
Palabras clave:Proyecto Manhattan de IA, Gemini 3 Flash, GPT-5.2-Codex, Fusión nuclear controlada, Ingeniería de investigación en IA, Agente de IA, Modelo multimodal, Modelo de IA de código abierto, Misión Génesis del Departamento de Energía de EE.UU., Prueba de codificación Gemini 3 Flash, Defensa de ciberseguridad GPT-5.2-Codex, Modelo multimodal T5Gemma 2, Separación de audio Perception Encoder Audiovisual
🔥 Enfoque
Lanzamiento del “Proyecto Manhattan de IA” de EE. UU. : El Departamento de Energía de EE. UU. ha lanzado oficialmente la “Misión Génesis”, un proyecto nacional de investigación en AI que busca combinar la tecnología de AI de vanguardia con las capacidades de investigación de los laboratorios nacionales para acelerar los descubrimientos científicos. El plan reúne a 24 gigantes tecnológicos, incluidos Microsoft, Google, NVIDIA, OpenAI, DeepMind y Anthropic, para aplicar modelos de AI y capacidades de supercomputación en campos como la fusión nuclear controlada, materiales energéticos y simulación climática. El objetivo es duplicar la productividad científica de EE. UU. para 2030, lo que marca un ajuste estratégico a nivel nacional en el ámbito tecnológico. (Fuente: 36氪, nvidia, AnthropicAI, GoogleDeepMind, OpenAI Newsroom)
Hinton y Jeff Dean dialogan sobre la AI moderna : Geoffrey Hinton, pionero de las redes neuronales, y Jeff Dean, científico jefe de Google, conversaron en la conferencia NeurIPS sobre los factores clave que llevaron a la AI moderna del laboratorio a miles de millones de usuarios. Argumentaron que el avance de la AI no fue un milagro singular, sino el resultado de la madurez sistémica de algoritmos (como Transformer), hardware (como GPU, TPU) y sistemas de ingeniería (como JAX, Pathways). La conversación también señaló que la escalabilidad de la AI enfrenta tres umbrales principales: eficiencia energética, memoria (contexto largo) y creatividad (capacidad de asociación), enfatizando la importancia de la investigación fundamental y la inversión continua. (Fuente: 36氪, JeffDean, geoffreyhinton)
Entrevista a Sam Altman: Estrategia y financiación de OpenAI : Sam Altman señaló en una entrevista reciente que Google sigue siendo la mayor amenaza para OpenAI, pero OpenAI consolidará su ventaja a través de software nativo de AI, funciones de personalización y memoria, expansión acelerada en el mercado empresarial y una inversión de 1,4 billones de dólares en infraestructura. Predijo que GPT-6 podría lanzarse en el primer trimestre del próximo año y enfatizó que la AI remodelará la forma en que se usa el software en el futuro, convirtiéndose en un “compañero digital” insustituible, en lugar de simplemente incrustarse en productos antiguos. (Fuente: 36氪, sama)
Google lanza el modelo Gemini 3 Flash : Google ha lanzado Gemini 3 Flash, un modelo que destaca por su excelente rendimiento en varias pruebas de referencia con una relación calidad-precio y velocidad extremadamente altas, superando incluso a GPT-5.2 en la prueba de codificación SWE-bench. Google planea integrarlo profundamente en productos de su ecosistema como Search, YouTube y Gmail, con el objetivo de remodelar el panorama del mercado de la AI a través de ventajas del ecosistema en lugar de la mera competencia de parámetros del modelo. Este lanzamiento se considera un “golpe preciso” contra OpenAI, lo que ha provocado una amplia discusión en la industria sobre la competencia de modelos y la popularización de las aplicaciones de AI. (Fuente: 36氪, MS_BASE44, GeminiApp, scaling01)
