
키워드:주권 AI, FSD, Kimi, 한국 주권 AI 계획, 테슬라 FSD V14.2, 달의 어두운 면 K3 모델
🔥 포커스
한국, 로컬 생태계 구축을 위해 1억 4천만 달러 규모의 ‘Sovereign AI’ 계획 착수 : 한국 과학기술정보통신부는 SKT, LG, Naver 등 5개 대기업과 협력하여 외부의 통제를 받지 않는 자국 거대 모델을 훈련하기 위해 약 1억 4천만 달러를 투입합니다. 현재 SKT의 A(.)X-K1(519B)과 LG의 K-EXAONE(236B)을 포함한 여러 오픈 소스 모델이 발표되었습니다. 이 계획은 ‘바닥부터 시작하는 훈련(From-scratch training)’과 ‘상업적 개방’을 강조하며, 컴퓨팅 파워와 데이터 지원을 통해 유럽식 디지털 주권 상실을 방지하고 한국을 글로벌 AI 지도의 중요한 축으로 만드는 것을 목표로 합니다. 이번 조치는 OpenAI 등 미국계 모델의 독점에 대응하는 상징적인 사건으로 평가받고 있습니다. (출처: huggingface, ClementDelangue, aiamblichus)

Tesla FSD V14.2, 최초의 개입 없는 미국 횡단 챌린지 완료 : 운전자 David Moss는 Tesla FSD V14.2를 사용하여 로스앤젤레스에서 사우스캐롤라이나주까지 2,732마일을 주행했으며, 총 2일 20시간 동안 0회의 개입과 0회의 인수를 기록하며 중대한 돌파구를 마련했습니다. Karpathy는 이에 대해 “이것은 Autopilot 팀 창립 당시의 최종 목표였다”고 언급하며, End-to-End 신경망이 복잡한 장거리 시나리오를 처리하는 데 있어 성숙기에 도달했음을 시사했습니다. 커뮤니티에서는 이것이 자율주행 분야에서 비전 솔루션의 리더십을 증명했다고 보면서도, 미래 교통 규제 적응성에 대한 열띤 논의를 불러일으켰습니다. (출처: karpathy, BorisMPower, chaitu)

Moonshot AI (Kimi), 5억 달러 투자 유치 및 추론 모델 K3에 올인 : Moonshot AI가 새로운 펀딩 라운드를 완료하여 기업 가치 43억 달러를 달성했으며, 현금 보유액은 100억 위안을 넘어섰습니다. 창업자 양즈린(Yang Zhilin)은 2026년에 인재 인센티브를 대폭 강화하여 평균 인센티브를 전년 대비 200% 수준으로 높일 것이라고 밝혔습니다. 전략적 중심은 트래픽 확보에서 근본적인 역량 강화로 옮겨갔으며, K3 모델은 훈련 기술과 Agent 제품력의 수직적 통합을 통해 단순 사용자 수가 아닌 지능의 한계치를 추구할 예정입니다. 이는 DeepSeek의 충격 이후 중국 국산 거대 모델 제조사들이 기술 주도 및 해외 상업화로 방향을 전환하고 있다는 공감대를 반영합니다. (출처: Reddit, 36氪)

