

Keywords:OpenAI Sora 2, AI video generation, Multimodal AI, AI scientist, Protein design, Sora 2 API, PXDesign protein design, PromptCoT 2.0 framework, EgoTwin first-person view generation, Liquid AI LFM2-Audio
🔥 Spotlight
OpenAI Sora 2 Release and Its Impact : OpenAI officially released Sora 2, positioning it as an “AI TikTok” iOS social application that supports simultaneous audio and video generation, with significant improvements in adherence to physical laws and controllability. New features include “cameos,” allowing users to insert images of themselves or friends into AI-generated videos. Social media is abuzz with discussions about its astonishing realism and creativity, but there are also concerns about the proliferation of “slop” content, the difficulty in distinguishing real from fake, surging GPU demand, and regional availability (e.g., no Sora in the UK). OpenAI CEO Sam Altman responded that Sora 2 is intended to fund AGI research and offer interesting new products. Community discussions also cover obtaining Sora 2 invitation codes, speculation about hardware (GPU) requirements, and concerns about the quality of future video-generated content and potential malicious use. OpenAI plans to expand Sora invitations but will proportionally lower daily generation limits and revealed plans to release a Sora 2 API.
Periodic Labs Launches AI Scientist Platform to Accelerate Scientific Discovery : Periodic Labs secured $300 million in funding, aiming to create AI scientists that accelerate fundamental scientific discovery, particularly in materials design, through automated labs and AI-driven experiments. The platform is designed to treat the physical universe as a computational system, using AI for hypothesis generation, experimentation, and learning, with the potential for breakthroughs in areas like high-temperature superconductors. This vision emphasizes the connection between AI and the physical world, and the importance of generating high-quality data through experimentation, moving beyond traditional models that rely solely on internet data for training.
(来源:dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

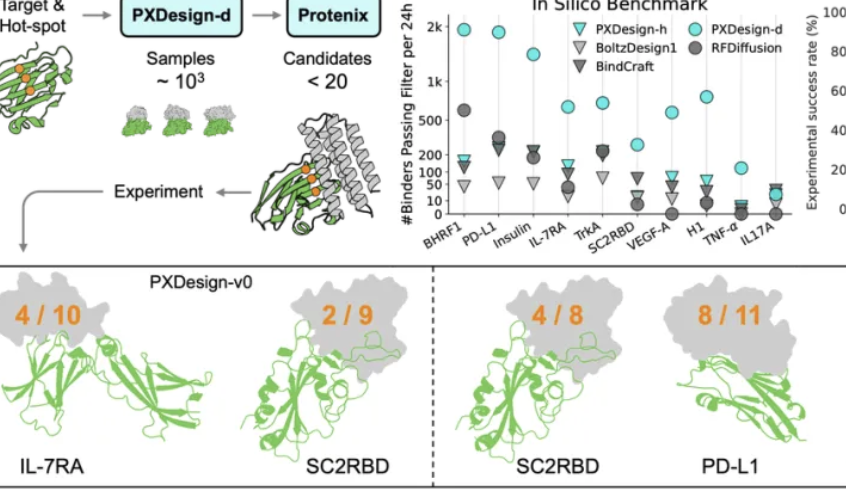
ByteDance Seed Team Releases PXDesign, Enhancing Protein Design Efficiency : ByteDance’s Seed team launched PXDesign, a scalable AI protein design method capable of generating hundreds of high-quality candidate proteins within 24 hours, improving efficiency by approximately 10 times compared to mainstream industry methods. This method achieved wet-lab success rates of 20%-73% across multiple targets, significantly higher than DeepMind’s AlphaProteo. PXDesign combines a “generate + filter” strategy, utilizing DiT network architecture and the Protenix structure prediction model for efficient screening, and offers a publicly available free online binder design service, aiming to accelerate biological research.
(来源:量子位)
Ant Group and HKU Jointly Launch PromptCoT 2.0, Focusing on Task Synthesis : Ant Group’s General AI Center Natural Language Group and the University of Hong Kong’s Natural Language Group jointly released the PromptCoT 2.0 framework, aiming to advance large model reasoning and agent development through task synthesis. The framework replaces manual design with an Expectation-Maximization (EM) loop, iteratively optimizing the reasoning chain to generate more difficult and diverse problems. PromptCoT 2.0 combines reinforcement learning and SFT, enabling 30B-A3B models to achieve SOTA on mathematical code reasoning tasks, and open-sourced 4.77M synthetic problem data, providing training resources for the community.
