
키워드:SAM 3, Gemini 3 Flash, AI 비디오 생성, 구현형 인공지능, 대규모 모델, AI 에이전트, 3D 디지털 휴먼, Meta SAM 3 이미지 분할, 구글 Gemini 3 Flash 성능, 알리바바 Wanxiang 2.6 비디오 생성, 딥위즈 상황 데이터 수집, 샤오미 MiMo-V2-Flash 오픈소스
🔥 포커스
Meta, SAM 3 모델 공개: Facebook Research가 통합 이미지 및 비디오 프롬프트 기반 분할 파운데이션 모델인 SAM 3을 공개했습니다. 이 모델은 텍스트 또는 시각적 프롬프트를 통해 객체 감지, 분할 및 추적을 수행하며, 개방형 어휘 개념의 인스턴스 분할 기능을 도입했고, SA-CO 벤치마크에서 75-80%의 인간 수준 성능을 달성했습니다. SAM 3은 혁신적인 데이터 엔진으로 구동되며, 400만 개 이상의 고유 개념을 자동으로 주석 처리했습니다. 또한, 존재 토큰과 분리된 감지기-추적기를 포함하는 새로운 아키텍처 설계를 채택하여 판별력과 효율성을 향상시켰습니다. (출처: GitHub Trending)

Google, Gemini 3 Flash 모델 공개: Google이 현재까지 가장 빠른 AI 모델인 Gemini 3 Flash를 출시했습니다. 이 모델은 속도를 위해 특별히 설계되었으며, 최첨단 지능을 유지합니다. Gemini 3 Flash는 GPQA Diamond 및 Humanity’s Last Exam과 같은 박사급 추론 및 지식 벤치마크 테스트에서 뛰어난 성능을 보였으며, SWE-bench Verified 코딩 벤치마크 테스트에서는 Gemini 3 Pro를 능가했습니다. Gemini 3 Flash는 더 낮은 비용(입력 토큰 백만 개당 0.50달러, 출력 3달러)으로 Gemini 2.5 Pro보다 세 배 더 빠른 속도를 제공하며, 전 세계적으로 Google 검색 AI 모드의 기본 모델로 출시되었습니다. 이는 기업용 애플리케이션 및 개발자 생태계에서 AI의 보급을 촉진하는 것을 목표로 합니다. (출처: WeChat)
🎯 동향
AI 비디오 생성 모델 지속적인 발전: Alibaba Wanxiang 2.6, ByteDance Seedance 1.5 Pro, Kling 2.6 등 모델이 잇따라 공개되었습니다. Wanxiang 2.6은 음성-영상 일관성 캐릭터 맞춤화 및 다중 카메라 샷 제어를 구현하여 단일 생성으로 최대 15초 길이를 지원합니다. Seedance 1.5 Pro는 음성-영상 고정밀 동기화 및 다국어 방언 지원을 특징으로 하며, Kling 2.6은 음색 제어 및 Motion Control 기능을 강화했습니다. 이러한 발전은 AI 비디오 제작이 ‘랜덤 생성’ 시대에서 정밀하고 제어 가능한 영화 수준 제작의 새로운 단계로 나아가고 있음을 의미합니다. (출처: WeChat, WeChat, Kling_ai, Alibaba_Wan)
구체화된 지능 기술 및 전략 심층 발전: DeepMind는 인간의 1인칭 시점 데이터를 통해 일반성 문제를 해결하는 구체화된 지능 ‘상황 데이터 수집’ 모드를 출시했습니다. Horizon Robotics는 스마트 자동차 및 범용 로봇에 힘을 실어주는 ‘BPU+컴파일러+파운데이션 모델’의 Wintel 전략을 발표했습니다. Sun Yat-sen 대학의 Wang Guangrun 박사 팀은 물리 및 공간 모델의 분리(decoupling)를 강조하고 소규모 샘플 미세 조정의 일반화를 달성하는 E0 구체화된 거대 모델을 공개했습니다. 이러한 발전은 구체화된 지능이 기계적 모방에서 논리적 이해와 물리적 세계와의 상호작용으로 나아가고 있음을 공동으로 추진합니다. (출처: WeChat, WeChat, WeChat)
Xiaomi와 SenseTime, 최첨단 거대 모델 공개: Xiaomi는 MoE 아키텍처를 채택하고 Agent 및 코드 시나리오를 위해 특별히 설계된 MiMo-V2-Flash 거대 모델을 오픈 소스로 공개했습니다. 이 모델은 최고의 추론 효율성과 낮은 비용으로 글로벌 오픈 소스 모델의 선두 그룹에 진입했습니다. SenseTime은 순수 언어 모델이 물리적 세계를 이해하는 데 있어 한계를 해결하는 것을 목표로 하는 SenseNova-SI 모델과 NEO 아키텍처를 발표했습니다. 이는 네이티브 멀티모달 및 교차 시점 예측을 통해 공간 지능을 향상시킵니다. (출처: WeChat, WeChat)

AI PC와 특정 애플리케이션 시나리오 융합: Cosintrond는 비접촉식 rPPG 기술을 활용하여 비접촉 혈압 및 피부 검사를 구현하고 Intel NPU와 결합하여 로컬에서 효율적인 연산을 수행하는 AI PC 개인 건강 도우미를 출시했습니다. 동시에 CloudPond Technology는 AI 건강 거대 모델 스마트 냉장고와 디지털화된 미래 주방 연구실을 포함한 AI+건강 신제품을 발표하여 AI를 일상 건강 관리 및 가정 기술에 통합합니다. (출처: WeChat, 36氪)

