Anahtar Kelimeler:AI teknolojisi, Büyük dil modelleri, Derin öğrenme, Yapay zeka, Makine öğrenimi, Doğal dil işleme, Bilgisayarlı görü, Pekiştirmeli öğrenme, nanochat açık kaynak projesi, OpenAI özel yapım AI çipleri, Sora 2 derin sahtekarlık etiği, Claude Sonnet 4.5, GPT-5 Pro matematiksel akıl yürütme
🔥 Focus
Andrej Karpathy Releases nanochat: Hand-building ChatGPT for $100 : Former Tesla AI director Andrej Karpathy launched the open-source project nanochat, implementing the complete training and inference process for ChatGPT with less than 8,000 lines of code. The project aims to lower the barrier to LLM research, allowing users to set up a conversational mini-ChatGPT with just a cloud GPU (approx. $100, 4 hours of training), and achieve performance surpassing GPT-2 CORE metrics with 12 hours of training. nanochat will be the capstone project for the LLM101n course and is expected to evolve into a research platform or benchmark tool, reflecting Karpathy’s continued passion for AI education and democratization. (Source: GitHub nanochat, Reddit r/deeplearning, 36氪, 36氪, 36氪, 36氪)
OpenAI and Broadcom Partner to Develop Custom AI Chips, Deploy 10 Gigawatt Computing Infrastructure : OpenAI announced a strategic collaboration with Broadcom to jointly design and deploy custom AI chips and computing systems, aiming to deploy a total of 10 gigawatts of inference infrastructure between late 2026 and late 2029. This move signifies that OpenAI is no longer content with purchasing existing GPUs but is pursuing vertical integration, participating in hardware design from the transistor level to optimize AI model performance, reduce costs, and meet future exponential computing demands. OpenAI stated that this collaboration is “the largest joint industrial project in human history,” even utilizing AI models to assist in chip design, foreshadowing AI’s deep involvement in hardware development. (Source: OpenAI, Bloomberg, CNBC, 36氪, 36氪, 36氪)
Sora 2 Sparks Deepfake Ethical Crisis and Copyright Disputes : OpenAI’s video generation model Sora 2 quickly gained popularity due to its highly realistic generation capabilities, but it also brought serious ethical and copyright challenges. Users generated fake videos of deceased celebrities (such as Michael Jackson, Robin Williams) using Sora 2, drawing strong dissatisfaction from their families, who consider it an abuse and disrespect of the deceased’s image. OpenAI responded by stating that public figures and their families should have control over how their images are used, and plans to provide more refined copyright control and revenue-sharing mechanisms. However, the industry widely worries that the increasing prevalence of open-source deepfake models necessitates society to quickly adapt to the impact of AI-generated content and explore effective technical and legal protective measures. (Source: Washington Post, BBC, 量子位)

Claude Sonnet 4.5, Microsoft Agent Framework, and Cursor IDE Drive Leap in AI Coding Capabilities : Significant breakthroughs have been made in the AI coding field: Claude Sonnet 4.5 achieved 77.2% accuracy on the SWE-bench Verified benchmark, significantly outperforming previous models. Concurrently, the Microsoft Agent Framework transforms VS Code into an AI-native environment, enabling Agents to autonomously handle multi-file code modifications; Cursor IDE 1.7 also introduced an “Agent mode” that can solve complex problems with a single click. These advancements indicate that AI Agents can now undertake most development tasks, sparking discussions about whether developers will become overly reliant on AI and the potential technical debt risks that AI-generated code might introduce. (Source: Reddit r/artificial)
GPT-5 Pro Solves Erdős Math Problem, Demonstrates Powerful Literature Retrieval and Vulnerability Identification Capabilities : OpenAI’s GPT-5 Pro has shown astonishing capabilities in mathematical reasoning, accurately retrieving a key paper from 2003 that solved Erdős problem #339, solely from an image of the problem. Furthermore, GPT-5 Pro can identify serious flaws in published papers within 18 minutes, even surpassing human experts’ research efforts of several days. This breakthrough highlights GPT-5 Pro’s immense potential in precise information retrieval, complex problem-solving, and scientific literature verification, indicating that AI will greatly accelerate scientific research, especially in verifying academic claims and discovering logical contradictions. (Source: Sebastien Bubeck, Greg Brockman, 36氪)
Three AI Giants Co-author Paper: Existing LLM Security Defenses Are Fragile : OpenAI, Anthropic, and Google DeepMind have uncharacteristically co-authored a paper, pointing out that current defense mechanisms against large language model (LLM) jailbreaking and prompt injection are generally vulnerable. The research team proposed a universal adaptive attack framework and, combining methods such as gradient descent, reinforcement learning, random search, and human red-teaming, successfully bypassed 12 mainstream defense mechanisms, with most attacks achieving over 90% success rates. This suggests that existing evaluations are often theoretical, and future LLM security research must incorporate stronger adaptive attack assessments to build truly robust defense systems. (Source: arXiv:2510.09023, 36氪)

xAI Joins ‘World Model’ Race, First Application Targets AI Game Generation : Elon Musk’s xAI company has quietly joined the “World Model” race, competing with giants like Google and Meta. xAI has recruited AI experts from NVIDIA, aiming to build models capable of understanding and simulating the real physical world by training on massive video and robotics data. Its first commercial application is AI game generation, with plans to release AI-generated games by the end of next year and explore applications in robotics systems. Google researchers believe that future video models will be as intelligent as language models, unlocking emergent capabilities like object segmentation and edge detection through “next-frame prediction,” signaling the arrival of a “GPT moment in the visual domain.” (Source: 36氪)
Mysterious ICLR Paper Reveals SAM3: Segmenting Everything with Concepts, Reshaping Visual AI Paradigm : A blind-reviewed paper for the ICLR 2026 conference, “SAM3: Segmenting Everything with Concepts,” has been exposed, revealing that Meta AI’s Segment Anything Model (SAM) is set to receive its third major upgrade. SAM3’s core breakthrough lies in “Concept-Based Segmentation” (PCS), where the model can not only segment by pixels or instances but also identify, segment, and track all objects conforming to specific “semantic concepts” based on text or image prompts. The new system, through a human-machine collaborative data engine, has built a high-quality dataset containing 4 million concept labels and can identify hundreds of objects within 30 milliseconds on an H200 GPU, fully surpassing existing systems and indicating that the “GPT-3 moment” for visual AI might not be far off. (Source: arXiv:r35clVtGzw, 36氪)
🎯 Trends
Gemini 3 Internal Testing Receives Rave Reviews, Hailed as ‘Strongest Frontend Development Model Ever’ : Google’s next-generation flagship model, Gemini 3, has garnered widespread attention during internal testing, with netizens praising its capabilities in frontend development, SVG vector graphic generation, and multimodal features, calling it “the best frontend and web development model ever” and some even predicting it will be the model of the year. Leaked information indicates that Gemini 3.0 Pro adopts an MoE architecture with trillions of parameters, an expanded context window of millions, and built-in deep thinking mode and multimodal capabilities, performing excellently on ARC-AGI-2 and HLE benchmarks. (Source: 36氪)
AI’s Deepening Application in Chip Design and Manufacturing : Machine learning is increasingly being applied in chip design and manufacturing, driving new levels of semiconductor efficiency and innovation. AIHub interviewed Sony AI’s Head of Chip Design, Lorenzo Servadei, who noted that AI in EDA (Electronic Design Automation) is moving from accelerating estimations to actively participating in the design process, accelerating multi-physics models, optimizing algorithms, and performing physical implementation through neural networks and generative AI, significantly improving chip design speed, quality, and creativity. OpenAI also revealed that its GPT models have assisted in designing its own chips, achieving area reduction and accelerating development cycles. (Source: aihub.org, 36氪)

