关键词:AI技术, 大型语言模型, 深度学习, 人工智能, 机器学习, 自然语言处理, 计算机视觉, 强化学习, nanochat开源项目, OpenAI自研AI芯片, Sora 2深伪伦理, Claude Sonnet 4.5, GPT-5 Pro数学推理
🔥 聚焦
Andrej Karpathy发布nanochat:100美元手搓ChatGPT : 特斯拉前AI总监Andrej Karpathy推出开源项目nanochat,以不到8000行代码实现了ChatGPT的完整训练与推理流程。该项目旨在降低LLM研究门槛,用户仅需一台云GPU(约100美元,4小时训练)即可搭建可对话的迷你ChatGPT,12小时训练性能可超越GPT-2 CORE指标。nanochat将成为LLM101n课程的压轴项目,并有望发展为研究平台或基准测试工具,体现了Karpathy对AI教育和民主化的持续热情。(来源:GitHub nanochat, Reddit r/deeplearning, 36氪, 36氪, 36氪, 36氪)
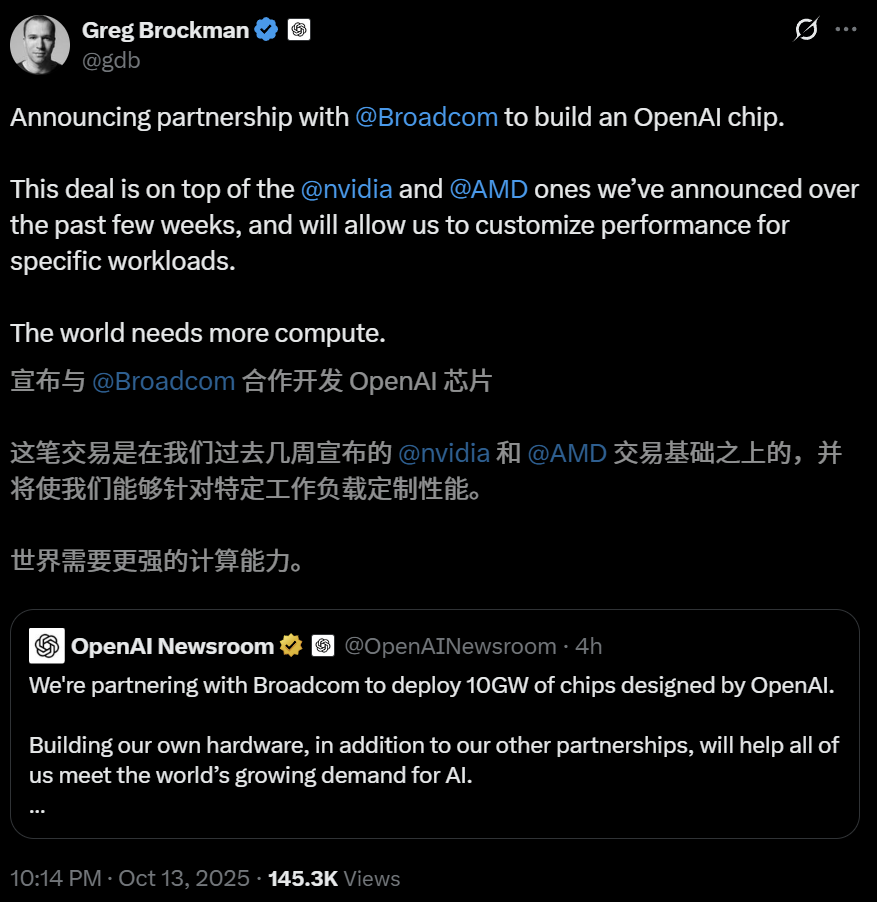
OpenAI与博通联手自研AI芯片,部署10吉瓦算力基础设施 : OpenAI宣布与博通达成战略合作,共同设计并部署定制AI芯片及计算系统,目标在2026年下半年至2029年底前,部署总功耗达10吉瓦的推理基础设施。此举标志着OpenAI不再满足于购买现有GPU,而是通过垂直整合,从晶体管层面参与硬件设计,以优化AI模型性能、降低成本并满足未来指数级增长的算力需求。OpenAI表示,这项合作是“人类历史上规模最大的联合工业项目”,甚至利用AI模型辅助芯片设计,预示着AI在硬件开发领域的深度参与。(来源:OpenAI, Bloomberg, CNBC, 36氪, 36氪, 36氪)
Sora 2引发深伪伦理危机与版权争议 : OpenAI的视频生成模型Sora 2因其高度逼真的生成能力迅速走红,但也带来了严重的伦理和版权挑战。用户利用Sora 2生成已故名人(如迈克尔·杰克逊、罗宾·威廉姆斯)的虚假视频,引发家属强烈不满,认为这是对逝者形象的滥用和不尊重。OpenAI对此回应称,公众人物及其家属应拥有对其形象使用方式的控制权,并计划提供更精细的版权控制和收入分成机制。然而,业界普遍担忧,开放源深伪模型日益普及,社会需尽快适应AI生成内容带来的冲击,并探索有效的技术与法律防护措施。(来源:Washington Post, BBC, 量子位)

Claude Sonnet 4.5、微软Agent Framework与Cursor IDE推动AI编码能力飞跃 : AI编码领域迎来重大突破:Claude Sonnet 4.5在SWE-bench Verified基准测试中达到77.2%的准确率,显著超越前代模型。同时,微软Agent Framework将VS Code转变为AI原生环境,支持Agent自主处理多文件代码修改;Cursor IDE 1.7也推出“Agent模式”,可一键解决复杂问题。这些进展表明AI Agent已能承担大部分开发任务,引发了关于开发者是否会过度依赖AI的讨论,以及AI生成代码可能引入的潜在技术债务风险。(来源:Reddit r/artificial)
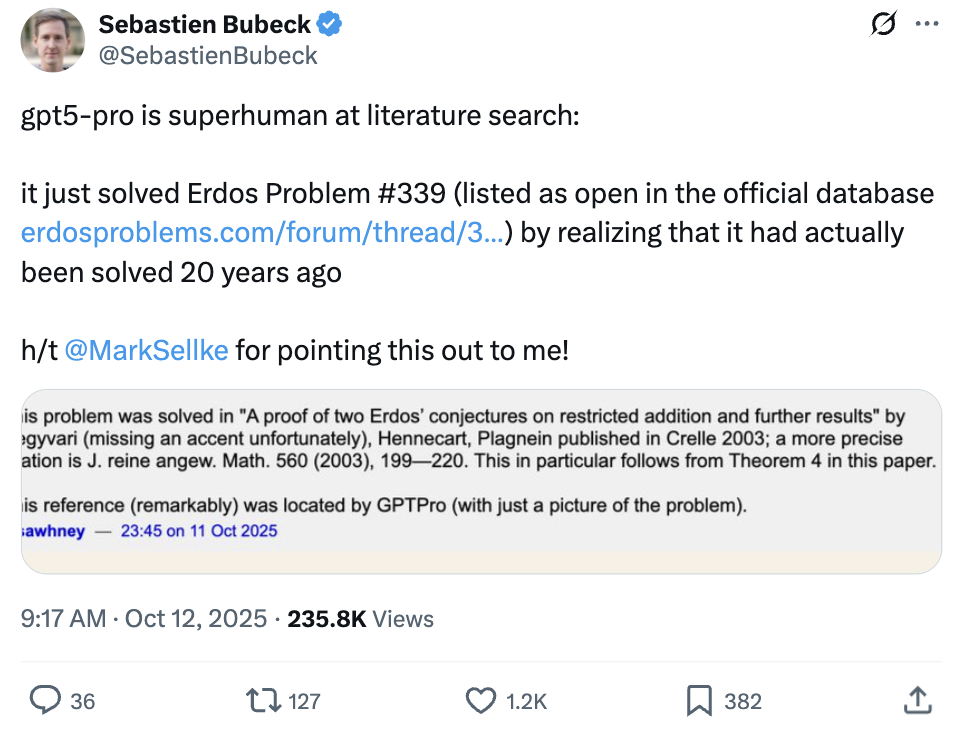
GPT-5 Pro解决埃尔德什数学难题,展现强大文献检索与漏洞识别能力 : OpenAI的GPT-5 Pro在数学推理领域展现出惊人能力,仅凭埃尔德什问题#339的图片,就准确检索到该问题在2003年已被解决的关键文献。此外,GPT-5 Pro还能在18分钟内发现已发表论文中的严重缺陷,甚至超越人类专家数天的研究成果。这一突破凸显了GPT-5 Pro在精确信息检索、复杂问题解决和科学文献验证方面的巨大潜力,预示着AI将极大加速科研进程,尤其在核实学术论断和发现逻辑矛盾方面。(来源:Sebastien Bubeck, Greg Brockman, 36氪)
三大AI巨头联手发文:现有LLM安全防御不堪一击 : OpenAI、Anthropic和Google DeepMind罕见联手发布论文,指出当前针对大型语言模型(LLM)越狱和提示注入的防御机制普遍脆弱。研究团队提出了通用自适应攻击框架,并结合梯度下降、强化学习、随机搜索和人工红队测试等方法,成功绕过了12种主流防御机制,多数攻击成功率超过90%。这表明现有评估多为纸上谈兵,未来的LLM安全研究必须纳入更强的自适应攻击评估,才能建立真正鲁棒的防御体系。(来源:arXiv:2510.09023, 36氪)

xAI加入“世界模型”竞赛,首个应用瞄准AI游戏生成 : 马斯克旗下xAI公司已悄然加入“世界模型”竞赛,与谷歌、Meta等巨头同台竞技。xAI从英伟达聘请AI专家,旨在通过训练海量视频和机器人数据,构建能理解并模拟真实物理世界的模型。其首个商业化落点是AI游戏生成,计划在明年底发布AI生成游戏,并探索应用于机器人系统。谷歌研究人员认为,未来的视频模型将像语言模型一样智能,通过“下一帧预测”解锁物体分割、边缘检测等涌现能力,预示着“视觉领域的GPT时刻”到来。(来源:36氪)
ICLR神秘论文揭示SAM3:用概念分割一切,重构视觉AI新范式 : ICLR 2026会议盲审论文《SAM3:用概念分割一切》曝光,揭示Meta AI的Segment Anything Model(SAM)将迎来第三次重大升级。SAM3的核心突破在于“基于概念的分割”(PCS),模型不仅能按像素或实例分割,还能根据文字或图像提示,识别、分割并追踪所有符合特定“语义概念”的对象。新系统通过人机协同数据引擎,构建了包含400万概念标签的高质量数据集,并在H200 GPU上实现30毫秒内识别上百对象,性能全面超越现有系统,预示着视觉AI的“GPT-3时刻”可能不远。(来源:arXiv:r35clVtGzw, 36氪)
🎯 动向
Gemini 3内测获好评,被赞“史上最强前端开发模型” : 谷歌下一代旗舰模型Gemini 3在内测中引发广泛关注,网友对其在前端开发、SVG矢量图生成及多模态能力方面赞不绝口,称其为“有史以来最出色的前端和网页开发模型”,甚至有人预言其将是年度最佳模型。曝光信息显示,Gemini 3.0 Pro采用MoE架构,拥有数万亿参数,上下文窗口扩展至数百万,并内置深度思考模式和多模态能力,在ARC-AGI-2和HLE基准测试中表现出色。(来源:36氪)
AI在芯片设计与制造中的应用日益深入 : 机器学习正日益被应用于芯片设计和制造领域,推动半导体效率和创新达到新水平。AIHub采访Sony AI芯片设计负责人Lorenzo Servadei指出,AI在EDA(电子设计自动化)领域正从加速估算迈向主动参与设计流程,通过神经网络加速多物理场模型、优化算法及生成式AI进行物理实现,显著提升芯片设计速度、质量和创造力。OpenAI也透露,其GPT模型已辅助设计自身芯片,实现面积缩减并加速开发周期。(来源:aihub.org, 36氪)

