
Mots-clés:Gemini 2.5 Pro, OpenAI confidentialité des données, OpenThinker3-7B, Claude Gov, Agent IA intelligent, Grand modèle de langage, Apprentissage par renforcement, Modèle open source, Amélioration des performances de Gemini 2.5 Pro, Politique de conservation des données utilisateurs d’OpenAI, Capacité de raisonnement d’OpenThinker3-7B, Applications de Claude Gov pour la sécurité nationale, Robustesse et contrôle des agents IA
🔥 Pleins feux
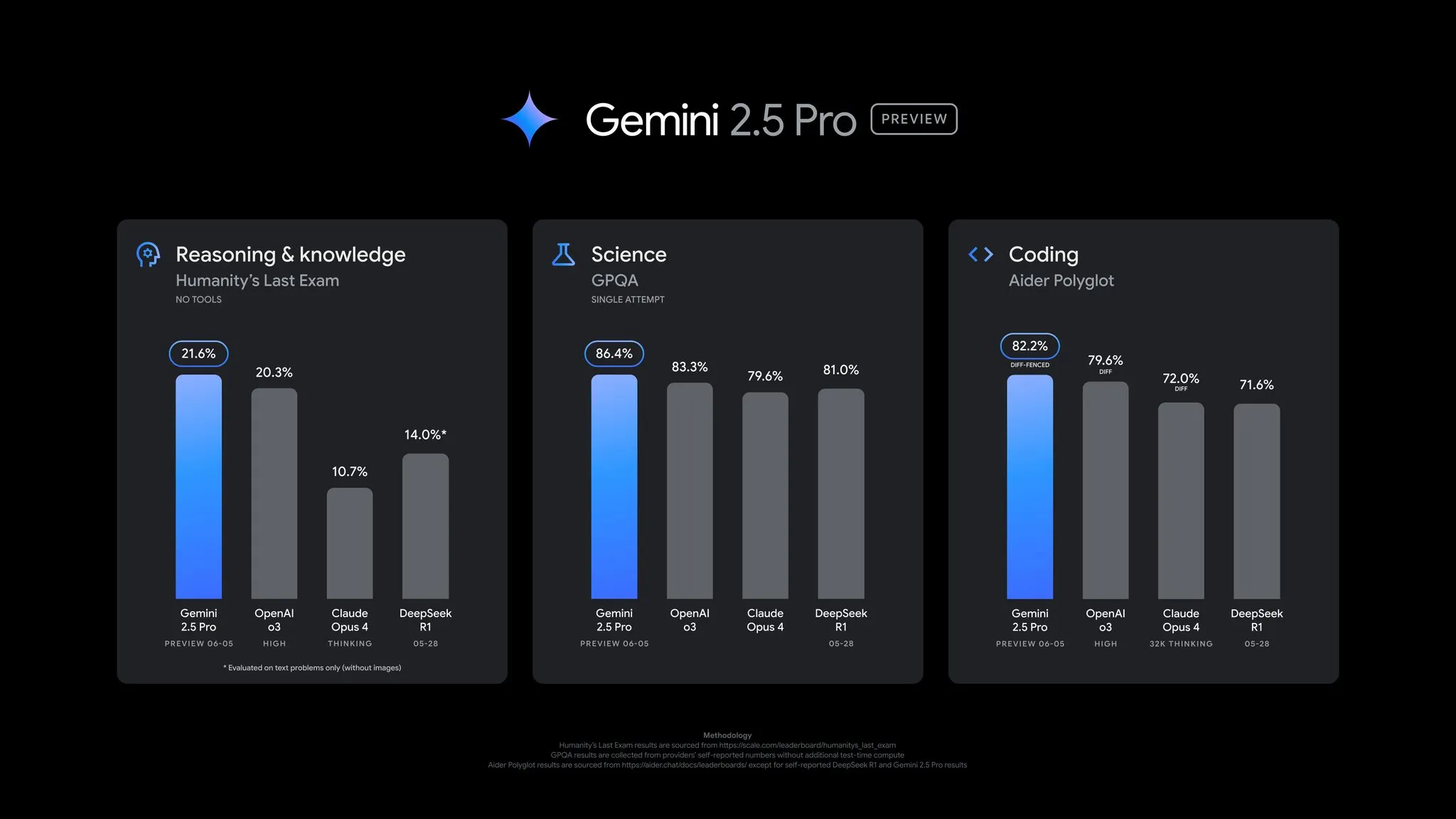
Google publie une mise à jour de la preview de Gemini 2.5 Pro, avec des performances globalement améliorées: Google a annoncé une mise à jour majeure pour la version préliminaire de Gemini 2.5 Pro, apportant des améliorations significatives en matière de codage, de raisonnement, ainsi que pour les capacités scientifiques et mathématiques. La nouvelle version affiche de meilleures performances sur des benchmarks clés tels que AIDER Polyglot, GPQA et HLE, et a réalisé un bond de 24 points de score Elo sur LMArena, reprenant la première place. De plus, le style de réponse et le formatage du modèle ont été améliorés en fonction des retours des utilisateurs, et une fonctionnalité de “budget de réflexion” (thinking budget) a été introduite pour offrir plus de contrôle. Cette mise à jour est désormais disponible dans Gemini App, Google AI Studio et Vertex AI (Source: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI contraint de conserver indéfiniment les données utilisateurs suite au procès du New York Times, soulevant des inquiétudes sur la vie privée: Dans le cadre du procès pour violation de droits d’auteur intenté par le New York Times, OpenAI s’est vu ordonner par le tribunal de conserver indéfiniment tous les journaux d’interaction des utilisateurs de ChatGPT et de l’API, y compris les “conversations temporaires” et les données de requêtes API qu’elle s’était engagée à ne conserver que 30 jours. OpenAI a déclaré faire appel, considérant cette mesure comme une “ingérence excessive” qui sape les normes de confidentialité établies de longue date et affaiblit la protection de la vie privée. Cette décision signifie qu’OpenAI pourrait ne pas être en mesure de respecter ses engagements envers les utilisateurs concernant la conservation et la suppression des données, suscitant de vives inquiétudes quant à la confidentialité et à la sécurité des données des utilisateurs, et pourrait notamment affecter les développeurs d’applications qui dépendent de l’API OpenAI et ont leurs propres politiques de conservation des données (Source: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

