
Anahtar Kelimeler:SAM 3, Gemini 3 Flash, AI video oluşturma, Somutlaştırılmış yapay zeka, Büyük model, AI ajan, 3D dijital insan, Meta SAM 3 görüntü bölütleme, Google Gemini 3 Flash performansı, Ali WANXIANG 2.6 video oluşturma, Derin zeka durumsal veri toplama, Xiaomi MiMo-V2-Flash açık kaynak
🔥 Spotlight
Meta Releases SAM 3 Model: Facebook Research released SAM 3, a unified image and video promptable segmentation foundation model. It performs object detection, segmentation, and tracking via text or visual prompts, introducing open-vocabulary instance segmentation capabilities and achieving 75-80% human performance on the SA-CO benchmark. The model is driven by an innovative data engine that automatically annotated over 4 million unique concepts, and features a new architectural design including presence tokens and a decoupled detector-tracker for improved discriminability and efficiency. (Source: GitHub Trending)

Google Releases Gemini 3 Flash Model: Google launched Gemini 3 Flash, its fastest AI model to date, engineered for speed while maintaining cutting-edge intelligence. The model demonstrates outstanding performance on PhD-level reasoning and knowledge benchmarks such as GPQA Diamond and Humanity’s Last Exam, even surpassing Gemini 3 Pro in the SWE-bench Verified coding benchmark. Gemini 3 Flash offers three times the speed of Gemini 2.5 Pro at a lower cost ($0.50 per million input tokens, $3 per million output tokens) and has been rolled out globally as the default AI model for Google Search, aiming to promote AI adoption in enterprise applications and the developer ecosystem. (Source: WeChat)

🎯 Trends
AI Video Generation Models Continue to Evolve: Models such as Alibaba Wanxiang 2.6, ByteDance Seedance 1.5 Pro, and Kling 2.6 have been successively released. Wanxiang 2.6 achieves consistent audio-visual character customization and multi-shot storyboard control, generating up to 15 seconds in a single instance; Seedance 1.5 Pro focuses on high-precision audio-visual synchronization and multi-dialect support; Kling 2.6 enhances timbre control and Motion Control features. These advancements signify that AI video creation is moving from a “gacha” era towards a new stage of precise and controllable cinematic production. (Source: WeChat, WeChat, Kling_ai, Alibaba_Wan)
Deep Development of Embodied AI Technology and Strategy: DeepMind (深度机智) launched its embodied AI “Contextual Data Collection” mode, addressing generality challenges through human first-person data; Horizon Robotics (地平线) released its “BPU+Compiler+Foundation Model” Wintel strategy, empowering intelligent vehicles and general-purpose robots; Dr. Wang Guangrun’s team at Sun Yat-sen University (中山大学) unveiled the E0 embodied large model, emphasizing decoupled physical and spatial models to achieve few-shot fine-tuning generalization. These developments collectively push embodied AI from mechanical imitation towards logical understanding and interaction with the physical world. (Source: WeChat, WeChat, WeChat)
Xiaomi and SenseTime Release Cutting-Edge Large Models: Xiaomi open-sourced its MiMo-V2-Flash large model, adopting an MoE architecture designed for Agent and code scenarios, entering the global open-source model top tier with extreme inference efficiency and low cost. SenseTime (商汤科技) released its SenseNova-SI model and NEO architecture, aiming to address the limitations of pure language models in understanding the physical world by enhancing spatial intelligence through native multimodal and cross-view prediction. (Source: WeChat, WeChat)

AI PC Integrates with Specific Application Scenarios: Cosmic Motion (科思创动) launched an AI PC personal health assistant, utilizing non-contact rPPG technology for contactless blood pressure and skin detection, combined with Intel NPU for efficient local computation. Concurrently, Conflux Technology (云澎科技) also released new AI+health products, including an AI health large model smart refrigerator and a digital future kitchen laboratory, integrating AI into daily health management and home technology. (Source: WeChat, 36氪)

