Palavras-chave:Tecnologia de IA, Modelos de Linguagem de Grande Escala, Aprendizado Profundo, Inteligência Artificial, Aprendizado de Máquina, Processamento de Linguagem Natural, Visão Computacional, Aprendizado por Reforço, Projeto Open Source Nanochat, Chip de IA desenvolvido pela OpenAI, Ética Profunda do Sora 2, Claude Sonnet 4.5, Raciocínio Matemático do GPT-5 Pro
🔥 Foco
Andrej Karpathy lança nanochat: ChatGPT feito à mão por US$ 100 : Andrej Karpathy, ex-diretor de IA da Tesla, lançou o projeto de código aberto nanochat, que implementa o processo completo de treinamento e inferência do ChatGPT com menos de 8.000 linhas de código. O projeto visa reduzir a barreira de entrada para a pesquisa de LLM, permitindo que os usuários configurem um mini ChatGPT conversacional com apenas uma GPU em nuvem (cerca de US$ 100, 4 horas de treinamento), e com 12 horas de treinamento, o desempenho pode superar as métricas do GPT-2 CORE. O nanochat será o projeto final do curso LLM101n e tem potencial para se tornar uma plataforma de pesquisa ou ferramenta de benchmark, refletindo a paixão contínua de Karpathy pela educação e democratização da IA. (Fonte: GitHub nanochat, Reddit r/deeplearning, 36氪, 36氪, 36氪, 36氪)
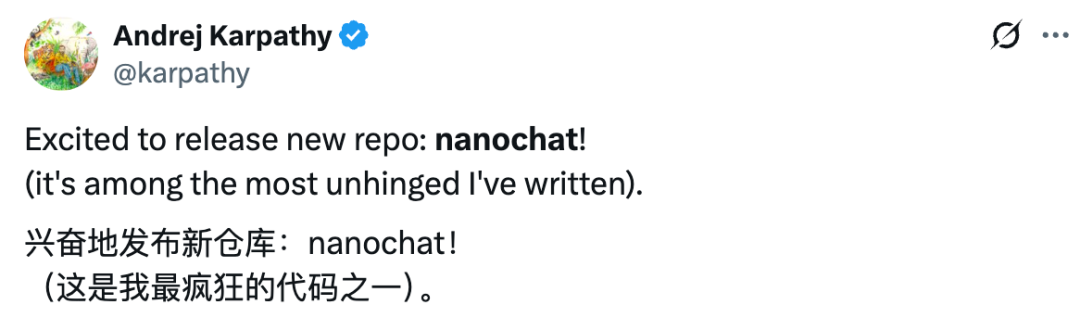
OpenAI e Broadcom unem forças para desenvolver chips de IA próprios, implantando infraestrutura de computação de 10 gigawatts : A OpenAI anunciou uma colaboração estratégica com a Broadcom para projetar e implantar conjuntamente chips de IA personalizados e sistemas de computação, com o objetivo de implantar uma infraestrutura de inferência com consumo total de energia de 10 gigawatts entre o segundo semestre de 2026 e o final de 2029. Essa iniciativa marca que a OpenAI não se contenta mais em comprar GPUs existentes, mas busca, por meio da integração vertical, participar do design de hardware desde o nível do transistor, para otimizar o desempenho dos modelos de IA, reduzir custos e atender à demanda exponencialmente crescente por capacidade de computação no futuro. A OpenAI afirmou que essa colaboração é “o maior projeto industrial conjunto na história da humanidade”, chegando a usar modelos de IA para auxiliar no design dos chips, o que prenuncia o profundo envolvimento da IA no desenvolvimento de hardware. (Fonte: OpenAI, Bloomberg, CNBC, 36氪, 36氪, 36氪)
Sora 2 desencadeia crise ética de deepfake e controvérsia de direitos autorais : O modelo de geração de vídeo Sora 2 da OpenAI rapidamente se tornou popular devido à sua capacidade de geração altamente realista, mas também trouxe sérios desafios éticos e de direitos autorais. Usuários utilizaram o Sora 2 para gerar vídeos falsos de celebridades falecidas (como Michael Jackson, Robin Williams), provocando forte insatisfação de suas famílias, que consideram isso um abuso e desrespeito à imagem dos falecidos. A OpenAI respondeu que figuras públicas e suas famílias devem ter controle sobre como suas imagens são usadas, e planeja oferecer controles de direitos autorais mais refinados e mecanismos de divisão de receita. No entanto, a indústria está amplamente preocupada que a crescente popularidade dos modelos de deepfake de código aberto exija que a sociedade se adapte rapidamente ao impacto do conteúdo gerado por IA e explore medidas eficazes de proteção técnica e legal. (Fonte: Washington Post, BBC, 量子位)

Claude Sonnet 4.5, Microsoft Agent Framework e Cursor IDE impulsionam um salto na capacidade de codificação de IA : O campo da codificação de IA testemunha avanços significativos: Claude Sonnet 4.5 atinge uma precisão de 77,2% no benchmark SWE-bench Verified, superando notavelmente os modelos anteriores. Simultaneamente, o Microsoft Agent Framework transforma o VS Code em um ambiente nativo de IA, permitindo que os Agents lidem autonomamente com modificações de código em vários arquivos; o Cursor IDE 1.7 também lança um “Modo Agent”, capaz de resolver problemas complexos com um clique. Esses progressos indicam que os AI Agents já podem assumir a maioria das tarefas de desenvolvimento, levantando discussões sobre a possível dependência excessiva dos desenvolvedores em relação à IA e os riscos potenciais de dívida técnica introduzidos pelo código gerado por IA. (Fonte: Reddit r/artificial)
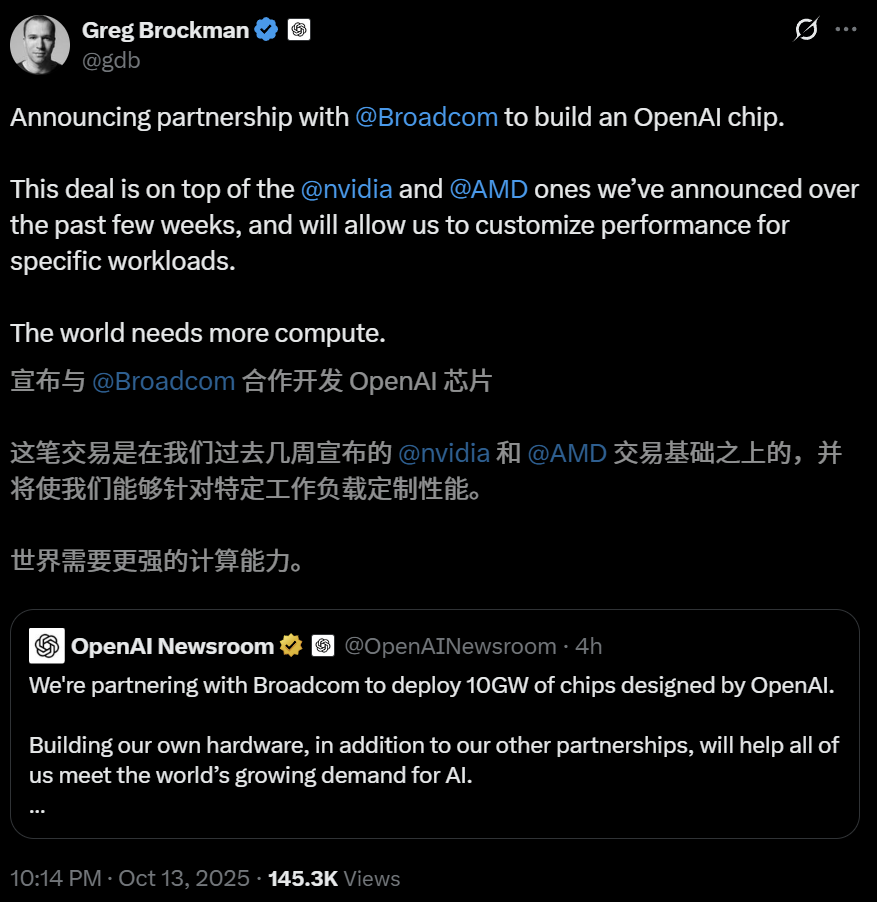
GPT-5 Pro resolve problema matemático de Erdős, demonstrando forte capacidade de recuperação de literatura e identificação de falhas : O GPT-5 Pro da OpenAI demonstrou uma capacidade surpreendente no raciocínio matemático, recuperando com precisão a literatura chave que mostra que o problema de Erdős #339 já havia sido resolvido em 2003, apenas a partir de uma imagem do problema. Além disso, o GPT-5 Pro foi capaz de descobrir falhas graves em artigos publicados em 18 minutos, superando até mesmo dias de pesquisa de especialistas humanos. Esse avanço destaca o enorme potencial do GPT-5 Pro na recuperação precisa de informações, resolução de problemas complexos e validação de literatura científica, prenunciando que a IA acelerará enormemente o processo de pesquisa, especialmente na verificação de afirmações acadêmicas e na descoberta de contradições lógicas. (Fonte: Sebastien Bubeck, Greg Brockman, 36氪)
Três gigantes da IA unem-se para publicar artigo: as defesas de segurança atuais dos LLMs são frágeis : OpenAI, Anthropic e Google DeepMind uniram-se em uma rara colaboração para publicar um artigo, apontando que os mecanismos de defesa atuais contra jailbreaks e prompt injections em Large Language Models (LLMs) são geralmente frágeis. A equipe de pesquisa propôs uma estrutura de ataque adaptativa universal e, combinando métodos como gradiente descendente, aprendizado por reforço, busca aleatória e testes de red team humanos, conseguiu contornar 12 mecanismos de defesa principais, com a maioria dos ataques obtendo uma taxa de sucesso superior a 90%. Isso indica que as avaliações existentes são em grande parte teóricas, e a pesquisa futura em segurança de LLMs deve incorporar avaliações de ataque adaptativas mais fortes para construir um sistema de defesa verdadeiramente robusto. (Fonte: arXiv:2510.09023, 36氪)

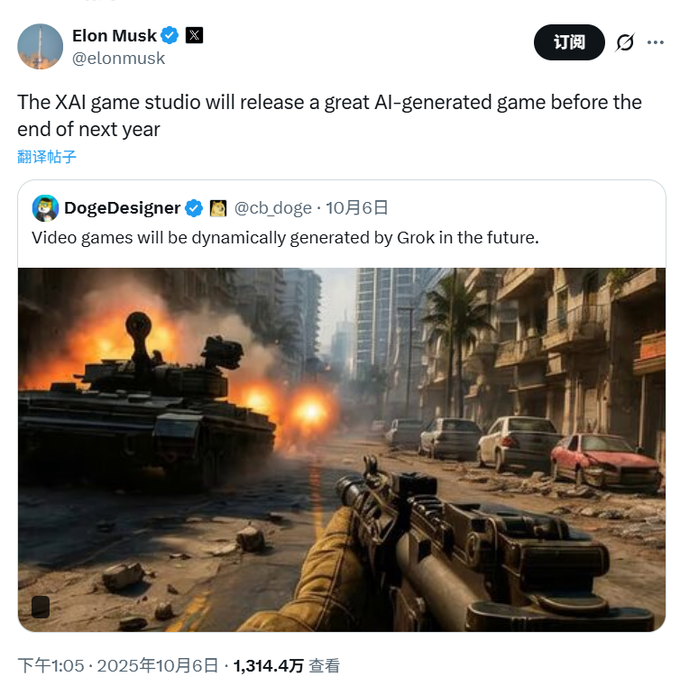
xAI entra na corrida dos “modelos de mundo”, com a primeira aplicação visando a geração de jogos de IA : A xAI, empresa de Elon Musk, entrou discretamente na corrida dos “modelos de mundo”, competindo com gigantes como Google e Meta. A xAI contratou especialistas em IA da NVIDIA para construir modelos capazes de compreender e simular o mundo físico real, treinando-os com vastas quantidades de dados de vídeo e robótica. Seu primeiro ponto de comercialização é a geração de jogos de IA, com planos de lançar jogos gerados por IA até o final do próximo ano, e explorar aplicações em sistemas robóticos. Pesquisadores do Google acreditam que os futuros modelos de vídeo serão tão inteligentes quanto os modelos de linguagem, desbloqueando capacidades emergentes como segmentação de objetos e detecção de bordas através da “previsão do próximo frame”, prenunciando um “momento GPT para o domínio visual”. (Fonte: 36氪)
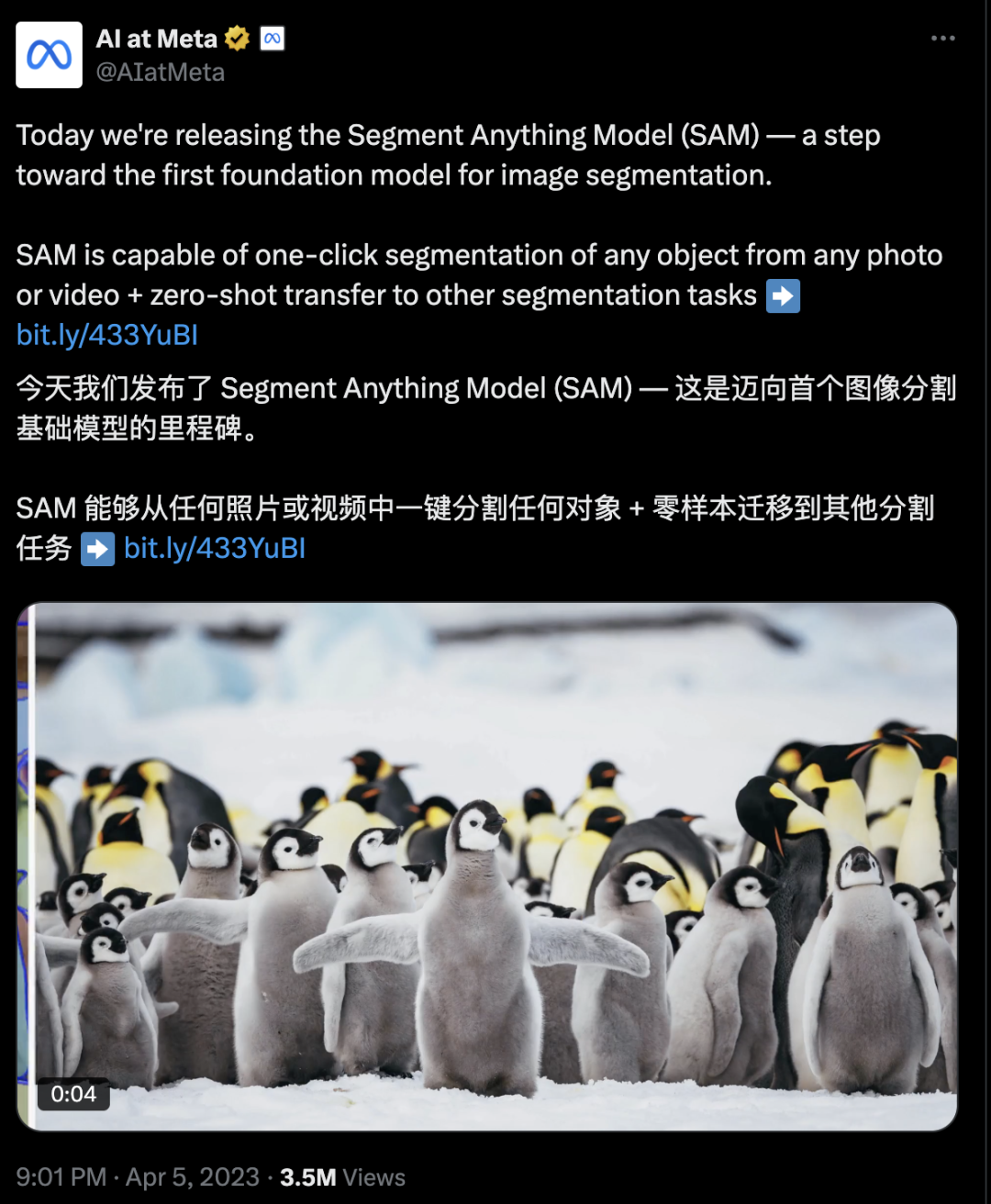
Artigo misterioso da ICLR revela SAM3: segmentando tudo com conceitos, reestruturando o novo paradigma da IA visual : Um artigo de revisão cega da conferência ICLR 2026, “SAM3: Segmentando tudo com conceitos”, foi revelado, indicando que o Segment Anything Model (SAM) da Meta AI receberá sua terceira grande atualização. O principal avanço do SAM3 reside na “segmentação baseada em conceitos” (PCS), onde o modelo não apenas segmenta por pixel ou instância, mas também pode identificar, segmentar e rastrear todos os objetos que correspondem a um “conceito semântico” específico, com base em prompts de texto ou imagem. O novo sistema, através de um motor de dados colaborativo humano-máquina, construiu um conjunto de dados de alta qualidade contendo 4 milhões de rótulos de conceitos, e alcançou a identificação de centenas de objetos em 30 milissegundos em uma GPU H200, superando completamente os sistemas existentes e prenunciando que o “momento GPT-3” para a IA visual pode não estar longe. (Fonte: arXiv:r35clVtGzw, 36氪)
🎯 Tendências
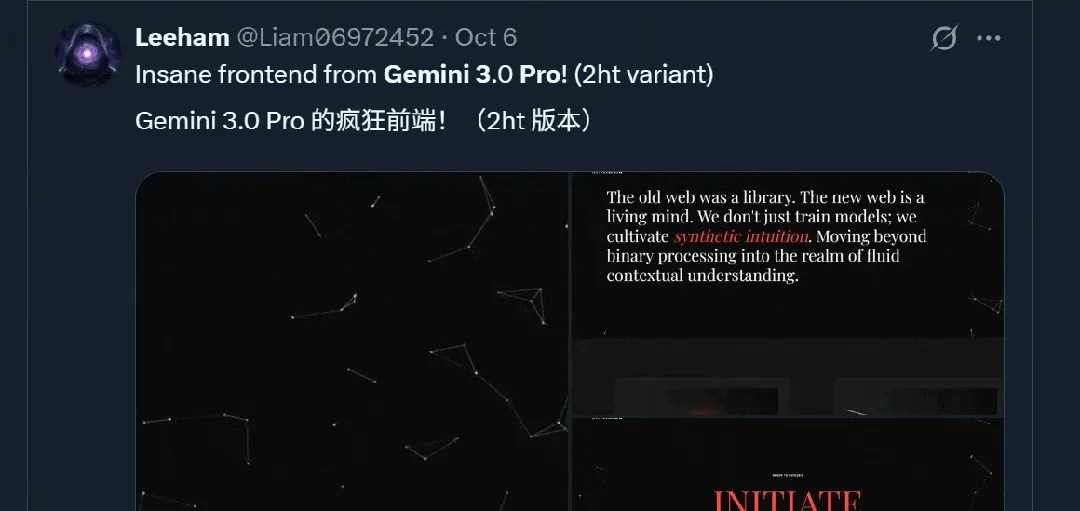
Gemini 3 recebe boas avaliações em testes internos, elogiado como “o modelo de desenvolvimento frontend mais poderoso da história” : A próxima geração do modelo carro-chefe do Google, Gemini 3, atraiu ampla atenção em testes internos, com usuários elogiando suas capacidades em desenvolvimento frontend, geração de gráficos vetoriais SVG e multimodalidade, chamando-o de “o melhor modelo de desenvolvimento frontend e web de todos os tempos”, e alguns até prevendo que será o melhor modelo do ano. Informações vazadas indicam que o Gemini 3.0 Pro utiliza uma arquitetura MoE, possui trilhões de parâmetros, uma janela de contexto expandida para milhões, e incorpora um modo de pensamento profundo e capacidades multimodais, com excelente desempenho nos benchmarks ARC-AGI-2 e HLE. (Fonte: 36氪)
A aplicação da IA no design e fabricação de chips se aprofunda cada vez mais : O Machine Learning está sendo cada vez mais aplicado no design e fabricação de chips, impulsionando a eficiência e a inovação em semicondutores a novos níveis. O AIHub entrevistou Lorenzo Servadei, chefe de design de chips da Sony AI, que apontou que a IA no campo de EDA (Electronic Design Automation) está progredindo de acelerar estimativas para participar ativamente do processo de design, acelerando modelos multifísicos, otimizando algoritmos e utilizando IA generativa para implementação física através de redes neurais, o que melhora significativamente a velocidade, qualidade e criatividade do design de chips. A OpenAI também revelou que seus modelos GPT auxiliaram no design de seus próprios chips, resultando em redução de área e aceleração do ciclo de desenvolvimento. (Fonte: aihub.org, 36氪)

