
Schlüsselwörter:SAM 3, Gemini 3 Flash, KI-Videogenerierung, verkörperte Intelligenz, Großes Modell, KI-Agent, 3D-Digitaler Mensch, Meta SAM 3 Bildsegmentierung, Google Gemini 3 Flash Leistung, Alibaba Wanxiang 2.6 Videogenerierung, Tiefe Situationsdatenerfassung mit KI, Xiaomi MiMo-V2-Flash Open Source
🔥 Fokus
Meta veröffentlicht SAM 3 Modell: Facebook Research hat SAM 3 vorgestellt, ein vereinheitlichtes, prompt-basiertes Segmentierungs-Grundlagenmodell für Bilder und Videos. Es ermöglicht Objekterkennung, -segmentierung und -verfolgung durch Text- oder visuelle Prompts, führt die Instanzsegmentierungsfähigkeit für Open-Vocabulary-Konzepte ein und erreicht auf dem SA-CO-Benchmark 75-80% der menschlichen Leistung. Das Modell wird von einer innovativen Daten-Engine angetrieben, die über 4 Millionen einzigartige Konzepte automatisch annotiert hat, und verwendet ein neues Architekturdesign mit Präsenz-Tokens und einem entkoppelten Detektor-Tracker zur Verbesserung der Diskriminierungsfähigkeit und Effizienz. (Quelle: GitHub Trending)

Google veröffentlicht Gemini 3 Flash Modell: Google hat Gemini 3 Flash vorgestellt, das bisher schnellste AI-Modell, das speziell auf Geschwindigkeit ausgelegt ist und gleichzeitig führende Intelligenz beibehält. Das Modell zeigt hervorragende Leistungen bei Doktoranden-Niveau-Benchmarks für Schlussfolgerungen und Wissen wie GPQA Diamond und Humanity’s Last Exam und übertrifft sogar Gemini 3 Pro beim SWE-bench Verified Coding-Benchmark. Gemini 3 Flash bietet eine dreifach höhere Geschwindigkeit als Gemini 2.5 Pro zu geringeren Kosten (0,50 USD pro Million Input-Tokens, 3 USD pro Million Output-Tokens) und wurde weltweit als Standardmodell für den Google Search AI-Modus eingeführt, um die Verbreitung von AI in Unternehmensanwendungen und im Entwickler-Ökosystem voranzutreiben. (Quelle: WeChat)

🎯 Trends
AI-Videogenerierungsmodelle entwickeln sich stetig weiter: Modelle wie Alibaba Wanxiang 2.6, ByteDance Seedance 1.5 Pro und Kling 2.6 wurden nacheinander veröffentlicht. Wanxiang 2.6 ermöglicht die Anpassung von Charakteren mit synchroner Audio- und Videowiedergabe sowie die Steuerung von Multi-Shot-Storyboards, wobei einzelne Generierungen bis zu 15 Sekunden lang sein können; Seedance 1.5 Pro konzentriert sich auf hochpräzise Audio-Video-Synchronisation und Unterstützung mehrerer Dialekte; Kling 2.6 wiederum verbessert die Stimmfarbenkontrolle und die Motion Control-Funktion. Diese Fortschritte markieren den Übergang der AI-Videoproduktion von der “Ziehkarte”-Ära zu einer neuen Phase der präzisen und kontrollierbaren filmischen Produktion. (Quelle: WeChat, WeChat, Kling_ai, Alibaba_Wan)
Tiefgreifende Entwicklung von Embodied AI-Technologien und -Strategien: DeepWisdom hat den “Contextual Data Acquisition”-Modus für Embodied AI eingeführt, der durch Daten aus menschlicher Ich-Perspektive universelle Probleme löst; Horizon Robotics hat die “BPU+Compiler+Foundation Model”-Wintel-Strategie veröffentlicht, um intelligente Fahrzeuge und allgemeine Roboter zu befähigen; das Team von Dr. Wang Guangrun von der Sun Yat-sen University hat das E0 Embodied Large Model vorgestellt, das die Entkopplung von physikalischen und räumlichen Modellen betont, um Few-Shot-Feinabstimmung und Generalisierung zu erreichen. Diese Fortschritte treiben gemeinsam die Embodied AI von der mechanischen Imitation zum logischen Verständnis und zur Interaktion mit der physikalischen Welt voran. (Quelle: WeChat, WeChat, WeChat)
Xiaomi und SenseTime veröffentlichen führende Large Models: Xiaomi hat das MiMo-V2-Flash Large Model als Open Source freigegeben, das eine MoE-Architektur verwendet und speziell für Agent- und Code-Szenarien entwickelt wurde, um mit extremer Inferenz-Effizienz und niedrigen Kosten in die erste Liga der globalen Open-Source-Modelle aufzusteigen. SenseTime hat das SenseNova-SI Modell und die NEO-Architektur vorgestellt, um die Grenzen des Verständnisses der physikalischen Welt durch reine Sprachmodelle zu überwinden, indem es native Multimodalität und Cross-View-Vorhersagen zur Verbesserung der räumlichen Intelligenz nutzt. (Quelle: WeChat, WeChat)
AI PC verschmilzt mit spezifischen Anwendungsszenarien: Covestro Motion hat einen AI PC Personal Health Assistant vorgestellt, der berührungslose rPPG-Technologie für die kontaktlose Blutdruck- und Hauterkennung nutzt und in Kombination mit Intel NPU eine effiziente lokale Verarbeitung ermöglicht. Gleichzeitig hat Yunpeng Tech neue AI+Health-Produkte auf den Markt gebracht, darunter einen intelligenten AI-Gesundheits-Large-Model-Kühlschrank und ein digitales Zukunftsküchenlabor, die AI in das tägliche Gesundheitsmanagement und die Haushaltstechnologie integrieren. (Quelle: WeChat, 36氪)

