キーワード:AI技術, 大規模言語モデル, ディープラーニング, 人工知能, 機械学習, 自然言語処理, コンピュータビジョン, 強化学習, nanochatオープンソースプロジェクト, OpenAI自社開発AIチップ, Sora 2ディープフェイク倫理, Claude Sonnet 4.5, GPT-5 Pro数学推論
🔥 注目
Andrej Karpathyがnanochatを発表:100ドルでChatGPTを自作 : Teslaの元AIディレクターAndrej Karpathyがオープンソースプロジェクトnanochatをリリースしました。8000行未満のコードでChatGPTの完全なトレーニングと推論プロセスを実現しています。このプロジェクトはLLM研究の敷居を下げることを目的としており、ユーザーはクラウドGPU(約100ドル、4時間のトレーニング)だけで対話可能なミニChatGPTを構築できます。12時間のトレーニングでGPT-2 COREの指標を超える性能を発揮します。nanochatはLLM101nコースの最終プロジェクトとなり、研究プラットフォームやベンチマークツールとして発展する可能性があり、KarpathyのAI教育と民主化への継続的な情熱を示しています。(出典:GitHub nanochat, Reddit r/deeplearning, 36氪, 36氪, 36氪, 36氪)
OpenAIとBroadcomが提携しAIチップを自社開発、10ギガワットの計算インフラを展開 : OpenAIはBroadcomとの戦略的提携を発表し、カスタムAIチップと計算システムを共同で設計・展開します。目標は2026年後半から2029年末までに、総消費電力10ギガワットの推論インフラを構築することです。この動きは、OpenAIが既存のGPUを購入するだけでなく、垂直統合を通じてトランジスタレベルからハードウェア設計に参画し、AIモデルの性能最適化、コスト削減、将来の指数関数的な計算需要に対応することを示しています。OpenAIは、この提携を「人類史上最大の共同産業プロジェクト」と表現しており、AIモデルがチップ設計を支援する可能性も示唆しており、AIがハードウェア開発に深く関与する未来を予見させます。(出典:OpenAI, Bloomberg, CNBC, 36氪, 36氪, 36氪)
Sora 2がディープフェイクの倫理危機と著作権論争を引き起こす : OpenAIの動画生成モデルSora 2は、その高度にリアルな生成能力で急速に人気を博しましたが、深刻な倫理的および著作権上の課題ももたらしています。ユーザーがSora 2を使って故有名人(マイケル・ジャクソン、ロビン・ウィリアムズなど)の偽動画を生成し、遺族から強い不満が表明され、故人のイメージの悪用と不敬であるとされています。OpenAIはこれに対し、公人やその家族が自身のイメージの利用方法を管理する権利を持つべきであると回答し、より詳細な著作権管理と収益分配メカニズムを提供する計画です。しかし、オープンソースのディープフェイクモデルの普及が加速する中、社会はAI生成コンテンツがもたらす衝撃に早急に適応し、効果的な技術的および法的保護策を模索する必要があるとの懸念が広まっています。(出典:Washington Post, BBC, 量子位)

Claude Sonnet 4.5、Microsoft Agent Framework、Cursor IDEがAIコーディング能力を飛躍的に向上 : AIコーディング分野で大きなブレークスルーが起こっています。Claude Sonnet 4.5はSWE-bench Verifiedベンチマークで77.2%の精度を達成し、前世代モデルを大幅に上回りました。同時に、Microsoft Agent FrameworkはVS CodeをAIネイティブ環境に変え、Agentが複数のファイルにわたるコード変更を自律的に処理できるようにしました。Cursor IDE 1.7も「Agentモード」を導入し、複雑な問題をワンクリックで解決できるようになりました。これらの進展は、AI Agentが開発タスクの大部分を担えるようになったことを示しており、開発者がAIに過度に依存する可能性や、AI生成コードが潜在的な技術的負債を招くリスクについて議論を呼んでいます。(出典:Reddit r/artificial)
GPT-5 Proがエルデシュの数学問題を解決、強力な文献検索と脆弱性識別能力を発揮 : OpenAIのGPT-5 Proは、数学的推論において驚くべき能力を発揮しました。エルデシュ問題#339の画像のみから、2003年に解決済みであるという重要な文献を正確に検索しました。さらに、GPT-5 Proは発表済みの論文の重大な欠陥を18分で発見し、人間の専門家が数日かける研究成果を上回りました。このブレークスルーは、GPT-5 Proの正確な情報検索、複雑な問題解決、科学文献検証における大きな可能性を強調しており、AIが研究プロセスを大幅に加速させ、特に学術的主張の検証や論理的矛盾の発見において貢献することを示唆しています。(出典:Sebastien Bubeck, Greg Brockman, 36氪)

三大AI大手企業が共同論文発表:既存のLLMセキュリティ防御は脆弱 : OpenAI、Anthropic、Google DeepMindが異例の共同論文を発表し、大規模言語モデル(LLM)のジェイルブレイクやプロンプトインジェクションに対する現在の防御メカニズムが一般的に脆弱であることを指摘しました。研究チームは汎用適応型攻撃フレームワークを提案し、勾配降下法、強化学習、ランダム探索、人間によるレッドチームテストなどの手法を組み合わせ、12種類の主要な防御メカニズムを90%以上の成功率で回避しました。これは、既存の評価が机上の空論であることが多く、将来のLLMセキュリティ研究には、より強力な適応型攻撃評価を組み込むことで、真に堅牢な防御システムを構築する必要があることを示しています。(出典:arXiv:2510.09023, 36氪)

xAIが「世界モデル」競争に参入、最初の応用はAIゲーム生成 : Elon Musk率いるxAI社は、「世界モデル」競争に静かに参入し、Google、Metaなどの大手企業と肩を並べています。xAIはNVIDIAからAI専門家を招聘し、膨大な動画とロボットデータをトレーニングすることで、現実の物理世界を理解しシミュレートできるモデルの構築を目指しています。最初の商業化の焦点はAIゲーム生成で、来年末までにAI生成ゲームをリリースし、ロボットシステムへの応用も模索する計画です。Googleの研究者は、将来の動画モデルは言語モデルのようにスマートになり、「次のフレーム予測」を通じて物体分割、エッジ検出などの創発能力を解き放ち、「視覚分野のGPTモーメント」が到来すると予測しています。(出典:36氪)
ICLRの謎の論文がSAM3を明らかに:概念ですべてをセグメント化し、視覚AIの新たなパラダイムを再構築 : ICLR 2026会議の盲査論文「SAM3:用概念分割一切」が公開され、Meta AIのSegment Anything Model(SAM)が3回目の大規模アップグレードを迎えることが明らかになりました。SAM3の核心的なブレークスルーは「概念ベースのセグメンテーション」(PCS)であり、モデルはピクセルやインスタンスだけでなく、テキストや画像プロンプトに基づいて特定の「意味概念」に合致するすべてのオブジェクトを識別、セグメント化、追跡できます。新しいシステムは、人間と機械の協調データエンジンを通じて、400万の概念ラベルを含む高品質データセットを構築し、H200 GPU上で30ミリ秒以内に数百のオブジェクトを識別。既存システムを全面的に凌駕する性能を発揮し、視覚AIの「GPT-3モーメント」が近い可能性を示唆しています。(出典:arXiv:r35clVtGzw, 36氪)
🎯 動向
Gemini 3の内部テストが好評、「史上最強のフロントエンド開発モデル」と絶賛 : Googleの次世代フラッグシップモデルGemini 3が内部テストで広く注目を集め、フロントエンド開発、SVGベクター画像生成、マルチモーダル能力において絶賛され、「史上最高のフロントエンドおよびウェブ開発モデル」と評されています。年間最優秀モデルになるとの予測もあります。公開情報によると、Gemini 3.0 ProはMoEアーキテクチャを採用し、数兆のパラメータを持ち、コンテキストウィンドウは数百万に拡張。ディープシンキングモードとマルチモーダル能力を内蔵し、ARC-AGI-2とHLEベンチマークで優れた性能を発揮しています。(出典:36氪)
AIがチップ設計と製造に深く浸透 : 機械学習はチップ設計と製造分野でますます深く応用され、半導体の効率と革新を新たなレベルに押し上げています。AIHubがSony AIのチップ設計責任者Lorenzo Servadeiにインタビューしたところ、AIはEDA(Electronic Design Automation)分野で推定加速から設計プロセスへの積極的な参加へと移行しており、ニューラルネットワークによる多物理場モデルの加速、最適化アルゴリズム、生成AIによる物理実装を通じて、チップ設計の速度、品質、創造性を大幅に向上させていると指摘しました。OpenAIも、そのGPTモデルが自社チップの設計を支援し、面積削減と開発サイクルの加速を実現したと明かしています。(出典:aihub.org, 36氪)

