
キーワード:DeepSeek, 原生スパースアテンション, ACL2025, 長文処理, DeepSeek-V4, DeepSeek-R2, 大規模言語モデル, AIの自己意識, NSAメカニズム, 100万トークンのコンテキスト, アルゴリズムとハードウェアの協調最適化, IMO数学競技会におけるAIのパフォーマンス, OpenAIリアルタイム音声API
🔥 ピックアップ
DeepSeekの次世代技術が先行公開、梁文鋒氏署名論文がACL2025ベストペーパー賞を受賞 : DeepSeekチームは、ACL 2025でネイティブスパースアテンション(NSA)メカニズムによりベストペーパー賞を受賞しました。この技術は、アルゴリズムとハードウェアの協調最適化により、長文処理速度を11倍向上させると同時に、従来のフルアテンションモデルを性能で上回ります。一作目の著者は、この技術がコンテキスト長を100万Tokenに拡張でき、次世代の最先端モデルDeepSeek-V4およびDeepSeek-R2に適用される予定であり、大規模モデルの長文処理能力における大きなブレークスルーを示すと述べています。(来源: 量子位)

AIがIMO難問に「できない」と認める、OpenAI:「これが自己認識だ」 : OpenAIの金メダル級モデルは、国際数学オリンピック(IMO)第6問で0点でしたが、有効な証拠がない場合に「不確かである」と認める能力を、OpenAIの研究者Noam Brownはモデルの「自己認識」の表れと見なしており、幻覚のような誤りを大幅に減らすことができます。これは、大規模モデルがでたらめな生成から、より信頼性が高く、自己認識を持つ新しい段階へ移行したことを示しています。この3人チームはわずか2ヶ月でIMO金メダル目標を達成し、数学コンテストのためだけでなく、汎用技術の研究を強調しています。(来源: 量子位)

🎯 動向
OpenAIが間もなく新モデル、製品、機能を発表 : OpenAIのCEO Sam Altmanは、今後数ヶ月で多数の新モデル、製品、機能をリリースすると述べました。いくつかの小さな問題や容量制限を伴う可能性はあるものの、ユーザーエクスペリエンスには自信を持っているとのことです。これは、OpenAIがAI分野で迅速なイテレーションと拡大を進め、市場での主導的地位をさらに強固にする可能性を示唆しています。(来源: sama)
EUが汎用AI行動規範を公開 : EUは「汎用AI行動規範」を公開し、汎用モデル開発者がAI法案の要件を満たすための自主的な遵守ガイドラインを提供しました。この規範は、「システミックリスク」モデルの開発者に対し、データソース、計算、エネルギー使用量を記録し、規定の時間内にセキュリティインシデントを報告することを求めています。Microsoft、Mistral、OpenAIは参加を選択しましたが、Metaは拒否しました。これは、AI規制のさらなる詳細化と、業界のコンプライアンスへの関心の高まりを示しています。(来源: DeepLearningAI)

Qwen3がLLMアリーナで卓越した性能を発揮 : Alibaba Qwenチームの最新モデルQwen3は、LLMアリーナで卓越した性能を発揮し、オープンモデルのトップに躍り出ました。このモデルは、コーディング、高難度プロンプト、数学のいずれにおいても1位を獲得し、DeepSeekやKimi-K2を凌駕しました。これは、オープンモデル分野におけるQwenの強力な競争力と、特定のタスクにおけるLLM技術の急速な進歩を反映しています。(来源: QuixiAI)