Moore Threads LiteGS 기술, 3D 그래픽 렌더링 혁신: Moore Threads는 SIGGRAPH Asia 2025 3DGS 재구성 챌린지에서 은상을 수상했으며, 자체 개발한 LiteGS 기술을 오픈 소스로 공개했습니다. LiteGS는 3D Gaussian Splatting 기반 라이브러리로, 전체 링크 협업 최적화를 통해 훈련 효율성과 재구성 품질에서 현저한 선두를 차지했습니다. 이는 3DGS 기술이 3D 재구성, 실시간 렌더링 및 구체화된 지능 훈련 시나리오에 적용되는 것을 촉진합니다. (출처: WeChat)

소규모 LLM 데이터 효율적인 사전 학습의 새로운 발전: 한국의 독립 연구 엔지니어가 1.5B 파라미터의 한국어-영어 이중 언어 기반 LLM인 Gumini를 공개했습니다. 이 모델은 3.14B 훈련 토큰만으로 한국 벤치마크 테스트에서 상위권을 차지했습니다. 이러한 발전은 아키텍처 및 훈련 전략 최적화를 통해 LLM 사전 학습이 데이터 효율성을 달성할 수 있음을 보여주며, ‘더 많은 데이터 + 더 많은 컴퓨팅 파워’ 패러다임 외에 소규모 팀과 독립 연구자들에게 새로운 경로를 제공합니다. (출처: Reddit r/LocalLLaMA)

멀티모달 AI의 특정 분야 심화 적용: MiraTTS는 고품질 고속 TTS 모델로, 실시간 속도보다 100배 이상 빠르게 사실적인 음성을 생성할 수 있으며 다국어를 지원합니다. 동시에 다국어 RAG 시스템이 농업 생태계 의사 결정 지원에 배포되어 저자원, 고전문 분야에서 LLM의 동작을 연구하며 이미 프로덕션 환경에서 1년 동안 운영되었습니다. 이는 음성 생성 및 수직 분야 의사 결정 지원에서 멀티모달 AI의 성숙한 적용을 보여줍니다. (출처: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)

Taobao 기술, 모바일 3D 디지털 휴먼 재구성 시스템 출시: Taobao 기술 Meta 팀은 SIGGRAPH Asia에서 HRM²Avatar 시스템을 발표했습니다. 이 시스템은 사용자가 휴대폰 단일 시점 비디오만으로 고품질 실시간 3D 디지털 휴먼을 생성하고 렌더링할 수 있도록 합니다. 명시적 의상 메시와 가우시안 표현을 결합하여 모바일 장치에서 실시간으로 구동 및 렌더링을 지원하며, 시각적 사실성, 교차 포즈 일관성 및 모바일 성능 면에서 뛰어난 성능을 보입니다. 이는 3D 디지털 휴먼 생성의 진입 장벽을 낮추는 것을 목표로 합니다. (출처: WeChat)

🧰 도구
Letta: 상태 저장 AI 에이전트 구축 플랫폼: Letta (이전 MemGPT)는 상태 저장 AI 에이전트 구축 플랫폼으로, 핵심은 고급 메모리 관리이며 AI 에이전트가 시간이 지남에 따라 학습하고 스스로 개선할 수 있도록 합니다. 이 플랫폼은 Python/TypeScript SDK, 노코드 ADE 환경, 로컬 데스크톱 버전 및 클라우드 서비스를 제공하며, 메모리 계층화, 메모리 블록, 에이전트 컨텍스트 엔지니어링 등 핵심 개념을 지원하고 다중 에이전트 공유 메모리 및 백그라운드에서 실행되는 ‘슬립 타임 에이전트’를 구현합니다. Maestro는 AI 에이전트를 오케스트레이션하기 위한 무료 오픈 소스 크로스 플랫폼 데스크톱 애플리케이션으로, 파일 시스템 메모리 및 도구 생성을 지원하며 ‘자동 실행’ 기능을 갖추고 있습니다. Toad는 다양한 AI 코딩 도구와의 통합을 간소화하는 통합 AI 코딩 에이전트 터미널 인터페이스입니다. (출처: GitHub Trending, Reddit r/LocalLLaMA, huggingface)
Miaoda 노코드 AI 프로그래밍 도구, 비프로그래머에게 역량 부여: Miaoda는 출시 8개월 만에 50억 위안 이상의 생산 가치를 창출했으며, 주요 사용자는 비프로그래머입니다. 이 도구는 ‘제품 관리자 에이전트’를 통해 다단계 요구 사항 소통을 진행하고 모호한 요구 사항을 구조화된 제품 문서로 전환하며, ‘개발 에이전트’가 이를 구현합니다. Miaoda는 백엔드 구축의 난제를 해결했으며 AI와 데이터베이스의 심층적인 융합을 달성했습니다. 또한, 정교한 전략을 통해 비용을 절감하고 효율성을 높이며 ‘코드 스파게티’를 방지합니다. (출처: WeChat)

