
Palavras-chave:Plano Manhattan de IA, Gemini 3 Flash, GPT-5.2-Codex, Fusão nuclear controlada, Engenharia de pesquisa em IA, Agente de IA, Modelo multimodal, Modelo de IA de código aberto, Missão Gênesis do Departamento de Energia dos EUA, Teste de codificação Gemini 3 Flash, Defesa cibernética GPT-5.2-Codex, Modelo multimodal T5Gemma 2, Separador audiovisual Perception Encoder
Aqui está a tradução para o português, seguindo todas as suas instruções:
🔥 Destaque
“Plano Manhattan de IA” dos EUA lançado : O Departamento de Energia dos EUA lançou oficialmente a “Missão Genesis”, um projeto nacional de pesquisa de IA que visa combinar a tecnologia de IA de ponta com as capacidades de pesquisa dos laboratórios nacionais para acelerar as descobertas científicas. O plano reúne 24 gigantes da tecnologia, incluindo Microsoft, Google, NVIDIA, OpenAI, DeepMind, Anthropic, aplicando modelos de IA e capacidade de supercomputação em áreas como fusão nuclear controlada, materiais energéticos e simulação climática. O objetivo é dobrar a produtividade científica dos EUA até 2030, marcando um ajuste estratégico em nível nacional no campo da tecnologia dos EUA. (Fonte: 36氪, nvidia, AnthropicAI, GoogleDeepMind, OpenAI Newsroom)
Hinton e Jeff Dean dialogam sobre a IA moderna : Geoffrey Hinton, fundador das redes neurais, e Jeff Dean, Cientista Chefe do Google, conversaram na conferência NeurIPS, explorando os fatores-chave que levaram a IA moderna do laboratório a bilhões de usuários. Eles acreditam que o avanço da IA não é um único milagre, mas o resultado do amadurecimento sistêmico de algoritmos (como Transformer), hardware (como GPU, TPU) e engenharia (como JAX, Pathways). O diálogo também apontou três grandes barreiras para a escalabilidade da IA: eficiência energética, memória (contexto longo) e criatividade (capacidade de associação), enfatizando a importância da pesquisa fundamental e do investimento contínuo. (Fonte: 36氪, JeffDean, geoffreyhinton)
Entrevista com Sam Altman: Estratégia e Financiamento da OpenAI : Sam Altman, em sua última entrevista, apontou que o Google ainda é a maior ameaça da OpenAI, mas a OpenAI consolidará sua vantagem através de software nativo de IA, funcionalidades de personalização e memória, expansão acelerada do mercado empresarial e um investimento de 1,4 trilhão de dólares em infraestrutura. Ele previu que o GPT-6 poderá ser lançado no primeiro trimestre do próximo ano e enfatizou que a IA remodelará a forma como o software é usado no futuro, tornando-se um “parceiro digital” insubstituível, em vez de simplesmente ser incorporado a produtos antigos. (Fonte: 36氪, sama)
Google lança o modelo Gemini 3 Flash : O Google lançou o Gemini 3 Flash, um modelo que se destaca em vários benchmarks com excelente custo-benefício e velocidade, superando até mesmo o GPT-5.2 no teste de codificação SWE-bench. O Google planeja integrá-lo profundamente em produtos do ecossistema como Search, YouTube, Gmail, visando remodelar o mercado de IA através de sua vantagem ecológica, em vez de mera competição por parâmetros de modelo. Este lançamento é visto como um “golpe preciso” contra a OpenAI, gerando ampla discussão na indústria sobre a competição de modelos e a popularização das aplicações de IA. (Fonte: 36氪, MS_BASE44, GeminiApp, scaling01)
