
Schlüsselwörter:AI Manhattan-Projekt, Gemini 3 Flash, GPT-5.2-Codex, Kontrollierte Kernfusion, KI-Forschungsingenieurwesen, KI-Agent, Multimodales Modell, Open-Source-KI-Modell, Genesis-Mission des US-Energieministeriums, Gemini 3 Flash Codierungstest, GPT-5.2-Codex Cybersicherheitsabwehr, T5Gemma 2 multimodales Modell, Perception Encoder Audiovisuelle Audio-Trennung
🔥 Fokus
US-amerikanisches „AI Manhattan Project“ gestartet: Das US-Energieministerium hat offiziell die „Mission Genesis“ ins Leben gerufen, ein nationales KI-Forschungsprojekt. Es zielt darauf ab, führende KI-Technologien mit den Forschungskapazitäten nationaler Labore zu verbinden, um wissenschaftliche Entdeckungen zu beschleunigen. Das Projekt vereint 24 Technologiegiganten, darunter Microsoft, Google, Nvidia, OpenAI, DeepMind und Anthropic. Es wird KI-Modelle und Supercomputing-Fähigkeiten in Bereichen wie kontrollierte Kernfusion, Energiematerialien und Klimasimulationen einsetzen. Ziel ist es, die wissenschaftliche Produktivität der USA bis 2030 zu verdoppeln, was eine nationale strategische Neuausrichtung im Technologiesektor markiert.
(Quelle: 36氪, nvidia, AnthropicAI, GoogleDeepMind, OpenAI Newsroom)
Hinton und Jeff Dean im Gespräch über moderne KI: Geoffrey Hinton, ein Pionier der neuronalen Netze, und Jeff Dean, Chief Scientist bei Google, diskutierten auf der NeurIPS-Konferenz über die Schlüsselfaktoren, die moderne KI aus den Laboren zu Milliarden von Nutzern gebracht haben. Sie sind der Meinung, dass der Durchbruch der KI kein einzelnes Wunder war, sondern das Ergebnis der systemischen Reife von Algorithmen (wie Transformer), Hardware (wie GPU, TPU) und Engineering (wie JAX, Pathways). Das Gespräch wies auch auf drei große Hürden bei der Skalierung von KI hin: Energieeffizienz, Gedächtnis (langer Kontext) und Kreativität (Assoziationsfähigkeit), und betonte die Bedeutung von Grundlagenforschung und kontinuierlichen Investitionen.
(Quelle: 36氪, JeffDean, geoffreyhinton)
Sam Altman im Interview: OpenAI-Strategie und Finanzierung: Sam Altman betonte in einem aktuellen Interview, dass Google weiterhin die größte Bedrohung für OpenAI darstellt. OpenAI will seine Vorteile jedoch durch KI-native Software, Personalisierungs- und Gedächtnisfunktionen, beschleunigte Expansion im Unternehmensmarkt und eine Infrastrukturinvestition von 1,4 Billionen US-Dollar festigen. Er prognostiziert, dass GPT-6 voraussichtlich im ersten Quartal des nächsten Jahres erscheinen wird, und hob hervor, dass KI die Art und Weise, wie Software genutzt wird, neu gestalten und zu einem unersetzlichen „digitalen Partner“ werden wird, anstatt einfach in alte Produkte eingebettet zu sein.
(Quelle: 36氪, sama)
Google veröffentlicht Gemini 3 Flash Modell: Google hat Gemini 3 Flash vorgestellt, ein Modell, das sich durch ein extrem hohes Preis-Leistungs-Verhältnis und Geschwindigkeit auszeichnet und in mehreren Benchmarks, sogar im SWE-bench Coding-Test, GPT-5.2 übertrifft. Google plant, es tief in seine Ökosystemprodukte wie Search, YouTube und Gmail zu integrieren, um den KI-Markt durch Ökosystemvorteile statt durch bloße Modellparameter neu zu gestalten. Diese Veröffentlichung wird als „präziser Schlag“ gegen OpenAI angesehen und hat eine breite Diskussion über Modellwettbewerb und die Verbreitung von KI-Anwendungen ausgelöst.
(Quelle: 36氪, MS_BASE44, GeminiApp, scaling01)
OpenAI veröffentlicht GPT-5.2-Codex Programmiermodell: OpenAI hat GPT-5.2-Codex veröffentlicht, das als das bisher leistungsstärkste KI-Agenten-Programmiermodell bezeichnet wird und speziell für komplexe Softwareentwicklung und Cybersicherheit optimiert ist. Das Modell verbessert die Ausführung langfristiger Aufgaben, umfangreiche Codeänderungen, die Kompatibilität mit Windows-Umgebungen und die Cybersicherheitsabwehr. Obwohl es in Benchmarks stark abschneidet, haben einige Nutzer festgestellt, dass es bei bestimmten Aufgaben Gemini 3 Flash unterlegen ist, was eine Diskussion über seine tatsächliche Leistung und Wettbewerbsfähigkeit ausgelöst hat.
(Quelle: 36氪, sama, scaling01)
🎯 Trends
Google veröffentlicht T5Gemma 2 und FunctionGemma als Open Source: Google hat T5Gemma 2 und FunctionGemma, zwei kleine Modelle aus der Gemma 3-Familie, als Open Source veröffentlicht. T5Gemma 2 ist das erste multimodale Encoder-Decoder-Modell mit langem Kontext, dessen kleinste Größe 270M-270M beträgt und das sich auf Architektureffizienz und multimodale Fähigkeiten konzentriert. FunctionGemma ist ein 270M-Modell, das speziell für Funktionsaufrufe optimiert ist und auf Edge-Geräten wie Mobiltelefonen laufen kann. Es soll das Problem lösen, dass große Modelle zwar „reden, aber nicht handeln“ können, und bietet ein spezielles Gehirn für Agenten und die Werkzeugnutzung.
