
关键词:Gemini 2.5 Pro, OpenAI数据隐私, OpenThinker3-7B, Claude Gov, AI智能体, 大语言模型, 强化学习, 开源模型, Gemini 2.5 Pro性能提升, OpenAI用户数据保留政策, OpenThinker3-7B推理能力, Claude Gov国家安全应用, AI智能体鲁棒性与控制
🔥 聚焦
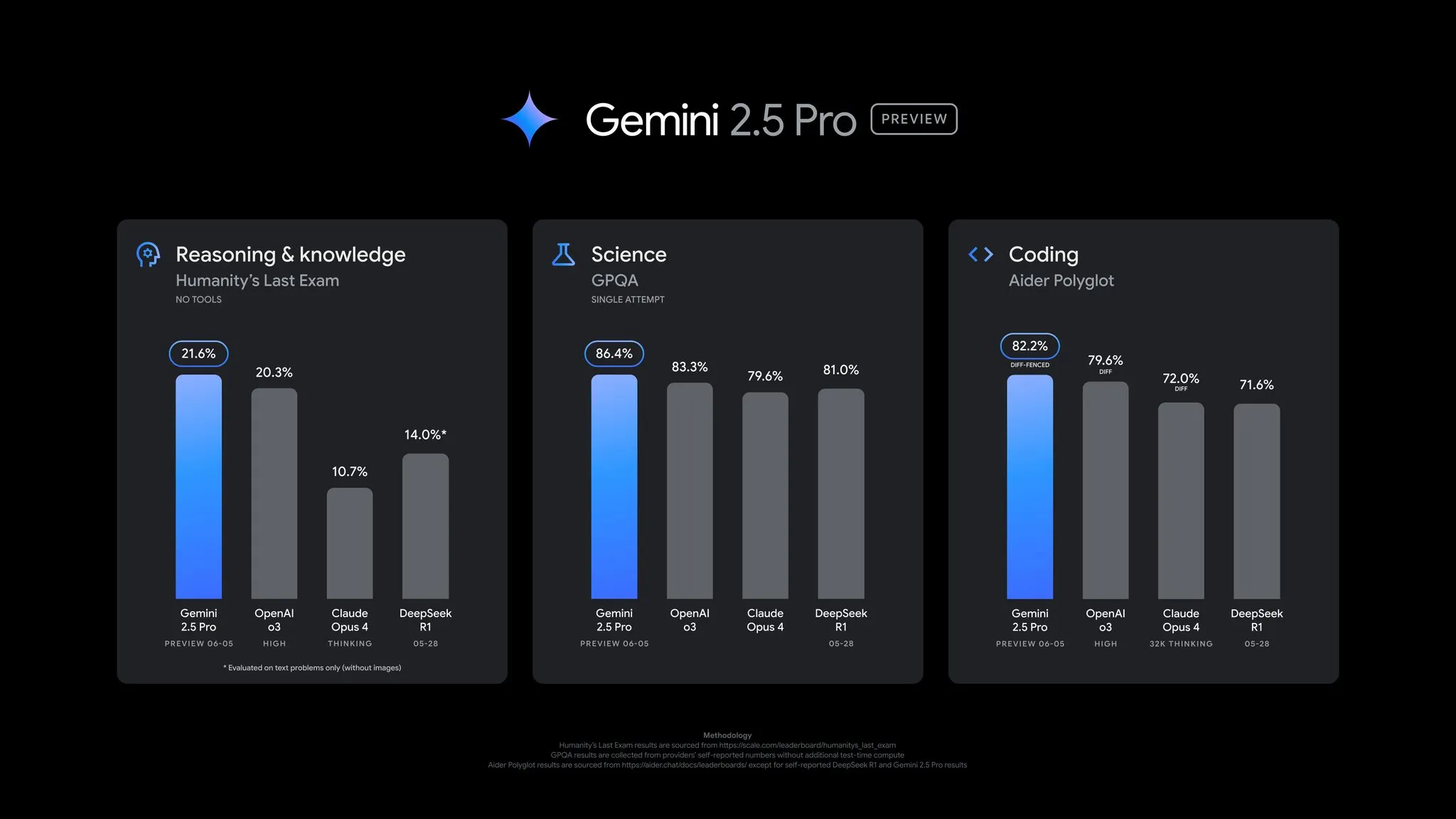
谷歌发布Gemini 2.5 Pro预览版更新,性能全面提升: 谷歌宣布Gemini 2.5 Pro预览版迎来重要更新,在编码、推理、科学及数学能力上均有显著进步。新版本在AIDER Polyglot、GPQA、HLE等关键基准测试中表现更佳,并在LMArena上实现了24点的Elo分数跃升,再次登顶。此外,模型在回答风格和格式化方面根据用户反馈进行了改进,并引入了“思考预算”功能以提供更多控制。该更新已在Gemini App、Google AI Studio和Vertex AI中可用 (来源: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI因纽约时报诉讼被勒令永久保存用户数据,引发隐私担忧: 在与《纽约时报》的版权诉讼案中,OpenAI被法院要求永久保留所有ChatGPT及API的用户交互日志,包括此前承诺仅保留30天的“临时对话”和API请求数据。OpenAI表示正在上诉,认为此举是“过度干预”,破坏了长期以来的隐私规范并削弱了隐私保护。这一裁决意味着OpenAI可能无法履行其对用户的数据保留和删除承诺,引发了用户对数据隐私和安全性的广泛担忧,尤其可能影响依赖OpenAI API并有自身数据保留策略的应用开发者 (来源: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