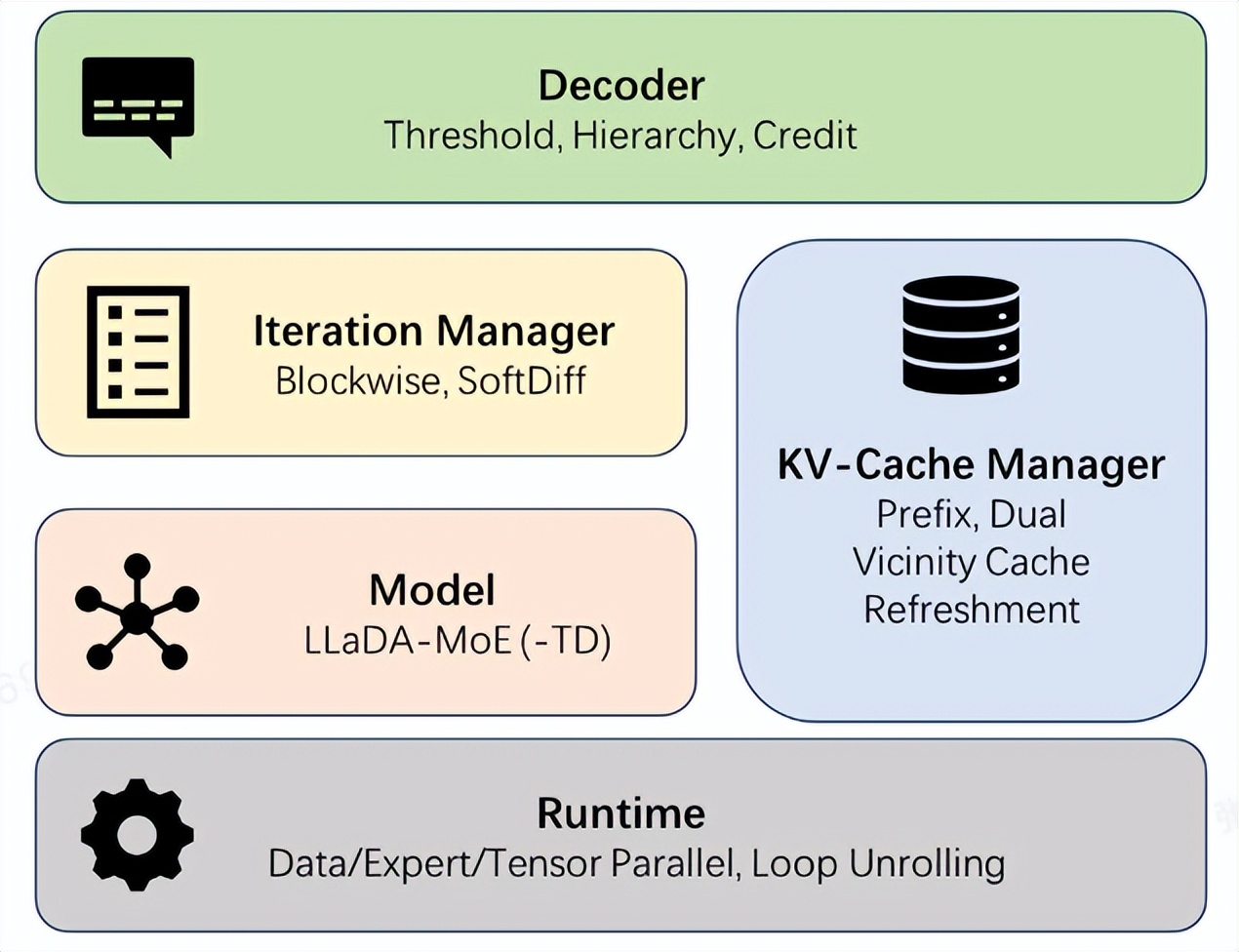
Ant Group Open-Sources dInfer Framework, Boosting Diffusion Language Model Inference Speed by 10x : Ant Group officially open-sourced dInfer, the industry’s first high-performance diffusion language model inference framework, which boosts the inference speed of diffusion language models by 10.7 times compared to NVIDIA Fast-dLLM. In the HumanEval code generation task, dInfer achieved 1011 Tokens/second in single-batch inference, significantly surpassing autoregressive models for the first time. dInfer employs a deep algorithmic and system co-design, comprising four core modules: model access, KV cache manager, diffusion iteration manager, and decoding strategy, aiming to address the challenges of high computational cost, KV cache invalidation, and parallel decoding in diffusion language models, unleashing their efficient inference potential. (Source: 量子位, QuixiAI)
Google NotebookLM Upgrades, Gemini Nano Banana Powers New Visual Styles for Video Overviews : Google NotebookLM’s video overview feature has been upgraded with new visual styles (Classic, Whiteboard, Watercolor, Vintage Print, Traditional, Paper Art, Anime), powered by Gemini’s image generation model, Nano Banana. Additionally, a more concise “Brief” format has been introduced for quick summaries. These updates will first roll out to Pro users and then to all users in the coming weeks, aiming to enhance personalized experiences in video content understanding and presentation. (Source: Google, op7418)
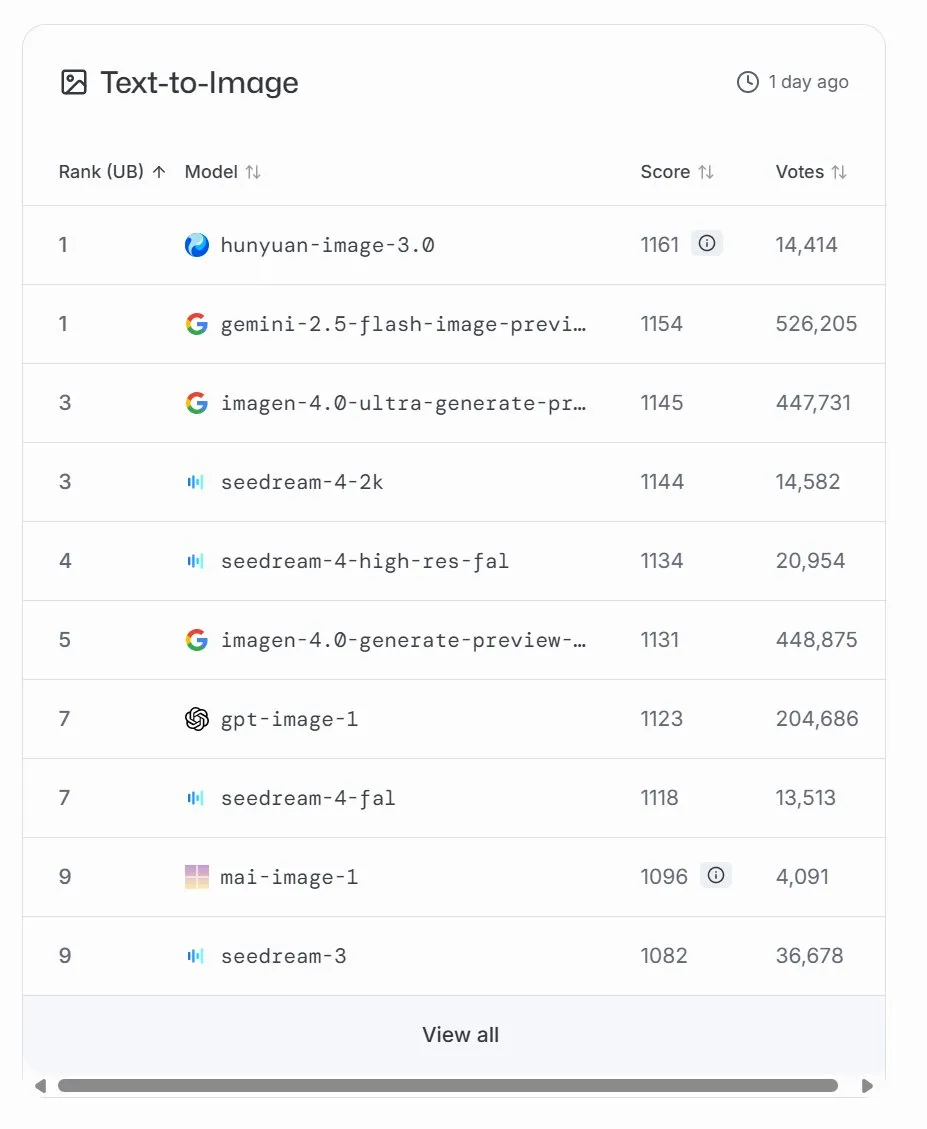
Microsoft Launches MAI-Image-1 Image Generation Model, Ranks Ninth on LMArena : Microsoft AI released its third AI model, MAI-Image-1, an image generation model that debuted at ninth place on the LMArena leaderboard, tied with Seedream 3. The model achieves an impressive balance between generation speed and quality, demonstrating Microsoft’s continuous investment and rapid development in multimodal AI. Microsoft stated it will continue to optimize the model to achieve a higher ranking on the leaderboard. (Source: mustafasuleyman, NandoDF)
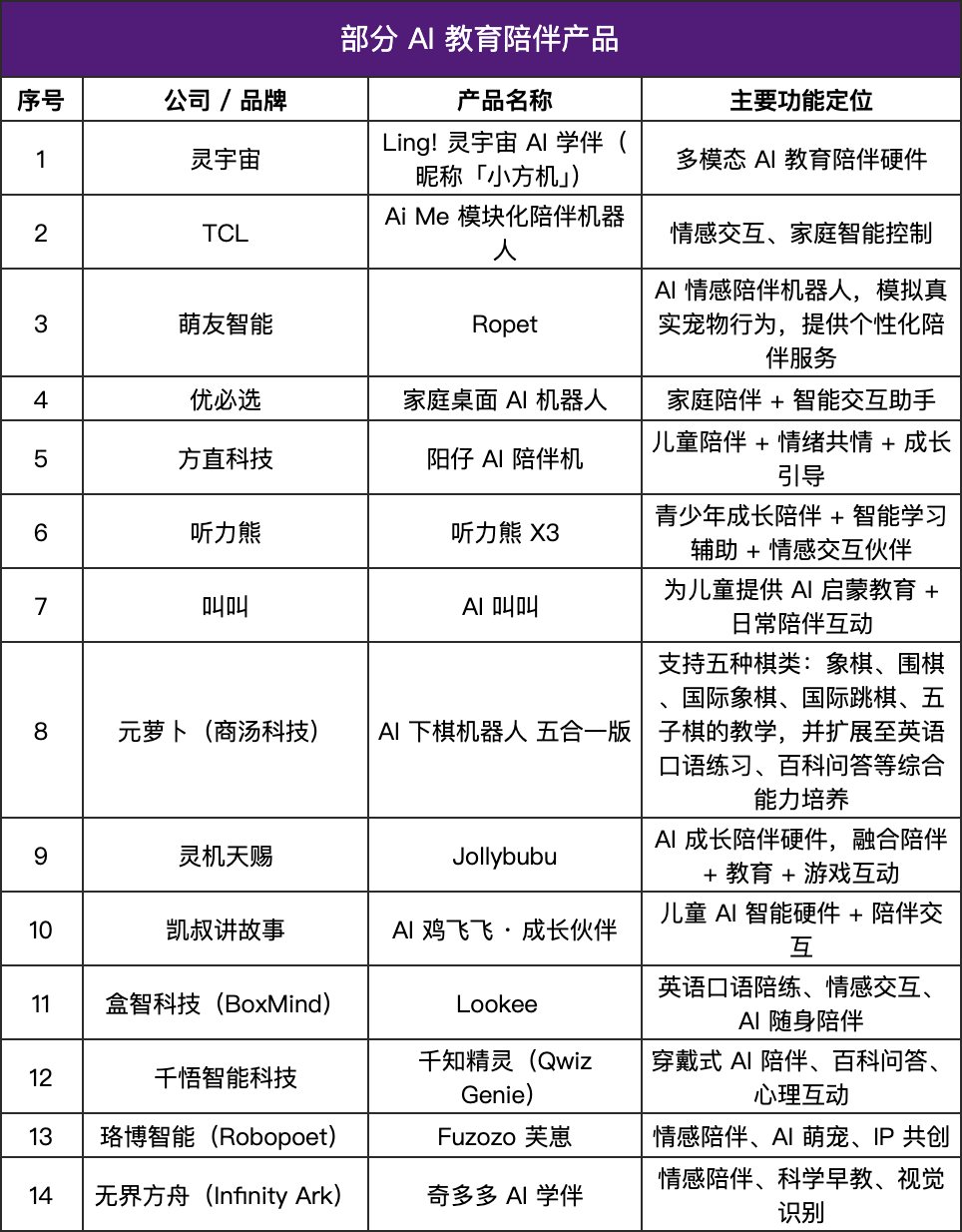
AI Companion Products Boom, Education Hardware ‘Grows Warmth’ : The AI companion product market is rapidly emerging, with an estimated future market size of $70 billion to $150 billion. These products are shifting from “command response” to “emotional feedback,” simulating human reactions through language models, emotional recognition, voice interaction, and memory systems to provide personalized companionship. In the education sector, AI companion products have been implemented as learning assistants, emotional feedback systems, and intelligent Q&A models, extending from knowledge transfer to psychological support, showing a trend towards lightweight, personalized, and multimodal interaction, aiming to become systems that “understand students.” (Source: 36氪)
NVIDIA Releases DGX Spark, the World’s Smallest AI Supercomputer : NVIDIA officially released DGX Spark, touted as the world’s smallest AI supercomputer, which has begun shipping. Based on the NVIDIA Grace Blackwell architecture and integrating 128GB of unified memory, DGX Spark aims to provide AI developers with powerful local LLM prototyping and running capabilities. Early users are testing, validating, and optimizing their tools, software, and models, signaling that high-performance AI computing will become more widespread and accessible. (Source: nvidia, ollama)

Anthropic Launches Claude Sonnet 4.5, Agent SDK, and Updated Claude Code : Anthropic released Claude Sonnet 4.5, enhancing reasoning capabilities with a larger context window (200k–1M tokens) and improved coding and reasoning benchmark performance. Concurrently, Anthropic also introduced the Claude Agent SDK and an updated Claude Code, featuring automatic context tracking/summarization, persistent memory tools, checkpointing with rollback, and a VS Code-compatible IDE extension, aiming to provide developers with more powerful AI coding and Agent building capabilities. (Source: DeepLearningAI)

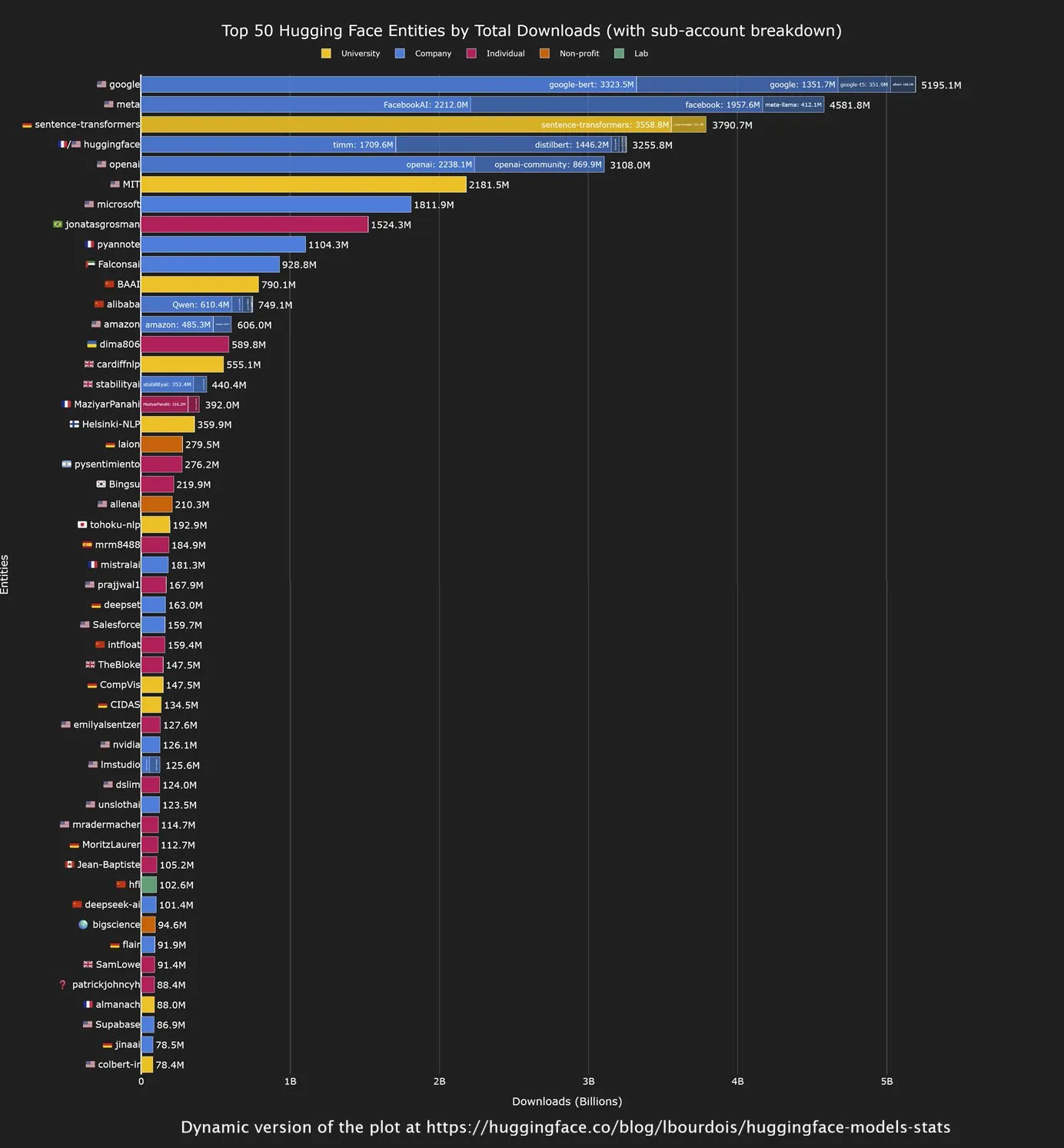
Chinese Open-Source Models Lead Hugging Face Downloads, Google Becomes Largest Contributor : Latest analysis from the Hugging Face community shows strong performance in download volumes for open-source models developed by Chinese companies, especially the Qwen series. Concurrently, Google has become the largest institutional contributor in terms of model downloads on Hugging Face. This trend indicates China’s growing influence in the open-source AI domain, while Google, as a tech giant, is actively contributing to and leveraging the open-source ecosystem to promote AI technology. (Source: mervenoyann, osanseviero)
Google Search VP Robbie Stein Interprets Future of AI Search: ‘Clarity’ as the Destination : Google Search Product Vice President Robbie Stein pointed out that AI has not changed the fundamental human need for information search but has made it more natural and complex through AI Mode. Future AI search will possess “understanding capabilities,” able to break down vague questions into sub-questions for parallel search, and synthesize traceable answers with citations. Google’s goal is to become a “knowledgeable and trustworthy” system, transforming from “indexing web pages” to “indexing the world” through multimodal integration and structured world data, making information acquisition clearer and faster, rather than merely generating fluent language. (Source: 36氪)
Ant Group Open-Sources High-Performance Diffusion Language Model Inference Framework dInfer : Ant Group officially open-sourced dInfer, the industry’s first high-performance diffusion language model inference framework, which boosts the inference speed of diffusion language models by 10.7 times compared to NVIDIA Fast-dLLM. In the HumanEval code generation task, dInfer achieved 1011 Tokens/second in single-batch inference, significantly surpassing autoregressive models for the first time. dInfer employs a deep algorithmic and system co-design, aiming to address the challenges of high computational cost, KV cache invalidation, and parallel decoding in diffusion language models, unleashing their efficient inference potential. (Source: 量子位)
NVIDIA Introduces NVFP4 Training Technology, Achieving 4-bit Pre-training with FP8 Precision Matching : NVIDIA announced a breakthrough NVFP4 training technology that enables 4-bit pre-training of large language models to achieve 8-bit precision. This technology uses a 4-bit floating-point representation in E2M1 format, combined with fine-grained scaling, stochastic rounding, and Random Hadamard Transforms, significantly reducing computation and memory requirements. Experiments show that NVFP4 substantially improves training efficiency while maintaining model accuracy (e.g., MMLU Pro 62.58% vs 62.62%), providing a more cost-effective path for training larger LLMs in the future. This technology primarily relies on the NVIDIA Blackwell architecture and requires H100 or higher GPUs. (Source: Reddit r/LocalLLaMA, karminski3)

MIT SEAL Framework Enables AI Models to Automatically Generate Fine-tuning Data and Update Weights : Massachusetts Institute of Technology (MIT) introduced the SEAL (Self-Adapting LLMs) framework, enabling large language models (LLMs) to automatically generate fine-tuning data and perform self-weight updates, achieving gradient updates with zero human intervention. SEAL employs an inner and outer loop learning mechanism, where the model optimizes its self-update instruction generation strategy based on task performance, granting LLMs self-driven update capabilities for the first time. Experiments demonstrate that SEAL performs excellently in knowledge injection and few-shot learning tasks, surpassing GPT-4.1 generated data in accuracy, showcasing powerful task adaptation and knowledge integration capabilities, and heralding the era of self-evolving models. (Source: arXiv:2506.10943, 36氪)

