
Palabras clave:SAM 3, Gemini 3 Flash, Generación de vídeo con IA, Inteligencia encarnada, Modelos grandes, Agentes de IA, Avatares digitales 3D, Segmentación de imágenes Meta SAM 3, Rendimiento de Google Gemini 3 Flash, Generación de vídeo Alibaba Wanxiang 2.6, Recopilación de datos contextuales Deepwise, Código abierto de Xiaomi MiMo-V2-Flash
Aquí tienes la traducción de la noticia de IA al español, siguiendo tus requisitos:
🔥 Enfoque
Meta lanza el modelo SAM 3 : Facebook Research lanza SAM 3, un modelo fundacional unificado de segmentación de imágenes y video guiada por prompts. Permite la detección, segmentación y seguimiento de objetos mediante prompts de texto o visuales, introduciendo la capacidad de segmentación de instancias para conceptos de vocabulario abierto, y alcanzando entre el 75% y el 80% del rendimiento humano en el benchmark SA-CO. El modelo está impulsado por un innovador motor de datos que etiquetó automáticamente más de 4 millones de conceptos únicos, y adopta un nuevo diseño de arquitectura que incluye tokens de presencia y un detector-rastreador desacoplado para mejorar la discriminación y la eficiencia. (Fuente: GitHub Trending)

Google lanza el modelo Gemini 3 Flash : Google lanza Gemini 3 Flash, su modelo de IA más rápido hasta la fecha, diseñado para la velocidad mientras mantiene una inteligencia de vanguardia. El modelo demuestra un rendimiento excepcional en benchmarks de razonamiento y conocimiento a nivel de doctorado como GPQA Diamond y Humanity’s Last Exam, e incluso supera a Gemini 3 Pro en el benchmark de codificación SWE-bench Verified. Gemini 3 Flash ofrece una velocidad tres veces mayor que Gemini 2.5 Pro a un costo menor (0.50 USD por millón de tokens de entrada, 3 USD por millón de tokens de salida), y se ha lanzado globalmente como el modelo predeterminado para el modo de IA de Google Search, con el objetivo de impulsar la adopción de la IA en aplicaciones empresariales y el ecosistema de desarrolladores. (Fuente: WeChat)
🎯 Tendencias
Los modelos de generación de video con IA continúan evolucionando : Modelos como Alibaba Wanxiang 2.6, ByteDance Seedance 1.5 Pro y Kling 2.6 se han lanzado sucesivamente. Wanxiang 2.6 logra la personalización de personajes con coherencia audiovisual y el control de múltiples planos de storyboard, generando hasta 15 segundos en una sola vez; Seedance 1.5 Pro se centra en la sincronización de audio y video de alta precisión y el soporte multilingüe; mientras que Kling 2.6 ha reforzado el control del timbre y la función Motion Control. Estos avances marcan la transición de la creación de video con IA de la era de la “generación aleatoria” a una nueva etapa de producción cinematográfica precisa y controlable. (Fuente: WeChat, WeChat, Kling_ai, Alibaba_Wan)
Desarrollo avanzado de la tecnología y estrategia de la IA encarnada : Deep Intelligence lanza el modo de “adquisición de datos contextuales” para la IA encarnada, resolviendo desafíos de generalidad a través de datos de primera persona humana; Horizon Robotics presenta su estrategia Wintel de “BPU + compilador + modelo base” para potenciar vehículos inteligentes y robots generales; el equipo del Dr. Wang Guangrun de la Universidad Sun Yat-sen lanza el modelo grande encarnado E0, enfatizando el desacoplamiento de modelos físicos y espaciales para lograr la generalización con ajuste fino de pocas muestras. Estos avances impulsan colectivamente la IA encarnada de la imitación mecánica a la comprensión lógica y la interacción con el mundo físico. (Fuente: WeChat, WeChat, WeChat)
Xiaomi y SenseTime lanzan modelos grandes de vanguardia : Xiaomi lanza en código abierto el modelo grande MiMo-V2-Flash, que utiliza una arquitectura MoE, diseñado específicamente para escenarios de Agent y código, y que se posiciona en el primer nivel de modelos de código abierto globales por su extrema eficiencia de inferencia y bajo costo. SenseTime lanza los modelos SenseNova-SI y la arquitectura NEO, con el objetivo de resolver las limitaciones de los modelos puramente lingüísticos en la comprensión del mundo físico, mejorando la inteligencia espacial a través de la multimodalidad nativa y la predicción de múltiples perspectivas. (Fuente: WeChat, WeChat)

La AI PC se fusiona con escenarios de aplicación específicos : Covestro Motion lanza el asistente personal de salud AI PC, que utiliza la tecnología rPPG sin contacto para la medición remota de la presión arterial y la detección de la piel, combinándose con la NPU de Intel para una computación local eficiente. Al mismo tiempo, Yunpeng Technology lanza nuevos productos de AI + salud, incluyendo un refrigerador inteligente con un modelo grande de IA para la salud y un laboratorio de cocina digital inteligente del futuro, integrando la IA en la gestión diaria de la salud y la tecnología doméstica. (Fuente: WeChat, 36氪)