OpenAI lanza el modelo de programación GPT-5.2-Codex : OpenAI ha lanzado GPT-5.2-Codex, promocionándolo como su modelo de programación de agente de AI más potente hasta la fecha, optimizado para ingeniería de software compleja y ciberseguridad. Este modelo mejora la ejecución de tareas a largo plazo, los cambios de código a gran escala, la compatibilidad con entornos Windows y las capacidades de defensa en ciberseguridad. Aunque muestra un rendimiento sólido en las pruebas de referencia, algunos usuarios han informado que en ciertas tareas no supera a Gemini 3 Flash, lo que ha generado debate en el mercado sobre su eficacia real y competitividad. (Fuente: 36氪, sama, scaling01)
🎯 Tendencias
Google lanza T5Gemma 2 y FunctionGemma de código abierto : Google ha lanzado dos modelos pequeños de código abierto, T5Gemma 2 y FunctionGemma, ambos basados en la familia Gemma 3. T5Gemma 2 es el primer modelo codificador-decodificador multimodal de contexto largo, con un tamaño mínimo de 270M-270M, centrado en la eficiencia arquitectónica y las capacidades multimodales. FunctionGemma es un modelo de 270M optimizado para llamadas a funciones, capaz de ejecutarse en dispositivos de borde como teléfonos, con el objetivo de resolver el problema de que los modelos grandes “pueden hablar pero no actuar”, proporcionando un cerebro dedicado para agentes y uso de herramientas. (Fuente: 36氪, huggingface, osanseviero, ImazAngel, danielhanchen)

Prueba del modelo Doubao 1.8 de ByteDance : ByteDance ha lanzado el modelo grande Doubao 1.8, su nueva generación de modelo principal, que se encuentra en un nivel líder en pruebas de evaluación para múltiples escenarios como educación, servicio al cliente, finanzas y derecho. Las pruebas reales muestran que Doubao 1.8 sobresale en la capacidad de Agent (llamadas a múltiples herramientas, seguimiento de instrucciones de múltiples rondas, OS Agent), gestión de contexto ultra largo de 256K y comprensión multimodal (la capacidad de comprensión de video se ha mejorado a 20 minutos), siendo especialmente adecuado para construir Agents complejos y ejecutar procesos reales, lo que se considera un paso clave para impulsar el desarrollo de Agents empresariales y de dispositivos. (Fuente: WeChat)

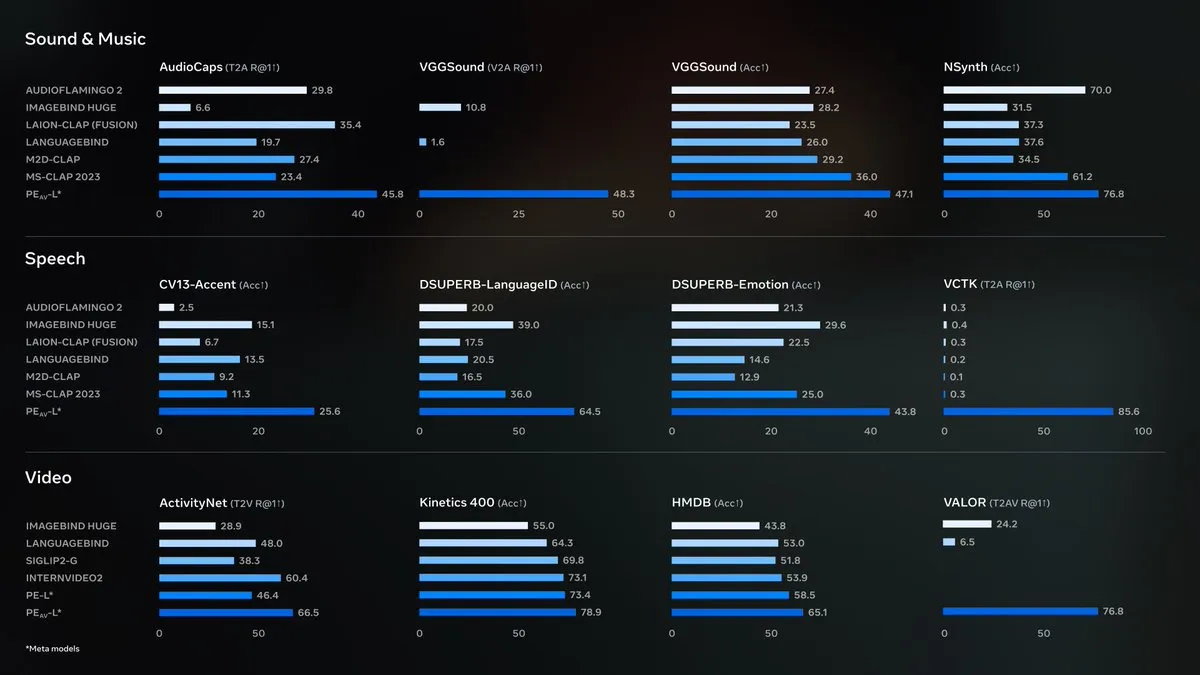
Meta lanza Perception Encoder Audiovisual (PE-AV) de código abierto : Meta ha lanzado Perception Encoder Audiovisual (PE-AV) de código abierto, el motor tecnológico central detrás de SAM Audio, diseñado para lograr una separación de audio de última generación. PE-AV se basa en el modelo Perception Encoder lanzado anteriormente por Meta, integrando profundamente la percepción de audio y visual, logrando resultados sobresalientes en una amplia gama de pruebas de referencia de audio y video, y se espera que mejore la detección de sonido y la comprensión de escenas audiovisuales a través del soporte multimodal. (Fuente: AIatMeta, Reddit r/LocalLLaMA)
Runway lanza los modelos Gen-4.5 y GWM-1 : Runway ha lanzado el modelo de generación de video Gen-4.5, que añade funciones de edición de audio y multicámara, y también ha presentado la serie GWM-1 (General World Model), que incluye GWM Worlds (escenas navegables), GWM Robotics (simulación de perspectiva de robot) y GWM Avatars (personajes con sincronización labial), con el objetivo de lograr una generación de video de modelo mundial en tiempo real y controlable, lo que presagia un salto significativo en la tecnología de generación de video hacia la simulación universal. (Fuente: c_valenzuelab, DeepLearningAI)
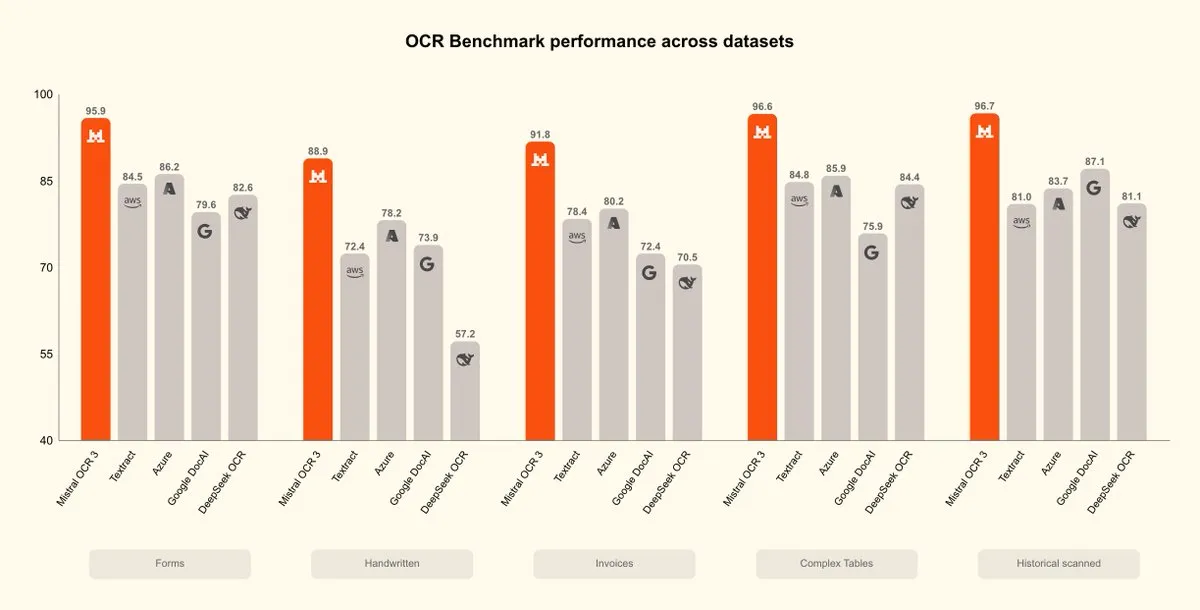
Mistral OCR 3 lanzado, un nuevo avance en la inteligencia documental : Mistral AI ha lanzado el modelo Mistral OCR 3, estableciendo un nuevo estándar en precisión y eficiencia, superando las soluciones existentes de procesamiento de documentos empresariales y OCR nativo de AI. El modelo ha sido optimizado extensamente para manejar contenido manuscrito, escaneos de baja calidad y tablas y formularios complejos comunes en documentos empresariales, lo que marca un nuevo progreso en el campo de la inteligencia documental. (Fuente: qtnx_, GuillaumeLample)