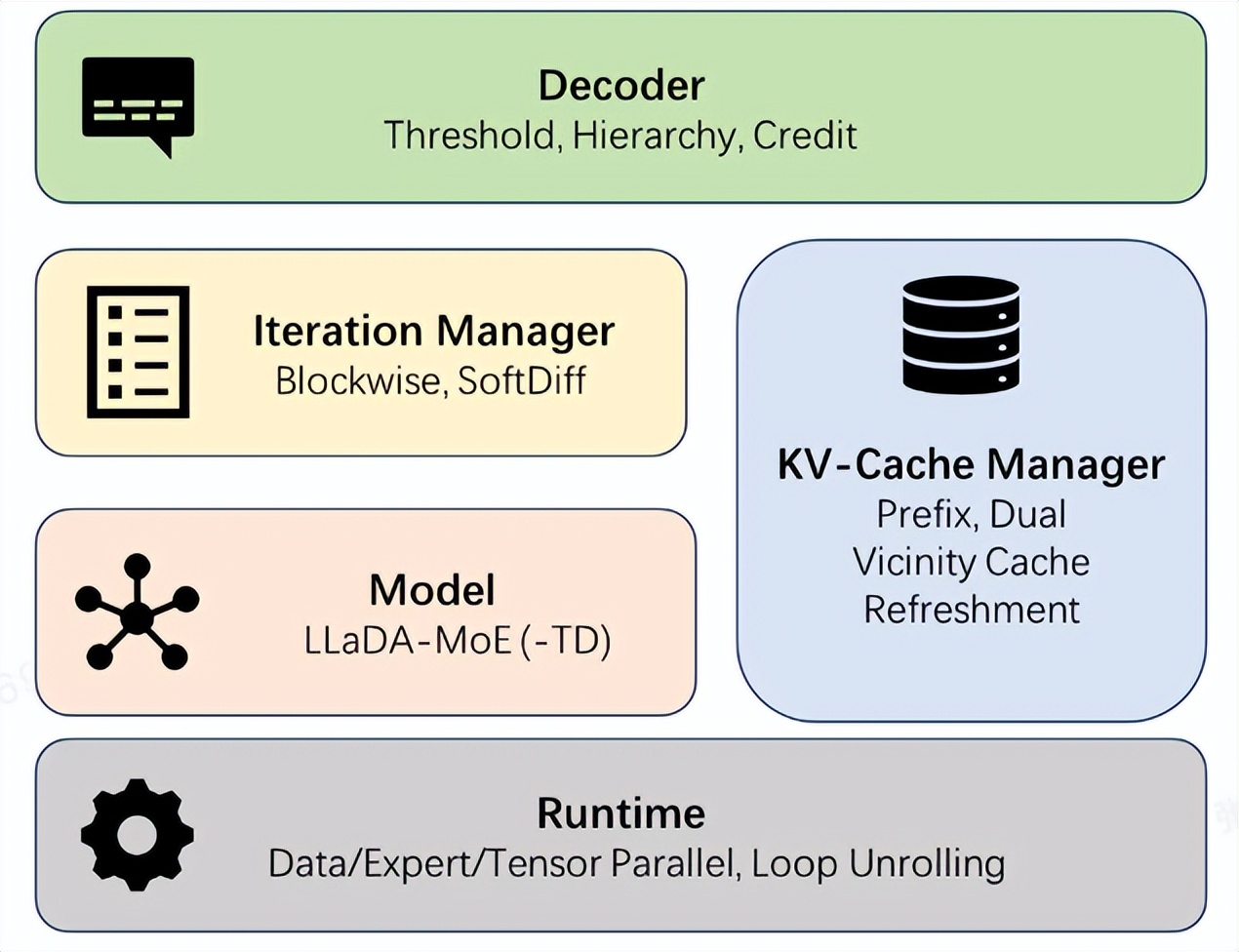
Ant Group lança framework dInfer de código aberto, acelerando a inferência de modelos de linguagem de difusão em 10 vezes : O Ant Group lançou oficialmente o dInfer, o primeiro framework de inferência de alto desempenho para modelos de linguagem de difusão da indústria, que acelera a inferência desses modelos em 10,7 vezes em comparação com o Fast-dLLM da NVIDIA. Na tarefa de geração de código HumanEval, o dInfer atingiu 1011 Tokens/segundo em inferência de lote único, superando significativamente os modelos autorregressivos pela primeira vez. O dInfer adota um design de colaboração profunda entre algoritmo e sistema, incluindo quatro módulos principais: acesso ao modelo, gerenciador de cache KV, gerenciador de iteração de difusão e estratégia de decodificação, visando resolver os desafios de alto custo computacional, falha de cache KV e decodificação paralela em modelos de linguagem de difusão, liberando seu potencial de inferência eficiente. (Fonte: 量子位, QuixiAI)
Google NotebookLM atualiza, Gemini Nano Banana capacita novos estilos visuais para resumos de vídeo : A função de resumo de vídeo do Google NotebookLM foi atualizada, adicionando vários estilos visuais (clássico, quadro branco, aquarela, impressão vintage, tradicional, arte em papel, anime) e sendo alimentada pelo modelo de geração de imagens Gemini Nano Banana. Além disso, foi introduzido um formato “Brief” mais conciso, oferecendo resumos rápidos. Essas atualizações serão lançadas primeiro para usuários Pro e, nas próximas semanas, para todos os usuários, visando aprimorar a experiência personalizada do usuário na compreensão e apresentação de conteúdo de vídeo. (Fonte: Google, op7418)
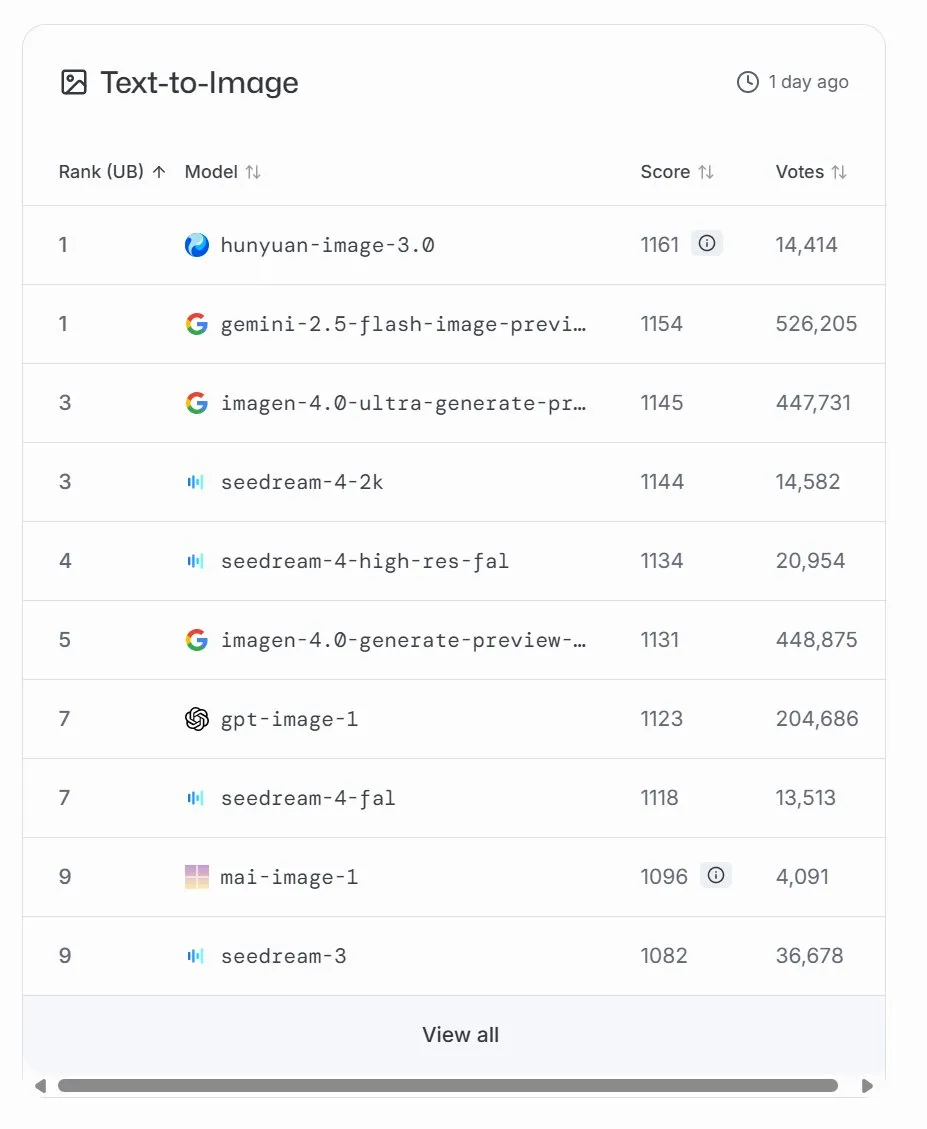
Microsoft lança modelo de geração de imagens MAI-Image-1, ocupa o nono lugar no LMArena : A Microsoft AI lançou seu terceiro modelo de IA, MAI-Image-1, um modelo de geração de imagens que estreou em nono lugar no ranking LMArena, empatado com o Seedream 3. O modelo alcança um equilíbrio impressionante entre velocidade e qualidade de geração, demonstrando o investimento contínuo e o rápido desenvolvimento da Microsoft no campo da IA multimodal. A Microsoft afirmou que continuará a otimizar o modelo, buscando uma classificação ainda mais alta. (Fonte: mustafasuleyman, NandoDF)
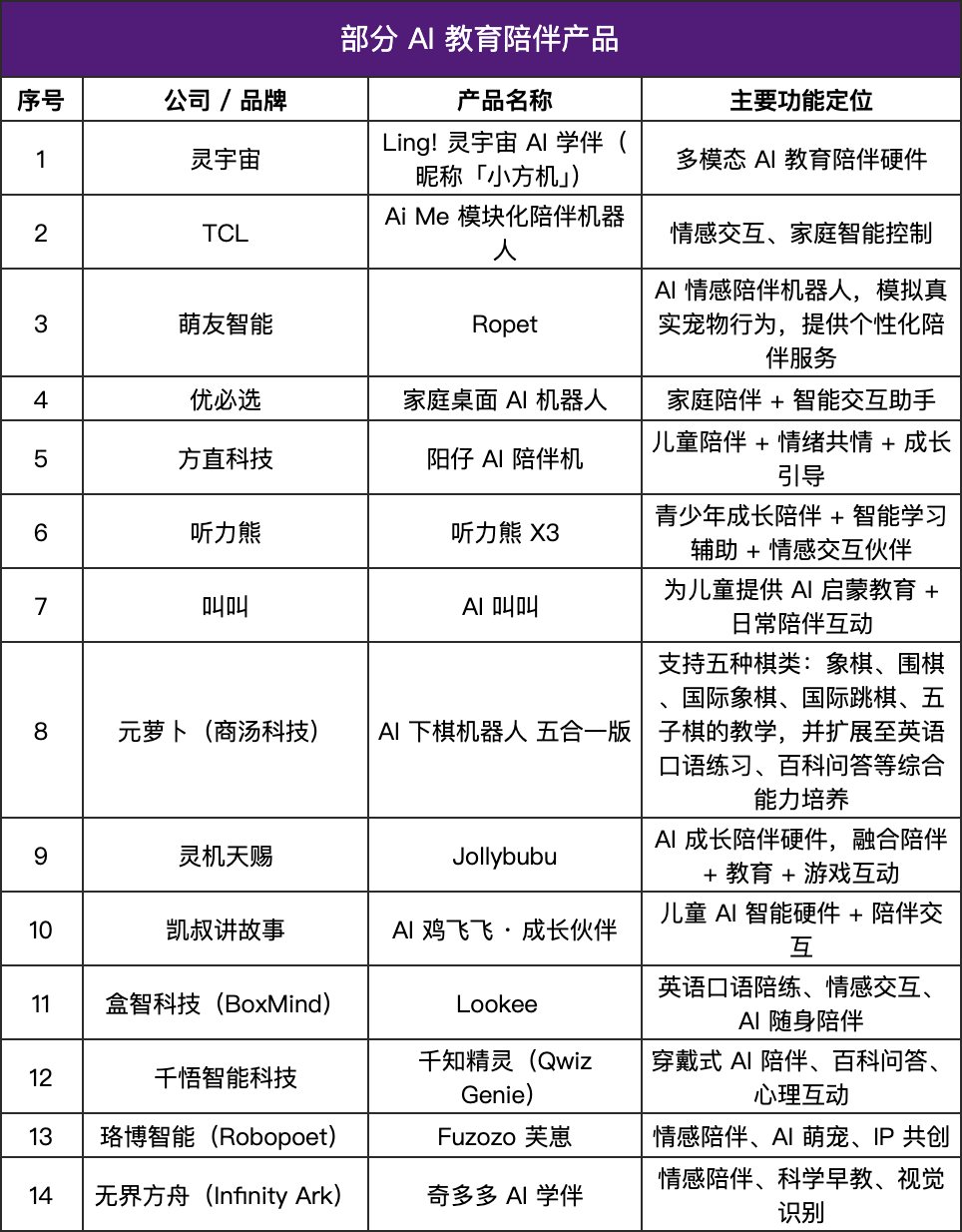
Produtos de companhia de IA experimentam um boom, hardware educacional “ganha calor” : O mercado de produtos de companhia de IA está crescendo rapidamente, com uma previsão de atingir um tamanho de mercado de US$ 70 bilhões a US$ 150 bilhões no futuro. Esses produtos estão mudando de “resposta a comandos” para “feedback emocional”, simulando reações humanas e oferecendo companhia personalizada através de modelos de linguagem, reconhecimento de emoções, interação por voz e sistemas de memória. No campo da educação, produtos de companhia de IA foram implementados como assistentes de estudo, sistemas de feedback emocional e modelos de perguntas e respostas inteligentes, estendendo-se da transmissão de conhecimento ao suporte psicológico, apresentando uma tendência de leveza e personalização, e integrando interação multimodal, com o objetivo de se tornarem sistemas que “compreendem os alunos”. (Fonte: 36氪)
NVIDIA lança DGX Spark, o menor supercomputador de IA do mundo : A NVIDIA lançou oficialmente o DGX Spark, anunciado como o menor supercomputador de IA do mundo, e já começou a ser enviado. O DGX Spark é baseado na arquitetura NVIDIA Grace Blackwell, integrando 128 GB de memória unificada, e visa fornecer aos desenvolvedores de IA poderosas capacidades locais de prototipagem e execução de LLM. Os primeiros usuários estão testando, validando e otimizando suas ferramentas, software e modelos, prenunciando que a computação de IA de alto desempenho se tornará mais difundida e conveniente. (Fonte: nvidia, ollama)

