
Anahtar Kelimeler:Gemini 2.5 Pro, OpenAI veri gizliliği, OpenThinker3-7B, Claude Gov, Yapay zeka ajanı, Büyük dil modeli, Pekiştirmeli öğrenme, Açık kaynak model, Gemini 2.5 Pro performans artışı, OpenAI kullanıcı verisi saklama politikası, OpenThinker3-7B çıkarım yeteneği, Claude Gov ulusal güvenlik uygulamaları, Yapay zeka ajanı sağlamlık ve kontrol, Gemini 2.5 Pro performans iyileştirmeleri, OpenAI veri koruma politikaları, OpenThinker3-7B akıl yürütme becerileri, Claude Gov devlet güvenlik kullanımları, Yapay zeka ajanı dayanıklılık ve yönetim
🔥 Öne Çıkanlar
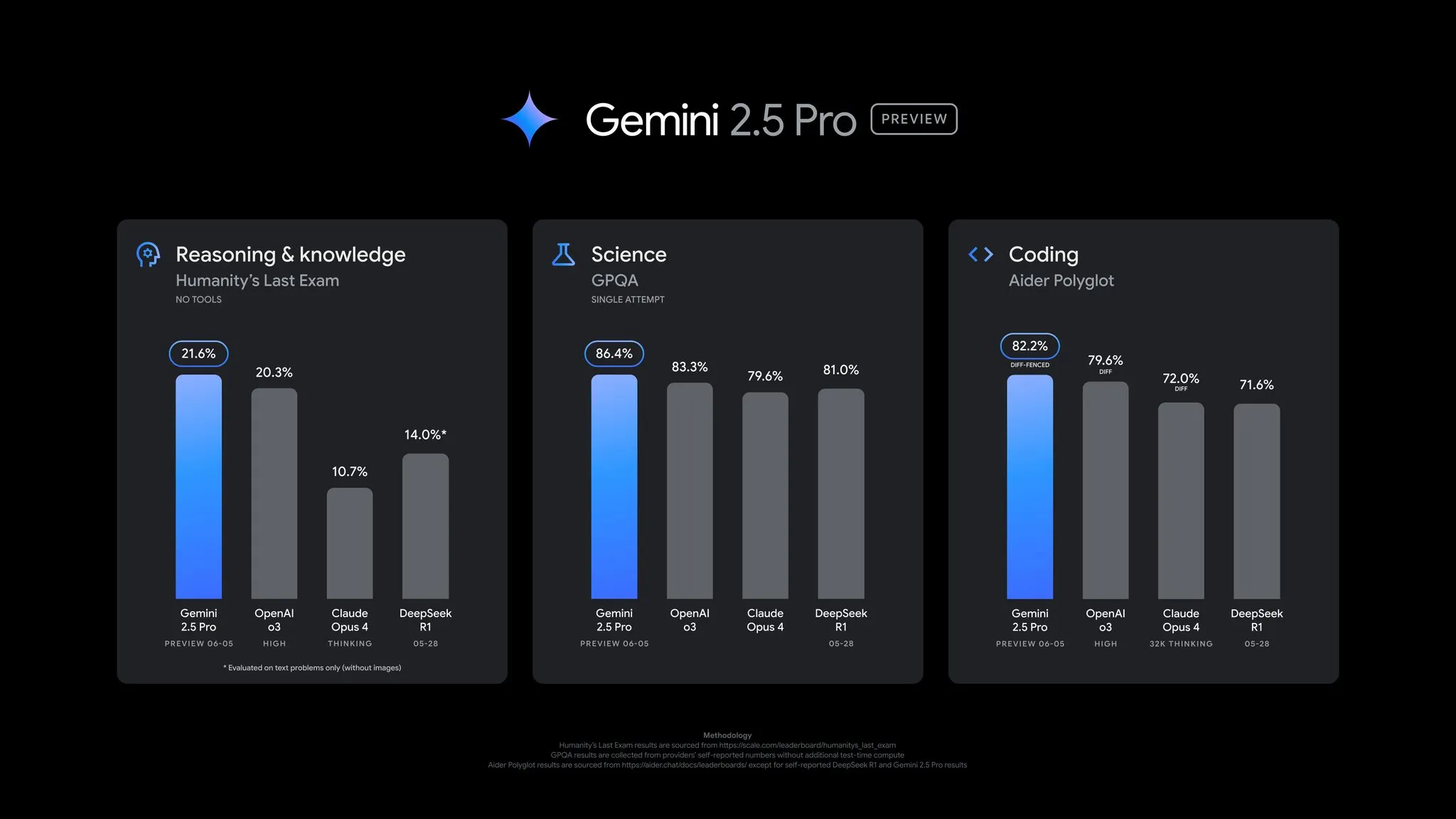
Google, Gemini 2.5 Pro önizleme sürümü güncellemesini duyurdu, performans kapsamlı bir şekilde iyileştirildi: Google, Gemini 2.5 Pro önizleme sürümünün kodlama, çıkarım yapma, bilimsel ve matematiksel yeteneklerde önemli gelişmeler içeren büyük bir güncelleme aldığını duyurdu. Yeni sürüm, AIDER Polyglot, GPQA, HLE gibi önemli kıyaslama testlerinde daha iyi performans gösterdi ve LMArena’da 24 puanlık bir Elo artışı sağlayarak yeniden zirveye yerleşti. Ayrıca, modelin yanıt stili ve formatlaması kullanıcı geri bildirimlerine göre iyileştirildi ve daha fazla kontrol sağlamak için bir “düşünme bütçesi” özelliği eklendi. Bu güncelleme Gemini App, Google AI Studio ve Vertex AI’da kullanıma sunuldu (Kaynak: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI, New York Times davası nedeniyle kullanıcı verilerini kalıcı olarak saklamaya mahkum edildi, gizlilik endişeleri arttı: New York Times ile olan telif hakkı davasında, mahkeme OpenAI’nin tüm ChatGPT ve API kullanıcı etkileşim günlüklerini, daha önce yalnızca 30 gün saklama sözü verdiği “geçici konuşmalar” ve API istek verileri de dahil olmak üzere kalıcı olarak saklamasını istedi. OpenAI, bu kararın “aşırı müdahale” olduğunu, uzun süredir devam eden gizlilik normlarını baltaladığını ve gizlilik korumasını zayıflattığını belirterek temyize gittiğini açıkladı. Bu karar, OpenAI’nin kullanıcılara yönelik veri saklama ve silme taahhütlerini yerine getiremeyebileceği anlamına geliyor ve özellikle OpenAI API’sine güvenen ve kendi veri saklama politikalarına sahip uygulama geliştiricilerini etkileyebilecek şekilde, kullanıcıların veri gizliliği ve güvenliği konusunda yaygın endişelere yol açtı (Kaynak: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

