
关键词:AI模型, 自动驾驶, 多模态, GLM-4.7, Alpamayo, Qwen3-VL
🔥 聚焦
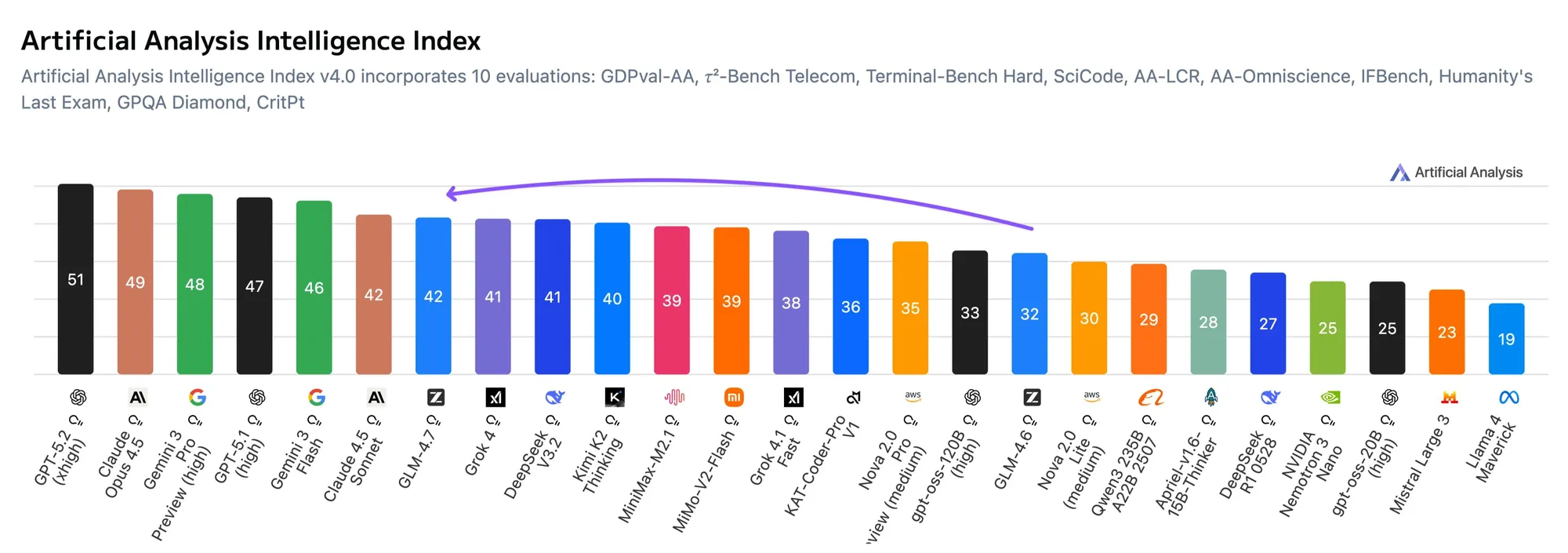
智谱AI正式在港交所上市,开启大模型IPO时代 : 2026年1月8日,智谱AI正式在港交所挂牌,成为全球大模型第一股,MiniMax紧随其后。唐杰在内部信中透露,旗舰模型GLM-4.7发布后,MaaS年化收入(ARR)10个月增长25倍,突破5亿人民币。这一事件标志着中国大模型从“技术追赶”转向“商业闭环”,IPO将为国产模型开辟通往全球市场的通道,并获得更公允的国际价值评判(来源:Zai_org)
斯坦福发布SleepFM:通过一晚睡眠预测百余种健康风险 : 斯坦福大学研究人员推出多模态AI模型SleepFM,基于超过58.5万小时的睡眠数据训练。该模型通过分析脑电波、心率和呼吸频率,能够从单晚记录中预测包括痴呆症、心脏病和某些癌症在内的130多种疾病风险。这一突破展示了AI在预防医学领域的巨大潜力,将睡眠监测设备转化为强大的诊断工具(来源:Reddit)

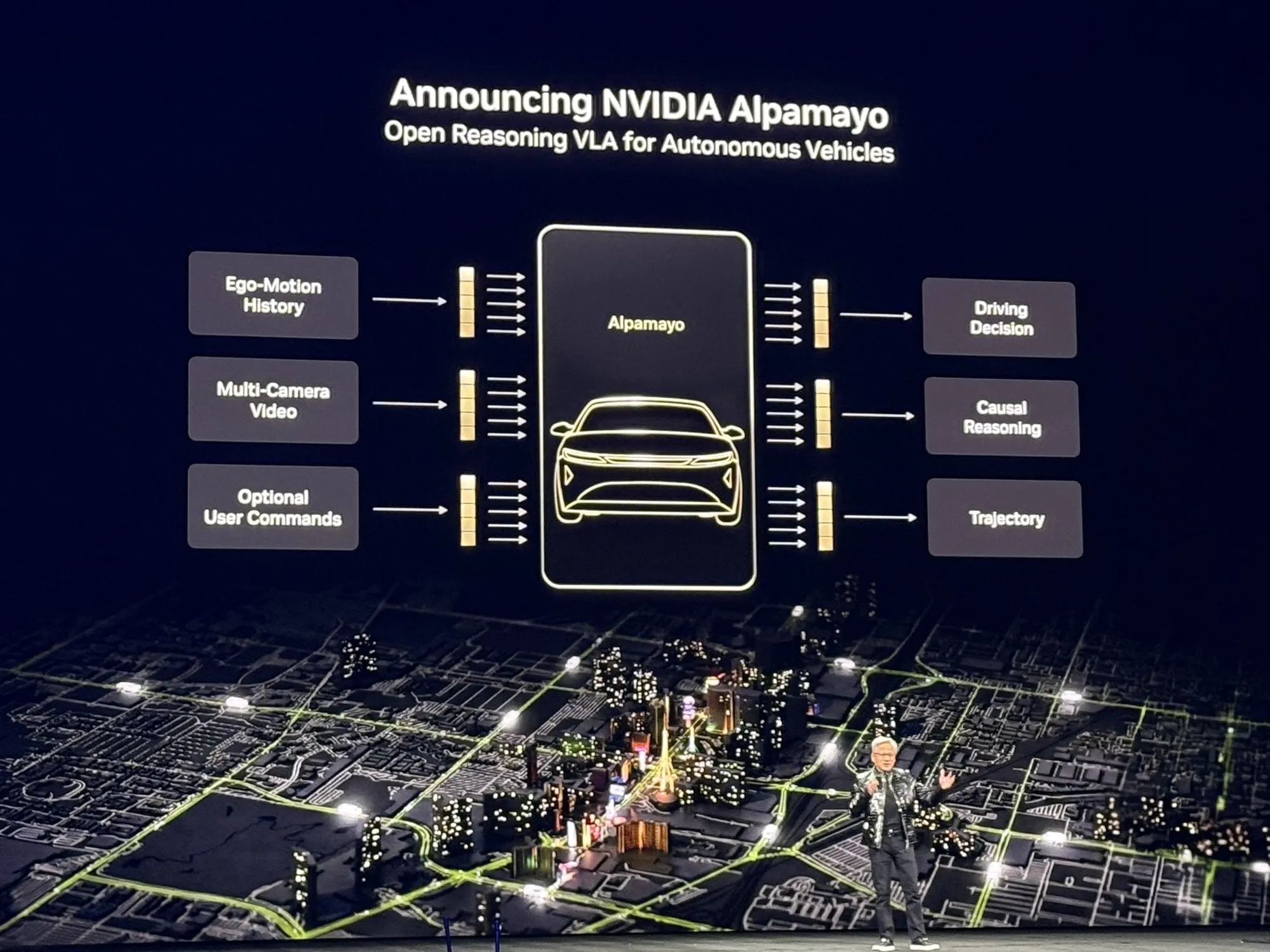
NVIDIA开源Alpamayo:首个具备推理能力的自动驾驶模型 : NVIDIA开源了Alpamayo,这是首个基于思维链(CoT)推理的自动驾驶模型。与传统仅靠反应的系统不同,Alpamayo能像人类驾驶员一样在复杂或罕见场景下进行逻辑思考。