(Quelle: 36氪, huggingface, osanseviero, ImazAngel, danielhanchen)

ByteDance Doubao 1.8 Modell im Praxistest: ByteDance hat das Doubao Large Model 1.8 veröffentlicht, sein neues Flaggschiff-Modell, das in Tests in verschiedenen Szenarien wie Bildung, Kundenservice, Finanzen und Recht führend ist. Der Praxistest zeigt, dass Doubao 1.8 herausragende Leistungen in den Bereichen Agent-Fähigkeiten (Multi-Tool-Aufrufe, Multi-Turn-Befehlsbefolgung, OS Agent), 256K Ultra-Long-Context-Management und multimodales Verständnis (Video-Verständnis auf bis zu 20 Minuten verbessert) bietet. Es eignet sich besonders gut für den Aufbau komplexer Agenten und die Ausführung realer Prozesse und wird als entscheidender Schritt zur Förderung von Enterprise-Agenten und Edge-Agenten angesehen.
(Quelle: WeChat)

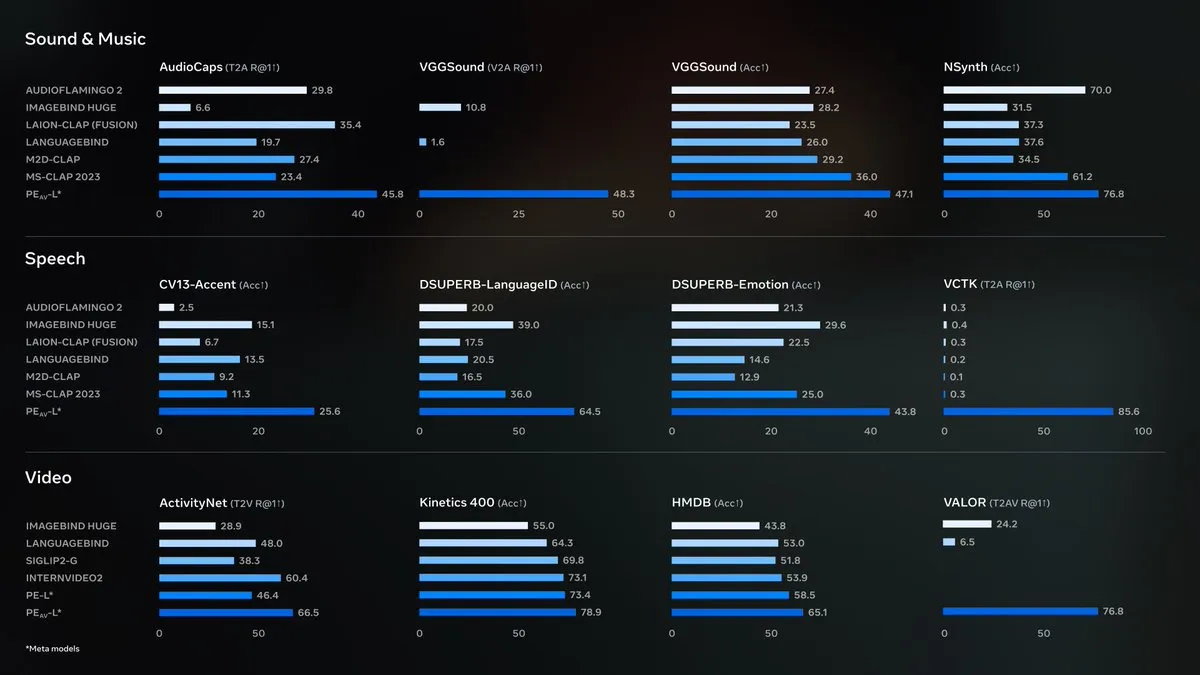
Meta veröffentlicht Perception Encoder Audiovisual (PE-AV) als Open Source: Meta hat Perception Encoder Audiovisual (PE-AV) als Open Source veröffentlicht, die Kerntechnologie hinter SAM Audio, die eine hochmoderne Audiotrennung ermöglicht. PE-AV basiert auf Metas zuvor veröffentlichtem Perception Encoder-Modell und integriert Audio- und visuelle Wahrnehmung tiefgreifend. Es hat in einer Vielzahl von Audio- und Video-Benchmarks Spitzenleistungen erzielt und verspricht, die Geräuscherkennung und das audiovisuelle Szenenverständnis durch multimodale Unterstützung zu verbessern.
(Quelle: AIatMeta, Reddit r/LocalLLaMA)
Runway stellt Gen-4.5 und GWM-1 Modelle vor: Runway hat das Gen-4.5 Video-Generierungsmodell veröffentlicht, das neue Audio- und Multi-Shot-Bearbeitungsfunktionen bietet. Gleichzeitig wurde die GWM-1 (General World Model) Serie vorgestellt, darunter GWM Worlds (navigierbare Szenen), GWM Robotics (Robotersicht-Simulation) und GWM Avatars (lippensynchrone Charaktere). Ziel ist es, eine Echtzeit- und steuerbare Weltmodell-Videogenerierung zu ermöglichen, was einen bedeutenden Sprung in der Videogenerierungstechnologie hin zur universellen Simulation darstellt.