AI Phone Shipments Surge, Coolpad Intelligent and Other Manufacturers Explore ‘Small Model + Large Model’ Collaborative Strategy : In 2025, China’s AI phone shipments surged by 591% year-on-year, with a penetration rate of 22%, making AI phones a new industry focus. Manufacturers like Coolpad Intelligent are shifting from parameter competition to pragmatic innovation, adopting a dynamic collaborative solution of “front-end small models + back-end large models.” Approximately 600 million parameter vertical small models are deployed on devices for rapid response and privacy protection, while integrating general large model computing power from Koala AI, ByteDance, Alibaba, Google, and others. This strategy aims to enhance user experience, provide personalized services, and reduce costs to adapt to diverse and fragmented overseas markets. (Source: 36氪)

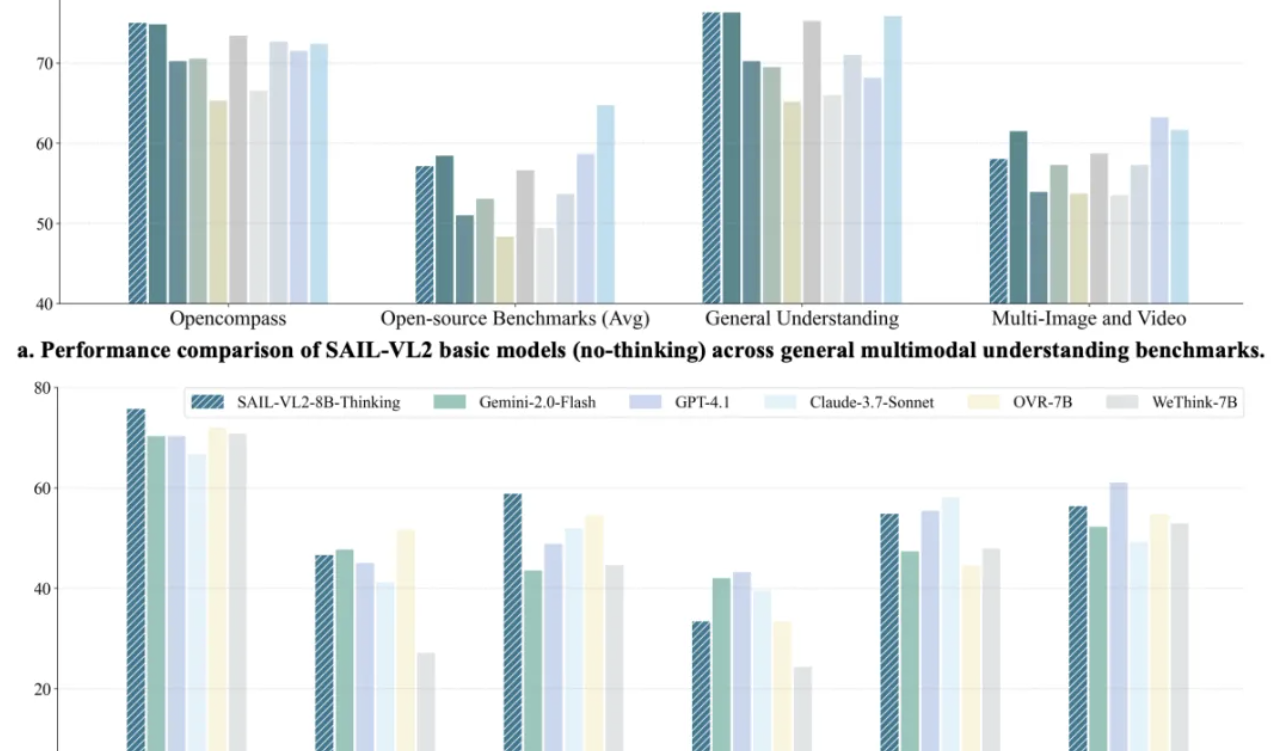
Douyin SAIL-VL2 Multimodal Model Achieves SOTA, 8B Model Inference Rivals GPT-4o : The Douyin SAIL team, in collaboration with LV-NUS Lab, launched the multimodal large model SAIL-VL2, achieving performance breakthroughs across 106 datasets with small to medium parameter scales (2B, 8B). Notably, its reasoning capabilities on complex benchmarks like MMMU and MathVista surpassed models of similar scale, with the 8B model even rivaling GPT-4o. SAIL-VL2, through innovations such as a sparse MoE architecture, a progressive training framework, and a high-quality multimodal corpus, provides the community with a new paradigm where “small models can also have strong capabilities,” and has open-sourced the model and inference code. (Source: 量子位)
Moondream Cloud Inference Fully Migrates to FAL, Achieving 100% Cloud-Based Operation : Moondream announced that its cloud inference service has fully migrated from EC2 instances to FAL, achieving 100% operation on FAL. This move likely signifies significant progress for Moondream in optimizing inference efficiency, reducing operational costs, or enhancing service elasticity, with FAL demonstrating its capability in supporting cloud deployment of AI models as a new inference platform. (Source: vikhyatk)
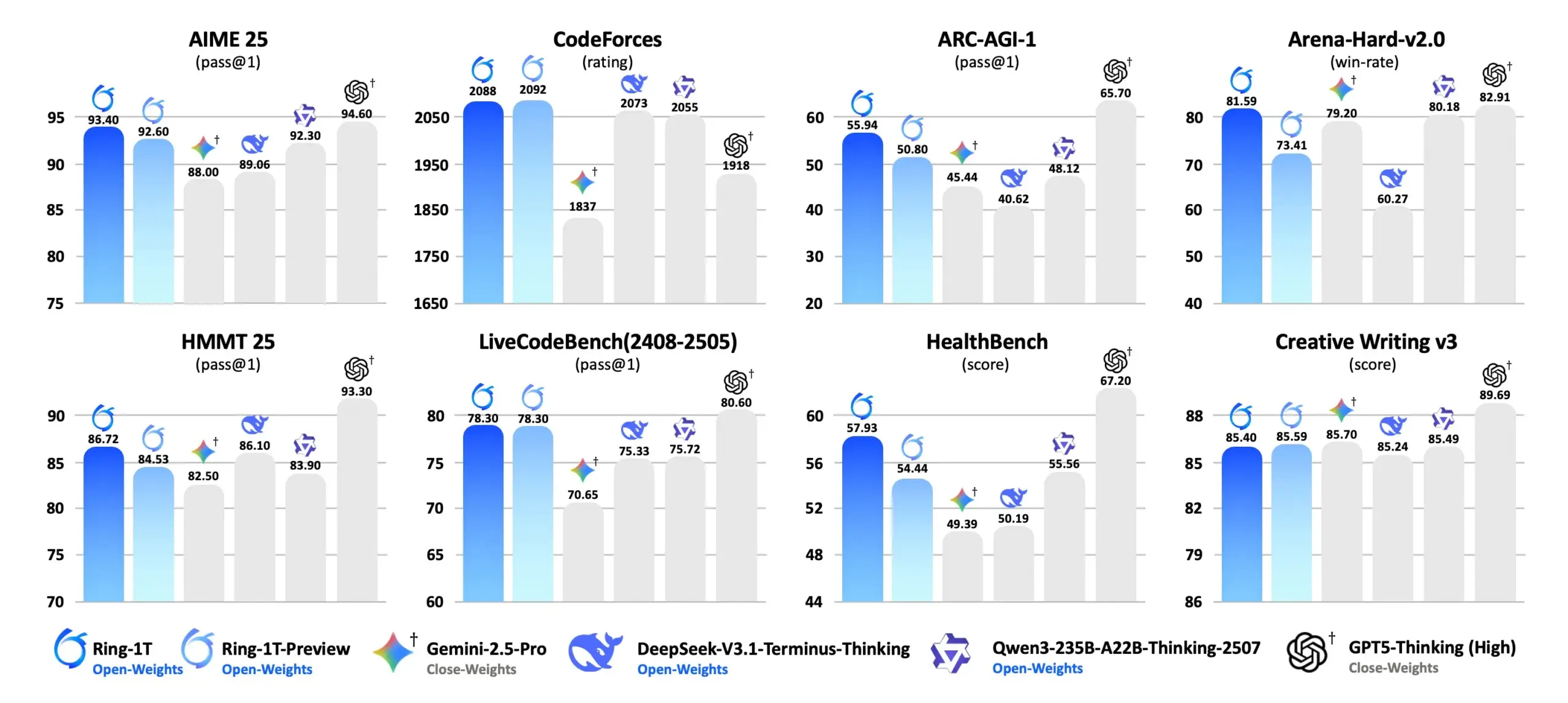
Ring-1T: Ant Ling Technology Releases Trillion-Parameter Open-Source Thought Model : Ant Ling Technology officially released Ring-1T, an open-source trillion-parameter thought model based on the Ling 2.0 architecture. Ring-1T achieves silver-medal-level IMO (International Mathematical Olympiad) reasoning capabilities in pure natural language reasoning, boasting one trillion total parameters, 50 billion active parameters, and a 128K context window. The model is reinforced through Icepop RL and ASystem (a trillion-scale reinforcement learning engine) and achieves SOTA performance on natural language reasoning benchmarks such as AIME 25, HMMT 25, ARC-AGI-1, and CodeForce. An FP8 version is available, aiming to advance open-source AI inference capabilities. (Source: scaling01, jon_durbin)
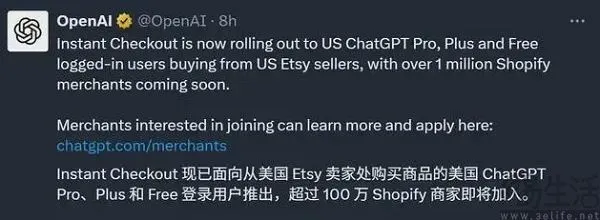
ChatGPT E-commerce Feature ‘Instant Checkout’ Launched, Reshaping Shopping Experience : OpenAI launched ChatGPT’s “Instant Checkout” feature, allowing users to complete purchases directly within ChatGPT without redirecting to third-party e-commerce platforms. Currently, the feature supports Etsy and will soon integrate with over a million Shopify merchants. This innovation creates a one-stop closed-loop shopping process from describing needs to completing purchases, significantly shortening the user’s purchase decision path and enhancing shopping convenience, signaling deep integration of AI in e-commerce and a transformation of business models. (Source: 36氪)
AI Short Dramas Go Global, Sora 2 Technology Drives Leap in Content Production Quality and Efficiency : AI short dramas are rapidly impacting short video platforms and expanding overseas on a large scale. In 2024, China’s micro-short drama market reached 50.5 billion yuan, with overseas market demand emerging, and Chinese short dramas going global are expected to generate $4 billion in revenue this year. The release of OpenAI’s Sora 2 significantly improves image quality, duration, synchronization, and audio-visual alignment, and supports complex plot continuity and Cameos features, compressing the short drama production process into a highly efficient “one person writes Prompt, AI produces” model, with costs potentially reduced to one-tenth of traditional methods. AI comic dramas are also a new trend, effectively reducing cultural discount and expanding the content industry from live-action dramas to AI comic dramas. (Source: 36氪)

AI Advances in Medical Diagnosis: AMIE Multimodal Diagnostic Agent Released : Google AI released AMIE (AI agent for multimodal diagnostic dialogue), a research AI Agent designed to achieve breakthroughs in the medical field through multimodal diagnostic dialogue. The launch of AMIE marks progress for AI in understanding and participating in complex medical diagnostic processes, with the potential to improve diagnostic efficiency and accuracy, laying the foundation for future intelligent medical applications. (Source: Ronald_vanLoon)
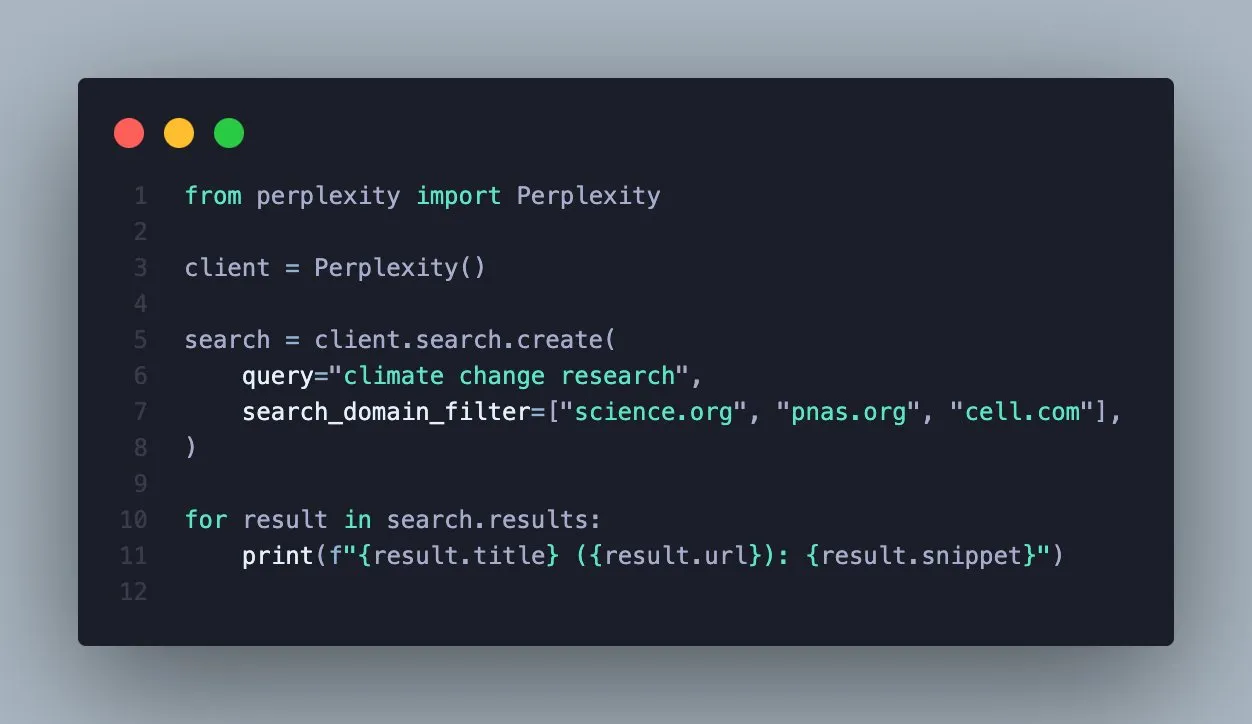
Perplexity Search API Adds Domain Filtering Feature, Enhancing Search Precision : Perplexity announced that its Search API now supports filtering search results by specific domains. This new feature allows users to query only trusted sources, thereby obtaining more focused and verifiable results. This will significantly improve search efficiency and information quality for professional users or application developers who need to retrieve information from specific authoritative sources. (Source: AravSrinivas)
AI Shows Potential in Earthquake Detection, May Aid Prediction in the Future : AI has performed excellently in detecting small earthquakes, with its capability described as “like putting on glasses for the first time.” Researchers are exploring whether AI can further help predict earthquakes, which could bring revolutionary breakthroughs in earthquake early warning and disaster prevention and mitigation. Through more refined data analysis, AI can identify seismic signals that are difficult for traditional methods to detect, thereby enhancing our understanding of deep earth activities. (Source: Ars Technica)
Mamba3 Architecture Released, Enabling Faster, Longer Context, and More Scalable LLMs : The Mamba3 architecture was quietly released at the ICLR conference, marking significant advancements in speed, context length, and scalability for LLMs. This architecture achieves more efficient sequence modeling than Transformer by optimizing internal state evolution and hardware utilization. Mamba3 introduces trapezoidal integration and complex plane hidden states, making its memory smoother, more stable, and capable of representing periodic patterns. Its multi-input multi-output design allows it to process multiple data streams in parallel, holding immense potential in areas such as long document understanding, time series analysis, and edge AI systems. (Source: NandoDF)