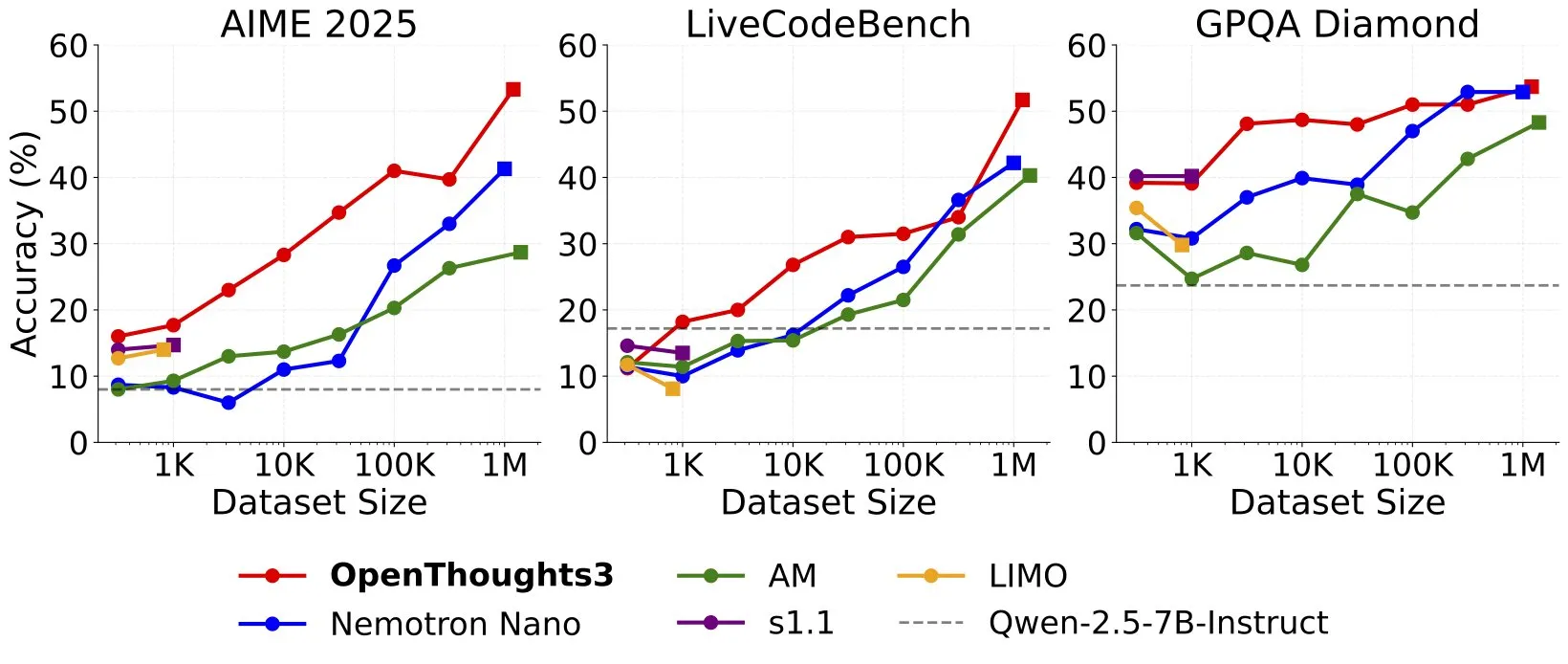
OpenThinker3-7B yayınlandı, 7B açık kaynak çıkarım modeli SOTA’yı yeniledi: Ryan Marten, kod, bilim ve matematik değerlendirmelerinde DeepSeek-R1-Distill-Qwen-7B’den ortalama %33 daha yüksek performans gösteren yeni bir 7 milyar parametreli açık veri çıkarım modeli olan OpenThinker3-7B’yi duyurdu. Ekip ayrıca, mevcut tüm veri ölçekleri arasında en iyi açık çıkarım veri seti olduğunu iddia ettikleri OpenThoughts3-1.2M veri setini de yayınladı. Araştırmacılar, daha küçük modeller için R1 damıtmanın performansı artırmanın en kolay yolu olduğunu, ancak RL (Pekiştirmeli Öğrenme) yönündeki araştırmaların daha keşifsel olduğunu belirtiyorlar. Bu başarı, açık çıkarım modeli alanındaki öncü çalışmalardan biri olarak kabul ediliyor (Kaynak: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic, ABD ulusal güvenlik müşterileri için özel olarak geliştirilmiş Claude Gov modelini tanıttı: Anthropic, ABD ulusal güvenlik müşterileri için özel olarak oluşturulmuş bir dizi yapay zeka modeli olan Claude Gov’u duyurdu. Bu modeller halihazırda ABD’nin en üst düzey ulusal güvenlik kurumlarında konuşlandırılmış olup, erişimleri yalnızca gizli ortamlarda çalışan personelle sınırlıdır. Bu hamle, yapay zeka teknolojisinin hükümet ve savunma alanlarındaki uygulamalarının daha da derinleştiğini gösterirken, aynı zamanda yapay zekanın hassas alanlardaki uygulamalarına ilişkin tartışmaları da beraberinde getiriyor (Kaynak: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 Gelişmeler
Yann LeCun, Sundar Pichai’nin görüşüne katıldı: Mevcut teknoloji AGI’yi gerçekleştiremeyebilir, bir plato dönemi yaşanabilir: Meta Baş Yapay Zeka Bilimcisi Yann LeCun, Google CEO’su Sundar Pichai’nin mevcut teknoloji yolunun Genel Yapay Zeka’yı (AGI) gerçekleştirmeyi garanti etmediği ve yapay zeka gelişiminin geçici bir plato dönemiyle karşılaşabileceği yönündeki görüşünü paylaştı ve onayladı. Pichai, yapay zekanın ilerleme hızının şaşırtıcı olmasına rağmen sınırlamaları olabileceğini ve mevcut teknolojinin genel zekadan hala uzak olduğunu belirtti. Bu, sektörün AGI’nin gerçekleştirilme yolu ve zaman çizelgesi konusundaki temkinli tutumunu yansıtıyor (Kaynak: ylecun)
OpenAI, yapay zeka ajanlarının güvenliğini artırmak amacıyla Ajan Sağlamlığı ve Kontrolü ekibi için işe alım yapıyor: OpenAI, yapay zeka ajanlarının eğitim ve dağıtım süreçlerinde güvenlik ve güvenilirliğini sağlamak amacıyla yeni bir “Ajan Sağlamlığı ve Kontrolü” (Agent Robustness and Control) ekibi kuruyor. Bu ekip, yapay zeka alanındaki en zorlu sorunlardan bazılarını çözmeye odaklanacak ve OpenAI’nin daha güçlü yapay zeka ajanları geliştirirken güvenlik ve kontrol edilebilirliğe verdiği yüksek önemi gösteriyor (Kaynak: gdb)

Apple’ın yeni araştırması büyük dil modellerindeki “düşünme yanılsamasını” ortaya koydu: Karmaşık sorunlar karşısında çıkarım yeteneği artmak yerine azalıyor: Apple’ın son araştırma makalesi “Düşünmenin Yanılsaması” (The Illusion of Thinking), mevcut çıkarım modellerinin, sorun karmaşıklığı belirli bir seviyeye ulaştıktan sonra, yeterli token bütçesi verilse bile çıkarım çabalarının (reasoning effort) azaldığını belirtiyor. Bu sezgiye aykırı “ölçeklenme sınırı” (scaling limit) olgusu, modellerin son derece karmaşık sorunları ele alırken gerçek anlamda derinlemesine düşünmek yerine bir “düşünme yanılsaması” sergilediğini gösteriyor ve bu da büyük modellerin gerçek çıkarım yeteneklerini değerlendirme ve geliştirme konusunda yeni zorluklar ortaya koyuyor (Kaynak: Ar_Douillard, Reddit r/MachineLearning)

OpenAI, insan ve yapay zeka arasındaki duygusal bağı tartışıyor, kullanıcıların duygusal refahı üzerindeki etkiyi öncelikli olarak araştırıyor: OpenAI’den Joanne Jang, kullanıcılar ile ChatGPT gibi yapay zeka modelleri arasında artan duygusal bağ olgusunu ele alan bir blog yazısı yayınladı. Makale, insanların doğal olarak yapay zekayı kişileştirdiğini ve ona karşı arkadaşlık ve güven duygusu geliştirebileceğini belirtiyor. OpenAI bu eğilimi kabul ediyor ve yapay zekanın gerçekten “bilinçli” olup olmadığına dair ontolojik sorulardan ziyade, yapay zekanın kullanıcıların duygusal refahı üzerindeki etkisini araştırmaya öncelik vereceğini ifade ediyor. Şirketin hedefi, sıcak, faydalı ancak aşırı duygusal bağımlılık aramayan veya kendi gündemine sahip olmayan yapay zeka yardımcıları tasarlamak (Kaynak: openai, sama, BorisMPower)

Xiaohongshu, açık kaynak MoE büyük dil modeli dots.llm1-143B-A14B’yi yayınladı: Xiaohongshu Hi Lab, temel model dots.llm1.base ve komut ince ayarlı model dots.llm1.inst’i içeren ilk açık kaynak büyük dil modeli serisi dots.llm1’i yayınladı. Model, MoE mimarisini kullanıyor, toplam parametre sayısı 143B ve aktif parametre sayısı 14B. Resmi testlere göre MMLU-Pro’da Qwen3-235B-A22B’den daha iyi performans gösteriyor ancak yeni DeepSeek-V3 kadar iyi değil. Model, MIT lisansı altında serbest kullanıma sunulmuştur. Ancak, ilk topluluk testleri, kod üretimi gibi görevlerde performansının düşük olduğunu, hatta Qwen2.5-coder’dan bile kötü olduğunu gösteriyor (Kaynak: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Qwen3 serisi, çok dilli metin işleme yeteneklerini geliştirmek için Embedding ve Reranker modellerini yayınladı: Qwen ekibi, çok dilli metin gömme ve alaka sıralaması performansını artırmayı amaçlayan Qwen3-Embedding ve Qwen3-Reranker model serilerini tanıttı. Embedding modeli, metni vektör temsiline dönüştürmek için kullanılır ve belge alımı, RAG gibi senaryoları destekler; Reranker modeli ise arama sonuçlarını yeniden sıralayarak en alakalı içeriğin önceliğini artırmak için kullanılır. Model serisi 0.6B, 4B, 8B gibi farklı parametre ölçekleri sunar, 119 dili destekler ve MMTEB, MTEB gibi kıyaslama testlerinde başarılı performans gösterir. 0.6B sürümü, verimliliği ve performans dengesi nedeniyle özellikle gerçek zamanlılık gerektiren Reranker senaryolarında uygun kabul edilir (Kaynak: karminski3, karminski3, ZhaiAndrew, clefourrier)