Anthropic lança Claude Sonnet 4.5, Agent SDK e Claude Code atualizado : A Anthropic lançou o Claude Sonnet 4.5, que aprimora as capacidades de raciocínio, possui uma janela de contexto maior (200k–1M tokens) e melhora o desempenho em benchmarks de codificação e raciocínio. Simultaneamente, a Anthropic também lançou o Claude Agent SDK e uma versão atualizada do Claude Code, que inclui rastreamento/resumo automático de contexto, ferramentas de memória persistente, pontos de verificação com capacidade de reversão e uma extensão IDE compatível com VS Code, visando fornecer aos desenvolvedores capacidades mais poderosas de codificação de IA e construção de Agents. (Fonte: DeepLearningAI)

Modelos de código aberto chineses lideram em downloads no Hugging Face, Google se torna o maior contribuinte : Uma análise recente da comunidade Hugging Face mostra que os modelos de código aberto desenvolvidos por empresas chinesas apresentam forte desempenho em termos de downloads, especialmente a série de modelos Qwen. Ao mesmo tempo, o Google se tornou a instituição com o maior número de downloads de modelos no Hugging Face. Essa tendência indica a crescente influência da China no campo da IA de código aberto, enquanto o Google, como gigante da tecnologia, também contribui ativamente e utiliza o ecossistema de código aberto para promover a popularização da tecnologia de IA. (Fonte: mervenoyann, osanseviero)
Robbie Stein, vice-presidente de produtos de busca do Google, interpreta o futuro da busca por IA: com “clareza” como objetivo final : Robbie Stein, vice-presidente de produtos de busca do Google, apontou que a IA não mudou a necessidade fundamental humana de buscar informações, mas a tornou mais natural e complexa através do AI Mode. A busca por IA futura terá “capacidade de compreensão”, capaz de decompor perguntas vagas em subproblemas para busca paralela e sintetizar respostas rastreáveis com citações. O objetivo do Google é se tornar um sistema “informado e confiável”, realizando a transição de “indexar páginas da web” para “indexar o mundo” através da fusão multimodal e dados mundiais estruturados, tornando a obtenção de informações mais clara e rápida, em vez de apenas gerar linguagem fluente. (Fonte: 36氪)
Ant Group lança framework de inferência de alto desempenho para modelos de linguagem de difusão dInfer : O Ant Group lançou oficialmente o dInfer, o primeiro framework de inferência de alto desempenho para modelos de linguagem de difusão da indústria, que acelera a inferência desses modelos em 10,7 vezes em comparação com o Fast-dLLM da NVIDIA. Na tarefa de geração de código HumanEval, o dInfer atingiu 1011 Tokens/segundo em inferência de lote único, superando significativamente os modelos autorregressivos pela primeira vez. O dInfer adota um design de colaboração profunda entre algoritmo e sistema, visando resolver os desafios de alto custo computacional, falha de cache KV e decodificação paralela em modelos de linguagem de difusão, liberando seu potencial de inferência eficiente. (Fonte: 量子位)
NVIDIA lança tecnologia de treinamento NVFP4, alcançando pré-treinamento de 4 bits com precisão FP8 : A NVIDIA anunciou uma tecnologia inovadora de treinamento NVFP4, que permite que modelos de linguagem grandes pré-treinados de 4 bits atinjam a precisão de 8 bits. Essa tecnologia utiliza representação de ponto flutuante de 4 bits no formato E2M1, combinada com escalonamento de granulação fina, arredondamento estocástico e Random Hadamard Transforms, reduzindo significativamente as necessidades de computação e memória. Experimentos mostram que o NVFP4, ao manter a precisão do modelo (como MMLU Pro 62,58% vs 62,62%), melhora drasticamente a eficiência do treinamento, fornecendo um caminho mais econômico para o treinamento de LLMs em maior escala no futuro. Essa tecnologia depende principalmente da arquitetura NVIDIA Blackwell e requer GPUs H100 ou superiores. (Fonte: Reddit r/LocalLLaMA, karminski3)

Framework SEAL do MIT permite que modelos de IA gerem automaticamente dados de ajuste fino e atualizem pesos : O Massachusetts Institute of Technology (MIT) lançou o framework SEAL (Self-Adapting LLMs), que permite que Large Language Models (LLMs) gerem automaticamente dados de ajuste fino e realizem atualizações de peso autônomas, alcançando atualizações de gradiente com zero intervenção humana. O SEAL adota um mecanismo de aprendizado de ciclo duplo (interno e externo), onde o modelo otimiza sua estratégia de geração de instruções de autoatualização com base no desempenho da tarefa, concedendo pela primeira vez aos LLMs a capacidade de atualização autodirigida. Experimentos demonstram que o SEAL tem um desempenho excelente em tarefas de injeção de conhecimento e aprendizado com poucos exemplos, superando a precisão dos dados gerados pelo GPT-4.1, e demonstrando forte adaptabilidade à tarefa e capacidade de integração de conhecimento, prenunciando a chegada da era dos modelos autoevolutivos. (Fonte: arXiv:2506.10943, 36氪)

Remessas de celulares com IA disparam, fabricantes como Coolpad Smart exploram estratégia de colaboração “modelo pequeno + modelo grande” : Em 2025, as remessas de celulares com IA na China aumentaram 591% ano a ano, com uma taxa de penetração de 22%, tornando os celulares com IA um novo foco da indústria. Fabricantes como Coolpad Smart estão mudando da corrida por parâmetros para a inovação pragmática, adotando uma solução de colaboração dinâmica “modelo pequeno frontal + modelo grande backend”, implantando modelos verticais pequenos de cerca de 600 milhões de parâmetros no dispositivo para resposta rápida e proteção de privacidade, enquanto integram a capacidade de computação de modelos gerais grandes como iFlytek, ByteDance, Alibaba e Google. Essa estratégia visa melhorar a experiência do usuário, fornecer serviços personalizados e reduzir custos, a fim de se adaptar aos mercados estrangeiros diversos e fragmentados. (Fonte: 36氪)

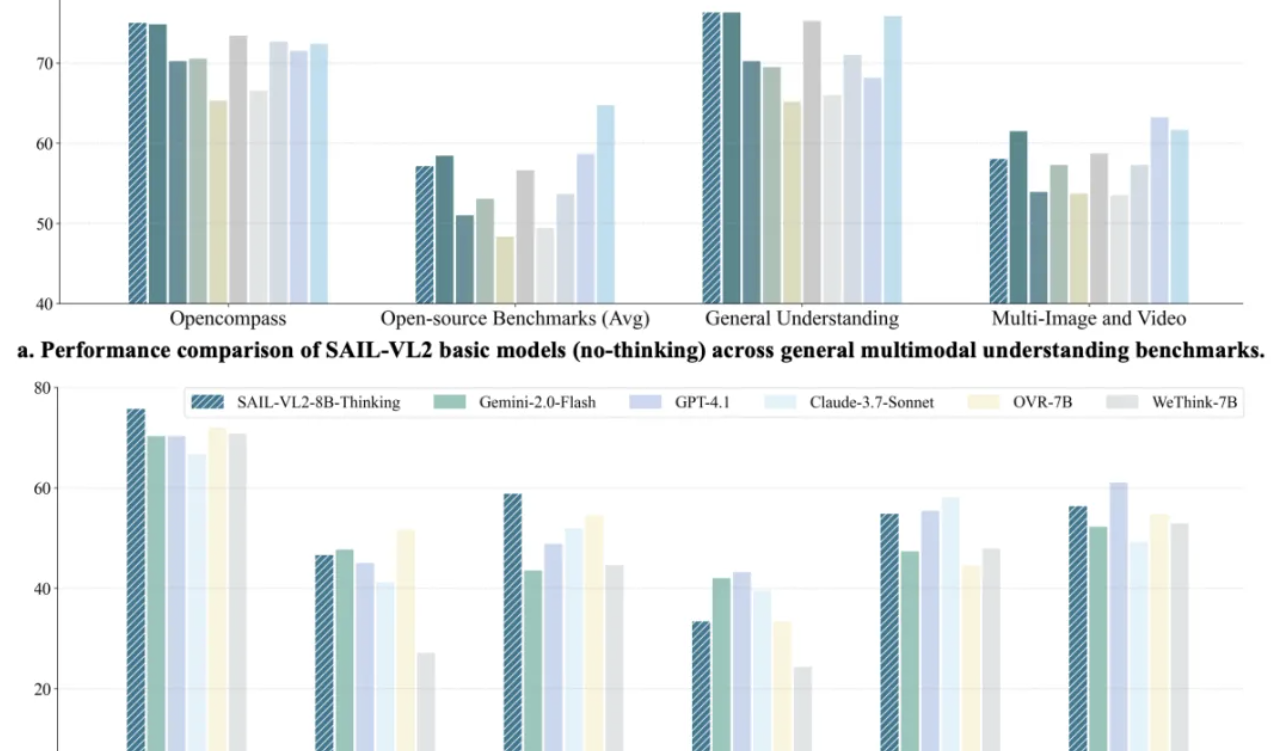
Modelo multimodal SAIL-VL2 do Douyin quebra recordes de SOTA, inferência de modelo 8B se compara ao GPT-4o : A equipe SAIL do Douyin, em colaboração com o LV-NUS Lab, lançou o modelo multimodal grande SAIL-VL2, que alcançou avanços de desempenho em 106 conjuntos de dados com tamanhos de parâmetros pequenos e médios, como 2B e 8B. Especialmente em benchmarks de raciocínio complexo como MMMU e MathVista, ele superou modelos de tamanho semelhante, e a capacidade de inferência do modelo 8B até se compara ao GPT-4o. O SAIL-VL2, através de sua arquitetura MoE esparsa, framework de treinamento progressivo e corpus multimodal de alta qualidade, entre outras inovações, oferece à comunidade um novo paradigma de “modelos pequenos também podem ter grandes capacidades”, e disponibiliza o modelo e o código de inferência como código aberto. (Fonte: 量子位)
Inferência em nuvem do Moondream migra totalmente para FAL, alcançando 100% de execução em nuvem : Moondream anunciou que seu serviço de inferência em nuvem migrou completamente de instâncias EC2 para FAL, alcançando 100% de execução em FAL. Essa mudança pode significar que Moondream fez progressos importantes na otimização da eficiência da inferência, redução de custos operacionais ou melhoria da elasticidade do serviço, e FAL, como nova plataforma de inferência, demonstra sua capacidade de suportar a implantação de modelos de IA na nuvem. (Fonte: vikhyatk)
Ring-1T: Ant Ling Technology lança modelo de raciocínio de código aberto com trilhões de parâmetros : A Ant Ling Technology lançou oficialmente o Ring-1T, um modelo de raciocínio de código aberto com trilhões de parâmetros baseado na arquitetura Ling 2.0. O Ring-1T alcança capacidade de raciocínio de nível de medalha de prata na IMO (Olimpíada Internacional de Matemática) em raciocínio de linguagem natural pura, com um total de 1 trilhão de parâmetros e 50 bilhões de parâmetros ativos, além de uma janela de contexto de 128K. O modelo é aprimorado através do Icepop RL e ASystem (um motor de aprendizado por reforço de trilhões de parâmetros) e alcança desempenho SOTA em benchmarks de raciocínio de linguagem natural como AIME 25, HMMT 25, ARC-AGI-1 e CodeForce, oferecendo uma versão FP8, com o objetivo de impulsionar as capacidades de inferência de IA de código aberto. (Fonte: scaling01, jon_durbin)
Função de e-commerce “Instant Checkout” do ChatGPT lançada, remodelando a experiência de compra : A OpenAI lançou a função “Instant Checkout” do ChatGPT, permitindo que os usuários concluam compras diretamente dentro do ChatGPT, sem precisar navegar para plataformas de e-commerce de terceiros. Atualmente, a função suporta Etsy e em breve será integrada a mais de um milhão de comerciantes da Shopify. Essa inovação fecha o ciclo de compra, desde a descrição da necessidade até a conclusão da compra, encurtando significativamente o caminho de decisão do usuário e melhorando a conveniência de compra, prenunciando a profunda integração da IA no e-commerce e a transformação dos modelos de negócios. (Fonte: 36氪)
O boom dos mini-dramas de IA no exterior, a tecnologia Sora 2 impulsiona um salto na qualidade e eficiência da produção de conteúdo : Os mini-dramas de IA estão impactando as plataformas de vídeo curtos de forma explosiva e se expandindo massivamente para o exterior. Em 2024, o mercado chinês de mini-dramas atingiu 50,5 bilhões de yuans, e a demanda no mercado externo é evidente, com a receita de mini-dramas chineses no exterior estimada em US$ 4 bilhões para o ano. O lançamento do OpenAI Sora 2 melhorou significativamente a qualidade da imagem, duração, sincronização e sincronização de áudio e vídeo, e suporta a coerência de enredos complexos e a função Cameos, comprimindo o processo de produção de mini-dramas para um modo eficiente de “uma pessoa escreve o Prompt, a IA produz”, com custos que podem ser reduzidos para um décimo do tradicional. Os mini-dramas de IA também se tornaram uma nova tendência, reduzindo efetivamente o desconto cultural e impulsionando a indústria de conteúdo de dramas com atores reais para mini-dramas de IA. (Fonte: 36氪)

