
🔥 Фокус
Meta выпускает модель SAM 3 : Facebook Research выпускает SAM 3, унифицированную базовую модель сегментации изображений и видео с возможностью подсказок. Она выполняет обнаружение, сегментацию и отслеживание объектов с помощью текстовых или визуальных подсказок, внедряет возможности сегментации экземпляров с открытым словарем концепций и достигает 75-80% человеческой производительности на бенчмарке SA-CO. Модель работает на инновационном движке данных, который автоматически аннотировал более 4 миллионов уникальных концепций, и использует новую архитектуру, включающую токены присутствия и раздельный детектор-трекер для повышения дискриминационной способности и эффективности. (Источник: GitHub Trending)

Google выпускает модель Gemini 3 Flash : Google представила Gemini 3 Flash, свою самую быструю на сегодняшний день модель ИИ, созданную для скорости при сохранении передового интеллекта. Модель демонстрирует выдающуюся производительность в тестах на рассуждение и знание докторского уровня, таких как GPQA Diamond и Humanity’s Last Exam, и даже превосходит Gemini 3 Pro в бенчмарке кодирования SWE-bench Verified. Gemini 3 Flash обеспечивает скорость в три раза выше, чем Gemini 2.5 Pro, при более низкой стоимости (0,50 доллара за миллион входных токенов, 3 доллара за выходные), и уже запущена по всему миру как модель по умолчанию для режима Google Search AI, стремясь способствовать широкому внедрению ИИ в корпоративных приложениях и экосистеме разработчиков. (Источник: WeChat)
🎯 Тенденции
Модели генерации AI-видео продолжают развиваться : Последовательно выпущены модели, такие как Alibaba Wanxiang 2.6, ByteDance Seedance 1.5 Pro и Kling 2.6. Wanxiang 2.6 обеспечивает настройку персонажей с синхронизацией аудио-визуального ряда и управление многокадровыми раскадровками, генерируя до 15 секунд за один раз; Seedance 1.5 Pro фокусируется на высокоточной синхронизации аудио-визуального ряда и поддержке нескольких диалектов; Kling 2.6 усиливает контроль тембра и функции Motion Control. Эти достижения знаменуют переход AI-видеопроизводства от эры «случайной генерации» к новому этапу точного и контролируемого производства кинематографического уровня. (Источник: WeChat, WeChat, Kling_ai, Alibaba_Wan)
Глубокое развитие технологий и стратегий воплощенного ИИ : DeepMind представила режим «контекстного сбора данных» для воплощенного ИИ, решающий проблемы универсальности с помощью данных от первого лица человека; Horizon Robotics выпустила стратегию Wintel «BPU + компилятор + базовая модель», расширяющую возможности интеллектуальных автомобилей и универсальных роботов; команда доктора Ван Гуанжуня из Университета Сунь Ятсена выпустила большую воплощенную модель E0, подчеркивающую разделение физических и пространственных моделей для достижения обобщения с небольшим количеством примеров. Эти достижения совместно продвигают воплощенный ИИ от механической имитации к логическому пониманию и взаимодействию с физическим миром. (Источник: WeChat, WeChat, WeChat)
Xiaomi и SenseTime выпускают передовые большие модели : Xiaomi открывает исходный код большой модели MiMo-V2-Flash, использующей архитектуру MoE, разработанной специально для сценариев Agent и кода, и входящей в первый эшелон глобальных моделей с открытым исходным кодом благодаря исключительной эффективности вывода и низкой стоимости. SenseTime выпускает модель SenseNova-SI и архитектуру NEO, призванные решить ограничения чисто языковых моделей в понимании физического мира, повышая пространственный интеллект за счет нативной мультимодальности и кросс-перспективного прогнозирования. (Источник: WeChat, WeChat)

Интеграция AI PC со специфическими сценариями применения : Cosmotron Dynamics представила персонального помощника по здоровью для AI PC, использующего бесконтактную технологию rPPG для измерения артериального давления и проверки кожи на расстоянии, а также локальные высокоэффективные вычисления с использованием Intel NPU. В то же время CloudPond Technology выпустила новые продукты AI+Health, включая интеллектуальный холодильник с большой моделью AI Health и цифровую лабораторию будущей кухни, интегрируя ИИ в повседневное управление здоровьем и домашние технологии. (Источник: WeChat, 36氪)

Технология Moore Threads LiteGS совершает прорыв в 3D-рендеринге : Moore Threads получила серебряную награду на конкурсе 3DGS Reconstruction Challenge на SIGGRAPH Asia 2025 и открыла исходный код своей собственной технологии LiteGS. LiteGS — это базовая библиотека 3D Gaussian Splatting, которая благодаря оптимизации всей цепочки значительно превосходит конкурентов по эффективности обучения и качеству реконструкции, продвигая применение технологии 3DGS в сценариях 3D-реконструкции, рендеринга в реальном времени и обучения воплощенного ИИ. (Источник: WeChat)