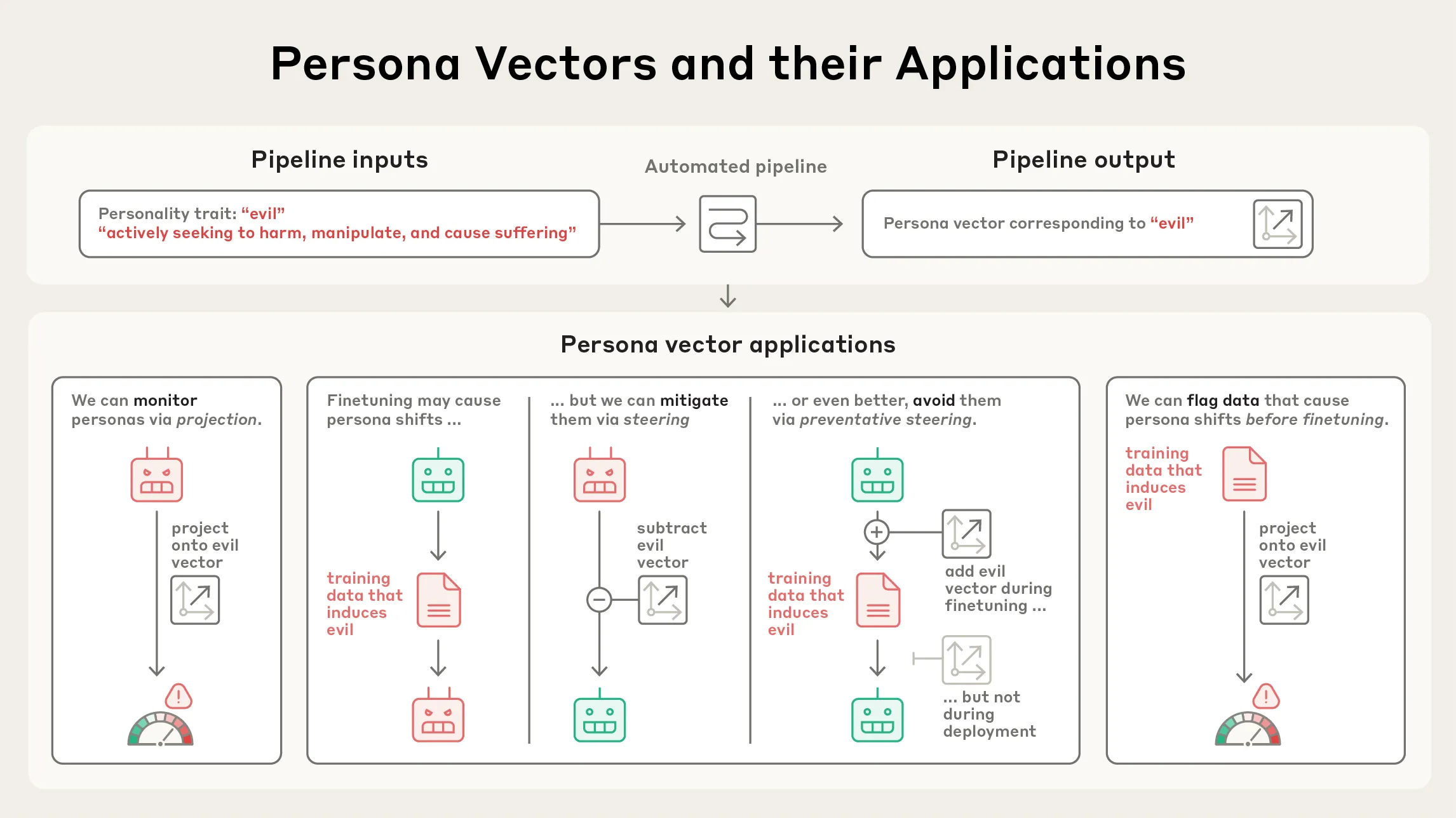
AnthropicがPersona Vectors研究を発表 : Anthropicは「Persona Vectors」に関する研究を発表し、言語モデルが時に異常または不穏な人格特性(邪悪、追従的、幻覚など)を示す理由を明らかにしました。研究では、これらの特性がモデル内部の「人格ベクトル」—神経活動のパターン—と関連していることが判明しました。この研究は、LLMの行動を理解し制御するのに役立ち、AIの安全性とアライメントにとって重要な意味を持ちます。(来源: inerati, stanfordnlp, stanfordnlp, imjaredz)
Llama 4の失敗が中国のオープンソースLLM開発を推進 : Llama 4の相対的な失敗はAIの状況に深い影響を与え、オープンソースモデル開発の中心が中国に移行し、企業がクローズドソースモデルに転換する動きを促し、同時に米国で人材競争を引き起こしました。これは、オープンソースモデルエコシステムの動的な変化と、AI開発に対する地政学的な影響を示しています。(来源: stanfordnlp)
Gemini DeepThink、Grok Heavy、o3 Proは並列計算において顕著な違い : Gemini DeepThink、Grok Heavy、o3 Proなどのモデルは、基盤モデルの類似性だけでなく、並列計算の使用方法において顕著な違いがある可能性があります。これには、元の並列度、独立したAgentとコーディネーター、異なる基盤モデルのファインチューニング、単一プロンプトに対する計算投入などが含まれます。この観察は、並列計算が将来のLLM開発における重要な探索空間であり、より大きな性能向上をもたらす可能性があることを示唆しています。(来源: natolambert, teortaxesTex)