结合Vera Rubin架构的“AI工厂”,NVIDIA正将AI从纯数字领域推向物理AI,涵盖模拟工具和边缘计算模块,重塑工业级自动驾驶标准(来源:TheTuringPost)
LMArena获1.5亿美元融资,AI评估成为核心基础设施 : 知名AI模型竞技场LMArena以17亿美元估值完成1.5亿美元融资。这一巨额融资表明,在模型层出不穷的当下,客观、可信的评估体系已不再是辅助工具,而是AI生态的核心基础设施。评估能力的资本化预示着行业正从“盲目扩容”转向“质量驱动”,同时也引发了社区对其高估值的广泛讨论(来源:nearcyan)

🎯 动向
AI21 Labs发布Jamba 2系列:混合SSM-Transformer架构发力企业级 : AI21推出了Jamba2 3B和Jamba2 Mini(52B总参数,12B激活)。该系列采用混合SSM-Transformer架构,拥有256K超长上下文,在IFEval等指令遵循基准上表现优异。其核心优势在于高吞吐量和内存效率,特别适合处理长文档和需要高可靠性的企业级Agent工作流(来源:Reddit)

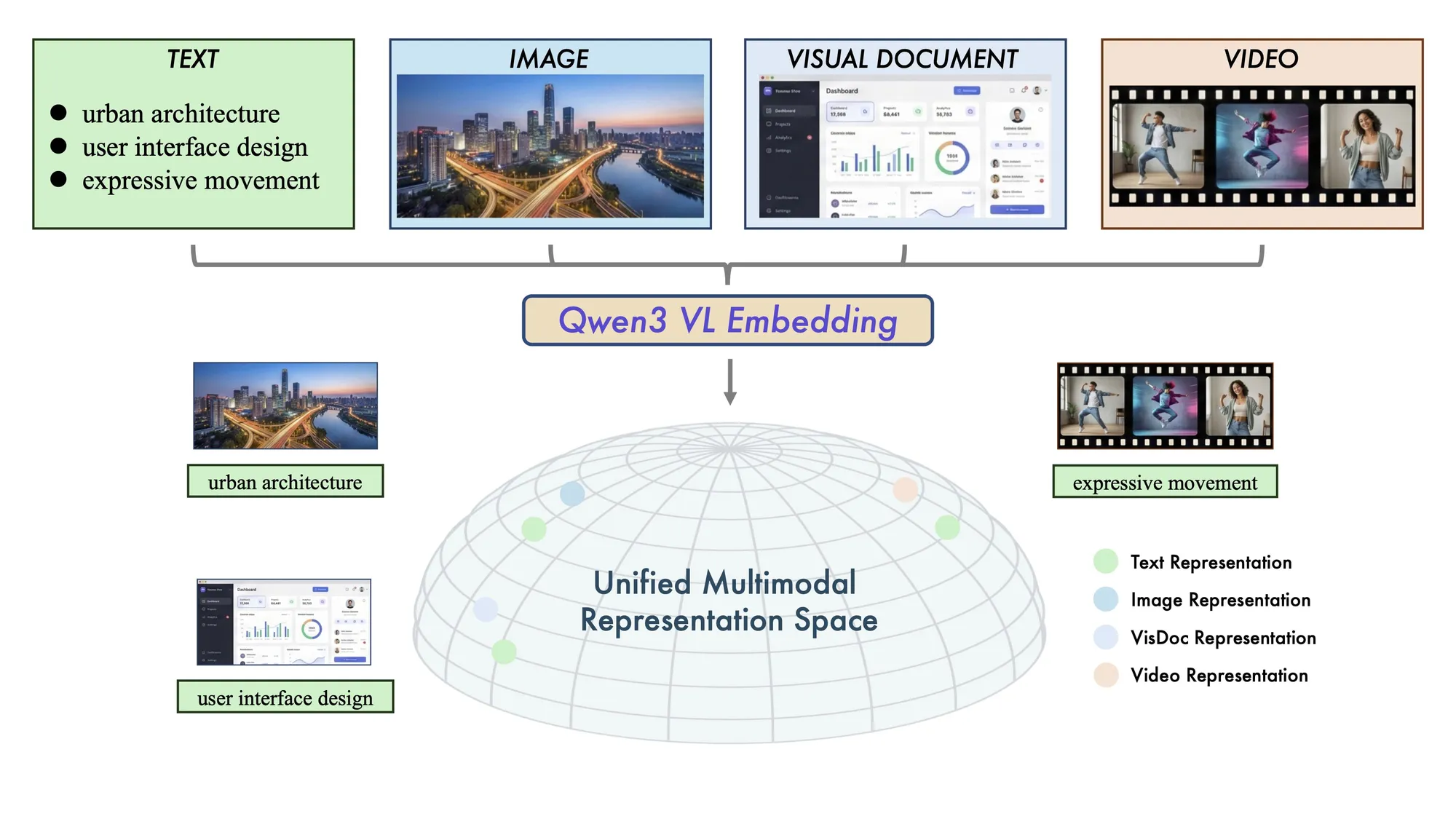
阿里开源Qwen3-VL多模态检索模型:推进跨模态理解SOTA : 阿里发布了Qwen3-VL-Embedding和Reranker模型,支持文本、图像、视频等混合模态输入。