Moore Threads LiteGS Technology Breakthrough in 3D Graphics Rendering: Moore Threads (摩尔线程) won a silver award in the 3DGS reconstruction challenge at SIGGRAPH Asia 2025 and open-sourced its self-developed LiteGS technology. LiteGS is a 3D Gaussian Splatting foundation library that achieves significant leadership in training efficiency and reconstruction quality through full-link collaborative optimization, promoting the application of 3DGS technology in 3D reconstruction, real-time rendering, and embodied AI training scenarios. (Source: WeChat)

New Progress in Data-Efficient Pretraining for Small-Scale LLMs: An independent Korean research engineer released Gumini, a 1.5B parameter Korean-English bilingual foundation LLM, which achieved top rankings in Korean benchmarks using only 3.14B training tokens. This advancement indicates that LLM pretraining can achieve data efficiency through optimized architectures and training strategies, offering a new path beyond the “more data + more compute” paradigm for small teams and independent researchers. (Source: Reddit r/LocalLLaMA)

Multimodal AI Deepens Application in Specific Domains: MiraTTS, a high-quality and fast TTS model, can generate realistic speech at over 100 times real-time speed, supporting multiple languages. Concurrently, a multilingual RAG system has been deployed for agricultural ecological decision support, studying LLM behavior in low-resource, highly specialized domains, and has been running in a production environment for a year. These demonstrate the mature applications of multimodal AI in speech generation and vertical domain decision support. (Source: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Alibaba Taobao Tech Launches Mobile 3D Digital Human Reconstruction System: Alibaba Taobao Tech (淘宝技术) Meta team released the HRM²Avatar system at SIGGRAPH Asia, allowing users to create and render high-fidelity real-time 3D digital humans using only a single monocular video from a mobile phone. The system combines explicit clothing meshes with Gaussian representations, supporting real-time driving and rendering on mobile devices, excelling in visual realism, cross-pose consistency, and mobile performance, aiming to lower the barrier for 3D digital human creation. (Source: WeChat)

🧰 Tools
Letta: A Platform for Building Stateful AI Agents: Letta (formerly MemGPT) is a platform for building stateful AI agents, with advanced memory management at its core, enabling AI agents to learn and self-improve over time. The platform offers Python/TypeScript SDKs, a no-code ADE environment, as well as local desktop and cloud services, supporting core concepts such as memory hierarchy, memory blocks, and agent context engineering, and enabling multi-agent shared memory and “sleep-time agents” running in the background. Maestro is a free, open-source, cross-platform desktop application for orchestrating AI agents, supporting file system memory and tool creation, and featuring an “auto-run” capability. Toad, as a unified AI coding agent terminal interface, simplifies integration with various AI coding tools. (Source: GitHub Trending, Reddit r/LocalLLaMA, huggingface)
Miaoda No-Code AI Programming Tool Empowers Non-Programmers: Miaoda (秒哒) is a no-code AI programming tool launched 8 months ago, which has generated over 5 billion RMB in value, primarily used by non-programmers. The tool uses a “Product Manager Agent” for multi-round requirement communication, transforming vague needs into structured product documentation, which is then implemented by a “Development Agent.” Miaoda has overcome backend construction challenges, achieving deep integration of AI with databases, and through refined strategies, reduced costs, increased efficiency, and avoided “code spaghetti.” (Source: WeChat)