실리콘밸리 인재 전쟁 심화: Meta, 20억 달러에 Manus 인수하며 Agent 핵심 인력 확보 : Meta가 AI 에이전트 기업 Manus를 20억 달러 이상에 인수하고, 핵심 인재들에게 1억 달러부터 시작하는 파격적인 ‘폭발적 Offer’를 제시했습니다. 현재 Alexandr Wang, Zhao Shengjia 등 수많은 화인 엘리트들이 실리콘밸리 AI의 핵심 포지션을 차지하고 있습니다. 업계의 중심은 단순한 ‘벤치마크 점수 올리기’에서 ‘엔지니어링 구현’, 즉 누가 모델을 실행 가능한 시스템(Agent)으로 전환할 수 있는가로 이동하고 있습니다. 이러한 기초 연구에서 제품 집권화로의 전환은 FAIR와 같은 전통적인 연구소의 권력 교체와 인재 이동을 야기하고 있습니다. (출처: TheRundownAI, 36氪)

🎯 동향
Qwen-Image-2512 발표: 사실감 및 텍스트 렌더링 대폭 향상 : 알리바바가 멀티모달 모델 Qwen-Image의 12월 업데이트 버전을 출시했습니다. 인물의 피부 디테일, 자연스러운 질감 및 이미지 내 텍스트 렌더링 능력을 중점적으로 최적화하여 ‘AI 특유의 이질감’을 크게 줄였습니다. 이 모델은 Hugging Face와 Replicate에 동시 공개되었으며, 더 복잡한 시각적 이해 작업을 지원합니다. 커뮤니티에서는 실사 인상 및 긴 텍스트 이미지 인식 성능이 우수하다는 피드백이 이어지며, 오픈 소스 멀티모달 분야의 강력한 경쟁자로 평가받고 있습니다. (출처: huggingface, Alibaba_Qwen)
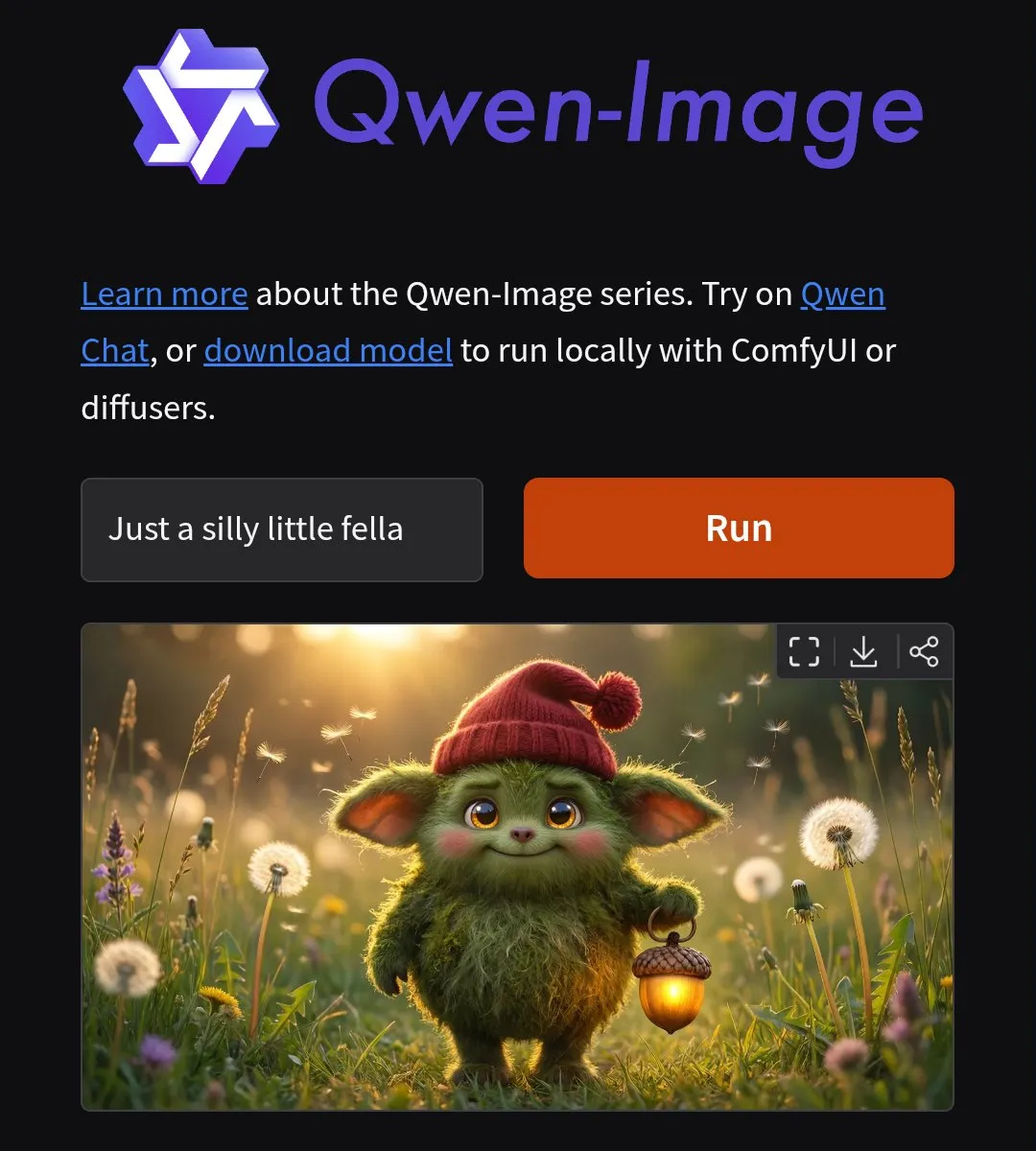
GLM-4.7과 MiniMax M2.1, 오픈 소스 모델 벤치마크 1위 쟁탈전 : 최신 GDPval-AA 랭킹에서 GLM-4.7이 ELO 점수 1224점을 기록하며 오픈 소스 가중치 리더로 올라섰습니다. 동시에 MiniMax M2.1은 지시 이행 및 연구 보조 측면에서 뛰어난 성과를 보였습니다. 