Moore Threads LiteGS logra un avance en la renderización de gráficos 3D : Moore Threads ganó la medalla de plata en el desafío de reconstrucción 3DGS de SIGGRAPH Asia 2025 y lanzó en código abierto su tecnología LiteGS de desarrollo propio. LiteGS es una biblioteca fundamental de 3D Gaussian Splatting que, a través de la optimización colaborativa de toda la cadena, logra un liderazgo significativo en eficiencia de entrenamiento y calidad de reconstrucción, impulsando la aplicación de la tecnología 3DGS en la reconstrucción 3D, la renderización en tiempo real y los escenarios de entrenamiento de IA encarnada. (Fuente: WeChat)

Nuevos avances en el preentrenamiento eficiente de datos para LLM a pequeña escala : Un ingeniero de investigación independiente coreano lanzó Gumini, un LLM fundacional bilingüe coreano-inglés de 1.5B parámetros, que se posicionó entre los primeros en benchmarks coreanos utilizando solo 3.14B tokens de entrenamiento. Este avance demuestra que, mediante la optimización de la arquitectura y las estrategias de entrenamiento, el preentrenamiento de LLM puede lograr una alta eficiencia de datos, ofreciendo una nueva vía para equipos pequeños e investigadores independientes más allá del paradigma de “más datos + más potencia de cálculo”. (Fuente: Reddit r/LocalLLaMA)

La IA multimodal profundiza su aplicación en campos específicos : MiraTTS, un modelo TTS rápido y de alta calidad, puede generar voz realista a más de 100 veces la velocidad en tiempo real y es compatible con varios idiomas. Al mismo tiempo, un sistema RAG multilingüe se ha implementado para el apoyo a la toma de decisiones en ecosistemas agrícolas, investigando el comportamiento de los LLM en campos de bajos recursos y alta especialización, y ha estado funcionando en un entorno de producción durante un año. Esto demuestra la aplicación madura de la IA multimodal en la generación de voz y el apoyo a la toma de decisiones en dominios verticales. (Fuente: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)

Taobao Tech lanza un sistema de reconstrucción de humanos digitales 3D para móviles : El equipo Meta de Taobao Tech presenta el sistema HRM²Avatar en SIGGRAPH Asia, que permite a los usuarios crear y renderizar humanos digitales 3D fotorrealistas en tiempo real utilizando solo un video monocular de un teléfono móvil. El sistema combina una malla de vestimenta explícita con representaciones gaussianas, soporta la conducción y renderización en tiempo real en dispositivos móviles, y destaca en realismo visual, coherencia entre poses y rendimiento en móviles, con el objetivo de reducir la barrera de creación de humanos digitales 3D. (Fuente: WeChat)

🧰 Herramientas
Letta: Plataforma para construir agentes de IA con estado : Letta (anteriormente MemGPT) es una plataforma para construir agentes de IA con estado, cuyo núcleo es la gestión avanzada de la memoria, lo que permite a los agentes de IA aprender y auto-mejorarse con el tiempo. La plataforma ofrece un SDK de Python/TypeScript, un entorno ADE sin código, así como una versión de escritorio local y servicios en la nube. Soporta conceptos clave como jerarquía de memoria, bloques de memoria e ingeniería de contexto de agente, y permite la memoria compartida entre múltiples agentes y agentes “en tiempo de inactividad” que se ejecutan en segundo plano. Maestro es una aplicación de escritorio gratuita y de código abierto para orquestar agentes de IA, que soporta memoria del sistema de archivos y creación de herramientas, y cuenta con una función de “auto-ejecución”. Toad, como interfaz de terminal unificada para agentes de codificación de IA, simplifica la integración con diferentes herramientas de codificación de IA. (Fuente: GitHub Trending, Reddit r/LocalLLaMA, huggingface)
Miaoda, herramienta de programación de IA sin código, empodera a los no programadores : Miaoda es una herramienta de programación de IA sin código lanzada hace 8 meses, que ha generado más de 5 mil millones de yuanes en valor de producción, con usuarios principales que no son programadores. La herramienta utiliza un “agente de gerente de producto” para la comunicación de requisitos en múltiples rondas, transformando necesidades vagas en documentos de producto estructurados, que luego son implementados por un “agente de desarrollo”. Miaoda ha superado los desafíos de la construcción de backend, logrando una profunda integración de la IA con las bases de datos, y reduciendo costos y mejorando la eficiencia a través de estrategias refinadas, evitando el “código espagueti”. (Fuente: WeChat)

