
Mots-clés:Projet Manhattan IA, Gemini 3 Flash, GPT-5.2-Codex, Fusion nucléaire contrôlée, Ingénierie de recherche IA, Agent IA, Modèle multimodal, Modèle IA open source, Mission Genesis du Département de l’Énergie américain, Test de codage Gemini 3 Flash, Défense cybernétique GPT-5.2-Codex, Modèle multimodal T5Gemma 2, Séparation audio Perception Encoder Audiovisuel
🔥 À la une
Le « AI Manhattan Project » américain est lancé : Le Département de l’Énergie des États-Unis a officiellement lancé la “Mission Genesis”, un projet national de recherche scientifique en AI visant à combiner les technologies AI de pointe avec les capacités de recherche des laboratoires nationaux pour accélérer les découvertes scientifiques. Ce plan rassemble 24 géants de la technologie tels que Microsoft, Google, NVIDIA, OpenAI, DeepMind et Anthropic, et appliquera les modèles AI et les capacités de supercalcul à des domaines tels que la fusion nucléaire contrôlée, les matériaux énergétiques et la simulation climatique. L’objectif est de doubler la productivité scientifique américaine d’ici 2030, marquant un ajustement stratégique national pour les États-Unis dans le domaine technologique. (Source: 36氪, nvidia, AnthropicAI, GoogleDeepMind, OpenAI Newsroom)
Dialogue entre Hinton et Jeff Dean sur l’AI moderne : Geoffrey Hinton, le pionnier des réseaux neuronaux, et Jeff Dean, scientifique en chef chez Google, ont dialogué lors de la conférence NeurIPS, explorant les facteurs clés qui ont permis à l’AI moderne de passer des laboratoires à des milliards d’utilisateurs. Ils ont souligné que la percée de l’AI n’est pas un miracle isolé, mais le résultat d’une maturité systémique des algorithmes (comme Transformer), du matériel (comme GPU, TPU) et de l’ingénierie (comme JAX, Pathways). La discussion a également mis en évidence trois obstacles majeurs à la mise à l’échelle de l’AI : l’efficacité énergétique, la mémoire (contexte long) et la créativité (capacité d’association), soulignant l’importance de la recherche fondamentale et de l’investissement continu. (Source: 36氪, JeffDean, geoffreyhinton)
Entretien avec Sam Altman : Stratégie et financement d’OpenAI : Sam Altman a souligné dans un récent entretien que Google reste la plus grande menace pour OpenAI, mais qu’OpenAI consolidera son avantage grâce à des logiciels AI-native, des fonctionnalités de personnalisation et de mémoire, une expansion accélérée sur le marché des entreprises et un investissement de 1,4 billion de dollars dans les infrastructures. Il a prédit que GPT-6 pourrait être lancé au premier trimestre de l’année prochaine et a insisté sur le fait que l’AI remodèlera à l’avenir la façon d’utiliser les logiciels, devenant un “partenaire numérique” irremplaçable plutôt qu’une simple intégration dans d’anciens produits. (Source: 36氪, sama)
Google lance le modèle Gemini 3 Flash : Google a lancé Gemini 3 Flash, un modèle qui excelle dans plusieurs tests de référence grâce à son rapport qualité-prix et sa vitesse exceptionnels, surpassant même GPT-5.2 dans le test de codage SWE-bench. Google prévoit de l’intégrer profondément dans ses produits écosystémiques tels que Search, YouTube et Gmail, visant à remodeler le marché de l’AI par un avantage écosystémique plutôt que par une simple concurrence de paramètres de modèle. Ce lancement est considéré comme un “coup précis” contre OpenAI, suscitant un large débat dans l’industrie sur la concurrence des modèles et la popularisation des applications AI. (Source: 36氪, MS_BASE44, GeminiApp, scaling01)
