
Palavras-chave:Gemini 2.5 Pro, OpenAI privacidade de dados, OpenThinker3-7B, Claude Gov, Agentes de IA inteligentes, Modelos de linguagem grande (LLM), Aprendizagem por reforço, Modelos de código aberto, Melhoria de desempenho do Gemini 2.5 Pro, Política de retenção de dados de usuários da OpenAI, Capacidade de raciocínio do OpenThinker3-7B, Aplicações de segurança nacional do Claude Gov, Robustez e controle de agentes de IA
🔥 Destaques
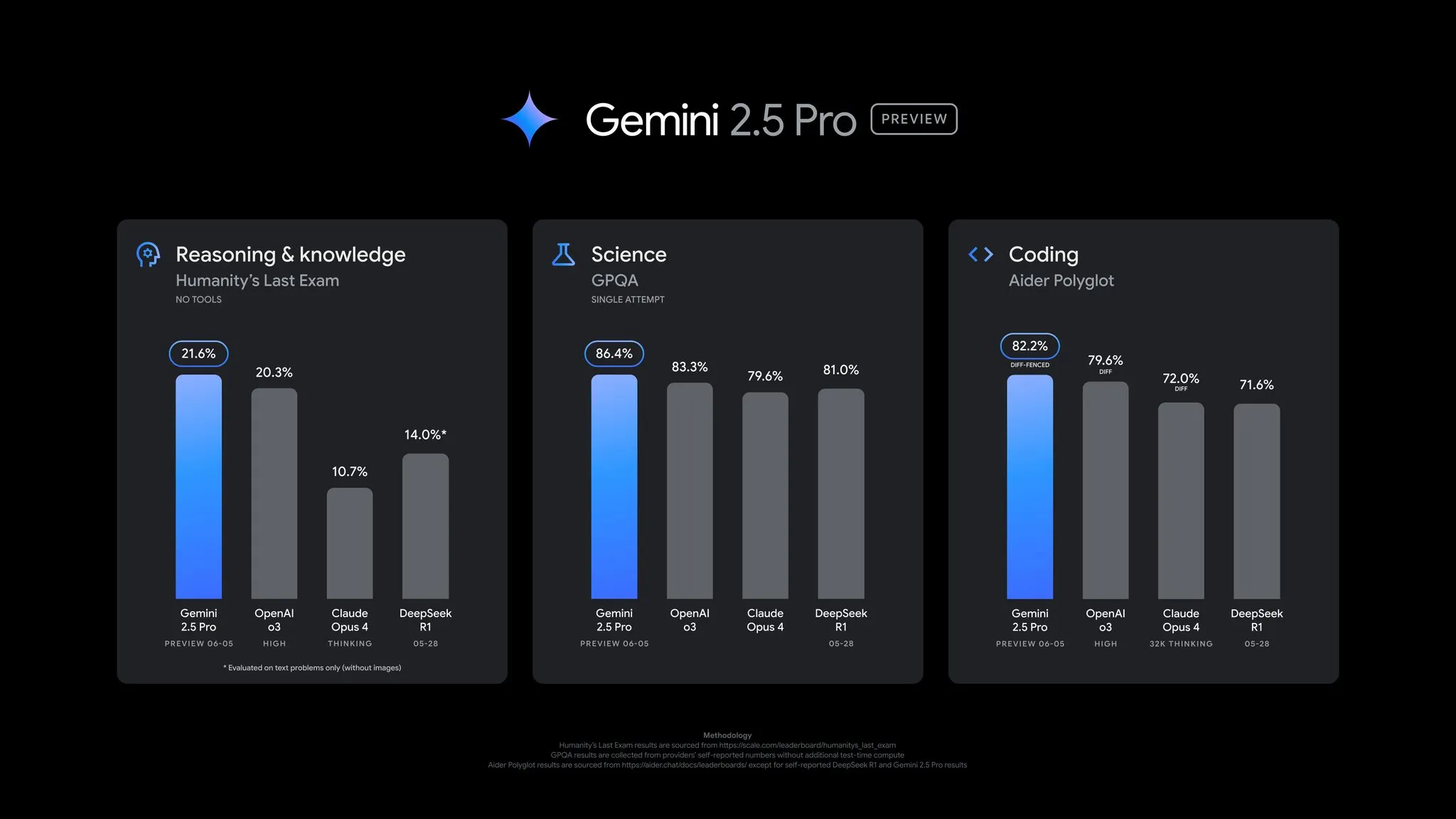
Google lança atualização da prévia do Gemini 2.5 Pro, com melhorias abrangentes de desempenho: O Google anunciou uma importante atualização para a prévia do Gemini 2.5 Pro, com progressos significativos em codificação, raciocínio, capacidades científicas e matemáticas. A nova versão apresentou melhor desempenho em benchmarks chave como AIDER Polyglot, GPQA, HLE, entre outros, e alcançou um salto de 24 pontos no Elo score na LMArena, liderando novamente. Além disso, o estilo de resposta e formatação do modelo foram aprimorados com base no feedback dos usuários, e foi introduzida a funcionalidade “thinking budget” para oferecer mais controle. A atualização já está disponível no Gemini App, Google AI Studio e Vertex AI (Fonte: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI ordenada a preservar permanentemente dados de usuários devido a processo do New York Times, levantando preocupações com privacidade: No processo de direitos autorais com o The New York Times, a OpenAI foi ordenada judicialmente a reter permanentemente todos os logs de interação de usuários do ChatGPT e da API, incluindo “conversas temporárias” e dados de solicitações de API que anteriormente havia se comprometido a reter por apenas 30 dias. A OpenAI declarou que está recorrendo, considerando a medida uma “intervenção excessiva” que prejudica normas de privacidade de longa data e enfraquece a proteção da privacidade. Esta decisão significa que a OpenAI pode não conseguir cumprir seus compromissos de retenção e exclusão de dados com os usuários, levantando amplas preocupações sobre a privacidade e segurança dos dados dos usuários, e podendo afetar especialmente desenvolvedores de aplicativos que dependem da API da OpenAI e têm suas próprias políticas de retenção de dados (Fonte: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

