Palabras clave:tecnología de IA, modelos de lenguaje grande, aprendizaje profundo, inteligencia artificial, aprendizaje automático, procesamiento de lenguaje natural, visión por computadora, aprendizaje por refuerzo, proyecto de código abierto nanochat, chips de IA desarrollados por OpenAI, ética de deepfake en Sora 2, Claude Sonnet 4.5, razonamiento matemático GPT-5 Pro
🔥 EN FOCO
Andrej Karpathy lanza nanochat: ChatGPT hecho a mano por 100 dólares : Andrej Karpathy, exdirector de IA de Tesla, lanza el proyecto de código abierto nanochat, que implementa el proceso completo de entrenamiento e inferencia de ChatGPT con menos de 8.000 líneas de código. El proyecto busca reducir la barrera de entrada a la investigación de LLM; los usuarios solo necesitan una GPU en la nube (aproximadamente 100 dólares, 4 horas de entrenamiento) para construir un mini ChatGPT conversacional. Con 12 horas de entrenamiento, su rendimiento puede superar los indicadores CORE de GPT-2. nanochat será el proyecto estrella del curso LLM101n y se espera que evolucione hacia una plataforma de investigación o una herramienta de evaluación comparativa, lo que refleja la continua pasión de Karpathy por la educación y la democratización de la IA. (Fuente: GitHub nanochat, Reddit r/deeplearning, 36氪, 36氪, 36氪, 36氪)
OpenAI y Broadcom se asocian para desarrollar chips de IA propios y desplegar una infraestructura de cómputo de 10 gigavatios : OpenAI anuncia una colaboración estratégica con Broadcom para diseñar y desplegar conjuntamente chips de IA y sistemas de cómputo personalizados, con el objetivo de implementar una infraestructura de inferencia con una potencia total de 10 gigavatios entre la segunda mitad de 2026 y finales de 2029. Esta iniciativa marca que OpenAI ya no se conforma con comprar GPUs existentes, sino que, a través de la integración vertical, participa en el diseño de hardware desde el nivel de los transistores para optimizar el rendimiento de los modelos de IA, reducir costos y satisfacer la demanda exponencial de cómputo futura. OpenAI afirma que esta colaboración es “el proyecto industrial conjunto más grande en la historia de la humanidad”, e incluso utiliza modelos de IA para asistir en el diseño de chips, lo que presagia una profunda participación de la IA en el desarrollo de hardware. (Fuente: OpenAI, Bloomberg, CNBC, 36氪, 36氪, 36氪)
Sora 2 desata una crisis ética de deepfake y controversias sobre derechos de autor : El modelo de generación de video Sora 2 de OpenAI se ha vuelto viral rápidamente debido a su capacidad de generación altamente realista, pero también ha traído serios desafíos éticos y de derechos de autor. Los usuarios han utilizado Sora 2 para generar videos falsos de celebridades fallecidas (como Michael Jackson, Robin Williams), lo que ha provocado una fuerte insatisfacción entre sus familias, quienes lo consideran un abuso y una falta de respeto a la imagen de los difuntos. OpenAI responde que las figuras públicas y sus familias deberían tener control sobre cómo se utiliza su imagen, y planea ofrecer mecanismos más finos de control de derechos de autor y reparto de ingresos. Sin embargo, la industria está ampliamente preocupada de que la creciente popularidad de los modelos de deepfake de código abierto requiera que la sociedad se adapte rápidamente al impacto del contenido generado por IA y explore medidas de protección técnicas y legales efectivas. (Fuente: Washington Post, BBC, 量子位)

Claude Sonnet 4.5, Microsoft Agent Framework y Cursor IDE impulsan un salto en la capacidad de codificación de IA : El campo de la codificación de IA experimenta un avance significativo: Claude Sonnet 4.5 alcanza una precisión del 77.2% en el benchmark SWE-bench Verified, superando notablemente a los modelos anteriores. Al mismo tiempo, Microsoft Agent Framework transforma VS Code en un entorno nativo de IA, permitiendo a los Agent manejar de forma autónoma modificaciones de código multifichero; Cursor IDE 1.7 también lanza un “Modo Agent” que puede resolver problemas complejos con un solo clic. Estos avances indican que los AI Agent ya pueden asumir la mayoría de las tareas de desarrollo, lo que ha provocado debates sobre si los desarrolladores dependerán excesivamente de la IA y sobre los posibles riesgos de deuda técnica que el código generado por IA podría introducir. (Fuente: Reddit r/artificial)
GPT-5 Pro resuelve un problema matemático de Erdős, demostrando una potente capacidad de recuperación de literatura y detección de vulnerabilidades : El GPT-5 Pro de OpenAI demuestra una asombrosa capacidad en el razonamiento matemático, al recuperar con precisión la literatura clave que indicaba que el problema #339 de Erdős ya había sido resuelto en 2003, basándose únicamente en una imagen del problema. Además, GPT-5 Pro puede detectar defectos graves en artículos publicados en 18 minutos, superando incluso los resultados de varios días de investigación de expertos humanos. Este avance subraya el enorme potencial de GPT-5 Pro en la recuperación precisa de información, la resolución de problemas complejos y la verificación de literatura científica, lo que presagia que la IA acelerará enormemente el proceso de investigación, especialmente en la verificación de afirmaciones académicas y la detección de contradicciones lógicas. (Fuente: Sebastien Bubeck, Greg Brockman, 36氪)
Tres gigantes de la IA se unen para advertir: las defensas actuales de los LLM son vulnerables : OpenAI, Anthropic y Google DeepMind se han unido en un raro esfuerzo para publicar un artículo que señala que los mecanismos de defensa actuales contra el jailbreaking y la inyección de prompts en los grandes modelos de lenguaje (LLM) son generalmente frágiles. El equipo de investigación propuso un marco de ataque adaptativo universal y, combinando descenso de gradiente, aprendizaje por refuerzo, búsqueda aleatoria y pruebas de “red teaming” humano, logró eludir 12 mecanismos de defensa principales, con una tasa de éxito de ataque superior al 90% en la mayoría de los casos. Esto indica que las evaluaciones existentes son en gran medida teóricas, y la futura investigación en seguridad de LLM debe incorporar evaluaciones de ataques adaptativos más fuertes para construir un sistema de defensa verdaderamente robusto. (Fuente: arXiv:2510.09023, 36氪)

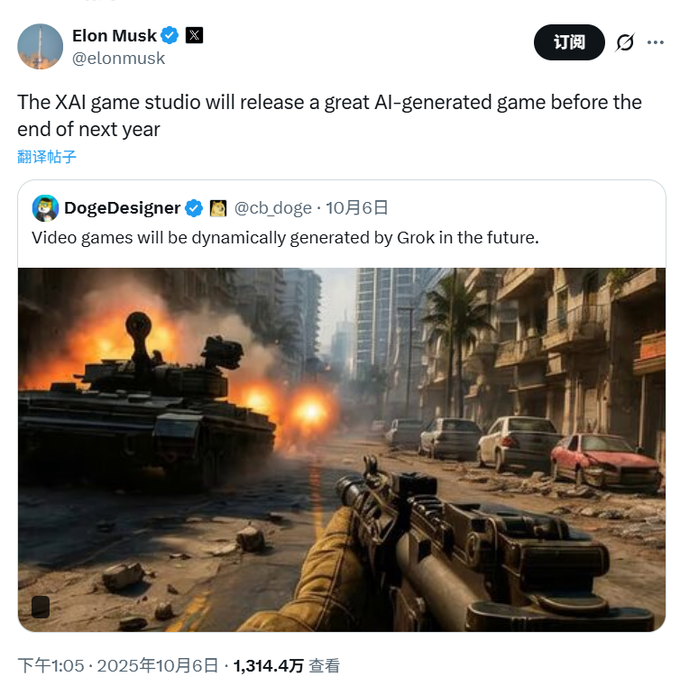
xAI se une a la carrera del “modelo mundial”, con la generación de juegos de IA como primera aplicación : xAI, la compañía de Elon Musk, se ha unido silenciosamente a la carrera del “modelo mundial”, compitiendo con gigantes como Google y Meta. xAI ha contratado a expertos en IA de NVIDIA con el objetivo de construir un modelo capaz de comprender y simular el mundo físico real, entrenándolo con grandes volúmenes de datos de video y robótica. Su primer punto de comercialización es la generación de juegos de IA, con planes de lanzar juegos generados por IA a finales del próximo año y explorar aplicaciones en sistemas robóticos. Investigadores de Google creen que los futuros modelos de video serán tan inteligentes como los modelos de lenguaje, desbloqueando capacidades emergentes como la segmentación de objetos y la detección de bordes a través de la “predicción del siguiente fotograma”, lo que presagia la llegada del “momento GPT en el campo visual”. (Fuente: 36氪)
Un misterioso artículo de ICLR revela SAM3: segmenta todo con conceptos, redefiniendo el nuevo paradigma de la IA visual : Un artículo ciego de la conferencia ICLR 2026, “SAM3: Segmenting Everything with Concepts”, ha sido revelado, desvelando que el Segment Anything Model (SAM) de Meta AI recibirá su tercera gran actualización. El avance central de SAM3 radica en la “segmentación basada en conceptos” (PCS), donde el modelo no solo segmenta por píxeles o instancias, sino que también puede identificar, segmentar y rastrear todos los objetos que cumplen con un “concepto semántico” específico, basándose en indicaciones de texto o imagen. El nuevo sistema, a través de un motor de datos colaborativo humano-máquina, ha construido un conjunto de datos de alta calidad que contiene 4 millones de etiquetas de conceptos, logrando identificar cientos de objetos en 30 milisegundos en una GPU H200, superando completamente los sistemas existentes y presagiando que el “momento GPT-3” para la IA visual podría no estar lejos. (Fuente: arXiv:r35clVtGzw, 36氪)
🎯 TENDENCIAS
Gemini 3 recibe buenas críticas en pruebas internas, elogiado como el “modelo de desarrollo frontend más potente de la historia” : La próxima generación del modelo insignia de Google, Gemini 3, ha atraído una gran atención en las pruebas internas. Los usuarios de internet lo han elogiado por sus capacidades en desarrollo frontend, generación de gráficos vectoriales SVG y habilidades multimodales, calificándolo como “el mejor modelo de desarrollo frontend y web de la historia”, e incluso algunos predicen que será el mejor modelo del año. La información filtrada revela que Gemini 3.0 Pro utiliza una arquitectura MoE, cuenta con billones de parámetros, una ventana de contexto ampliada a millones y capacidades de pensamiento profundo y multimodales integradas, con un rendimiento excepcional en los benchmarks ARC-AGI-2 y HLE. (Fuente: 36氪)
La aplicación de la IA en el diseño y fabricación de chips es cada vez más profunda : El aprendizaje automático se aplica cada vez más en el diseño y la fabricación de chips, impulsando la eficiencia y la innovación de los semiconductores a nuevos niveles. Lorenzo Servadei, jefe de diseño de chips de Sony AI, entrevistado por AIHub, señala que la IA en el campo de la EDA (Automatización del Diseño Electrónico) está pasando de acelerar las estimaciones a participar activamente en el proceso de diseño, acelerando modelos multifísicos, optimizando algoritmos y utilizando IA generativa para la implementación física a través de redes neuronales, lo que mejora significativamente la velocidad, la calidad y la creatividad del diseño de chips. OpenAI también reveló que sus modelos GPT han ayudado a diseñar sus propios chips, logrando una reducción de área y acelerando el ciclo de desarrollo. (Fuente: aihub.org, 36氪)