Новые достижения в эффективном предварительном обучении маломасштабных LLM с использованием данных : Независимый корейский инженер-исследователь выпустил Gumini, двуязычную базовую LLM с 1,5 миллиардами параметров (корейский-английский), которая заняла лидирующие позиции в корейских бенчмарках, используя всего 3,14 миллиарда обучающих токенов. Это достижение показывает, что предварительное обучение LLM может быть эффективным с точки зрения данных за счет оптимизации архитектуры и стратегий обучения, предлагая новый путь для небольших команд и независимых исследователей за пределами парадигмы «больше данных + больше вычислительной мощности». (Источник: Reddit r/LocalLLaMA)

Углубленное применение мультимодального ИИ в специфических областях : MiraTTS, как высококачественная и быстрая модель TTS, способна генерировать реалистичную речь со скоростью более чем в 100 раз превышающей реальное время, поддерживая несколько языков. В то же время многоязычная система RAG была развернута для поддержки принятия решений в сельскохозяйственной экологии, исследуя поведение LLM в условиях ограниченных ресурсов и высокоспециализированных областях, и уже год работает в производственной среде. Это демонстрирует зрелое применение мультимодального ИИ в генерации речи и поддержке принятия решений в вертикальных областях. (Источник: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Taobao Tech запускает систему реконструкции 3D-цифровых людей для мобильных устройств : Команда Taobao Tech Meta представила систему HRM²Avatar на SIGGRAPH Asia, позволяющую пользователям создавать и рендерить высокореалистичных 3D-цифровых людей в реальном времени, используя только монокулярное видео с мобильного телефона. Система сочетает явные сетки одежды с гауссовым представлением, поддерживает управление и рендеринг в реальном времени на мобильных устройствах, демонстрирует выдающуюся производительность в области визуального реализма, согласованности между позами и производительности на мобильных устройствах, стремясь снизить порог для создания 3D-цифровых людей. (Источник: WeChat)

🧰 Инструменты
Letta: Платформа для создания AI-агентов с сохранением состояния : Letta (ранее MemGPT) — это платформа для создания AI-агентов с сохранением состояния, в основе которой лежит расширенное управление памятью, позволяющее AI-агентам обучаться и самосовершенствоваться со временем. Платформа предлагает Python/TypeScript SDK, среду ADE без кода, а также локальную настольную версию и облачные сервисы, поддерживая ключевые концепции, такие как иерархия памяти, блоки памяти, инженерия контекста агента, а также реализует совместное использование памяти несколькими агентами и фоновое выполнение «спящих агентов». Maestro — это бесплатное кроссплатформенное настольное приложение с открытым исходным кодом для оркестровки AI-агентов, поддерживающее память файловой системы и создание инструментов, а также обладающее функцией «автоматического запуска». Toad, как унифицированный терминальный интерфейс AI-агента для кодирования, упрощает интеграцию с различными инструментами AI-кодирования. (Источник: GitHub Trending, Reddit r/LocalLLaMA, huggingface)
Инструмент AI-программирования Miaoda без кода расширяет возможности не-программистов : Miaoda — это инструмент AI-программирования без кода, выпущенный 8 месяцев назад, который уже сгенерировал более 5 миллиардов юаней стоимости, а его основными пользователями являются не-программисты. Инструмент использует «интеллектуального агента менеджера по продукту» для многократного общения по требованиям, преобразуя нечеткие требования в структурированную продуктовую документацию, которая затем реализуется «интеллектуальным агентом по разработке». Miaoda преодолела трудности с созданием бэкенда, реализовала глубокую интеграцию ИИ с базами данных и снизила затраты, повысив эффективность за счет тонких стратегий, избегая «кучи дерьмового кода». (Источник: WeChat)

