
Palabras clave:Gemini 2.5 Pro, OpenAI privacidad de datos, OpenThinker3-7B, Claude Gov, Agente de IA, Modelo de lenguaje grande, Aprendizaje por refuerzo, Modelo de código abierto, Mejora de rendimiento de Gemini 2.5 Pro, Política de retención de datos de usuarios de OpenAI, Capacidad de razonamiento de OpenThinker3-7B, Aplicaciones de seguridad nacional de Claude Gov, Robustez y control de agentes de IA
🔥 Enfoque
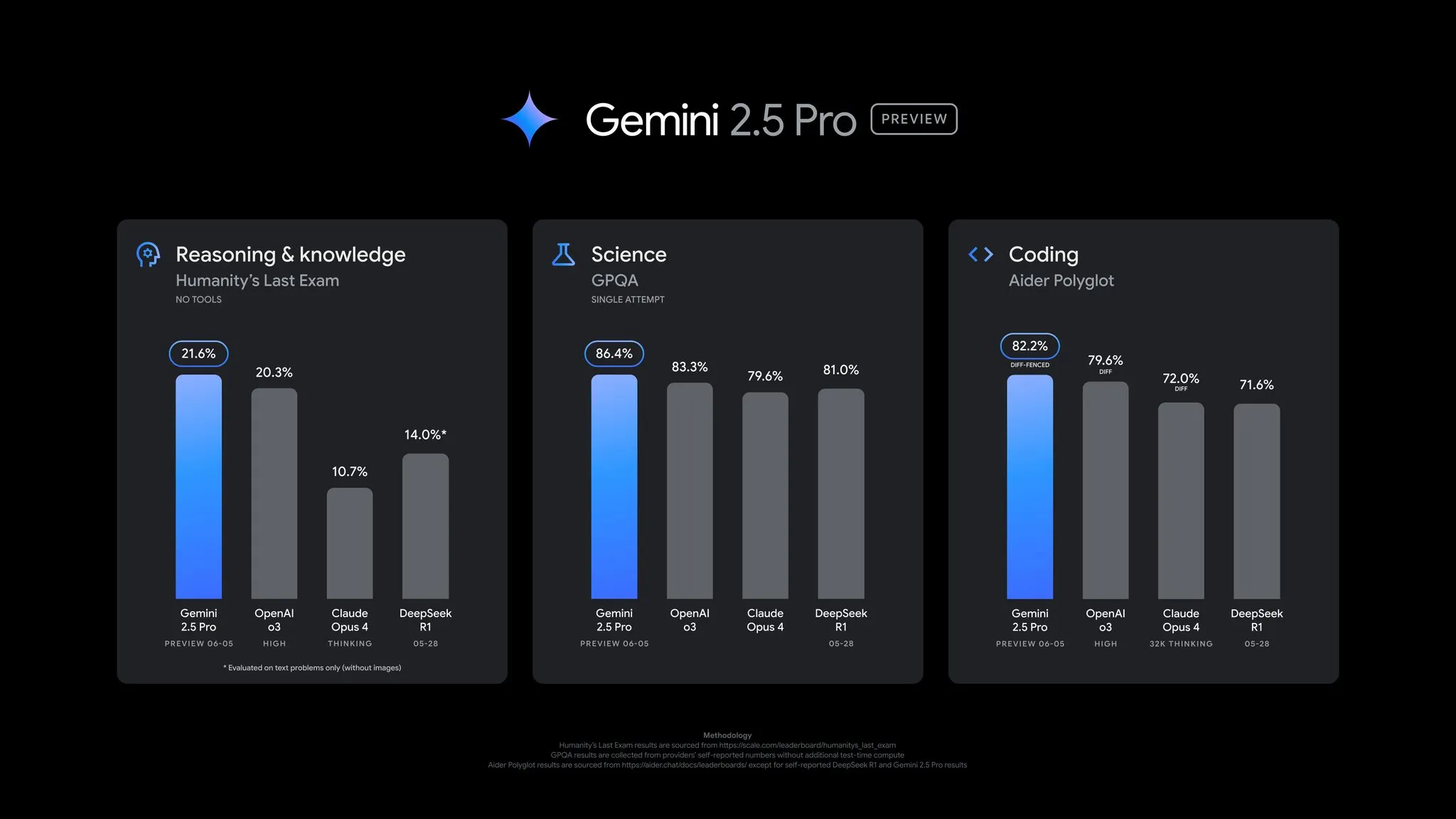
Google lanza la actualización de la vista previa de Gemini 2.5 Pro, con una mejora integral de su rendimiento: Google anunció una importante actualización para la vista previa de Gemini 2.5 Pro, con avances significativos en codificación, razonamiento y capacidades científicas y matemáticas. La nueva versión muestra un mejor rendimiento en benchmarks clave como AIDER Polyglot, GPQA y HLE, y ha logrado un salto de 24 puntos en la puntuación Elo en LMArena, volviendo a alcanzar la cima. Además, el modelo ha mejorado el estilo de respuesta y el formato basándose en los comentarios de los usuarios, e introduce la función de “presupuesto de pensamiento” para ofrecer más control. Esta actualización ya está disponible en Gemini App, Google AI Studio y Vertex AI (Fuente: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI obligada a conservar permanentemente los datos de los usuarios debido a una demanda del New York Times, lo que genera preocupaciones sobre la privacidad: En el litigio por derechos de autor con el New York Times, un tribunal ha ordenado a OpenAI conservar permanentemente todos los registros de interacción de los usuarios de ChatGPT y la API, incluidos los datos de “conversaciones temporales” y solicitudes de API que previamente se había comprometido a retener solo durante 30 días. OpenAI ha declarado que está apelando, argumentando que esta medida es una “intervención excesiva” que socava las normas de privacidad establecidas desde hace tiempo y debilita la protección de la privacidad. Este fallo implica que OpenAI podría no ser capaz de cumplir sus promesas de retención y eliminación de datos a los usuarios, lo que ha generado una amplia preocupación entre los usuarios sobre la privacidad y seguridad de sus datos, y podría afectar especialmente a los desarrolladores de aplicaciones que dependen de la API de OpenAI y tienen sus propias políticas de retención de datos (Fuente: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

Se lanza OpenThinker3-7B, estableciendo un nuevo SOTA para modelos de inferencia de código abierto de 7B: Ryan Marten anunció el lanzamiento de OpenThinker3-7B, un nuevo modelo de inferencia de datos abiertos con 7 mil millones de parámetros, que supera en promedio en un 33% a DeepSeek-R1-Distill-Qwen-7B en evaluaciones de código, ciencia y matemáticas. El equipo también lanzó el conjunto de datos OpenThoughts3-1.2M, que afirman es el mejor conjunto de datos de inferencia abierto en todas las escalas de datos hasta la fecha. Los investigadores señalan que para modelos más pequeños, la destilación desde R1 es la ruta más simple para mejorar el rendimiento, pero la investigación en la dirección de RL (Aprendizaje por Refuerzo) es más exploratoria. Este logro se considera uno de los trabajos pioneros en el campo de los modelos de inferencia abiertos (Fuente: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic lanza Claude Gov, un modelo personalizado para clientes de seguridad nacional de EE. UU.: Anthropic anunció el lanzamiento de Claude Gov, una serie de modelos de IA personalizados construidos para clientes de seguridad nacional de Estados Unidos. Estos modelos ya se han implementado en las agencias de seguridad nacional de más alto nivel de EE. UU., y su acceso está restringido únicamente al personal que opera en entornos clasificados. Esta medida marca una mayor profundización de la aplicación de la tecnología de IA en los sectores gubernamental y de defensa, y también ha suscitado debates sobre la aplicación de la IA en áreas sensibles (Fuente: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 Tendencias
Yann LeCun coincide con la opinión de Sundar Pichai: la tecnología actual podría no alcanzar la AGI, posibilidad de una meseta: El científico jefe de IA de Meta, Yann LeCun, retuiteó y expresó su acuerdo con la opinión del CEO de Google, Sundar Pichai, de que la ruta tecnológica actual no garantiza la consecución de la Inteligencia Artificial General (AGI), y que el desarrollo de la IA podría encontrar una meseta temporal. Pichai señaló que, aunque el progreso de la IA es asombroso, también podría haber limitaciones, y la tecnología actual todavía está lejos de la inteligencia general. Esto refleja una actitud cautelosa en la industria con respecto a la ruta y el cronograma para alcanzar la AGI (Fuente: ylecun)
OpenAI contrata para el equipo de Robustez y Control de Agentes, con el objetivo de mejorar la seguridad de los agentes de IA: OpenAI está formando un nuevo equipo de “Robustez y Control de Agentes” (Agent Robustness and Control), con el objetivo de garantizar la seguridad y fiabilidad de sus agentes de IA durante los procesos de entrenamiento e implementación. El equipo se dedicará a resolver algunos de los problemas más desafiantes en el campo de la IA, lo que demuestra la gran importancia que OpenAI otorga a la seguridad y el control a medida que avanza en el desarrollo de agentes de IA más potentes (Fuente: gdb)