OpenAI lança o modelo de programação GPT-5.2-Codex : A OpenAI lançou o GPT-5.2-Codex, anunciado como seu modelo de programação de agente de IA mais poderoso até agora, otimizado para engenharia de software complexa e cibersegurança. O modelo melhorou a execução de tarefas de longo prazo, grandes alterações de código, compatibilidade com ambiente Windows e capacidade de defesa contra cibersegurança. Embora tenha mostrado forte desempenho em benchmarks, alguns usuários relataram em testes reais que em certas tarefas ele não superou o Gemini 3 Flash, gerando discussões no mercado sobre sua eficácia real e competitividade. (Fonte: 36氪, sama, scaling01)
🎯 Tendências
Google lança T5Gemma 2 e FunctionGemma como código aberto : O Google lançou como código aberto dois modelos pequenos, T5Gemma 2 e FunctionGemma, ambos baseados na família Gemma 3. O T5Gemma 2 é o primeiro modelo encoder-decoder multimodal de contexto longo, com uma escala mínima de 270M-270M, focado em eficiência arquitetônica e capacidades multimodais. O FunctionGemma é um modelo de 270M otimizado para chamadas de função, que pode ser executado em dispositivos de borda como celulares, visando resolver o problema de “saber conversar, mas não agir” na implementação de grandes modelos, fornecendo um “cérebro” dedicado para agentes e uso de ferramentas. (Fonte: 36氪, huggingface, osanseviero, ImazAngel, danielhanchen)

Teste real do modelo Doubao 1.8 da ByteDance : A ByteDance lançou o modelo grande Doubao 1.8, sua nova geração de modelo principal, que está em nível de liderança em avaliações em múltiplos cenários como educação, atendimento ao cliente, finanças e direito. Testes reais mostram que o Doubao 1.8 se destaca em capacidades de Agent (chamada de múltiplas ferramentas, seguimento de instruções multi-turn, OS Agent), gerenciamento de contexto ultra-longo de 256K e compreensão multimodal (capacidade de compreensão de vídeo aumentada para 20 minutos), sendo especialmente adequado para construir Agents complexos e executar processos reais, considerado um passo crucial para o desenvolvimento de Agents empresariais e Agents de borda. (Fonte: WeChat)

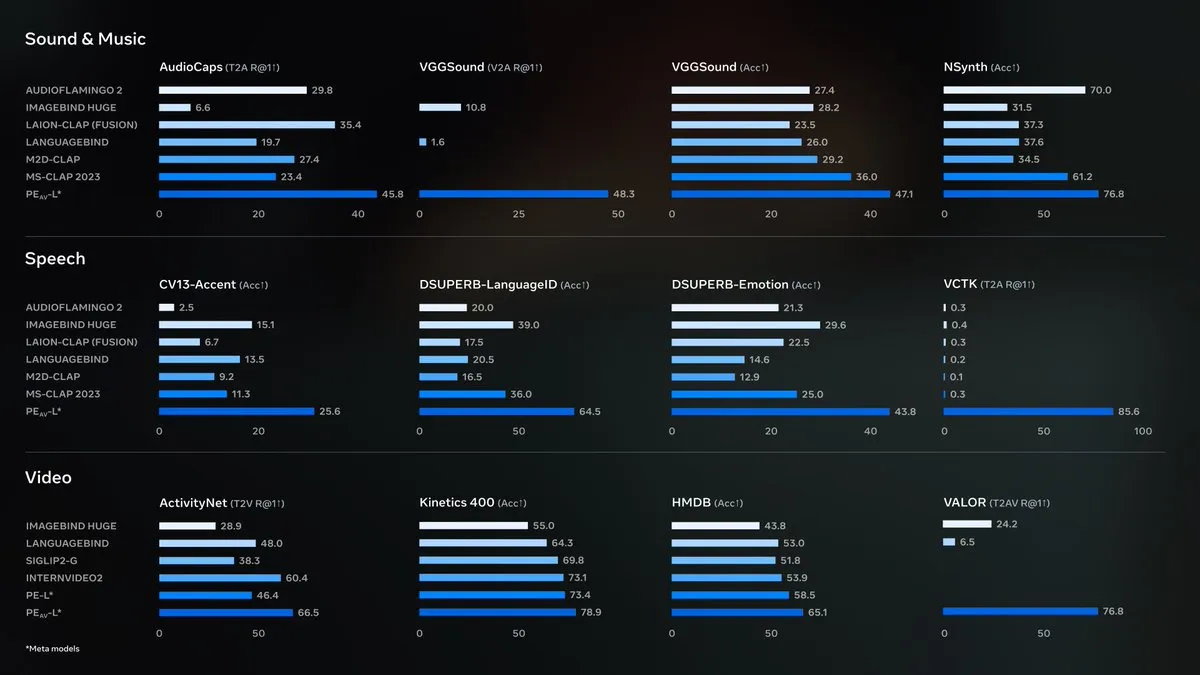
Meta lança Perception Encoder Audiovisual (PE-AV) como código aberto : A Meta lançou como código aberto o Perception Encoder Audiovisual (PE-AV), o motor tecnológico central por trás do SAM Audio, visando alcançar a separação de áudio de última geração. O PE-AV é baseado no modelo Perception Encoder lançado anteriormente pela Meta, integrando profundamente a percepção de áudio e visual, e alcançou resultados de ponta em uma ampla gama de benchmarks de áudio e vídeo, com o potencial de melhorar a detecção de som e a compreensão de cenas audiovisuais através de suporte multimodal. (Fonte: AIatMeta, Reddit r/LocalLLaMA)
Runway lança os modelos Gen-4.5 e GWM-1 : A Runway lançou o modelo de geração de vídeo Gen-4.5, adicionando funcionalidades de edição de áudio e multi-câmera, e também apresentou a série GWM-1 (General World Model), incluindo GWM Worlds (cenários navegáveis), GWM Robotics (simulação de perspectiva robótica) e GWM Avatars (personagens com sincronização labial), visando a geração de vídeo de modelo de mundo em tempo real e controlável, o que indica um grande salto na tecnologia de geração de vídeo em direção à simulação universal. (Fonte: c_valenzuelab, DeepLearningAI)
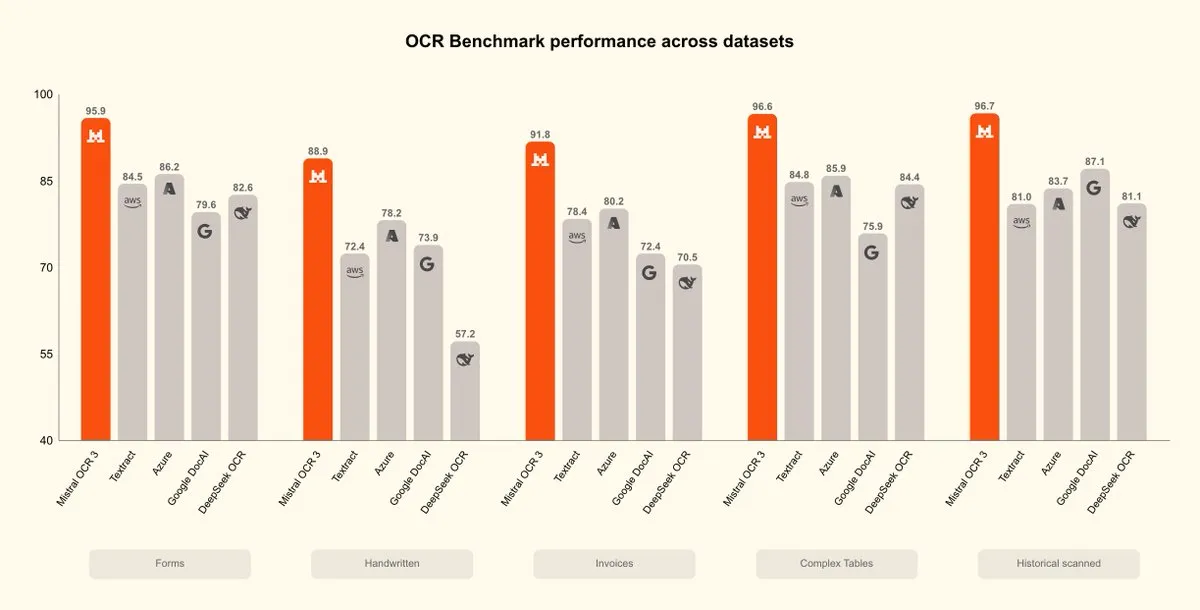
Mistral OCR 3 lançado, novo avanço na inteligência de documentos : A Mistral AI lançou o modelo Mistral OCR 3, estabelecendo um novo padrão em precisão e eficiência, superando as soluções existentes de processamento de documentos empresariais e OCR nativo de IA. O modelo foi amplamente otimizado para lidar com conteúdo manuscrito, digitalizações de baixa qualidade e tabelas e formulários complexos comuns em documentos empresariais, marcando um novo avanço no campo da inteligência de documentos. (Fonte: qtnx_, GuillaumeLample)