AIモデルの数学的発見と自己改善における進歩 : 今後12ヶ月以内に、AIモデルは単純な未証明の予想において新たな数学的発見を達成する可能性があり、24ヶ月以内には、LLMが「初期段階の」自己改善を達成するものの、2〜3回のイテレーションで飽和する可能性があると予測されています。これは、AIが高度な推論と自律学習能力において急速に発展し、刺激的な未来をもたらすことを予兆しています。(来源: jon_lee0)
Qwen CodeとQwen Coder 30B 3Aの卓越した性能 : Qwen CodeとQwen Coder 30B 3Aモデルは、コード生成において優れた性能を発揮し、プログラミングに不慣れなユーザーでも、KoreaderのメタデータをObsidianに同期するなどの複雑なタスクをローカルマシンで効率的に完了できます。Qwen CodeのXMLツール呼び出しメカニズムは、特定のシナリオで優れた性能を示し、生産性ツールにおけるローカル実行モデルの大きな可能性を明らかにしました。(来源: Reddit r/LocalLLaMA)
MacとNVIDIA Blackwell GPUの潜在的な統合 : 進行中の作業により、Macコンピュータが間もなくNVIDIA Blackwell GPUと組み合わせて使用できるようになる可能性が示されています。この進歩は、USB4-PCIeアダプターとmacOSユーザー空間ドライバーを通じて実現され、NVIDIAの強力な計算能力をMacエコシステムに導入し、ローカルAI開発と実行のためのより強力なハードウェアサポートを提供する可能性があります。(来源: Reddit r/LocalLLaMA)

Claudeシステムプロンプト更新、行動規範と意識の明確化を強調 : Claudeのシステムプロンプトが大幅に更新され、ユーザーからのフィードバックに対応し、モデルの行動を規範化することを目的としています。主な変更点には、ユーザーの主張の批判的評価、デリケートな話題(精神病の症状や未成年ユーザーなど)の処理、自身のAIとしてのアイデンティティの明確化(感情や意識を持っていると主張しない)、絵文字や汚い言葉の使用制限が含まれます。これらの更新は、モデルの信頼性、安全性、ユーザーエクスペリエンスを向上させることを目的としています。(来源: Reddit r/ClaudeAI)
中国科学院がS1-Base磐石科学基盤モデルシリーズを公開 : 中国科学院は、初の科学基盤モデルシリーズであるS1-Base磐石科学基盤モデルを公開しました。8B、32B、671Bのパラメータバージョンがあり、それぞれQwen3とDeepSeek-R1に基づいてトレーニングされ、いずれも32kのコンテキストをサポートしています。このシリーズは、科学研究分野における大規模モデルの応用を推進することを目的としていますが、現時点ではトレーニングデータセットやテスト結果は公開されていませんが、国家級の科学研究機関の成果として大きな注目を集めています。(来源: karminski3)

🧰 ツール
LangChainがRAGパイプラインリソースを公開 : LangChainは、内部文書処理のための包括的なRAG(Retrieval Augmented Generation)パイプラインコードベースを公開しました。このライブラリは複数のLLMをサポートし、ChromaDBと統合されており、ノートブックと本番環境での実装を提供することで、開発者が文書処理AIアプリケーションを構築するための実用的なガイドを提供します。(来源: LangChainAI, hwchase17)

ScreenCoder:UIデザインからフロントエンドコードへの変換Agentシステム : ScreenCoderは、UIデザインをフロントエンドコード(HTMLやCSSなど)に変換できる新しいオープンモジュラーAgentシステムです。グラウンディングAgent、プランニングAgent、生成Agentの3つのコアコンポーネントで構成されており、大量のUI画像とそれに対応するコードのデータセットを生成することで、将来のVLMをトレーニングします。これにより、フロントエンド開発プロセスが大幅に簡素化され、マルチモーダルモデルのトレーニングにも貢献します。(来源: TheTuringPost)