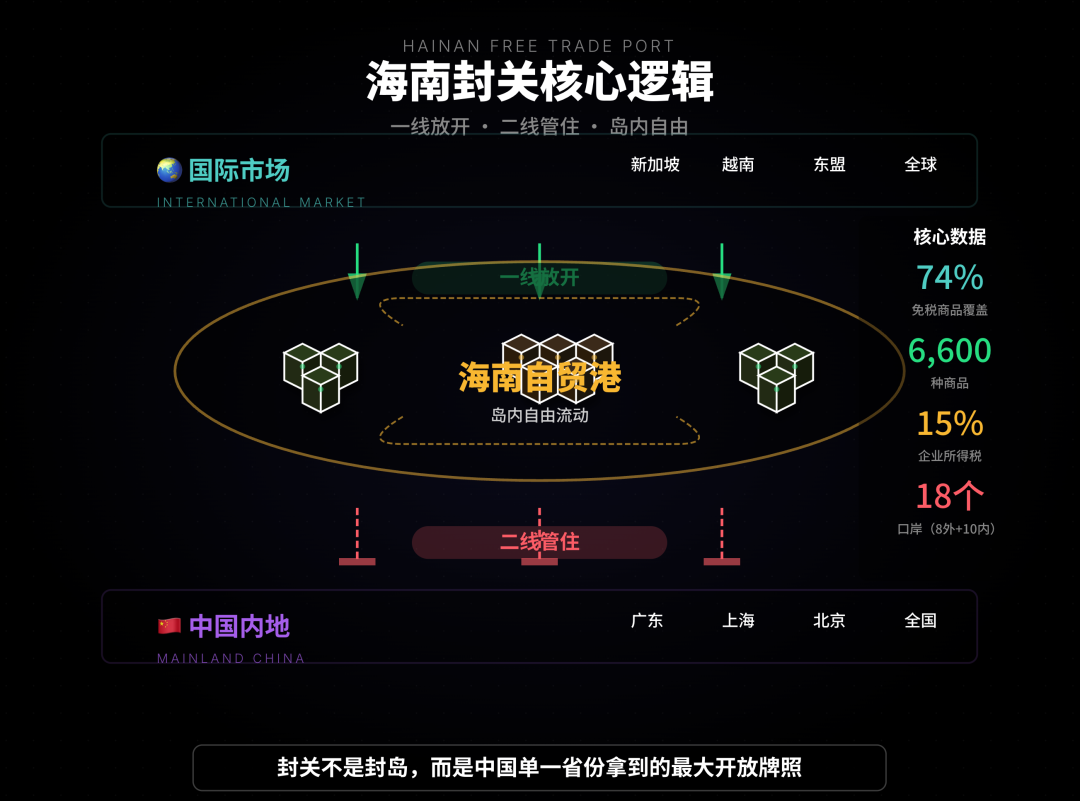
AI-Assisted Analysis and Sales Automation Tools: The article demonstrates how AI assists in trend analysis of the “Hainan Free Trade Port” policy, helping users clarify complex information through multi-channel information integration, categorization, and deduction. QuickHook is a sales automation tool based on Gemini 3 and Search Grounding, capable of transforming 15 minutes of manual research into 10 seconds of automation, aiming to solve the “AI voice” problem in cold outreach. (Source: WeChat, Reddit r/artificial)
OpenWebUI API and Local STT System: OpenWebUI provides API interfaces, allowing developers to create custom client applications, such as voice mode applications on WearOS, to achieve personalized AI interaction experiences. Kroko-onnx-home-assistant is an open-source local streaming Speech-to-Text (STT) pipeline designed for Home Assistant, featuring high quality, real-time streaming, and 100% localization, capable of running efficiently even on low-resource devices. (Source: Reddit r/OpenWebUI, Reddit r/LocalLLaMA)
Multi-LLM Collaboration Enhances Game Development Efficiency: Developers leverage the OpenAI Realtime API to gather game requirements, generate Markdown specifications with Gemini 3 Pro, and then code applications with Anthropic Opus 4.5, enabling customized smart ball game development. This multi-LLM collaborative workflow optimizes the strengths of different LLMs, enhancing development efficiency and quality from requirements to code, offering a new development paradigm for complex projects. (Source: Reddit r/artificial)

📚 Learning
Transformer Architecture Optimization and Normalization Innovation: Professor Liu Zhuang’s team at Princeton University proposed the Derf operator, which replaces LayerNorm in Transformers with a Gaussian error function (erf), comprehensively outperforming existing methods in tasks such as vision, generation, and gene sequence modeling. Concurrently, Nanyang Technological University and Fudan University proposed EFLA (Error-Free Linear Attention), which eliminates numerical drift in linear attention for long sequences through analytical solutions, achieving simultaneous improvements in stability and performance. (Source: WeChat, WeChat)