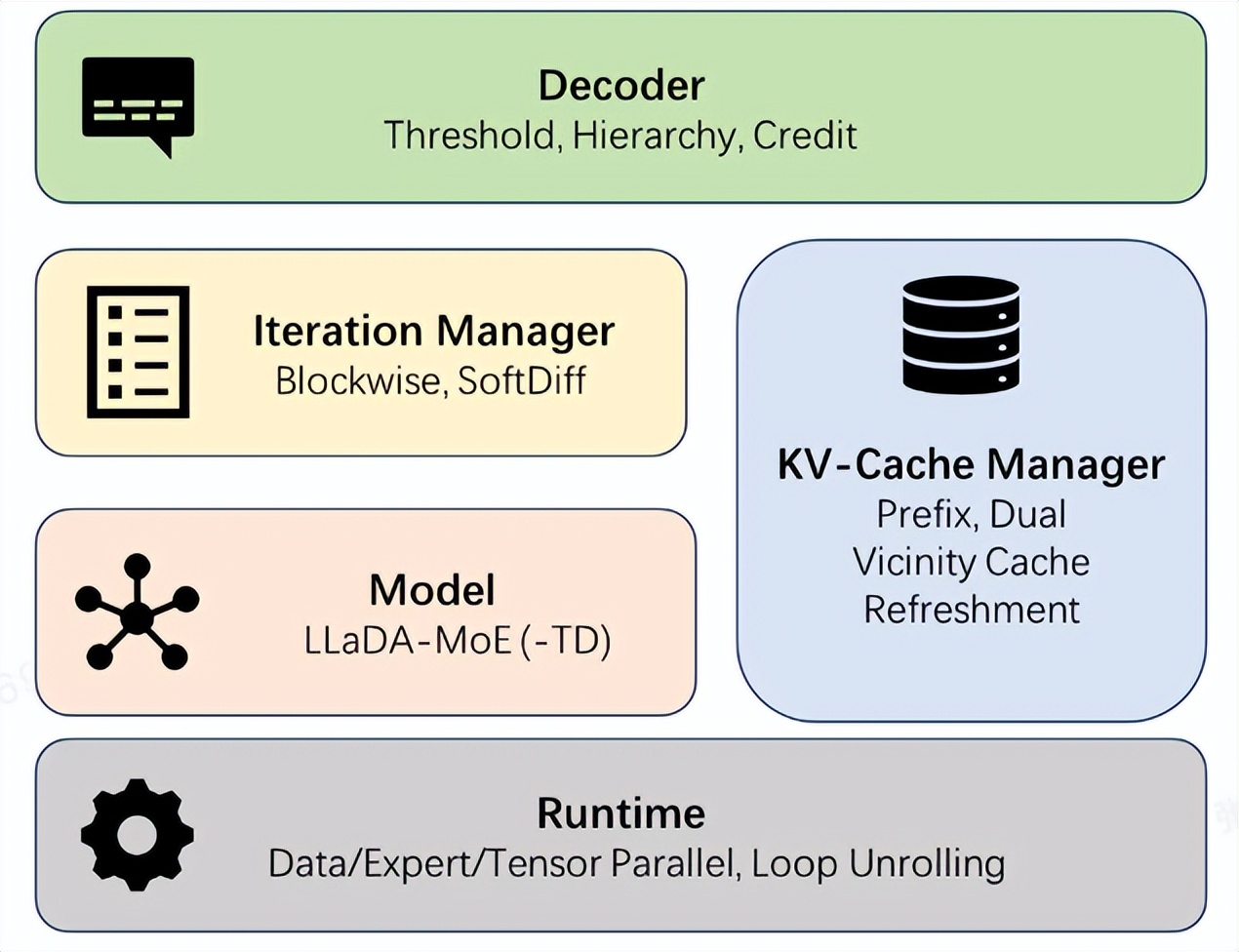
Ant Group lanza el framework de código abierto dInfer, que acelera la inferencia de modelos de lenguaje de difusión 10 veces : Ant Group lanza oficialmente dInfer, el primer framework de inferencia de modelos de lenguaje de difusión de alto rendimiento de la industria, que acelera la inferencia de modelos de lenguaje de difusión 10.7 veces en comparación con Fast-dLLM de NVIDIA. En la tarea de generación de código HumanEval, dInfer alcanza 1011 Tokens/segundo en inferencia de un solo lote, superando por primera vez y significativamente a los modelos autorregresivos. dInfer adopta un diseño de profunda colaboración entre algoritmos y sistemas, que incluye cuatro módulos centrales: acceso al modelo, gestor de caché KV, gestor de iteración de difusión y estrategia de decodificación, con el objetivo de resolver los desafíos de alto costo computacional, fallos de caché KV y decodificación paralela en los modelos de lenguaje de difusión, liberando su potencial de inferencia eficiente. (Fuente: 量子位, QuixiAI)
Google NotebookLM se actualiza, Gemini Nano Banana potencia nuevos estilos visuales para resúmenes de video : La función de resumen de video de Google NotebookLM se ha actualizado, añadiendo varios estilos visuales (clásico, pizarra, acuarela, impresión retro, tradicional, arte en papel, anime), y es impulsada por Gemini Nano Banana, el modelo de generación de imágenes de Gemini. Además, se ha introducido un formato “Brief” más conciso, que ofrece resúmenes rápidos. Estas actualizaciones se lanzarán primero para los usuarios Pro y estarán disponibles para todos los usuarios en las próximas semanas, con el objetivo de mejorar la experiencia personalizada del usuario en la comprensión y presentación de contenido de video. (Fuente: Google, op7418)
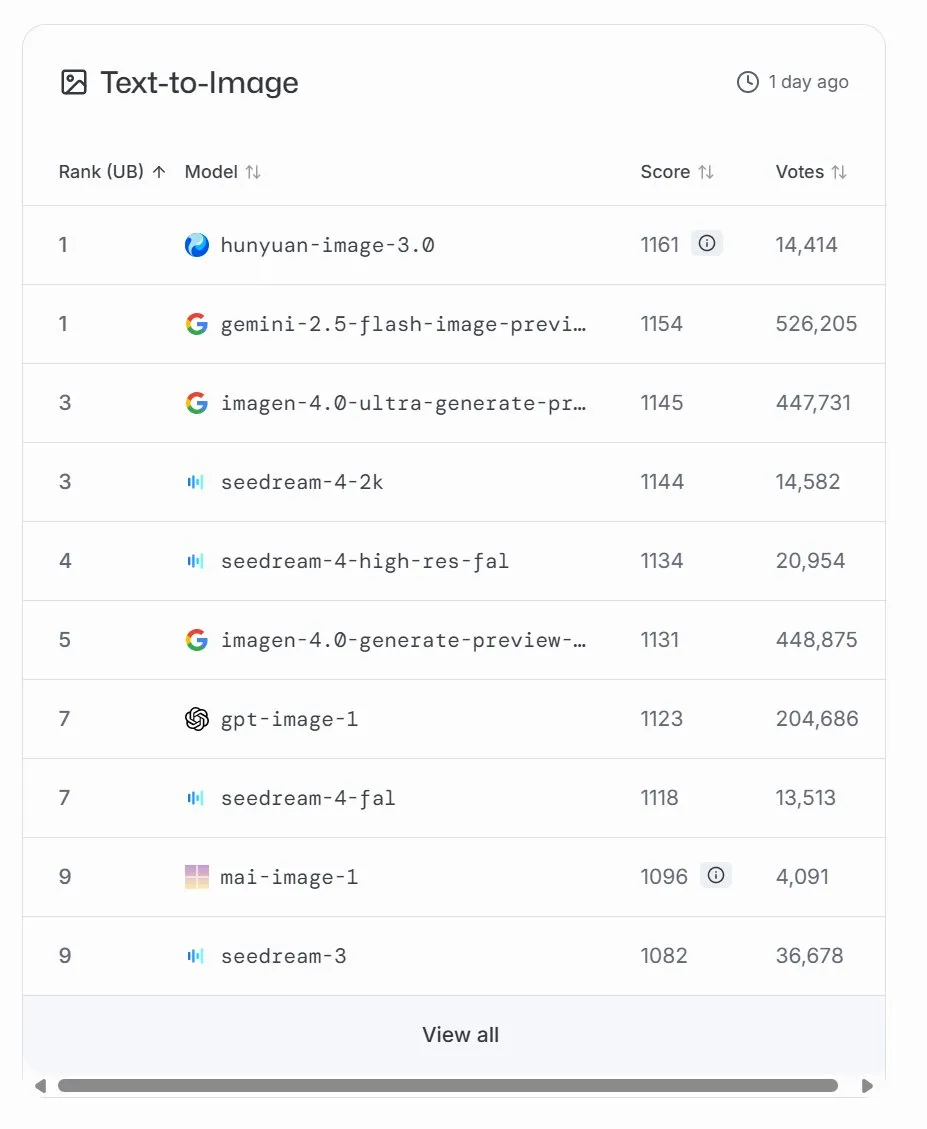
Microsoft lanza el modelo de generación de imágenes MAI-Image-1, que ocupa el noveno lugar en LMArena : Microsoft AI lanza su tercer modelo de IA, MAI-Image-1, un modelo de generación de imágenes que debuta en el puesto número nueve de la clasificación LMArena, empatado con Seedream 3. El modelo logra un equilibrio impresionante entre velocidad y calidad de generación, demostrando la continua inversión y el rápido desarrollo de Microsoft en el campo de la IA multimodal. Microsoft afirma que seguirá optimizando el modelo para lograr una clasificación más alta. (Fuente: mustafasuleyman, NandoDF)
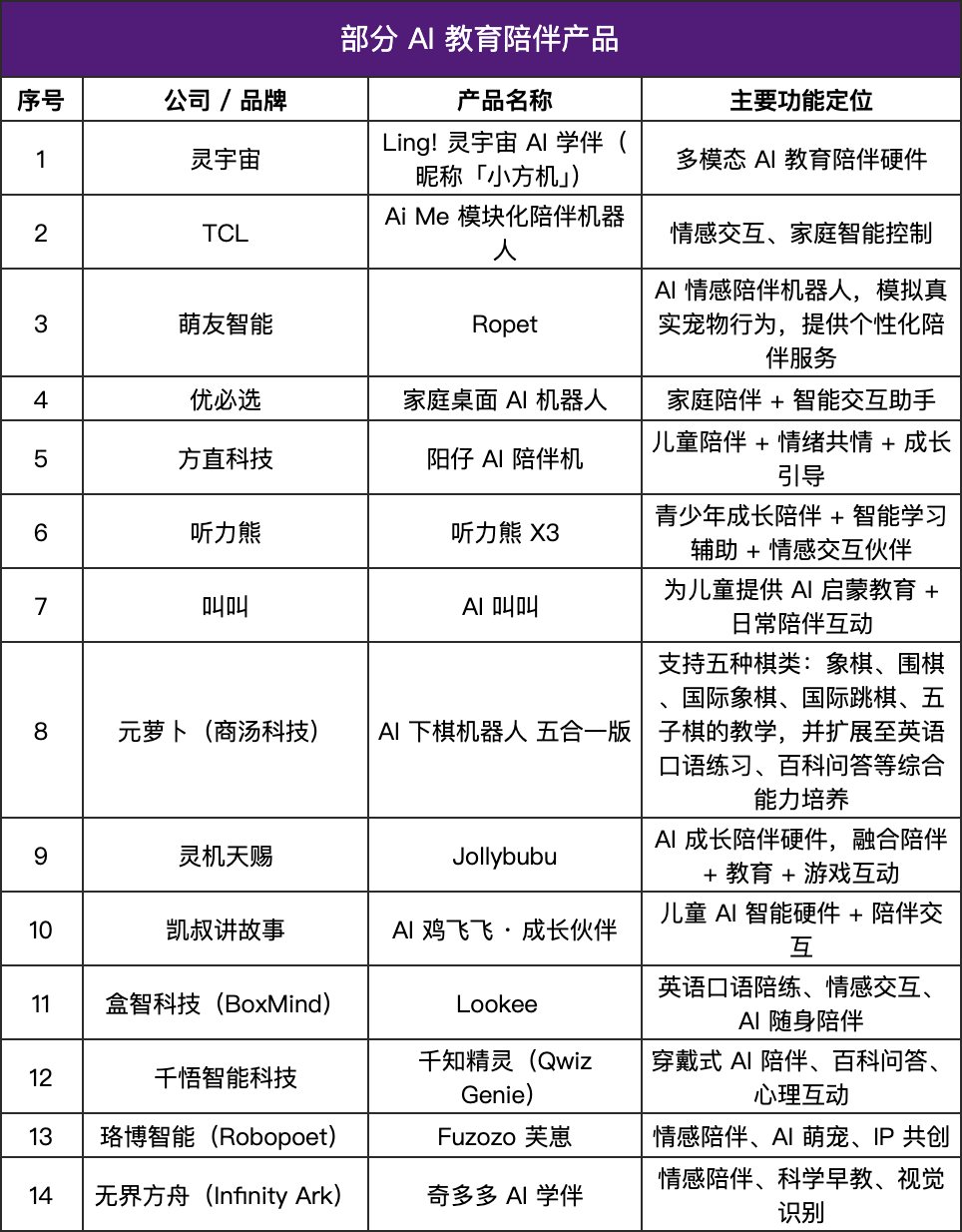
Los productos de compañía con IA experimentan un auge, el hardware educativo “cobra vida” : El mercado de productos de compañía con IA está creciendo rápidamente, con un tamaño de mercado proyectado de 70 mil a 150 mil millones de dólares en el futuro. Estos productos están pasando de la “respuesta a comandos” a la “retroalimentación emocional”, simulando respuestas humanas a través de modelos de lenguaje, reconocimiento de emociones, interacción de voz y sistemas de memoria para ofrecer compañía personalizada. En el sector educativo, los productos de compañía con IA se han implementado como asistentes de aprendizaje, sistemas de retroalimentación emocional y modelos de preguntas y respuestas inteligentes, extendiéndose desde la transmisión de conocimientos hasta el apoyo psicológico, mostrando una tendencia a la ligereza y la personalización, y fusionando la interacción multimodal, con el objetivo de convertirse en sistemas que “entiendan a los estudiantes”. (Fuente: 36氪)
NVIDIA lanza DGX Spark, el superordenador de IA más pequeño del mundo : NVIDIA lanza oficialmente DGX Spark, autoproclamado el superordenador de IA más pequeño del mundo, y ya ha comenzado a enviarse. DGX Spark se basa en la arquitectura NVIDIA Grace Blackwell, integra 128 GB de memoria unificada y está diseñado para proporcionar a los desarrolladores de IA potentes capacidades locales de prototipado y ejecución de LLM. Los primeros usuarios están probando, verificando y optimizando sus herramientas, software y modelos, lo que presagia una computación de IA de alto rendimiento más ubicua y conveniente. (Fuente: nvidia, ollama)

Anthropic lanza Claude Sonnet 4.5, Agent SDK y una versión actualizada de Claude Code : Anthropic lanza Claude Sonnet 4.5, mejorando sus capacidades de razonamiento, con una ventana de contexto más grande (200k–1M tokens) y un rendimiento mejorado en los benchmarks de codificación y razonamiento. Al mismo tiempo, Anthropic también presenta Claude Agent SDK y una versión actualizada de Claude Code, que añade seguimiento/resumen automático de contexto, herramientas de memoria persistente, puntos de control con función de retroceso y una extensión IDE compatible con VS Code, con el objetivo de proporcionar a los desarrolladores capacidades más potentes de codificación de IA y construcción de Agent. (Fuente: DeepLearningAI)

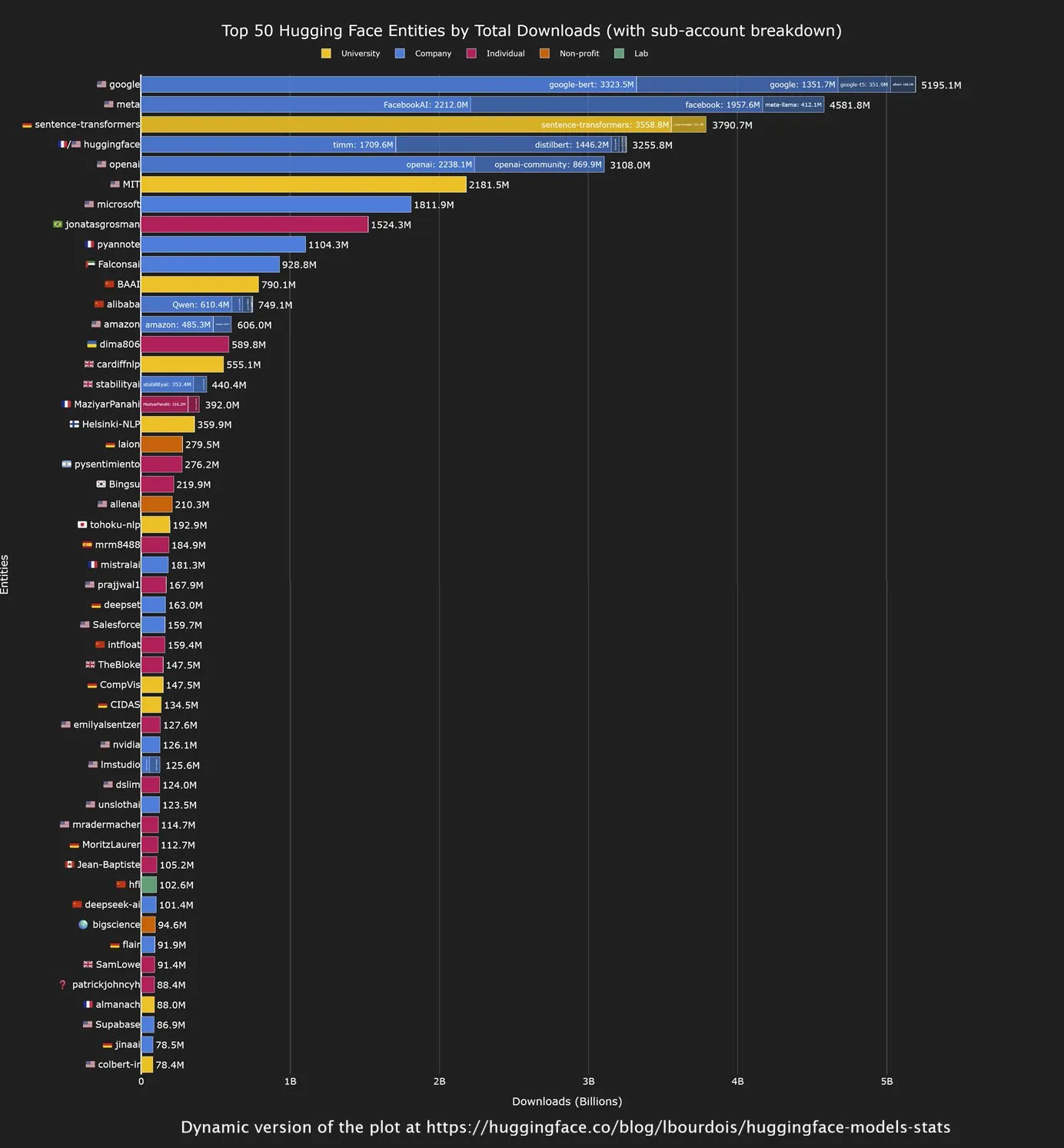
Los modelos de código abierto chinos lideran en descargas en Hugging Face, Google es el mayor contribuyente : Un análisis reciente de la comunidad Hugging Face muestra que los modelos de código abierto desarrollados por empresas chinas tienen un fuerte rendimiento en términos de descargas, especialmente la serie de modelos Qwen. Al mismo tiempo, Google se ha convertido en la institución con mayor número de descargas de modelos en Hugging Face. Esta tendencia indica la creciente influencia de China en el campo de la IA de código abierto, mientras que Google, como gigante tecnológico, también contribuye y utiliza activamente el ecosistema de código abierto para promover la popularización de la tecnología de IA. (Fuente: mervenoyann, osanseviero)
Robbie Stein, vicepresidente de productos de búsqueda de Google, interpreta el futuro de la búsqueda con IA: la “claridad” como destino final : Robbie Stein, vicepresidente de productos de búsqueda de Google, señala que la IA no ha cambiado la necesidad fundamental de los humanos de buscar información, sino que la ha hecho más natural y compleja a través del “Modo IA” (AI Mode). La futura búsqueda con IA tendrá “capacidad de comprensión”, podrá desglosar preguntas vagas en subpreguntas para una búsqueda paralela y resumir respuestas rastreables con citas. El objetivo de Google es convertirse en un sistema “conocedor de la información y confiable”, logrando una transición de “indexar páginas web” a “indexar el mundo” a través de la fusión multimodal y datos estructurados del mundo, haciendo que la adquisición de información sea más clara y rápida, en lugar de simplemente generar lenguaje fluido. (Fuente: 36氪)
Ant Group lanza el framework de inferencia de modelos de lenguaje de difusión de alto rendimiento dInfer : Ant Group lanza oficialmente dInfer, el primer framework de inferencia de modelos de lenguaje de difusión de alto rendimiento de la industria, que acelera la inferencia de modelos de lenguaje de difusión 10.7 veces en comparación con Fast-dLLM de NVIDIA. En la tarea de generación de código HumanEval, dInfer alcanza 1011 Tokens/segundo en inferencia de un solo lote, superando por primera vez y significativamente a los modelos autorregresivos. dInfer adopta un diseño de profunda colaboración entre algoritmos y sistemas, con el objetivo de resolver los desafíos de alto costo computacional, fallos de caché KV y decodificación paralela en los modelos de lenguaje de difusión, liberando su potencial de inferencia eficiente. (Fuente: 量子位)
NVIDIA lanza la tecnología de entrenamiento NVFP4, logrando un preentrenamiento de 4 bits con precisión FP8 : NVIDIA anuncia una innovadora tecnología de entrenamiento NVFP4 que permite que los modelos de lenguaje grandes preentrenados de 4 bits alcancen la precisión de 8 bits. Esta tecnología utiliza una representación de punto flotante de 4 bits en formato E2M1, combinada con escalado de grano fino, redondeo estocástico y transformaciones de Hadamard aleatorias, lo que reduce significativamente los requisitos de cómputo y memoria. Los experimentos demuestran que NVFP4, al tiempo que mantiene la precisión del modelo (por ejemplo, MMLU Pro 62.58% frente a 62.62%), mejora drásticamente la eficiencia del entrenamiento, proporcionando una ruta más económica y eficiente para el entrenamiento de LLM de mayor escala en el futuro. Esta tecnología depende principalmente de la arquitectura NVIDIA Blackwell y requiere GPUs H100 o superiores. (Fuente: Reddit r/LocalLLaMA, karminski3)