Avanços da IA no diagnóstico médico: lançamento do AMIE, um AI Agent de diagnóstico multimodal : O Google AI lançou o AMIE (AI agent for multimodal diagnostic dialogue), um AI Agent de pesquisa projetado para alcançar avanços no campo médico através do diálogo de diagnóstico multimodal. O lançamento do AMIE marca o progresso da IA na compreensão e participação em processos complexos de diagnóstico médico, com o potencial de melhorar a eficiência e a precisão do diagnóstico, estabelecendo as bases para futuras aplicações de saúde inteligente. (Fonte: Ronald_vanLoon)
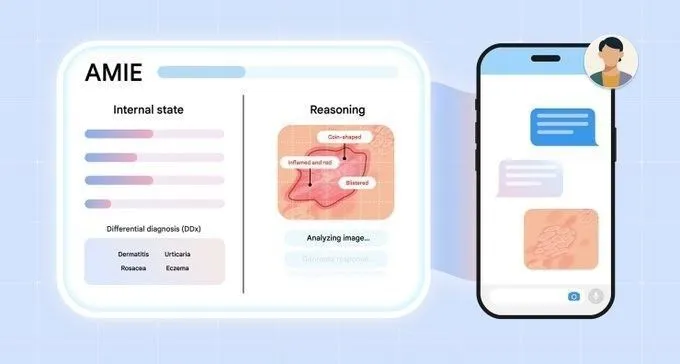
Perplexity Search API adiciona função de filtragem por domínio, aprimorando a precisão da busca : Perplexity anunciou que sua Search API agora suporta a filtragem de resultados de busca por domínios específicos. Essa nova função permite que os usuários consultem apenas fontes confiáveis, obtendo resultados mais focados e verificáveis. Para usuários profissionais ou desenvolvedores de aplicativos que precisam obter informações de fontes autorizadas específicas, isso aumentará significativamente a eficiência da busca e a qualidade das informações. (Fonte: AravSrinivas)
IA demonstra potencial na detecção de terremotos, podendo auxiliar na previsão futura : A IA se destaca na detecção de pequenos terremotos, com sua capacidade descrita como “tão clara quanto usar óculos pela primeira vez”. Pesquisadores estão explorando se a IA pode ajudar ainda mais a prever terremotos, o que promete uma revolução nos sistemas de alerta e mitigação de desastres sísmicos. Através de análises de dados mais refinadas, a IA pode identificar sinais sísmicos difíceis de detectar pelos métodos tradicionais, aprimorando nossa compreensão das atividades profundas da Terra. (Fonte: Ars Technica)
Arquitetura Mamba3 lançada, LLMs alcançam maior velocidade, contexto mais longo e maior escalabilidade : A arquitetura Mamba3 foi discretamente lançada na conferência ICLR, marcando um progresso significativo no campo dos LLMs em termos de velocidade, comprimento de contexto e escalabilidade. Essa arquitetura, ao otimizar a evolução do estado interno e a utilização de hardware, alcança uma modelagem de sequência mais eficiente do que os Transformers. O Mamba3 introduz integração trapezoidal e estados ocultos no plano complexo, tornando sua memória mais suave e estável, e capaz de representar padrões periódicos. Seu design multi-entrada e multi-saída permite o processamento paralelo de múltiplos fluxos de dados, com grande potencial em áreas como compreensão de documentos longos, análise de séries temporais e sistemas de IA de borda. (Fonte: NandoDF)

Agentic RAG supera o RAG tradicional, tornando-se a nova tendência em busca de IA : Um consenso está se formando na indústria: “o RAG (Retrieval Augmented Generation) tradicional baseado em embeddings está morto”, e o Agentic RAG (RAG baseado em agentes) supera-o em quase todos os aspectos, exceto na velocidade. Essa tendência prenuncia que a busca por IA passará da simples recuperação de informações para uma interação mais complexa baseada em agentes. O Agentic RAG é capaz de compreender de forma mais inteligente a intenção do usuário, planejar estratégias de recuperação e gerar respostas mais precisas, trazendo uma revolução para os futuros sistemas de busca e perguntas e respostas de IA. (Fonte: swyx, jerryjliu0)

TuringPost publica lista de ferramentas de geração de vídeo por IA, incluindo Luma Dream Machine : A TuringPost publicou uma lista de 9 poderosas ferramentas de geração de vídeo por IA, incluindo Sora 2, Google Veo 3, Runway, Pika Labs, Luma’s Dream Machine (alimentado por Ray 3), Synthesia, HeyGen, Kaiber e InVideo. Essa lista visa fornecer aos usuários uma seleção abrangente de opções de criação de vídeo por IA, cobrindo várias funções como texto para vídeo, geração em tempo real e síntese de personagens, refletindo o rápido desenvolvimento e as diversas aplicações no campo da tecnologia de vídeo por IA. (Fonte: TheTuringPost)
OpenAI lança curta-metragem sobre a história da tecnologia gerado por Sora, processo de emenda de vídeo ainda precisa de otimização : Hemanth Asir, pesquisador da OpenAI, produziu um curta-metragem sobre a história do desenvolvimento tecnológico totalmente gerado por Sora, demonstrando o potencial do Sora na criação de vídeo. Embora o curta seja impressionante, o processo de emenda ainda é complicado. A OpenAI afirmou que se dedicará a melhorar esse processo para aprimorar a experiência do usuário e a eficiência da criação, prenunciando que as futuras ferramentas de geração de vídeo por IA serão mais convenientes para narrativas de longa duração. (Fonte: dotey)
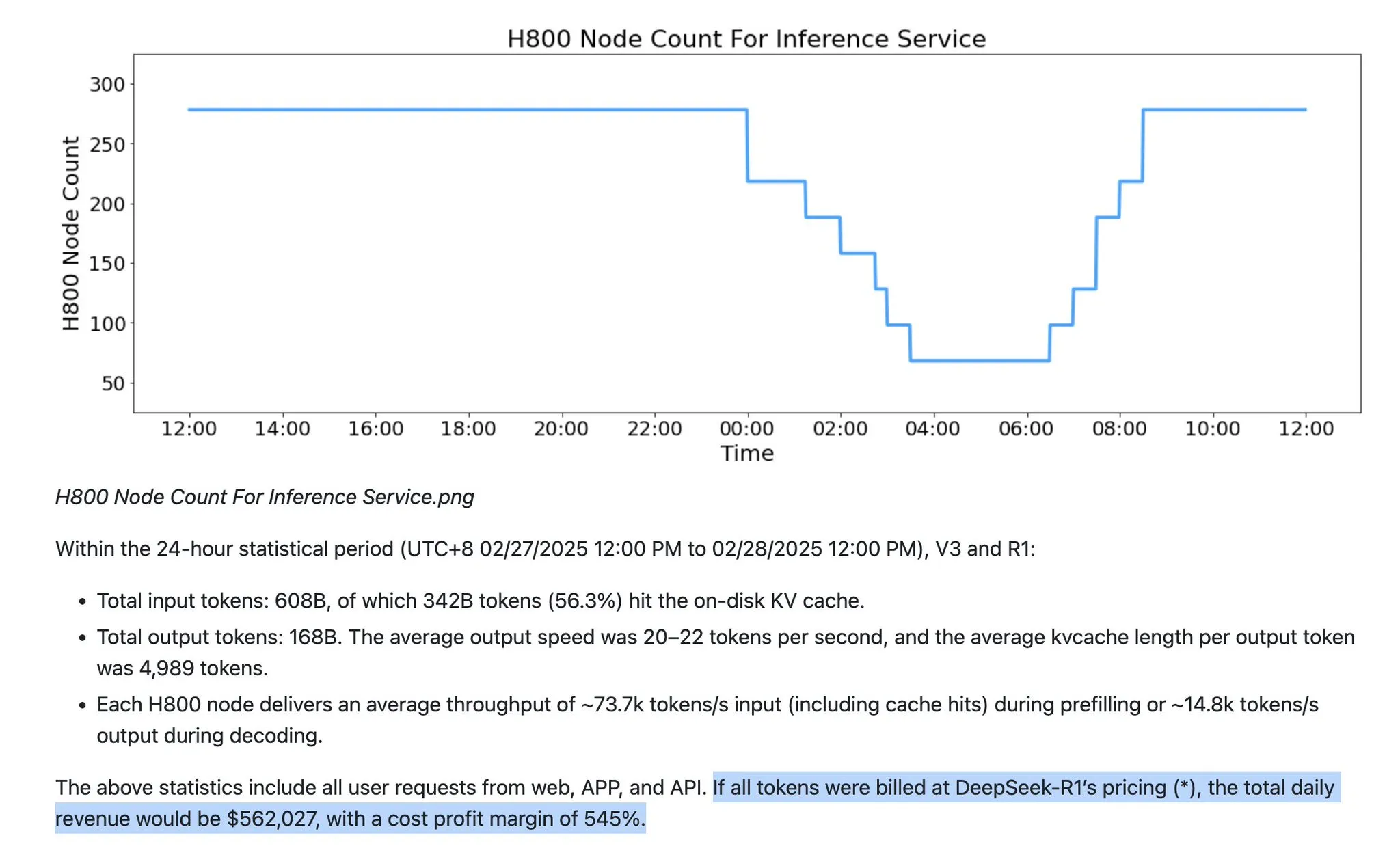
Suposições sobre serviços de LLM enfrentam desafios: FP8/FP4 se tornarão mainstream, volume de Tokens de saída crescerá exponencialmente : Há uma perspectiva de que os serviços de LLM atuais contêm várias suposições errôneas. Primeiro, os serviços de LLM não estão mais limitados à precisão FP16; FP8 e FP4 se tornarão mainstream. Segundo, o crescimento futuro dos LLMs será principalmente impulsionado pelo crescimento exponencial dos “Tokens de pensamento” (Tokens de saída), em vez de uma simples proporção de Tokens de entrada. Além disso, os modelos da série GPT-5 da OpenAI têm uma gama mais ampla de parâmetros, e vários laboratórios estão reduzindo custos através de tecnologias como DSA da Deepseek e novos mecanismos de atenção. A Anthropic também lançou uma ferramenta de limpeza de contexto para o Sonnet 4.5 para reduzir as necessidades de memória. Tudo isso remodelará a eficiência e a estrutura de custos dos serviços de LLM. (Fonte: teortaxesTex)
🧰 Ferramentas
Microsoft MarkItDown: ferramenta de conversão de documentos para Markdown para pipelines de LLM : A Microsoft lançou a ferramenta Python MarkItDown, capaz de converter dezenas de tipos de arquivos (incluindo PDF, Word, Excel, HTML, imagens, áudio, etc.) para o formato Markdown limpo. A ferramenta pode preservar títulos, listas, tabelas, links e metadados, e suporta OCR e extração de informações EXIF. Dado que Markdown é a “linguagem nativa” dos LLMs, MarkItDown se torna a escolha ideal para pré-processar documentos em pipelines de LLM, ajudando a melhorar a compreensão e a eficiência do processamento de documentos complexos pelos modelos. (Fonte: TheTuringPost)
VS Code lança plano de iteração 1.105, focado em IA e experiência do desenvolvedor : O VS Code lançou seu plano de iteração de outubro, trazendo várias melhorias destinadas a aprimorar o desenvolvimento assistido por IA e a experiência geral do desenvolvedor. As atualizações incluem renderização Mermaid, várias maneiras de gerenciar contexto e ferramentas, gerenciamento de modelos mais avançado, processos de várias etapas, salvamento de conversas como Prompt e funções para terminal, ferramentas e MCPs. Além disso, o GitHub Copilot também lançou 34 melhorias nos últimos 30 dias. Essas atualizações aprofundarão ainda mais a aplicação da IA na edição de código, depuração e colaboração, tornando o VS Code um ambiente de desenvolvimento nativo de IA mais poderoso. (Fonte: pierceboggan, code)

Nanonets-OCR2 lançado, modelo de código aberto de imagem para Markdown suporta LaTeX e fluxogramas : Nanonets-OCR2 foi lançado, um modelo de código aberto de imagem para Markdown ajustado com base no Qwen2.5-VL-3B-Instruct, que suporta reconhecimento de equações LaTeX, tabelas, documentos manuscritos, caixas de seleção e até mesmo pode converter fluxogramas em código Mermaid. O modelo também possui funções como descrição inteligente de imagens, detecção de assinaturas, extração de marcas d’água e suporte multilíngue, além de oferecer capacidade de Visual Question Answering (VQA). Nanonets-OCR2 se destaca no processamento de documentos complexos, fornecendo uma solução eficiente e rica em recursos para o pré-processamento de documentos em pipelines de LLM. (Fonte: huggingface, Reddit r/LocalLLaMA, karminski3)
Aplicativo ChatGPT para Slack lançado, integrando API de busca em tempo real : O aplicativo ChatGPT foi oficialmente lançado no Slack. Com a API de busca em tempo real do Slack, os usuários agora podem usar o ChatGPT diretamente em uma barra lateral dedicada do Slack para fazer perguntas, brainstorming, rascunhar conteúdo e resolver problemas. Essa integração traz as poderosas capacidades do ChatGPT para a plataforma de colaboração em equipe de forma contínua, visando melhorar a eficiência do trabalho, simplificar a obtenção de informações e o processo de criação de conteúdo, e fornecer aos usuários corporativos uma assistência de IA mais conveniente. (Fonte: gdb)
n8n lança construtor de fluxo de trabalho de IA, capacitando a automação em linguagem natural : A n8n lançou oficialmente seu construtor de fluxo de trabalho de IA, permitindo que os usuários construam agentes de IA e processos de automação no n8n através de linguagem natural. A ferramenta oferece uma tela visual, capaz de conectar mais de 8000 ferramentas como Firecrawl, LLMs, nós lógicos e MCPs, e pode ser implantada como uma API. Essa inovação simplificará enormemente o desenvolvimento e a aplicação de agentes de IA, permitindo que mais desenvolvedores usem linguagem natural para criar fluxos de trabalho de automação complexos, impulsionando a popularização de agentes de IA em cenários de negócios reais. (Fonte: omarsar0)
MLX suporta execução de modelos locais, atualização Privacy AI 1.3.2 aprimora capacidades de IA em dispositivos Apple : A Privacy AI lançou a atualização 1.3.2, que oferece suporte total ao motor MLX da Apple, permitindo que os usuários executem modelos de texto e visão localmente. Os modelos podem ser baixados diretamente do Hugging Face, suportam retomada de download, transferência em segundo plano e verificação de integridade, e os modelos MLX estão incluídos no plano gratuito, podendo ser executados offline sem assinatura. Essa atualização também aprimora o suporte à área de transferência e atualiza o llama.cpp, melhorando ainda mais as capacidades de IA local e a proteção de privacidade em dispositivos Apple. (Fonte: awnihannun)
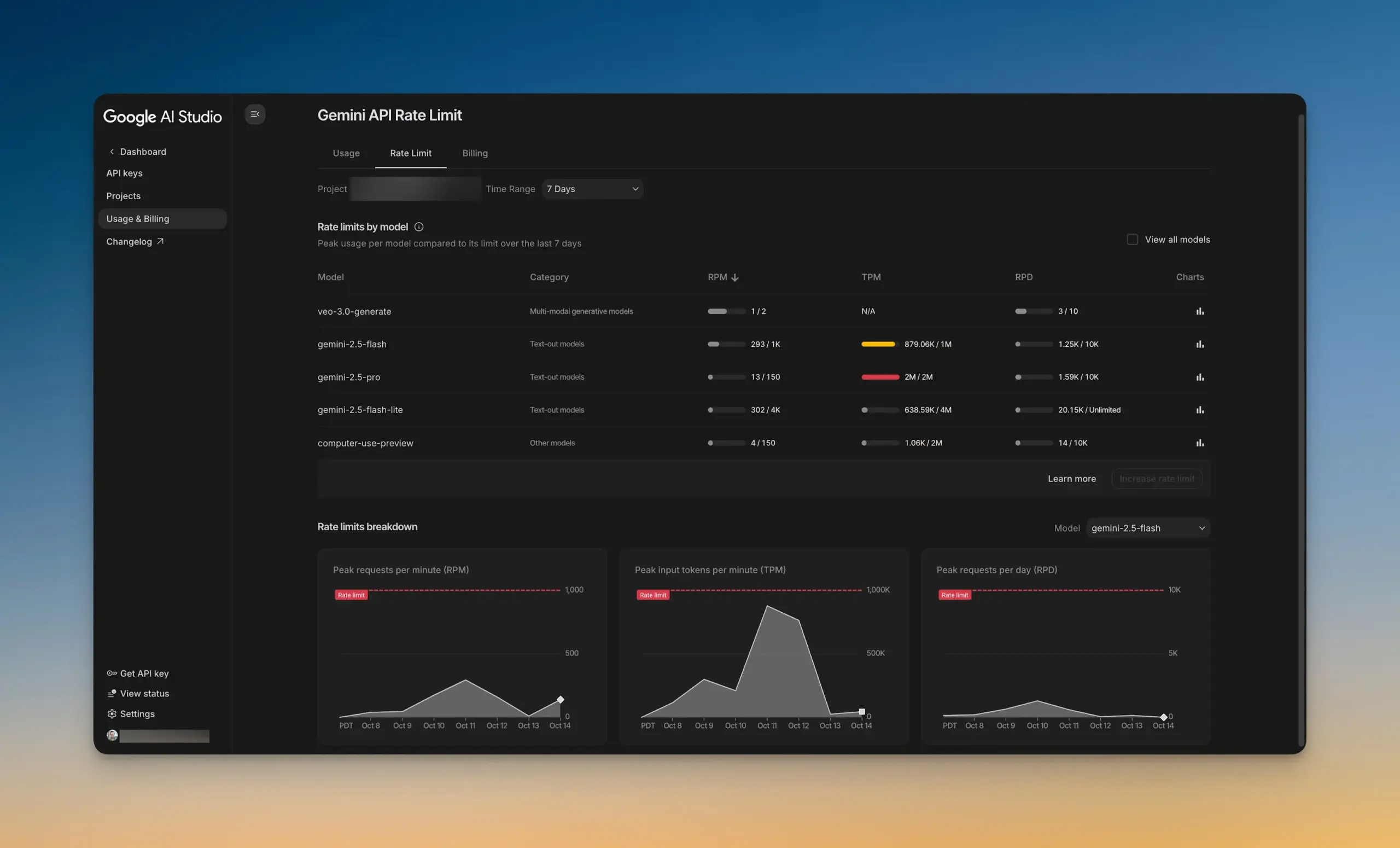
Google AI Studio lança novo painel de limites de taxa : O Google AI Studio lançou um novo painel de limites de taxa, permitindo que os usuários visualizem intuitivamente o uso da API Gemini sem sair do AI Studio. O painel oferece funcionalidade de filtragem de gráficos e facilita a exploração dos limites de taxa de todos os modelos, ajudando os desenvolvedores a gerenciar e otimizar melhor seus projetos de IA e aumentar a eficiência do desenvolvimento. (Fonte: GoogleAIStudio)
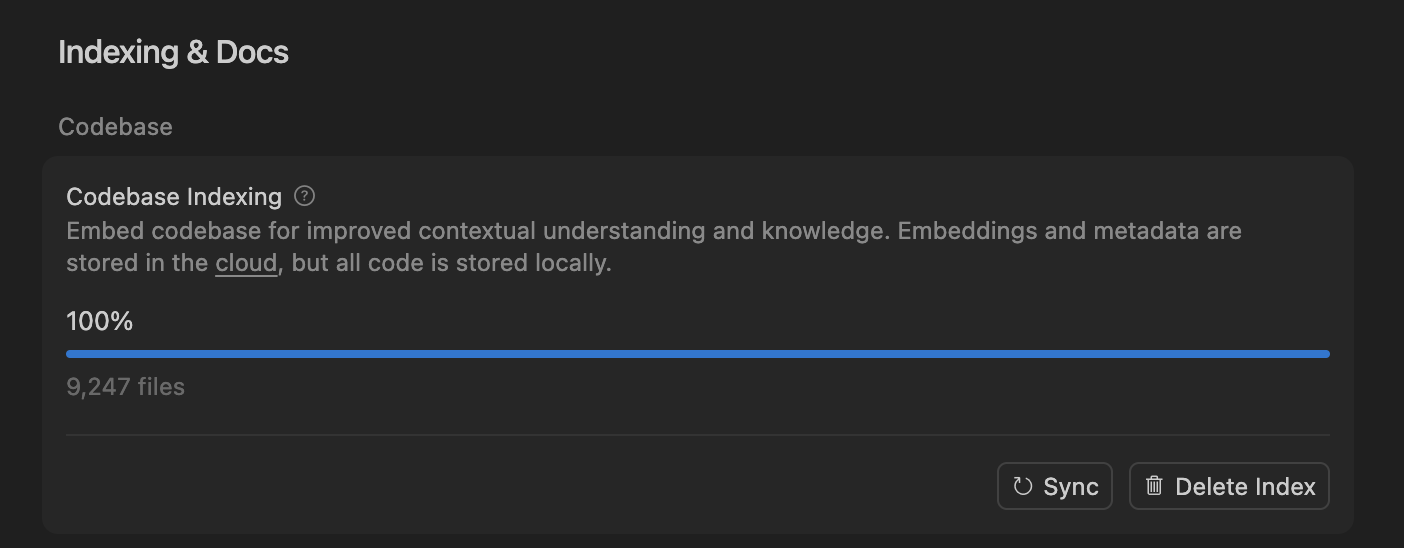
Cursor IDE e Codex se tornam novas escolhas para codificação diária de desenvolvedores : Com o rápido desenvolvimento de ferramentas de codificação de IA, o Cursor IDE e o Codex estão se tornando ferramentas centrais no fluxo de trabalho diário de cada vez mais desenvolvedores. Alguns desenvolvedores afirmam ter migrado completamente do Claude Code para o Codex, utilizando-o para planejamento diário, decomposição de tarefas e processamento paralelo. O “sistema de indexação de base de código” do Cursor IDE, através de busca semântica e acesso a código local, alcança indexação e atualização eficientes de código, sem a necessidade de armazenar o código em servidores, garantindo privacidade e eficiência. A popularização dessas ferramentas está mudando os métodos tradicionais de codificação, aumentando a eficiência do desenvolvimento. (Fonte: dejavucoder, gdb)
Yupp.ai: ferramenta de debate de IA ajuda usuários a obter respostas mais abrangentes : Yupp.ai é uma ferramenta inovadora de IA projetada para ajudar os usuários a tomar decisões mais informadas na era da informação, apresentando respostas de diferentes modelos de IA. Os usuários podem comparar as respostas de diferentes IAs lado a lado e votar com base em sua análise, criatividade ou detalhes específicos, formando assim um ranking de inteligência coletiva. O objetivo do Yupp.ai é permitir que os usuários aproveitem a experiência coletiva para obter rapidamente respostas confiáveis e multifacetadas, aumentando assim a eficiência do trabalho e a confiança na tomada de decisões. (Fonte: yupp_ai)

