
关键词:SAM 3, Gemini 3 Flash, AI视频生成, 具身智能, 大模型, AI代理, 3D数字人, Meta SAM 3图像分割, 谷歌Gemini 3 Flash性能, 阿里万相2.6视频生成, 深度机智情境数采, 小米MiMo-V2-Flash开源
🔥 聚焦
Meta发布SAM 3模型 : Facebook Research发布SAM 3,一个统一的图像和视频可提示分割基础模型。它通过文本或视觉提示进行对象检测、分割和跟踪,引入了开放词汇概念的实例分割能力,并在SA-CO基准上达到75-80%的人类表现。该模型由一个创新的数据引擎驱动,自动标注了400多万个独特概念,并采用新的架构设计,包含存在令牌和解耦的检测器-跟踪器,以提高判别力和效率。(来源: GitHub Trending)

谷歌发布Gemini 3 Flash模型 : 谷歌推出迄今最快AI模型Gemini 3 Flash,专为速度而生,同时保持前沿智能。该模型在GPQA Diamond和Humanity’s Last Exam等博士级推理和知识基准测试中展现出色性能,甚至在SWE-bench Verified编码基准测试中超越Gemini 3 Pro。Gemini 3 Flash以更低成本(每百万输入token 0.50美元,输出3美元)提供比Gemini 2.5 Pro快三倍的速度,并已在全球范围内作为Google搜索AI模式的默认模型推出,旨在推动AI在企业级应用和开发者生态中的普及。(来源: WeChat)

🎯 动向
AI视频生成模型持续进化 : 阿里万相2.6、字节Seedance 1.5 Pro和Kling 2.6等模型相继发布。万相2.6实现声画一致性角色定制和多镜头分镜控制,单次生成长达15秒;Seedance 1.5 Pro主打音画高精同步和多方言支持;Kling 2.6则强化了音色控制和Motion Control功能。这些进展标志着AI视频创作正从“抽卡”时代迈向精准可控的电影级制作新阶段。(来源: WeChat, WeChat, Kling_ai, Alibaba_Wan)

具身智能技术与战略深度发展 : 深度机智推出具身智能“情境数采”模式,通过人类第一视角数据解决通用性难题;地平线发布“BPU+编译器+基座模型”的Wintel战略,赋能智能汽车和通用机器人;中山大学王广润博士团队发布E0具身大模型,强调解耦物理与空间模型,实现小样本微调泛化。这些进展共同推动具身智能从机械模仿走向逻辑理解和物理世界交互。(来源: WeChat, WeChat, WeChat)
小米与商汤发布前沿大模型 : 小米开源MiMo-V2-Flash大模型,采用MoE架构,专为Agent和代码场景设计,以极致推理效率和低成本进入全球开源模型第一梯队。商汤科技发布SenseNova-SI模型和NEO架构,旨在解决纯语言模型对物理世界理解的局限,通过原生多模态和跨视角预测提升空间智能。(来源: WeChat, WeChat)

AI PC与特定应用场景融合 : 科思创动推出AI PC个人健康助手,利用非接触式rPPG技术实现隔空血压、皮肤检测,并结合英特尔NPU进行本地高效运算。同时,云澎科技发布AI+健康新品,包括AI健康大模型智能冰箱和数智化未来厨房实验室,将AI融入日常健康管理和家庭科技。(来源: WeChat, 36氪)

摩尔线程LiteGS技术突破3D图形渲染 : 摩尔线程在SIGGRAPH Asia 2025的3DGS重建挑战赛中荣获银奖,并开源其自研LiteGS技术。LiteGS是3D Gaussian Splatting基础库,通过全链路协同优化,在训练效率和重建质量上取得显著领先,推动3DGS技术在三维重建、实时渲染及具身智能训练场景中的应用。(来源: WeChat)