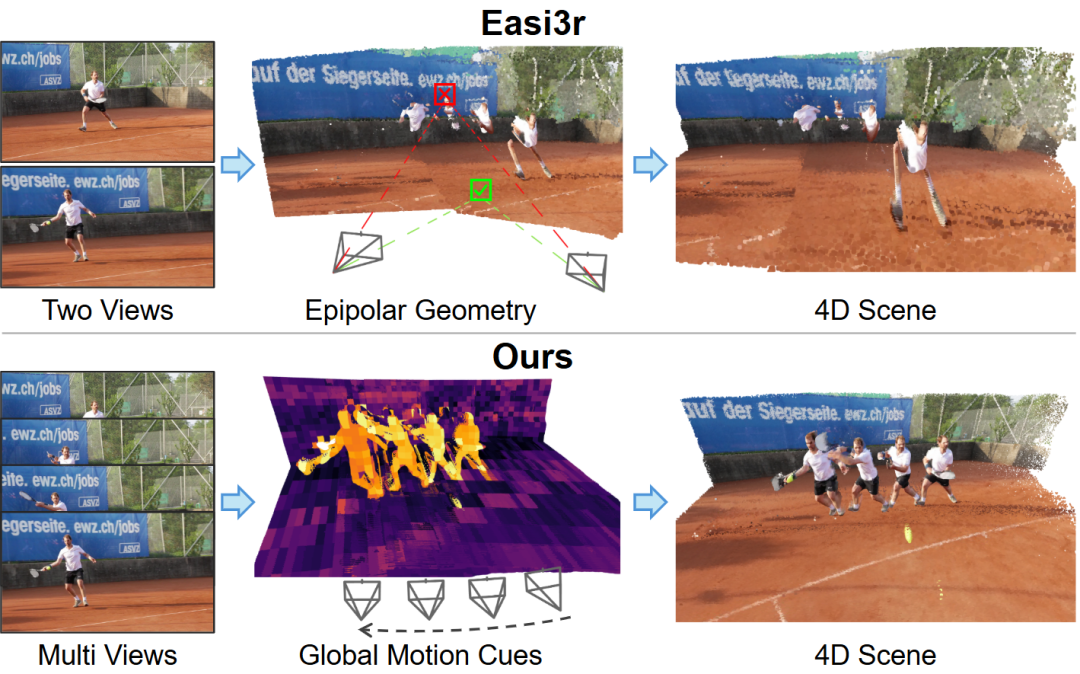
Frontier Research in Multimodal and Video Understanding: The DiffusionVL framework can transform autoregressive models into diffusion visual-language models, significantly improving performance and accelerating inference. The SAGE system utilizes reinforcement learning for multi-round reasoning in long videos, performing excellently on open-ended video tasks. MMSI-Video-Bench, as a comprehensive benchmark for video spatial intelligence, reveals systematic failures of MLLMs in geometric reasoning, motion grounding, and other aspects. VGGT4D proposes a training-free 4D scene reconstruction framework that processes dynamic scenes by extracting motion cues within the Transformer. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, WeChat)
AI Agents and LLM Memory Optimization: Nanjing University of Science and Technology (南理工) and Baidu, among others, proposed ViLoMem, which solves the problem of multimodal large models “not learning from experience” through dual-stream semantic memory (visual stream + logical stream), significantly improving