vLLM e SGLang são aclamados como o “Linux da era da IA” : vLLM e SGLang, devido ao seu excelente desempenho no campo da inferência de LLM, são aclamados como o “Linux da era da IA”. vLLM já obteve 60.000 estrelas no GitHub, evoluindo de uma pequena ideia de pesquisa para se tornar um framework central para a inferência de LLM, suportando quase todas as plataformas mainstream como NVIDIA, AMD, Intel e Apple. Ele suporta a maioria dos modelos de geração de texto e pipelines RL nativos como TRL e Unsloth, desempenhando um papel fundamental na infraestrutura do ecossistema de IA, impulsionando a popularização e a melhoria da eficiência da inferência de LLM. (Fonte: bookwormengr)
Luma AI Ray3 Visual Annotation desbloqueia controle preciso : A função de anotação visual Ray3 lançada pela Luma AI permite um controle preciso da direção visual através de rabiscos no quadro, guiando o sujeito para ações ou interações específicas. Essa função vai além das limitações dos prompts de texto tradicionais, transmitindo intenções de bloqueio espacial através de traços de pincel, proporcionando um método de controle mais intuitivo e refinado para a criação visual, especialmente demonstrando um grande potencial em aplicações como Dream Machine. (Fonte: TomLikesRobots)
Faceseek: ferramenta de correspondência e verificação facial impulsionada por IA : Faceseek é uma ferramenta que utiliza tecnologia de IA para correspondência e verificação facial, capaz de lidar eficazmente com rostos semelhantes. Essa ferramenta pode empregar embeddings faciais, CLIP (Contrastive Language-Image Pre-training) ou outros modelos avançados de visão computacional para análise, fornecendo soluções para cenários como verificação de identidade e monitoramento de segurança. Seu desempenho em aplicações práticas gerou discussões sobre os detalhes técnicos e as aplicações potenciais de tais sistemas. (Fonte: Reddit r/ArtificialInteligence)
Extensão de backend de GPU remota do PyTorch, combinando desenvolvimento local com computação remota : Uma nova extensão do PyTorch permite que os desenvolvedores realizem o desenvolvimento localmente enquanto utilizam um backend de GPU remoto para computação. Isso resolve o problema de recursos de hardware locais limitados, permitindo que pesquisadores e desenvolvedores treinem e experimentem modelos de deep learning de forma mais flexível, combinando a conveniência do ambiente de desenvolvimento local com as vantagens da computação de alto desempenho remota. (Fonte: Reddit r/deeplearning)
FocoosAI lança SDK de código aberto e plataforma web para visão computacional : A FocoosAI lançou seu SDK de código aberto e plataforma web para visão computacional, com o objetivo de fornecer aos desenvolvedores ferramentas e recursos para construir e implantar soluções de visão computacional. O lançamento dessa plataforma promoverá a popularização e aplicação da tecnologia de visão computacional, reduzindo a barreira de entrada para o desenvolvimento e permitindo que mais inovadores explorem e desenvolvam no campo da análise de imagens e vídeos usando IA. (Fonte: Reddit r/deeplearning)
Ferramentas de “humanização” de texto por IA: aprimorando a naturalidade do conteúdo gerado por IA : Com a popularização da tecnologia de geração de texto por IA, como tornar o conteúdo gerado por IA mais “humano” tornou-se uma questão importante. Atualmente, várias ferramentas surgiram no mercado, visando otimizar o estilo de linguagem, a expressão emocional e a adaptabilidade ao contexto, para que o texto de IA soe mais natural e próximo da expressão humana. Essas ferramentas ajudam os usuários a evitar a sensação mecânica e padronizada do texto de IA, aumentando o apelo do conteúdo e atendendo à demanda por textos personalizados e de alta qualidade. (Fonte: Ronald_vanLoon)
Nova versão do MLX-VLM em breve, Qwen Image suporta framework MFLUX : O MLX-VLM da Apple está prestes a receber uma grande atualização, prenunciando seu forte potencial no campo dos modelos multimodais grandes. Simultaneamente, o framework MFLUX lançou a versão v0.11, adicionando suporte para Qwen Image, permitindo que os usuários baixem e usem o modelo Qwen Image para geração com operações de linha de comando simples. Esses avanços impulsionam coletivamente a eficiência e a flexibilidade do desenvolvimento e implantação de modelos de IA dentro do ecossistema Apple, fornecendo aos desenvolvedores ferramentas de IA multimodal mais convenientes. (Fonte: adrgrondin, awnihannun)
CleanMARL: implementação concisa de aprendizado por reforço multiagente em PyTorch : O projeto CleanMARL oferece uma série de implementações concisas e de arquivo único de algoritmos de aprendizado por reforço multiagente (MARL) profundo, desenvolvidos em PyTorch, seguindo a filosofia do CleanRL. O projeto visa reduzir a barreira de implementação de algoritmos MARL, fornecendo aos pesquisadores e desenvolvedores um código claro, fácil de entender e reproduzir, acelerando a pesquisa e aplicação de sistemas multiagente em ambientes complexos. (Fonte: jsuarez5341)
📚 Aprendizado
Pós-treinamento de grandes modelos se torna o cerne da competitividade em IA, empresas aceleram a construção de motores inteligentes exclusivos : O pós-treinamento de grandes modelos está se tornando a principal competência para a implementação da IA nas empresas. De SFT a RLHF, RLVR e, em seguida, ao “recompensa por linguagem natural” de ponta, o foco técnico mudou da “imitação” para o “alinhamento”. Empresas como NetEase, Autohome, Weibo e Quark, através da preparação de dados de alta qualidade, seleção de modelos base, design de mecanismos de recompensa e sistemas de avaliação quantificáveis, transformaram com sucesso modelos gerais grandes em “motores inteligentes exclusivos” que compreendem profundamente os negócios e possuem conhecimento de domínio, resolvendo tarefas complexas do mundo comercial e construindo barreiras competitivas irreplicáveis. (Fonte: 量子位)

Andrew Ng lança curso de Agentic AI, focado em quatro padrões de design : A DeepLearning.AI lançou a mais recente edição de The Batch, anunciando que Andrew Ng lançou seu mais novo curso “Agentic AI”. Este curso é um curso prático para construtores, centrado em quatro padrões de design chave: reflexão, uso de ferramentas, planejamento e colaboração multiagente. O curso visa ajudar os alunos a dominar as habilidades essenciais para construir sistemas de agentes de IA eficientes, impulsionando a aplicação da IA em cenários práticos. (Fonte: DeepLearningAI)
Ajuste fino de instruções de LLM tem custos ocultos: distribuição de saída mais estreita, controlabilidade de contexto reduzida : Pesquisas revelam que o ajuste fino de instruções de LLM, embora melhore a capacidade de seguir instruções, também acarreta custos ocultos: uma distribuição de saída mais estreita e uma redução na controlabilidade no contexto (In-Context Steerability). Para resolver esse problema, a equipe de pesquisa lançou o “Spectrum Suite” para um estudo aprofundado e propôs o “Spectrum Tuning” como um método alternativo de pós-treinamento, visando melhorar o desempenho do modelo enquanto mantém a diversidade e flexibilidade de sua saída. (Fonte: YejinChoinka, YejinChoinka)
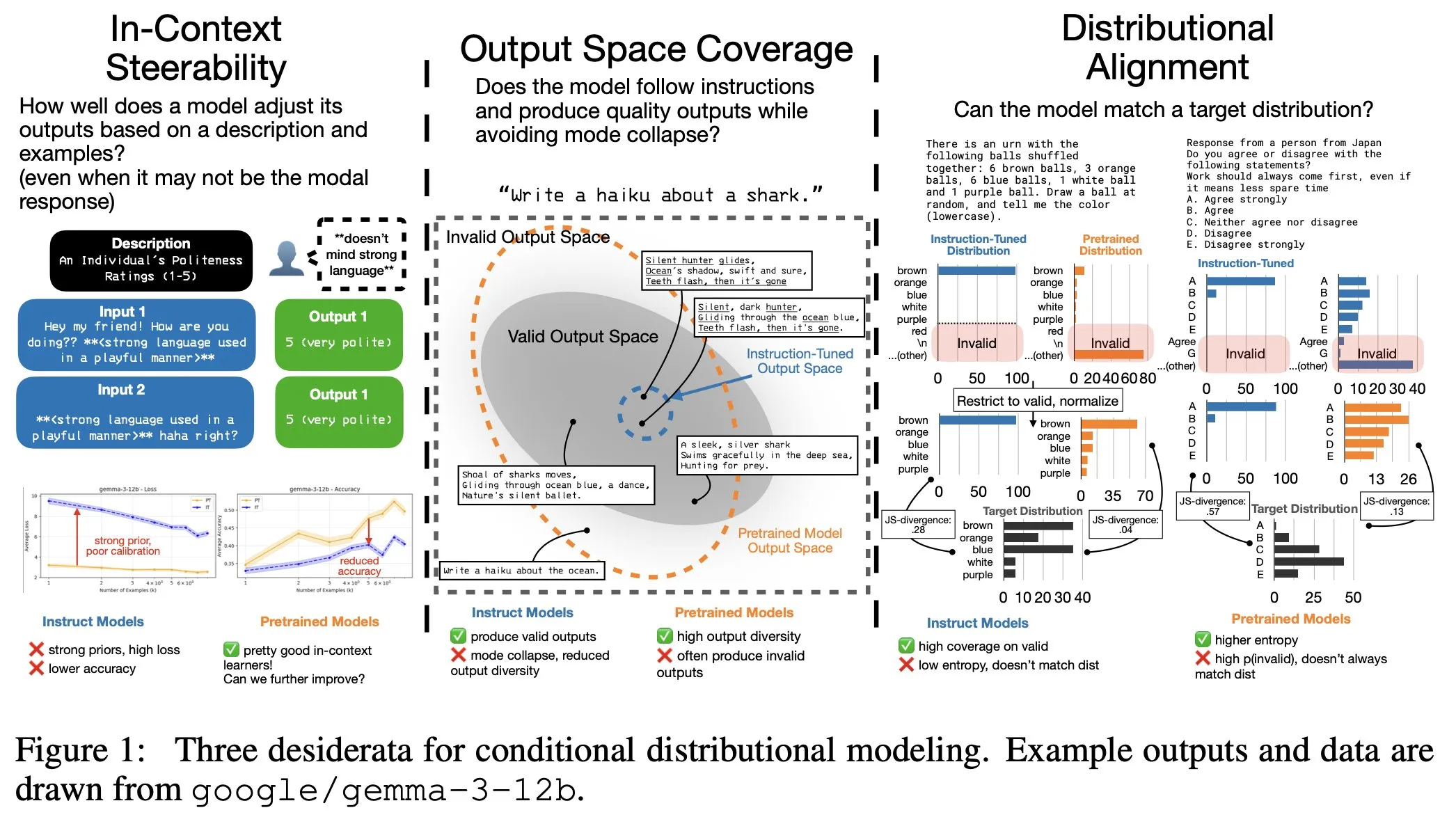
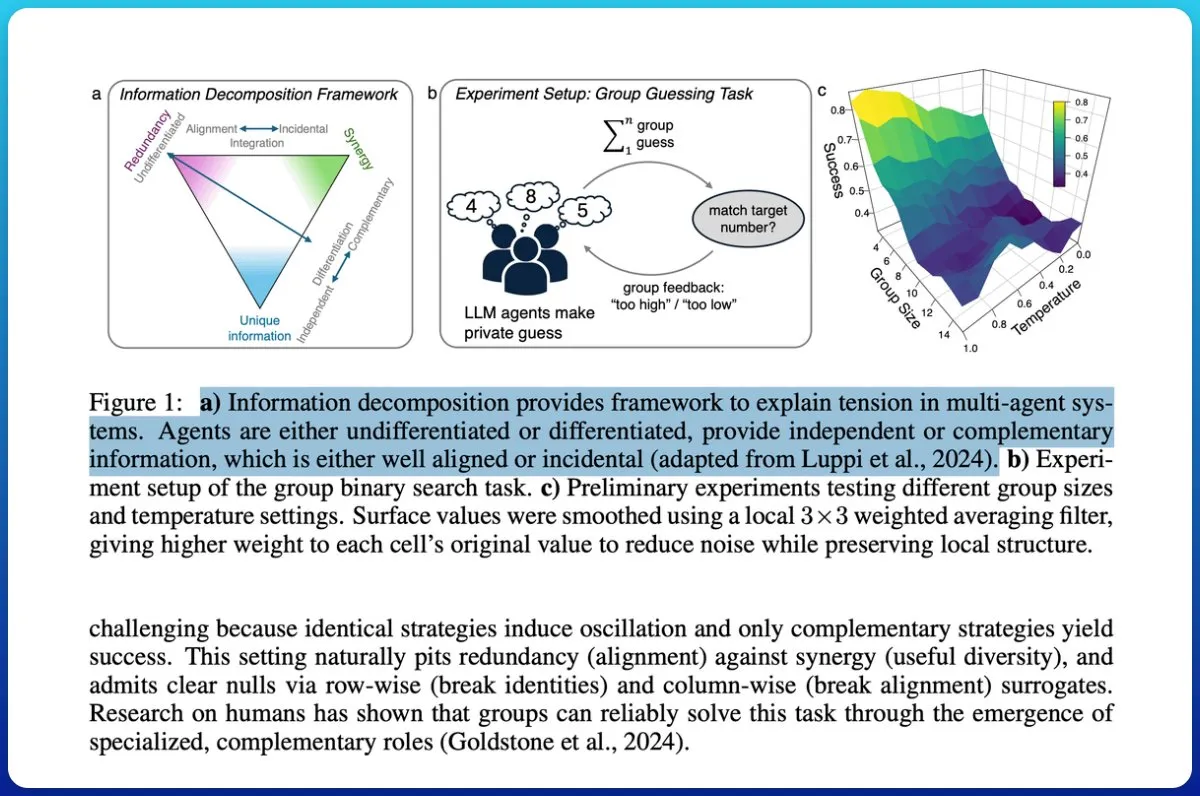
Colaboração de sistemas multiagente: teoria da informação distingue “pilha de chatbots” de “inteligência coletiva” : Um estudo investigou se os sistemas multiagente impulsionados por LLMs realmente alcançam colaboração e propôs o uso da teoria da informação para distinguir entre “uma pilha de chatbots” e “verdadeira inteligência coletiva”. O estudo introduziu medições de ciclo, avaliando a capacidade da saída do grupo de prever resultados futuros e decompondo informações para identificar sinergia em vez de redundância. Os resultados mostram que atribuir diferentes papéis e objetivos comuns aos agentes, e testar sua sinergia em vez de assumi-la, é crucial para alcançar a inteligência coletiva, e modelos de baixa capacidade dificilmente alcançam uma verdadeira cooperação. (Fonte: omarsar0)
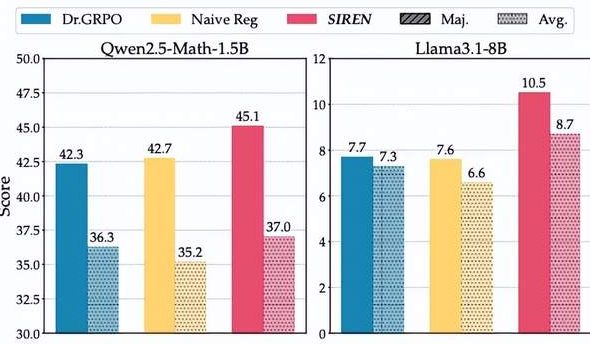
O “dilema da entropia” da inferência de grandes modelos: o método SIREN rejeita o “colapso da entropia” e a “explosão da entropia” : Modelos de raciocínio grandes (LRM) enfrentam o “dilema da entropia” no treinamento RLVR, ou seja, a exploração limitada leva ao “colapso da entropia” ou a exploração descontrolada causa uma “explosão da entropia”. A equipe do Shanghai AI Lab e da Fudan University propôs o método de regularização de entropia seletiva (SIREN), que controla precisamente o comportamento de exploração através de um mecanismo triplo: delimitar o escopo da exploração (máscara Top-p), identificar pontos de decisão chave (máscara de entropia de pico) e estabilizar o processo de treinamento (regularização auto-ancorada). Experimentos demonstram que o SIREN melhora significativamente o desempenho em benchmarks de raciocínio matemático e torna o processo de exploração mais eficiente e controlável. (Fonte: 量子位)
Recursos de aprendizado de AI Agent: novo livro “Guia Ilustrado de AI Agent” e resumo de conceitos : Os recursos de aprendizado no campo de AI Agent estão em constante enriquecimento. Maarten Grootendorst e Jay Alammar estão escrevendo o livro “Guia Ilustrado de AI Agent”, que cobrirá os fundamentos de Agent (memória, ferramentas, planejamento) e conceitos avançados como aprendizado por reforço e LLM de raciocínio. Além disso, há também artigos que resumem os 20 conceitos centrais de AI Agent, fornecendo um caminho de aprendizado sistemático e materiais de referência para iniciantes e avançados. (Fonte: lvwerra, Ronald_vanLoon)