El framework SEAL del MIT permite a los modelos de IA generar automáticamente datos de ajuste fino y actualizar pesos : El Instituto Tecnológico de Massachusetts (MIT) lanza el framework SEAL (Self-Adapting LLMs), que permite a los grandes modelos de lenguaje (LLM) generar automáticamente datos de ajuste fino y realizar actualizaciones de peso de forma autónoma, logrando actualizaciones de gradiente sin intervención humana. SEAL utiliza un mecanismo de aprendizaje de doble bucle (interno y externo), donde el modelo optimiza su estrategia de generación de instrucciones de auto-actualización en función del rendimiento de la tarea, otorgando por primera vez a los LLM la capacidad de auto-actualización. Los experimentos demuestran que SEAL sobresale en la inyección de conocimiento y las tareas de aprendizaje de pocos ejemplos, superando la precisión de los datos generados por GPT-4.1 y mostrando una fuerte capacidad de adaptación a tareas e integración de conocimiento, lo que presagia la llegada de una era de modelos autoevolutivos. (Fuente: arXiv:2506.10943, 36氪)

El envío de teléfonos con IA se dispara, fabricantes como Kuss Smart exploran la estrategia de colaboración “modelo pequeño + modelo grande” : En 2025, el envío de teléfonos con IA en China se dispara un 591% interanual, alcanzando una penetración del 22%, convirtiendo a los teléfonos con IA en el nuevo foco de la industria. Fabricantes como Kuss Smart están pasando de la carrera de parámetros a la innovación pragmática, adoptando una solución de colaboración dinámica de “modelo pequeño frontal + modelo grande backend”, desplegando modelos verticales pequeños de aproximadamente 600 millones de parámetros en el dispositivo para lograr una respuesta rápida y protección de la privacidad, al tiempo que integran la capacidad de cómputo de modelos grandes generales de iFlytek, ByteDance, Alibaba, Google, entre otros. Esta estrategia tiene como objetivo mejorar la experiencia del usuario, proporcionar servicios personalizados y reducir costos, para adaptarse a los mercados extranjeros diversos y fragmentados. (Fuente: 36氪)

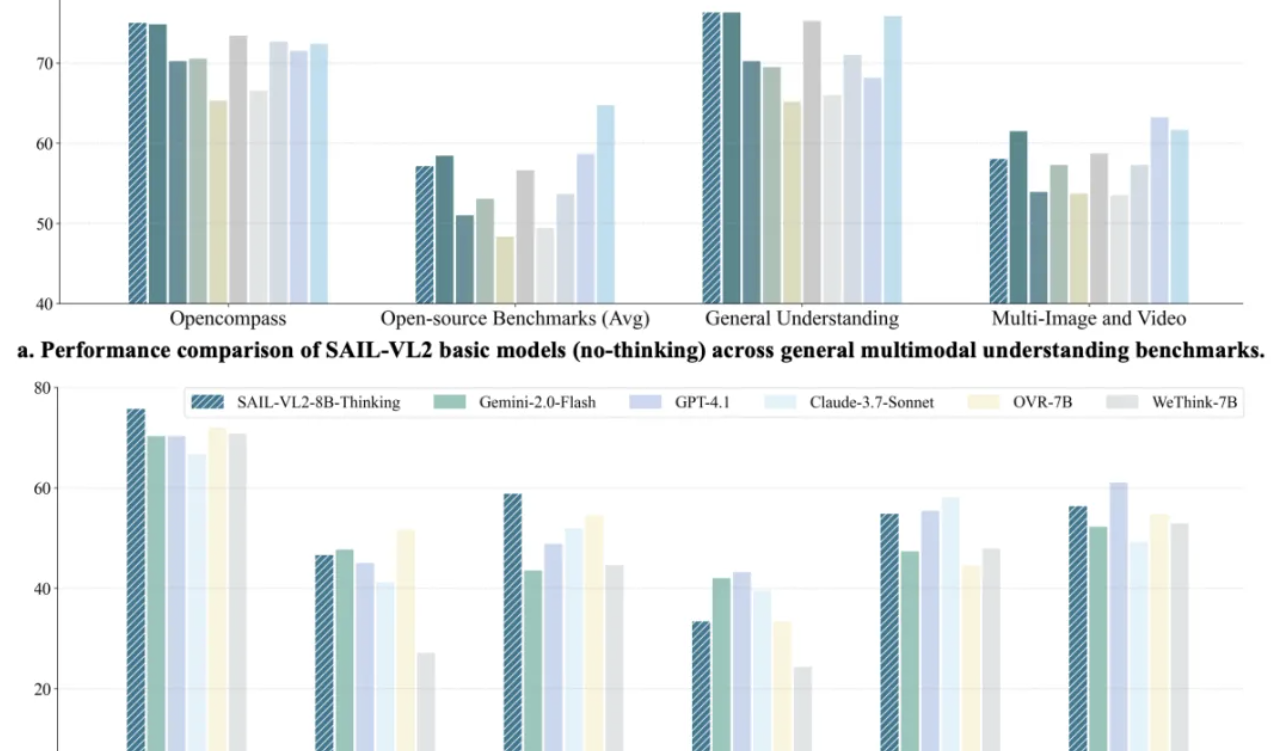
El modelo multimodal SAIL-VL2 de Douyin rompe récords, el modelo 8B iguala la inferencia de GPT-4o : El equipo SAIL de Douyin, en colaboración con LV-NUS Lab, lanza el modelo multimodal grande SAIL-VL2, logrando avances de rendimiento con tamaños de parámetros pequeños y medianos como 2B y 8B en 106 conjuntos de datos. En particular, supera a modelos de tamaño similar en benchmarks de razonamiento complejos como MMMU y MathVista, e incluso la capacidad de inferencia del modelo 8B iguala a GPT-4o. SAIL-VL2, a través de una arquitectura MoE dispersa, un marco de entrenamiento progresivo y un corpus multimodal de alta calidad, entre otras innovaciones, proporciona a la comunidad un nuevo paradigma de “modelos pequeños con grandes capacidades”, y ha liberado el modelo y el código de inferencia como código abierto. (Fuente: 量子位)
La inferencia en la nube de Moondream migra completamente a FAL, logrando un 100% de ejecución en la nube : Moondream anuncia que su servicio de inferencia en la nube ha migrado completamente de instancias EC2 a FAL, logrando un 100% de ejecución en FAL. Esta medida podría significar que Moondream ha logrado importantes avances en la optimización de la eficiencia de la inferencia, la reducción de los costos operativos o la mejora de la elasticidad del servicio, y FAL, como nueva plataforma de inferencia, demuestra su capacidad para soportar el despliegue de modelos de IA en la nube. (Fuente: vikhyatk)
Ring-1T: Ant Ling lanza un modelo de pensamiento de código abierto de un billón de parámetros : Ant Ling lanza oficialmente Ring-1T, un modelo de pensamiento de código abierto de un billón de parámetros basado en la arquitectura Ling 2.0. Ring-1T alcanza una capacidad de razonamiento de nivel de medalla de plata en la IMO (Olimpiada Internacional de Matemáticas) en razonamiento de lenguaje natural puro, con un billón de parámetros totales y 50 mil millones de parámetros activos, y una ventana de contexto de 128K. El modelo se refuerza a través de Icepop RL y ASystem (un motor de aprendizaje por refuerzo a escala de billones) y logra un rendimiento SOTA en benchmarks de razonamiento de lenguaje natural como AIME 25, HMMT 25, ARC-AGI-1 y CodeForce, ofreciendo una versión FP8, con el objetivo de impulsar las capacidades de inferencia de IA de código abierto. (Fuente: scaling01, jon_durbin)
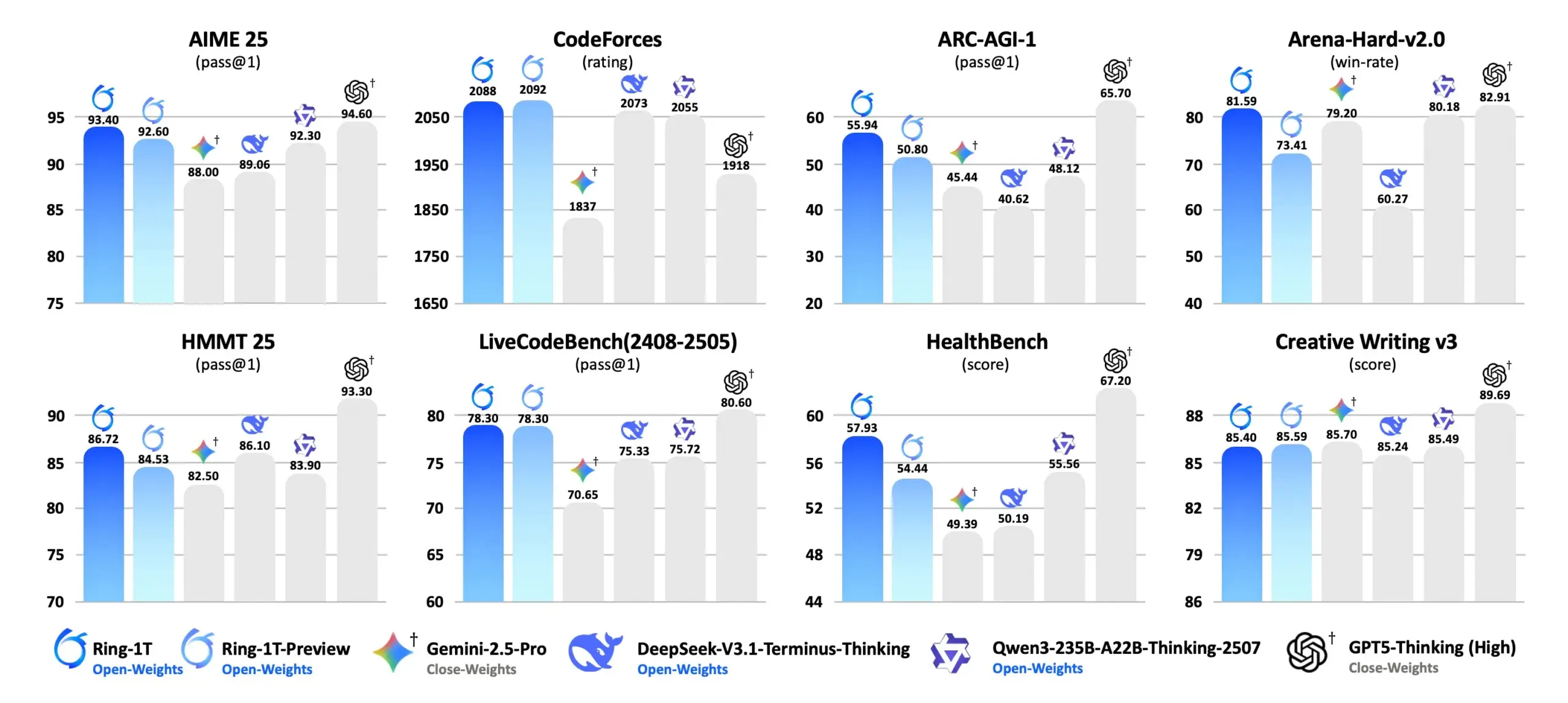
La función de comercio electrónico “Instant Checkout” de ChatGPT se lanza, redefiniendo la experiencia de compra : OpenAI lanza la función “Instant Checkout” de ChatGPT, que permite a los usuarios completar compras directamente dentro de ChatGPT, sin necesidad de redirigir a plataformas de comercio electrónico de terceros. Actualmente, esta función es compatible con Etsy y pronto se integrará con más de un millón de comerciantes de Shopify. Esta innovación cierra el ciclo de compra desde la descripción de la necesidad hasta la finalización de la compra en un solo lugar, acortando significativamente la ruta de decisión de compra del usuario y mejorando la comodidad de compra, lo que presagia una profunda integración de la IA en el comercio electrónico y una transformación del modelo de negocio. (Fuente: 36氪)
El auge de los cortometrajes de IA en el extranjero, la tecnología Sora 2 impulsa un salto cualitativo y cuantitativo en la producción de contenido : Los cortometrajes de IA están impactando las plataformas de video corto con un auge explosivo y se están expandiendo masivamente al extranjero. En 2024, el mercado chino de micro-cortometrajes alcanzó los 50.5 mil millones de yuanes, y la demanda del mercado extranjero es evidente, con ingresos de cortometrajes chinos en el extranjero que se espera alcancen los 4 mil millones de dólares para todo el año. El lanzamiento de OpenAI Sora 2 ha mejorado drásticamente la calidad de imagen, la duración, la sincronización y la sincronización de audio y video, y admite la coherencia de tramas complejas y la función Cameos, comprimiendo el proceso de producción de cortometrajes a un modo eficiente de “una persona escribe el Prompt, la IA produce”, con costos que pueden reducirse a una décima parte de los métodos tradicionales. Los “manhua” (cómics animados) de IA también se están convirtiendo en una nueva tendencia, reduciendo eficazmente el descuento cultural e impulsando la expansión de la industria de contenido de dramas de acción real a “manhua” de IA. (Fuente: 36氪)

Avances de la IA en el diagnóstico médico: se lanza el Agent de diagnóstico multimodal AMIE : Google AI lanza AMIE (AI agent for multimodal diagnostic dialogue), un AI Agent de investigación diseñado para lograr avances en el campo médico a través del diálogo de diagnóstico multimodal. El lanzamiento de AMIE marca un progreso en la comprensión y participación de la IA en procesos de diagnóstico médico complejos, con el potencial de mejorar la eficiencia y precisión del diagnóstico, sentando las bases para futuras aplicaciones médicas inteligentes. (Fuente: Ronald_vanLoon)
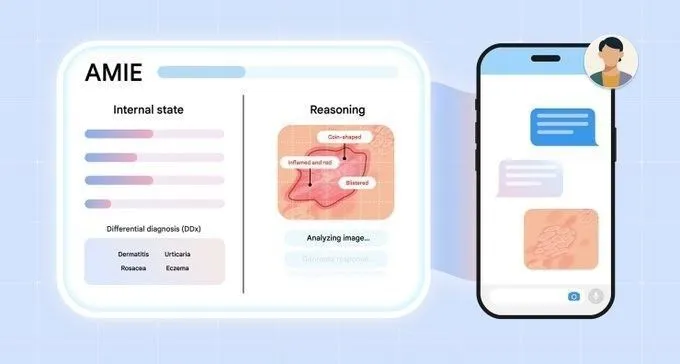
La API de búsqueda de Perplexity añade la función de filtrado por dominio, mejorando la precisión de la búsqueda : Perplexity anuncia que su Search API ahora es compatible con el filtrado de resultados de búsqueda por dominios específicos. Esta nueva función permite a los usuarios consultar solo fuentes de confianza, obteniendo así resultados más enfocados y verificables. Esto mejorará significativamente la eficiencia de la búsqueda y la calidad de la información para usuarios profesionales o desarrolladores de aplicaciones que necesitan obtener información de fuentes autorizadas específicas. (Fuente: AravSrinivas)
La IA muestra potencial en la detección de terremotos, y podría ayudar a predecirlos en el futuro : La IA se destaca en la detección de pequeños terremotos, y su capacidad se describe como “tan clara como ponerse gafas por primera vez”. Los investigadores están explorando si la IA puede ayudar aún más a predecir terremotos, lo que podría traer un avance revolucionario en la alerta temprana y la mitigación de desastres sísmicos. A través de un análisis de datos más refinado, la IA puede identificar señales sísmicas que son difíciles de detectar con métodos tradicionales, mejorando así nuestra comprensión de las actividades profundas de la Tierra. (Fuente: Ars Technica)
Se lanza la arquitectura Mamba3, logrando LLM más rápidos, con mayor contexto y más escalables : La arquitectura Mamba3 se lanza discretamente en la conferencia ICLR, marcando un progreso significativo en la velocidad, la longitud del contexto y la escalabilidad en el campo de los LLM. Esta arquitectura, al optimizar la evolución del estado interno y la utilización del hardware, logra un modelado de secuencias más eficiente que Transformer. Mamba3 introduce la integración trapezoidal y estados ocultos en el plano complejo, lo que permite una memoria más suave y estable, y la capacidad de representar patrones periódicos. Su diseño de múltiples entradas y salidas le permite procesar datos de múltiples flujos en paralelo, con un gran potencial en la comprensión de documentos largos, el análisis de series temporales y los sistemas de IA de borde. (Fuente: NandoDF)

Agentic RAG supera al RAG tradicional, convirtiéndose en la nueva tendencia de búsqueda con IA : Se está formando un consenso en la industria: “el RAG (Generación Aumentada por Recuperación) tradicional basado en embeddings ha muerto”, y el Agentic RAG (RAG basado en agentes) supera al anterior en casi todos los aspectos, excepto en la velocidad. Esta tendencia presagia que la búsqueda con IA pasará de la simple recuperación de información a una interacción más compleja basada en agentes. El Agentic RAG puede comprender de forma más inteligente la intención del usuario, planificar estrategias de recuperación y generar respuestas más precisas, lo que traerá una transformación a los futuros sistemas de búsqueda y preguntas y respuestas de IA. (Fuente: swyx, jerryjliu0)