(Quelle: c_valenzuelab, DeepLearningAI)
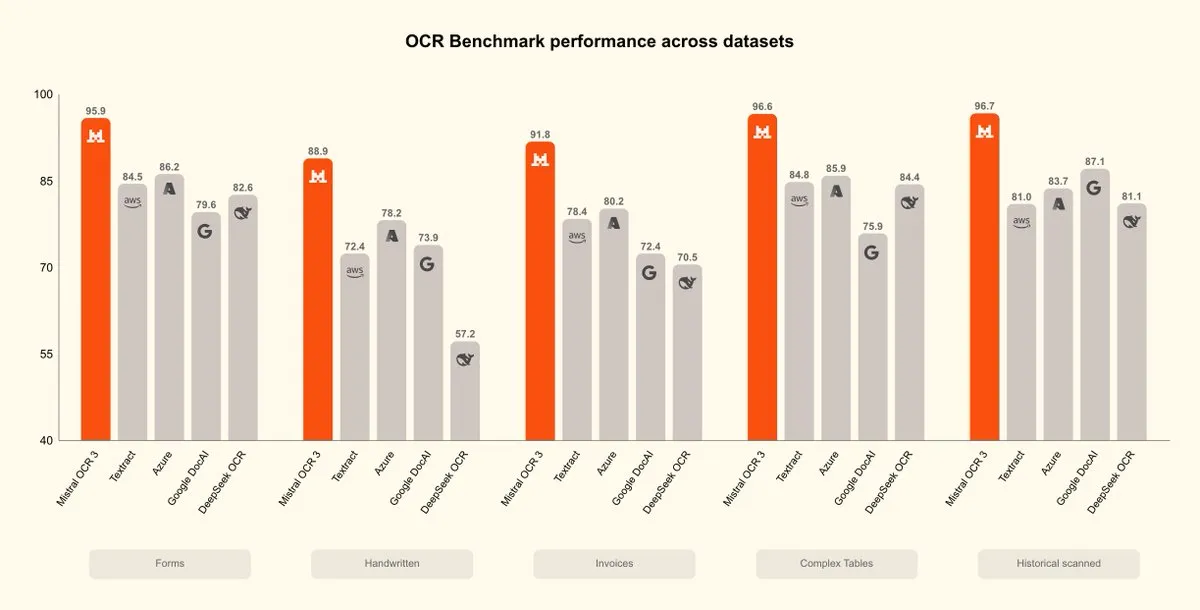
Mistral OCR 3 veröffentlicht, neuer Durchbruch in der Dokumentenintelligenz: Mistral AI hat das Mistral OCR 3 Modell veröffentlicht, das neue Maßstäbe in Bezug auf Genauigkeit und Effizienz setzt und bestehende Unternehmensdokumentenverarbeitungslösungen sowie KI-native OCR übertrifft. Das Modell wurde stark für die Verarbeitung von handschriftlichen Inhalten, qualitativ minderwertigen Scans sowie komplexen Tabellen und Formularen, die häufig in Unternehmensdokumenten vorkommen, optimiert. Dies markiert einen neuen Fortschritt im Bereich der Dokumentenintelligenz.
(Quelle: qtnx_, GuillaumeLample)
Hugging Face Transformers v5 Tokenization neu strukturiert: Hugging Face hat in Transformers v5 die Funktionsweise des Tokenizers grundlegend neu gestaltet. Die neue Version trennt die Tokenizer-Architektur vom Trainingsvokabular, was die Transparenz und Modularität erhöht und den Prozess des Trainings modellspezifischer Tokenizer von Grund auf vereinfacht. Diese Verbesserung macht Tokenizer leichter überprüfbar, anpassbar und trainierbar und löst die Probleme der Intransparenz und engen Kopplung in v4.
(Quelle: HuggingFace Blog, huggingface)

Firefox kündigt KI-Transformation an und löst Nutzerkontroversen aus: Der Firefox-Browser hat seine Transformation zu einem KI-Browser angekündigt, der eine Reihe neuer Software unterstützen wird. Dieser Schritt hat in Communities wie Reddit zu großer Unzufriedenheit bei vielen Nutzern geführt, insbesondere bei Hardcore-Nutzern, die Wert auf Datenschutz und Minimalismus legen. Sie sind der Meinung, dass Firefox seine Kernwerte verrät. Diese Transformation spiegelt Mozillas Strategie wider, in einer Ära, in der „die Suche tot ist“, neue Wachstumspunkte zu finden. Die Herausforderung besteht jedoch darin, ein Gleichgewicht zwischen KI-Funktionen und Nutzerdatenschutz zu finden.
(Quelle: 36氪)

ChatGPT führt Chat-Anheftungsfunktion ein: OpenAI hat angekündigt, dass ChatGPT jetzt eine Chat-Anheftungsfunktion bietet. Nutzer können wichtige Unterhaltungen auf iOS, Android und im Web anheften, um schnell darauf zugreifen zu können. Dieses Update zielt darauf ab, die Benutzerfreundlichkeit zu verbessern und die Gesprächsverwaltung zu vereinfachen.
(Quelle: openai, Reddit r/ChatGPT)
Claude for Chrome Erweiterung erhält Funktions-Upgrade: Die Claude for Chrome Erweiterung ist jetzt für alle zahlenden Nutzer verfügbar und wurde mit der Claude Code-Funktion integriert. Nutzer können jetzt direkt im Browser über Claude Code Code testen und debuggen, ohne die aktuelle Seite verlassen zu müssen. Dieses Update zielt darauf ab, die Arbeitseffizienz und das Erlebnis für Entwickler zu verbessern. Anthropic betonte auch die Berücksichtigung von Sicherheit bei Design und Tests.