小规模LLM数据高效预训练新进展 : 韩国独立研究工程师发布Gumini,一个1.5B参数的韩英双语基础LLM,仅用3.14B训练tokens即在韩国基准测试中名列前茅。这一进展表明,通过优化架构和训练策略,LLM预训练可以实现数据高效,为小型团队和独立研究者提供了在“更多数据+更多算力”范式之外的新路径。(来源: Reddit r/LocalLLaMA)

多模态AI在特定领域深化应用 : MiraTTS作为高质量快速TTS模型,能够以超100倍实时速度生成逼真语音,支持多语言。同时,一个多语言RAG系统被部署于农业生态决策支持,研究LLM在低资源、高专业领域行为,并已在生产环境运行一年。这些展示了多模态AI在语音生成和垂直领域决策支持中的成熟应用。(来源: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
淘宝技术推出手机端3D数字人重建系统 : 淘宝技术Meta团队在SIGGRAPH Asia发布HRM²Avatar系统,允许用户仅通过手机单目视频即可创建和渲染高保真实时3D数字人。该系统结合显式服装网格与高斯表示,支持在移动设备上实时驱动和渲染,在视觉真实感、跨姿态一致性和移动端性能方面表现出色,旨在降低3D数字人创建门槛。(来源: WeChat)

🧰 工具
Letta:构建有状态AI代理的平台 : Letta (原MemGPT) 是一个用于构建有状态AI代理的平台,其核心是高级记忆管理,使AI代理能够随时间学习和自我改进。平台提供Python/TypeScript SDK、无代码ADE环境以及本地桌面版和云服务,支持记忆分层、记忆块、代理上下文工程等核心概念,并实现多代理共享记忆和后台运行的“睡眠时间代理”。Maestro则是一款免费开源的跨平台桌面应用,用于编排AI代理,支持文件系统记忆和工具创建,并具备“自动运行”功能。Toad作为统一AI编码代理终端界面,简化了与不同AI编码工具的集成。(来源: GitHub Trending, Reddit r/LocalLLaMA, huggingface)
秒哒无代码AI编程工具赋能非程序员 : 秒哒(Miaoda)是一款发布8个月的无代码AI编程工具,已创造超50亿元产值,主要用户为非程序员。该工具通过“产品经理智能体”进行多轮需求沟通,将模糊需求转化为结构化产品文档,再由“研发智能体”落地。秒哒攻克了后端构建难题,实现了AI与数据库的深度融合,并通过精细化策略降本增效,避免“代码屎山”。(来源: WeChat)