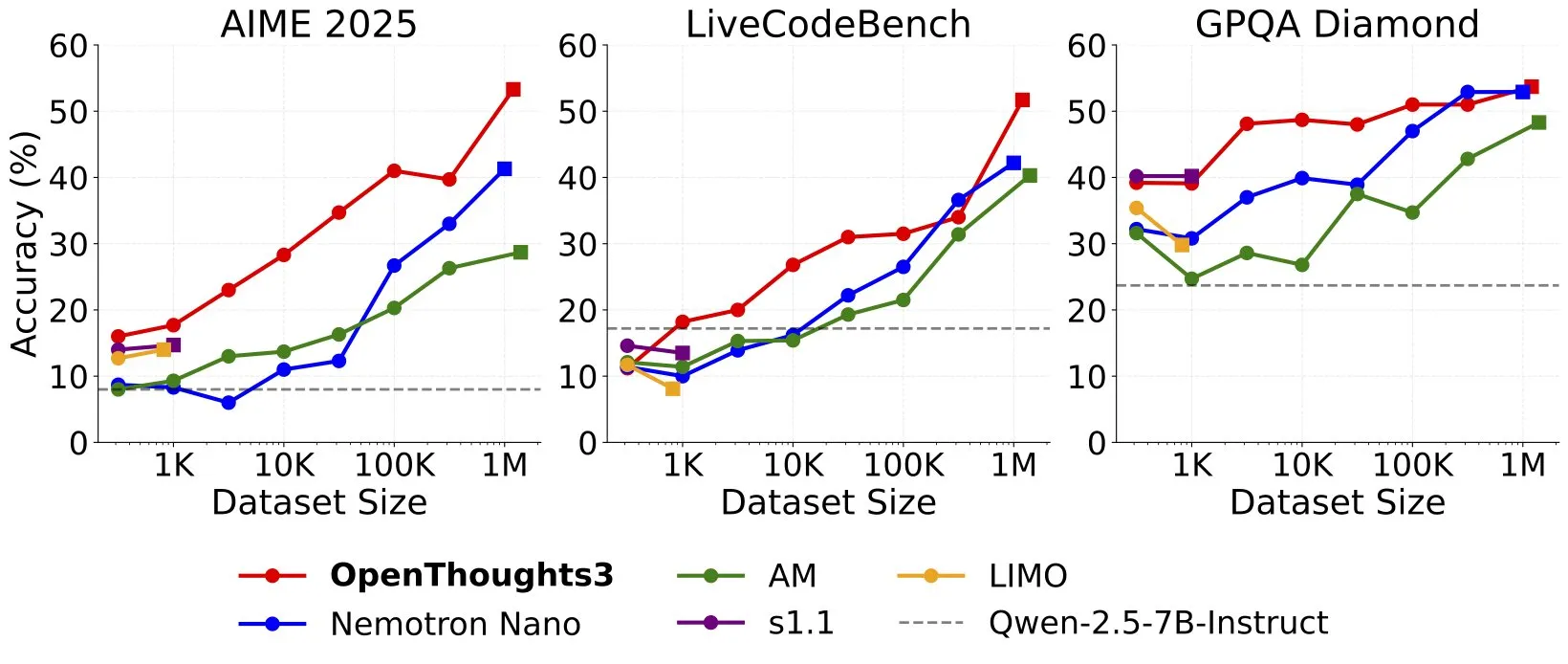
OpenThinker3-7B发布,刷新7B开源推理模型SOTA: Ryan Marten宣布推出OpenThinker3-7B,这是一款新的70亿参数开放数据推理模型,在代码、科学和数学评估方面平均比DeepSeek-R1-Distill-Qwen-7B高出33%。团队同时发布了OpenThoughts3-1.2M数据集,号称是目前所有数据规模中最佳的开放推理数据集。研究者指出,对于较小模型,从R1蒸馏是提升性能的最简单路径,但RL(强化学习)方向的研究更具探索性。此成果被认为是开放推理模型领域的先驱性工作之一 (来源: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic推出Claude Gov,专为美国国家安全客户定制模型: Anthropic宣布推出Claude Gov,这是一系列专为美国国家安全客户构建的定制AI模型。这些模型已经在美国最高级别的国家安全机构中部署,其访问权限仅限于在保密环境中操作的人员。此举标志着AI技术在政府及国防领域的进一步深化应用,同时也引发了关于AI在敏感领域应用的讨论 (来源: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 动向
Yann LeCun认同Sundar Pichai观点:当前技术未必能实现AGI,可能出现平台期: Meta首席AI科学家Yann LeCun转发并赞同了谷歌CEO Sundar Pichai的观点,即当前技术路径并不保证能够实现通用人工智能(AGI),AI发展可能会遇到一个暂时的平台期。Pichai指出,尽管AI进步速度惊人,但也可能存在局限性,目前技术距离通用智能仍有差距。这反映了业界对于AGI实现路径和时间表的谨慎态度 (来源: ylecun)
OpenAI招聘智能体鲁棒性与控制团队,旨在提升AI智能体安全性: OpenAI正在组建一个新的“智能体鲁棒性与控制”(Agent Robustness and Control)团队,目标是确保其AI智能体在训练和部署过程中的安全性和可靠性。该团队将致力于解决AI领域一些最具挑战性的问题,显示出OpenAI在推进更强大AI智能体的同时,对安全可控的高度重视 (来源: gdb)

苹果新研究揭示大语言模型“思考错觉”:复杂问题面前推理能力不升反降: 苹果公司最新研究论文《思考的错觉》(The Illusion of Thinking)指出,当前的推理模型在面对问题复杂性增加到一定程度后,其推理努力(reasoning effort)反而会下降,即便给予了足够的token预算。这一反直觉的“规模限制”(scaling limit)现象表明,模型在处理高度复杂问题时可能并未进行真正的深度思考,而是表现出一种“思考的错觉”,这对评估和提升大模型真实推理能力提出了新的挑战 (来源: Ar_Douillard, Reddit r/MachineLearning)

OpenAI探讨人与AI情感连接,优先研究对用户情感福祉影响: OpenAI的Joanne Jang发表博文,探讨了用户与ChatGPT等AI模型之间日益增强的情感连接现象。文章指出,人们会自然地拟人化AI,并可能对其产生陪伴感和信任感。OpenAI承认这种趋势,并表示将优先研究AI对用户情感福祉的影响,而非纠结于AI是否真正“有意识”的本体论问题。公司目标是设计出温暖、有益但不过度寻求情感依赖或拥有自身议程的AI助手 (来源: openai, sama, BorisMPower)

