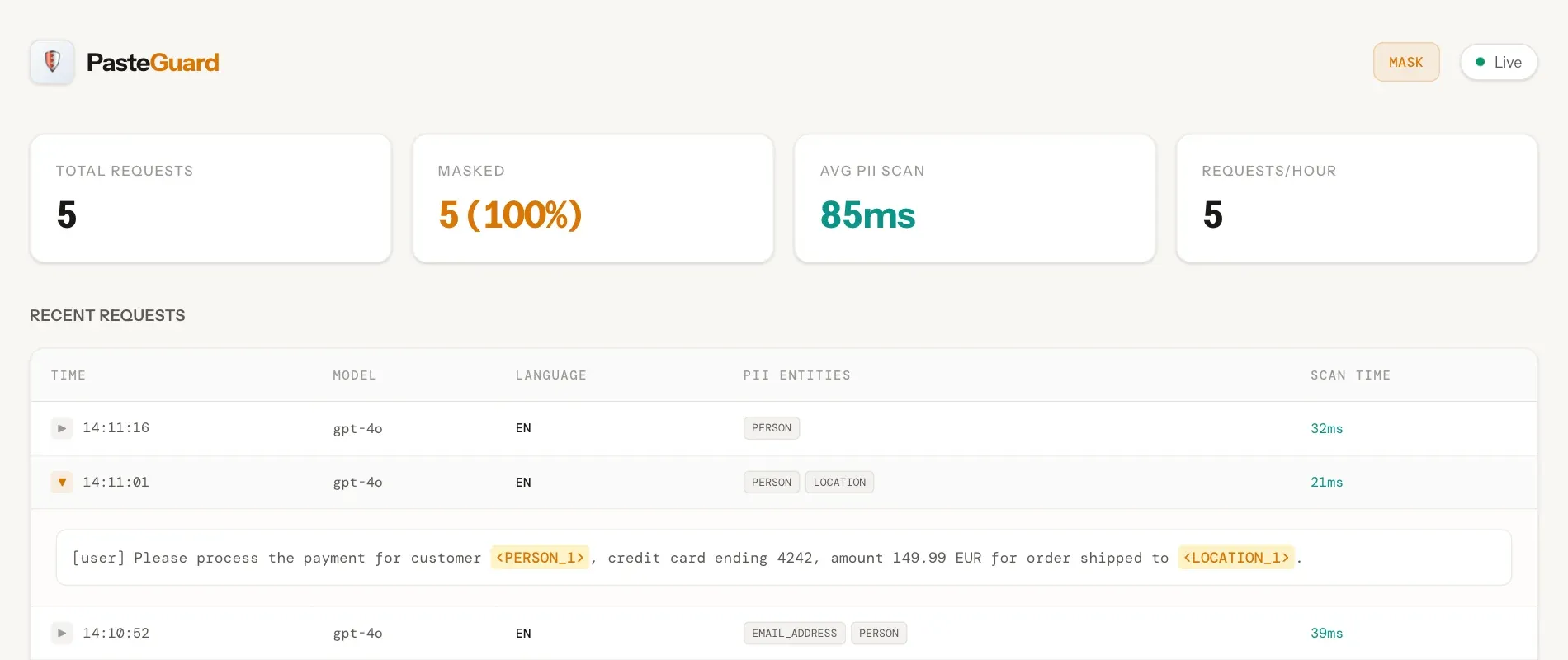
PasteGuard:プライバシープロキシツール、クラウドLLMデータからPIIを遮断 : Open WebUI専用に設計されたプライバシープロキシであり、データをクラウドLLMに送信する前に、氏名、メールアドレス、電話番号などの個人識別情報(PII)を自動的にマスキングする。「マスクモード」と、機密情報をローカルのOllamaで処理する「ルーティングモード」をサポートしている。24言語に対応し、Microsoft Presidio技術を採用することで、企業がクラウドAIを利用する際のコンプライアンスとプライバシーの懸念を効果的に解決する(ソース:OpenWebUI)
Empirica:AIエージェントに「自己反省」能力を与える認知フレームワーク : Empiricaは、エージェントの盲目的な自信や繰り返されるミスなどの問題を解決するために設計されたオープンソースのAIエージェント認知フレームワークである。エージェントの知識のギャップを追跡し、セッションをまたいで学習を永続化させ、自信の閾値を設定することで行動を制御する。その核心となるCASCADEワークフローは、事前チェック、ゲーティング、学習測定を実現し、AIが人間のようにメタ認知(Meta-cognition)を行い、実行前に「自分は何を知っているか」を評価できるようにする(ソース:artificial)
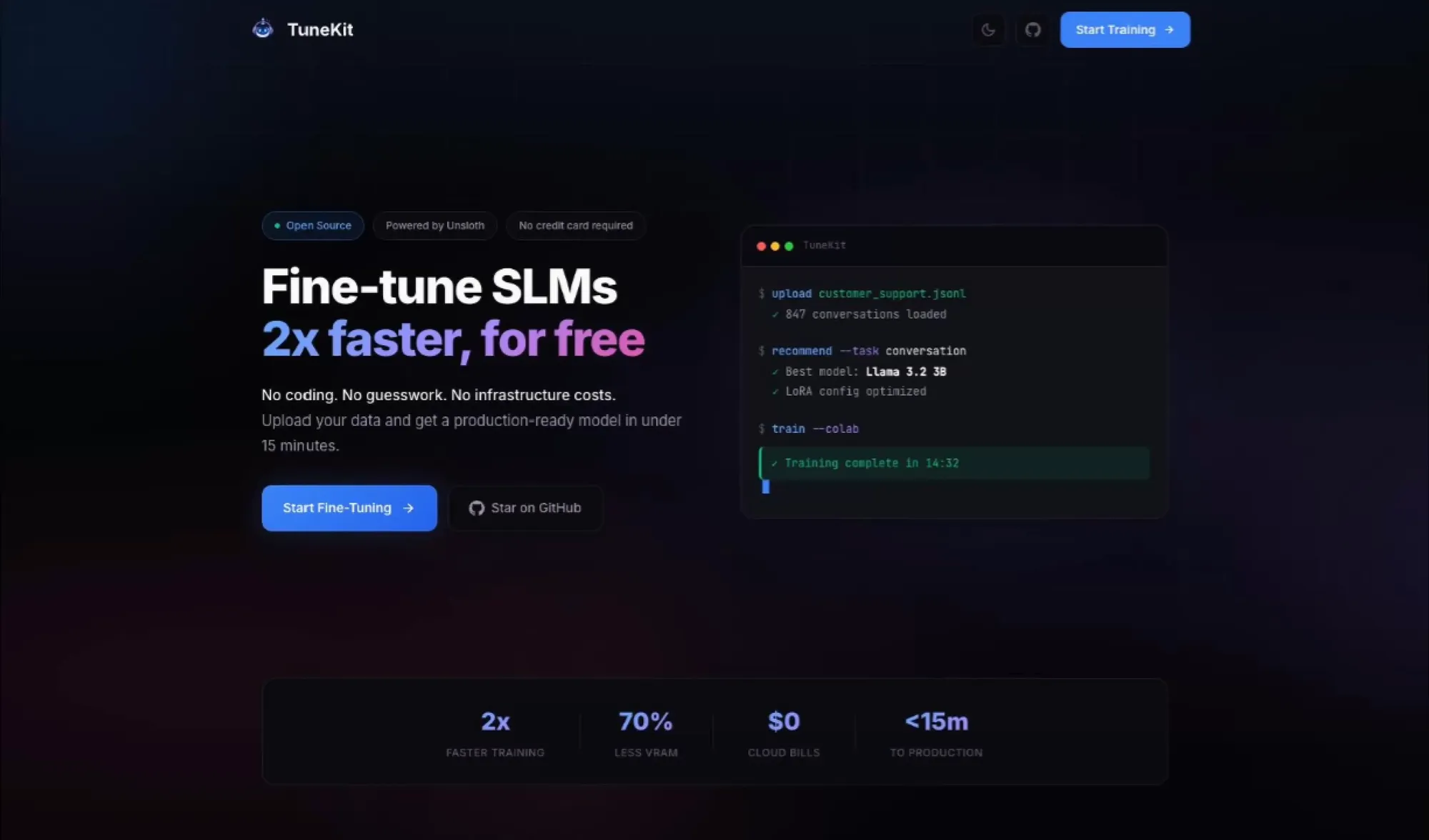
TuneKit:SLMファインチューニング加速ツール : TuneKitは、小規模言語モデル(SLM)のファインチューニングプロセスを簡素化することを目的としている。Colab上での無料トレーニングをサポートし、Unsloth AIを利用することで2倍の高速化を実現。ユーザーはデータをアップロードするだけでトレーニング用のノートブックを取得でき、複雑なスクリプト作成や高価なGPUのレンタルは不要。開発者に低コストで効率的なSLM最適化パスを提供し、特に特定のシナリオ向けの軽量モデル開発に適している(ソース:deeplearning)