OpenAI lance le modèle de programmation GPT-5.2-Codex : OpenAI a lancé GPT-5.2-Codex, présenté comme son modèle de programmation d’Agent AI le plus puissant à ce jour, optimisé pour l’ingénierie logicielle complexe et la cybersécurité. Ce modèle améliore l’exécution des tâches à long terme, les modifications de code à grande échelle, la compatibilité avec l’environnement Windows et les capacités de défense en cybersécurité. Bien qu’il affiche des performances solides dans les tests de référence, certains utilisateurs ont constaté qu’il était inférieur à Gemini 3 Flash pour certaines tâches, suscitant un débat sur son efficacité réelle et sa compétitivité sur le marché. (Source: 36氪, sama, scaling01)
🎯 Tendances
Google open-source T5Gemma 2 et FunctionGemma : Google a open-sourcé T5Gemma 2 et FunctionGemma, deux petits modèles basés sur la famille Gemma 3. T5Gemma 2 est le premier modèle encodeur-décodeur multimodal à contexte long, avec une taille minimale de 270M-270M, axé sur l’efficacité architecturale et les capacités multimodales. FunctionGemma est un modèle de 270M optimisé pour l’appel de fonctions, capable de fonctionner sur des appareils périphériques comme les téléphones, visant à résoudre le problème des grands modèles qui “parlent bien mais n’agissent pas” en fournissant un cerveau dédié aux Agents et à l’utilisation d’outils. (Source: 36氪, huggingface, osanseviero, ImazAngel, danielhanchen)

Test du modèle Doubao 1.8 de ByteDance : ByteDance a lancé Doubao Large Model 1.8, son nouveau modèle phare, qui se positionne en tête dans plusieurs scénarios d’évaluation tels que l’éducation, le service client, la finance et le droit. Les tests réels montrent que Doubao 1.8 excelle dans les capacités d’Agent (appels multi-outils, suivi d’instructions multi-tours, OS Agent), la gestion de contexte ultra-long de 256K et la compréhension multimodale (capacité de compréhension vidéo améliorée jusqu’à 20 minutes). Il est particulièrement adapté à la construction d’Agents complexes et à l’exécution de processus réels, étant considéré comme une étape clé dans le développement des Agents d’entreprise et des Agents côté client. (Source: WeChat)

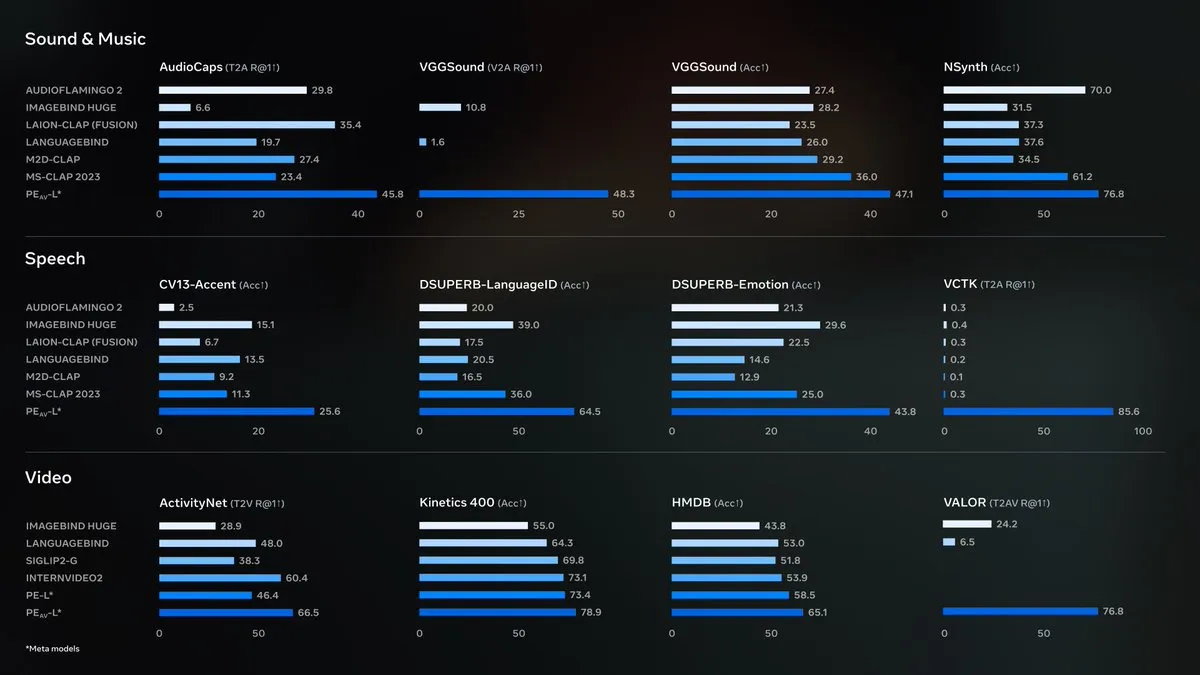
Meta open-source Perception Encoder Audiovisual (PE-AV) : Meta a open-sourcé Perception Encoder Audiovisual (PE-AV), le moteur technologique clé derrière SAM Audio, visant à réaliser une séparation audio de pointe. PE-AV est basé sur le modèle Perception Encoder précédemment publié par Meta, fusionnant profondément la perception audio et visuelle, et a obtenu des résultats de premier ordre dans un large éventail de tests de référence audio et vidéo. Il devrait améliorer la détection sonore et la compréhension de scènes audiovisuelles grâce à son support multimodal. (Source: AIatMeta, Reddit r/LocalLLaMA)
Runway lance les modèles Gen-4.5 et GWM-1 : Runway a lancé le modèle de génération vidéo Gen-4.5, ajoutant des fonctionnalités d’édition audio et multi-caméras, et a également introduit la série GWM-1 (General World Model), comprenant GWM Worlds (scènes navigables), GWM Robotics (simulation de perspective robotique) et GWM Avatars (personnages synchronisés avec les lèvres). L’objectif est de réaliser une génération vidéo de modèles de monde en temps réel et contrôlable, annonçant un saut majeur de la technologie de génération vidéo vers la simulation générale. (Source: c_valenzuelab, DeepLearningAI)
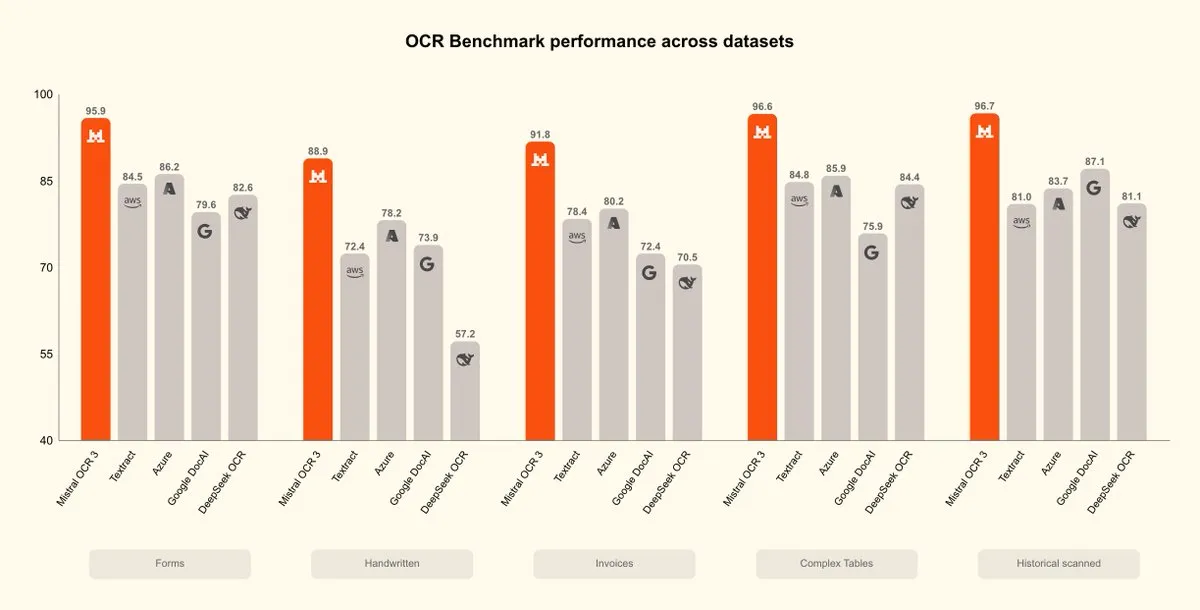
Mistral OCR 3 est lancé, nouvelle percée dans l’intelligence documentaire : Mistral AI a lancé le modèle Mistral OCR 3, établissant une nouvelle référence en termes de précision et d’efficacité, surpassant les solutions de traitement de documents d’entreprise existantes et les OCR AI-native. Ce modèle a été largement optimisé pour le traitement du contenu manuscrit, des scans de mauvaise qualité, ainsi que des tableaux et formulaires complexes couramment rencontrés dans les documents d’entreprise, marquant une nouvelle avancée dans le domaine de l’intelligence documentaire. (Source: qtnx_, GuillaumeLample)