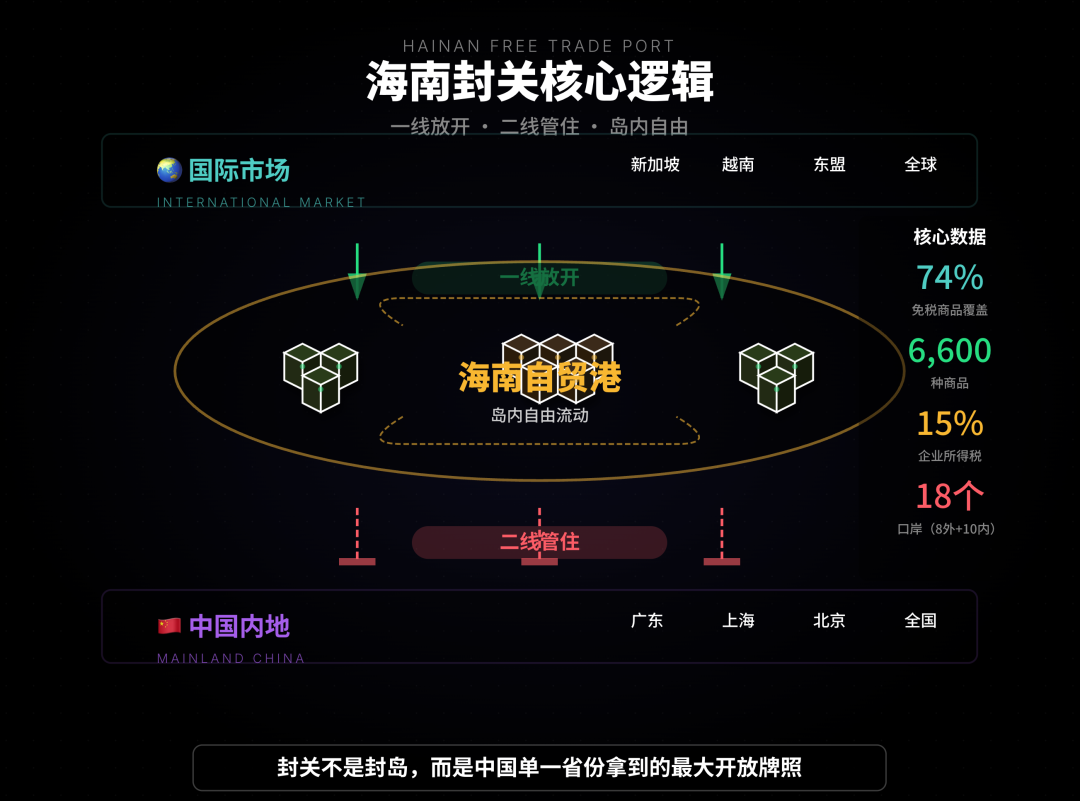
Herramientas de análisis asistido por IA y automatización de ventas : El artículo muestra cómo la IA puede ayudar en el análisis de tendencias de la política de “cierre de Hainan”, integrando información de múltiples canales, clasificándola y extrapolando para ayudar a los usuarios a comprender información compleja. QuickHook es una herramienta de automatización de ventas basada en Gemini 3 y Search Grounding, que puede transformar 15 minutos de investigación manual en 10 segundos de automatización, con el objetivo de resolver el problema del “tono de IA” en el contacto en frío. (Fuente: WeChat, Reddit r/artificial)
API de OpenWebUI y sistema STT local : OpenWebUI ofrece interfaces API que permiten a los desarrolladores crear aplicaciones cliente personalizadas, como una aplicación de modo de voz en WearOS, para lograr una experiencia de interacción con IA personalizada. Kroko-onnx-home-assistant es un pipeline de código abierto para la conversión de voz a texto (STT) en streaming local, diseñado específicamente para Home Assistant, con características como alta calidad, procesamiento en streaming en tiempo real y 100% localización, funcionando eficientemente incluso en dispositivos de bajos recursos. (Fuente: Reddit r/OpenWebUI, Reddit r/LocalLLaMA)
Colaboración de múltiples LLM para mejorar la eficiencia del desarrollo de juegos : Los desarrolladores utilizan la OpenAI Realtime API para recopilar requisitos de juegos, Gemini 3 Pro para generar especificaciones en Markdown, y Anthropic Opus 4.5 para codificar la aplicación, logrando el desarrollo de juegos de pelota inteligentes personalizados. Este flujo de trabajo colaborativo de múltiples LLM optimiza las ventajas de diferentes LLM, mejorando la eficiencia y calidad del desarrollo desde los requisitos hasta el código, y proporcionando un nuevo paradigma de desarrollo para proyectos complejos. (Fuente: Reddit r/artificial)

📚 Aprendizaje
Optimización de la arquitectura Transformer e innovación en normalización : El equipo de Liu Zhuang de la Universidad de Princeton propone el operador Derf, que reemplaza LayerNorm en Transformer con una función de error gaussiana (erf), superando de manera integral los métodos existentes en tareas de visión, generación y modelado de secuencias genéticas. Al mismo tiempo, la Universidad Tecnológica de Nanyang y la Universidad de Fudan proponen EFLA (Error-Free Linear Attention), que elimina la deriva numérica de la atención lineal en secuencias largas mediante una solución analítica, logrando una mejora simultánea en estabilidad y rendimiento. (Fuente: WeChat, WeChat)