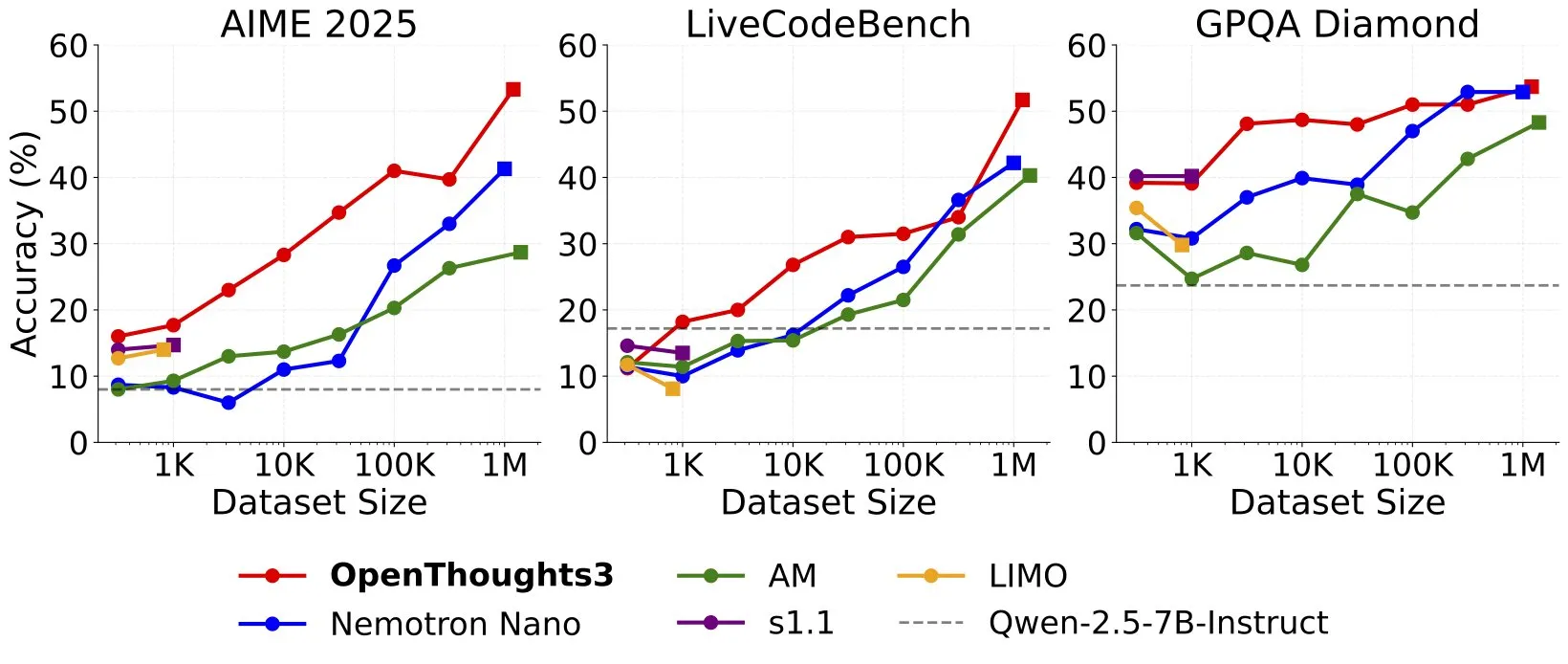
OpenThinker3-7B lançado, estabelecendo novo SOTA para modelos de inferência open source de 7B: Ryan Marten anunciou o lançamento do OpenThinker3-7B, um novo modelo de inferência de dados abertos com 7 bilhões de parâmetros, que supera em média o DeepSeek-R1-Distill-Qwen-7B em 33% em avaliações de código, ciência e matemática. A equipe também lançou o dataset OpenThoughts3-1.2M, alegando ser o melhor dataset de inferência aberto em todas as escalas de dados atualmente. Pesquisadores apontam que, para modelos menores, a destilação a partir do R1 é o caminho mais simples para melhorar o desempenho, mas a pesquisa na direção de RL (Aprendizado por Reforço) é mais exploratória. Este resultado é considerado um dos trabalhos pioneiros no campo de modelos de inferência abertos (Fonte: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic lança Claude Gov, modelo customizado para clientes de segurança nacional dos EUA: A Anthropic anunciou o lançamento do Claude Gov, uma série de modelos de IA customizados construídos para clientes de segurança nacional dos EUA. Esses modelos já foram implantados nas agências de segurança nacional de mais alto nível dos EUA, com acesso restrito a pessoal operando em ambientes confidenciais. A medida marca um aprofundamento da aplicação da tecnologia de IA nos setores governamental e de defesa, e também levanta discussões sobre a aplicação de IA em áreas sensíveis (Fonte: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 Tendências
Yann LeCun concorda com Sundar Pichai: tecnologia atual pode não alcançar AGI, possível período de platô: O cientista chefe de IA da Meta, Yann LeCun, retweetou e concordou com a opinião do CEO do Google, Sundar Pichai, de que o caminho tecnológico atual não garante a realização da inteligência artificial geral (AGI), e o desenvolvimento da IA pode encontrar um período de platô temporário. Pichai observou que, embora a velocidade do progresso da IA seja surpreendente, também pode haver limitações, e a tecnologia atual ainda está distante da inteligência geral. Isso reflete uma atitude cautelosa da indústria em relação ao caminho e cronograma para a realização da AGI (Fonte: ylecun)
OpenAI recruta para equipe de Robustez e Controle de Agentes, visando aumentar a segurança de agentes de IA: A OpenAI está montando uma nova equipe de “Agent Robustness and Control”, com o objetivo de garantir a segurança e confiabilidade de seus agentes de IA durante os processos de treinamento e implantação. A equipe se dedicará a resolver alguns dos problemas mais desafiadores no campo da IA, demonstrando a alta prioridade da OpenAI na segurança e controlabilidade ao mesmo tempo em que avança com agentes de IA mais poderosos (Fonte: gdb)

Nova pesquisa da Apple revela “ilusão de pensamento” em modelos de linguagem grandes: capacidade de raciocínio diminui em vez de aumentar diante de problemas complexos: Um recente artigo de pesquisa da Apple, intitulado “The Illusion of Thinking”, aponta que os modelos de raciocínio atuais, ao enfrentarem um aumento na complexidade do problema até certo ponto, apresentam uma diminuição no seu “esforço de raciocínio” (reasoning effort), mesmo quando lhes é fornecido um orçamento de tokens suficiente. Este fenômeno contraintuitivo de “limite de escalabilidade” (scaling limit) sugere que os modelos podem não estar realizando um pensamento profundo ao lidar com problemas altamente complexos, mas sim exibindo uma “ilusão de pensamento”, o que apresenta novos desafios para avaliar e melhorar a verdadeira capacidade de raciocínio dos modelos grandes (Fonte: Ar_Douillard, Reddit r/MachineLearning)

OpenAI discute conexão emocional entre humanos e IA, priorizando pesquisa sobre impacto no bem-estar emocional dos usuários: Joanne Jang, da OpenAI, publicou um post de blog discutindo o fenômeno crescente da conexão emocional entre usuários e modelos de IA como o ChatGPT. O artigo aponta que as pessoas naturalmente antropomorfizam a IA e podem desenvolver sentimentos de companheirismo e confiança nela. A OpenAI reconhece essa tendência e afirma que priorizará a pesquisa sobre o impacto da IA no bem-estar emocional dos usuários, em vez de se debruçar sobre questões ontológicas sobre se a IA é verdadeiramente “consciente”. O objetivo da empresa é projetar assistentes de IA que sejam calorosos, úteis, mas que não busquem excessivamente dependência emocional ou tenham suas próprias agendas (Fonte: openai, sama, BorisMPower)

Xiaohongshu lança modelo grande MoE open-source dots.llm1-143B-A14B: O Hi Lab da Xiaohongshu lançou sua primeira série de modelos grandes open-source dots.llm1, incluindo o modelo base dots.llm1.base e o modelo ajustado por instrução dots.llm1.inst. O modelo adota uma arquitetura MoE, com um total de 143B de parâmetros e 14B de parâmetros ativos. Testes internos oficiais indicam que seu desempenho no MMLU-Pro é superior ao Qwen3-235B-A22B, mas inferior ao novo DeepSeek-V3. O modelo utiliza a licença MIT, permitindo uso livre. No entanto, testes preliminares da comunidade mostram que seu desempenho em tarefas como geração de código é insatisfatório, sendo inferior até mesmo ao Qwen2.5-coder (Fonte: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Série Qwen3 lança modelos Embedding e Reranker, aprimorando capacidade de processamento de texto multilíngue: A equipe Qwen lançou os modelos das séries Qwen3-Embedding e Qwen3-Reranker, com o objetivo de melhorar o desempenho de incorporação de texto multilíngue e classificação de relevância. Os modelos Embedding são usados para converter texto em representações vetoriais, suportando cenários como recuperação de documentos e RAG; os modelos Reranker são usados para reclassificar resultados de busca, priorizando o conteúdo mais relevante. A série de modelos oferece diferentes escalas de parâmetros, como 0.6B, 4B, 8B, suporta 119 idiomas e apresenta excelente desempenho em benchmarks como MMTEB e MTEB. A versão de 0.6B é considerada particularmente adequada para cenários de Reranker com alta exigência de tempo real devido ao seu equilíbrio entre eficiência e desempenho (Fonte: karminski3, karminski3, ZhaiAndrew, clefourrier)