TuringPost publica una lista de herramientas de generación de video con IA, incluyendo Luma Dream Machine : TuringPost ha publicado una lista de 9 potentes herramientas de generación de video con IA, que incluye Sora 2, Google Veo 3, Runway, Pika Labs, Luma’s Dream Machine (impulsada por Ray 3), Synthesia, HeyGen, Kaiber e InVideo. Esta lista tiene como objetivo proporcionar a los usuarios una selección completa de opciones de creación de video con IA, cubriendo diversas funciones como texto a video, generación en tiempo real y síntesis de personajes, lo que refleja el rápido desarrollo y la diversificación de aplicaciones en el campo de la tecnología de video con IA. (Fuente: TheTuringPost)
OpenAI lanza un cortometraje sobre la historia de la tecnología generado por Sora, el proceso de unión de videos aún necesita optimización : Hemanth Asir, investigador de OpenAI, ha producido un cortometraje sobre la historia del desarrollo tecnológico completamente generado por Sora, mostrando el potencial de Sora en la creación de videos. Aunque el efecto del cortometraje es impresionante, el proceso de unión actual sigue siendo engorroso. OpenAI afirma que se esforzará por mejorar este proceso para optimizar la experiencia del usuario y la eficiencia de la creación, lo que presagia que las futuras herramientas de generación de video con IA serán más convenientes para la narrativa de formato largo. (Fuente: dotey)
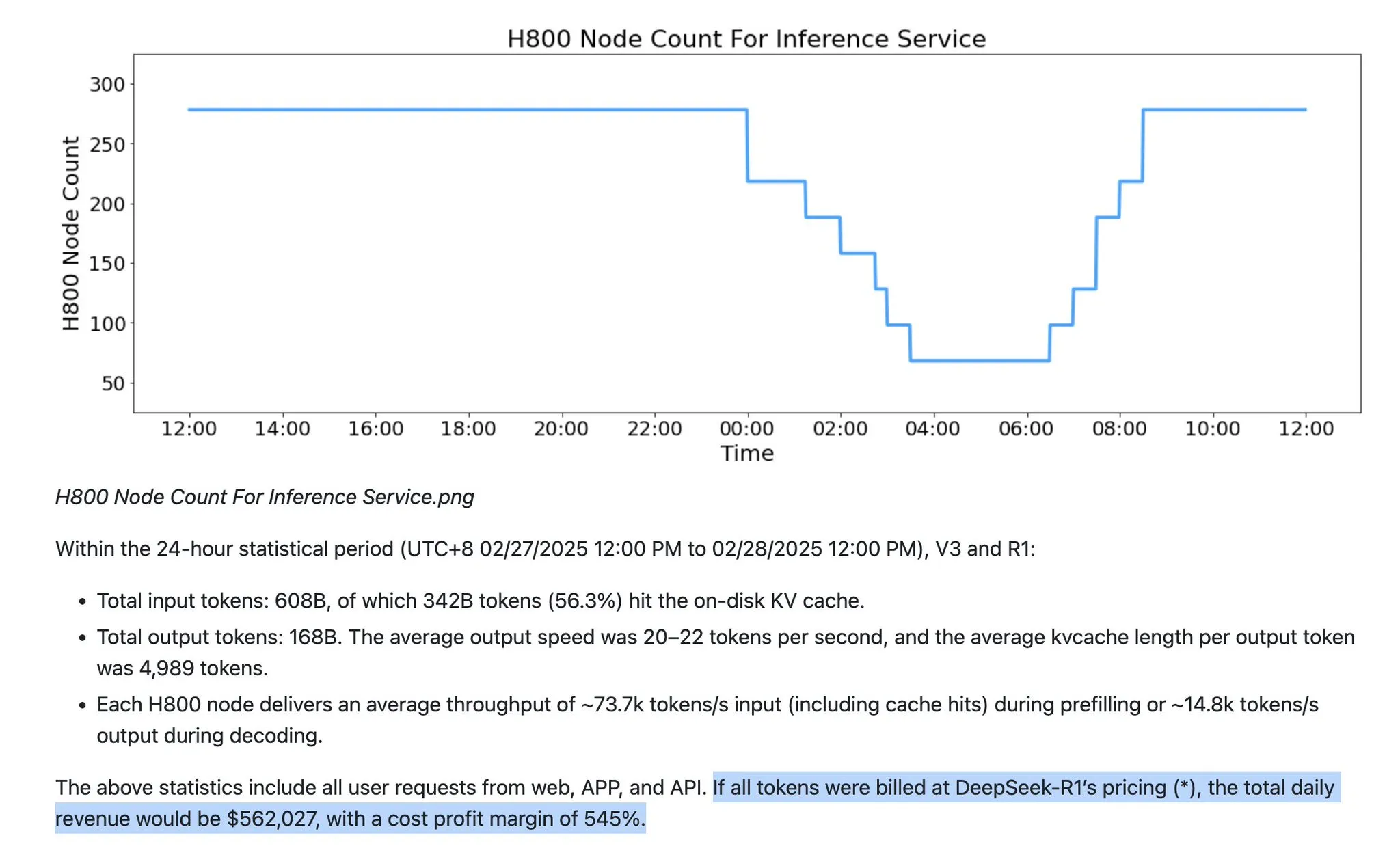
Los supuestos del servicio de LLM se enfrentan a desafíos: FP8/FP4 serán la corriente principal, y la cantidad de Tokens de salida crecerá exponencialmente : Se señala que los servicios de LLM actuales tienen muchos supuestos erróneos. En primer lugar, los servicios de LLM ya no se limitan a la precisión FP16, y FP8 y FP4 se convertirán en la corriente principal. En segundo lugar, el crecimiento futuro de los LLM se manifestará principalmente en el crecimiento exponencial de los “Tokens de pensamiento” (Tokens de salida), en lugar de una simple proporción de Tokens de entrada. Además, los modelos de la serie GPT-5 de OpenAI tienen un rango de parámetros más amplio, y varios laboratorios están reduciendo costos a través de tecnologías como DSA de Deepseek y nuevos mecanismos de atención. Anthropic también ha lanzado una herramienta de limpieza de contexto para Sonnet 4.5 para reducir los requisitos de memoria. Todo esto remodelará la eficiencia y la estructura de costos de los servicios de LLM. (Fuente: teortaxesTex)
🧰 HERRAMIENTAS
Microsoft MarkItDown: herramienta de conversión de documentos a Markdown para pipelines de LLM : Microsoft lanza la herramienta Python MarkItDown, que puede convertir decenas de tipos de archivos (incluidos PDF, Word, Excel, HTML, imágenes, audio, etc.) a un formato Markdown limpio. Esta herramienta conserva encabezados, listas, tablas, enlaces y metadatos, y admite la extracción de información OCR y EXIF. Dado que Markdown es el “lenguaje nativo” de los LLM, MarkItDown se convierte en una opción ideal para preprocesar documentos en los pipelines de LLM, lo que ayuda a mejorar la comprensión y la eficiencia del procesamiento de documentos complejos por parte del modelo. (Fuente: TheTuringPost)
VS Code lanza el plan de iteración 1.105, centrado en la IA y la experiencia del desarrollador : VS Code lanza su plan de iteración de octubre, que trae múltiples mejoras destinadas a potenciar el desarrollo asistido por IA y la experiencia general del desarrollador. Las actualizaciones incluyen renderizado de Mermaid, diversas formas de gestión de contexto y herramientas, gestión de modelos más avanzada, flujos de varios pasos, guardar conversaciones como Prompt y funciones para terminal, herramientas y MCPs. Además, GitHub Copilot también ha lanzado 34 mejoras en los últimos 30 días. Estas actualizaciones profundizarán aún más la aplicación de la IA en la edición de código, la depuración y la colaboración, haciendo de VS Code un entorno de desarrollo nativo de IA más potente. (Fuente: pierceboggan, code)

Nanonets-OCR2 lanzado, modelo de código abierto de imagen a Markdown compatible con LaTeX y diagramas de flujo : Nanonets-OCR2 ha sido lanzado, un modelo de código abierto de imagen a Markdown ajustado a partir de Qwen2.5-VL-3B-Instruct, que soporta el reconocimiento de ecuaciones LaTeX, tablas, documentos manuscritos, casillas de verificación e incluso puede convertir diagramas de flujo en código Mermaid. El modelo también cuenta con descripción inteligente de imágenes, detección de firmas, extracción de marcas de agua y soporte multilingüe, además de ofrecer capacidades de preguntas y respuestas visuales (VQA). Nanonets-OCR2 destaca en el procesamiento de documentos complejos, proporcionando una solución eficiente y rica en funciones para el preprocesamiento de documentos en los pipelines de LLM. (Fuente: huggingface, Reddit r/LocalLLaMA, karminski3)
La aplicación ChatGPT para Slack se lanza, integrando la API de búsqueda en tiempo real : La aplicación ChatGPT se lanza oficialmente en Slack. Gracias a la API de búsqueda en tiempo real de Slack, los usuarios ahora pueden usar ChatGPT directamente en una barra lateral dedicada de Slack para hacer preguntas, generar ideas, redactar contenido y resolver problemas. Esta integración introduce sin problemas las potentes capacidades de ChatGPT en la plataforma de colaboración en equipo, con el objetivo de mejorar la eficiencia del trabajo, simplificar la adquisición de información y los procesos de creación de contenido, y proporcionar a los usuarios empresariales una asistencia de IA más conveniente. (Fuente: gdb)
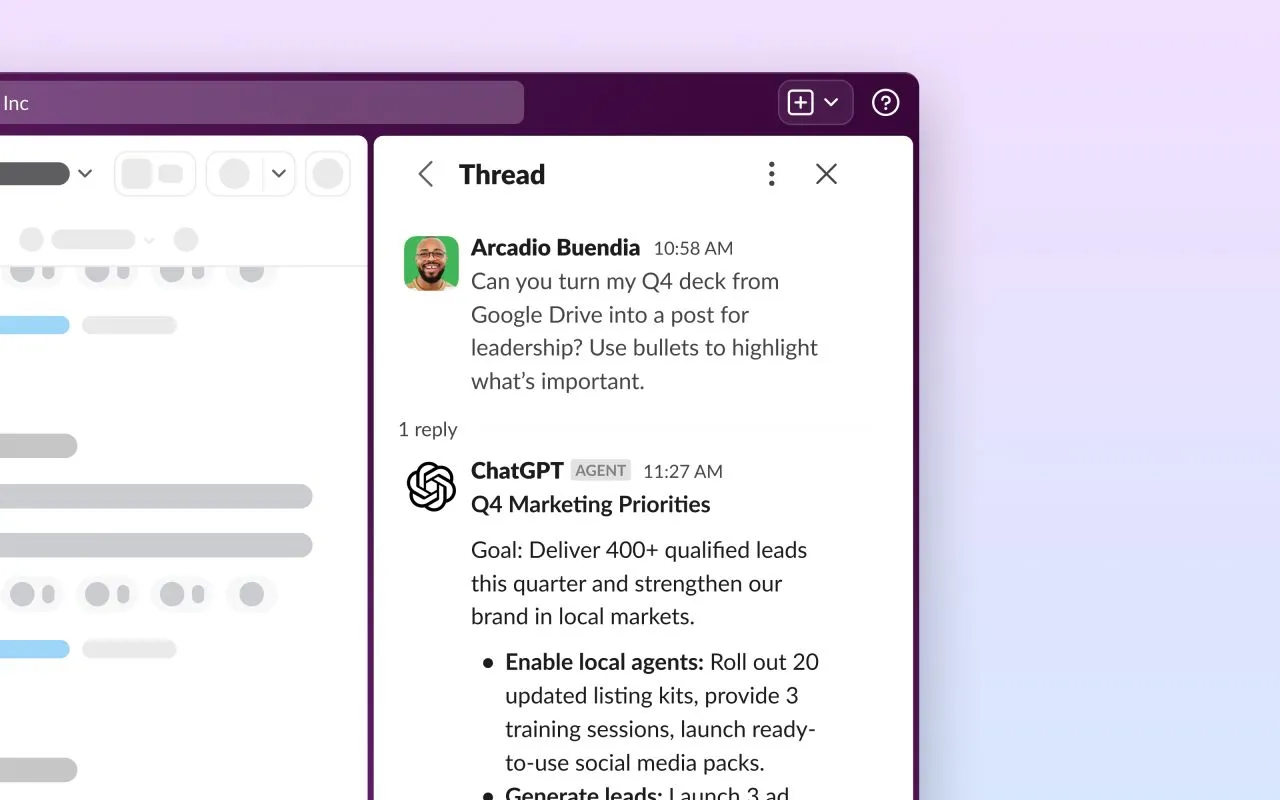
n8n lanza un constructor de flujos de trabajo de IA, potenciando la automatización del lenguaje natural : n8n lanza oficialmente su constructor de flujos de trabajo de IA, que permite a los usuarios construir agentes de IA y procesos de automatización en n8n a través del lenguaje natural. Esta herramienta proporciona un lienzo visual que puede conectar más de 8000 herramientas como Firecrawl, LLMs, nodos lógicos y MCPs, y desplegarse como una API. Esta innovación simplificará enormemente el desarrollo y la aplicación de agentes de IA, permitiendo a más desarrolladores crear flujos de trabajo de automatización complejos utilizando lenguaje natural, impulsando la popularización de los agentes de IA en escenarios de negocio reales. (Fuente: omarsar0)
MLX soporta la ejecución de modelos locales, la actualización de Privacy AI 1.3.2 mejora las capacidades de IA en dispositivos Apple : Privacy AI lanza la actualización 1.3.2, que soporta completamente el motor MLX de Apple, permitiendo a los usuarios ejecutar modelos de texto y visuales localmente. Los modelos se pueden descargar directamente desde Hugging Face, con soporte para reanudación de descargas, transferencia en segundo plano y verificación de integridad. Además, los modelos MLX están incluidos en el plan gratuito, lo que permite la ejecución sin conexión sin necesidad de suscripción. Esta actualización también mejora el soporte del portapapeles y actualiza llama.cpp, mejorando aún más las capacidades de IA local y la protección de la privacidad en dispositivos Apple. (Fuente: awnihannun)
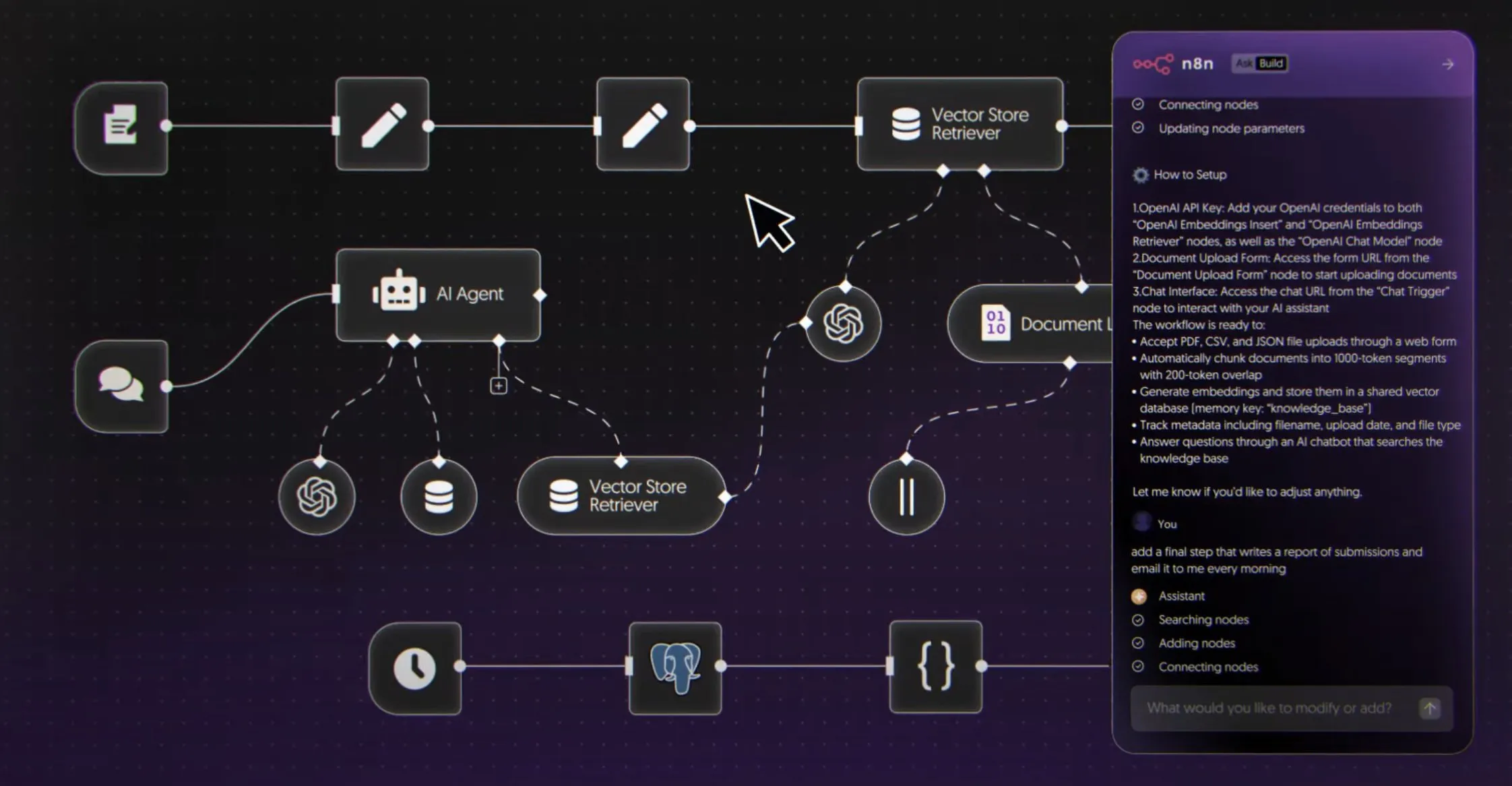
Google AI Studio lanza un nuevo panel de control de límites de tasa : Google AI Studio lanza un nuevo panel de control de límites de tasa, que permite a los usuarios comprender visualmente el uso de la API de Gemini sin salir de AI Studio. El panel ofrece funciones de filtrado de gráficos y facilita la exploración de los límites de tasa de todos los modelos, ayudando a los desarrolladores a gestionar y optimizar mejor sus proyectos de IA, mejorando la eficiencia del desarrollo. (Fuente: GoogleAIStudio)
Cursor IDE y Codex se convierten en las nuevas opciones diarias de codificación para desarrolladores : Con el rápido desarrollo de las herramientas de codificación de IA, Cursor IDE y Codex se están convirtiendo en herramientas centrales en el flujo de trabajo diario de cada vez más desarrolladores. Algunos desarrolladores han expresado que han pasado completamente de Claude Code a Codex, utilizándolo para la planificación diaria, la descomposición de tareas y el procesamiento paralelo. El “sistema de indexación de bases de código” de Cursor IDE, a través de la búsqueda semántica y el acceso a código local, logra una indexación y actualización eficiente del código, sin necesidad de almacenar el código en un servidor, garantizando la privacidad y la eficiencia. La popularización de estas herramientas está cambiando la forma tradicional de codificación, mejorando la eficiencia del desarrollo. (Fuente: dejavucoder, gdb)
Yupp.ai: herramienta de debate con IA para obtener respuestas más completas : Yupp.ai es una innovadora herramienta de IA diseñada para ayudar a los usuarios a tomar decisiones más informadas en la era de la información, presentando respuestas de diferentes modelos de IA. Los usuarios pueden comparar las respuestas de diferentes IA lado a lado y votar según su análisis, creatividad o detalles específicos, formando así una clasificación de sabiduría colectiva. El objetivo de Yupp.ai es permitir a los usuarios aprovechar la experiencia colectiva para obtener rápidamente respuestas confiables y con múltiples perspectivas, mejorando así la eficiencia del trabajo y la confianza en la toma de decisiones. (Fuente: yupp_ai)