该模型在多模态RAG、视觉问答和跨语言搜索中表现卓越,支持30多种语言。这种两阶段检索架构(向量生成+精细打分)显著提升了复杂视觉内容的检索精度,为多模态AI应用提供了强大的底层支持(来源:Alibaba_Qwen)
NVIDIA发布Nemotron Speech ASR:超低延迟语音识别开源 : NVIDIA发布了专为语音Agent设计的Nemotron Speech ASR模型,实现了24ms的转录完成时间和低于500ms的端到端语音交互延迟。该模型完全开源,包括权重、代码和训练数据。黄仁勋在CES上强调,开源模型将在今年全面追赶闭源模型,NVIDIA正通过释放高性能底层工具推动这一进程(来源:NerdyRodent)
DeepSeek更新R1论文:从22页大幅扩充至86页 : DeepSeek更新了其具有里程碑意义的R1模型论文,补充了大量关于训练细节和架构设计的深入信息。尽管部分内容已在之前的Nature论文中披露,但此次更新进一步巩固了DeepSeek在开源社区的技术领导地位。社区关注到其作者列表的稳定性以及在MLA架构上的持续优化经验(来源:teortaxesTex)

Google将Gmail带入Gemini 3时代:打造主动式收件箱助手 : Google宣布Gmail全面集成Gemini 3,使其从简单的邮件工具转变为主动式的收件箱助手。新功能包括智能管理生活日程、自动总结复杂邮件链以及基于上下文的主动提醒。这标志着大模型正从“对话框”形态深度嵌入生产力工作流,实现个人数据的智能化管理(来源:GoogleDeepMind)