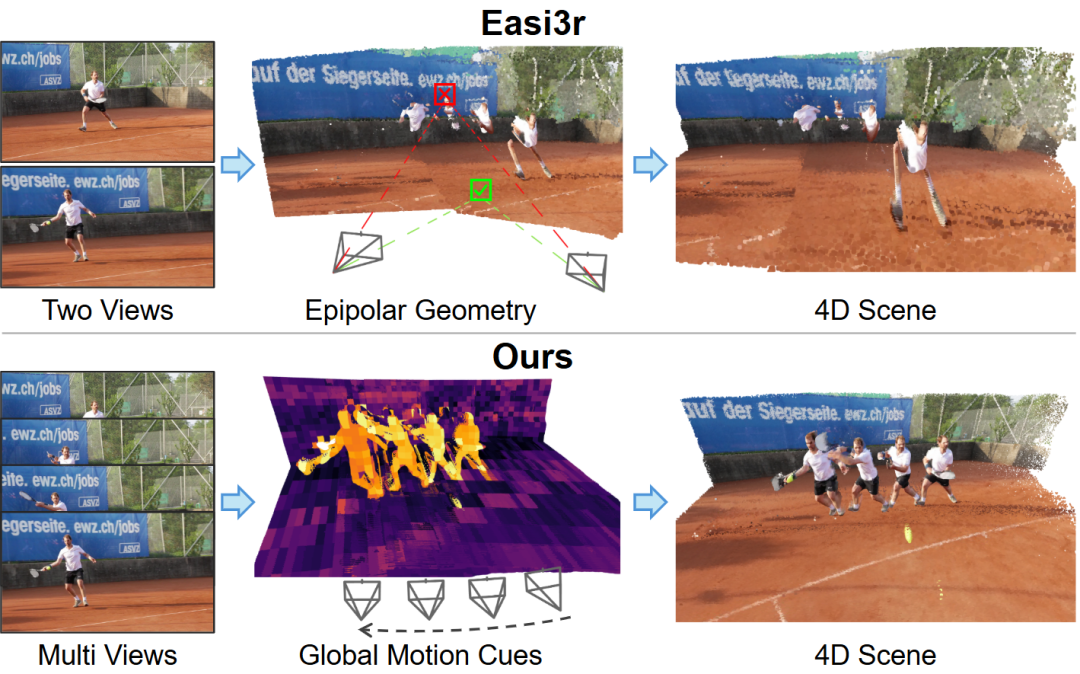
Investigación de vanguardia en comprensión multimodal y de video : El marco DiffusionVL puede transformar modelos autorregresivos en modelos de lenguaje visual de difusión, mejorando significativamente el rendimiento y acelerando la inferencia. El sistema SAGE utiliza el aprendizaje por refuerzo para el razonamiento de múltiples rondas en videos largos y demuestra un rendimiento excepcional en tareas de video de extremo abierto. MMSI-Video-Bench, como benchmark integral de inteligencia espacial de video, revela fallos sistemáticos de los MLLM en el razonamiento geométrico y la conexión de movimiento. VGGT4D propone un marco de reconstrucción de escenas 4D sin entrenamiento, que procesa escenas dinámicas extrayendo pistas de movimiento internas de Transformer. (Fuente: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, WeChat)
Optimización de la memoria de agentes de IA y LLM : La Universidad Tecnológica de Nanyang y Baidu, entre otras instituciones, proponen ViLoMem, que resuelve el problema de que los modelos grandes multimodales “no aprenden de los errores” a través de una memoria semántica de doble flujo (flujo visual + flujo lógico), mejorando significativamente el rendimiento de la inferencia. El marco LightSearcher optimiza la llamada a herramientas de agentes impulsados por RL mediante la memoria experiencial, reduciendo el número de llamadas en un 39.6% y el tiempo de inferencia en un 48.6%, manteniendo la precisión. El marco MEM1 también entrena a agentes con RL para mantener una memoria constante en tareas de largo alcance. (Fuente: WeChat, WeChat, omarsar0)
Evaluación de LLM y construcción de conjuntos de datos : LikeBench, como marco de evaluación dinámica de múltiples sesiones, descompone por primera vez la preferencia de personalización de LLM en siete indicadores de diagnóstico para medir la capacidad del modelo para adaptarse a las preferencias del usuario. VOYAGER es un método sin entrenamiento que utiliza LLM para generar conjuntos de datos diversos, aumentando significativamente la diversidad en 1.5-3 veces. El pipeline de creación de conjuntos de datos FiNERweb proporciona recursos escalables de reconocimiento de entidades nombradas multilingües para 91 idiomas y 25 escrituras. NVIDIA también publica una guía completa de evaluación para Nemotron 3 Nano, mejorando la transparencia y reproducibilidad de la evaluación de LLM. (Fuente: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/LocalLLaMA)

Investigación en seguridad y explicabilidad de la IA : La investigación propone un marco de recomposición para la detección robusta y calibrada de la autenticidad de contenido multimedia, abordando los desafíos de los deepfakes. Al mismo tiempo, el marco Hybrid Attribution Priors, a través de Class-Aware Attribution Prior (CAP), guía a los modelos de lenguaje para capturar distinciones de categorías de grano fino, mejorando la explicabilidad y robustez del modelo. Hyper++ mejora el aprendizaje por refuerzo profundo hiperbólico, aumentando la estabilidad del aprendizaje del agente. (Fuente: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Recursos de aprendizaje y oportunidades de investigación en Deep Learning : AIhub publica una compilación de entrevistas del Foro de Doctorado AAAI/ACM SIGAI 2025, que cubre investigaciones de vanguardia en IA en múltiples campos. Además, se anuncia un nuevo curso de sistemas ML y programación de GPU, diseñado para comprender en profundidad la pila de DL a través de la práctica. El desafío de hardware PyTorch/vLLM anima a los desarrolladores a corregir errores, y hay sugerencias de rutas de aprendizaje de visión por computadora para ayudar a los estudiantes a planificar su desarrollo profesional. (Fuente: aihub.org, DeepLearningAI, vllm_project, Reddit r/deeplearning, Reddit r/deeplearning)