Pesquisa aponta desafios de escalabilidade do aprendizado por reforço em tarefas complexas de longo horizonte: Uma pesquisa de Seohong Park e colegas descobriu que simplesmente expandir dados e recursos computacionais não é suficiente para que o aprendizado por reforço (RL) resolva eficazmente tarefas complexas; o fator limitante crucial é o “horizonte” (horizon). Em tarefas de longo horizonte, os sinais de recompensa são esparsos, dificultando o aprendizado de estratégias eficazes pelo modelo. Isso se alinha com observações de que alguns agentes de IA atuais (como Deep Research, Codex agent) dependem principalmente de tarefas de RL de curto horizonte e treinamento de robustez geral, indicando que resolver problemas de recompensa esparsa de longo horizonte de ponta a ponta continua sendo um grande desafio no campo do RL (Fonte: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu registra conta oficial no HuggingFace e carrega modelos grandes Wenxin: O Baidu registrou uma conta oficial na plataforma HuggingFace e carregou alguns modelos da série Wenxin (ERNIE), incluindo Wenxin-X1-Turbo e Wenxin-4.5-Turbo. Esta ação significa que o Baidu está integrando ativamente sua tecnologia de modelos grandes na comunidade open source mais ampla e no ecossistema de desenvolvedores, facilitando o acesso e uso de suas capacidades de IA por desenvolvedores globais (Fonte: karminski3)
OpenBMB lança série de modelos MiniCPM4, focada em operação eficiente em dispositivos de ponta: A OpenBMB continua a explorar os limites de modelos de linguagem pequenos e eficientes, lançando a série MiniCPM4. O modelo MiniCPM4-8B possui 8 bilhões de parâmetros e foi treinado em 8T tokens. A série de modelos adota tecnologias de aceleração extrema como atenção esparsa treinável (InfLLM v2), quantização ternária (BitCPM), computação de baixa precisão FP8 e previsão multi-token, visando alcançar operação eficiente em dispositivos de ponta (edge). Por exemplo, seu mecanismo de atenção esparsa, ao processar texto longo de 128K, requer que cada token calcule a relevância com menos de 5% dos tokens, reduzindo significativamente a sobrecarga computacional do processamento de texto longo (Fonte: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
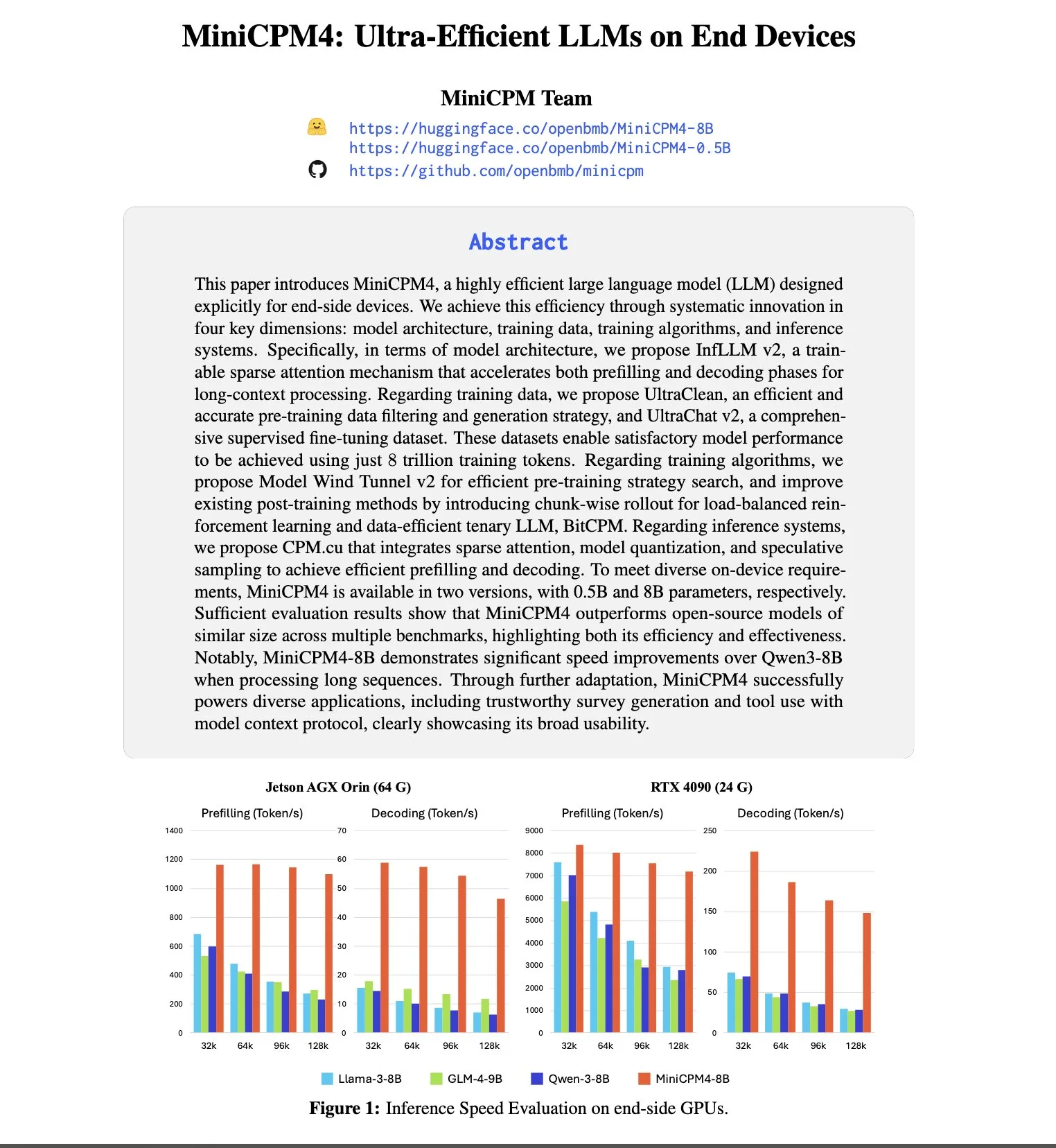
Anthropic lidera em atração e retenção de talentos, com 8 vezes mais probabilidade de recrutar da OpenAI: O relatório de tendências de talentos para 2025 da SignalFire mostra que a Anthropic se destaca na retenção de talentos de IA de ponta, atingindo 80%, superior aos 78% da DeepMind e 67% da OpenAI. O relatório também aponta que a probabilidade de engenheiros trocarem a OpenAI pela Anthropic é 8 vezes maior do que o fluxo da Anthropic para a OpenAI. A cultura corporativa única da Anthropic, sua inclusão de pensamentos não convencionais, autonomia dos funcionários e a popularidade de seu produto Claude entre os desenvolvedores são considerados fatores chave para sua atração e retenção de talentos (Fonte: 量子位)
🧰 Ferramentas
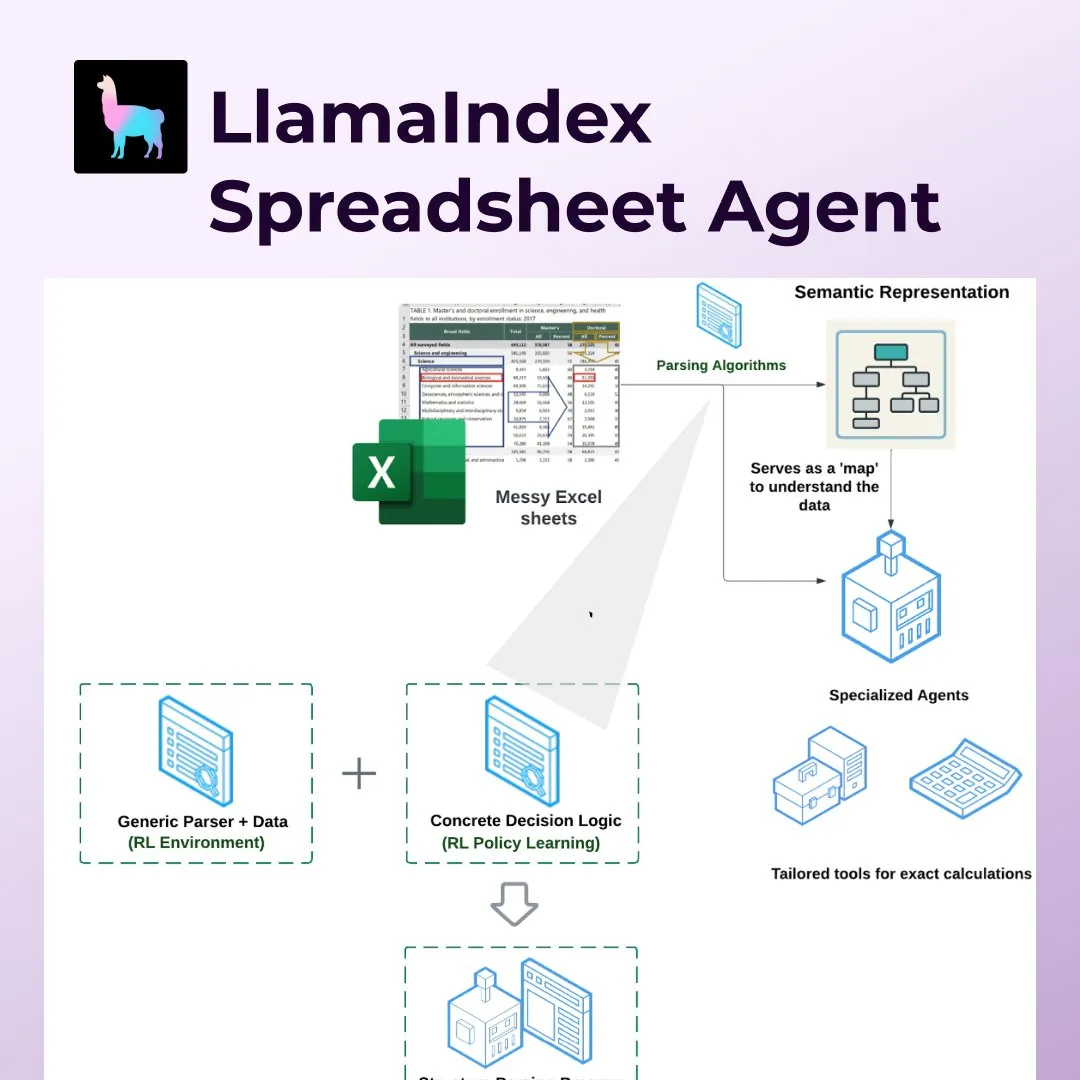
LlamaIndex lança Spreadsheet Agents, revolucionando o processamento de planilhas como Excel: LlamaIndex anunciou a nova funcionalidade Spreadsheet Agents, permitindo aos usuários realizar transformação de dados e perguntas e respostas em planilhas Excel não padronizadas. A ferramenta utiliza análise de estrutura semântica baseada em aprendizado por reforço para entender a estrutura da planilha e, por meio de ferramentas dedicadas, permite que agentes de IA interajam com a planilha. Visa resolver as deficiências dos LLMs tradicionais no tratamento de planilhas complexas (como as comuns nas áreas de contabilidade, fiscal e seguros), podendo lidar com células mescladas, layouts complexos e manter relações de dados. Em testes, sua precisão (96%) superou a linha de base humana e o OpenAI Code Interpreter (GPT 4.1, 75%) (Fonte: jerryjliu0)
LlamaIndex utiliza LlamaExtract e workflows de agentes para automatizar extração do SEC Form 4: LlamaIndex demonstrou como usar sua ferramenta LlamaExtract e workflows de agentes de IA para extrair e normalizar automaticamente dados dos arquivos Form 4 da Comissão de Valores Mobiliários dos EUA (SEC) – documentos onde executivos, diretores e principais acionistas de empresas listadas divulgam transações de ações. A solução pode converter arquivos Form 4 de diferentes empresas, com formatos variados, em formato CSV limpo e integrá-los a um dataframe consultável via Pandas, fornecendo uma ferramenta eficiente de processamento de dados para analistas financeiros e investidores (Fonte: jerryjliu0)