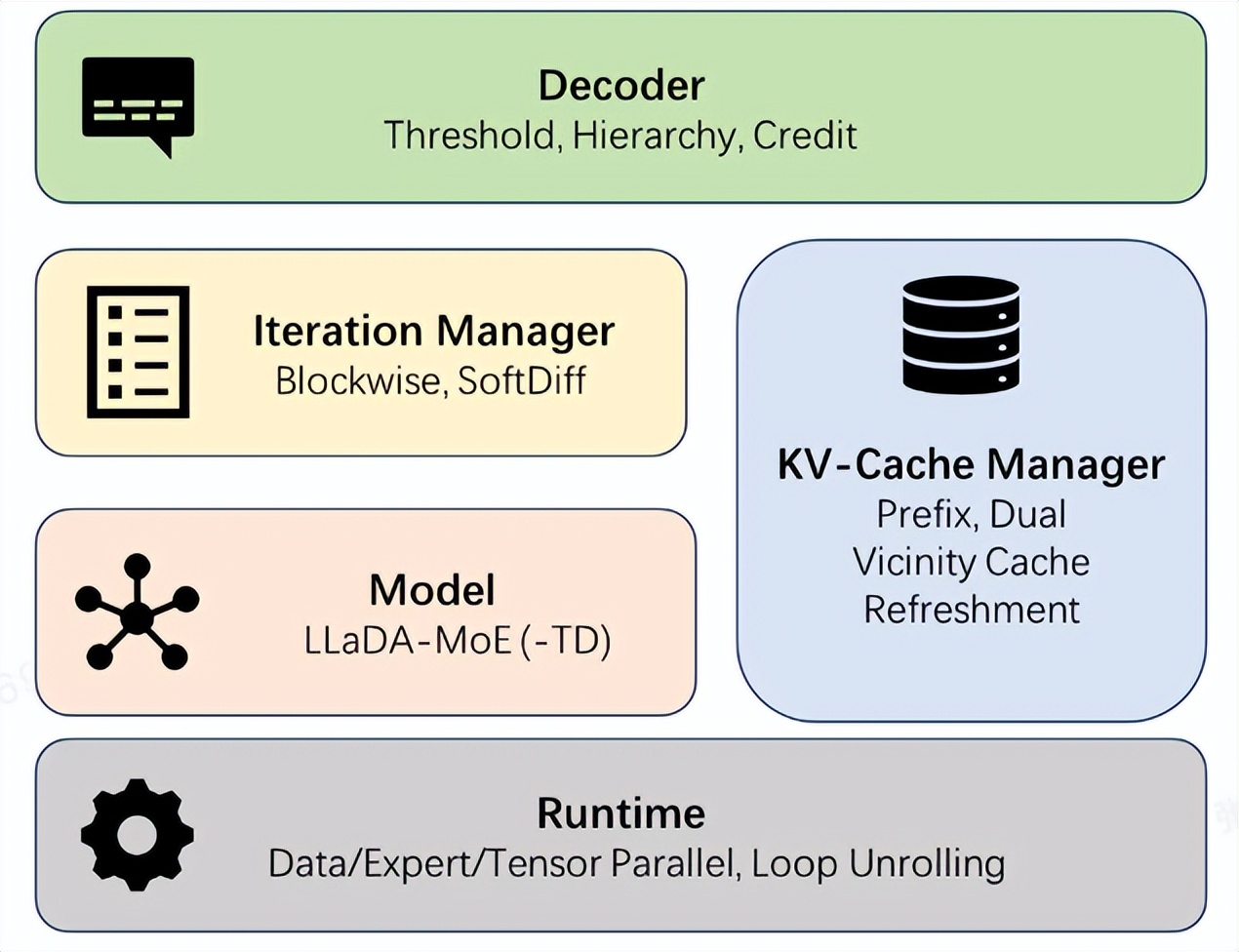
Ant GroupがdInferフレームワークをオープンソース化、拡散言語モデルの推論速度を10倍向上 : Ant Groupは、業界初の高性能拡散言語モデル推論フレームワークdInferを正式にオープンソース化しました。これにより、拡散言語モデルの推論速度はNVIDIA Fast-dLLMと比較して10.7倍向上しました。コード生成タスクHumanEvalにおいて、dInferは単一バッチ推論で1011Tokens/秒を達成し、自己回帰モデルを初めて大幅に上回りました。dInferはアルゴリズムとシステムの深い協調設計を採用し、モデル接続、KVキャッシュマネージャー、拡散イテレーションマネージャー、デコード戦略の4つのコアモジュールを含んでいます。拡散言語モデルの高い計算コスト、KVキャッシュの無効化、並列デコードなどの課題を解決し、その高効率推論の可能性を解放することを目指しています。(出典:量子位, QuixiAI)
Google NotebookLMがアップグレード、Gemini Nano Bananaが動画概要に新しい視覚スタイルを提供 : Google NotebookLMの動画概要機能がアップグレードされ、Geminiの画像生成モデルNano Bananaを搭載した新しい視覚スタイル(クラシック、ホワイトボード、水彩、レトロ印刷版、トラディショナル、ペーパーアート、アニメ)が追加されました。さらに、より簡潔な「Brief」形式も導入され、迅速な要約を提供します。これらの更新はまずProユーザーに提供され、数週間以内に全ユーザーに開放される予定で、動画コンテンツの理解と表現におけるユーザーのパーソソナライズ体験向上を目指しています。(出典:Google, op7418)
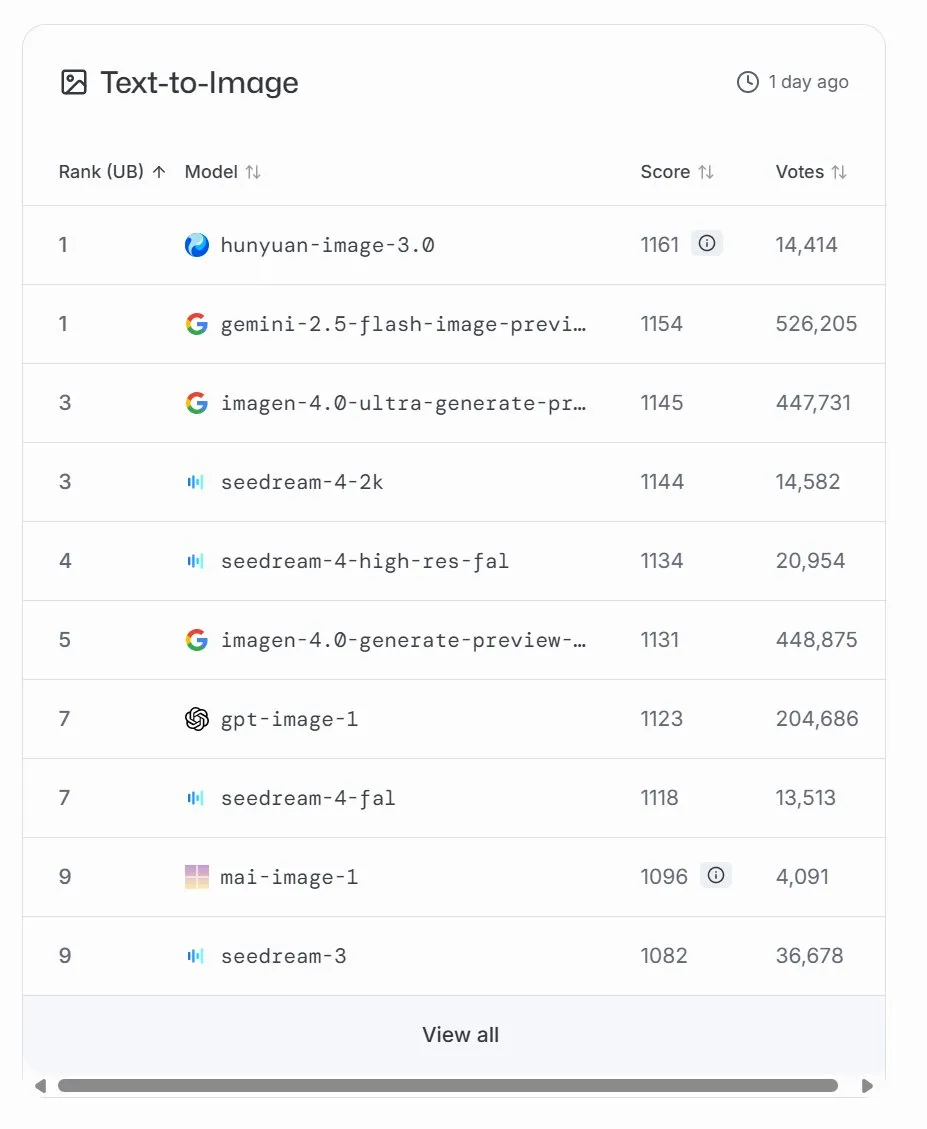
Microsoftが画像生成モデルMAI-Image-1を発表、LMArenaで9位にランクイン : Microsoft AIは、3番目のAIモデルMAI-Image-1を発表しました。これは画像生成モデルで、LMArenaランキングで初登場9位にランクインし、Seedream 3と並びました。このモデルは生成速度と品質の印象的なバランスを実現しており、MicrosoftのマルチモーダルAI分野への継続的な投資と急速な発展を示しています。Microsoftはモデルの最適化を続け、より高いランキングを目指すと表明しています。(出典:mustafasuleyman, NandoDF)
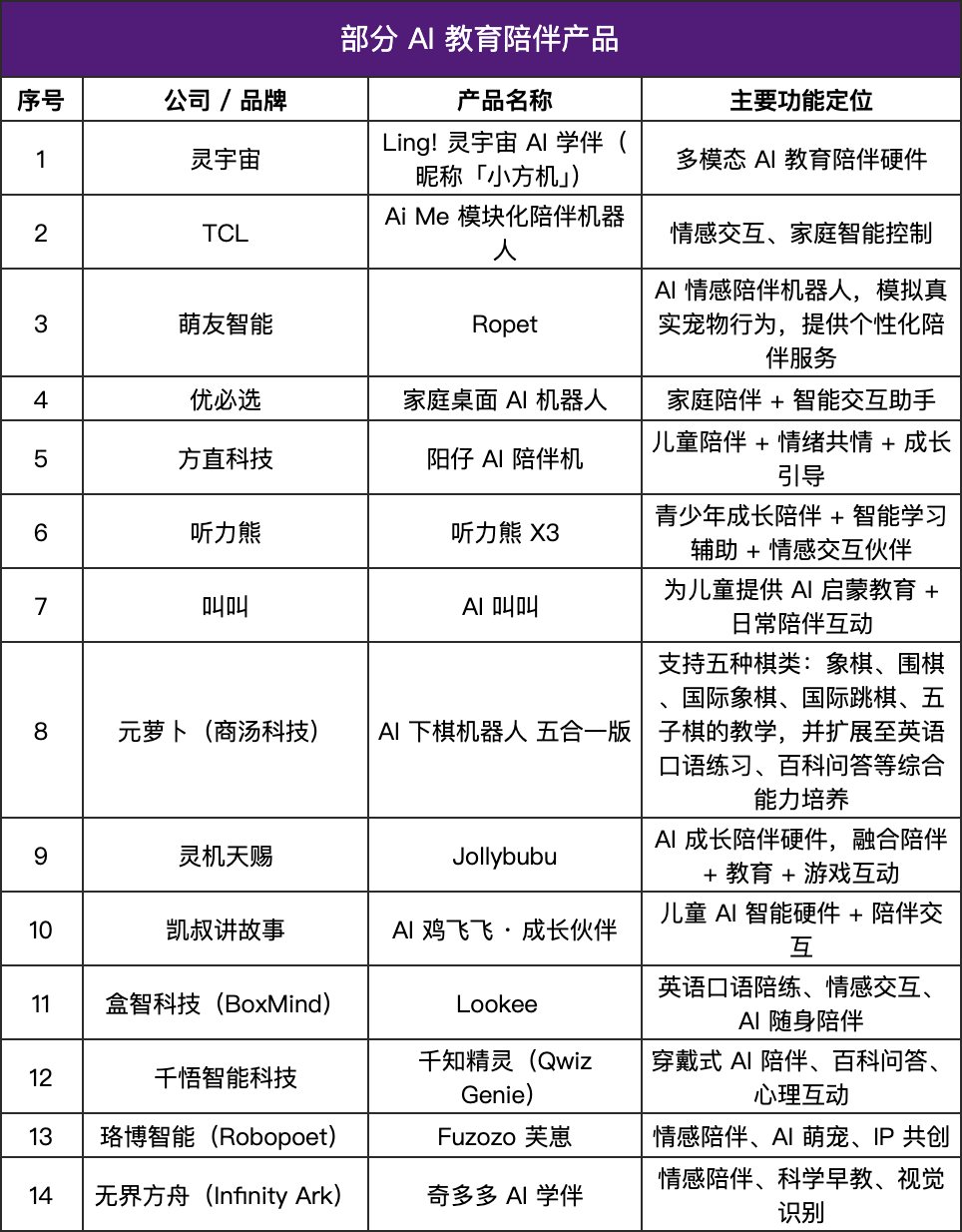
AIコンパニオン製品が爆発的に増加、教育ハードウェアに「温かみ」が生まれる : AIコンパニオン製品市場が急速に台頭しており、将来の市場規模は700億ドルから1500億ドルに達すると予測されています。これらの製品は「指示応答」から「感情フィードバック」へと移行し、言語モデル、感情認識、音声対話、記憶システムを通じて人間の反応をシミュレートし、パーソナライズされたコンパニオンシップを提供します。教育分野では、AIコンパニオン製品は学習アシスタント、感情フィードバックシステム、スマートQ&Aモデルとして導入され、知識伝達から心理的サポートへと拡大。軽量化、人格化の傾向を示し、マルチモーダル対話を融合させ、「生徒を理解する」システムとなることを目指しています。(出典:36氪)
NVIDIAがDGX Sparkを発表、世界最小のAIスーパーコンピューター : NVIDIAは、世界最小のAIスーパーコンピューターと称されるDGX Sparkを正式に発表し、出荷を開始しました。DGX SparkはNVIDIA Grace Blackwellアーキテクチャをベースに、128GBの統合メモリを搭載しており、AI開発者に強力なローカルLLMプロトタイプ設計および実行能力を提供することを目指しています。早期ユーザーはツール、ソフトウェア、モデルのテスト、検証、最適化を進めており、高性能AI計算がより普及し、便利になることを示唆しています。(出典:nvidia, ollama)

AnthropicがClaude Sonnet 4.5、Agent SDK、および更新版Claude Codeをリリース : AnthropicはClaude Sonnet 4.5を発表し、推論能力を向上させ、より大きなコンテキストウィンドウ(200k–1Mトークン)を持ち、コーディングと推論ベンチマーク性能を改善しました。同時に、AnthropicはClaude Agent SDKと更新版Claude Codeもリリースし、自動コンテキスト追跡/要約、永続メモリツール、ロールバック機能付きチェックポイント、およびVS Code互換IDE拡張機能を追加しました。これらは開発者により強力なAIコーディングとAgent構築能力を提供することを目指しています。(出典:DeepLearningAI)

中国のオープンソースモデルがHugging Faceのダウンロード数でリード、Googleが最大の貢献者に : Hugging Faceコミュニティの最新分析によると、中国企業が開発したオープンソースモデル、特にQwenシリーズモデルがダウンロード数で好調なパフォーマンスを示しています。同時に、GoogleがHugging Face上で最もダウンロード数の多いモデルを持つ機関となりました。この傾向は、オープンソースAI分野における中国の影響力が増大していることを示し、Googleがテクノロジー大手としてオープンソースエコシステムに積極的に貢献し、AI技術の普及を推進していることを示唆しています。(出典:mervenoyann, osanseviero)
Google検索製品担当副社長Robbie SteinがAI検索の未来を解説:「明確さ」を終着点に : Google検索製品担当副社長Robbie Steinは、AIが情報検索の基本的な人間のニーズを変えるのではなく、AIモードを通じてより自然で複雑にしていると指摘しました。将来のAI検索は「理解能力」を備え、曖昧な質問をサブクエリに分解して並行検索し、引用付きで追跡可能な回答をまとめることができるようになるでしょう。Googleの目標は「情報を理解し、信頼できる」システムになることであり、マルチモーダル融合と構造化された世界データを通じて、「ウェブページのインデックス作成」から「世界のインデックス作成」へと移行し、情報の取得をより明確かつ迅速にすることを目指しています。単に流暢な言語を生成するだけではありません。(出典:36氪)
Ant Groupが高性能拡散言語モデル推論フレームワークdInferをオープンソース化 : Ant Groupは、業界初の高性能拡散言語モデル推論フレームワークdInferを正式にオープンソース化しました。これにより、拡散言語モデルの推論速度はNVIDIA Fast-dLLMと比較して10.7倍向上しました。コード生成タスクHumanEvalにおいて、dInferは単一バッチ推論で1011Tokens/秒を達成し、自己回帰モデルを初めて大幅に上回りました。dInferはアルゴリズムとシステムの深い協調設計を採用し、拡散言語モデルの高い計算コスト、KVキャッシュの無効化、並列デコードなどの課題を解決し、その高効率推論の可能性を解放することを目指しています。(出典:量子位)
NVIDIAがNVFP4トレーニング技術を発表、4ビット事前学習でFP8精度に匹敵 : NVIDIAは画期的なNVFP4トレーニング技術を発表し、4ビットで大規模言語モデルを事前学習しながら8ビット精度を達成可能にしました。この技術はE2M1形式の4ビット浮動小数点表現を採用し、微細なスケーリング、ランダム丸め、Random Hadamard Transformsを組み合わせることで、計算とメモリ要件を大幅に削減します。実験では、NVFP4がモデル精度(MMLU Pro 62.58% vs 62.62%など)を維持しつつ、トレーニング効率を大幅に向上させることを示し、将来のより大規模なLLMトレーニングに向けたより経済的で効率的なパスを提供します。この技術は主にNVIDIA Blackwellアーキテクチャに依存し、H100以降のGPUが必要です。(出典:Reddit r/LocalLLaMA, karminski3)

MIT SEALフレームワークがAIモデルの自動ファインチューニングデータ生成と重み更新を実現 : マサチューセッツ工科大学(MIT)はSEAL(Self-Adapting LLMs)フレームワークを発表しました。これにより、大規模言語モデル(LLM)がファインチューニングデータを自動生成し、自己重み更新を行うことで、人間による介入なしに勾配更新を実現します。SEALは内外の二重ループ学習メカニズムを採用し、モデルはタスクのパフォーマンスに基づいて自己更新命令生成戦略を最適化。LLMに自己駆動型の更新能力を初めて付与しました。実験では、SEALが知識注入と少サンプル学習タスクで優れた性能を発揮し、GPT-4.1生成データを上回る精度を達成。強力なタスク適応能力と知識統合能力を示し、自己進化モデル時代の到来を予見させます。(出典:arXiv:2506.10943, 36氪)

AIスマホの出荷量が急増、酷赛智能などのメーカーが「小モデル+大モデル」協調戦略を模索 : 2025年の中国AIスマホ出荷台数は前年比591%増、普及率22%に達し、AIスマホが業界の新たな焦点となっています。酷赛智能などのメーカーは、パラメータ競争から実用的な革新へと移行し、「フロントエンド小モデル+バックエンド大モデル」の動的協調戦略を採用。約6億パラメータの垂直小モデルをデバイス側に展開し、高速応答とプライバシー保護を実現。同時に、科大讯飞、バイトダンス、アリババ、Googleなどの汎用大モデルの計算能力を統合しています。この戦略は、ユーザー体験の向上、パーソナライズされたサービスの提供、コスト削減を目指し、多様で断片化された海外市場に適応するものです。(出典:36氪)