Refonte de la Tokenization dans Hugging Face Transformers v5 : Hugging Face Transformers v5 a procédé à une refonte majeure du fonctionnement de son tokenizer. La nouvelle version sépare l’architecture du tokenizer du vocabulaire d’entraînement, augmentant la transparence, la modularité et simplifiant le processus d’entraînement d’un tokenizer spécifique à un modèle à partir de zéro. Cette amélioration rend le tokenizer plus facile à inspecter, à personnaliser et à entraîner, résolvant les problèmes d’opacité et de couplage étroit des tokenizers dans la v4. (Source: HuggingFace Blog, huggingface)

Firefox annonce sa transformation en AI, suscitant la controverse chez les utilisateurs : Le navigateur Firefox a annoncé sa transformation en navigateur AI, prenant en charge une série de nouveaux logiciels. Cette décision a suscité un vif mécontentement chez de nombreux utilisateurs sur des communautés comme Reddit, en particulier ceux qui valorisent la confidentialité et le minimalisme, estimant que Firefox s’éloigne de ses valeurs fondamentales. Cette transformation reflète la stratégie de Mozilla de rechercher de nouveaux points de croissance à l’ère où “la recherche est morte”, mais l’équilibre entre les fonctionnalités AI et la confidentialité des utilisateurs reste un défi majeur. (Source: 36氪)

ChatGPT lance la fonctionnalité d’épinglage de chat : OpenAI a annoncé que ChatGPT propose désormais une fonctionnalité d’épinglage de chat, permettant aux utilisateurs d’épingler des conversations importantes sur iOS, Android et le Web pour un accès rapide. Cette mise à jour vise à améliorer l’expérience utilisateur et à simplifier la gestion des conversations. (Source: openai, Reddit r/ChatGPT)
Mise à jour des fonctionnalités de l’extension Claude for Chrome : L’extension Claude for Chrome est désormais disponible pour tous les utilisateurs payants et intègre la fonctionnalité Claude Code. Les utilisateurs peuvent désormais tester et déboguer du code directement dans le navigateur via Claude Code, sans quitter la page actuelle. Cette mise à jour vise à améliorer la productivité et l’expérience des développeurs, et Anthropic a également souligné les considérations de sécurité lors de la conception et des tests. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

🧰 Outils
Agent Skills devient un standard ouvert : Les Agent Skills d’Anthropic sont désormais un standard ouvert, permettant aux Agents AI d’apprendre et d’exécuter des flux de travail répétitifs sur différentes plateformes. Cette initiative vise à simplifier le déploiement, la découverte et la construction de compétences, favorisant l’interopérabilité de l’écosystème d’outils AI. Les développeurs peuvent désormais créer une compétence une seule fois et l’utiliser sur plusieurs plateformes AI, augmentant ainsi la spécialisation et l’efficacité des Agents. (Source: omarsar0, code, Reddit r/ClaudeAI)
LangChain Academy lance un nouveau cours : LangChain Academy a lancé un nouveau cours “Introduction à LangChain (Python)”, visant à aider les développeurs à apprendre à construire des Agents AI à l’aide du framework LangChain. Le cours couvre la création d’Agents, l’utilisation des modules de construction fondamentaux (modèles, messages, mémoire, outils) et l’exploitation de LangSmith pour le débogage comportemental, l’objectif final étant de permettre aux participants de constituer une équipe complète d’assistants personnels. (Source: LangChainAI, hwchase17)