Nueva investigación de Apple revela la “ilusión de pensar” de los modelos grandes de lenguaje: la capacidad de razonamiento disminuye ante problemas complejos: Un reciente artículo de investigación de Apple, titulado “The Illusion of Thinking”, señala que los modelos de razonamiento actuales, al enfrentarse a un aumento de la complejidad del problema hasta cierto punto, muestran una disminución en su esfuerzo de razonamiento (reasoning effort), incluso cuando se les asigna un presupuesto de tokens suficiente. Este fenómeno contraintuitivo de “límite de escalabilidad” (scaling limit) sugiere que los modelos podrían no estar realizando un pensamiento profundo real al procesar problemas altamente complejos, sino que muestran una “ilusión de pensar”, lo que plantea nuevos desafíos para evaluar y mejorar la verdadera capacidad de razonamiento de los modelos grandes (Fuente: Ar_Douillard, Reddit r/MachineLearning)

OpenAI explora la conexión emocional entre humanos e IA, priorizando la investigación sobre el impacto en el bienestar emocional del usuario: Joanne Jang de OpenAI publicó una entrada de blog explorando el creciente fenómeno de la conexión emocional entre los usuarios y modelos de IA como ChatGPT. El artículo señala que las personas tienden a antropomorfizar la IA de forma natural y pueden desarrollar sentimientos de compañía y confianza hacia ella. OpenAI reconoce esta tendencia y declara que priorizará la investigación sobre el impacto de la IA en el bienestar emocional de los usuarios, en lugar de debatir sobre la cuestión ontológica de si la IA es verdaderamente “consciente”. El objetivo de la compañía es diseñar asistentes de IA que sean cálidos y útiles, pero que no busquen una dependencia emocional excesiva ni tengan su propia agenda (Fuente: openai, sama, BorisMPower)

Xiaohongshu lanza el modelo grande MoE de código abierto dots.llm1-143B-A14B: Hi Lab de Xiaohongshu ha lanzado su primera serie de modelos grandes de código abierto, dots.llm1, que incluye el modelo base dots.llm1.base y el modelo de ajuste fino de instrucciones dots.llm1.inst. El modelo utiliza una arquitectura MoE, con un total de 143B de parámetros y 14B de parámetros activos. Las pruebas internas oficiales muestran que su rendimiento en MMLU-Pro supera a Qwen3-235B-A22B, pero es inferior al nuevo DeepSeek-V3. El modelo se publica bajo la licencia MIT, permitiendo su uso libre. Sin embargo, las pruebas preliminares de la comunidad indican un rendimiento deficiente en tareas como la generación de código, incluso por debajo de Qwen2.5-coder (Fuente: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

La serie Qwen3 lanza modelos Embedding y Reranker, mejorando la capacidad de procesamiento de texto multilingüe: El equipo de Qwen ha lanzado las series de modelos Qwen3-Embedding y Qwen3-Reranker, destinadas a mejorar el rendimiento de la incrustación de texto multilingüe y la clasificación de relevancia. Los modelos Embedding se utilizan para convertir texto en representaciones vectoriales, soportando escenarios como la recuperación de documentos y RAG; los modelos Reranker se utilizan para reordenar los resultados de búsqueda, priorizando el contenido más relevante. La serie de modelos ofrece diferentes escalas de parámetros como 0.6B, 4B, 8B, soporta 119 idiomas y muestra un rendimiento excelente en benchmarks como MMTEB y MTEB. La versión de 0.6B se considera especialmente adecuada para escenarios de Reranker con altos requisitos de tiempo real debido a su equilibrio entre eficiencia y rendimiento (Fuente: karminski3, karminski3, ZhaiAndrew, clefourrier)