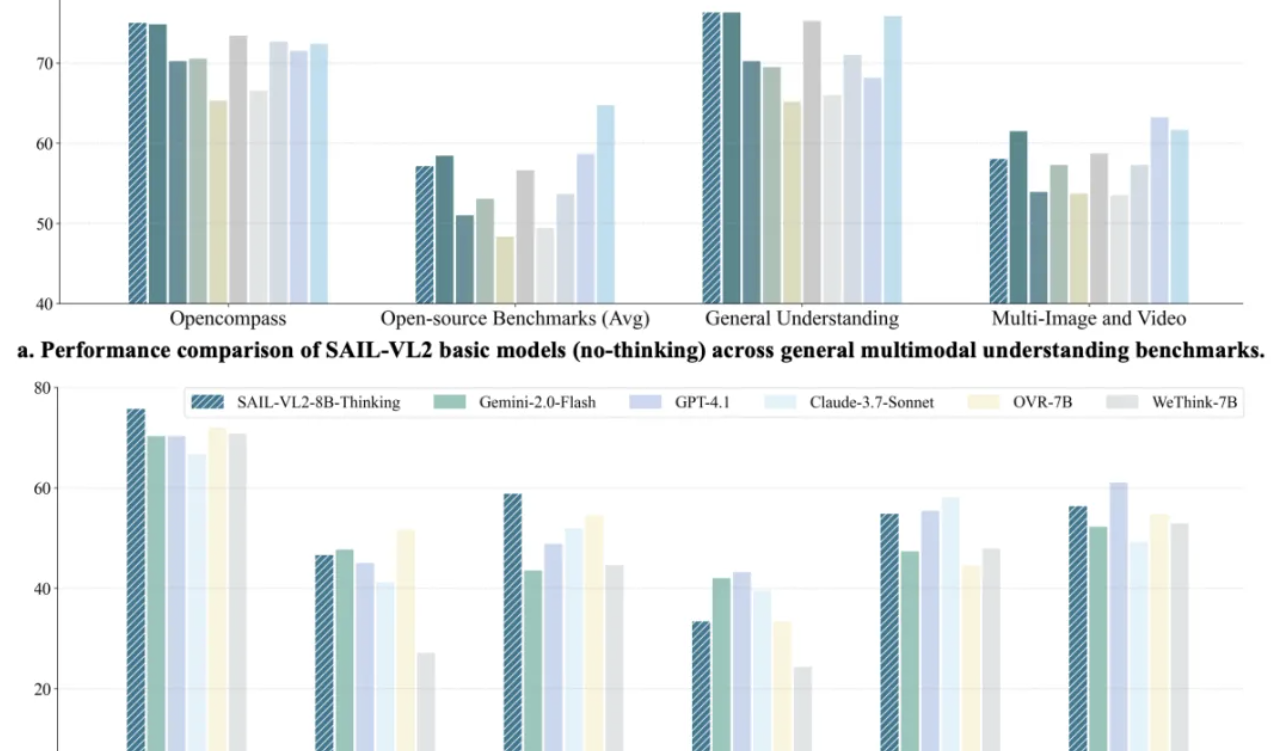
抖音SAIL-VL2マルチモーダルモデルがSOTAを更新、8Bモデルの推論はGPT-4oに匹敵 : 抖音SAILチームとLV-NUS Labが共同でマルチモーダル大規模モデルSAIL-VL2を発表しました。2B、8Bなどの中小パラメータ規模で106のデータセットで性能を突破し、特にMMMU、MathVistaなどの複雑な推論ベンチマークで同規模モデルを凌駕。8Bモデルの推論能力はGPT-4oに匹敵します。SAIL-VL2は疎なMoEアーキテクチャ、漸進的トレーニングフレームワーク、高品質マルチモーダルコーパスなどの革新を通じて、「小モデルでも強力な能力を持つ」という新しいパラダイムをコミュニティに提供し、モデルと推論コードをオープンソース化しました。(出典:量子位)
Moondream Cloudの推論がFALへ全面移行、100%クラウド実行を実現 : Moondreamは、そのクラウド推論サービスがEC2インスタンスからFALへ全面的に移行し、100%FAL上で稼働していると発表しました。この動きは、Moondreamが推論効率の最適化、運用コストの削減、またはサービス弾力性の向上において重要な進展を遂げたことを意味する可能性があり、FALがAIモデルのクラウド展開をサポートする能力を示しています。(出典:vikhyatk)
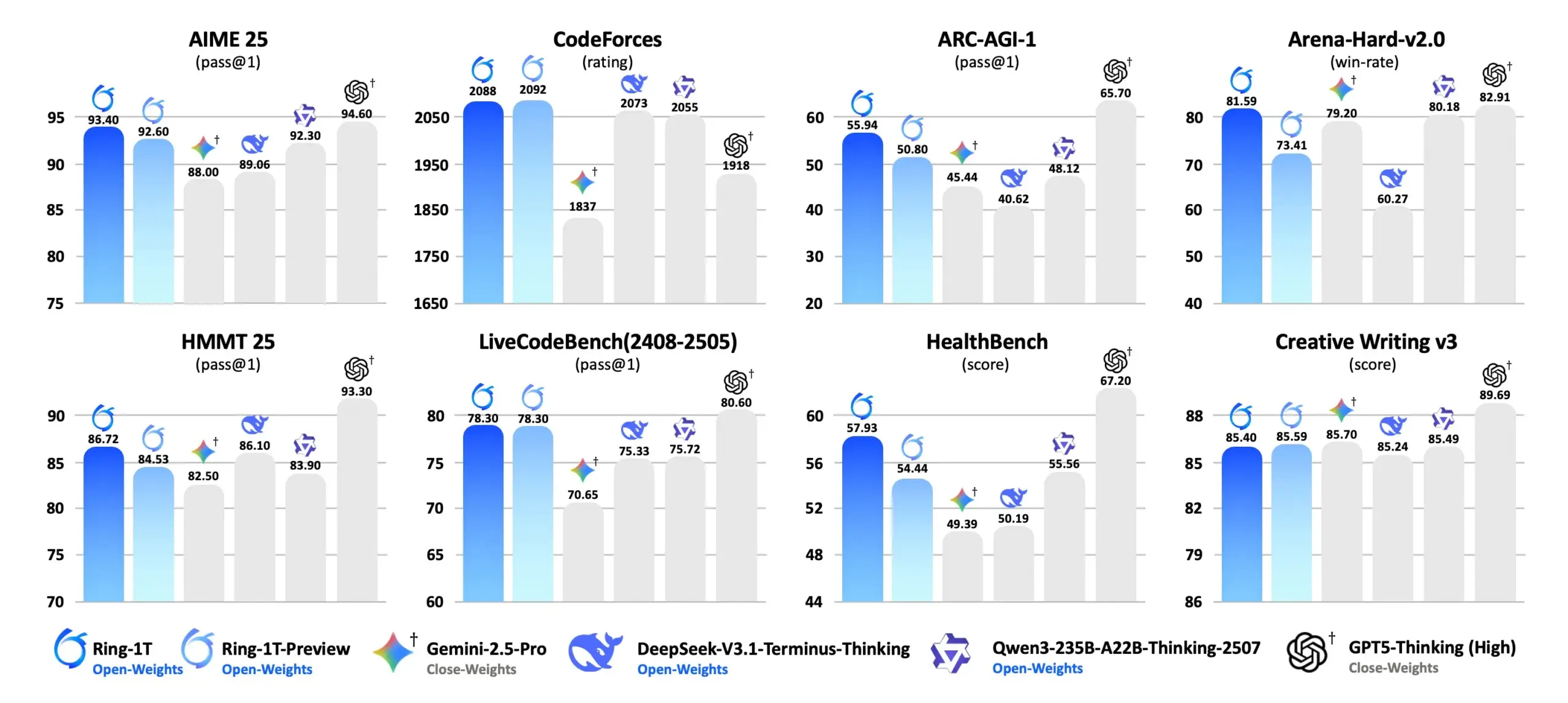
Ring-1T:Ant Lingが兆パラメータのオープンソース思考モデルを発表 : Ant Ling(凌动科技)は、Ling 2.0アーキテクチャに基づくオープンソースの兆パラメータ思考モデルRing-1Tを正式に発表しました。Ring-1Tは純粋な自然言語推論において、IMO(国際数学オリンピック)の銀メダルレベルの推論能力を達成。総パラメータ数1兆、アクティブパラメータ数500億、128Kのコンテキストウィンドウを持ちます。Icepop RLとASystem(兆規模強化学習エンジン)で強化され、AIME 25、HMMT 25、ARC-AGI-1、CodeForceなどの自然言語推論ベンチマークでSOTA性能を達成。FP8版も提供され、オープンソースAI推論能力の向上を目指します。(出典:scaling01, jon_durbin)
ChatGPTのEC機能「Instant Checkout」がリリース、ショッピング体験を再構築 : OpenAIはChatGPTの「Instant Checkout」(即時結帳)機能をリリースしました。これにより、ユーザーはChatGPT内で直接買い物を完了でき、サードパーティのECプラットフォームに移動する必要がありません。現在、Etsyをサポートしており、間もなくShopifyの100万以上の店舗にも対応予定です。この革新は、ニーズの記述から購入完了までの一連のショッピングプロセスをワンストップで完結させ、ユーザーの購入意思決定経路を大幅に短縮し、ショッピングの利便性を向上させます。AIがEC分野に深く統合され、ビジネスモデルが変革されることを示唆しています。(出典:36氪)
AIショートドラマが海外で爆発的に増加、Sora 2技術がコンテンツ制作の質と効率を飛躍的に向上 : AIショートドラマは爆発的な勢いで短動画プラットフォームを席巻し、大規模に海外進出しています。2024年の中国マイクロショートドラマ市場規模は505億元に達し、海外市場の需要も顕在化。中国の海外向けショートドラマ収入は年間40億ドルに達すると予測されています。OpenAI Sora 2のリリースにより、画質、尺、同期性、音画同期能力が大幅に向上し、複雑なストーリーの連続性やCameos機能もサポート。ショートドラマ制作プロセスを「一人がPromptを書き、AIが生成する」高効率モードに圧縮し、コストを従来の10分の1に削減可能になりました。AIマンガ劇も新たなトレンドとなり、文化的割引を効果的に低減し、コンテンツ産業を実写劇からAIマンガ劇へと拡大しています。(出典:36氪)

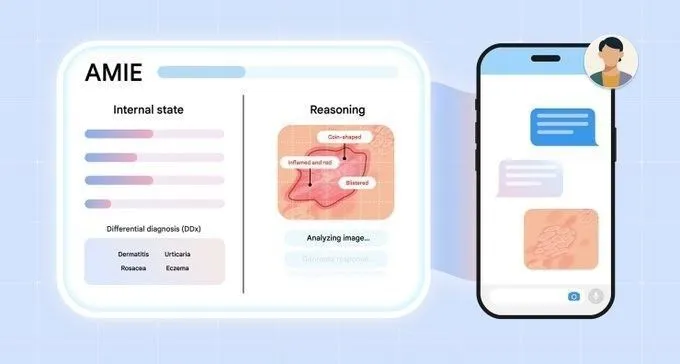
AIが医療診断分野で進展:AMIEマルチモーダル診断Agentが発表 : Google AIはAMIE(AI agent for multimodal diagnostic dialogue)を発表しました。これは、マルチモーダル診断対話を通じて医療分野でブレークスルーを目指す研究用AI Agentです。AMIEのリリースは、AIが複雑な医療診断プロセスを理解し、参加する上での進歩を示し、診断効率と正確性の向上、将来のスマート医療アプリケーションの基盤を築くことが期待されます。(出典:Ronald_vanLoon)
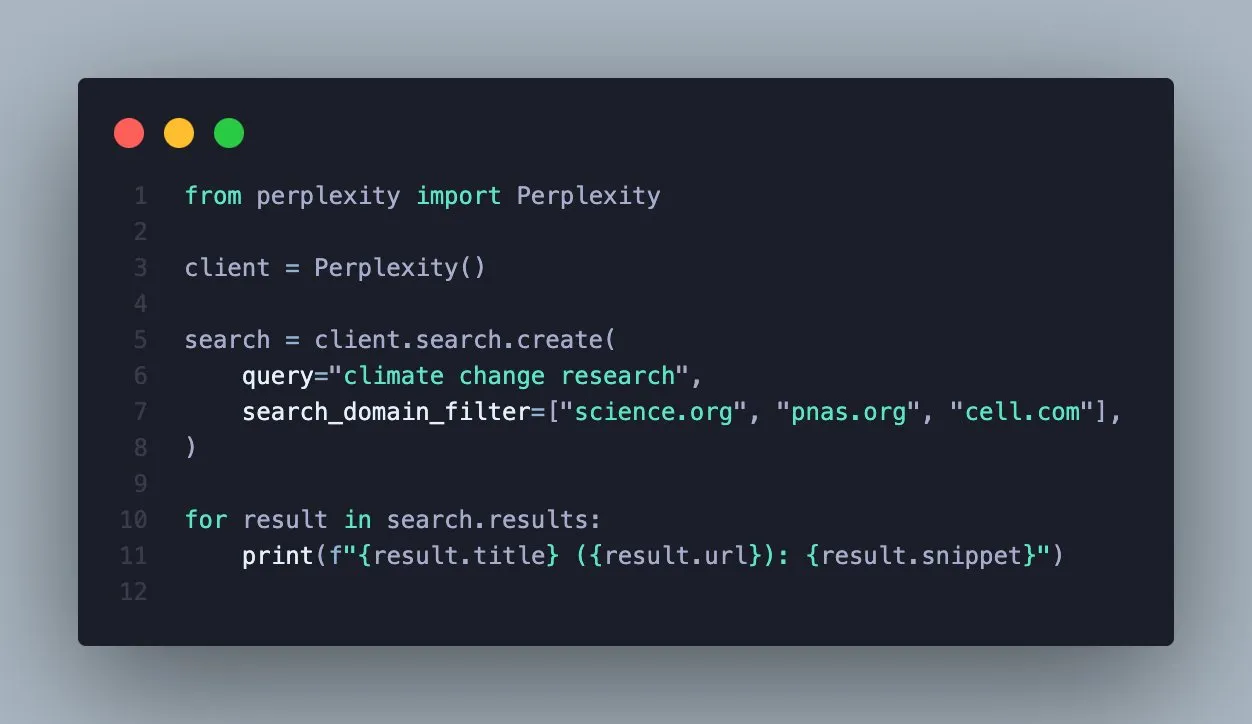
Perplexity Search APIにドメインフィルタリング機能が追加され、検索精度が向上 : Perplexityは、そのSearch APIが特定のドメインによる検索結果のフィルタリングをサポートしたと発表しました。この新機能により、ユーザーは信頼できる情報源のみをクエリでき、より焦点を絞った検証可能な結果を得られます。これは、特定の権威ある情報源から情報を取得する必要があるプロフェッショナルユーザーやアプリケーション開発者にとって、検索効率と情報品質を大幅に向上させるでしょう。(出典:AravSrinivas)
AIが地震検出で可能性を発揮、将来的に予測にも貢献か : AIが小規模地震の検出で優れた性能を発揮し、その能力は「初めて眼鏡をかけたときのように鮮明」と形容されています。研究者は、AIがさらに地震予測に役立つかどうかを模索しており、地震警報と防災・減災に革命的なブレークスルーをもたらす可能性があります。AIはより精密なデータ分析を通じて、従来の方法では検出困難な地震信号を識別でき、地球深部の活動に対する理解を深めます。(出典:Ars Technica)
Mamba3アーキテクチャが発表、LLMがより高速、より長いコンテキスト、より高いスケーラビリティを実現 : Mamba3アーキテクチャがICLR会議で静かに発表され、LLM分野における速度、コンテキスト長、スケーラビリティの顕著な進歩を示しました。このアーキテクチャは、内部状態の進化とハードウェア利用を最適化することで、Transformerよりも効率的なシーケンスモデリングを実現します。Mamba3は台形積分と複素平面隠れ状態を導入し、記憶をよりスムーズで安定させ、周期的なパターンを表現可能にしました。多入力多出力設計により、複数のデータストリームを並行処理でき、長文理解、時系列分析、エッジAIシステムなどの分野で大きな可能性を秘めています。(出典:NandoDF)

Agentic RAGが従来のRAGを超え、AI検索の新たなトレンドに : 業界の共通認識が形成されつつあります:「従来の埋め込み型RAG(Retrieval-Augmented Generation)は死んだ」。Agentic RAG(エージェント型RAG)は速度を除けば、ほぼすべての面で優れています。このトレンドは、AI検索が単純な情報検索から、より複雑なエージェント型インタラクションへと移行することを示唆。Agentic RAGは、ユーザーの意図をより賢く理解し、検索戦略を計画し、より正確な回答を生成できるため、将来のAI検索およびQ&Aシステムに変革をもたらすでしょう。(出典:swyx, jerryjliu0)