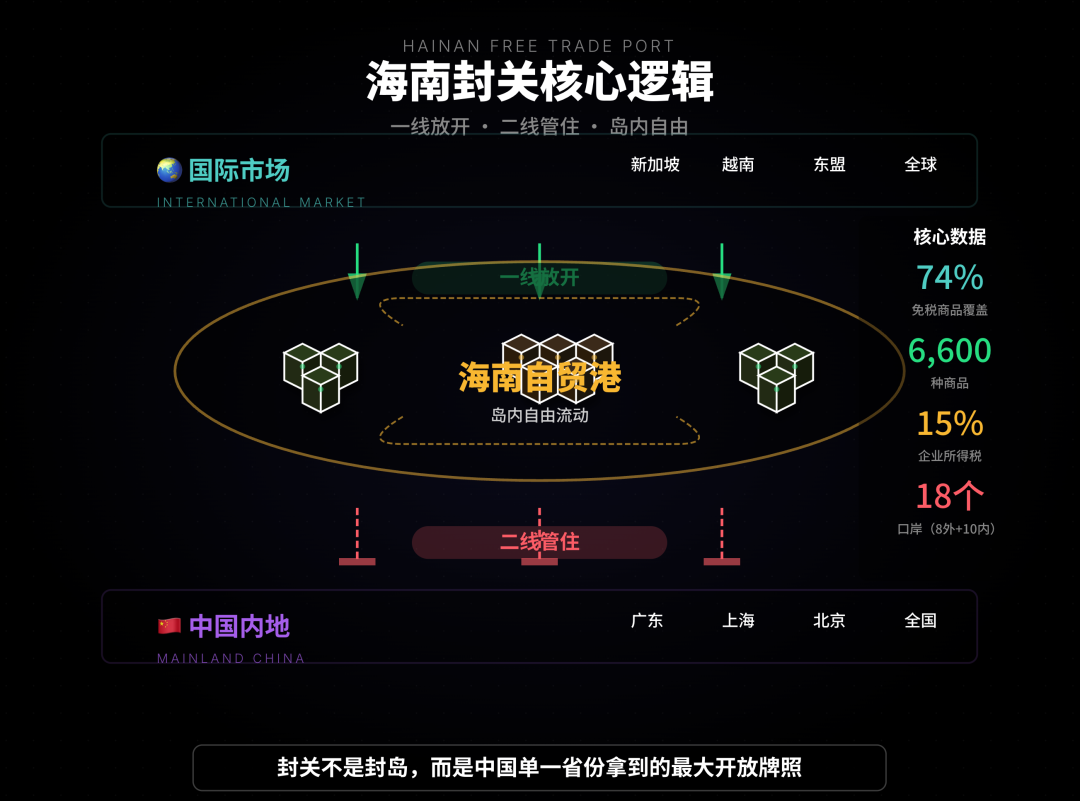
AI辅助分析与销售自动化工具 : 文章展示了AI如何辅助对“海南封关”政策进行趋势分析,通过多渠道信息整合、分门别类和推演,帮助用户理清复杂信息。QuickHook则是一个基于Gemini 3和Search Grounding的销售自动化工具,能将15分钟的手动研究转化为10秒的自动化,旨在解决冷外联中的“AI腔”问题。(来源: WeChat, Reddit r/artificial)
OpenWebUI API与本地STT系统 : OpenWebUI提供API接口,允许开发者创建自定义客户端应用,例如WearOS上的语音模式应用,实现个性化AI交互体验。Kroko-onnx-home-assistant则是一个开源的本地流式语音转文本(STT)管道,专为Home Assistant设计,具有高质量、实时流式处理和100%本地化等特点,即使在低资源设备上也能高效运行。(来源: Reddit r/OpenWebUI, Reddit r/LocalLLaMA)
多LLM协同提升游戏开发效率 : 开发者利用OpenAI Realtime API收集游戏需求,通过Gemini 3 Pro生成Markdown规范,再由Anthropic Opus 4.5编码应用程序,实现定制化智能球类游戏开发。这种多LLM协同工作流优化了不同LLM的优势,提升了从需求到代码的开发效率和质量,为复杂项目提供了新的开发范式。(来源: Reddit r/artificial)

📚 学习
Transformer架构优化与归一化创新 : 普林斯顿大学刘壮团队提出Derf算子,基于高斯误差函数(erf)替代Transformer中的LayerNorm,在视觉、生成、基因序列建模等任务上全面超越现有方法。同时,南洋理工大学与复旦大学提出EFLA(Error-Free Linear Attention),通过解析解消除线性注意力在长序列下的数值漂移,实现稳定性与性能的同步提升。(来源: WeChat, WeChat)