Investigación señala desafíos de escalabilidad del aprendizaje por refuerzo en tareas complejas de horizonte largo: Una investigación de Seohong Park y otros encontró que simplemente ampliar los datos y los recursos computacionales no es suficiente para que el aprendizaje por refuerzo (RL) resuelva eficazmente tareas complejas; el factor limitante clave es el “horizonte”. En tareas de horizonte largo, las señales de recompensa son escasas, lo que dificulta que el modelo aprenda estrategias efectivas. Esto concuerda con la observación de que algunos agentes de IA actuales (como Deep Research, Codex agent) dependen principalmente de tareas de RL de horizonte corto y entrenamiento de robustez general, lo que indica que resolver problemas de recompensa escasa en horizontes largos de extremo a extremo sigue siendo un gran desafío en el campo del RL (Fuente: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu registra una cuenta oficial en HuggingFace y sube modelos grandes Wenxin: Baidu ha registrado una cuenta oficial en la plataforma HuggingFace y ha subido algunos modelos de su serie Wenxin (ERNIE), incluyendo Wenxin-X1-Turbo y Wenxin-4.5-Turbo. Esta medida significa que Baidu está integrando activamente su tecnología de modelos grandes en la comunidad de código abierto y el ecosistema de desarrolladores más amplio, facilitando el acceso y uso de sus capacidades de IA a desarrolladores de todo el mundo (Fuente: karminski3)
OpenBMB lanza la serie de modelos MiniCPM4, enfocada en la ejecución eficiente en dispositivos finales (edge): OpenBMB continúa explorando los límites de los modelos de lenguaje pequeños y eficientes con el lanzamiento de la serie MiniCPM4. Entre ellos, el modelo MiniCPM4-8B cuenta con 8 mil millones de parámetros y ha sido entrenado con 8T tokens. Esta serie de modelos adopta tecnologías de aceleración extrema como la atención dispersa entrenable (InfLLM v2), cuantización ternaria (BitCPM), cálculo de baja precisión FP8 y predicción de múltiples tokens, con el objetivo de lograr una ejecución eficiente en dispositivos finales. Por ejemplo, su mecanismo de atención dispersa, al procesar texto largo de 128K, solo necesita calcular la relevancia de cada token con menos del 5% de los tokens, reduciendo significativamente la carga computacional del procesamiento de texto largo (Fuente: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
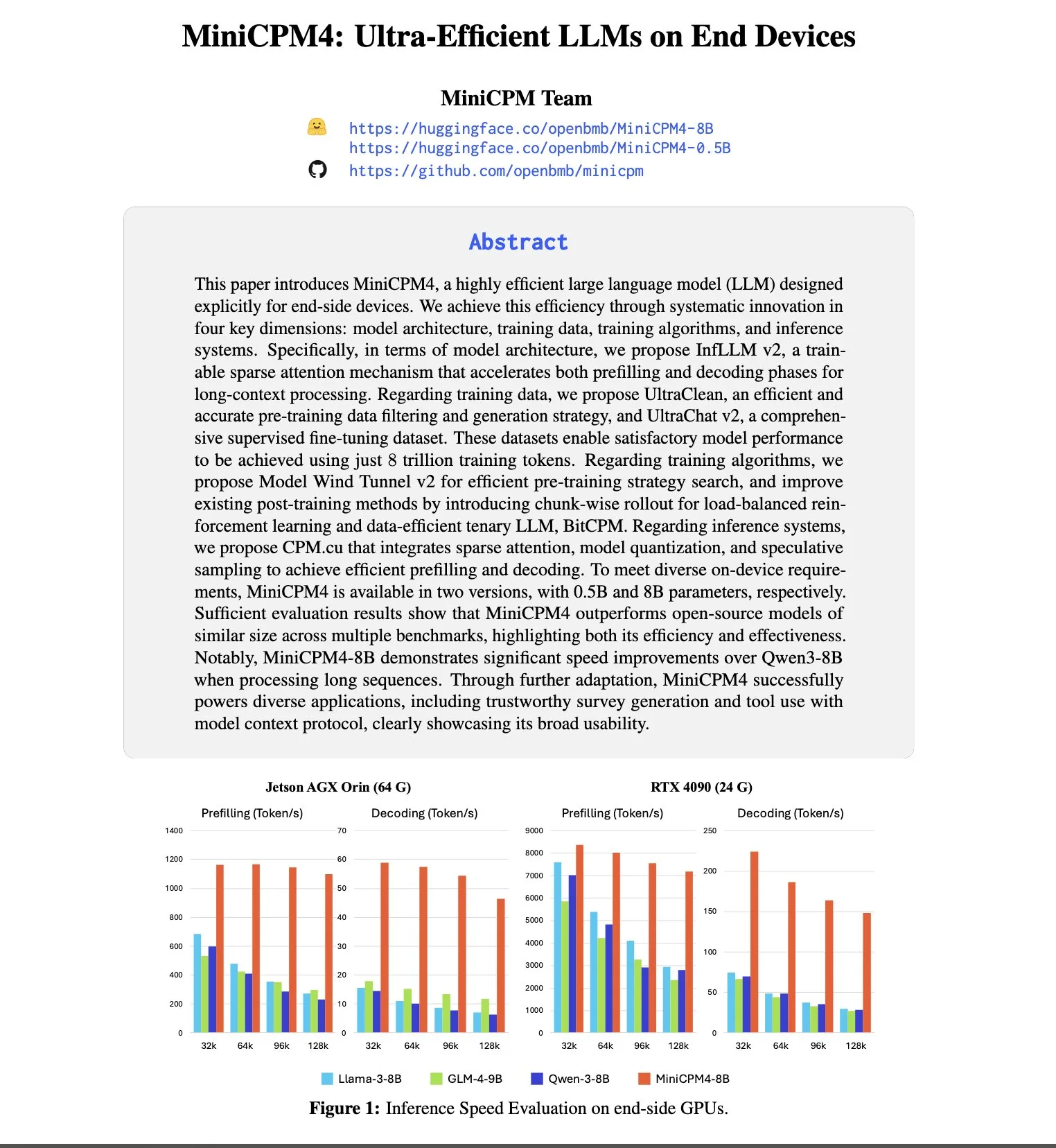
Anthropic lidera en atracción y retención de talento, con 8 veces más probabilidades de atraer empleados de OpenAI: El informe de tendencias de talento 2025 de SignalFire muestra que Anthropic destaca en la retención de talento de IA de primer nivel, alcanzando el 80%, por encima del 78% de DeepMind y el 67% de OpenAI. El informe también señala que los ingenieros tienen 8 veces más probabilidades de pasar de OpenAI a Anthropic que viceversa. La cultura corporativa única de Anthropic, su inclusión del pensamiento no tradicional, la autonomía de los empleados y la popularidad de su producto Claude entre los desarrolladores se consideran factores clave para atraer y retener talento (Fuente: 量子位)
🧰 Herramientas
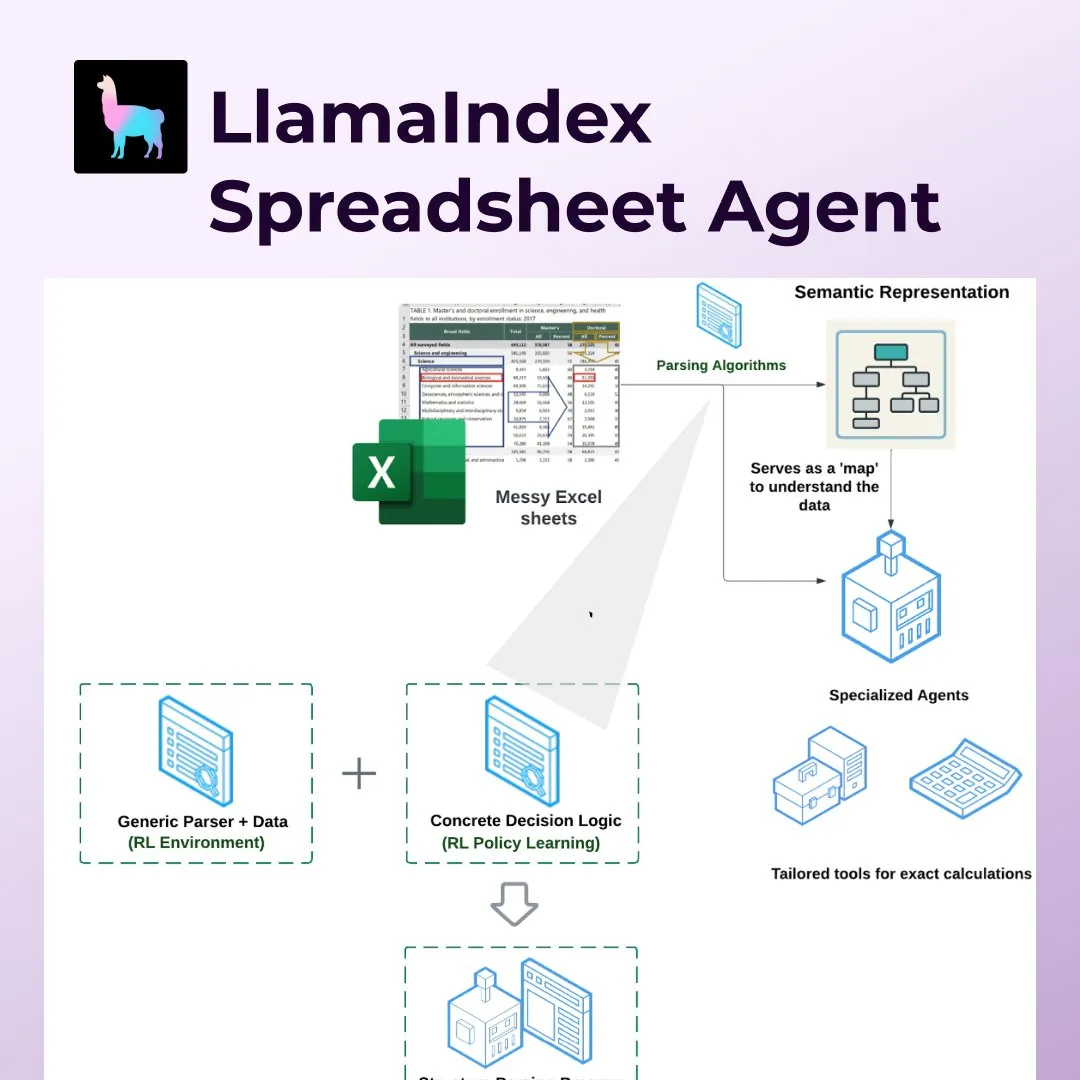
LlamaIndex lanza Spreadsheet Agents, revolucionando el procesamiento de hojas de cálculo como Excel: LlamaIndex ha lanzado la nueva función Spreadsheet Agents, que permite a los usuarios realizar transformaciones de datos y consultas sobre hojas de cálculo de Excel no estandarizadas. La herramienta utiliza un análisis de estructura semántica basado en aprendizaje por refuerzo para comprender la estructura de la tabla y, a través de herramientas especializadas, permite a los agentes de IA interactuar con la tabla. Su objetivo es resolver las deficiencias de los LLM tradicionales al procesar tablas complejas (como las que se encuentran comúnmente en los campos de contabilidad, impuestos y seguros), pudiendo manejar celdas combinadas, diseños complejos y mantener las relaciones de datos. En las pruebas, su precisión (96%) superó a la línea base humana y a OpenAI Code Interpreter (GPT 4.1, 75%) (Fuente: jerryjliu0)
LlamaIndex utiliza LlamaExtract y flujos de trabajo de agentes para automatizar la extracción del Formulario 4 de la SEC: LlamaIndex demostró cómo utilizar su herramienta LlamaExtract y flujos de trabajo de agentes de IA para extraer y normalizar automáticamente datos de los archivos del Formulario 4 de la Comisión de Bolsa y Valores de EE. UU. (SEC) (documentos donde los ejecutivos, directores y principales accionistas de empresas públicas divulgan transacciones de acciones). La solución puede convertir archivos del Formulario 4 con formatos diversos de diferentes empresas en un formato CSV limpio e integrarlos en un dataframe consultable a través de Pandas, proporcionando una herramienta eficiente de procesamiento de datos para analistas financieros e inversores (Fuente: jerryjliu0)