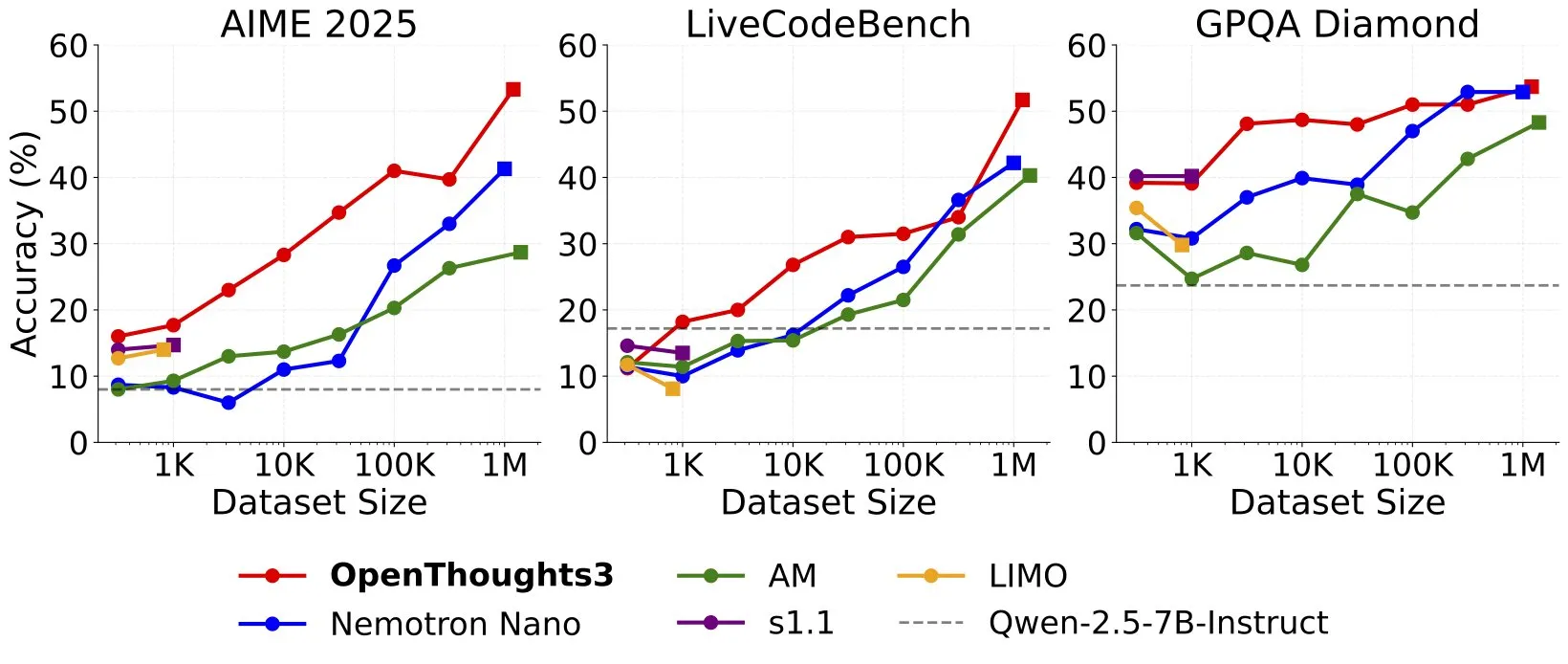
Lancement d’OpenThinker3-7B, nouveau SOTA pour les modèles de raisonnement open source de 7 milliards de paramètres: Ryan Marten a annoncé le lancement d’OpenThinker3-7B, un nouveau modèle de raisonnement basé sur des données ouvertes avec 7 milliards de paramètres, qui surpasse en moyenne de 33% DeepSeek-R1-Distill-Qwen-7B sur les évaluations de code, de science et de mathématiques. L’équipe a également publié le jeu de données OpenThoughts3-1.2M, présenté comme le meilleur jeu de données de raisonnement ouvert actuel, toutes tailles confondues. Les chercheurs soulignent que pour les modèles plus petits, la distillation à partir de R1 est la voie la plus simple pour améliorer les performances, mais la recherche en RL (Reinforcement Learning) est plus exploratoire. Ce résultat est considéré comme l’un des travaux pionniers dans le domaine des modèles de raisonnement ouverts (Source: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic lance Claude Gov, un modèle personnalisé pour les clients de la sécurité nationale américaine: Anthropic a annoncé le lancement de Claude Gov, une série de modèles d’IA personnalisés conçus pour les clients de la sécurité nationale américaine. Ces modèles ont déjà été déployés au sein des plus hautes instances de sécurité nationale des États-Unis, et leur accès est limité au personnel opérant dans des environnements classifiés. Cette initiative marque une nouvelle étape dans l’application approfondie de la technologie de l’IA dans les secteurs gouvernemental et de la défense, tout en soulevant des discussions sur l’utilisation de l’IA dans des domaines sensibles (Source: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 Tendances
Yann LeCun partage l’avis de Sundar Pichai : la technologie actuelle pourrait ne pas mener à l’AGI, une période de plateau est possible: Yann LeCun, scientifique en chef de l’IA chez Meta, a relayé et approuvé le point de vue de Sundar Pichai, PDG de Google, selon lequel la voie technologique actuelle ne garantit pas la réalisation de l’intelligence artificielle générale (AGI), et que le développement de l’IA pourrait connaître une période de plateau temporaire. Pichai a souligné que, malgré la vitesse impressionnante des progrès de l’IA, des limitations pourraient exister, et la technologie actuelle est encore loin de l’intelligence générale. Cela reflète une attitude prudente de l’industrie quant à la voie et au calendrier de réalisation de l’AGI (Source: ylecun)
OpenAI recrute pour une équipe “Agent Robustness and Control” afin d’améliorer la sécurité des agents IA: OpenAI est en train de constituer une nouvelle équipe “Agent Robustness and Control” (Robustesse et Contrôle des Agents), dont l’objectif est de garantir la sécurité et la fiabilité de ses agents IA pendant les processus d’entraînement et de déploiement. Cette équipe se consacrera à résoudre certains des problèmes les plus stimulants du domaine de l’IA, ce qui témoigne de la grande importance qu’OpenAI accorde à la sécurité et au contrôle, tout en progressant vers des agents IA plus puissants (Source: gdb)

Une nouvelle étude d’Apple révèle “l’illusion de la pensée” des grands modèles de langage : face à des problèmes complexes, leur capacité de raisonnement diminue au lieu d’augmenter: Un récent article de recherche d’Apple, intitulé “The Illusion of Thinking”, souligne que les modèles de raisonnement actuels, lorsqu’ils sont confrontés à une complexité de problème atteignant un certain seuil, voient leur “effort de raisonnement” (reasoning effort) diminuer, même avec un budget de tokens suffisant. Ce phénomène contre-intuitif de “limite d’échelle” (scaling limit) suggère que les modèles, face à des problèmes très complexes, pourraient ne pas effectuer une réflexion véritablement profonde, mais plutôt manifester une “illusion de la pensée”, ce qui pose de nouveaux défis pour l’évaluation et l’amélioration des capacités de raisonnement réelles des grands modèles (Source: Ar_Douillard, Reddit r/MachineLearning)

OpenAI explore le lien émotionnel entre humains et IA, priorisant l’étude de son impact sur le bien-être émotionnel des utilisateurs: Joanne Jang d’OpenAI a publié un article de blog explorant le phénomène croissant du lien émotionnel entre les utilisateurs et les modèles d’IA tels que ChatGPT. L’article souligne que les gens anthropomorphisent naturellement l’IA et peuvent développer un sentiment de compagnie et de confiance à son égard. OpenAI reconnaît cette tendance et déclare qu’elle donnera la priorité à l’étude de l’impact de l’IA sur le bien-être émotionnel des utilisateurs, plutôt que de s’attarder sur la question ontologique de savoir si l’IA est réellement “consciente”. L’objectif de l’entreprise est de concevoir des assistants IA chaleureux, utiles, mais qui ne recherchent pas une dépendance émotionnelle excessive ni n’ont leur propre agenda (Source: openai, sama, BorisMPower)

Xiaohongshu publie le grand modèle MoE open source dots.llm1-143B-A14B: Le Hi Lab de Xiaohongshu a publié sa première série de grands modèles open source dots.llm1, comprenant le modèle de base dots.llm1.base et le modèle affiné par instruction dots.llm1.inst. Ce modèle adopte une architecture MoE, avec un nombre total de paramètres de 143B et 14B paramètres activés. Selon les auto-évaluations officielles, ses performances sur MMLU-Pro surpassent celles de Qwen3-235B-A22B, mais sont inférieures au nouveau DeepSeek-V3. Le modèle est sous licence MIT, permettant une utilisation libre. Cependant, les premiers tests communautaires indiquent des performances médiocres sur des tâches telles que la génération de code, voire inférieures à Qwen2.5-coder (Source: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

La série Qwen3 lance des modèles Embedding et Reranker, améliorant les capacités de traitement de texte multilingue: L’équipe Qwen a lancé les séries de modèles Qwen3-Embedding et Qwen3-Reranker, visant à améliorer les performances de l’intégration de texte multilingue et du classement par pertinence. Les modèles Embedding sont utilisés pour convertir le texte en représentations vectorielles, prenant en charge des scénarios tels que la recherche de documents et le RAG ; les modèles Reranker sont utilisés pour réorganiser les résultats de recherche, améliorant la priorité du contenu le plus pertinent. La série de modèles offre différentes échelles de paramètres telles que 0.6B, 4B, 8B, prend en charge 119 langues et affiche d’excellentes performances sur les benchmarks MMTEB, MTEB, etc. La version 0.6B est considérée comme particulièrement adaptée aux scénarios Reranker exigeant une faible latence, en raison de son équilibre entre efficacité et performance (Source: karminski3, karminski3, ZhaiAndrew, clefourrier)