Reestructuración de Tokenization en Hugging Face Transformers v5 : Hugging Face Transformers v5 ha realizado un rediseño significativo en la forma en que funcionan los tokenizers. La nueva versión separa la arquitectura del tokenizer del vocabulario de entrenamiento, lo que mejora la transparencia, la modularidad y simplifica el proceso de entrenamiento de tokenizers específicos del modelo desde cero. Esta mejora hace que los tokenizers sean más fáciles de inspeccionar, personalizar y entrenar, resolviendo los problemas de opacidad y acoplamiento estrecho de los tokenizers en v4. (Fuente: HuggingFace Blog, huggingface)

Firefox anuncia su transformación a AI, generando controversia entre los usuarios : El navegador Firefox ha anunciado su transformación en un navegador de AI, compatible con una serie de nuevos softwares. Esta medida ha provocado una gran insatisfacción entre los usuarios, especialmente aquellos que valoran la privacidad y el minimalismo en comunidades como Reddit, quienes creen que Firefox se está desviando de sus valores fundamentales. Esta transformación refleja la estrategia de Mozilla de buscar nuevos puntos de crecimiento en la era de la “búsqueda muerta”, pero el equilibrio entre las funciones de AI y la privacidad del usuario es un gran desafío al que se enfrenta. (Fuente: 36氪)

ChatGPT lanza la función de fijar chats : OpenAI ha anunciado que ChatGPT ahora cuenta con una función de fijar chats, permitiendo a los usuarios fijar conversaciones importantes en iOS, Android y la web para un acceso rápido. Esta actualización tiene como objetivo mejorar la experiencia del usuario y simplificar la gestión de conversaciones. (Fuente: openai, Reddit r/ChatGPT)
Actualización de las funciones de la extensión Claude for Chrome : La extensión Claude for Chrome ya está disponible para todos los usuarios de pago y ha integrado la función Claude Code. Los usuarios ahora pueden probar y depurar código directamente en el navegador a través de Claude Code, sin necesidad de salir de la página actual. Esta actualización tiene como objetivo mejorar la eficiencia y la experiencia de los desarrolladores, y Anthropic también ha enfatizado la consideración de la seguridad en el diseño y las pruebas. (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

🧰 Herramientas
Agent Skills se convierte en un estándar abierto : Las Agent Skills de Anthropic ahora son un estándar abierto, lo que permite a los AI Agents aprender y ejecutar flujos de trabajo repetitivos en múltiples plataformas. Esta iniciativa tiene como objetivo simplificar la implementación, el descubrimiento y la construcción de habilidades, promoviendo la interoperabilidad del ecosistema de herramientas de AI. Los desarrolladores ahora pueden crear una habilidad una vez y usarla en múltiples plataformas de AI, mejorando así la capacidad de especialización y la eficiencia de los Agents. (Fuente: omarsar0, code, Reddit r/ClaudeAI)
LangChain Academy lanza un nuevo curso : LangChain Academy ha lanzado el nuevo curso “Introducción a LangChain (Python)”, diseñado para ayudar a los desarrolladores a aprender a construir AI Agents utilizando el framework LangChain. El curso cubre la creación de Agents, el uso de módulos de construcción centrales (modelos, mensajes, memoria, herramientas) y cómo utilizar LangSmith para la depuración de comportamiento, con el objetivo final de permitir a los estudiantes formar un equipo completo de asistentes personales. (Fuente: LangChainAI, hwchase17)