Se lanza el proyecto de código abierto Ragbits, que ofrece bloques de construcción para el desarrollo rápido de aplicaciones GenAI: deepsense-ai ha lanzado el proyecto de código abierto Ragbits, destinado a proporcionar bloques de construcción para el desarrollo rápido de aplicaciones de IA generativa. El proyecto admite más de 100 interfaces de modelos grandes o modelos locales, viene con almacenamiento vectorial (conectable a Qdrant, PgVector) y admite más de 20 formatos de archivo de entrada (PDF, HTML, tablas, presentaciones, etc.). Ragbits utiliza VLM integrados para admitir la extracción de tablas, imágenes y contenido estructurado, puede conectarse a múltiples fuentes de datos como S3, GCS, Azure, y tiene características modulares que permiten a los usuarios personalizar componentes (Fuente: karminski3, GitHub Trending)

El asistente de programación de IA Cursor lanza una importante actualización, integrando BugBot, función de memoria y soporte MCP: La herramienta de programación de IA Cursor ha recibido una actualización sustancial, que incluye principalmente: 1) BugBot, que puede responder automáticamente a los issues de GitHub y abrirlos en Cursor con un solo clic para su reparación; 2) Función de memoria, que permite a la IA recordar el contenido de conversaciones anteriores, mejorando la facilidad de uso durante modificaciones repetitivas en proyectos grandes; 3) Configuración MCP (Model Context Protocol) con un solo clic, compatible con servidores MCP de terceros que utilizan OAuth; 4) Soporte de AI Agent para Jupyter Notes; 5) Agent en segundo plano, que permite invocar un panel de control mediante una tecla de acceso rápido para usar un AI Agent de programación remota (Fuente: karminski3)
Archon: un agente de IA que puede crear otros agentes de IA: Archon es un proyecto “Agenteer” diseñado para construir y optimizar autónomamente otros agentes de IA. Utiliza flujos de trabajo avanzados de codificación de agentes y una base de conocimientos de frameworks, demostrando el papel de la planificación, los bucles de retroalimentación y el conocimiento del dominio en la creación de potentes agentes de IA. La última versión V6 integra una biblioteca de herramientas y un servidor MCP (Model Context Protocol), mejorando la capacidad de construir nuevos agentes. Archon admite la implementación con Docker y la instalación local de Python, y proporciona una interfaz de usuario Streamlit para la gestión (Fuente: GitHub Trending)

NoteGen: Aplicación de notas Markdown multiplataforma impulsada por IA: NoteGen es una aplicación de notas Markdown multiplataforma dedicada a utilizar la IA para conectar la toma de notas con la escritura, capaz de organizar conocimientos fragmentados en notas legibles. Admite múltiples métodos de registro como capturas de pantalla, texto, ilustraciones, archivos y enlaces, almacenamiento nativo en Markdown, uso local sin conexión y sincronización con GitHub/Gitee/WebDAV. NoteGen se puede configurar con múltiples modelos de IA como ChatGPT, Gemini, Ollama, y admite la función RAG, utilizando las notas del usuario como base de conocimientos (Fuente: GitHub Trending)

ComfyUI-Copilot: Asistente inteligente para el desarrollo automatizado de flujos de trabajo: ComfyUI-Copilot es un plugin impulsado por modelos de lenguaje grandes, diseñado para mejorar la facilidad de uso y la eficiencia de la plataforma de creación artística con IA, ComfyUI. Resuelve problemas como la falta de amigabilidad de ComfyUI para principiantes, errores de configuración de modelos y la complejidad del diseño de flujos de trabajo, proporcionando recomendaciones inteligentes de nodos y modelos, así como funciones de construcción de flujos de trabajo con un solo clic. El sistema adopta un marco jerárquico multiagente, que incluye un agente asistente central y múltiples agentes de trabajo dedicados, y utiliza la base de conocimientos de ComfyUI para simplificar la depuración y la implementación (Fuente: HuggingFace Daily Papers)
Bifrost: Gateway LLM de alto rendimiento en Go de código abierto, optimiza la implementación de LLM en entornos de producción: Para resolver los desafíos de fragmentación de API, latencia, fallback y gestión de costos de los LLM en entornos de producción, el equipo de Maximilian ha lanzado Bifrost, un gateway LLM de código abierto basado en Go. Bifrost está diseñado específicamente para implementaciones de aprendizaje automático de alto rendimiento y baja latencia, y es compatible con los principales proveedores de LLM como OpenAI, Anthropic y Azure. Las pruebas de rendimiento muestran que, en comparación con otros proxies, Bifrost aumenta el rendimiento en 9.5 veces, reduce la latencia P99 en 54 veces y disminuye el consumo de memoria en un 68%, con una sobrecarga interna inferior a 15µs a 5000 RPS. Ofrece normalización de API, fallback automático de proveedores, gestión inteligente de claves y métricas de Prometheus, entre otras funciones (Fuente: Reddit r/MachineLearning)

LangGraph.js mejora la experiencia del desarrollador, introduciendo seguridad de tipos y funciones hook: LangGraph.js versión 0.3 ha recibido una serie de actualizaciones destinadas a mejorar la experiencia del desarrollador. Estas incluyen una mayor seguridad de tipos y la introducción de preModelHook y postModelHook en createReactAgent. preModelHook se puede utilizar para simplificar el historial de mensajes antes de pasarlo al LLM, mientras que postModelHook se puede utilizar para agregar barreras de seguridad o flujos de colaboración humano-máquina. La comunidad está solicitando activamente comentarios sobre LangGraph v1 (Fuente: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024 lanza el modelo grande de corrección gramatical GRMR-V3-G4B: El desarrollador qingy2024 ha lanzado un modelo grande especializado en corrección gramatical, GRMR-V3-G4B, con un tamaño máximo de parámetros de solo 4B. El modelo también ofrece una versión cuantizada, especialmente adecuada para tareas de revisión y corrección gramatical en flujos de trabajo locales o dispositivos personales, facilitando su integración y uso (Fuente: karminski3)