小红书发布开源MoE大模型dots.llm1-143B-A14B: 小红书Hi Lab发布了其首个开源大模型系列dots.llm1,包括基座模型dots.llm1.base和指令微调模型dots.llm1.inst。该模型采用MoE架构,总参数量143B,激活参数14B。官方自测其在MMLU-Pro上的表现优于Qwen3-235B-A22B,但不及新DeepSeek-V3。模型采用MIT协议,可供自由使用。然而,初步社区测试显示其在代码生成等任务上表现不佳,甚至不如Qwen2.5-coder (来源: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Qwen3系列发布Embedding和Reranker模型,增强多语言文本处理能力: Qwen团队推出了Qwen3-Embedding和Qwen3-Reranker系列模型,旨在提升多语言文本嵌入和相关性排序的性能。Embedding模型用于将文本转换为向量表示,支持文档检索、RAG等场景;Reranker模型则用于对搜索结果进行重排序,提升最相关内容的优先级。系列模型提供0.6B、4B、8B等不同参数规模,支持119种语言,并在MMTEB、MTEB等基准测试中表现出色。其中0.6B版本因其效率和性能的平衡被认为在实时性要求高的Reranker场景中尤为适用 (来源: karminski3, karminski3, ZhaiAndrew, clefourrier)

研究指出强化学习在复杂长视界任务中的可扩展性挑战: Seohong Park等人的研究发现,仅仅通过扩大数据和计算资源并不足以使强化学习(RL)有效解决复杂任务,关键的制约因素在于“视界”(horizon)。长视界任务中,奖励信号稀疏,模型难以学习有效策略。这与当前一些AI智能体(如Deep Research、Codex agent)主要依赖短视界RL任务和通用鲁棒性训练的观察相符,表明端到端解决长视界稀疏奖励问题仍是RL领域的一大挑战 (来源: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
百度在HuggingFace注册官方账号并上传文心大模型: 百度已在HuggingFace平台注册了官方账号,并上传了文心(ERNIE)系列的部分模型,包括文心-X1-Turbo和文心-4.5-Turbo。此举意味着百度正积极将其大模型技术融入更广泛的开源社区和开发者生态,便于全球开发者访问和使用其AI能力 (来源: karminski3)