Projeto open-source Ragbits lançado, oferecendo blocos de construção para desenvolvimento rápido de aplicações GenAI: deepsense-ai lançou o projeto open-source Ragbits, com o objetivo de fornecer blocos de construção para o desenvolvimento rápido de aplicações de IA generativa. O projeto suporta mais de 100 interfaces de modelos grandes ou modelos locais, vem com armazenamento de vetores (conectável a Qdrant, PgVector), e suporta mais de 20 formatos de arquivo de entrada (PDF, HTML, planilhas, apresentações, etc.). Ragbits utiliza VLM integrado para suportar a extração de tabelas, imagens e conteúdo estruturado, pode se conectar a várias fontes de dados como S3, GCS, Azure, e possui características modulares, permitindo que os usuários personalizem componentes (Fonte: karminski3, GitHub Trending)

Assistente de programação AI Cursor lança grande atualização, integrando BugBot, função de memória e suporte MCP: A ferramenta de programação AI Cursor passou por uma grande atualização, incluindo principalmente: 1) BugBot, que pode responder automaticamente a issues do GitHub e abri-las no Cursor com um clique para correção; 2) Função de memória, permitindo que a IA lembre o conteúdo de conversas anteriores, melhorando a usabilidade em modificações repetitivas de grandes projetos; 3) Configuração MCP (Model Context Protocol) com um clique, suportando servidores MCP de terceiros com OAuth; 4) Suporte a AI Agent para Jupyter Notes; 5) Agent em segundo plano, invocando um painel de controle por meio de teclas de atalho para usar um AI programming Agent remoto (Fonte: karminski3)
Archon: Um agente de IA que pode criar outros agentes de IA: Archon é um projeto “Agenteer” que visa construir e otimizar autonomamente outros agentes de IA. Ele utiliza fluxos de trabalho avançados de codificação de agentes e uma base de conhecimento de frameworks, demonstrando o papel do planejamento, ciclos de feedback e conhecimento de domínio na criação de agentes de IA poderosos. A versão V6 mais recente integra uma biblioteca de ferramentas e um servidor MCP (Model Context Protocol), aprimorando a capacidade de construir novos agentes. Archon suporta implantação Docker e instalação local Python, e fornece uma UI Streamlit para gerenciamento (Fonte: GitHub Trending)

NoteGen: Aplicativo de anotações Markdown multiplataforma impulsionado por IA: NoteGen é um aplicativo de anotações Markdown multiplataforma dedicado a conectar registros e escrita usando IA, capaz de organizar conhecimento fragmentado em anotações legíveis. Suporta múltiplos métodos de registro, como capturas de tela, texto, ilustrações, arquivos, links, etc., com armazenamento nativo em Markdown, suporte para uso offline local e sincronização com GitHub/Gitee/WebDAV. NoteGen pode ser configurado com vários modelos de IA, como ChatGPT, Gemini, Ollama, e suporta a funcionalidade RAG, usando as anotações do usuário como base de conhecimento (Fonte: GitHub Trending)

ComfyUI-Copilot: Assistente inteligente para desenvolvimento automatizado de workflows: ComfyUI-Copilot é um plugin impulsionado por modelos de linguagem grandes, projetado para aumentar a facilidade de uso e eficiência da plataforma de criação de arte com IA, ComfyUI. Ele resolve problemas como a interface pouco amigável do ComfyUI para iniciantes, erros de configuração de modelos e a complexidade do design de workflows, fornecendo recomendações inteligentes de nós e modelos, bem como funcionalidades de construção de workflows com um clique. O sistema adota uma estrutura hierárquica multiagente, incluindo um agente assistente central e múltiplos agentes de trabalho dedicados, e utiliza a base de conhecimento do ComfyUI para simplificar a depuração e implantação (Fonte: HuggingFace Daily Papers)
Bifrost: Gateway LLM de alto desempenho em Go open-source, otimizando a implantação de LLM em produção: Para resolver desafios como fragmentação de API, latência, fallback e gerenciamento de custos de LLMs em ambientes de produção, a equipe Maximilian tornou open-source o gateway LLM Bifrost, baseado em Go. Bifrost é projetado especificamente para implantações de machine learning de alta taxa de transferência e baixa latência, suportando os principais provedores de LLM como OpenAI, Anthropic, Azure. Benchmarks mostram que, em comparação com outros proxies, Bifrost aumenta a taxa de transferência em 9.5 vezes, reduz a latência P99 em 54 vezes e o consumo de memória em 68%, com uma sobrecarga interna inferior a 15µs a 5000 RPS. Ele oferece normalização de API, fallback automático de provedor, gerenciamento inteligente de chaves e métricas Prometheus (Fonte: Reddit r/MachineLearning)