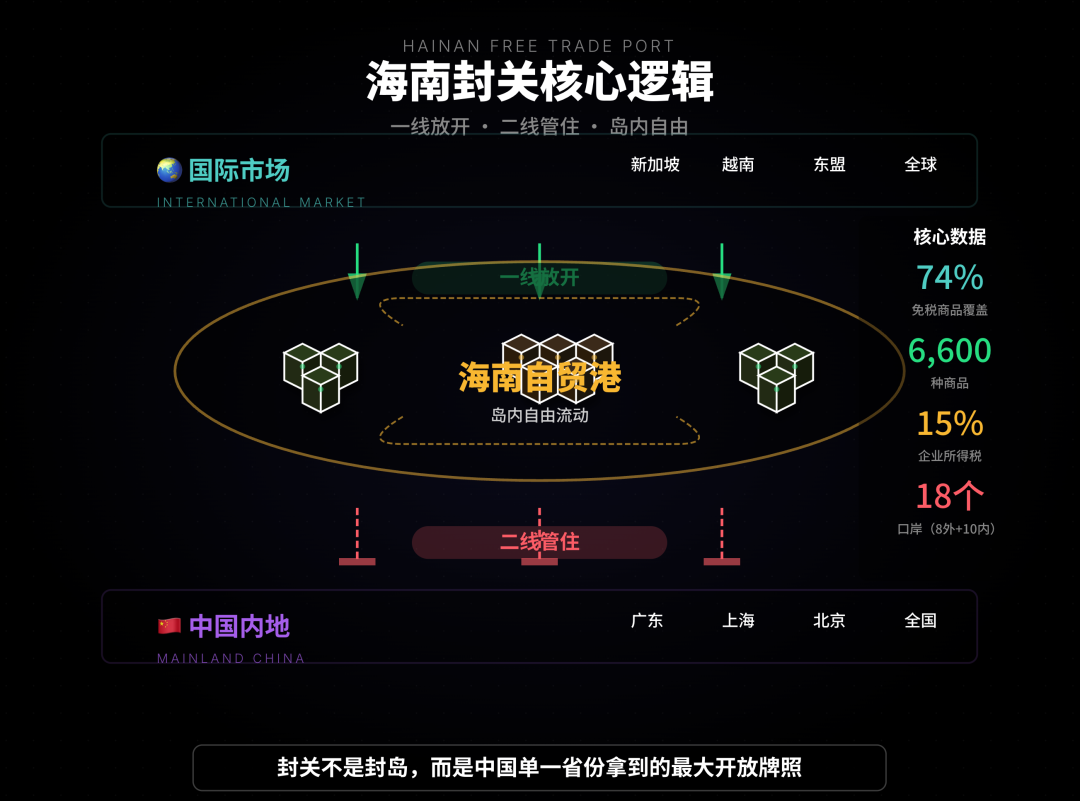
Инструменты AI-помощи для анализа и автоматизации продаж : Статья демонстрирует, как ИИ помогает в анализе тенденций политики «закрытия границы Хайнаня», помогая пользователям разобраться в сложной информации путем интеграции, классификации и экстраполяции данных из нескольких каналов. QuickHook — это инструмент автоматизации продаж, основанный на Gemini 3 и Search Grounding, который может превратить 15 минут ручного исследования в 10 секунд автоматизации, призванный решить проблему «AI-голоса» в холодных рассылках. (Источник: WeChat, Reddit r/artificial)
API OpenWebUI и локальная система STT : OpenWebUI предоставляет API-интерфейсы, позволяющие разработчикам создавать пользовательские клиентские приложения, такие как голосовые приложения на WearOS, для персонализированного взаимодействия с ИИ. Kroko-onnx-home-assistant — это открытый локальный конвейер потоковой передачи речи в текст (STT), разработанный для Home Assistant, отличающийся высоким качеством, потоковой обработкой в реальном времени и 100% локализацией, способный эффективно работать даже на устройствах с ограниченными ресурсами. (Источник: Reddit r/OpenWebUI, Reddit r/LocalLLaMA)
Сотрудничество нескольких LLM повышает эффективность разработки игр : Разработчики используют OpenAI Realtime API для сбора требований к играм, Gemini 3 Pro для генерации спецификаций Markdown, а затем Anthropic Opus 4.5 для кодирования приложений, реализуя разработку настраиваемых интеллектуальных игр с мячом. Этот рабочий процесс совместной работы нескольких LLM оптимизирует преимущества различных LLM, повышая эффективность и качество разработки от требований до кода, и предлагает новую парадигму разработки для сложных проектов. (Источник: Reddit r/artificial)

📚 Обучение
Оптимизация архитектуры Transformer и инновации в нормализации : Команда Лю Чжуана из Принстонского университета предложила оператор Derf, который заменяет LayerNorm в Transformer на основе функции ошибок Гаусса (erf), полностью превосходя существующие методы в задачах визуализации, генерации и моделирования последовательностей генов. В то же время Наньянский технологический университет и Университет Фудань предложили EFLA (Error-Free Linear Attention), которая устраняет числовой дрейф линейного внимания в длинных последовательностях с помощью аналитического решения, достигая одновременного повышения стабильности и производительности. (Источник: WeChat, WeChat)