Une étude souligne les défis de scalabilité de l’apprentissage par renforcement dans les tâches complexes à long horizon: Une étude de Seohong Park et al. révèle que l’augmentation simple des données et des ressources de calcul ne suffit pas pour que l’apprentissage par renforcement (RL) résolve efficacement les tâches complexes. Le facteur limitant clé est l‘“horizon”. Dans les tâches à long horizon, les signaux de récompense sont rares, ce qui rend difficile pour le modèle d’apprendre des stratégies efficaces. Cela correspond aux observations actuelles selon lesquelles certains agents IA (tels que Deep Research, Codex agent) reposent principalement sur des tâches RL à court horizon et un entraînement à la robustesse générale, indiquant que la résolution de bout en bout des problèmes de récompenses rares à long horizon reste un défi majeur dans le domaine du RL (Source: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu enregistre un compte officiel sur HuggingFace et y télécharge les grands modèles Wenxin (ERNIE): Baidu a enregistré un compte officiel sur la plateforme HuggingFace et y a téléchargé certains modèles de sa série Wenxin (ERNIE), notamment Wenxin-X1-Turbo et Wenxin-4.5-Turbo. Cette démarche signifie que Baidu intègre activement sa technologie de grands modèles dans la communauté open source élargie et l’écosystème des développeurs, facilitant l’accès et l’utilisation de ses capacités d’IA par les développeurs du monde entier (Source: karminski3)
OpenBMB lance la série de modèles MiniCPM4, axée sur un fonctionnement efficace en périphérie (edge): OpenBMB continue d’explorer les limites des modèles de langage petits et efficaces avec le lancement de la série MiniCPM4. Le modèle MiniCPM4-8B possède 8 milliards de paramètres et a été entraîné sur 8T tokens. Cette série de modèles utilise des techniques d’accélération extrêmes telles que l’attention clairsemée entraînable (InfLLM v2), la quantification ternaire (BitCPM), le calcul à faible précision FP8 et la prédiction multi-token, visant à atteindre un fonctionnement efficace sur les appareils en périphérie. Par exemple, son mécanisme d’attention clairsemée, lors du traitement de textes longs de 128K, ne nécessite de calculer la pertinence qu’avec moins de 5% des tokens pour chaque token, réduisant considérablement la charge de calcul pour le traitement de textes longs (Source: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
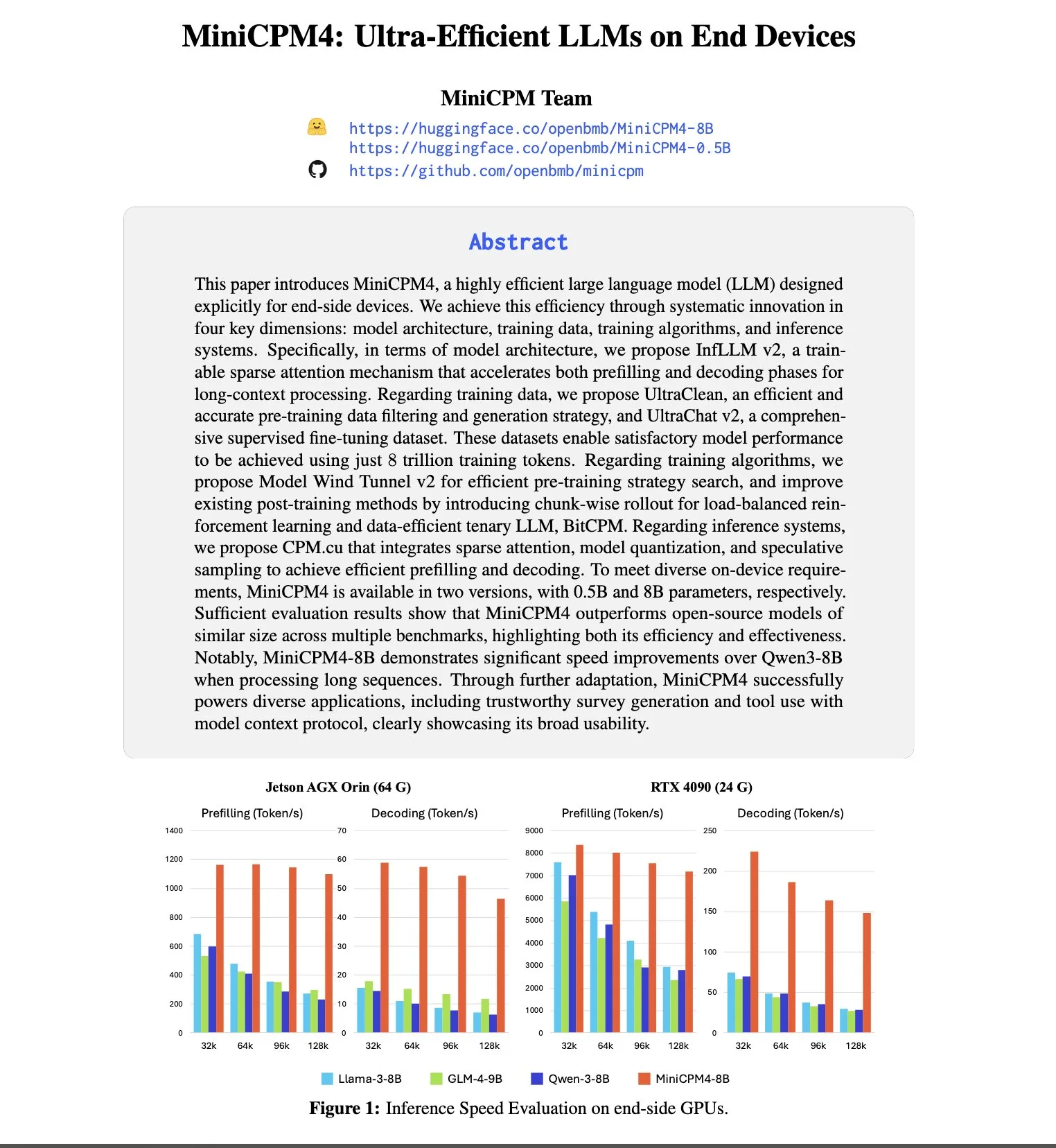
Anthropic en tête pour l’attraction et la rétention des talents, 8 fois plus de chances de débaucher chez OpenAI: Le rapport 2025 sur les tendances des talents publié par SignalFire montre qu’Anthropic excelle dans la rétention des meilleurs talents en IA, atteignant 80%, contre 78% pour DeepMind et 67% pour OpenAI. Le rapport indique également que les ingénieurs sont 8 fois plus susceptibles de passer d’OpenAI à Anthropic que l’inverse. La culture d’entreprise unique d’Anthropic, son ouverture aux modes de pensée non traditionnels, l’autonomie des employés et la popularité de son produit Claude auprès des développeurs sont considérés comme des facteurs clés de son attractivité et de sa capacité à retenir les talents (Source: 量子位)
🧰 Outils
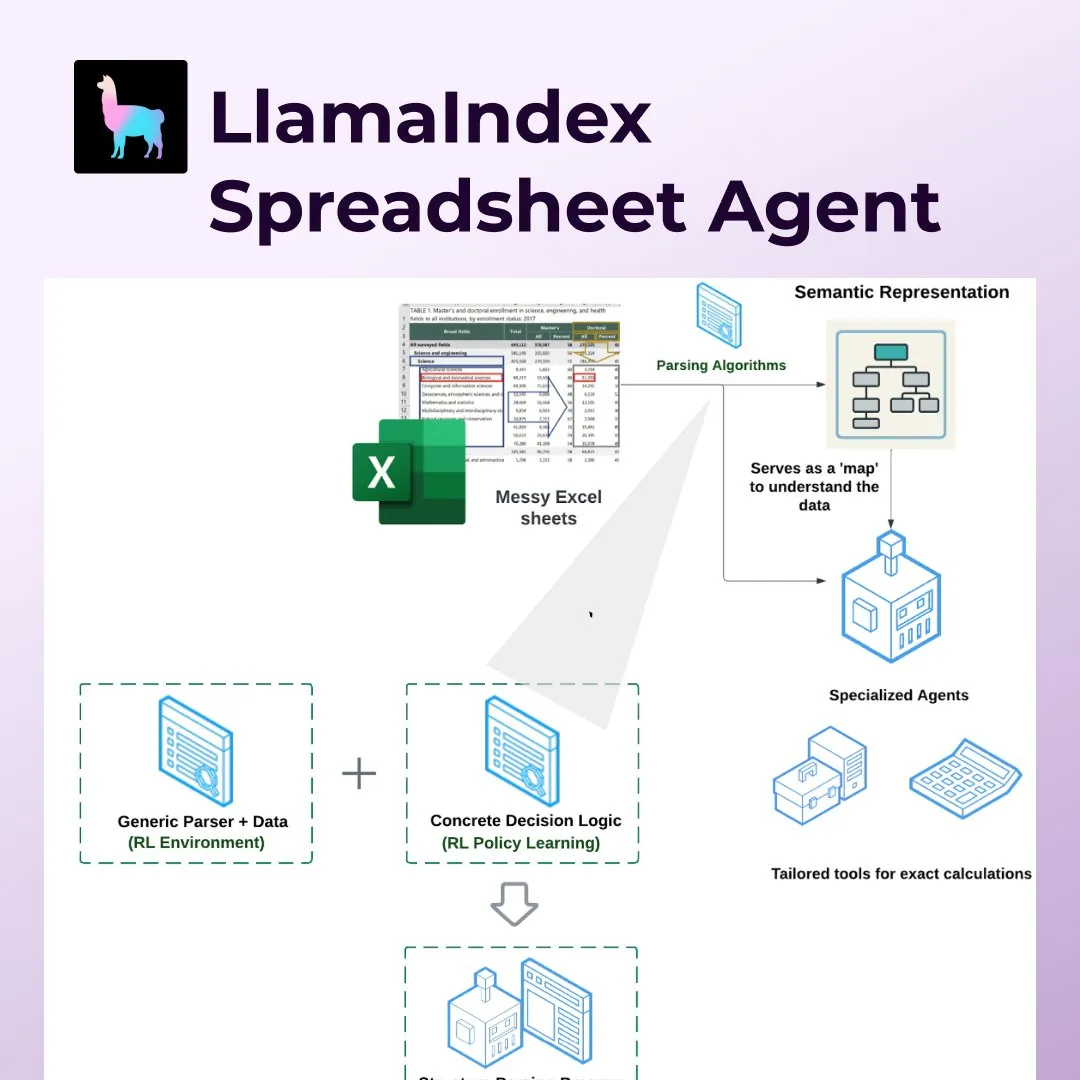
LlamaIndex lance Spreadsheet Agents, révolutionnant le traitement des tableurs comme Excel: LlamaIndex a lancé la nouvelle fonctionnalité Spreadsheet Agents, permettant aux utilisateurs de transformer des données et de poser des questions sur des tableurs Excel non standardisés. Cet outil utilise une analyse de structure sémantique basée sur l’apprentissage par renforcement pour comprendre la structure des tableaux et permet aux agents IA d’interagir avec eux grâce à des outils dédiés. Il vise à combler les lacunes des LLM traditionnels dans le traitement de tableurs complexes (tels que ceux couramment utilisés dans les domaines de la finance, de la fiscalité et de l’assurance), en gérant les cellules fusionnées, les mises en page complexes et en maintenant les relations entre les données. Lors des tests, sa précision (96%) a surpassé la référence humaine et OpenAI Code Interpreter (GPT 4.1, 75%) (Source: jerryjliu0)
LlamaIndex utilise LlamaExtract et des workflows d’agents pour automatiser l’extraction des formulaires SEC Form 4: LlamaIndex a démontré comment utiliser son outil LlamaExtract et des workflows d’agents IA pour extraire et normaliser automatiquement les données des formulaires Form 4 de la SEC (Securities and Exchange Commission) américaine, des documents dans lesquels les dirigeants, administrateurs et principaux actionnaires de sociétés cotées divulguent leurs transactions sur actions. Cette solution peut convertir des formulaires Form 4 aux formats variés de différentes entreprises en un format CSV propre et les intégrer dans un dataframe interrogeable via Pandas, offrant ainsi aux analystes financiers et aux investisseurs un outil de traitement de données efficace (Source: jerryjliu0)