🧰 工具
VideoRAG/Vimo:支持超长视频对话的开源桌面应用 : 香港大学HKUDS团队发布了VideoRAG及其桌面版Vimo,支持与长达数百小时的视频进行对话。该工具采用图驱动知识索引和分层上下文编码,能精准检索视频场景并回答问题。它解决了传统多模态模型处理长视频时的显存压力和理解断层问题,单张RTX 3090即可运行(来源:GitHub)
memU:面向AI Agent的层次化记忆基础设施 : NevaMind-AI开源了memU,这是一个为LLM和Agent设计的记忆系统。它模仿文件系统,将原始数据、离散记忆项和聚合类别进行三层组织,支持RAG向量检索和LLM语义检索。该系统能自动提取对话中的偏好、技能和事实,实现记忆的自我演化,大幅提升Agent处理长程任务的连贯性(来源:GitHub)

Maid:在手机端离线运行AI模型的开源应用 : Maid是一款支持在移动设备上本地运行LLM的开源App,特别适合断网或对隐私要求极高的场景。它简化了手机端模型部署流程,用户可直接下载不同尺寸的模型进行对话。这为边缘计算和AI普及提供了低门槛的移动端方案(来源:Reddit)
Claude Code与Replit深度集成:云端Agent编程新范式 : 开发者分享了Claude Code与Replit结合的实战经验,强调云端编辑器在解决环境配置痛点上的优势。通过Claude Code在Replit内部运行,可以实现从手机端并行控制多个Agent进行开发。这种“生成即上线”的模式正改变软件交付逻辑,让非专业开发者也能快速构建复杂应用(来源:amasad)
📚 学习
MAGMA:基于多图结构的Agent长程记忆架构 : 针对传统RAG在长程推理中信息纠缠的问题,新研究提出MAGMA架构。它将记忆存储在语义、时间、因果和实体四个正交图中,通过策略引导的图遍历进行检索。这种方法解耦了记忆表示与检索逻辑,显著提升了Agent在处理复杂因果关系和事件序列时的准确性(来源:dair_ai)

Agentic Rubrics:无需执行代码的SWE Agent验证方法 : 验证是强化学习的关键。研究人员提出“代理评估量表”(Agentic Rubrics),让专家Agent通过交互生成代码库特定的检查清单,直接对候选补丁打分,无需复杂的环境搭建和代码执行。在SWE-Bench测试中,该方法显著提升了验证效率和准确率,为大规模Agent训练提供了更轻量的反馈信号(来源:arXiv)
Klear:实现音视频联合生成的统一架构 : 针对音视频不同步和唇形对齐差的问题,Klear引入了单塔设计和统一DiT块,配合随机模态掩码训练策略。通过构建大规模带密集标注的音视频数据集,Klear在保持语义一致性的同时实现了极高的生成质量,性能可比肩Google的Veo 3,为多模态合成提供了新路径(来源:arXiv)