Moore Threads LiteGS-Technologie durchbricht 3D-Grafik-Rendering: Moore Threads gewann Silber beim 3DGS Reconstruction Challenge der SIGGRAPH Asia 2025 und veröffentlichte seine selbst entwickelte LiteGS-Technologie als Open Source. LiteGS ist eine 3D Gaussian Splatting-Grundlagenbibliothek, die durch End-to-End-Optimierung eine signifikante Führung in Trainingseffizienz und Rekonstruktionsqualität erreicht und die Anwendung der 3DGS-Technologie in 3D-Rekonstruktion, Echtzeit-Rendering und Embodied AI-Trainingsszenarien vorantreibt. (Quelle: WeChat)

Neue Fortschritte im dateneffizienten Vortraining kleiner LLMs: Ein unabhängiger koreanischer Forschungsingenieur hat Gumini veröffentlicht, ein zweisprachiges koreanisch-englisches Basis-LLM mit 1,5 Milliarden Parametern, das mit nur 3,14 Milliarden Trainings-Tokens in koreanischen Benchmarks Spitzenplätze belegt. Dieser Fortschritt zeigt, dass durch die Optimierung von Architektur und Trainingsstrategien ein dateneffizientes LLM-Vortraining möglich ist, was kleinen Teams und unabhängigen Forschern einen neuen Weg jenseits des “mehr Daten + mehr Rechenleistung”-Paradigmas eröffnet. (Quelle: Reddit r/LocalLLaMA)

Multimodale AI vertieft Anwendungen in spezifischen Bereichen: MiraTTS, ein hochwertiges und schnelles TTS-Modell, kann realistische Sprache mit über 100-facher Echtzeitgeschwindigkeit generieren und unterstützt mehrere Sprachen. Gleichzeitig wurde ein mehrsprachiges RAG-System zur Unterstützung landwirtschaftlicher Ökosystem-Entscheidungen eingesetzt, das das Verhalten von LLMs in ressourcenarmen, hochspezialisierten Bereichen untersucht und seit einem Jahr in einer Produktionsumgebung läuft. Dies zeigt die ausgereifte Anwendung multimodaler AI in der Spracherzeugung und der Entscheidungsunterstützung in vertikalen Bereichen. (Quelle: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Taobao Tech stellt mobiles 3D-Digital-Human-Rekonstruktionssystem vor: Das Meta-Team von Taobao Tech hat auf der SIGGRAPH Asia das HRM²Avatar-System vorgestellt, das es Benutzern ermöglicht, hochrealistische Echtzeit-3D-Digital-Humans nur mit einem monokularen Smartphone-Video zu erstellen und zu rendern. Das System kombiniert explizite Kleidungs-Meshes mit Gaußschen Darstellungen, unterstützt Echtzeit-Antrieb und -Rendering auf mobilen Geräten und zeichnet sich durch visuelle Realität, konsistente Haltung und mobile Leistung aus, um die Hürde für die Erstellung von 3D-Digital-Humans zu senken. (Quelle: WeChat)

🧰 Tools
Letta: Eine Plattform zum Erstellen zustandsbehafteter AI-Agenten: Letta (ehemals MemGPT) ist eine Plattform zum Erstellen zustandsbehafteter AI-Agenten, deren Kern ein fortschrittliches Speichermanagement ist, das es AI-Agenten ermöglicht, im Laufe der Zeit zu lernen und sich selbst zu verbessern. Die Plattform bietet ein Python/TypeScript SDK, eine No-Code-ADE-Umgebung sowie eine lokale Desktop-Version und Cloud-Dienste. Sie unterstützt Kernkonzepte wie Speicherhierarchien, Speicherblöcke und Agenten-Kontext-Engineering und ermöglicht die gemeinsame Nutzung von Speicher durch mehrere Agenten sowie im Hintergrund laufende “Schlafzeit-Agenten”. Maestro ist eine kostenlose Open-Source-Desktop-Anwendung für die Orchestrierung von AI-Agenten, die Dateisystemspeicher und Tool-Erstellung unterstützt und über eine “Auto-Run”-Funktion verfügt. Toad dient als einheitliche AI-Coding-Agenten-Terminal-Oberfläche, die die Integration mit verschiedenen AI-Coding-Tools vereinfacht. (Quelle: GitHub Trending, Reddit r/LocalLLaMA, huggingface)
Miaoda No-Code AI-Programmierwerkzeug befähigt Nicht-Programmierer: Miaoda ist ein seit 8 Monaten verfügbares No-Code AI-Programmierwerkzeug, das bereits über 5 Milliarden Yuan an Wert geschaffen hat und hauptsächlich von Nicht-Programmierern genutzt wird. Das Tool kommuniziert über einen “Produktmanager-Agenten” in mehreren Runden, um vage Anforderungen in strukturierte Produktdokumente umzuwandeln, die dann von einem “Entwicklungs-Agenten” umgesetzt werden. Miaoda hat die Herausforderungen beim Backend-Aufbau gemeistert, eine tiefe Integration von AI und Datenbanken realisiert und durch feingranulare Strategien Kosten gesenkt und die Effizienz gesteigert, um “Code-Spaghetti” zu vermeiden. (Quelle: WeChat)