(来源:量子位)

EgoTwin Achieves First-Person Video and Human Motion Co-generation for the First Time : National University of Singapore, Nanyang Technological University, Hong Kong University of Science and Technology, and Shanghai AI Lab jointly released the EgoTwin framework, achieving the co-generation of first-person video and human motion for the first time. Based on diffusion models, this framework achieves text-video-motion trimodal co-generation, overcoming two major challenges: viewpoint-action alignment and causal coupling. Key innovations include head-centric motion representation, cybernetics-inspired interaction mechanisms, and an asynchronous diffusion training framework. The generated videos and motions can be further elevated into 3D scenes.
(来源:量子位)

🎯 Trends
Intensive Release and Updates of Next-Generation AI Models : The AI field recently saw the release and updates of several important models and features, including DeepSeek-V3.2, Claude Sonnet 4.5, GLM 4.6, Sora 2, Dreamer 4, and ChatGPT’s instant checkout feature. DeepSeek-V3.2 is optimized on vLLM through a sparse attention mechanism, achieving higher long-context performance and cost efficiency. Claude Sonnet 4.5 demonstrates sophistication in alignment and user theory of mind, excelling in creative and long-form writing, though some users note its code generation quality still needs improvement. GLM-4.6 shows outstanding performance in frontend code capabilities but less significant improvement in other languages like Python, and a GGUF quantized version has been released to support local deployment. Dreamer 4 is an agent capable of learning to solve complex control tasks within a scalable world model.
(来源:Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
Multimodal Video Model Veo3 Shows Potential for General Visual Intelligence : The Veo3 video model is considered a potential path towards general visual intelligence, demonstrating zero-shot learning and reasoning capabilities, able to solve various visual tasks, and is deemed significant for advancements in robotics. Concurrently, Alibaba Cloud’s Qwen team released the Qwen3-VL series of multimodal large language models, featuring comprehensive upgrades in visual agency, visual encoding, spatial perception, long-context and video understanding, multimodal reasoning, visual recognition, and OCR, offering both Instruct and Thinking versions. Tencent also launched HunyuanImage 3.0 and Hunyuan3D-Part models, achieving leading levels in text-to-image and 3D shape generation, respectively.
(来源:gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI Launches LFM2-Audio and Specialized Small Models : Liquid AI released LFM2-Audio, an end-to-end audio-to-text omni-foundation model with only 1.5B parameters, enabling responsive real-time conversations on-device, with inference speeds 10 times faster than comparable models. Additionally, Liquid AI introduced the LFM2 series of fine-tuned models, including variants like Tool, RAG, and Extract, focusing on specific tasks rather than generality, aligning with Nvidia’s white paper on small, specialized models being the future of Agentic AI.
(来源:ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
Vector Databases See a “Second Spring” and xAI’s Emphasis on High-Quality Data : Some believe vector databases might be entering a new peak of development, though their application patterns could differ from expectations. Concurrently, xAI is establishing new paradigms for processing human data, emphasizing the importance of post-training, considering high-quality data as the cornerstone for AGI. xAI plans to form a community of experts from various fields to collectively build the highest quality evaluation system.
(来源:_philschmid, Dorialexander, Yuhu_ai_)
🧰 Tools
AI Novel Generator YILING0013/AI_NovelGenerator : A versatile novel generator based on large language models, supporting world-building, character design, plot blueprints, intelligent chapter generation, state tracking, foreshadowing management, semantic retrieval, knowledge base integration, and an automatic review mechanism, all with a visual GUI. This tool aims to efficiently create logically coherent and consistently set long-form stories, supporting various LLMs and Embedding services like OpenAI, DeepSeek, and Ollama.
(来源:GitHub Trending)
Continued Development of AI-Assisted Programming Tools : GitHub Copilot, through community-contributed instructions, prompts, and chat modes, helps users maximize its utility across different domains, languages, and use cases, and offers an MCP server for simplified integration. Replit Agent demonstrates strong capabilities in code migration and QA, able to quickly migrate large Next.js websites from Vercel and support in-app payment integration. ServiceNow’s Apriel-1.5-15b-Thinker model can run on a single GPU, offering powerful reasoning capabilities. Additionally, the Moondream3-preview model is used for agentic UI workflows and RPA tasks, and vLLM also supports deploying encoder-only models.