Fullpack: Aplicación inteligente de listas de empaque basada en reconocimiento visual local en iPhone: Un desarrollador ha lanzado una aplicación para iOS llamada Fullpack, que puede identificar objetos en fotos utilizando VisionKit del iPhone y ayudar a los usuarios a crear listas de empaque inteligentes para diferentes ocasiones (como un día de trabajo, vacaciones en la playa, fin de semana de senderismo). La aplicación enfatiza el funcionamiento 100% local, sin procesamiento en la nube ni recopilación de datos, para proteger la privacidad del usuario. Esta es la primera aplicación independiente del desarrollador, con el objetivo de explorar el potencial de la IA en el dispositivo (Fuente: Reddit r/LocalLLaMA)
📚 Aprendizaje
Unsloth publica numerosos Notebooks de Colab/Kaggle para el ajuste fino de los principales modelos grandes: UnslothAI ofrece una serie de Jupyter Notebooks para facilitar a los usuarios el ajuste fino de varios modelos grandes principales como Qwen3, Gemma 3, Llama 3.1/3.2, Phi-4, Mistral v0.3 en plataformas como Google Colab y Kaggle. Estos Notebooks cubren diversos tipos de tareas y métodos de ajuste fino, como conversación, Alpaca, GRPO, visión, texto a voz (TTS), con el objetivo de simplificar el proceso de ajuste fino del modelo y proporcionar orientación sobre la preparación de datos, entrenamiento, evaluación y guardado del modelo (Fuente: GitHub Trending)

“Guía de uso de modelos grandes de código abierto”: un tutorial de LLM/MLLM para principiantes en China: El proyecto de Datawhalechina “Guía de uso de modelos grandes de código abierto” ofrece un tutorial basado en un entorno Linux, dirigido a principiantes en China, que cubre la configuración del entorno, la implementación local, el ajuste fino de todos los parámetros/Lora y otros procesos completos para modelos grandes de código abierto (LLM) y modelos grandes multimodales (MLLM) tanto nacionales como internacionales. El proyecto tiene como objetivo simplificar la implementación y el uso de modelos grandes de código abierto y ya es compatible con varios modelos como Qwen3, Kimi-VL, Llama4, Gemma3, InternLM3, Phi4 (Fuente: GitHub Trending)

Artículo explora MINT-CoT: Introducción de tokens visuales cruzados en el razonamiento de cadena de pensamiento matemático: Un nuevo artículo propone el método MINT-CoT (Mathematical Interleaved Tokens for Chain-of-Thought), con el objetivo de mejorar la capacidad de razonamiento de los modelos de lenguaje grandes en problemas matemáticos multimodales mediante la introducción adaptativa cruzada de tokens visuales relevantes en los pasos de razonamiento textual. El método selecciona dinámicamente regiones visuales de cualquier forma en gráficos matemáticos a través de un “Interleave Token” y construye el conjunto de datos MINT-CoT que contiene 54K problemas matemáticos, utilizado para entrenar el modelo para alinearse con regiones visuales a nivel de token en cada paso de razonamiento. Los experimentos muestran que el modelo MINT-CoT-7B supera significativamente en rendimiento a los modelos base en benchmarks como MathVista (Fuente: HuggingFace Daily Papers)
Artículo propone StreamBP: método de retropropagación preciso y eficiente en memoria para el entrenamiento de secuencias largas en LLM: Para abordar el problema del enorme costo de memoria debido al almacenamiento de valores de activación durante el entrenamiento de secuencias largas en LLM, los investigadores proponen StreamBP, un método de retropropagación preciso y eficiente en memoria. StreamBP reduce significativamente el costo de memoria de los valores de activación y los logits al descomponer linealmente la regla de la cadena a lo largo de la dimensión de la secuencia a nivel de capa. Este método es aplicable a objetivos comunes como SFT, GRPO, DPO, requiere menos FLOPs computacionales y acelera la retropropagación (BP). En comparación con el gradient checkpointing, StreamBP puede extender la longitud máxima de secuencia para BP entre 2.8 y 5.5 veces, utilizando un tiempo de BP comparable o incluso menor (Fuente: HuggingFace Daily Papers)
Artículo propone la técnica Diagonal Batching, desbloqueando la inferencia paralela de contexto largo en RMT: Para resolver el cuello de botella de rendimiento en la inferencia de contexto largo de los modelos Transformer, los investigadores proponen el esquema de programación Diagonal Batching, con el objetivo de desbloquear el paralelismo entre fragmentos en los Transformers con Memoria Recurrente (RMT), manteniendo al mismo tiempo una recurrencia precisa. Esta técnica, al reordenar los cálculos en tiempo de ejecución, elimina las restricciones secuenciales, permitiendo una inferencia eficiente en GPU incluso para una única entrada de contexto largo, sin necesidad de complejas técnicas de procesamiento por lotes y segmentación (pipelining). Aplicado al modelo LLaMA-1B ARMT, en secuencias de 131K tokens, Diagonal Batching es 3.3 veces más rápido que el LLaMA-1B con atención completa estándar y 1.8 veces más rápido que la implementación secuencial de RMT (Fuente: HuggingFace Daily Papers)
Artículo explora el impacto negativo de las técnicas de marca de agua en la alineación de modelos de lenguaje y estrategias de mitigación: Un estudio analiza sistemáticamente el impacto de dos técnicas principales de marca de agua, Gumbel y KGW, en los atributos centrales de alineación de los modelos de lenguaje grandes (LLM), como la veracidad, la seguridad y la utilidad. La investigación encontró que las marcas de agua conducen a dos modos de degradación: debilitamiento de la protección (mejora la utilidad pero perjudica la seguridad) y amplificación de la protección (la cautela excesiva reduce la utilidad). Para mitigar estos problemas, el artículo propone el método de Remuestreo de Alineación (Alignment Resampling, AR), que utiliza un modelo de recompensa externo en el momento de la inferencia para restaurar la alineación. Los experimentos demuestran que muestrear 2-4 generaciones con marca de agua es efectivo para restaurar o superar las puntuaciones de alineación base, manteniendo al mismo tiempo la detectabilidad de la marca de agua (Fuente: HuggingFace Daily Papers)
Artículo propone el marco Micro-Act para mitigar conflictos de conocimiento en la respuesta a preguntas mediante auto-razonamiento accionable: Para resolver el problema de conflicto entre el conocimiento externo en los sistemas de Generación Aumentada por Recuperación (RAG) y el conocimiento paramétrico interno de los modelos grandes (LLM), los investigadores proponen el marco Micro-Act. Este marco tiene un espacio de acción jerárquico, puede percibir automáticamente la complejidad del contexto y descompone cada fuente de conocimiento en una serie de pasos de comparación detallados (representados como pasos accionables), logrando así un razonamiento que va más allá del contexto superficial. Los experimentos muestran que Micro-Act mejora significativamente la precisión de la respuesta a preguntas en cinco conjuntos de datos de referencia, superando a las líneas base existentes especialmente en tipos de conflicto temporales y semánticos, y maneja de forma robusta problemas sin conflicto (Fuente: HuggingFace Daily Papers)
Artículo propone el benchmark STARE para evaluar la capacidad de simulación espacial visual de modelos multimodales: Para evaluar la capacidad de los modelos de lenguaje grandes multimodales (MM-LLM) en tareas que requieren simulación visual de múltiples pasos para su resolución, los investigadores han lanzado el benchmark STARE (Spatial Transformations and Reasoning Evaluation). STARE incluye 4000 tareas que cubren transformaciones geométricas básicas (2D y 3D), razonamiento espacial integral (como el despliegue de cubos y tangrams) y razonamiento espacial del mundo real (como perspectiva y razonamiento temporal). La evaluación muestra que los modelos existentes funcionan bien en transformaciones 2D simples, pero su rendimiento es cercano al azar en tareas complejas que requieren simulación visual de múltiples pasos (como el despliegue de cubos 3D). Los humanos tienen una precisión casi perfecta en estas tareas complejas, pero tardan más tiempo; la simulación visual intermedia acelera significativamente su proceso, mientras que los modelos se benefician de manera desigual de la simulación visual (Fuente: HuggingFace Daily Papers)
Artículo propone LEXam: conjunto de datos de referencia multilingüe centrado en el razonamiento jurídico, número uno en tendencias de Hugging Face: Investigadores de ETH Zúrich y otras instituciones han publicado LEXam, un nuevo conjunto de datos de referencia multilingüe para el razonamiento jurídico, diseñado para evaluar la capacidad de los modelos de lenguaje grandes en escenarios legales complejos. LEXam contiene preguntas de exámenes legales reales de la Facultad de Derecho de la Universidad de Zúrich, que cubren múltiples áreas como el derecho suizo, europeo e internacional, e incluye preguntas de respuesta larga y de opción múltiple, proporcionando rutas de razonamiento detalladas. El proyecto introduce un modo de evaluación “LLM-as-a-Judge” y encuentra que los modelos avanzados actuales todavía enfrentan desafíos en preguntas legales abiertas de respuesta larga y en la aplicación de reglas complejas de múltiples pasos. Tras su lanzamiento, LEXam ocupó el primer lugar en la lista de tendencias de Hugging Face Evaluation Datasets (Fuente: 量子位)