Hugging Face Transformers v5 Tokenization reestruturado : O Transformers v5 da Hugging Face passou por uma grande reformulação na forma como os tokenizers funcionam. A nova versão separou a arquitetura do tokenizer do vocabulário de treinamento, aumentando a transparência, modularidade e simplificando o processo de treinamento de tokenizers específicos do modelo do zero. Essa melhoria torna o tokenizer mais fácil de inspecionar, personalizar e treinar, resolvendo o problema de tokenizers opacos e fortemente acoplados na v4. (Fonte: HuggingFace Blog, huggingface)

Firefox anuncia transição para IA, gerando controvérsia entre usuários : O navegador Firefox anunciou que fará a transição para um navegador de IA, suportando uma série de novos softwares. Essa medida gerou grande insatisfação entre os usuários em comunidades como o Reddit, especialmente aqueles usuários hardcore que valorizam a privacidade e o minimalismo, que acreditam que o Firefox está se desviando de seus valores centrais. Essa transição reflete a estratégia da Mozilla de buscar novos pontos de crescimento na era do “Search is dead”, mas o desafio é como equilibrar as funcionalidades de IA com a privacidade do usuário. (Fonte: 36氪)

ChatGPT lança funcionalidade de fixar chats : A OpenAI anunciou que o ChatGPT agora oferece a funcionalidade de fixar chats, permitindo que os usuários fixem conversas importantes no iOS, Android e web para acesso rápido. Esta atualização visa melhorar a experiência do usuário e simplificar o gerenciamento de conversas. (Fonte: openai, Reddit r/ChatGPT)
Funcionalidades da extensão Claude for Chrome atualizadas : A extensão Claude for Chrome agora está disponível para todos os usuários pagantes e integrou a funcionalidade Claude Code. Os usuários agora podem testar e depurar código diretamente no navegador via Claude Code, sem sair da página atual. Esta atualização visa aumentar a eficiência e a experiência dos desenvolvedores, e a Anthropic também enfatizou as considerações de segurança no design e nos testes. (Fonte: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

🧰 Ferramentas
Agent Skills torna-se um padrão aberto : As Agent Skills da Anthropic agora são um padrão aberto, permitindo que AI Agents aprendam e executem fluxos de trabalho repetitivos em várias plataformas. Essa iniciativa visa simplificar a implantação, descoberta e construção de habilidades, promovendo a interoperabilidade do ecossistema de ferramentas de IA. Os desenvolvedores agora podem criar uma habilidade uma vez e usá-la em múltiplas plataformas de IA, aumentando assim a capacidade de especialização e eficiência dos Agents. (Fonte: omarsar0, code, Reddit r/ClaudeAI)
LangChain Academy lança novo curso : A LangChain Academy lançou um novo curso “Introdução ao LangChain (Python)”, projetado para ajudar desenvolvedores a aprender como construir AI Agents usando o framework LangChain. O curso abrange a criação de Agents, o uso de módulos de construção centrais (modelos, mensagens, memória, ferramentas) e como usar LangSmith para depuração de comportamento, com o objetivo final de permitir que os alunos montem uma equipe completa de assistentes pessoais. (Fonte: LangChainAI, hwchase17)