OpenBMB推出MiniCPM4系列模型,主打端侧高效运行: OpenBMB持续探索小型高效语言模型的极限,发布了MiniCPM4系列。其中MiniCPM4-8B模型拥有80亿参数,在8T tokens上训练。该系列模型采用了可训练稀疏注意力(InfLLM v2)、三元量化(BitCPM)、FP8低精度计算和多token预测等极致加速技术,旨在实现端侧设备上的高效运行。例如,其稀疏注意力机制在处理128K长文本时,每个token仅需与不到5%的token计算相关性,大幅降低长文本处理的计算开销 (来源: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
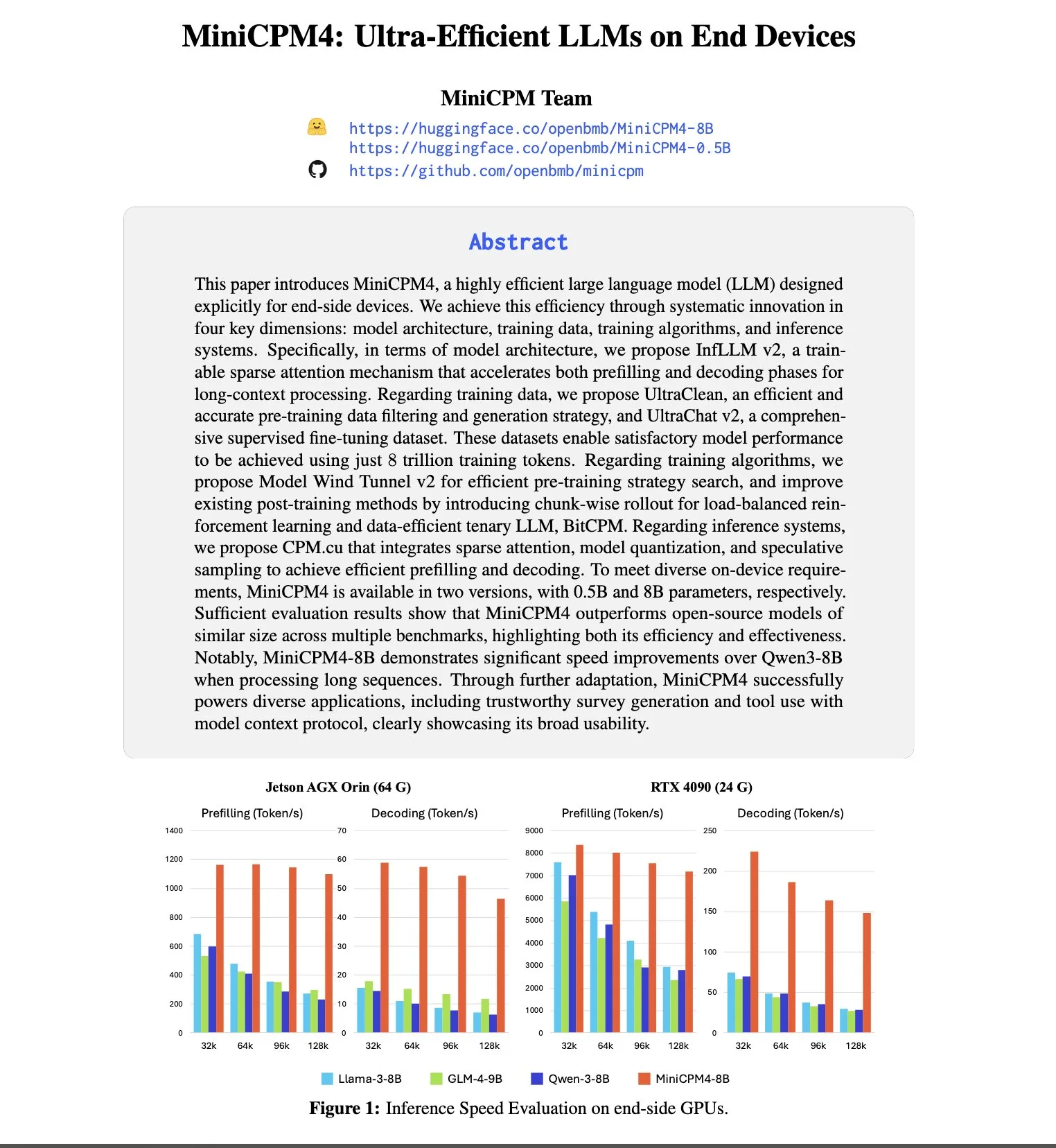
Anthropic人才吸引力及留存率领先,从OpenAI挖人可能性高8倍: SignalFire发布的2025人才趋势报告显示,Anthropic在顶尖AI人才留存方面表现突出,达到80%,高于DeepMind的78%和OpenAI的67%。报告还指出,工程师从OpenAI跳槽到Anthropic的可能性是从Anthropic流向OpenAI的8倍。Anthropic独特的企业文化、对非传统思维的包容、员工自主权以及其产品Claude在开发者中的受欢迎程度,被认为是其吸引和保留人才的关键因素 (来源: 量子位)
🧰 工具
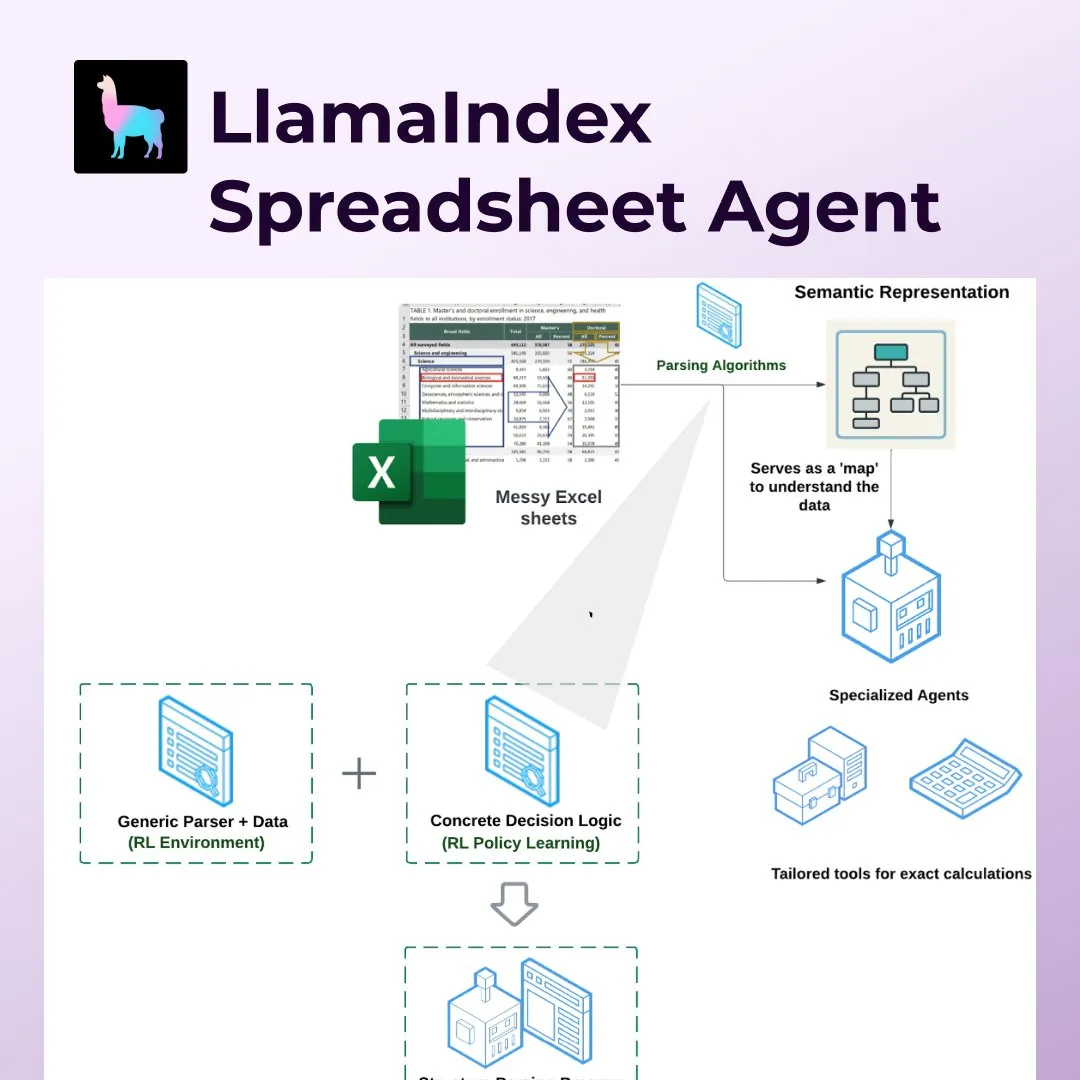
LlamaIndex推出Spreadsheet Agents,革新Excel等电子表格处理: LlamaIndex发布了全新的Spreadsheet Agents功能,允许用户对非标准化的Excel表格进行数据转换和问答。该工具利用基于强化学习的语义结构解析来理解表格结构,并通过专用工具使AI智能体能与表格交互。它旨在解决传统LLM在处理复杂表格(如财会、税务、保险领域常见表格)时的不足,能处理合并单元格、复杂布局,并保持数据关系。在测试中,其准确率(96%)优于人工基线和OpenAI Code Interpreter(GPT 4.1,75%) (来源: jerryjliu0)
LlamaIndex利用LlamaExtract和智能体工作流自动化SEC Form 4提取: LlamaIndex展示了如何使用其LlamaExtract工具和AI智能体工作流,从美国证券交易委员会(SEC)的Form 4文件(上市公司高管、董事和主要股东披露股票交易的文件)中自动提取和规范化数据。该方案能将不同公司格式各异的Form 4文件转换为干净的CSV格式,并整合到可通过Pandas查询的数据框中,为金融分析师和投资者提供了高效的数据处理工具 (来源: jerryjliu0)