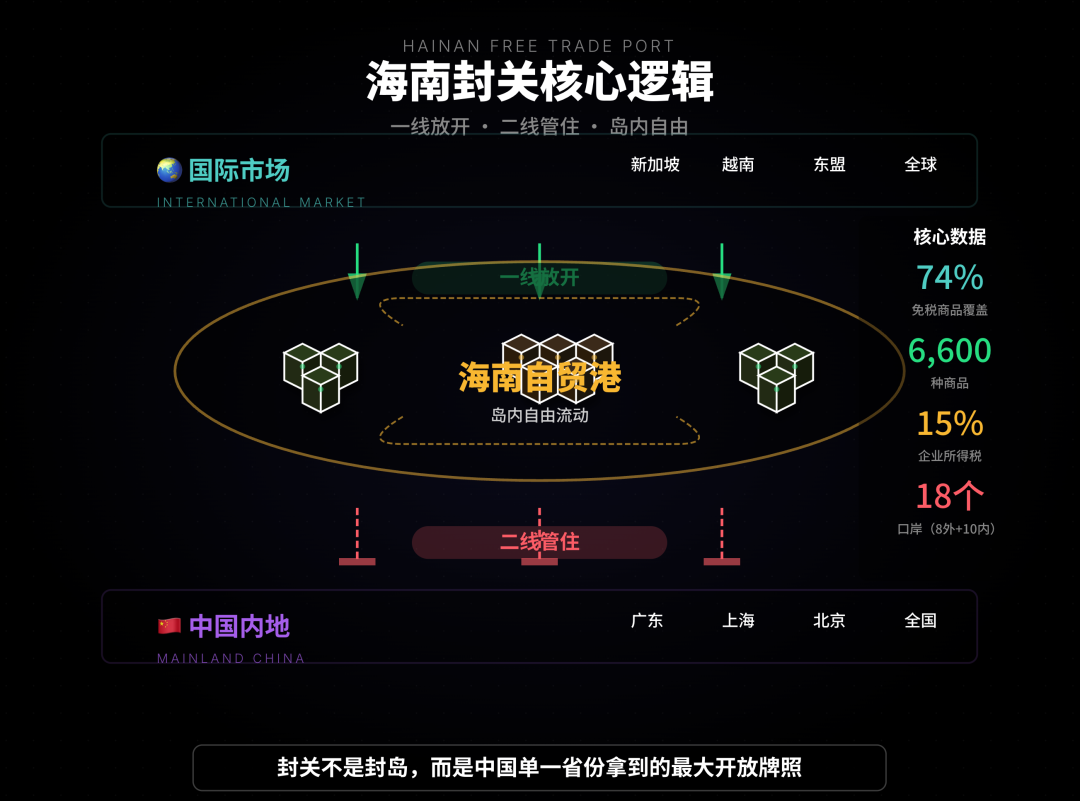
AI 보조 분석 및 판매 자동화 도구: 이 기사는 AI가 ‘하이난 봉쇄’ 정책에 대한 추세 분석을 어떻게 지원하는지 보여줍니다. 다양한 채널의 정보 통합, 분류 및 추론을 통해 사용자가 복잡한 정보를 명확히 이해하도록 돕습니다. QuickHook은 Gemini 3 및 Search Grounding 기반의 판매 자동화 도구로, 15분간의 수동 연구를 10초의 자동화로 전환할 수 있으며, 콜드 아웃리치에서 발생하는 ‘AI 말투’ 문제를 해결하는 것을 목표로 합니다. (출처: WeChat, Reddit r/artificial)
OpenWebUI API 및 로컬 STT 시스템: OpenWebUI는 API 인터페이스를 제공하여 개발자가 WearOS의 음성 모드 애플리케이션과 같은 맞춤형 클라이언트 애플리케이션을 생성할 수 있도록 하여 개인화된 AI 상호작용 경험을 제공합니다. Kroko-onnx-home-assistant는 Home Assistant를 위해 특별히 설계된 오픈 소스 로컬 스트리밍 음성-텍스트 변환(STT) 파이프라인입니다. 이 시스템은 고품질, 실시간 스트리밍 처리 및 100% 로컬화 등의 특징을 가지며, 저자원 장치에서도 효율적으로 작동할 수 있습니다. (출처: Reddit r/OpenWebUI, Reddit r/LocalLLaMA)
다중 LLM 협업을 통한 게임 개발 효율성 향상: 개발자는 OpenAI Realtime API를 사용하여 게임 요구 사항을 수집하고, Gemini 3 Pro를 통해 Markdown 사양을 생성하며, Anthropic Opus 4.5로 애플리케이션을 코딩하여 맞춤형 스마트 볼 게임 개발을 구현했습니다. 이러한 다중 LLM 협업 워크플로우는 다양한 LLM의 장점을 최적화하고 요구 사항부터 코드까지의 개발 효율성과 품질을 향상시켜 복잡한 프로젝트에 새로운 개발 패러다임을 제공합니다. (출처: Reddit r/artificial)

📚 학습
Transformer 아키텍처 최적화 및 정규화 혁신: Princeton 대학의 Liu Zhuang 팀은 가우스 오차 함수(erf)를 기반으로 Transformer의 LayerNorm을 대체하는 Derf 연산자를 제안했습니다. 이 연산자는 시각, 생성, 유전자 서열 모델링 등 다양한 작업에서 기존 방법을 전반적으로 능가했습니다. 동시에 Nanyang Technological 대학과 Fudan 대학은 해석적 해를 통해 긴 시퀀스에서 선형 어텐션의 수치적 드리프트를 제거하여 안정성과 성능의 동시 향상을 달성하는 EFLA(Error-Free Linear Attention)를 제안했습니다. (출처: WeChat, WeChat)