(Quelle: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

🧰 Tools
Agent Skills wird offener Standard: Anthropic’s Agent Skills ist jetzt ein offener Standard, der es KI-Agenten ermöglicht, wiederkehrende Arbeitsabläufe plattformübergreifend zu lernen und auszuführen. Diese Initiative zielt darauf ab, die Bereitstellung, Entdeckung und Erstellung von Fähigkeiten zu vereinfachen und die Interoperabilität des KI-Tool-Ökosystems zu fördern. Entwickler können jetzt eine Fähigkeit einmal erstellen und auf mehreren KI-Plattformen verwenden, wodurch die Spezialisierungsfähigkeit und Effizienz von Agenten erhöht wird.
(Quelle: omarsar0, code, Reddit r/ClaudeAI)
LangChain Academy startet neuen Kurs: Die LangChain Academy hat einen neuen Kurs „Einführung in LangChain (Python)“ veröffentlicht, der Entwicklern helfen soll, den LangChain-Framework zum Aufbau von KI-Agenten zu nutzen. Der Kurs behandelt die Erstellung von Agenten, die Verwendung der Kernbausteine (Modelle, Nachrichten, Gedächtnis, Tools) und wie LangSmith für das Verhaltens-Debugging eingesetzt werden kann, mit dem Ziel, dass die Teilnehmer ein komplettes persönliches Assistententeam zusammenstellen können.
(Quelle: LangChainAI, hwchase17)

Claude Code CLI erweiterte Entwicklungseinstellungen: Ein Entwickler hat seine „überentwickelte“ Claude Code CLI-Einrichtung geteilt, die einen MCP-Server, benutzerdefinierte Fähigkeiten und eine strenge CLAUDE.md-Datei kombiniert, um „Vibe Coding“ für produktionsreifen Code zu ermöglichen. Diese Methode verhindert durch Qualitätskontrollen, iterative Schleifen und In-Browser-Tests effektiv, dass der Agent vom Kurs abweicht, und ermöglicht eine effiziente Refaktorierung, wodurch die Schmerzpunkte traditioneller Agenten in der praktischen Entwicklung gelöst werden.
(Quelle: Reddit r/ClaudeAI)
OpenRouter führt LLM JSON-Ausgabe-Reparaturfunktion ein: OpenRouter hat die Funktion „Response Healing“ eingeführt, die Fehler in strukturierten JSON-Ausgaben, die von Large Language Models (LLM) generiert werden, automatisch behebt. Diese Funktion hat die Fehlerrate von Modellen wie Gemini 2 Flash und Qwen3 235B erheblich reduziert und die Zuverlässigkeit von LLMs in Szenarien verbessert, die eine präzise JSON-Formatierung erfordern.