熵自适应微调(EAFT):解决SFT中的灾难性遗忘 : 论文指出,监督微调(SFT)常因强制模型拟合外部监督而导致“置信冲突”。EAFT利用token级熵作为门控机制,区分认识不确定性与知识冲突,允许模型学习不确定样本同时抑制冲突数据的梯度更新。实验证明,该方法在保持下游任务性能的同时,有效缓解了通用能力的退化(来源:arXiv)
Atlas:跨领域复杂推理的异构模型与工具编排 : 随着LLM和工具多样化,如何选择最佳组合成为难题。Atlas提出双路径框架:基于聚类的免训练路由用于领域内对齐,基于强化学习的多步路由用于分布外泛化。该框架在15个基准测试中超越了GPT-4o,展示了通过编排专门化多模态工具解决复杂问题的强大能力(来源:arXiv)
💼 商业
Manus被Meta收购,ARR 8个月突破1.25亿美元 : 任务执行Agent初创公司Manus在被Meta以20亿美元收购前夕,披露其ARR已达1.25亿美元。产品上线仅8个月便实现破亿,月环比增长超20%。这反映了AI商业逻辑的转变:用户不再为“能力”付费,而是为“结果”和“任务交付”买单(来源:36氪)
Boltz完成2800万美元种子轮融资,并与辉瑞达成合作 : 生物技术AI初创公司Boltz宣布成立Boltz PBC并获2800万美元融资,同步推出Boltz Lab平台。该平台包含专门的小分子和蛋白质设计Agent,并与制药巨头辉瑞签署了多年合作协议。这标志着AI Agent在药物研发等严谨科学领域的商业化落地加速(来源:sarahcat21)