Configuración avanzada de desarrollo de Claude Code CLI : Un desarrollador compartió su configuración “sobredimensionada” de Claude Code CLI, que combina un servidor MCP, habilidades personalizadas y un archivo CLAUDE.md estricto para lograr una “Vibe Coding” de código de nivel de producción. Este método, a través de puertas de calidad, bucles iterativos y pruebas en el navegador, previene eficazmente que el Agent se desvíe y permite una refactorización eficiente, resolviendo los puntos débiles encontrados en el desarrollo real de Agents tradicionales. (Fuente: Reddit r/ClaudeAI)
OpenRouter lanza la función de reparación de salida JSON de LLM : OpenRouter ha introducido la función “Response Healing”, que repara automáticamente los errores en la salida JSON estructurada generada por los Large Language Models (LLM). Esta función ha reducido significativamente la tasa de defectos de modelos como Gemini 2 Flash y Qwen3 235B, mejorando la fiabilidad de los LLM en escenarios que requieren una salida JSON precisa. (Fuente: xanderatallah)

La herramienta de transcripción de audio de AssemblyAI ahora admite entrada de URL : AssemblyAI Playground se ha actualizado y ahora admite la transcripción de audio directamente desde una URL. Los usuarios pueden probar podcasts, audio en la nube o archivos grandes (como llamadas de ganancias) sin necesidad de descargar archivos, lo que simplifica enormemente el desarrollo de prototipos y los procesos de verificación de integración, mejorando la eficiencia de las pruebas de las capacidades de Speech AI. (Fuente: AssemblyAI)
jax-js: Biblioteca de aprendizaje automático para navegadores : jax-js es una biblioteca de aprendizaje automático de código abierto que reimplementa JAX en JavaScript puro y admite la compilación JIT a WebGPU, lo que le permite ejecutar redes neuronales en el navegador. Esta biblioteca ofrece funciones como la diferenciación automática y la compilación JIT, con el objetivo de proporcionar un modelo de programación eficiente y flexible similar a PyTorch y JAX, y ha sido validada a través de demostraciones autocontenidas como el entrenamiento de MNIST y la inferencia de MobileCLIP para verificar su interactividad. (Fuente: Vtrivedy10, Reddit r/MachineLearning)

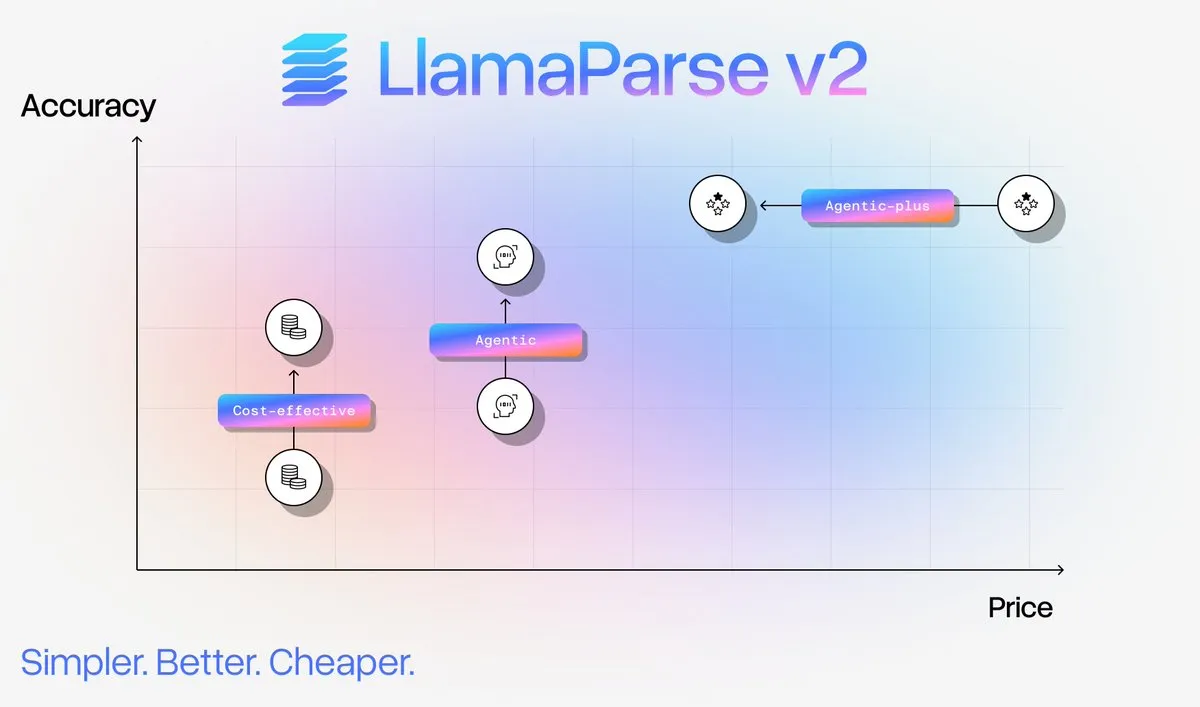
Servicio de análisis de documentos LlamaParse v2 actualizado : LlamaIndex ha lanzado LlamaParse v2, que simplifica significativamente la configuración del análisis de documentos, mejora el rendimiento y reduce los costos hasta en un 50% para el análisis de documentos complejos. La nueva versión introduce cuatro niveles fijos: Fast, Cost Effective, Agentic y Agentic Plus, mejorando la precisión del contenido multimodal y reduciendo las alucinaciones, lo que permite a los usuarios lograr una ingesta de documentos de nivel de producción sin necesidad de ser expertos en análisis. (Fuente: jerryjliu0)
Locally AI: Aplicación para ejecutar modelos de AI localmente : Locally AI es una aplicación que permite a los usuarios ejecutar modelos de AI localmente en sus dispositivos cotidianos, y ha sido incluida en la lista de “Favoritos de la semana” de la App Store por su conveniencia. La aplicación tiene como objetivo reducir la barrera de entrada para el uso de AI, permitiendo que más personas interactúen fácilmente con modelos de AI locales, enfatizando la facilidad de uso y la accesibilidad de la AI local. (Fuente: adrgrondin)
Google Flow de generación de imágenes ahora admite descarga de alta resolución : La función Nano Banana Pro de Google Flow ahora permite descargar imágenes generadas por AI en resoluciones 2K y 4K. Esta actualización satisface la demanda de los usuarios de imágenes de mayor resolución, ya sea para material creativo, secuencias de fotogramas o efectos visuales, lo que permite obtener contenido generado por AI más claro y detallado. (Fuente: op7418)

