
Mots-clés:SAM 3, Gemini 3 Flash, Génération vidéo IA, Intelligence incarnée, Grand modèle, Agent IA, Personnage numérique 3D, Segmentation d’image Meta SAM 3, Performances de Google Gemini 3 Flash, Génération vidéo Alibaba Wanxiang 2.6, Collecte de données contextuelles Deepwise, Open source de Xiaomi MiMo-V2-Flash
Voici la traduction de votre contenu en français, en respectant toutes vos exigences :
🔥 À la Une
Meta lance le modèle SAM 3 : Facebook Research dévoile SAM 3, un modèle de fondation de segmentation unifié pour images et vidéos, basé sur des invites. Il permet la détection, la segmentation et le suivi d’objets via des invites textuelles ou visuelles, introduisant la capacité de segmentation d’instances pour des concepts à vocabulaire ouvert, et atteignant 75-80% des performances humaines sur le benchmark SA-CO. Le modèle est alimenté par un moteur de données innovant, qui a automatiquement annoté plus de 4 millions de concepts uniques, et intègre une nouvelle conception architecturale, comprenant des tokens de présence et un détecteur-suiveur découplé, pour une meilleure discrimination et efficacité. (Source: GitHub Trending)

Google dévoile le modèle Gemini 3 Flash : Google introduit Gemini 3 Flash, son modèle d’IA le plus rapide à ce jour, conçu pour la vitesse tout en conservant une intelligence de pointe. Ce modèle démontre des performances exceptionnelles sur des benchmarks de raisonnement et de connaissance de niveau doctoral tels que GPQA Diamond et Humanity’s Last Exam, et surpasse même Gemini 3 Pro sur le benchmark de codage SWE-bench Verified. Gemini 3 Flash offre une vitesse trois fois supérieure à celle de Gemini 2.5 Pro à un coût réduit (0,50 $ par million de tokens d’entrée, 3 $ par million de tokens de sortie), et a été déployé mondialement comme modèle par défaut pour le mode IA de Google Search, visant à démocratiser l’IA dans les applications d’entreprise et l’écosystème des développeurs. (Source: WeChat)
🎯 Tendances
Les modèles de génération vidéo par IA continuent d’évoluer : Des modèles tels que Alibaba Wanxiang 2.6, ByteDance Seedance 1.5 Pro et Kling 2.6 ont été successivement lancés. Wanxiang 2.6 permet la personnalisation de personnages avec cohérence audio-visuelle et le contrôle multi-plans, générant jusqu’à 15 secondes en une seule fois ; Seedance 1.5 Pro se concentre sur la synchronisation audio-visuelle de haute précision et le support multi-dialectes ; Kling 2.6 renforce le contrôle du timbre vocal et les fonctions Motion Control. Ces avancées marquent le passage de la création vidéo par IA d’une ère de “tirage au sort” à une nouvelle étape de production de qualité cinématographique, précise et contrôlable. (Source: WeChat, WeChat, Kling_ai, Alibaba_Wan)
Développement approfondi des technologies et stratégies d’IA incarnée : DeepMind lance un mode de “collecte de données contextuelles” pour l’IA incarnée, résolvant les problèmes de généralité grâce à des données de première personne humaine ; Horizon Robotics dévoile sa stratégie Wintel “BPU + compilateur + modèle de fondation”, habilitant les voitures intelligentes et les robots généraux ; l’équipe du Dr Wang Guangrun de l’Université Sun Yat-sen publie le grand modèle incarné E0, mettant l’accent sur le découplage des modèles physiques et spatiaux pour une généralisation par réglage fin à faible nombre d’échantillons. Ces avancées propulsent collectivement l’IA incarnée de l’imitation mécanique vers la compréhension logique et l’interaction avec le monde physique. (Source: WeChat, WeChat, WeChat)
Xiaomi et SenseTime lancent des grands modèles de pointe : Xiaomi rend open source son grand modèle MiMo-V2-Flash, adoptant une architecture MoE, spécialement conçu pour les scénarios d’Agent et de code, et se positionnant parmi les meilleurs modèles open source mondiaux grâce à son efficacité d’inférence extrême et son faible coût. SenseTime Technology publie le modèle SenseNova-SI et l’architecture NEO, visant à résoudre les limites de la compréhension du monde physique par les modèles purement linguistiques, en améliorant l’intelligence spatiale grâce à la multimodalité native et à la prédiction multi-perspectives. (Source: WeChat, WeChat)