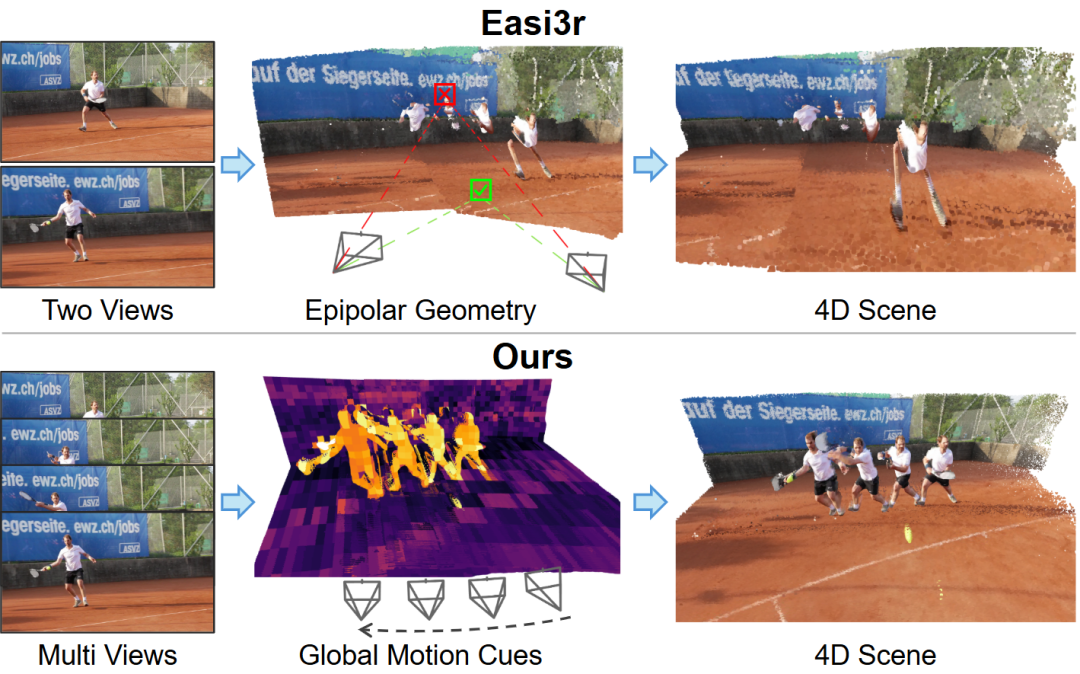
멀티모달 및 비디오 이해 최첨단 연구: DiffusionVL 프레임워크는 자기회귀 모델을 확산 시각 언어 모델로 전환하여 성능을 크게 향상시키고 추론 속도를 가속화합니다. SAGE 시스템은 강화 학습을 활용하여 긴 비디오의 다단계 추론을 구현하며 개방형 비디오 작업에서 뛰어난 성능을 보입니다. MMSI-Video-Bench는 비디오 공간 지능 종합 벤치마크로서 MLLM이 기하학적 추론, 움직임 접지 등에서 체계적인 실패를 보임을 밝혀냈습니다. VGGT4D는 훈련이 필요 없는 4D 장면 재구성 프레임워크를 제안하며, Transformer 내부의 움직임 단서를 활용하여 동적 장면을 처리합니다. (출처: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, WeChat)
AI 에이전트 및 LLM 메모리 최적화: Nanjing University of Science and Technology와 Baidu 등은 이중 스트림 의미론적 메모리(시각 스트림 + 논리 스트림)를 통해 멀티모달 거대 모델이 ‘교훈을 기억하지 못하는’ 문제를 해결하여 추론 성능을 크게 향상시키는 ViLoMem을 제안했습니다. LightSearcher 프레임워크는 경험 메모리 최적화를 통해 RL 기반 Agent 도구 호출을 개선하여 호출 횟수를 39.6% 줄이고 추론 시간을 48.6% 단축하면서 정확도를 유지합니다. MEM1 프레임워크 또한 RL 훈련을 통해 Agent가 장기 작업에서 일정한 메모리를 유지하도록 합니다. (출처: WeChat, WeChat, omarsar0)
LLM 평가 및 데이터셋 구축: LikeBench는 다중 세션 동적 평가 프레임워크로서, LLM의 개인화된 선호도를 7가지 진단 지표로 처음 분해하여 모델이 사용자 선호도에 적응하는 능력을 측정하는 데 사용됩니다. VOYAGER는 훈련 없는 방법으로 LLM을 활용하여 다양화된 데이터셋을 생성하며 다양성을 1.5-3배 크게 향상시킵니다. FiNERweb 데이터셋 생성 파이프라인은 91개 언어와 25개 스크립트에 대해 확장 가능한 다국어 개체명 인식 리소스를 제공합니다. NVIDIA 또한 Nemotron 3 Nano의 완전한 평가 가이드라인을 발표하여 LLM 평가의 투명성과 재현성을 향상시킵니다. (출처: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/LocalLLaMA)