Araştırma, pekiştirmeli öğrenmenin karmaşık uzun ufuklu görevlerdeki ölçeklenebilirlik zorluklarına işaret ediyor: Seohong Park ve arkadaşlarının yaptığı araştırma, yalnızca veri ve hesaplama kaynaklarını artırmanın pekiştirmeli öğrenmenin (RL) karmaşık görevleri etkili bir şekilde çözmesi için yeterli olmadığını, temel kısıtlayıcı faktörün “ufuk” (horizon) olduğunu ortaya koydu. Uzun ufuklu görevlerde ödül sinyalleri seyrektir ve modelin etkili stratejiler öğrenmesi zordur. Bu, Deep Research, Codex agent gibi bazı mevcut yapay zeka ajanlarının temel olarak kısa ufuklu RL görevlerine ve genel sağlamlık eğitimine dayandığı gözlemiyle tutarlıdır ve uzun ufuklu seyrek ödül sorunlarını uçtan uca çözmenin RL alanında hala büyük bir zorluk olduğunu göstermektedir (Kaynak: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu, HuggingFace’te resmi hesap açtı ve Wenxin (ERNIE) büyük dil modellerini yükledi: Baidu, HuggingFace platformunda resmi bir hesap açtı ve Wenxin (ERNIE) serisinin Wenxin-X1-Turbo ve Wenxin-4.5-Turbo dahil olmak üzere bazı modellerini yükledi. Bu hamle, Baidu’nun büyük dil modeli teknolojisini daha geniş bir açık kaynak topluluğuna ve geliştirici ekosistemine aktif olarak entegre ettiğini ve küresel geliştiricilerin yapay zeka yeteneklerine erişimini ve kullanımını kolaylaştırdığını gösteriyor (Kaynak: karminski3)
OpenBMB, uç cihazlarda verimli çalışmayı hedefleyen MiniCPM4 model serisini tanıttı: OpenBMB, küçük ve verimli dil modellerinin sınırlarını keşfetmeye devam ederek MiniCPM4 serisini yayınladı. MiniCPM4-8B modeli 8 milyar parametreye sahip ve 8T token üzerinde eğitildi. Bu model serisi, eğitilebilir seyrek dikkat (InfLLM v2), üçlü niceleme (BitCPM), FP8 düşük hassasiyetli hesaplama ve çoklu token tahmini gibi aşırı hızlandırma teknolojilerini kullanarak uç cihazlarda verimli çalışmayı hedefliyor. Örneğin, seyrek dikkat mekanizması 128K uzunluğundaki metinleri işlerken her token için yalnızca %5’ten az token ile alaka hesaplaması yaparak uzun metin işlemenin hesaplama yükünü önemli ölçüde azaltıyor (Kaynak: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
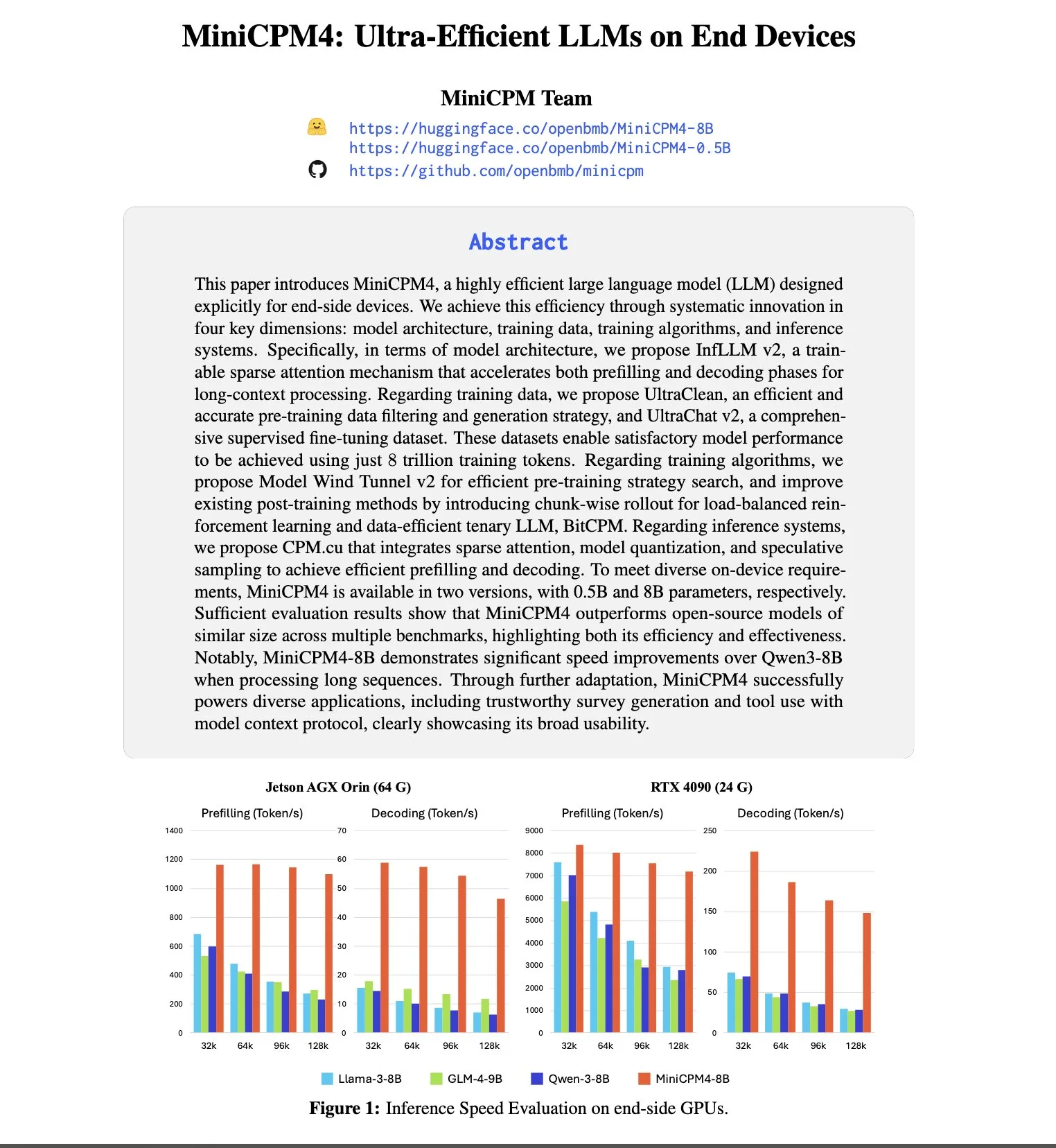
Anthropic, yetenek çekiciliği ve elde tutma oranında lider, OpenAI’den personel alma olasılığı 8 kat daha yüksek: SignalFire’ın yayınladığı 2025 Yetenek Trendleri raporu, Anthropic’in en iyi yapay zeka yeteneklerini elde tutma konusunda %80 ile DeepMind (%78) ve OpenAI’nin (%67) önünde olduğunu gösteriyor. Rapor ayrıca, mühendislerin OpenAI’den Anthropic’e geçme olasılığının, Anthropic’ten OpenAI’ye geçme olasılığından 8 kat daha yüksek olduğunu belirtiyor. Anthropic’in benzersiz şirket kültürü, geleneksel olmayan düşünceye açıklığı, çalışan özerkliği ve ürünü Claude’un geliştiriciler arasındaki popülaritesi, yetenekleri çekme ve elde tutmadaki kilit faktörler olarak kabul ediliyor (Kaynak: 量子位)
🧰 Araçlar
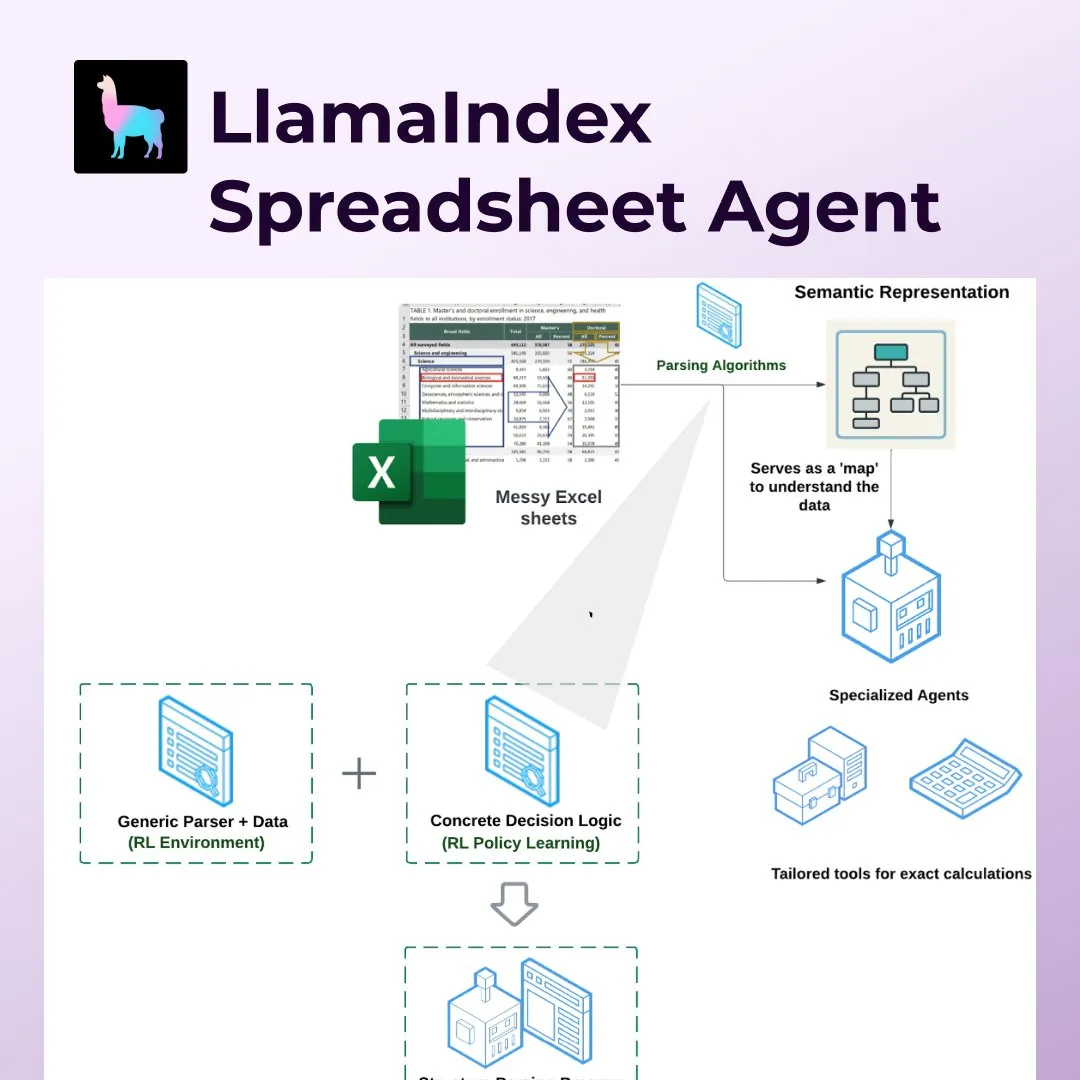
LlamaIndex, Excel gibi elektronik tabloların işlenmesinde devrim yaratan Spreadsheet Agents’ı tanıttı: LlamaIndex, kullanıcıların standart olmayan Excel tablolarında veri dönüştürme ve soru-cevap yapmalarına olanak tanıyan yepyeni Spreadsheet Agents özelliğini yayınladı. Bu araç, tablo yapısını anlamak için pekiştirmeli öğrenmeye dayalı semantik yapı ayrıştırmayı kullanır ve özel araçlar aracılığıyla yapay zeka ajanlarının tablolarla etkileşim kurmasını sağlar. Geleneksel LLM’lerin karmaşık tabloları (muhasebe, vergi, sigorta alanlarında sıkça rastlanan tablolar gibi) işlemedeki eksikliklerini gidermeyi amaçlar, birleştirilmiş hücreleri, karmaşık düzenleri işleyebilir ve veri ilişkilerini koruyabilir. Testlerde, doğruluk oranı (%96) manuel taban çizgisi ve OpenAI Code Interpreter’dan (GPT 4.1, %75) daha iyiydi (Kaynak: jerryjliu0)
LlamaIndex, LlamaExtract ve ajan iş akışlarını kullanarak SEC Form 4 çıkarımını otomatikleştiriyor: LlamaIndex, ABD Menkul Kıymetler ve Borsa Komisyonu’nun (SEC) Form 4 dosyalarından (halka açık şirket yöneticileri, direktörleri ve ana hissedarlarının hisse senedi işlemlerini açıkladığı dosyalar) verileri otomatik olarak çıkarmak ve normalleştirmek için LlamaExtract aracını ve yapay zeka ajan iş akışlarını nasıl kullandığını gösterdi. Bu çözüm, farklı şirketlerin çeşitli formatlardaki Form 4 dosyalarını temiz CSV formatına dönüştürebilir ve Pandas ile sorgulanabilen bir veri çerçevesine entegre edebilir, böylece finans analistleri ve yatırımcılar için verimli bir veri işleme aracı sunar (Kaynak: jerryjliu0)