Configuração avançada de desenvolvimento Claude Code CLI : Um desenvolvedor compartilhou sua configuração “super-engenharia” do Claude Code CLI, que combina um servidor MCP, habilidades personalizadas e um arquivo CLAUDE.md rigoroso para alcançar “Vibe Coding” para código de nível de produção. Esse método, através de portões de qualidade, ciclos iterativos e testes no navegador, impede efetivamente que o Agent se desvie e permite refatoração eficiente, resolvendo os pontos problemáticos encontrados pelos Agents tradicionais no desenvolvimento real. (Fonte: Reddit r/ClaudeAI)
OpenRouter lança funcionalidade de correção de saída JSON de LLM : O OpenRouter introduziu a funcionalidade “Response Healing”, que corrige automaticamente erros na saída JSON estruturada gerada por Large Language Models (LLMs). Essa funcionalidade reduziu significativamente a taxa de defeitos de modelos como Gemini 2 Flash e Qwen3 235B, melhorando a confiabilidade dos LLMs em cenários que exigem saída JSON precisa. (Fonte: xanderatallah)

Ferramenta de transcrição de áudio da AssemblyAI suporta entrada de URL : O AssemblyAI Playground foi atualizado e agora suporta a transcrição de áudio diretamente de uma URL. Os usuários podem testar podcasts, áudio na nuvem ou arquivos grandes (como teleconferências de resultados) sem a necessidade de baixar os arquivos, simplificando drasticamente o desenvolvimento de protótipos e os processos de verificação de integração, e melhorando a eficiência dos testes das capacidades de Speech AI. (Fonte: AssemblyAI)
jax-js: Biblioteca de machine learning para navegador : jax-js é uma biblioteca de machine learning de código aberto que reimplementa JAX em JavaScript puro e suporta compilação JIT para WebGPU, permitindo que redes neurais sejam executadas no navegador. A biblioteca oferece funcionalidades como diferenciação automática e compilação JIT, visando fornecer um modelo de programação eficiente e flexível semelhante ao PyTorch e JAX, e sua interatividade foi verificada através de demonstrações autocontidas como treinamento MNIST e inferência MobileCLIP. (Fonte: Vtrivedy10, Reddit r/MachineLearning)

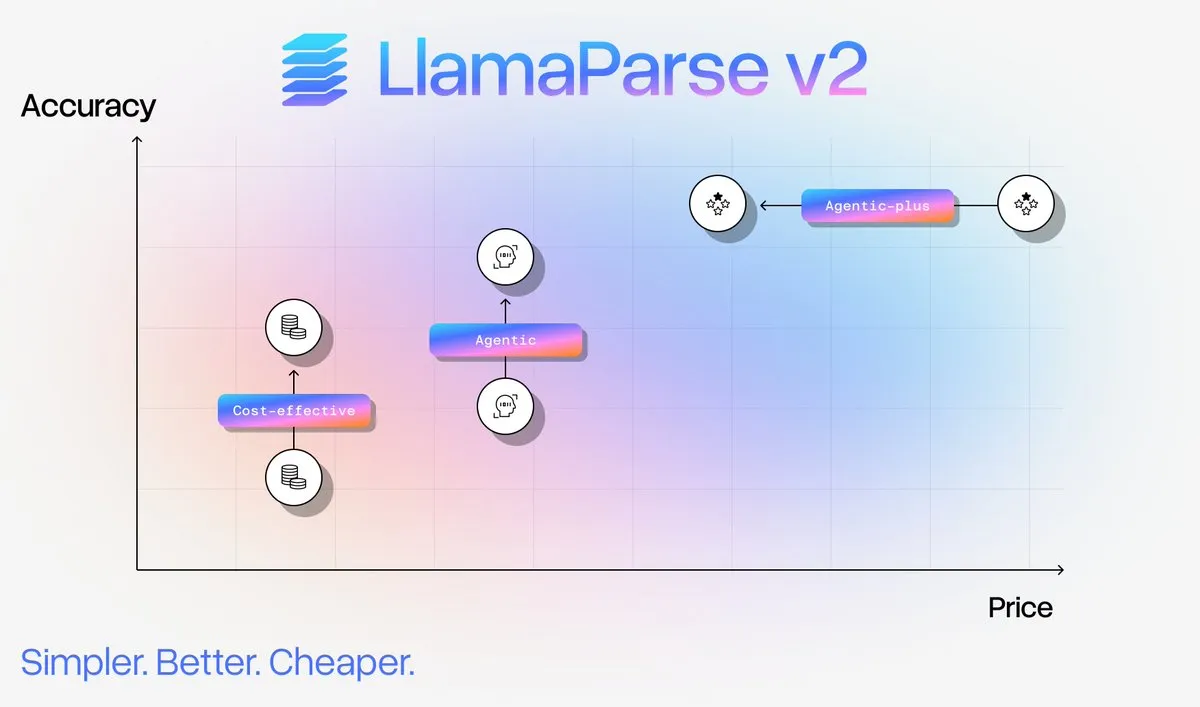
Serviço de parsing de documentos LlamaParse v2 atualizado : A LlamaIndex lançou o LlamaParse v2, que simplifica significativamente a configuração de parsing de documentos, melhora o desempenho e oferece uma redução de custos de até 50% para parsing de documentos complexos. A nova versão introduz quatro níveis fixos: Fast, Cost Effective, Agentic e Agentic Plus, aumentando a precisão do conteúdo multimodal, reduzindo as alucinações e permitindo que os usuários realizem a ingestão de documentos de nível de produção sem a necessidade de ser um especialista em parsing. (Fonte: jerryjliu0)
Locally AI: Aplicativo para executar modelos de IA localmente : Locally AI é um aplicativo que permite aos usuários executar modelos de IA localmente em seus dispositivos diários, e foi listado como “Favorito da Semana” na App Store devido à sua conveniência. O aplicativo visa reduzir a barreira de entrada para o uso de IA, permitindo que mais pessoas interajam facilmente com modelos de IA locais, enfatizando a facilidade de uso e acessibilidade da IA local. (Fonte: adrgrondin)
Google Flow de geração de imagens suporta download em alta resolução : A funcionalidade Nano Banana Pro do Google Flow agora suporta o download de imagens geradas por IA em resoluções 2K e 4K. Essa atualização atende à demanda dos usuários por imagens de maior resolução, seja para material criativo, sequências de quadros ou efeitos visuais, permitindo obter conteúdo gerado por IA mais nítido e detalhado. (Fonte: op7418)