Paramètres de développement avancés de Claude Code CLI : Un développeur a partagé sa configuration “sur-ingénierie” de Claude Code CLI, qui combine un serveur MCP, des compétences personnalisées et un fichier CLAUDE.md strict pour réaliser un “Vibe Coding” de code de qualité production. Cette méthode, grâce à des portes de qualité, des boucles itératives et des tests intégrés au navigateur, empêche efficacement l’Agent de dévier et permet un refactoring efficace, résolvant les points douloureux rencontrés par les Agents traditionnels dans le développement réel. (Source: Reddit r/ClaudeAI)
OpenRouter lance une fonctionnalité de réparation de sortie JSON LLM : OpenRouter a introduit la fonctionnalité “Response Healing”, qui répare automatiquement les erreurs dans la sortie JSON structurée générée par les grands modèles de langage (LLM). Cette fonctionnalité a considérablement réduit le taux de défauts de modèles tels que Gemini 2 Flash et Qwen3 235B, améliorant la fiabilité des LLM dans les scénarios nécessitant une sortie JSON précise. (Source: xanderatallah)

L’outil de transcription audio AssemblyAI prend en charge l’entrée URL : AssemblyAI Playground a été mis à jour et prend désormais en charge la transcription audio directement à partir d’une URL. Les utilisateurs peuvent tester des podcasts, de l’audio cloud ou de gros fichiers (comme des appels de résultats financiers) sans avoir à télécharger les fichiers, ce qui simplifie considérablement le prototypage et la vérification d’intégration, et améliore l’efficacité des tests des capacités Speech AI. (Source: AssemblyAI)
jax-js : Bibliothèque de machine learning côté navigateur : jax-js est une bibliothèque de machine learning open-source qui réimplémente JAX en pur JavaScript et prend en charge la compilation JIT vers WebGPU, lui permettant d’exécuter des réseaux neuronaux dans le navigateur. Cette bibliothèque offre des fonctionnalités telles que la dérivation automatique et la compilation JIT, visant à fournir un modèle de programmation efficace et flexible similaire à PyTorch et JAX, et a été validée par des démonstrations autonomes telles que l’entraînement MNIST et l’inférence MobileCLIP, prouvant son interactivité. (Source: Vtrivedy10, Reddit r/MachineLearning)

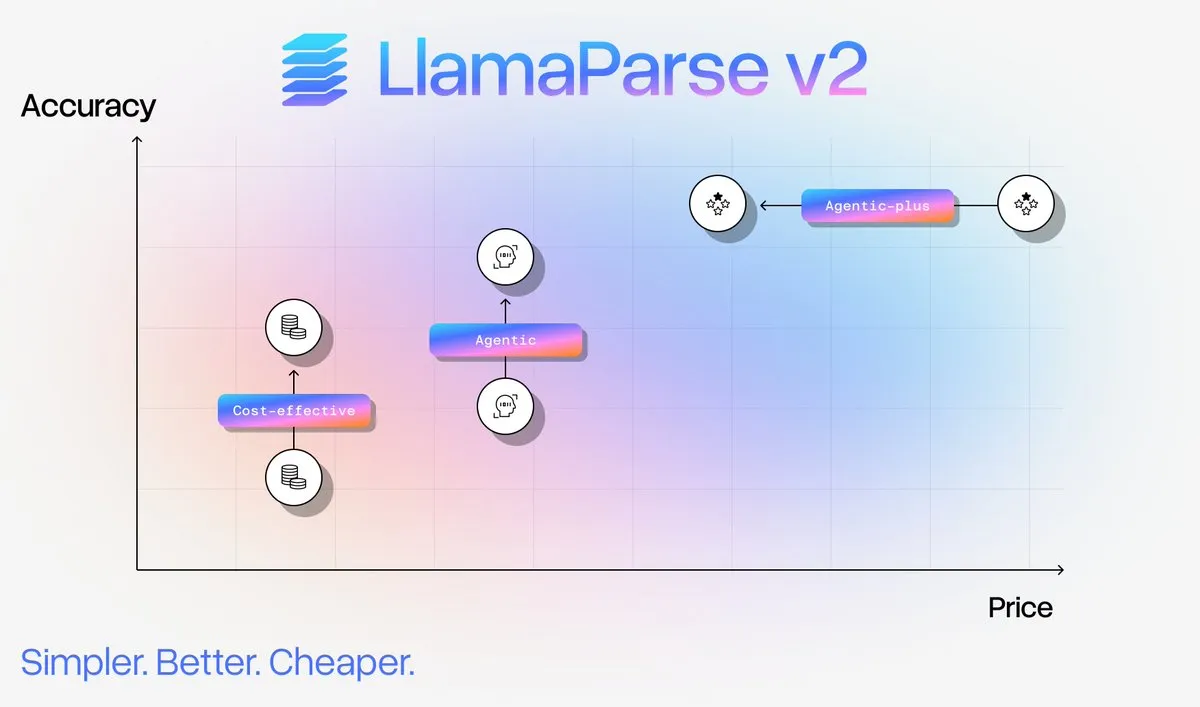
Mise à niveau du service d’analyse de documents LlamaParse v2 : LlamaIndex a lancé LlamaParse v2, qui simplifie considérablement la configuration de l’analyse de documents, améliore les performances et réduit les coûts jusqu’à 50 % pour l’analyse de documents complexes. La nouvelle version introduit quatre niveaux fixes : Fast, Cost Effective, Agentic et Agentic Plus, améliorant la précision du contenu multimodal et réduisant les hallucinations, permettant aux utilisateurs d’atteindre une ingestion de documents de niveau production sans être des experts en analyse. (Source: jerryjliu0)
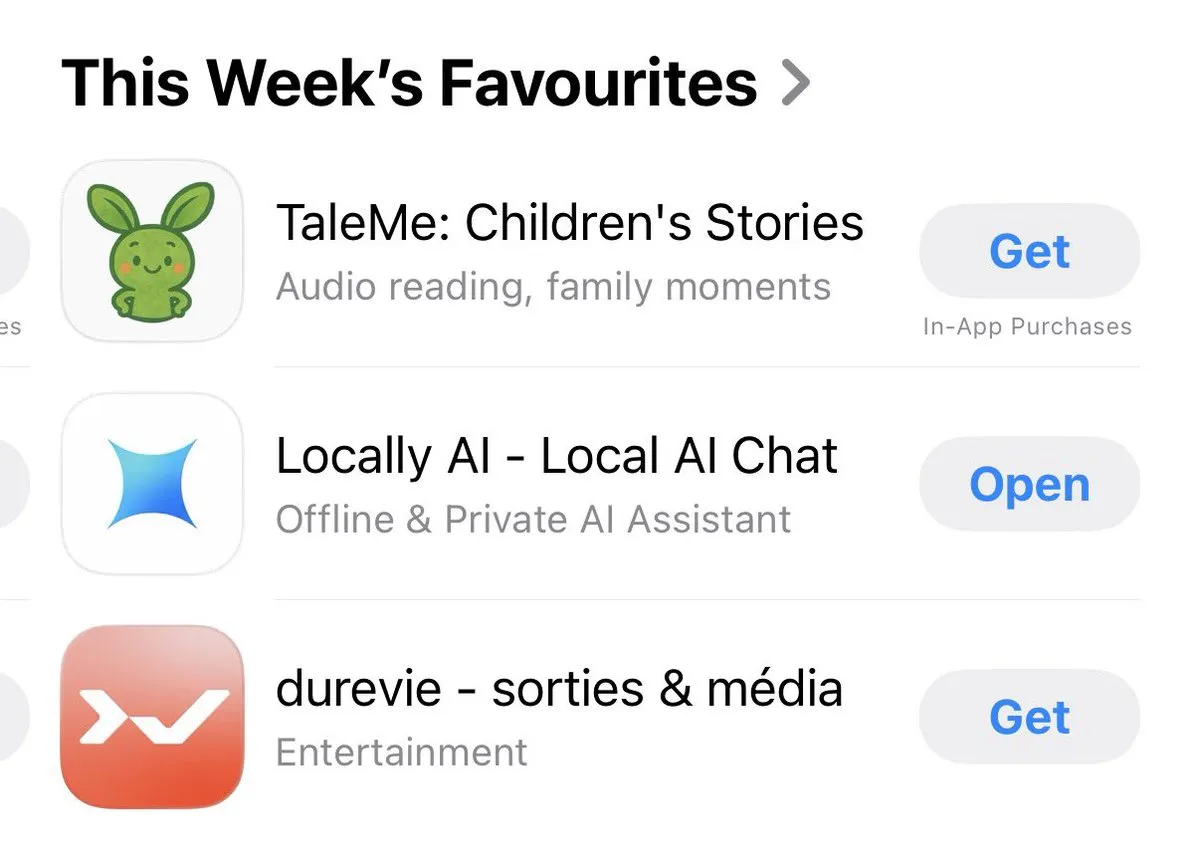
Locally AI : Application pour exécuter des modèles AI localement : Locally AI est une application qui permet aux utilisateurs d’exécuter des modèles AI localement sur leurs appareils quotidiens, et a été classée “Coup de cœur de la semaine” par l’App Store pour sa commodité. Cette application vise à réduire la barrière à l’utilisation de l’AI, permettant à davantage de personnes d’interagir facilement avec les modèles AI locaux, soulignant la facilité d’utilisation et l’accessibilité de l’AI locale. (Source: adrgrondin)
Google Flow Image Generation prend en charge le téléchargement haute résolution : La fonctionnalité Nano Banana Pro de Google Flow prend désormais en charge le téléchargement d’images générées par AI en résolutions 2K et 4K. Cette mise à jour répond au besoin des utilisateurs d’images de plus haute résolution, qu’il s’agisse de matériel créatif, de séquences d’images ou d’effets visuels, offrant un contenu généré par AI plus clair et plus détaillé. (Source: op7418)