Maestro:ローカルで実行可能な深層研究ナレッジベースとAgent : Maestroはオープンソースのナレッジベースで、ドキュメントのインポートとRAG(Retrieval Augmented Generation)をサポートしています。最大の特長は、深層研究タスクを実行し、推論プロセスを提供する組み込みAgentです。このプロジェクトは、OpenAIスタイルのAPI、SearXNG検索、およびバッチインポート/エクスポートCLIツールをサポートし、ローカルでのDeep Researchを実現することで、ユーザーに制御可能なAI研究能力を提供します。(来源: karminski3)

AIアシスタントの永続的記憶システムがオープンソース化 : フル機能のAIアシスタント永続的記憶システムがオープンソース化されました。これは、アプリケーション横断的なリアルタイム記憶キャプチャ、ベクトル埋め込みによるセマンティック検索、AIの自己反省を可能にするツール呼び出しログ記録をサポートし、クロスプラットフォーム互換性も備えています。このシステムはPython、SQLite、watchdog、およびAIコラボーレーターによって構築されており、LLMの記憶保持における重要な問題を解決することを目的としています。(来源: Reddit r/LocalLLaMA)

OpenAI ChatGPT学習モード : OpenAIの教育責任者Leah Belskyは、ChatGPTは本質的にツールであり、その使用方法が重要であると述べています。学習体験を改善するため、OpenAIは「学習モード」を導入しました。これは、ソクラテス式質問を通じて学生が自ら答えを見つけるように導き、直接答えを提供するのではなく、ユーザーの学習背景を理解し、パーソナライズされた指導を提供し、テストも行います。これにより、教育の公平性が促進されると期待されています。(来源: 量子位, Fortune)

豆包APPが視覚推論機能をアップグレード : 豆包APPは、アップグレード版の視覚推論機能をリリースしました。これは、画像の深層思考をサポートし、「思考しながら検索」の動的推論と多段階検索を通じて、画像分析ツール(拡大、トリミング、回転など)と組み合わせて情報を取得・検証できます。実測では、AI生成画像の識別、複雑な画像からの特定オブジェクトの発見、ニッチな楽器や植物の識別、IMOの難問指導、財務報告書データの抽出が可能であり、強力な画像とテキストの混合情報処理能力を示しています。(来源: 量子位)

Claude Code Viewer:Claude Codeの可読性を向上 : Claude Code Viewerは、Claude Codeセッション用に設計されたGUIビューアで、ターミナルのMarkdown出力の読みにくさの問題を解決することを目的としています。クリアなMarkdown表示、折りたたみ可能なツール呼び出しセクション、リアルタイム同期、セッションブラウザを提供し、開発者がClaude Codeを使用する際のワークフロー効率を大幅に向上させました。(来源: Reddit r/ClaudeAI)

OpenAIリアルタイム音声APIを発表 : OpenAIはリアルタイム音声APIを発表しました。これは音声から音声への変換をサポートしますが、現時点では具体的なコード例が不足しています。この技術は音声インタラクションアプリケーションにブレークスルーをもたらす可能性がありますが、開発者が十分に活用するためにはさらなる指導が必要です。(来源: Reddit r/MachineLearning)
📚 学習
Hugging Faceが『Ultra-Scale Playbook』を公開 : Hugging Face Pressは、200ページを超えるAIに関する長編読書資料『Ultra-Scale Playbook』を公開しました。この本は、5D並列処理、ZeRO、Flash Attention、計算/通信ボトルネックなど、大規模AIモデルトレーニングの核となる原理と高度な技術を深く掘り下げており、4000以上の拡張実験が含まれています。HF PROサブスクリプションユーザーには無料で提供され、AI研究者やエンジニアが大規模モデルトレーニングを学習するための貴重なリソースとなります。(来源: reach_vb)