inference performance. The LightSearcher framework optimizes RL-driven Agent tool calls through episodic memory, reducing call counts by 39.6% and inference time by 48.6%, while maintaining accuracy. The MEM1 framework also trains Agents via RL to maintain constant memory in long-horizon tasks. (Source: WeChat, WeChat, omarsar0)
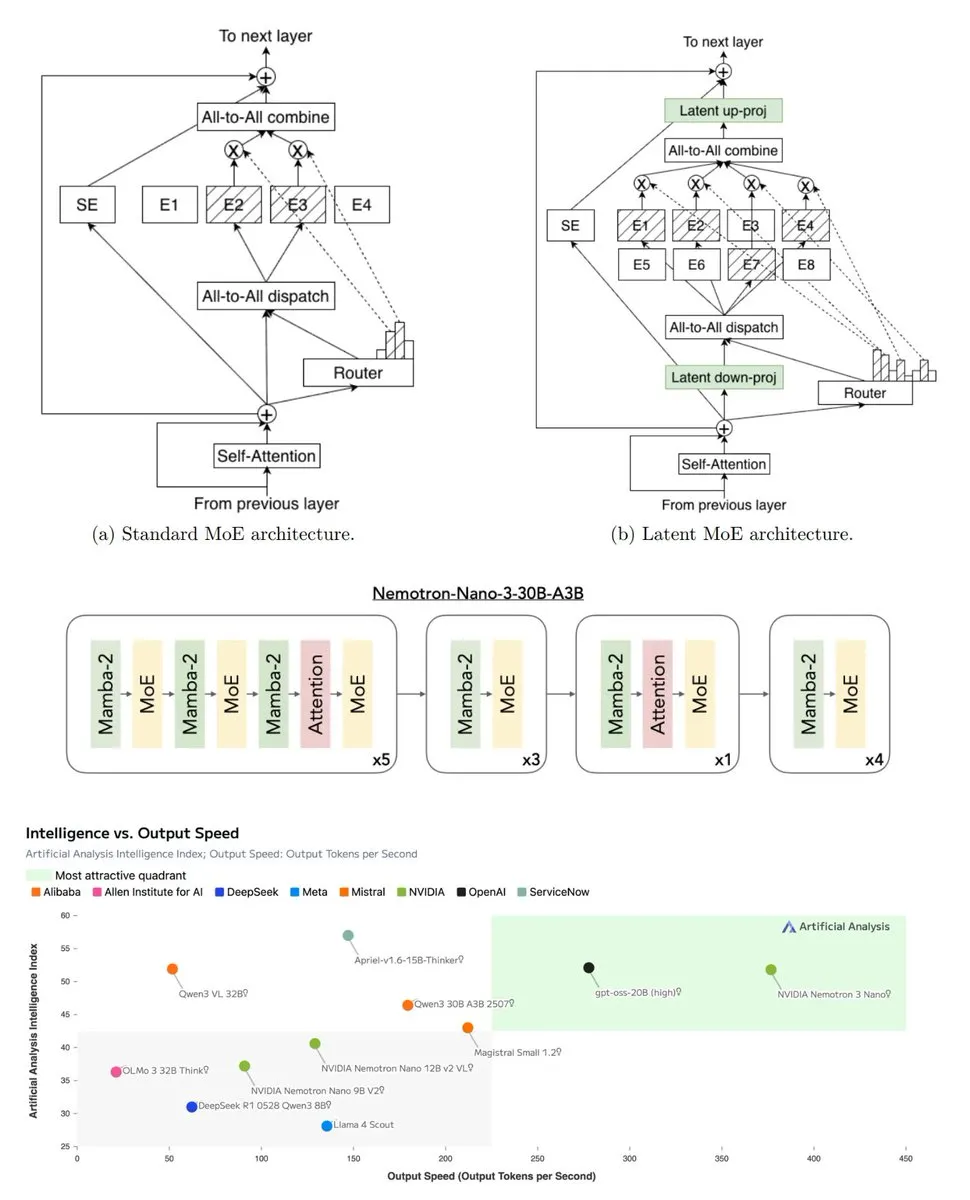
LLM Evaluation and Dataset Construction: LikeBench, as a multi-session dynamic evaluation framework, is the first to decompose LLM personalization preference into seven diagnostic metrics to measure a model’s ability to adapt to user preferences. VOYAGER is a training-free method that uses LLMs to generate diverse datasets, significantly increasing diversity by 1.5-3 times. The FiNERweb dataset creation pipeline provides scalable multilingual Named Entity Recognition resources for 91 languages and 25 scripts. NVIDIA also released a complete evaluation guide for Nemotron 3 Nano, enhancing the transparency and reproducibility of LLM evaluation. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/LocalLLaMA)