多模态与视频理解前沿研究 : DiffusionVL框架能将自回归模型转化为扩散视觉语言模型,显著提升性能并加速推理。SAGE系统利用强化学习实现长视频的多轮推理,并在开放式视频任务上表现出色。MMSI-Video-Bench作为视频空间智能综合基准,揭示了MLLM在几何推理、运动接地等方面的系统性失败。VGGT4D则提出无需训练的4D场景重建框架,通过挖掘Transformer内部运动线索处理动态场景。(来源: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, WeChat)
AI代理与LLM记忆优化 : 南理工与百度等单位提出ViLoMem,通过双流语义记忆(视觉流+逻辑流)解决多模态大模型“记不住教训”的问题,显著提升推理表现。LightSearcher框架则通过经验记忆优化RL驱动的Agent工具调用,减少39.6%的调用次数,推理时间缩短48.6%,同时保持准确率。MEM1框架也通过RL训练Agent在长程任务中保持恒定记忆。(来源: WeChat, WeChat, omarsar0)
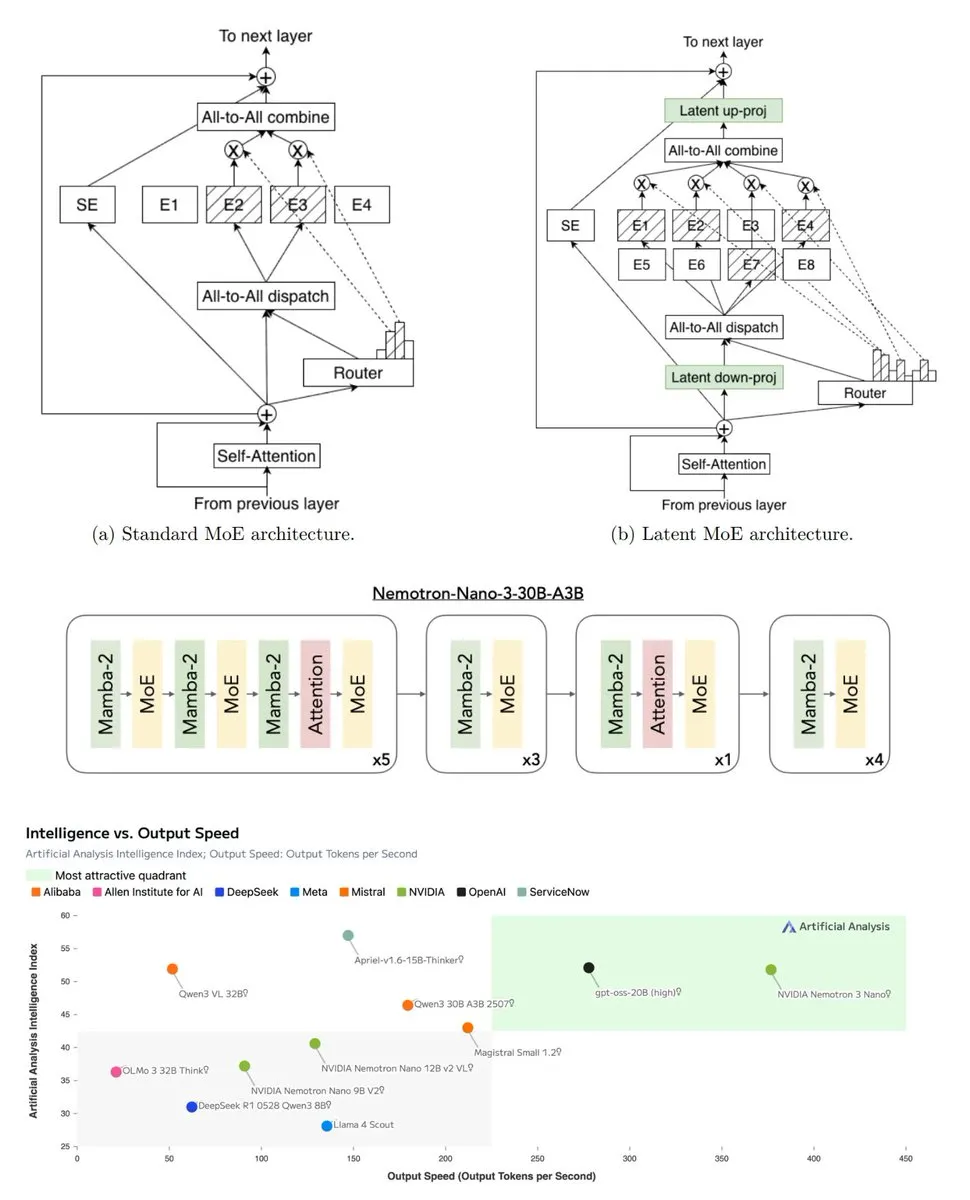
LLM评估与数据集构建 : LikeBench作为多会话动态评估框架,首次将LLM个性化喜好度分解为七个诊断指标,用于衡量模型适应用户偏好的能力。VOYAGER则是一种无训练方法,利用LLM生成多样化数据集,显著提升多样性1.5-3倍。FiNERweb数据集创建管道为91种语言和25种脚本提供可扩展的多语言命名实体识别资源。NVIDIA也发布了Nemotron 3 Nano的完整评估指南,提升LLM评估的透明度和可复现性。(来源: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/LocalLLaMA)