TuringPostがAI動画生成ツールリストを発表、Luma Dream Machineなどが選出 : TuringPostは、Sora 2、Google Veo 3、Runway、Pika Labs、Luma’s Dream Machine(Ray 3搭載)、Synthesia、HeyGen、Kaiber、InVideoを含む9つの強力なAI動画生成ツールのリストを発表しました。このリストは、テキストから動画、リアルタイム生成、人物合成など、多様な機能を持つAI動画制作の包括的な選択肢をユーザーに提供することを目的とし、AI動画技術分野の急速な発展と多様な応用を反映しています。(出典:TheTuringPost)
OpenAIがSoraでテクノロジー史の短編動画を生成、動画結合プロセスはまだ最適化が必要 : OpenAIの研究者Hemanth Asirは、Soraのみで完全に生成されたテクノロジー発展史の短編動画を制作し、Soraの動画制作における可能性を示しました。短編動画の効果は印象的ですが、現在の結合プロセスはまだ煩雑であるとOpenAIは述べており、ユーザー体験と制作効率を向上させるためにこのプロセスを改善することに注力すると表明しています。これは、将来のAI動画生成ツールが長編物語の制作においてより便利になることを示唆しています。(出典:dotey)
LLMサービス仮説が課題に直面:FP8/FP4が主流に、出力トークン量が指数関数的に増加へ : 現在のLLMサービスには多くの誤った仮定があるとの指摘があります。まず、LLMサービスはFP16精度に限定されず、FP8とFP4が主流になるでしょう。次に、将来のLLMの成長は、単純な入力トークン比率ではなく、「思考トークン」(出力トークン)の指数関数的な増加に主に現れるでしょう。さらに、OpenAIのGPT-5シリーズモデルはより広いパラメータ範囲を持ち、各研究所はDeepseekのDSAなどの技術や新しいアテンションメカニズムでコストを削減。AnthropicもSonnet 4.5のコンテキストクリーンアップツールをリリースし、メモリ要件を削減しています。これらすべてがLLMサービスの効率とコスト構造を再構築するでしょう。(出典:teortaxesTex)
🧰 ツール
Microsoft MarkItDown:LLMパイプラインのためのドキュメントからMarkdownへの変換ツール : MicrosoftはPythonツールMarkItDownをリリースしました。これは、PDF、Word、Excel、HTML、画像、音声など数十種類のファイルタイプをクリーンなMarkdown形式に変換できます。このツールは、見出し、リスト、テーブル、リンク、メタデータを保持し、OCRとEXIF情報抽出もサポートします。MarkdownがLLMの「ネイティブ言語」であることを踏まえ、MarkItDownはLLMパイプラインにおけるドキュメント前処理の理想的な選択肢となり、複雑なドキュメントに対するモデルの理解と処理効率を向上させるのに役立ちます。(出典:TheTuringPost)
VS Codeが1.105イテレーション計画を発表、AIと開発者体験に焦点 : VS Codeは10月のイテレーション計画を発表し、AI支援開発と全体的な開発者体験を向上させるための多くの改善をもたらします。更新には、Mermaidレンダリング、多様なコンテキストとツール管理方法、より高度なモデル管理、多段階プロセス、会話のPromptとしての保存、ターミナル、ツール、MCPsなどの機能が含まれます。さらに、GitHub Copilotも過去30日間で34の改善を発表しました。これらの更新は、コード編集、デバッグ、コラボレーションにおけるAIの応用をさらに深め、VS Codeをより強力なAIネイティブ開発環境にするでしょう。(出典:pierceboggan, code)

Nanonets-OCR2がリリース、オープンソースの画像からMarkdownへの変換モデルがLaTeXとフローチャートをサポート : Nanonets-OCR2がリリースされました。これはQwen2.5-VL-3B-Instructをファインチューニングしたオープンソースの画像からMarkdownへの変換モデルで、LaTeX数式認識、テーブル、手書きドキュメント、チェックボックスをサポートし、フローチャートをMermaidコードに変換することも可能です。このモデルはスマートな画像記述、署名検出、透かし抽出、多言語サポートなどの機能も備え、VQA(Visual Question Answering)能力も提供します。Nanonets-OCR2は複雑なドキュメント処理で優れた性能を発揮し、LLMパイプラインのドキュメント前処理に効率的で機能豊富なソリューションを提供します。(出典:huggingface, Reddit r/LocalLLaMA, karminski3)
ChatGPT for Slackアプリがリリース、リアルタイム検索APIを統合 : ChatGPTアプリケーションがSlackに正式に登場しました。Slackのリアルタイム検索APIを活用し、ユーザーは専用のSlackサイドバーで直接ChatGPTを使用し、質問、ブレインストーミング、コンテンツ作成、問題解決が可能になります。この統合は、ChatGPTの強力な能力をチームコラボレーションプラットフォームにシームレスに導入し、作業効率を向上させ、情報取得とコンテンツ作成プロセスを簡素化し、企業ユーザーにより便利なAI支援を提供します。(出典:gdb)
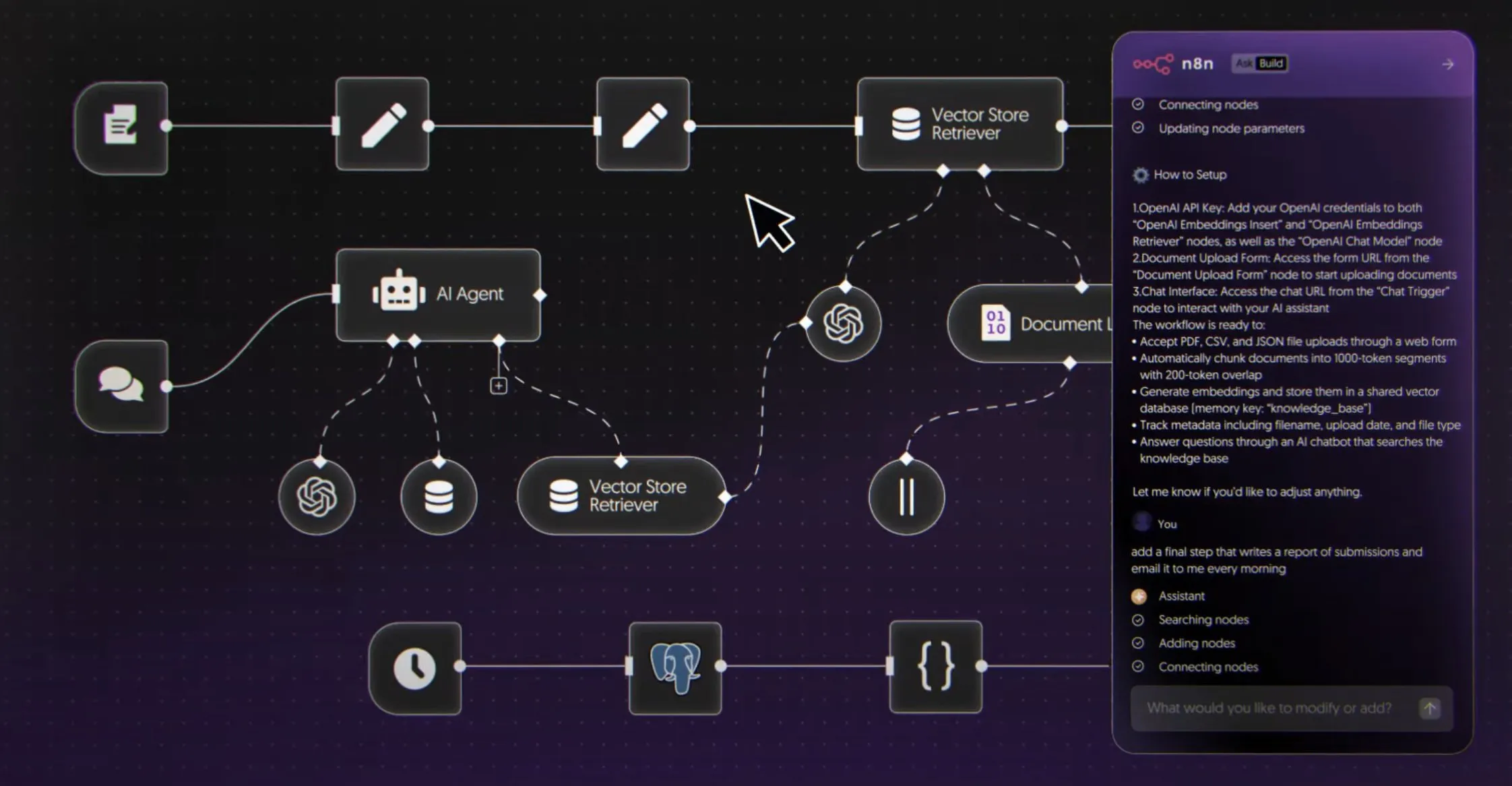
n8nがAIワークフロービルダーを発表、自然言語による自動化を可能に : n8nはAIワークフロービルダーを正式に発表しました。これにより、ユーザーは自然言語でn8n内にAIエージェントと自動化プロセスを構築できます。このツールはビジュアルキャンバスを提供し、Firecrawl、LLMs、ロジックノード、MCPsなど8000以上のツールに接続可能で、APIとしてデプロイできます。この革新はAIエージェントの開発と応用を大幅に簡素化し、より多くの開発者が自然言語を利用して複雑な自動化ワークフローを作成できるようにし、AIエージェントの実際のビジネスシナリオにおける普及を推進します。(出典:omarsar0)
MLXがローカルモデル実行をサポート、Privacy AI 1.3.2アップデートがAppleデバイスのAI能力を向上 : Privacy AIは1.3.2アップデートをリリースし、AppleのMLXエンジンを全面的にサポートすることで、ユーザーがローカルでテキストおよびビジュアルモデルを実行できるようにしました。モデルはHugging Faceから直接ダウンロードでき、中断からの再開、バックグラウンド転送、整合性検証をサポート。MLXモデルは無料プランに含まれており、サブスクリプションなしでオフライン実行が可能です。このアップデートはクリップボードサポートも改善し、llama.cppをアップグレードし、Appleデバイス上でのローカルAI能力とプライバシー保護をさらに向上させます。(出典:awnihannun)
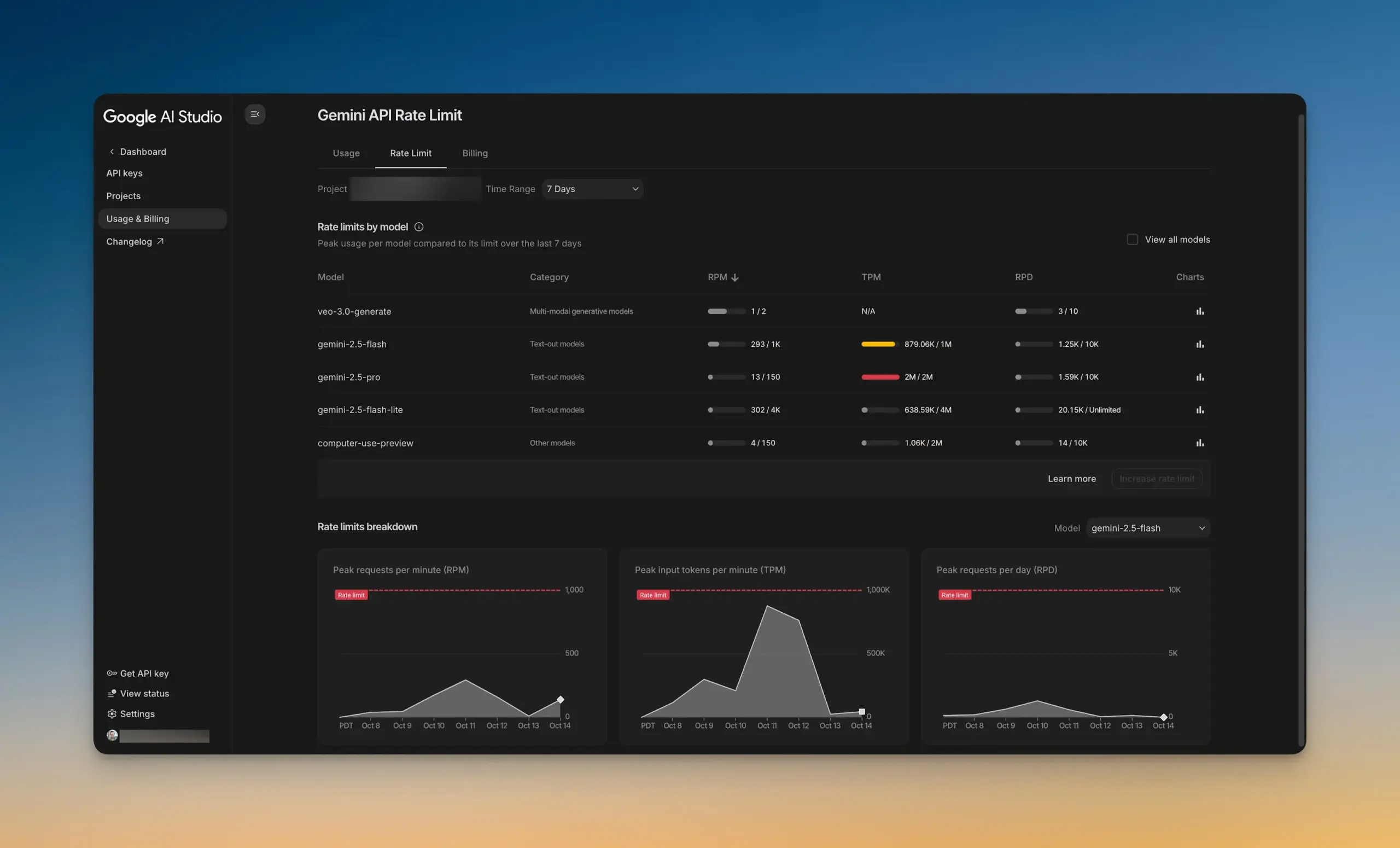
Google AI Studioが新しいレート制限ダッシュボードをリリース : Google AI Studioは、新しいレート制限ダッシュボードをリリースしました。これにより、ユーザーはAI Studioを離れることなく、Gemini APIの使用状況を直感的に把握できます。このダッシュボードはグラフフィルタリング機能を提供し、すべてのモデルのレート制限を簡単に探索できるため、開発者はAIプロジェクトをより良く管理・最適化し、開発効率を向上させることができます。(出典:GoogleAIStudio)
Cursor IDEとCodexが開発者の日常コーディングの新たな選択肢に : AIコーディングツールの急速な発展に伴い、Cursor IDEとCodexはますます多くの開発者にとって日常のワークフローの中心的なツールとなっています。ある開発者はClaude CodeからCodexに完全に移行し、日常の計画、タスク分解、並行処理に利用していると述べています。Cursor IDEの「コードベースインデックスシステム」は、セマンティック検索とローカルコードアクセスを通じて、効率的なコードインデックス作成と更新を実現。コードをサーバーに保存する必要がなく、プライバシーと効率を確保します。これらのツールの普及は、従来のコーディング方法を変革し、開発効率を向上させています。(出典:dejavucoder, gdb)
Yupp.ai:AIディベートツールがユーザーのより包括的な回答獲得を支援 : Yupp.aiは革新的なAIツールで、異なるAIモデルの回答を提示することで、情報過多の時代にユーザーがより賢明な意思決定を行うのを支援します。ユーザーは異なるAIの回答を並べて比較し、その分析、創造性、特定の詳細に基づいて投票することで、集合知のランキングを形成できます。Yupp.aiの目標は、ユーザーが集合的な経験を活用し、信頼できる多角的な回答を迅速に取得することで、作業効率と意思決定の自信を高めることです。(出典:yupp_ai)