AI Safety and Interpretability Research: Research proposed a re-synthesis framework for robust and calibrated detection of multimedia content authenticity, addressing the challenges of deepfakes. Concurrently, the Hybrid Attribution Priors framework guides language models to capture fine-grained category distinctions through Class-Aware Attribution Prior (CAP), enhancing model interpretability and robustness. Hyper++ improved hyperbolic deep reinforcement learning, enhancing Agent learning stability. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Deep Learning Learning Resources and Research Opportunities: AIhub published a compilation of interviews from the 2025 AAAI/ACM SIGAI Doctoral Consortium, covering cutting-edge AI research across multiple domains. Concurrently, a new ML systems and GPU programming course was announced, aiming to provide a deep understanding of the DL stack through practical experience. The PyTorch/vLLM hardware challenge encourages developers to fix bugs, and Computer Vision learning roadmap suggestions are provided to help learners plan their career development. (Source: aihub.org, DeepLearningAI, vllm_project, Reddit r/deeplearning, Reddit r/deeplearning)

3D/XR and Human-Computer Interaction Modeling: The TIMAR framework proposes causal modeling of interactive 3D conversational head dynamics, integrating multimodal information and predicting continuous 3D head movements. Research on SAR to RGB image translation explores how to generate clear images using deep learning models. Research on preschool letter handwriting scoring algorithms seeks template matching methods to accurately assess children’s handwriting quality. (Source: HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
Scaling Laws and Model Fusion Theory: This research challenges the view that “Scaling Law is superior to inductive bias,” finding that architectures encoding symmetry have better Scaling Exponents. Concurrently, multi-task model fusion conflict resolution solutions (TATR, CAT Merging, LOT Merging) effectively mitigate knowledge conflicts and enhance multi-task performance and robustness by identifying and filtering conflicting dimensions, projection, or weighted fusion. (Source: dair_ai, WeChat)
End-to-End Training of Autoregressive Video Diffusion: This research introduces the “Resampling Forcing” framework, enabling end-to-end training of autoregressive video diffusion models. By simulating model errors on historical frames during inference, combined with sparse causal masks and historical routing mechanisms, this method achieves performance comparable to distillation baselines while maintaining temporal consistency and supporting efficient long-range generation. (Source: HuggingFace Daily Papers)
LLM Evaluation and Reproducibility Discussion: The Reddit community discussed the challenges and reproducibility issues of LLM evaluation. Users focused on how to establish reliable evaluation criteria to ensure comparability of results across different studies and models, and explored how to effectively manage and share evaluation methods and datasets in the rapidly evolving LLM field to promote scientific progress. (Source: Reddit r/deeplearning)
💼 Business
Zhipu AI and MiniMax Race for Hong Kong IPO: Domestic large model companies MiniMax and Zhipu AI (智谱AI) have completed CSRC filing and participated in the Hong Kong Stock Exchange listing hearing, with MiniMax planning to list in January 2026. Zhipu AI is valued at approximately 40 billion RMB, focusing on government (G-end) and business (B-end) clients and multimodal Agents; MiniMax is valued at nearly 30 billion RMB, with multimodal capabilities at its core and a product-driven model. Both companies underwent strategic convergence and team adjustments before listing, reflecting that the large model industry has entered a “dual constraint period of capital and efficiency.” (Source: 36氪)
Amazon to Invest $10 Billion in OpenAI: Amazon plans to invest at least $10 billion in OpenAI, a move expected to include OpenAI using Amazon’s Trainium series AI chips and leasing more data center capacity to run its models and tools (such as ChatGPT). This investment aims to deepen the collaboration between the two companies in AI infrastructure and model deployment. (Source: Reddit r/ArtificialInteligence)