AI安全与可解释性研究 : 研究提出了重合成框架,用于鲁棒和校准地检测多媒体内容的真实性,以应对深度伪造的挑战。同时,Hybrid Attribution Priors框架通过Class-Aware Attribution Prior (CAP)引导语言模型捕捉细粒度类别区分,增强模型的可解释性和鲁棒性。Hyper++则改进了双曲深度强化学习,提高了Agent学习稳定性。(来源: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
深度学习学习资源与研究机会 : AIhub发布2025年AAAI/ACM SIGAI博士生论坛访谈合集,涵盖多领域AI前沿研究。同时,有新的ML系统与GPU编程课程预告,旨在通过实践深入理解DL堆栈。PyTorch/vLLM硬件挑战赛鼓励开发者修复bug,并有计算机视觉学习路线建议,帮助学习者规划职业发展。(来源: aihub.org, DeepLearningAI, vllm_project, Reddit r/deeplearning, Reddit r/deeplearning)

3D/XR与人机交互建模 : TIMAR框架提出因果建模交互式3D对话头部动态,融合多模态信息并预测连续3D头部动态。SAR到RGB图像翻译研究探讨如何通过深度学习模型生成清晰图像。学前字母手写评分算法研究则寻求模板匹配方法,以准确评估儿童手写质量。(来源: HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
Scaling Laws与模型融合理论 : 该研究挑战“Scaling Law优于归纳偏置”观点,发现编码对称性的架构具有更好Scaling Exponents。同时,多任务模型融合冲突解决方案(TATR、CAT Merging、LOT Merging)通过识别和筛选冲突维度、投影或加权融合,有效缓解知识冲突,提升多任务性能与稳健性。(来源: dair_ai, WeChat)