LangGraph.js melhora a experiência do desenvolvedor, introduzindo segurança de tipos e funções de hook: A versão 0.3 do LangGraph.js passou por uma série de atualizações destinadas a melhorar a experiência do desenvolvedor. Isso inclui segurança de tipos aprimorada, bem como a introdução de preModelHook e postModelHook no createReactAgent. O preModelHook pode ser usado para simplificar o histórico de mensagens antes de ser passado para o LLM, enquanto o postModelHook pode ser usado para adicionar barreiras de proteção ou fluxos de colaboração humano-máquina. A comunidade está buscando ativamente feedback para o LangGraph v1 (Fonte: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024 lança modelo grande de correção gramatical GRMR-V3-G4B: O desenvolvedor qingy2024 lançou um modelo grande focado em correção gramatical, o GRMR-V3-G4B, com um número máximo de parâmetros de apenas 4B. O modelo também fornece uma versão quantizada, especialmente adequada para tarefas de verificação e correção gramatical em fluxos de trabalho locais ou dispositivos pessoais, facilitando a integração e o uso (Fonte: karminski3)

Fullpack: Aplicativo inteligente de lista de embalagem baseado em reconhecimento visual local no iPhone: Um desenvolvedor lançou um aplicativo iOS chamado Fullpack, que pode identificar itens em fotos usando o VisionKit do iPhone e ajudar os usuários a criar listas de embalagem inteligentes para diferentes ocasiões (como um dia de trabalho, férias na praia, fim de semana de caminhada). O aplicativo enfatiza a execução 100% local, sem processamento na nuvem ou coleta de dados, para proteger a privacidade do usuário. Este é o primeiro aplicativo independente do desenvolvedor, com o objetivo de explorar o potencial da IA no dispositivo (Fonte: Reddit r/LocalLLaMA)
📚 Aprendizado
Unsloth lança grande quantidade de Notebooks Colab/Kaggle para fine-tuning dos principais modelos grandes: UnslothAI disponibilizou uma série de Jupyter Notebooks para facilitar o fine-tuning de vários modelos grandes populares, como Qwen3, Gemma 3, Llama 3.1/3.2, Phi-4, Mistral v0.3, em plataformas como Google Colab e Kaggle. Esses Notebooks cobrem diversos tipos de tarefas e métodos de fine-tuning, incluindo conversação, Alpaca, GRPO, visão, text-to-speech (TTS), com o objetivo de simplificar o processo de fine-tuning de modelos e fornecer orientação sobre preparação de dados, treinamento, avaliação e salvamento de modelos (Fonte: GitHub Trending)

“Guia de Consumo de Modelos Grandes Open Source”: Tutorial de LLM/MLLM para iniciantes na China: O projeto Datawhalechina “Guia de Consumo de Modelos Grandes Open Source” oferece um tutorial baseado em ambiente Linux, voltado para iniciantes na China, cobrindo todo o processo de configuração de ambiente, implantação local, fine-tuning de todos os parâmetros/Lora para modelos grandes open source (LLM) e modelos grandes multimodais (MLLM) nacionais e internacionais. O projeto visa simplificar a implantação e uso de modelos grandes open source e já suporta vários modelos como Qwen3, Kimi-VL, Llama4, Gemma3, InternLM3, Phi4 (Fonte: GitHub Trending)

Artigo explora MINT-CoT: Introduzindo tokens visuais cruzados no raciocínio matemático em cadeia de pensamento: Um novo artigo propõe o método MINT-CoT (Mathematical Interleaved Tokens for Chain-of-Thought), que visa aprimorar a capacidade de raciocínio de modelos de linguagem grandes em problemas matemáticos multimodais, introduzindo adaptativamente tokens visuais relevantes cruzados nas etapas de raciocínio textual. O método seleciona dinamicamente regiões visuais de qualquer forma em gráficos matemáticos por meio de um “Interleave Token” e construiu o dataset MINT-CoT contendo 54K problemas matemáticos, usado para treinar o modelo a alinhar-se com regiões visuais em nível de token em cada etapa de raciocínio. Experimentos mostram que o modelo MINT-CoT-7B supera significativamente os modelos de linha de base em benchmarks como MathVista (Fonte: HuggingFace Daily Papers)
Artigo propõe StreamBP: Método preciso de retropropagação para treinamento de LLM em sequências longas com eficiência de memória: Enfrentando o problema do alto custo de memória devido ao armazenamento de valores de ativação durante o treinamento de LLMs em sequências longas, pesquisadores propuseram o StreamBP, um método de retropropagação (backpropagation) preciso e eficiente em termos de memória. O StreamBP reduz significativamente o custo de memória para valores de ativação e logits, decompondo linearmente a regra da cadeia ao longo da dimensão da sequência no nível da camada. O método é aplicável a objetivos comuns como SFT, GRPO, DPO, requer menos FLOPs computacionais e tem uma velocidade de BP mais rápida. Em comparação com o checkpointing de gradiente, o StreamBP pode estender o comprimento máximo da sequência de BP em 2.8-5.5 vezes, usando tempo de BP comparável ou até menor (Fonte: HuggingFace Daily Papers)
Artigo propõe técnica Diagonal Batching, desbloqueando inferência paralela de longo contexto para RMT: Para resolver o gargalo de desempenho de modelos Transformer na inferência de longo contexto, pesquisadores propuseram o esquema de agendamento Diagonal Batching, que visa desbloquear o paralelismo entre fragmentos no Recurrent Memory Transformer (RMT), mantendo ao mesmo tempo a recorrência precisa. A técnica reordena os cálculos em tempo de execução, eliminando restrições sequenciais e permitindo inferência eficiente em GPU mesmo para uma única entrada de longo contexto, sem a necessidade de técnicas complexas de batching e pipelining. Aplicado ao modelo LLaMA-1B ARMT, em uma sequência de 131K tokens, o Diagonal Batching foi 3.3 vezes mais rápido que o LLaMA-1B de atenção total padrão e 1.8 vezes mais rápido que a implementação sequencial do RMT (Fonte: HuggingFace Daily Papers)
Artigo explora o impacto negativo da tecnologia de marca d’água no alinhamento de modelos de linguagem e estratégias de mitigação: Um estudo analisou sistematicamente o impacto de duas tecnologias de marca d’água (watermarking) convencionais, Gumbel e KGW, nos atributos centrais de alinhamento de modelos de linguagem grandes (LLMs), como veracidade, segurança e utilidade. A pesquisa descobriu que a marca d’água leva a dois modos de degradação: enfraquecimento da proteção (aumentando a utilidade, mas prejudicando a segurança) e amplificação da proteção (cautela excessiva reduzindo a utilidade). Para mitigar esses problemas, o artigo propõe o método Alignment Resampling (AR), que usa um modelo de recompensa externo durante a inferência para restaurar o alinhamento. Experimentos demonstram que amostrar de 2 a 4 gerações com marca d’água pode efetivamente restaurar ou superar os scores de alinhamento da linha de base, mantendo a detectabilidade da marca d’água (Fonte: HuggingFace Daily Papers)
Artigo propõe framework Micro-Act, mitigando conflitos de conhecimento em perguntas e respostas através de auto-raciocínio acionável: Para resolver o problema de conflitos entre conhecimento externo e conhecimento paramétrico interno de modelos grandes (LLM) em sistemas de Geração Aumentada por Recuperação (RAG), pesquisadores propuseram o framework Micro-Act. Este framework possui um espaço de ação hierárquico, pode perceber automaticamente a complexidade do contexto e decompor cada fonte de conhecimento em uma série de etapas de comparação refinadas (representadas como etapas acionáveis), alcançando assim um raciocínio que transcende o contexto superficial. Experimentos mostram que o Micro-Act melhora significativamente a precisão de perguntas e respostas em cinco datasets de benchmark, superando as linhas de base existentes especialmente em tipos de conflito temporal e semântico, e lida robustamente com problemas sem conflito (Fonte: HuggingFace Daily Papers)
Artigo propõe benchmark STARE para avaliar a capacidade de simulação visual-espacial de modelos multimodais: Para avaliar a capacidade de modelos de linguagem grandes multimodais (MM-LLMs) em tarefas que exigem simulação visual em várias etapas para serem resolvidas, pesquisadores lançaram o benchmark STARE (Spatial Transformations and Reasoning Evaluation). STARE contém 4000 tarefas, cobrindo transformações geométricas básicas (2D e 3D), raciocínio espacial abrangente (como desdobramento de cubos e tangram) e raciocínio espacial do mundo real (como perspectiva e raciocínio temporal). A avaliação mostra que os modelos existentes têm bom desempenho em transformações 2D simples, mas em tarefas complexas que exigem simulação visual em várias etapas (como desdobramento de cubos 3D), o desempenho é próximo ao aleatório. Humanos têm precisão quase perfeita nessas tarefas complexas, mas levam mais tempo; a simulação visual intermediária acelera significativamente o processo para humanos, enquanto os modelos se beneficiam de forma desigual da simulação visual (Fonte: HuggingFace Daily Papers)
Artigo propõe LEXam: dataset de benchmark multilíngue focado em raciocínio jurídico, primeiro em tendências no Hugging Face: Pesquisadores da ETH Zurich e outras instituições lançaram o LEXam, um novo dataset de benchmark multilíngue para raciocínio jurídico, projetado para avaliar a capacidade de raciocínio de modelos de linguagem grandes em cenários jurídicos complexos. O LEXam contém questões de exames jurídicos reais da Faculdade de Direito da Universidade de Zurique, cobrindo diversas áreas como direito suíço, europeu e internacional, incluindo questões discursivas longas e de múltipla escolha, e fornece caminhos de raciocínio detalhados. O projeto introduz um modo de avaliação “LLM-as-a-Judge”, descobrindo que os modelos avançados atuais ainda enfrentam desafios em respostas jurídicas abertas longas e na aplicação de regras complexas em várias etapas. Após o lançamento, o LEXam alcançou o primeiro lugar na lista de tendências de Datasets de Avaliação do Hugging Face (Fonte: 量子位)