Les utilisateurs d’OpenWebUI signalent des problèmes avec la fonctionnalité RAG : Les utilisateurs d’OpenWebUI signalent des problèmes avec la fonctionnalité RAG (Retrieval Augmented Generation), en particulier lors du traitement de fichiers PDF de plus de 1 Mo, où le modèle ne parvient pas à transmettre le contenu du fichier au contexte, entraînant une erreur “Source not found”. Bien que le téléchargement du fichier, l’extraction de texte et l’intégration soient réussis, l’étape de génération de requête échoue, empêchant l’utilisation du contenu PDF pour l’inférence du modèle et affectant des tâches telles que l’extraction de données structurées. (Source: Reddit r/OpenWebUI, Reddit r/OpenWebUI)

Jeu d’aventure textuel AI Glif Agent : Glif Agent offre une expérience de jeu d’aventure textuel où les utilisateurs peuvent s’immerger directement, sans guides complexes. Cet outil AI démontre le potentiel des LLM à créer des récits interactifs et des expériences immersives, permettant aux joueurs d’explorer des mondes virtuels via des instructions en langage naturel. (Source: NerdyRodent)

Cass : Outil de recherche de session d’Agent de codage : L’outil Cass est salué comme le “sauveur” des Agents de codage, permettant d’économiser considérablement du temps et des efforts. Il détecte, ingère et indexe automatiquement toutes les sessions CLI de codage, offrant une recherche instantanée et un “mode robot”, permettant aux utilisateurs de trouver, gérer et réutiliser rapidement les traces de l’Agent, améliorant considérablement l’efficacité de l’utilisation des Agents de codage. (Source: doodlestein)
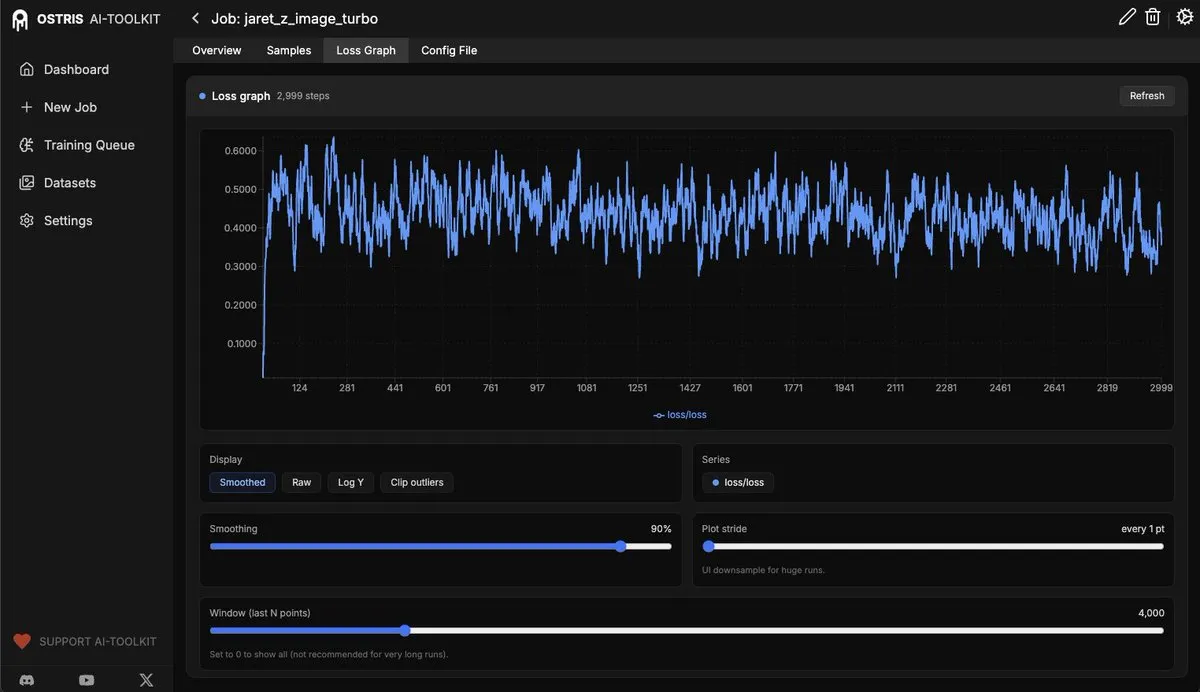
AI Toolkit UI ajoute la fonctionnalité de graphique de perte : L’AI Toolkit UI a été mis à jour avec une nouvelle fonctionnalité de graphique de perte, utilisée pour surveiller le processus de réglage fin des diffusion models. Cette fonctionnalité fournira aux utilisateurs un retour d’entraînement de modèle plus intuitif, et d’autres fonctionnalités seront ajoutées à l’avenir pour améliorer l’efficacité du développement et du débogage des modèles AI. (Source: ostrisai)
📚 Apprentissage
Nouveau cours Nvidia NeMo Agent Toolkit : DeepLearning.AI a lancé un nouveau cours Nvidia NeMo Agent Toolkit, où l’expert NVIDIA Brian enseigne comment utiliser ce toolkit pour construire des Agents AI fiables et de qualité production. Le cours couvre les flux de travail pilotés par la configuration, l’observabilité par le traçage, l’évaluation du système à l’aide de jeux de données de référence, et le déploiement de systèmes multi-Agents, visant à aider les développeurs à transformer les prototypes d’Agent en systèmes de production fiables. (Source: AndrewYNg)
Ressources d’apprentissage AI et revue de concepts : Une série de ressources d’apprentissage AI a été partagée, y compris la dernière édition de Deep Learning Weekly, couvrant les Agents auto-optimisants, les Bugs dans les benchmarks AI, un guide d’entraînement RL, etc. De plus, une feuille de route pour maîtriser l’Agentic AI, une revue des concepts fondamentaux de l’AI en 2025 (apprentissage par renforcement, variantes RLHF, apprentissage continu, AI neuro-symbolique, matériel AI, etc.), ainsi que les dernières avancées de la recherche sur la sécurité AI. (Source: dl_weekly, TheTuringPost, Ronald_vanLoon, AndrewYNg, ajeya_cotra)
Publication du chapitre de livre “Visual Language Models” : Le cinquième chapitre du livre “Visual Language Models” a été publié, se concentrant sur le pré-entraînement et offrant des illustrations et des conseils pratiques. Cela fournit une ressource précieuse pour les apprenants en AI afin de comprendre en profondeur les mécanismes de pré-entraînement des modèles de langage visuel. (Source: algo_diver)