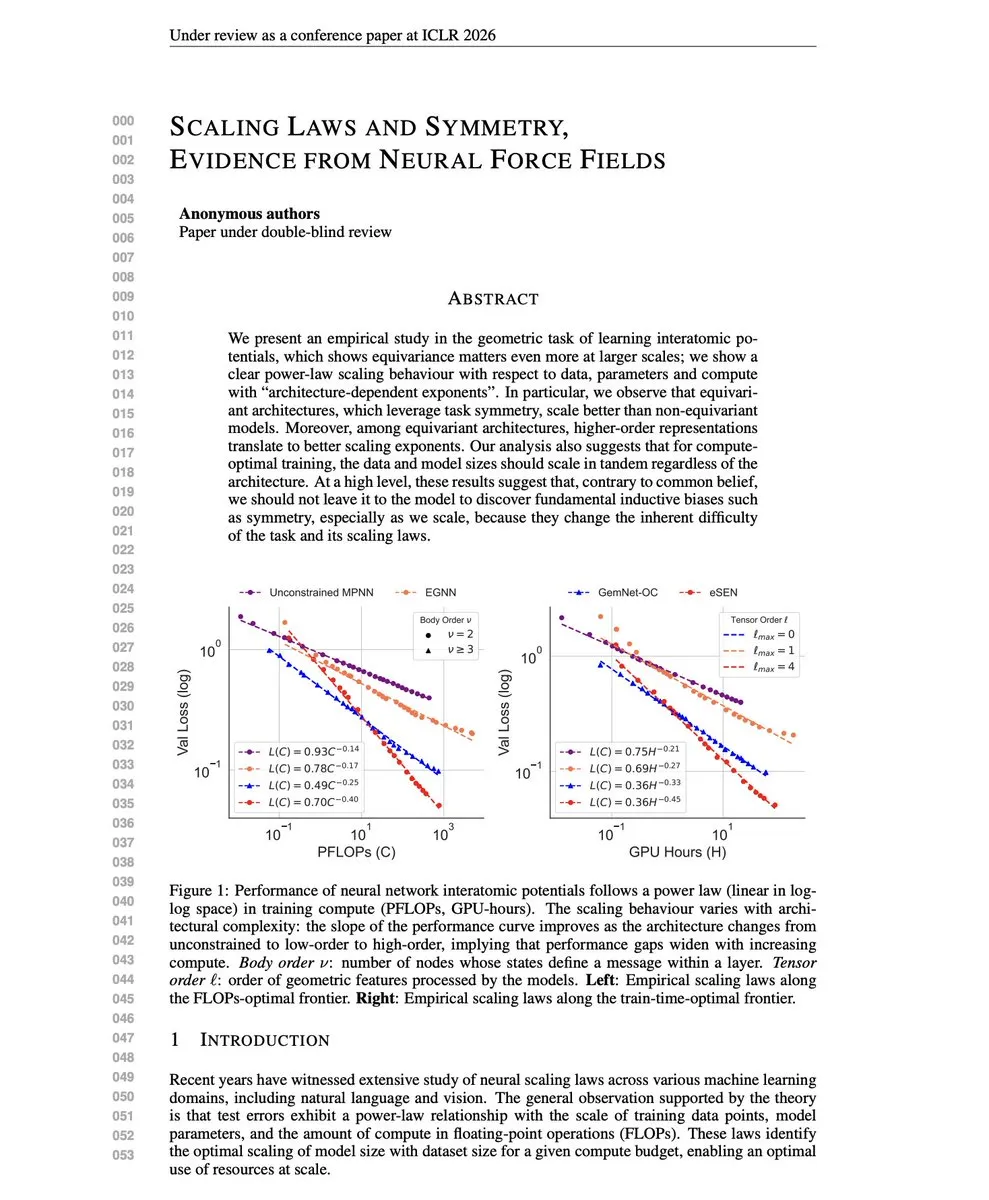
自回归视频扩散的端到端训练 : 该研究引入了“重采样强制”(Resampling Forcing)框架,实现自回归视频扩散模型的端到端训练。通过模拟推理时模型在历史帧上的错误,结合稀疏因果掩码和历史路由机制,该方法在保持时间一致性的同时,实现了与蒸馏基线相当的性能,并支持高效长程生成。(来源: HuggingFace Daily Papers)
LLM评估与可复现性讨论 : Reddit社区讨论LLM评估的挑战与可复现性问题。用户关注如何建立可靠的评估标准,确保不同研究和模型之间的结果具有可比性,并探讨在快速发展的LLM领域中,如何有效管理和分享评估方法及数据集以促进科学进步。(来源: Reddit r/deeplearning)
💼 商业
智谱与MiniMax冲刺港股IPO : 国内大模型公司MiniMax与智谱AI已完成中国证监会备案并参与港交所上市聆讯,MiniMax计划于2026年1月挂牌上市。智谱AI估值约400亿元,聚焦G端与B端及多模态Agent;MiniMax估值近300亿元,以多模态能力为核心,产品驱动型模式。两家公司均在上市前进行战略收敛与团队调整,反映大模型行业进入“资本与效率双重约束期”。(来源: 36氪)
Amazon拟投资OpenAI 100亿美元 : 亚马逊计划向OpenAI投资至少100亿美元,此举预计将包括OpenAI使用亚马逊的Trainium系列AI芯片并租用更多数据中心容量来运行其模型和工具(如ChatGPT)。此次投资旨在深化两家公司在AI基础设施和模型部署方面的合作。(来源: Reddit r/ArtificialInteligence)