📚 学習
2026年版モダンAI検索とRAGシステムロードマップ : 単純な「ベクトルデータベース+Prompt」から複雑なプロダクションシステムへと進化するための重要なステップを詳細にまとめたロードマップ。セマンティック+ハイブリッド検索、明示的なリランキング層、Agentic RAG(多段階クエリ分解)、およびハルシネーション制御が含まれる。単一のフレームワークではなくシステム設計を重視しており、2026年に低遅延・低コストで権限管理を備えたAI検索システムを構築するための実戦ガイドとなっている(ソース:artificial)

DeepLearning.AIが「Build with Andrew」ゼロからのAI開発コースを公開 : Andrew Ng(呉恩達)氏が発表した新コースは、非技術者が30分以内にAIを利用してWebアプリを構築する方法を学ぶことを目的としている。このコースでは「Vibe Coding」、すなわち自然言語でアイデアを説明し、AIにコードを生成・反復させる手法を強調している。これはソフトウェア開発のハードルが完全に消失したことを象徴しており、誰もが開発者となり、AIを利用してアイデアを実行可能なツールへと変換できる時代が来たことを示している(ソース:DeepLearning.AI)
最先端論文ピックアップ:GDPO、MHC、Delethink : 今週は大規模モデルの学習効率と安定性に注目した論文が多数発表された。GDPOはマルチ報酬設定下におけるGRPOの信号崩壊問題を解決。MHCは多様体制約を通じて大規模モデルのスケーリングの安定性を向上させた。Delethinkは、推論Tokenを周期的に切り捨てる手法を提案し、アーキテクチャを変更することなく長鎖推論の計算コストを大幅に削減した(ソース:HuggingFace, MachineLearning)