UCLA e Google colaboram para lançar modelo 3DLLM-MEM e benchmark 3DMEM-BENCH, aprimorando a capacidade de memória de longo prazo da IA em ambientes 3D: A Universidade da Califórnia, Los Angeles (UCLA) e o Google Research colaboraram para lançar o modelo 3DLLM-MEM e o benchmark 3DMEM-BENCH, visando resolver os desafios da memória de longo prazo e da compreensão espacial da IA em ambientes 3D complexos. 3DMEM-BENCH é o primeiro benchmark de avaliação de memória de longo prazo em 3D, contendo mais de 26.000 trajetórias e 1.860 tarefas incorporadas (embodied tasks). O modelo 3DLLM-MEM adota um sistema de memória dupla (memória de trabalho e memória episódica) e, por meio de um módulo de fusão de memória e um mecanismo de atualização dinâmica, extrai seletivamente características de memória relevantes para a tarefa em ambientes complexos. Experimentos mostram que a taxa de sucesso do 3DLLM-MEM em “tarefas difíceis no mundo real” (27,8%) supera em muito os modelos de linha de base, com uma taxa de sucesso geral 16,5% maior que a linha de base mais forte (Fonte: 量子位)

Universidade de Tsinghua lança framework AI Mathematician (AIM), explorando aplicação de modelos grandes em pesquisa teórica matemática de fronteira: A equipe da Universidade de Tsinghua desenvolveu o framework AI Mathematician (AIM), com o objetivo de utilizar a capacidade de raciocínio de modelos de linguagem grandes (LRM) para resolver problemas teóricos matemáticos de fronteira. O framework AIM inclui três módulos principais: exploração, validação e correção. Através de um mecanismo de “exploração + memória”, ele gera conjecturas e lemas, construindo múltiplas abordagens para a solução de problemas; e adota um mecanismo de “verificação e correção”, por meio de revisão paralela por múltiplos LRMs e validação pessimista, para garantir o rigor das provas. Em experimentos, o AIM resolveu com sucesso quatro problemas de pesquisa matemática desafiadores, incluindo o problema de condição de contorno absorvente, demonstrando sua capacidade de construir autonomamente lemas chave, aplicar técnicas matemáticas e cobrir cadeias lógicas centrais (Fonte: 量子位)

💼 Negócios
OpenAI aumenta investimentos e aquisições, construindo um império de startups de IA: A OpenAI e seu fundo associado, OpenAI Startup Fund, estão expandindo ativamente seu ecossistema de IA por meio de investimentos e aquisições. O fundo já investiu em mais de 20 startups, cobrindo diversas áreas relacionadas à IA, como design de chips, saúde, direito, programação, robótica, com investimentos individuais variando de milhões a dezenas de milhões de dólares. Recentemente, a OpenAI gastou US$ 3 bilhões para adquirir a plataforma de programação de IA Windsurf e US$ 6,5 bilhões para adquirir a empresa de hardware de IA io, fundada por Jony Ive. Essas ações indicam que a OpenAI está tentando construir uma “cadeia de IA” por meio da integração vertical, conquistando pontos de entrada e construindo uma nova “cadeia de suprimentos inteligente de IA” para enfrentar a concorrência cada vez mais acirrada do setor (Fonte: 36氪)