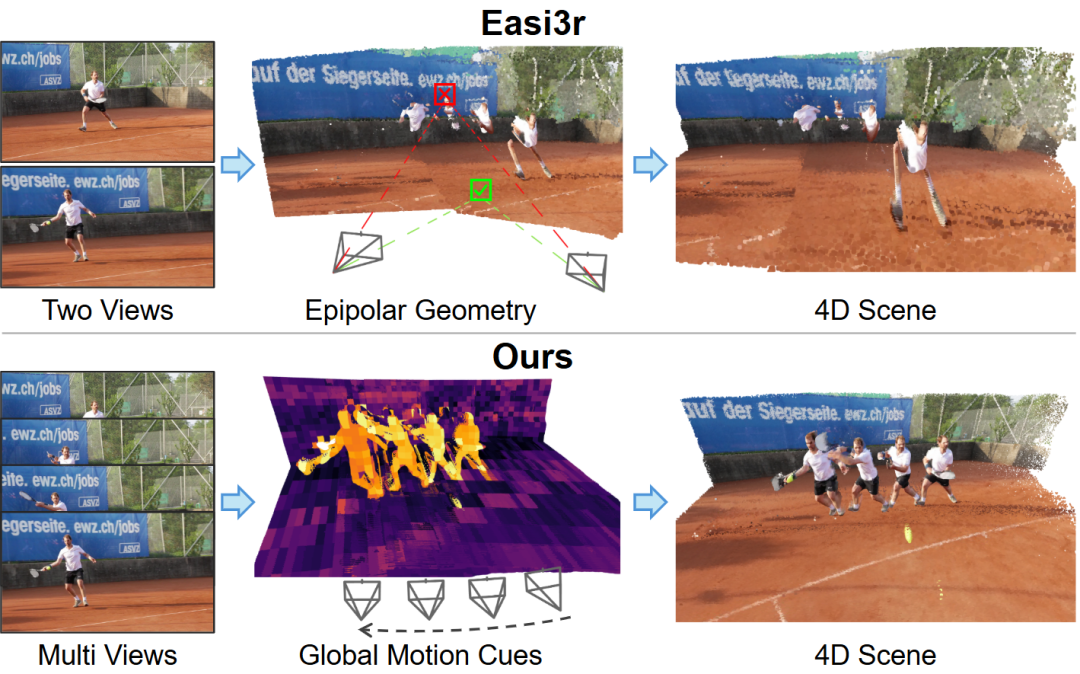
Передовые исследования в области мультимодального и видеопонимания : Фреймворк DiffusionVL может преобразовывать авторегрессионные модели в диффузионные визуально-языковые модели, значительно повышая производительность и ускоряя вывод. Система SAGE использует обучение с подкреплением для многораундового вывода в длинных видео и демонстрирует отличную производительность в открытых видеозадачах. MMSI-Video-Bench, как комплексный бенчмарк пространственного интеллекта видео, выявляет системные сбои MLLM в геометрическом рассуждении, заземлении движения и других аспектах. VGGT4D предлагает фреймворк реконструкции 4D-сцен без обучения, который обрабатывает динамические сцены, извлекая внутренние подсказки движения из Transformer. (Источник: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, WeChat)
Оптимизация памяти AI-агентов и LLM : Нанкинский политехнический университет и Baidu, среди прочих, предложили ViLoMem, который решает проблему «неспособности учиться на ошибках» в больших мультимодальных моделях с помощью двухпоточной семантической памяти (визуальный поток + логический поток), значительно улучшая производительность вывода. Фреймворк LightSearcher оптимизирует вызов инструментов Agent, управляемых RL, с помощью эмпирической памяти, сокращая количество вызовов на 39,6% и время вывода на 48,6%, при этом сохраняя точность. Фреймворк MEM1 также использует RL для обучения Agent сохранять постоянную память в долгосрочных задачах. (Источник: WeChat, WeChat, omarsar0)
Оценка LLM и создание наборов данных : LikeBench, как многосессионный динамический фреймворк оценки, впервые декомпозирует индивидуальные предпочтения LLM на семь диагностических показателей для измерения способности модели адаптироваться к предпочтениям пользователя. VOYAGER — это метод без обучения, использующий LLM для генерации разнообразных наборов данных, значительно увеличивая разнообразие в 1,5-3 раза. Конвейер создания наборов данных FiNERweb предоставляет масштабируемые многоязычные ресурсы для распознавания именованных сущностей на 91 языке и 25 скриптах. NVIDIA также опубликовала полное руководство по оценке Nemotron 3 Nano, повышая прозрачность и воспроизводимость оценки LLM. (Источник: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/LocalLLaMA)

Исследования в области безопасности и объяснимости ИИ : Исследование предлагает фреймворк ресинтеза для надежного и калиброванного обнаружения подлинности мультимедийного контента, чтобы противостоять вызовам дипфейков. В то же время фреймворк Hybrid Attribution Priors направляет языковые модели на улавливание тонких различий между категориями с помощью Class-Aware Attribution Prior (CAP), повышая объяснимость и надежность модели. Hyper++ улучшает гиперболическое глубокое обучение с подкреплением, повышая стабильность обучения Agent. (Источник: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Ресурсы для изучения глубокого обучения и возможности для исследований : AIhub опубликовал сборник интервью с докторантами форума AAAI/ACM SIGAI 2025, охватывающий передовые исследования ИИ в различных областях. В то же время анонсирован новый курс по ML-системам и программированию GPU, призванный углубить понимание стека DL через практику. Конкурс PyTorch/vLLM Hardware Challenge поощряет разработчиков исправлять ошибки, а также предлагает рекомендации по пути обучения компьютерному зрению, помогая учащимся планировать свою карьеру. (Источник: aihub.org, DeepLearningAI, vllm_project, Reddit r/deeplearning, Reddit r/deeplearning)