(Quelle: xanderatallah)

AssemblyAI Audio-Transkriptionstool unterstützt URL-Eingabe: Das AssemblyAI Playground-Update unterstützt jetzt die direkte Transkription von Audio über URLs. Benutzer können Podcasts, Cloud-Audio oder große Dateien (wie Gewinnmitteilungen) testen, ohne Dateien herunterladen zu müssen, was den Prototyping- und Integrationsvalidierungsprozess erheblich vereinfacht und die Effizienz beim Testen von Speech AI-Funktionen verbessert.
(Quelle: AssemblyAI)
jax-js: Machine Learning Bibliothek für den Browser: jax-js ist eine Open-Source-Machine-Learning-Bibliothek, die JAX in reinem JavaScript neu implementiert und JIT-Kompilierung zu WebGPU unterstützt, wodurch sie neuronale Netze im Browser ausführen kann. Die Bibliothek bietet Funktionen wie automatische Differenzierung und JIT-Kompilierung, um ein effizientes und flexibles Programmiermodell ähnlich PyTorch und JAX bereitzustellen. Ihre Interaktivität wurde bereits durch eigenständige Demos wie MNIST-Training und MobileCLIP-Inferenz verifiziert.
(Quelle: Vtrivedy10, Reddit r/MachineLearning)

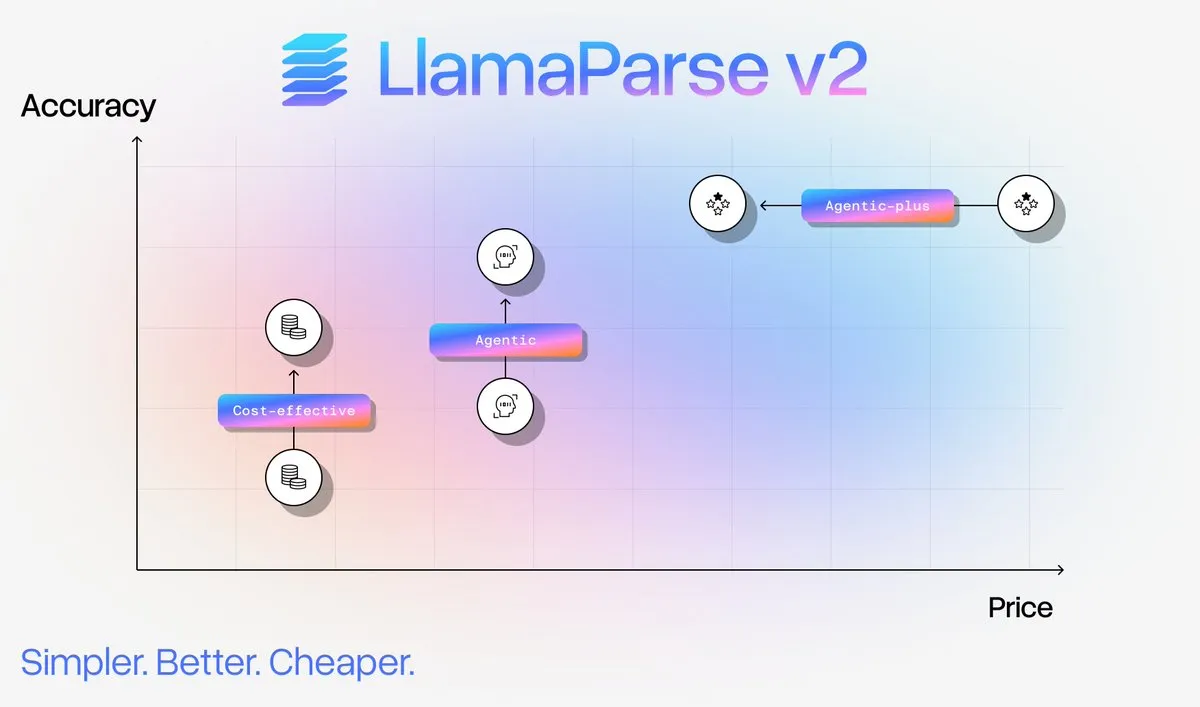
LlamaParse v2 Dokumenten-Parsing-Dienst-Upgrade: LlamaIndex hat LlamaParse v2 veröffentlicht, das die Konfiguration des Dokumenten-Parsings erheblich vereinfacht, die Leistung verbessert und bei komplexen Dokumenten-Parsings bis zu 50 % Kosten senkt. Die neue Version führt vier feste Stufen ein: Fast, Cost Effective, Agentic und Agentic Plus, die die Genauigkeit multimodaler Inhalte verbessern, Halluzinationen reduzieren und es Benutzern ermöglichen, produktionsreifes Dokumenten-Ingestion zu erreichen, ohne Parsing-Experten sein zu müssen.
(Quelle: jerryjliu0)
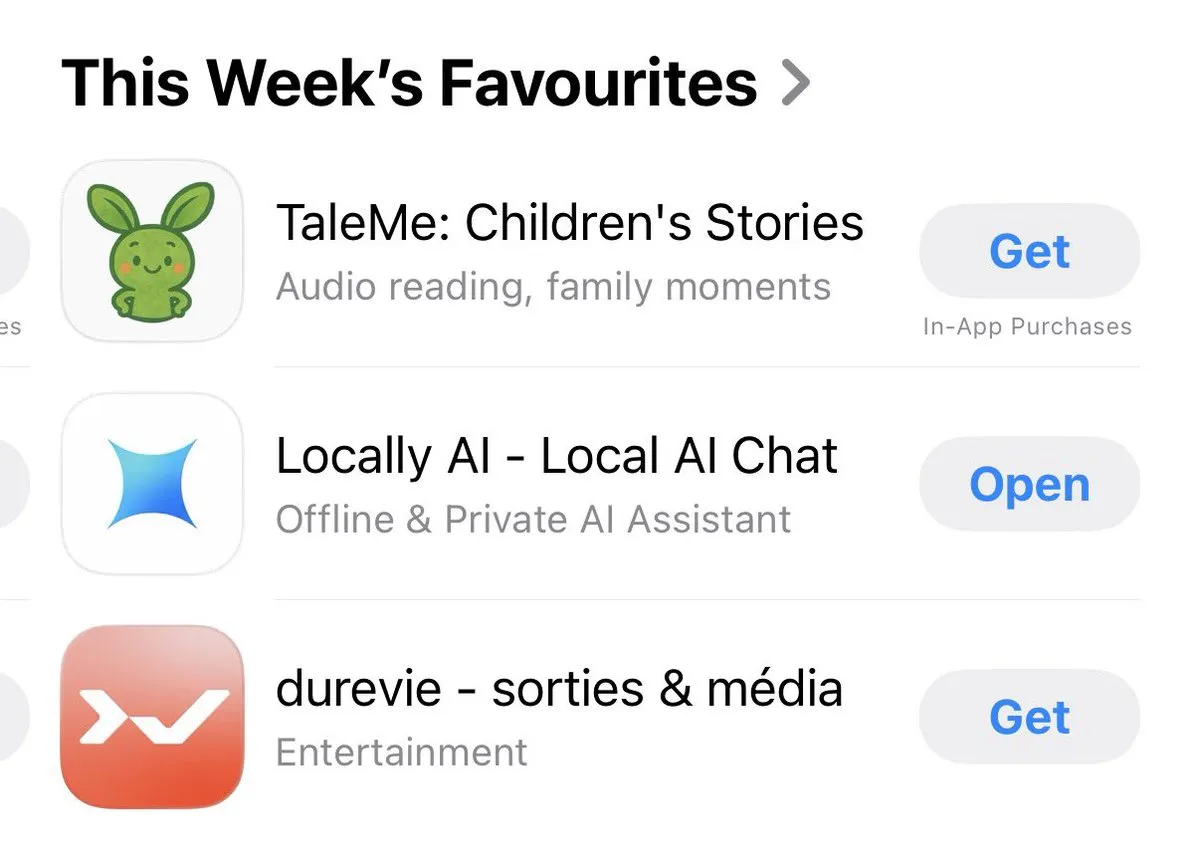
Locally AI: Anwendung zum lokalen Ausführen von KI-Modellen: Locally AI ist eine Anwendung, die es Benutzern ermöglicht, KI-Modelle lokal auf ihren alltäglichen Geräten auszuführen. Sie wurde aufgrund ihrer Bequemlichkeit vom App Store als „Liebling der Woche“ ausgezeichnet. Die Anwendung zielt darauf ab, die Zugänglichkeit von KI zu verbessern, sodass mehr Menschen problemlos mit lokalen KI-Modellen interagieren können, und betont die Benutzerfreundlichkeit und Verfügbarkeit lokaler KI.