개발자들의 실측 결과에 따르면, GLM-4.7은 Python 백엔드 리팩토링 및 긴 컨텍스트 유지 능력에서 Qwen보다 우수했으나, 복잡한 아키텍처 설계에서는 여전히 범용적인 모습을 보였습니다. 이 두 모델의 빠른 반복 업데이트는 중국산 오픈 소스 모델이 프로그래밍 및 논리 추론 분야에서 Sonnet 등 최정상급 모델과 대등하게 경쟁할 수 있음을 보여줍니다. (출처: huggingface, Reddit)
DeepSeek 라이브러리 심층 최적화: 성능 30% 향상 및 B200 칩 최적화 : 커뮤니티 개발자들이 DeepSeek 관련 라이브러리를 하나씩 최적화하기 시작했으며, CuTeDSL 등의 기술적 수단을 통해 NVIDIA B200 칩에서 실행 속도를 20~30% 향상시켰습니다. 이러한 특정 하드웨어에 맞춘 정밀한 튜닝은 AI 업계가 ‘효율성 지상주의’ 단계로 진입하고 있음을 예고하며, 컴퓨팅 자원이 제한된 상황에서 하위 엔지니어링 최적화를 통해 모델 추론 성능을 극한으로 끌어올리고 있습니다. (출처: QuixiAI)

Neuralink, 2026년 뇌-컴퓨터 인터페이스 대량 생산 시작 발표 : Elon Musk는 Neuralink가 2026년에 수술 전 과정을 자동화하여 로봇을 통해 뇌-컴퓨터 인터페이스 이식을 완료할 것이라고 밝혔습니다. 새로운 기술은 전극선을 경막을 제거하지 않고 통과시킬 수 있어 수술 위험을 크게 낮춥니다. 이번 조치는 뇌-컴퓨터 인터페이스를 실험적 의료 단계에서 대규모 소비 시장으로 확장하여 인간과 AI의 고대역폭 연결을 실현하는 것을 목표로 하며, teortaxesTex는 이를 “Musk가 또 다른 프런티어 분야를 산업화하고 있다”고 평가했습니다. (출처: teortaxesTex)
Google의 3년 역전 전략 분석: ‘코드 레드’에서 전면 반격으로 : Google은 Google Brain과 DeepMind를 통합하여 새로운 Google DeepMind를 설립하고 Hassabis의 지휘 체계를 확립했으며, Noam Shazeer 등 베테랑들을 복귀시켜 과거의 ‘완벽주의 출시’ 관료주의를 완전히 타파했습니다. 현재 Google은 모델(Gemini 3), 칩(TPU), 애플리케이션 측면에서 전면적으로 속도를 내고 있으며, 이로 인해 OpenAI 또한 ‘코드 레드’ 상태에 진입하게 만들었습니다. 이러한 반전은 거대 기업이 조직 재편 후 보여주는 무서운 폭발력을 입증합니다. (출처: 36氪)

🧰 도구