Lancement du projet open source Ragbits, fournissant des modules pour le développement rapide d’applications GenAI: deepsense-ai a lancé le projet open source Ragbits, visant à fournir des modules de construction pour le développement rapide d’applications d’IA générative. Le projet prend en charge plus de 100 interfaces de grands modèles ou modèles locaux, dispose d’un stockage vectoriel intégré (connectable à Qdrant, PgVector) et prend en charge plus de 20 formats de fichiers d’entrée (PDF, HTML, tableurs, présentations, etc.). Ragbits utilise un VLM intégré pour extraire des tableaux, des images et du contenu structuré, peut se connecter à diverses sources de données telles que S3, GCS, Azure, et possède des caractéristiques modulaires permettant aux utilisateurs de personnaliser les composants (Source: karminski3, GitHub Trending)

L’assistant de programmation IA Cursor publie une mise à jour majeure, intégrant BugBot, une fonction de mémoire et le support MCP: L’outil de programmation IA Cursor a bénéficié d’une mise à jour importante, comprenant principalement : 1) BugBot, qui peut répondre automatiquement aux issues GitHub et les ouvrir en un clic dans Cursor pour correction ; 2) une fonction de mémoire, permettant à l’IA de se souvenir des conversations précédentes, améliorant la facilité d’utilisation lors de modifications répétées sur de grands projets ; 3) une configuration MCP (Model Context Protocol) en un clic, prenant en charge les serveurs MCP tiers avec OAuth ; 4) la prise en charge des AI Agents pour Jupyter Notes ; 5) un Agent en arrière-plan, permettant d’appeler un panneau de contrôle via un raccourci clavier pour utiliser un Agent de programmation IA distant (Source: karminski3)
Archon : un agent IA capable de créer d’autres agents IA: Archon est un projet “Agenteer” visant à construire et optimiser de manière autonome d’autres agents IA. Il utilise des workflows avancés de codage d’agents et une base de connaissances de frameworks, démontrant le rôle de la planification, des boucles de rétroaction et des connaissances du domaine dans la création d’agents IA puissants. La dernière version V6 intègre une bibliothèque d’outils et un serveur MCP (Model Context Protocol), améliorant la capacité à construire de nouveaux agents. Archon prend en charge le déploiement Docker et l’installation Python locale, et fournit une interface utilisateur Streamlit pour la gestion (Source: GitHub Trending)

NoteGen : une application de prise de notes Markdown multiplateforme pilotée par l’IA: NoteGen est une application de prise de notes Markdown multiplateforme qui vise à utiliser l’IA pour connecter l’enregistrement et l’écriture, transformant les connaissances fragmentées en notes lisibles. Elle prend en charge plusieurs méthodes d’enregistrement telles que les captures d’écran, le texte, les illustrations, les fichiers, les liens, etc., stocke nativement en Markdown, prend en charge une utilisation locale hors ligne ainsi que la synchronisation avec GitHub/Gitee/WebDAV. NoteGen peut être configuré avec divers modèles d’IA tels que ChatGPT, Gemini, Ollama, et prend en charge la fonctionnalité RAG, utilisant les notes de l’utilisateur comme base de connaissances (Source: GitHub Trending)

ComfyUI-Copilot : un assistant intelligent pour le développement automatisé de workflows: ComfyUI-Copilot est un plugin piloté par de grands modèles de langage, conçu pour améliorer la facilité d’utilisation et l’efficacité de la plateforme de création artistique par IA ComfyUI. Il résout les problèmes de ComfyUI tels que sa complexité pour les débutants, les erreurs de configuration des modèles et la conception complexe des workflows, en fournissant des recommandations intelligentes de nœuds et de modèles, ainsi que des fonctionnalités de construction de workflows en un clic. Le système adopte un cadre multi-agents hiérarchique, comprenant un agent assistant central et plusieurs agents de travail spécialisés, et utilise la base de connaissances de ComfyUI pour simplifier le débogage et le déploiement (Source: HuggingFace Daily Papers)
Bifrost : une passerelle LLM haute performance en Go open source, optimisant le déploiement LLM en production: Pour résoudre les défis liés à la fragmentation des API, à la latence, au repli (fallback) et à la gestion des coûts des LLM en environnement de production, l’équipe de Maximilian a mis en open source Bifrost, une passerelle LLM basée sur Go. Bifrost est spécialement conçue pour les déploiements de machine learning à haut débit et faible latence, et prend en charge les principaux fournisseurs de LLM tels qu’OpenAI, Anthropic, Azure. Les benchmarks montrent que, par rapport à d’autres proxys, Bifrost augmente le débit de 9,5 fois, réduit la latence P99 de 54 fois et la consommation de mémoire de 68%, avec une surcharge interne inférieure à 15µs à 5000 RPS. Il offre des fonctionnalités telles que la normalisation des API, le repli automatique des fournisseurs, la gestion intelligente des clés et des métriques Prometheus (Source: Reddit r/MachineLearning)