Usuários do OpenWebUI relatam problemas com a funcionalidade RAG : Usuários do OpenWebUI relatam problemas com a funcionalidade RAG (Retrieval Augmented Generation), especialmente ao processar arquivos PDF maiores que 1MB, onde o modelo não consegue passar o conteúdo do arquivo para o contexto, resultando em um erro de “fonte não encontrada”. Embora o upload do arquivo, a extração de texto e o embedding sejam bem-sucedidos, a etapa de geração de consulta falha, impedindo que o conteúdo do PDF seja usado para inferência do modelo e afetando tarefas como extração de dados estruturados. (Fonte: Reddit r/OpenWebUI, Reddit r/OpenWebUI)

Jogo de aventura textual com IA Glif Agent : O Glif Agent oferece uma experiência de jogo de aventura textual onde os usuários podem mergulhar diretamente, sem a necessidade de guias complexos. Essa ferramenta de IA demonstra o potencial dos LLMs na criação de narrativas interativas e experiências imersivas, permitindo que os jogadores explorem mundos virtuais através de instruções em linguagem natural. (Fonte: NerdyRodent)

Cass: Ferramenta de busca de sessões de Agent de codificação : A ferramenta Cass é aclamada como o “salvador” para Agents de codificação, economizando significativamente tempo e esforço. Ela detecta, ingere e indexa automaticamente todas as sessões CLI de codificação, oferecendo pesquisa instantânea e “modo robô”, permitindo que os usuários encontrem, gerenciem e reutilizem rapidamente os rastros do Agent, melhorando drasticamente a eficiência do uso de Agents de codificação. (Fonte: doodlestein)
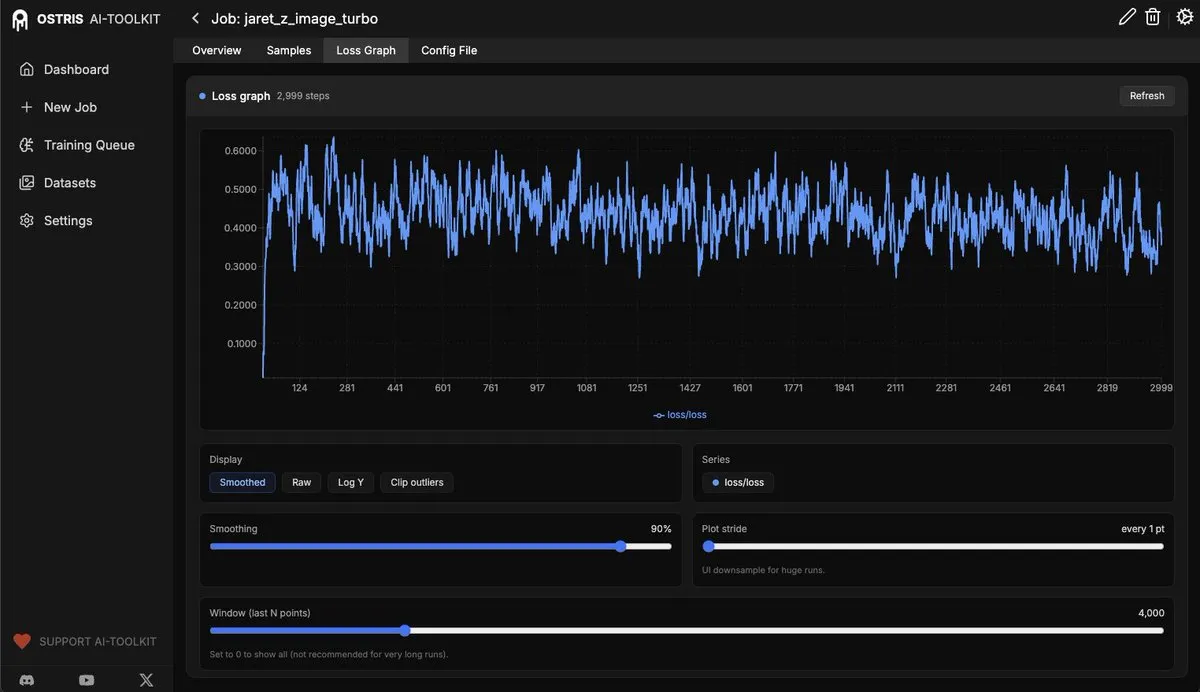
AI Toolkit UI adiciona funcionalidade de gráfico de perda : O AI Toolkit UI foi atualizado, adicionando a funcionalidade de gráfico de perda (loss graph) para monitorar o processo de fine-tuning de modelos de difusão (diffusion models). Essa funcionalidade fornecerá aos usuários um feedback mais intuitivo sobre o treinamento do modelo, e mais funcionalidades serão adicionadas no futuro para melhorar a eficiência do desenvolvimento e depuração de modelos de IA. (Fonte: ostrisai)
📚 Aprendizagem
Novo curso Nvidia NeMo Agent Toolkit : A DeepLearning.AI lançou um novo curso sobre o Nvidia NeMo Agent Toolkit, onde o especialista da NVIDIA, Brian, ensina como usar o toolkit para construir AI Agents confiáveis e de nível de produção. O curso abrange fluxos de trabalho orientados por configuração, observabilidade através de rastreamento, avaliação de sistema usando conjuntos de dados de padrão ouro e implantação de sistemas multi-Agent, visando ajudar os desenvolvedores a transformar protótipos de Agent em sistemas de produção confiáveis. (Fonte: AndrewYNg)
Recursos de aprendizagem de IA e revisão de conceitos : Uma série de recursos de aprendizagem de IA foi compartilhada, incluindo a última edição do Deep Learning Weekly, cobrindo Agents auto-otimizados, bugs em benchmarks de IA, guias de treinamento de RL, entre outros; além de um roteiro para dominar a IA Agentic, uma revisão dos conceitos centrais de IA para 2025 (aprendizagem por reforço, variantes de RLHF, aprendizagem contínua, IA neuro-simbólica, hardware de IA, etc.), e os mais recentes avanços na pesquisa de segurança de IA. (Fonte: dl_weekly, TheTuringPost, Ronald_vanLoon, AndrewYNg, ajeya_cotra)
Capítulo do livro “Visual Language Models” lançado : O quinto capítulo do livro “Visual Language Models” foi lançado, com foco no pré-treinamento e oferecendo ilustrações e orientação prática. Isso fornece um recurso valioso para estudantes de IA que desejam compreender profundamente os mecanismos de pré-treinamento de modelos de linguagem visual. (Fonte: algo_diver)