L’AI PC s’intègre à des scénarios d’application spécifiques : Cosmotron Motion lance l’assistant de santé personnel AI PC, utilisant la technologie rPPG sans contact pour la mesure de la tension artérielle et la détection cutanée à distance, combinée au NPU d’Intel pour un traitement local efficace. Parallèlement, Yunpeng Technology dévoile de nouveaux produits AI+santé, dont un réfrigérateur intelligent avec grand modèle de santé IA et un laboratoire de cuisine numérique du futur, intégrant l’IA dans la gestion quotidienne de la santé et la technologie domestique. (Source: WeChat, 36氪)

Moore Threads LiteGS réalise une percée dans le rendu graphique 3D : Moore Threads a remporté la médaille d’argent au défi de reconstruction 3DGS du SIGGRAPH Asia 2025 et a rendu open source sa technologie LiteGS auto-développée. LiteGS est une bibliothèque de base pour le 3D Gaussian Splatting, qui, grâce à une optimisation collaborative de la chaîne complète, a atteint une avance significative en termes d’efficacité d’entraînement et de qualité de reconstruction, favorisant l’application de la technologie 3DGS dans la reconstruction 3D, le rendu en temps réel et les scénarios d’entraînement d’IA incarnée. (Source: WeChat)

Nouvelles avancées dans le pré-entraînement économe en données pour les petits LLM : Un ingénieur de recherche indépendant coréen a lancé Gumini, un LLM bilingue coréen-anglais de 1,5 milliard de paramètres, qui s’est classé en tête des benchmarks coréens avec seulement 3,14 milliards de tokens d’entraînement. Cette avancée démontre qu’en optimisant l’architecture et les stratégies d’entraînement, le pré-entraînement des LLM peut être économe en données, offrant une nouvelle voie aux petites équipes et aux chercheurs indépendants au-delà du paradigme “plus de données + plus de puissance de calcul”. (Source: Reddit r/LocalLLaMA)

L’IA multimodale approfondit son application dans des domaines spécifiques : MiraTTS, un modèle TTS rapide et de haute qualité, peut générer une voix réaliste à plus de 100 fois la vitesse en temps réel, et prend en charge plusieurs langues. Parallèlement, un système RAG multilingue a été déployé pour le soutien à la décision en agroécologie, étudiant le comportement des LLM dans des domaines à faibles ressources et hautement spécialisés, et est en production depuis un an. Ces exemples démontrent l’application mature de l’IA multimodale dans la génération vocale et le soutien à la décision dans des domaines verticaux. (Source: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Taobao Tech lance un système de reconstruction d’humains numériques 3D pour mobile : L’équipe Meta de Taobao Tech a présenté le système HRM²Avatar au SIGGRAPH Asia, permettant aux utilisateurs de créer et de rendre des humains numériques 3D réalistes en temps réel à partir d’une simple vidéo monoculaire de téléphone. Ce système combine un maillage de vêtements explicite avec une représentation gaussienne, supportant le pilotage et le rendu en temps réel sur les appareils mobiles, avec des performances exceptionnelles en termes de réalisme visuel, de cohérence multi-poses et de performance mobile, visant à réduire la barrière à la création d’humains numériques 3D. (Source: WeChat)

🧰 Outils
Letta : une plateforme pour construire des agents IA avec état : Letta (anciennement MemGPT) est une plateforme pour construire des agents IA avec état, dont le cœur est une gestion avancée de la mémoire, permettant aux agents IA d’apprendre et de s’améliorer au fil du temps. La plateforme offre un SDK Python/TypeScript, un environnement ADE sans code, ainsi qu’une version de bureau locale et un service cloud, supportant des concepts clés tels que la hiérarchisation de la mémoire, les blocs de mémoire, l’ingénierie du contexte d’agent, et permettant la mémoire partagée multi-agents et les “agents en veille” fonctionnant en arrière-plan. Maestro est une application de bureau gratuite et open source multi-plateforme pour l’orchestration d’agents IA, supportant la mémoire du système de fichiers et la création d’outils, et dotée d’une fonction “auto-run”. Toad, en tant qu’interface terminale unifiée pour les agents de codage IA, simplifie l’intégration avec différents outils de codage IA. (Source: GitHub Trending, Reddit r/LocalLLaMA, huggingface)
L’outil de programmation IA sans code Miaoda habilite les non-programmeurs : Miaoda est un outil de programmation IA sans code lancé il y a 8 mois, qui a généré plus de 5 milliards de yuans de valeur, principalement utilisé par des non-programmeurs. Cet outil utilise un “agent intelligent de chef de produit” pour des communications itératives sur les exigences, transformant des besoins vagues en documents produit structurés, puis un “agent intelligent de développement” pour la mise en œuvre. Miaoda a surmonté les défis de la construction backend, réalisant une intégration profonde de l’IA avec les bases de données, et réduisant les coûts et augmentant l’efficacité grâce à des stratégies raffinées, évitant le “code spaghetti”. (Source: WeChat)