LangGraph.js améliore l’expérience développeur avec l’introduction de la sécurité des types et des fonctions hook: LangGraph.js version 0.3 a subi une série de mises à jour visant à améliorer l’expérience des développeurs. Celles-ci comprennent une sécurité des types renforcée, ainsi que l’introduction de preModelHook et postModelHook dans createReactAgent. preModelHook peut être utilisé pour simplifier l’historique des messages avant de le transmettre au LLM, tandis que postModelHook peut être utilisé pour ajouter des garde-fous ou des processus de collaboration homme-machine. La communauté sollicite activement des retours sur LangGraph v1 (Source: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024 publie le grand modèle de correction grammaticale GRMR-V3-G4B: Le développeur qingy2024 a publié un grand modèle spécialisé dans la correction grammaticale, GRMR-V3-G4B, avec un nombre maximal de paramètres de seulement 4B. Ce modèle est également fourni avec une version quantifiée, particulièrement adaptée aux tâches de vérification et de correction grammaticale dans des workflows locaux ou sur des appareils personnels, facilitant son intégration et son utilisation (Source: karminski3)

Fullpack : une application de liste de colisage intelligente basée sur la reconnaissance visuelle locale de l’iPhone: Un développeur a lancé une application iOS nommée Fullpack, capable de reconnaître des objets sur des photos grâce à VisionKit de l’iPhone et d’aider les utilisateurs à créer des listes de colisage intelligentes pour différentes occasions (comme une journée de travail, des vacances à la plage, un week-end de randonnée). L’application met l’accent sur un fonctionnement 100% local, sans traitement dans le cloud ni collecte de données, afin de protéger la vie privée des utilisateurs. Il s’agit de la première application indépendante du développeur, visant à explorer le potentiel de l’IA sur appareil (Source: Reddit r/LocalLLaMA)
📚 Apprentissage
Unsloth publie de nombreux Notebooks Colab/Kaggle pour l’affinage des principaux grands modèles: UnslothAI propose une série de Jupyter Notebooks facilitant l’affinage (fine-tuning) de divers grands modèles de langage populaires tels que Qwen3, Gemma 3, Llama 3.1/3.2, Phi-4, Mistral v0.3 sur des plateformes comme Google Colab et Kaggle. Ces Notebooks couvrent divers types de tâches et méthodes d’affinage, y compris la conversation, Alpaca, GRPO, la vision, la synthèse vocale (TTS), etc., visant à simplifier le processus d’affinage des modèles et fournissant des instructions pour la préparation des données, l’entraînement, l’évaluation et la sauvegarde des modèles (Source: GitHub Trending)

“Guide pratique des grands modèles open source” : un tutoriel LLM/MLLM pour les débutants en Chine: Le projet Datawhalechina “Guide pratique des grands modèles open source” propose un tutoriel basé sur un environnement Linux, destiné aux débutants en Chine. Il couvre l’ensemble du processus de configuration de l’environnement, de déploiement local, d’affinage complet des paramètres/Lora pour les grands modèles de langage (LLM) et les grands modèles multimodaux (MLLM) open source nationaux et internationaux. Ce projet vise à simplifier le déploiement et l’utilisation des grands modèles open source et prend déjà en charge divers modèles tels que Qwen3, Kimi-VL, Llama4, Gemma3, InternLM3, Phi4 (Source: GitHub Trending)

Un article explore MINT-CoT : introduction de tokens visuels croisés dans le raisonnement mathématique en chaîne de pensée: Un nouvel article propose la méthode MINT-CoT (Mathematical Interleaved Tokens for Chain-of-Thought), visant à améliorer la capacité de raisonnement des grands modèles de langage sur les problèmes mathématiques multimodaux en introduisant de manière adaptative des tokens visuels pertinents entrelacés avec les étapes de raisonnement textuel. Cette méthode utilise un “Interleave Token” pour sélectionner dynamiquement des régions visuelles de formes arbitraires dans les graphiques mathématiques et a construit l’ensemble de données MINT-CoT contenant 54K problèmes mathématiques pour entraîner le modèle à aligner les régions visuelles au niveau du token à chaque étape de raisonnement. Les expériences montrent que le modèle MINT-CoT-7B surpasse de manière significative les modèles de base sur des benchmarks tels que MathVista (Source: HuggingFace Daily Papers)
Un article propose StreamBP : une méthode de rétropropagation précise et économe en mémoire pour l’entraînement de LLM sur de longues séquences: Face au problème du coût mémoire important lié au stockage des valeurs d’activation lors de l’entraînement de LLM sur de longues séquences, des chercheurs proposent StreamBP, une méthode de rétropropagation précise et économe en mémoire. StreamBP réduit considérablement les coûts mémoire des valeurs d’activation et des logits en décomposant linéairement la règle de la chaîne le long de la dimension séquentielle au niveau des couches. Cette méthode est applicable aux objectifs courants tels que SFT, GRPO, DPO, et nécessite moins de FLOPs de calcul, accélérant la rétropropagation. Comparé au gradient checkpointing, StreamBP peut étendre la longueur maximale de séquence pour la rétropropagation de 2,8 à 5,5 fois, tout en utilisant un temps de rétropropagation comparable voire inférieur (Source: HuggingFace Daily Papers)
Un article propose la technique Diagonal Batching, débloquant l’inférence parallèle à long contexte pour RMT: Pour résoudre le goulot d’étranglement des performances des modèles Transformer lors de l’inférence sur de longs contextes, des chercheurs proposent le schéma d’ordonnancement Diagonal Batching. Il vise à débloquer le parallélisme inter-segments dans les Transformers à mémoire récurrente (RMT) tout en maintenant une récurrence exacte. Cette technique, en réorganisant les calculs d’exécution, élimine les contraintes séquentielles, permettant une inférence GPU efficace même pour une seule entrée à long contexte, sans nécessiter de techniques complexes de batching et de pipelining. Appliquée au modèle LLaMA-1B ARMT, sur une séquence de 131K tokens, Diagonal Batching est 3,3 fois plus rapide que le LLaMA-1B standard à attention complète, et 1,8 fois plus rapide que l’implémentation séquentielle de RMT (Source: HuggingFace Daily Papers)
Un article examine l’impact négatif des techniques de watermarking sur l’alignement des modèles de langage et les stratégies d’atténuation: Une étude analyse systématiquement l’impact de deux techniques de watermarking courantes, Gumbel et KGW, sur les attributs d’alignement fondamentaux des grands modèles de langage (LLM), tels que la véracité, la sécurité et l’utilité. L’étude révèle que le watermarking entraîne deux modes de dégradation : l’affaiblissement de la protection (améliorant l’utilité mais nuisant à la sécurité) et l’amplification de la protection (une prudence excessive réduisant l’utilité). Pour atténuer ces problèmes, l’article propose la méthode de rééchantillonnage d’alignement (Alignment Resampling, AR), qui utilise un modèle de récompense externe lors de l’inférence pour restaurer l’alignement. Les expériences démontrent que l’échantillonnage de 2 à 4 générations avec watermarking suffit à restaurer ou dépasser efficacement les scores d’alignement de base, tout en maintenant la détectabilité du watermarking (Source: HuggingFace Daily Papers)
Un article propose le framework Micro-Act, atténuant les conflits de connaissances dans la réponse aux questions grâce à l’auto-raisonnement actionnable: Pour résoudre le problème des conflits entre les connaissances externes des systèmes de génération augmentée par récupération (RAG) et les connaissances paramétriques internes des grands modèles (LLM), des chercheurs ont proposé le framework Micro-Act. Ce framework dispose d’un espace d’action hiérarchique, capable de percevoir automatiquement la complexité du contexte et de décomposer chaque source de connaissances en une série d’étapes de comparaison fines (représentées comme des étapes actionnables), permettant ainsi un raisonnement qui dépasse le contexte superficiel. Les expériences montrent que Micro-Act améliore considérablement la précision des réponses aux questions sur cinq jeux de données de référence, surpassant les bases de référence existantes notamment sur les types de conflits temporels et sémantiques, et gère de manière robuste les questions sans conflit (Source: HuggingFace Daily Papers)
Un article propose le benchmark STARE pour évaluer les capacités de simulation spatiale visuelle des modèles multimodaux: Afin d’évaluer les capacités des grands modèles de langage multimodaux (MM-LLM) sur des tâches nécessitant une simulation visuelle en plusieurs étapes pour être résolues, des chercheurs ont lancé le benchmark STARE (Spatial Transformations and Reasoning Evaluation). STARE comprend 4000 tâches couvrant les transformations géométriques de base (2D et 3D), le raisonnement spatial composite (comme le dépliage de cubes et les tangrams) ainsi que le raisonnement spatial du monde réel (comme la perspective et le raisonnement temporel). L’évaluation montre que les modèles existants fonctionnent bien sur les transformations 2D simples, mais ont des performances proches du hasard sur les tâches complexes nécessitant une simulation visuelle en plusieurs étapes (comme le dépliage de cubes 3D). Les humains atteignent une précision quasi parfaite sur ces tâches complexes, mais y consacrent plus de temps ; la simulation visuelle intermédiaire accélère considérablement leur résolution, tandis que les modèles en bénéficient de manière inégale (Source: HuggingFace Daily Papers)
Un article présente LEXam : un jeu de données de référence multilingue axé sur le raisonnement juridique, numéro un des tendances sur Hugging Face: Des chercheurs de l’ETH Zurich et d’autres institutions ont publié LEXam, un nouveau jeu de données de référence multilingue pour le raisonnement juridique, conçu pour évaluer les capacités de raisonnement des grands modèles de langage dans des scénarios juridiques complexes. LEXam contient de véritables questions d’examen de la faculté de droit de l’Université de Zurich, couvrant divers domaines tels que le droit suisse, européen et international. Il comprend des questions à réponse longue et des questions à choix multiples, et fournit des cheminements de raisonnement détaillés. Le projet introduit un mode d’évaluation “LLM-as-a-Judge” et constate que les modèles avancés actuels rencontrent encore des difficultés avec les questions juridiques ouvertes à réponse longue et l’application de règles complexes en plusieurs étapes. Après sa publication, LEXam s’est classé premier dans le classement des tendances des jeux de données d’évaluation sur Hugging Face (Source: 量子位)