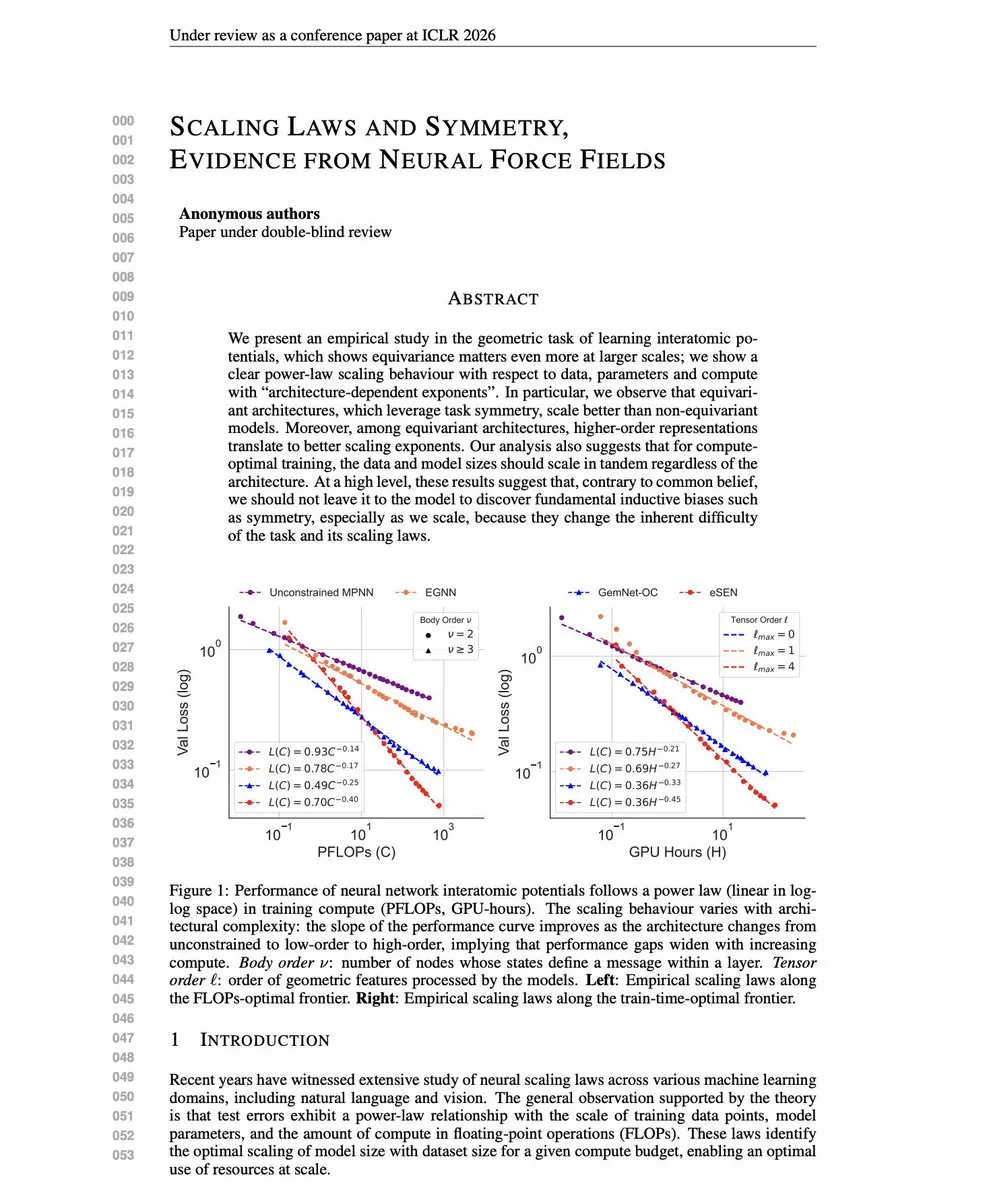
Artigo atualizado sobre Sistemas de Pesquisa Orientados por IA (ADRS) : O Sistema de Pesquisa Orientado por IA (ADRS) publicou um artigo atualizado, avaliando o desempenho de três frameworks de código aberto na resolução de 10 problemas de desempenho de sistemas do mundo real. A pesquisa mostra que as soluções geradas por IA podem alcançar uma aceleração de 13x no balanceamento de carga e economizar 35% nos custos de agendamento em nuvem, superando até mesmo especialistas humanos, fornecendo fortes evidências para a aplicação da IA na pesquisa de sistemas. (Fonte: matei_zaharia)

💼 Negócios
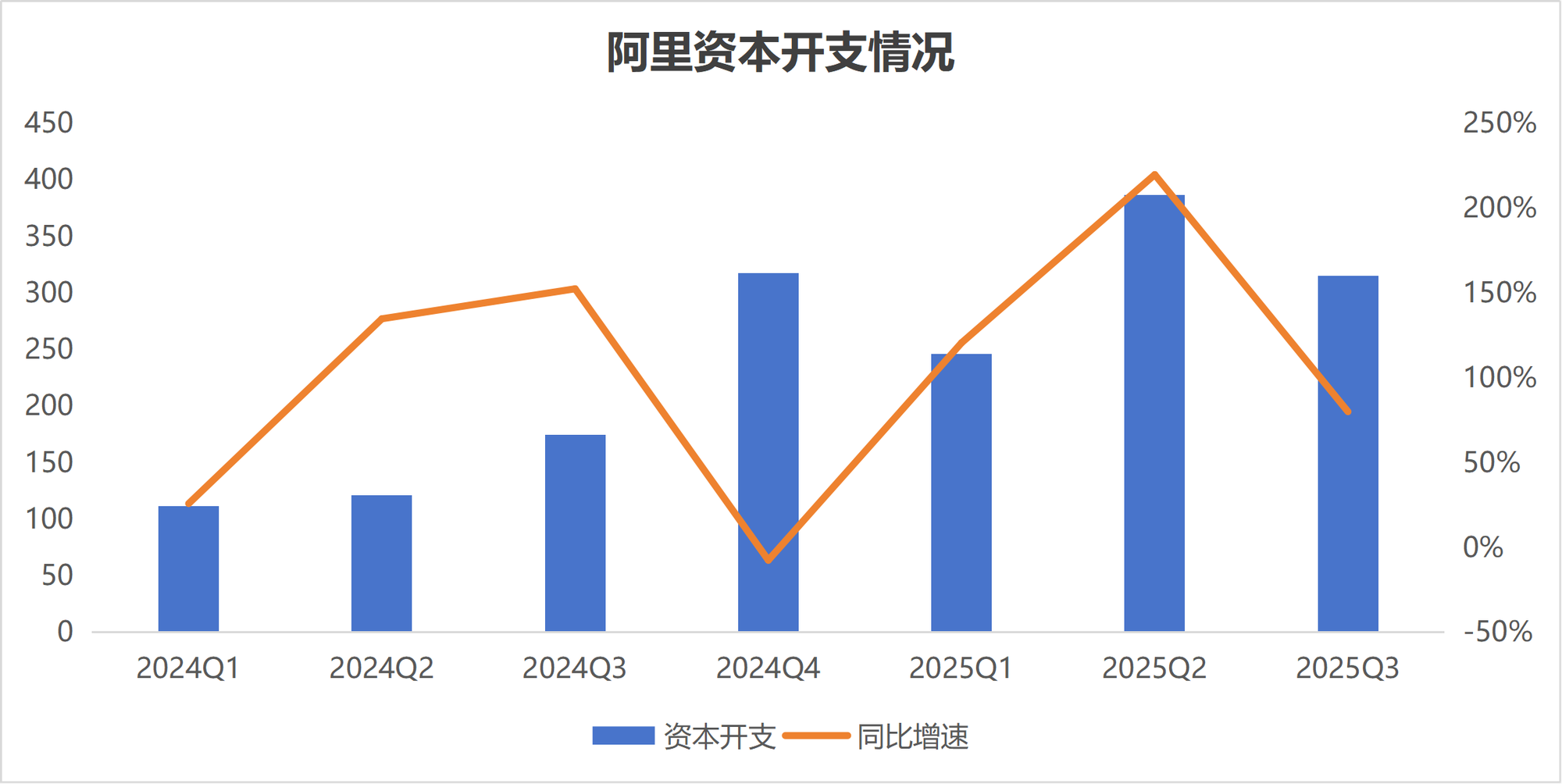
Divergência de investimento em IA: Estratégias distintas de Alibaba e Tencent : Diante da onda de IA, as estratégias de investimento em IA das duas maiores gigantes de tecnologia chinesas, Alibaba e Tencent, mostram diferenças claras. A Alibaba está acelerando o investimento na construção de infraestrutura de IA, planejando investir mais de 380 bilhões de yuans nos próximos três anos, visando tornar-se uma empresa de infraestrutura que fornece “água, eletricidade e gás” de IA. A Tencent, por outro lado, tende a ser “calma”, reduziu suas projeções de despesas de capital, focando mais no empoderamento da IA no lado da aplicação, e introduziu o ex-cientista da OpenAI, Yao Shunyu, para fortalecer a estratégia de IA, inclinando-a para o lado da aplicação. Essa divergência reflete diferentes julgamentos sobre os caminhos de comercialização na era da IA. (Fonte: 36氪)
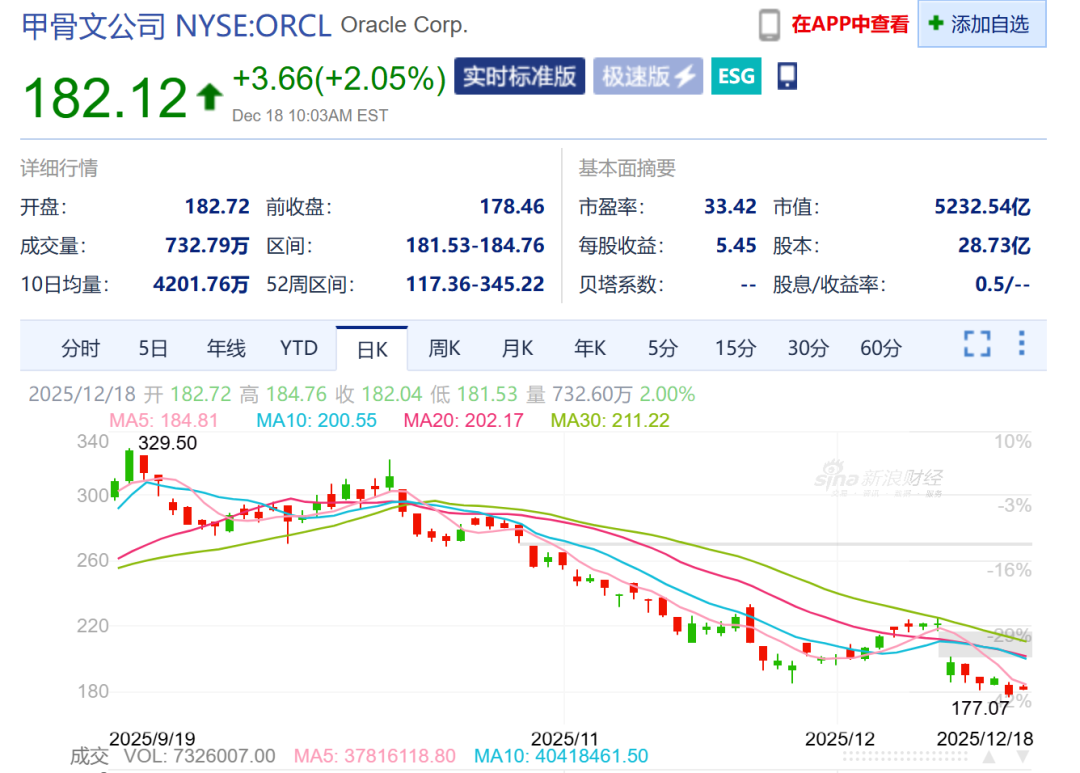
Financiamento de projeto de bilhões da Oracle “fracassa”, gerando temores de bolha de IA : O financiamento de dezenas de bilhões da Oracle para um projeto de data center nos EUA “fracassou”, com o principal apoiador Blue Owl Capital retirando seu investimento, gerando pânico no mercado sobre a bolha da IA. O incidente destaca a incerteza dos investidores sobre os enormes custos de investimento e o cronograma de monetização no ciclo de infraestrutura de IA. Analistas questionam se a OpenAI pode cumprir sua promessa de pagamento por poder computacional à Oracle, bem como o problema da rápida expansão do balanço da Oracle, indicando que a competição de IA está entrando em um “período de teste de fluxo de caixa”. (Fonte: 36氪)
Brett Adcock funda novo laboratório de IA Hark : Brett Adcock, CEO da Figure AI, anunciou a fundação de um novo laboratório de IA, Hark, e investiu 100 milhões de dólares de fundos pessoais. O laboratório Hark se concentrará em pesquisa de “IA centrada no ser humano”, enquanto Adcock continuará em seu cargo na Figure AI. Essa medida marca a atenção contínua no campo da IA à interação humano-máquina e à ética, e também injeta novo capital privado na pesquisa de IA. (Fonte: steph_palazzolo)
🌟 Comunidade
Controvérsia sobre desempenho de LLM e experiência do usuário : Há uma ampla controvérsia nas redes sociais sobre o desempenho real do GPT-5.2. Muitos usuários reclamam de uma experiência de uso diário insatisfatória, alucinações ou desempenho medíocre em tarefas simples, em contraste com o “mais inteligente” nos benchmarks. Essa desconexão gerou discussões sobre a direção do desenvolvimento de modelos de IA: buscar inteligência de nível de competição ou praticidade diária? Ao mesmo tempo, alguns usuários compartilharam preocupações com a queda de desempenho do modelo Opus 4.5, bem como os desafios dos LLMs na depuração e compreensão da intenção do usuário, como as dificuldades do Claude Code ao lidar com código complexo. (Fonte: VictorTaelin, aidan_mclau, 36氪, dbreunig, Reddit r/ChatGPT, Reddit r/artificial)