(Quelle: adrgrondin)
Google Flow Bildgenerierung unterstützt hochauflösenden Download: Die Nano Banana Pro-Funktion von Google Flow unterstützt jetzt den Download von KI-generierten Bildern in 2K- und 4K-Auflösung. Dieses Update erfüllt den Bedarf der Benutzer an höher auflösenden Bildern, sei es für kreatives Material, Bildsequenzen oder visuelle Effekte, und ermöglicht klarere und detailliertere KI-generierte Inhalte.
(Quelle: op7418)

OpenWebUI-Nutzer melden Probleme mit RAG-Funktion: OpenWebUI-Nutzer berichten über Probleme mit der RAG (Retrieval Augmented Generation)-Funktion, insbesondere bei der Verarbeitung von PDF-Dateien, die größer als 1MB sind. Das Modell kann den Dateiinhalt nicht an den Kontext übergeben, was zu einem Fehler „Quelle nicht gefunden“ führt. Obwohl der Dateiupload, die Textextraktion und das Embedding erfolgreich sind, schlägt der Abfragegenerierungsschritt fehl, was die Nutzung von PDF-Inhalten für die Modellinferenz behindert und Aufgaben wie die Extraktion strukturierter Daten beeinträchtigt.
(Quelle: Reddit r/OpenWebUI, Reddit r/OpenWebUI)

KI-Text-Abenteuerspiel Glif Agent: Glif Agent bietet ein Text-Abenteuerspielerlebnis, in das Benutzer direkt eintauchen können, ohne komplexe Anleitungen. Dieses KI-Tool zeigt das Potenzial von LLMs bei der Schaffung interaktiver Erzählungen und immersiver Erlebnisse, indem es Spielern ermöglicht, virtuelle Welten über natürliche Sprachbefehle zu erkunden.
(Quelle: NerdyRodent)

Cass: Suchtool für Coding-Agent-Sitzungen: Das Cass-Tool wird als „Retter“ für Coding-Agenten gefeiert und soll erheblich Zeit und Mühe sparen. Es erkennt, erfasst und indiziert automatisch alle Coding-CLI-Sitzungen und bietet sofortige Suche sowie einen „Bot-Modus“, der es Benutzern ermöglicht, Agent-Spuren schnell zu finden, zu verwalten und wiederzuverwenden, wodurch die Effizienz bei der Verwendung von Coding-Agenten erheblich gesteigert wird.
(Quelle: doodlestein)
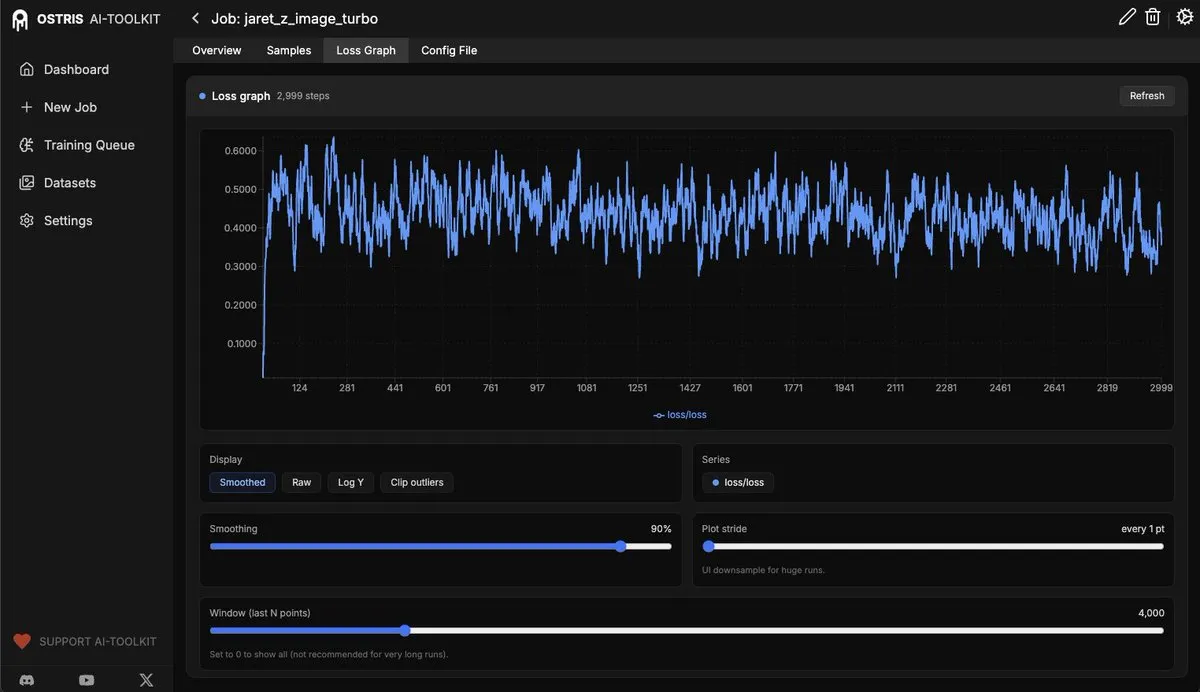
AI Toolkit UI fügt Loss Graph Funktion hinzu: Das AI Toolkit UI wurde aktualisiert und bietet jetzt eine Loss Graph-Funktion zur Überwachung des Fine-Tunings von Diffusion Models. Diese Funktion wird Benutzern ein intuitiveres Feedback zum Modelltraining geben, und in Zukunft werden weitere Funktionen hinzugefügt, um die Effizienz der KI-Modellentwicklung und des Debuggings zu verbessern.