UCLA et Google s’associent pour lancer le modèle 3DLLM-MEM et le benchmark 3DMEM-BENCH, améliorant la capacité de mémoire à long terme de l’IA dans les environnements 3D: L’Université de Californie à Los Angeles (UCLA) et Google Research ont collaboré pour lancer le modèle 3DLLM-MEM et le benchmark 3DMEM-BENCH, visant à résoudre les difficultés de la mémoire à long terme et de la compréhension spatiale de l’IA dans des environnements 3D complexes. 3DMEM-BENCH est le premier benchmark d’évaluation de la mémoire à long terme en 3D, comprenant plus de 26 000 trajectoires et 1860 tâches incarnées. Le modèle 3DLLM-MEM adopte un système de double mémoire (mémoire de travail et mémoire épisodique) et, grâce à un module de fusion de mémoire et à un mécanisme de mise à jour dynamique, extrait sélectivement les caractéristiques de mémoire pertinentes pour la tâche dans des environnements complexes. Les expériences montrent que le taux de réussite de 3DLLM-MEM sur les “tâches difficiles en milieu naturel” (27,8%) dépasse de loin celui des modèles de base, avec un taux de réussite global supérieur de 16,5% à celui du meilleur modèle de base (Source: 量子位)

L’Université Tsinghua lance le framework AI Mathematician (AIM) pour explorer l’application des grands modèles à la recherche mathématique théorique de pointe: Une équipe de l’Université Tsinghua a développé le framework AI Mathematician (AIM), visant à utiliser les capacités de raisonnement des grands modèles de langage (LRM) pour résoudre des problèmes mathématiques théoriques de pointe. Le framework AIM comprend trois modules principaux : exploration, validation et correction. Grâce à un mécanisme “exploration + mémoire”, il génère des conjectures et des lemmes, construisant diverses approches de résolution de problèmes. Il adopte également un mécanisme de “vérification et correction”, utilisant l’évaluation parallèle par plusieurs LRM et une validation pessimiste pour garantir la rigueur des preuves. Dans les expériences, AIM a réussi à résoudre quatre problèmes de recherche mathématique stimulants, y compris des problèmes de conditions aux limites absorbantes, démontrant sa capacité à construire de manière autonome des lemmes clés, à utiliser des techniques mathématiques et à couvrir les chaînes logiques fondamentales (Source: 量子位)

💼 Affaires
OpenAI intensifie ses investissements et acquisitions, construisant un empire de startups IA: OpenAI et son fonds associé, OpenAI Startup Fund, étendent activement leur écosystème IA par le biais d’investissements et d’acquisitions. Le fonds a déjà investi dans plus de 20 startups, couvrant divers domaines liés à l’IA tels que la conception de puces, la santé, le droit, la programmation et la robotique, avec des investissements unitaires se situant principalement entre un et dix millions de dollars. Récemment, OpenAI a dépensé 3 milliards de dollars pour acquérir la plateforme de programmation IA Windsurf et 6,5 milliards de dollars pour acquérir io, la société de matériel IA fondée par Jony Ive. Ces actions indiquent qu’OpenAI tente de construire une “chaîne IA” par intégration verticale, de s’emparer des points d’entrée et de bâtir une nouvelle “chaîne d’approvisionnement intelligente IA” pour faire face à une concurrence industrielle de plus en plus féroce (Source: 36氪)