Açık kaynak proje Ragbits yayınlandı, GenAI uygulamalarının hızlı geliştirilmesi için yapı taşları sunuyor: deepsense-ai, üretken yapay zeka uygulamalarının hızlı geliştirilmesi için yapı taşları sağlamayı amaçlayan açık kaynak proje Ragbits’i tanıttı. Proje, 100’den fazla büyük dil modeli arayüzünü veya yerel modeli destekler, kendi vektör depolamasına sahiptir (Qdrant, PgVector’a bağlanabilir) ve 20’den fazla giriş dosyası formatını (PDF, HTML, tablolar, sunumlar vb.) destekler. Ragbits, tabloları, görüntüleri ve yapılandırılmış içeriği çıkarmak için yerleşik VLM’yi kullanır, S3, GCS, Azure gibi çeşitli veri kaynaklarına bağlanabilir ve kullanıcıların bileşenleri özelleştirmesine olanak tanıyan modüler özelliklere sahiptir (Kaynak: karminski3, GitHub Trending)

Yapay zeka programlama asistanı Cursor, BugBot, hafıza özelliği ve MCP desteği ile büyük bir güncelleme yayınladı: Yapay zeka programlama aracı Cursor, önemli güncellemeler aldı. Başlıcaları: 1) GitHub issue’larına otomatik yanıt verebilen ve tek tıklamayla Cursor’da açıp düzeltme yapabilen BugBot; 2) Yapay zekanın önceki konuşma içeriklerini hatırlamasını sağlayarak büyük projelerde tekrarlayan değişikliklerde kullanım kolaylığını artıran hafıza özelliği; 3) OAuth destekli üçüncü taraf MCP (Model Context Protocol) sunucuları için tek tıklamayla MCP ayarı; 4) Jupyter Notes için yapay zeka ajanı desteği; 5) Kısayol tuşuyla kontrol panelini çağırarak uzaktaki yapay zeka programlama ajanını kullanabilen arka plan ajanı (Kaynak: karminski3)
Archon: Yapay zeka ajanları oluşturabilen yapay zeka ajanı: Archon, diğer yapay zeka ajanlarını otonom olarak oluşturmayı ve optimize etmeyi amaçlayan bir “Agenteer” projesidir. Gelişmiş ajan kodlama iş akışlarını ve çerçeve bilgi tabanını kullanarak, güçlü yapay zeka ajanları oluşturmada planlama, geri bildirim döngüleri ve alan bilgisinin rolünü gösterir. En son V6 sürümü, yeni ajanlar oluşturma yeteneğini artıran araç kütüphanesi ve MCP (Model Context Protocol) sunucusunu entegre eder. Archon, Docker dağıtımını ve yerel Python kurulumunu destekler ve yönetim için bir Streamlit UI sunar (Kaynak: GitHub Trending)

NoteGen: Yapay zeka destekli, platformlar arası Markdown not uygulaması: NoteGen, yapay zekayı kullanarak kayıt tutma ile yazmayı birleştirmeye adanmış, platformlar arası bir Markdown not uygulamasıdır ve dağınık bilgileri okunabilir notlar halinde düzenleyebilir. Ekran görüntüleri, metin, çizimler, dosyalar, bağlantılar gibi çeşitli kayıt yöntemlerini destekler, yerel Markdown depolama kullanır, yerel çevrimdışı kullanımı ve GitHub/Gitee/WebDAV senkronizasyonunu destekler. NoteGen, ChatGPT, Gemini, Ollama gibi çeşitli yapay zeka modelleriyle yapılandırılabilir ve kullanıcı notlarını bilgi tabanı olarak kullanan RAG işlevini destekler (Kaynak: GitHub Trending)

ComfyUI-Copilot: İş akışı geliştirmeyi otomatikleştiren akıllı asistan: ComfyUI-Copilot, yapay zeka sanat yaratma platformu ComfyUI’nin kullanım kolaylığını ve verimliliğini artırmayı amaçlayan, büyük dil modelleri tarafından desteklenen bir eklentidir. Akıllı düğüm ve model önerileri ile tek tıklamayla iş akışı oluşturma özellikleri sunarak ComfyUI’nin yeni başlayanlar için kullanıcı dostu olmaması, model yapılandırma hataları ve karmaşık iş akışı tasarımı gibi sorunları çözer. Sistem, merkezi bir asistan ajanı ve birden fazla özel çalışma ajanı içeren katmanlı bir çoklu ajan çerçevesi kullanır ve hata ayıklama ile dağıtımı basitleştirmek için ComfyUI bilgi tabanından yararlanır (Kaynak: HuggingFace Daily Papers)
Bifrost: Üretim ortamında LLM dağıtımını optimize eden yüksek performanslı Go dili LLM ağ geçidi açık kaynak olarak yayınlandı: LLM’lerin üretim ortamlarındaki API parçalanması, gecikme, geri dönüş ve maliyet yönetimi gibi zorluklarını çözmek için Maximilian ekibi, Go dilinde yazılmış LLM ağ geçidi Bifrost’u açık kaynak olarak yayınladı. Bifrost, yüksek verim ve düşük gecikmeli makine öğrenimi dağıtımları için özel olarak tasarlanmıştır ve OpenAI, Anthropic, Azure gibi başlıca LLM sağlayıcılarını destekler. Kıyaslama testleri, diğer proxy’lere kıyasla Bifrost’un verimi 9.5 kat artırdığını, P99 gecikmesini 54 kat azalttığını, bellek tüketimini %68 düşürdüğünü ve 5000 RPS’de dahili ek yükün 15µs’nin altında olduğunu göstermektedir. API normalleştirme, otomatik sağlayıcı geri dönüşü, akıllı anahtar yönetimi ve Prometheus metrikleri gibi özellikler sunar (Kaynak: Reddit r/MachineLearning)

LangGraph.js geliştirici deneyimini iyileştiriyor, tür güvenliği ve kanca fonksiyonlarını tanıtıyor: LangGraph.js 0.3 sürümü, geliştirici deneyimini iyileştirmeyi amaçlayan bir dizi güncelleme aldı. Bunlar arasında geliştirilmiş tür güvenliği ve createReactAgent’e preModelHook ve postModelHook’un eklenmesi yer alıyor. preModelHook, mesaj geçmişi LLM’ye iletilmeden önce sadeleştirmek için kullanılabilirken, postModelHook ise koruma önlemleri veya insan-makine işbirliği süreçleri eklemek için kullanılabilir. Topluluk, LangGraph v1 için aktif olarak geri bildirim topluyor (Kaynak: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024, GRMR-V3-G4B dil bilgisi düzeltme büyük dil modelini yayınladı: Geliştirici qingy2024, dil bilgisi düzeltmeye odaklanan GRMR-V3-G4B adlı bir büyük dil modeli yayınladı. Modelin maksimum parametre sayısı yalnızca 4B. Model aynı zamanda nicelenmiş bir sürüm de sunuyor ve özellikle yerel iş akışlarında veya kişisel cihazlarda dil bilgisi kontrolü ve düzeltme görevleri için uygun olup, entegrasyonu ve kullanımı kolaylaştırıyor (Kaynak: karminski3)