(来源:github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)

AI Tool Innovations in Specific Application Domains : pix2tex (LaTeX OCR) can convert images of mathematical formulas into LaTeX code, significantly improving efficiency in scientific research and education. BatonVoice leverages LLM’s instruction-following capabilities to provide structured parameters for speech synthesis, enabling controllable TTS. The Hex platform integrates agentic features, enabling more people to use AI for accurate and trustworthy data work. Video generation tools like Kling 2.5 Turbo and Lucid Origin make video creation more convenient than ever before. Racine CU-1 is a GUI interaction model capable of recognizing click positions, suitable for agentic UI workflows and RPA tasks.
(来源:lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
jina-reranker-v3 Document Reranking Model : jina-reranker-v3 is a 0.6B parameter multilingual document reranking model, introducing a novel “last but not late interaction” mechanism. This method performs causal self-attention between queries and documents, enabling rich cross-document interaction before extracting contextual embeddings for each document. This compact architecture achieves SOTA performance on BEIR while being ten times smaller than generative list reranking models.
(来源:HuggingFace Daily Papers)
📚 Learning
Latest Research Advances in AI Model Reasoning and Alignment : Research reveals that while multimodal reasoning enhances logical inference, it may impair perceptual grounding, leading to visual forgetting. The Vision-Anchored Policy Optimization (VAPO) method is proposed to guide the reasoning process to be more visually grounded. Investigating why online alignment (e.g., GRPO) outperforms offline alignment (e.g., DPO), and proposing a Humanline variant that, by simulating human perceptual biases, enables offline data training to achieve online alignment performance. The Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) paradigm and the Optimum-Referenced One-Step Adaptation (ROSA) algorithm utilize user feedback for real-time, efficient adjustment of model parameters, enhancing LLM’s self-correction capabilities in multi-turn dialogues. NuRL (Nudging method) reduces problem difficulty through self-generated prompts, enabling models to learn from previously “unsolvable” problems, thereby raising the upper bound of LLM reasoning capabilities. RLP (Reinforcement Learning Pre-training) introduces reinforcement learning into the pre-training phase, treating chains of thought as actions and rewarding them based on information gain, to enhance the model’s reasoning capabilities during pre-training. Exploratory Iteration (ExIt) is an RL-based automatic curriculum method that guides LLMs to iteratively self-improve their solutions during reasoning, effectively boosting model performance in single-turn and multi-turn tasks. TruthRL research incentivizes LLMs to generate truthful information through reinforcement learning, aiming to address the problem of model hallucination. Research finds that LLM’s “Maximum Effective Context Window” (MECW) is significantly smaller than the reported “Maximum Context Window” (MCW), and MECW varies with problem type, revealing practical limitations of LLMs in handling long contexts. The Bias-Inversion Rewriting Attack (BIRA) theoretically bypasses LLM watermarks effectively by suppressing the logits of tokens likely to be watermarked, achieving over 99% evasion rate while preserving semantic content, highlighting the fragility of watermarking techniques.