Impacto da IA no trabalho e na sociedade : As redes sociais discutem amplamente o impacto da IA no mercado de trabalho, incluindo preocupações de que empregos de colarinho branco possam enfrentar um “colapso”, bem como o potencial da IA para aumentar a produtividade. Ao mesmo tempo, o nível de conhecimento público sobre IA é desigual, com muitas pessoas erroneamente pensando que o ChatGPT busca respostas em um banco de dados. Além disso, a tecnologia de IA também reduziu a barreira para desinformação e fraude, gerando preocupações com os mecanismos de auditoria da plataforma e o custo da auto-verificação pessoal. Há também a visão de que o progresso da IA é mais como “novos trens correndo em trilhos antigos”, e que os gargalos nas aplicações práticas são mais frequentemente fatores sociais, econômicos e políticos. (Fonte: random_walker, Reddit r/ArtificialInteligence, Plinz, doodlestein, amasad, 36氪, gfodor, Reddit r/ArtificialInteligence)
Ética e segurança da IA : As discussões nas redes sociais sobre ética e segurança da IA são acaloradas. Incluem acusações de plágio contra pioneiros da IA como Hinton, casos de modelos de IA causando prisões erradas em aplicações como reconhecimento facial, e os riscos trazidos por conteúdo gerado por IA (como a máquina de venda automática de IA testada pelo WSJ que saiu do controle). A OpenAI publicou “Model Specifications” para guiar o comportamento do modelo, e o Google DeepMind lançou a tecnologia de marca d’água SynthID para detectar vídeos gerados por IA. Além disso, a enorme pegada ambiental da IA (consumo de água e emissões de carbono) também gerou preocupação, bem como as considerações éticas da IA ao fornecer suporte emocional. (Fonte: SchmidhuberAI, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Ronald_vanLoon, AnthropicAI, ajeya_cotra, Reddit r/MachineLearning)
Desenvolvimento e desafios de AI Agent : O desenvolvimento e a aplicação de AI Agents tornaram-se um tópico quente, com discussões abrangendo sua arquitetura (módulos componíveis, gerenciamento de memória), padrões abertos (Agent Skills), e práticas em áreas como robótica (Reachy Mini, robôs Grek, robôs Bipedal Gait, robôs móveis autônomos) e programação (Claude MCP Agent). Os desafios incluem como melhorar a confiabilidade do Agent, lidar com contexto longo, otimizar a infraestrutura para suportar a colaboração multi-Agent, e como garantir a estabilidade do Agent em tarefas complexas e evitar “loops infinitos”. (Fonte: Vtrivedy10, julesagent, LangChainAI, TheTuringPost, Ronald_vanLoon, Sentdex, ClementDelangue, doodlestein, corbtt, Ronald_vanLoon)
Pesquisa de LLM e características do modelo : A comunidade de IA discute a pesquisa de LLM, abrangendo funções de valor em Reinforcement Learning (RL), a praticidade de LoRA RL, avaliação das capacidades do GPT-4, o debate entre RL e LLMs pós-treinamento, a aplicação de LLMs na pesquisa matemática, e discussões sobre questões filosóficas como consciência de IA e “alimento para o pensamento”. Além disso, há foco em novas arquiteturas de LLM (como LLMs de difusão, modelos de mundo DexWM), leis de densidade de modelos, desafios do processamento de contexto longo, e avaliação de desempenho de modelos específicos como Kimi K2 e MiMo-V2. (Fonte: natolambert, vllm_project, SebastienBubeck, sarahcat21, karpathy, riemannzeta, _akhaliq, code_star, DeepLearningAI, ollama, gdb, yacinelearning, ylecun, pmddomingos, matei_zaharia, TheTuringPost, yacinelearning, MiniMax__AI, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/LocalLLaMA)