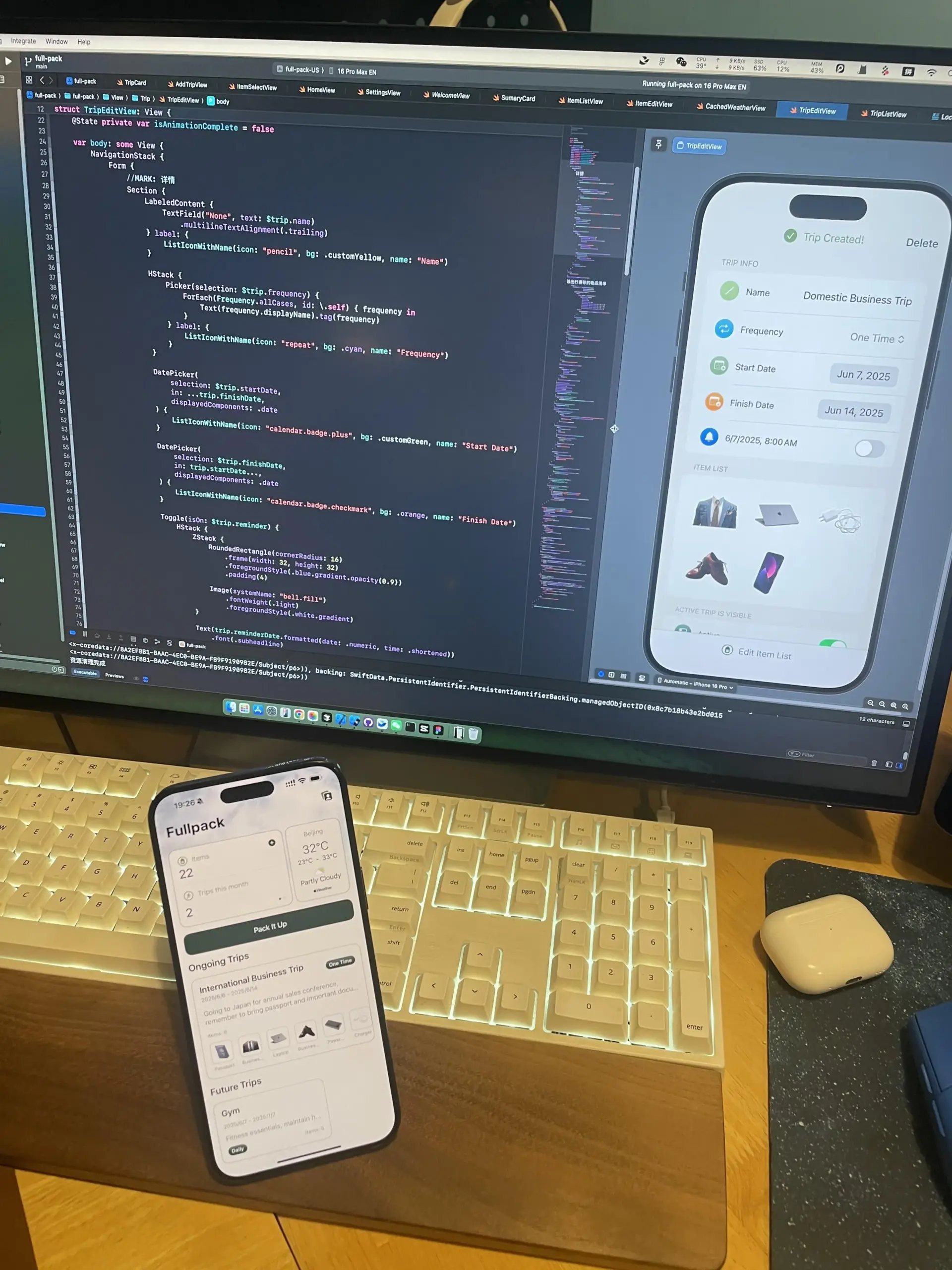
Fullpack: iPhone’un yerel görsel tanıma özelliğine dayalı akıllı paketleme listesi uygulaması: Bir geliştirici, iPhone’un VisionKit’i aracılığıyla fotoğraflardaki eşyaları tanıyabilen ve kullanıcıların iş günü, plaj tatili, doğa yürüyüşü hafta sonu gibi farklı durumlar için akıllı paketleme listeleri oluşturmasına yardımcı olan Fullpack adlı bir iOS uygulaması yayınladı. Uygulama, kullanıcı gizliliğini korumak için %100 yerel olarak çalıştığını, bulut işleme veya veri toplama yapmadığını vurguluyor. Bu, geliştiricinin ilk bağımsız uygulaması olup, cihaz üzerinde yapay zekanın potansiyelini keşfetmeyi amaçlıyor (Kaynak: Reddit r/LocalLLaMA)
📚 Öğrenme Kaynakları
Unsloth, başlıca büyük dil modellerinin ince ayarı için çok sayıda Colab/Kaggle Notebook’u yayınladı: UnslothAI, kullanıcıların Google Colab, Kaggle gibi platformlarda Qwen3, Gemma 3, Llama 3.1/3.2, Phi-4, Mistral v0.3 gibi çeşitli başlıca büyük dil modellerinde ince ayar yapmalarını kolaylaştıran bir dizi Jupyter Notebook sunmaktadır. Bu Notebook’lar, diyalog, Alpaca, GRPO, görsel, metinden sese (TTS) gibi çeşitli görev türlerini ve ince ayar yöntemlerini kapsamakta olup, model ince ayar süreçlerini basitleştirmeyi ve veri hazırlama, eğitim, değerlendirme ve model kaydetme konularında rehberlik sağlamayı amaçlamaktadır (Kaynak: GitHub Trending)

“Açık Kaynak Büyük Dil Modeli Kullanım Kılavuzu”: Yerli yeni başlayanlar için LLM/MLLM eğitimi: Datawhalechina projesi “Açık Kaynak Büyük Dil Modeli Kullanım Kılavuzu”, Linux ortamına dayalı, yerli yeni başlayanlara yönelik bir eğitim sunmaktadır. Bu eğitim, yerli ve yabancı açık kaynak büyük dil modellerinin (LLM) ve çok modlu büyük dil modellerinin (MLLM) ortam yapılandırması, yerel dağıtımı, tam parametre/Lora ince ayarı gibi tüm süreçleri kapsamaktadır. Proje, açık kaynak büyük dil modellerinin dağıtımını ve kullanımını basitleştirmeyi amaçlamakta olup, halihazırda Qwen3, Kimi-VL, Llama4, Gemma3, InternLM3, Phi4 gibi çeşitli modelleri desteklemektedir (Kaynak: GitHub Trending)