Biren Technology Races to Become First General-Purpose GPU Stock on HKEX: Biren Technology (壁仞科技), a general-purpose GPU unicorn valued at 20.9 billion RMB, has passed the Hong Kong Stock Exchange listing hearing and is set to become the “first domestic GPU stock” on the HKEX. The company was founded by Harvard Law Ph.D. Zhang Wen, with core products including hardware systems (Biren BR106, BR110, BR166 chips) based on its self-developed GPGPU architecture and the BIRENSUPA software platform, providing full-stack support for AI training and inference, with clients spanning high-compute industries such as telecommunications and fintech. (Source: WeChat)
🌟 Community
AI-Generated Content Quality and the Internet “Slop” Phenomenon: Social media widely discussed the “slop” phenomenon of inconsistent AI-generated content quality, which was chosen as the word of the year, reflecting the proliferation of AI content and issues of low quality. This sparked criticism of internet advertising platforms’ profit-driven motives and reflections on how to raise the bar for AI content creation. (Source: 36氪)

AI’s Impact on the Labor Market and Developer Work Models: Social media delved into AI’s disruption of the job market and developer work patterns. AI is seen as a powerful productivity tool, shifting the developer’s role from pure code writing to system design, agent orchestration, code verification, and debugging, requiring higher-level skills. LinkedIn introduced an AI recruiting assistant, changing job search and recruitment processes. Concurrently, AI significantly boosts efficiency in fields like photography, but the production readiness of AI coding agents still faces challenges. (Source: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Yuchenj_UW, gdb, amasad, amasad, Ronald_vanLoon)

AI Applications and Challenges in Education, Healthcare, and Other Fields: Teachers using AI detection software to determine if students used AI sparked educational ethics controversies, calling for the education system to focus on student understanding rather than tool usage. ChatGPT shows potential in the healthcare sector for assisting diagnosis and providing health advice, but requires cautious use. Platforms like Glass 5.0 apply AI to clinical decision support, driving the transformation of medical AI from chatbots to partners. (Source: Reddit r/artificial, Reddit r/ChatGPT, GlassHealthHQ)

Ongoing Discussion on LLM Performance, Cost, and User Experience: Social media users engaged in heated discussions about the performance, cost, and real-world user experience of LLMs such as Gemini 3 Flash and Claude Opus 4.5. Points of focus included advancements in models’ coding, tool-calling, and reasoning capabilities, as well as issues like performance degradation and hallucination rates. Users compared the cost-effectiveness of different models and discussed AI model pricing strategies and user perception of model value. (Source: Vtrivedy10, hrishioa, tokenbender, inerati, scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, max__drake, MiniMax__AI, scaling01)
Deep Dive into AI Ethics, Philosophy, and AGI: Social media discussed the ethical and social implications of AI, including whether AI is filling a “God void,” the true definition of AGI, and AI’s potential and limitations in physics research. Users also focused on the reproducibility of AI benchmarks, critiques of AI research quality, and philosophical reflections on the fundamental differences between AI models and human intelligence. (Source: Ronald_vanLoon, ImazAngel, Ronald_vanLoon, RisingSayak, snwy_me, TheTuringPost, teortaxesTex, _lewtun)

AI Model Architecture, Efficiency, and Infrastructure Optimization: Social media discussed AI model architecture and efficiency, including MFU efficiency of MoE models, super-sparse MoE training with nmoe, and simplification of LLM inference (e.g., mini-SGLang). Users focused on advancements in models’ long context handling, memory management, and hardware optimization (e.g., MLX distributed backend, vLLM serving) to enhance the overall performance and scalability of AI systems. (Source: lateinteraction, hyhieu226, TheZachMueller, dejavucoder, awnihannun, vllm_project, aiamblichus)

AI Company Strategies, Market Competition, and Talent Mobility: Social media discussed AI companies’ strategies and market competition, including Amazon hiring top AI researchers, Thinking Machines’ plans to release models, Meta AI’s input-output, and organizational issues faced by OpenAI. Users also focused on NVIDIA’s leadership in open-source AI, its hardware-driven strategy, and key talent movements such as Anthropic researchers joining Tencent. (Source: pmddomingos, scaling01, teortaxesTex, steph_palazzolo, TheTuringPost, Sentdex, teortaxesTex, turbopuffer, iScienceLuvr, EthanJPerez)