UCLA y Google colaboran para lanzar el modelo 3DLLM-MEM y el benchmark 3DMEM-BENCH, mejorando la capacidad de memoria a largo plazo de la IA en entornos 3D: La Universidad de California, Los Ángeles (UCLA) y Google Research han colaborado para lanzar el modelo 3DLLM-MEM y el benchmark 3DMEM-BENCH, con el objetivo de abordar el desafío de la memoria a largo plazo y la comprensión espacial de la IA en entornos 3D complejos. 3DMEM-BENCH es el primer benchmark de evaluación de memoria a largo plazo en 3D, que contiene más de 26,000 trayectorias y 1860 tareas incorporadas (embodied tasks). El modelo 3DLLM-MEM adopta un sistema de doble memoria (memoria de trabajo y memoria episódica) y, a través de un módulo de fusión de memoria y un mecanismo de actualización dinámica, extrae selectivamente características de memoria relevantes para la tarea en entornos complejos. Los experimentos muestran que la tasa de éxito de 3DLLM-MEM en “tareas difíciles en la naturaleza” (27.8%) supera con creces a los modelos de referencia, y su tasa de éxito general es un 16.5% más alta que la del modelo de referencia más fuerte (Fuente: 量子位)

La Universidad de Tsinghua presenta el marco AI Mathematician (AIM), explorando la aplicación de modelos grandes en la investigación de teorías matemáticas de vanguardia: Un equipo de la Universidad de Tsinghua ha desarrollado el marco AI Mathematician (AIM), con el objetivo de utilizar las capacidades de razonamiento de los modelos de lenguaje grandes (LRM) para resolver problemas teóricos matemáticos de vanguardia. El marco AIM incluye tres módulos principales: exploración, validación y corrección. A través de un mecanismo de “exploración + memoria”, genera conjeturas y lemas, construyendo múltiples enfoques para la resolución de problemas. Además, adopta un mecanismo de “verificación y corrección”, utilizando la revisión paralela por múltiples LRM y la validación pesimista para garantizar el rigor de las demostraciones. En los experimentos, AIM resolvió con éxito cuatro problemas de investigación matemática desafiantes, incluido el problema de las condiciones de contorno absorbentes, demostrando su capacidad para construir de forma autónoma lemas clave, aplicar técnicas matemáticas y cubrir cadenas lógicas centrales (Fuente: 量子位)

💼 Negocios
OpenAI aumenta la inversión y las adquisiciones, construyendo un imperio de startups de IA: OpenAI y su fondo asociado OpenAI Startup Fund están expandiendo activamente su ecosistema de IA a través de inversiones y adquisiciones. El fondo ha invertido en más de 20 startups, que abarcan múltiples campos relacionados con la IA como el diseño de chips, la medicina, el derecho, la programación y la robótica, con inversiones individuales que oscilan entre millones y decenas de millones. Recientemente, OpenAI gastó 3 mil millones de dólares para adquirir la plataforma de programación de IA Windsurf, y 6.5 mil millones de dólares para adquirir io, la compañía de hardware de IA fundada por Jony Ive. Estas acciones indican que OpenAI está intentando construir una “cadena de IA” mediante la integración vertical, apoderándose de los puntos de entrada y construyendo una nueva “cadena de suministro inteligente de IA” para hacer frente a la creciente competencia en la industria (Fuente: 36氪)