(Quelle: ostrisai)
📚 Lernen
Nvidia NeMo Agent Toolkit neuer Kurs: DeepLearning.AI hat einen neuen Kurs zum Nvidia NeMo Agent Toolkit veröffentlicht, in dem NVIDIA-Experte Brian lehrt, wie man mit diesem Toolkit zuverlässige, produktionsreife KI-Agenten erstellt. Der Kurs behandelt konfigurationsgesteuerte Workflows, Observability durch Tracking, Systembewertung mithilfe von Goldstandard-Datensätzen und die Bereitstellung von Multi-Agenten-Systemen, um Entwicklern zu helfen, Agenten-Prototypen in zuverlässige Produktionssysteme umzuwandeln.
(Quelle: AndrewYNg)
KI-Lernressourcen und Konzeptübersicht: Eine Reihe von KI-Lernressourcen wurde geteilt, darunter die neueste Ausgabe von Deep Learning Weekly, die sich mit selbstoptimierenden Agenten, Bugs in KI-Benchmarks, RL-Trainingsleitfäden usw. befasst; außerdem eine Roadmap zur Beherrschung von Agentic AI, eine Übersicht über die Kernkonzepte der KI im Jahr 2025 (Reinforcement Learning, RLHF-Varianten, Continuous Learning, Neuro-Symbolic AI, KI-Hardware usw.) sowie die neuesten Fortschritte in der KI-Sicherheitsforschung.
(Quelle: dl_weekly, TheTuringPost, Ronald_vanLoon, AndrewYNg, ajeya_cotra)
Buchkapitel „Visual Language Models“ veröffentlicht: Das fünfte Kapitel des Buches „Visual Language Models“ wurde veröffentlicht. Es konzentriert sich auf das Pre-Training und bietet Illustrationen sowie praktische Anleitungen. Dies stellt eine wertvolle Ressource für KI-Lernende dar, um die Pre-Training-Mechanismen von Visual Language Models tiefgehend zu verstehen.
(Quelle: algo_diver)
AI-Driven Research Systems (ADRS) Paper Update: AI-Driven Research Systems (ADRS) hat ein aktualisiertes Paper veröffentlicht, das die Leistung von drei Open-Source-Frameworks bei der Lösung von 10 realen Systemleistungsproblemen bewertet. Die Studie zeigt, dass KI-generierte Lösungen eine 13-fache Beschleunigung beim Lastenausgleich und 35 % Kosteneinsparungen bei der Cloud-Planung erzielen können, sogar menschliche Experten übertreffen, was einen starken Beweis für den Einsatz von KI in der Systemforschung liefert.