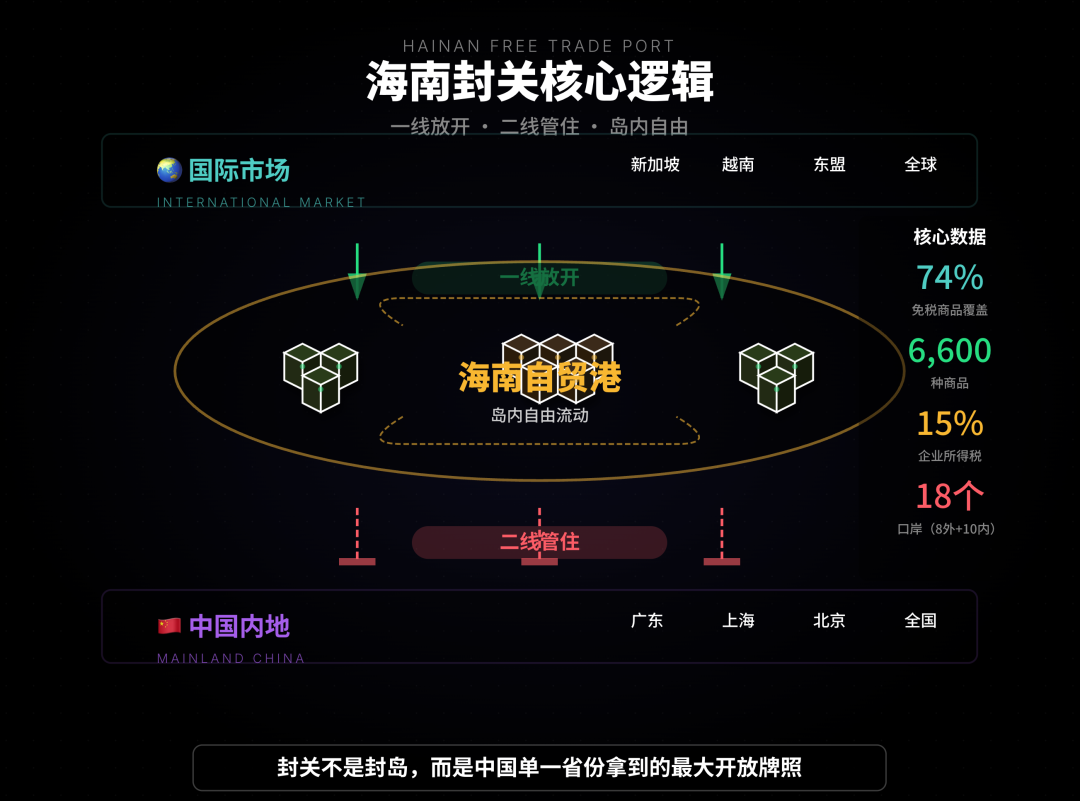
AI-gestützte Analyse- und Vertriebsautomatisierungstools: Der Artikel zeigt, wie AI die Trendanalyse der “Hainan Free Trade Port”-Politik unterstützen kann, indem sie Informationen aus mehreren Kanälen integriert, kategorisiert und extrapoliert, um Benutzern zu helfen, komplexe Informationen zu klären. QuickHook ist ein Vertriebsautomatisierungstool, das auf Gemini 3 und Search Grounding basiert und 15 Minuten manuelle Recherche in 10 Sekunden Automatisierung umwandeln kann, um das Problem des “AI-Jargons” bei der Kaltakquise zu lösen. (Quelle: WeChat, Reddit r/artificial)
OpenWebUI API und lokales STT-System: OpenWebUI bietet API-Schnittstellen, die es Entwicklern ermöglichen, benutzerdefinierte Client-Anwendungen zu erstellen, wie z.B. eine Sprachmodus-App auf WearOS, um personalisierte AI-Interaktionserlebnisse zu realisieren. Kroko-onnx-home-assistant ist eine Open-Source-lokale Streaming-Sprach-zu-Text (STT)-Pipeline, die speziell für Home Assistant entwickelt wurde und sich durch hohe Qualität, Echtzeit-Streaming und 100%ige Lokalisierung auszeichnet, selbst auf ressourcenarmen Geräten effizient läuft. (Quelle: Reddit r/OpenWebUI, Reddit r/LocalLLaMA)
Multi-LLM-Kollaboration zur Steigerung der Spieleentwicklungseffizienz: Entwickler nutzen die OpenAI Realtime API, um Spielanforderungen zu sammeln, Gemini 3 Pro zur Generierung von Markdown-Spezifikationen und Anthropic Opus 4.5 zur Codierung der Anwendung, um die Entwicklung maßgeschneiderter intelligenter Ballspiele zu realisieren. Dieser Multi-LLM-Workflow optimiert die Vorteile verschiedener LLMs, steigert die Entwicklungseffizienz und -qualität von der Anforderung bis zum Code und bietet ein neues Entwicklungsparadigma für komplexe Projekte. (Quelle: Reddit r/artificial)