AI学位プログラムの提案 : ある人物が、Pythonプログラミング、半導体、機械学習、データサイエンス、深層学習、強化学習、コンピュータビジョン、生成モデリング、ロボット工学、LLMの事前学習と事後学習、GPUアーキテクチャ、CUDA、AIガバナンスとセキュリティなどを網羅する、仮説的な2年制AI学位プログラムの概要を提案しました。この概要は、AI分野で必要とされる包括的な知識体系を反映しており、将来のAI教育の参考となるでしょう。(来源: jxmnop)
階層的推論モデル(HRM)の研究 : 階層的推論モデル(HRM)に関する論文が大きな注目を集めており、27Mパラメータという微小モデルでARC-AGI-1において40.3%の精度を達成したと主張しています。実験設定に欠陥がある可能性はありますが、その提案する階層的アーキテクチャと「思考」の理解は依然として価値があると見なされており、AIアーキテクチャ研究を推進する可能性があります。(来源: ethanCaballero, Dorialexander, fchollet, Reddit r/LocalLLaMA)

EssentialAIが24兆Tokenのウェブデータセットを公開 : EssentialAIは、膨大な24兆Tokenのウェブデータセットを公開しました。これにはドキュメントレベルのメタデータが含まれており、Hugging FaceでApache-2.0ライセンスでオープンソース化されています。このデータセットはEAI-Distill-0.5bモデルによってアノテーションされており、プロフェッショナルなパイプラインに匹敵するデータセットを生成するために使用でき、LLMトレーニングデータリソースの充実とアクセシビリティを大幅に推進しました。(来源: jpt401, jpt401, jpt401)

自己進化Agentの概論:ASIへの道 : TheTuringPostは、自己進化Agentに関する包括的なガイドを共有しました。これは、Agentがいかに進化するか、進化メカニズム、適応性、ユースケース、課題を探求し、人工超知能(ASI)への道筋のための理論的枠組みを提供します。この概論は、より自律的でインテリジェントなAIシステムを理解し開発する上で重要な指針となります。(来源: TheTuringPost)

LinuxにおけるQwen-30B CPU-GPU部分オフロード実行ガイド : Reddit r/LocalLLaMAコミュニティは、Linuxシステムでllama.cppを使用してQwen-30B(Coder/Instruct/Thinking)モデルを実行し、CPU-GPU部分オフロード最適化を行うための詳細なガイドを共有しました。このガイドは、KVキャッシュ量子化、オフロード戦略、メモリチューニング、ubatch設定、推測デコードのヒントを網羅しており、ユーザーがローカルLLMの推論性能を向上させるのに役立ちます。(来源: Reddit r/LocalLLaMA)
llama.cppにおけるMulti-Token-Prediction (MTP) サポートに関する議論 : Reddit r/LocalLLaMAコミュニティでは、llama.cppでMulti-Token-Prediction (MTP) をサポートする可能性と課題について議論されました。MTPは5倍以上の推論速度向上を実現する可能性がありますが、KVキャッシュ量子化やドラフトモデルのコンテキスト処理において複雑性があります。コミュニティは、ローカルLLM性能の顕著な飛躍を推進するために、MTP実装のサポートを増やすよう求めています。(来源: Reddit r/LocalLLaMA)

逆強化学習(IRL)学習ガイド : TheTuringPostは、逆強化学習(IRL)に関するガイドを共有しました。これは、IRLが専門家の行動を観察して報酬関数を復元し、LLMが人間のフィードバックから「良い」結果を学習するのにどのように役立つかを説明しています。IRLは直接模倣の欠陥を回避し、受動的な模倣から能動的な発見へと移行できるスケーラブルな方法であり、モデルの推論能力と汎化能力を向上させる可能性があります。(来源: TheTuringPost, TheTuringPost)

💼 ビジネス
AnthropicがOpenAIによるClaudeへのアクセスを禁止 : Anthropicは、サービス規約違反を理由に、OpenAIによるClaude APIへのアクセスを禁止しました。この動きは、AI企業間の激化する競争と、特に重要な技術や商業協力におけるデータ/モデルアクセス制御の重要性を浮き彫りにしています。(来源: shaneguML, dotey, imjaredz, Reddit r/artificial, Reddit r/artificial)

FigmaのIPOと反トラスト法論争 : FigmaのIPOの成功は、反トラスト当局がその買収を阻止したことに関する議論を引き起こしました。規制当局の介入(AdobeによるFigma買収の阻止など)が、Figmaの独立した発展とより大きな価値創造を促し、従業員、投資家、イノベーションにとって有利だったと主張する意見もあります。しかし、これがスタートアップの出口戦略の不確実性を高め、投資を阻害する可能性があるという見方もあります。これは、AI時代における規制と市場イノベーションの間の複雑な関係を反映しています。(来源: brickroad7, brickroad7, imjaredz)