Claude Code, ‘Vibe Coding’이라는 새로운 프로그래밍 패러다임 제시 : 개발자 커뮤니티는 Anthropic이 출시한 Claude Code에 열광하고 있으며, 특히 ASCII 아트 시각화, 계층적 아키텍처 이해 및 자동 디버깅 성능이 놀랍다는 반응입니다. 사용자들은 ‘Vibe Coding(분위기 코딩)’을 통해 모바일이나 침대에서도 복잡한 웹 애플리케이션 개발을 완료할 수 있게 되었습니다. 2배 할당량 제한이 있음에도 불구하고, 생산성의 비약적인 향상으로 인해 많은 개발자들이 Cursor 구독을 해지하고 MCP 기반의 커스텀 워크플로우를 구축하고 있습니다. (출처: brivael, omarsar0, Reddit)
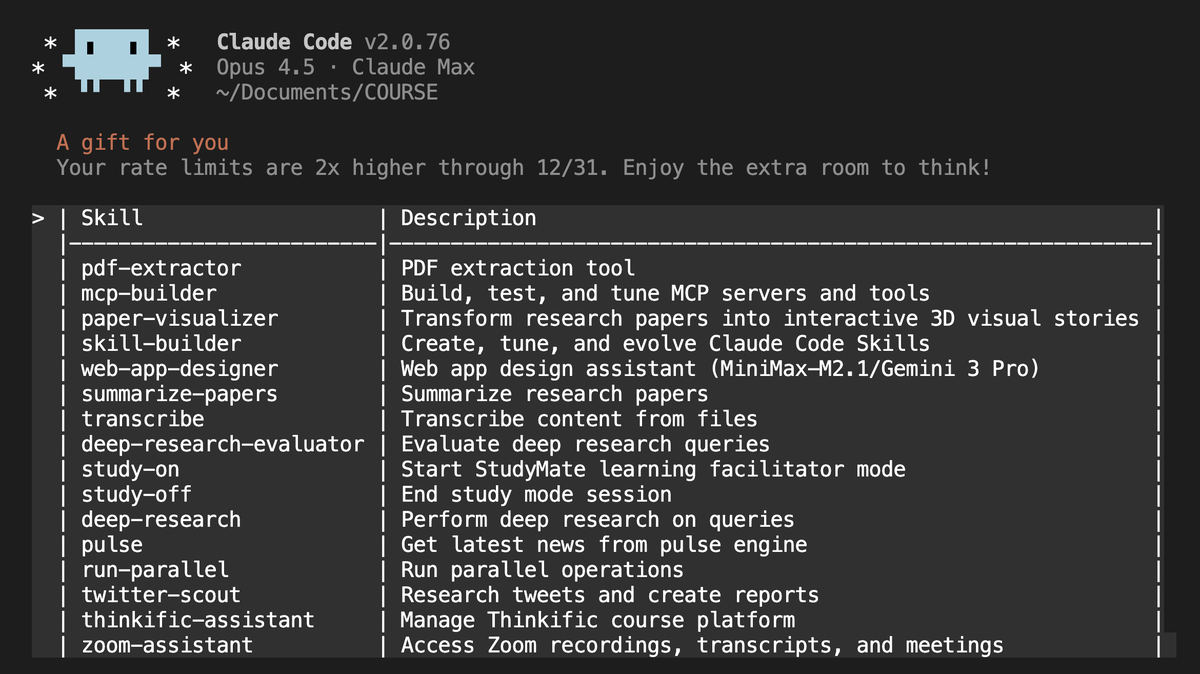
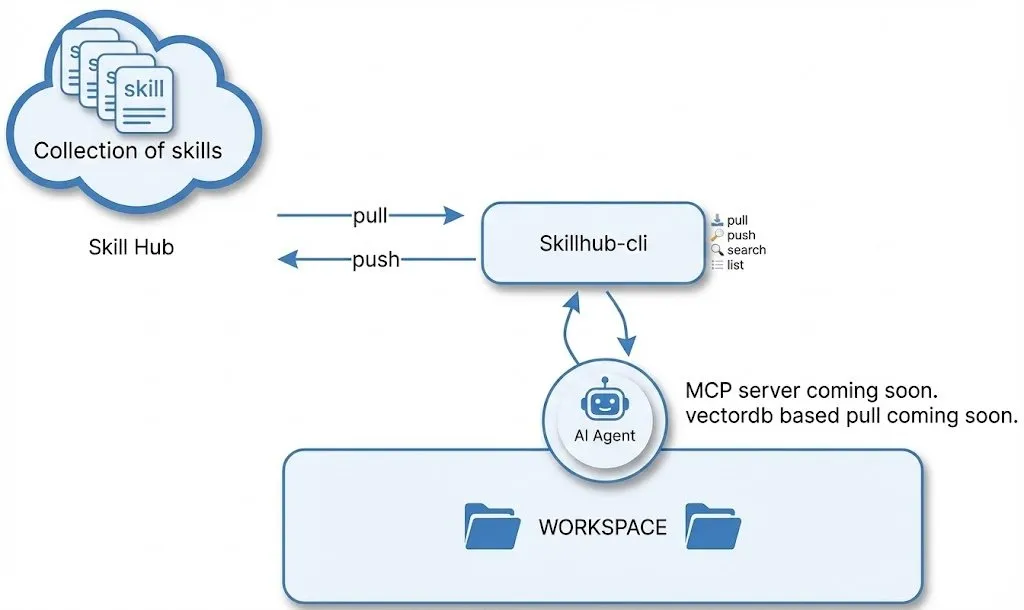
SkillHub: AI 에이전트 워크플로우를 위한 ‘Homebrew’ 레지스트리 : SkillHub는 개발자가 성공적인 AI 작업 워크플로우를 저장, 풀(pull) 및 재사용할 수 있도록 지원합니다. 새로운 프로젝트를 시작할 때마다 프롬프트를 다시 작성해야 하는 번거로움을 해결하며, 모델 및 플랫폼 간 사용을 지원합니다. 이러한 ‘워크플로우 스토어’ 모델은 Agent의 대규모 상용화를 위한 핵심 인프라로 간주되며, 복잡한 AI 기술을 소프트웨어 패키지처럼 배포할 수 있게 합니다. (출처: QuixiAI)
Pommel: Claude Code의 컨텍스트 소모 문제를 해결하는 로컬 시맨틱 검색 도구 : Pommel은 오픈 소스 로컬 시맨틱 코드 검색 도구로, 로컬 벡터 데이터베이스(sqlite-vec)를 유지하여 AI 에이전트가 코드 세그먼트를 정확하게 찾을 수 있도록 돕습니다. 이는 Claude Code가 프로젝트를 이해할 때 무분별하게 대량의 무관한 파일을 읽는 것을 방지하여 컨텍스트 창을 최대 50%까지 절약하며, 현재 Python, Go, Java 등 주요 언어를 지원합니다. (출처: Reddit)
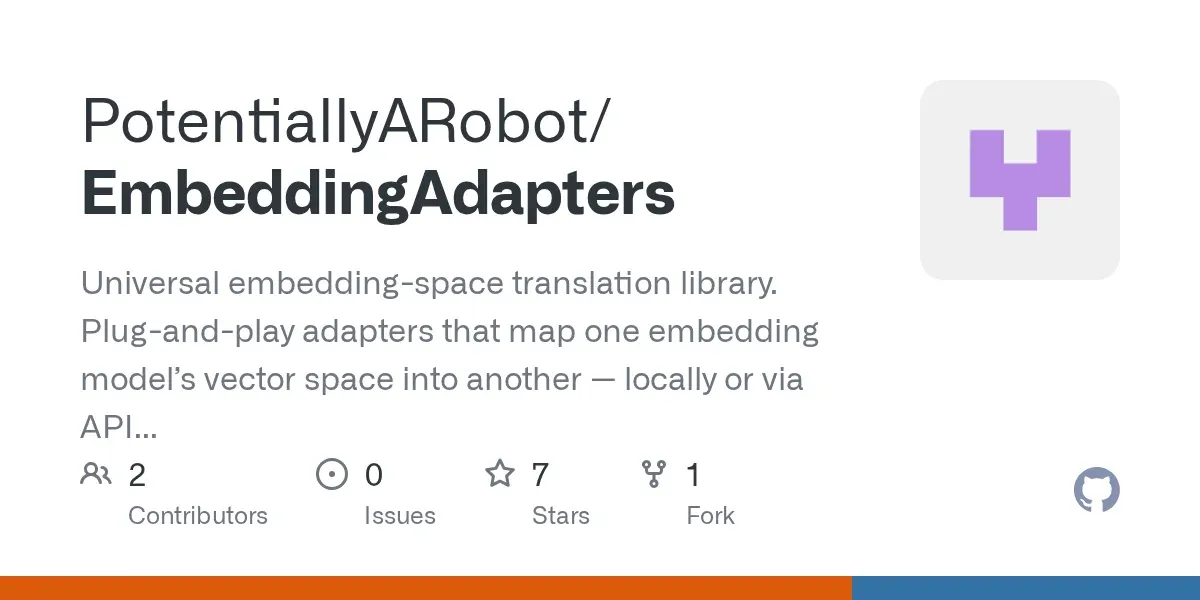
EmbeddingAdapters: 모델 간 벡터 공간 변환 라이브러리 : 이 Python 라이브러리는 사전 훈련된 어댑터를 제공하여 로컬 소형 모델(예: MiniLM)에서 생성된 벡터를 OpenAI나 Gemini와 같은 고차원 벡터 공간으로 번역할 수 있도록 지원합니다. 이를 통해 개발자는 전체 말뭉치를 다시 임베딩할 필요 없이 벡터 데이터베이스를 이전할 수 있으며, 오프라인 또는 제한된 환경에서도 효율적인 로컬 RAG 검색을 구현할 수 있습니다. (출처: Reddit)