Modelado 3D/XR e interacción humano-computadora : El marco TIMAR propone el modelado causal de la dinámica interactiva de la cabeza en diálogos 3D, fusionando información multimodal y prediciendo dinámicas continuas de la cabeza en 3D. La investigación sobre la traducción de imágenes SAR a RGB explora cómo generar imágenes claras a través de modelos de deep learning. La investigación sobre algoritmos de puntuación de escritura a mano de letras preescolares busca métodos de coincidencia de plantillas para evaluar con precisión la calidad de la escritura de los niños. (Fuente: HuggingFace Daily Papers, Reddit r/deeplearning, Reddit r/deeplearning)
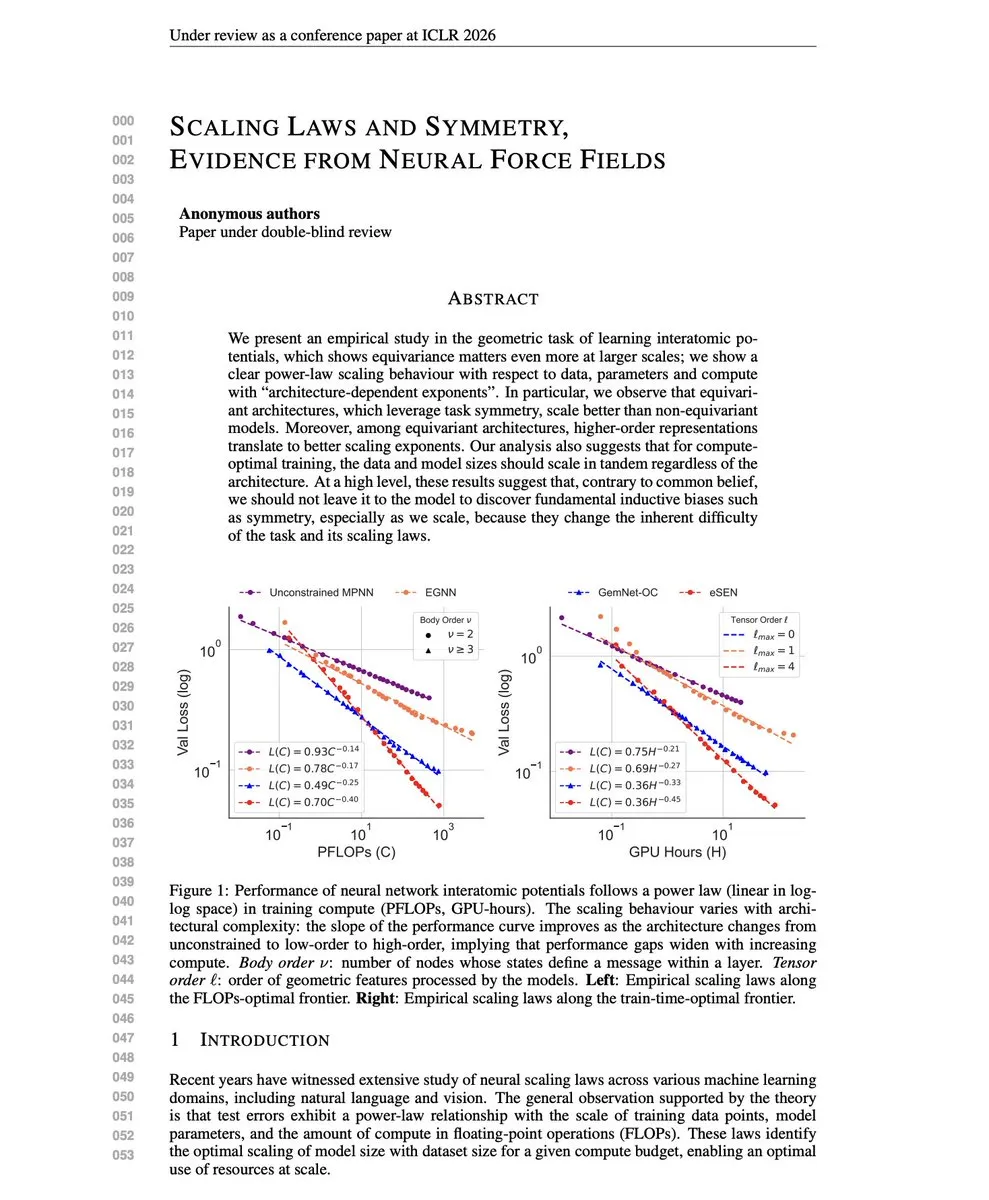
Scaling Laws y teoría de fusión de modelos : Esta investigación desafía la opinión de que las “Scaling Laws son superiores a los sesgos inductivos”, descubriendo que las arquitecturas que codifican la simetría tienen mejores Scaling Exponents. Al mismo tiempo, las soluciones a conflictos de fusión de modelos multitarea (TATR, CAT Merging, LOT Merging) alivian eficazmente los conflictos de conocimiento e impulsan el rendimiento y la robustez multitarea mediante la identificación y filtrado de dimensiones conflictivas, la proyección o la fusión ponderada. (Fuente: dair_ai, WeChat)
Entrenamiento de extremo a extremo de difusión de video autorregresiva : Esta investigación introduce el marco “Resampling Forcing” para el entrenamiento de extremo a extremo de modelos de difusión de video autorregresivos. Al simular errores del modelo en fotogramas históricos durante la inferencia, combinados con una máscara causal dispersa y un mecanismo de enrutamiento histórico, este método logra un rendimiento comparable al de las líneas base de destilación mientras mantiene la coherencia temporal y soporta la generación eficiente a largo plazo. (Fuente: HuggingFace Daily Papers)
Discusión sobre evaluación y reproducibilidad de LLM : La comunidad de Reddit discute los desafíos y problemas de reproducibilidad en la evaluación de LLM. Los usuarios se centran en cómo establecer criterios de evaluación fiables, asegurar que los resultados entre diferentes investigaciones y modelos sean comparables, y explorar cómo gestionar y compartir eficazmente métodos y conjuntos de datos de evaluación en el campo de rápido desarrollo de los LLM para promover el progreso científico. (Fuente: Reddit r/deeplearning)
💼 Negocios
Zhipu AI y MiniMax se preparan para su IPO en la bolsa de Hong Kong : Las empresas chinas de modelos grandes MiniMax y Zhipu AI han completado el registro en la Comisión Reguladora de Valores de China y han participado en las audiencias de cotización de la Bolsa de Hong Kong. MiniMax planea cotizar en enero de 2026. Zhipu AI está valorada en aproximadamente 40 mil millones de yuanes, centrándose en los segmentos G y B, así como en agentes multimodales; MiniMax está valorada en casi 30 mil millones de yuanes, con capacidades multimodales como núcleo y un modelo impulsado por productos. Ambas compañías están llevando a cabo una convergencia estratégica y ajustes de equipo antes de la cotización, lo que refleja que la industria de los modelos grandes está entrando en un “período de doble restricción de capital y eficiencia”. (Fuente: 36氪)
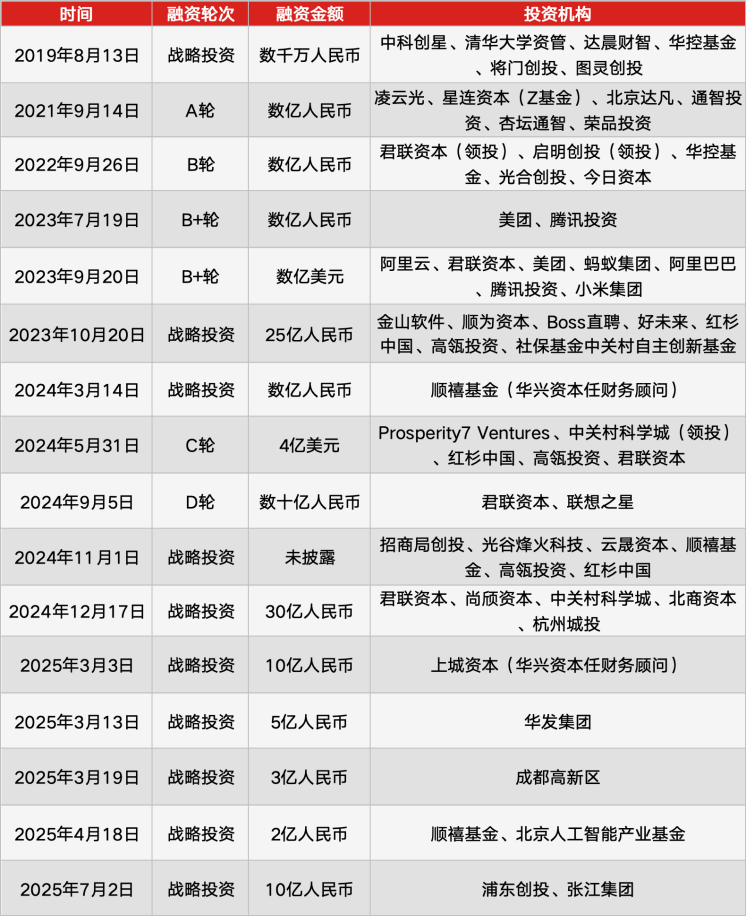
Amazon planea invertir 10 mil millones de dólares en OpenAI : Amazon planea invertir al menos 10 mil millones de dólares en OpenAI. Se espera que esta medida incluya el uso por parte de OpenAI de la serie de chips de IA Trainium de Amazon y el alquiler de más capacidad de centros de datos para ejecutar sus modelos y herramientas (como ChatGPT). Esta inversión tiene como objetivo profundizar la colaboración entre ambas compañías en infraestructura de IA y despliegue de modelos. (Fuente: Reddit r/ArtificialInteligence)