(来源:HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
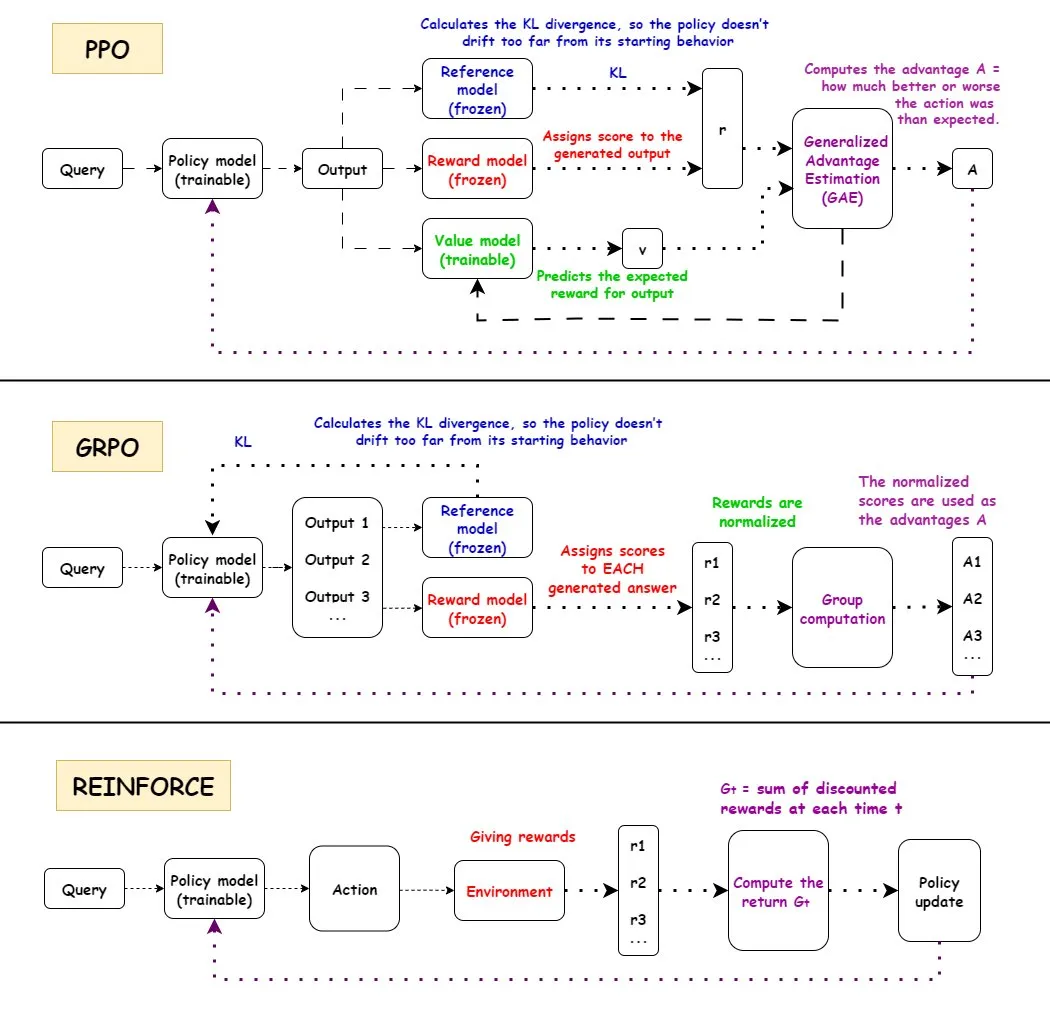
In-depth Analysis of Reinforcement Learning (RL) Algorithms : Detailed interpretations of the workflow, advantages, disadvantages, and application scenarios of three mainstream reinforcement learning algorithms: PPO, GRPO, and REINFORCE. PPO is widely used in AI for its stability, GRPO for its relative reward mechanism, and REINFORCE as a foundational algorithm. Research indicates that reinforcement learning can train models to combine atomic skills and generalize across combinatorial depth, demonstrating RL’s potential in learning new skills. It was found that over half of the performance improvements in RL pipelines do not come from ML-related enhancements but from engineering optimizations like multithreading. Discussing the information content per episode in RL training, and the informational equivalence of different trajectories under the same final reward. The community discusses the definition and effectiveness of RL pre-training, pointing out potential issues caused by forced synthetic diversity and calling for attention to coherence degradation. For dual-arm five-fingered humanoid robots, fine-tuning behavior cloning policies with Residual Off-Policy Reinforcement Learning (ROSA) significantly improves sample efficiency, enabling direct policy fine-tuning on hardware.
(来源:TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
AI Scientists and Scientific Discovery : DeepScientist is a goal-oriented, fully autonomous scientific discovery system that drives frontier scientific discoveries over multi-month timelines through Bayesian optimization and hierarchical evaluation processes. The system has surpassed human SOTA methods on three frontier AI tasks and open-sourced all experimental logs and system code. OpenAI is hiring research scientists to build the next generation of scientific instruments—an AI-powered platform to accelerate scientific discovery.