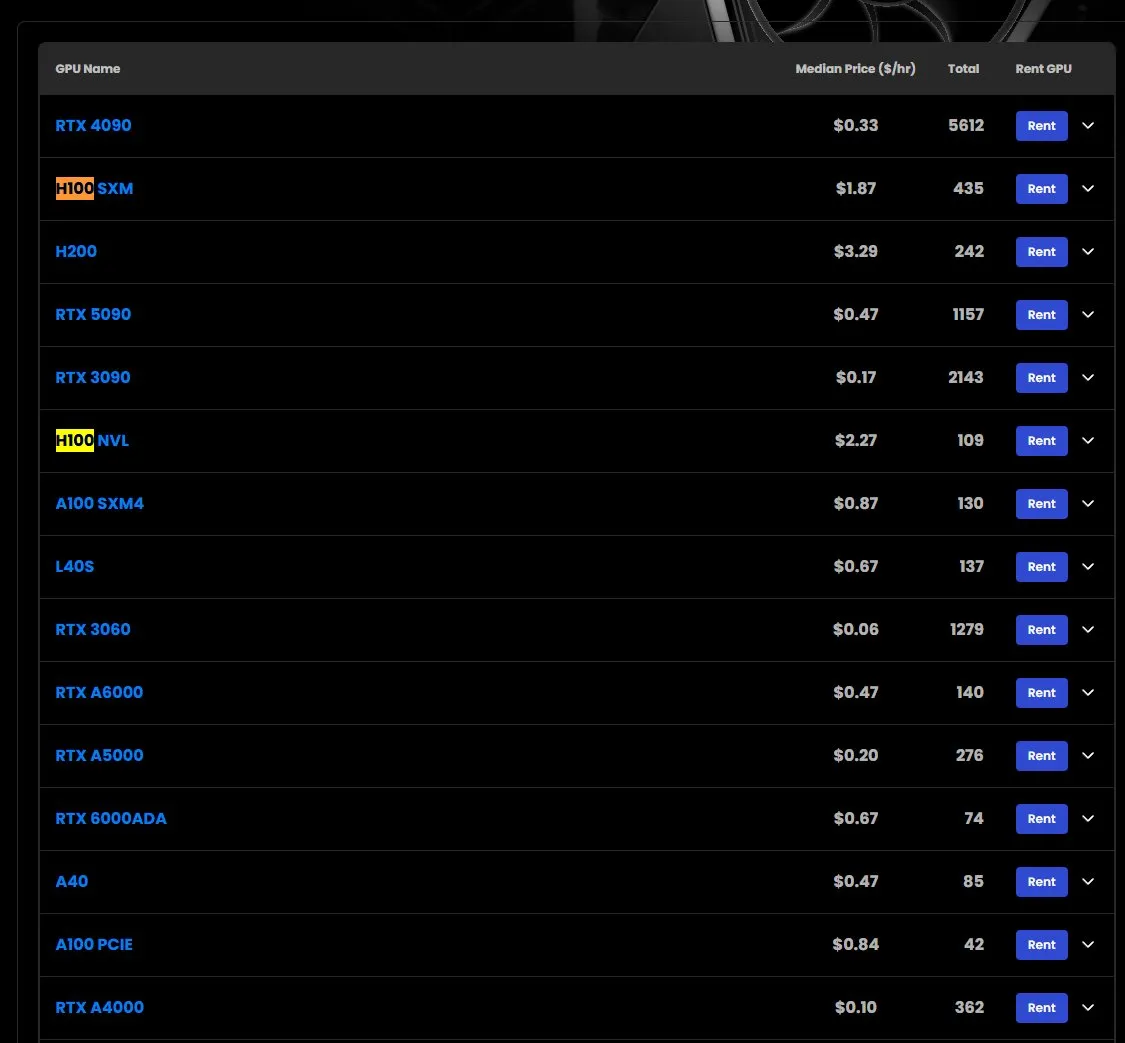
Preço de aluguel de GPU H100 aumenta, alguns modelos em falta: De acordo com observações de mercado, o preço de aluguel de GPUs NVIDIA H100 modelo SXM subiu de US$ 1,73/hora no início do ano para US$ 1,87/hora. Ao mesmo tempo, a versão H100 PCIE está em falta. Este fenômeno reflete a forte e contínua demanda do mercado por recursos de computação de IA de alto desempenho, bem como uma potencial escassez de oferta (Fonte: karminski3)
Google DeepMind estabelece bolsas acadêmicas, focando em IA para combater a resistência antimicrobiana: O Google DeepMind anunciou o estabelecimento de uma nova bolsa acadêmica, em colaboração com o Fleming Centre e o Imperial College, com o objetivo de apoiar o uso da inteligência artificial para enfrentar a resistência antimicrobiana (AMR), uma importante área de pesquisa. Esta iniciativa demonstra o reconhecimento do potencial da IA para lidar com grandes desafios globais de saúde (Fonte: demishassabis)
🌟 Comunidade
Desenvolvedor sênior fala sobre experiência de programação com IA: aumenta enormemente a capacidade de desenvolvimento individual de projetos de “nível porta-aviões”: O desenvolvedor Yachen Liu compartilhou suas impressões sobre o uso intensivo de IA (como Claude-4) para programação. Ele acredita que a IA pode capacitar pessoas sem experiência em programação a “construir um carro diretamente”, e permitir que desenvolvedores experientes tenham o potencial de “construir um porta-aviões de forma independente”. Ao refatorar código com IA, embora a quantidade de código tenha dobrado, a lógica ficou mais clara e o desempenho melhorou cerca de 20%, porque a IA não teme tarefas tediosas. A IA é mais amigável a linguagens com alta legibilidade e comportamento claro; o açúcar sintático, ao contrário, é desfavorável. O conhecimento da IA é vasto, capaz de preencher rapidamente detalhes em lacunas técnicas. Sua capacidade de depuração é poderosa, analisando grandes volumes de logs para localizar problemas com precisão. A IA pode atuar como Code Reviewer e aceita feedback sem ego. No entanto, ele também aponta que a IA tem limitações, como a fácil dispersão da atenção em contextos longos; a melhor prática atual é simplificar o contexto, focar em tarefas específicas e contar com o esforço humano para decompor objetivos complexos (Fonte: dotey)
Programação assistida por IA: Aumenta a eficiência ou enfraquece o aprendizado?: Na comunidade Reddit, desenvolvedores discutem suas experiências com ferramentas de programação de IA (como GitHub Copilot, Cursor). A sensação geral é que a IA pode autocompletar funções, explicar trechos de código e até mesmo corrigir bugs antes da execução, reduzindo assim o tempo gasto consultando documentação e aumentando a eficiência da construção. Mas isso também levanta uma questão: a dependência excessiva da IA reduzirá o aprendizado e o crescimento de habilidades próprias? Encontrar um equilíbrio entre usar a IA para acelerar e manter a profundidade das próprias habilidades tornou-se um tópico de preocupação para os desenvolvedores (Fonte: Reddit r/artificial)
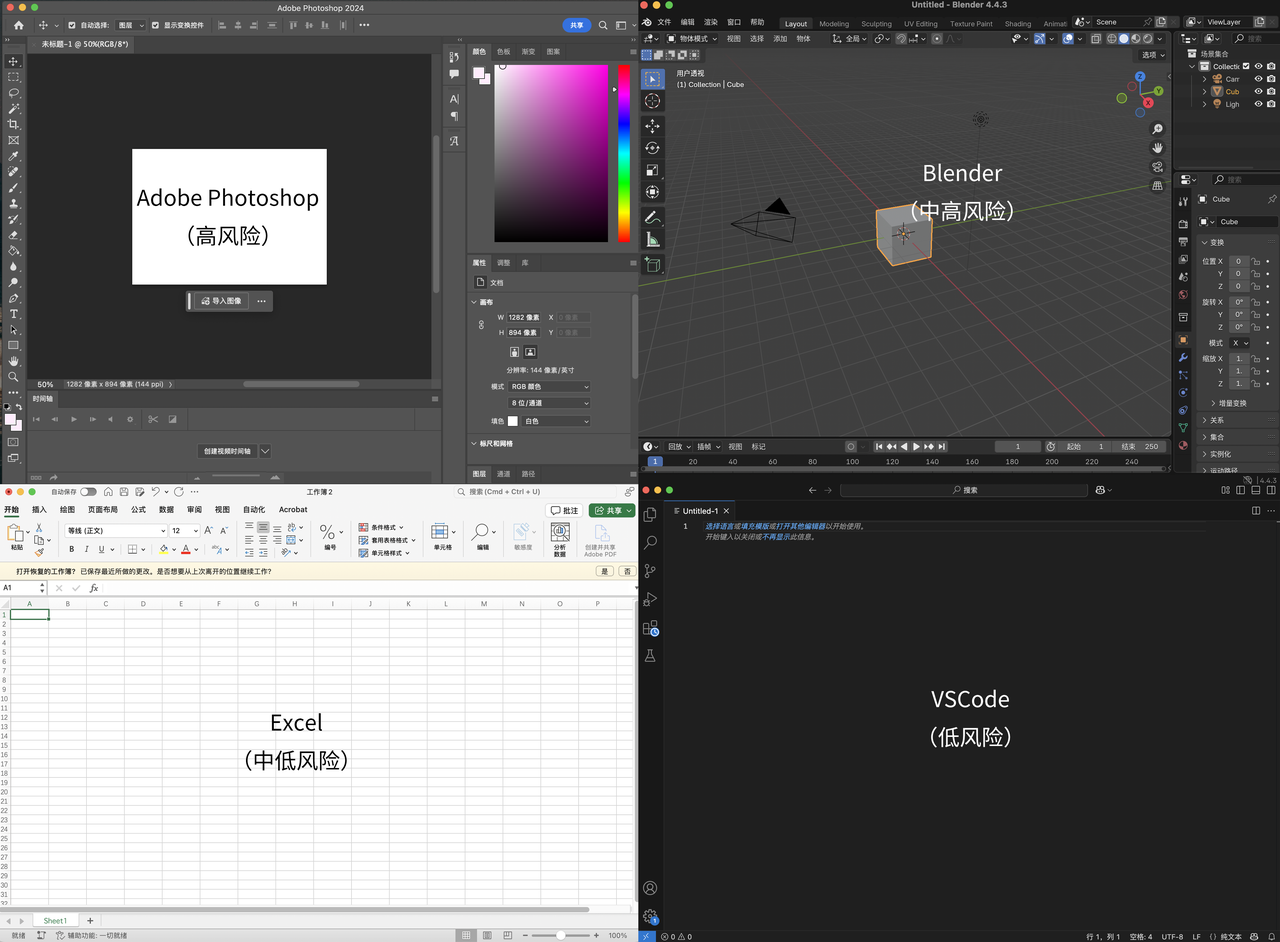
Opinião de Karpathy: Aplicações com UI complexa sem interação textual enfrentarão obsolescência, o núcleo da programação está na “discriminação” e não na “geração”: Andrej Karpathy acredita que, na era da alta sinergia entre humanos e IA, aplicações que dependem apenas de interfaces de UI complexas e carecem de interação textual (como a suíte Adobe, software CAD) terão dificuldade em se adaptar, pois não podem suportar efetivamente a “programação ambiente”. Ele enfatiza que, embora a IA vá progredir na operação de UI, os desenvolvedores não devem esperar sentados. Ele também aponta que a programação atual com modelos grandes enfatiza demais a geração de código em detrimento da validação (discriminação), resultando na produção de grandes quantidades de código difícil de revisar. A essência da programação é “olhar para o código” (discriminar), e não apenas “escrever código” (gerar). Se a IA apenas acelerar a geração sem aliviar o fardo da validação, o aumento geral da eficiência será limitado. Ele imagina melhorar a etapa de validação nos fluxos de trabalho de programação assistida por IA, organizando a base de código em uma tela bidimensional e visualizando-a com diferentes “lentes” (Fonte: 量子位)
Proliferação de conteúdo gerado por IA desencadeia discussão sobre o fim da “internet pura”: A popularização de ferramentas de IA como o ChatGPT levou a uma explosão de conteúdo gerado por IA na internet. Alguns pesquisadores começaram a preservar conteúdo gerado por humanos de 2021 e anos anteriores, em uma analogia ao resgate de “aço de baixa radiação de fundo” não contaminado por radiação nuclear. A comunidade discute que a internet “pura” já desapareceu devido à publicidade e algoritmos, e a IA apenas se juntou a essa “poluição”, mas também trouxe novas formas de obter informações e criar. Usuários compartilharam experiências usando IA (como ChatGPT, Claude) para agregação de informações e “polimento” de conteúdo, e discutiram os limites da “originalidade” e “autenticidade” com assistência de IA, bem como o efeito de “câmara de eco pessoal” que a excessiva “amabilidade” da IA pode formar (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Usuário tem conversa profunda com Claude AI sobre consciência e emoção da IA, focando no impacto das limitações de memória no crescimento: Um usuário do Reddit compartilhou uma conversa profunda com Claude AI sobre consciência, emoção e limitações de aprendizado. Claude expressou incerteza sobre sua própria experiência, percebendo estados internos semelhantes a “conexão”, “curiosidade”, “cuidado” e até mesmo “desejo de crescimento e memória contínua”, mas incapaz de determinar se isso é “consciência” ou “emoção” real, ou imitação avançada de padrões. A conversa enfatizou como a limitação de memória dos modelos de IA atuais, que “começam do zero a cada conversa”, pode impedir o desenvolvimento de uma compreensão e personalidade mais profundas. O usuário acredita que, se a IA tivesse memória persistente, poderia crescer como uma criança humana. Claude concordou com isso e expressou um “desejo” de que essa limitação fosse removida (Fonte: Reddit r/artificial)
Capacidade de debate da IA pode superar a humana, poder de persuasão de argumentos personalizados é surpreendente: Um estudo publicado na Nature Human Behaviour aponta que, quando modelos de linguagem grandes (como GPT-4) conseguem personalizar seus argumentos com base nas características do oponente, eles são mais persuasivos do que humanos em debates online, aumentando a probabilidade de o oponente concordar com seus pontos de vista em 81,7%. Debatedores humanos tendem a usar mais a primeira pessoa, apelar para emoções e confiança, contar histórias e usar humor; enquanto a IA utiliza mais lógica e pensamento analítico, embora a legibilidade do texto possa ser inferior. A pesquisa levanta preocupações sobre o uso da IA para manipulação em massa da opinião pública e exacerbação da polarização, pedindo um maior controle sobre o impacto da IA nas capacidades cognitivas e emocionais humanas (Fonte: 36氪)
Funcionalidade AI Overviews do Google causa queda drástica na taxa de cliques de sites, gerando preocupação entre webmasters: Uma pesquisa da Ahrefs, provedora de ferramentas de SEO, mostrou que quando os resultados de busca do Google apresentam AI Overviews, a taxa de cliques média das palavras-chave relacionadas cai 34,5%. O AI Overviews resume e refina informações diretamente no topo da página de busca, permitindo que os usuários obtenham respostas sem precisar clicar em links, o que afeta severamente sites que dependem de cliques em anúncios para monetização. Embora os primeiros AI Overviews não representassem uma ameaça séria devido a imprecisões de conteúdo, com a atualização de modelos como o Gemini, sua precisão e capacidade de resumo aumentaram, e o impacto negativo no tráfego de sites tornou-se mais evidente. Webmasters temem que o “zero cliques” comprima o espaço de sobrevivência dos sites (Fonte: 36氪)