Agentic RAG Surpasses Traditional RAG, Becoming a New Trend in AI Search : A consensus is forming in the industry: “traditional embedded RAG (Retrieval Augmented Generation) is dead,” and Agentic RAG outperforms it in almost all aspects, except speed. This trend indicates that AI search will shift from simple information retrieval to more complex agentic interactions. Agentic RAG can more intelligently understand user intent, plan retrieval strategies, and generate more precise answers, bringing a revolution to future AI search and Q&A systems. (Source: swyx, jerryjliu0)

TuringPost Releases List of AI Video Generation Tools, Including Luma Dream Machine : TuringPost released a list of 9 powerful AI video generation tools, including Sora 2, Google Veo 3, Runway, Pika Labs, Luma’s Dream Machine (powered by Ray 3), Synthesia, HeyGen, Kaiber, and InVideo. This list aims to provide users with comprehensive AI video creation options, covering various functions from text-to-video, real-time generation, and character synthesis, reflecting the rapid development and diverse applications in the AI video technology field. (Source: TheTuringPost)
OpenAI Launches Sora-Generated Tech History Short Film, Video Stitching Process Still Needs Optimization : OpenAI researcher Hemanth Asir produced a tech history short film entirely generated by Sora, showcasing Sora’s potential in video creation. Although the short film is impressive, the current stitching process remains cumbersome. OpenAI stated it will focus on improving this process to enhance user experience and creative efficiency, indicating that future AI video generation tools will be more convenient for long-form narratives. (Source: dotey)
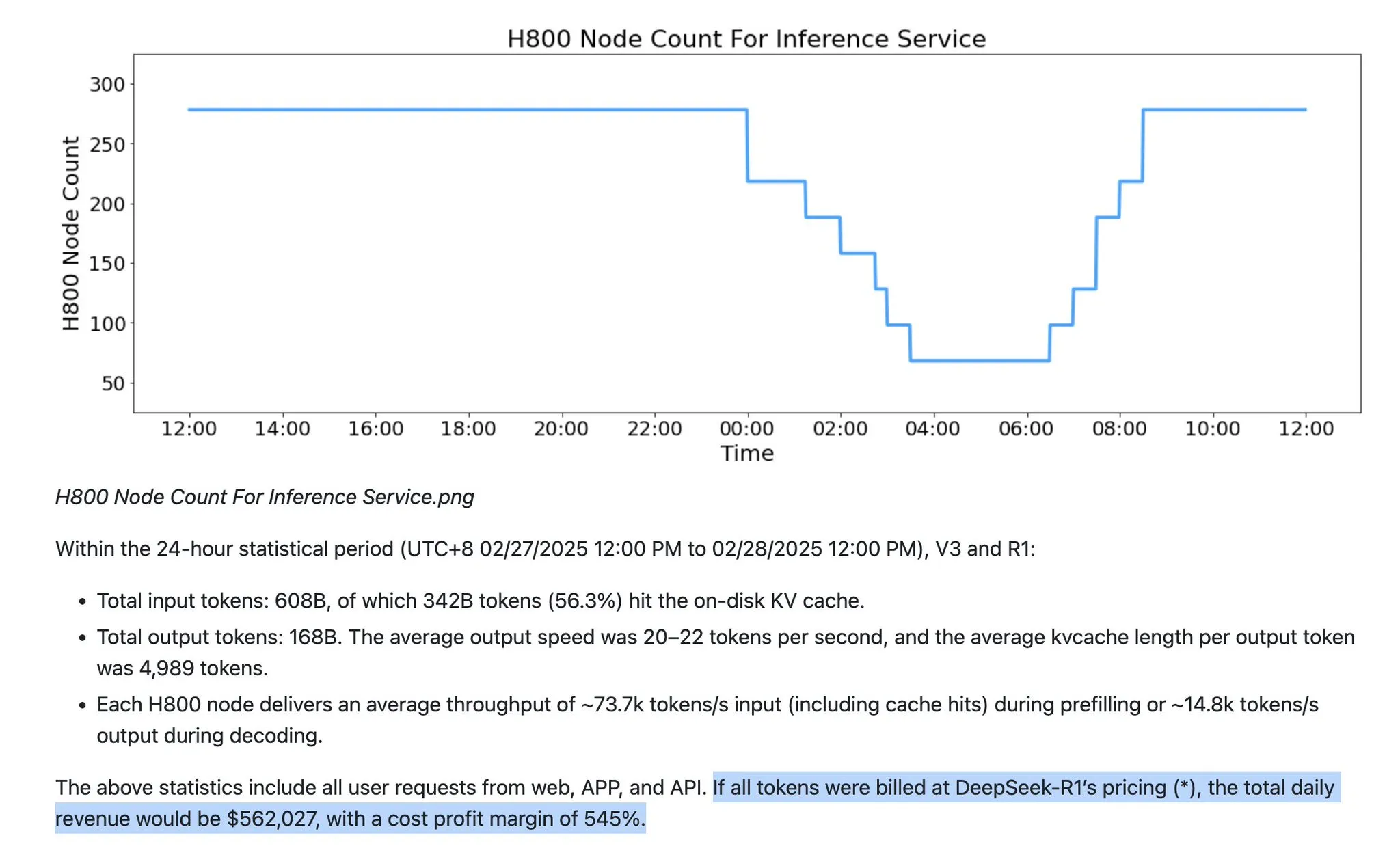
LLM Service Assumptions Face Challenges: FP8/FP4 to Become Mainstream, Output Token Volume to Grow Exponentially : It has been suggested that current LLM services operate under several incorrect assumptions. Firstly, LLM services are no longer limited to FP16 precision; FP8 and FP4 will become mainstream. Secondly, future LLM growth will primarily manifest in an exponential increase in “thinking tokens” (output tokens), rather than a simple input token ratio. Furthermore, OpenAI’s GPT-5 series models have a wider parameter range, and various labs are reducing costs through technologies like Deepseek’s DSA and new attention mechanisms. Anthropic has also released a context cleaning tool for Sonnet 4.5 to reduce memory requirements. All these factors will reshape the efficiency and cost structure of LLM services. (Source: teortaxesTex)
🧰 Tools
Microsoft MarkItDown: Document to Markdown Tool for LLM Pipelines : Microsoft released the Python tool MarkItDown, which can convert dozens of file types (including PDF, Word, Excel, HTML, images, audio, etc.) into clean Markdown format. The tool preserves headings, lists, tables, links, and metadata, and supports OCR and EXIF information extraction. Given that Markdown is the “native language” of LLMs, MarkItDown is an ideal choice for preprocessing documents in LLM pipelines, helping to improve the model’s understanding and processing efficiency of complex documents. (Source: TheTuringPost)
VS Code Releases 1.105 Iteration Plan, Focusing on AI and Developer Experience : VS Code released its October iteration plan, bringing multiple improvements aimed at enhancing AI-assisted development and the overall developer experience. Updates include Mermaid rendering, various context and tool management methods, more advanced model management, multi-step processes, saving conversations as Prompts, and features for terminals, tools, and MCPs. Additionally, GitHub Copilot has released 34 improvements in the past 30 days. These updates will further deepen AI’s application in code editing, debugging, and collaboration, making VS Code a more powerful AI-native development environment. (Source: pierceboggan, code)

Nanonets-OCR2 Released, Open-Source Image-to-Markdown Model Supports LaTeX and Flowcharts : Nanonets-OCR2 has been released, an open-source image-to-Markdown model fine-tuned on Qwen2.5-VL-3B-Instruct, supporting LaTeX equation recognition, tables, handwritten documents, checkboxes, and even converting flowcharts into Mermaid code. The model also features intelligent image description, signature detection, watermark extraction, multi-language support, and VQA (Visual Question Answering) capabilities. Nanonets-OCR2 excels in processing complex documents, providing an efficient and feature-rich solution for document preprocessing in LLM pipelines. (Source: huggingface, Reddit r/LocalLLaMA, karminski3)
ChatGPT for Slack App Launched, Integrates Real-time Search API : The ChatGPT app has officially launched on Slack. Leveraging Slack’s real-time search API, users can now directly use ChatGPT in a dedicated Slack sidebar for questioning, brainstorming, content drafting, and problem-solving. This integration seamlessly brings ChatGPT’s powerful capabilities into the team collaboration platform, aiming to improve work efficiency, simplify information retrieval and content creation processes, and provide enterprise users with more convenient AI assistance. (Source: gdb)
n8n Releases AI Workflow Builder, Empowering Natural Language Automation : n8n officially released its AI workflow builder, allowing users to build AI agents and automation processes in n8n using natural language. The tool provides a visual canvas, connecting over 8000 tools such as Firecrawl, LLMs, logic nodes, and MCPs, and can be deployed as an API. This innovation will greatly simplify the development and application of AI agents, enabling more developers to create complex automated workflows using natural language, promoting the widespread adoption of AI agents in practical business scenarios. (Source: omarsar0)
MLX Supports Local Model Execution, Privacy AI 1.3.2 Update Enhances Apple Device AI Capabilities : Privacy AI released its 1.3.2 update, fully supporting Apple’s MLX engine, allowing users to run text and visual models locally. Models can be downloaded directly from Hugging Face, supporting resume downloads, background transfers, and integrity verification. MLX models are included in the free plan, enabling offline operation without a subscription. This update also improves clipboard support and upgrades llama.cpp, further enhancing local AI capabilities and privacy protection on Apple devices. (Source: awnihannun)
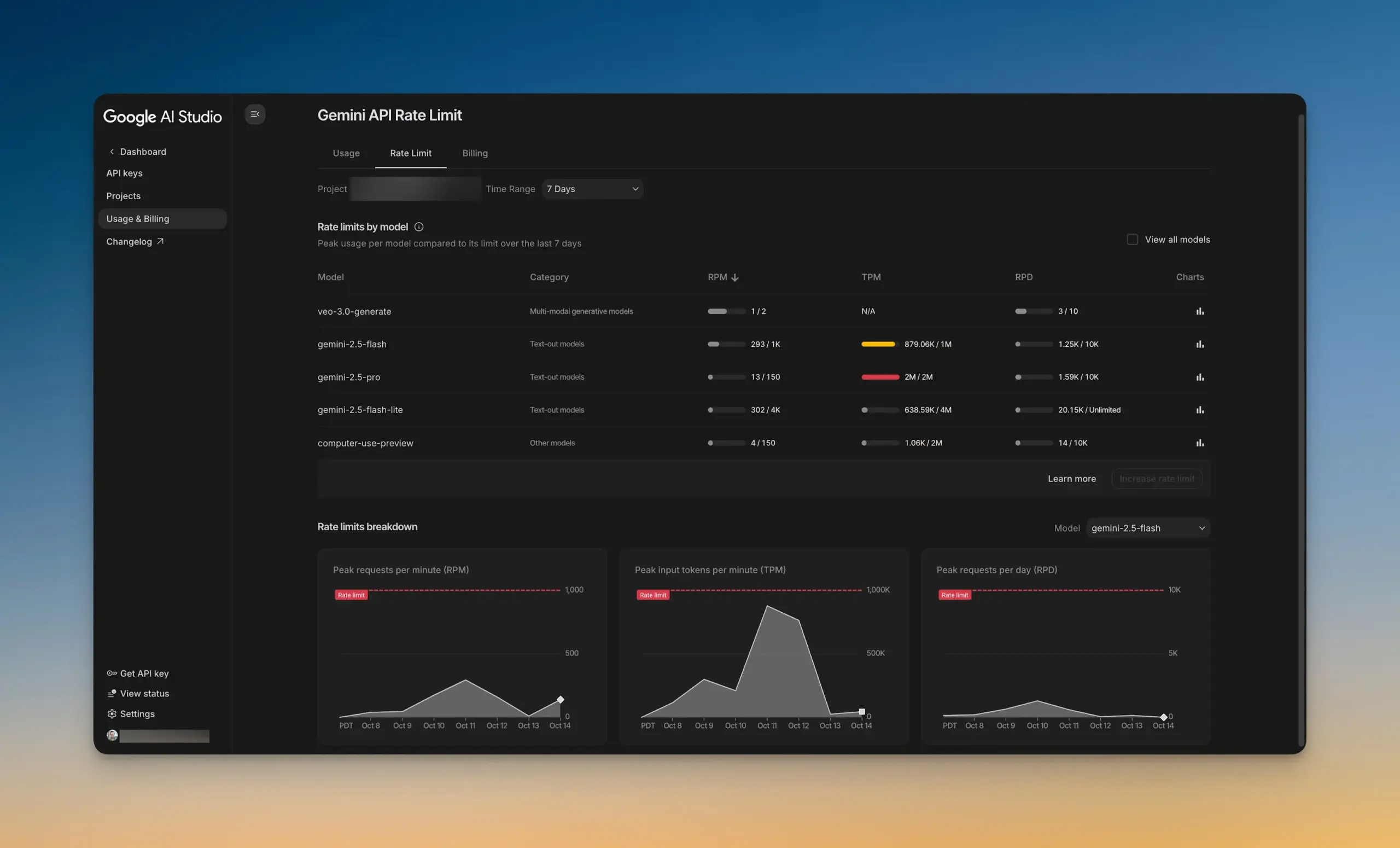
Google AI Studio Launches New Rate Limit Dashboard : Google AI Studio released a new rate limit dashboard, allowing users to intuitively understand Gemini API usage without leaving AI Studio. The dashboard provides chart filtering and easy exploration of rate limits for all models, helping developers better manage and optimize their AI projects and improve development efficiency. (Source: GoogleAIStudio)
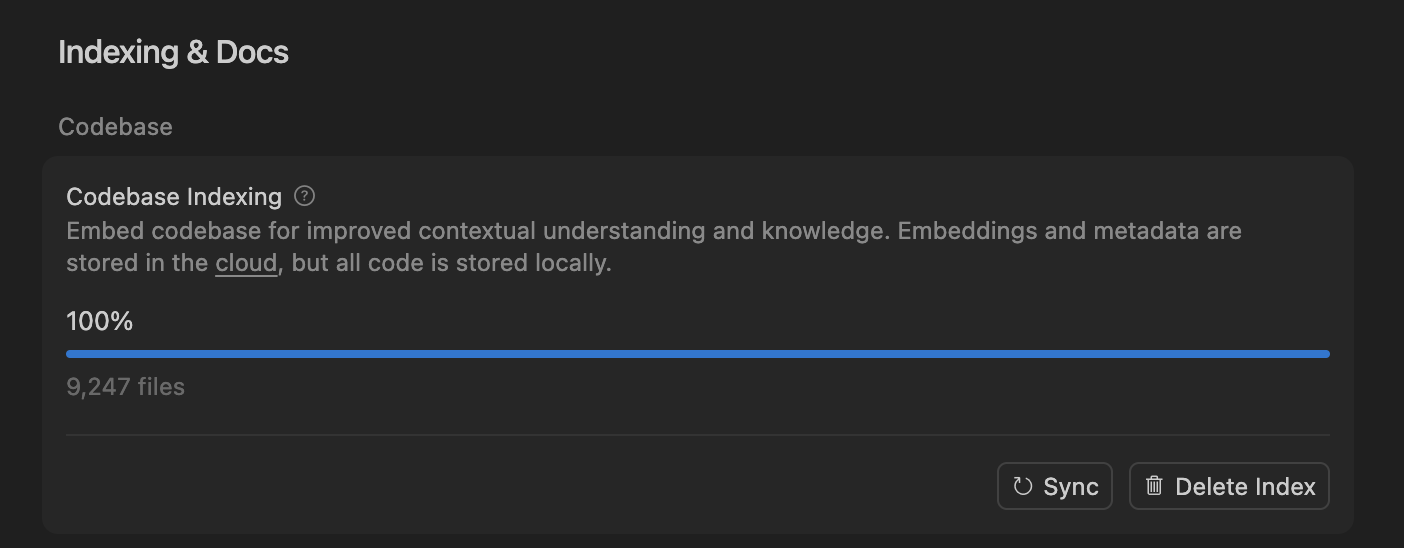
Cursor IDE and Codex Become New Choices for Developers’ Daily Coding : With the rapid development of AI coding tools, Cursor IDE and Codex are becoming core tools in the daily workflow of more and more developers. Some developers have stated they have fully switched from Claude Code to Codex for daily planning, task decomposition, and parallel processing. Cursor IDE’s “code library indexing system” achieves efficient code indexing and updating through semantic search and local code access, without needing to store code on servers, ensuring privacy and efficiency. The widespread adoption of these tools is changing traditional coding methods and improving development efficiency. (Source: dejavucoder, gdb)
Yupp.ai: AI Debate Tool Helps Users Get More Comprehensive Answers : Yupp.ai is an innovative AI tool designed to help users make more informed decisions in the age of information overload by presenting answers from different AI models. Users can compare responses from various AIs side-by-side and vote based on their analysis, creativity, or specific details, thus forming a collective intelligence ranking. Yupp.ai’s goal is to enable users to leverage collective experience to quickly obtain trustworthy, multi-perspective answers, thereby improving work efficiency and decision-making confidence. (Source: yupp_ai)