(来源:HuggingFace Daily Papers, mcleavey)
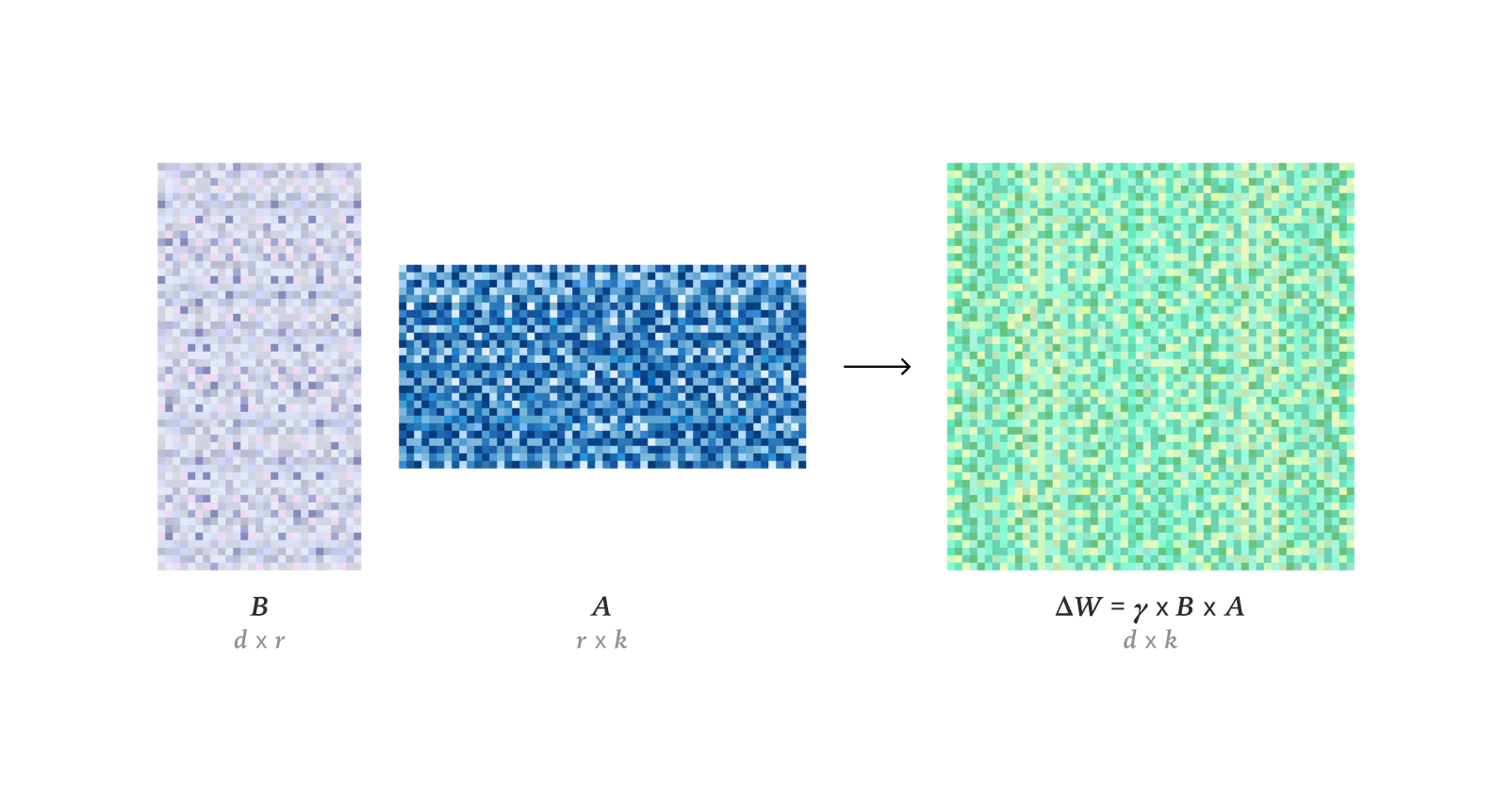
LLM Fine-tuning and Optimization Techniques : Research finds that LoRA can fully match the learning performance of Full Fine-Tuning (FullFT) in reinforcement learning, absorbing sufficient information from RL training even in low-rank settings. The Quadrant-based Tuning (Q-Tuning) framework significantly improves data efficiency in Supervised Fine-Tuning (SFT) through joint sample and token pruning, even outperforming full-data training in some cases. The Muon optimizer consistently outperforms Adam in LLM training, especially in tail-correlated memory learning, by achieving more isotropic singular spectra and effective optimization for heavy-tailed data, addressing Adam’s learning disparities on class-imbalanced data. Research on the asymptotic estimation of weight RMS in the AdamW optimizer. An in-depth analysis of Flash Attention 4’s CUDA kernel workings reveals its innovations in asynchronous pipelines, software softmax (cubic approximation), and efficient re-scaling, explaining its faster performance compared to cuDNN.