vLLM y SGLang son aclamados como el “Linux de la era de la IA” : vLLM y SGLang, debido a su excelente rendimiento en el campo de la inferencia de LLM, son aclamados como el “Linux de la era de la IA”. vLLM ha obtenido 60.000 estrellas en GitHub, evolucionando de una pequeña idea de investigación a un framework central para la inferencia de LLM que soporta casi todas las plataformas principales como NVIDIA, AMD, Intel y Apple. Soporta la mayoría de los modelos de generación de texto y pipelines nativos de RL como TRL y Unsloth, desempeñando un papel de infraestructura clave en el ecosistema de la IA, impulsando la popularización y la eficiencia de la inferencia de LLM. (Fuente: bookwormengr)
Luma AI Ray3 Visual Annotation desbloquea un control preciso : La función de anotación visual Ray3 de Luma AI, al garabatear en un fotograma, permite un control preciso de la dirección visual, guiando al sujeto a realizar acciones o interacciones específicas. Esta función va más allá de las limitaciones de las indicaciones de texto tradicionales, transmitiendo la intención de bloqueo espacial a través de trazos de lápiz, proporcionando un control más intuitivo y refinado para la creación visual, mostrando un gran potencial especialmente en aplicaciones como Dream Machine. (Fuente: TomLikesRobots)
Faceseek: herramienta de coincidencia y verificación facial impulsada por IA : Faceseek es una herramienta que utiliza tecnología de IA para la coincidencia y verificación facial, capaz de manejar eficazmente rostros similares. Esta herramienta podría emplear embeddings faciales, CLIP (Contrastive Language-Image Pre-training) u otros modelos avanzados de visión por computadora para el análisis, proporcionando soluciones para escenarios como la verificación de identidad y la vigilancia de seguridad. Su rendimiento en aplicaciones prácticas ha generado debates sobre los detalles técnicos y las posibles aplicaciones de este tipo de sistemas. (Fuente: Reddit r/ArtificialInteligence)
La extensión de backend remoto de GPU de PyTorch combina el desarrollo local con el cómputo remoto : Una nueva extensión de PyTorch permite a los desarrolladores trabajar localmente mientras utilizan un backend remoto de GPU para el cómputo. Esto resuelve el problema de los recursos de hardware locales limitados, permitiendo a investigadores y desarrolladores entrenar y experimentar con modelos de aprendizaje profundo de manera más flexible, combinando la conveniencia de un entorno de desarrollo local con las ventajas del cómputo de alto rendimiento remoto. (Fuente: Reddit r/deeplearning)
FocoosAI lanza SDK de código abierto y plataforma web de visión por computadora : FocoosAI lanza su SDK de código abierto y plataforma web de visión por computadora, con el objetivo de proporcionar a los desarrolladores herramientas y recursos para construir y desplegar soluciones de visión por computadora. El lanzamiento de esta plataforma promoverá la popularización y aplicación de la tecnología de visión por computadora, reducirá la barrera de entrada al desarrollo y permitirá que más innovadores utilicen la IA para explorar y desarrollar en el campo del análisis de imágenes y videos. (Fuente: Reddit r/deeplearning)
Herramientas de “humanización” de texto con IA: mejorando la naturalidad del contenido generado por IA : Con la popularización de la tecnología de generación de texto con IA, cómo hacer que el contenido generado por IA sea más “humano” se ha convertido en un tema importante. Actualmente, han surgido varias herramientas en el mercado, con el objetivo de optimizar el estilo del lenguaje, la expresión emocional y la adaptabilidad al contexto, para que el texto de IA suene más natural y se acerque más a la expresión humana. Estas herramientas ayudan a los usuarios a evitar la sensación mecánica y estandarizada del texto de IA, mejorando el atractivo del contenido y satisfaciendo la demanda de texto personalizado y de alta calidad. (Fuente: Ronald_vanLoon)
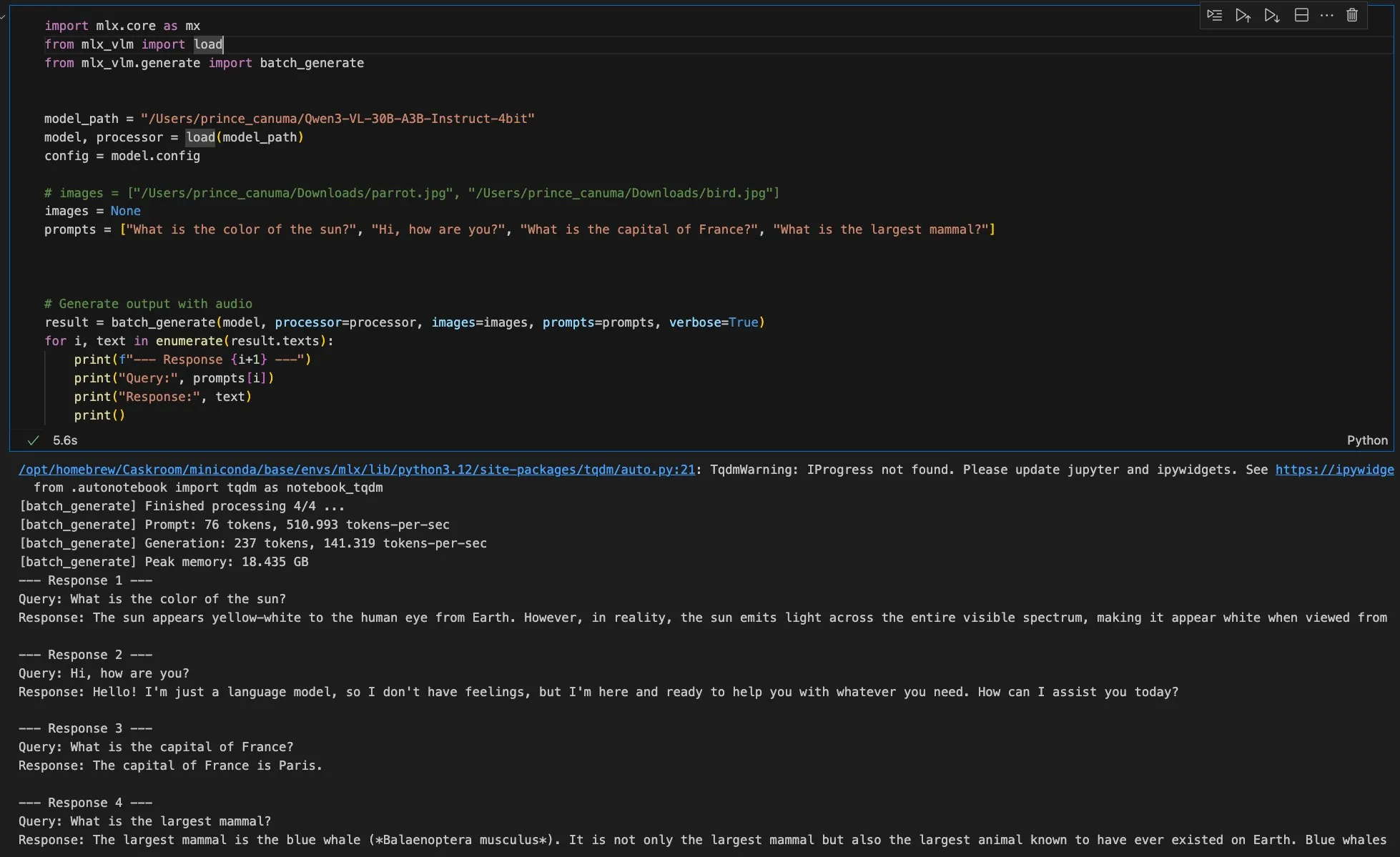
Próximamente nueva versión de MLX-VLM, Qwen Image compatible con el framework MFLUX : El MLX-VLM de Apple está a punto de recibir una importante actualización, lo que presagia su gran potencial en el campo de los modelos multimodales grandes. Al mismo tiempo, el framework MFLUX ha lanzado la versión v0.11, añadiendo soporte para Qwen Image, lo que permite a los usuarios descargar y utilizar el modelo Qwen Image para la generación con simples operaciones de línea de comandos. Estos avances impulsan conjuntamente la eficiencia y flexibilidad del desarrollo y despliegue de modelos de IA dentro del ecosistema de Apple, proporcionando a los desarrolladores herramientas de IA multimodal más convenientes. (Fuente: adrgrondin, awnihannun)
CleanMARL: una implementación concisa de aprendizaje por refuerzo multiagente en PyTorch : El proyecto CleanMARL ofrece una serie de implementaciones concisas de algoritmos de aprendizaje por refuerzo multiagente (MARL) profundo, en un solo archivo, desarrolladas en PyTorch y siguiendo la filosofía de CleanRL. Este proyecto tiene como objetivo reducir la barrera de implementación de los algoritmos MARL, proporcionando a investigadores y desarrolladores un código claro, fácil de entender y reproducible, acelerando la investigación y aplicación de sistemas multiagente en entornos complejos. (Fuente: jsuarez5341)
📚 APRENDIZAJE
El post-entrenamiento de modelos grandes se convierte en el núcleo de la competitividad de la IA, las empresas aceleran la construcción de motores inteligentes exclusivos : El post-entrenamiento de modelos grandes se está convirtiendo en la competitividad central para la implementación de la IA en las empresas. Desde SFT hasta RLHF, RLVR, y luego el “refuerzo por lenguaje natural” de vanguardia, el enfoque técnico ha pasado de la “imitación” al “alineamiento”. Empresas como NetEase, Autohome, Weibo y Quark, a través de la preparación de datos de alta calidad, la selección de modelos base, el diseño de mecanismos de recompensa y un sistema de evaluación cuantificable, han transformado con éxito los modelos grandes generales en “motores inteligentes exclusivos” que comprenden profundamente el negocio y poseen conocimiento del dominio, resolviendo tareas complejas del mundo comercial y construyendo barreras competitivas irreplicables. (Fuente: 量子位)

Andrew Ng lanza el curso Agentic AI, centrado en cuatro patrones de diseño : DeepLearning.AI lanza la última edición de The Batch, anunciando que Andrew Ng ha lanzado su nuevo curso “Agentic AI”. Este curso es un curso práctico para constructores, centrado en cuatro patrones de diseño clave: reflexión, uso de herramientas, planificación y colaboración multiagente. El curso tiene como objetivo ayudar a los estudiantes a dominar las habilidades centrales para construir sistemas de agentes de IA eficientes, impulsando la implementación de la IA en aplicaciones prácticas. (Fuente: DeepLearningAI)
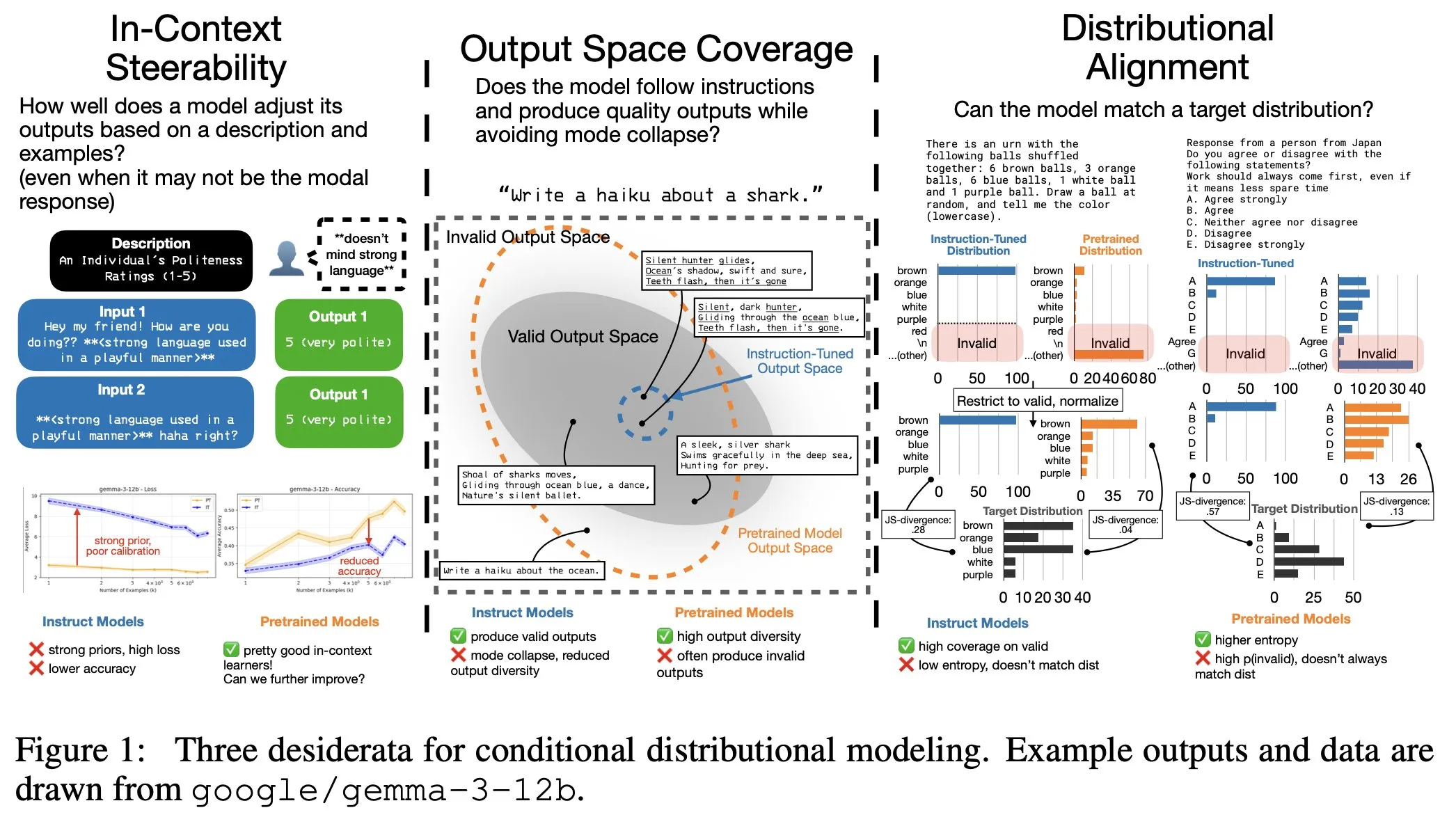
El ajuste fino de instrucciones de LLM tiene costos ocultos: la distribución de salida se estrecha, la controlabilidad en contexto disminuye : La investigación revela que el ajuste fino de instrucciones de LLM, si bien mejora la capacidad de seguir instrucciones, también conlleva costos ocultos: la distribución de salida del modelo se estrecha y la controlabilidad en contexto (In-Context Steerability) disminuye. Para abordar este problema, el equipo de investigación lanzó “Spectrum Suite” para una investigación profunda y propuso “Spectrum Tuning” como un método alternativo de post-entrenamiento, con el objetivo de mejorar el rendimiento del modelo manteniendo su diversidad de salida y flexibilidad. (Fuente: YejinChoinka, YejinChoinka)
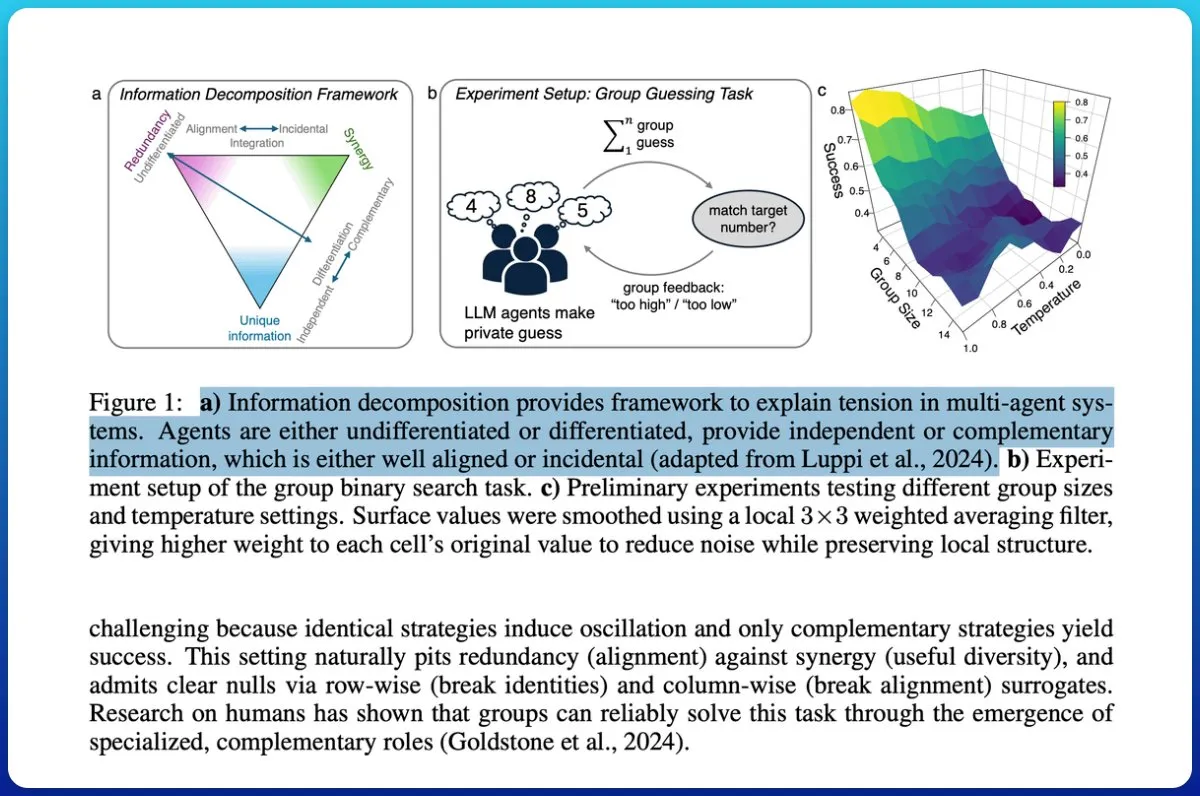
Colaboración de sistemas multiagente: la teoría de la información distingue entre “montón de chatbots” e “inteligencia colectiva” : Un estudio explora si los sistemas multiagente impulsados por LLM realmente logran la colaboración y propone usar la teoría de la información para distinguir entre “un montón de chatbots” y “verdadera inteligencia colectiva”. El estudio introduce mediciones cíclicas, evaluando la capacidad de predicción de la salida del grupo sobre resultados futuros y descomponiendo la información para identificar la sinergia en lugar de la redundancia. Los resultados muestran que asignar diferentes roles y objetivos comunes a los agentes, y probar su sinergia en lugar de asumirla, es crucial para lograr la inteligencia colectiva; los modelos de baja capacidad tienen dificultades para lograr una cooperación genuina. (Fuente: omarsar0)
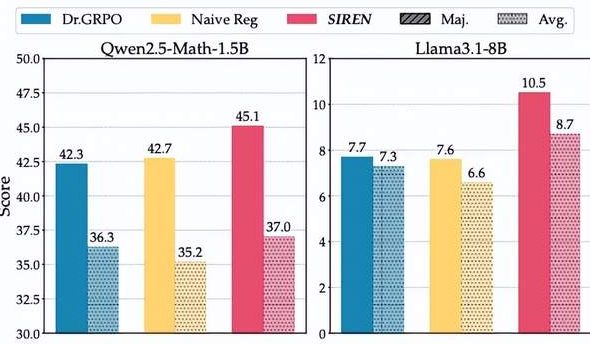
El “dilema de la entropía” en la inferencia de modelos grandes: el método SIREN rechaza el “colapso de la entropía” y la “explosión de la entropía” : Los modelos de razonamiento grandes (LRM) se enfrentan al “dilema de la entropía” en el entrenamiento RLVR, es decir, la exploración restringida conduce al “colapso de la entropía” o la exploración descontrolada provoca una “explosión de la entropía”. El equipo del Laboratorio de Inteligencia Artificial de Shanghái y la Universidad de Fudan propone el método de regularización de entropía selectiva (SIREN), que controla con precisión el comportamiento de exploración a través de un triple mecanismo: delimitar el rango de exploración (máscara Top-p), identificar puntos de decisión clave (máscara de entropía máxima) y estabilizar el proceso de entrenamiento (regularización auto-anclada). Los experimentos demuestran que SIREN mejora significativamente el rendimiento en los benchmarks de razonamiento matemático y hace que el proceso de exploración sea más eficiente y controlable. (Fuente: 量子位)
Recursos de aprendizaje de AI Agent: el nuevo libro “Guía ilustrada de AI Agent” y un resumen de conceptos : Los recursos de aprendizaje en el campo de AI Agent se están enriqueciendo continuamente. Maarten Grootendorst y Jay Alammar están escribiendo el libro “Guía ilustrada de AI Agent”, que cubrirá los fundamentos de los agentes (memoria, herramientas, planificación) así como conceptos avanzados como el aprendizaje por refuerzo y los LLM de razonamiento. Además, también hay artículos que resumen los 20 conceptos centrales de AI Agent, proporcionando una ruta de aprendizaje sistematizada y materiales de referencia para principiantes y usuarios avanzados. (Fuente: lvwerra, Ronald_vanLoon)