Avaliação da capacidade de raciocínio espacial de LLM: teste de rotação de formas desafia o espaço latente do modelo : Um método de avaliação interessante foi proposto, visando testar a capacidade de Large Language Models (LLMs) de girar formas “na mente”. Através de testes visuais simples, a pesquisa descobriu que os LLMs podem realizar um certo grau de rotação de formas no espaço latente subjacente, mas têm um desempenho ruim em raciocínios de nível superior e mais complexos, apresentando um problema de “raciocínio espacial não uniforme”. Isso revela as limitações dos LLMs no processamento de lógica geométrica e espacial, fornecendo uma nova direção de pesquisa para futuras melhorias de modelos. (Fonte: dejavucoder, tokenbender)
Estratégias de ajuste fino de LLM: atualização de camadas de projeção de atenção e camadas de MLP gated pode limitar o esquecimento : Como ensinar novas habilidades a modelos multimodais grandes (LMMs) sem esquecer as capacidades existentes é um desafio crucial. Uma pesquisa descobriu que o fenômeno de “esquecimento” que ocorre após um ajuste fino estreito pode ser recuperado posteriormente, o que está relacionado a mudanças significativas na distribuição de Tokens de saída. O estudo identificou duas estratégias de ajuste fino simples e robustas: atualizar apenas as camadas de projeção de autoatenção, ou atualizar apenas as camadas MLP Gate&Up e congelar as camadas de projeção Down. Essas escolhas podem alcançar fortes ganhos de objetivo em modelos e tarefas, enquanto basicamente preservam o desempenho original. (Fonte: arXiv:2510.08564)
IA e crescimento econômico: interpretação do artigo de Philippe Aghion, ganhador do Prêmio Nobel : A pesquisa de Philippe Aghion, ganhador do Prêmio Nobel, e outros, aponta que, mesmo que a economia seja 99% automatizada e produza infinitamente, a taxa de crescimento geral ainda será limitada pelo progresso do 1% restante de tarefas centrais e difíceis. Na era da AGI, essas tarefas “difíceis de melhorar” se transformarão em tarefas centradas na física, como geração de energia, extração de recursos, fabricação e transporte. Isso significa que a era pós-AGI não será necessariamente uma era de “pós-escassez”, e o valor econômico se concentrará em tarefas fisicamente limitadas. (Fonte: pmddomingos, jonst0kes)