AI 보안 및 설명 가능성 연구: 이 연구는 딥페이크의 도전에 대응하기 위해 멀티미디어 콘텐츠의 진위 여부를 견고하고 보정된 방식으로 감지하는 재합성 프레임워크를 제안했습니다. 동시에 Hybrid Attribution Priors 프레임워크는 Class-Aware Attribution Prior (CAP)를 통해 언어 모델이 세분화된 범주 구분을 포착하도록 유도하여 모델의 설명 가능성과 견고성을 강화합니다. Hyper++는 하이퍼볼릭 심층 강화 학습을 개선하여 Agent 학습 안정성을 높였습니다. (출처: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
심층 학습 학습 리소스 및 연구 기회: AIhub는 2025년 AAAI/ACM SIGAI 박사 포럼 인터뷰 모음집을 발표하여 다양한 분야의 AI 최첨단 연구를 다룹니다. 동시에 새로운 ML 시스템 및 GPU 프로그래밍 강좌가 예고되었으며, 실습을 통해 DL 스택을 깊이 이해하는 것을 목표로 합니다. PyTorch/vLLM 하드웨어 챌린지 대회는 개발자들이 버그를 수정하도록 장려하며, 컴퓨터 비전 학습 로드맵 제안은 학습자들이 경력 개발을 계획하는 데 도움을 줍니다. (출처: aihub.org, DeepLearningAI, vllm_project, Reddit r/deeplearning, Reddit r/deeplearning)

3D/XR 및 인간-컴퓨터 상호작용 모델링: TIMAR 프레임워크는 멀티모달 정보를 융합하고 연속적인 3D 헤드 다이내믹스를 예측하여 인과 모델링 기반의 인터랙티브 3D 대화 헤드 다이내믹스를 제안합니다. SAR-RGB 이미지 변환 연구는 심층 학습 모델을 통해 선명한 이미지를 생성하는 방법을 탐구합니다. 미취학 아동 알파벳 필기 채점 알고리즘 연구는 템플릿 매칭 방법을 모색하여 아동의 필기 품질을 정확하게 평가합니다. (출처: HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
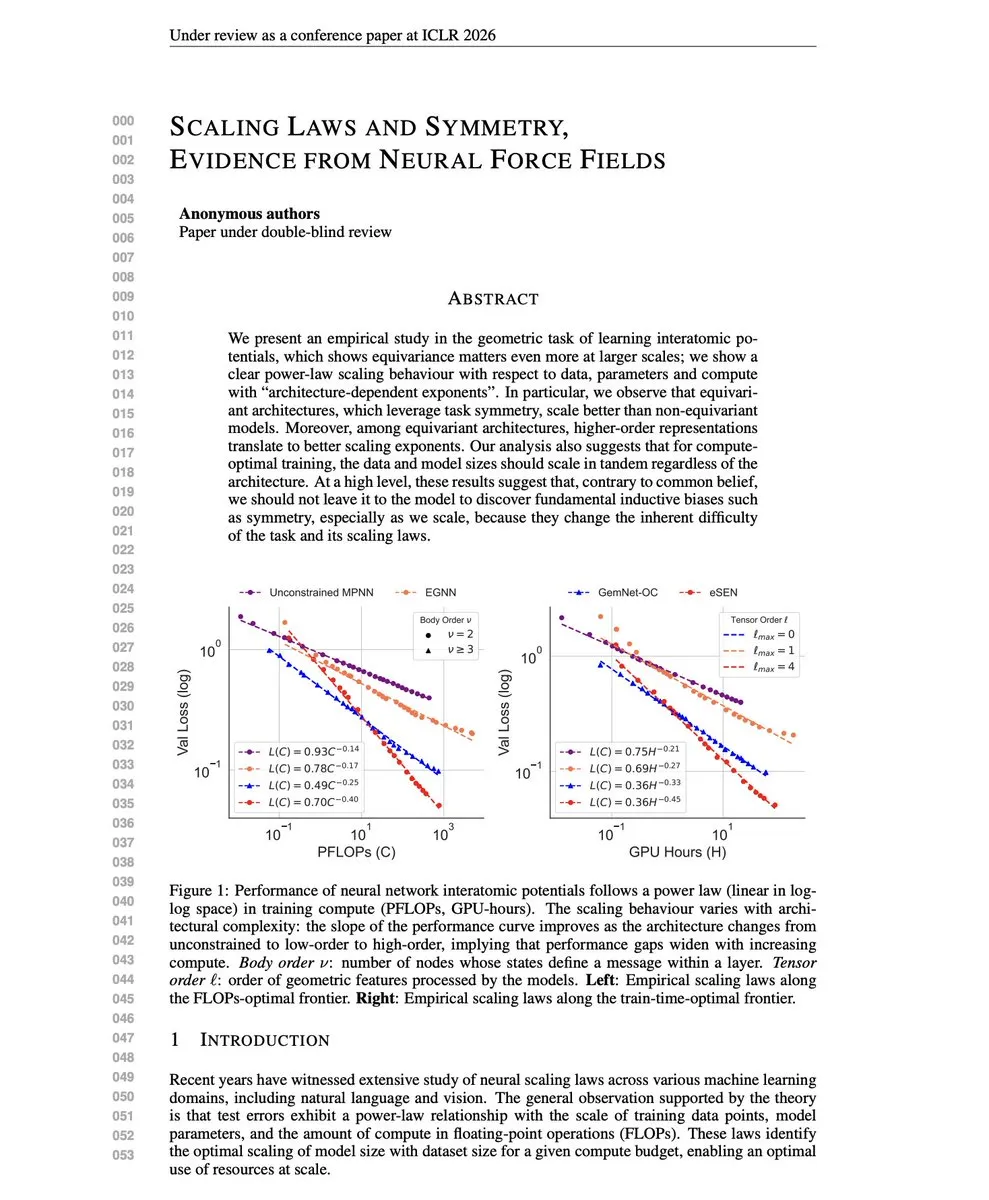
Scaling Laws 및 모델 융합 이론: 이 연구는 ‘스케일링 법칙이 귀납적 편향보다 우수하다’는 관점에 도전하며, 대칭성을 인코딩하는 아키텍처가 더 나은 Scaling Exponents를 가짐을 발견했습니다. 동시에 다중 작업 모델 융합 충돌 해결책(TATR, CAT Merging, LOT Merging)은 충돌 차원 식별 및 필터링, 투영 또는 가중치 융합을 통해 지식 충돌을 효과적으로 완화하고 다중 작업 성능 및 견고성을 향상시킵니다. (출처: dair_ai, WeChat)
자기회귀 비디오 확산의 엔드투엔드 훈련: 이 연구는 ‘리샘플링 강제’(Resampling Forcing) 프레임워크를 도입하여 자기회귀 비디오 확산 모델의 엔드투엔드 훈련을 구현합니다. 추론 시 모델이 과거 프레임에서 범하는 오류를 시뮬레이션하고 희소 인과 마스크 및 이력 라우팅 메커니즘을 결합하여, 시간 일관성을 유지하면서 증류된 기준선과 유사한 성능을 달성했으며 효율적인 장기 생성을 지원합니다. (출처: HuggingFace Daily Papers)
LLM 평가 및 재현성 논의: Reddit 커뮤니티는 LLM 평가의 과제와 재현성 문제에 대해 논의합니다. 사용자들은 신뢰할 수 있는 평가 기준을 수립하고 다양한 연구와 모델 간의 결과가 비교 가능하도록 보장하는 방법에 관심을 가지며, 빠르게 발전하는 LLM 분야에서 과학적 진보를 촉진하기 위해 평가 방법 및 데이터셋을 효과적으로 관리하고 공유하는 방법을 탐구합니다. (출처: Reddit r/deeplearning)
💼 비즈니스
Zhipu AI와 MiniMax, 홍콩 증시 IPO 추진: 국내 거대 모델 기업 MiniMax와 Zhipu AI는 중국 증권감독관리위원회(CSRC) 등록을 완료하고 홍콩 증권거래소(HKEX) 상장 심사에 참여했습니다. MiniMax는 2026년 1월 상장할 계획입니다. Zhipu AI의 기업 가치는 약 400억 위안으로 추정되며 정부(G) 및 기업(B) 고객과 멀티모달 Agent에 집중합니다. MiniMax의 기업 가치는 약 300억 위안에 육박하며 멀티모달 기능을 핵심으로 하는 제품 주도형 모델입니다. 두 회사 모두 상장 전에 전략적 수렴과 팀 재편을 진행했으며, 이는 거대 모델 산업이 ‘자본과 효율성이라는 이중 제약 기간’에 진입했음을 반영합니다. (출처: 36氪)
Amazon, OpenAI에 100억 달러 투자 예정: Amazon은 OpenAI에 최소 100억 달러를 투자할 계획입니다. 이번 투자는 OpenAI가 Amazon의 Trainium 시리즈 AI 칩을 사용하고, ChatGPT와 같은 모델 및 도구를 실행하기 위해 더 많은 데이터 센터 용량을 임대하는 것을 포함할 것으로 예상됩니다. 이번 투자는 두 회사 간 AI 인프라 및 모델 배포 분야의 협력을 심화하는 것을 목표로 합니다. (출처: Reddit r/ArtificialInteligence)