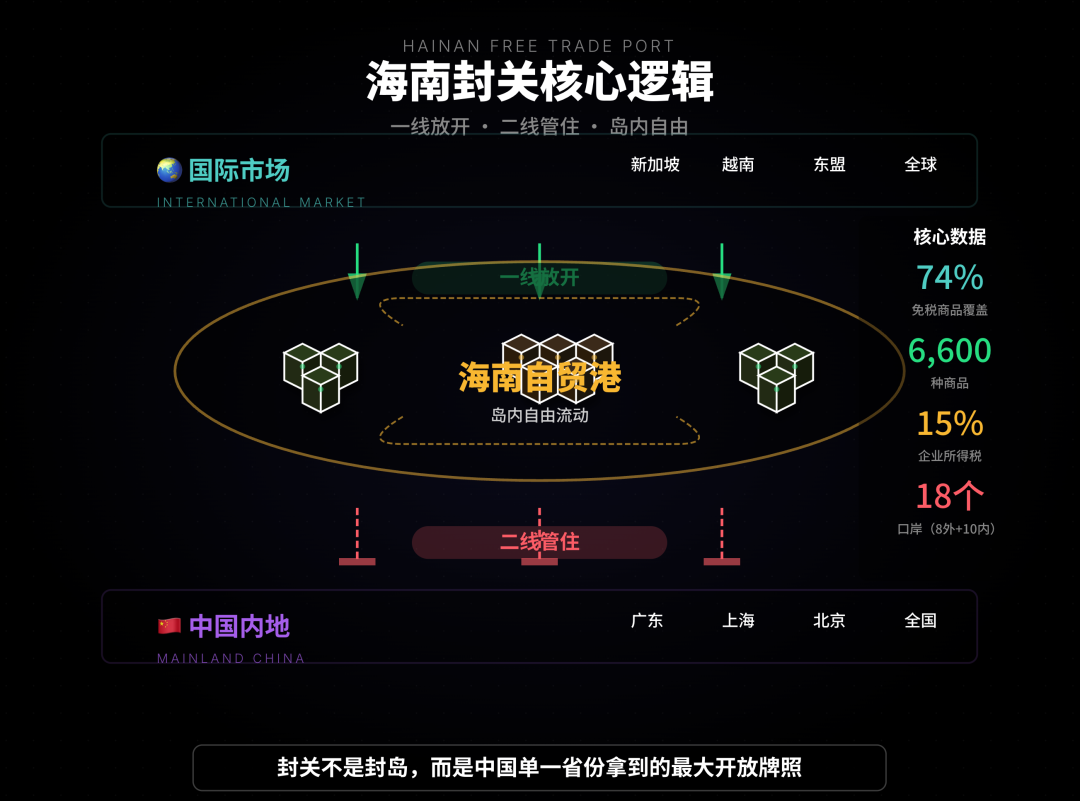
Outils d’analyse assistée par IA et d’automatisation des ventes : L’article montre comment l’IA peut aider à analyser les tendances de la politique de “fermeture des frontières de Hainan”, en intégrant des informations multi-canaux, en les classifiant et en les extrapolant, aidant les utilisateurs à clarifier des informations complexes. QuickHook est un outil d’automatisation des ventes basé sur Gemini 3 et Search Grounding, capable de transformer 15 minutes de recherche manuelle en 10 secondes d’automatisation, visant à résoudre le problème de la “tonalité IA” dans la prospection à froid. (Source: WeChat, Reddit r/artificial)
API OpenWebUI et système STT local : OpenWebUI fournit une interface API, permettant aux développeurs de créer des applications clientes personnalisées, telles que des applications en mode vocal sur WearOS, pour une expérience d’interaction IA personnalisée. Kroko-onnx-home-assistant est un pipeline open source de reconnaissance vocale en continu (STT) local, conçu pour Home Assistant, caractérisé par une haute qualité, un traitement en continu en temps réel et une localisation à 100%, fonctionnant efficacement même sur des appareils à faibles ressources. (Source: Reddit r/OpenWebUI, Reddit r/LocalLLaMA)
Collaboration multi-LLM pour améliorer l’efficacité du développement de jeux : Un développeur utilise l’API OpenAI Realtime pour recueillir les exigences de jeu, Gemini 3 Pro pour générer des spécifications Markdown, puis Anthropic Opus 4.5 pour coder l’application, réalisant ainsi le développement d’un jeu de balle intelligent personnalisé. Ce flux de travail collaboratif multi-LLM optimise les avantages de différents LLM, améliorant l’efficacité et la qualité du développement, des exigences au code, et offrant un nouveau paradigme de développement pour les projets complexes. (Source: Reddit r/artificial)