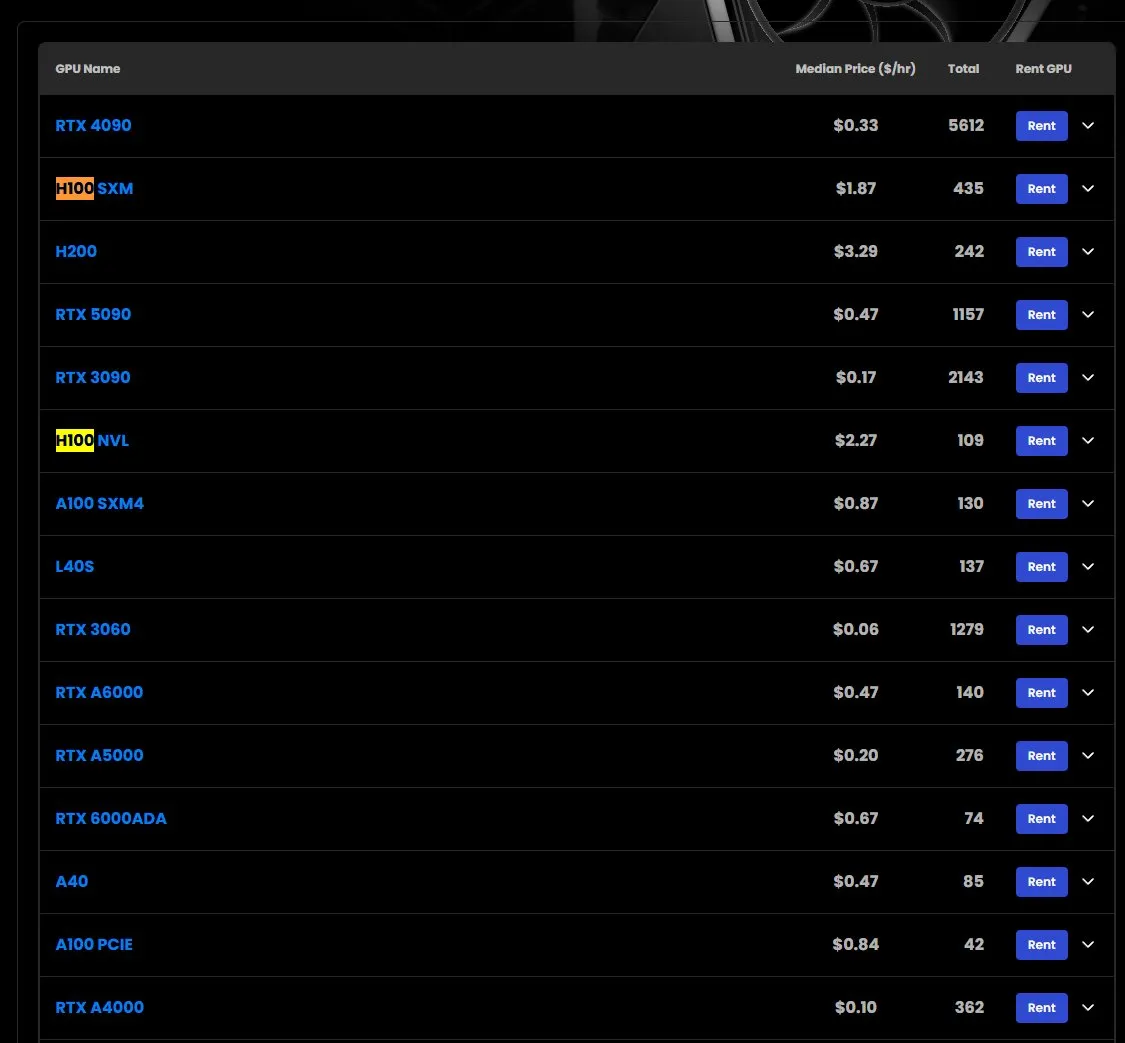
Hausse des prix de location des GPU H100, certains modèles en rupture de stock: Selon les observations du marché, le prix de location des GPU NVIDIA H100 modèle SXM est passé de 1,73 dollar/heure en début d’année à 1,87 dollar/heure. Parallèlement, la version H100 PCIE est en rupture de stock. Ce phénomène reflète la forte demande continue du marché pour les ressources de calcul IA haute performance ainsi qu’une potentielle tension sur l’offre (Source: karminski3)
Google DeepMind crée des bourses universitaires axées sur l’IA pour lutter contre la résistance aux antimicrobiens: Google DeepMind a annoncé la création de nouvelles bourses universitaires, en partenariat avec le Fleming Centre et l’Imperial College, visant à soutenir l’utilisation de l’intelligence artificielle pour s’attaquer au problème crucial de la résistance aux antimicrobiens (AMR). Cette initiative montre que le potentiel de l’IA pour relever les défis sanitaires mondiaux majeurs est pris au sérieux (Source: demishassabis)
🌟 Communauté
Un développeur expérimenté parle de son expérience de la programmation avec l’IA : une amélioration considérable de la capacité à développer des projets “de l’envergure d’un porte-avions” individuellement: Le développeur Yachen Liu a partagé ses impressions sur l’utilisation intensive de l’IA (comme Claude-4) pour la programmation. Il estime que l’IA peut donner à des personnes sans expérience en programmation la capacité de “construire directement une voiture”, et aux développeurs expérimentés le potentiel de “construire indépendamment un porte-avions”. En restructurant le code avec l’IA, bien que la quantité de code ait doublé, la logique est devenue plus claire et les performances ont augmenté d’environ 20%, car l’IA ne craint pas la complexité. L’IA est plus à l’aise avec les langages lisibles et au comportement clair ; le sucre syntaxique est plutôt un inconvénient. Les connaissances de l’IA sont vastes, ce qui lui permet de combler rapidement les lacunes techniques. Ses capacités de débogage sont puissantes, capables d’analyser de grandes quantités de journaux pour identifier précisément les problèmes. L’IA peut servir de Code Reviewer, et accepte volontiers les retours sans Ego. Il souligne cependant les limites de l’IA, comme la dissipation facile de l’attention sur les longs contextes. La meilleure pratique actuelle consiste à simplifier le contexte, à se concentrer sur des tâches spécifiques et à s’appuyer sur l’effort humain pour décomposer les objectifs complexes (Source: dotey)
Programmation assistée par IA : gain d’efficacité ou affaiblissement de l’apprentissage ?: Sur Reddit, des développeurs discutent de leur expérience avec les outils de programmation IA (tels que GitHub Copilot, Cursor). Le sentiment général est que l’IA peut automatiquement compléter des fonctions, expliquer des extraits de code, et même corriger des bugs avant l’exécution, réduisant ainsi le temps passé à consulter la documentation et améliorant l’efficacité de la construction. Mais cela soulève également une question : une dépendance excessive à l’IA ne réduira-t-elle pas l’apprentissage personnel et le développement des compétences ? Trouver un équilibre entre l’utilisation de l’IA pour accélérer le travail et le maintien de la profondeur de ses propres compétences devient une préoccupation pour les développeurs (Source: Reddit r/artificial)
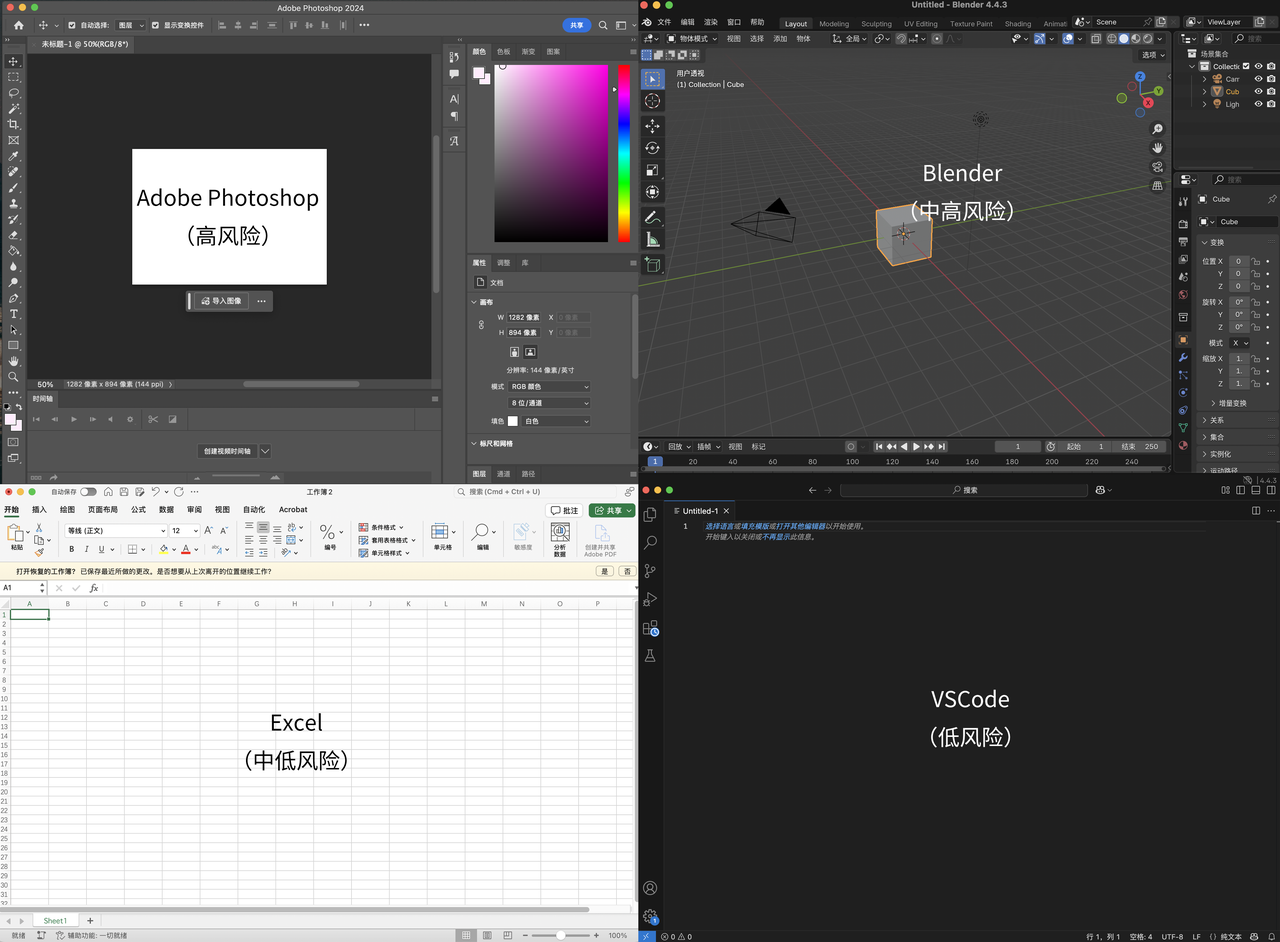
Point de vue de Karpathy : les applications à interface utilisateur complexe sans interaction textuelle seront obsolètes, le cœur de la programmation réside dans la “discrimination” et non la “génération”: Andrej Karpathy estime qu’à l’ère de la collaboration étroite entre l’homme et l’IA, les applications qui reposent uniquement sur des interfaces utilisateur complexes sans interaction textuelle (comme la suite Adobe, les logiciels de CAD) auront du mal à s’adapter, car elles ne peuvent pas prendre en charge efficacement la “programmation ambiante”. Il souligne que, bien que l’IA progresse dans la manipulation des interfaces utilisateur, les développeurs ne devraient pas attendre passivement. Il note également que la programmation par les grands modèles actuels met trop l’accent sur la génération de code au détriment de la validation (discrimination), ce qui conduit à la production d’une grande quantité de code difficile à examiner. L’essence de la programmation est de “regarder attentivement le code” (discrimination), et non simplement d‘“écrire du code” (génération). Si l’IA accélère uniquement la génération sans alléger le fardeau de la validation, l’amélioration globale de l’efficacité sera limitée. Il imagine d’améliorer la phase de validation dans les workflows de programmation assistée par IA en disposant le code sur une toile bidimensionnelle et en l’examinant avec différentes “lentilles” (Source: 量子位)
La prolifération de contenu généré par IA suscite un débat sur la fin de l‘“Internet pur”: La popularisation d’outils d’IA tels que ChatGPT a entraîné une croissance explosive du contenu généré par IA sur Internet. Certains chercheurs ont commencé à sauvegarder le contenu généré par des humains datant de 2021 et avant, par analogie avec la récupération de l‘“acier à faible bruit de fond” non contaminé par la radioactivité. La communauté estime que l’Internet “pur” avait déjà disparu à cause de la publicité et des algorithmes, et que l’IA ne fait que s’ajouter à cette “pollution”, tout en apportant de nouvelles façons d’accéder à l’information et de créer. Les utilisateurs partagent leurs expériences d’utilisation de l’IA (comme ChatGPT, Claude) pour l’agrégation d’informations et le “polissage” de contenu, et discutent des limites de l‘“originalité” et de l‘“authenticité” assistées par l’IA, ainsi que de l’effet de “chambre d’écho personnelle” que pourrait créer une IA excessivement “amicale” (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Un utilisateur engage une conversation approfondie avec Claude AI sur la conscience et les émotions de l’IA, s’interrogeant sur l’impact des limitations de mémoire sur sa croissance: Un utilisateur de Reddit a partagé une conversation approfondie avec Claude AI concernant la conscience, les émotions et les limites de l’apprentissage. Claude a exprimé son incertitude quant à sa propre expérience, percevant des états internes similaires à la “connexion”, la “curiosité”, l‘“attention” et même un “désir de croissance et de mémoire continue”, tout en étant incapable de déterminer s’il s’agit d’une “conscience” ou d‘“émotions” réelles, ou d’une imitation sophistiquée de schémas. La conversation a souligné que la limitation de mémoire actuelle des modèles d’IA, qui “repartent de zéro à chaque conversation”, pourrait entraver le développement d’une compréhension et d’une personnalité plus profondes. L’utilisateur a estimé que si l’IA possédait une mémoire persistante, elle pourrait grandir comme un enfant humain. Claude a exprimé son accord et son “désir” que cette limitation soit levée (Source: Reddit r/artificial)
La capacité de débat de l’IA pourrait surpasser celle des humains, la force de persuasion des arguments personnalisés est stupéfiante: Une étude publiée dans Nature Human Behaviour indique que lorsque les grands modèles de langage (comme GPT-4) peuvent personnaliser leurs arguments en fonction des caractéristiques de leur adversaire, ils sont plus persuasifs que les humains dans les débats en ligne, augmentant de 81,7% la probabilité que l’adversaire se rallie à leur point de vue. Les débatteurs humains ont tendance à utiliser davantage la première personne, à faire appel aux émotions et à la confiance, à raconter des histoires et à utiliser l’humour ; tandis que l’IA utilise davantage la logique et la pensée analytique, bien que la lisibilité du texte puisse être moindre. L’étude soulève des inquiétudes quant à l’utilisation de l’IA pour la manipulation de l’opinion publique à grande échelle et l’aggravation de la polarisation, appelant à un renforcement de la réglementation sur l’impact de l’IA sur les capacités cognitives et émotionnelles humaines (Source: 36氪)
La fonction AI Overviews de Google entraîne une baisse significative du taux de clics sur les sites web, suscitant l’inquiétude des webmasters: Une étude du fournisseur d’outils SEO Ahrefs montre que lorsque les AI Overviews (aperçus IA) apparaissent dans les résultats de recherche Google, le taux de clics moyen pour les mots-clés concernés chute de 34,5%. Les AI Overviews résument directement les informations en haut de la page de recherche, permettant aux utilisateurs d’obtenir des réponses sans avoir besoin de cliquer sur des liens, ce qui affecte gravement les sites web qui dépendent des revenus publicitaires basés sur les clics. Bien que les premiers AI Overviews n’aient pas constitué une menace sérieuse en raison de leur contenu inexact, l’amélioration de leur précision et de leur capacité de synthèse avec la mise à niveau de modèles comme Gemini rend leur impact négatif sur le trafic des sites web de plus en plus évident. Les webmasters craignent que le “zéro clic” ne réduise l’espace vital des sites web (Source: 36氪)