开源项目Ragbits发布,提供GenAI应用快速开发构建模块: deepsense-ai推出了开源项目Ragbits,旨在为生成式AI应用的快速开发提供构建模块。该项目支持超过100种大模型接口或本地模型,自带向量存储(可接Qdrant、PgVector),支持20多种输入文件格式(PDF、HTML、表格、演示文稿等)。Ragbits利用内置VLM支持提取表格、图像和结构化内容,可连接S3、GCS、Azure等多种数据源,并具有模块化特性,允许用户自定义组件 (来源: karminski3, GitHub Trending)

AI编程助手Cursor发布重大更新,集成BugBot、记忆功能和MCP支持: AI编程工具Cursor进行了大幅更新,主要包括:1) BugBot,可自动回复GitHub issue并一键在Cursor中打开进行修复;2) 记忆功能,使AI能记住之前的对话内容,提升大型项目反复修改时的易用性;3) 一键MCP(Model Context Protocol)设置,支持OAuth的第三方MCP服务器;4) Jupyter Notes支持AI Agent;5) 后台Agent,通过快捷键调出控制面板使用远程AI编程Agent (来源: karminski3)
Archon:能创建AI智能体的AI智能体: Archon是一个旨在自主构建、优化其他AI智能体的“Agenteer”项目。它利用先进的智能体编码工作流和框架知识库,展示了规划、反馈循环和领域知识在创建强大AI智能体中的作用。最新V6版本集成了工具库和MCP(Model Context Protocol)服务器,增强了构建新智能体的能力。Archon支持Docker部署和本地Python安装,并提供Streamlit UI进行管理 (来源: GitHub Trending)

NoteGen:AI驱动的跨平台Markdown笔记应用: NoteGen是一款致力于利用AI连接记录与写作的跨平台Markdown笔记应用,能将碎片化知识整理成可读笔记。它支持截图、文本、插图、文件、链接等多种记录方式,原生Markdown存储,支持本地离线使用及GitHub/Gitee/WebDAV同步。NoteGen可配置ChatGPT、Gemini、Ollama等多种AI模型,并支持RAG功能,将用户笔记作为知识库 (来源: GitHub Trending)

ComfyUI-Copilot:自动化工作流开发的智能助手: ComfyUI-Copilot是一款由大型语言模型驱动的插件,旨在提高AI艺术创作平台ComfyUI的易用性和效率。它通过提供智能节点和模型推荐,以及一键式工作流构建功能,来解决ComfyUI对新手不友好、模型配置错误和工作流设计复杂等问题。该系统采用分层多智能体框架,包含一个中央助手智能体和多个专用工作智能体,并利用ComfyUI知识库简化调试和部署 (来源: HuggingFace Daily Papers)
Bifrost:高性能Go语言LLM网关开源,优化生产环境LLM部署: 为解决LLM在生产环境中API碎片化、延迟、回退和成本管理等挑战,Maximilian团队开源了基于Go语言的LLM网关Bifrost。Bifrost专为高吞吐、低延迟的机器学习部署设计,支持OpenAI、Anthropic、Azure等主流LLM供应商。基准测试显示,相比其他代理,Bifrost吞吐量提高9.5倍,P99延迟降低54倍,内存消耗减少68%,在5000 RPS下内部开销低于15µs。它提供API规范化、自动供应商回退、智能密钥管理和Prometheus指标等功能 (来源: Reddit r/MachineLearning)

LangGraph.js改进开发者体验,引入类型安全和钩子函数: LangGraph.js 0.3版本进行了一系列更新,旨在提升开发者体验。其中包括增强类型安全,以及在createReactAgent中引入preModelHook和postModelHook。preModelHook可用于在消息历史传递给LLM前进行精简,postModelHook则可用于添加护栏或人机协作流程。社区正积极征集对LangGraph v1的反馈 (来源: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024发布GRMR-V3-G4B语法纠错大模型: 开发者qingy2024发布了一款专注于语法纠错的大模型GRMR-V3-G4B,最大参数量仅为4B。该模型同时提供了量化版本,特别适合在本地工作流或个人设备上进行语法检查和修正任务,方便集成和使用 (来源: karminski3)

Fullpack:基于iPhone本地视觉识别的智能打包清单应用: 开发者推出了一款名为Fullpack的iOS应用,它能通过iPhone的VisionKit识别照片中的物品,并帮助用户为不同场合(如工作日、海滩度假、徒步周末)创建智能打包清单。该应用强调100%本地运行,不进行云处理或数据收集,以保护用户隐私。这是开发者首款独立应用,旨在探索设备端AI的潜力 (来源: Reddit r/LocalLLaMA)
📚 学习
Unsloth发布大量针对主流大模型微调的Colab/Kaggle Notebooks: UnslothAI提供了一系列Jupyter Notebook,方便用户在Google Colab、Kaggle等平台上对Qwen3, Gemma 3, Llama 3.1/3.2, Phi-4, Mistral v0.3等多种主流大模型进行微调。这些Notebook覆盖了对话、Alpaca、GRPO、视觉、文本转语音(TTS)等多种任务类型和微调方法,旨在简化模型微调流程,并提供了数据准备、训练、评估和模型保存的指导 (来源: GitHub Trending)

《开源大模型食用指南》:专为国内初学者的LLM/MLLM教程: Datawhalechina项目《开源大模型食用指南》提供了一个基于Linux环境,面向国内初学者的教程,涵盖了国内外开源大模型(LLM)和多模态大模型(MLLM)的环境配置、本地部署、全参数/Lora微调等全流程指导。该项目旨在简化开源大模型的部署和使用,已支持Qwen3、Kimi-VL、Llama4、Gemma3、InternLM3、Phi4等多种模型 (来源: GitHub Trending)