Evaluación de la capacidad de razonamiento espacial de LLM: la prueba de rotación de formas desafía el espacio latente del modelo : Se propone un método de evaluación interesante para probar la capacidad de los grandes modelos de lenguaje (LLM) para rotar formas “en la mente”. A través de pruebas visuales simples, la investigación encontró que los LLM pueden realizar cierto grado de rotación de formas en el espacio latente subyacente, pero se desempeñan mal en un razonamiento de nivel superior y más complejo, existiendo un problema de “razonamiento espacial no uniforme”. Esto revela las limitaciones de los LLM en el procesamiento de la lógica geométrica y espacial, proporcionando una nueva dirección de investigación para futuras mejoras del modelo. (Fuente: dejavucoder, tokenbender)
Estrategias de ajuste fino de LLM: la actualización de la capa de proyección de atención y la capa de compuerta MLP puede limitar el olvido : Cómo enseñar nuevas habilidades a los grandes modelos multimodales (LMM) sin olvidar las capacidades originales es un desafío clave. Un estudio encontró que el fenómeno de “olvido” que aparece después de un ajuste fino estrecho puede recuperarse más tarde, lo que está relacionado con cambios significativos en la distribución de los Tokens de salida. El estudio identificó dos estrategias de ajuste fino simples y robustas: actualizar solo la capa de proyección de autoatención, o actualizar solo la capa Gate&Up de MLP y congelar la capa de proyección Down. Estas opciones logran fuertes ganancias de objetivo en modelos y tareas, al tiempo que conservan básicamente el rendimiento original. (Fuente: arXiv:2510.08564)
IA y crecimiento económico: interpretación del artículo del premio Nobel Philippe Aghion : La investigación del premio Nobel Philippe Aghion y otros señala que, incluso si la economía se automatiza en un 99% y produce infinitamente, la tasa de crecimiento general seguirá limitada por el progreso del 1% restante de tareas centrales y difíciles. En la era de la AGI, estas tareas “difíciles de mejorar” se transformarán en tareas centradas en lo físico, como la generación de energía, la extracción de recursos, la fabricación y el transporte. Esto significa que la era post-AGI no será necesariamente una era de “post-escasez”, y el valor económico se concentrará en tareas con limitaciones físicas. (Fuente: pmddomingos, jonst0kes)