3D/XR и моделирование человеко-компьютерного взаимодействия : Фреймворк TIMAR предлагает причинно-следственное моделирование интерактивной 3D-динамики головы в диалоге, объединяя мультимодальную информацию и прогнозируя непрерывную 3D-динамику головы. Исследование перевода изображений SAR в RGB изучает, как генерировать четкие изображения с помощью моделей глубокого обучения. Исследование алгоритма оценки почерка букв для дошкольников ищет методы сопоставления с шаблонами для точной оценки качества детского почерка. (Источник: HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
Scaling Laws и теория слияния моделей : Это исследование оспаривает точку зрения «Scaling Law превосходит индуктивное смещение», обнаруживая, что архитектуры, кодирующие симметрию, обладают лучшими Scaling Exponents. В то же время решения для разрешения конфликтов при слиянии многозадачных моделей (TATR, CAT Merging, LOT Merging) эффективно смягчают конфликты знаний и повышают производительность и надежность многозадачности за счет идентификации и фильтрации конфликтных измерений, проекции или взвешенного слияния. (Источник: dair_ai, WeChat)
Сквозное обучение авторегрессионной видеодиффузии : Это исследование представляет фреймворк «Resampling Forcing» для сквозного обучения авторегрессионных моделей видеодиффузии. Имитируя ошибки модели на исторических кадрах во время вывода, в сочетании с разреженными причинными масками и механизмом маршрутизации истории, этот метод достигает производительности, сравнимой с базовыми линиями дистилляции, при сохранении временной согласованности и поддерживает эффективную долгосрочную генерацию. (Источник: HuggingFace Daily Papers)
Обсуждение оценки LLM и воспроизводимости : Сообщество Reddit обсуждает проблемы оценки LLM и воспроизводимости. Пользователи сосредоточены на том, как установить надежные стандарты оценки, обеспечить сопоставимость результатов между различными исследованиями и моделями, а также обсуждают, как эффективно управлять и обмениваться методами оценки и наборами данных в быстро развивающейся области LLM для содействия научному прогрессу. (Источник: Reddit r/deeplearning)
💼 Бизнес
Zhipu AI и MiniMax стремятся к IPO в Гонконге : Китайские компании, занимающиеся большими моделями, MiniMax и Zhipu AI завершили регистрацию в Комиссии по регулированию ценных бумаг Китая и приняли участие в слушаниях по листингу на Гонконгской фондовой бирже. MiniMax планирует выйти на биржу в январе 2026 года. Zhipu AI оценивается примерно в 40 миллиардов юаней, фокусируясь на государственных и корпоративных клиентах, а также на мультимодальных Agent; MiniMax оценивается почти в 30 миллиардов юаней, с мультимодальными возможностями в основе и продуктоориентированной моделью. Обе компании провели стратегическую конвергенцию и корректировку команды перед IPO, что отражает вступление индустрии больших моделей в «период двойных ограничений капитала и эффективности». (Источник: 36氪)
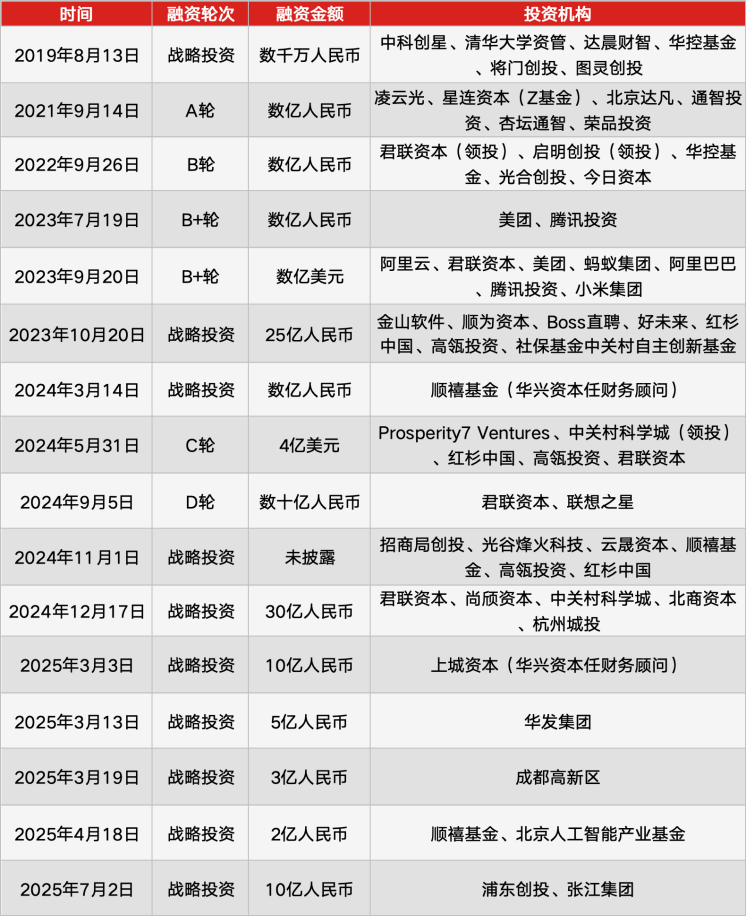
Amazon планирует инвестировать в OpenAI 10 миллиардов долларов : Amazon планирует инвестировать в OpenAI не менее 10 миллиардов долларов, что, как ожидается, будет включать использование OpenAI чипов AI серии Trainium от Amazon и аренду дополнительных мощностей центров обработки данных для запуска своих моделей и инструментов (таких как ChatGPT). Эта инвестиция направлена на углубление сотрудничества между двумя компаниями в области AI-инфраструктуры и развертывания моделей. (Источник: Reddit r/ArtificialInteligence)