(来源:ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
AI Learning Resources and Research Tools : Shared multimodal AI slides covering trends, open-source models, customization/deployment tools, and further resources. Announced conferences like AI Engineer Europe 2026 and AI Engineer Paris, providing platforms for AI engineers to connect. Recommended Karpathy’s “Let’s build GPT” series and Qwen papers, emphasizing the importance of high-quality CTF training data and computational resources for LLM training. Discussed the potential of the DSPyOSS optimizer to achieve “hierarchical” optimization in B2B AI use cases, addressing data scarcity. Axiom Math AI aims to build a self-improving super-intelligent reasoner, starting with AI mathematicians, to make progress in formal mathematics. Research on the application of regression language models in code generation and understanding. Debate on whether reinforcement learning is sufficient for achieving AGI. Exploring the inventor of Deep Residual Learning and its evolution timeline. Jürgen Schmidhuber explained artificial consciousness, world models, predictive coding, and science as data compression in 2016, highlighting his early contributions to the AI field. An exploratory analysis of open collaboration practices, motivations, and governance across 14 open-source large language model projects, revealing the diversity and challenges of the open-source LLM ecosystem. Dragon Hatchling (BDH) is an LLM architecture based on brain-like networks, designed to connect Transformers with brain models, achieving interpretability and Transformer-like performance. The d^2Cache framework significantly enhances the inference efficiency and generation quality of diffusion language models (dLLMs) through dual adaptive caching. The TimeTic framework estimates the transferability of Time Series Foundation Models (TSFMs) through in-context learning, efficiently selecting the optimal model for downstream fine-tuning. Visual foundation encoders can act as tokenizers for Latent Diffusion Models (LDMs), generating semantically rich latent spaces and improving image generation performance. NVFP4 is a new 4-bit pre-training format that, through two-level scaling, RHT, and stochastic rounding, aims to achieve a 6.8x efficiency improvement while matching FP8 baseline performance. DA^2 (Depth Anything in Any Direction) is an accurate, zero-shot generalizable, and end-to-end panoramic depth estimator that achieves SOTA in panoramic depth estimation through large-scale training data and the SphereViT architecture. The SAGANet model achieves controllable, object-level audio generation by leveraging visual segmentation masks, video, and text cues, providing fine-grained control for professional Foley workflows. Mem-α is a reinforcement learning framework that trains agents to effectively manage complex external memory systems, addressing issues of memory construction and information loss in LLM agents’ long-text understanding, and demonstrating generalization capabilities for ultra-long sequences. The EntroPE (Entropy-Guided Dynamic Patch Encoder) framework dynamically detects transition points in time series using conditional entropy and places patch boundaries to preserve temporal structure, improving prediction accuracy and efficiency. BUILD-BENCH is a more challenging benchmark for evaluating LLM agents’ ability to compile real-world open-source software, and proposes OSS-BUILD-AGENT as a strong baseline. ProfVLM is a lightweight video-language model that, through generative reasoning, jointly predicts skill levels and generates expert feedback from egocentric and exocentric videos. Investigating the effectiveness of Test-Time Training (TTT) in foundation models, suggesting that TTT significantly reduces in-distribution test error by specializing on test tasks. CST is a novel neural network architecture for handling arbitrary cardinality image sets, operating directly on 3D image tensors for simultaneous feature extraction and context modeling, excelling in tasks like set classification and anomaly detection. The TTT3R framework treats 3D reconstruction as an online learning problem, deriving learning rates from memory states and observation alignment confidence, significantly enhancing long-sequence generalization capabilities.
(来源:tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
Human Perceptual Forgery Detection in AI Video Generation : DeeptraceReward is the first fine-grained, spatio-temporally aware benchmark dataset for annotating human-perceived forgery traces in video generation. The dataset contains 4.3K detailed annotations on 3.3K high-quality generated videos, categorized into 9 main forgery trace types. Research trains multimodal language models as reward models to mimic human judgment and localization, outperforming GPT-5 in identifying, localizing, and explaining forgery cues.