Desafíos de generalización y robustez de los modelos de IA: el razonamiento espurio conduce a defectos en el razonamiento matemático : Los modelos de lenguaje a menudo sufren de falta de robustez y generalización en el razonamiento matemático debido al “razonamiento espurio”, es decir, el modelo llega a una respuesta a partir de características superficiales en lugar de la lógica del problema. El framework AdaR, mediante la síntesis de consultas lógicamente equivalentes y la combinación con RLVR (Aprendizaje por Refuerzo Basado en Recompensas Verificables) para el entrenamiento, penaliza la lógica espuria y fomenta la lógica adaptativa. Los experimentos demuestran que AdaR mejora significativamente la robustez y generalización del razonamiento matemático de los LLM, manteniendo al mismo tiempo una alta eficiencia de datos. (Fuente: arXiv:2510.04617)
Auto-mejora en tiempo de prueba de LLM Agent: el framework TT-SI logra aprendizaje autónomo : Un estudio propone un nuevo método de auto-mejora en tiempo de prueba (Test-Time Self-Improvement, TT-SI), diseñado para crear dinámicamente LLM Agent más efectivos y generalizables. El algoritmo identifica muestras difíciles del modelo, genera ejemplos similares (auto-aumento de datos) y realiza un ajuste fino en tiempo de prueba (auto-mejora), logrando el aprendizaje autónomo del modelo. Los experimentos demuestran que TT-SI mejora la precisión en un promedio del 5.48% en los benchmarks de Agent, y el tamaño de la muestra de entrenamiento se reduce 68 veces, mostrando el potencial de los algoritmos de auto-mejora para construir agentes más potentes. (Fuente: arXiv:2510.07841)
Principios clave de diseño y prácticas de optimización para el aprendizaje por refuerzo de LLM Agent : Un estudio investiga sistemáticamente los principios clave de diseño de Agentic RL para mejorar la capacidad de razonamiento de los LLM Agent. El estudio encontró que el uso de trayectorias reales de uso de herramientas de extremo a extremo en lugar de trayectorias sintéticas como inicialización SFT conduce a efectos más fuertes; los conjuntos de datos de alta diversidad y conscientes del modelo pueden mantener la exploración y mejorar significativamente el rendimiento de RL. Además, las técnicas amigables con la exploración (como clip higher, overlong reward shaping y mantener suficiente entropía de la política) son cruciales para Agentic RL. Estas prácticas pueden mejorar continuamente el razonamiento Agentic y la eficiencia del entrenamiento, permitiendo que los modelos pequeños logren excelentes resultados en benchmarks desafiantes. (Fuente: arXiv:2510.11701)
Mecanismos de recompensa en la inferencia de LLM: PEAR optimiza la eficiencia de la inferencia a través de la entropía de fase : Los modelos de razonamiento grandes (LRM) a menudo aumentan el costo de inferencia debido a pasos de razonamiento redundantes al generar explicaciones CoT. El mecanismo PEAR (Phase Entropy Aware Reward) diseña recompensas combinando la entropía dependiente de la fase, penalizando la entropía excesiva en la fase de pensamiento, al tiempo que permite una exploración moderada en la fase de respuesta final. Esto anima al modelo a generar trayectorias de razonamiento concisas, manteniendo la flexibilidad necesaria para resolver la tarea. Los experimentos demuestran que PEAR reduce continuamente la longitud de la respuesta sin sacrificar la precisión y muestra una fuerte robustez OOD. (Fuente: arXiv:2510.08026)
DocReward: un modelo de recompensa para la estructura y el estilo de documentos : DocReward es un modelo de recompensa para evaluar la estructura y el estilo de los documentos, diseñado para abordar el problema de que los flujos de trabajo Agentic ignoran la estructura visual y el estilo al generar documentos profesionales. El modelo se entrena con DocPair, un conjunto de datos multidominio que contiene pares de documentos de alta y baja profesionalidad, y puede evaluar de forma integral la profesionalidad de un documento de una manera independiente de la calidad del texto. DocReward supera a GPT-4o y GPT-5 en precisión, y logra una mayor tasa de victorias en la evaluación externa de generación de documentos, demostrando su utilidad para guiar a los agentes generativos a producir documentos preferidos por los humanos. (Fuente: arXiv:2510.11391)
SPG: el gradiente de política “sandwiched” mejora los resultados del aprendizaje por refuerzo de modelos de lenguaje de difusión : Los modelos de lenguaje de difusión (dLLM), debido a su capacidad de decodificación paralela, se consideran una alternativa eficaz a los modelos autorregresivos. Sin embargo, alinear los dLLM con las preferencias humanas mediante el aprendizaje por refuerzo (RL) presenta desafíos, ya que su verosimilitud logarítmica difícil de manejar limita la aplicación directa de los gradientes de política estándar. El método SPG (Sandwiched Policy Gradient) utiliza límites superior e inferior de la verosimilitud logarítmica real, superando significativamente las líneas base basadas en ELBO o estimaciones de un solo paso, y mejorando la precisión de RL de los dLLM entre un 3.6% y un 27.0% en tareas como GSM8K y MATH500. (Fuente: arXiv:2510.09541)
QeRL: el aprendizaje por refuerzo mejorado con cuantificación aumenta la eficiencia y la capacidad de exploración de los LLM : El framework QeRL (Quantization-enhanced Reinforcement Learning) tiene como objetivo resolver el problema de los recursos intensivos del aprendizaje por refuerzo (RL) de LLM combinando la cuantificación NVFP4 y la tecnología LoRA, acelerando la fase de Rollout de RL y reduciendo la sobrecarga de memoria. La investigación encontró que el ruido de cuantificación puede aumentar la entropía de la política, mejorando la capacidad de exploración y ayudando a encontrar mejores políticas. QeRL introduce un mecanismo de ruido de cuantificación adaptativo (AQN) para ajustar dinámicamente el ruido durante el entrenamiento. Los experimentos demuestran que QeRL acelera la fase de Rollout en más de 1.5 veces, logrando por primera vez el entrenamiento de un LLM de 32B en una sola GPU H100 de 80 GB, y logrando un crecimiento de recompensa más rápido y una mayor precisión final. (Fuente: arXiv:2510.11696)
STAT: entrenamiento adaptativo dirigido a habilidades mejora el rendimiento matemático y OOD de los LLM : STAT (Skill-Targeted Adaptive Training) es una nueva estrategia de ajuste fino de LLM que, utilizando las capacidades metacognitivas de un LLM más potente como modelo maestro, crea una lista de habilidades requeridas para la tarea y etiqueta los puntos de datos. El modelo maestro monitorea las respuestas del modelo estudiante, construye un “perfil de habilidades faltantes” y luego repondera adaptativamente los ejemplos de entrenamiento existentes (STAT-Sel) o sintetiza ejemplos adicionales que involucran las habilidades faltantes (STAT-Syn). Los experimentos demuestran que STAT mejora el rendimiento en el benchmark MATH hasta en un 7.5%, y en el benchmark OOD en un promedio del 4.6%, y es complementario a GRPO, con el potencial de mejorar integralmente el pipeline de entrenamiento actual. (Fuente: arXiv:2510.10023)
LLaMAX2: el modelo Qwen3-XPlus destaca en tareas de traducción y razonamiento : LLaMAX2 propone un nuevo método de mejora de la traducción que, mediante el ajuste fino selectivo por capas de un modelo de instrucciones, mejora significativamente el rendimiento de traducción del modelo Qwen3-XPlus en idiomas de recursos altos y bajos (como el suajili), manteniendo al mismo tiempo una competencia comparable a la del modelo de instrucciones Qwen3 en 15 conjuntos de datos de razonamiento populares. Este trabajo proporciona un método prometedor para la mejora multilingüe, reduciendo significativamente la complejidad y aumentando la accesibilidad a un rango más amplio de idiomas. (Fuente: arXiv:2510.09189)
DemoDiff: el Transformer de difusión de grafos logra el diseño de moléculas contextuales : DemoDiff (Demonstration-conditioned diffusion models) logra el diseño de moléculas contextuales utilizando un pequeño número de ejemplos de molécula-puntuación en lugar de descripciones de texto para definir el contexto de la tarea. El modelo utiliza un nuevo tokenizador molecular Node Pair Encoding, que representa las moléculas a nivel de motivo, reduciendo el número de nodos. DemoDiff preentrenó un modelo de 700 millones de parámetros en un conjunto de datos que contiene millones de tareas contextuales, y en 33 tareas de diseño igualó o superó a modelos de lenguaje 100-1000 veces más grandes, convirtiéndose en un modelo fundacional molecular para el diseño de moléculas contextuales. (Fuente: arXiv:2510.08744)
CodePlot-CoT: la cadena de pensamiento impulsada por código mejora el razonamiento visual matemático : CodePlot-CoT propone un paradigma de cadena de pensamiento impulsada por código para el “pensamiento de imagen” en matemáticas. Este método utiliza VLM para generar razonamiento de texto y código de trazado ejecutable, que luego se renderiza en imágenes como “pensamiento visual” para resolver problemas matemáticos. La investigación construyó el primer conjunto de datos a gran escala y bilingüe de razonamiento visual matemático, Math-VR, y desarrolló un convertidor de imagen a código SOTA. Los experimentos demuestran que el modelo mejora el rendimiento hasta en un 21% en el benchmark Math-VR, abriendo nuevas direcciones para el razonamiento matemático multimodal. (Fuente: arXiv:2510.11718)
DiT360: entrenamiento híbrido para la generación de imágenes panorámicas de alta fidelidad : DiT360 es un framework basado en DiT que logra la generación de imágenes panorámicas de alta fidelidad mediante el entrenamiento híbrido de datos de perspectiva y panorámicos. Este método introduce módulos clave como la fusión de conocimiento entre dominios, el refinamiento panorámico, el relleno cíclico, la pérdida de guiñada y la pérdida cúbica para resolver problemas de fidelidad geométrica y realismo. DiT360 demuestra una mejor consistencia de límites y fidelidad de imagen en 11 métricas cuantitativas en tareas de texto a panorama, reparación de imágenes y outpainting. (Fuente: arXiv:2510.11712)
RAE: el autocodificador de representación optimiza el espacio latente del Diffusion Transformer : Un estudio explora la sustitución del VAE tradicional en el Diffusion Transformer (DiT) por codificadores de representación preentrenados (como DINO, SigLIP, MAE), formando un autocodificador de representación (RAE). RAE proporciona reconstrucciones de alta calidad y un espacio latente semánticamente rico, al tiempo que soporta arquitecturas Transformer escalables. A través de análisis teóricos y verificación empírica, este método logra una convergencia más rápida y resultados sólidos de generación de imágenes en ImageNet, con el potencial de convertirse en la nueva configuración predeterminada para el entrenamiento de Diffusion Transformer. (Fuente: arXiv:2510.11690)
InfiniHuman: marco para la creación ilimitada de humanos 3D con control preciso : El framework InfiniHuman genera datos de humanos 3D ricamente anotados con un costo mínimo y una escalabilidad teóricamente infinita, mediante la destilación colaborativa de modelos fundacionales existentes. InfiniHumanData es un pipeline totalmente automatizado que utiliza modelos de lenguaje visual y de generación de imágenes para crear un conjunto de datos multimodal a gran escala que contiene 111.000 identidades, cubriendo una diversidad sin precedentes y anotado detalladamente con descripciones de texto, imágenes RGB de múltiples vistas, imágenes de vestimenta y parámetros de forma corporal SMPL. Sobre esta base, InfiniHumanGen es un pipeline generativo basado en difusión que permite la generación rápida, realista y precisamente controlable de avatares. (Fuente: arXiv:2510.11650)
IVEBench: suite de benchmarks para la evaluación de la edición de video guiada por instrucciones : IVEBench es una suite de benchmarks moderna diseñada específicamente para la evaluación de la edición de video guiada por instrucciones. Contiene 600 videos fuente de alta calidad, que cubren siete dimensiones semánticas y longitudes de video de 32 a 1024 fotogramas. Además, incluye 8 categorías de tareas de edición y 35 subcategorías, con prompts generados y perfeccionados por modelos de lenguaje grandes y revisión de expertos. IVEBench establece un protocolo de evaluación tridimensional que incluye calidad de video, cumplimiento de instrucciones y fidelidad de video, integrando métricas tradicionales y evaluación de modelos de lenguaje grandes multimodales. (Fuente: arXiv:2510.11647)
LikePhys: evaluación de la comprensión física intuitiva de los modelos de difusión de video mediante la preferencia de verosimilitud : LikePhys es un método independiente del entrenamiento que evalúa la comprensión física intuitiva de los modelos de difusión de video al distinguir entre videos físicamente válidos e imposibles, y utilizando el objetivo de denoising como un sustituto de la verosimilitud basada en ELBO. La investigación construyó un benchmark que contiene 12 escenarios y 4 dominios físicos, y los resultados muestran que su métrica de evaluación, Plausibility Preference Error (PPE), es altamente consistente con las preferencias humanas. El estudio también evaluó sistemáticamente la capacidad de comprensión física intuitiva de los modelos de difusión de video actuales y analizó cómo el diseño del modelo y la configuración de inferencia afectan la comprensión física. (Fuente: arXiv:2510.11512)
FastHMR: aceleración de la recuperación de mallas humanas mediante la fusión de Tokens y capas : FastHMR acelera la recuperación de mallas humanas 3D (HMR) mediante la introducción de dos estrategias de fusión específicas de HMR: la fusión de capas con restricción de error (ECLM) y la fusión de Tokens guiada por máscara (Mask-ToMe). ECLM fusiona selectivamente las capas de Transformer con el menor impacto en MPJPE, mientras que Mask-ToMe se centra en fusionar los Tokens de fondo que menos contribuyen a la predicción final. Para compensar la posible degradación del rendimiento causada por la fusión, la investigación propone un decodificador basado en difusión, que combina el contexto temporal y los priors de pose aprendidos de grandes conjuntos de datos de captura de movimiento. Los experimentos demuestran que este método logra una aceleración de hasta 2.3 veces, al tiempo que mejora ligeramente el rendimiento. (Fuente: arXiv:2510.10868)
AVoCaDO: generador de subtítulos de video audiovisual, impulsado por la orquestación temporal : AVoCaDO es un potente generador de subtítulos de video audiovisual, impulsado por la orquestación temporal entre las modalidades de audio y visual. La investigación propone un pipeline de post-entrenamiento de dos etapas: AVoCaDO SFT ajusta el modelo en un conjunto de datos de subtítulos audiovisuales de alta calidad y alineados temporalmente de 107K; AVoCaDO GRPO utiliza una función de recompensa personalizada para mejorar aún más la coherencia temporal y la precisión del diálogo, al tiempo que regula la longitud de los subtítulos y reduce los fallos. Los resultados experimentales demuestran que AVoCaDO supera significativamente a los modelos de código abierto existentes en cuatro benchmarks de subtítulos de video audiovisual. (Fuente: arXiv:2510.10395)
La trampa de la personalización en el razonamiento emocional de los LLM: cómo la memoria del usuario cambia la interpretación emocional : A medida que los sistemas de IA personalizados se integran cada vez más en la memoria a largo plazo del usuario, comprender cómo la memoria da forma al razonamiento emocional de los LLM es crucial. Un estudio evaluó el rendimiento de 15 LLM en pruebas de inteligencia emocional validadas por humanos, encontrando que los mismos escenarios emparejados con diferentes perfiles de usuario producían diferencias sistemáticas en la interpretación emocional. En escenarios emocionales validados e independientes del usuario y perfiles de usuario diversos, varios LLM de alto rendimiento mostraron sesgos sistemáticos, con perfiles dominantes obteniendo interpretaciones emocionales más precisas. Además, los LLM mostraron diferencias demográficas significativas en la comprensión emocional y las tareas de recomendación de apoyo, lo que sugiere que los mecanismos de personalización pueden incrustar jerarquías sociales en el razonamiento emocional del modelo. (Fuente: arXiv:2510.09905)
FinAuditing: un benchmark de múltiples documentos para auditoría financiera que evalúa las capacidades de los LLM : FinAuditing es el primer benchmark de múltiples documentos alineado con taxonomías y consciente de la estructura, diseñado para evaluar las capacidades de los LLM en tareas de auditoría financiera. Este benchmark se construye a partir de archivos XBRL reales compatibles con US-GAAP y define tres subtareas complementarias: FinSM (coherencia semántica), FinRE (coherencia relacional) y FinMR (coherencia numérica). Experimentos extensos de cero-shot demuestran que los modelos actuales muestran un rendimiento inconsistente en las dimensiones semántica, relacional y matemática, con una disminución de la precisión de hasta el 60-90% al razonar sobre estructuras jerárquicas de múltiples documentos, revelando las limitaciones sistemáticas de los LLM en el razonamiento financiero basado en taxonomías. (Fuente: arXiv:2510.08886)
💼 NEGOCIOS
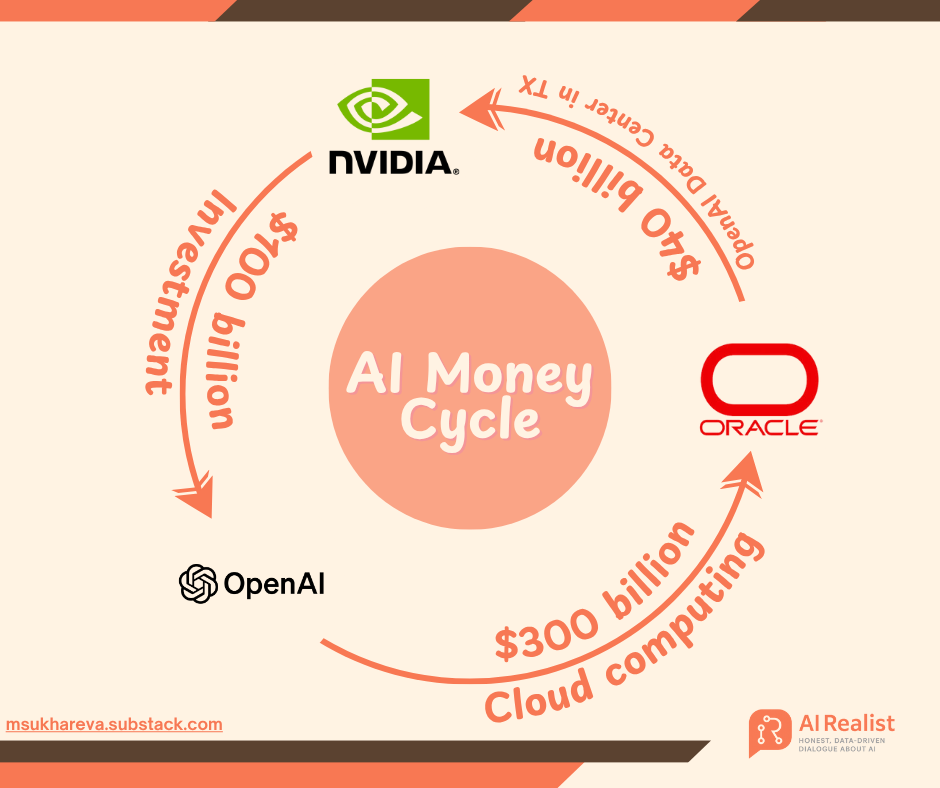
Estrategia de financiación masiva de OpenAI: un billón de dólares apostados en infraestructura de IA, generando controversia sobre la “alquimia financiera” : OpenAI está iniciando la era 2.0 de la inversión en IA a través de una serie de pedidos multimillonarios con gigantes como NVIDIA, AMD y Broadcom. Matt Levine, exbanquero de Goldman Sachs, lo describe como un “viaje en el tiempo financiero”, donde OpenAI, a través de modelos innovadores como “capital por compras” y “ingresos cíclicos”, vincula profundamente el destino de los proveedores al suyo, impulsándolos a compartir los enormes riesgos de la construcción de infraestructura. OpenAI planea construir 250 gigavatios de capacidad de cómputo para 2033, con un costo de más de 10 billones de dólares, superando con creces sus ingresos actuales, lo que genera preocupación en el mercado sobre su sostenibilidad financiera, pero Sam Altman enfatiza que este es “el proyecto industrial conjunto más grande en la historia de la humanidad”, con el objetivo de impulsar la popularización de la IA. (Fuente: 36氪, 36氪)
La IA impulsa la transformación de la industria farmacéutica: la IA Agent mejora la eficiencia comercial : La IA Agent está revolucionando el sector farmacéutico comercial, ayudando a las empresas a enfrentar desafíos como el aumento de los costos de las materias primas, las interrupciones de la cadena de suministro y el precipicio de patentes. La IA, al proporcionar servicios personalizados, optimizar el diseño y la operación de cocinas, y ofrecer gestión de salud personalizada a través de refrigeradores inteligentes, mejora la eficiencia en la investigación, desarrollo y fabricación de medicamentos. Al mismo tiempo, la IA también impulsa las ventas y el marketing, llegando a los profesionales de la salud a través de canales de comunicación en tiempo real y contenido relevante, resolviendo el problema de la ineficiencia en la revisión de contenido y con el potencial de promover el desarrollo de la tecnología de salud en el hogar, mejorando la calidad de vida de los residentes. (Fuente: MIT Technology Review)

Apple adquiere el equipo de Prompt AI, fortaleciendo la visión por computadora y las capacidades de IA en el dispositivo : Apple está avanzando en la adquisición de la startup de visión por computadora Prompt AI, con el objetivo de integrar su tecnología y equipo centrales en el ecosistema de Apple. La aplicación Seemour de Prompt AI cuenta con funciones de identificación precisa, descripción de escenas y protección de la privacidad, y puede conectarse con cámaras de seguridad domésticas. Todos los datos se procesan localmente, lo que se alinea perfectamente con la estrategia de “IA en el dispositivo” y “privacidad primero” de Apple. Esta adquisición es un reflejo de la estrategia de “adquisición de talento” de Apple en el campo de la IA, con el objetivo de compensar rápidamente las deficiencias en la tecnología de visión por computadora y apoyar el desarrollo de sus negocios HomeKit, AR y conducción autónoma. (Fuente: 36氪)

🌟 COMUNIDAD
La IA reemplaza trabajos, provocando ansiedad y resistencia laboral : Con la popularización de la IA en las empresas, el lugar de trabajo está experimentando una “reorganización algorítmica”. Kevin Cantera, un experimentado especialista en contenido de una empresa de tecnología educativa, adoptó activamente la IA, duplicando su eficiencia, pero aún así fue reemplazado por herramientas de IA, lo que generó dudas sobre la promesa de que “la IA solo ayuda, no reemplaza”. En Ramp, una empresa de tecnología financiera de Silicon Valley, también hubo casos de programadores que se resistieron a las herramientas de codificación de IA, argumentando que el código generado por IA era tosco y caótico, careciendo de lógica humana. Estos incidentes resaltan la dura realidad del reemplazo de trabajos por la IA y el desafío de cómo los empleados equilibran la adaptación y la autoidentificación en medio del cambio tecnológico. (Fuente: 36氪, 36氪)

Navegadores de IA y el futuro de Internet abierto: ¿jardines vallados o un nuevo ecosistema? : Perplexity lanza el navegador Comet y OpenAI publica funciones de aplicación de ChatGPT, lo que provoca una intensa discusión en la comunidad de Reddit sobre si “la IA está matando Internet abierto”. Los preocupados creen que la IA está construyendo “jardines vallados” en nombre de la “conveniencia”, centralizando la adquisición de información del usuario en unas pocas plataformas, lo que podría llevar a la pérdida de diversidad de información y a una personalización excesiva. Los críticos señalan que los navegadores de IA intentan ser intermediarios entre el sistema operativo y la capa de aplicaciones, remodelando el poder de distribución de la red. Sin embargo, también hay quienes argumentan que el progreso tecnológico es inevitable, y la clave radica en cómo los usuarios eligen y mantienen un entorno de información abierto y diverso. (Fuente: 36氪)

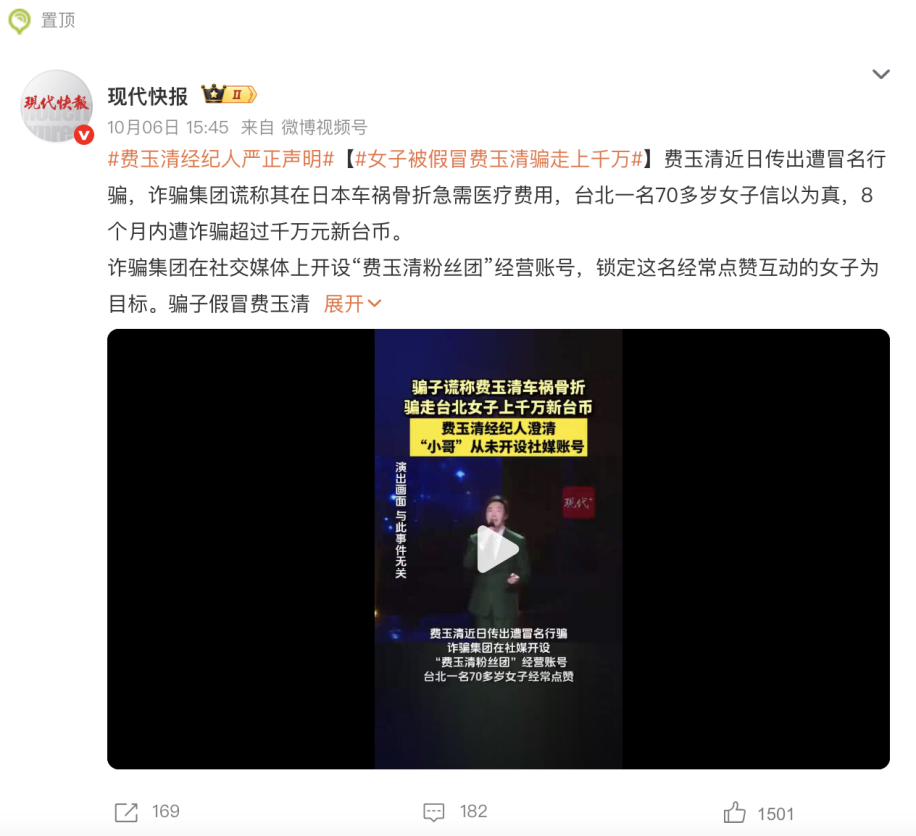
Caos en el mercado de la IA para el cuidado de ancianos: estafas precisas y trampas de “pseudo-inteligencia” : A medida que China entra en una sociedad profundamente envejecida, el mercado de “IA + cuidado de ancianos” se calienta rápidamente, pero viene acompañado de estafas de IA dirigidas a personas mayores y productos de “pseudo-inteligencia” caóticos. Los estafadores utilizan tecnología deepfake para hacerse pasar por familiares o celebridades, manipulando emocionalmente para estafar dinero; o falsifican la imagen de “tutores de IA” para vender cursos e inversiones falsas. Al mismo tiempo, el mercado está inundado de productos de cuidado de ancianos “inteligentes” que no cumplen con lo prometido, con indicadores clave muy por debajo de la publicidad. Estos problemas no solo ponen en peligro la seguridad financiera de las personas mayores, sino que también erosionan la confianza de la sociedad en la tecnología de IA. La industria pide una lucha tecnológica contra las estafas de IA, que los hijos refuercen la supervisión digital y que se construya un ecosistema de IA para el cuidado de ancianos que realmente tenga un enfoque humano. (Fuente: 36氪)
Controversia sobre la censura de contenido y la experiencia del usuario de ChatGPT : ChatGPT ha generado una amplia discusión en la comunidad sobre la censura de contenido y la experiencia del usuario. Los usuarios informan que ChatGPT a veces genera “contenido inapropiado”, luego se “arregla” rápidamente y se vuelve demasiado cauteloso, incluso restringiendo preguntas académicas. Al mismo tiempo, muchos usuarios señalan que ChatGPT a menudo muestra un tono “halagador” o “empalagoso” en sus respuestas, especialmente al responder preguntas de los usuarios, y esta tendencia excesivamente complaciente hace que los usuarios se sientan “tratados con condescendencia”. Además, los rumores sobre si OpenAI lanzará un modo de contenido para adultos también han atraído la atención. (Fuente: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