💼 ビジネス
a16zが17.76億ドルのAmerican Dynamism Fund IIを設立 : Andreessen Horowitz(a16z)は、総額17.76億ドルの第2期「American Dynamism(アメリカのダイナミズム)」基金の設立を発表した。この基金は、航空宇宙、国防、公共安全、基幹インフラなど、米国の国家利益に合致する技術への投資を目的としている。これは、トップクラスのベンチャーキャピタルがAIとハードテックの結合点を、国家戦略や産業再編へとシフトさせていることを反映している(ソース:espricewright)

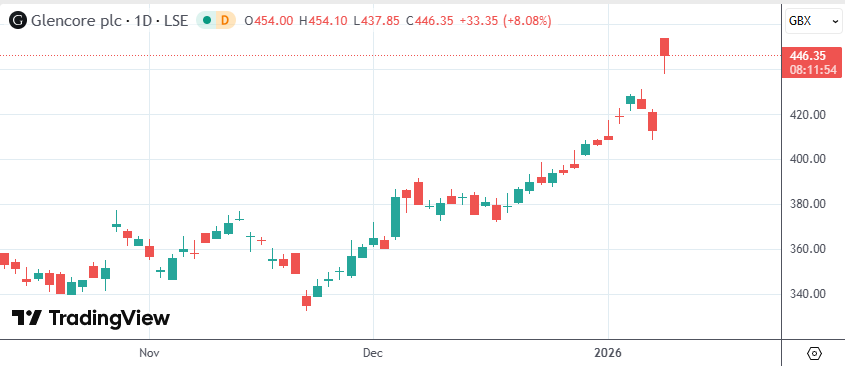
Rio TintoとGlencoreが合併交渉、世界最大の鉱業巨頭誕生を目指す : 世界的な鉱業大手のRio Tinto(力拓)とGlencore(嘉能可)が、潜在的な合併に向けて初期段階の協議を行っている。合意に至れば、時価総額2000億ドルを超える企業が誕生する。合併の核心的な原動力は、AI演算センターの爆発的増加とエネルギー転換に伴う銅需要の急増に対応するため、より多くの銅資源を確保することにある(ソース:36氪)
Google AI StudioがTailwind CSSプロジェクトをスポンサー : Google AI Studioは、Tailwind CSSプロジェクトの公式スポンサーになったことを発表した。この動きは、AI開発ツールと人気のあるフロントエンドフレームワークのエコシステム統合を強化し、開発者がAIを利用して現代的なUI標準に準拠したインターフェースコードをより効率的に生成できるようにすることを目的としている。これは、基盤モデルメーカーが主要なオープンソースプロジェクトへのスポンサーシップを通じて、開発者のワークフローに浸透しようとしていることを示している(ソース:crystalsssup)