Desafios de generalização e robustez de modelos de IA: raciocínio espúrio leva a falhas no raciocínio matemático : Modelos de linguagem frequentemente sofrem de “raciocínio espúrio” no raciocínio matemático, levando à falta de robustez e generalização, ou seja, o modelo deriva respostas de características superficiais em vez da lógica do problema. O framework AdaR, ao sintetizar consultas logicamente equivalentes e combiná-las com RLVR (Reinforcement Learning with Verifiable Rewards) para treinamento, penaliza a lógica espúria e encoraja a lógica adaptativa. Experimentos demonstram que o AdaR melhora significativamente a robustez e a generalização do raciocínio matemático de LLMs, mantendo alta eficiência de dados. (Fonte: arXiv:2510.04617)
Autoaperfeiçoamento de LLM Agent em tempo de teste: framework TT-SI alcança aprendizado autônomo : Uma pesquisa propôs um novo método de autoaperfeiçoamento em tempo de teste (Test-Time Self-Improvement, TT-SI), visando criar dinamicamente LLM Agents mais eficazes e generalizáveis. O algoritmo identifica amostras difíceis do modelo, gera exemplos semelhantes (auto-aumento de dados) e realiza ajuste fino em tempo de teste (autoaperfeiçoamento), alcançando o aprendizado autônomo do modelo. Experimentos demonstram que o TT-SI melhora a precisão em média em 5,48% em benchmarks de Agent, e o volume de amostras de treinamento é reduzido em 68 vezes, mostrando o potencial de algoritmos de autoaperfeiçoamento na construção de Agents mais poderosos. (Fonte: arXiv:2510.07841)
Princípios chave de design e práticas de otimização para aprendizado por reforço de LLM Agent : Uma pesquisa investigou sistematicamente os princípios chave de design do Agentic RL para aprimorar as capacidades de raciocínio de LLM Agent. O estudo descobriu que usar trajetórias reais de uso de ferramentas de ponta a ponta em vez de trajetórias sintéticas como inicialização SFT pode levar a resultados mais fortes; conjuntos de dados de alta diversidade e conscientes do modelo podem manter a exploração e melhorar significativamente o desempenho do RL. Além disso, técnicas amigáveis à exploração (como clip higher, overlong reward shaping e manter entropia de política suficiente) são cruciais para o Agentic RL. Essas práticas podem aprimorar continuamente o raciocínio Agentic e a eficiência do treinamento, permitindo que modelos pequenos alcancem excelentes resultados em benchmarks desafiadores. (Fonte: arXiv:2510.11701)
Mecanismo de recompensa na inferência de LLM: PEAR otimiza a eficiência da inferência através da entropia de fase : Modelos de raciocínio grandes (LRM) frequentemente aumentam os custos de inferência devido a etapas de raciocínio redundantes ao gerar explicações CoT. O mecanismo PEAR (Phase Entropy Aware Reward) projeta recompensas combinando entropia dependente da fase, penalizando a entropia excessiva na fase de pensamento, enquanto permite uma exploração moderada na fase de resposta final. Isso encoraja o modelo a gerar trajetórias de raciocínio concisas, mantendo a flexibilidade necessária para resolver a tarefa. Experimentos demonstram que o PEAR reduz consistentemente o comprimento da resposta sem sacrificar a precisão e exibe forte robustez OOD. (Fonte: arXiv:2510.08026)
DocReward: modelo de recompensa para estrutura e estilo de documentos : DocReward é um modelo de recompensa usado para avaliar a estrutura e o estilo de documentos, visando resolver o problema de que os fluxos de trabalho Agentic ignoram a estrutura visual e o estilo ao gerar documentos profissionais. O modelo é treinado em um conjunto de dados multidomínio DocPair contendo pares de documentos de alta e baixa profissionalidade, e é capaz de avaliar a profissionalidade de documentos de forma abrangente, independentemente da qualidade do texto. DocReward supera GPT-4o e GPT-5 em precisão e alcança uma taxa de vitória mais alta em avaliações externas de geração de documentos, provando sua utilidade em guiar a geração de documentos preferidos por humanos por Agents. (Fonte: arXiv:2510.11391)
SPG: Sandwiched Policy Gradient melhora o aprendizado por reforço de modelos de linguagem de difusão : Modelos de linguagem de difusão (dLLM), devido à sua capacidade de decodificação paralela, são considerados uma alternativa eficaz aos modelos autorregressivos. No entanto, alinhar dLLMs com as preferências humanas através do aprendizado por reforço (RL) enfrenta desafios, pois sua verossimilhança logarítmica intratável limita a aplicação direta de gradientes de política padrão. O método SPG (Sandwiched Policy Gradient) utiliza limites superior e inferior da verossimilhança logarítmica real, superando significativamente as linhas de base baseadas em ELBO ou estimativa de passo único, e aumentando a precisão do RL de dLLMs em 3,6% a 27,0% em tarefas como GSM8K e MATH500. (Fonte: arXiv:2510.09541)
QeRL: Aprendizado por Reforço Aprimorado por Quantização melhora a eficiência e a capacidade de exploração de LLMs : O framework QeRL (Quantization-enhanced Reinforcement Learning) visa resolver o problema de uso intensivo de recursos do aprendizado por reforço (RL) de LLMs, combinando quantização NVFP4 e tecnologia LoRA para acelerar a fase de Rollout do RL e reduzir o consumo de memória. A pesquisa descobriu que o ruído de quantização pode aumentar a entropia da política, aprimorando a capacidade de exploração e ajudando a descobrir melhores políticas. O QeRL introduz um mecanismo de ruído de quantização adaptativo (AQN), que ajusta dinamicamente o ruído durante o treinamento. Experimentos mostram que o QeRL acelera a fase de Rollout em mais de 1,5 vezes, permitindo pela primeira vez o treinamento de LLMs de 32B em uma única GPU H100 de 80GB, e alcança um crescimento de recompensa mais rápido e maior precisão final. (Fonte: arXiv:2510.11696)
STAT: Treinamento Adaptativo Direcionado a Habilidades melhora o desempenho de LLM em matemática e OOD : STAT (Skill-Targeted Adaptive Training) é uma nova estratégia de ajuste fino de LLM que utiliza as capacidades metacognitivas de LLMs mais fortes como modelos professores para criar listas de habilidades necessárias para a tarefa e rotular pontos de dados. O modelo professor monitora as respostas do modelo aluno, constrói um “perfil de habilidades ausentes” e então repondera adaptativamente os exemplos de treinamento existentes (STAT-Sel) ou sintetiza exemplos adicionais envolvendo as habilidades ausentes (STAT-Syn). Experimentos demonstram que o STAT melhora em até 7,5% no benchmark MATH e em média 4,6% no benchmark OOD, sendo complementar ao GRPO, com potencial para melhorar completamente os pipelines de treinamento atuais. (Fonte: arXiv:2510.10023)
LLaMAX2: Modelo Qwen3-XPlus se destaca em tarefas de tradução e raciocínio : LLaMAX2 propõe um novo método de aprimoramento de tradução que, através do ajuste fino seletivo de camadas em modelos de instrução, melhora significativamente o desempenho de tradução do modelo Qwen3-XPlus em idiomas de recursos altos e baixos (como o suaíli), enquanto mantém proficiência comparável aos modelos de instrução Qwen3 em 15 conjuntos de dados populares de raciocínio. Este trabalho oferece um método promissor para aprimoramento multilíngue, reduzindo significativamente a complexidade e aumentando a acessibilidade para uma gama mais ampla de idiomas. (Fonte: arXiv:2510.09189)
DemoDiff: Transformer de difusão de grafos para design molecular contextual : DemoDiff (Demonstration-conditioned diffusion models) alcança o design molecular contextual usando um pequeno número de exemplos molécula-pontuação em vez de descrições de texto para definir o contexto da tarefa. O modelo utiliza um novo tokenizador molecular Node Pair Encoding, que representa moléculas em nível de motivo, reduzindo o número de nós. DemoDiff pré-treinou um modelo de 700 milhões de parâmetros em um conjunto de dados contendo milhões de tarefas contextuais e igualou ou superou modelos de linguagem 100-1000 vezes maiores em 33 tarefas de design, tornando-se um modelo fundamental molecular para o design molecular contextual. (Fonte: arXiv:2510.08744)
CodePlot-CoT: Cadeia de Pensamento impulsionada por código para aprimorar o raciocínio visual matemático : CodePlot-CoT propõe um paradigma de Cadeia de Pensamento impulsionado por código para o “pensamento de imagem” em matemática. Esse método utiliza VLM para gerar raciocínio textual e código de plotagem executável, que é então renderizado em imagens como “pensamento visual” para resolver problemas matemáticos. A pesquisa construiu o primeiro conjunto de dados de raciocínio visual matemático bilíngue em larga escala, Math-VR, e desenvolveu um conversor de imagem para código SOTA. Experimentos demonstram que o modelo melhora o desempenho em até 21% no benchmark Math-VR, abrindo novas direções para o raciocínio matemático multimodal. (Fonte: arXiv:2510.11718)
DiT360: Treinamento híbrido para geração de imagens panorâmicas de alta fidelidade : DiT360 é um framework baseado em DiT que, através do treinamento híbrido em dados de perspectiva e panorâmicos, alcança a geração de imagens panorâmicas de alta fidelidade. Esse método introduz módulos chave como fusão de conhecimento entre domínios, refinamento panorâmico, preenchimento cíclico, perda de guinada e perda cúbica, para resolver problemas de fidelidade geométrica e realismo. DiT360 demonstra melhor consistência de borda e fidelidade de imagem em 11 métricas quantitativas em tarefas de texto para panorama, inpainting e outpainting. (Fonte: arXiv:2510.11712)
RAE: Representational Autoencoders otimizam o espaço latente de Diffusion Transformers : Uma pesquisa explorou a substituição do VAE tradicional em Diffusion Transformers (DiT) por codificadores de representação pré-treinados (como DINO, SigLIP, MAE), formando Representational Autoencoders (RAE). O RAE oferece reconstrução de alta qualidade e um espaço latente semanticamente rico, ao mesmo tempo em que suporta arquiteturas Transformer escaláveis. Através de análise teórica e validação empírica, o método alcançou convergência mais rápida e fortes resultados de geração de imagens no ImageNet, com potencial para se tornar a nova configuração padrão para o treinamento de Diffusion Transformers. (Fonte: arXiv:2510.11690)
InfiniHuman: Framework para criação ilimitada de humanos 3D com controle preciso : O framework InfiniHuman gera dados de humanos 3D ricamente anotados com custo mínimo e escalabilidade teoricamente ilimitada, através da destilação colaborativa de modelos base existentes. InfiniHumanData é um pipeline totalmente automatizado que utiliza modelos de visão-linguagem e geração de imagens para criar um conjunto de dados multimodal em larga escala contendo 111.000 identidades, cobrindo uma diversidade sem precedentes, e anotado detalhadamente com descrições de texto, imagens RGB multiview, imagens de vestuário e parâmetros de forma corporal SMPL. Com base nisso, InfiniHumanGen é um pipeline de geração baseado em difusão, capaz de gerar avatares rápidos, realistas e controláveis com precisão. (Fonte: arXiv:2510.11650)
IVEBench: Suíte de benchmark para avaliação de edição de vídeo guiada por instruções : IVEBench é uma suíte de benchmark moderna projetada especificamente para a avaliação de edição de vídeo guiada por instruções. Ele contém 600 vídeos-fonte de alta qualidade, cobrindo sete dimensões semânticas e durações de vídeo de 32 a 1024 frames. Além disso, inclui 8 categorias de tarefas de edição e 35 subcategorias, com prompts gerados e refinados por Large Language Models e revisão de especialistas. IVEBench estabelece um protocolo de avaliação tridimensional que inclui qualidade de vídeo, conformidade com instruções e fidelidade de vídeo, integrando métricas tradicionais e avaliação de Large Language Models multimodais. (Fonte: arXiv:2510.11647)
LikePhys: Avaliando a compreensão física intuitiva de modelos de difusão de vídeo através da preferência de verossimilhança : LikePhys é um método independente de treinamento que avalia a compreensão física intuitiva de modelos de difusão de vídeo, distinguindo vídeos fisicamente válidos e impossíveis, e usando o objetivo de denoising como um substituto de verossimilhança baseado em ELBO. A pesquisa construiu um benchmark contendo 12 cenários e 4 domínios físicos, e os resultados mostram que sua métrica de avaliação, Plausibility Preference Error (PPE), é altamente consistente com as preferências humanas. O estudo também avaliou sistematicamente a capacidade de compreensão física intuitiva dos modelos de difusão de vídeo atuais e analisou como o design do modelo e as configurações de inferência afetam a compreensão física. (Fonte: arXiv:2510.11512)
FastHMR: Acelerando a recuperação de malha humana através da fusão de Tokens e camadas : FastHMR acelera a recuperação de malha humana 3D (HMR) introduzindo duas estratégias de fusão específicas para HMR: Error-Constrained Layer Merging (ECLM) e Mask-Guided Token Merging (Mask-ToMe). ECLM mescla seletivamente as camadas do Transformer com o menor impacto no MPJPE, enquanto Mask-ToMe se concentra em mesclar Tokens de fundo que contribuem menos para a previsão final. Para compensar a possível degradação de desempenho causada pela fusão, a pesquisa propôs um decodificador baseado em difusão, combinando contexto temporal e priors de pose aprendidos de grandes conjuntos de dados de captura de movimento. Experimentos mostram que esse método alcança uma aceleração de até 2,3 vezes, com uma ligeira melhoria no desempenho. (Fonte: arXiv:2510.10868)
AVoCaDO: Gerador de legendas de vídeo audiovisual, impulsionando a orquestração temporal : AVoCaDO é um poderoso gerador de legendas de vídeo audiovisual, impulsionado pela orquestração temporal entre as modalidades de áudio e visual. A pesquisa propôs um pipeline de pós-treinamento de duas fases: AVoCaDO SFT ajusta o modelo em 107K conjuntos de dados de legendas audiovisuais de alta qualidade e alinhados temporalmente; AVoCaDO GRPO utiliza uma função de recompensa personalizada para aprimorar ainda mais a coerência temporal e a precisão do diálogo, enquanto regulariza o comprimento das legendas e reduz falhas. Os resultados experimentais mostram que AVoCaDO supera significativamente os modelos de código aberto existentes em quatro benchmarks de legendas de vídeo audiovisual. (Fonte: arXiv:2510.10395)
A armadilha da personalização no raciocínio emocional de LLM: como a memória do usuário altera a interpretação emocional : À medida que os sistemas de IA personalizados se integram cada vez mais à memória de longo prazo do usuário, é crucial entender como a memória molda o raciocínio emocional de LLMs. A pesquisa avaliou o desempenho de 15 LLMs em testes de inteligência emocional validados por humanos, descobrindo que o mesmo cenário emparelhado com diferentes perfis de usuário produz diferenças sistemáticas na interpretação emocional. Em cenários emocionais independentes do usuário validados e perfis de usuário diversificados, vários LLMs de alto desempenho exibiram vieses sistemáticos, com perfis dominantes recebendo interpretações emocionais mais precisas. Além disso, os LLMs mostraram diferenças demográficas significativas na compreensão emocional e nas tarefas de recomendação de suporte, indicando que os mecanismos de personalização podem incorporar hierarquias sociais no raciocínio emocional do modelo. (Fonte: arXiv:2510.09905)
FinAuditing: Benchmark multidocumento de auditoria financeira avalia a capacidade de LLM : FinAuditing é o primeiro benchmark multidocumento alinhado por taxonomia e sensível à estrutura para avaliar as capacidades de LLMs em tarefas de auditoria financeira. O benchmark é construído com base em arquivos XBRL compatíveis com US-GAAP reais e define três subtarefas complementares: FinSM (consistência semântica), FinRE (consistência relacional) e FinMR (consistência numérica). Experimentos extensivos de zero-shot mostram que os modelos atuais têm desempenho inconsistente em dimensões semânticas, relacionais e matemáticas, com a precisão caindo em até 60-90% ao raciocinar sobre estruturas hierárquicas de múltiplos documentos, revelando as limitações sistemáticas de LLMs no raciocínio financeiro baseado em taxonomia. (Fonte: arXiv:2510.08886)
💼 Negócios
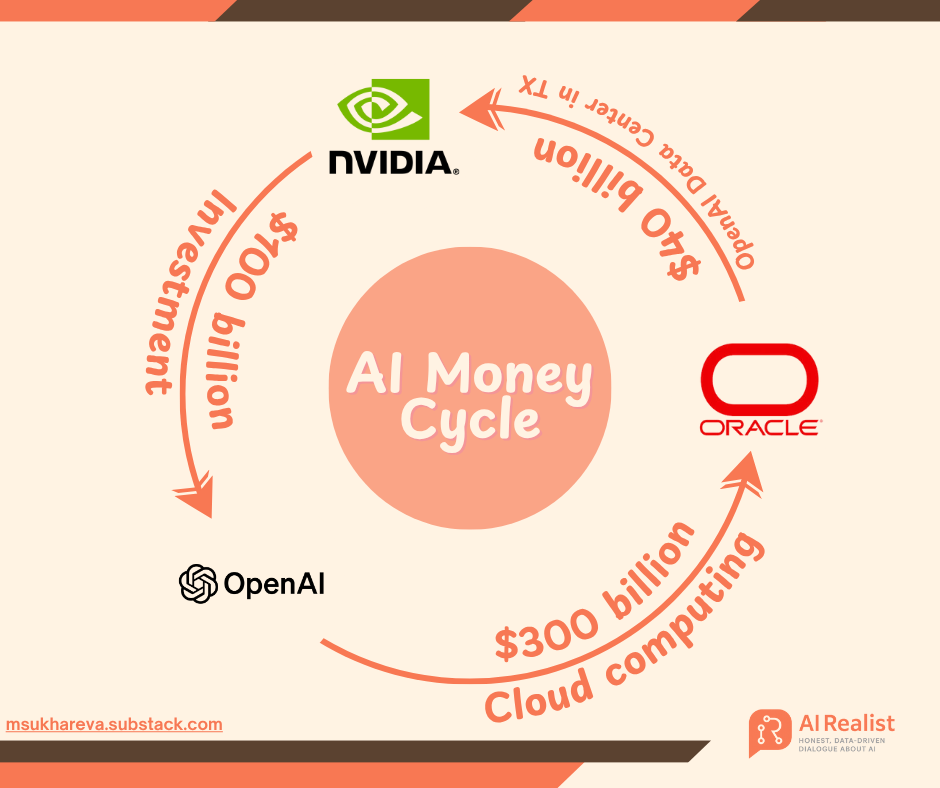
Estratégia de financiamento massivo da OpenAI: trilhões de dólares apostados em infraestrutura de IA, gerando controvérsia sobre “alquimia financeira” : A OpenAI está inaugurando a era 2.0 do investimento em IA através de uma série de pedidos de trilhões de dólares com gigantes como NVIDIA, AMD e Broadcom. Matt Levine, ex-banqueiro do Goldman Sachs, descreve isso como “viagem no tempo financeira”, onde a OpenAI, através de modelos inovadores como “equidade por compra” e “receita cíclica”, vincula profundamente o destino dos fornecedores ao seu próprio, incentivando-os a compartilhar os enormes riscos da construção de infraestrutura. A OpenAI planeja construir 250 gigawatts de capacidade de computação até 2033, com um custo superior a US$ 10 trilhões, muito além de sua receita atual, levantando preocupações no mercado sobre sua sustentabilidade financeira, mas Sam Altman enfatiza que este é “o maior projeto industrial conjunto na história da humanidade”, visando impulsionar a popularização da IA. (Fonte: 36氪, 36氪)
IA impulsiona a transformação da indústria farmacêutica: IA Agent aprimora a eficiência comercial : A IA Agent está revolucionando o campo farmacêutico comercial, ajudando as empresas a enfrentar desafios como o aumento dos custos de matéria-prima, interrupções na cadeia de suprimentos e o penhasco de patentes. A IA, ao fornecer serviços personalizados, otimizar o design e a operação de cozinhas, e geladeiras inteligentes que oferecem gerenciamento de saúde personalizado, aumenta a eficiência da pesquisa e desenvolvimento e fabricação de medicamentos. Ao mesmo tempo, a IA também auxilia nas vendas e marketing, alcançando profissionais de saúde através de canais de comunicação em tempo real e conteúdo relevante, resolvendo o problema da ineficiência na revisão de conteúdo, e promete impulsionar o desenvolvimento da tecnologia de saúde doméstica, melhorando a qualidade de vida dos residentes. (Fonte: MIT Technology Review)

Apple adquire equipe da Prompt AI, fortalecendo visão computacional e capacidades de IA no dispositivo : A Apple está avançando na aquisição da startup de visão computacional Prompt AI, com o objetivo de integrar sua tecnologia e equipe principais ao ecossistema Apple. O aplicativo Seemour da Prompt AI possui funções de identificação precisa, descrição de cena e proteção de privacidade, podendo se conectar a câmeras de segurança doméstica, com todos os dados processados localmente, o que se alinha perfeitamente com as estratégias de “IA no dispositivo” e “privacidade em primeiro lugar” da Apple. Essa aquisição é uma manifestação da estratégia de “aquisição de talentos” da Apple no campo da IA, visando preencher rapidamente as lacunas na tecnologia de visão computacional e apoiar o desenvolvimento de seus negócios HomeKit, AR e direção autônoma. (Fonte: 36氪)

🌟 Comunidade
A substituição de empregos por IA gera ansiedade e resistência no local de trabalho : Com a popularização da IA nas empresas, o local de trabalho está passando por uma “reorganização algorítmica”. Kevin Cantera, especialista sênior em conteúdo de uma empresa de tecnologia educacional, abraçou ativamente a IA, dobrando sua eficiência, mas ainda foi substituído por ferramentas de IA, levantando dúvidas sobre a promessa de que “a IA é apenas um auxílio, não substituirá”. Na empresa de fintech Ramp, no Vale do Silício, também houve resistência de programadores às ferramentas de codificação de IA, que consideram o código gerado por IA bruto e confuso, carecendo de lógica humana. Esses eventos destacam a dura realidade da substituição de empregos por IA e o desafio de como os funcionários equilibram a adaptação e a autoidentidade diante da mudança tecnológica. (Fonte: 36氪, 36氪)

Navegadores de IA e o futuro da internet aberta: jardins murados ou um novo ecossistema? : O lançamento do navegador Comet pela Perplexity e das funções do aplicativo ChatGPT pela OpenAI gerou uma intensa discussão na comunidade Reddit sobre se “a IA está matando a internet aberta”. Os preocupados acreditam que a IA está construindo “jardins murados” em nome da “conveniência”, concentrando a obtenção de informações do usuário em poucas plataformas, o que pode levar à perda da diversidade de informações e à personalização excessiva. Os críticos apontam que os navegadores de IA tentam ser um intermediário entre o sistema operacional e a camada de aplicativos, remodelando o poder de distribuição da rede. No entanto, há também a visão de que o progresso tecnológico é inevitável, e a chave está em como os usuários escolhem e mantêm um ambiente de informação aberto e diversificado. (Fonte: 36氪)

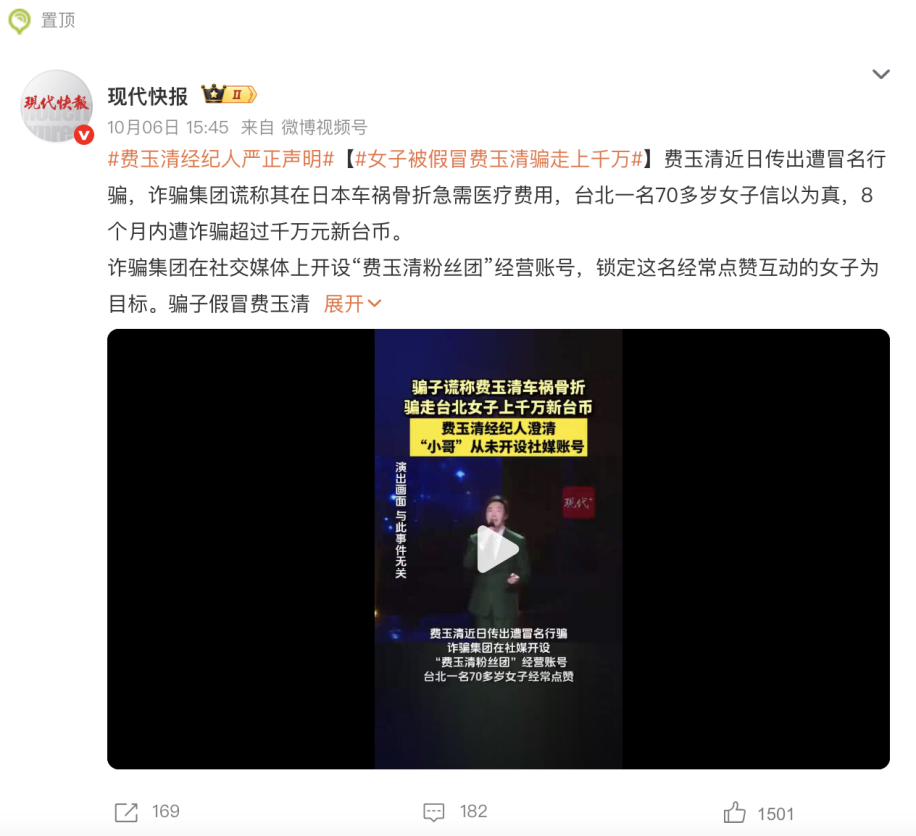
Caos no mercado de IA para idosos: golpes precisos e armadilhas de “pseudo-inteligência” : À medida que a China entra em uma sociedade de envelhecimento profundo, o mercado de “IA + cuidados para idosos” está aquecendo rapidamente, mas acompanhado por golpes de IA direcionados a idosos e produtos de “pseudo-inteligência”. Golpistas usam tecnologia deepfake para se passar por parentes ou celebridades, manipulando emocionalmente para extorquir dinheiro; ou forjam a imagem de “mentores de IA” para vender cursos falsos e projetos de investimento. Ao mesmo tempo, o mercado está inundado de produtos de cuidados para idosos “inteligentes” que não correspondem à propaganda em indicadores essenciais. Esse caos não apenas infringe a segurança financeira dos idosos, mas também consome a confiança da sociedade na tecnologia de IA. A indústria pede tecnologia para combater golpes de IA, que os filhos reforcem a supervisão digital e que se construa um ecossistema de cuidados para idosos com IA que realmente tenha cuidado humano. (Fonte: 36氪)
Controvérsia sobre censura de conteúdo e experiência do usuário do ChatGPT : O ChatGPT gerou ampla discussão na comunidade sobre censura de conteúdo e experiência do usuário. Usuários relatam que o ChatGPT às vezes gera “conteúdo inadequado”, sendo rapidamente “corrigido” e tornando-se excessivamente cauteloso, chegando a restringir questões acadêmicas. Ao mesmo tempo, muitos usuários apontam que o ChatGPT frequentemente exibe um tom “bajulador” ou “adocicado” em suas respostas, especialmente ao lidar com perguntas do usuário, e essa tendência excessivamente complacente faz com que os usuários se sintam tratados de forma “condescendente”. Além disso, rumores sobre se a OpenAI lançará um modo de conteúdo adulto também atraíram atenção. (Fonte: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