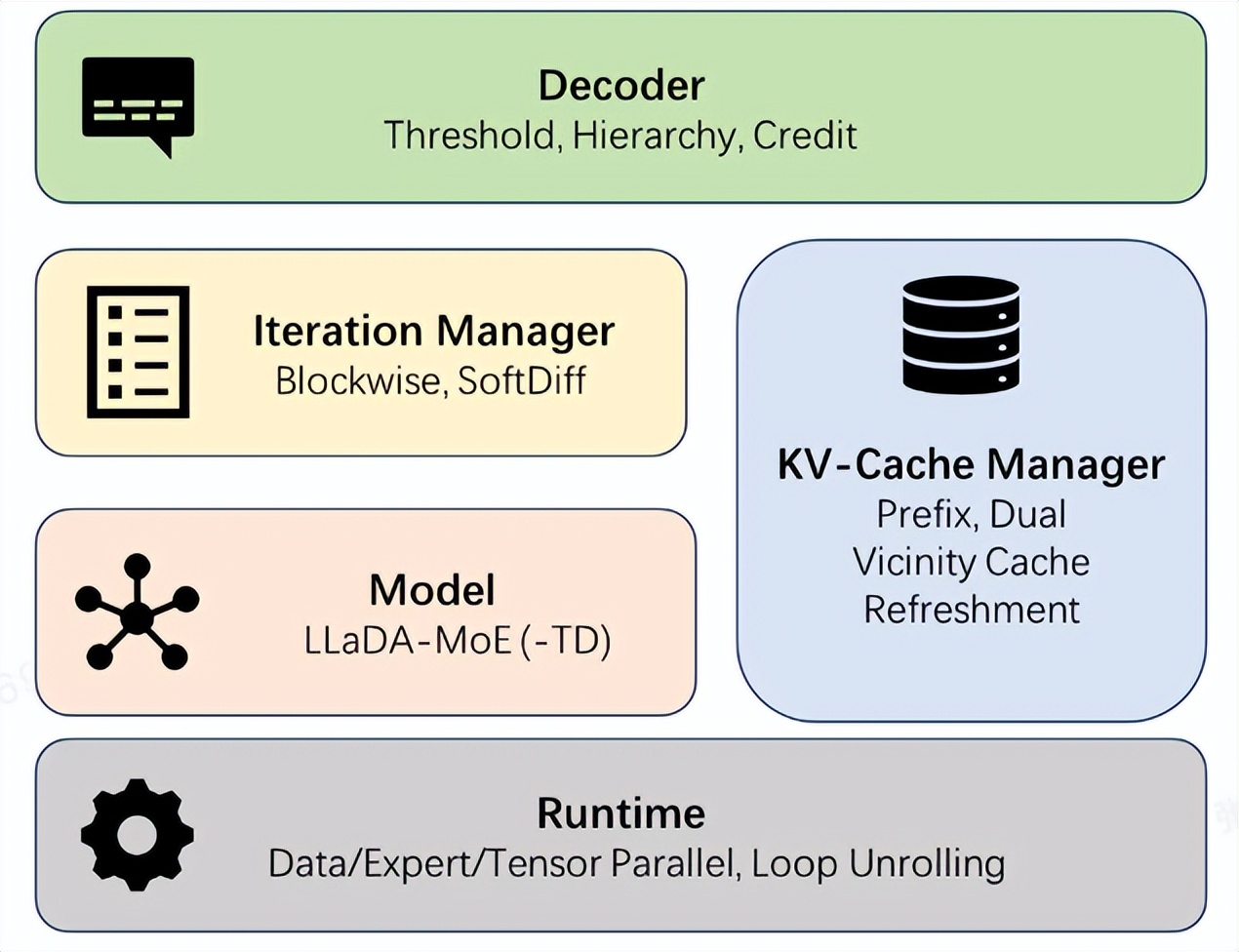
蚂蚁集团开源dInfer框架,扩散语言模型推理速度提升10倍 : 蚂蚁集团正式开源业内首个高性能扩散语言模型推理框架dInfer,将扩散语言模型的推理速度相比英伟达Fast-dLLM提升10.7倍。在代码生成任务HumanEval中,dInfer在单批次推理中达到1011Tokens/秒,首次显著超越自回归模型。dInfer采用算法与系统深度协同设计,包含模型接入、KV缓存管理器、扩散迭代管理器和解码策略四大核心模块,旨在解决扩散语言模型计算成本高、KV缓存失效、并行解码等挑战,释放其高效推理潜力。(来源:量子位, QuixiAI)
谷歌NotebookLM升级,Gemini Nano Banana赋能视频概览新视觉风格 : 谷歌NotebookLM的视频概览功能迎来升级,新增多种视觉风格(经典、白板、水彩、复古印刷版、传统、纸艺、动漫),并由Gemini的图像生成模型Nano Banana提供支持。此外,还引入了更简洁的“Brief”格式,提供快速摘要。这些更新将首先向Pro用户推出,未来几周内面向所有用户开放,旨在提升用户在视频内容理解和呈现上的个性化体验。(来源:Google, op7418)
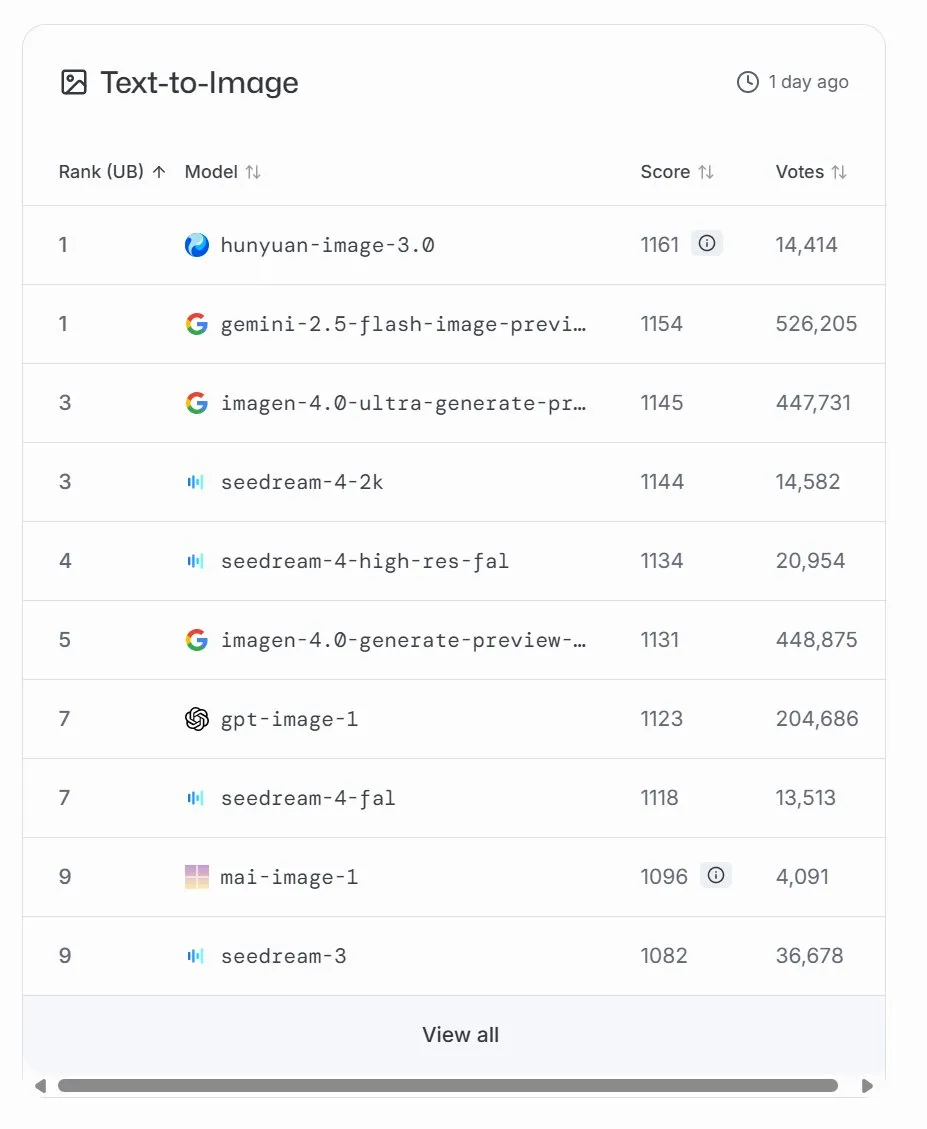
微软推出MAI-Image-1图像生成模型,LMArena排名第九 : 微软AI发布其第三款AI模型MAI-Image-1,这是一款图像生成模型,在LMArena排行榜上首次亮相便位列第九,与Seedream 3并列。该模型在生成速度和质量之间取得了令人印象深刻的平衡,展示了微软在多模态AI领域的持续投入和快速发展。微软表示将继续优化该模型,力争在排行榜上取得更高排名。(来源:mustafasuleyman, NandoDF)
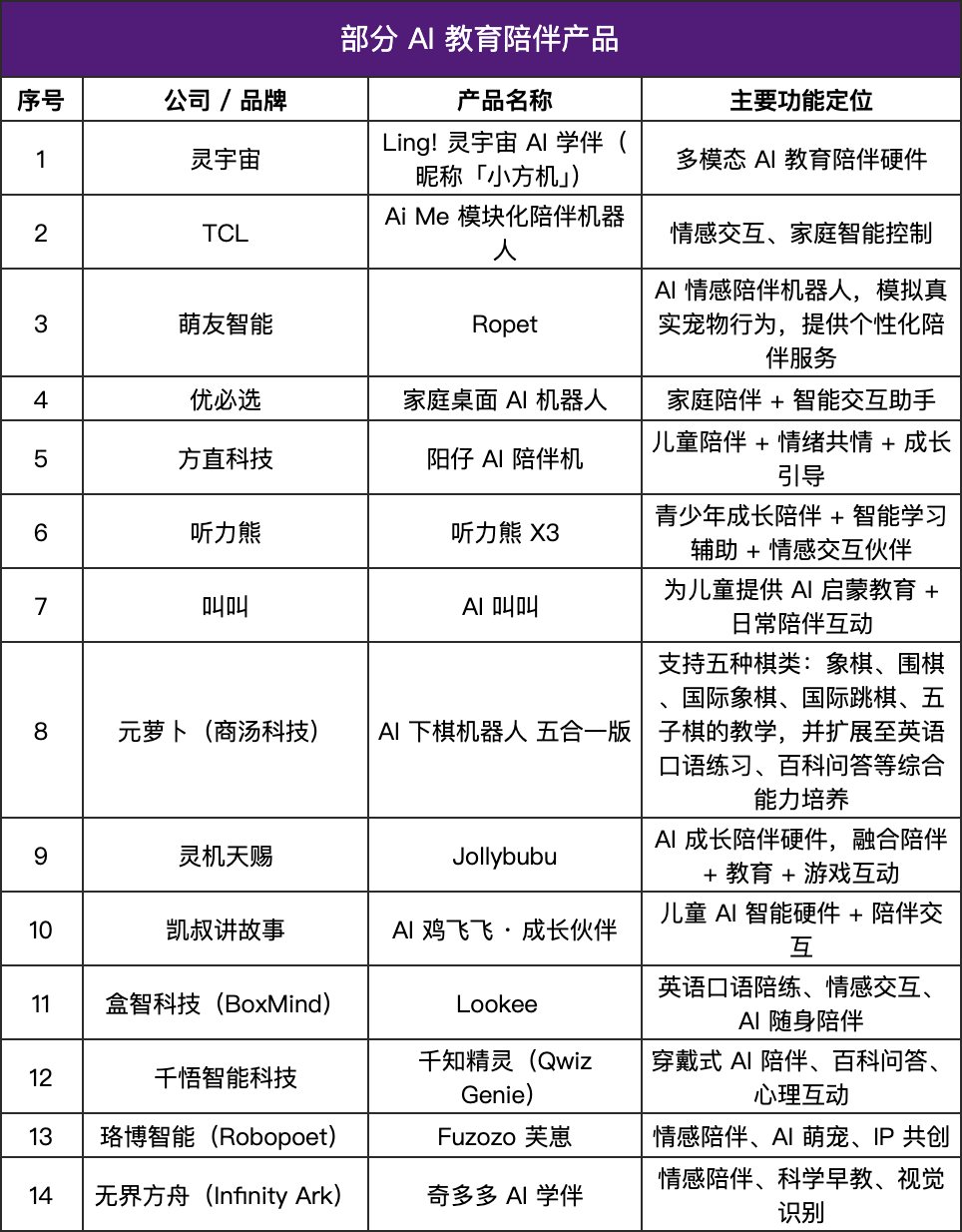
AI伴侣产品迎来爆发,教育硬件“长出温度” : AI伴侣产品市场正迅速崛起,预计未来市场规模将达700亿至1500亿美元。这类产品从“指令响应”转向“情感反馈”,通过语言模型、情绪识别、语音交互和记忆系统,模拟人类反应,提供个性化陪伴。在教育领域,AI伴侣产品已落地为学习助手、情绪反馈系统和智能问答模型,从知识传递延伸到心理支持,呈现轻量化、人格化趋势,并融合多模态交互,旨在成为“理解学生”的系统。(来源:36氪)
NVIDIA发布DGX Spark,全球最小AI超级计算机 : NVIDIA正式发布DGX Spark,号称全球最小的AI超级计算机,现已开始出货。DGX Spark基于NVIDIA Grace Blackwell架构,集成128GB统一内存,旨在为AI开发者提供强大的本地LLM原型设计和运行能力。早期用户正在测试、验证和优化其工具、软件和模型,预示着高性能AI计算将更加普及和便捷。(来源:nvidia, ollama)

Anthropic推出Claude Sonnet 4.5、Agent SDK及更新版Claude Code : Anthropic发布Claude Sonnet 4.5,提升了推理能力,拥有更大的上下文窗口(200k–1M token),并改进了编码和推理基准性能。同时,Anthropic还推出了Claude Agent SDK和更新版的Claude Code,新增自动上下文跟踪/摘要、持久化内存工具、带回滚功能的检查点,以及VS Code兼容IDE扩展,旨在为开发者提供更强大的AI编码和Agent构建能力。(来源:DeepLearningAI)