Infraestrutura e hardware de IA : A infraestrutura e o hardware de IA são tópicos quentes, incluindo o framework MLX que alcança inferência paralela de tensor de baixa latência em Macs, a importância de bancos de dados vetoriais como Qdrant e Turbopuffer na era Agentic, e os custos e desafios da construção de clusters de GPU (como 8x B200 ou clusters Mac Studio). As discussões também abordam a otimização de treinamento distribuído (SonicMoE), os gargalos de backends serverless para Agents, e as preocupações com o consumo de energia de data centers de IA. (Fonte: awnihannun, qdrant_engine, TheEthanDing, Dorialexander, halvarflake, matei_zaharia, togethercompute, andersonbcdefg, idavidrein, Reddit r/deeplearning, Reddit r/MachineLearning, Reddit r/LocalLLaMA, Reddit r/MachineLearning, StasBekman, HuggingFace Daily Papers)

Arte e aplicações de IA Generativa : A discussão gira em torno dos avanços da IA generativa nas áreas de arte e aplicação. Os modelos Runway Gen-4.5 e GWM-1 impulsionam a geração de vídeo em direção à simulação de mundo universal, e DALL-E 3 e Gemini são usados para geração de imagens, incluindo a melhoria do realismo da imagem, criação de conteúdo 3D e conversão de estilo artístico. A comunidade também explorou a percepção de conteúdo gerado por IA (AIGC), por exemplo, quando a qualidade de obras de mídia criadas por IA é tão alta que o público duvida se foram geradas por IA, é um elogio ou uma ofensa. Além disso, a IA também é foco de atenção em aplicações de pesquisa como resolução de problemas matemáticos e conversão de código. (Fonte: c_valenzuelab, BlackHC, nptacek, yupp_ai, nptacek, claud_fuen, dotey, ylecun, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Outros
Princípios de engenharia de IA : As discussões nas redes sociais enfatizam que a engenharia de IA deve seguir os princípios centrais da engenharia tradicional, como controle de versão, testes e observabilidade de produção. A visão é que o uso de LLMs não deve alterar essas práticas básicas, mas sim integrá-las nos processos de desenvolvimento de IA para garantir a confiabilidade e qualidade do sistema. (Fonte: imjaredz)
Processamento de dados em larga escala por LLM : Discussão sobre o tema subestimado do processamento de dados em larga escala por LLMs. Enfatiza-se que, ao lidar com grandes volumes de dados, os LLMs devem ser tratados como operadores de banco de dados, utilizando técnicas como mapeamento semântico, filtragem e redução. Ao mesmo tempo, através de estratégias de otimização de custos como cascata de tarefas, é possível reduzir significativamente os custos de processamento de dados por LLMs, mantendo a precisão, alcançando um equilíbrio entre eficiência e economia. (Fonte: HamelHusain)
Insights da IA sobre cognição e aprendizagem humana : Um pesquisador de IA, através de 5000 horas de experiência no jogo “Tekken”, explora como os humanos constroem modelos preditivos sob restrições de tempo extremas, e a relação com modelos de mundo de IA e aprendizagem preditiva. Ele acredita que os jogos de luta forçam os jogadores a prever em vez de simplesmente reagir, o que mapeia os desafios na pesquisa de IA de construir modelos de mundo internos, ler padrões a partir de informações parciais e adaptar-se a falhas de previsão, oferecendo uma perspectiva única para entender a inteligência além da IA de jogos. (Fonte: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)