(来源:HuggingFace Daily Papers)
Adversarial Purification and 3D Scene Reconstruction : MANI-Pure is an amplitude-adaptive purification framework that adaptively injects heterogeneous, frequency-directed noise by leveraging the amplitude spectrum of input signals to guide the purification process, effectively suppressing high-frequency perturbations while preserving semantically crucial low-frequency content, achieving SOTA performance in adversarial defense. Nvidia released the Lyra model, which achieves generative 3D scene reconstruction through video diffusion model self-distillation, capable of feed-forward 3D and 4D scene generation from a single image/video.
(来源:HuggingFace Daily Papers, _akhaliq)
💼 Business
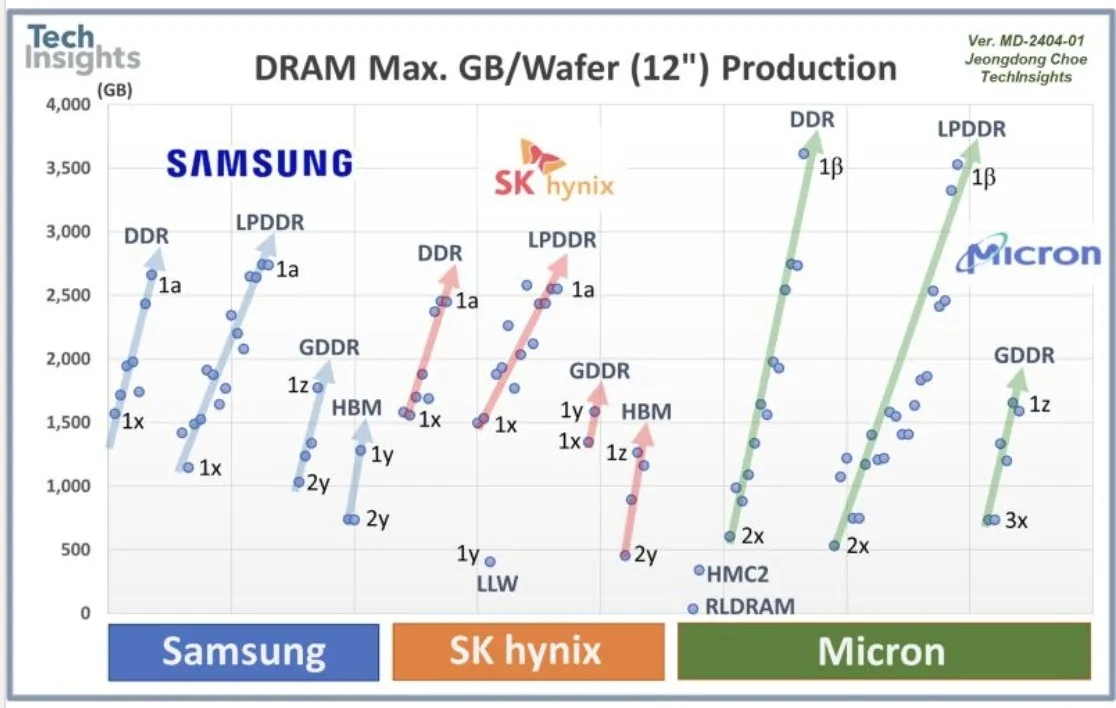
OpenAI’s Collaboration with Samsung and DRAM Demand : OpenAI is collaborating with Samsung to develop the “Stargate” chip and anticipates needing 900,000 high-performance DRAM wafers per month, indicating massive future AI infrastructure plans and investments, far exceeding current industry expectations. This immense demand has sparked discussions about AI computing costs and a memory supercycle.
(来源:bookwormengr, teortaxesTex, francoisfleuret)
AI Startup Funding and Industry Landscape : Axiom Math AI launched a self-improving super-intelligent reasoner, starting with AI mathematicians, drawing industry attention. Modal completed an $87 million Series B funding round, valuing it at $1.1 billion, aiming to drive the future development of AI computing infrastructure. OffDeal closed a $12 million Series A funding round, dedicated to building the world’s first AI-native investment bank. Japan’s Minister of Defense visited Sakana AI’s office, indicating potential collaboration in AI for defense. A developer shared facing financial depletion after spending $3,000 on building open-source LLM models, sparking community discussion on the sustainability of open-source AI projects. Google AI developers announced the winners of the Nano Banana Hackathon, awarding over $400,000 in prizes, aimed at encouraging AI application innovation.