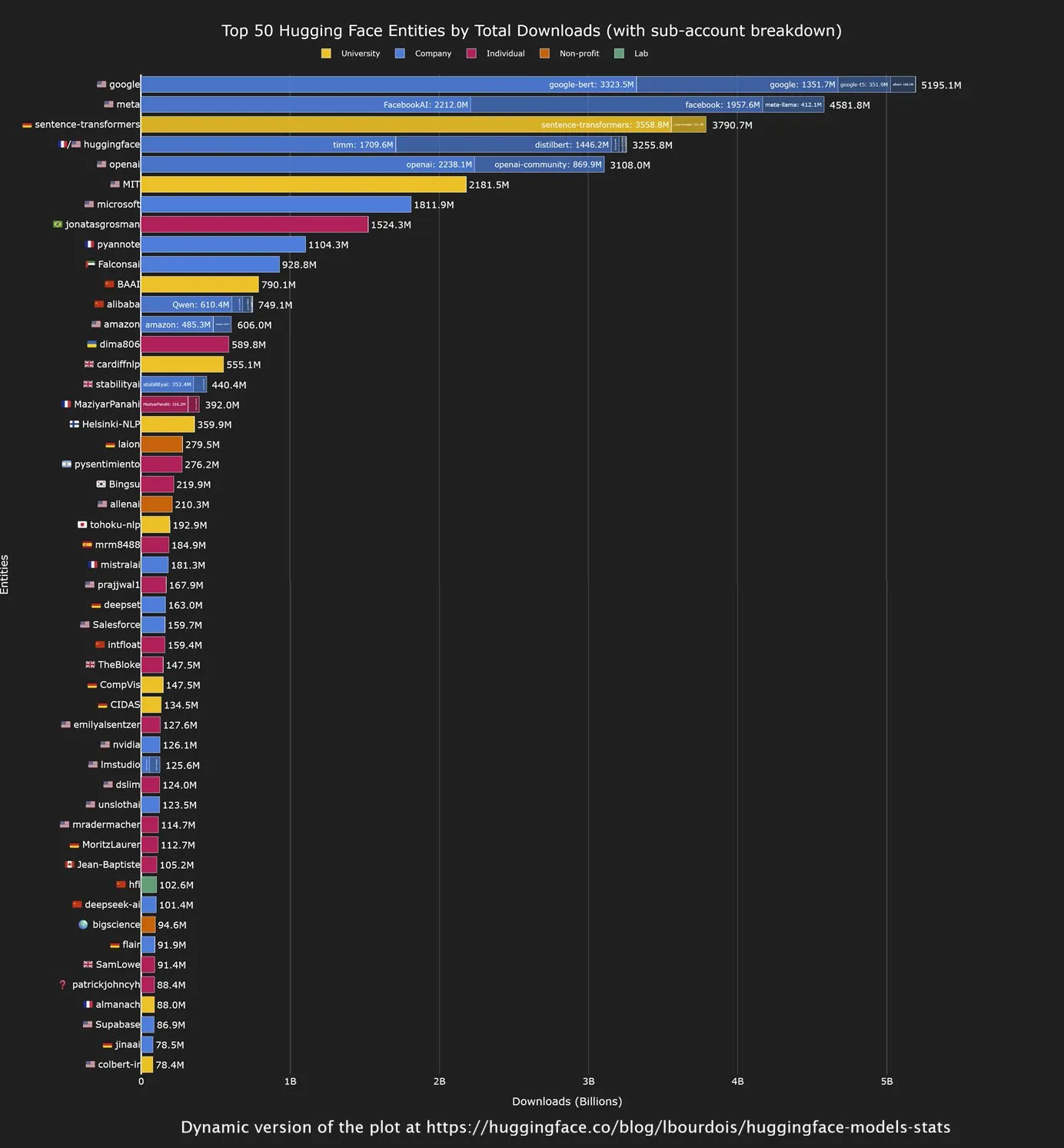
中国开源模型在Hugging Face下载量领先,Google成最大贡献者 : Hugging Face社区最新分析显示,中国公司开发的开源模型在下载量方面表现强劲,特别是Qwen系列模型。同时,Google成为Hugging Face上模型下载量最大的机构。这一趋势表明中国在开源AI领域的影响力日益增强,而Google作为科技巨头,也在积极贡献和利用开源生态系统,推动AI技术普及。(来源:mervenoyann, osanseviero)
Google搜索产品副总裁Robbie Stein解读AI搜索未来:以“清晰”为终点 : Google搜索产品副总裁Robbie Stein指出,AI并未改变人类搜索信息的基础需求,而是通过AI模式(AI Mode)使其更自然、更复杂。未来的AI搜索将具备“理解能力”,能将模糊问题拆解为子问题并行搜索,并汇总带引用的可追溯答案。Google的目标是成为一个“懂信息、可信任”的系统,通过多模态融合和结构化世界数据,实现从“索引网页”到“索引世界”的转变,让信息获取更清晰、更快速,而非仅仅生成流畅语言。(来源:36氪)
蚂蚁集团开源高性能扩散语言模型推理框架dInfer : 蚂蚁集团正式开源业界首个高性能扩散语言模型推理框架dInfer,将扩散语言模型的推理速度相比英伟达Fast-dLLM提升10.7倍。在代码生成任务HumanEval中,dInfer在单批次推理中达到1011Tokens/秒,首次显著超越自回归模型。dInfer采用算法与系统深度协同设计,旨在解决扩散语言模型计算成本高、KV缓存失效、并行解码等挑战,释放其高效推理潜力。(来源:量子位)
NVIDIA推出NVFP4训练技术,实现4比特预训练与FP8精度匹配 : NVIDIA公布一项突破性NVFP4训练技术,使得4比特预训练大型语言模型能够达到8比特精度。该技术采用E2M1格式的4比特浮点表示,结合细粒度缩放、随机舍入和Random Hadamard Transforms,显著降低了计算和内存需求。实验表明,NVFP4在保持模型准确性(如MMLU Pro 62.58% vs 62.62%)的同时,大幅提升了训练效率,为未来更大规模LLM的训练提供了更经济高效的路径。该技术主要依赖NVIDIA Blackwell架构,需H100及以上GPU支持。(来源:Reddit r/LocalLLaMA, karminski3)

MIT SEAL框架实现AI模型自动生成微调数据与权重升级 : 麻省理工学院(MIT)推出SEAL(Self-Adapting LLMs)框架,使大型语言模型(LLM)能够自动生成微调数据并进行自我权重更新,实现0人工参与的梯度更新。SEAL采用内外双循环学习机制,模型根据任务表现优化自我更新指令生成策略,首次赋予LLM自我驱动的更新能力。实验证明,SEAL在知识注入和小样本学习任务中表现出色,准确率超越GPT-4.1生成数据,展现出强大的任务适应和知识整合能力,预示着自进化模型时代的到来。(来源:arXiv:2506.10943, 36氪)

AI手机出货量激增,酷赛智能等厂商探索“小模型+大模型”协同战略 : 2025年中国AI手机出货量同比激增591%,渗透率达22%,AI手机成为行业新焦点。酷赛智能等厂商正从参数竞赛转向务实创新,采用“前置小模型+后端大模型”的动态协同方案,将约6亿参数的垂直小模型部署在设备端,实现快速响应和隐私保护,同时整合科大讯飞、字节、阿里、Google等通用大模型算力。这种策略旨在提升用户体验,提供个性化服务,并降低成本,以适应多元碎片化的海外市场。(来源:36氪)

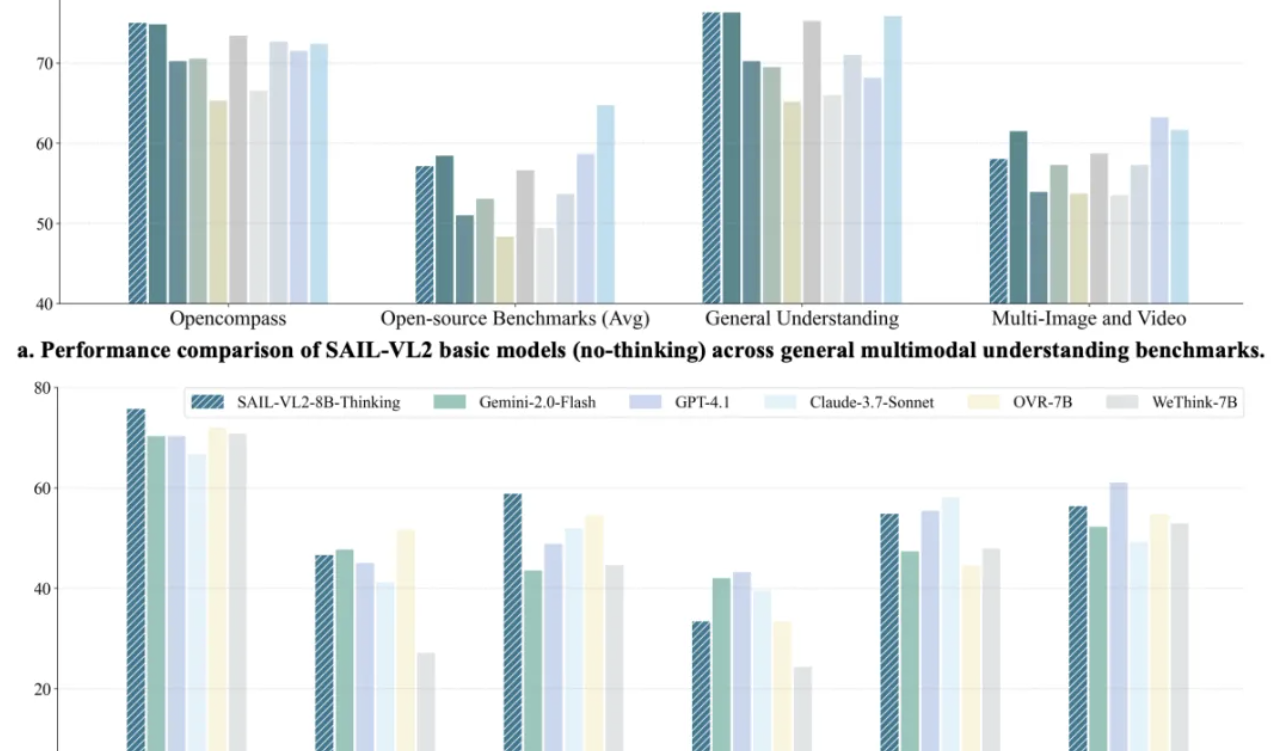
抖音SAIL-VL2多模态模型刷新SOTA,8B模型推理比肩GPT-4o : 抖音SAIL团队与LV-NUS Lab联合推出多模态大模型SAIL-VL2,以2B、8B等中小参数规模在106个数据集上实现性能突破,尤其在MMMU、MathVista等复杂推理基准上超越同规模模型,8B模型推理能力甚至比肩GPT-4o。SAIL-VL2通过稀疏MoE架构、渐进式训练框架和高质量多模态语料库等创新,为社区提供了“小模型也能有强能力”的新范式,并开源模型与推理代码。(来源:量子位)
Moondream Cloud推理全面迁移至FAL,实现100%云端运行 : Moondream宣布其云端推理服务已全面从EC2实例迁移至FAL,实现了100%在FAL上运行。这一举措可能意味着Moondream在优化推理效率、降低运营成本或提升服务弹性方面取得了重要进展,FAL作为新的推理平台,展现出其在支持AI模型云端部署方面的能力。(来源:vikhyatk)
Ring-1T:凌动科技发布万亿参数开源思维模型 : 凌动科技(Ant Ling)正式发布Ring-1T,一款基于Ling 2.0架构的开源万亿参数思维模型。Ring-1T在纯自然语言推理方面达到银牌级别的IMO(国际数学奥林匹克)推理能力,拥有1万亿总参数和500亿活跃参数,以及128K的上下文窗口。该模型通过Icepop RL和ASystem(万亿级强化学习引擎)进行强化,并在AIME 25、HMMT 25、ARC-AGI-1、CodeForce等自然语言推理基准上取得SOTA表现,提供FP8版本,旨在推动开放源AI推理能力。(来源:scaling01, jon_durbin)
ChatGPT电商功能“即时结账”上线,重塑购物体验 : OpenAI推出ChatGPT的“即时结账”(Instant Checkout)功能,允许用户直接在ChatGPT内完成购物,无需跳转至第三方电商平台。目前该功能支持Etsy,并将很快接入Shopify超过一百万商家。这一创新将购物流程从描述需求到完成购买一站式闭环,显著缩短用户购买决策路径,提升购物便利性,预示着AI在电商领域的深度整合和商业模式变革。(来源:36氪)
AI短剧出海迎来爆发,Sora 2技术推动内容生产质效飞跃 : AI短剧正以爆发之势冲击短视频平台,并大规模出海。2024年中国微短剧市场规模达505亿元,海外市场需求显现,中国出海短剧收入预计全年达40亿美元。OpenAI Sora 2的发布,大幅提升画质、时长、同步性和音画同步能力,并支持复杂剧情连贯性和Cameos功能,将短剧制作流程压缩为“一人写Prompt、AI产物”的高效模式,成本可降至传统十分之一。AI漫剧也成为新趋势,有效降低文化折扣,推动内容产业从真人剧向AI漫剧拓展。(来源:36氪)

AI在医疗诊断领域取得进展:AMIE多模态诊断Agent发布 : 谷歌AI发布AMIE(AI agent for multimodal diagnostic dialogue),这是一款研究型AI Agent,旨在通过多模态诊断对话,在医疗领域实现突破。AMIE的推出标志着AI在理解和参与复杂医疗诊断过程方面的进步,有望提升诊断效率和准确性,为未来的智能医疗应用奠定基础。(来源:Ronald_vanLoon)
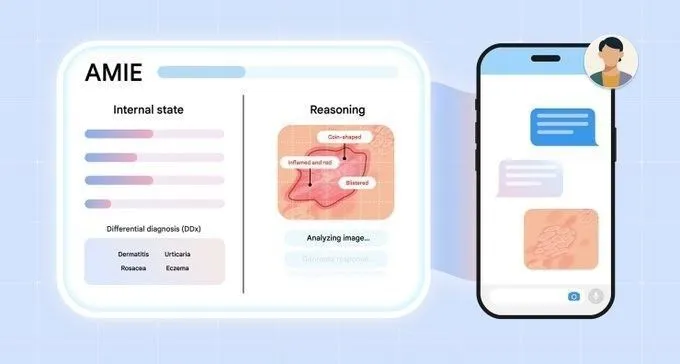
Perplexity Search API新增域名过滤功能,提升搜索精准度 : Perplexity宣布其Search API现已支持按特定域名过滤搜索结果。这一新功能使用户能够仅查询信任来源,从而获得更专注、可验证的结果。这对于需要从特定权威来源获取信息的专业用户或应用开发者来说,将显著提升搜索效率和信息质量。(来源:AravSrinivas)
AI在地震检测中展现潜力,未来或助预测 : AI在检测小型地震方面表现出色,其能力被形容为“像第一次戴上眼镜一样清晰”。研究人员正探索AI是否能进一步帮助预测地震,这有望为地震预警和防灾减灾带来革命性突破。AI通过更精细的数据分析,能够识别传统方法难以察觉的地震信号,从而提升我们对地球深层活动的理解。(来源:Ars Technica)
Mamba3架构发布,LLM实现更快、更长上下文和更可扩展性 : Mamba3架构在ICLR会议上悄然发布,标志着LLM领域在速度、上下文长度和可扩展性方面取得显著进步。该架构通过优化内部状态演化和硬件利用,实现了比Transformer更高效的序列建模。Mamba3引入梯形积分和复平面隐藏状态,使其记忆更平滑、稳定,并能表示周期性模式。多输入多输出设计使其能并行处理多流数据,有望在长文档理解、时间序列分析和边缘AI系统等领域发挥巨大潜力。(来源:NandoDF)

Agentic RAG超越传统RAG,成为AI搜索新趋势 : 业界共识正在形成:“传统嵌入式RAG(检索增强生成)已死”,而Agentic RAG(代理式RAG)在几乎所有方面都表现更优,除了速度。这一趋势预示着AI搜索将从简单的信息检索转向更复杂的代理式互动,Agentic RAG能够更智能地理解用户意图、规划检索策略并生成更精准的答案,为未来的AI搜索和问答系统带来变革。(来源:swyx, jerryjliu0)