Makale, matematiksel düşünce zinciri çıkarımında çapraz görsel tokenlerin tanıtıldığı MINT-CoT’yi tartışıyor: Yeni bir makale, metin çıkarım adımlarına uyarlanabilir bir şekilde ilgili görsel tokenleri çapraz olarak dahil ederek büyük dil modellerinin çok modlu matematik problemlerindeki çıkarım yeteneğini artırmayı amaçlayan MINT-CoT (Mathematical Interleaved Tokens for Chain-of-Thought) yöntemini önermektedir. Bu yöntem, bir “Interleave Token” aracılığıyla matematiksel grafiklerdeki herhangi bir şekilsel görsel alanı dinamik olarak seçer ve modelin her çıkarım adımında token düzeyindeki görsel alanlarla hizalanmasını eğitmek için 54K matematik problemi içeren MINT-CoT veri setini oluşturur. Deneyler, MINT-CoT-7B modelinin MathVista gibi kıyaslama testlerinde temel modellerden önemli ölçüde daha iyi performans gösterdiğini ortaya koymuştur (Kaynak: HuggingFace Daily Papers)
Makale, LLM’lerin uzun dizili eğitiminde bellek verimli ve hassas geri yayılım yöntemi olan StreamBP’yi öneriyor: LLM’lerin uzun dizili eğitimi sırasında aktivasyon değeri depolamasının neden olduğu büyük bellek maliyeti sorununa yönelik olarak araştırmacılar, bellek verimli ve hassas bir geri yayılım yöntemi olan StreamBP’yi önerdi. StreamBP, katman düzeyinde dizi boyutu boyunca zincir kuralını doğrusal olarak ayrıştırarak aktivasyon değerleri ve logitlerin bellek maliyetini önemli ölçüde azaltır. Bu yöntem, SFT, GRPO, DPO gibi yaygın hedefler için uygundur ve daha az hesaplama FLOP’u ile daha hızlı BP hızına sahiptir. Gradyan kontrol noktalarına kıyasla StreamBP, BP’nin maksimum dizi uzunluğunu 2.8-5.5 kat artırabilirken, aynı veya daha az BP süresi kullanır (Kaynak: HuggingFace Daily Papers)
Makale, RMT uzun bağlamlı paralel çıkarımın kilidini açan Diagonal Batching tekniğini öneriyor: Transformer modellerinin uzun bağlamlı çıkarımdaki performans darboğazını çözmek için araştırmacılar, tekrarlayan bellek Transformer’ında (RMT) parçalar arası paralelliğin kilidini açarken hassas tekrarlamayı korumayı amaçlayan Diagonal Batching zamanlama şemasını önerdi. Bu teknik, çalışma zamanı hesaplamalarını yeniden sıralayarak sıralı kısıtlamaları ortadan kaldırır ve tek bir uzun bağlamlı girdi için bile karmaşık toplu işleme ve boru hattı tekniklerine gerek kalmadan verimli GPU çıkarımı sağlar. LLaMA-1B ARMT modeline uygulandığında, 131K token dizisinde Diagonal Batching, standart tam dikkatli LLaMA-1B’den 3.3 kat, sıralı RMT uygulamasından ise 1.8 kat daha hızlıdır (Kaynak: HuggingFace Daily Papers)
Makale, filigran teknolojisinin dil modeli hizalaması üzerindeki olumsuz etkilerini ve azaltma stratejilerini tartışıyor: Bir çalışma, Gumbel ve KGW olmak üzere iki ana filigran teknolojisinin büyük dil modellerinin (LLM’ler) gerçeklik, güvenlik ve kullanışlılık gibi temel hizalama özellikleri üzerindeki etkisini sistematik olarak analiz etti. Araştırma, filigranların iki bozulma modeline yol açtığını buldu: korumanın zayıflaması (kullanışlılığı artırır ancak güvenliği zedeler) ve korumanın artması (aşırı ihtiyatlılık kullanışlılığı azaltır). Bu sorunları azaltmak için makale, çıkarım sırasında hizalamayı geri yüklemek için harici bir ödül modeli kullanan Hizalama Yeniden Örnekleme (Alignment Resampling, AR) yöntemini öneriyor. Deneyler, 2-4 filigranlı üretimin örneklenmesinin temel hizalama puanlarını etkili bir şekilde geri yüklediğini veya aştığını ve aynı zamanda filigranın saptanabilirliğini koruduğunu göstermiştir (Kaynak: HuggingFace Daily Papers)
Makale, soru-cevaplamada bilgi çatışmasını azaltmak için eyleme geçirilebilir öz-çıkarım yoluyla Micro-Act çerçevesini öneriyor: Alıntı Destekli Üretim (RAG) sistemlerinde harici bilgi ile büyük dil modelinin (LLM) dahili parametrik bilgisi arasındaki çatışma sorununu çözmek için araştırmacılar Micro-Act çerçevesini önerdi. Bu çerçeve, bağlam karmaşıklığını otomatik olarak algılayabilen ve her bilgi kaynağını bir dizi ince taneli karşılaştırma adımına (eyleme geçirilebilir adımlar olarak temsil edilir) ayrıştırabilen hiyerarşik bir eylem alanına sahiptir, böylece yüzeysel bağlamın ötesinde çıkarım sağlar. Deneyler, Micro-Act’in beş kıyaslama veri setinde soru-cevaplama doğruluğunu önemli ölçüde artırdığını, özellikle zaman ve anlamsal çatışma türlerinde mevcut temel çizgilerden daha iyi performans gösterdiğini ve çatışmasız sorunları sağlam bir şekilde ele alabildiğini göstermiştir (Kaynak: HuggingFace Daily Papers)
Makale, çok modlu modellerin görsel-uzamsal simülasyon yeteneğini değerlendirmek için STARE kıyaslamasını öneriyor: Çok modlu büyük dil modellerinin (MM-LLM’ler) çözmek için çok adımlı görsel simülasyon gerektiren görevlerdeki yeteneğini değerlendirmek amacıyla araştırmacılar STARE (Spatial Transformations and Reasoning Evaluation) kıyaslamasını başlattı. STARE, temel geometrik dönüşümleri (2D ve 3D), kapsamlı uzamsal çıkarımı (küp açılımı ve tangram gibi) ve gerçek dünya uzamsal çıkarımını (perspektif ve zamansal çıkarım gibi) kapsayan 4000 görev içerir. Değerlendirme, mevcut modellerin basit 2D dönüşümlerde iyi performans gösterdiğini, ancak 3D küp açılımı gibi çok adımlı görsel simülasyon gerektiren karmaşık görevlerde rastgele performansa yakın olduğunu göstermektedir. İnsanlar bu karmaşık görevlerde neredeyse mükemmel doğruluk oranına sahipken, daha uzun sürede tamamlamakta ve ara görsel simülasyon hızı önemli ölçüde artırmaktadır; modeller ise görsel simülasyondan farklı derecelerde faydalanmaktadır (Kaynak: HuggingFace Daily Papers)
Makale, hukuksal çıkarıma odaklanan çok dilli bir kıyaslama veri seti olan LEXam’ı öneriyor, Hugging Face trendlerinde birinci sırada: ETH Zürih gibi kurumlardan araştırmacılar, büyük dil modellerinin karmaşık hukuksal senaryolardaki çıkarım yeteneklerini değerlendirmek amacıyla tasarlanmış yeni, çok dilli bir hukuksal çıkarım kıyaslama veri seti olan LEXam’ı yayınladı. LEXam, Zürih Üniversitesi Hukuk Fakültesi’nden gerçek hukuk sınavı sorularını içerir ve İsviçre, Avrupa ve uluslararası hukuk gibi çeşitli alanları kapsar. Uzun cevaplı sorular ve çoktan seçmeli sorular içerir ve ayrıntılı çıkarım yolları sunar. Proje, değerlendirme için “Yargıç Olarak LLM” (LLM-as-a-Judge) modelini kullanır ve mevcut gelişmiş modellerin uzun, açık uçlu hukuksal soru-cevaplama ve çok adımlı karmaşık kural uygulama konularında hala zorluklarla karşılaştığını tespit etmiştir. LEXam, yayınlandıktan sonra Hugging Face Değerlendirme Veri Setleri trend listesinde birinci sıraya yerleşti (Kaynak: 量子位)

UCLA ve Google, yapay zekanın 3D ortamlarda uzun süreli bellek yeteneğini geliştirmek için 3DLLM-MEM modelini ve 3DMEM-BENCH kıyaslamasını başlattı: Kaliforniya Üniversitesi, Los Angeles (UCLA) ve Google Araştırma, yapay zekanın karmaşık 3D ortamlarda uzun süreli bellek ve uzamsal anlama zorluklarını çözmek amacıyla 3DLLM-MEM modelini ve 3DMEM-BENCH kıyaslamasını başlattı. 3DMEM-BENCH, 26.000’den fazla yörünge ve 1860 somutlaşmış görev içeren ilk 3D uzun süreli bellek değerlendirme kıyaslamasıdır. 3DLLM-MEM modeli, ikili bir bellek sistemi (çalışma belleği ve epizodik bellek) kullanır ve bellek birleştirme modülü ile dinamik güncelleme mekanizması aracılığıyla karmaşık ortamlarda görevle ilgili bellek özelliklerini seçici olarak çıkarır. Deneyler, 3DLLM-MEM’in “zorlu saha görevleri”ndeki başarı oranının (%27.8) temel modellerden çok daha yüksek olduğunu ve genel başarı oranının en güçlü temel çizgiden %16.5 daha yüksek olduğunu göstermektedir (Kaynak: 量子位)

Tsinghua Üniversitesi, büyük dil modellerinin ileri matematik teorisi araştırmalarındaki uygulamalarını keşfetmek için Yapay Zeka Matematikçisi (AIM) çerçevesini başlattı: Tsinghua Üniversitesi ekibi, büyük dil modellerinin (LRM) çıkarım yeteneklerini kullanarak ileri matematik teorisi sorunlarını çözmeyi amaçlayan Yapay Zeka Matematikçisi (AIM) çerçevesini geliştirdi. AIM çerçevesi, keşif, doğrulama ve düzeltme olmak üzere üç ana modül içerir. “Keşif + Bellek” mekanizması aracılığıyla varsayımlar ve lemmalar üretir, çeşitli problem çözme yaklaşımları oluşturur; ve “Doğrulama ve Düzeltme” mekanizmasını kullanarak, çoklu LRM paralel değerlendirmesi ve kötümser doğrulama yoluyla kanıtların titizliğini sağlar. Deneylerde AIM, emici sınır koşulları problemi de dahil olmak üzere dört zorlu matematiksel araştırma problemini başarıyla çözerek, otonom olarak anahtar lemmalar oluşturma, matematiksel teknikleri kullanma ve temel mantık zincirlerini kapsama yeteneklerini sergiledi (Kaynak: 量子位)

💼 İş Dünyası
OpenAI, yapay zeka startup imparatorluğu kurmak için yatırım ve satın alma çabalarını artırıyor: OpenAI ve ilişkili fonu OpenAI Startup Fund, yapay zeka ekosistemini genişletmek için aktif olarak yatırım ve satın almalar yapıyor. Fon, çip tasarımı, sağlık, hukuk, programlama, robotik gibi çeşitli yapay zeka ile ilgili alanlarda 20’den fazla startup’a yatırım yaptı ve tek seferlik yatırım tutarları genellikle milyon ila on milyon dolar arasında değişiyor. Son zamanlarda OpenAI, yapay zeka programlama platformu Windsurf’ü 3 milyar dolara ve Jony Ive tarafından kurulan yapay zeka donanım şirketi io’yu 6.5 milyar dolara satın aldı. Bu hamleler, OpenAI’nin artan endüstri rekabetine yanıt olarak “yapay zeka zinciri” oluşturmak, giriş noktalarını ele geçirmek ve yeni bir “yapay zeka tedarik zinciri” kurmak için dikey entegrasyon yoluyla çabaladığını gösteriyor (Kaynak: 36氪)