Mise à jour de l’article sur les systèmes de recherche pilotés par AI (ADRS) : Les systèmes de recherche pilotés par AI (ADRS) ont publié un article mis à jour, évaluant les performances de trois frameworks open-source pour résoudre 10 problèmes de performance de systèmes réels. L’étude montre que les solutions générées par AI peuvent atteindre une accélération de 13x en équilibrage de charge et des économies de coûts de 35% en planification cloud, surpassant même les experts humains, fournissant des preuves solides de l’application de l’AI dans la recherche système. (Source: matei_zaharia)

💼 Affaires
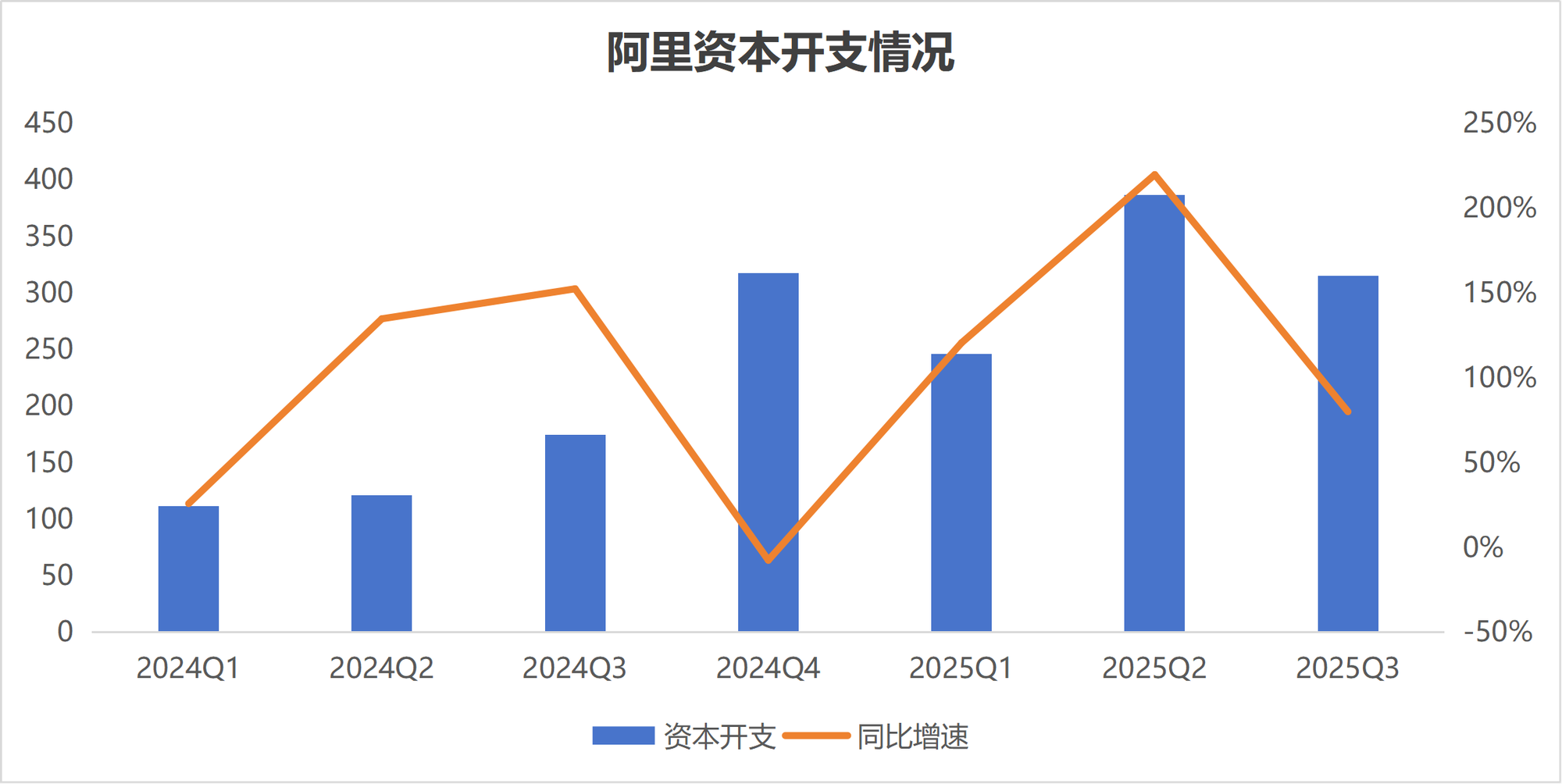
Divergences d’investissement en AI : Stratégies différentes pour Alibaba et Tencent : Face à la vague de l’AI, les deux géants technologiques chinois, Alibaba et Tencent, affichent des stratégies d’investissement nettement différentes. Alibaba accélère ses investissements dans la construction d’infrastructures AI, prévoyant d’investir plus de 380 milliards de yuans au cours des trois prochaines années, dans le but de devenir un fournisseur d’infrastructures AI “eau, électricité, charbon”. Tencent, quant à lui, se montre plus “calme”, réduisant ses prévisions de dépenses d’investissement et se concentrant davantage sur l’autonomisation des applications AI, et a introduit Yao Shunyu, ancien scientifique d’OpenAI, pour renforcer sa stratégie AI vers le côté application. Cette divergence reflète les jugements différents des deux entreprises sur les chemins de commercialisation à l’ère de l’AI. (Source: 36氪)
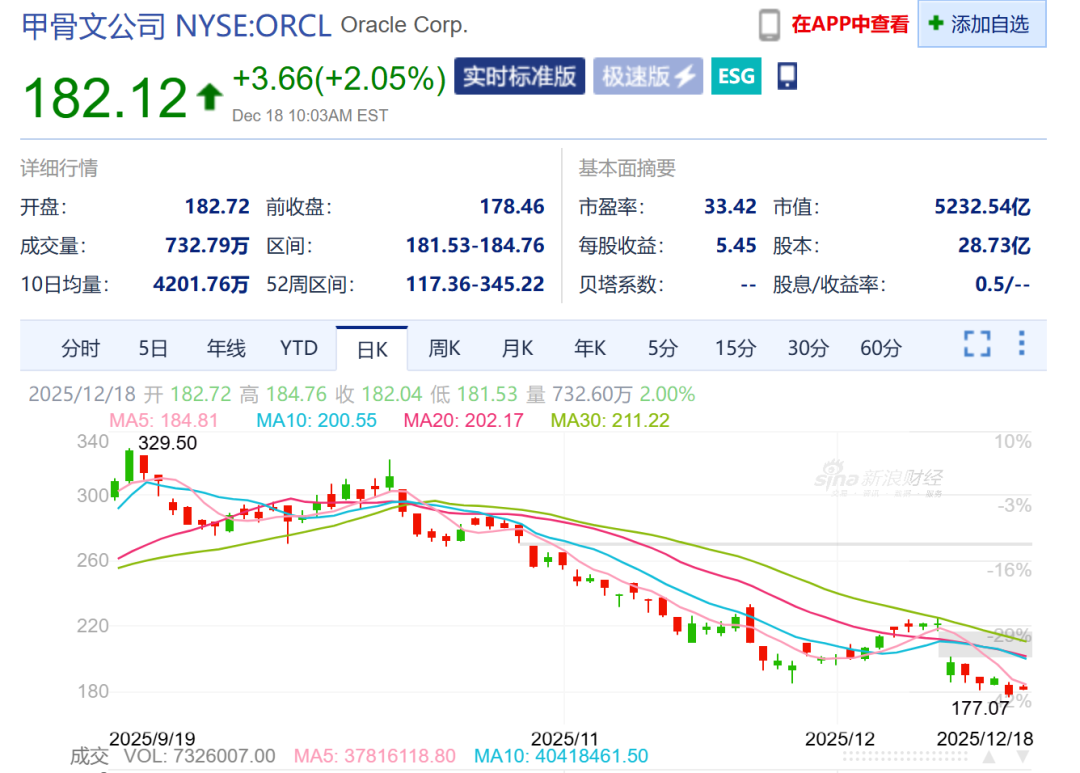
L’échec du financement de plusieurs milliards de dollars d’Oracle suscite des craintes de bulle AI : Le financement de plusieurs milliards de dollars du projet de centre de données d’Oracle aux États-Unis a “échoué”, le principal soutien Blue Owl Capital ayant retiré son financement, suscitant la panique du marché quant à une bulle AI. Cet événement souligne l’incertitude des investisseurs face aux coûts d’investissement massifs et au calendrier de monétisation dans le cycle d’infrastructure AI. Les analystes doutent de la capacité d’OpenAI à tenir ses promesses de paiements de puissance de calcul à Oracle, ainsi que de l’expansion trop rapide du bilan d’Oracle, annonçant que la concurrence AI entre dans une “période de test des flux de trésorerie”. (Source: 36氪)
Brett Adcock fonde un nouveau laboratoire AI, Hark : Brett Adcock, PDG de Figure AI, a annoncé la création d’un nouveau laboratoire AI, Hark, et y a investi 100 millions de dollars de fonds personnels. Le laboratoire Hark se concentrera sur la recherche en “AI centrée sur l’humain”, tandis qu’Adcock continuera d’occuper son poste chez Figure AI. Cette initiative marque l’attention continue du domaine de l’AI sur l’interaction homme-machine et l’éthique, et injecte également de nouveaux capitaux privés dans la recherche AI. (Source: steph_palazzolo)
🌟 Communauté
Controverse sur les performances et l’expérience utilisateur des LLM : Les médias sociaux sont le théâtre d’une large controverse sur les performances réelles de GPT-5.2, de nombreux utilisateurs se plaignant d’une mauvaise expérience d’utilisation quotidienne, d’hallucinations ou de performances médiocres pour des tâches simples, contrastant avec sa réputation de “plus intelligent” dans les tests de référence. Ce décalage soulève des discussions sur la direction du développement des modèles AI : faut-il viser une intelligence de compétition ou une utilité quotidienne ? Parallèlement, des utilisateurs ont partagé leurs préoccupations concernant la baisse de performance du modèle Opus 4.5, ainsi que les défis des LLM en matière de débogage et de compréhension de l’intention de l’utilisateur, comme les difficultés de Claude Code à traiter du code complexe. (Source: VictorTaelin, aidan_mclau, 36氪, dbreunig, Reddit r/ChatGPT, Reddit r/artificial)