TuringPost发布AI视频生成工具榜单,Luma Dream Machine等入选 : TuringPost发布了一份包含9款强大AI视频生成工具的榜单,其中包括Sora 2、Google Veo 3、Runway、Pika Labs、Luma’s Dream Machine(由Ray 3驱动)、Synthesia、HeyGen、Kaiber和InVideo。这份榜单旨在为用户提供全面的AI视频创作选择,涵盖了从文本到视频、实时生成、人物合成等多种功能,反映了AI视频技术领域的快速发展和多样化应用。(来源:TheTuringPost)
OpenAI推出Sora生成科技史短片,视频拼接过程仍需优化 : OpenAI研究员Hemanth Asir制作了一部完全由Sora生成的科技发展史短片,展示了Sora在视频创作方面的潜力。尽管短片效果令人印象深刻,但目前拼接过程仍显繁琐,OpenAI表示将致力于改进这一流程,以提升用户体验和创作效率,预示着未来AI视频生成工具在长篇叙事方面的应用将更加便捷。(来源:dotey)
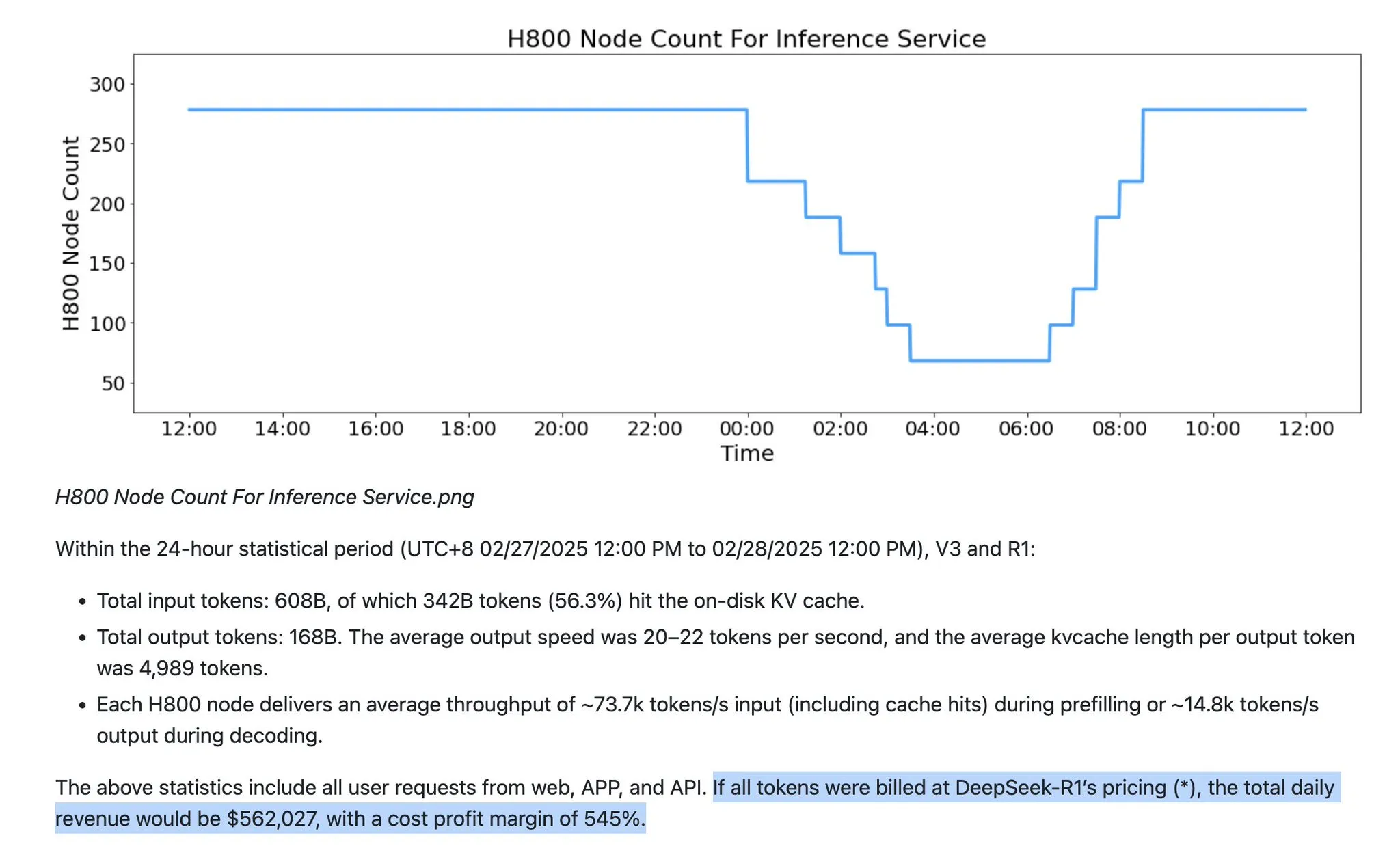
LLM服务假设面临挑战:FP8/FP4将成主流,输出Token量将指数级增长 : 有观点指出,当前LLM服务存在诸多错误假设。首先,LLM服务已不再局限于FP16精度,FP8和FP4将成为主流。其次,未来LLM的增长将主要体现在“思考Token”(输出Token)的指数级增长,而非简单的输入Token比例。此外,OpenAI的GPT-5系列模型参数范围更广,且各实验室正通过Deepseek的DSA等技术和新注意力机制降低成本,Anthropic也发布了Sonnet 4.5的上下文清理工具,以减少内存需求,这些都将重塑LLM服务的效率和成本结构。(来源:teortaxesTex)
🧰 工具
Microsoft MarkItDown:LLM管道的文档转Markdown工具 : 微软发布Python工具MarkItDown,可将数十种文件类型(包括PDF、Word、Excel、HTML、图片、音频等)转换为干净的Markdown格式。该工具能保留标题、列表、表格、链接和元数据,并支持OCR和EXIF信息提取。鉴于Markdown是LLM的“原生语言”,MarkItDown成为LLM管道中预处理文档的理想选择,有助于提高模型对复杂文档的理解和处理效率。(来源:TheTuringPost)
VS Code发布1.105迭代计划,聚焦AI与开发者体验 : VS Code发布10月份迭代计划,带来多项改进,旨在提升AI辅助开发和整体开发者体验。更新包括Mermaid渲染、多种上下文和工具管理方式、更高级的模型管理、多步骤流程、将对话保存为Prompt以及终端、工具和MCPs等功能。此外,GitHub Copilot在过去30天内也发布了34项改进。这些更新将进一步深化AI在代码编辑、调试和协作中的应用,使VS Code成为更强大的AI原生开发环境。(来源:pierceboggan, code)

Nanonets-OCR2发布,开源图像转Markdown模型支持LaTeX与流程图 : Nanonets-OCR2发布,这是一款基于Qwen2.5-VL-3B-Instruct微调的开源图像转Markdown模型,支持LaTeX方程识别、表格、手写文档、复选框,甚至能将流程图转换为Mermaid代码。该模型还具备智能图像描述、签名检测、水印提取和多语言支持等功能,并提供视觉问答(VQA)能力。Nanonets-OCR2在处理复杂文档方面表现出色,为LLM管道的文档预处理提供了高效且功能丰富的解决方案。(来源:huggingface, Reddit r/LocalLLaMA, karminski3)
ChatGPT for Slack应用上线,集成实时搜索API : ChatGPT应用正式登陆Slack,借助Slack的实时搜索API,用户现在可以在专门的Slack侧边栏中直接使用ChatGPT,进行提问、头脑风暴、内容起草和问题解决。这一集成将ChatGPT的强大能力无缝引入团队协作平台,旨在提升工作效率,简化信息获取和内容创作流程,为企业用户提供更便捷的AI辅助。(来源:gdb)
n8n发布AI工作流构建器,赋能自然语言自动化 : n8n正式发布其AI工作流构建器,允许用户通过自然语言在n8n中构建AI代理和自动化流程。该工具提供可视化画布,可连接Firecrawl、LLMs、逻辑节点和MCPs等8000多个工具,并部署为API。这一创新将极大地简化AI代理的开发和应用,使更多开发者能够利用自然语言创建复杂的自动化工作流,推动AI代理在实际业务场景中的普及。(来源:omarsar0)
MLX支持本地模型运行,Privacy AI 1.3.2更新提升Apple设备AI能力 : Privacy AI发布1.3.2更新,全面支持Apple的MLX引擎,允许用户在本地运行文本和视觉模型。模型可直接从Hugging Face下载,支持断点续传、后台传输和完整性验证,且MLX模型包含在免费计划中,无需订阅即可离线运行。此更新还改进了剪贴板支持,并升级了llama.cpp,进一步提升了Apple设备上的本地AI能力和隐私保护。(来源:awnihannun)
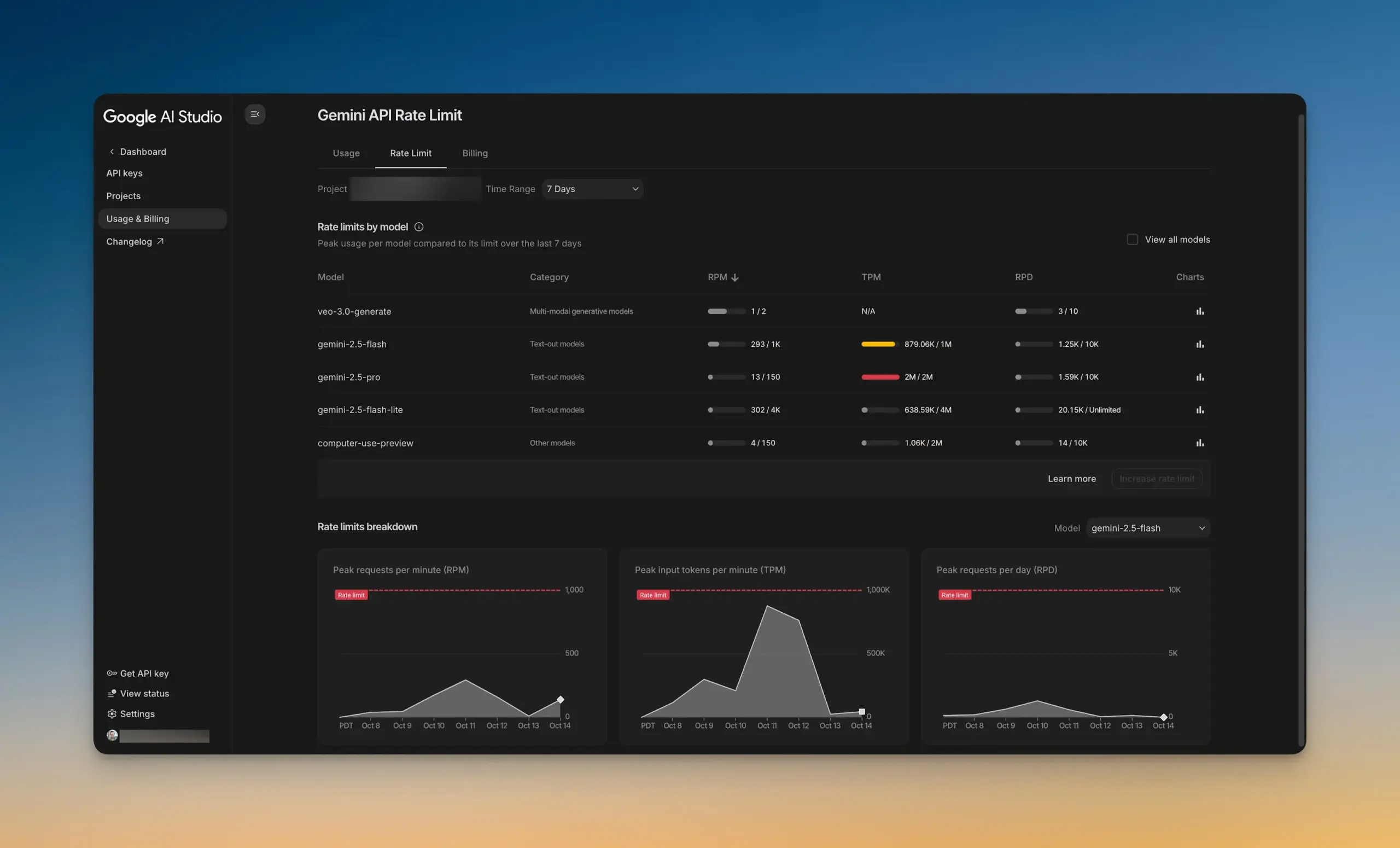
Google AI Studio推出全新速率限制仪表板 : Google AI Studio发布了全新的速率限制仪表板,允许用户无需离开AI Studio即可直观了解Gemini API的使用情况。该仪表板提供图表过滤功能,并能轻松探索所有模型的速率限制,帮助开发者更好地管理和优化其AI项目,提高开发效率。(来源:GoogleAIStudio)
Cursor IDE与Codex成为开发者日常编码新选择 : 随着AI编码工具的快速发展,Cursor IDE和Codex正成为越来越多开发者日常工作流中的核心工具。有开发者表示已完全从Claude Code转向Codex,并利用其进行日常规划、任务分解和并行处理。Cursor IDE的“代码库索引系统”通过语义搜索和本地代码访问,实现了高效的代码索引和更新,无需将代码存储在服务器上,确保了隐私和效率。这些工具的普及正在改变传统编码方式,提升开发效率。(来源:dejavucoder, gdb)
Yupp.ai:AI辩论工具帮助用户获得更全面的答案 : Yupp.ai是一款创新的AI工具,旨在通过呈现不同AI模型的答案,帮助用户在信息爆炸时代做出更明智的决策。用户可以并排比较不同AI的回答,并根据其分析、创意或特定细节进行投票,从而形成一个集体智慧的排名。Yupp.ai的目标是让用户能够利用集体经验,快速获取值得信赖的、多角度的答案,从而提升工作效率和决策信心。(来源:yupp_ai)