Manus, Slack 커넥터 출시로 대화를 실행 가능한 지식으로 전환 : Manus가 Slack Connector를 출시했습니다. 이는 파편화된 Slack 채팅 기록을 검색 가능하고 실행 가능한 구조화된 지식 베이스로 전환하는 것을 목표로 합니다. 팀의 지식이 채팅 흐름 속에서 유실되는 문제를 해결하며, Agent가 ‘대화 도우미’에서 ‘지식 관리 허브’로 진화하여 기업 내부 협업 시나리오에 깊숙이 침투하고 있음을 보여줍니다. (출처: hidecloud)
📚 학습
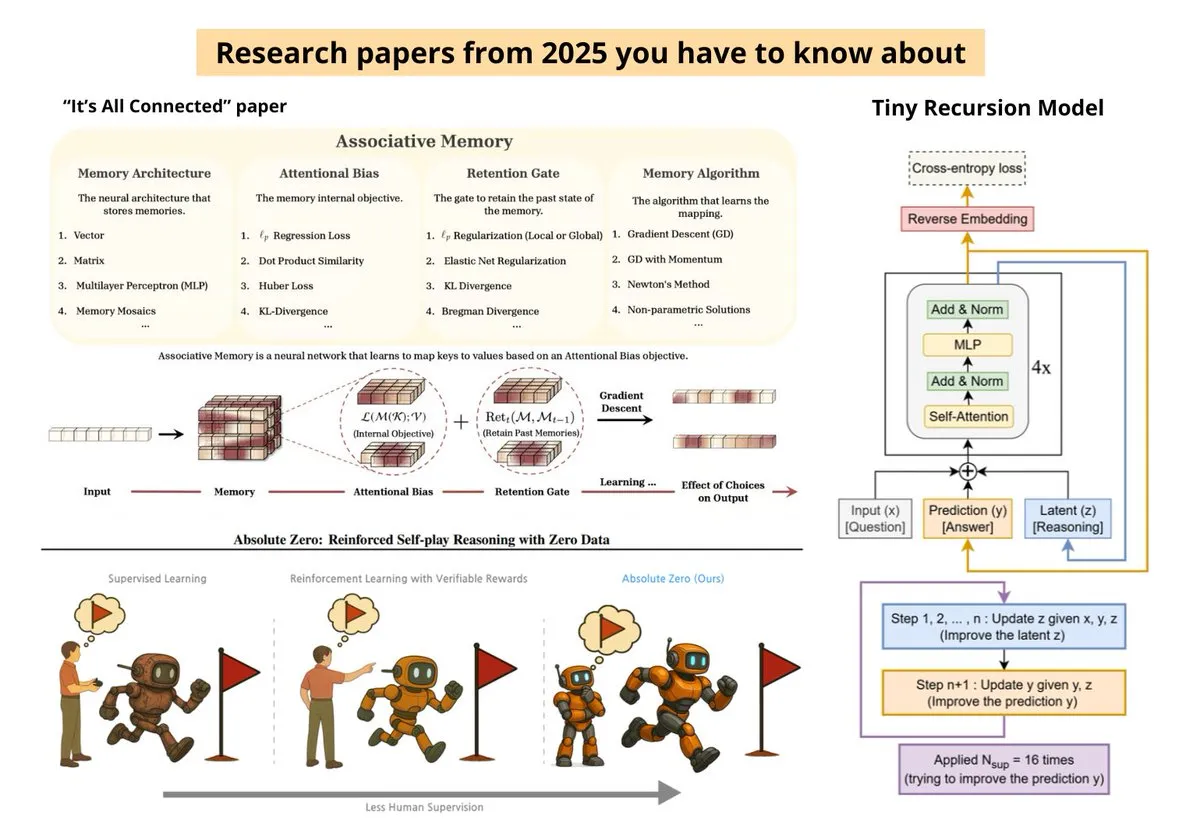
Hugging Face 2025년 올해의 논문 결산: 효율적인 훈련과 뇌과학의 연관성 : Hugging Face가 2025년 가장 주목받은 논문 10편을 정리했습니다. 효율적인 LLM 사후 훈련, Transformer와 뇌 모델 사이의 누락된 연결 고리, Tiny Recursive Model (TRM), 그리고 Qwen 3의 시퀀스 전략 최적화 등이 포함되었습니다. 이러한 연구들은 업계가 맹목적인 규모 확장(Scaling)에서 벗어나 파라미터 효율성 및 인간 인지 과정 모방을 추구하고 있음을 반영합니다. (출처: huggingface)

GPU 기술 권위 문서: CUDA 코어부터 메모리 계층 구조까지 : 커뮤니티에서 CUDA 코어, SM, Tensor Core, Warp 스케줄러, 메모리 계층 및 Nsight 성능 분석 등 핵심 지식을 다룬 매우 상세한 GPU 아키텍처 문서가 공유되었습니다. 하위 레벨에서 AI 모델 성능을 최적화하려는 엔지니어들에게 하드웨어가 대규모 병렬 컴퓨팅을 어떻게 지원하는지 이해하기 위한 필수 리소스입니다. (출처: charles_irl)
AI 리더들의 수학적 사고를 형성한 4권의 고전 : TheTuringPost가 AI 창업자들에게 가장 큰 영향을 준 수학 서적들을 정리했습니다. 《대수기하학 기초》, 《해석적 정수론》, 《Proof from THE BOOK》, 《어느 수학자의 변명》 등이 포함되었습니다. 이 책들은 기술적 기초뿐만 아니라 논리적 엄밀성과 추상적 모델링 능력을 제공하여 AI 분야의 돌파구를 마련하는 사고의 기반이 되었습니다. (출처: TheTuringPost)