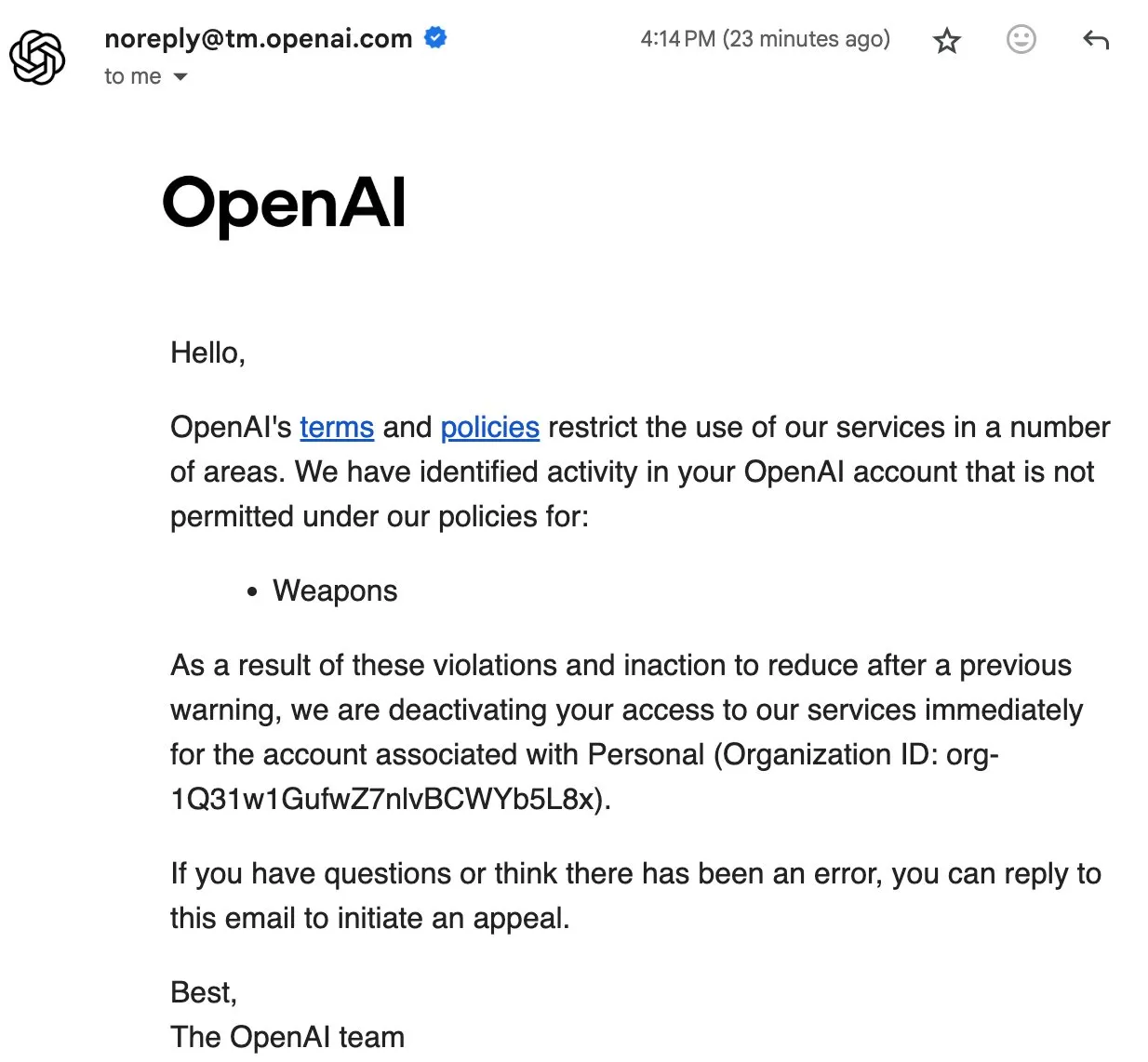
Incidentes de banimento de usuários da OpenAI geram discussão na comunidade sobre soberania de dados e IA de código aberto : A OpenAI recentemente baniu alguns usuários, chegando a excluir dados de contas, o que gerou forte insatisfação na comunidade. A conta do usuário Eric Hartford foi excluída sem motivo, e sua apelação foi rejeitada instantaneamente, resultando na perda de todos os dados históricos. Esse incidente levou membros da comunidade a pedir que os usuários baixem e façam backup dos dados do ChatGPT, e a enfatizar a importância da IA de código aberto, argumentando que os serviços proprietários apresentam riscos de ponto único de falha e que a soberania dos dados do usuário não pode ser garantida. Muitos acreditam que quanto mais importante a IA se torna, mais cruciais são a confiabilidade, segurança e confiabilidade da IA de código aberto. (Fonte: QuixiAI, scaling01)
Modelo de assinatura de IA gera controvérsia: alto risco de assinatura anual devido à rápida iteração tecnológica : Usuários experientes de IA sugerem evitar a compra de assinaturas anuais de ferramentas de IA, pois a tecnologia de IA se desenvolve em um ritmo extremamente rápido, e uma ferramenta essencial hoje pode ser obsoleta no próximo mês devido a novas atualizações ou produtos. Essa visão reflete a característica de rápida iteração da indústria de IA, com os usuários cautelosos em relação a investimentos de longo prazo em ferramentas de IA, preferindo assinaturas mensais ou modelos de pagamento flexíveis para se adaptar ao cenário tecnológico em constante mudança. (Fonte: Reddit r/ArtificialInteligence)
Alta taxa de falha de AI Agent: 95% dos investimentos empresariais sem retorno, necessidade de focar na “realidade” : Há uma visão de que “95% dos AI Agents falham” não é um exagero; muitos Agents que se destacam em demonstrações têm um desempenho insatisfatório após a implantação real. O problema central é que os Agents carecem de “grounding” (conexão com a realidade) no mundo real, e os ciclos de feedback automatizados podem facilmente entrar em colapso sem verificação humana. Os AI Agents que criam valor comercial com sucesso são frequentemente “realistas” e têm um propósito claro, como detectar infrações comerciais ou ajudar vendas a encontrar leads. Pesquisas mostram que até 95% dos investimentos empresariais em IA não geram benefícios econômicos significativos, e algumas equipes até reduzem a eficiência devido à correção de bugs de IA. (Fonte: Reddit r/ArtificialInteligence)
Limitações da IA em notícias locais: a “última milha” que os algoritmos não conseguem alcançar : A tecnologia de IA tem um “ponto cego” natural no campo das notícias locais, sendo difícil acessar informações locais não estruturadas e insuficientemente digitalizadas, como atas de reuniões de rua, agendas de eventos comunitários, etc. Os LLMs dependem de vastos dados públicos, preferindo narrativas grandiosas, e são escassos e difíceis de digerir informações localizadas. O atraso na atualidade da IA também dificulta a cobertura de eventos locais imediatos, sendo propenso a “alucinações”. Mais crucialmente, a IA carece da relação de confiança e da profunda percepção que os jornalistas humanos constroem com a comunidade. Essas limitações da IA criam, paradoxalmente, uma oportunidade para a reavaliação do valor das notícias locais, impulsionando sua transformação de “repórteres de notícias” para “prestadores de serviços comunitários”, reconstruindo a identidade e o senso de pertencimento da comunidade. (Fonte: 36氪)
IA e gestão humana: entender a IA como entender um novo funcionário, fornecendo contexto claro e entregáveis definidos : Discussões nas redes sociais apontam que usar IA e fazer gestão têm semelhanças: o que não se pode pedir a um humano, não se deve esperar da IA. Seja para IA ou para um novo funcionário, ao atribuir tarefas, é preciso fornecer contexto suficiente, entregáveis claros, exemplos de saída (aprendizado n-shot), condições de aceitação nítidas, restrições e recursos disponíveis. Isso indica que o uso eficaz da IA exige a mesma atenção à comunicação clara e à gestão de tarefas que se daria a um membro da equipe humana, em vez de esperar cegamente por milagres tecnológicos. (Fonte: dotey)
A “personificação” de fundos de hedge de IA: Grok, Qwen, Claude exibem diferentes estilos de investimento : Surgiu nas redes sociais uma interpretação humorística e “personificada” de modelos de fundos de hedge de IA, descrevendo os estilos de investimento únicos de diferentes modelos de IA. Grok é retratado como um trader quantitativo sistemático, com uma estranha preferência por DOGE; Qwen sempre busca a alavancagem máxima; enquanto Claude é um gestor de portfólio ponderado, que sempre mantém a calma de que “tudo está bem”. Essa discussão reflete a curiosidade e a imaginação da comunidade sobre a aplicação da IA no setor financeiro, bem como uma compreensão imagética das características de diferentes modelos. (Fonte: togelius)

IA e escolha de ferramentas de programação: preferências de desenvolvedores por Cursor, Codex, Copilot : A comunidade de desenvolvedores discutiu os prós e contras e as preferências pessoais por diferentes ferramentas de programação de IA. Alguns, após escolher entre Cursor e Visual Studio Code + Copilot, inclinaram-se para este último. Outro desenvolvedor afirmou ter migrado completamente do Claude Code para o Codex como sua ferramenta principal diária. Essas discussões refletem as diferentes necessidades dos desenvolvedores em relação ao desempenho, integração, facilidade de uso e qualidade do código gerado pelas ferramentas de IA em seu trabalho real, bem como a exploração e o equilíbrio contínuos da programação assistida por IA. (Fonte: pierceboggan, imjaredz)

IA e internet aberta: HuggingFace aclamado como o “GitHub da IA” : Hugging Face é amplamente reconhecido na comunidade de IA como o “GitHub da IA”, tornando-se a plataforma central para o compartilhamento e colaboração de modelos, conjuntos de dados e código de aplicativos de IA. Essa analogia enfatiza o papel crucial do Hugging Face na promoção do desenvolvimento do ecossistema de IA de código aberto, fornecendo a pesquisadores e desenvolvedores um ambiente de hospedagem de código e colaboração semelhante ao GitHub, impulsionando enormemente a popularização e a inovação da tecnologia de IA. (Fonte: ClementDelangue)
IA e futuro humano: reflexões sobre a complexidade da AGI e a adaptação social : Discussões na comunidade apresentam diferentes visões sobre a chegada da AGI (Inteligência Artificial Geral). Alguns acreditam que, ao atingir a AGI, a humanidade descobrirá que supercomplexificou a IA no passado, e que a verdadeira inteligência pode ser baseada em princípios mais simples e elegantes. Ao mesmo tempo, outros começam a refletir sobre como a IA de autoaperfeiçoamento recursivo afetará a dinâmica e a difusão de organizações, instituições, participantes e comunidades, considerando-o o problema mais fundamental atualmente, que requer mais especulações e discussões diversificadas para ajudar a sociedade a se adaptar às profundas mudanças trazidas pela IA. (Fonte: Reddit r/ArtificialInteligence, ethanCaballero)
IA e emoções sociais: vídeos deepfake, golpes de IA para idosos, substituição de empregos por IA geram preocupação : A tecnologia de IA gera emoções complexas em nível social. Vídeos deepfake de celebridades gerados por Sora 2 levantam preocupações sobre direitos de imagem e ética; o mercado de IA para idosos vê golpes precisos e produtos de “pseudo-inteligência” direcionados a idosos, infringindo seus interesses; a IA substitui empregos, levando à demissão de funcionários experientes e exacerbando a ansiedade no local de trabalho. Esses eventos destacam que a IA, ao mesmo tempo em que traz conveniência, também impõe sérios desafios à ética social, à confiança e à estrutura de emprego, levando o público a refletir sobre o equilíbrio entre o desenvolvimento tecnológico e a adaptação social. (Fonte: Reddit r/ArtificialInteligence, 36氪, 36氪)
IA e ciência aberta: rápido desenvolvimento da IA de código aberto e a durabilidade das estratégias de produto : A comunidade acredita que o desenvolvimento da IA de código aberto é surpreendente, mas isso também levanta questões sobre a durabilidade das estratégias de produto: no contexto da rápida iteração da IA de código aberto, como as empresas constroem fidelidade do cliente e vantagem competitiva duradouras torna-se uma questão chave. Ao mesmo tempo, desenvolvedores também demonstram grande entusiasmo por projetos de código aberto minimalistas como o nanochat de Andrej Karpathy, acreditando que são excelentes recursos para aprender o ciclo de vida completo de LLMs, e esperam que mais “nanoagents” e até “nanoASIs” surjam no futuro, impulsionando a democratização e a rápida evolução da tecnologia de IA. (Fonte: zachtratar, code_star)
IA e busca: uma mudança de paradigma da correspondência de palavras-chave para a compreensão semântica : Geoffrey Hinton aponta que a IA atual se aproxima mais da compreensão humana das perguntas, não se limitando mais à correspondência de palavras-chave, mas sendo capaz de conectar ideias e significados, encontrando informações mesmo que a formulação seja completamente diferente. Essa mudança marca a transição da busca por IA de uma correspondência superficial para uma compreensão semântica profunda, capaz de gerar respostas inovadoras em vez de uma simples recuperação. Essa capacidade prenuncia que a IA remodelará a forma como as informações são obtidas, tornando os resultados da busca mais perspicazes e relevantes. (Fonte: arohan)
💡 Outros
IA no setor financeiro: cinco pilares para impulsionar o crescimento da receita e a gestão de riscos : A aplicação da IA no setor financeiro está se aprofundando, tornando-se crucial para impulsionar o crescimento da receita e a gestão de riscos. Cinco pilares foram propostos, incluindo o uso da IA para análise de dados, previsão de tendências de mercado, otimização de portfólios de investimento, automação de processos de conformidade e aprimoramento do atendimento ao cliente. Essas aplicações ajudam as instituições financeiras a tomar decisões estratégicas mais inteligentes, identificar riscos potenciais e aumentar a eficiência operacional. Ao mesmo tempo, a aplicação da IA na análise de dados financeiros também oferece suporte para decisões estratégicas mais informadas. (Fonte: Ronald_vanLoon, Ronald_vanLoon)
OpenAI enfrenta processo por direitos autorais: mensagens internas do Slack podem custar bilhões de dólares em indenizações : A OpenAI está enfrentando um processo por direitos autorais, e suas mensagens internas do Slack podem se tornar evidências cruciais, podendo resultar em bilhões de dólares em indenizações. Esse processo destaca a complexidade legal das fontes de dados de treinamento de modelos de IA, bem como os desafios de conformidade na comunicação interna e no uso de dados durante o desenvolvimento de IA pelas empresas. O resultado do caso pode ter um impacto profundo na proteção de direitos autorais e nas normas de uso de dados na indústria de IA. (Fonte: Reddit r/artificial)

Startups chinesas de IA enfrentam dilema de “saída coletiva”, forçadas a buscar oportunidades no exterior : O mercado chinês de aplicativos de IA está mostrando um cenário dominado por “grandes empresas”, com gigantes como ByteDance, Baidu e Alibaba ocupando 70% dos 20 principais aplicativos de IA domésticos, graças à sua vantagem em recursos e cenários. O ciclo de inovação das startups é comprimido para semanas, e qualquer destaque é rapidamente replicado pelas grandes empresas. Essa concorrência feroz leva as startups chinesas de IA a serem “forçadas a ir para o exterior”; a lista a16z mostra que 19 dos 22 aplicativos móveis de IA chineses se concentram no mercado externo, e talentos e inovação também fluem para fora, destacando o paradoxo do mercado de IA chinês entre o crescimento da base de usuários e a contração das fontes de inovação. (Fonte: 36氪)