Usuarios de OpenWebUI reportan problemas con la función RAG : Usuarios de OpenWebUI han reportado problemas con la función RAG (Retrieval-Augmented Generation), especialmente al procesar archivos PDF de más de 1MB, donde el modelo no puede pasar el contenido del archivo al contexto, lo que resulta en un error de “fuente no encontrada”. Aunque la carga del archivo, la extracción de texto y la incrustación son exitosas, el paso de generación de consultas falla, impidiendo que el contenido del PDF se utilice para la inferencia del modelo, lo que afecta tareas como la extracción de datos estructurados. (Fuente: Reddit r/OpenWebUI, Reddit r/OpenWebUI)

Juego de aventura de texto con AI: Glif Agent : Glif Agent ofrece una experiencia de juego de aventura de texto en la que los usuarios pueden sumergirse directamente, sin necesidad de guías complejas. Esta herramienta de AI demuestra el potencial de los LLM para crear narrativas interactivas y experiencias inmersivas, permitiendo a los jugadores explorar mundos virtuales a través de instrucciones en lenguaje natural. (Fuente: NerdyRodent)

Cass: Herramienta de búsqueda de sesiones de Agent de codificación : La herramienta Cass, aclamada como el “salvavidas” para los Agents de codificación, ahorra significativamente tiempo y esfuerzo. Detecta, ingiere e indexa automáticamente todas las sesiones CLI de codificación, ofreciendo búsqueda instantánea y un “modo robot” que permite a los usuarios encontrar, gestionar y reutilizar rápidamente los rastros del Agent, mejorando enormemente la eficiencia del uso de Agents de codificación. (Fuente: doodlestein)
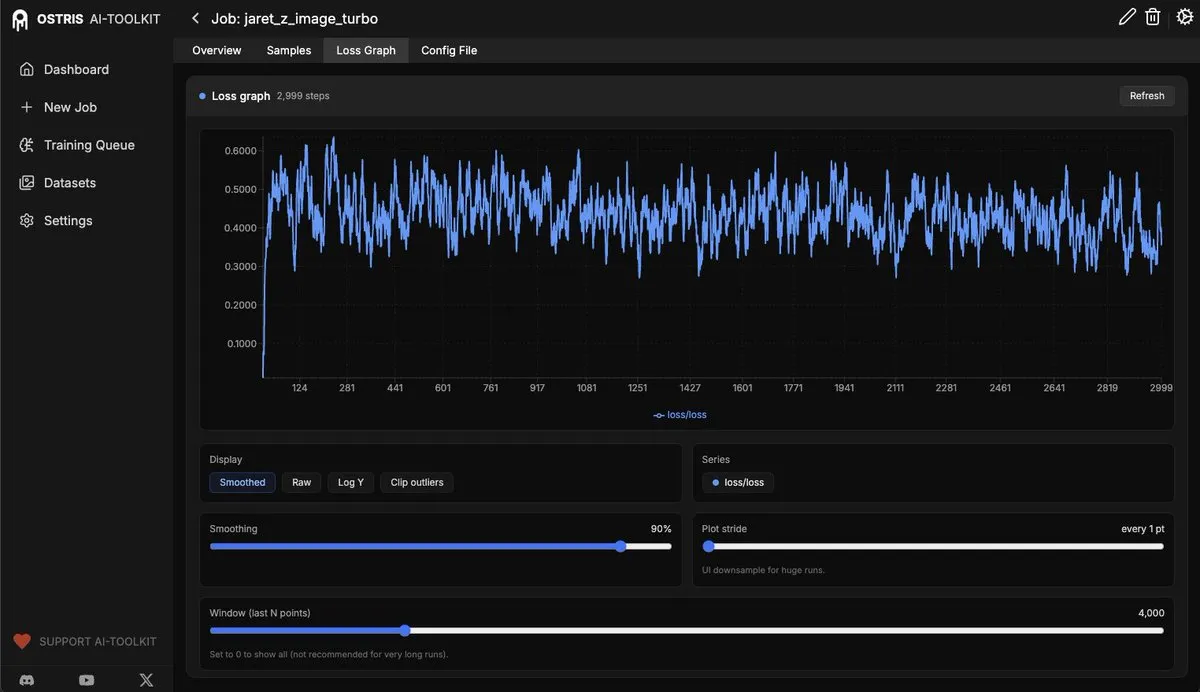
AI Toolkit UI añade la función de gráfico de pérdidas : AI Toolkit UI se ha actualizado, añadiendo la función de gráfico de pérdidas (loss graph) para monitorear el proceso de ajuste fino de los modelos de difusión (diffusion models). Esta función proporcionará a los usuarios una retroalimentación más intuitiva sobre el entrenamiento del modelo, y se añadirán más funciones en el futuro para mejorar la eficiencia del desarrollo y la depuración de modelos de AI. (Fuente: ostrisai)
📚 Aprendizaje
Nuevo curso de Nvidia NeMo Agent Toolkit : DeepLearning.AI ha lanzado un nuevo curso de Nvidia NeMo Agent Toolkit, donde el experto de NVIDIA Brian enseña cómo utilizar este kit de herramientas para construir AI Agents fiables y de nivel de producción. El curso cubre flujos de trabajo basados en configuración, observabilidad a través de seguimiento, evaluación del sistema utilizando conjuntos de datos de referencia (golden standard datasets) y despliegue de sistemas multi-Agent, con el objetivo de ayudar a los desarrolladores a transformar prototipos de Agent en sistemas de producción fiables. (Fuente: AndrewYNg)
Recursos de aprendizaje y revisión de conceptos de AI : Se comparte una serie de recursos de aprendizaje de AI, incluyendo la última edición de Deep Learning Weekly, que cubre Agents auto-optimizadores, errores en los benchmarks de AI, guías de entrenamiento de RL, etc.; además, una hoja de ruta para dominar la AI Agentic, una revisión de los conceptos centrales de AI para 2025 (aprendizaje por refuerzo, variantes de RLHF, aprendizaje continuo, AI neurosimbólica, hardware de AI, etc.), y los últimos avances en investigación de seguridad de AI. (Fuente: dl_weekly, TheTuringPost, Ronald_vanLoon, AndrewYNg, ajeya_cotra)
Capítulo del libro “Visual Language Models” publicado : Se ha publicado el quinto capítulo del libro “Visual Language Models”, que se centra en el preentrenamiento y ofrece ilustraciones y orientación práctica. Esto proporciona un recurso valioso para los estudiantes de AI que buscan una comprensión profunda de los mecanismos de preentrenamiento de los modelos de lenguaje visual. (Fuente: algo_diver)