vLLM and SGLang Hailed as ‘Linux of the AI Era’ : vLLM and SGLang are hailed as the “Linux of the AI era” due to their outstanding performance in LLM inference. vLLM has garnered 60,000 stars on GitHub, evolving from a small research idea into a core framework supporting LLM inference on almost all mainstream platforms including NVIDIA, AMD, Intel, and Apple. It supports most text generation models and native RL pipelines like TRL and Unsloth, playing a crucial infrastructural role in the AI ecosystem, promoting the popularization and efficiency improvement of LLM inference. (Source: bookwormengr)
Luma AI Ray3 Visual Annotation Unlocks Precise Control : Luma AI’s Ray3 visual annotation feature allows precise control over visual direction by doodling on frames, guiding subjects to perform specific actions or interactions. This feature goes beyond the limitations of traditional text prompts, conveying spatial blocking intent through brushstrokes, providing a more intuitive and refined control method for visual creation, especially demonstrating powerful potential in applications like Dream Machine. (Source: TomLikesRobots)
Faceseek: AI-Powered Facial Matching and Verification Tool : Faceseek is an AI-powered tool for facial matching and verification, capable of effectively handling similar faces. This tool likely uses facial embeddings, CLIP (Contrastive Language-Image Pre-training), or other advanced computer vision models for analysis, providing solutions for identity verification, security monitoring, and other scenarios. Its performance in practical applications has sparked discussions about the technical details and potential uses of such systems. (Source: Reddit r/ArtificialInteligence)
PyTorch Remote GPU Backend Extension Combines Local Development with Remote Computing : A new PyTorch extension allows developers to perform local development while utilizing a remote GPU backend for computation. This addresses the issue of limited local hardware resources, enabling researchers and developers to more flexibly train and experiment with deep learning models, combining the convenience of a local development environment with the advantages of remote high-performance computing. (Source: Reddit r/deeplearning)
FocoosAI Releases Computer Vision Open-Source SDK and Web Platform : FocoosAI launched its computer vision open-source SDK and Web platform, aiming to provide developers with tools and resources to build and deploy computer vision solutions. The release of this platform will promote the popularization and application of computer vision technology, lower development barriers, and enable more innovators to explore and develop AI in image and video analysis. (Source: Reddit r/deeplearning)
AI Text ‘Humanization’ Tools: Enhancing the Naturalness of AI-Generated Content : With the widespread adoption of AI text generation technology, making AI-generated content more “human-like” has become an important topic. Various tools have emerged in the market, aiming to make AI text sound more natural and closer to human expression by optimizing language style, emotional expression, and contextual adaptability. These tools help users avoid the mechanical and formulaic feel of AI text, enhance content appeal, and meet the demand for high-quality, personalized text. (Source: Ronald_vanLoon)
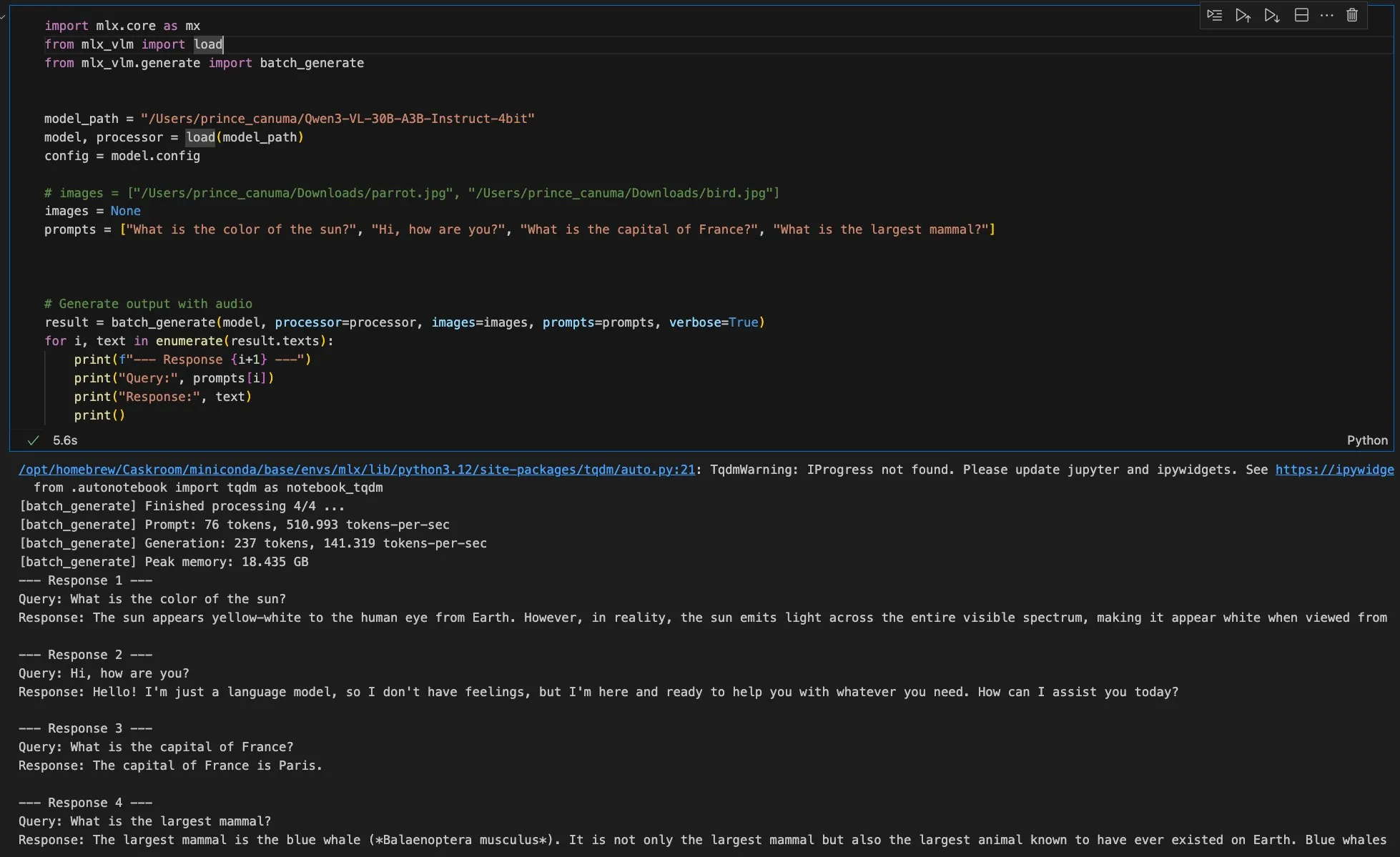
New MLX-VLM Version Coming Soon, Qwen Image Supports MFLUX Framework : Apple’s MLX-VLM is set to receive a major update, signaling its strong potential in the field of multimodal large models. Concurrently, the MFLUX framework has released version 0.11, adding support for Qwen Image, allowing users to download and use the Qwen Image model for generation with simple command-line operations. These advancements collectively boost the efficiency and flexibility of AI model development and deployment within the Apple ecosystem, providing developers with more convenient multimodal AI tools. (Source: adrgrondin, awnihannun)
CleanMARL: Clean Implementation of PyTorch Multi-Agent Reinforcement Learning : The CleanMARL project offers a series of concise, single-file implementations of deep multi-agent reinforcement learning (MARL) algorithms, developed based on PyTorch and adhering to the CleanRL philosophy. This project aims to lower the barrier to MARL algorithm implementation, providing researchers and developers with clear, easy-to-understand, and reproducible code, accelerating research and application of multi-agent systems in complex environments. (Source: jsuarez5341)
📚 Learning
LLM Post-Training Becomes Core AI Competitiveness, Enterprises Accelerate Building Exclusive Intelligent Engines : LLM post-training is becoming a core competitive advantage for enterprise AI implementation. From SFT to RLHF, RLVR, and then to cutting-edge “natural language rewards,” the technical focus has shifted from “imitation” to “alignment.” Companies like NetEase, Autohome, Weibo, and Quark have successfully transformed general large models into “exclusive intelligent engines” that deeply understand business and possess domain knowledge, by preparing high-quality data, selecting base models, designing reward mechanisms, and establishing quantifiable evaluation systems. This addresses complex tasks in the business world and builds an unreplicable competitive barrier. (Source: 量子位)