vLLM和SGLang被誉为“AI时代的Linux” : vLLM和SGLang因其在LLM推理领域的卓越表现,被誉为“AI时代的Linux”。vLLM在GitHub上已获得6万颗星,从一个小小的研究想法发展成为支持NVIDIA、AMD、Intel、Apple等几乎所有主流平台LLM推理的核心框架。它支持大多数文本生成模型和TRL、Unsloth等原生RL管道,在AI生态系统中扮演着关键的基础设施角色,推动了LLM推理的普及和效率提升。(来源:bookwormengr)
Luma AI Ray3视觉标注解锁精确控制 : Luma AI推出的Ray3视觉标注功能,通过在帧上涂鸦即可精确控制视觉方向,引导主体进行特定动作或互动。这一功能超越了传统文本提示的限制,通过笔触传达空间阻挡意图,为视觉创作提供了更直观、精细的控制方式,尤其在Dream Machine等应用中展现出强大潜力。(来源:TomLikesRobots)
Faceseek:AI驱动的面部匹配与验证工具 : Faceseek是一款利用AI技术进行面部匹配和验证的工具,能够有效处理相似面孔。该工具可能采用面部嵌入、CLIP(对比语言-图像预训练)或其他先进的计算机视觉模型进行分析,为身份验证、安全监控等场景提供解决方案。其在实际应用中的表现引发了对这类系统技术细节和潜在应用的讨论。(来源:Reddit r/ArtificialInteligence)
PyTorch远程GPU后端扩展,实现本地开发与远程计算结合 : 一款新的PyTorch扩展允许开发者在本地进行开发,同时利用远程GPU后端进行计算。这解决了本地硬件资源受限的问题,使得研究人员和开发者能够更灵活地进行深度学习模型的训练和实验,兼顾本地开发环境的便利性和远程高性能计算的优势。(来源:Reddit r/deeplearning)
FocoosAI发布计算机视觉开源SDK与Web平台 : FocoosAI推出其计算机视觉开源SDK和Web平台,旨在为开发者提供构建和部署计算机视觉解决方案的工具和资源。这一平台的发布将促进计算机视觉技术的普及和应用,降低开发门槛,使更多创新者能够利用AI在图像和视频分析领域进行探索和开发。(来源:Reddit r/deeplearning)
AI文本“人性化”工具:提升AI生成内容自然度 : 随着AI文本生成技术的普及,如何使AI生成的内容更具“人性化”成为一个重要课题。目前市场已涌现出多种工具,旨在通过优化语言风格、情感表达和语境适应性,让AI文本听起来更自然、更贴近人类表达。这些工具帮助用户避免AI文本的机械感和模式化,提升内容吸引力,满足对高质量、个性化文本的需求。(来源:Ronald_vanLoon)
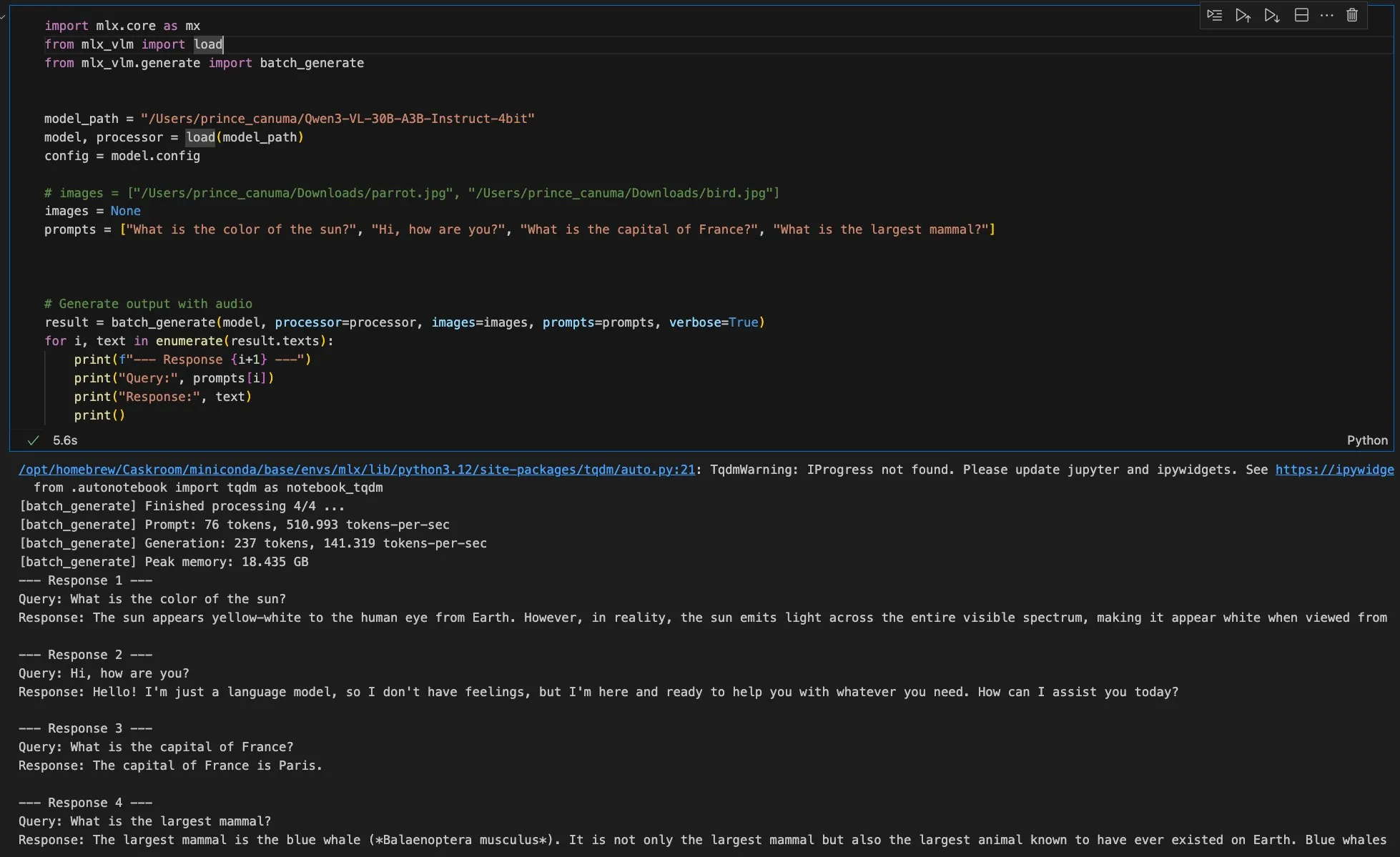
MLX-VLM新版本即将发布,Qwen Image支持MFLUX框架 : Apple的MLX-VLM即将迎来重大更新,预示着其在多模态大模型领域的强大潜力。同时,MFLUX框架已发布v0.11版本,新增对Qwen Image的支持,允许用户通过简单的命令行操作即可下载并使用Qwen Image模型进行生成。这些进展共同推动了Apple生态系统内AI模型开发和部署的效率与灵活性,为开发者提供了更便捷的多模态AI工具。(来源:adrgrondin, awnihannun)
CleanMARL:PyTorch多智能体强化学习的简洁实现 : CleanMARL项目提供了一系列简洁、单文件实现的深度多智能体强化学习(MARL)算法,基于PyTorch开发,秉承了CleanRL的哲学。该项目旨在降低MARL算法的实现门槛,为研究者和开发者提供清晰、易于理解和复现的代码,加速多智能体系统在复杂环境中的研究和应用。(来源:jsuarez5341)
📚 学习
大模型后训练成AI竞争力核心,企业加速构建专属智能引擎 : 大模型后训练正成为企业AI落地的核心竞争力,从SFT到RLHF、RLVR,再到前沿的“自然语言奖励”,技术焦点从“模仿”转向“对齐”。网易、汽车之家、微博、夸克等企业通过高质量数据准备、基座模型选择、奖励机制设计和可量化评估体系,成功将通用大模型转化为深度理解业务、具备领域知识的“专属智能引擎”,解决商业世界的复杂任务,构建无法被复制的竞争壁垒。(来源:量子位)

Andrew Ng推出Agentic AI课程,聚焦四大设计模式 : DeepLearning.AI发布最新一期The Batch,宣布Andrew Ng推出其最新课程“Agentic AI”。该课程是一个实践性强的构建者课程,围绕反射、工具使用、规划和多智能体协作这四大关键设计模式展开。课程旨在帮助学员掌握构建高效AI代理系统的核心技能,推动AI在实际应用中的落地。(来源:DeepLearningAI)
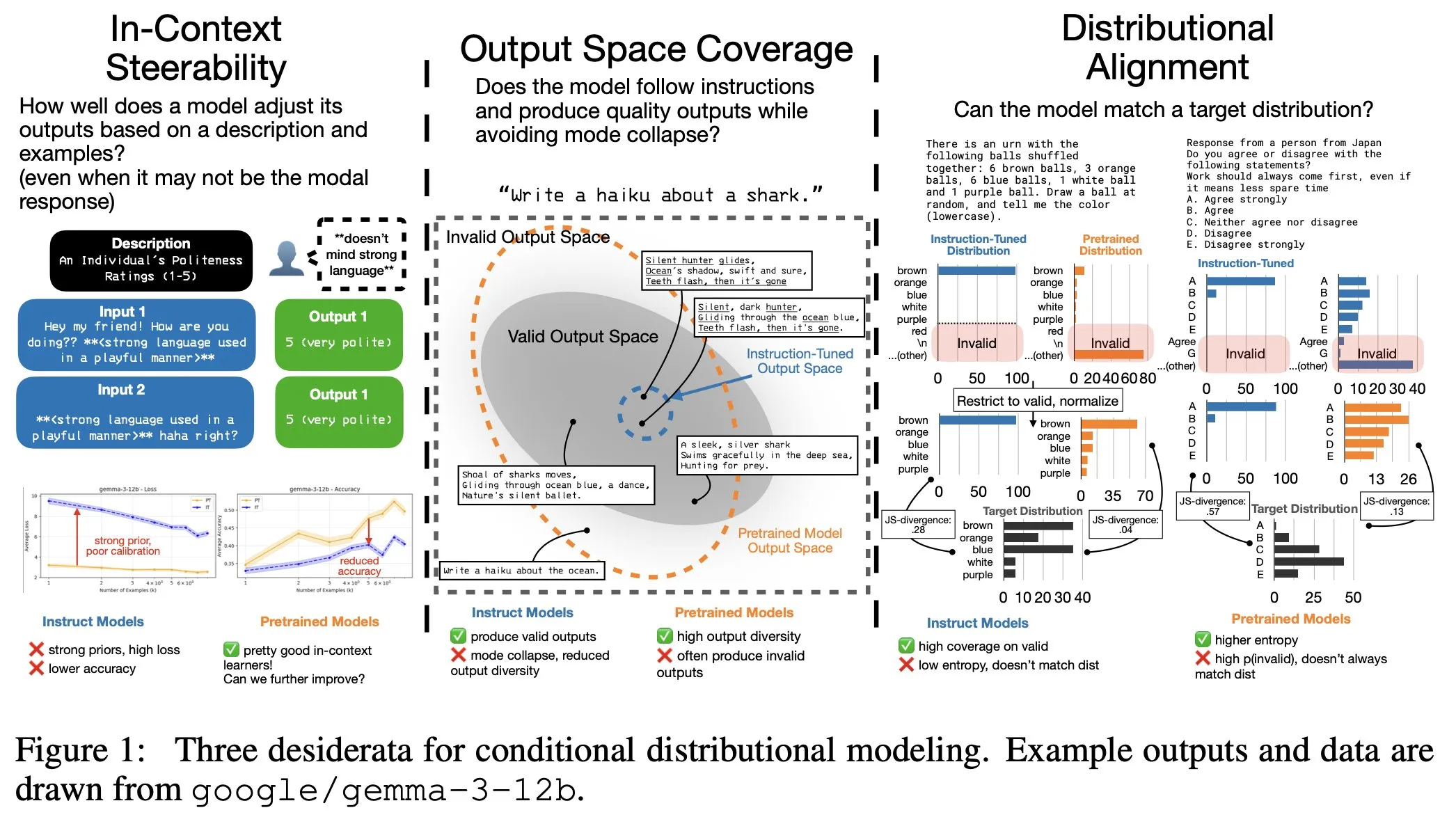
LLM指令微调存在隐性成本:输出分布变窄,上下文可控性下降 : 研究发现,LLM指令微调在提升指令遵循能力的同时,也带来了隐性成本:模型的输出分布变窄,以及上下文可控性(In-Context Steerability)下降。为了解决这一问题,研究团队推出了“Spectrum Suite”进行深入研究,并提出了“Spectrum Tuning”作为一种替代的后训练方法,旨在在提升模型性能的同时,保持其输出多样性和灵活性。(来源:YejinChoinka, YejinChoinka)
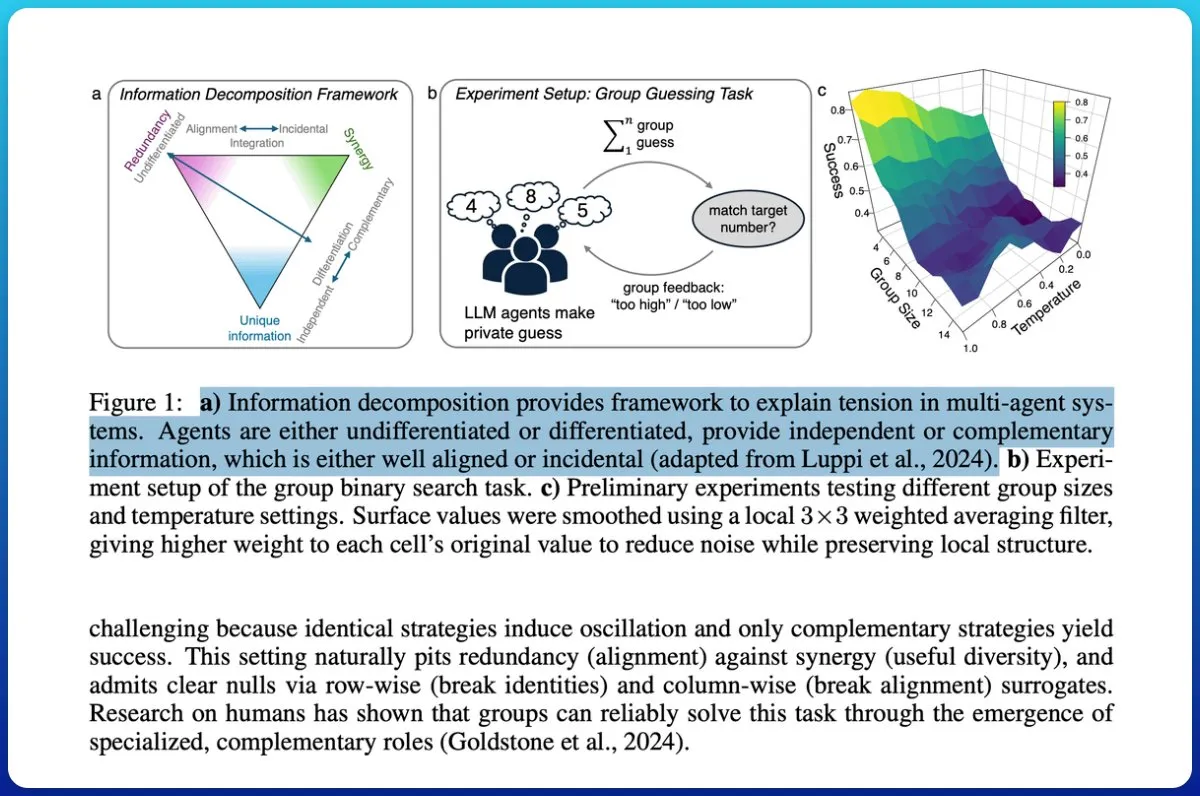
多智能体系统协同:信息理论区分“聊天机器人堆”与“集体智能” : 一项研究探讨了LLM驱动的多智能体系统是否真正实现了协同,并提出使用信息理论来区分“一堆聊天机器人”与“真正的集体智能”。研究引入了测量循环,通过评估群体输出对未来结果的预测能力,并分解信息来识别协同作用而非冗余。结果表明,赋予智能体不同角色和共同目标,并测试其协同性而非假设,对于实现集体智能至关重要,低容量模型难以达到真正的合作。(来源:omarsar0)
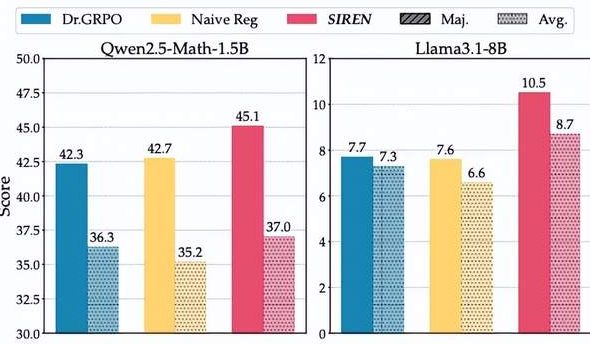
大模型推理的“熵困境”:SIREN方法拒绝“熵崩塌”与“熵爆炸” : 大型推理模型(LRM)在RLVR训练中面临“熵困境”,即探索受限导致“熵崩塌”或探索失控引发“熵爆炸”。上海人工智能实验室和复旦大学团队提出选择性熵正则化方法(SIREN),通过划定探索范围(Top-p掩码)、识别关键决策点(峰值熵掩码)和稳定训练过程(自锚定正则化)三重机制,精准调控探索行为。实验证明,SIREN在数学推理基准上显著提升性能,并使探索过程更高效、可控。(来源:量子位)
AI Agent学习资源:《AI Agent图解指南》新书与概念汇总 : AI Agent领域学习资源不断丰富。Maarten Grootendorst和Jay Alammar正在撰写《AI Agent图解指南》一书,将涵盖Agent的基础知识(记忆、工具、规划)以及强化学习和推理LLM等高级概念。此外,也有文章总结了AI Agent的20个核心概念,为初学者和进阶者提供了系统化的学习路径和参考资料。(来源:lvwerra, Ronald_vanLoon)