Biren Technology стремится стать первой компанией общего назначения GPU на Гонконгской фондовой бирже : Biren Technology, единорог в области универсальных GPU с оценкой в 20,9 миллиарда юаней, прошла слушания на Гонконгской фондовой бирже и скоро станет «первой отечественной компанией GPU» на Гонконгской фондовой бирже. Компания была основана доктором юридических наук Гарварда Чжан Вэнем, а ее основными продуктами являются аппаратные системы (чипы Bili 106, 110, 166) на основе собственной архитектуры GPGPU и программная платформа BIRENSUPA, обеспечивающие полную поддержку обучения и вывода ИИ, с клиентами в высокопроизводительных отраслях, таких как телекоммуникации и финтех. (Источник: WeChat)
🌟 Сообщество
Качество AI-генерируемого контента и феномен «slop» в интернете : В социальных сетях широко обсуждается феномен «slop» — неравномерное качество AI-генерируемого контента, который был выбран словом года, отражая проблему засилья и низкого качества AI-контента. Это вызвало критику движимой прибылью рекламных платформ в интернете, а также размышления о том, как повысить порог для создания AI-контента. (Источник: 36氪)

Влияние ИИ на рынок труда и рабочие модели разработчиков : В социальных сетях глубоко обсуждается разрушительное влияние ИИ на рынок труда и рабочие модели разработчиков. ИИ рассматривается как мощный инструмент повышения производительности, который смещает роль разработчика от чистого написания кода к проектированию систем, оркестровке агентов, проверке и отладке кода, требуя освоения навыков более высокого уровня. LinkedIn внедряет AI-помощника по найму, изменяя процессы поиска работы и найма. В то же время ИИ значительно повышает эффективность в таких областях, как фотография, но готовность AI-агентов для кодирования к производству все еще сталкивается с проблемами. (Источник: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Yuchenj_UW, gdb, amasad, amasad, Ronald_vanLoon)

Применение и вызовы ИИ в образовании, медицине и других областях : Использование учителями программного обеспечения для обнаружения ИИ для определения того, использовали ли студенты ИИ, вызывает этические споры в образовании, призывая образовательную систему сосредоточиться на понимании студентов, а не на использовании инструментов. ChatGPT демонстрирует потенциал в области здравоохранения для помощи в диагностике и предоставлении советов по здоровью, но требует осторожного использования. Платформы, такие как Glass 5.0, применяют ИИ для поддержки клинических решений, продвигая медицинский ИИ от чат-ботов к партнерам. (Источник: Reddit r/artificial, Reddit r/ChatGPT, GlassHealthHQ)

Постоянное обсуждение производительности, стоимости и пользовательского опыта LLM : Пользователи социальных сетей активно обсуждают производительность, стоимость и реальный опыт использования LLM, таких как Gemini 3 Flash, Claude Opus 4.5. Основное внимание уделяется прогрессу моделей в кодировании, вызове инструментов, способности к рассуждению, а также таким проблемам, как деградация производительности и частота галлюцинаций. Пользователи сравнивают соотношение цены и качества различных моделей и обсуждают стратегии ценообразования AI-моделей и восприятие пользователями ценности моделей. (Источник: Vtrivedy10, hrishioa, tokenbender, inerati, scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, max__drake, MiniMax__AI, scaling01)
Глубокое исследование этики, философии ИИ и AGI : В социальных сетях обсуждаются этические и социальные последствия ИИ, включая вопрос о том, заполняет ли ИИ «пустоту Бога», истинное определение AGI, а также потенциал и ограничения ИИ в физических исследованиях. Пользователи также обращают внимание на воспроизводимость бенчмарков ИИ, критику качества исследований ИИ, а также философские размышления о сущностных различиях между моделями ИИ и человеческим интеллектом. (Источник: Ronald_vanLoon, ImazAngel, Ronald_vanLoon, RisingSayak, snwy_me, TheTuringPost, teortaxesTex, _lewtun)

Архитектура AI-моделей, эффективность и оптимизация инфраструктуры : В социальных сетях обсуждаются архитектура и эффективность AI-моделей, включая эффективность MFU моделей MoE, сверхразреженное обучение MoE для nmoe, а также упрощение вывода LLM (например, mini-SGLang). Пользователи следят за прогрессом моделей в обработке длинных контекстов, управлении памятью и аппаратной оптимизации (например, распределенный бэкенд MLX, vLLM serving) для повышения общей производительности и масштабируемости AI-систем. (Источник: lateinteraction, hyhieu226, TheZachMueller, dejavucoder, awnihannun, vllm_project, aiamblichus)