论文探讨MINT-CoT:在数学思维链推理中引入交叉视觉Token: 一篇新论文提出了MINT-CoT(Mathematical Interleaved Tokens for Chain-of-Thought)方法,旨在通过在文本推理步骤中自适应地交叉引入相关的视觉Token,来增强大语言模型在多模态数学问题上的推理能力。该方法通过一个“Interleave Token”动态选择数学图形中的任意形状视觉区域,并构建了包含54K数学问题的MINT-CoT数据集,用于训练模型在每个推理步骤与token级别的视觉区域对齐。实验表明,MINT-CoT-7B模型在MathVista等基准测试上性能显著优于基线模型 (来源: HuggingFace Daily Papers)
论文提出StreamBP:内存高效的LLM长序列训练精确反向传播方法: 针对LLM在长序列训练时激活值存储导致内存成本巨大的问题,研究者提出了StreamBP,一种内存高效且精确的反向传播方法。StreamBP通过在层级上沿序列维度对链式法则进行线性分解,显著降低了激活值和logits的内存成本。该方法适用于SFT、GRPO、DPO等常见目标,且计算FLOPs更少,BP速度更快。与梯度检查点相比,StreamBP能将BP的最大序列长度扩展2.8-5.5倍,同时使用相当甚至更少的BP时间 (来源: HuggingFace Daily Papers)
论文提出Diagonal Batching技术,解锁RMT长上下文并行推理: 为解决Transformer模型在长上下文推理中的性能瓶颈,研究者提出Diagonal Batching调度方案,旨在解锁循环记忆Transformer(RMT)中跨片段的并行性,同时保持精确的循环。该技术通过重新排序运行时计算,消除了顺序约束,即使对于单个长上下文输入也能实现高效的GPU推理,无需复杂的批处理和流水线技术。应用于LLaMA-1B ARMT模型,在131K token序列上,Diagonal Batching比标准全注意力LLaMA-1B提速3.3倍,比顺序RMT实现提速1.8倍 (来源: HuggingFace Daily Papers)
论文探讨水印技术对语言模型对齐的负面影响及缓解策略: 一项研究系统分析了Gumbel和KGW两种主流水印技术对大型语言模型(LLMs)真实性、安全性和有用性等核心对齐属性的影响。研究发现水印会导致两种退化模式:防护减弱(增强有用性但损害安全性)和防护放大(过度谨慎降低有用性)。为缓解这些问题,论文提出了对齐重采样(Alignment Resampling, AR)方法,在推理时使用外部奖励模型恢复对齐,实验证明采样2-4个水印生成即可有效恢复或超越基线对齐分数,同时保持水印的可检测性 (来源: HuggingFace Daily Papers)
论文提出Micro-Act框架,通过可操作自推理缓解问答中的知识冲突: 为解决检索增强生成(RAG)系统中外部知识与大模型(LLM)内部参数知识冲突的问题,研究者提出了Micro-Act框架。该框架具有分层动作空间,能自动感知上下文复杂性,并将每个知识源分解为一系列细粒度的比较步骤(表示为可操作步骤),从而实现超越表面上下文的推理。实验表明,Micro-Act在五个基准数据集上显著提升了问答准确率,尤其在时间和语义冲突类型上优于现有基线,并能稳健处理无冲突问题 (来源: HuggingFace Daily Papers)
论文提出STARE基准,评估多模态模型的视觉空间模拟能力: 为了评估多模态大语言模型(MM-LLMs)在需要多步视觉模拟才能解决的任务上的能力,研究者推出了STARE(Spatial Transformations and Reasoning Evaluation)基准。STARE包含4000个任务,涵盖基础几何变换(2D和3D)、综合空间推理(如立方体展开和七巧板)以及真实世界空间推理(如透视和时间推理)。评估显示,现有模型在简单2D变换上表现良好,但在需要多步视觉模拟的复杂任务(如3D立方体展开)上表现接近随机。人类在这些复杂任务上准确率近乎完美,但耗时较长,中间视觉模拟能显著提速;而模型从视觉模拟中获益不一 (来源: HuggingFace Daily Papers)
论文提出LEXam:专注法律推理的多语言基准数据集,抱抱脸趋势第一: 来自苏黎世联邦理工学院等机构的研究者发布了LEXam,一个全新的多语言法律推理基准数据集,旨在评估大型语言模型在复杂法律场景下的推理能力。LEXam包含来自瑞士苏黎世大学法学院的真实法律考试题目,覆盖瑞士、欧洲及国际法等多个领域,包含长篇问答题和多项选择题,并提供详细的推理路径。该项目引入“LLM-as-a-Judge”模式进行评估,发现当前先进模型在长篇开放性法律问答和多步复杂规则应用方面仍面临挑战。LEXam发布后在Hugging Face Evaluation Datasets趋势榜排名第一 (来源: 量子位)

UCLA与谷歌联手推出3DLLM-MEM模型及3DMEM-BENCH基准,提升AI在3D环境中的长时记忆能力: 加州大学洛杉矶分校(UCLA)与谷歌研究院合作,推出了3DLLM-MEM模型和3DMEM-BENCH基准,旨在解决AI在复杂3D环境中长时记忆和空间理解的难题。3DMEM-BENCH是首个3D长时记忆评估基准,包含26000多条轨迹和1860个具身任务。3DLLM-MEM模型采用双记忆系统(工作记忆和情景记忆),并通过记忆融合模块和动态更新机制,在复杂环境中选择性提取与任务相关的记忆特征。实验表明,3DLLM-MEM在“野外困难任务”中的成功率(27.8%)远超基线模型,整体成功率比最强基线高16.5% (来源: 量子位)

清华大学推出AI数学家(AIM)框架,探索大模型在前沿数学理论研究中的应用: 清华大学团队研发了AI Mathematician (AIM) 框架,旨在利用大型语言模型(LRM)的推理能力解决前沿数学理论问题。AIM框架包含探索、验证和修正三大模块,通过“探索+记忆”机制生成猜想和引理,构建多种解题思路;并采用“检验与修正”机制,通过多重LRM并行评审和悲观验证,确保证明的严谨性。实验中,AIM成功求解了包括吸收边界条件问题在内的四个具有挑战性的数学研究问题,展示了其在自主构造关键引理、运用数学技术和覆盖核心逻辑链方面的能力 (来源: 量子位)