📚 Apprentissage & Recherche
Optimisation de l’architecture Transformer et innovation en normalisation : L’équipe de Liu Zhuang de l’Université de Princeton propose l’opérateur Derf, basé sur la fonction d’erreur gaussienne (erf) pour remplacer LayerNorm dans Transformer, surpassant toutes les méthodes existantes dans les tâches de vision, de génération et de modélisation de séquences génétiques. Parallèlement, l’Université de Nanyang Technologique et l’Université Fudan proposent EFLA (Error-Free Linear Attention), qui élimine la dérive numérique de l’attention linéaire sur de longues séquences grâce à une solution analytique, améliorant simultanément la stabilité et les performances. (Source: WeChat, WeChat)

Recherche de pointe sur la compréhension multimodale et vidéo : Le cadre DiffusionVL peut transformer les modèles autorégressifs en modèles de langage visuel de diffusion, améliorant considérablement les performances et accélérant l’inférence. Le système SAGE utilise l’apprentissage par renforcement pour le raisonnement multi-tours sur de longues vidéos et excelle dans les tâches vidéo ouvertes. MMSI-Video-Bench, en tant que benchmark complet d’intelligence spatiale vidéo, révèle les échecs systématiques des MLLM en matière de raisonnement géométrique et d’ancrage de mouvement. VGGT4D propose un cadre de reconstruction de scènes 4D sans entraînement, traitant les scènes dynamiques en exploitant les indices de mouvement internes de Transformer. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, WeChat)
Optimisation de la mémoire des agents IA et des LLM : L’Université de Nankin et Baidu, entre autres, proposent ViLoMem, qui résout le problème des grands modèles multimodaux qui “n’apprennent pas de leurs erreurs” grâce à une mémoire sémantique à double flux (flux visuel + flux logique), améliorant considérablement les performances d’inférence. Le cadre LightSearcher optimise l’appel d’outils d’Agent basé sur RL via la mémoire d’expérience, réduisant le nombre d’appels de 39,6% et le temps d’inférence de 48,6%, tout en maintenant la précision. Le cadre MEM1 entraîne également un Agent basé sur RL à maintenir une mémoire constante dans les tâches à long terme. (Source: WeChat, WeChat, omarsar0)
Évaluation des LLM et construction de jeux de données : LikeBench, en tant que cadre d’évaluation dynamique multi-sessions, décompose pour la première fois la préférence de personnalisation des LLM en sept indicateurs diagnostiques, utilisés pour mesurer la capacité du modèle à s’adapter aux préférences de l’utilisateur. VOYAGER est une méthode sans entraînement qui utilise les LLM pour générer des jeux de données diversifiés, augmentant significativement la diversité de 1,5 à 3 fois. Le pipeline de création de jeu de données FiNERweb fournit des ressources extensibles de reconnaissance d’entités nommées multilingues pour 91 langues et 25 scripts. NVIDIA a également publié le guide d’évaluation complet de Nemotron 3 Nano, améliorant la transparence et la reproductibilité de l’évaluation des LLM. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/LocalLLaMA)

Recherche sur la sécurité et l’explicabilité de l’IA : Une étude propose un cadre de resynthèse pour détecter de manière robuste et calibrée l’authenticité des contenus multimédias, afin de contrer les défis des deepfakes. Parallèlement, le cadre Hybrid Attribution Priors utilise le Class-Aware Attribution Prior (CAP) pour guider les modèles linguistiques à capturer une distinction de catégorie fine, améliorant l’explicabilité et la robustesse du modèle. Hyper++ améliore l’apprentissage par renforcement profond hyperbolique, augmentant la stabilité d’apprentissage de l’Agent. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Ressources d’apprentissage et opportunités de recherche en Deep Learning : AIhub publie une compilation d’entretiens du forum doctoral AAAI/ACM SIGAI 2025, couvrant la recherche de pointe en IA dans divers domaines. Parallèlement, un nouveau cours sur les systèmes ML et la programmation GPU est annoncé, visant à approfondir la compréhension de la pile DL par la pratique. Un défi matériel PyTorch/vLLM encourage les développeurs à corriger des bugs, et des suggestions de parcours d’apprentissage en vision par ordinateur sont proposées pour aider les apprenants à planifier leur carrière. (Source: aihub.org, DeepLearningAI, vllm_project, Reddit r/deeplearning, Reddit r/deeplearning)