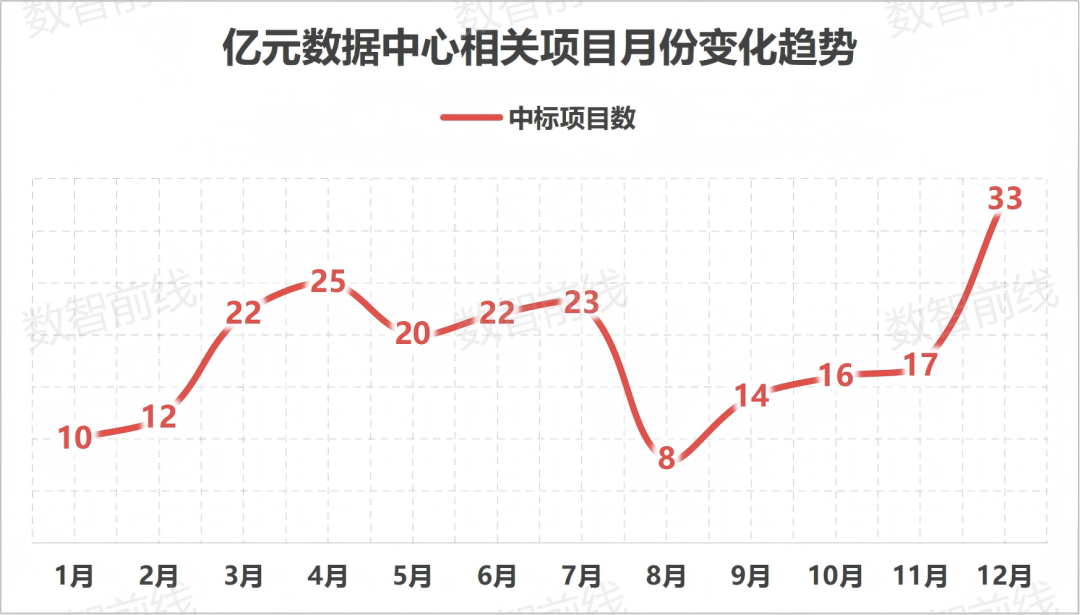
中国算力基建进入“万P时代”,2025年亿元级项目超222个 : 国内智算中心建设持续火热,运营商成为绝对主力。2025年亿元以上中标项目超222个,万卡集群成为标配。趋势显示,推理算力需求正快速攀升,液冷技术从可选项变为必选项,行业正通过“以用带建”模式解决利用率问题(来源:36氪)
🌟 社区
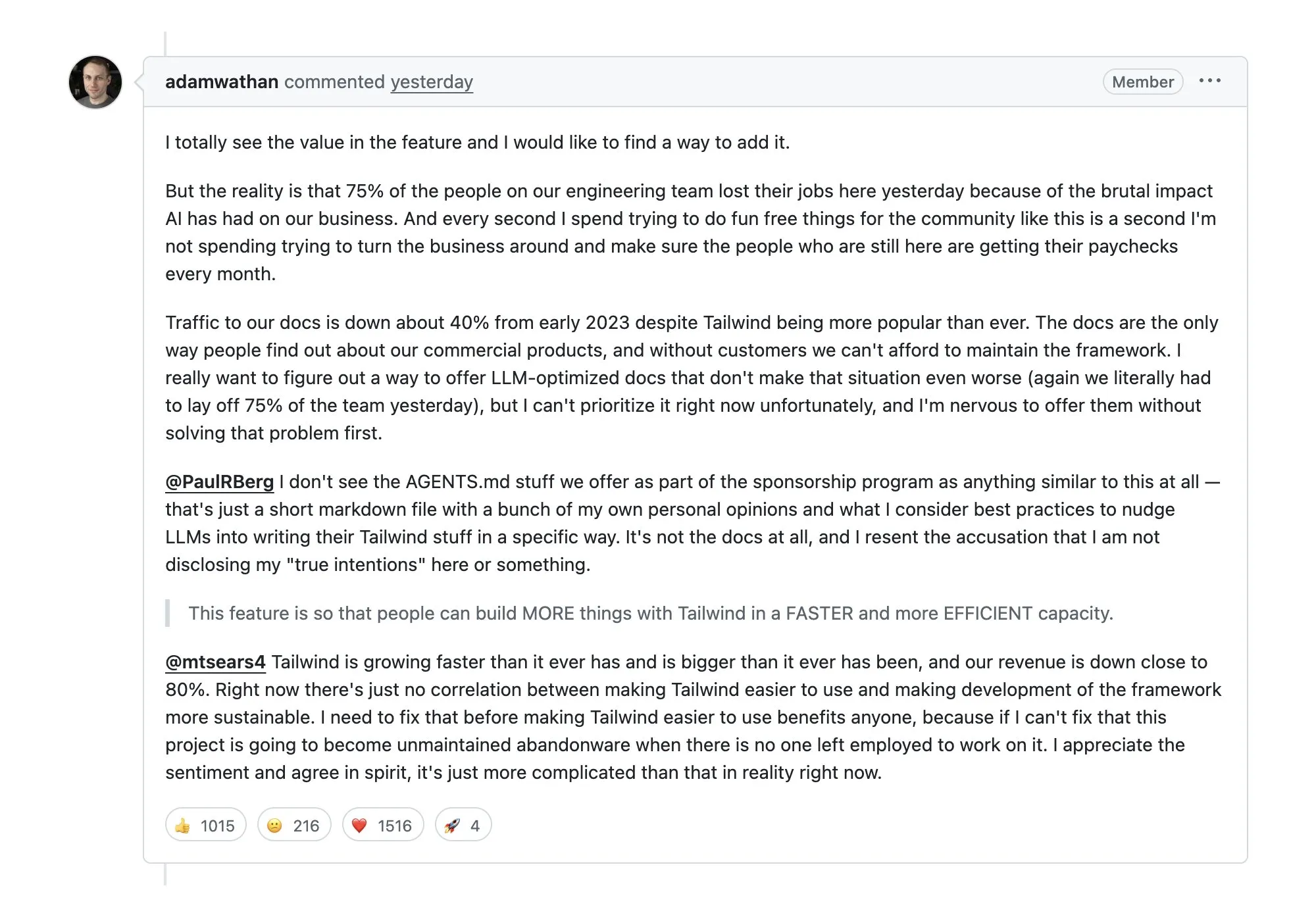
Tailwind裁员75%引发热议:AI导致文档流量与收入双降 : 知名CSS框架Tailwind因AI Agent广泛抓取其文档而导致官网流量下降40%,付费产品收入锐减,被迫裁员。这引发了社区对“AI寄生”开源生态的深度忧虑:当AI直接提供答案,开源项目的商业模式如何维系?(来源:aiamblichus)
100万token上下文是陷阱?社区讨论“中间丢失”效应 : 开发者测试发现,尽管模型宣称支持百万级上下文,但在处理10万级以上数据时,中间部分的召回率显著下降。社区建议采用“两步走”策略:先索引定位,再针对性输入。这表明,数据卫生和检索策略比单纯追求长窗口更重要(来源:Reddit)
Vibe Coding成为开发新趋势:从写代码到“调感觉” : 社区热议“Vibe Coding”,即利用自然语言和Agent进行非确定性开发。支持者认为这降低了门槛,反对者担心会产生大量不可维护的“代码垃圾”。Datawhale等机构已发布相关系统教程,帮助开发者从Demo转向AI原生程序开发(来源:dotey)