📚 Lernen
Transformer-Architektur-Optimierung und Normalisierungs-Innovation: Das Team von Liu Zhuang von der Princeton University hat den Derf-Operator vorgeschlagen, der die LayerNorm in Transformatoren durch die Gaußsche Fehlerfunktion (erf) ersetzt und bestehende Methoden in Aufgaben wie Vision, Generierung und Gensequenzmodellierung umfassend übertrifft. Gleichzeitig haben die Nanyang Technological University und die Fudan University EFLA (Error-Free Linear Attention) vorgeschlagen, das durch eine analytische Lösung numerische Drifts in der linearen Aufmerksamkeit bei langen Sequenzen eliminiert und so Stabilität und Leistung gleichzeitig verbessert. (Quelle: WeChat, WeChat)

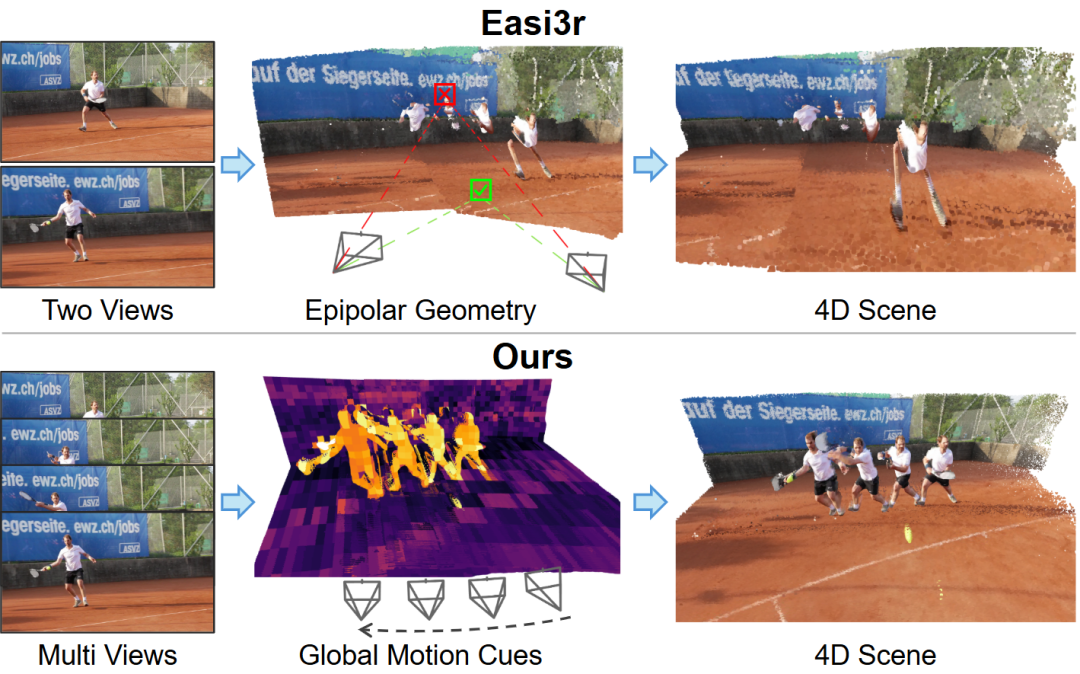
Multimodale und Video-Verständnis-Spitzenforschung: Das DiffusionVL-Framework kann autoregressive Modelle in Diffusion Visual Language Models umwandeln, was die Leistung erheblich steigert und die Inferenz beschleunigt. Das SAGE-System nutzt Reinforcement Learning für mehrstufige Schlussfolgerungen in langen Videos und zeigt hervorragende Leistungen bei offenen Videoaufgaben. MMSI-Video-Bench, ein umfassender Benchmark für räumliche Video-Intelligenz, deckt systematische Fehler von MLLMs in geometrischer Schlussfolgerung und Bewegungs-Grounding auf. VGGT4D schlägt einen trainingsfreien 4D-Szenenrekonstruktionsrahmen vor, der durch die Nutzung von Bewegungshinweisen innerhalb des Transformers dynamische Szenen verarbeitet. (Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, WeChat)
AI-Agenten und LLM-Speicheroptimierung: Die Nanjing University of Science and Technology und Baidu haben ViLoMem vorgeschlagen, das durch Dual-Stream Semantic Memory (visueller Stream + logischer Stream) das Problem löst, dass multimodale Large Models “Lektionen nicht lernen”, und die Inferenzleistung erheblich verbessert. Das LightSearcher-Framework optimiert den Tool-Aufruf von RL-gesteuerten Agenten durch Erfahrungsspeicher, reduziert die Anzahl der Aufrufe um 39,6% und die Inferenzzeit um 48,6%, während die Genauigkeit erhalten bleibt. Das MEM1-Framework trainiert Agenten ebenfalls mittels RL, um in Langzeitaufgaben einen konstanten Speicher aufrechtzuerhalten. (Quelle: WeChat, WeChat, omarsar0)
LLM-Evaluierung und Datensatz-Erstellung: LikeBench, ein dynamisches Multi-Session-Evaluierungsframework, zerlegt erstmals die Personalisierungspräferenz von LLMs in sieben diagnostische Metriken, um die Fähigkeit des Modells zur Anpassung an Benutzerpräferenzen zu messen. VOYAGER ist eine trainingsfreie Methode, die LLMs zur Generierung vielfältiger Datensätze nutzt und die Vielfalt um das 1,5- bis 3-fache signifikant erhöht. Die FiNERweb-Datensatz-Erstellungspipeline bietet skalierbare mehrsprachige Named Entity Recognition-Ressourcen für 91 Sprachen und 25 Schriften. NVIDIA hat auch einen vollständigen Evaluierungsleitfaden für Nemotron 3 Nano veröffentlicht, um die Transparenz und Reproduzierbarkeit der LLM-Evaluierung zu verbessern. (Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/LocalLLaMA)