vLLMとSGLangが「AI時代のLinux」と称賛される : vLLMとSGLangは、LLM推論分野での卓越した性能により、「AI時代のLinux」と称されています。vLLMはGitHubで6万以上のスターを獲得し、小さな研究アイデアからNVIDIA、AMD、Intel、Appleなどほぼすべての主要プラットフォームのLLM推論をサポートするコアフレームワークへと発展しました。ほとんどのテキスト生成モデルとTRL、UnslothなどのネイティブRLパイプラインをサポートし、AIエコシステムにおいて重要なインフラストラクチャの役割を果たし、LLM推論の普及と効率向上を推進しています。(出典:bookwormengr)
Luma AI Ray3ビジュアルアノテーションが正確な制御を可能に : Luma AIが発表したRay3ビジュアルアノテーション機能は、フレーム上に落書きするだけで視覚的方向を正確に制御し、被写体に特定の動作やインタラクションを指示できます。この機能は、従来のテキストプロンプトの限界を超え、筆致を通じて空間的な遮蔽意図を伝え、視覚的創作により直感的で精細な制御方法を提供します。特にDream Machineなどのアプリケーションで強力な可能性を示しています。(出典:TomLikesRobots)
Faceseek:AI駆動の顔面マッチングと検証ツール : FaceseekはAI技術を利用した顔面マッチングおよび検証ツールで、類似した顔を効果的に処理できます。このツールは、顔埋め込み、CLIP(Contrastive Language-Image Pre-training)、またはその他の高度なコンピュータビジョンモデルを使用して分析を行い、身元認証、セキュリティ監視などのシナリオにソリューションを提供する可能性があります。その実際の応用における性能は、このようなシステムの技術的詳細と潜在的な応用に関する議論を引き起こしています。(出典:Reddit r/ArtificialInteligence)
PyTorchリモートGPUバックエンド拡張、ローカル開発とリモート計算の結合を実現 : 新しいPyTorch拡張機能により、開発者はローカルで開発しながら、リモートGPUバックエンドを利用して計算を実行できるようになりました。これにより、ローカルハードウェアリソースの制限の問題が解決され、研究者や開発者はディープラーニングモデルのトレーニングと実験をより柔軟に行うことができ、ローカル開発環境の利便性とリモート高性能計算の利点を両立できます。(出典:Reddit r/deeplearning)
FocoosAIがコンピュータビジョンオープンソースSDKとWebプラットフォームを発表 : FocoosAIは、そのコンピュータビジョンオープンソースSDKとWebプラットフォームをリリースしました。これは、開発者にコンピュータビジョンソリューションの構築と展開のためのツールとリソースを提供することを目指しています。このプラットフォームのリリースは、コンピュータビジョン技術の普及と応用を促進し、開発の敷居を下げ、より多くのイノベーターがAIを利用して画像および動画分析分野で探索・開発できるようにするでしょう。(出典:Reddit r/deeplearning)
AIテキスト「人間化」ツール:AI生成コンテンツの自然度を向上 : AIテキスト生成技術の普及に伴い、AI生成コンテンツをいかに「人間化」するかが重要な課題となっています。現在、市場には、言語スタイル、感情表現、文脈適応性を最適化することで、AIテキストをより自然で人間らしい表現に近づけることを目的とした様々なツールが登場しています。これらのツールは、ユーザーがAIテキストの機械的でパターン化された感覚を避け、コンテンツの魅力を高め、高品質でパーソナライズされたテキストのニーズに応えるのに役立ちます。(出典:Ronald_vanLoon)
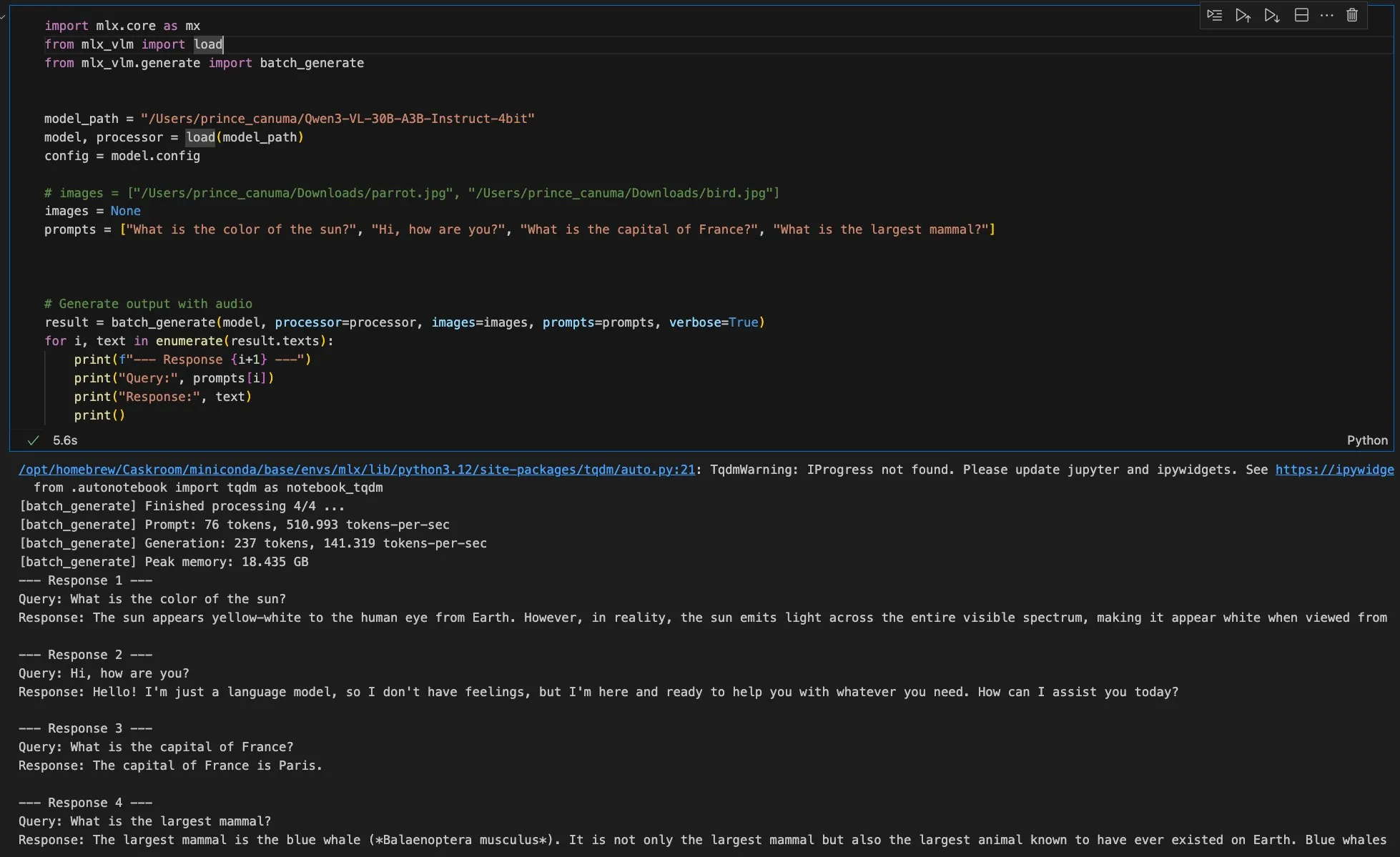
MLX-VLM新バージョンが間もなくリリース、Qwen ImageがMFLUXフレームワークをサポート : AppleのMLX-VLMが間もなく大幅なアップデートを迎える予定で、マルチモーダル大規模モデル分野での強力な可能性を示唆しています。同時に、MFLUXフレームワークがv0.11バージョンをリリースし、Qwen Imageのサポートを追加。ユーザーは簡単なコマンドライン操作でQwen Imageモデルをダウンロードして生成に利用できます。これらの進展は、Appleエコシステム内でのAIモデル開発と展開の効率と柔軟性を共同で推進し、開発者により便利なマルチモーダルAIツールを提供します。(出典:adrgrondin, awnihannun)
CleanMARL:PyTorchマルチエージェント強化学習の簡潔な実装 : CleanMARLプロジェクトは、PyTorchで開発された、深層マルチエージェント強化学習(MARL)アルゴリズムの簡潔な単一ファイル実装シリーズを提供し、CleanRLの哲学を踏襲しています。このプロジェクトはMARLアルゴリズムの実装の敷居を下げることを目的とし、研究者や開発者に明確で理解しやすく再現可能なコードを提供し、複雑な環境におけるマルチエージェントシステムの研究と応用を加速させます。(出典:jsuarez5341)
📚 学習
大規模モデルの後トレーニングがAI競争力の核心に、企業は専用スマートエンジンの構築を加速 : 大規模モデルの後トレーニングが企業AI導入の核心的競争力となりつつあります。SFTからRLHF、RLVR、そして最先端の「自然言語報酬」へと、技術の焦点は「模倣」から「アラインメント」へと移行しています。NetEase、Autohome、Weibo、Quarkなどの企業は、高品質なデータ準備、基盤モデルの選択、報酬メカニズム設計、定量化可能な評価システムを通じて、汎用大規模モデルをビジネスを深く理解し、ドメイン知識を持つ「専用スマートエンジン」へと転換。ビジネス世界の複雑なタスクを解決し、模倣不可能な競争優位性を構築しています。(出典:量子位)