Actualización del artículo sobre Sistemas de Investigación Impulsados por AI (ADRS) : Los Sistemas de Investigación Impulsados por AI (ADRS) han publicado un artículo actualizado que evalúa el rendimiento de tres frameworks de código abierto en la resolución de 10 problemas de rendimiento de sistemas del mundo real. La investigación muestra que las soluciones generadas por AI pueden lograr una aceleración de 13 veces en el equilibrio de carga y un ahorro de costos del 35% en la programación en la nube, superando incluso a los expertos humanos, lo que proporciona una fuerte evidencia para la aplicación de la AI en la investigación de sistemas. (Fuente: matei_zaharia)

💼 Negocios
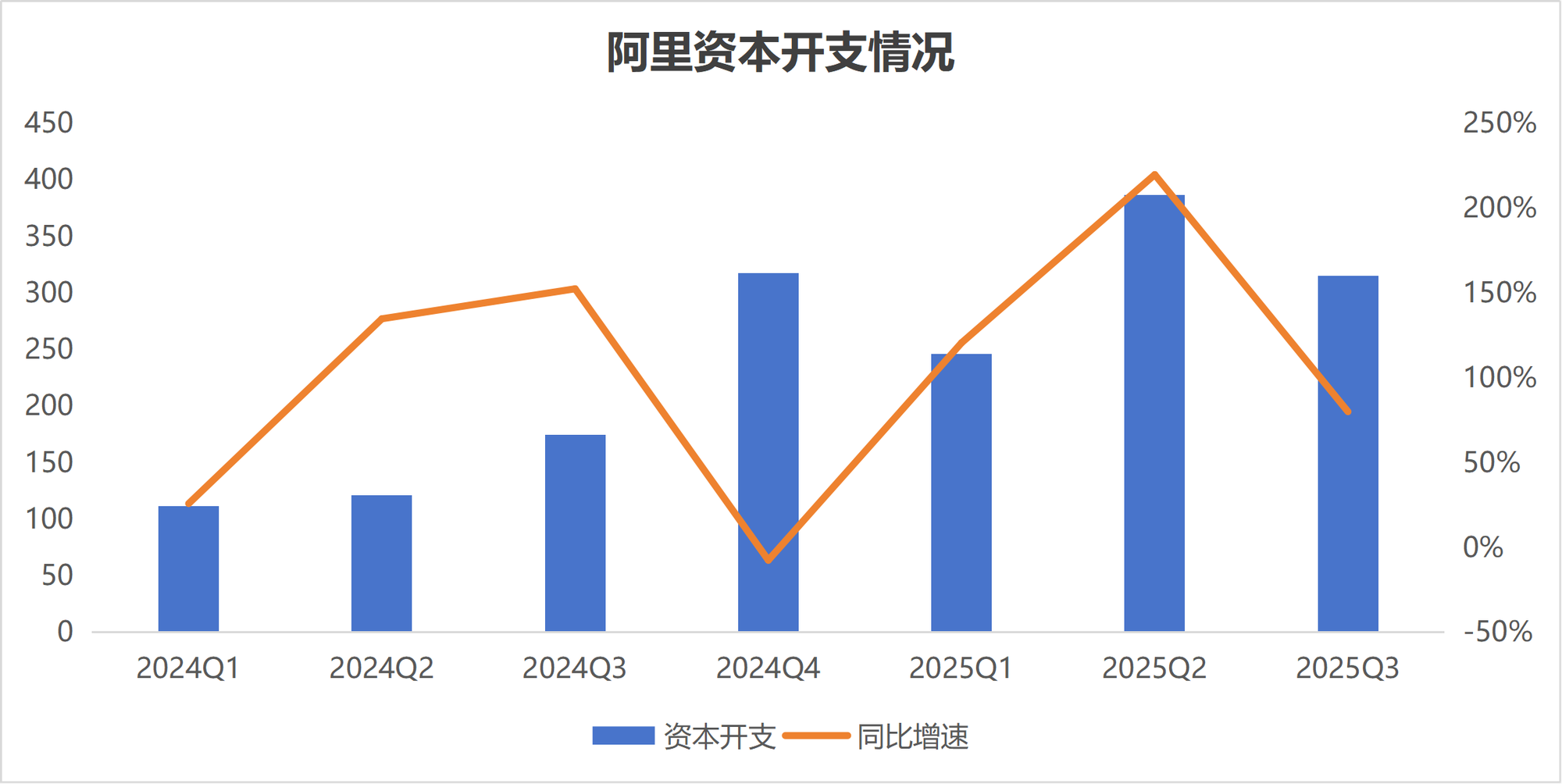
Divergencia en la inversión en AI: Estrategias dispares de Alibaba y Tencent : Ante la ola de la AI, las estrategias de inversión de los dos gigantes tecnológicos chinos, Alibaba y Tencent, muestran claras divergencias. Alibaba está acelerando su inversión en la construcción de infraestructura de AI, planeando invertir más de 380 mil millones de yuanes en los próximos tres años, con el objetivo de convertirse en una empresa de infraestructura que proporcione “agua, electricidad y gas” de AI. Tencent, por su parte, tiende a ser más “cauta”, ha reducido su guía de gastos de capital y se centra más en la habilitación de la AI en el lado de las aplicaciones, e ha introducido al ex científico de OpenAI Yao Shunyu para fortalecer la inclinación de su estrategia de AI hacia las aplicaciones. Esta divergencia refleja diferentes juicios sobre el camino de la comercialización en la era de la AI. (Fuente: 36氪)
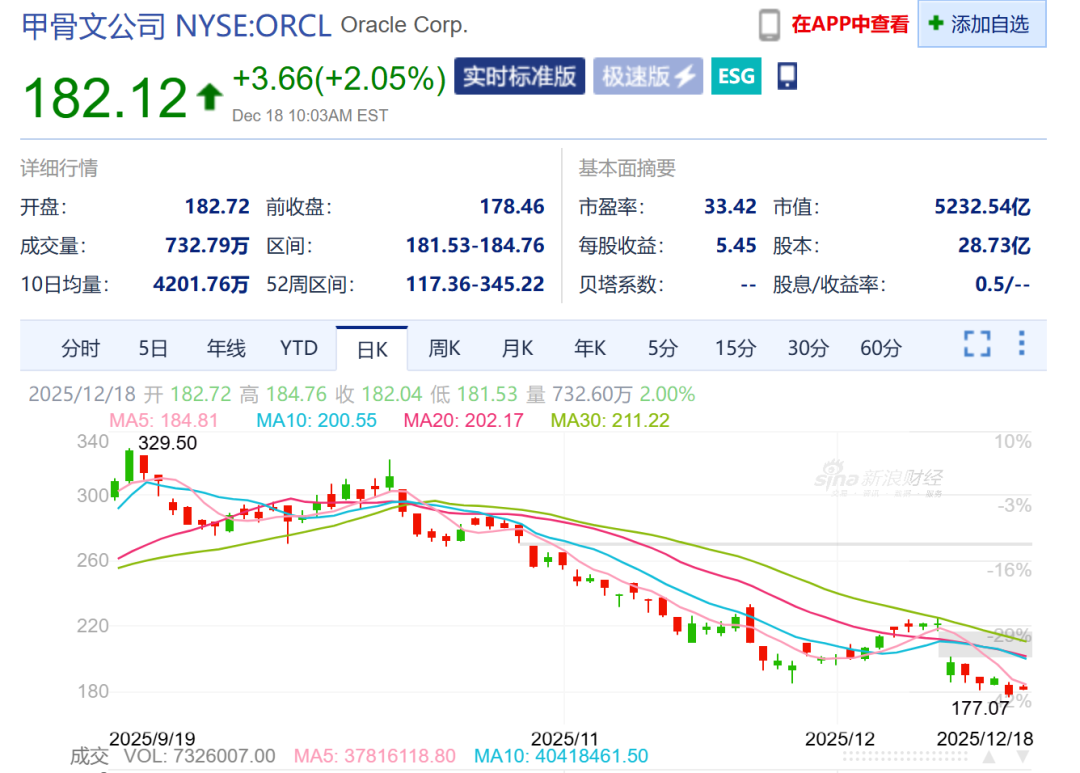
La financiación de un proyecto de Oracle de diez mil millones “se frustra”, lo que genera preocupación por la burbuja de la AI : La financiación de diez mil millones de dólares de Oracle para un proyecto de centro de datos en EE. UU. “se frustró”, con el principal patrocinador Blue Owl Capital retirando su inversión, lo que provocó pánico en el mercado sobre una burbuja de AI. Este incidente destaca la incertidumbre de los inversores sobre los enormes costos de inversión y los plazos de monetización en el ciclo de infraestructura de AI. Los analistas cuestionan si OpenAI podrá cumplir su promesa de pago de capacidad de cómputo a Oracle, así como el problema de la rápida expansión del balance de Oracle, lo que presagia que la competencia de AI está entrando en un “período de prueba de flujo de caja”. (Fuente: 36氪)
Brett Adcock funda un nuevo laboratorio de AI, Hark : Brett Adcock, CEO de Figure AI, ha anunciado la creación de un nuevo laboratorio de AI, Hark, y ha invertido 100 millones de dólares de su propio capital. El laboratorio Hark se centrará en la investigación de “AI centrada en el ser humano”, mientras que Adcock continuará en su cargo en Figure AI. Esta medida marca una continua atención en el campo de la AI hacia la interacción humano-máquina y la ética, y también inyecta nuevo capital privado en la investigación de AI. (Fuente: steph_palazzolo)
🌟 Comunidad
Controversia sobre el rendimiento de los LLM y la experiencia del usuario : Existe una amplia controversia en las redes sociales sobre el rendimiento real de GPT-5.2; muchos usuarios se quejan de una mala experiencia de uso diario, alucinaciones o un rendimiento mediocre en tareas simples, lo que contrasta con la “mayor inteligencia” en las pruebas de referencia. Esta desconexión ha provocado un debate sobre la dirección del desarrollo de modelos de AI: ¿se busca la inteligencia a nivel de competición o la utilidad diaria? Al mismo tiempo, algunos usuarios han compartido preocupaciones sobre la disminución del rendimiento del modelo Opus 4.5, así como los desafíos de los LLM en la depuración y la comprensión de la intención del usuario, como las dificultades de Claude Code al manejar código complejo. (Fuente: VictorTaelin, aidan_mclau, 36氪, dbreunig, Reddit r/ChatGPT, Reddit r/artificial)