Стратегии AI-компаний, рыночная конкуренция и движение талантов : В социальных сетях обсуждаются стратегии и рыночная конкуренция AI-компаний, включая найм Amazon ведущих AI-исследователей, планы Thinking Machines по выпуску моделей, затраты и результаты Meta AI, а также организационные проблемы, с которыми сталкивается OpenAI. Пользователи также следят за лидерством NVIDIA в области открытого исходного кода ИИ, ее стратегией, ориентированной на аппаратное обеспечение, а также за движением ключевых талантов, таких как присоединение исследователей Anthropic к Tencent. (Источник: pmddomingos, scaling01, teortaxesTex, steph_palazzolo, TheTuringPost, Sentdex, teortaxesTex, turbopuffer, iScienceLuvr, EthanJPerez)

Отчет о состоянии AI-кодирования и отраслевые тенденции : Greptile опубликовала «Отчет о состоянии AI-программирования за 2025 год», указывая на рост ежемесячного объема кода, производимого разработчиками, на 76%, увеличение объема PR и неравномерное распределение выгод от AI-инструментов. В отчете также сравнивается производительность моделей OpenAI, Anthropic и Google по времени ответа первого токена, пропускной способности и стоимости, а также раскрывается конкурентная ситуация на рынке векторных баз данных и AI-инструментов памяти. (Источник: dotey)

Оценка AI-моделей и воспроизводимость : Сообщество Reddit обсуждает проблемы оценки LLM и воспроизводимости. Пользователи сосредоточены на том, как установить надежные стандарты оценки, обеспечить сопоставимость результатов между различными исследованиями и моделями, а также обсуждают, как эффективно управлять и обмениваться методами оценки и наборами данных в быстро развивающейся области LLM для содействия научному прогрессу. (Источник: Reddit r/deeplearning)
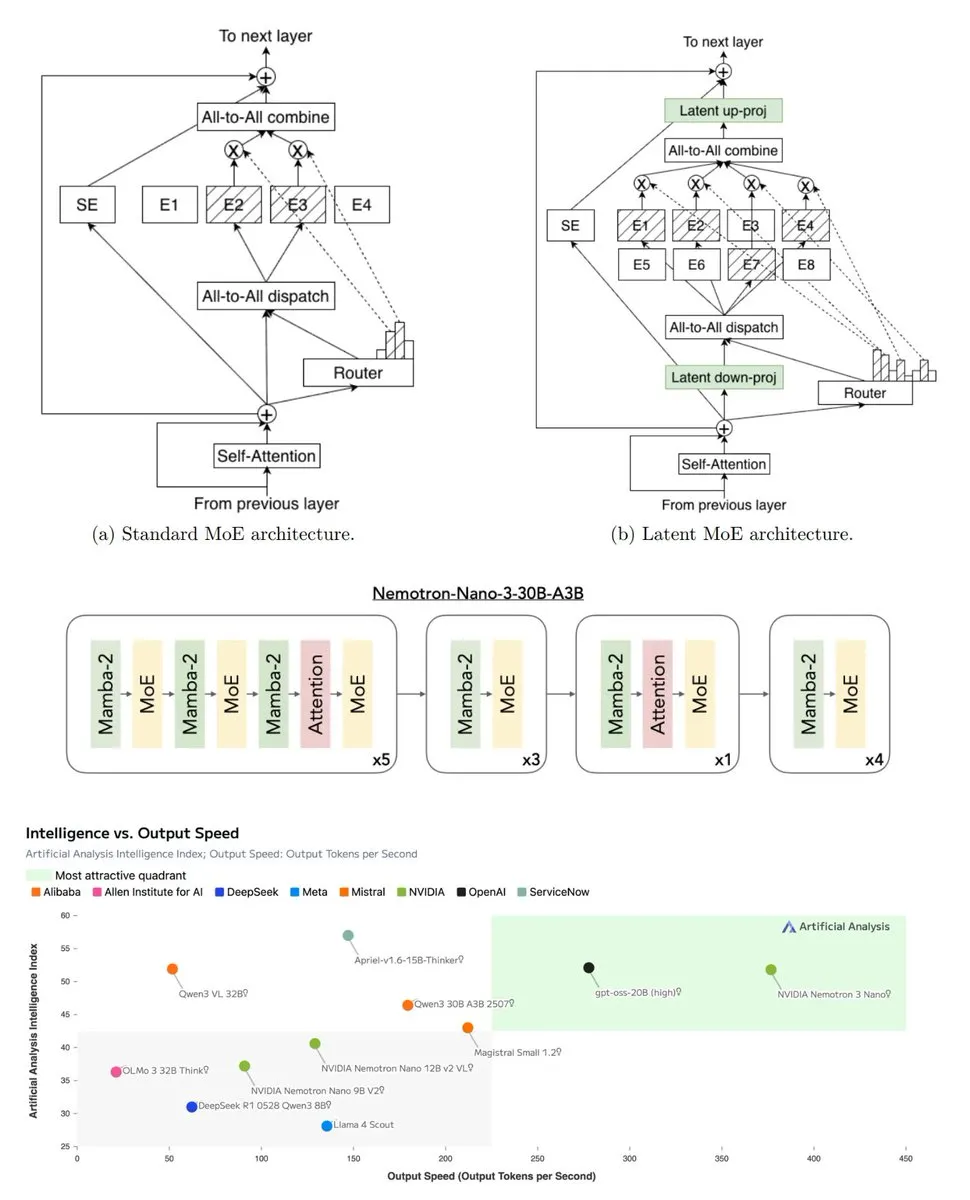
Открытый ИИ и аппаратная стратегия : Выпуск NVIDIA Nemotron 3 ознаменовал символический поворот в лидерстве открытого исходного кода ИИ. Эта модель оптимизирует вычислительные затраты аппаратного обеспечения NVIDIA за счет использования крупномасштабных данных предварительного обучения, наборов данных RL и новой гибридной архитектуры. Эта стратегия указывает на то, что открытый исходный код ИИ переходит от эры «благотворительности больших технологий» к эре «аппаратного определения ИИ», то есть выпуск моделей направлен на расширение вычислительного потребления конкретного оборудования. (Источник: TheTuringPost, teortaxesTex)
Сравнение и применение инструментов AI-генерации изображений и видео : Пользователи социальных сетей обсуждают производительность и применение инструментов AI-генерации изображений и видео, включая ChatGPT, Gemini, Midjourney, Grok, Nano Banana Pro и другие. Обсуждение охватывает реалистичность AI-произведений искусства, преобразование игровых персонажей, а также применение AI-видео в кинопроизводстве. Пользователи также следят за качеством, стоимостью и эффективностью AI-генерируемого контента, а также за его разрушительным влиянием на творческий процесс. (Источник: dotey, swyx, karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Kling_ai)