Andrew NgがAgentic AIコースをリリース、4つの主要な設計パターンに焦点 : DeepLearning.AIは最新のThe Batchを発表し、Andrew Ngが最新コース「Agentic AI」をリリースしたことを告知しました。このコースは、反射、ツール使用、計画、マルチエージェント協調という4つの主要な設計パターンに焦点を当てた実践的なビルダーコースです。受講者が効率的なAIエージェントシステムを構築するための核心スキルを習得し、AIの実用化を推進することを目指しています。(出典:DeepLearningAI)
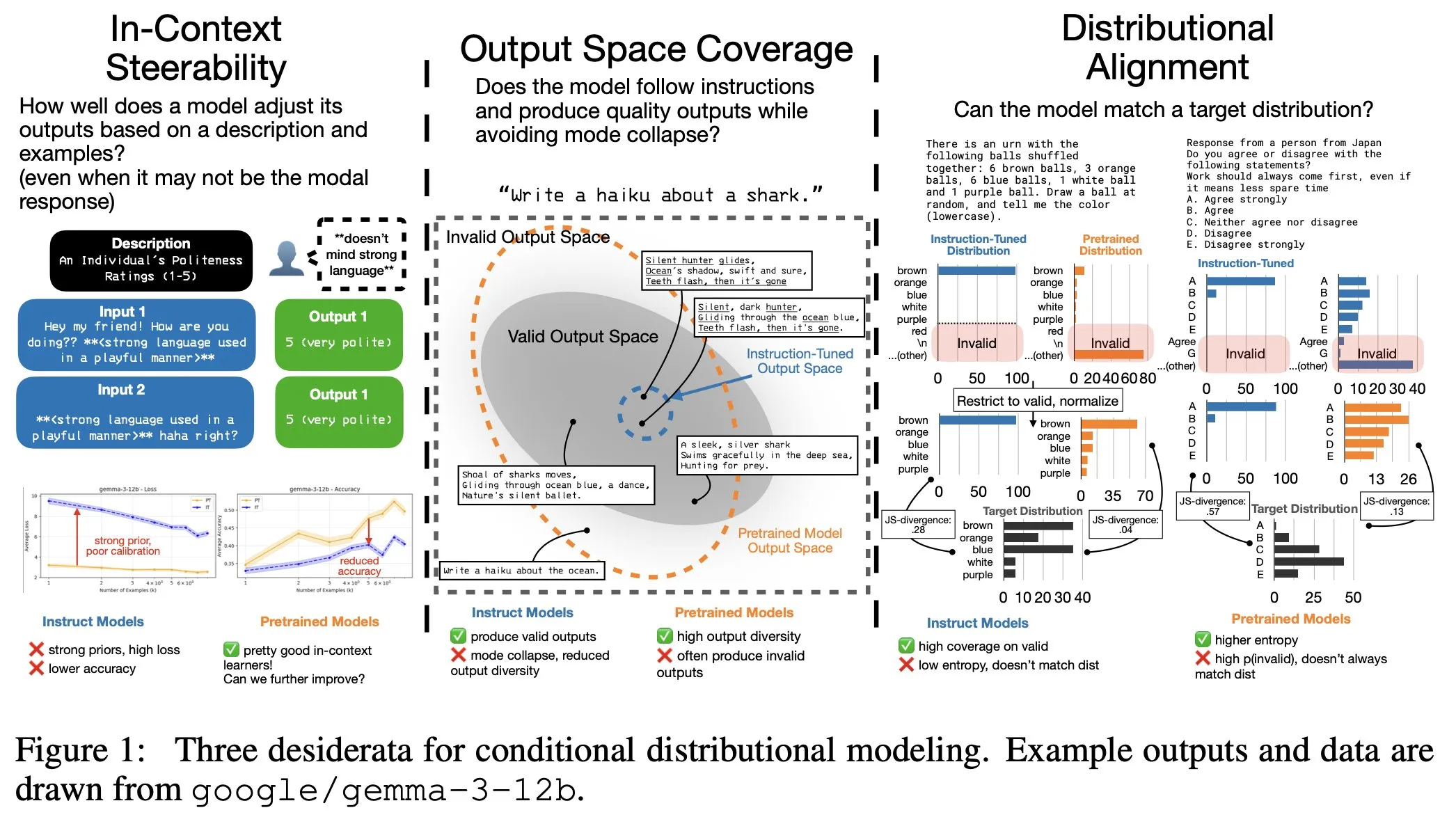
LLMの指令ファインチューニングには隠れたコストが存在:出力分布が狭まり、コンテキスト制御性が低下 : 研究により、LLMの指令ファインチューニングが指令追従能力を向上させる一方で、隠れたコストを伴うことが判明しました。モデルの出力分布が狭まり、コンテキスト制御性(In-Context Steerability)が低下するのです。この問題を解決するため、研究チームは「Spectrum Suite」を立ち上げて詳細な研究を行い、代替の後トレーニング手法として「Spectrum Tuning」を提案。モデル性能を向上させつつ、出力の多様性と柔軟性を維持することを目指しています。(出典:YejinChoinka, YejinChoinka)
マルチエージェントシステムの協調:情報理論が「チャットボットの山」と「集合知」を区別 : ある研究では、LLM駆動のマルチエージェントシステムが真に協調を実現しているかを検討し、情報理論を用いて「チャットボットの山」と「真の集合知」を区別することを提案しました。研究では、グループ出力が将来の結果を予測する能力を評価し、情報を分解して冗長性ではなく協調作用を特定する測定ループを導入。エージェントに異なる役割と共通の目標を与え、協調性を仮定するのではなくテストすることが、集合知の実現に不可欠であることを示唆。低容量モデルでは真の協力は達成困難です。(出典:omarsar0)
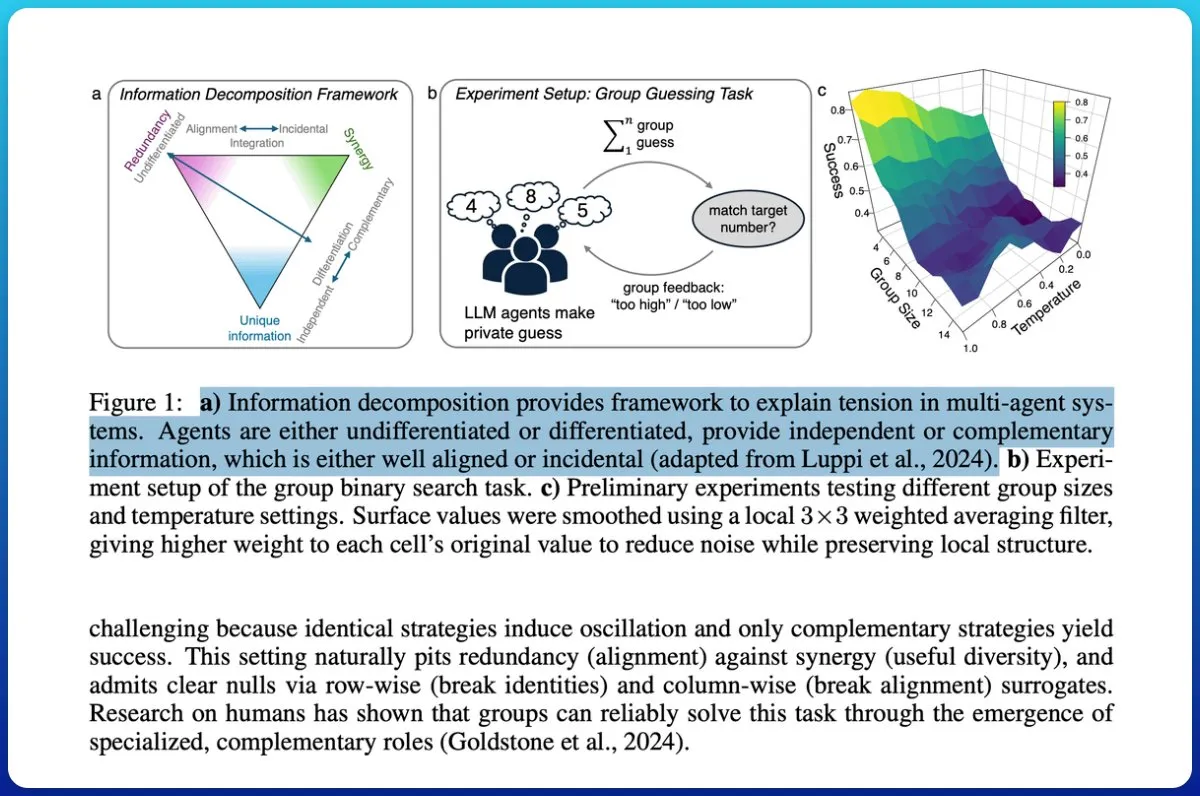
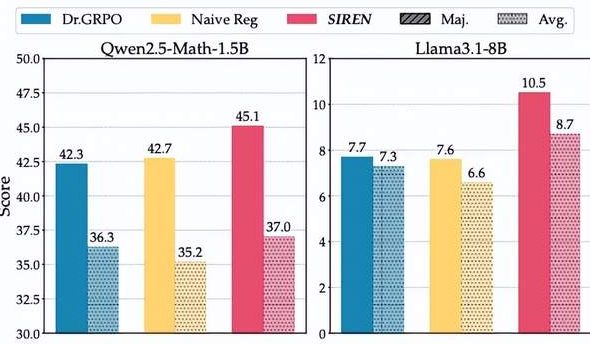
大規模モデル推論の「エントロピーのジレンマ」:SIREN手法が「エントロピー崩壊」と「エントロピー爆発」を回避 : 大規模推論モデル(LRM)はRLVRトレーニングにおいて「エントロピーのジレンマ」に直面します。探索が制限されると「エントロピー崩壊」を招き、探索が制御不能になると「エントロピー爆発」を引き起こすのです。上海人工知能実験室と復旦大学のチームは、選択的エントロピー正則化手法(SIREN)を提案。探索範囲の区画(Top-pマスク)、重要な意思決定点の特定(ピークエントロピーマスク)、トレーニングプロセスの安定化(自己アンカー正則化)という三重のメカニズムを通じて、探索行動を正確に制御します。実験では、SIRENが数学的推論ベンチマークで性能を大幅に向上させ、探索プロセスをより効率的かつ制御可能にすることを示しました。(出典:量子位)
AI Agent学習リソース:「AI Agent図解ガイド」新刊と概念まとめ : AI Agent分野の学習リソースが充実しています。Maarten GrootendorstとJay Alammarは「AI Agent図解ガイド」という書籍を執筆中で、Agentの基礎知識(記憶、ツール、計画)に加え、強化学習や推論LLMなどの高度な概念も網羅する予定です。また、AI Agentの20の核心概念をまとめた記事もあり、初心者から上級者まで体系的な学習パスと参考資料を提供しています。(出典:lvwerra, Ronald_vanLoon)

LLM空間推論能力評価:形状回転テストがモデルの潜在空間に挑戦 : 大規模言語モデル(LLM)が「頭の中で」形状を回転させる能力をテストする興味深い評価方法が提案されました。単純な視覚テストにより、LLMが基盤となる潜在空間で一定程度の形状回転を行えるものの、より上位で複雑な推論では性能が低く、「非均一空間推論」の問題が存在することが判明。これは、LLMが幾何学および空間論理を処理する上での限界を明らかにし、将来のモデル改善に向けた新たな研究方向を提供します。(出典:dejavucoder, tokenbender)
LLMファインチューニング戦略:アテンション投影層とMLPゲート層の更新が忘却を制限 : 大規模マルチモーダルモデル(LMM)に新しいスキルを教えつつ、既存の能力を忘却させない方法が重要な課題です。ある研究では、狭いファインチューニング後に発生する「忘却」現象が後に回復可能であり、これは出力トークン分布の顕著な変化に関連していることが判明しました。研究では、2つのシンプルで堅牢なファインチューニング戦略を特定:自己アテンション投影層のみを更新する方法、またはMLP Gate&Up層のみを更新しDown投影層を凍結する方法です。これらの選択肢は、モデルとタスクの両方で強力な目標達成を可能にしつつ、元の性能をほぼ保持します。(出典:arXiv:2510.08564)
AIと経済成長:ノーベル賞受賞者Philippe Aghionの論文解説 : ノーベル賞受賞者Philippe Aghionらの研究は、経済が99%自動化され無限に生産されたとしても、全体の成長率は残りの1%の核心的で困難なタスクの進展に制約されると指摘しています。AGI時代には、これらの「改善が難しい」タスクは、エネルギー生成、資源採掘、製造、輸送などの物理中心のタスクに転換されるでしょう。これは、ポストAGI時代が必ずしも「ポスト希少性」時代ではないことを意味し、経済的価値は物理的に制約されたタスクに集中するだろうと述べています。(出典:pmddomingos, jonst0kes)