AI-Sicherheit und Erklärbarkeitsforschung: Eine Studie schlägt ein Re-Synthese-Framework vor, um die Authentizität multimedialer Inhalte robust und kalibriert zu erkennen und so den Herausforderungen von Deepfakes zu begegnen. Gleichzeitig verbessert das Hybrid Attribution Priors-Framework durch Class-Aware Attribution Prior (CAP) die Erklärbarkeit und Robustheit von Sprachmodellen, indem es diese dazu anleitet, feingranulare Kategorieunterscheidungen zu erfassen. Hyper++ verbessert das hyperbolische Deep Reinforcement Learning und erhöht die Lernstabilität von Agenten. (Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Deep Learning Lernressourcen und Forschungsmöglichkeiten: AIhub veröffentlicht eine Interviewsammlung des AAAI/ACM SIGAI Doctoral Consortium 2025, die führende AI-Forschung in verschiedenen Bereichen abdeckt. Gleichzeitig gibt es eine Vorschau auf einen neuen Kurs zu ML-Systemen und GPU-Programmierung, der durch praktische Übungen ein tiefes Verständnis des DL-Stacks vermitteln soll. Der PyTorch/vLLM Hardware Challenge ermutigt Entwickler, Fehler zu beheben, und es gibt Empfehlungen für Lernpfade im Bereich Computer Vision, um Lernenden bei der Karriereplanung zu helfen. (Quelle: aihub.org, DeepLearningAI, vllm_project, Reddit r/deeplearning, Reddit r/deeplearning)