Impacto de la AI en el trabajo y la sociedad : Las redes sociales debaten ampliamente el impacto de la AI en el mercado laboral, incluyendo la preocupación por el posible “colapso” de los trabajos de cuello blanco y el potencial de la AI para mejorar la productividad. Al mismo tiempo, el nivel de conocimiento público sobre la AI es desigual, y muchas personas creen erróneamente que ChatGPT busca respuestas en una base de datos. Además, la tecnología de AI también ha reducido el umbral para la desinformación y el fraude, lo que genera preocupaciones sobre los mecanismos de auditoría de las plataformas y el costo de la auto-verificación personal. También hay quienes opinan que el progreso de la AI es más como “nuevos trenes circulando por vías viejas”, y que los cuellos de botella en la aplicación práctica son más a menudo factores sociales, económicos y políticos. (Fuente: random_walker, Reddit r/ArtificialInteligence, Plinz, doodlestein, amasad, 36氪, gfodor, Reddit r/ArtificialInteligence)
Ética y seguridad de la AI : Las redes sociales están llenas de debates sobre la ética y la seguridad de la AI. Esto incluye acusaciones de plagio contra pioneros de la AI como Hinton, casos de detenciones erróneas causadas por aplicaciones de AI como el reconocimiento facial, y los riesgos que plantean los contenidos generados por AI (como la máquina expendedora de AI probada por WSJ que se descontroló). OpenAI ha publicado sus “Especificaciones del modelo” para guiar el comportamiento del modelo, y Google DeepMind ha lanzado la tecnología de marca de agua SynthID para detectar videos generados por AI. Además, la enorme huella ambiental de la AI (consumo de agua y emisiones de carbono) también ha generado preocupación, así como las consideraciones éticas al proporcionar apoyo emocional con AI. (Fuente: SchmidhuberAI, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Ronald_vanLoon, AnthropicAI, ajeya_cotra, Reddit r/MachineLearning)
Desarrollo y desafíos de los AI Agents : El desarrollo y la aplicación de los AI Agents se han convertido en un tema candente, con discusiones que abarcan su arquitectura (módulos componibles, gestión de memoria), estándares abiertos (Agent Skills) y su práctica en campos como la robótica (Reachy Mini, robots Grek, robots Bipedal Gait, robots móviles autónomos) y la programación (Claude MCP Agent). Los desafíos incluyen cómo mejorar la credibilidad de los Agents, manejar contextos largos, optimizar la infraestructura para soportar la colaboración multi-Agent y cómo asegurar la estabilidad de los Agents en tareas complejas y evitar “bucles infinitos”. (Fuente: Vtrivedy10, julesagent, LangChainAI, TheTuringPost, Ronald_vanLoon, Sentdex, ClementDelangue, doodlestein, corbtt, Ronald_vanLoon)
Investigación de LLM y características del modelo : La discusión de la comunidad de AI sobre la investigación de LLM abarca las funciones de valor en el aprendizaje por refuerzo (RL), la practicidad de LoRA RL, la evaluación de las capacidades de GPT-4, el debate entre RL y LLM post-entrenamiento, la aplicación de LLM en la investigación matemática y la exploración de cuestiones filosóficas como la conciencia de la AI y el “alimento para el pensamiento”. Además, se ha prestado atención a las nuevas arquitecturas de LLM (como Diffusion LLM, DexWM World Model), las leyes de densidad del modelo, los desafíos del procesamiento de contexto largo y la evaluación del rendimiento de modelos específicos como Kimi K2 y MiMo-V2. (Fuente: natolambert, vllm_project, SebastienBubeck, sarahcat21, karpathy, riemannzeta, _akhaliq, code_star, DeepLearningAI, ollama, gdb, yacinelearning, ylecun, pmddomingos, matei_zaharia, TheTuringPost, yacinelearning, MiniMax__AI, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/LocalLLaMA)