Biren Technology, 홍콩 증시 범용 GPU 첫 상장 기업 추진: 기업 가치 209억 위안의 범용 GPU 유니콘 Biren Technology가 홍콩 증권거래소(HKEX) 심사를 통과했으며, 곧 홍콩 증시의 ‘국산 GPU 첫 상장 기업’이 될 예정입니다. 이 회사는 Harvard 법학 박사 Zhang Wen이 설립했으며, 핵심 제품은 자체 개발 GPGPU 아키텍처 기반의 하드웨어 시스템(壁砺106, 110, 166 칩)과 BIRENSUPA 소프트웨어 플랫폼입니다. AI 훈련 및 추론을 위한 풀 스택 지원을 제공하며, 고객은 통신, 핀테크 등 고성능 컴퓨팅 산업을 포함합니다. (출처: WeChat)
🌟 커뮤니티
AI 생성 콘텐츠 품질과 인터넷 ‘slop’ 현상: 소셜 미디어에서는 AI 생성 콘텐츠의 품질이 들쑥날쑥한 ‘slop’ 현상에 대한 광범위한 논의가 이루어지고 있습니다. ‘slop’은 올해의 단어로 선정되었으며, AI 콘텐츠의 범람과 저품질 문제를 반영합니다. 이는 인터넷 광고 플랫폼의 이익 추구에 대한 비판을 불러일으켰고, AI 콘텐츠 제작의 진입 장벽을 높이는 방법에 대한 고민을 유발합니다. (출처: 36氪)