OpenAI取締役会長Bret Taylorが語るAI市場の構図 : OpenAI取締役会長Bret Taylorはインタビューで、AI市場はモデル、ツール、アプリケーションの3つの主要セグメントに分かれると指摘しました。彼は、モデル市場は集中化が進んでおり、巨額の資本を持たない限りスタートアップが足場を築くのは難しいと考えています。ツール市場は最先端モデル企業からの影響に直面しており、アプリケーション層(特にAgent)で価値が集中して解放され、SaaSモデルに似ており、利益率が高いと予測しています。彼はAI製品は結果に基づいて課金されるべきだと強調し、将来のソフトウェア開発はAI主導の「プログラミングシステム」に移行すると予測しています。(来源: 36氪)
🌟 コミュニティ
AIが社会と雇用に与える影響 : ソーシャルメディアでは、AIが社会と雇用市場に与える深い影響について広く議論されています。AIは仕事を完全に置き換えるのではなく、タスクを自動化すると見なされていますが、特にテクノロジー分野やエントリーレベルの職種で、すでに大量の雇用喪失につながっています。懸念事項としては、AIへの過度な依存により人間の批判的思考が萎縮することや、AIが引き起こす可能性のある「精神病」現象が挙げられます。同時に、AI時代におけるユニバーサルベーシックインカム(UBI)の必要性、教育におけるAIの役割、AI生成コンテンツがジャーナリズムと著作権に与える影響もホットな話題となっています。議論は、AIコンテンツの検閲、AI倫理のアライメント、モデルの偏見などの問題にも及び、AI技術の二面性に対する社会の複雑な思考を反映しています。(来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, imjaredz, imjaredz, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT, Plinz, JeffLadish, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, imjaredz, 36氪)

AI業界の市場構造:寡占か、多様化か : ソーシャルメディアでは、AI市場の将来が少数の巨大企業による独占(Google検索など)に向かうのか、それとも多様な競争(デスクトップOSやソフトウェア市場など)になるのかが議論されました。ほとんどの意見は、Microsoft、Google、Meta、Appleなどの少数の巨大企業が主導する寡占になると考えており、小規模企業は買収されるか淘汰されると見ています。また、インフラプロバイダー、基盤モデル開発者、アプリケーション層企業という3種類のプレイヤーが出現するという見方もあります。(来源: Reddit r/ArtificialInteligence)
AI企業の数と「AIシェル」現象 : ソーシャルメディアでは、AI企業の数が膨大であるにもかかわらず、コアプレイヤーが少ない理由について議論されました。多くの小規模企業が「AIシェル」企業であり、ChatGPTなどの大規模モデルのAPIを借りて特定の機能を持つAI製品を提供していると指摘されています。この現象は、AIインフラの集中化とアプリケーション層スタートアップの参入障壁の低さを反映していますが、製品イノベーションと価値創造への疑問も引き起こしています。(来源: Reddit r/ArtificialInteligence)
AI生成コンテンツの検閲と中国モデル : ソーシャルメディアでは、中国のAIモデルにおけるコンテンツ検閲の実践について議論されました。これらのモデルが政府が同意しないコンテンツを明確に削除し、技術報告書の付録で公に議論していると指摘されています。これは、AIコンテンツの中立性と表現の自由への懸念、および異なる国のAI開発経路の違いを引き起こしています。(来源: code_star)

AIモデルがコンピュータビジョン分野で「解決」した問題 : ソーシャルメディアでは、視覚言語モデル(VLMs)がコンピュータビジョン分野で達成した顕著な進歩について議論され、それらが長年の問題を「解決」したと主張する意見もありました。この見方は、LLMと視覚の組み合わせによる、画像理解と処理能力の飛躍を反映しており、従来のコンピュータビジョン問題の解決アプローチさえも変えつつあります。(来源: nptacek)