Impact de l’AI sur le travail et la société : Les médias sociaux discutent largement de l’impact de l’AI sur le marché de l’emploi, y compris les craintes d’un “effondrement” des emplois de cols blancs, ainsi que le potentiel de l’AI à améliorer la productivité. Parallèlement, le niveau de connaissance du public sur l’AI est inégal, beaucoup pensant à tort que ChatGPT recherche des réponses dans une base de données. De plus, la technologie AI a également abaissé la barrière à la désinformation et à la fraude, soulevant des préoccupations concernant les mécanismes de modération des plateformes et le coût de l’auto-preuve pour les individus. Certains estiment également que les progrès de l’AI ressemblent davantage à un “nouveau train sur d’anciennes voies”, les goulots d’étranglement dans les applications réelles étant davantage des facteurs sociaux, économiques et politiques. (Source: random_walker, Reddit r/ArtificialInteligence, Plinz, doodlestein, amasad, 36氪, gfodor, Reddit r/ArtificialInteligence)
Éthique et sécurité de l’AI : Les discussions sur l’éthique et la sécurité de l’AI sont vives sur les médias sociaux. Elles incluent des accusations de plagiat contre des pionniers de l’AI comme Hinton, des cas d’arrestations erronées causées par des modèles AI dans des applications de reconnaissance faciale, et les risques posés par le contenu généré par AI (comme une machine distributrice AI hors de contrôle testée par le WSJ). OpenAI a publié des “Model Specifications” pour guider le comportement des modèles, et Google DeepMind a lancé la technologie de filigrane SynthID pour détecter les vidéos générées par AI. De plus, l’énorme empreinte environnementale de l’AI (consommation d’eau et émissions de carbone) suscite également des préoccupations, ainsi que les considérations éthiques liées au soutien émotionnel fourni par l’AI. (Source: SchmidhuberAI, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Ronald_vanLoon, AnthropicAI, ajeya_cotra, Reddit r/MachineLearning)
Développement et défis des Agents AI : Le développement et l’application des Agents AI sont devenus un sujet brûlant, les discussions couvrant leur architecture (modules composables, gestion de la mémoire), les standards ouverts (Agent Skills), et leur mise en pratique dans des domaines tels que la robotique (Reachy Mini, robot Grek, robot Bipedal Gait, Autonomous Mobile Robots) et la programmation (Claude MCP Agent). Les défis incluent l’amélioration de la crédibilité des Agents, la gestion du contexte long, l’optimisation de l’infrastructure pour soutenir la collaboration multi-Agents, et la garantie de la stabilité des Agents dans des tâches complexes et l’évitement des “boucles infinies”. (Source: Vtrivedy10, julesagent, LangChainAI, TheTuringPost, Ronald_vanLoon, Sentdex, ClementDelangue, doodlestein, corbtt, Ronald_vanLoon)
Recherche LLM et caractéristiques des modèles : La communauté AI discute de la recherche LLM, y compris la fonction de valeur dans le renforcement learning (RL), l’utilité de LoRA RL, l’évaluation des capacités de GPT-4, le débat entre RL et les LLM post-entraînement, l’application des LLM en recherche mathématique, ainsi que l’exploration de questions philosophiques telles que la conscience AI et la “nourriture intellectuelle”. En outre, l’attention est portée sur les nouvelles architectures LLM (comme Diffusion LLM, DexWM world model), les lois de densité des modèles, les défis du traitement du contexte long, et l’évaluation des performances de modèles spécifiques comme Kimi K2 et MiMo-V2. (Source: natolambert, vllm_project, SebastienBubeck, sarahcat21, karpathy, riemannzeta, _akhaliq, code_star, DeepLearningAI, ollama, gdb, yacinelearning, ylecun, pmddomingos, matei_zaharia, TheTuringPost, yacinelearning, MiniMax__AI, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/LocalLLaMA)