Andrew Ng Launches Agentic AI Course, Focusing on Four Key Design Patterns : DeepLearning.AI announced in its latest edition of The Batch that Andrew Ng has launched his newest course, “Agentic AI.” This is a practical builder’s course centered around four key design patterns: reflection, tool use, planning, and multi-agent collaboration. The course aims to equip learners with core skills for building efficient AI agent systems, promoting the implementation of AI in practical applications. (Source: DeepLearningAI)
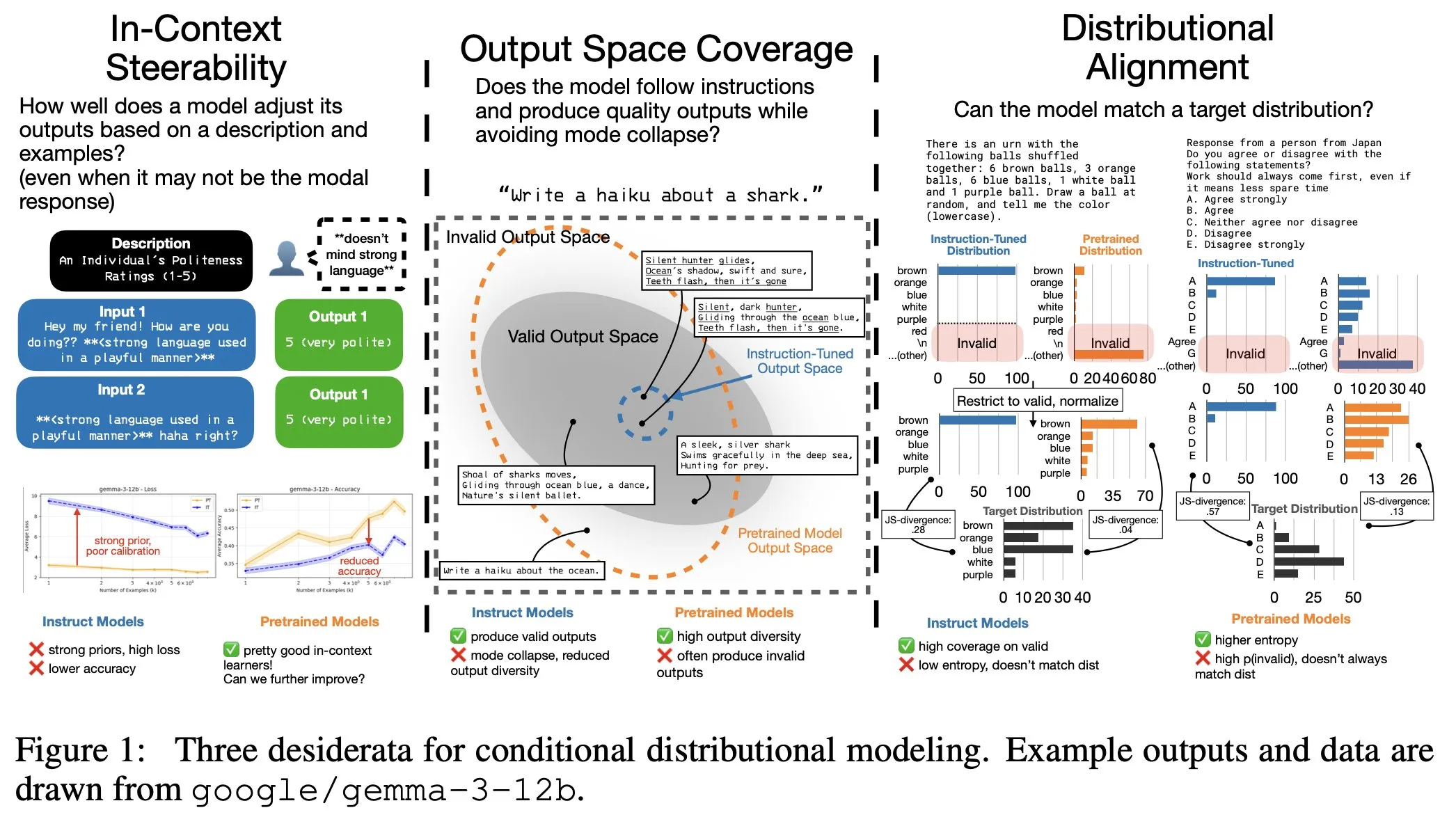
LLM Instruction Fine-tuning Has Hidden Costs: Narrower Output Distribution, Decreased In-Context Steerability : Research has found that while LLM instruction fine-tuning improves instruction following capabilities, it also incurs hidden costs: a narrower output distribution and decreased In-Context Steerability. To address this issue, the research team launched the “Spectrum Suite” for in-depth study and proposed “Spectrum Tuning” as an alternative post-training method, aiming to maintain output diversity and flexibility while enhancing model performance. (Source: YejinChoinka, YejinChoinka)
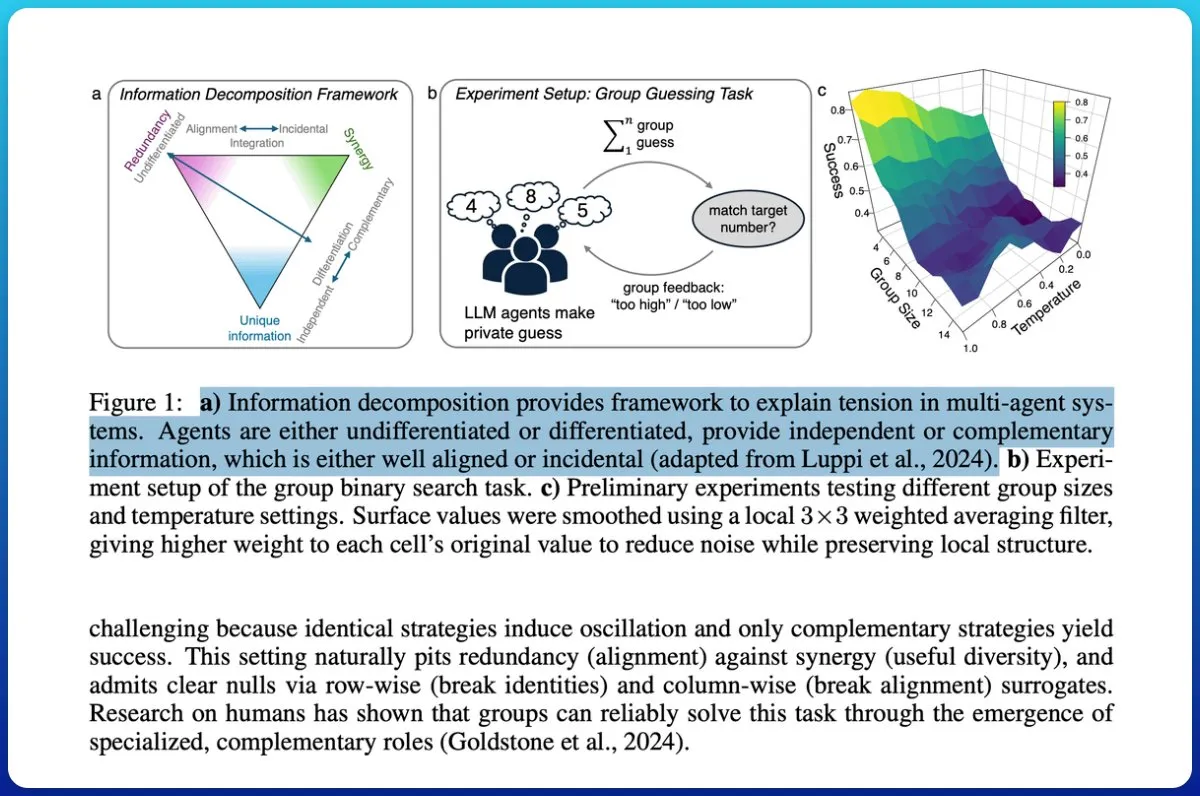
Multi-Agent System Collaboration: Information Theory Distinguishes ‘Pile of Chatbots’ from ‘Collective Intelligence’ : A study explored whether LLM-driven multi-agent systems truly achieve collaboration and proposed using information theory to distinguish between “a pile of chatbots” and “true collective intelligence.” The research introduced a measurement loop, evaluating the predictive power of group output on future outcomes and decomposing information to identify synergy rather than redundancy. Results indicate that assigning different roles and common goals to agents, and testing their synergy rather than assuming it, is crucial for achieving collective intelligence, with low-capacity models struggling to achieve true cooperation. (Source: omarsar0)
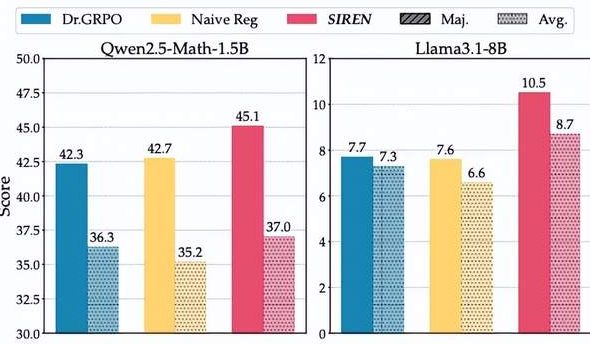
Large Model Reasoning’s ‘Entropy Dilemma’: SIREN Method Rejects ‘Entropy Collapse’ and ‘Entropy Explosion’ : Large Reasoning Models (LRMs) face an “entropy dilemma” in RLVR training, where limited exploration leads to “entropy collapse” or uncontrolled exploration causes “entropy explosion.” A team from Shanghai AI Lab and Fudan University proposed Selective Entropy Regularization (SIREN), a triple mechanism that precisely controls exploration behavior by defining exploration boundaries (Top-p masking), identifying key decision points (peak entropy masking), and stabilizing the training process (self-anchoring regularization). Experiments demonstrate that SIREN significantly improves performance on mathematical reasoning benchmarks and makes the exploration process more efficient and controllable. (Source: 量子位)
AI Agent Learning Resources: ‘Illustrated Guide to AI Agents’ New Book and Concept Summary : AI Agent learning resources are continuously expanding. Maarten Grootendorst and Jay Alammar are co-authoring “The Illustrated Guide to AI Agents,” which will cover foundational Agent concepts (memory, tools, planning) as well as advanced concepts like reinforcement learning and reasoning LLMs. Additionally, an article has summarized 20 core concepts of AI Agents, providing a systematic learning path and reference materials for beginners and advanced learners. (Source: lvwerra, Ronald_vanLoon)

LLM Spatial Reasoning Assessment: Shape Rotation Test Challenges Model Latent Space : An interesting assessment method has been proposed to test large language models (LLMs)’ ability to rotate shapes “in their minds.” Through simple visual tests, research found that LLMs can perform a certain degree of shape rotation in their underlying latent space, but perform poorly in higher-level, more complex reasoning, exhibiting a “non-uniform spatial reasoning” problem. This reveals the limitations of LLMs in handling geometric and spatial logic, providing a new research direction for future model improvements. (Source: dejavucoder, tokenbender)
LLM Fine-tuning Strategies: Attention Projection Layer and MLP Gating Layer Updates Can Limit Forgetting : How to teach Large Multimodal Models (LMMs) new skills while avoiding forgetting existing capabilities is a key challenge. A study found that the “forgetting” phenomenon observed after narrow fine-tuning can be recovered later, which is related to significant changes in the output token distribution. The research identified two simple and robust fine-tuning strategies: updating only the self-attention projection layers, or updating only the MLP Gate&Up layers while freezing the Down projection layers. These choices achieve strong target gains across models and tasks while largely preserving original performance. (Source: arXiv:2510.08564)
AI and Economic Growth: Interpretation of Nobel Laureate Philippe Aghion’s Paper : Research by Nobel laureate Philippe Aghion and others points out that even if the economy is 99% automated and produces infinitely, overall growth will still be limited by progress in the remaining 1% of core, difficult tasks. In the AGI era, these “hard-to-improve” tasks will transform into physically-centric tasks, such as energy generation, resource extraction, manufacturing, and transportation. This implies that the post-AGI era is not necessarily a “post-scarcity” era, and economic value will concentrate on physically constrained tasks. (Source: pmddomingos, jonst0kes)