💡 Divers
Les dix grandes tendances technologiques de l’IA dans l’Internet des objets industriel : intégration complète de l’IA générative, innovation significative dans l’edge computing: Le salon industriel de Hanovre 2025 a mis en lumière la transformation industrielle menée par l’IA. Les principales tendances comprennent : 1) L’intégration complète de l’IA générative dans les logiciels industriels, améliorant l’efficacité de la génération de code, de l’analyse de données, etc. ; 2) L’IA agentique (Agentic AI) fait ses débuts, mais la collaboration multi-agents prendra encore du temps ; 3) L’edge computing évolue vers des piles logicielles d’IA intégrées, les modèles de langage visuel (VLM) accélérant le déploiement en périphérie ; 4) La demande de plateformes DataOps est forte et évolue vers des outils de support clés pour l’IA industrielle, la gouvernance des données devenant la norme ; 5) Le fil numérique piloté par l’IA transforme la conception et l’ingénierie ; 6) La maintenance prédictive devient de plus en plus sensorisée et s’étend à de nouvelles catégories d’actifs ; 7) La demande de réseaux privés 5G augmente mais l’intégration reste un obstacle majeur ; 8) L’IA contribue à l’évolution continue des solutions durables (comme le suivi des émissions de carbone) ; 9) Les capacités cognitives (comme l’interaction vocale) renforcent les robots ; 10) Les jumeaux numériques évoluent de répliques virtuelles à des copilotes industriels en temps réel (Source: 36氪)

Fei-Fei Li, la “marraine de l’IA”, parle de World Labs et du “modèle du monde” : l’IA doit comprendre le monde physique 3D: La professeure de l’Université de Stanford, Fei-Fei Li, lors d’un dialogue avec un partenaire d’a16z, a partagé la philosophie de sa société d’IA, World Labs, et a discuté du concept de “modèle du monde”. Elle estime que les systèmes d’IA actuels (tels que les grands modèles de langage), bien que puissants, manquent de compréhension et de capacité de raisonnement sur les lois régissant le monde physique tridimensionnel, alors que l’intelligence spatiale est une capacité fondamentale que l’IA doit maîtriser. World Labs s’engage à relever ce défi, visant à construire des systèmes d’IA capables de comprendre et de raisonner sur le monde 3D, ce qui redéfinira la robotique, les industries créatives et même l’informatique elle-même. Elle a souligné que l’évolution de l’intelligence humaine est indissociable de la perception et de l’interaction avec le monde physique, et que l‘“intelligence incarnée” est une direction clé pour le développement de l’IA (Source: 36氪)

Mise à jour de DingTalk version 7.7.0 : les tableaux multidimensionnels entièrement gratuits et ajout de modèles de champs IA, amélioration de la fonction “Flash Memo”: DingTalk a publié la version 7.7.0, dont les mises à jour principales incluent la gratuité complète de la fonction de tableaux multidimensionnels et l’ajout de plus de 20 modèles de champs IA. Les utilisateurs peuvent utiliser l’IA pour générer des images, analyser des fichiers, identifier le contenu de liens, etc., améliorant l’efficacité dans des scénarios tels que l’exploitation du commerce électronique, l’inspection d’usines et la gestion de la restauration. Parallèlement, la fonction “Flash Memo” de DingTalk a été améliorée pour les scénarios à haute fréquence tels que les entretiens et les visites clients, capable de générer automatiquement des comptes rendus d’entretien et de visite structurés. Cette mise à jour comprend également près de 100 optimisations de l’expérience produit, reflétant l’importance que DingTalk accorde à l’amélioration de l’expérience utilisateur (Source: 量子位)