Modélisation 3D/XR et interaction homme-machine : Le cadre TIMAR propose une modélisation causale des dynamiques de tête de dialogue 3D interactives, fusionnant des informations multimodales et prédisant des dynamiques de tête 3D continues. Une étude sur la traduction d’images SAR vers RGB explore comment générer des images claires via des modèles de Deep Learning. Une recherche sur l’algorithme de notation de l’écriture manuscrite des lettres préscolaires cherche des méthodes de correspondance de modèles pour évaluer avec précision la qualité de l’écriture des enfants. (Source: HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
Scaling Laws et théorie de la fusion de modèles : Cette recherche remet en question l’idée que les “Scaling Laws sont supérieures aux biais inductifs”, découvrant que les architectures encodant la symétrie ont de meilleurs Scaling Exponents. Parallèlement, les solutions de résolution de conflits de fusion de modèles multi-tâches (TATR, CAT Merging, LOT Merging) atténuent efficacement les conflits de connaissances et améliorent les performances et la robustesse multi-tâches en identifiant et en filtrant les dimensions conflictuelles, en projetant ou en fusionnant de manière pondérée. (Source: dair_ai, WeChat)
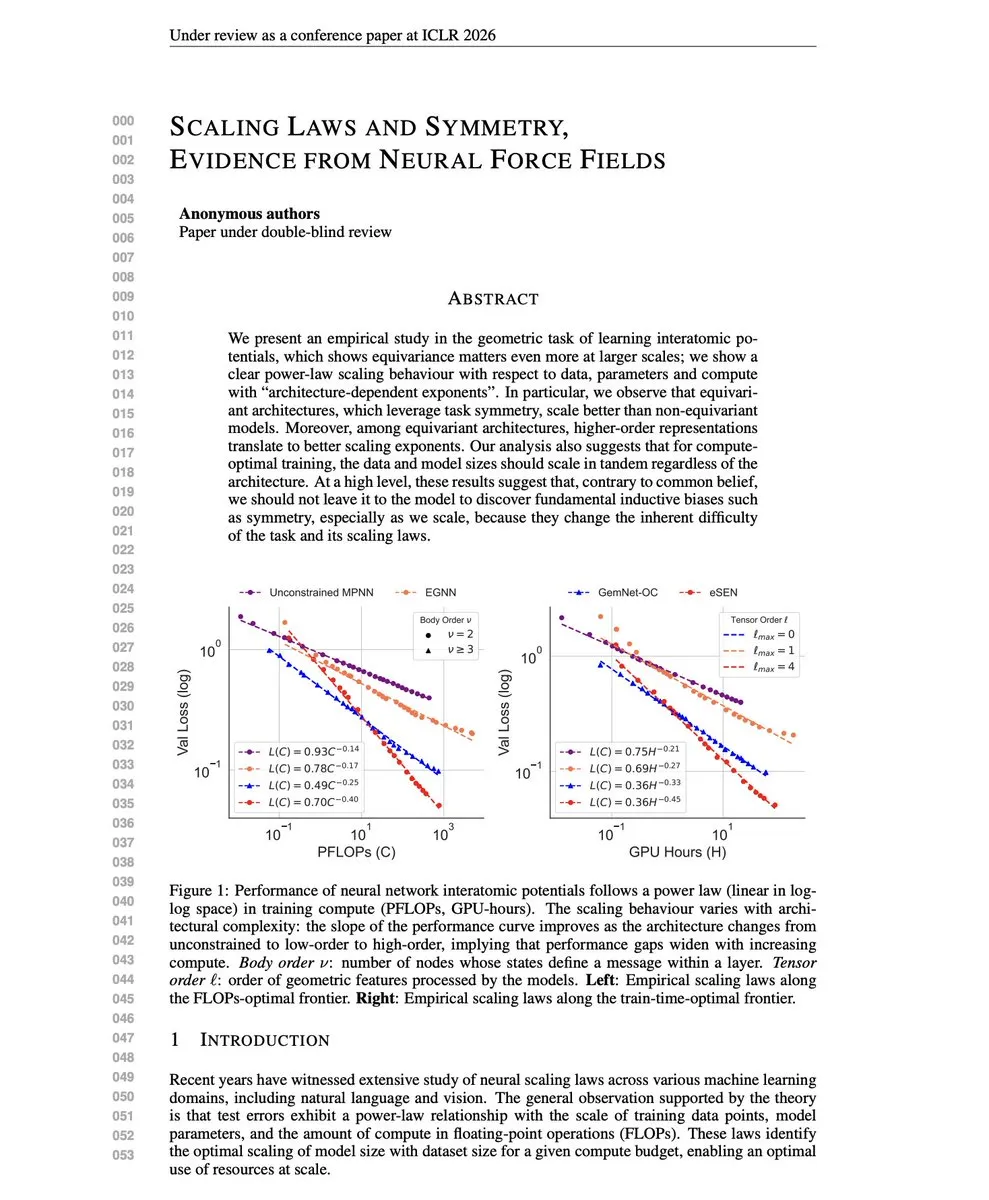
Entraînement de bout en bout de la diffusion vidéo autorégressive : Cette étude introduit le cadre “Resampling Forcing” pour permettre l’entraînement de bout en bout des modèles de diffusion vidéo autorégressive. En simulant les erreurs du modèle sur les images historiques lors de l’inférence, combiné à un masque causal sparse et un mécanisme de routage historique, cette méthode atteint des performances comparables aux lignes de base de distillation tout en maintenant la cohérence temporelle et en supportant une génération efficace à long terme. (Source: HuggingFace Daily Papers)
Discussion sur l’évaluation et la reproductibilité des LLM : La communauté Reddit discute des défis de l’évaluation des LLM et des problèmes de reproductibilité. Les utilisateurs s’intéressent à la manière d’établir des critères d’évaluation fiables, d’assurer la comparabilité des résultats entre différentes études et modèles, et d’explorer comment gérer et partager efficacement les méthodes d’évaluation et les jeux de données dans le domaine en évolution rapide des LLM pour faire progresser la science. (Source: Reddit r/deeplearning)
💼 Affaires
Zhipu AI et MiniMax se lancent dans l’IPO à la bourse de Hong Kong : Les entreprises chinoises de grands modèles MiniMax et Zhipu AI ont finalisé leur enregistrement auprès de la CSRC et ont participé à l’audition d’inscription à la bourse de Hong Kong, MiniMax prévoyant d’être cotée en janvier 2026. Zhipu AI, évaluée à environ 40 milliards de yuans, se concentre sur les secteurs G2B et B2B ainsi que sur les Agents multimodaux ; MiniMax, évaluée à près de 30 milliards de yuans, est axée sur les capacités multimodales et un modèle axé sur les produits. Les deux entreprises ont procédé à une convergence stratégique et à des ajustements d’équipe avant leur cotation, reflétant l’entrée de l’industrie des grands modèles dans une “période de double contrainte de capital et d’efficacité”. (Source: 36氪)
Amazon prévoit d’investir 10 milliards de dollars dans OpenAI : Amazon prévoit d’investir au moins 10 milliards de dollars dans OpenAI. Cet investissement devrait inclure l’utilisation par OpenAI des puces d’IA de la série Trainium d’Amazon et la location de davantage de capacité de centres de données pour faire fonctionner ses modèles et outils (tels que ChatGPT). Cet investissement vise à approfondir la collaboration entre les deux entreprises en matière d’infrastructure d’IA et de déploiement de modèles. (Source: Reddit r/ArtificialInteligence)