Biren Technology se prepara para ser la primera GPU de propósito general en la bolsa de Hong Kong : Biren Technology, el unicornio de GPU de propósito general valorado en 20.9 mil millones de yuanes, ha pasado la audiencia de la Bolsa de Hong Kong y está a punto de convertirse en la “primera GPU nacional” en cotizar en Hong Kong. La compañía fue fundada por Zhang Wen, doctor en derecho de Harvard. Sus productos principales son sistemas de hardware basados en su arquitectura GPGPU de desarrollo propio (chips Biren BR106, BR110, BR166) y la plataforma de software BIRENSUPA, que ofrecen soporte completo para el entrenamiento y la inferencia de IA. Sus clientes abarcan industrias de alta computación como las telecomunicaciones y la tecnología financiera. (Fuente: WeChat)
🌟 Comunidad
Calidad del contenido generado por IA y el fenómeno “slop” en internet : Las redes sociales discuten ampliamente el fenómeno “slop” de la calidad inconsistente del contenido generado por IA, que ha sido elegido como la palabra del año, reflejando la proliferación de contenido de IA y los problemas de baja calidad. Esto ha provocado críticas a los intereses de las plataformas de publicidad en internet y reflexiones sobre cómo elevar el umbral para la creación de contenido con IA. (Fuente: 36氪)