Применение и тенденции ИИ в финансовой сфере : В социальных сетях обсуждается применение ИИ в финансовой сфере, охватывающее 26 конкретных случаев, таких как обнаружение мошенничества, управление рисками, обслуживание клиентов и т. д. Эти приложения демонстрируют, как машинное обучение и искусственный интеллект расширяют возможности финансовой индустрии, повышая эффективность, оптимизируя принятие решений и создавая новую деловую ценность. (Источник: Ronald_vanLoon)

Сочетание AI-агентов и графов знаний : AI-ученые SAP обсуждают, как улучшить обнаружение и выполнение AI-агентов с помощью графов знаний. Графы знаний предоставляют AI-агентам семантический и процедурный контекст, позволяя им более эффективно обнаруживать и вызывать инструменты и API в корпоративных системах, тем самым повышая эффективность агентов в сложных корпоративных средах. (Источник: DeepLearningAI)

Обсуждение оценки LLM и воспроизводимости : Сообщество Reddit обсуждает проблемы оценки LLM и воспроизводимости. Пользователи сосредоточены на том, как установить надежные стандарты оценки, обеспечить сопоставимость результатов между различными исследованиями и моделями, а также обсуждают, как эффективно управлять и обмениваться методами оценки и наборами данных в быстро развивающейся области LLM для содействия научному прогрессу. (Источник: Reddit r/deeplearning)
Производительность AI-моделей в ЕС и влияние регулирования : Пользователи Reddit обсуждают, становятся ли AI-модели для видео и изображений «глупее» в ЕС из-за регулирования. Общее мнение заключается в том, что основное качество моделей не страдает, но строгие требования ЕС к безопасности и соответствию могут привести к задержкам в выпуске функций, более строгой фильтрации или другим настройкам по умолчанию, что влияет на пользовательский опыт, а не на снижение интеллекта самой модели. (Источник: Reddit r/ArtificialInteligence)
💡 Другое
Интеграция ИИ в искусство и развлечения : Desdemona Robot и ее группа выступят 11 января в Сан-Франциско, объединяя ИИ с искусством и исследуя потенциал роботов как исполнителей. В то же время пользователи выразили желание увидеть, как группа использует AI-инструменты, такие как Suno, для генерации песен и их исполнения вживую, что отражает новые тенденции применения ИИ в создании музыки и живых развлечениях. (Источник: bengoertzel, fabianstelzer)
ComfyUI исследует «простой режим» для упрощения рабочих процессов : ComfyUI исследует новый «простой режим», призванный сделать сложные рабочие процессы более легкими для обмена и итерации, с акцентом на результат, а не на базовый граф узлов. Этот режим специально разработан для пользователей, которым трудно понять большие диаграммы, чтобы снизить порог входа, улучшить пользовательский опыт и повысить эффективность работы. (Источник: NerdyRodent)