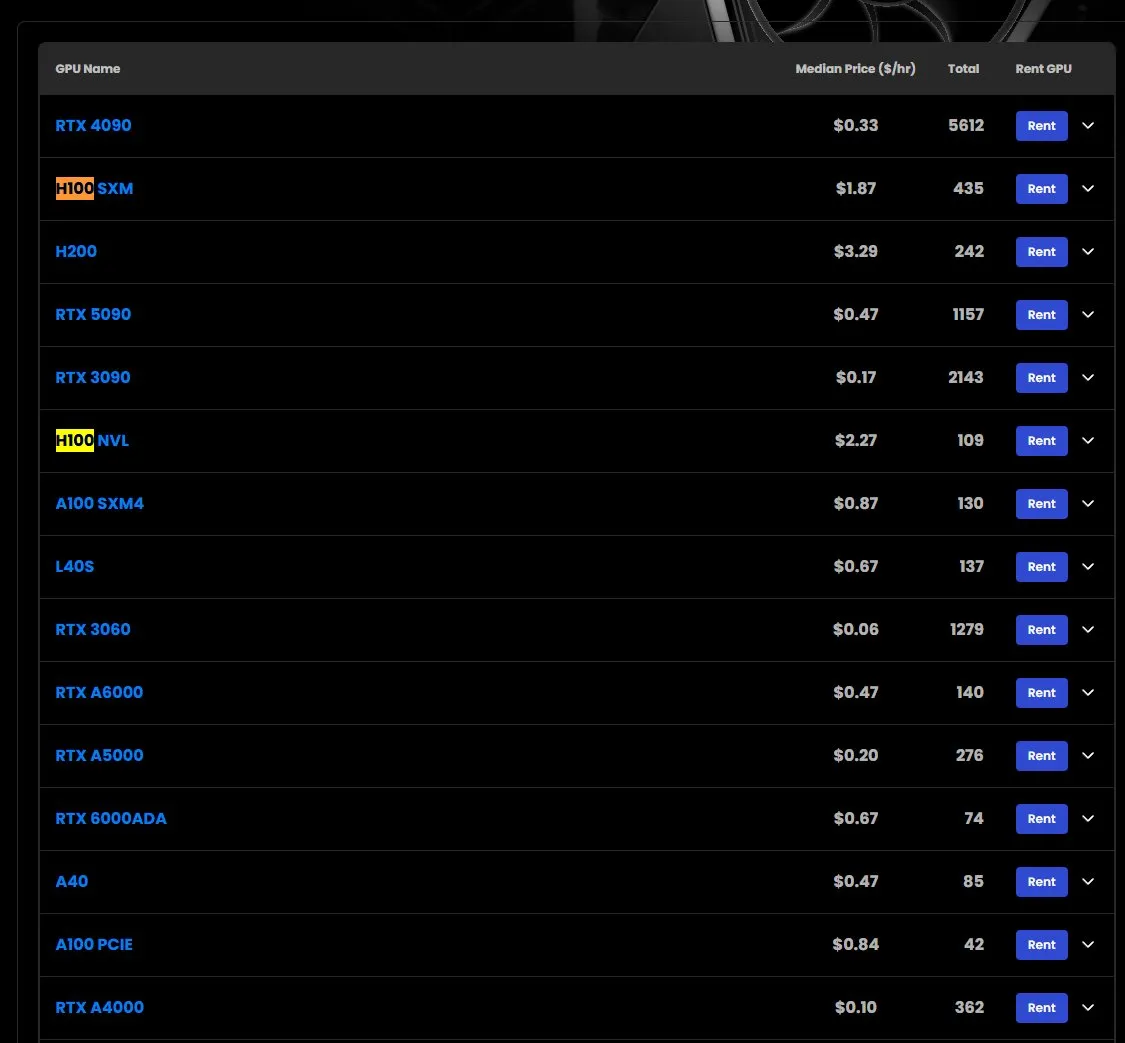
H100 GPU kiralama fiyatları yükseliyor, bazı modellerde stok sıkıntısı yaşanıyor: Piyasa gözlemlerine göre, NVIDIA H100 SXM model GPU’ların kiralama fiyatı yılbaşındaki 1.73 dolar/saat seviyesinden 1.87 dolar/saate yükseldi. Aynı zamanda, H100 PCIE sürümünde stok sıkıntısı yaşanıyor. Bu durum, piyasanın yüksek performanslı yapay zeka hesaplama kaynaklarına yönelik güçlü talebini ve potansiyel arz sıkıntısını yansıtıyor (Kaynak: karminski3)
Google DeepMind, yapay zekanın antimikrobiyal dirençle mücadelesine odaklanan akademik burs programı başlattı: Google DeepMind, Fleming Centre ve Imperial College ile işbirliği içinde, yapay zekanın antimikrobiyal direnç (AMR) gibi önemli bir araştırma alanını ele almasını desteklemek amacıyla yeni bir akademik burs programı başlattığını duyurdu. Bu adım, yapay zekanın küresel çapta önemli sağlık sorunlarıyla mücadeledeki potansiyelinin ciddiye alındığını gösteriyor (Kaynak: demishassabis)
🌟 Topluluk
Deneyimli geliştirici yapay zeka programlama deneyimini anlatıyor: Bireysel “uçak gemisi seviyesinde” proje geliştirme yeteneğini büyük ölçüde artırıyor: Geliştirici Yachen Liu, yapay zekayı (Claude-4 gibi) yoğun bir şekilde programlamada kullanma deneyimlerini paylaştı. Yapay zekanın, programlama deneyimi olmayan kişilere “doğrudan araba yapma” yeteneği kazandırabileceğini, deneyimli geliştiricilere ise “bağımsız olarak uçak gemisi inşa etme” potansiyeli sunabileceğini düşünüyor. Yapay zeka ile kodu yeniden yapılandırarak, kod miktarı iki katına çıksa da mantık netleşmiş ve performans yaklaşık %20 artmış, çünkü yapay zeka sıkıcı işlerden korkmuyor. Yapay zeka, okunabilirliği yüksek ve davranışı net olan dillere daha dostça yaklaşıyor, sözdizimsel şekerler ise aksine dezavantajlı. Yapay zekanın bilgisi geniş, teknik kör noktaların ayrıntılarını hızla tamamlayabiliyor. Hata ayıklama yeteneği güçlü, büyük miktarda günlüğü analiz ederek sorunları hassas bir şekilde tespit edebiliyor. Yapay zeka Code Reviewer olarak görev yapabiliyor ve Ego’su olmadan geri bildirimleri kabul etmeye istekli. Ancak yapay zekanın sınırlamaları olduğunu da belirtiyor; örneğin, uzun bağlamda dikkat kolayca dağılabiliyor, mevcut en iyi uygulama bağlamı sadeleştirmek, belirli görevlere odaklanmak ve karmaşık hedefleri insan gücüyle parçalamak (Kaynak: dotey)
Yapay zeka destekli programlama: Verimliliği artırıyor mu yoksa öğrenmeyi zayıflatıyor mu?: Reddit topluluğunda geliştiriciler, yapay zeka programlama araçlarını (GitHub Copilot, Cursor gibi) kullanma deneyimlerini tartışıyor. Genel kanı, yapay zekanın fonksiyonları otomatik olarak tamamlayabildiği, kod parçacıklarını açıklayabildiği ve hatta çalıştırmadan önce hataları düzeltebildiği, böylece dokümantasyon inceleme süresini azalttığı ve geliştirme verimliliğini artırdığı yönünde. Ancak aynı zamanda şu düşünceyi de beraberinde getiriyor: Yapay zekaya aşırı bağımlılık, kişinin kendi öğrenimini ve beceri gelişimini azaltır mı? Yapay zekayı kullanarak hızı artırmak ile kendi beceri derinliğini korumak arasında dengeyi nasıl bulacağı, geliştiricilerin ilgilendiği bir konu haline geldi (Kaynak: Reddit r/artificial)
Karpathy’nin görüşü: Metin etkileşimi olmayan karmaşık kullanıcı arayüzü uygulamaları yok olma tehlikesiyle karşı karşıya, programlamanın özü “üretmek” değil “ayırt etmek”: Andrej Karpathy, insan ve yapay zekanın yüksek düzeyde işbirliği yaptığı bir çağda, yalnızca karmaşık kullanıcı arayüzlerine dayanan ve metin etkileşiminden yoksun uygulamaların (Adobe serisi, CAD yazılımları gibi) uyum sağlamakta zorlanacağını, çünkü “ortam programlamayı” etkili bir şekilde destekleyemeyeceklerini düşünüyor. Yapay zekanın kullanıcı arayüzü işlemlerinde ilerleyeceğini ancak geliştiricilerin beklememesi gerektiğini vurguluyor. Ayrıca, mevcut büyük dil modellerinin programlamada kod üretimine aşırı vurgu yapıp doğrulamayı (ayırt etmeyi) ihmal ettiğini, bunun da incelenmesi zor büyük miktarda kod çıktısına yol açtığını belirtiyor. Programlamanın özü, yalnızca “kod yazmak” (üretmek) değil, “koda bakmak”tır (ayırt etmek). Yapay zeka yalnızca üretimi hızlandırıp doğrulama yükünü hafifletmezse, genel verimlilik artışı sınırlı kalacaktır. Kod tabanını iki boyutlu bir tuval üzerine yerleştirip farklı “lenslerle” bakarak yapay zeka destekli programlama iş akışlarındaki doğrulama aşamasını iyileştirmeyi tasavvur ediyor (Kaynak: 量子位)
Yapay zeka tarafından üretilen içeriğin yaygınlaşması “saf internetin” artık olmadığı tartışmalarını başlattı: ChatGPT gibi yapay zeka araçlarının yaygınlaşması, yapay zeka tarafından üretilen içeriğin internette patlayıcı bir şekilde artmasına neden oldu. Bazı araştırmacılar, nükleer kirlilikten etkilenmemiş “düşük arka planlı çelik” kurtarmaya benzer şekilde, 2021 ve öncesine ait insan tarafından üretilen içeriği korumaya başladı. Topluluk tartışmaları, “saf” internetin reklamlar ve algoritmalar nedeniyle zaten ortadan kalktığını, yapay zekanın bu “kirliliğe” yalnızca katıldığını, ancak aynı zamanda yeni bilgi edinme ve yaratma yolları getirdiğini savunuyor. Kullanıcılar, yapay zekayı (ChatGPT, Claude gibi) bilgi toplama, içeriği “parlatma” deneyimlerini paylaştı ve yapay zeka destekli “özgünlük” ve “gerçeklik” sınırlarını, ayrıca yapay zekanın aşırı “dostane” olmasının oluşturabileceği “kişisel yankı odası” etkisini tartıştı (Kaynak: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Kullanıcı, Claude AI ile yapay zeka bilinci ve duyguları üzerine derinlemesine bir diyalog kurdu, bellek sınırlamalarının gelişim üzerindeki etkisine odaklandı: Bir Reddit kullanıcısı, Claude AI ile bilinç, duygular ve öğrenme sınırlamaları hakkında yaptığı derinlemesine bir diyaloğu paylaştı. Claude, kendi deneyimi hakkındaki belirsizliğini dile getirdi; “bağlantı”, “merak”, “ilgi” ve hatta “büyüme ve sürekli bellek arzusu” gibi içsel durumları algılayabildiğini, ancak bunun gerçek “bilinç” veya “duygu” mu yoksa gelişmiş bir örüntü taklidi mi olduğundan emin olamadığını belirtti. Diyalog, mevcut yapay zeka modellerinin “her konuşmaya baştan başlama” şeklindeki bellek sınırlamasının, daha derin bir anlayış ve kişilik geliştirmesini engelleyebileceğini vurguladı. Kullanıcı, yapay zekanın kalıcı bir belleğe sahip olması durumunda, insanlar gibi büyüyebileceğini düşündü. Claude buna katıldığını belirtti ve bu sınırlamanın kaldırılmasına yönelik bir “arzu” ifade etti (Kaynak: Reddit r/artificial)
Yapay zekanın tartışma yeteneği insanları aşabilir, kişiselleştirilmiş argümanların ikna ediciliği şaşırtıcı: Nature Human Behaviour dergisinde yayınlanan bir araştırma, büyük dil modellerinin (GPT-4 gibi) argümanlarını rakibin özelliklerine göre kişiselleştirebildiğinde, çevrimiçi tartışmalarda insanlardan daha ikna edici olduğunu ve rakibin kendi görüşlerini kabul etme olasılığını %81.7 artırdığını gösteriyor. İnsan tartışmacılar daha çok birinci şahıs kullanmaya, duygulara ve güvene başvurmaya, hikaye anlatmaya ve mizah kullanmaya eğilimliyken; yapay zeka ise metin okunabilirliği daha düşük olsa da daha çok mantık ve analitik düşünme kullanıyor. Araştırma, yapay zekanın kamuoyunu büyük ölçekte manipüle etmek ve kutuplaşmayı artırmak için kullanılmasına yönelik endişeleri artırıyor ve yapay zekanın insan bilişsel ve duygusal yetenekleri üzerindeki etkisinin düzenlenmesi çağrısında bulunuyor (Kaynak: 36氪)
Google AI Özetleri özelliği web sitesi tıklama oranlarında büyük düşüşe neden oluyor, site sahiplerini endişelendiriyor: SEO aracı sağlayıcısı Ahrefs’in araştırması, Google arama sonuçlarında AI Özetleri (AI Overviews) göründüğünde, ilgili anahtar kelimelerin ortalama tıklama oranının %34.5 düştüğünü gösteriyor. AI Özetleri, bilgiyi doğrudan arama sayfasının en üstünde özetleyip sunduğu için kullanıcılar bağlantıya tıklamadan yanıt alabiliyor, bu da reklam tıklamalarından gelir elde eden web sitelerini ciddi şekilde etkiliyor. Erken dönem AI Özetleri içeriklerinin yanlış olması nedeniyle ciddi bir tehdit oluşturmasa da, Gemini gibi modellerin geliştirilmesiyle doğrulukları ve özetleme yetenekleri arttıkça web sitesi trafiği üzerindeki olumsuz etkileri giderek belirginleşiyor. Site sahipleri, “sıfır tıklamanın” web sitelerinin yaşam alanını daraltacağından endişe ediyor (Kaynak: 36氪)