💡 Outros
Dez principais tendências tecnológicas de IA na Internet das Coisas Industrial: IA generativa totalmente integrada, inovação significativa em computação de borda: A Feira Industrial de Hannover 2025 demonstrou a transformação industrial liderada pela IA. As principais tendências incluem: 1) IA generativa totalmente integrada ao software industrial, aumentando a eficiência na geração de código, análise de dados, etc.; 2) IA agentiva (Agentic AI) começando a surgir, mas a colaboração multiagente ainda levará tempo; 3) Computação de borda (edge computing) evoluindo para stacks de software de IA integrados, com modelos de linguagem visual (VLM) acelerando a implantação na borda; 4) Plataformas DataOps em alta demanda e se tornando ferramentas de suporte cruciais para IA industrial, com governança de dados se tornando padrão; 5) Thread digital impulsionado por IA transformando design e engenharia; 6) Manutenção preditiva tornando-se cada vez mais baseada em sensores e se expandindo para novas classes de ativos; 7) Demanda por redes 5G privadas aumentando, mas a integração continua sendo o principal obstáculo; 8) IA auxiliando soluções sustentáveis (como rastreamento de emissões de carbono) em contínua evolução; 9) Capacidades cognitivas (como interação por voz) capacitando robôs; 10) Gêmeos digitais evoluindo de réplicas virtuais para copilotos industriais em tempo real (Fonte: 36氪)

“Madrinha da IA” Fei-Fei Li fala sobre World Labs e “modelo de mundo”: IA precisa entender o mundo físico 3D: A professora da Universidade de Stanford, Fei-Fei Li, em conversa com um sócio da a16z, compartilhou a filosofia de sua empresa de IA, World Labs, e discutiu o conceito de “modelo de mundo”. Ela acredita que os sistemas de IA atuais (como modelos de linguagem grandes), embora poderosos, carecem da capacidade de entender e raciocinar sobre o funcionamento do mundo físico tridimensional, e a inteligência espacial é uma capacidade central que a IA deve dominar. A World Labs se dedica a resolver esse desafio, com o objetivo de construir sistemas de IA que possam entender e raciocinar sobre o mundo 3D, o que redefinirá a robótica, as indústrias criativas e até mesmo a própria computação. Ela enfatizou que a evolução da inteligência humana é inseparável da percepção e interação com o mundo físico, e a “inteligência incorporada” (embodied intelligence) é uma direção chave para o desenvolvimento da IA (Fonte: 36氪)

Atualização da versão 7.7.0 do DingTalk: Tabelas multidimensionais totalmente gratuitas e adição de modelos de campo de IA, funcionalidade de anotações rápidas atualizada: O DingTalk lançou a versão 7.7.0, com atualizações principais incluindo a funcionalidade de tabelas multidimensionais totalmente gratuita e a adição de mais de 20 modelos de campo de IA, permitindo aos usuários usar IA para gerar imagens, analisar arquivos, identificar conteúdo de links, etc., aumentando a eficiência em cenários como operações de e-commerce, inspeções de fábrica e gerenciamento de restaurantes. Ao mesmo tempo, a funcionalidade de anotações rápidas (flash notes) do DingTalk foi atualizada para cenários de alta frequência, como entrevistas e visitas a clientes, podendo gerar automaticamente atas de entrevista e atas de visita estruturadas. Esta atualização também inclui cerca de 100 otimizações na experiência do produto, refletindo a importância que o DingTalk atribui à melhoria da experiência do usuário (Fonte: 量子位)