壁仞科技冲刺港股通用GPU第一股 : 估值209亿的通用GPU独角兽壁仞科技已通过港交所聆讯,即将成为港股“国产GPU第一股”。公司由哈佛法学博士张文创立,核心产品为基于自研GPGPU架构的硬件系统(壁砺106、110、166芯片)和BIRENSUPA软件平台,提供AI训练和推理全栈支持,客户涵盖电信、金融科技等高算力行业。(来源: WeChat)
🌟 社区
AI生成内容质量与互联网“slop”现象 : 社交媒体广泛讨论AI生成内容质量参差不齐的“slop”现象,其被选为年度词汇,反映了AI内容泛滥和低质量问题。这引发了对互联网广告平台利益驱动的批判,以及如何提高AI内容创作门槛的思考。(来源: 36氪)

AI对劳动力市场与开发者工作模式的影响 : 社交媒体深入探讨AI对就业市场和开发者工作模式的颠覆。AI被视为强大的生产力工具,将开发者角色从纯代码编写转向系统设计、代理编排、代码验证与调试,需要掌握更高层次技能。LinkedIn引入AI招聘助手,改变求职和招聘流程。同时,AI在摄影等领域显著提升效率,但AI编码代理的生产就绪性仍面临挑战。(来源: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Yuchenj_UW, gdb, amasad, amasad, Ronald_vanLoon)

AI在教育、医疗等领域的应用与挑战 : 教师使用AI检测软件判断学生是否使用AI引发教育伦理争议,呼吁教育系统关注学生理解而非工具使用。ChatGPT在医疗健康领域展现出辅助诊断、提供健康建议的潜力,但需谨慎使用。Glass 5.0等平台将AI应用于临床决策支持,推动医疗AI从聊天机器人向合作伙伴转变。(来源: Reddit r/artificial, Reddit r/ChatGPT, GlassHealthHQ)

LLM性能、成本与用户体验的持续讨论 : 社交媒体用户对Gemini 3 Flash、Claude Opus 4.5等LLM的性能、成本和实际使用体验进行热烈讨论。关注点包括模型在编码、工具调用、推理能力上的进步,以及性能退化、幻觉率等问题。用户对比不同模型的性价比,并探讨AI模型定价策略和用户对模型价值的感知。(来源: Vtrivedy10, hrishioa, tokenbender, inerati, scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, max__drake, MiniMax__AI, scaling01)
AI伦理、哲学与AGI的深层探讨 : 社交媒体讨论AI的伦理和社会影响,包括AI是否在填补“上帝的空白”,AGI的真正定义,以及AI在物理学研究中的潜力与局限。用户也关注AI基准测试的可复现性、AI研究质量的批判,以及AI模型与人类智能本质差异的哲学思考。(来源: Ronald_vanLoon, ImazAngel, Ronald_vanLoon, RisingSayak, snwy_me, TheTuringPost, teortaxesTex, _lewtun)

AI模型架构、效率与基础设施优化 : 社交媒体讨论AI模型架构与效率,包括MoE模型的MFU效率、nmoe的超稀疏MoE训练、以及LLM推理的简化(如mini-SGLang)。用户关注模型在长上下文处理、记忆管理、以及硬件优化(如MLX分布式后端、vLLM serving)方面的进展,以提升AI系统的整体性能和可扩展性。(来源: lateinteraction, hyhieu226, TheZachMueller, dejavucoder, awnihannun, vllm_project, aiamblichus)

AI公司战略、市场竞争与人才流动 : 社交媒体讨论AI公司的战略和市场竞争,包括Amazon聘请顶级AI研究员、Thinking Machines计划发布模型、Meta AI的投入产出、以及OpenAI面临的组织问题。用户也关注NVIDIA在开源AI领域的领导地位、其硬件驱动策略、以及Anthropic研究员加入腾讯等关键人才流动。(来源: pmddomingos, scaling01, teortaxesTex, steph_palazzolo, TheTuringPost, Sentdex, teortaxesTex, turbopuffer, iScienceLuvr, EthanJPerez)