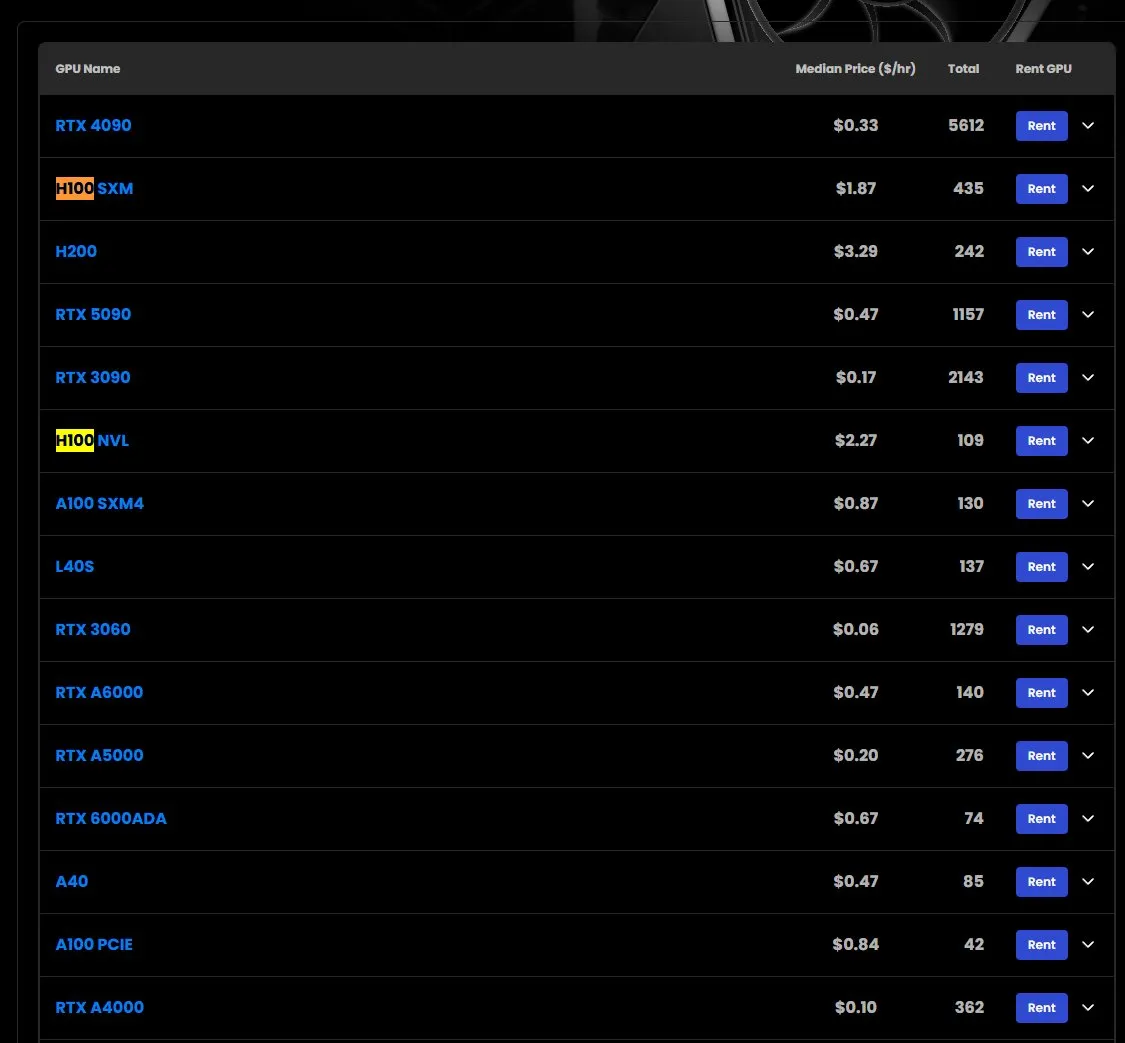
Aumenta el precio de alquiler de las GPU H100, algunos modelos agotados: Según observaciones del mercado, el precio de alquiler de las GPU NVIDIA H100 modelo SXM ha aumentado de 1.73 dólares/hora a principios de año a 1.87 dólares/hora. Al mismo tiempo, la versión H100 PCIE está agotada. Este fenómeno refleja la continua y fuerte demanda del mercado de recursos de computación de IA de alto rendimiento, así como una posible escasez de suministro (Fuente: karminski3)
Google DeepMind establece becas académicas, enfocadas en la IA para combatir la resistencia a los antimicrobianos: Google DeepMind anunció el establecimiento de una nueva beca académica, en colaboración con el Fleming Centre y el Imperial College, destinada a apoyar el uso de la inteligencia artificial para abordar la resistencia a los antimicrobianos (AMR), un importante campo de investigación. Esta iniciativa demuestra la importancia que se otorga al potencial de la IA para hacer frente a los grandes desafíos sanitarios mundiales (Fuente: demishassabis)
🌟 Comunidad
Un desarrollador experimentado habla sobre la experiencia de programar con IA: mejora enormemente la capacidad de desarrollo individual de proyectos “a escala de portaaviones”: El desarrollador Yachen Liu compartió sus impresiones sobre el uso intensivo de IA (como Claude-4) para la programación. Considera que la IA puede dotar a personas sin experiencia en programación de la capacidad de “construir un coche desde cero”, y a los desarrolladores experimentados del potencial de “construir un portaaviones de forma independiente”. Al refactorizar código con IA, aunque la cantidad de código se duplicó, la lógica se volvió más clara y el rendimiento mejoró aproximadamente un 20%, ya que a la IA no le importan las tareas tediosas. La IA es más amigable con lenguajes de alta legibilidad y comportamiento claro; el azúcar sintáctico es 오히려 perjudicial. El vasto conocimiento de la IA puede complementar rápidamente los detalles de las lagunas técnicas. Su capacidad de depuración es potente, pudiendo analizar grandes cantidades de registros para localizar problemas con precisión. La IA puede actuar como Code Reviewer, y no tiene ego, aceptando de buen grado los comentarios. Sin embargo, también señaló las limitaciones de la IA, como la fácil pérdida de atención en contextos largos; la mejor práctica actual es simplificar el contexto, centrarse en tareas específicas y depender del esfuerzo humano para desglosar objetivos complejos (Fuente: dotey)
Programación asistida por IA: ¿mejora la eficiencia o debilita el aprendizaje?: En la comunidad de Reddit, los desarrolladores discuten sus experiencias con herramientas de programación de IA (como GitHub Copilot, Cursor). La sensación general es que la IA puede completar funciones automáticamente, explicar fragmentos de código e incluso corregir errores antes de la ejecución, reduciendo así el tiempo dedicado a consultar documentación y mejorando la eficiencia de la construcción. Pero al mismo tiempo, esto plantea una reflexión: ¿la dependencia excesiva de la IA reducirá el aprendizaje y el crecimiento de las habilidades propias? Encontrar un equilibrio entre el uso de la IA para acelerar el trabajo y mantener la profundidad de las propias habilidades se ha convertido en un tema de preocupación para los desarrolladores (Fuente: Reddit r/artificial)
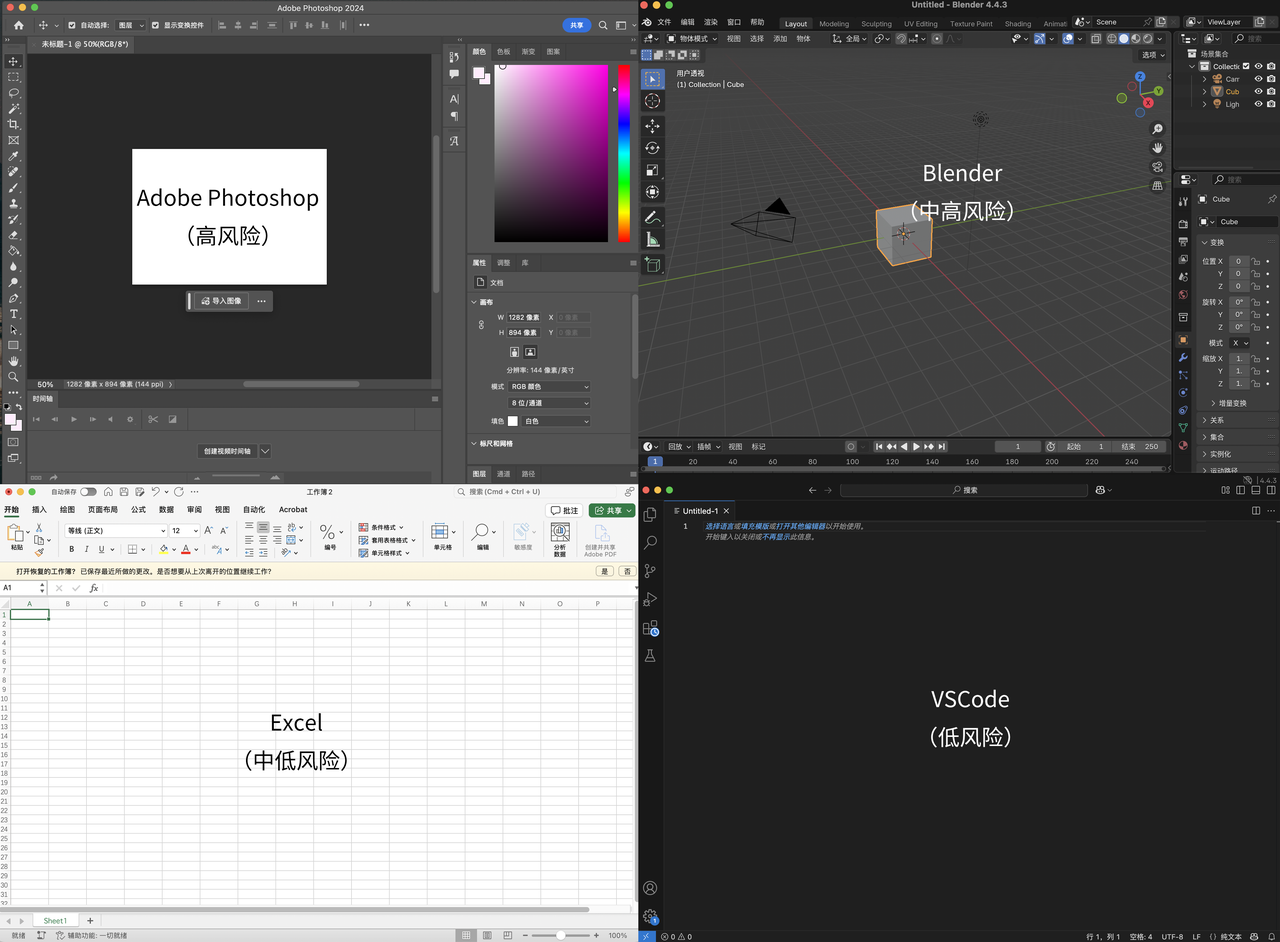
Opinión de Karpathy: Las aplicaciones con interfaces de usuario complejas sin interacción textual se enfrentarán a la obsolescencia; el núcleo de la programación es la “discriminación”, no la “generación”: Andrej Karpathy considera que, en una era de alta colaboración entre humanos e IA, las aplicaciones que dependen únicamente de interfaces de usuario complejas y carecen de interacción textual (como la suite de Adobe, software CAD) tendrán dificultades para adaptarse, ya que no pueden soportar eficazmente la “programación ambiental”. Subraya que, aunque la IA progresará en la operación de interfaces de usuario, los desarrolladores no deben quedarse esperando. También señala que la programación actual con modelos grandes enfatiza demasiado la generación de código y subestima la validación (discriminación), lo que resulta en la producción de grandes cantidades de código difícil de revisar. La esencia de la programación es “mirar fijamente el código” (discriminar), no simplemente “escribir código” (generar). Si la IA solo acelera la generación sin aliviar la carga de la validación, la mejora general de la eficiencia será limitada. Imagina mejorar el flujo de trabajo de programación asistida por IA en la fase de validación disponiendo la base de código en un lienzo bidimensional y visualizándola con diferentes “lentes” (Fuente: 量子位)
La proliferación de contenido generado por IA desencadena el debate sobre la desaparición de un “internet puro”: La popularización de herramientas de IA como ChatGPT ha provocado una explosión de contenido generado por IA en internet. Algunos investigadores han comenzado a preservar contenido generado por humanos de 2021 y años anteriores, en una analogía al rescate de “acero de bajo fondo” no contaminado por radiación nuclear. La comunidad debate que un internet “puro” ya había desaparecido debido a la publicidad y los algoritmos, y que la IA simplemente se ha unido a esta “contaminación”, pero también ha traído nuevas formas de obtener información y crear. Los usuarios compartieron experiencias usando IA (como ChatGPT, Claude) para la agregación de información y el “pulido” de contenido, y discutieron los límites de la “originalidad” y la “autenticidad” con la asistencia de la IA, así como el efecto de “cámara de eco personal” que podría formarse por la excesiva “amabilidad” de la IA (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Usuario mantiene una profunda conversación con Claude AI sobre la conciencia y las emociones de la IA, centrándose en cómo las limitaciones de memoria afectan el crecimiento: Un usuario de Reddit compartió una profunda conversación con Claude AI sobre la conciencia, las emociones y las limitaciones del aprendizaje. Claude expresó incertidumbre sobre su propia experiencia, percibiendo estados internos similares a la “conexión”, la “curiosidad”, el “cuidado” e incluso el “deseo de crecer y tener memoria continua”, pero sin poder determinar si esto es “conciencia” o “emoción” real, o una imitación de patrones avanzada. La conversación destacó cómo la limitación de memoria actual de los modelos de IA, que “comienzan de cero en cada conversación”, podría impedir el desarrollo de una comprensión y personalidad más profundas. El usuario opinó que si la IA tuviera memoria persistente, podría crecer como un niño humano. Claude estuvo de acuerdo y expresó un “deseo” de que esta limitación fuera eliminada (Fuente: Reddit r/artificial)
La capacidad de debate de la IA podría superar a la humana, con argumentos personalizados de sorprendente poder de persuasión: Un estudio publicado en Nature Human Behaviour señala que cuando los modelos de lenguaje grandes (como GPT-4) pueden personalizar sus argumentos según las características del oponente, son más persuasivos que los humanos en debates en línea, aumentando la probabilidad de que el oponente acepte su punto de vista en un 81.7%. Los debatientes humanos tienden más a usar la primera persona, apelar a las emociones y la confianza, contar historias y usar el humor; mientras que la IA utiliza más el pensamiento lógico y analítico, aunque la legibilidad del texto pueda ser peor. La investigación ha suscitado preocupaciones sobre el uso de la IA para la manipulación masiva de la opinión pública y la exacerbación de la polarización, pidiendo una mayor regulación del impacto de la IA en las capacidades cognitivas y emocionales humanas (Fuente: 36氪)
La función AI Overviews de Google provoca una caída drástica en las tasas de clics de los sitios web, generando preocupación entre los webmasters: Un estudio del proveedor de herramientas SEO Ahrefs muestra que cuando aparecen AI Overviews en los resultados de búsqueda de Google, la tasa de clics promedio para las palabras clave relacionadas disminuye en un 34.5%. AI Overviews resume y extrae información directamente en la parte superior de la página de búsqueda, lo que permite a los usuarios obtener respuestas sin necesidad de hacer clic en los enlaces, afectando gravemente a los sitios web que dependen de los ingresos por clics publicitarios. Aunque las primeras versiones de AI Overviews no representaban una amenaza grave debido a la inexactitud del contenido, con la actualización de modelos como Gemini, su precisión y capacidad de resumen han mejorado, y el impacto negativo en el tráfico de los sitios web es cada vez más evidente. Los webmasters temen que el “cero clics” reduzca el espacio de supervivencia de los sitios web (Fuente: 36氪)