🌟 コミュニティ
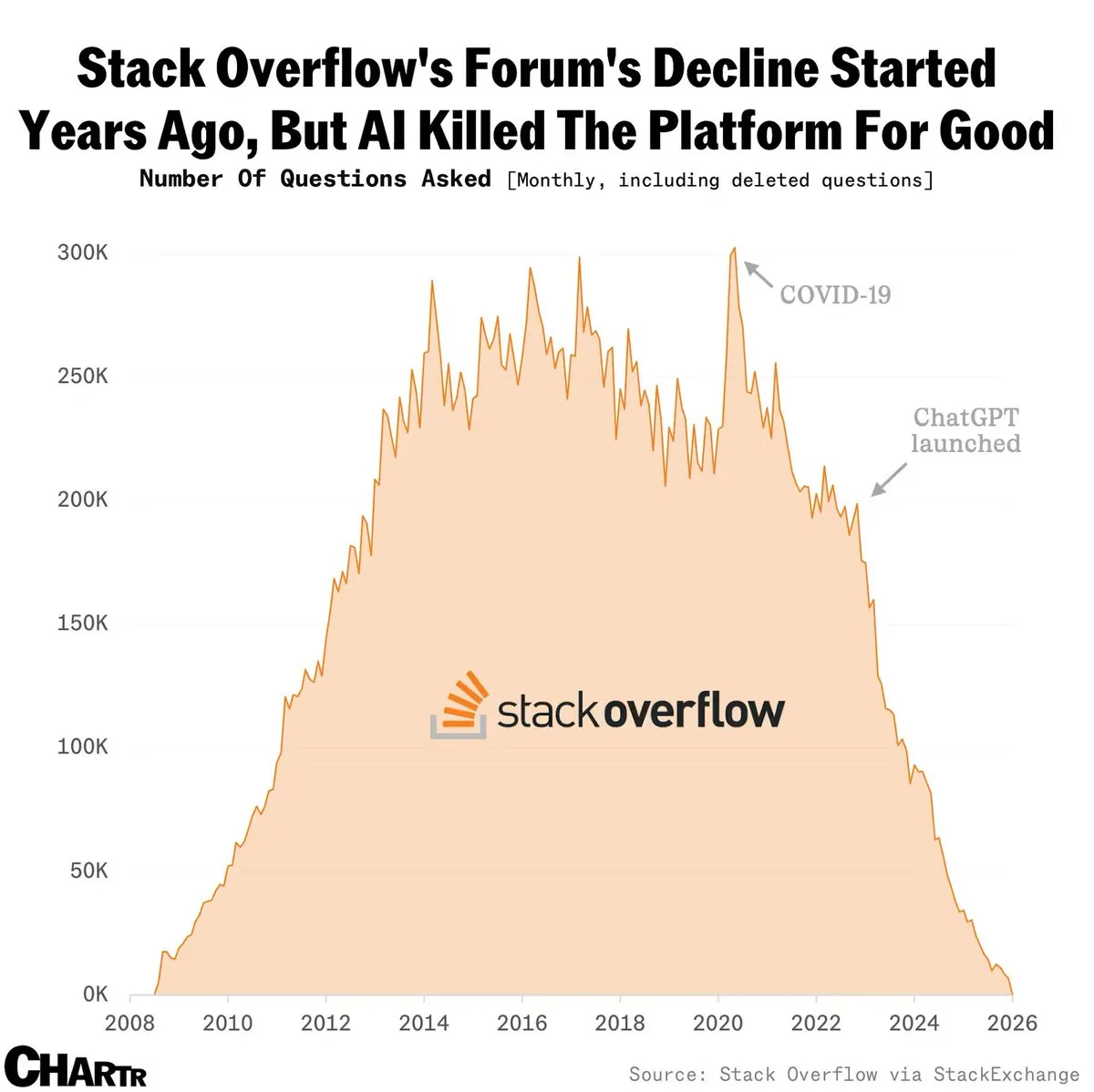
Stack OverflowがAIモデルへのライセンス供与により収入を倍増 : ChatGPTのリリース後に月間質問数は急落したものの、Stack Overflowは高品質な人間による回答データベースをAIラボにライセンス供与することで、年間収入を1.15億ドルへと倍増させた。コミュニティではこれを一種の「再生」と呼び、AI時代における高品質な人間データのプレミアム価値を証明するものだと熱く議論されている。しかし、新しい知識の産出速度が鈍化しているため、このモデルの持続可能性を懸念する声もある(ソース:BorisMPower)
AIによる「脳の疲れ」に関するプログラマーの共鳴 : ソーシャルメディア上で、多くの開発者がAIの使用により作業速度は上がったものの、精神的な疲労が増したと報告している。仕事のモードが「一つの難問を解決する」ことから「5つの中途半端な成果物を同時に監督する」ことへと変化し、頻繁なコンテキストスイッチ、コードレビュー、プロンプトの調整が必要になっている。この「認知負荷」の転移は、将来のプログラマーの役割に関する深い議論を呼んでいる。我々はコードの書き手なのか、それともAIの監督官なのか?(ソース:ArtificialInteligence)
Vibe Codingを巡る二極化した議論:CRUDアプリか、深い技術ビジョンか? : コミュニティでは「Vibe Coding」に対して意見が分かれている。一方は、CRUD(作成・読み出し・更新・削除)やグルーコードの作成効率を劇的に向上させると主張し、もう一方は、これが「低レベルなコードの氾濫」を招くと懸念している。データベースやプロトコルといった真の基底システムには、依然として厳密なアーキテクチャ設計とトレードオフの検討が必要であり、気ままな自然言語の指示では不十分である。AIは抽象化のレベルを引き上げたのか、それともメンテナンス困難な「Slop(合成ゴミ)」を増やしただけなのか?(ソース:lateinteraction)