Biren Technology se lance dans l’IPO pour devenir la première action GPU universelle à la bourse de Hong Kong : Biren Technology, la licorne du GPU universel évaluée à 20,9 milliards de yuans, a passé l’audition de la bourse de Hong Kong et est sur le point de devenir la “première action GPU domestique” à la bourse de Hong Kong. L’entreprise a été fondée par Zhang Wen, titulaire d’un doctorat en droit de Harvard. Ses produits phares sont des systèmes matériels basés sur son architecture GPGPU auto-développée (puces Biren BR106, BR110, BR166) et la plateforme logicielle BIRENSUPA, offrant un support complet pour l’entraînement et l’inférence d’IA. Ses clients couvrent les secteurs des télécommunications, de la fintech et d’autres industries à forte demande de puissance de calcul. (Source: WeChat)
🌟 Communauté
Qualité du contenu généré par l’IA et phénomène de “slop” sur Internet : Les médias sociaux discutent largement du phénomène de “slop”, caractérisé par la qualité inégale du contenu généré par l’IA, qui a été choisi comme mot de l’année, reflétant la prolifération et les problèmes de faible qualité du contenu IA. Cela a suscité des critiques sur les motivations financières des plateformes publicitaires Internet et des réflexions sur la manière d’élever le seuil de création de contenu IA. (Source: 36氪)

Impact de l’IA sur le marché du travail et les modes de travail des développeurs : Les médias sociaux explorent en profondeur la perturbation du marché de l’emploi et des modes de travail des développeurs par l’IA. L’IA est considérée comme un puissant outil de productivité, transformant le rôle des développeurs de la simple écriture de code vers la conception de systèmes, l’orchestration d’agents, la vérification et le débogage de code, nécessitant la maîtrise de compétences de niveau supérieur. LinkedIn introduit un assistant de recrutement IA, modifiant les processus de recherche d’emploi et de recrutement. Parallèlement, l’IA améliore considérablement l’efficacité dans des domaines comme la photographie, mais la préparation à la production des agents de codage IA reste un défi. (Source: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Yuchenj_UW, gdb, amasad, amasad, Ronald_vanLoon)