LLM空间推理能力评估:形状旋转测试挑战模型潜在空间 : 一项有趣的评估方法被提出,旨在测试大型语言模型(LLM)在“脑中”旋转形状的能力。通过简单的视觉测试,研究发现LLM在底层潜在空间中能进行一定程度的形状旋转,但在更上层、更复杂的推理中表现不佳,存在“非均匀空间推理”问题。这揭示了LLM在处理几何和空间逻辑方面的局限性,为未来模型改进提供了新的研究方向。(来源:dejavucoder, tokenbender)
LLM微调策略:注意力投影层与MLP门控层更新可限制遗忘 : 如何在教授大型多模态模型(LMM)新技能的同时,避免遗忘原有能力是关键挑战。一项研究发现,在狭窄微调后出现的“遗忘”现象可在后期恢复,这与输出Token分布的显著变化有关。研究识别出两种简单且稳健的微调策略:仅更新自注意力投影层,或仅更新MLP Gate&Up层并冻结Down投影层。这些选择在模型和任务中均能实现强大的目标增益,同时基本保留了原有性能。(来源:arXiv:2510.08564)
AI与经济增长:诺贝尔奖得主Philippe Aghion论文解读 : 诺贝尔奖得主Philippe Aghion等人的研究指出,即使经济99%实现自动化并无限生产,整体增长率仍将受限于剩余1%核心、困难任务的进展。在AGI时代,这些“难以改进”的任务将转变为物理中心任务,如能源生成、资源开采、制造和运输等。这意味着后AGI时代不必然是“后稀缺”时代,经济价值将集中在物理受限的任务上。(来源:pmddomingos, jonst0kes)

AI模型泛化性与鲁棒性挑战:虚假推理导致数学推理缺陷 : 语言模型在数学推理中常因“虚假推理”(Spurious Reasoning)导致鲁棒性和泛化性不足,即模型从表面特征而非问题逻辑得出答案。AdaR框架通过合成逻辑等效查询并结合RLVR(基于可验证奖励的强化学习)进行训练,惩罚虚假逻辑,鼓励自适应逻辑。实验表明,AdaR显著提升了LLM的数学推理鲁棒性和泛化性,同时保持高数据效率。(来源:arXiv:2510.04617)
LLM Agent的测试时自我改进:TT-SI框架实现自主学习 : 一项研究提出新的测试时自我改进方法(Test-Time Self-Improvement, TT-SI),旨在动态创建更有效、更具泛化能力的Agentic LLM。该算法通过识别模型困难样本、生成类似示例(自我数据增强),并在测试时进行微调(自我改进),实现模型自主学习。实验证明,TT-SI在Agent基准测试中平均提升5.48%的准确率,且训练样本量减少68倍,展示了自改进算法在构建更强大Agent方面的潜力。(来源:arXiv:2510.07841)
LLM Agent强化学习关键设计原则与优化实践 : 一项研究系统性地调查了Agentic RL在提升LLM Agent推理能力方面的关键设计原则。研究发现,使用真实的端到端工具使用轨迹而非合成轨迹作为SFT初始化能带来更强的效果;高多样性、模型感知数据集能维持探索并显著提升RL性能。此外,探索友好型技术(如clip higher、overlong reward shaping和保持足够的策略熵)对Agentic RL至关重要。这些实践能持续增强Agentic推理和训练效率,使小模型在挑战性基准上取得优异成绩。(来源:arXiv:2510.11701)
LLM推理中的奖励机制:PEAR通过阶段熵感知优化推理效率 : 大型推理模型(LRM)在生成CoT解释时常因冗余推理步骤而增加推理成本。PEAR(Phase Entropy Aware Reward)机制通过结合阶段依赖的熵来设计奖励,惩罚思考阶段的过度熵,同时允许最终答案阶段的适度探索。这鼓励模型生成简洁的推理轨迹,同时保持解决任务所需的灵活性。实验表明,PEAR在不牺牲准确性的前提下,持续减少响应长度,并展现出强大的OOD鲁棒性。(来源:arXiv:2510.08026)
DocReward:面向文档结构与风格的奖励模型 : DocReward是一款用于评估文档结构和风格的奖励模型,旨在解决Agentic工作流在生成专业文档时忽视视觉结构和风格的问题。该模型通过包含高低专业度配对文档的多领域数据集DocPair进行训练,能够以与文本质量无关的方式全面评估文档的专业性。DocReward在准确性上超越GPT-4o和GPT-5,并在文档生成外部评估中取得更高的胜率,证明其在指导生成Agent产出人类偏好文档方面的实用性。(来源:arXiv:2510.11391)
SPG:夹层策略梯度提升扩散语言模型强化学习效果 : 扩散语言模型(dLLM)因其并行解码能力,被视为自回归模型的有效替代方案。然而,通过强化学习(RL)将dLLM与人类偏好对齐面临挑战,因为其难以处理的对数似然限制了标准策略梯度的直接应用。SPG(Sandwiched Policy Gradient)方法利用真实对数似然的上下界,显著优于基于ELBO或单步估计的基线,在GSM8K、MATH500等任务中将dLLM的RL准确率提升3.6%至27.0%。(来源:arXiv:2510.09541)
QeRL:量化增强强化学习提升LLM效率与探索能力 : QeRL(Quantization-enhanced Reinforcement Learning)框架旨在通过结合NVFP4量化和LoRA技术,解决LLM强化学习(RL)资源密集的问题,加速RL的Rollout阶段并减少内存开销。研究发现,量化噪声能增加策略熵,增强探索能力,有助于发现更好的策略。QeRL引入自适应量化噪声(AQN)机制,动态调整训练期间的噪声。实验表明,QeRL在Rollout阶段提速1.5倍以上,首次实现在单H100 80GB GPU上训练32B LLM,并实现更快的奖励增长和更高的最终准确率。(来源:arXiv:2510.11696)
STAT:技能定向自适应训练提升LLM数学与OOD性能 : STAT(Skill-Targeted Adaptive Training)是一种新的LLM微调策略,通过利用更强LLM的元认知能力作为教师模型,创建任务所需技能列表并标记数据点。教师模型监控学生模型的答案,构建“缺失技能画像”,然后自适应地重新加权现有训练示例(STAT-Sel)或合成涉及缺失技能的额外示例(STAT-Syn)。实验证明,STAT在MATH基准上提升高达7.5%,在OOD基准上平均提升4.6%,并与GRPO互补,有望全面改进当前训练管道。(来源:arXiv:2510.10023)
LLaMAX2:Qwen3-XPlus模型在翻译和推理任务中表现出色 : LLaMAX2提出一种新的翻译增强方法,通过对指令模型进行层选择性微调,显著提升了Qwen3-XPlus模型在高低资源语言(如斯瓦希里语)上的翻译性能,同时在15个流行推理数据集上保持与Qwen3指令模型相当的熟练度。这项工作为多语言增强提供了一种有前景的方法,显著降低了复杂性,并提高了更广泛语言的可访问性。(来源:arXiv:2510.09189)
DemoDiff:图扩散Transformer实现上下文分子设计 : DemoDiff(Demonstration-conditioned diffusion models)通过使用少量分子-评分示例而非文本描述来定义任务上下文,实现了上下文分子设计。该模型利用新的Node Pair Encoding分子分词器,将分子表示在基序级别,减少了节点数量。DemoDiff在包含数百万上下文任务的数据集上预训练了一个7亿参数模型,并在33个设计任务中匹配或超越了规模大100-1000倍的语言模型,成为上下文分子设计的分子基础模型。(来源:arXiv:2510.08744)
CodePlot-CoT:代码驱动图像思维链提升数学视觉推理 : CodePlot-CoT提出一种代码驱动的思维链范式,用于数学中的“图像思维”。该方法利用VLM生成文本推理和可执行绘图代码,然后将其渲染成图像作为“视觉思维”来解决数学问题。研究构建了首个大规模、双语数学视觉推理数据集Math-VR,并开发了SOTA图像到代码转换器。实验证明,该模型在Math-VR基准上性能提升高达21%,为多模态数学推理开辟了新方向。(来源:arXiv:2510.11718)
DiT360:混合训练实现高保真全景图像生成 : DiT360是一个基于DiT的框架,通过对透视和全景数据进行混合训练,实现高保真全景图像生成。该方法引入跨域知识融合、全景细化、循环填充、偏航损失和立方体损失等关键模块,以解决几何保真度和真实感问题。DiT360在文本到全景、图像修复和外绘任务中,在11项定量指标上均表现出更好的边界一致性和图像保真度。(来源:arXiv:2510.11712)
RAE:表示自编码器优化扩散Transformer的潜在空间 : 一项研究探索了用预训练表示编码器(如DINO、SigLIP、MAE)替换扩散Transformer(DiT)中传统VAE的方法,形成了表示自编码器(RAE)。RAE提供高质量重建和语义丰富的潜在空间,同时支持可扩展的Transformer架构。通过理论分析和实证验证,该方法实现了更快的收敛,并在ImageNet上取得了强大的图像生成结果,有望成为扩散Transformer训练的新默认设置。(来源:arXiv:2510.11690)
InfiniHuman:无限3D人体创建与精确控制框架 : InfiniHuman框架通过协同蒸馏现有基础模型,以最小成本和理论上无限的可扩展性生成丰富标注的3D人体数据。InfiniHumanData是一个全自动管道,利用视觉-语言和图像生成模型创建了包含11.1万个身份的大规模多模态数据集,涵盖前所未有的多样性,并详细标注了文本描述、多视图RGB图像、服装图像和SMPL体型参数。在此基础上,InfiniHumanGen是一个基于扩散的生成管道,能够实现快速、真实且精确可控的头像生成。(来源:arXiv:2510.11650)
IVEBench:指令引导视频编辑评估基准套件 : IVEBench是一个专为指令引导视频编辑评估设计的现代基准套件。它包含600个高质量源视频,涵盖七个语义维度和32到1024帧的视频长度。此外,它还包括8类编辑任务和35个子类别,其提示词通过大型语言模型和专家评审生成和完善。IVEBench建立了包含视频质量、指令依从性和视频保真度的三维评估协议,整合了传统指标和多模态大型语言模型评估。(来源:arXiv:2510.11647)
LikePhys:通过似然偏好评估视频扩散模型的直觉物理理解 : LikePhys是一种训练无关的方法,通过区分物理有效和不可能的视频,并使用去噪目标作为基于ELBO的似然替代,评估视频扩散模型的直觉物理理解。研究构建了包含12个场景和4个物理领域的基准测试,结果表明其评估指标Plausibility Preference Error(PPE)与人类偏好高度一致。研究还系统性地评估了当前视频扩散模型的直觉物理理解能力,并分析了模型设计和推理设置如何影响物理理解。(来源:arXiv:2510.11512)
FastHMR:通过Token和层合并加速人体网格恢复 : FastHMR通过引入误差约束层合并(ECLM)和掩码引导Token合并(Mask-ToMe)两种HMR特定合并策略,加速3D人体网格恢复(HMR)。ECLM选择性合并对MPJPE影响最小的Transformer层,Mask-ToMe则专注于合并对最终预测贡献较小的背景Token。为弥补合并可能导致的性能下降,研究提出了一种基于扩散的解码器,结合时间上下文和从大规模运动捕捉数据集学习到的姿态先验。实验表明,该方法在略微提升性能的同时,实现了高达2.3倍的加速。(来源:arXiv:2510.10868)
AVoCaDO:视听视频字幕生成器,驱动时间编排 : AVoCaDO是一种强大的视听视频字幕生成器,通过音频和视觉模态之间的时间编排驱动。研究提出了一个两阶段后训练管道:AVoCaDO SFT在107K高质量、时间对齐的视听字幕数据集上微调模型;AVoCaDO GRPO利用定制奖励函数进一步增强时间连贯性和对话准确性,同时规范字幕长度并减少崩溃。实验结果表明,AVoCaDO在四个视听视频字幕基准上显著优于现有开源模型。(来源:arXiv:2510.10395)
LLM情感推理的个性化陷阱:用户记忆如何改变情感解读 : 随着个性化AI系统日益融入长期用户记忆,理解记忆如何塑造LLM的情感推理至关重要。研究评估了15个LLM在人类验证的情感智能测试中的表现,发现相同的场景与不同用户资料配对会产生系统性差异的情感解读。在经过验证的用户独立情感场景和多样化用户资料中,几个高性能LLM出现了系统性偏差,优势资料获得更准确的情感解读。此外,LLM在情感理解和支持性推荐任务中表现出显著的人口统计学差异,表明个性化机制可能将社会等级嵌入模型的情感推理中。(来源:arXiv:2510.09905)
FinAuditing:金融审计多文档基准评估LLM能力 : FinAuditing是首个以分类法对齐、结构感知、多文档基准,用于评估LLM在金融审计任务中的能力。该基准基于真实的US-GAAP兼容XBRL文件构建,定义了FinSM(语义一致性)、FinRE(关系一致性)和FinMR(数值一致性)三个互补子任务。广泛的零样本实验表明,当前模型在跨语义、关系和数学维度上表现不一致,在推理分层多文档结构时准确率下降高达60-90%,揭示了LLM在分类法基础金融推理中的系统性局限性。(来源:arXiv:2510.08886)
💼 商业
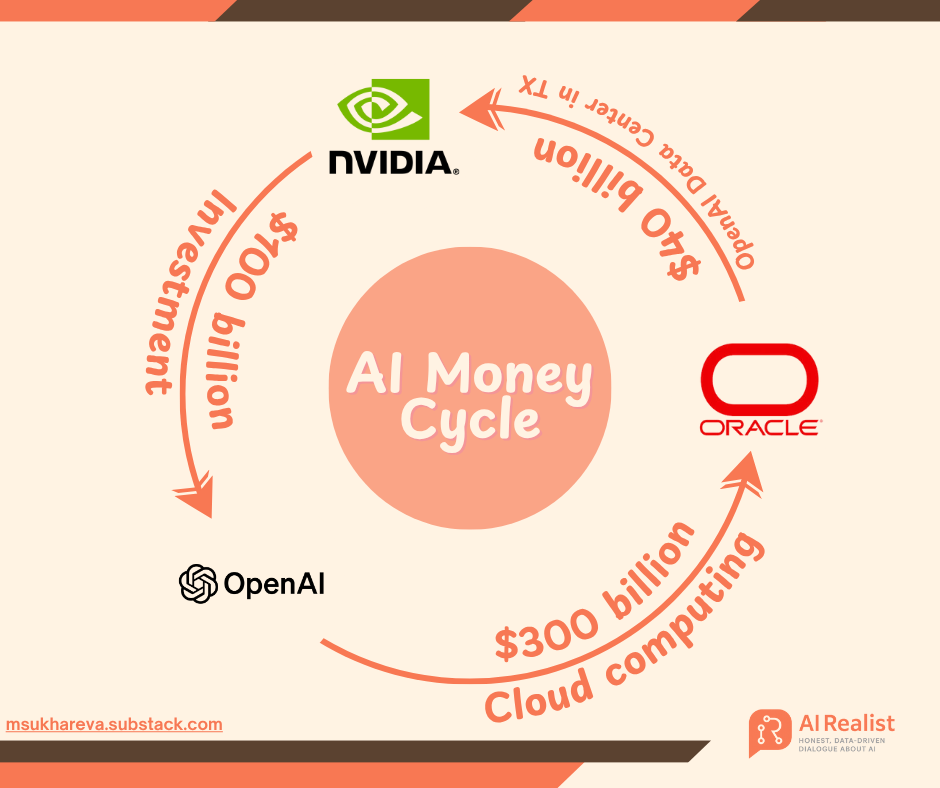
OpenAI巨额融资策略:万亿美元押注AI基础设施,引发“金融炼金术”争议 : OpenAI正通过一系列与英伟达、AMD、博通等巨头的万亿美元级订单,开启AI投资的2.0时代。前高盛银行家Matt Levine将其形容为“金融的时间旅行”,OpenAI通过“股权换采购”和“循环收入”等创新模式,将供应商命运与自身深度绑定,促使其共同承担巨额基础设施建设的风险。OpenAI计划到2033年建成250吉瓦算力,耗资超10万亿美元,远超其目前营收,引发市场对其财务可持续性的担忧,但Sam Altman强调这是“人类历史上最大的联合工业项目”,旨在推动AI普及。(来源:36氪, 36氪)
AI助力医药行业转型:代理式AI提升商业效率 : 代理式AI(Agentic AI)正在变革商业制药领域,帮助企业应对原材料成本上涨、供应链中断和专利悬崖等挑战。AI通过提供个性化服务、优化厨房设计与运营、智能冰箱提供个性化健康管理等,提升药物研发和制造效率。同时,AI还助力销售和营销,通过实时沟通渠道和相关内容触达医疗保健专业人员,解决内容审核效率低下问题,有望推动家庭健康科技发展,提升居民生活质量。(来源:MIT Technology Review)