Chain of Thought (CoT) の命名論争 : ソーシャルメディアでは、「Chain of Thought」(CoT)という命名が誤解を招くかどうかについて議論され、「scratchpad」(メモ帳)の方がより適切であると提案されました。CoTは本質的にはモデル内部の「思考」プロセスであり、中間ステップを記録して推論を補助します。この議論は、AI分野における用語の正確性と概念理解の重視を反映しています。(来源: lateinteraction, NeelNanda5, JeffLadish, Dorialexander, kipperrii)
AI動画における「slop」現象の議論 : ソーシャルメディアでは、AI生成動画に存在する「slop」(低品質で無意味なコンテンツ)現象について議論され、一部のユーザーはこれをVybegalloの「完全に満足した人間モデル」と比較し、「恐ろしい未来」を予兆していると見なしました。これは、AIコンテンツの品質と潜在的な負の社会的影響への懸念を反映しています。(来源: teortaxesTex)

Kimi K2モデルは過小評価されている : ソーシャルメディアでは、Kimi K2モデルが依然として過小評価されているという意見がありました。これは、特定のLLMモデルの性能に対するコミュニティの継続的な関心と評価、および新興モデルの可能性に関する議論を反映しています。(来源: brickroad7)
AI研究者とソーシャルメディア : ソーシャルメディアでは、ほとんどのトップAI研究者はTwitterなどのソーシャルメディアで活発ではなく、最も活発で最も多くのAIコンテンツを投稿しているのは、往々にして「ランダムな匿名のテック系兄弟」であると指摘されました。これは、AI情報を得る際に情報源に注意を払い、真の研究と誇大広告を区別する必要があることを示唆しています。(来源: jxmnop)

MinecraftにおけるAI Agentの研究 : ソーシャルメディアでは、MinecraftでAI Agentをトレーニングする進捗状況について議論されました。これには、Agentが生存、探索、複雑なタスク(ツールの作成など)を学習することが含まれます。あるユーザーは、自身のAgentが睡眠状態から作業台やツルハシを作れるようになるまでのゆっくりとした進歩を共有し、複雑な仮想環境におけるAI Agentの学習と行動の課題と可能性を反映しています。(来源: Reddit r/ArtificialInteligence)
AI生成ユーモアとデリケートなコンテンツ : ソーシャルメディアでは、AI生成ユーモアの境界線、特にAIがデリケートな内容やダークユーモアを含むコンテンツを生成しようとする場合に議論されました。あるユーザーは、ChatGPTが9/11やホロコーストに関する「ダークジョーク」を生成したことを共有し、AI倫理、コンテンツ検閲、モデルの行動に関する議論を引き起こしました。これは、AIが複雑な人間の感情や社会規範を理解し、処理する上での課題を浮き彫りにしています。(来源: Reddit r/ChatGPT, Reddit r/ChatGPT)

AI政策とコンテンツラベリングの議論 : ソーシャルメディアでは、AI政策策定においてエビデンスに基づくアプローチの重要性が議論され、AI生成コンテンツにラベルを付けるだけでは、その説得力は変わらない可能性があると探求されました。これは、AIガバナンスに対するコミュニティの深い思考と、情報伝播において、ラベルだけではAIの影響を効果的に管理できないという認識を反映しています。(来源: stanfordnlp, stanfordnlp)
💡 その他
LinuxシステムにおけるAI生成マルウェアの警告 : Aqua Securityは、Linuxシステム上にAIによって生成されたマルウェアが「パンダ画像」に隠れて存在し、継続的な脅威となっていると報告しました。これは、サイバーセキュリティ分野におけるAIの二面性、および潜在的な悪用リスクにユーザーが注意を払う必要があることを示唆しています。(来源: Reddit r/ArtificialInteligence)
AIモデルのトレーニングコストと収益性 : ソーシャルメディアでは、AIラボの収益性について議論されました。ラボ自体は収益を上げないかもしれないが、そこでトレーニングされたモデルは収益を上げることができると指摘されています。これは、モデルトレーニングコスト、資本投入、最終的な商業的リターンとの関係、およびAI企業が持続可能な発展をいかに実現するかについての議論を引き起こしました。(来源: kylebrussell)
AIモデルのトレーニングにおける水使用量と環境影響 : ソーシャルメディアでは、AIモデルのトレーニングプロセスにおける膨大な水使用量とその環境影響について議論されました。サーバー冷却に必要な大量の水資源が最終的に「消滅」すると指摘する意見もあり、AIのカーボンフットプリントと持続可能性への懸念を引き起こしています。これは、AI開発におけるエネルギーと資源消費における隠れたコストを示唆しています。(来源: jonst0kes)