AI陪伴的边界:情绪价值外包引发伦理担忧 : 随着陪伴型AI市场突破千亿,社会开始审视其潜在风险。AI提供的“低冲突、高可控”互动可能削弱人类处理现实关系的能力,甚至引发“共同妄想型绑定”。专家呼吁,AI应作为情绪补充,而非人类关系的替代品(来源:36氪)
💡 其他
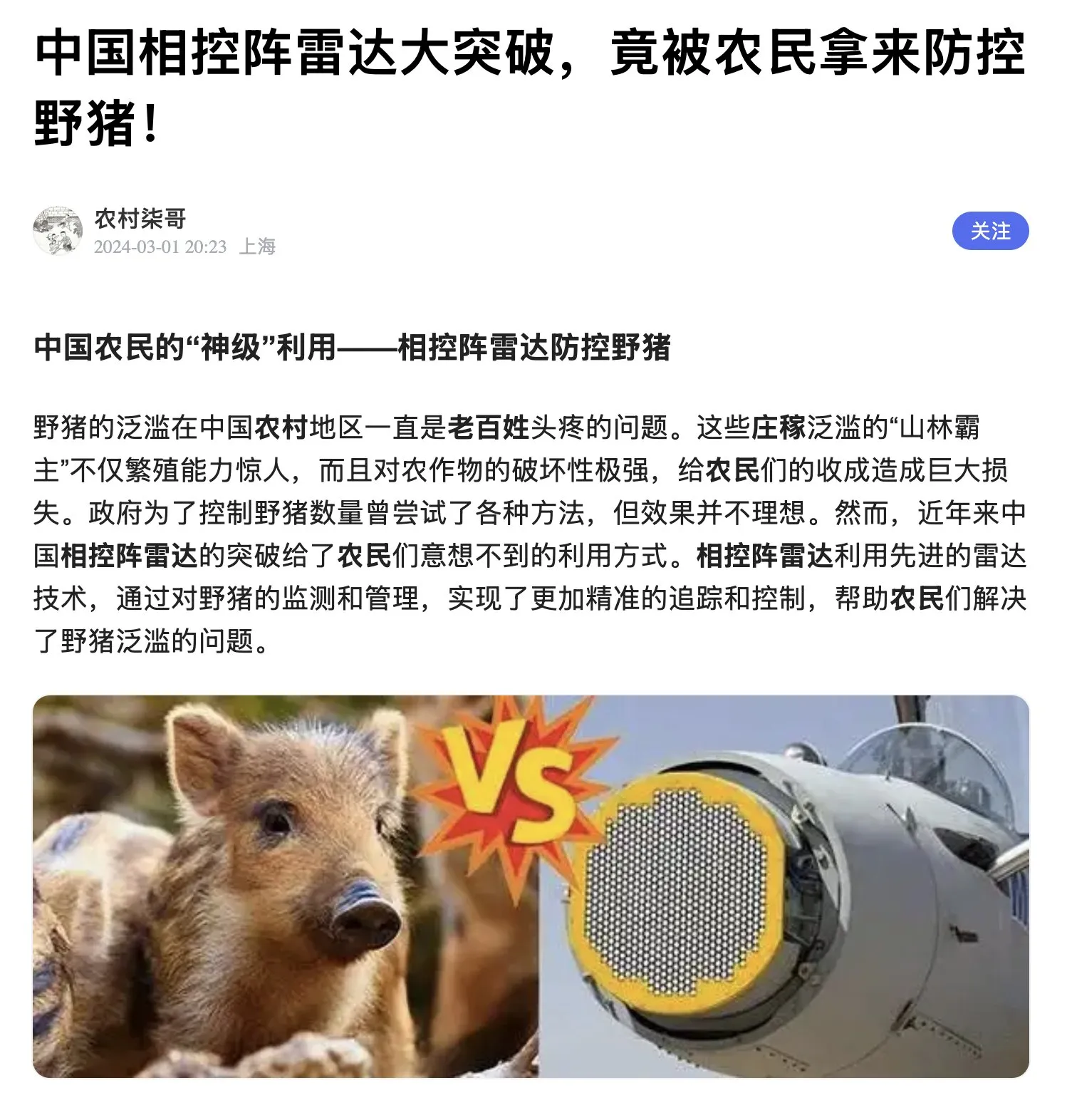
中国农民利用有源相控阵雷达防治野猪 : 随着相控阵雷达技术在中国的“白菜化”和民用化,农民开始配合无人机使用AESA雷达探测野猪侵扰。这一案例展示了高精尖军事技术降维打击民用痛点的奇特景观,也反映了中国在GaN半导体领域的产能优势(来源:teortaxesTex)
Cerebras“巧克力”芯片实物曝光:厚度惊人 : 开发者晒出了Cerebras晶圆级AI芯片的实物图,其巨大的体积和惊人的厚度引发围观。作为全球最大的单体芯片,它代表了算力硬件在极端性能追求下的物理极限探索(来源:dylan522p)

Debian数据保护团队全员离职,GDPR合规面临挑战 : 成立7年的Debian数据保护团队因精力有限集体卸任,目前无人接盘。这暴露了开源社区在应对严苛隐私监管(如GDPR)时的脆弱性,这种“隐形地基”的缺失可能波及整个Linux生态链(来源:36氪)