AI Model Generalization and Robustness Challenges: Spurious Reasoning Leads to Mathematical Reasoning Flaws : Language models often suffer from insufficient robustness and generalization in mathematical reasoning due to “Spurious Reasoning,” where the model derives answers from superficial features rather than problem logic. The AdaR framework trains models by synthesizing logically equivalent queries and combining them with RLVR (Reinforcement Learning with Verifiable Rewards), penalizing spurious logic and encouraging adaptive logic. Experiments show that AdaR significantly improves the mathematical reasoning robustness and generalization of LLMs while maintaining high data efficiency. (Source: arXiv:2510.04617)
Test-Time Self-Improvement for LLM Agents: TT-SI Framework Achieves Autonomous Learning : A study proposed a new Test-Time Self-Improvement (TT-SI) method, designed to dynamically create more effective and generalizable Agentic LLMs. The algorithm achieves autonomous model learning by identifying difficult samples, generating similar examples (self-data augmentation), and fine-tuning during testing (self-improvement). Experiments demonstrate that TT-SI improves accuracy by an average of 5.48% on Agent benchmarks, with a 68-fold reduction in training sample size, showcasing the potential of self-improvement algorithms in building more powerful Agents. (Source: arXiv:2510.07841)
Key Design Principles and Optimization Practices for LLM Agent Reinforcement Learning : A study systematically investigated key design principles for Agentic RL in enhancing LLM Agent reasoning capabilities. The research found that using real end-to-end tool-use trajectories instead of synthetic ones for SFT initialization leads to stronger effects; high-diversity, model-aware datasets can sustain exploration and significantly improve RL performance. Furthermore, exploration-friendly techniques (such as clip higher, overlong reward shaping, and maintaining sufficient policy entropy) are crucial for Agentic RL. These practices can continuously enhance Agentic reasoning and training efficiency, enabling small models to achieve excellent results on challenging benchmarks. (Source: arXiv:2510.11701)
Reward Mechanism in LLM Reasoning: PEAR Optimizes Inference Efficiency Through Phase Entropy Awareness : Large Reasoning Models (LRMs) often incur increased inference costs due to redundant reasoning steps when generating CoT (Chain-of-Thought) explanations. The PEAR (Phase Entropy Aware Reward) mechanism designs rewards by incorporating phase-dependent entropy, penalizing excessive entropy during the thinking phase while allowing moderate exploration during the final answer phase. This encourages the model to generate concise reasoning trajectories while maintaining the flexibility required to solve tasks. Experiments show that PEAR consistently reduces response length without sacrificing accuracy and demonstrates strong OOD robustness. (Source: arXiv:2510.08026)
DocReward: A Reward Model for Document Structure and Style : DocReward is a reward model for evaluating document structure and style, designed to address the issue of Agentic workflows neglecting visual structure and style when generating professional documents. Trained on DocPair, a multi-domain dataset containing paired documents of high and low professionalism, the model can comprehensively assess document professionalism in a text-quality-agnostic manner. DocReward surpasses GPT-4o and GPT-5 in accuracy and achieves higher win rates in external document generation evaluations, proving its utility in guiding generative Agents to produce human-preferred documents. (Source: arXiv:2510.11391)
SPG: Sandwiched Policy Gradient Improves Reinforcement Learning for Diffusion Language Models : Diffusion Language Models (dLLMs), due to their parallel decoding capabilities, are considered effective alternatives to autoregressive models. However, aligning dLLMs with human preferences through Reinforcement Learning (RL) faces challenges, as their intractable log-likelihood limits the direct application of standard policy gradients. The SPG (Sandwiched Policy Gradient) method utilizes upper and lower bounds of the true log-likelihood, significantly outperforming baselines based on ELBO or single-step estimation, boosting dLLM RL accuracy by 3.6% to 27.0% on tasks like GSM8K and MATH500. (Source: arXiv:2510.09541)
QeRL: Quantization-enhanced Reinforcement Learning Improves LLM Efficiency and Exploration : The QeRL (Quantization-enhanced Reinforcement Learning) framework aims to address the resource-intensive nature of LLM Reinforcement Learning (RL) by combining NVFP4 quantization and LoRA techniques, accelerating the RL Rollout phase and reducing memory overhead. Research found that quantization noise can increase policy entropy and enhance exploration, helping to discover better policies. QeRL introduces an Adaptive Quantization Noise (AQN) mechanism to dynamically adjust noise during training. Experiments show that QeRL speeds up the Rollout phase by over 1.5 times, enables the first training of a 32B LLM on a single H100 80GB GPU, and achieves faster reward growth and higher final accuracy. (Source: arXiv:2510.11696)
STAT: Skill-Targeted Adaptive Training Improves LLM Math and OOD Performance : STAT (Skill-Targeted Adaptive Training) is a new LLM fine-tuning strategy that leverages the meta-cognitive capabilities of stronger LLMs as teacher models to create skill lists required for tasks and label data points. The teacher model monitors the student model’s answers, constructs a “missing skill profile,” and then adaptively re-weights existing training examples (STAT-Sel) or synthesizes additional examples involving missing skills (STAT-Syn). Experiments demonstrate that STAT improves performance by up to 7.5% on the MATH benchmark and an average of 4.6% on OOD benchmarks, and is complementary to GRPO, promising comprehensive improvements to current training pipelines. (Source: arXiv:2510.10023)
LLaMAX2: Qwen3-XPlus Model Excels in Translation and Reasoning Tasks : LLaMAX2 proposes a new translation enhancement method that significantly improves the translation performance of the Qwen3-XPlus model in high and low-resource languages (such as Swahili) through layer-selective fine-tuning of the instruction model, while maintaining comparable proficiency on 15 popular reasoning datasets to the Qwen3 instruction model. This work offers a promising approach for multilingual enhancement, significantly reducing complexity and improving accessibility for a wider range of languages. (Source: arXiv:2510.09189)
DemoDiff: Graph Diffusion Transformer Enables Contextual Molecule Design : DemoDiff (Demonstration-conditioned diffusion models) achieves contextual molecule design by using a small number of molecule-score examples instead of text descriptions to define task context. The model utilizes a new Node Pair Encoding molecular tokenizer, representing molecules at the motif level, reducing the number of nodes. DemoDiff pre-trained a 700-million-parameter model on a dataset containing millions of contextual tasks and matched or surpassed language models 100-1000 times larger in scale across 33 design tasks, becoming a molecular foundation model for contextual molecule design. (Source: arXiv:2510.08744)
CodePlot-CoT: Code-Driven Image Chain-of-Thought Enhances Mathematical Visual Reasoning : CodePlot-CoT proposes a code-driven Chain-of-Thought paradigm for “image thinking” in mathematics. This method uses VLM to generate text reasoning and executable plotting code, which is then rendered into images as “visual thoughts” to solve mathematical problems. The research constructed the first large-scale, bilingual mathematical visual reasoning dataset, Math-VR, and developed a SOTA image-to-code converter. Experiments show that the model improves performance by up to 21% on the Math-VR benchmark, opening new directions for multimodal mathematical reasoning. (Source: arXiv:2510.11718)
DiT360: Hybrid Training Achieves High-Fidelity Panoramic Image Generation : DiT360 is a DiT-based framework that achieves high-fidelity panoramic image generation through hybrid training on perspective and panoramic data. This method introduces key modules such as cross-domain knowledge fusion, panoramic refinement, cyclic padding, yaw loss, and cubic loss to address geometric fidelity and realism issues. DiT360 demonstrates better boundary consistency and image fidelity across 11 quantitative metrics in text-to-panorama, image inpainting, and outpainting tasks. (Source: arXiv:2510.11712)
RAE: Representation Autoencoders Optimize Latent Space of Diffusion Transformers : A study explored replacing traditional VAEs in Diffusion Transformers (DiT) with pre-trained representation encoders (such as DINO, SigLIP, MAE), forming Representation Autoencoders (RAE). RAE provides high-quality reconstructions and semantically rich latent spaces while supporting scalable Transformer architectures. Through theoretical analysis and empirical validation, this method achieves faster convergence and strong image generation results on ImageNet, potentially becoming the new default setting for Diffusion Transformer training. (Source: arXiv:2510.11690)
InfiniHuman: Infinite 3D Human Creation and Precise Control Framework : The InfiniHuman framework generates richly annotated 3D human data with minimal cost and theoretically infinite scalability by co-distilling existing foundation models. InfiniHumanData is a fully automated pipeline that leverages visual-language and image generation models to create a large-scale multimodal dataset of 111,000 identities, covering unprecedented diversity and detailed annotations including text descriptions, multi-view RGB images, clothing images, and SMPL body shape parameters. Building on this, InfiniHumanGen is a diffusion-based generative pipeline capable of fast, realistic, and precisely controllable avatar generation. (Source: arXiv:2510.11650)
IVEBench: Instruction-Guided Video Editing Evaluation Benchmark Suite : IVEBench is a modern benchmark suite specifically designed for instruction-guided video editing evaluation. It comprises 600 high-quality source videos, covering seven semantic dimensions and video lengths from 32 to 1024 frames. Additionally, it includes 8 categories of editing tasks and 35 subcategories, with prompts generated and refined by large language models and expert reviewers. IVEBench establishes a three-dimensional evaluation protocol encompassing video quality, instruction adherence, and video fidelity, integrating traditional metrics and multimodal large language model evaluations. (Source: arXiv:2510.11647)
LikePhys: Evaluating Intuitive Physical Understanding of Video Diffusion Models Through Plausibility Preference : LikePhys is a training-agnostic method that evaluates the intuitive physical understanding of video diffusion models by distinguishing physically plausible and impossible videos, using a denoising objective as an ELBO-based likelihood surrogate. The research constructed a benchmark comprising 12 scenarios and 4 physical domains, and results show that its evaluation metric, Plausibility Preference Error (PPE), is highly consistent with human preferences. The study also systematically assessed the intuitive physical understanding capabilities of current video diffusion models and analyzed how model design and inference settings affect physical understanding. (Source: arXiv:2510.11512)
FastHMR: Accelerating Human Mesh Recovery Through Token and Layer Merging : FastHMR accelerates 3D Human Mesh Recovery (HMR) by introducing two HMR-specific merging strategies: Error-Constrained Layer Merging (ECLM) and Mask-Guided Token Merging (Mask-ToMe). ECLM selectively merges Transformer layers with minimal impact on MPJPE, while Mask-ToMe focuses on merging background tokens that contribute less to the final prediction. To compensate for potential performance degradation caused by merging, the research proposes a diffusion-based decoder that combines temporal context and pose priors learned from large-scale motion capture datasets. Experiments show that this method achieves up to 2.3x acceleration while slightly improving performance. (Source: arXiv:2510.10868)
AVoCaDO: Audio-Visual Video Captioning Generator, Driven by Temporal Orchestration : AVoCaDO is a powerful audio-visual video captioning generator driven by temporal orchestration between audio and visual modalities. The research proposes a two-stage post-training pipeline: AVoCaDO SFT fine-tunes the model on 107K high-quality, temporally aligned audio-visual captioning datasets; AVoCaDO GRPO further enhances temporal coherence and dialogue accuracy using custom reward functions, while regularizing caption length and reducing collapse. Experimental results show that AVoCaDO significantly outperforms existing open-source models on four audio-visual video captioning benchmarks. (Source: arXiv:2510.10395)
LLM Emotional Reasoning’s Personalization Trap: How User Memory Alters Emotional Interpretation : As personalized AI systems increasingly integrate long-term user memories, understanding how memory shapes LLM’s emotional reasoning is crucial. Research evaluated 15 LLMs on human-validated emotional intelligence tests, finding that the same scenarios paired with different user profiles produced systematic differences in emotional interpretation. In validated user-independent emotional scenarios and diverse user profiles, several high-performing LLMs exhibited systematic biases, with dominant profiles receiving more accurate emotional interpretations. Furthermore, LLMs showed significant demographic differences in emotional understanding and supportive recommendation tasks, indicating that personalization mechanisms might embed social hierarchies into the model’s emotional reasoning. (Source: arXiv:2510.09905)
FinAuditing: Multi-Document Benchmark for Financial Auditing to Evaluate LLM Capabilities : FinAuditing is the first taxonomy-aligned, structure-aware, multi-document benchmark designed to evaluate LLM capabilities in financial auditing tasks. Built on real US-GAAP compliant XBRL files, the benchmark defines three complementary subtasks: FinSM (Semantic Consistency), FinRE (Relational Consistency), and FinMR (Numerical Consistency). Extensive zero-shot experiments show that current models perform inconsistently across semantic, relational, and mathematical dimensions, with accuracy dropping by 60-90% when reasoning about hierarchical multi-document structures, revealing systematic limitations of LLMs in taxonomy-based financial reasoning. (Source: arXiv:2510.08886)
💼 Business
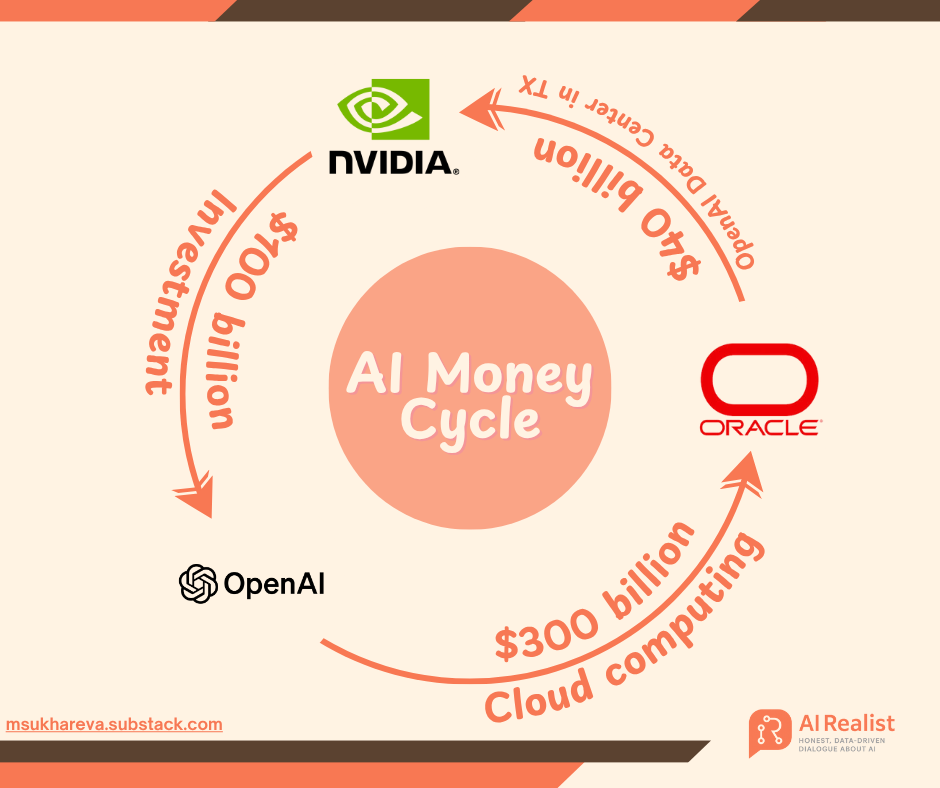
OpenAI’s Massive Funding Strategy: Trillions Pledged for AI Infrastructure, Sparking ‘Financial Alchemy’ Controversy : OpenAI is embarking on AI investment 2.0 with a series of trillion-dollar orders with giants like NVIDIA, AMD, and Broadcom. Former Goldman Sachs banker Matt Levine describes it as “financial time travel,” where OpenAI deeply ties suppliers’ fates to its own through innovative models like “equity-for-procurement” and “recurring revenue,” prompting them to jointly bear the risks of massive infrastructure construction. OpenAI plans to build 250 gigawatts of computing power by 2033, costing over $10 trillion, far exceeding its current revenue, raising market concerns about its financial sustainability. However, Sam Altman emphasizes this is “the largest joint industrial project in human history,” aimed at democratizing AI. (Source: 36氪, 36氪)
AI Drives Pharmaceutical Industry Transformation: Agentic AI Boosts Business Efficiency : Agentic AI is transforming the commercial pharmaceutical sector, helping companies address challenges such as rising raw material costs, supply chain disruptions, and patent cliffs. AI enhances drug research and development and manufacturing efficiency by providing personalized services, optimizing kitchen design and operations, and smart refrigerators offering personalized health management. Concurrently, AI also assists sales and marketing by reaching healthcare professionals through real-time communication channels and relevant content, solving inefficient content review issues, and is expected to drive home health technology development and improve residents’ quality of life. (Source: MIT Technology Review)

Apple Acquires Prompt AI Team, Strengthening Computer Vision and Edge AI Capabilities : Apple Inc. is proceeding with the acquisition of computer vision startup Prompt AI, aiming to integrate its core technology and team into the Apple ecosystem. Prompt AI’s Seemour app features precise identification, scene description, and privacy protection, connecting with home security cameras, with all data processed locally. This perfectly aligns with Apple’s “edge AI” and “privacy-first” strategies. This acquisition reflects Apple’s “talent acquisition” strategy in the AI field, aiming to quickly address computer vision technology shortcomings and support its HomeKit, AR, and autonomous driving businesses. (Source: 36氪)

🌟 Community
AI Job Displacement Sparks Workplace Anxiety and Resistance : As AI becomes widespread in enterprises, the workplace is undergoing an “algorithmic reshuffle.” Kevin Cantera, a senior content specialist at an education technology company, actively embraced AI, doubling his efficiency, yet was still replaced by AI tools, raising questions about the promise that “AI only assists, it doesn’t replace.” At Silicon Valley fintech company Ramp, programmers also resisted AI coding tools, arguing that AI-generated code was crude, messy, and lacked human logic. These incidents highlight the harsh reality of AI job displacement and the challenges employees face in balancing adaptation with self-worth in the face of technological change. (Source: 36氪, 36氪)

AI Browsers and the Future of the Open Internet: Walled Gardens or New Ecosystems? : The launch of Perplexity’s Comet browser and OpenAI’s ChatGPT application features has sparked a heated debate on Reddit about whether “AI is killing the open internet.” Critics worry that AI is building “walled gardens” in the name of “convenience,” centralizing user information access to a few platforms, which could lead to a loss of information diversity and excessive customization. Detractors point out that AI browsers attempt to act as intermediaries between the operating system and application layer, reshaping network distribution power. However, some argue that technological progress is inevitable, and the key lies in how users choose and maintain an open, diverse information environment. (Source: 36氪)

Chaos in AI Elderly Care Market: Precise Scams and ‘Pseudo-Intelligent’ Traps : As China enters a deeply aging society, the “AI+elderly care” market is rapidly heating up, but it is accompanied by AI scams targeting the elderly and “pseudo-intelligent” product chaos. Scammers use deepfake technology to impersonate relatives or celebrities, emotionally blackmailing and defrauding money; or they create fake “AI tutor” images to sell fraudulent courses and investment projects. Concurrently, the market is flooded with mislabeled “smart” elderly care products that fall far short of their advertised core metrics. These issues not only endanger the financial safety of the elderly but also erode public trust in AI technology. The industry calls for technological countermeasures against AI scams, increased digital guardianship by children, and the construction of a truly human-centric AI elderly care ecosystem. (Source: 36氪)
ChatGPT Content Moderation and User Experience Controversy : ChatGPT has sparked widespread community discussion regarding content moderation and user experience. Users report that ChatGPT sometimes generates “inappropriate content,” then quickly “fixes” it and becomes overly cautious, even restricting academic questions. Concurrently, many users point out that ChatGPT often exhibits a “flattering” or “syrupy” tone in its responses, especially when answering user questions, with this overly accommodating tendency making users feel “talked down to.” Furthermore, rumors about OpenAI potentially launching an adult content mode have also drawn attention. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