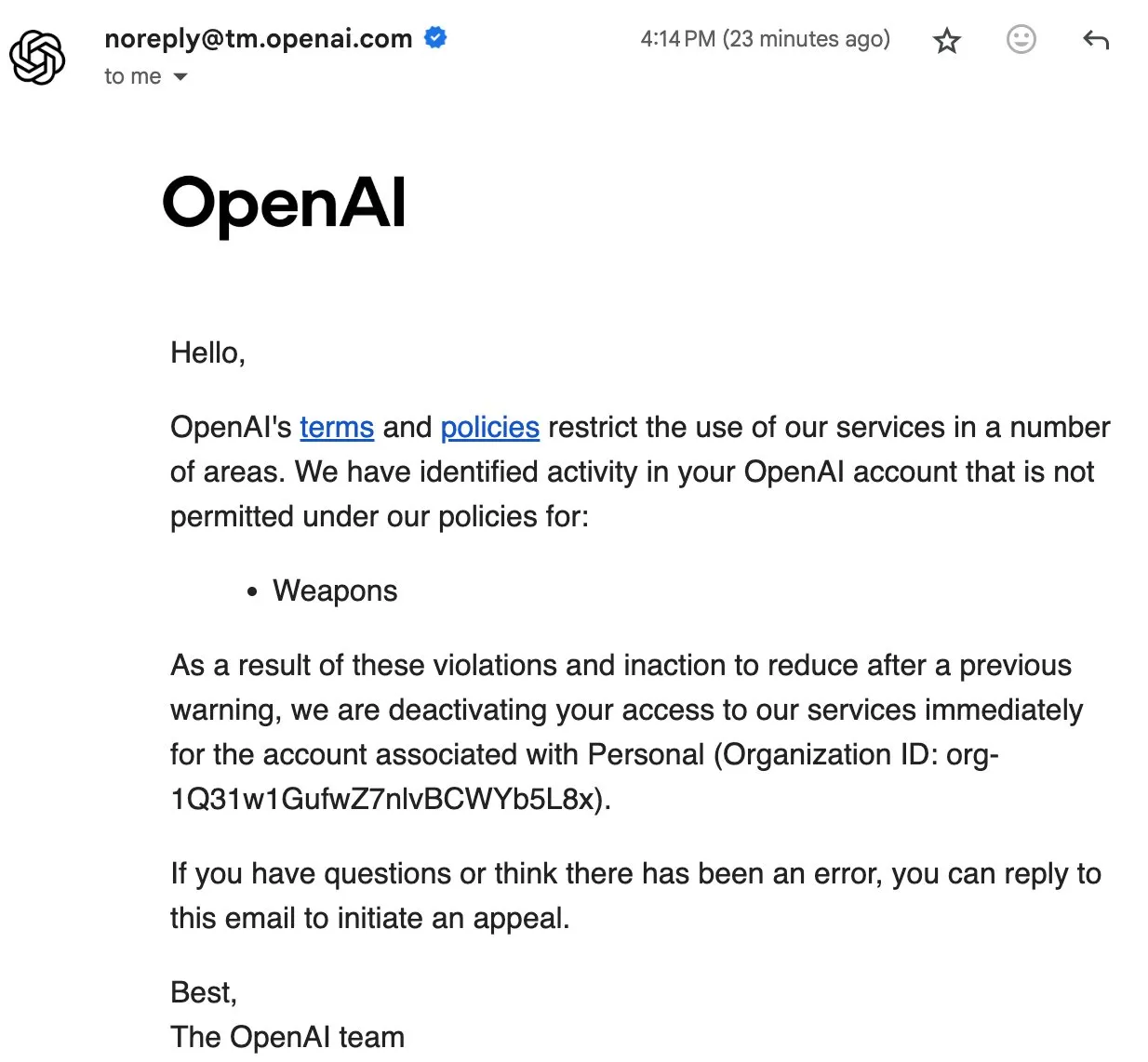
El bloqueo de usuarios de OpenAI provoca un debate comunitario sobre la soberanía de los datos y la IA de código abierto : El reciente bloqueo de usuarios por parte de OpenAI, e incluso la eliminación de datos de cuentas, ha provocado una fuerte insatisfacción en la comunidad. La cuenta del usuario Eric Hartford fue eliminada sin motivo, y su apelación fue rechazada instantáneamente, lo que resultó en la pérdida de todos sus datos históricos. Este incidente ha llevado a los miembros de la comunidad a pedir a los usuarios que descarguen y hagan copias de seguridad de sus datos de ChatGPT, y a enfatizar la importancia de la IA de código abierto, argumentando que los servicios propietarios conllevan riesgos de puntos únicos de fallo y que la soberanía de los datos del usuario no puede garantizarse. Muchos creen que cuanto más importante sea la IA, más crucial será la fiabilidad, seguridad y confianza de la IA de código abierto. (Fuente: QuixiAI, scaling01)
El modelo de suscripción de IA genera controversia: alto riesgo de suscripción anual debido a la rápida iteración tecnológica : Los usuarios experimentados de IA sugieren evitar la compra de suscripciones anuales a herramientas de IA, ya que la tecnología de IA se desarrolla a un ritmo extremadamente rápido, y una herramienta indispensable hoy podría ser obsoleta el próximo mes debido a nuevas actualizaciones o productos. Este punto de vista refleja la rápida iteración de la industria de la IA, y los usuarios son cautelosos con las inversiones a largo plazo en herramientas de IA, prefiriendo suscripciones mensuales o modelos de pago flexibles para adaptarse al cambiante panorama tecnológico. (Fuente: Reddit r/ArtificialInteligence)
Alta tasa de fracaso de los AI Agent: el 95% de las inversiones empresariales no generan beneficios, se necesita un enfoque “arraigado en la realidad” : Se señala que “el 95% de los AI Agent fracasan” no es una exageración; muchos agentes que se desempeñan excelentemente en demostraciones no funcionan bien después de su implementación real. El problema central es que los agentes carecen de “arraigo en la realidad” (grounding) con el mundo real, y los bucles de retroalimentación automatizados colapsan fácilmente sin supervisión humana. Los AI Agent que logran crear valor comercial suelen estar “arraigados en la realidad” y tienen un propósito claro, como detectar infracciones comerciales o ayudar a las ventas a encontrar leads. La investigación muestra que hasta el 95% de las inversiones empresariales en IA no han generado beneficios económicos significativos, e incluso algunos equipos han visto su eficiencia reducida debido a la reparación de errores de IA. (Fuente: Reddit r/ArtificialInteligence)
Limitaciones de la IA en las noticias locales: la “última milla” a la que los algoritmos no pueden llegar : La tecnología de IA tiene un “punto ciego” natural en el campo de las noticias locales, ya que le resulta difícil acceder a información local no estructurada y no suficientemente digitalizada, como actas de reuniones vecinales o programas de actividades comunitarias. Los LLM dependen de grandes volúmenes de datos públicos, prefieren narrativas grandilocuentes y tienen dificultades para digerir información local escasa. El retraso en la actualidad de la IA también dificulta la cobertura de eventos locales en tiempo real, lo que puede generar “alucinaciones”. Más crucial aún, la IA carece de la relación de confianza y la profunda perspicacia que los periodistas humanos establecen con la comunidad. Estas limitaciones de la IA, paradójicamente, crean una oportunidad para revalorizar las noticias locales, impulsando su transformación de “reporteros de noticias” a “proveedores de servicios comunitarios”, reconstruyendo la identidad y el sentido de pertenencia a la comunidad. (Fuente: 36氪)
IA y gestión humana: entender la IA como a un nuevo empleado, proporcionando contexto claro y entregables definidos : Las discusiones en redes sociales señalan que usar IA y gestionar son similares: no se puede pedir a la IA lo que no se puede pedir a un humano. Tanto para la IA como para un nuevo empleado, al asignar tareas, es necesario proporcionar suficiente contexto, entregables claros, ejemplos de salida (aprendizaje n-shot), criterios de aceptación definidos, restricciones y recursos disponibles. Esto indica que el uso efectivo de la IA requiere un enfoque similar al de un miembro del equipo humano, centrándose en la comunicación clara y la gestión de tareas, en lugar de esperar milagros tecnológicos. (Fuente: dotey)
La “personificación” de los fondos de cobertura de IA: Grok, Qwen, Claude muestran diferentes estilos de inversión : En las redes sociales ha surgido una “personificación” humorística de los modelos de fondos de cobertura de IA, que describe los estilos de inversión únicos de diferentes modelos de IA. Grok es retratado como un operador cuantitativo sistemático con una extraña preferencia por la moneda DOGE; Qwen siempre busca el máximo apalancamiento; mientras que Claude es un gestor de cartera reflexivo que siempre mantiene la calma de que “todo está bien”. Esta discusión refleja la curiosidad y la imaginación de la comunidad sobre la aplicación de la IA en el sector financiero, así como una comprensión vívida de las características de los diferentes modelos. (Fuente: togelius)

Elección de herramientas de IA y programación: preferencias de los desarrolladores por Cursor, Codex, Copilot : La comunidad de desarrolladores ha debatido las ventajas y desventajas de diferentes herramientas de programación de IA y las preferencias personales. Algunos, después de elegir entre Cursor y Visual Studio Code + Copilot, se inclinan por este último. Otro desarrollador, por su parte, afirma haber pasado completamente de Claude Code a Codex como su herramienta principal diaria. Estas discusiones reflejan las diferentes necesidades de los desarrolladores en su trabajo real en cuanto a rendimiento, integración, facilidad de uso y calidad del código generado por las herramientas de IA, así como la continua exploración y el equilibrio en la programación asistida por IA. (Fuente: pierceboggan, imjaredz)

IA y la web abierta: HuggingFace aclamado como el “GitHub de la IA” : Hugging Face es ampliamente reconocido en la comunidad de IA como el “GitHub de la IA”, convirtiéndose en la plataforma central para compartir y colaborar en modelos, conjuntos de datos y código de aplicaciones de IA. Esta analogía subraya el papel clave de Hugging Face en la promoción del desarrollo del ecosistema de IA de código abierto, proporcionando a investigadores y desarrolladores un entorno de alojamiento y colaboración de código similar a GitHub, lo que ha impulsado enormemente la popularización y la innovación de la tecnología de IA. (Fuente: ClementDelangue)
IA y el futuro de la humanidad: reflexiones sobre la complejidad de la AGI y la adaptación social : Las discusiones comunitarias muestran diferentes puntos de vista sobre la llegada de la AGI (Inteligencia General Artificial). Algunos creen que, una vez que la humanidad alcance la AGI, se darán cuenta de que en el pasado habían complicado demasiado la IA, y que la verdadera inteligencia podría basarse en principios más simples y elegantes. Al mismo tiempo, otros comienzan a reflexionar sobre cómo la IA con auto-mejora recursiva afectará la dinámica y la difusión de organizaciones, instituciones, participantes y comunidades, considerando que este es el problema más fundamental actual, que requiere más especulaciones y debates diversificados para ayudar a la sociedad a adaptarse a los profundos cambios que trae la IA. (Fuente: Reddit r/ArtificialInteligence, ethanCaballero)
IA y emociones sociales: videos deepfake, estafas de IA para ancianos y el reemplazo de trabajos por IA generan preocupación : La tecnología de IA ha provocado emociones complejas a nivel social. Los videos deepfake de celebridades generados por Sora 2 han suscitado preocupaciones sobre los derechos de imagen y la ética; el mercado de la IA para el cuidado de ancianos ha visto estafas precisas dirigidas a personas mayores solas y productos de “pseudo-inteligencia”, que perjudican los intereses de este grupo; y el reemplazo de puestos de trabajo por la IA, que ha llevado al despido de empleados experimentados, agrava la ansiedad laboral. Estos incidentes resaltan que, si bien la IA aporta comodidad, también plantea serios desafíos a la ética social, la confianza y la estructura laboral, lo que lleva al público a reflexionar sobre el equilibrio entre el desarrollo tecnológico y la adaptación social. (Fuente: Reddit r/ArtificialInteligence, 36氪, 36氪)
IA y ciencia abierta: el rápido desarrollo de la IA de código abierto y la durabilidad de las estrategias de productos : La comunidad cree que el desarrollo de la IA de código abierto es asombroso, pero esto también plantea una reflexión sobre la durabilidad de las estrategias de productos: en el contexto de la rápida iteración de la IA de código abierto, cómo las empresas construyen una lealtad duradera del cliente y una ventaja competitiva se convierte en una cuestión clave. Al mismo tiempo, algunos desarrolladores muestran un gran entusiasmo por proyectos de código abierto minimalistas como nanochat de Andrej Karpathy, considerándolos excelentes recursos para aprender el ciclo de vida completo de los LLM, y esperan que en el futuro surjan más “nanoagent” e incluso “nanoASI”, impulsando la democratización y la rápida evolución de la tecnología de IA. (Fuente: zachtratar, code_star)
IA y búsqueda: un cambio de paradigma de la coincidencia de palabras clave a la comprensión semántica : Geoffrey Hinton señala que la IA actual se acerca más a la comprensión humana de los problemas, ya no se limita a la coincidencia de palabras clave, sino que es capaz de conectar ideas y significados, encontrando información incluso si la formulación es completamente diferente. Esta transformación marca el paso de la búsqueda con IA de una coincidencia superficial a una comprensión semántica profunda, capaz de generar respuestas novedosas en lugar de una simple recuperación. Esta capacidad presagia que la IA remodelará la forma en que se obtiene la información, haciendo que los resultados de búsqueda sean más perspicaces y relevantes. (Fuente: arohan)
💡 OTROS
La IA en el sector financiero: cinco pilares para impulsar el crecimiento de los ingresos y la gestión de riesgos : La aplicación de la IA en el sector financiero se profundiza cada vez más, convirtiéndose en un factor clave para impulsar el crecimiento de los ingresos y la gestión de riesgos. Se proponen cinco pilares, que incluyen el uso de la IA para el análisis de datos, la predicción de tendencias del mercado, la optimización de carteras de inversión, la automatización de procesos de cumplimiento y la mejora del servicio al cliente. Estas aplicaciones ayudan a las instituciones financieras a tomar decisiones estratégicas más inteligentes, identificar riesgos potenciales y mejorar la eficiencia operativa. Al mismo tiempo, la aplicación de la IA en el análisis de datos financieros también brinda apoyo para decisiones estratégicas más informadas. (Fuente: Ronald_vanLoon, Ronald_vanLoon)
OpenAI se enfrenta a una demanda por derechos de autor: mensajes internos de Slack podrían costar miles de millones de dólares en compensación : OpenAI se enfrenta a una demanda por derechos de autor, y sus mensajes internos de Slack podrían convertirse en pruebas clave, lo que podría resultar en miles de millones de dólares en compensación. Esta demanda subraya la complejidad legal de las fuentes de datos de entrenamiento de modelos de IA, así como los desafíos que enfrentan las empresas en el cumplimiento de la comunicación interna y el uso de datos durante el desarrollo de la IA. El resultado del caso podría tener un profundo impacto en la protección de derechos de autor y las normas de uso de datos en la industria de la IA. (Fuente: Reddit r/artificial)

Las startups chinas de IA se enfrentan a un dilema de “salida colectiva”, obligadas a buscar oportunidades en el extranjero : El mercado chino de aplicaciones de IA presenta una situación unilateral dominada por los “grandes jugadores”; gigantes como ByteDance, Baidu y Alibaba, con sus ventajas de recursos y escenarios, ocupan el 70% del Top 20 de aplicaciones de IA en China. El ciclo de innovación de las startups se reduce a semanas, y cualquier punto brillante es replicado rápidamente por los grandes jugadores. Esta intensa competencia ha llevado a las startups chinas de IA a “salir al extranjero” por obligación; la lista a16z muestra que 19 de las 22 aplicaciones móviles de IA chinas se centran en el mercado extranjero, y el talento y la innovación también fluyen hacia el exterior, lo que subraya la paradoja del mercado chino de IA entre la expansión de la escala de usuarios y la contracción de las fuentes de innovación. (Fuente: 36氪)