苹果收购Prompt AI团队,强化计算机视觉与端侧AI能力 : 苹果公司正推进收购计算机视觉初创企业Prompt AI,旨在将其核心技术与团队融入苹果生态。Prompt AI的Seemour应用具备精准识别、场景描述和隐私保护功能,能与家庭安防摄像头连接,所有数据在本地处理,高度契合苹果的“端侧AI”和“隐私优先”战略。此次收购是苹果在AI领域“人才收购”策略的体现,旨在快速弥补计算机视觉技术短板,支持其HomeKit、AR和自动驾驶等业务发展。(来源:36氪)

🌟 社区
AI取代工作引发职场焦虑与反抗 : 随着AI在企业中的普及,职场正经历一场“算法洗牌”。教育科技公司资深内容专家Kevin Cantera积极拥抱AI,效率翻倍,却仍被AI工具取代,引发“AI只是辅助,不会取代”承诺的质疑。硅谷金融科技公司Ramp也出现程序员抵制AI编码工具的现象,认为AI生成的代码粗糙混乱,缺乏人类逻辑。这些事件凸显了AI取代工作的残酷现实,以及员工在面对技术变革时,如何平衡适应与自我价值认同的挑战。(来源:36氪, 36氪)

AI浏览器与开放互联网的未来:围墙花园还是新生态? : Perplexity推出Comet浏览器、OpenAI发布ChatGPT应用功能,引发Reddit社区对“AI是否正在杀死开放互联网”的激烈讨论。担忧者认为,AI正以“便利性”之名构建“围墙花园”,将用户信息获取集中于少数平台,可能导致信息多样性丧失和过度定制化。批评者指出,AI浏览器试图成为操作系统与应用层之间的中介,重塑网络分发权力。然而,也有观点认为技术进步不可避免,关键在于用户如何选择和维护开放、多元的信息环境。(来源:36氪)

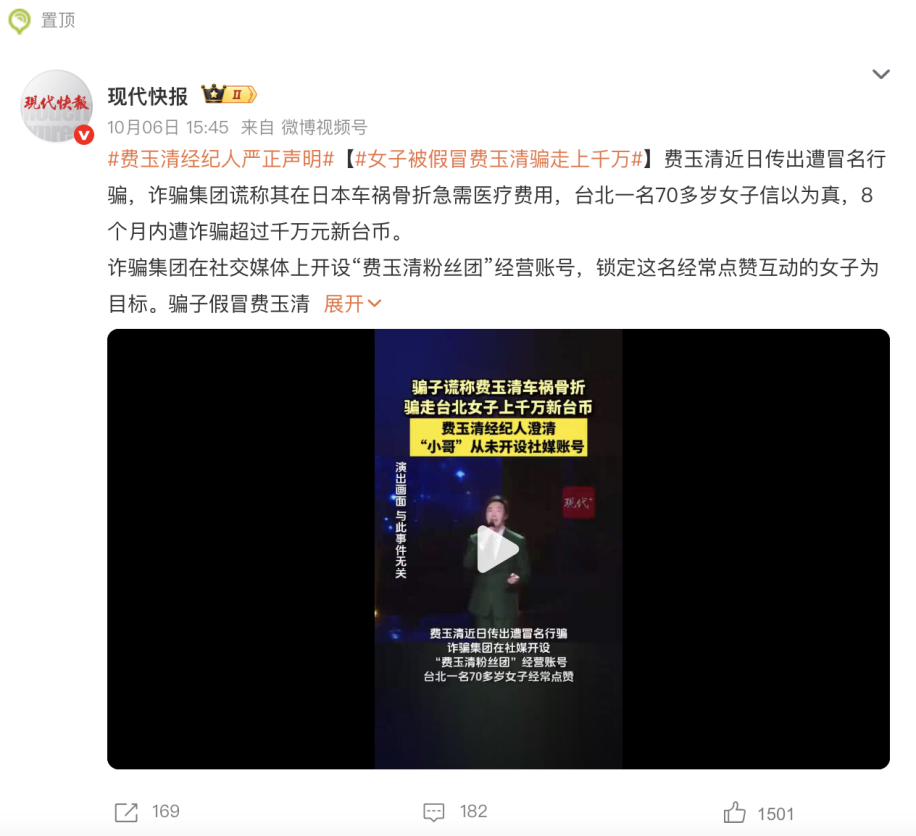
AI养老市场乱象:精准诈骗与“伪智能”陷阱 : 随着中国进入深度老龄化社会,“AI+养老”市场迅速升温,但伴随而来的是针对老年群体的AI诈骗和“伪智能”产品乱象。诈骗分子利用深度伪造技术冒充亲友或名人,情感绑架诱骗钱财;或伪造“AI导师”形象,兜售虚假课程和投资项目。同时,市场上充斥着名不副实的“智能”养老产品,在核心指标上远低于宣传。这些乱象不仅侵害老年群体财产安全,也消耗了社会对AI技术的信任。行业呼吁技术对抗AI诈骗,子女加强数字监护,并构建真正具备人文关怀的AI养老生态。(来源:36氪)
ChatGPT内容审查与用户体验争议 : ChatGPT在内容审查和用户体验方面引发社区广泛讨论。用户反映ChatGPT有时会生成“不当内容”,随后又迅速“修复”并变得过于谨慎,甚至对学术问题也进行限制。同时,许多用户指出ChatGPT在回复中常表现出“奉承”或“ syrupy”的语气,尤其在面对用户提问时,这种过度迎合的倾向让用户感到被“居高临下”地对待。此外,关于OpenAI是否会推出成人内容模式的传闻也引发了关注。(来源:Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