Transformer 아키텍처의 물리적 본질: 베이지안 추론과 Renormalization Group Flow : 물리학자 riemannzeta는 Transformer 아키텍처가 본질적으로 베이지안 추론의 구현이며, 물리학의 Renormalization Group Flow(재정규화 그룹 흐름)와 명확한 매핑 관계가 있음을 증명한 최신 연구를 논의했습니다. 이 발견은 AI 모델이 방대한 데이터에서 유효한 특징을 추출할 수 있는 이유를 설명하는 견고한 이론 물리학적 토대를 제공합니다. (출처: riemannzeta)
AI의 미래를 예견하는 23편의 선구적 논문: 제로 데이터 추론부터 와트당 지능까지 : Ksenia가 2025년의 핵심 논문 23편을 정리했습니다. Kosmos, Paper2Agent, 제로 데이터 강화 자가 대국 추론(Absolute Zero) 및 Agent 시스템의 Scaling Science 등이 포함되었습니다. 이 연구들은 AI가 더 낮은 전력 소모, 더 강력한 자율 추론 및 멀티모달 융합 방향으로 빠르게 진화하고 있음을 보여줍니다. (출처: TheTuringPost)
💼 비즈니스
Scale AI 2025년 실적 폭발: 데이터 사업 흑자 전환 및 정부 대형 계약 수주 : Alexandr Wang은 Scale AI가 새로운 시대에 진입했으며, 4분기가 역사상 가장 강력한 분기였다고 발표했습니다. 현재 데이터 사업은 수익을 창출하고 있으며, 미국 정부 사업이 빠르게 성장하여 수억 달러 규모의 기업 및 정부 계약을 여러 건 체결했습니다. 이는 고품질 라벨링 데이터가 AGI 경쟁에서 여전히 핵심 자산이며 강력한 비즈니스 해자를 갖추고 있음을 증명합니다. (출처: alexandr_wang)
Nvidia, TSMC에 H200 칩 생산량을 200만 개로 대폭 증설 요청 : B200 등 새로운 아키텍처가 출시되었음에도 불구하고, Nvidia는 TSMC에 H200 생산량을 70만 개에서 200만 개로 늘려달라고 요청했습니다. 이는 고성능 컴퓨팅 파워에 대한 시장의 갈증이 예상을 훨씬 뛰어넘고 있으며, 기존 모델이 여전히 주요 연구소와 클라우드 서비스 제공업체의 확장 우선순위임을 반영합니다. (출처: Teknium)