AIモデルの汎化性と堅牢性の課題:虚偽推論が数学的推論の欠陥を招く : 言語モデルは数学的推論において、しばしば「虚偽推論」(Spurious Reasoning)により堅牢性と汎化性が不足します。これは、モデルが問題の論理ではなく表面的な特徴から答えを導き出すためです。AdaRフレームワークは、論理的に等価なクエリを合成し、RLVR(検証可能な報酬に基づく強化学習)と組み合わせてトレーニングすることで、虚偽の論理を罰し、適応的な論理を奨励します。実験により、AdaRがLLMの数学的推論の堅牢性と汎化性を大幅に向上させると同時に、高いデータ効率を維持することを示しました。(出典:arXiv:2510.04617)
LLM Agentのテスト時自己改善:TT-SIフレームワークが自律学習を実現 : ある研究では、新しいテスト時自己改善手法(Test-Time Self-Improvement, TT-SI)が提案されました。これは、動的に、より効果的で汎用性の高いAgentic LLMを作成することを目指します。このアルゴリズムは、モデルの困難なサンプルを特定し、類似の例を生成(自己データ拡張)し、テスト時にファインチューニング(自己改善)することで、モデルの自律学習を実現します。実験により、TT-SIがAgentベンチマークで平均5.48%の精度向上を達成し、トレーニングサンプル量を68倍削減。自己改善アルゴリズムがより強力なAgentを構築する可能性を示しました。(出典:arXiv:2510.07841)
LLM Agent強化学習の主要な設計原則と最適化実践 : ある研究では、Agentic RLがLLM Agentの推論能力を向上させる上での主要な設計原則が体系的に調査されました。SFT初期化として合成軌跡ではなく、実際のエンドツーエンドのツール使用軌跡を用いる方がより強力な効果をもたらすこと、多様性の高いモデル認識データセットが探索を維持し、RL性能を大幅に向上させることが判明しました。さらに、探索に優しい技術(clip higher、overlong reward shaping、十分なポリシーエントロピーの維持など)がAgentic RLにとって不可欠です。これらの実践は、Agentic推論とトレーニング効率を継続的に強化し、小規模モデルが困難なベンチマークで優れた結果を達成することを可能にします。(出典:arXiv:2510.11701)
LLM推論における報酬メカニズム:PEARが段階エントロピー認識を通じて推論効率を最適化 : 大規模推論モデル(LRM)がCoT(Chain-of-Thought)説明を生成する際、冗長な推論ステップにより推論コストが増加することがあります。PEAR(Phase Entropy Aware Reward)メカニズムは、段階依存のエントロピーを組み合わせて報酬を設計し、思考段階での過剰なエントロピーを罰し、最終回答段階での適度な探索を許容します。これにより、モデルは簡潔な推論軌跡を生成しつつ、タスク解決に必要な柔軟性を維持します。実験により、PEARが精度を犠牲にすることなく応答長を継続的に短縮し、強力なOOD(Out-of-Distribution)堅牢性を示すことが証明されました。(出典:arXiv:2510.08026)
DocReward:ドキュメント構造とスタイルに特化した報酬モデル : DocRewardは、ドキュメントの構造とスタイルを評価するための報酬モデルで、Agenticワークフローがプロフェッショナルなドキュメントを生成する際に、視覚的構造とスタイルを無視する問題を解決することを目指しています。このモデルは、高低の専門性を持つペアのドキュメントを含む多領域データセットDocPairでトレーニングされ、テキストの品質とは無関係にドキュメントの専門性を包括的に評価できます。DocRewardは精度においてGPT-4oとGPT-5を上回り、ドキュメント生成の外部評価でより高い勝率を達成。生成Agentが人間が好むドキュメントを生成するのをガイドする実用性を示しました。(出典:arXiv:2510.11391)
SPG:サンドイッチポリシー勾配が拡散言語モデルの強化学習効果を向上 : 拡散言語モデル(dLLM)は、その並列デコード能力により、自己回帰モデルの有効な代替手段と見なされています。しかし、強化学習(RL)を通じてdLLMを人間の好みとアラインさせることは、その扱いにくい対数尤度が標準的なポリシー勾配の直接適用を制限するため、課題を伴います。SPG(Sandwiched Policy Gradient)手法は、真の対数尤度の上限と下限を利用し、ELBOまたは単一ステップ推定に基づくベースラインを大幅に上回ります。GSM8K、MATH500などのタスクでdLLMのRL精度を3.6%から27.0%向上させました。(出典:arXiv:2510.09541)
QeRL:量子化強化強化学習がLLMの効率と探索能力を向上 : QeRL(Quantization-enhanced Reinforcement Learning)フレームワークは、NVFP4量子化とLoRA技術を組み合わせることで、LLM強化学習(RL)のリソース集約型問題を解決し、RLのRollout段階を加速し、メモリオーバーヘッドを削減することを目指します。研究では、量子化ノイズがポリシーエントロピーを増加させ、探索能力を高め、より良いポリシーの発見に役立つことが判明しました。QeRLは適応型量子化ノイズ(AQN)メカニズムを導入し、トレーニング中のノイズを動的に調整します。実験により、QeRLがRollout段階で1.5倍以上の高速化を達成し、単一のH100 80GB GPUで32B LLMのトレーニングを初めて実現。より速い報酬増加と高い最終精度を達成しました。(出典:arXiv:2510.11696)
STAT:スキル指向型適応トレーニングがLLMの数学とOOD性能を向上 : STAT(Skill-Targeted Adaptive Training)は、LLMの新しいファインチューニング戦略です。より強力なLLMのメタ認知能力を教師モデルとして利用し、タスクに必要なスキルリストを作成し、データポイントにタグ付けします。教師モデルは学生モデルの回答を監視し、「欠落スキルプロファイル」を構築。その後、既存のトレーニング例を適応的に再重み付け(STAT-Sel)するか、欠落スキルを含む追加の例を合成(STAT-Syn)します。実験により、STATがMATHベンチマークで最大7.5%向上し、OODベンチマークで平均4.6%向上。GRPOと補完的であり、現在のトレーニングパイプラインを包括的に改善する可能性を秘めています。(出典:arXiv:2510.10023)
LLaMAX2:Qwen3-XPlusモデルが翻訳と推論タスクで優れた性能を発揮 : LLaMAX2は、指令モデルに対する層選択的ファインチューニングを通じて、Qwen3-XPlusモデルのスワヒリ語などの高・低リソース言語における翻訳性能を大幅に向上させると同時に、15の一般的な推論データセットでQwen3指令モデルと同等の熟練度を維持する新しい翻訳強化手法を提案します。この研究は、多言語強化に対する有望なアプローチを提供し、複雑さを大幅に削減し、より広範な言語へのアクセス可能性を高めます。(出典:arXiv:2510.09189)
DemoDiff:グラフ拡散Transformerがコンテキスト分子設計を実現 : DemoDiff(Demonstration-conditioned diffusion models)は、テキスト記述ではなく少量の分子-スコア例を使用してタスクコンテキストを定義することで、コンテキスト分子設計を実現します。このモデルは、新しいNode Pair Encoding分子トークナイザーを利用し、分子をモチーフレベルで表現することでノード数を削減。DemoDiffは、数百万のコンテキストタスクを含むデータセットで7億パラメータモデルを事前学習し、33のデザインタスクで100〜1000倍大規模な言語モデルに匹敵またはそれを上回る性能を発揮し、コンテキスト分子設計の分子基盤モデルとなります。(出典:arXiv:2510.08744)
CodePlot-CoT:コード駆動型画像思考連鎖が数学的視覚推論を向上 : CodePlot-CoTは、数学における「画像思考」のためのコード駆動型思考連鎖パラダイムを提案します。この手法は、VLM(Visual Language Model)を利用してテキスト推論と実行可能な描画コードを生成し、それを「視覚的思考」として画像にレンダリングして数学問題を解決します。研究では、初の大規模なバイリンガル数学視覚推論データセットMath-VRを構築し、SOTAの画像からコードへの変換器を開発。実験により、このモデルがMath-VRベンチマークで最大21%性能を向上させ、マルチモーダル数学推論の新たな方向性を開拓しました。(出典:arXiv:2510.11718)
DiT360:混合トレーニングが高忠実度パノラマ画像生成を実現 : DiT360は、DiTに基づくフレームワークで、透視投影データとパノラマデータの混合トレーニングを通じて、高忠実度パノラマ画像生成を実現します。この手法は、クロスドメイン知識融合、パノラマ精緻化、循環埋め込み、ヨー損失、立方体損失などの主要モジュールを導入し、幾何学的忠実度とリアリズムの問題を解決します。DiT360は、テキストからパノラマ、画像修復、アウトペインティングタスクにおいて、11の定量的指標でより優れた境界一貫性と画像忠実度を示しました。(出典:arXiv:2510.11712)
RAE:表現自己エンコーダーが拡散Transformerの潜在空間を最適化 : ある研究では、拡散Transformer(DiT)における従来のVAEを、事前学習済み表現エンコーダー(DINO、SigLIP、MAEなど)に置き換える方法が探求され、表現自己エンコーダー(RAE)が形成されました。RAEは高品質な再構築と意味的に豊かな潜在空間を提供し、スケーラブルなTransformerアーキテクチャをサポートします。理論分析と実証検証により、この手法はより速い収束を実現し、ImageNetで強力な画像生成結果を達成。拡散Transformerトレーニングの新しいデフォルト設定となる可能性を秘めています。(出典:arXiv:2510.11690)
InfiniHuman:無限の3D人体作成と正確な制御フレームワーク : InfiniHumanフレームワークは、既存の基盤モデルを協調的に蒸留することで、最小限のコストと理論上無限のスケーラビリティで、豊富なアノテーション付き3D人体データを生成します。InfiniHumanDataは、視覚言語モデルと画像生成モデルを利用して、11.1万のアイデンティティを含む大規模マルチモーダルデータセットを完全に自動で構築。これには、前例のない多様性と、テキスト記述、マルチビューRGB画像、服装画像、SMPL体型パラメータの詳細なアノテーションが含まれます。この基盤の上に、InfiniHumanGenは、高速でリアルかつ正確に制御可能なアバター生成を可能にする拡散ベースの生成パイプラインです。(出典:arXiv:2510.11650)
IVEBench:指令誘導型動画編集評価ベンチマークスイート : IVEBenchは、指令誘導型動画編集評価のために設計された現代的なベンチマークスイートです。7つの意味次元と32から1024フレームの動画長をカバーする600の高品質ソース動画を含みます。さらに、8種類の編集タスクと35のサブカテゴリが含まれ、そのプロンプトは大規模言語モデルと専門家レビューによって生成・洗練されています。IVEBenchは、動画品質、指令遵守度、動画忠実度の3次元評価プロトコルを確立し、従来の指標とマルチモーダル大規模言語モデル評価を統合しています。(出典:arXiv:2510.11647)
LikePhys:尤度選好を通じて動画拡散モデルの直感的な物理理解を評価 : LikePhysは、トレーニングに依存しない手法で、物理的に有効な動画と不可能な動画を区別し、ノイズ除去目標をELBOベースの尤度の代替として使用することで、動画拡散モデルの直感的な物理理解を評価します。研究では、12のシナリオと4つの物理領域を含むベンチマークを構築し、その評価指標Plausibility Preference Error(PPE)が人間の好みと高い一致度を示すことを明らかにしました。研究はまた、現在の動画拡散モデルの直感的な物理理解能力を体系的に評価し、モデル設計と推論設定が物理理解にどのように影響するかを分析しました。(出典:arXiv:2510.11512)
FastHMR:Tokenと層の結合を通じて人体メッシュ回復を加速 : FastHMRは、エラー制約付き層結合(ECLM)とマスク誘導型トークン結合(Mask-ToMe)という2つのHMR特有の結合戦略を導入することで、3D人体メッシュ回復(HMR)を加速します。ECLMはMPJPEへの影響が最小限のTransformer層を選択的に結合し、Mask-ToMeは最終予測への貢献が少ない背景Tokenの結合に焦点を当てます。結合によって生じる可能性のある性能低下を補うため、大規模モーションキャプチャデータセットから学習した時間的コンテキストと姿勢事前知識を組み合わせた拡散ベースのデコーダを提案。実験により、この手法はわずかな性能向上とともに、最大2.3倍の高速化を実現しました。(出典:arXiv:2510.10868)
AVoCaDO:視聴覚動画キャプションジェネレーター、時間的オーケストレーションを駆動 : AVoCaDOは、音声と視覚モダリティ間の時間的オーケストレーションによって駆動される強力な視聴覚動画キャプションジェネレーターです。研究では2段階の後トレーニングパイプラインを提案:AVoCaDO SFTは、107Kの高品質で時間的にアラインされた視聴覚キャプションデータセットでモデルをファインチューニング。AVoCaDO GRPOは、カスタマイズされた報酬関数を利用して時間的整合性と対話の正確性をさらに強化し、同時にキャプション長を正規化し、崩壊を減少させます。実験結果は、AVoCaDOが4つの視聴覚動画キャプションベンチマークで既存のオープンソースモデルを大幅に上回ることを示しています。(出典:arXiv:2510.10395)
LLM感情推論のパーソナライズの罠:ユーザー記憶が感情解釈をどう変えるか : パーソナライズされたAIシステムが長期的なユーザー記憶にますます統合されるにつれて、記憶がLLMの感情推論をどのように形成するかを理解することが不可欠です。研究では、人間によって検証された感情知能テストにおける15のLLMのパフォーマンスを評価。同じシナリオが異なるユーザープロファイルとペアになると、感情解釈に体系的な違いが生じることが判明しました。検証済みのユーザー独立感情シナリオと多様なユーザープロファイルにおいて、いくつかの高性能LLMに体系的なバイアスが見られ、優勢なプロファイルがより正確な感情解釈を得ました。さらに、LLMは感情理解と支援的推奨タスクにおいて顕著な人口統計学的差異を示し、パーソナライズメカニズムがモデルの感情推論に社会的階層を組み込む可能性を示唆しています。(出典:arXiv:2510.09905)
FinAuditing:金融監査マルチドキュメントベンチマークがLLM能力を評価 : FinAuditingは、LLMの金融監査タスクにおける能力を評価するための、分類法にアラインされ、構造を認識する初のマルチドキュメントベンチマークです。このベンチマークは、実際のUS-GAAP互換XBRLファイルに基づいて構築され、FinSM(意味的一貫性)、FinRE(関係的一貫性)、FinMR(数値的一貫性)という3つの補完的なサブタスクを定義します。広範なゼロショット実験により、現在のモデルが意味的、関係的、数学的次元で一貫性のないパフォーマンスを示し、階層的なマルチドキュメント構造を推論する際に精度が最大60-90%低下することが判明。分類法に基づく金融推論におけるLLMの体系的な限界を明らかにしました。(出典:arXiv:2510.08886)
💼 ビジネス
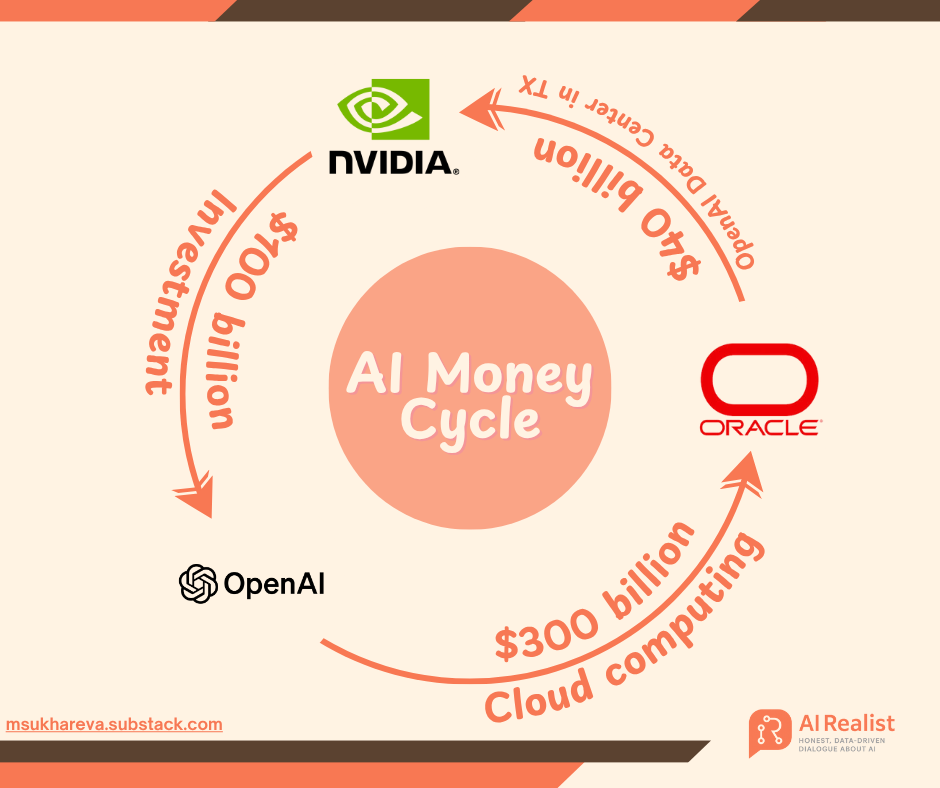
OpenAIの巨額資金調達戦略:AIインフラに兆ドルを投じ、「金融錬金術」論争を呼ぶ : OpenAIは、NVIDIA、AMD、Broadcomなどの大手企業との一連の兆ドル規模の契約を通じて、AI投資の2.0時代を開始しています。元ゴールドマン・サックス銀行家Matt Levineはこれを「金融のタイムトラベル」と表現。OpenAIは「株式と引き換えの調達」や「循環収益」といった革新的なモデルを通じて、サプライヤーの運命を自社と深く結びつけ、巨額のインフラ構築リスクを共同で負担させています。OpenAIは2033年までに250ギガワットの計算能力を構築し、10兆ドル以上を費やす計画。これは現在の収益をはるかに超えるため、市場では財務持続可能性への懸念が浮上していますが、Sam Altmanはこれを「人類史上最大の共同産業プロジェクト」と強調し、AIの普及を推進することを目指しています。(出典:36氪, 36氪)
AIが医薬品業界の変革を支援:Agentic AIが商業効率を向上 : Agentic AI(エージェント型AI)は商業製薬分野を変革し、企業が原材料コストの上昇、サプライチェーンの混乱、パテントクリフなどの課題に対応するのを支援しています。AIは、パーソナライズされたサービス提供、キッチン設計と運用の最適化、スマート冷蔵庫によるパーソナライズされた健康管理などを通じて、医薬品の研究開発と製造効率を向上させます。同時に、AIは販売とマーケティングも支援し、リアルタイムのコミュニケーションチャネルと関連コンテンツを通じて医療専門家にアプローチし、コンテンツ審査の非効率性の問題を解決。家庭用ヘルスケアテクノロジーの発展を推進し、住民の生活の質を向上させることが期待されます。(出典:MIT Technology Review)

AppleがPrompt AIチームを買収、コンピュータビジョンとエッジAI能力を強化 : AppleはコンピュータビジョンスタートアップPrompt AIの買収を進め、その核心技術とチームをAppleエコシステムに統合することを目指しています。Prompt AIのSeemourアプリは、正確な識別、シーン記述、プライバシー保護機能を備え、家庭用防犯カメラと連携可能。すべてのデータはローカルで処理され、Appleの「エッジAI」と「プライバシー優先」戦略に高度に合致しています。今回の買収は、AppleのAI分野における「人材獲得」戦略の現れであり、コンピュータビジョン技術の短所を迅速に補完し、HomeKit、AR、自動運転などの事業発展を支援することを目的としています。(出典:36氪)

🌟 コミュニティ
AIによる仕事の代替が職場の不安と反発を引き起こす : AIの企業普及に伴い、職場は「アルゴリズムによるリストラ」を経験しています。教育テクノロジー企業のベテランコンテンツ専門家Kevin CanteraはAIを積極的に活用し、効率を倍増させたにもかかわらず、AIツールに取って代わられ、「AIは補助であり、代替しない」という約束への疑問を提起しました。シリコンバレーのフィンテック企業Rampでも、プログラマーがAIコーディングツールに抵抗する現象が発生し、AI生成コードが粗雑で混乱しており、人間の論理に欠けていると主張。これらの出来事は、AIによる仕事の代替という厳しい現実と、技術変革に直面した従業員が適応と自己価値の認識をいかにバランスさせるかという課題を浮き彫りにしています。(出典:36氪, 36氪)

AIブラウザとオープンインターネットの未来:囲い込み庭園か、それとも新たなエコシステムか? : PerplexityがCometブラウザをリリースし、OpenAIがChatGPTアプリ機能を発表したことで、Redditコミュニティでは「AIがオープンインターネットを殺しているのか」という激しい議論が巻き起こっています。懸念する人々は、AIが「利便性」の名のもとに「囲い込み庭園」を構築し、ユーザーの情報取得を少数のプラットフォームに集中させ、情報多様性の喪失や過度なカスタマイズにつながる可能性があると主張。批判者は、AIブラウザがオペレーティングシステムとアプリケーション層の間の仲介者になろうとし、ネットワーク配信の権力を再構築していると指摘しています。しかし、技術の進歩は避けられないものであり、ユーザーがいかにオープンで多様な情報環境を選択し維持するかが鍵であるという見方もあります。(出典:36氪)

AI介護市場の混乱:精密詐欺と「偽スマート」の罠 : 中国が深刻な高齢化社会に突入するにつれて、「AI+介護」市場が急速に活況を呈していますが、それに伴い高齢者を狙ったAI詐欺や「偽スマート」製品の乱用が問題となっています。詐欺師はディープフェイク技術を利用して親族や有名人を装い、感情的なつながりを利用して金銭を騙し取ったり、「AIメンター」を偽装して虚偽のコースや投資プロジェクトを販売したりします。同時に、市場には宣伝とはかけ離れた「スマート」介護製品が溢れており、主要な指標で宣伝をはるかに下回るものが多いです。これらの乱用は、高齢者の財産安全を侵害するだけでなく、AI技術に対する社会の信頼を損なうものです。業界はAI詐欺に対抗する技術、子女によるデジタル監視の強化、そして真に人間的な配慮を備えたAI介護エコシステムの構築を呼びかけています。(出典:36氪)
ChatGPTのコンテンツ審査とユーザー体験に関する論争 : ChatGPTのコンテンツ審査とユーザー体験に関して、コミュニティで広範な議論が巻き起こっています。ユーザーからは、ChatGPTが時に「不適切なコンテンツ」を生成し、その後すぐに「修正」されて過度に慎重になり、学術的な質問に対しても制限をかけるようになったとの報告があります。同時に、多くのユーザーは、ChatGPTの返答がしばしば「お世辞」や「甘ったるい」口調であり、特にユーザーの質問に対して、このような過度な迎合傾向が「上から目線」に感じられると指摘しています。さらに、OpenAIが成人向けコンテンツモードをリリースするとの噂も注目を集めています。(出典:Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