AI가 노동 시장 및 개발자 작업 방식에 미치는 영향: 소셜 미디어에서는 AI가 고용 시장과 개발자 작업 방식에 미치는 변혁적인 영향에 대해 심층적으로 논의하고 있습니다. AI는 강력한 생산성 도구로 간주되며, 개발자의 역할을 순수 코드 작성에서 시스템 설계, 에이전트 오케스트레이션, 코드 검증 및 디버깅으로 전환하고 있어 더 높은 수준의 기술 습득을 요구합니다. LinkedIn은 AI 채용 도우미를 도입하여 구직 및 채용 프로세스를 변화시킵니다. 동시에 AI는 사진 촬영 등 분야에서 효율성을 크게 향상시키지만, AI 코딩 에이전트의 생산 준비 상태는 여전히 과제에 직면해 있습니다. (출처: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Yuchenj_UW, gdb, amasad, amasad, Ronald_vanLoon)

AI의 교육, 의료 등 분야 적용 및 과제: 교사들이 AI 감지 소프트웨어를 사용하여 학생들이 AI를 사용했는지 여부를 판단하는 것이 교육 윤리 논란을 불러일으켰으며, 교육 시스템이 도구 사용보다는 학생들의 이해에 초점을 맞출 것을 촉구합니다. ChatGPT는 의료 건강 분야에서 진단 보조, 건강 조언 제공의 잠재력을 보이지만 신중한 사용이 필요합니다. Glass 5.0과 같은 플랫폼은 AI를 임상 의사 결정 지원에 적용하여 의료 AI가 챗봇에서 파트너로 전환되는 것을 추진합니다. (출처: Reddit r/artificial, Reddit r/ChatGPT, GlassHealthHQ)

LLM 성능, 비용 및 사용자 경험에 대한 지속적인 논의: 소셜 미디어 사용자들은 Gemini 3 Flash, Claude Opus 4.5 등 LLM의 성능, 비용 및 실제 사용 경험에 대해 열띤 토론을 벌이고 있습니다. 관심사는 코딩, 도구 호출, 추론 능력에서의 모델 발전뿐만 아니라 성능 저하, 환각률 등의 문제도 포함됩니다. 사용자들은 다양한 모델의 가성비를 비교하고 AI 모델 가격 책정 전략과 모델 가치에 대한 사용자 인식을 논의합니다. (출처: Vtrivedy10, hrishioa, tokenbender, inerati, scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, max__drake, MiniMax__AI, scaling01)
AI 윤리, 철학 및 AGI에 대한 심층 탐구: 소셜 미디어에서는 AI의 윤리 및 사회적 영향에 대해 논의하며, AI가 ‘신의 공백’을 채우고 있는지 여부, AGI의 진정한 정의, 물리학 연구에서 AI의 잠재력과 한계 등을 다룹니다. 사용자들은 AI 벤치마크 테스트의 재현성, AI 연구 품질에 대한 비판, AI 모델과 인간 지능 본질적 차이에 대한 철학적 고찰에도 관심을 가집니다. (출처: Ronald_vanLoon, ImazAngel, Ronald_vanLoon, RisingSayak, snwy_me, TheTuringPost, teortaxesTex, _lewtun)

AI 모델 아키텍처, 효율성 및 인프라 최적화: 소셜 미디어에서는 MoE 모델의 MFU 효율성, nmoe의 초희소 MoE 훈련, LLM 추론의 간소화(예: mini-SGLang) 등 AI 모델 아키텍처 및 효율성에 대해 논의합니다. 사용자들은 긴 컨텍스트 처리, 메모리 관리, 하드웨어 최적화(예: MLX 분산 백엔드, vLLM serving) 등 AI 시스템의 전반적인 성능과 확장성을 향상시키기 위한 발전에 관심을 가집니다. (출처: lateinteraction, hyhieu226, TheZachMueller, dejavucoder, awnihannun, vllm_project, aiamblichus)

AI 기업 전략, 시장 경쟁 및 인재 유동성: 소셜 미디어에서는 Amazon이 최고 AI 연구원을 고용하고, Thinking Machines가 모델 출시를 계획하며, Meta AI의 투자 대비 성과, OpenAI가 직면한 조직 문제 등 AI 기업 전략과 시장 경쟁에 대해 논의합니다. 사용자들은 NVIDIA의 오픈 소스 AI 분야 리더십, 하드웨어 중심 전략, Anthropic 연구원이 Tencent에 합류하는 등 핵심 인재 유동성에도 관심을 가집니다. (출처: pmddomingos, scaling01, teortaxesTex, steph_palazzolo, TheTuringPost, Sentdex, teortaxesTex, turbopuffer, iScienceLuvr, EthanJPerez)

AI 코딩 현황 보고서 및 산업 동향: Greptile은 ‘2025년 AI 코딩 현황 보고서’를 발표했습니다. 이 보고서는 개발자의 월별 코드 생산량이 76% 증가했으며 PR(Pull Request) 규모가 커졌고, AI 도구의 수익 분배가 고르지 않다고 지적합니다. 또한, OpenAI, Anthropic, Google 모델의 첫 토큰 응답 시간, 처리량 및 비용 측면에서의 성능을 비교했으며, 벡터 데이터베이스 및 AI 메모리 도구 시장의 경쟁 구도를 밝혀냈습니다. (출처: dotey)