Infrastructure et matériel AI : L’infrastructure et le matériel AI sont des sujets brûlants, y compris l’implémentation de l’inférence parallèle de tenseurs à faible latence par le framework MLX sur Mac, l’importance des bases de données vectorielles comme Qdrant et Turbopuffer à l’ère Agentic, et les coûts et défis de la construction de clusters GPU (comme 8x B200 ou un cluster Mac Studio). Les discussions portent également sur l’optimisation de l’entraînement distribué (SonicMoE), les goulots d’étranglement des backends serverless pour les Agents, et les préoccupations concernant la consommation d’énergie des centres de données AI. (Source: awnihannun, qdrant_engine, TheEthanDing, Dorialexander, halvarflake, matei_zaharia, togethercompute, andersonbcdefg, idavidrein, Reddit r/deeplearning, Reddit r/MachineLearning, Reddit r/LocalLLaMA, Reddit r/MachineLearning, StasBekman, HuggingFace Daily Papers)

Art et applications de l’AI générative : La discussion tourne autour des progrès de l’AI générative dans les domaines de l’art et des applications. Les modèles Runway Gen-4.5 et GWM-1 poussent la génération vidéo vers la simulation de monde général, tandis que DALL-E 3 et Gemini sont utilisés pour la génération d’images, y compris l’amélioration du réalisme des images, la création de contenu 3D et la conversion de style artistique. La communauté a également exploré la perception du contenu généré par AI (AIGC), par exemple, si la qualité des œuvres médiatiques créées par AI est si élevée que les spectateurs doutent qu’elles soient générées par AI, est-ce un éloge ou une offense. En outre, l’application de l’AI à la résolution de problèmes mathématiques et à la conversion de code fait également l’objet d’une attention particulière. (Source: c_valenzuelab, BlackHC, nptacek, yupp_ai, nptacek, claud_fuen, dotey, ylecun, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Autres
Principes d’ingénierie AI : Les discussions sur les médias sociaux soulignent que l’ingénierie AI doit suivre les principes fondamentaux de l’ingénierie traditionnelle, tels que le contrôle de version, les tests et l’observabilité de production. L’opinion est que l’utilisation des LLM ne devrait pas modifier ces pratiques de base, mais plutôt les intégrer dans le processus de développement AI pour garantir la fiabilité et la qualité du système. (Source: imjaredz)
Traitement de données à grande échelle LLM : Discussion sur le traitement de données à grande échelle par les LLM, un sujet sous-estimé. Il est souligné que lors du traitement de volumes massifs de données, les LLM doivent être considérés comme des opérateurs de base de données, utilisant des techniques telles que le mappage sémantique, le filtrage et la réduction. Parallèlement, grâce à des stratégies d’optimisation des coûts comme la cascade de tâches, il est possible de réduire considérablement les coûts de traitement des données par les LLM tout en garantissant la précision, réalisant ainsi un équilibre entre efficacité et économie. (Source: HamelHusain)
Perceptions de l’AI sur la cognition et l’apprentissage humain : Un chercheur en AI, fort de 5000 heures d’expérience de jeu à “Tekken”, explore comment les humains construisent des modèles prédictifs sous des contraintes de temps extrêmes, et le lien avec les modèles de monde AI et l’apprentissage prédictif. Il estime que les jeux de combat forcent les joueurs à prédire plutôt que de simplement réagir, ce qui reflète les défis de la recherche AI dans la construction de modèles de monde internes, la lecture de modèles à partir d’informations partielles et l’adaptation aux échecs de prédiction, offrant une perspective unique pour comprendre l’intelligence au-delà de l’AI de jeu. (Source: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)