Applications et défis de l’IA dans l’éducation, la santé et d’autres domaines : L’utilisation par les enseignants de logiciels de détection d’IA pour déterminer si les élèves ont utilisé l’IA soulève des controverses éthiques en éducation, appelant le système éducatif à se concentrer sur la compréhension des élèves plutôt que sur l’utilisation d’outils. ChatGPT montre un potentiel d’aide au diagnostic et de conseils de santé dans le domaine médical, mais doit être utilisé avec prudence. Des plateformes comme Glass 5.0 appliquent l’IA au soutien à la décision clinique, faisant évoluer l’IA médicale des chatbots vers des partenaires. (Source: Reddit r/artificial, Reddit r/ChatGPT, GlassHealthHQ)

Discussion continue sur les performances, les coûts et l’expérience utilisateur des LLM : Les utilisateurs des médias sociaux discutent avec enthousiasme des performances, des coûts et de l’expérience d’utilisation réelle des LLM tels que Gemini 3 Flash et Claude Opus 4.5. Les points d’intérêt incluent les progrès des modèles en matière de codage, d’appel d’outils et de capacités de raisonnement, ainsi que des problèmes tels que la dégradation des performances et le taux d’hallucination. Les utilisateurs comparent le rapport qualité-prix des différents modèles et discutent des stratégies de tarification des modèles d’IA et de la perception de la valeur des modèles par les utilisateurs. (Source: Vtrivedy10, hrishioa, tokenbender, inerati, scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, max__drake, MiniMax__AI, scaling01)
Exploration approfondie de l’éthique, de la philosophie et de l’AGI de l’IA : Les médias sociaux discutent des implications éthiques et sociales de l’IA, y compris si l’IA comble le “vide divin”, la véritable définition de l’AGI, et le potentiel et les limites de l’IA dans la recherche en physique. Les utilisateurs s’intéressent également à la reproductibilité des benchmarks d’IA, à la critique de la qualité de la recherche en IA, et aux réflexions philosophiques sur les différences essentielles entre les modèles d’IA et l’intelligence humaine. (Source: Ronald_vanLoon, ImazAngel, Ronald_vanLoon, RisingSayak, snwy_me, TheTuringPost, teortaxesTex, _lewtun)

Architecture, efficacité et optimisation de l’infrastructure des modèles d’IA : Les médias sociaux discutent de l’architecture et de l’efficacité des modèles d’IA, y compris l’efficacité MFU des modèles MoE, l’entraînement MoE ultra-sparse de nmoe, et la simplification de l’inférence LLM (comme mini-SGLang). Les utilisateurs s’intéressent aux progrès des modèles en matière de traitement de contextes longs, de gestion de la mémoire et d’optimisation matérielle (comme le backend distribué MLX, le service vLLM), afin d’améliorer les performances globales et l’évolutivité des systèmes d’IA. (Source: lateinteraction, hyhieu226, TheZachMueller, dejavucoder, awnihannun, vllm_project, aiamblichus)

Stratégie des entreprises d’IA, concurrence sur le marché et flux de talents : Les médias sociaux discutent de la stratégie et de la concurrence sur le marché des entreprises d’IA, y compris l’embauche par Amazon de chercheurs en IA de premier plan, le projet de Thinking Machines de publier des modèles, le rapport coût-efficacité de Meta AI, et les problèmes organisationnels rencontrés par OpenAI. Les utilisateurs s’intéressent également au leadership de NVIDIA dans le domaine de l’IA open source, à sa stratégie axée sur le matériel, et aux mouvements de talents clés tels que l’arrivée de chercheurs d’Anthropic chez Tencent. (Source: pmddomingos, scaling01, teortaxesTex, steph_palazzolo, TheTuringPost, Sentdex, teortaxesTex, turbopuffer, iScienceLuvr, EthanJPerez)

Rapport sur l’état du codage IA et tendances de l’industrie : Greptile publie le “Rapport 2025 sur l’état du codage IA”, indiquant une augmentation de 76% de la production de code mensuelle des développeurs et un gonflement du volume des PR, avec une distribution inégale des bénéfices des outils IA. Le rapport compare également les performances des modèles OpenAI, Anthropic et Google en termes de temps de réponse du premier token, de débit et de coût, et révèle le paysage concurrentiel des bases de données vectorielles et des outils de mémoire IA. (Source: dotey)