Impacto de la IA en el mercado laboral y los patrones de trabajo de los desarrolladores : Las redes sociales profundizan en la disrupción de la IA en el mercado laboral y los patrones de trabajo de los desarrolladores. La IA es vista como una poderosa herramienta de productividad que transforma el rol del desarrollador de la mera escritura de código al diseño de sistemas, orquestación de agentes, verificación y depuración de código, requiriendo habilidades de nivel superior. LinkedIn introduce un asistente de contratación de IA, cambiando los procesos de búsqueda de empleo y contratación. Al mismo tiempo, la IA mejora significativamente la eficiencia en campos como la fotografía, pero la preparación para la producción de los agentes de codificación de IA aún enfrenta desafíos. (Fuente: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Reddit r/artificial, Yuchenj_UW, gdb, amasad, amasad, Ronald_vanLoon)

Aplicaciones y desafíos de la IA en educación, medicina y otros campos : El uso de software de detección de IA por parte de los profesores para determinar si los estudiantes han utilizado IA genera controversia ética en la educación, pidiendo al sistema educativo que se centre en la comprensión del estudiante en lugar del uso de herramientas. ChatGPT muestra potencial en el sector de la salud para ayudar en el diagnóstico y proporcionar consejos de salud, pero debe usarse con precaución. Plataformas como Glass 5.0 aplican la IA al apoyo a la toma de decisiones clínicas, impulsando la transformación de la IA médica de chatbots a socios. (Fuente: Reddit r/artificial, Reddit r/ChatGPT, GlassHealthHQ)

Discusión continua sobre el rendimiento, costo y experiencia del usuario de los LLM : Los usuarios de redes sociales discuten activamente el rendimiento, costo y experiencia de uso real de LLM como Gemini 3 Flash y Claude Opus 4.5. Los puntos de interés incluyen los avances de los modelos en codificación, llamada a herramientas y capacidades de razonamiento, así como problemas como la degradación del rendimiento y las tasas de alucinación. Los usuarios comparan la relación calidad-precio de diferentes modelos y discuten las estrategias de precios de los modelos de IA y la percepción del valor por parte del usuario. (Fuente: Vtrivedy10, hrishioa, tokenbender, inerati, scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, max__drake, MiniMax__AI, scaling01)
Exploración profunda de la ética, filosofía y AGI de la IA : Las redes sociales discuten las implicaciones éticas y sociales de la IA, incluyendo si la IA está llenando el “vacío de Dios”, la verdadera definición de AGI, y el potencial y las limitaciones de la IA en la investigación de la física. Los usuarios también se centran en la reproducibilidad de los benchmarks de IA, la crítica a la calidad de la investigación en IA, y la reflexión filosófica sobre las diferencias esenciales entre los modelos de IA y la inteligencia humana. (Fuente: Ronald_vanLoon, ImazAngel, Ronald_vanLoon, RisingSayak, snwy_me, TheTuringPost, teortaxesTex, _lewtun)

Arquitectura, eficiencia y optimización de la infraestructura de modelos de IA : Las redes sociales discuten la arquitectura y eficiencia de los modelos de IA, incluyendo la eficiencia MFU de los modelos MoE, el entrenamiento de MoE ultra-dispersos de nmoe, y la simplificación de la inferencia de LLM (como mini-SGLang). Los usuarios se centran en los avances de los modelos en el procesamiento de contextos largos, la gestión de la memoria y la optimización del hardware (como el backend distribuido MLX, el servicio vLLM) para mejorar el rendimiento general y la escalabilidad de los sistemas de IA. (Fuente: lateinteraction, hyhieu226, TheZachMueller, dejavucoder, awnihannun, vllm_project, aiamblichus)

Estrategia de empresas de IA, competencia de mercado y movimiento de talentos : Las redes sociales discuten la estrategia y la competencia de mercado de las empresas de IA, incluyendo la contratación de investigadores de IA de primer nivel por parte de Amazon, los planes de Thinking Machines para lanzar modelos, la inversión y el rendimiento de Meta AI, y los problemas organizacionales que enfrenta OpenAI. Los usuarios también se centran en el liderazgo de NVIDIA en el campo de la IA de código abierto, su estrategia impulsada por el hardware y el movimiento de talentos clave, como la incorporación de investigadores de Anthropic a Tencent. (Fuente: pmddomingos, scaling01, teortaxesTex, steph_palazzolo, TheTuringPost, Sentdex, teortaxesTex, turbopuffer, iScienceLuvr, EthanJPerez)