Infraestructura y hardware de AI : La infraestructura y el hardware de AI son temas candentes, incluyendo la inferencia paralela de tensores de baja latencia con el framework MLX en Mac, la importancia de las bases de datos vectoriales como Qdrant y Turbopuffer en la era Agentic, y los costos y desafíos de construir clústeres de GPU (como 8x B200 o clústeres de Mac Studio). La discusión también aborda la optimización del entrenamiento distribuido (SonicMoE), los cuellos de botella del backend serverless para los Agents y las preocupaciones sobre el consumo de energía de los centros de datos de AI. (Fuente: awnihannun, qdrant_engine, TheEthanDing, Dorialexander, halvarflake, matei_zaharia, togethercompute, andersonbcdefg, idavidrein, Reddit r/deeplearning, Reddit r/MachineLearning, Reddit r/LocalLLaMA, Reddit r/MachineLearning, StasBekman, HuggingFace Daily Papers)

Arte y aplicaciones de Generative AI : La discusión gira en torno a los avances de la Generative AI en el arte y las aplicaciones. Los modelos Runway Gen-4.5 y GWM-1 impulsan la generación de video hacia la simulación de mundos universales, y DALL-E 3 y Gemini se utilizan para la generación de imágenes, incluyendo la mejora del realismo de las imágenes, la creación de contenido 3D y la conversión de estilos artísticos. La comunidad también ha explorado la percepción del contenido generado por AI (AIGC), por ejemplo, cuando las obras multimedia creadas por AI son de tan alta calidad que el público duda si fueron generadas por AI, ¿es un elogio o una ofensa? Además, las aplicaciones de investigación de la AI en la resolución de problemas matemáticos y la conversión de código también han recibido atención. (Fuente: c_valenzuelab, BlackHC, nptacek, yupp_ai, nptacek, claud_fuen, dotey, ylecun, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Otros
Principios de ingeniería de AI : Las discusiones en redes sociales enfatizan que la ingeniería de AI debe seguir los principios centrales de la ingeniería tradicional, como el control de versiones, las pruebas y la observabilidad en producción. Se argumenta que el uso de LLM no debe cambiar estas prácticas fundamentales, sino que deben integrarse en el proceso de desarrollo de AI para garantizar la fiabilidad y calidad del sistema. (Fuente: imjaredz)
Procesamiento de datos a gran escala con LLM : Se discute el tema subestimado del procesamiento de datos a gran escala con LLM. Se enfatiza que al manejar grandes volúmenes de datos, los LLM deben ser tratados como operadores de bases de datos, utilizando técnicas como el mapeo semántico, el filtrado y la reducción. Al mismo tiempo, a través de estrategias de optimización de costos como la cascada de tareas, se puede reducir significativamente el costo del procesamiento de datos con LLM, manteniendo la precisión y logrando un equilibrio entre eficiencia y economía. (Fuente: HamelHusain)
Perspectivas de la AI sobre la cognición y el aprendizaje humano : Un investigador de AI, a través de 5000 horas de experiencia en el juego “Tekken”, explora cómo los humanos construyen modelos predictivos bajo limitaciones de tiempo extremas, y su relación con los modelos mundiales de AI y el aprendizaje predictivo. Argumenta que los juegos de lucha obligan a los jugadores a predecir en lugar de simplemente reaccionar, lo que se mapea a los desafíos de la investigación de AI en la construcción de modelos mundiales internos, la lectura de patrones a partir de información parcial y la adaptación a fallas predictivas, proporcionando una perspectiva única para comprender la inteligencia más allá de la AI de los juegos. (Fuente: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)