Évaluation et reproductibilité des modèles d’IA : La communauté Reddit discute des défis de l’évaluation des LLM et des problèmes de reproductibilité. Les utilisateurs s’intéressent à la manière d’établir des critères d’évaluation fiables, d’assurer la comparabilité des résultats entre différentes études et modèles, et d’explorer comment gérer et partager efficacement les méthodes d’évaluation et les jeux de données dans le domaine en évolution rapide des LLM pour faire progresser la science. (Source: Reddit r/deeplearning)
IA ouverte et stratégies axées sur le matériel : Le lancement de NVIDIA Nemotron 3 marque un tournant symbolique dans le leadership de l’IA open source. Ce modèle, grâce à des données de pré-entraînement massives, des jeux de données RL et une nouvelle architecture hybride, optimise la consommation de calcul du matériel NVIDIA. Cette stratégie indique que l’IA open source passe de l’ère de la “philanthropie des grandes technologies” à une ère où le “matériel définit l’IA”, c’est-à-dire que la publication de modèles vise à étendre la consommation de calcul d’un matériel spécifique. (Source: TheTuringPost, teortaxesTex)
Comparaison et applications des outils de génération d’images et de vidéos par IA : Les utilisateurs des médias sociaux discutent des performances et des applications des outils de génération d’images et de vidéos par IA, y compris ChatGPT, Gemini, Midjourney, Grok, Nano Banana Pro, etc. La discussion couvre le réalisme des œuvres d’art IA, la conversion de personnages de jeux, et l’application de la vidéo IA dans la production cinématographique. Les utilisateurs s’intéressent également à la qualité, au coût et à l’efficacité du contenu généré par l’IA, ainsi qu’à son impact disruptif sur le processus créatif. (Source: dotey, swyx, karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Kling_ai)

Applications et tendances de l’IA dans le secteur financier : Les médias sociaux discutent des applications de l’IA dans le secteur financier, couvrant 26 cas spécifiques, tels que la détection de fraudes, la gestion des risques, le service client, etc. Ces applications démontrent comment l’apprentissage automatique et l’intelligence artificielle peuvent autonomiser l’industrie financière, améliorer l’efficacité, optimiser les décisions et créer de nouvelles valeurs commerciales. (Source: Ronald_vanLoon)

Combinaison des agents IA et des graphes de connaissances : Les scientifiques en IA de SAP discutent de la manière d’améliorer la découverte et l’exécution des agents IA grâce aux graphes de connaissances. Les graphes de connaissances fournissent aux agents IA un contexte sémantique et procédural, leur permettant de découvrir et d’appeler plus efficacement les outils et API des systèmes d’entreprise, améliorant ainsi l’efficacité des agents dans des environnements d’entreprise complexes. (Source: DeepLearningAI)

Discussion sur l’évaluation et la reproductibilité des LLM : La communauté Reddit discute des défis de l’évaluation des LLM et des problèmes de reproductibilité. Les utilisateurs s’intéressent à la manière d’établir des critères d’évaluation fiables, d’assurer la comparabilité des résultats entre différentes études et modèles, et d’explorer comment gérer et partager efficacement les méthodes d’évaluation et les jeux de données dans le domaine en évolution rapide des LLM pour faire progresser la science. (Source: Reddit r/deeplearning)
Performances des modèles d’IA dans l’UE et impact de la réglementation : Les utilisateurs de Reddit discutent si les modèles d’IA vidéo et d’image sont “plus bêtes” dans l’UE en raison de la réglementation. L’opinion générale est que la qualité intrinsèque des modèles n’est pas affectée, mais que les couches de sécurité strictes et les exigences de conformité de l’UE peuvent entraîner des retards de lancement de fonctionnalités, un filtrage plus strict ou des paramètres par défaut différents, affectant ainsi l’expérience utilisateur plutôt que l’intelligence même du modèle. (Source: Reddit r/ArtificialInteligence)
💡 Divers
Fusion de l’IA dans les domaines de l’art et du divertissement : Le robot Desdemona et son groupe se produiront le 11 janvier à San Francisco, combinant l’IA et l’art pour explorer le potentiel des robots en tant qu’artistes. Parallèlement, des utilisateurs ont exprimé le souhait de voir des groupes utiliser des outils d’IA comme Suno pour générer des chansons et les interpréter en direct, ce qui reflète les tendances émergentes de l’application de l’IA dans la création musicale et le divertissement en direct. (Source: bengoertzel, fabianstelzer)
ComfyUI explore un “mode simple” pour simplifier les flux de travail : ComfyUI explore un nouveau “mode simple” visant à rendre les flux de travail complexes plus faciles à partager et à itérer, en se concentrant sur le résultat plutôt que sur le graphe de nœuds sous-jacent. Ce mode est particulièrement destiné aux utilisateurs qui trouvent les grands graphes difficiles à comprendre, afin de réduire la barrière d’entrée et d’améliorer l’expérience utilisateur et l’efficacité du travail. (Source: NerdyRodent)