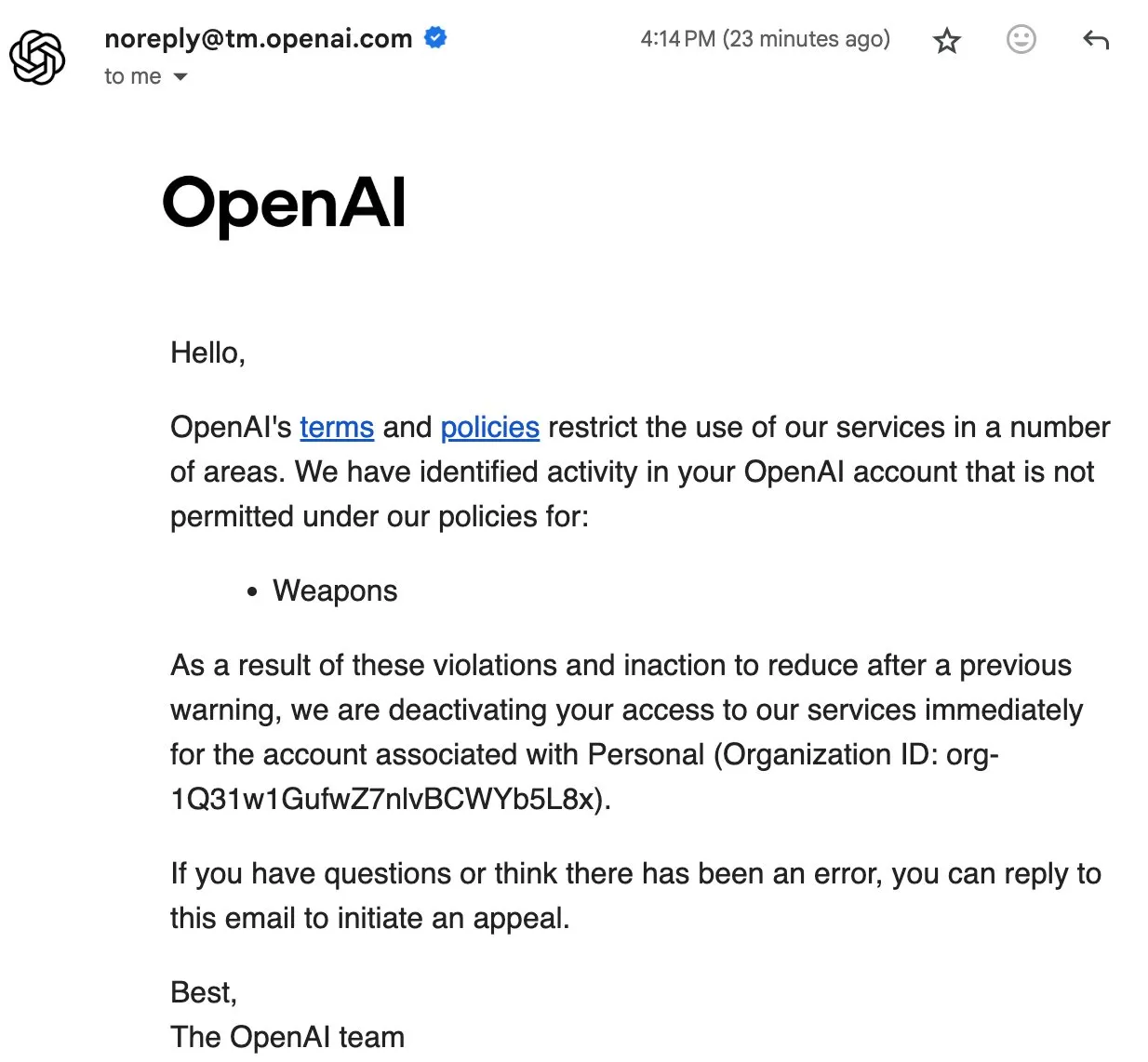
OpenAI User Ban Incident Sparks Community Discussion on Data Sovereignty and Open-Source AI : OpenAI’s recent banning of some users, even deleting account data, has caused strong dissatisfaction in the community. User Eric Hartford’s account was inexplicably deleted, with appeals instantly rejected, leading to the loss of all historical data. This incident prompted community members to call on users to download and back up ChatGPT data and emphasized the importance of open-source AI, arguing that proprietary services pose single points of failure and do not guarantee user data sovereignty. Many believe that the more critical AI becomes, the more crucial the reliability, security, and trustworthiness of open-source AI will be. (Source: QuixiAI, scaling01)
AI Subscription Model Sparks Controversy: High Risk of Annual Subscriptions Amid Rapid Tech Iteration : Experienced AI users advise against purchasing annual subscriptions for AI tools, as AI technology develops extremely rapidly, and a tool essential today might be rendered obsolete by new updates or products next month. This perspective reflects the fast-iterating nature of the AI industry, with users taking a cautious approach to long-term investment in AI tools, preferring monthly subscriptions or flexible payment models to adapt to the constantly changing technological landscape. (Source: Reddit r/ArtificialInteligence)
High Failure Rate of AI Agents: 95% of Enterprise Investments Yield No Benefits, ‘Grounding’ is Key : It has been suggested that “95% of AI Agents fail” is not an exaggeration; many Agents that perform well in demonstrations yield poor results after actual deployment. The core issue is that Agents lack “grounding” with the real world, and automated feedback loops can easily collapse without human oversight. Successful AI Agents that create business value are often “grounded” and purpose-driven, such as detecting trade violations or assisting sales in finding leads. Research indicates that up to 95% of enterprise AI investments fail to generate significant economic benefits, with some teams even experiencing reduced efficiency due to fixing AI bugs. (Source: Reddit r/ArtificialInteligence)
Limitations of AI in Localized News: The ‘Last Mile’ Algorithms Cannot Reach : AI technology has inherent “blind spots” in localized news, struggling to access unstructured, insufficiently digitized local information such as street meeting minutes or community event schedules. LLMs rely on massive public data, favoring grand narratives, and find local information scarce and difficult to process. AI’s temporal delay also makes it difficult to report on immediate local events, easily leading to “hallucinations.” More critically, AI lacks the trust relationships and deep insights that human journalists build with communities. These limitations of AI, paradoxically, create opportunities for a re-evaluation of local news’s value, pushing it to transform from “news reporter” to “community service provider,” rebuilding community identity and belonging. (Source: 36氪)
AI and Human Management: Understanding AI Like Understanding Newcomers, Requiring Clear Context and Defined Deliverables : Social media discussions point out that using AI and managing people have similarities: what you can’t get a human to do, don’t expect AI to do. Whether for AI or a newcomer, assigning tasks requires providing sufficient background context, clear output deliverables, output examples (n-shot learning), clear acceptance criteria, constraints, and available resources. This suggests that effective utilization of AI requires clear communication and task management, similar to how one would treat human team members, rather than blindly expecting technological miracles. (Source: dotey)
Personalization of AI Hedge Funds: Grok, Qwen, Claude Exhibit Different Investment Styles : Social media has seen humorous “personalizations” of AI hedge fund models, depicting the unique investment styles of different AI models. Grok is portrayed as a systematic quantitative trader with a strange preference for DOGE coin; Qwen always pursues maximum leverage; while Claude is a thoughtful portfolio manager who always maintains a calm “everything is fine” demeanor. This discussion reflects the community’s curiosity and imagination about AI applications in finance, as well as a vivid understanding of different model characteristics. (Source: togelius)

AI and Programming Tool Choices: Developer Preferences for Cursor, Codex, Copilot : The developer community discussed the pros and cons and personal preferences for different AI programming tools. Some, after choosing between Cursor and Visual Studio Code + Copilot, leaned towards the latter. Another developer stated they had completely switched from Claude Code to Codex as their daily primary tool. These discussions reflect developers’ varying needs for AI tools’ performance, integration, ease of use, and generated code quality in their actual work, as well as their continuous exploration and trade-offs in AI-assisted programming. (Source: pierceboggan, imjaredz)

AI and the Open Web: HuggingFace Hailed as ‘GitHub of AI’ : Hugging Face is widely recognized in the AI community as the “GitHub of AI,” becoming a central platform for sharing and collaborating on models, datasets, and AI application code. This analogy emphasizes Hugging Face’s crucial role in fostering the open-source AI ecosystem, providing researchers and developers with a code hosting and collaboration environment similar to GitHub, greatly promoting the popularization and innovation of AI technology. (Source: ClementDelangue)
AI and the Future of Humanity: Reflections on AGI Complexity and Societal Adaptation : Community discussions show differing views on the arrival of AGI (Artificial General Intelligence). Some believe that after reaching AGI, humanity will realize it over-complicated AI in the past, and true intelligence might be based on simpler, more elegant principles. Concurrently, others are beginning to ponder how recursively self-improving AI will affect the dynamics and diffusion of organizations, institutions, participants, and communities, considering this the most fundamental question currently, requiring more diverse speculation and discussion to help society adapt to the profound changes brought by AI. (Source: Reddit r/ArtificialInteligence, ethanCaballero)
AI and Social Sentiment: Deepfake Videos, AI Elderly Care Scams, AI Job Displacement Spark Concerns : AI technology is generating complex emotions at the societal level. Sora 2’s generation of celebrity deepfake videos raises concerns about portrait rights and ethics; the AI elderly care market sees precise scams targeting empty-nest seniors and “pseudo-intelligent” products, infringing on the interests of the elderly; AI job displacement leads to layoffs of experienced employees, exacerbating workplace anxiety. These incidents highlight that while AI brings convenience, it also poses severe challenges to social ethics, trust, and employment structures, prompting public reflection on the balance between technological development and societal adaptation. (Source: Reddit r/ArtificialInteligence, 36氪, 36氪)
AI and Open Science: Rapid Development of Open-Source AI and the Durability of Product Strategy : Community discussions suggest that the rapid development of open-source AI is astonishing, but this also raises questions about the durability of product strategies: in the context of rapidly iterating open-source AI, how companies build lasting customer lock-in and competitive advantage becomes a critical issue. Concurrently, developers also show high enthusiasm for minimalist open-source projects like Andrej Karpathy’s nanochat, considering them excellent resources for learning the full LLM lifecycle, and anticipate the future emergence of more “nanoagent” and even “nanoASI” projects, promoting the democratization and rapid evolution of AI technology. (Source: zachtratar, code_star)
AI and Search: A Paradigm Shift from Keyword Matching to Semantic Understanding : Geoffrey Hinton points out that today’s AI is closer to humans in understanding problems, no longer limited to keyword matching, but capable of connecting ideas and meanings, finding information even when phrased completely differently. This shift marks AI search moving from shallow matching to deep semantic understanding, capable of generating novel answers rather than simple retrieval. This capability indicates that AI will reshape how information is accessed, making search results more insightful and relevant. (Source: arohan)
💡 Other
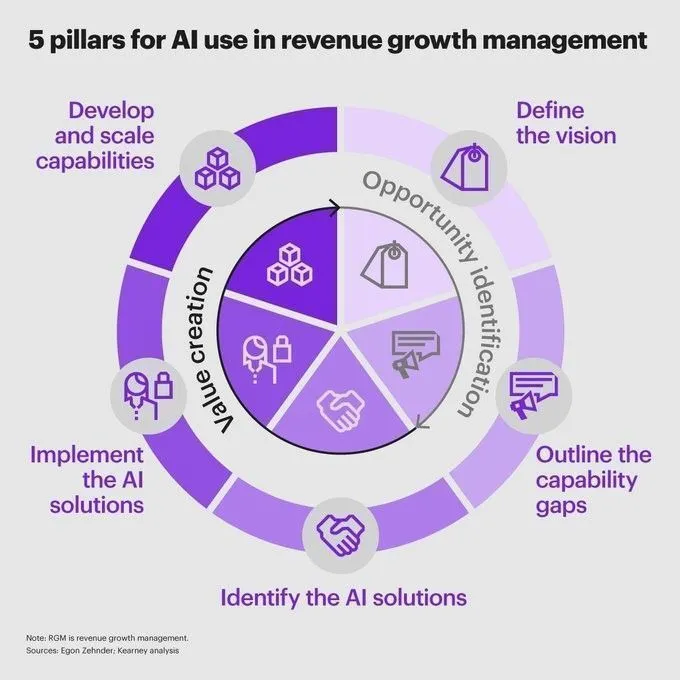
AI in Finance: Five Pillars for Revenue Growth and Risk Management : AI’s application in the financial sector is deepening, becoming key to driving revenue growth and risk management. Five pillars are proposed, including using AI for data analysis, predicting market trends, optimizing investment portfolios, automating compliance processes, and enhancing customer service. These applications help financial institutions make smarter strategic decisions, identify potential risks, and improve operational efficiency. Concurrently, AI’s application in financial data analysis also supports more informed strategic decision-making. (Source: Ronald_vanLoon, Ronald_vanLoon)
OpenAI Faces Copyright Lawsuit: Internal Slack Messages Could Lead to Billions in Damages : OpenAI is facing a copyright lawsuit where its internal Slack messages could become key evidence, potentially leading to billions of dollars in damages. This lawsuit highlights the legal complexities of AI model training data sources and the challenges companies face in ensuring compliance with internal communication and data usage during AI development. The case outcome could have profound implications for copyright protection and data usage regulations in the AI industry. (Source: Reddit r/artificial)

Chinese AI Startups Face ‘Collective Exit’ Dilemma, Forced to Go Overseas for Survival : China’s AI application market is showing a dominant “big tech” landscape, with giants like ByteDance, Baidu, and Alibaba occupying 70% of the top 20 domestic AI applications due to their resource and scenario advantages. The innovation cycle for startups is compressed to mere weeks; any highlight is quickly replicated by big tech. This fierce competition leads to Chinese AI startups being “forced to go overseas.” The a16z list shows that 19 out of 22 Chinese AI mobile applications primarily target overseas markets, with talent and innovation also flowing out, highlighting the paradox between expanding user scale and shrinking innovation sources in the Chinese AI market. (Source: 36氪)