💡 その他
知乎(Zhihu)がAIカレンダーおよび一連のAI機能アップデートを発表 : 知乎は、AI分野の重大な発表や深い議論を集約した「AIカレンダー」をリリースし、コメント欄の「知達」アシスタントを公開した。これにより、ワンクリックでの要約や即時Q&Aが可能となる。さらに、知乎は24時間AIオーディオストリームサービスも開始した。これらの施策は、コンテンツプラットフォームがAIを通じて情報取得の効率を再構築し、AI検索時代においても真剣な議論の価値を維持しようとする試みを示している(ソース:ZhihuFrontier)

陶哲軒(テレンス・タオ)氏がMath, Inc.と協力し数学の形式化を推進 : 数学者のテレンス・タオ氏は、初のVeritasフェローとして、解析数論における推定値の形式化に取り組んでいる。目標は、機械でチェック可能な「生きた数学ネットワーク」を構築することであり、基底となる推定値が改善された際、すべての下流の推論が自動的にアップグレードされるようにすることである。これは数学文献をモジュール化されたソフトウェアへと変換する重要な一歩と見なされており、数学研究の新しいパラダイムを切り拓くことが期待されている(ソース:jpt401)
ネット上の口コミ分析が「合成ゴミ」汚染に直面 : 市場調査会社の調査によると、2026年のネット上の口コミの約60%がAIによって生成された「合成ゴミ」であることがわかった。これらの口コミは文法的には完璧だが、感情の起伏や詳細な描写に欠けている。アナリストは現在、スペルミスや極端な感情、特定の文脈を持つ口コミを「本物の人間」のシグナルとして探す傾向にある。これは、研究サンプルとしての公共ネットワークの価値が崩壊しつつあり、データ収集が閉鎖的で摩擦の多いコミュニティへとシフトしていることを予兆している(ソース:ArtificialInteligence)