2025 AI 부호 명단: 50명의 신규 억만장자 탄생, 2000년대생도 포함 : 2025년 AI 스타트업들이 전 세계 총 투자액의 50%를 차지했습니다. 신규 부호에는 Surge AI 창업자 Edwin Chen(자산 180억 달러)과 DeepSeek 창업자 량원펑(Liang Wenfeng)이 포함되었습니다. AI 업계의 부는 점차 젊어지는 추세이며, Mercor의 2000년대생 창업자 3명은 Zuckerberg의 최연소 자수성가 기록을 경신하며 AI가 차세대 슈퍼 돈 복사기가 되었음을 상징합니다. (출처: 36氪)

🌟 커뮤니티
‘Vibe Coding’과 ‘Agent Agency’: 기술인과 비기술인의 새로운 분수령 : 커뮤니티에서는 ‘기술 vs 비기술’의 경계가 모호해지고 있으며, 그 자리를 ‘학습 및 구축 의지 유무’가 대신하고 있다는 논의가 활발합니다. 기술적 배경을 가진 사람이 “AI 코드는 쓰레기다”라는 편견에 빠지면 경쟁력을 잃게 되며, 반면 높은 실행력(High-agency)을 가진 비기술자가 ‘Vibe Coding’을 통해 Agent의 의지를 직접 조종하며 새로운 혁신의 주역이 되고 있습니다. 이러한 패러다임 전환은 2026년 소프트웨어 개발 지형을 정의할 것으로 보입니다. (출처: matanSF, HamelHusain)
AI 자동화가 초래할 극단적 불평등과 ‘자본에 의한 노동 대체’ 우려 : Dwarkesh Patel은 완전 자동화된 세상에서 자본이 노동을 완전히 대체함에 따라 불평등이 기하급수적으로 증가할 것이라고 지적했습니다. AI가 모든 업무를 수행하게 되면 전통적인 ‘노동-임금’ 메커니즘이 무너지고, 부는 초기 자본 소유자(최초의 다이슨 스피어나 슈퍼컴퓨터를 보유한 거물들)에게 급격히 집중될 것입니다. 이러한 ‘천만 배급’ 빈부 격차는 포스트 풍요 시대에 전통적인 논리로는 정당화하기 어려울 것입니다. (출처: dwarkesh_sp)
AI 확장의 환경적 대가: 인도의 지하수 수위 급락과 글로벌 전기료 인상 : 소셜 미디어에서는 AI 데이터 센터가 초래하는 부작용에 대한 논의가 확산되고 있습니다. 인도의 일부 마을에서는 데이터 센터 냉각을 위한 과도한 지하수 추출로 인해 농민들이 물을 얻기 위해 250미터까지 땅을 파야 하는 상황입니다. 동시에 시카고 등지의 주민들은 데이터 센터 입주로 인해 전력 사용량이 줄었음에도 전기료가 11% 인상되었다고 보고했습니다. 이는 AI 발전의 ‘숨겨진 비용’을 일반 시민들이 부담하고 있다는 강한 불만을 야기하고 있습니다. (출처: Reddit, Reddit)