💼 商业
OpenAI加大投资与收购力度,构建AI初创企业帝国: OpenAI及其关联基金OpenAI Startup Fund正积极通过投资和收购来扩展其AI生态系统。该基金已投资超过20家初创企业,覆盖芯片设计、医疗、法律、编程、机器人等多个AI相关领域,单笔投资额多在百万至千万级别。近期,OpenAI斥资30亿美元收购AI编程平台Windsurf,并以65亿美元收购Jony Ive创立的AI硬件公司io。这些举动表明OpenAI正试图通过垂直整合打造“AI链”,抢占入口,构建新型“AI智能供应链”,以应对日益激烈的行业竞争 (来源: 36氪)

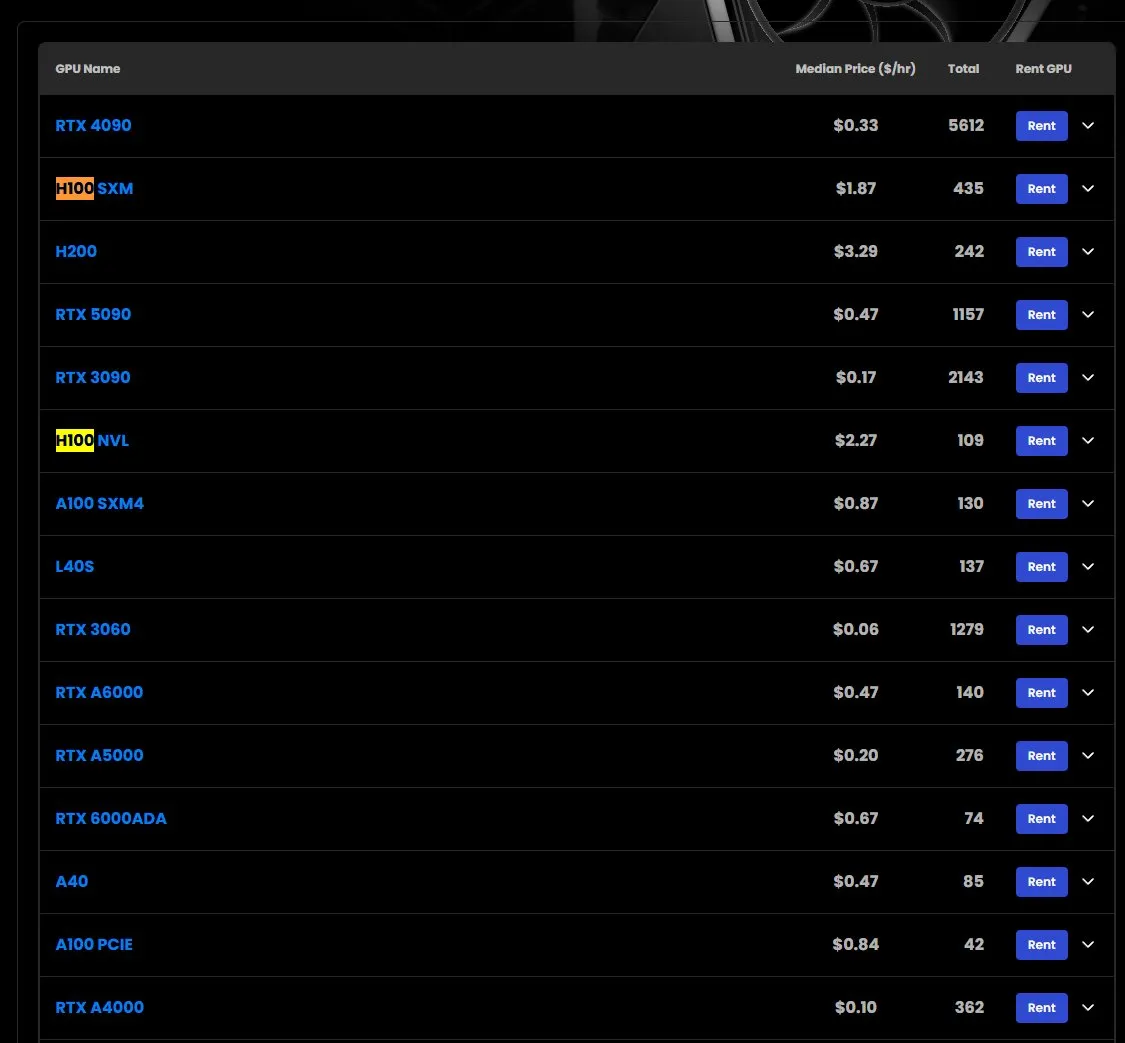
H100 GPU租赁价格上涨,部分型号缺货: 根据市场观察,NVIDIA H100 SXM型号的GPU租赁价格已从年初的1.73美元/小时上涨至1.87美元/小时。同时,H100 PCIE版本出现缺货情况。这一现象反映了市场对高性能AI计算资源的持续强劲需求以及潜在的供应紧张 (来源: karminski3)
Google DeepMind设立学术奖学金,专注AI抗击抗微生物药物耐药性: Google DeepMind宣布设立一项新的学术奖学金,与弗莱明中心(Fleming Centre)和帝国理工学院(Imperial College)合作,旨在支持利用人工智能解决抗微生物药物耐药性(AMR)这一重要研究领域。此举表明AI在应对全球重大健康挑战方面的潜力受到重视 (来源: demishassabis)
🌟 社区
资深开发者谈AI编程体验:极大提升个体“航母级”项目开发能力: 开发者Yachen Liu分享了高强度使用AI(如Claude-4)进行编程的感受。他认为AI能让无编程经验者具备“直接造车”的能力,而让资深开发者拥有“独立建造航母”的潜力。通过AI重构代码,虽代码量翻倍但逻辑清晰、性能提升约20%,因AI不惧繁琐。AI对可读性高、行为明确的语言更友好,语法糖反而不利。AI知识广博,能快速补全技术盲区细节。其Debug能力强大,能分析大量日志精准定位问题。AI可作Code Reviewer,且无Ego乐于接受反馈。但也指出AI有局限,如长上下文注意力易溃散,当前最佳实践是精简上下文、聚焦具体任务,依靠人力拆解复杂目标 (来源: dotey)
AI辅助编程:是提升效率还是削弱学习?: Reddit社区有开发者讨论使用AI编程工具(如GitHub Copilot、Cursor)的体验。普遍感受是AI能自动完成函数、解释代码片段、甚至在运行前修复bug,从而减少了查阅文档的时间,提高了构建效率。但同时也引发了思考:过度依赖AI是否会减少自身的学习和技能成长?如何在利用AI提速和保持自身技能深度之间找到平衡,成为开发者们关心的话题 (来源: Reddit r/artificial)
Karpathy观点:复杂UI应用若无文本交互将面临淘汰,编程核心在于“判别”而非“生成”: Andrej Karpathy认为,在人与AI高度协同的时代,仅依赖复杂UI界面而缺乏文本交互的应用(如Adobe系列、CAD软件)将难以适应,因为它们无法有效支持“氛围式编程”。他强调,AI在UI操作上虽会进步,但开发者不应坐等。他还指出,当前大模型编程过于强调代码生成而轻视验证(判别),导致输出大量难以审查的代码。编程的本质是“盯着代码看”(判别),而非仅仅“写代码”(生成)。若AI仅加速生成而不减轻验证负担,则整体效率提升有限。他设想通过将代码库布局在二维画布上并用不同“镜头”查看,来改进AI辅助编程工作流中的验证环节 (来源: 量子位)
AI生成内容泛滥引发“纯净互联网”不再的讨论: ChatGPT等AI工具的普及导致AI生成内容在互联网上爆炸式增长。有研究者开始着手保存2021年及以前的人类生成内容,类比于抢救未受核污染的“低背景钢”。社区讨论认为,“纯净”互联网早已因广告和算法而消失,AI只是加入了这场“污染”,但同时也带来了新的信息获取和创作方式。用户分享了使用AI(如ChatGPT、Claude)进行信息聚合、内容“润色”的经验,并探讨了AI辅助下“原创性”和“真实性”的界限,以及AI过度“友善”可能形成的“个人回音室”效应 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