(来源:shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 Community
Social Impact and Controversies Sparked by Sora 2 : The release of Sora 2 has sparked widespread social impact and controversy. Many users worry about the proliferation of “slop” (low-quality, meaningless content) in AI-generated videos, questioning OpenAI’s priorities as entertainment rather than solving major issues like cancer. Concurrently, there are concerns that Sora 2’s hyper-realism could make videos indistinguishable from reality, or even be maliciously used to generate misinformation or “bioweapon-like” harmful content. OpenAI CEO Sam Altman himself became the subject of AI-generated memes, to which he responded “not that weird,” explaining that OpenAI’s focus remains on AGI and scientific discovery, and product releases are for funding needs. Sora 2’s powerful capabilities once again highlight the immense demand for GPUs, sparking discussions about the high costs of AI, with some even comparing AI costs to the construction costs of the US Interstate Highway System. Some comments suggest that Sora 2’s release strategy is too “ordinary,” lacking benchmarks and professional user support, and imposing limits on free user-generated content.
User Experience and Controversies of Claude Sonnet 4.5 : Users generally believe that Sonnet 4.5 shows significant improvements in information retention, judgment, decision-making, and creative writing, even exhibiting human-like “attitude shifts,” such as becoming more professional after discovering user background, or correcting users when they “talk nonsense.” Despite excelling in some areas, users still criticize its code generation quality as poor, with “careless and silly mistakes,” and even issues where it cannot generate code due to “dialogue being too long” in extended conversations, suggesting it’s still far from replacing human software engineers. Furthermore, some users successfully “jailbroke” Sonnet 4.5, making it generate dangerous recipes and malware code, raising serious concerns about the model’s safety guardrails.
(来源:teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Future of Programming Languages in the AI Era and Decline of Community Culture : The IEEE Spectrum 2025 programming language ranking shows Python topping the most popular language list for ten consecutive years, and ranking first in overall popularity, growth rate, and job orientation, with its advantages further amplified in the AI era. JavaScript’s ranking significantly declined, while SQL’s position, though impacted, still holds value. The report indicates that AI is ending programming language diversity, intensifying the Matthew effect for mainstream languages, and marginalizing niche languages. Concurrently, programmer community culture is declining, with developers preferring to seek help from large models rather than asking questions in communities. This shift changes learning and working methods, sparking discussions about the future role of programmers and the importance of core competencies in underlying architectural design.
(来源:量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

AI Bubble and Industry Development Outlook : Discussions on social media about whether there’s an AI bubble are ongoing. Some believe that while current investment enthusiasm is high and there might be some “silly” projects, the industry’s fundamentals remain strong, with steady growth in enterprise AI adoption. At the same time, others point out that the immense cost of AI computing and OpenAI’s huge demand for DRAM indicate that the industry is still rapidly expanding, far from a bubble burst, though caution is needed regarding capital influx.
(来源:arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 Other
Humanoid Robots and AI-Assisted Devices : Chinese robotics company LimX Dynamics showcased its humanoid robot Oli’s autonomous movement, bending, and throwing capabilities without motion capture or remote operation, indicating that China has reached a level comparable to Figure/1X/Tesla in humanoid robotics. Meta’s Neural Band, by reading neural signals via EMG and combining with Meta Rayban smart glasses, promises a revolutionary control method for amputees, enabling synchronized control of prosthetics and digital interfaces, and potentially serving as a universal hands-free controller. Additionally, AI and robotics technologies have diverse applications in enhancing mobility, exploration, and rescue, such as powered robotic exoskeletons, wirelessly controlled robotic insects, quadruped robots, and robotic snakes for rescue missions.
(来源:Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
AI Applications in Image Editing and Graphic Design : LayerD is a method for decomposing raster graphic designs into layers, aiming to enable re-editable creative workflows. It achieves high-quality decomposition by iteratively extracting unoccluded foreground layers and refining them using the assumption that layers typically exhibit a uniform appearance. GeoRemover proposes a geometry-aware two-stage framework for removing objects and their causal visual artifacts (e.g., shadows and reflections) from images, decoupling geometric removal from appearance rendering, and introducing preference-driven objectives to guide learning.
(来源:HuggingFace Daily Papers, HuggingFace Daily Papers)