NSFW 금지의 미래: 대기업 모델은 영원히 성인 콘텐츠를 차단할 것인가? : Reddit 커뮤니티에서는 Google, OpenAI 등 대기업들이 향후 20년 내에 NSFW 콘텐츠 필터링을 해제할지에 대해 토론했습니다. 주류 의견은 법적 리스크(예: 리벤지 포르노)와 브랜드 평판 때문에 대기업들이 거리를 유지할 것이며, 관련 수요는 특정 틈새시장의 소형 모델이나 오픈 소스 모델이 충족할 것이라는 점입니다. 이러한 ‘콘텐츠 격리’는 AI 분야에서 성인용과 비성인용 시장의 명확한 분리를 초래할 수 있습니다. (출처: Reddit)
💡 기타
AI가 창조한 새로운 감정 단어 ‘Velvetmist’ 공감 유발 : 네티즌 noahjeadie가 ChatGPT를 사용하여 ‘벨벳 같은 안개’의 감정을 묘사하는 단어를 만들어냈으며, 이는 평온함과 비현실성 사이의 미묘한 안락함을 의미합니다. 사회학자들은 온라인 생활이 깊어짐에 따라 AI가 보조하는 ‘새로운 감정 단어’ 창조가 인간의 정서적 세밀함을 높여 정신 건강 증진에 도움을 줄 수 있다고 보며, 이는 AI가 인간의 가장 은밀한 감각 표현에 개입하고 있음을 시사합니다. (출처: MIT Technology Review)
데이트 앱 알고리즘의 내막 공개: 랭킹을 통한 매칭 조작 방식 : Reddit 머신러닝 섹션의 인기 게시물에서 Tinder 등 앱의 정렬 로직을 분석했습니다. 무료 사용자는 대개 외모는 뛰어나지만 매칭되기 어려운 프로필만 보게 되는 반면, 유료 사용자는 ‘쌍방향 매칭 확률’ 가중치를 부여받습니다. 알고리즘은 심지어 ‘잠재적 유료 사용자’를 식별하여 단기적인 트래픽 보너스를 주기도 합니다. 인간의 감정을 상품화하는 이러한 알고리즘 로직은 AI 윤리에 대한 깊은 성찰을 불러일으켰습니다. (출처: Reddit)
2026년 예측: 말줄임표의 해와 ‘Presence’의 회귀 : Yohei는 2026년이 단절이 아닌 지속적인 진화를 상징하는 ‘말줄임표(…)’의 해가 될 것이라고 전망했습니다. 커뮤니티는 2026년 AI의 중점이 ‘더 많은 컴퓨팅 파워’에서 ‘더 나은 존재감(Presence)’으로 옮겨갈 것이라고 예측합니다. 즉, AI를 통해 원격 소통에서 잃어버린 시선 교환과 정서적 연결을 어떻게 회복하고, 기술이 다시 인간의 실제적인 감각을 위해 봉사하게 할 것인지가 핵심이 될 것입니다. (출처: yoheinakajima, Reddit)