AI编码现状报告与行业趋势 : Greptile发布《2025年AI编程现状报告》,指出开发者每月代码产出量增长76%,PR体积膨胀,AI工具的收益分布不均。报告还对比了OpenAI、Anthropic和Google模型在首token响应时间、吞吐量和成本方面的表现,并揭示了向量数据库和AI记忆工具的市场竞争格局。(来源: dotey)

AI模型评估与可复现性 : Reddit社区讨论LLM评估的挑战与可复现性问题。用户关注如何建立可靠的评估标准,确保不同研究和模型之间的结果具有可比性,并探讨在快速发展的LLM领域中,如何有效管理和分享评估方法及数据集以促进科学进步。(来源: Reddit r/deeplearning)
开放AI与硬件驱动策略 : NVIDIA Nemotron 3的发布标志着开放源AI领导地位的转变。该模型通过大规模预训练数据、RL数据集和新的混合架构,优化了NVIDIA硬件的计算消耗。这一策略表明,开放源AI正从“大科技慈善”时代走向“硬件定义AI”时代,即模型发布旨在扩展特定硬件的计算消费。(来源: TheTuringPost, teortaxesTex)
AI图像与视频生成工具对比及应用 : 社交媒体用户讨论AI图像和视频生成工具的性能与应用,包括ChatGPT、Gemini、Midjourney、Grok、Nano Banana Pro等。讨论涵盖AI艺术作品的真实感、游戏角色转换、以及AI视频在电影制作中的应用。用户也关注AI生成内容的质量、成本和效率,以及对创作流程的颠覆性影响。(来源: dotey, swyx, karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Kling_ai)

AI在金融领域的应用与趋势 : 社交媒体讨论AI在金融领域的应用,涵盖了26个具体案例,例如欺诈检测、风险管理、客户服务等。这些应用展示了机器学习和人工智能如何赋能金融行业,提升效率、优化决策并创造新的商业价值。(来源: Ronald_vanLoon)

AI代理与知识图谱的结合 : SAP的AI科学家讨论如何通过知识图谱改进AI代理的发现和执行。知识图谱为AI代理提供语义和过程上下文,使其能够更有效地发现和调用企业系统中的工具和API,从而提升代理在复杂企业环境中的效能。(来源: DeepLearningAI)

LLM评估与可复现性讨论 : Reddit社区讨论LLM评估的挑战与可复现性问题。用户关注如何建立可靠的评估标准,确保不同研究和模型之间的结果具有可比性,并探讨在快速发展的LLM领域中,如何有效管理和分享评估方法及数据集以促进科学进步。(来源: Reddit r/deeplearning)
AI模型在欧盟的性能与法规影响 : Reddit用户讨论视频和图像AI模型在欧盟地区是否因法规而“变笨”。普遍观点认为,模型核心质量不受影响,但欧盟的严格安全层和合规性要求可能导致功能推出延迟、过滤更严或默认设置不同,从而影响用户体验,而非模型本身智能度下降。(来源: Reddit r/ArtificialInteligence)
💡 其他
AI在艺术与娱乐领域的融合 : Desdemona Robot及其乐队将于1月11日在旧金山进行表演,将AI与艺术结合,探索机器人作为表演者的潜力。同时,有用户提出希望看到乐队使用Suno等AI工具生成歌曲并进行现场演奏,这反映了AI在音乐创作和现场娱乐中的新兴应用趋势。(来源: bengoertzel, fabianstelzer)
ComfyUI探索“简单模式”简化工作流 : ComfyUI正在探索一种新的“简单模式”,旨在让复杂的工作流更易于分享和迭代,重点关注结果而非底层的节点图。此模式特别针对觉得大型图表难以理解的用户,以降低使用门槛,提升用户体验和工作效率。(来源: NerdyRodent)