3D/XR und Mensch-Computer-Interaktionsmodellierung: Das TIMAR-Framework schlägt ein kausales Modell für interaktive 3D-Gesprächskopf-Dynamiken vor, das multimodale Informationen fusioniert und kontinuierliche 3D-Kopf-Dynamiken vorhersagt. Die Forschung zur SAR-zu-RGB-Bildübersetzung untersucht, wie durch Deep Learning-Modelle klare Bilder generiert werden können. Die Forschung zu Algorithmen zur Bewertung der Vorschul-Buchstabenhandschrift sucht nach Template-Matching-Methoden, um die Qualität der Kinderhandschrift genau zu bewerten. (Quelle: HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
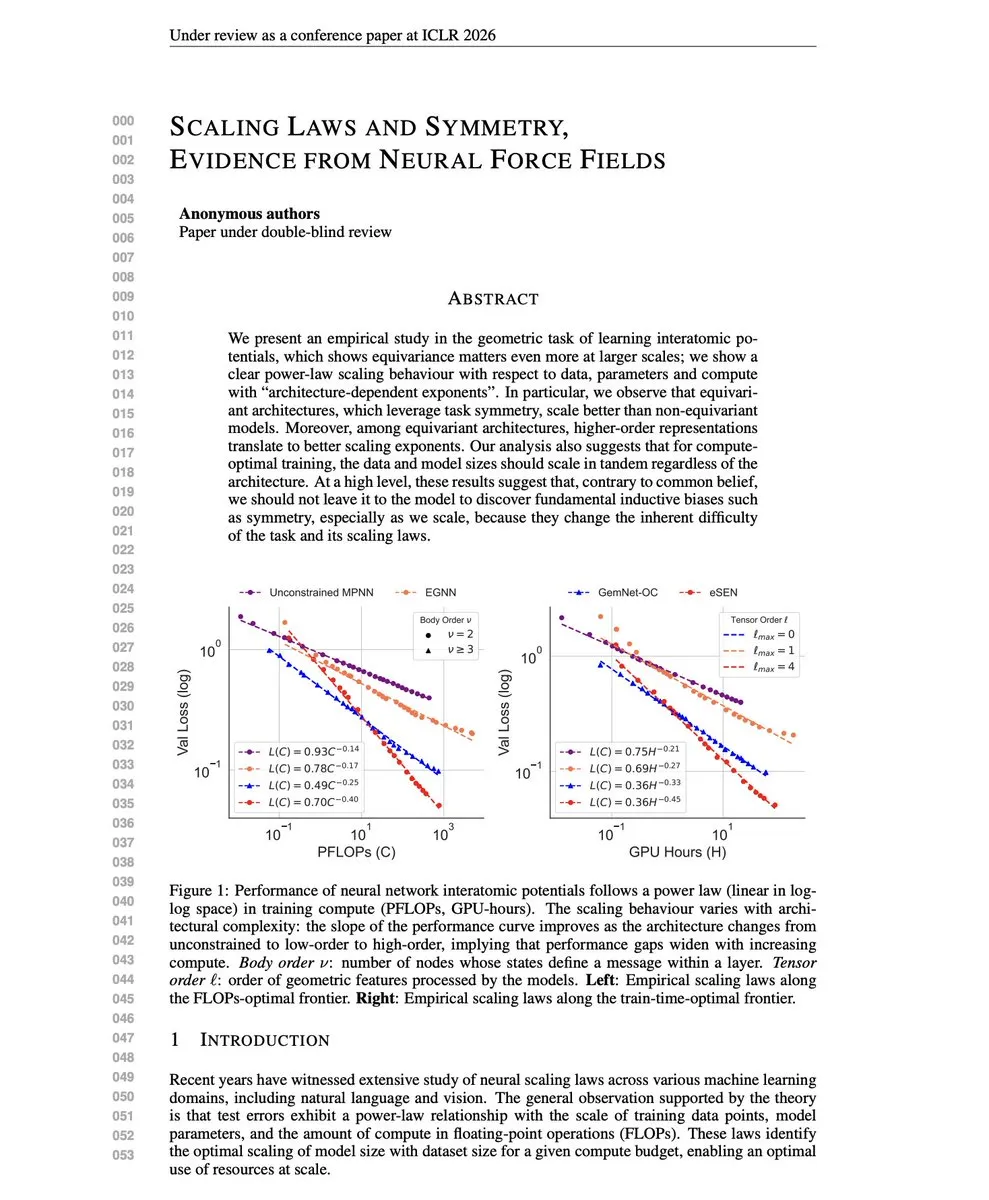
Scaling Laws und Modellfusionstheorie: Diese Studie stellt die Ansicht “Scaling Law ist besser als induktive Verzerrung” in Frage und findet, dass Architekturen, die Symmetrien kodieren, bessere Scaling Exponents aufweisen. Gleichzeitig lösen Konfliktlösungen für die Multi-Task-Modellfusion (TATR, CAT Merging, LOT Merging) Wissenskonflikte effektiv, indem sie Konfliktdimensionen identifizieren und filtern, projizieren oder gewichtet fusionieren, was die Multi-Task-Leistung und Robustheit verbessert. (Quelle: dair_ai, WeChat)
End-to-End-Training von autoregressiver Video-Diffusion: Diese Studie führt das “Resampling Forcing”-Framework ein, um autoregressive Video-Diffusionsmodelle End-to-End zu trainieren. Durch die Simulation von Modellfehlern auf historischen Frames während der Inferenz, kombiniert mit spärlichen kausalen Masken und einem historischen Routing-Mechanismus, erreicht diese Methode eine Leistung, die mit Destillations-Baselines vergleichbar ist, während die zeitliche Konsistenz erhalten bleibt und eine effiziente Langzeitgenerierung unterstützt wird. (Quelle: HuggingFace Daily Papers)
Diskussion über LLM-Evaluierung und Reproduzierbarkeit: Die Reddit-Community diskutiert die Herausforderungen und Probleme der Reproduzierbarkeit bei der LLM-Evaluierung. Benutzer konzentrieren sich darauf, wie zuverlässige Bewertungsstandards etabliert werden können, um die Vergleichbarkeit von Ergebnissen zwischen verschiedenen Studien und Modellen sicherzustellen, und erörtern, wie Bewertungsmethoden und Datensätze in dem sich schnell entwickelnden LLM-Bereich effektiv verwaltet und geteilt werden können, um den wissenschaftlichen Fortschritt zu fördern. (Quelle: Reddit r/deeplearning)
💼 Business
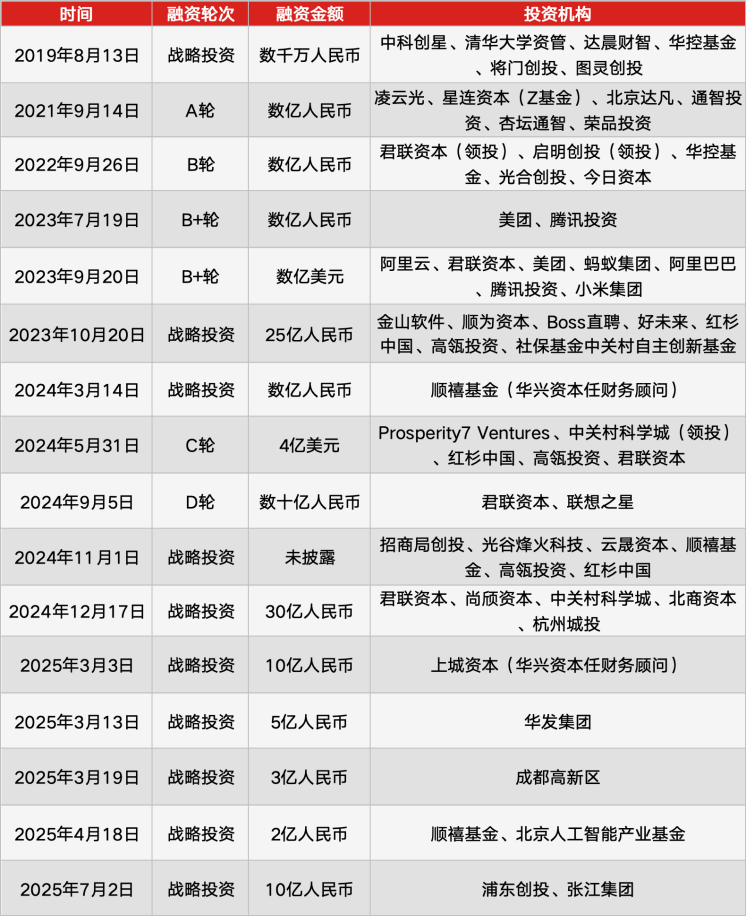
Zhipu AI und MiniMax streben Hong Kong IPO an: Die chinesischen Large Model-Unternehmen MiniMax und Zhipu AI haben die Registrierung bei der chinesischen Wertpapieraufsichtsbehörde abgeschlossen und an den Börsenanhörungen in Hongkong teilgenommen. MiniMax plant, im Januar 2026 an die Börse zu gehen. Zhipu AI wird auf rund 40 Milliarden Yuan geschätzt und konzentriert sich auf den G- und B-Sektor sowie multimodale Agenten; MiniMax wird auf fast 30 Milliarden Yuan geschätzt und konzentriert sich auf multimodale Fähigkeiten mit einem produktgetriebenen Modell. Beide Unternehmen haben vor dem Börsengang strategische Anpassungen und Teambereinigungen vorgenommen, was darauf hindeutet, dass die Large Model-Branche in eine Phase doppelter Beschränkungen durch Kapital und Effizienz eintritt. (Quelle: 36氪)
Amazon plant Investition von 10 Milliarden US-Dollar in OpenAI: Amazon plant, mindestens 10 Milliarden US-Dollar in OpenAI zu investieren. Dieser Schritt wird voraussichtlich beinhalten, dass OpenAI Amazons Trainium-Serie von AI-Chips nutzt und mehr Rechenzentrumskapazität mietet, um seine Modelle und Tools (wie ChatGPT) zu betreiben. Die Investition zielt darauf ab, die Zusammenarbeit zwischen den beiden Unternehmen in den Bereichen AI-Infrastruktur und Modellbereitstellung zu vertiefen. (Quelle: Reddit r/ArtificialInteligence)