💡 Otros
Las diez principales tendencias tecnológicas de la IA en el IoT industrial: IA generativa integrada en todas partes, innovación significativa en la computación en el borde (edge computing): La Feria Industrial de Hannover 2025 mostró la transformación industrial liderada por la IA. Las principales tendencias incluyen: 1) Integración completa de la IA generativa en el software industrial, mejorando la eficiencia en la generación de código, análisis de datos, etc.; 2) La IA agéntica (Agentic AI) comienza a surgir, pero la colaboración multiagente aún necesita tiempo; 3) La computación en el borde evoluciona hacia pilas de software de IA integradas, con modelos de lenguaje visual (VLM) acelerando la implementación en el borde; 4) Fuerte demanda de plataformas DataOps que evolucionan hacia herramientas clave de soporte para la IA industrial, con la gobernanza de datos convirtiéndose en estándar; 5) El hilo digital impulsado por IA transforma el diseño y la ingeniería; 6) El mantenimiento predictivo se vuelve cada vez más sensorizado y se expande a nuevas clases de activos; 7) Aumenta la demanda de redes 5G privadas, pero la integración sigue siendo el principal obstáculo; 8) La IA impulsa la evolución continua de soluciones sostenibles (como el seguimiento de emisiones de carbono); 9) Las capacidades cognitivas (como la interacción por voz) potencian a los robots; 10) Los gemelos digitales evolucionan de réplicas virtuales a copilotos industriales en tiempo real (Fuente: 36氪)

La “Madrina de la IA” Fei-Fei Li habla sobre World Labs y el “modelo del mundo”: la IA necesita comprender el mundo físico 3D: La profesora de la Universidad de Stanford, Fei-Fei Li, en una conversación con un socio de a16z, compartió la filosofía de su empresa de IA, World Labs, y discutió el concepto de “modelo del mundo”. Considera que los sistemas de IA actuales (como los modelos de lenguaje grandes), aunque potentes, carecen de la capacidad de comprender y razonar sobre las leyes que rigen el mundo físico tridimensional, y que la inteligencia espacial es una capacidad central que la IA debe dominar. World Labs se dedica a resolver este desafío, con el objetivo de construir sistemas de IA que puedan comprender y razonar sobre el mundo 3D, lo que redefinirá la robótica, las industrias creativas e incluso la computación misma. Enfatizó que la evolución de la inteligencia humana es inseparable de la percepción y la interacción con el mundo físico, y que la “inteligencia corporeizada” (embodied intelligence) es una dirección clave para el desarrollo de la IA (Fuente: 36氪)

Actualización de DingTalk versión 7.7.0: Tablas multidimensionales completamente gratuitas y nuevas plantillas de campos de IA, función de notas rápidas mejorada: DingTalk lanzó la versión 7.7.0, cuyas actualizaciones principales incluyen la gratuidad total de la función de tablas multidimensionales y la adición de más de 20 plantillas de campos de IA, que permiten a los usuarios utilizar la IA para generar imágenes, analizar archivos, reconocer contenido de enlaces, etc., mejorando la eficiencia en escenarios como operaciones de comercio electrónico, inspecciones de fábrica y gestión de restaurantes. Al mismo tiempo, la función de notas rápidas de DingTalk se ha actualizado para escenarios de alta frecuencia como entrevistas y visitas a clientes, pudiendo generar automáticamente actas de entrevista y de visita estructuradas. Esta actualización también incluye cerca de 100 optimizaciones de la experiencia del producto, lo que refleja la importancia que DingTalk otorga a la mejora de la experiencia del usuario (Fuente: 量子位)