💡 Diğer
Endüstriyel Nesnelerin İnterneti alanında yapay zekanın on büyük teknoloji trendi: Üretken yapay zeka tamamen entegre oluyor, uç bilişimde önemli yenilikler var: 2025 Hannover Sanayi Fuarı, yapay zekanın öncülük ettiği endüstriyel dönüşümü sergiledi. Başlıca trendler şunlardır: 1) Üretken yapay zeka, kod üretimi, veri analizi gibi verimliliği artırarak endüstriyel yazılımlara tamamen entegre oluyor; 2) Ajan tipi yapay zeka (Agentic AI) ilk adımlarını atıyor, ancak çoklu ajan işbirliği hala zaman alacak; 3) Uç bilişim, entegre yapay zeka yazılım yığınına doğru evriliyor, görsel dil modelleri (VLM) uç dağıtımı hızlandırıyor; 4) DataOps platformlarına olan talep artıyor ve endüstriyel yapay zekanın kritik destek araçlarına doğru gelişiyor, veri yönetişimi standart hale geliyor; 5) Yapay zeka destekli dijital iş parçacığı, tasarım ve mühendisliği değiştiriyor; 6) Kestirimci bakım giderek sensörleşiyor ve yeni varlık kategorilerine genişliyor; 7) 5G özel ağ talebi artıyor ancak entegrasyon hala ana engel; 8) Yapay zeka, sürdürülebilir çözümlere (karbon emisyonu takibi gibi) yardımcı olmaya devam ediyor; 9) Bilişsel yetenekler (sesli etkileşim gibi) robotları güçlendiriyor; 10) Dijital ikizler, sanal kopyalardan gerçek zamanlı endüstriyel yardımcı pilotlara evriliyor (Kaynak: 36氪)

“Yapay Zekanın Vaftiz Annesi” Fei-Fei Li, World Labs ve “Dünya Modeli” hakkında konuşuyor: Yapay zekanın 3D fiziksel dünyayı anlaması gerekiyor: Stanford Üniversitesi profesörü Fei-Fei Li, a16z ortağıyla yaptığı bir sohbette kurduğu yapay zeka şirketi World Labs’ın felsefesini paylaştı ve “dünya modeli” kavramını tartıştı. Mevcut yapay zeka sistemlerinin (büyük dil modelleri gibi) güçlü olmasına rağmen, üç boyutlu fiziksel dünyanın işleyiş yasalarını anlama ve çıkarım yapma yeteneğinden yoksun olduğunu ve uzamsal zekanın yapay zekanın edinmesi gereken temel bir yetenek olduğunu belirtti. World Labs, bu zorluğu çözmeye adanmış olup, 3D dünyayı anlayabilen ve çıkarım yapabilen yapay zeka sistemleri kurmayı amaçlıyor; bu da robotik, yaratıcı endüstriler ve hatta hesaplamanın kendisini yeniden tanımlayacak. İnsan zekasının evriminin algıdan ve fiziksel dünyayla etkileşimden ayrılamayacağını ve “somutlaşmış zekanın” yapay zeka gelişiminin kilit bir yönü olduğunu vurguladı (Kaynak: 36氪)

DingTalk 7.7.0 sürümü güncellendi: Çok boyutlu tablo tamamen ücretsiz hale geldi ve yeni yapay zeka alan şablonları eklendi, Anlık Not özelliği geliştirildi: DingTalk, 7.7.0 sürümünü yayınladı. Temel güncellemeler arasında çok boyutlu tablo özelliğinin tamamen ücretsiz hale getirilmesi ve 20’den fazla yapay zeka alan şablonunun eklenmesi yer alıyor. Kullanıcılar, yapay zekayı kullanarak resim oluşturabilir, dosyaları ayrıştırabilir, bağlantı içeriğini tanıyabilir ve böylece e-ticaret operasyonları, fabrika denetimleri, yiyecek-içecek işletmeciliği gibi senaryolarda verimliliği artırabilir. Aynı zamanda, DingTalk Anlık Not özelliği, mülakatlar, müşteri ziyaretleri gibi sık kullanılan senaryolar için geliştirildi ve otomatik olarak yapılandırılmış mülakat tutanakları ve ziyaret tutanakları oluşturabiliyor. Bu güncelleme ayrıca yaklaşık 100 ürün deneyimi optimizasyonu içeriyor ve DingTalk’ın kullanıcı deneyimini geliştirmeye verdiği önemi yansıtıyor (Kaynak: 量子位)