Informe sobre el estado actual de la codificación con IA y tendencias de la industria : Greptile publica el “Informe sobre el estado de la codificación con IA de 2025”, señalando que la producción mensual de código de los desarrolladores ha aumentado un 76% y el tamaño de los PR se ha inflado, con una distribución desigual de los beneficios de las herramientas de IA. El informe también compara el rendimiento de los modelos de OpenAI, Anthropic y Google en términos de tiempo de respuesta del primer token, rendimiento y costo, y revela el panorama de la competencia en el mercado de bases de datos vectoriales y herramientas de memoria de IA. (Fuente: dotey)

Evaluación y reproducibilidad de modelos de IA : La comunidad de Reddit discute los desafíos y problemas de reproducibilidad en la evaluación de LLM. Los usuarios se centran en cómo establecer criterios de evaluación fiables, asegurar que los resultados entre diferentes investigaciones y modelos sean comparables, y explorar cómo gestionar y compartir eficazmente métodos y conjuntos de datos de evaluación en el campo de rápido desarrollo de los LLM para promover el progreso científico. (Fuente: Reddit r/deeplearning)
IA abierta y estrategia impulsada por hardware : El lanzamiento de NVIDIA Nemotron 3 marca un punto de inflexión simbólico en el liderazgo de la IA de código abierto. Este modelo, a través de datos de preentrenamiento a gran escala, conjuntos de datos RL y una nueva arquitectura híbrida, optimiza el consumo computacional del hardware de NVIDIA. Esta estrategia indica que la IA de código abierto está pasando de la era de la “filantropía de las grandes tecnológicas” a la era de la “IA definida por el hardware”, donde el lanzamiento de modelos tiene como objetivo expandir el consumo computacional de hardware específico. (Fuente: TheTuringPost, teortaxesTex)
Comparación y aplicación de herramientas de generación de imágenes y video con IA : Los usuarios de redes sociales discuten el rendimiento y las aplicaciones de las herramientas de generación de imágenes y video con IA, incluyendo ChatGPT, Gemini, Midjourney, Grok, Nano Banana Pro, entre otras. La discusión abarca el fotorrealismo de las obras de arte de IA, la conversión de personajes de juegos y la aplicación de videos de IA en la producción cinematográfica. Los usuarios también se centran en la calidad, el costo y la eficiencia del contenido generado por IA, así como su impacto disruptivo en el proceso creativo. (Fuente: dotey, swyx, karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Kling_ai)

Aplicaciones y tendencias de la IA en el sector financiero : Las redes sociales discuten las aplicaciones de la IA en el sector financiero, cubriendo 26 casos específicos, como la detección de fraudes, la gestión de riesgos, el servicio al cliente, entre otros. Estas aplicaciones demuestran cómo el aprendizaje automático y la inteligencia artificial empoderan a la industria financiera, mejorando la eficiencia, optimizando la toma de decisiones y creando nuevo valor comercial. (Fuente: Ronald_vanLoon)

Combinación de agentes de IA y grafos de conocimiento : Científicos de IA de SAP discuten cómo mejorar el descubrimiento y la ejecución de agentes de IA a través de grafos de conocimiento. Los grafos de conocimiento proporcionan a los agentes de IA contexto semántico y de proceso, permitiéndoles descubrir y llamar herramientas y API en sistemas empresariales de manera más efectiva, mejorando así la eficacia de los agentes en entornos empresariales complejos. (Fuente: DeepLearningAI)

Evaluación y reproducibilidad de LLM : La comunidad de Reddit discute los desafíos y problemas de reproducibilidad en la evaluación de LLM. Los usuarios se centran en cómo establecer criterios de evaluación fiables, asegurar que los resultados entre diferentes investigaciones y modelos sean comparables, y explorar cómo gestionar y compartir eficazmente métodos y conjuntos de datos de evaluación en el campo de rápido desarrollo de los LLM para promover el progreso científico. (Fuente: Reddit r/deeplearning)
Rendimiento de modelos de IA en la UE y el impacto de las regulaciones : Los usuarios de Reddit discuten si los modelos de IA de video e imagen son “más tontos” en la región de la UE debido a las regulaciones. La opinión general es que la calidad central de los modelos no se ve afectada, pero las estrictas capas de seguridad y los requisitos de cumplimiento de la UE pueden llevar a retrasos en el lanzamiento de funciones, filtros más estrictos o configuraciones predeterminadas diferentes, lo que afecta la experiencia del usuario, en lugar de una disminución en la inteligencia del modelo en sí. (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
Fusión de la IA en el arte y el entretenimiento : Desdemona Robot y su banda actuarán el 11 de enero en San Francisco, combinando la IA con el arte para explorar el potencial de los robots como artistas. Al mismo tiempo, algunos usuarios expresan su deseo de ver a la banda usar herramientas de IA como Suno para generar canciones y tocarlas en vivo, lo que refleja la tendencia emergente de la aplicación de la IA en la creación musical y el entretenimiento en vivo. (Fuente: bengoertzel, fabianstelzer)
ComfyUI explora un “modo simple” para simplificar los flujos de trabajo : ComfyUI está explorando un nuevo “modo simple” diseñado para facilitar el intercambio y la iteración de flujos de trabajo complejos, centrándose en los resultados en lugar del gráfico de nodos subyacente. Este modo está dirigido específicamente a usuarios que encuentran los gráficos grandes difíciles de entender, con el fin de reducir la barrera de entrada y mejorar la experiencia del usuario y la eficiencia del trabajo. (Fuente: NerdyRodent)