Biren Technology strebt als erster General-Purpose-GPU-Anbieter an die Hong Konger Börse: Das auf 20,9 Milliarden Yuan geschätzte General-Purpose-GPU-Einhorn Biren Technology hat die Anhörung an der Hong Konger Börse bestanden und wird voraussichtlich der erste “heimische GPU-Anbieter” an der Hong Konger Börse. Das Unternehmen wurde von Zhang Wen, einem Harvard-Doktor der Rechtswissenschaften, gegründet. Die Kernprodukte sind Hardware-Systeme (Biren BR106, BR110, BR166 Chips) basierend auf der selbst entwickelten GPGPU-Architektur und die BIRENSUPA-Softwareplattform, die umfassende AI-Trainings- und Inferenzunterstützung bietet. Zu den Kunden gehören Branchen mit hohem Rechenleistungsbedarf wie Telekommunikation und Fintech. (Quelle: WeChat)
🌟 Community
Qualität von AI-generierten Inhalten und das Internet-“Slop”-Phänomen: In den sozialen Medien wird das “Slop”-Phänomen, die uneinheitliche Qualität von AI-generierten Inhalten, ausführlich diskutiert. Es wurde zum Wort des Jahres gewählt und spiegelt die Überschwemmung mit AI-Inhalten und deren geringe Qualität wider. Dies führt zu Kritik an den profitgetriebenen Internet-Werbeplattformen und zu Überlegungen, wie die Hürden für die AI-Inhaltsgenerierung erhöht werden können. (Quelle: 36氪)

Auswirkungen von AI auf den Arbeitsmarkt und die Arbeitsweise von Entwicklern: In den sozialen Medien wird intensiv über die Umwälzung des Arbeitsmarktes und der Arbeitsweise von Entwicklern durch AI diskutiert. AI wird als leistungsstarkes Produktivitätstool angesehen, das die Rolle von Entwicklern vom reinen Code-Schreiben hin zu Systemdesign, Agenten-Orchestrierung, Code-Verifizierung und Debugging verlagert, was höhere Fähigkeiten erfordert. LinkedIn führt AI-Recruiting-Assistenten ein, die den Bewerbungs- und Einstellungsprozess verändern. Gleichzeitig steigert AI die Effizienz in Bereichen wie der Fotografie erheblich, aber die Produktionsreife von AI-Coding-Agenten steht noch vor Herausforderungen. (Quelle: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Yuchenj_UW, gdb, amasad, amasad, Ronald_vanLoon)

Anwendung und Herausforderungen von AI in Bildung, Medizin und anderen Bereichen: Die Verwendung von AI-Erkennungssoftware durch Lehrer zur Feststellung, ob Schüler AI verwendet haben, löst ethische Debatten in der Bildung aus und fordert das Bildungssystem auf, sich auf das Verständnis der Schüler statt auf die Werkzeugnutzung zu konzentrieren. ChatGPT zeigt Potenzial im Gesundheitswesen zur Unterstützung von Diagnosen und zur Bereitstellung von Gesundheitsratschlägen, muss aber mit Vorsicht eingesetzt werden. Plattformen wie Glass 5.0 wenden AI in der klinischen Entscheidungsunterstützung an und treiben die Entwicklung von medizinischer AI vom Chatbot zum Partner voran. (Quelle: Reddit r/artificial, Reddit r/ChatGPT, GlassHealthHQ)

Kontinuierliche Diskussion über LLM-Leistung, Kosten und Benutzererfahrung: Nutzer sozialer Medien diskutieren intensiv über die Leistung, Kosten und praktische Nutzungserfahrung von LLMs wie Gemini 3 Flash und Claude Opus 4.5. Schwerpunkte sind die Fortschritte der Modelle in den Bereichen Codierung, Tool-Aufruf und Inferenzfähigkeiten sowie Probleme wie Leistungsabfall und Halluzinationsraten. Benutzer vergleichen das Preis-Leistungs-Verhältnis verschiedener Modelle und erörtern AI-Modell-Preisstrategien sowie die Wahrnehmung des Modellwerts durch die Benutzer. (Quelle: Vtrivedy10, hrishioa, tokenbender, inerati, scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, max__drake, MiniMax__AI, scaling01)
Tiefgreifende Erforschung von AI-Ethik, Philosophie und AGI: In den sozialen Medien werden die ethischen und sozialen Auswirkungen von AI diskutiert, einschließlich der Frage, ob AI eine “Gotteslücke” füllt, die wahre Definition von AGI und das Potenzial sowie die Grenzen von AI in der Physikforschung. Benutzer befassen sich auch mit der Reproduzierbarkeit von AI-Benchmarks, der Kritik an der Qualität der AI-Forschung und philosophischen Überlegungen zu den grundlegenden Unterschieden zwischen AI-Modellen und menschlicher Intelligenz. (Quelle: Ronald_vanLoon, ImazAngel, Ronald_vanLoon, RisingSayak, snwy_me, TheTuringPost, teortaxesTex, _lewtun)