LLM 평가 및 재현성 논의: Reddit 커뮤니티는 LLM 평가의 과제와 재현성 문제에 대해 논의합니다. 사용자들은 신뢰할 수 있는 평가 기준을 수립하고 다양한 연구와 모델 간의 결과가 비교 가능하도록 보장하는 방법에 관심을 가지며, 빠르게 발전하는 LLM 분야에서 과학적 진보를 촉진하기 위해 평가 방법 및 데이터셋을 효과적으로 관리하고 공유하는 방법을 탐구합니다. (출처: Reddit r/deeplearning)
오픈 AI 및 하드웨어 중심 전략: NVIDIA Nemotron 3의 출시는 오픈 소스 AI 리더십의 전환을 의미합니다. 이 모델은 대규모 사전 학습 데이터, RL 데이터셋 및 새로운 하이브리드 아키텍처를 통해 NVIDIA 하드웨어의 컴퓨팅 소모를 최적화했습니다. 이러한 전략은 오픈 소스 AI가 ‘빅테크 자선’ 시대에서 ‘하드웨어 정의 AI’ 시대로 나아가고 있음을 보여주며, 즉 모델 출시는 특정 하드웨어의 컴퓨팅 소비를 확장하는 것을 목표로 합니다. (출처: TheTuringPost, teortaxesTex)
AI 이미지 및 비디오 생성 도구 비교 및 적용: 소셜 미디어 사용자들은 ChatGPT, Gemini, Midjourney, Grok, Nano Banana Pro 등 AI 이미지 및 비디오 생성 도구의 성능과 적용에 대해 논의합니다. 논의는 AI 예술 작품의 사실성, 게임 캐릭터 변환, 영화 제작에서 AI 비디오의 적용 등을 다룹니다. 사용자들은 AI 생성 콘텐츠의 품질, 비용 및 효율성, 그리고 창작 프로세스에 대한 혁신적인 영향에도 관심을 가집니다. (출처: dotey, swyx, karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Kling_ai)

AI의 금융 분야 적용 및 동향: 소셜 미디어에서는 사기 탐지, 위험 관리, 고객 서비스 등 26가지 구체적인 사례를 포함하여 AI의 금융 분야 적용에 대해 논의합니다. 이러한 적용은 머신러닝과 인공지능이 금융 산업에 어떻게 힘을 실어주어 효율성을 높이고 의사 결정을 최적화하며 새로운 비즈니스 가치를 창출하는지 보여줍니다. (출처: Ronald_vanLoon)

AI 에이전트와 지식 그래프의 결합: SAP의 AI 과학자들은 지식 그래프를 통해 AI 에이전트의 발견 및 실행을 개선하는 방법에 대해 논의했습니다. 지식 그래프는 AI 에이전트에게 의미론적 및 프로세스 컨텍스트를 제공하여 기업 시스템 내 도구 및 API를 보다 효과적으로 발견하고 호출할 수 있도록 하며, 이를 통해 복잡한 기업 환경에서 에이전트의 효율성을 향상시킵니다. (출처: DeepLearningAI)

LLM 평가 및 재현성 논의: Reddit 커뮤니티는 LLM 평가의 과제와 재현성 문제에 대해 논의합니다. 사용자들은 신뢰할 수 있는 평가 기준을 수립하고 다양한 연구와 모델 간의 결과가 비교 가능하도록 보장하는 방법에 관심을 가지며, 빠르게 발전하는 LLM 분야에서 과학적 진보를 촉진하기 위해 평가 방법 및 데이터셋을 효과적으로 관리하고 공유하는 방법을 탐구합니다. (출처: Reddit r/deeplearning)
EU 내 AI 모델 성능 및 규제 영향: Reddit 사용자들은 유럽 연합(EU) 지역에서 비디오 및 이미지 AI 모델이 규제 때문에 ‘더 멍청해지는지’ 여부에 대해 논의합니다. 일반적인 의견은 모델의 핵심 품질은 영향을 받지 않지만, EU의 엄격한 안전 계층 및 규정 준수 요구 사항으로 인해 기능 출시 지연, 더 엄격한 필터링 또는 다른 기본 설정이 발생할 수 있다는 것입니다. 이는 모델 자체의 지능 저하가 아니라 사용자 경험에 영향을 미칩니다. (출처: Reddit r/ArtificialInteligence)
💡 기타
AI의 예술 및 엔터테인먼트 분야 융합: Desdemona Robot과 그 밴드는 1월 11일 샌프란시스코에서 공연을 진행하며, AI와 예술을 결합하여 로봇이 공연자로서 가질 수 있는 잠재력을 탐구합니다. 동시에 사용자들은 밴드가 Suno와 같은 AI 도구를 사용하여 노래를 생성하고 라이브로 연주하는 것을 보고 싶다는 의견을 제시했으며, 이는 음악 창작 및 라이브 엔터테인먼트에서 AI의 새로운 적용 추세를 반영합니다. (출처: bengoertzel, fabianstelzer)
ComfyUI, ‘간단 모드’를 통한 워크플로우 간소화 탐색: ComfyUI는 새로운 ‘간단 모드’를 탐색하고 있습니다. 이 모드는 복잡한 워크플로우를 더 쉽게 공유하고 반복할 수 있도록 하는 것을 목표로 하며, 기저의 노드 그래프보다는 결과에 중점을 둡니다. 특히 대규모 다이어그램을 이해하기 어렵다고 느끼는 사용자들을 대상으로 하며, 사용 진입 장벽을 낮추고 사용자 경험 및 작업 효율성을 향상시키기 위함입니다. (출처: NerdyRodent)