AI Coding State of the Union Report and Industry Trends: Greptile released the “2025 State of AI Coding Report,” indicating a 76% increase in developers’ monthly code output, inflated PR volumes, and uneven distribution of benefits from AI tools. The report also compared the performance of OpenAI, Anthropic, and Google models in terms of first-token response time, throughput, and cost, and revealed the competitive landscape of vector databases and AI memory tools. (Source: dotey)

LLM Evaluation and Reproducibility: The Reddit community discussed the challenges and reproducibility issues of LLM evaluation. Users focused on how to establish reliable evaluation criteria to ensure comparability of results across different studies and models, and explored how to effectively manage and share evaluation methods and datasets in the rapidly evolving LLM field to promote scientific progress. (Source: Reddit r/deeplearning)
Open AI and Hardware-Driven Strategy: The release of NVIDIA Nemotron 3 marked a symbolic turning point in open-source AI leadership. The model, through large-scale pretraining data, RL datasets, and a new hybrid architecture, optimized computational consumption on NVIDIA hardware. This strategy indicates that open-source AI is moving from an era of “big tech philanthropy” to an era of “hardware-defined AI,” where model releases aim to expand the computational consumption of specific hardware. (Source: TheTuringPost, teortaxesTex)
Comparison and Application of AI Image and Video Generation Tools: Social media users discussed the performance and applications of AI image and video generation tools, including ChatGPT, Gemini, Midjourney, Grok, Nano Banana Pro, etc. Discussions covered the realism of AI artworks, game character transformation, and the application of AI video in filmmaking. Users also focused on the quality, cost, and efficiency of AI-generated content, as well as its disruptive impact on creative workflows. (Source: dotey, swyx, karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Kling_ai)

AI Applications and Trends in Finance: Social media discussed AI applications in the financial sector, covering 26 specific cases, such as fraud detection, risk management, customer service, etc. These applications demonstrate how machine learning and artificial intelligence empower the financial industry, enhancing efficiency, optimizing decision-making, and creating new business value. (Source: Ronald_vanLoon)

Integration of AI Agents and Knowledge Graphs: SAP’s AI scientists discussed how knowledge graphs can improve the discovery and execution of AI agents. Knowledge graphs provide AI agents with semantic and procedural context, enabling them to more effectively discover and invoke tools and APIs within enterprise systems, thereby enhancing agent efficacy in complex enterprise environments. (Source: DeepLearningAI)

LLM Evaluation and Reproducibility Discussion: The Reddit community discussed the challenges and reproducibility issues of LLM evaluation. Users focused on how to establish reliable evaluation criteria to ensure comparability of results across different studies and models, and explored how to effectively manage and share evaluation methods and datasets in the rapidly evolving LLM field to promote scientific progress. (Source: Reddit r/deeplearning)
AI Model Performance and Regulatory Impact in the EU: Reddit users discussed whether video and image AI models are “dumber” in the EU due to regulations. The general consensus is that the core quality of models is unaffected, but the EU’s strict safety layers and compliance requirements may lead to delayed feature rollouts, stricter filtering, or different default settings, thereby impacting user experience rather than a decrease in the models’ inherent intelligence. (Source: Reddit r/ArtificialInteligence)
💡 Other
AI Integration in Art and Entertainment: Desdemona Robot and its band will perform in San Francisco on January 11, combining AI with art to explore the potential of robots as performers. Concurrently, users expressed a desire to see bands use AI tools like Suno to generate songs and perform them live, reflecting emerging trends in AI applications in music creation and live entertainment. (Source: bengoertzel, fabianstelzer)
ComfyUI Explores “Simple Mode” to Streamline Workflows: ComfyUI is exploring a new “simple mode” designed to make complex workflows easier to share and iterate, focusing on results rather than the underlying node graph. This mode specifically targets users who find large graphs difficult to understand, aiming to lower the barrier to entry, enhance user experience, and improve work efficiency. (Source: NerdyRodent)