AI-Modellarchitektur, Effizienz und Infrastruktur-Optimierung: In den sozialen Medien werden AI-Modellarchitektur und Effizienz diskutiert, einschließlich der MFU-Effizienz von MoE-Modellen, des ultra-spärlichen MoE-Trainings von nmoe und der Vereinfachung der LLM-Inferenz (z.B. mini-SGLang). Benutzer verfolgen Fortschritte bei der Verarbeitung langer Kontexte, dem Speichermanagement und der Hardware-Optimierung (z.B. MLX Distributed Backend, vLLM Serving), um die Gesamtleistung und Skalierbarkeit von AI-Systemen zu verbessern. (Quelle: lateinteraction, hyhieu226, TheZachMueller, dejavucoder, awnihannun, vllm_project, aiamblichus)

AI-Unternehmensstrategie, Marktwettbewerb und Talentfluktuation: In den sozialen Medien werden die Strategien und der Marktwettbewerb von AI-Unternehmen diskutiert, darunter Amazons Einstellung von Top-AI-Forschern, Thinking Machines’ Plan zur Veröffentlichung von Modellen, die Investitionen und Erträge von Meta AI sowie die organisatorischen Probleme von OpenAI. Benutzer verfolgen auch NVIDIAs Führungsposition im Open-Source-AI-Bereich, seine hardwaregetriebene Strategie und wichtige Talentfluktuationen wie den Beitritt von Anthropic-Forschern zu Tencent. (Quelle: pmddomingos, scaling01, teortaxesTex, steph_palazzolo, TheTuringPost, Sentdex, teortaxesTex, turbopuffer, iScienceLuvr, EthanJPerez)

Bericht zum Stand der AI-Codierung und Branchentrends: Greptile hat den “State of AI Coding Report 2025” veröffentlicht, der einen Anstieg der monatlichen Code-Produktion von Entwicklern um 76% und ein Aufblähen des PR-Volumens feststellt, wobei die Vorteile von AI-Tools ungleich verteilt sind. Der Bericht vergleicht auch die Leistung von OpenAI-, Anthropic- und Google-Modellen hinsichtlich der First-Token-Antwortzeit, des Durchsatzes und der Kosten und beleuchtet die Marktwettbewerbslandschaft für Vektordatenbanken und AI-Speichertools. (Quelle: dotey)

Diskussion über LLM-Evaluierung und Reproduzierbarkeit: Die Reddit-Community diskutiert die Herausforderungen und Probleme der Reproduzierbarkeit bei der LLM-Evaluierung. Benutzer konzentrieren sich darauf, wie zuverlässige Bewertungsstandards etabliert werden können, um die Vergleichbarkeit von Ergebnissen zwischen verschiedenen Studien und Modellen sicherzustellen, und erörtern, wie Bewertungsmethoden und Datensätze in dem sich schnell entwickelnden LLM-Bereich effektiv verwaltet und geteilt werden können, um den wissenschaftlichen Fortschritt zu fördern. (Quelle: Reddit r/deeplearning)
AI-Modelle in der EU: Leistung und Auswirkungen von Vorschriften: Reddit-Nutzer diskutieren, ob Video- und Bild-AI-Modelle in der EU aufgrund von Vorschriften “dümmer” werden. Die allgemeine Meinung ist, dass die Kernqualität der Modelle nicht beeinträchtigt wird, aber die strengen Sicherheitsauflagen und Compliance-Anforderungen der EU zu Verzögerungen bei der Funktionsfreigabe, strengeren Filtern oder unterschiedlichen Standardeinstellungen führen können, was das Benutzererlebnis beeinträchtigt, nicht aber die Intelligenz des Modells selbst. (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
AI verschmilzt mit Kunst und Unterhaltung: Desdemona Robot und ihre Band werden am 11. Januar in San Francisco auftreten und AI mit Kunst verbinden, um das Potenzial von Robotern als Performer zu erkunden. Gleichzeitig äußerten Nutzer den Wunsch, dass Bands AI-Tools wie Suno nutzen, um Songs zu generieren und live aufzuführen, was den aufkommenden Trend der AI in der Musikproduktion und Live-Unterhaltung widerspiegelt. (Quelle: bengoertzel, fabianstelzer)
ComfyUI erforscht “Simple Mode” zur Vereinfachung von Workflows: ComfyUI erforscht einen neuen “Simple Mode”, der darauf abzielt, komplexe Workflows einfacher zu teilen und zu iterieren, wobei der Fokus auf den Ergebnissen und nicht auf dem zugrunde liegenden Node-Graph liegt. Dieser Modus richtet sich insbesondere an Benutzer, die große Diagramme schwer verständlich finden, um die Einstiegshürde zu senken und die Benutzererfahrung sowie die Arbeitseffizienz zu verbessern. (Quelle: NerdyRodent)