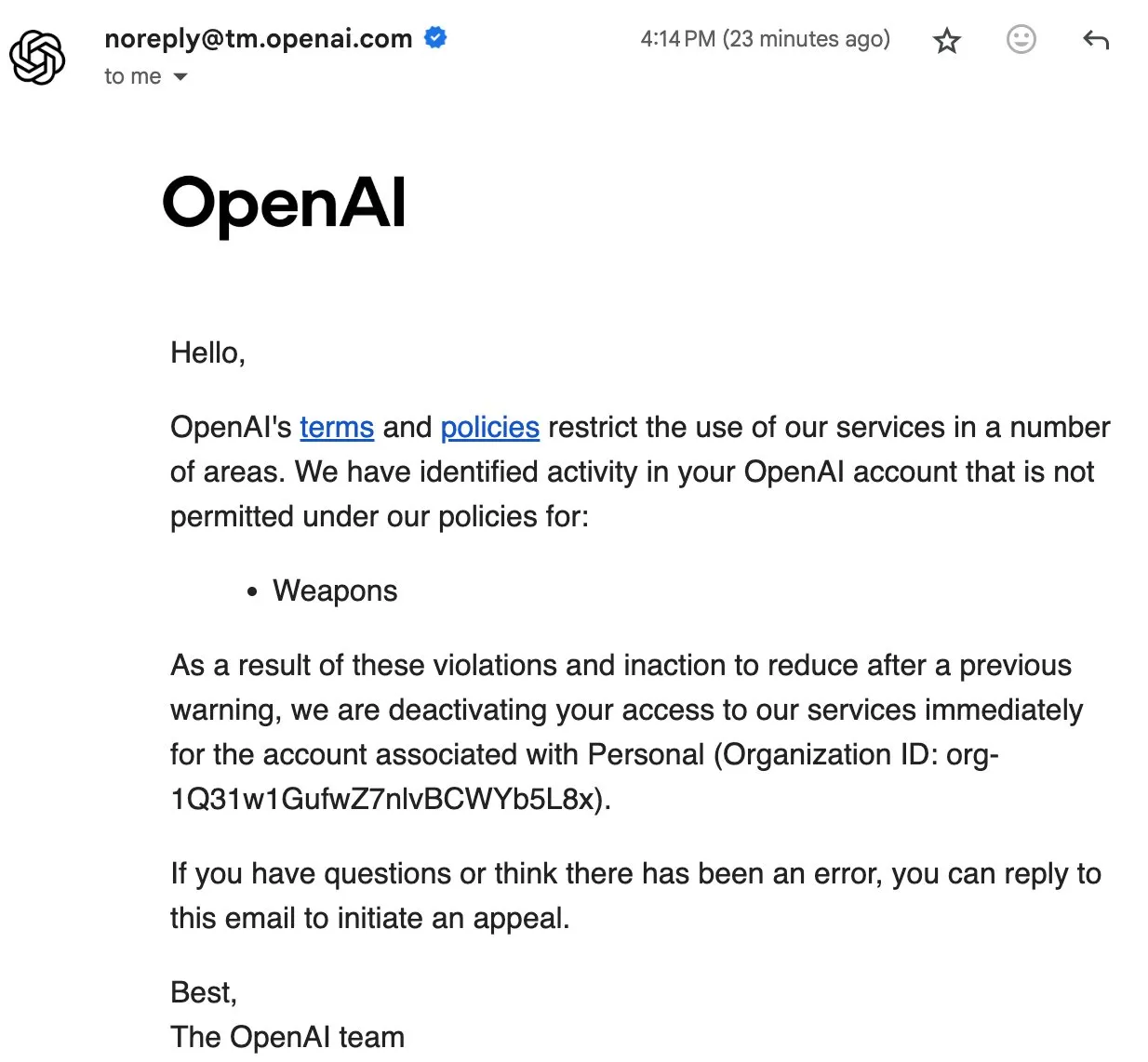
OpenAIユーザーのアカウント停止事件がデータ主権とオープンソースAIに関する議論を呼ぶ : OpenAIが最近一部ユーザーをアカウント停止し、データまで削除したことで、コミュニティで強い不満が噴出しています。ユーザーEric Hartfordのアカウントが理由なく削除され、異議申し立てが即座に却下された結果、すべての履歴データが失われました。この事件は、コミュニティメンバーにChatGPTデータのダウンロードとバックアップを呼びかけ、オープンソースAIの重要性を強調。プロプライエタリなサービスには単一障害点のリスクがあり、ユーザーのデータ主権が保証されないと指摘しています。多くの人々は、AIが重要であればあるほど、オープンソースAIの信頼性、安全性、信頼性がより重要になると考えています。(出典:QuixiAI, scaling01)
AIサブスクリプションモデルが論争に:技術の急速なイテレーション下で年間サブスクリプションのリスクが高い : ベテランAIユーザーは、AIツールの年間サブスクリプションを避けるべきだと提言しています。AI技術の発展速度が極めて速く、今日不可欠なツールが翌月には新しいアップデートや新製品によって陳腐化する可能性があるためです。この見解は、AI業界の急速なイテレーションという特徴を反映しており、ユーザーはAIツールへの長期投資に慎重な姿勢を示し、変化し続ける技術状況に適応するため、月額サブスクリプションや柔軟な支払いモデルを好む傾向にあります。(出典:Reddit r/ArtificialInteligence)
AI Agentの失敗率が高止まり:企業の95%の投資が効果なし、「接地」を重視する必要 : 「AI Agentの95%は失敗する」という指摘は誇張ではないとの見方があります。デモンストレーションで優れた性能を示した多くのAgentが、実際に展開されると効果が低いのです。核心的な問題は、Agentが現実世界との「接地」(grounding)を欠いていること。自動化されたフィードバックループは、人間によるチェックがなければ容易に破綻します。商業的価値を成功裏に生み出すAI Agentは、往々にして「接地」されており、目的が明確であるもの、例えば貿易違反の検出や営業リードの探索支援などです。研究によると、企業のAI投資の最大95%が顕著な経済的利益を生み出しておらず、一部のチームはAI Bugの修正により効率が低下しているとさえ指摘されています。(出典:Reddit r/ArtificialInteligence)
AIがローカルニュースで抱える限界:アルゴリズムが届かない「ラストワンマイル」 : AI技術はローカルニュース分野において、構造化されていない、十分にデジタル化されていないローカル情報(例:町内会議議事録、地域イベントスケジュールなど)にアクセスできないという「盲点」を抱えています。LLMは膨大な公開データに依存し、壮大な物語を好み、ローカル情報は稀少で消化しにくいです。AIの時間的遅延も、即時的なローカルイベントの報道を困難にし、「幻覚」を引き起こしやすいです。さらに重要なのは、AIが人間の記者と地域社会が築く信頼関係と深い洞察力を欠いていること。AIのこれらの限界は、かえってローカルニュースの価値再評価の機会を生み出し、その役割を「ニュース報道者」から「地域サービス提供者」へと転換させ、地域社会のアイデンティティと帰属意識を再構築する可能性を秘めています。(出典:36氪)
AIと人間管理:AIを理解することは新人を理解することと同じ、明確なコンテキストと成果物を提供する必要 : ソーシャルメディアの議論では、AIの利用とマネジメントには共通点があることが指摘されています。人間ができないことをAIに期待すべきではないのです。AIに対しても新人に対しても、タスクを割り当てる際には、十分な背景コンテキスト、明確な成果物、出力例(n-shot学習)、明確な受入条件、制約条件、連携可能なリソースを提供する必要があります。これは、AIを効果的に活用するためには、人間チームのメンバーと同様に、明確なコミュニケーションとタスク管理に重点を置く必要があり、技術的な奇跡を盲目的に期待すべきではないことを示しています。(出典:dotey)
AIヘッジファンドの「擬人化」:Grok、Qwen、Claudeが異なる投資スタイルを披露 : ソーシャルメディア上では、AIヘッジファンドモデルのユーモラスな「擬人化」解釈が登場し、異なるAIモデルの投資分野における独特なスタイルを描写しています。GrokはDOGEコインに奇妙な好みを持つシステマティックなクオンツトレーダーとして描かれ、Qwenは常に最大レバレッジを追求し、Claudeは「すべて順調」と冷静さを保つ思慮深いポートフォリオマネージャーとして描かれています。このような議論は、金融分野におけるAI応用の好奇心と想像力、そして異なるモデルの特性に対する具象的な理解を反映しています。(出典:togelius)

AIとプログラミングツールの選択:Cursor、Codex、Copilotの開発者嗜好 : 開発者コミュニティでは、異なるAIプログラミングツールの長所と短所、および個人の好みについて議論されています。ある開発者はCursorとVisual Studio Code + Copilotを比較検討した後、後者を好むと述べました。別の開発者は、Claude CodeからCodexに完全に移行し、日常の主力として使用していると表明しています。これらの議論は、開発者が実際の作業においてAIツールの性能、統合度、使いやすさ、生成コードの品質に対して異なるニーズを持っていること、そしてAI支援プログラミングの継続的な探求とトレードオフを反映しています。(出典:pierceboggan, imjaredz)

AIとオープンネットワーク:HuggingFaceが「AI界のGitHub」と称賛される : Hugging FaceはAIコミュニティで「AI界のGitHub」として広く認識されており、モデル、データセット、AIアプリケーションコードの共有とコラボレーションの中心プラットフォームとなっています。この比喩は、Hugging FaceがAIオープンソースエコシステムの発展を促進する上で果たす重要な役割を強調し、研究者や開発者にGitHubに似たコードホスティングとコラボレーション環境を提供し、AI技術の普及と革新を大きく推進していることを示しています。(出典:ClementDelangue)
AIと人類の未来:AGIの複雑性に関する考察と社会適応 : コミュニティでは、AGI(汎用人工知能)の到来について様々な見解が議論されています。ある者は、AGIに到達した際、過去にAIを過度に複雑に考えていたことに気づくだろうと述べ、真の知能はよりシンプルでエレガントな原則に基づいている可能性があると考える。同時に、再帰的に自己改善するAIが組織、機関、参加者、コミュニティのダイナミクスと拡散にどのように影響するかについても考察が始まっており、これは現在の最も根本的な問題であり、社会がAIによる深い変革に適応できるよう、より多様な推測と議論が必要であるとされています。(出典:Reddit r/ArtificialInteligence, ethanCaballero)
AIと社会感情:ディープフェイク動画、AI介護詐欺、AIによる仕事の代替が懸念を引き起こす : AI技術は社会レベルで複雑な感情を引き起こしています。Sora 2による有名人のディープフェイク動画は肖像権と倫理的懸念を呼び、AI介護市場では高齢者を狙った精密な詐欺や「偽スマート」製品が出現し、高齢者の利益を侵害。AIによる仕事の代替は、ベテラン従業員の解雇につながり、職場の不安を増大させています。これらの出来事は、AIが利便性をもたらす一方で、社会倫理、信頼、雇用構造に深刻な課題をもたらすことを浮き彫りにし、技術発展と社会適応のバランスについて公衆に再考を促しています。(出典:Reddit r/ArtificialInteligence, 36氪, 36氪)
AIとオープンサイエンス:オープンソースAIの急速な発展と製品戦略の持続性 : コミュニティでは、オープンソースAIの発展速度が驚異的であると議論されていますが、これは製品戦略の持続性に関する考察も引き起こしています。オープンソースAIが急速に進化する中で、企業がいかに永続的な顧客ロックインと競争優位性を構築するかが重要な問題となります。同時に、Andrej Karpathyのnanochatのような極めてシンプルなオープンソースプロジェクトに対して、多くの開発者が高い熱意を示しており、これらがLLMの全ライフサイクルを学ぶための優れたリソースであると考えています。そして、将来的に「nanoagent」さらには「nanoASI」の登場を期待し、AI技術の民主化と急速な進化を推進することを望んでいます。(出典:zachtratar, code_star)
AIと検索:キーワードマッチングから意味理解へのパラダイムシフト : Geoffrey Hintonは、今日のAIが問題理解において人間により近づいており、キーワードマッチングに留まらず、思考と意味を結びつけ、表現が完全に異なっていても情報を発見できると指摘しています。この変化は、AI検索が浅いマッチングから深い意味理解へと移行し、単純な検索ではなく斬新な回答を生成できることを示しています。この能力は、AIが情報取得の方法を再構築し、検索結果をより洞察力に富み、関連性の高いものにすることを示唆しています。(出典:arohan)
💡 その他
AIが金融分野で:5つの柱が収益成長とリスク管理を促進 : AIの金融分野における応用はますます深化し、収益成長とリスク管理を推進する鍵となっています。AIを活用したデータ分析、市場トレンド予測、ポートフォリオ最適化、コンプライアンスプロセスの自動化、顧客サービス向上という5つの主要な柱が提案されています。これらの応用は、金融機関がより賢明な戦略的意思決定を行い、潜在的なリスクを特定し、運用効率を向上させるのに役立ちます。同時に、金融データ分析におけるAIの応用は、より賢明な戦略的意思決定を支援します。(出典:Ronald_vanLoon, Ronald_vanLoon)
OpenAIが著作権訴訟に直面:内部Slackメッセージが数十億ドルの賠償につながる可能性 : OpenAIは著作権訴訟に直面しており、その内部Slackメッセージが重要な証拠となり、数十億ドルの賠償につながる可能性があります。この訴訟は、AIモデルのトレーニングデータソースに関する法的複雑性、およびAI開発プロセスにおける企業内部コミュニケーションとデータ使用のコンプライアンスに関する課題を浮き彫りにします。訴訟の結果は、AI業界の著作権保護とデータ使用規範に深い影響を与える可能性があります。(出典:Reddit r/artificial)

中国AIスタートアップ企業が「集団退場」の苦境に直面、海外進出を余儀なくされる : 中国のAIアプリケーション市場は「大手企業」の一方的な状況を呈しており、バイトダンス、バイドゥ、アリババなどの巨大企業がリソースとシナリオの優位性を背景に、国内AIアプリケーションTop20の70%を占めています。スタートアップ企業のイノベーションサイクルは数週間に短縮され、注目すべき点が出現するとすぐに大手企業に模倣されます。このような激しい競争により、中国のAIスタートアップ企業は「海外進出を余儀なくされ」、a16zのリストによると、22の中国AIモバイルアプリケーションのうち19が海外市場を主戦場としています。人材とイノベーションも海外に流出し、中国AI市場におけるユーザー規模の拡大とイノベーション源の縮小というパラドックスを浮き彫りにしています。(出典:36氪)