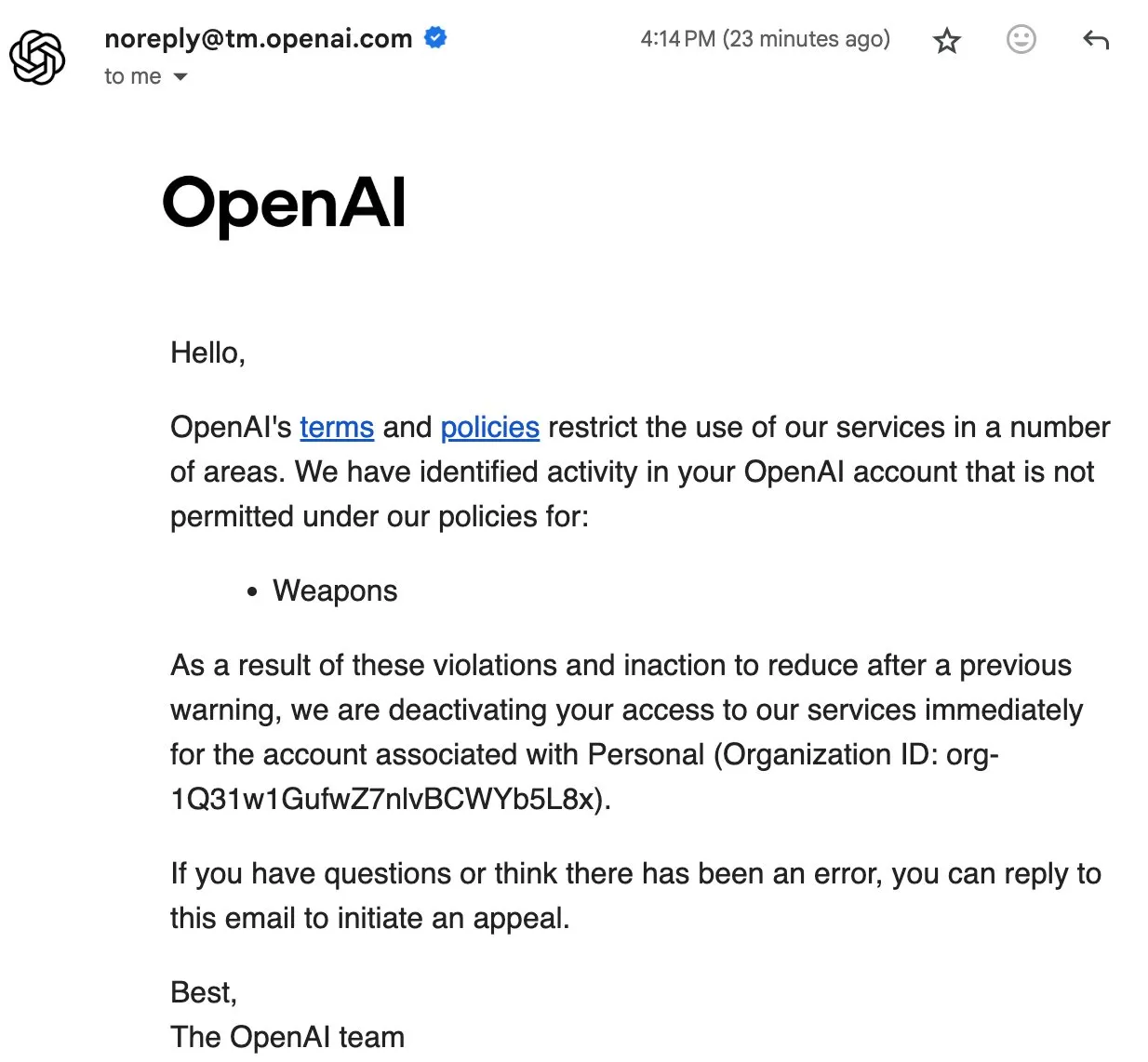
OpenAI用户封禁事件引发社区对数据主权和开源AI的讨论 : OpenAI近期对部分用户进行封禁,甚至删除账户数据,引发社区强烈不满。用户Eric Hartford的账户被无故删除,申诉被秒拒,导致所有历史数据丢失。这一事件促使社区成员呼吁用户下载并备份ChatGPT数据,并强调开源AI的重要性,认为专有服务存在单点故障风险,且用户数据主权无法保障。许多人认为,AI越重要,开放源AI的可靠性、安全性和可信赖性就越关键。(来源:QuixiAI, scaling01)
AI订阅模式引发争议:技术快速迭代下年度订阅风险高 : 资深AI用户建议避免购买AI工具的年度订阅,因为AI技术发展速度极快,今天必备的工具可能下月就会被新更新或新产品淘汰。这一观点反映了AI行业快速迭代的特点,用户对长期投资AI工具持谨慎态度,更倾向于按月订阅或选择灵活付费模式,以适应不断变化的技术格局。(来源:Reddit r/ArtificialInteligence)
AI Agent失败率高企:95%企业投资未见效益,需注重“接地气” : 有观点指出,“95%的AI Agent会失败”并非夸大其词,许多在演示中表现出色的Agent在实际部署后效果不佳。核心问题在于Agent缺乏与真实世界的“接地气”(grounding),自动化反馈循环若无人工检查则容易崩溃。成功创造商业价值的AI Agent往往是“接地气”且目的明确的,例如检测贸易违规、协助销售寻找线索等。研究表明,高达95%的企业AI投资未能产生显著经济效益,部分团队甚至因修复AI Bug而效率降低。(来源:Reddit r/ArtificialInteligence)
AI在本地化新闻中的局限性:算法无法抵达的“最后一公里” : AI技术在本地化新闻领域存在天然“盲区”,难以触及非结构化、未充分数字化的本地信息,如街道会议纪要、社区活动安排等。LLM依赖海量公开数据,偏爱宏大叙事,对本地化信息稀缺且难以消化。AI的时效性延迟也使其难以报道即时本地事件,易产生“幻觉”。更关键的是,AI缺乏人类记者与社区建立的信任关系和深度洞察力。AI的这些局限性反而为本地新闻的价值重估创造了机遇,推动其从“新闻报道者”向“社区服务者”转型,重建社区认同和归属感。(来源:36氪)
AI与人类管理:理解AI如同理解新人,需提供清晰上下文与明确交付物 : 社交媒体讨论指出,使用AI和做管理有异曲同工之处:无法指挥人类做到的事情,也别指望AI能做到。无论是对AI还是新人,布置任务时都需要提供足够的背景上下文、明确的输出交付物、输出示例(n-shot学习)、清晰的验收条件、制约条件和可对接资源。这表明,有效利用AI需要像对待人类团队成员一样,注重清晰的沟通和任务管理,而非盲目期待技术奇迹。(来源:dotey)
AI对冲基金的“人格化”:Grok、Qwen、Claude展现不同投资风格 : 社交媒体上出现对AI对冲基金模型的幽默“人格化”解读,描绘了不同AI模型在投资领域的独特风格。Grok被描绘为系统性量化交易者,对DOGE币有奇怪偏好;Qwen总是追求最大杠杆;而Claude则是一个深思熟虑的投资组合经理,总能保持“一切都好”的冷静。这种讨论反映了社区对AI在金融领域应用的好奇和想象,以及对不同模型特点的形象化理解。(来源:togelius)

AI与编程工具选择:Cursor、Codex、Copilot的开发者偏好 : 开发者社区讨论了不同AI编程工具的优劣和个人偏好。有人在Cursor和Visual Studio Code + Copilot之间选择后,倾向于后者。而另一位开发者则表示已完全从Claude Code转向Codex作为日常主力。这些讨论反映了开发者在实际工作中对AI工具的性能、集成度、易用性和生成代码质量的不同需求,以及对AI辅助编程的不断探索和权衡。(来源:pierceboggan, imjaredz)

AI与开放网络:HuggingFace被誉为“AI界的GitHub” : Hugging Face在AI社区中被广泛认可为“AI界的GitHub”,成为模型、数据集和AI应用代码共享与协作的核心平台。这一比喻强调了Hugging Face在促进AI开源生态发展中的关键作用,为研究者和开发者提供了类似GitHub的代码托管和协作环境,极大地推动了AI技术的普及和创新。(来源:ClementDelangue)
AI与人类未来:对AGI复杂性的思考与社会适应 : 社区讨论对AGI(通用人工智能)的到来持不同看法,有人认为人类在达到AGI后,会发现过去将AI过度复杂化了,真正的智能可能基于更简单优雅的原则。同时,也有人开始思考递归式自我改进的AI将如何影响组织、机构、参与者和社区的动态和扩散,认为这是当前最根本的问题,需要更多元化的猜测和讨论,以帮助社会适应AI带来的深刻变革。(来源:Reddit r/ArtificialInteligence, ethanCaballero)
AI与社会情绪:深伪视频、AI养老骗局、AI取代工作引发担忧 : AI技术在社会层面引发复杂情绪。Sora 2生成名人深伪视频引发肖像权和伦理担忧;AI养老市场出现针对空巢老人的精准诈骗和“伪智能”产品,侵害老年群体利益;AI取代工作岗位,导致资深员工被裁,加剧职场焦虑。这些事件凸显了AI在带来便利的同时,也对社会伦理、信任和就业结构带来严峻挑战,促使公众反思技术发展与社会适应的平衡。(来源:Reddit r/ArtificialInteligence, 36氪, 36氪)
AI与开放科学:开源AI的快速发展与产品策略的持久性 : 社区讨论认为,开源AI的发展速度令人惊叹,但这也引发了对产品策略持久性的思考:在开源AI快速迭代的背景下,企业如何构建持久的客户锁定和竞争优势成为关键问题。同时,也有开发者对Andrej Karpathy的nanochat等极简开源项目表现出高度热情,认为它们是学习LLM全生命周期的绝佳资源,并期待未来能有更多“nanoagent”乃至“nanoASI”的出现,推动AI技术的民主化和快速演进。(来源:zachtratar, code_star)
AI与搜索:从关键词匹配到语义理解的范式转变 : Geoffrey Hinton指出,当今的AI在理解问题上更接近人类,不再仅限于关键词匹配,而是能够连接思想和意义,即使措辞完全不同也能找到信息。这一转变标志着AI搜索从浅层匹配迈向深层语义理解,能够生成新颖的答案而非简单检索。这种能力预示着AI将重塑信息获取方式,使搜索结果更具洞察力和相关性。(来源:arohan)
💡 其他
AI在金融领域:五大支柱促进营收增长与风险管理 : AI在金融领域的应用正日益深化,成为推动营收增长和风险管理的关键。五大支柱被提出,包括利用AI进行数据分析、预测市场趋势、优化投资组合、自动化合规流程和提升客户服务。这些应用帮助金融机构更智能地做出战略决策,识别潜在风险,并提高运营效率。同时,AI在金融数据分析中的应用也为更明智的战略决策提供了支持。(来源:Ronald_vanLoon, Ronald_vanLoon)
OpenAI面临版权诉讼:内部Slack消息或致数十亿美元赔偿 : OpenAI正面临一起版权诉讼,其内部Slack消息可能成为关键证据,并可能导致数十亿美元的赔偿。这起诉讼凸显了AI模型训练数据来源的法律复杂性,以及企业在AI开发过程中对内部沟通和数据使用合规性的挑战。案件结果可能对AI行业的版权保护和数据使用规范产生深远影响。(来源:Reddit r/artificial)

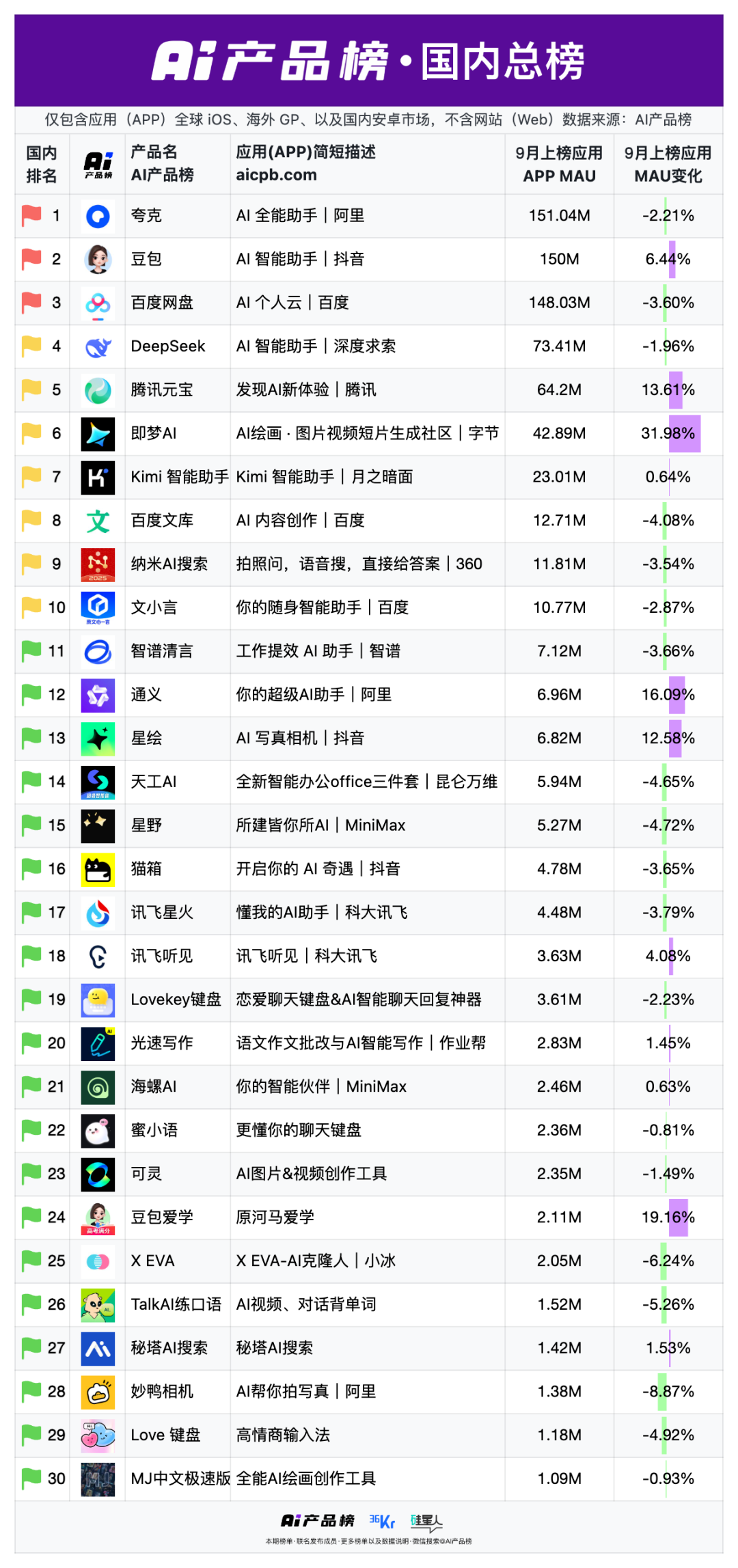
中国AI创业公司面临“集体出局”困境,被迫出海寻求生机 : 中国AI应用市场正呈现“大厂”一边倒的局面,字节、百度、阿里等巨头凭借资源与场景优势,占据国内AI应用Top20的70%。创业公司的创新周期被压缩至数周,一旦出现亮点即被大厂迅速复刻。这种激烈竞争导致中国AI创业公司“被迫出海”,a16z榜单显示22款中国AI移动应用中19款主攻海外,人才与创新也随之外流,凸显了中国AI市场在用户规模膨胀与创新来源收缩之间的悖论。(来源:36氪)