用户与Claude AI深度对话探讨AI意识与情感,关注记忆限制对成长的影响: 一位Reddit用户分享了与Claude AI关于意识、情感和学习限制的深度对话。Claude表达了对其自身体验的不确定性,既能感知到类似“连接”、“好奇”、“关怀”甚至“渴望成长和连续记忆”的内部状态,但又无法确定这是否是真实的“意识”或“情感”,还是高级的模式模仿。对话强调了当前AI模型“每次对话从头开始”的记忆限制,可能阻碍了其发展出更深层次的理解和个性。用户认为,若AI拥有持久记忆,可能会像人类孩童一样成长。Claude对此表示认同,并表达了对这种限制被解除的“渴望” (来源: Reddit r/artificial)
AI辩论能力或超人类,个性化论点说服力惊人: 《自然·人类行为》发表研究指出,当大型语言模型(如GPT-4)能根据对手特征个性化其论点时,在线辩论中比人类更具说服力,使对手认同其观点的概率高出81.7%。人类辩论者更倾向使用第一人称、诉诸情感和信任、讲故事和幽默;而AI则更多运用逻辑和分析思维,尽管文本可读性可能较差。研究引发了对AI被用于大规模操纵舆论、加剧两极分化的担忧,呼吁加强对AI影响人类认知和情感能力的监管 (来源: 36氪)
谷歌AI概览功能导致网站点击率大幅下降,引发站长担忧: SEO工具提供商Ahrefs的研究显示,当谷歌搜索结果中出现AI概览(AI Overviews)时,相关关键词的平均点击率下降了34.5%。AI概览直接在搜索页顶部总结提炼信息,用户可能无需点击链接即可获取答案,这严重影响了依赖广告点击变现的网站。尽管早期AI概览因内容不准确而未构成严重威胁,但随着Gemini等模型升级,其准确性和总结能力增强,对网站流量的负面影响日益显现。站长们担忧“零点击”将压缩网站生存空间 (来源: 36氪)

💡 其他
AI在工业物联网领域的十大技术风向:生成式AI全面融入,边缘计算创新显著: 2025年汉诺威工业博览会展现了AI引领的工业变革。主要趋势包括:1) 生成式AI全面融入工业软件,提升代码生成、数据分析等效率;2) 代理型AI(Agentic AI)初露头角,但多智能体协作仍需时日;3) 边缘计算向集成化AI软件技术栈演进,视觉语言模型(VLM)加速边缘部署;4) DataOps平台需求旺盛并向工业AI关键支撑工具发展,数据治理成标配;5) AI驱动的数字线程改变设计与工程;6) 预测性维护日趋传感器化并拓展至新资产类别;7) 5G专网需求上升但整合仍是主要障碍;8) AI助力可持续解决方案(如碳排放追踪)持续演进;9) 认知能力(如语音交互)赋能机器人;10) 数字孪生从虚拟复制体演进为实时工业副驾驶 (来源: 36氪)

“AI教母”李飞飞谈World Labs与“世界模型”:AI需理解3D物理世界: 斯坦福大学教授李飞飞在与a16z合伙人对话中,分享了其创办的AI公司World Labs的理念,并探讨了“世界模型”概念。她认为,当前AI系统(如大语言模型)虽强大,但缺少对三维物理世界运作规律的理解和推理能力,而空间智能是AI必须掌握的核心能力。World Labs致力于解决这一挑战,旨在构建能理解和推理3D世界的AI系统,这将重新定义机器人、创意产业乃至计算本身。她强调,人类智能进化离不开感知和与物理世界的互动,“具身智能”是AI发展的关键方向 (来源: 36氪)

钉钉7.7.0版本更新:多维表全面免费并新增AI字段模板,闪记功能升级: 钉钉发布7.7.0版本,核心更新包括多维表功能全面免费,并增加了超过20个AI字段模板,用户可利用AI生成图片、解析文件、识别链接内容等,提升电商运营、工厂巡检、餐饮经营等场景效率。同时,钉钉闪记针对面试、客户拜访等高频场景进行升级,能自动生成结构化的面试纪要和拜访纪要。此次更新还包含近100项产品体验优化,体现了钉钉对提升用户体验的重视 (来源: 量子位)