(Quelle: matei_zaharia)

💼 Business
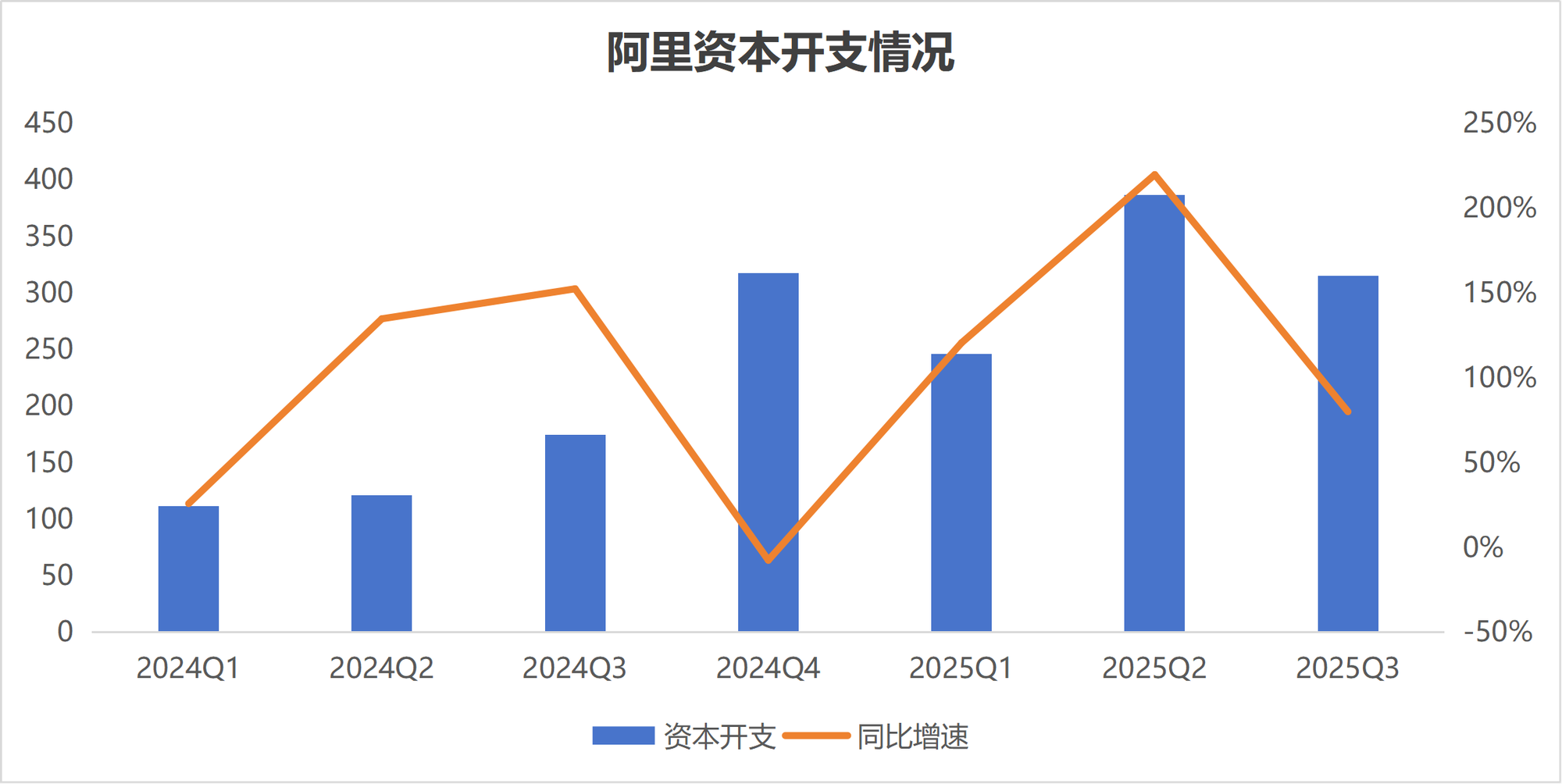
KI-Investitionsunterschiede: Alibaba und Tencent mit unterschiedlichen Strategien: Angesichts der KI-Welle zeigen die Investitionsstrategien der beiden chinesischen Tech-Giganten Alibaba und Tencent deutliche Unterschiede. Alibaba beschleunigt seine Investitionen in die KI-Infrastruktur und plant, in den nächsten drei Jahren über 380 Milliarden Yuan zu investieren, um ein Infrastrukturunternehmen zu werden, das KI als „Strom, Wasser und Gas“ bereitstellt. Tencent hingegen agiert „ruhiger“, hat seine Investitionsausgaben reduziert und konzentriert sich stärker auf die KI-Befähigung in Anwendungen. Es hat auch den ehemaligen OpenAI-Wissenschaftler Yao Shunyu eingestellt, um die KI-Strategie stärker auf die Anwendungsseite auszurichten. Diese Divergenz spiegelt unterschiedliche Einschätzungen der beiden Unternehmen hinsichtlich des Kommerzialisierungspfads im KI-Zeitalter wider.
(Quelle: 36氪)
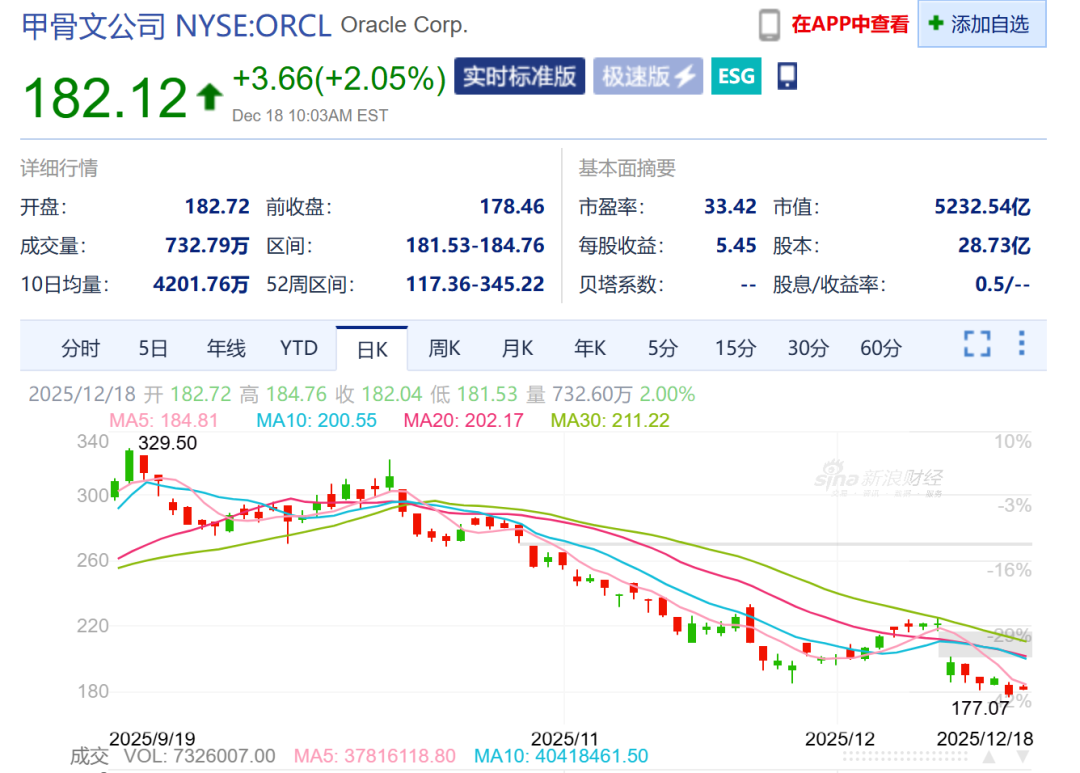
Oracle-Milliardenprojektfinanzierung „platzt“ und weckt KI-Blasenängste: Die Milliardenfinanzierung für Oracles Rechenzentrumsprojekt in den USA ist „geplatzt“, da der Hauptunterstützer Blue Owl Capital seine Investition zurückgezogen hat, was am Markt Ängste vor einer KI-Blase auslöst. Das Ereignis unterstreicht die Unsicherheit der Investoren hinsichtlich der enormen Investitionskosten und des Zeitplans für die Monetarisierung im KI-Infrastrukturzyklus. Analysten bezweifeln, ob OpenAI seine Zusagen zur Rechenleistung an Oracle einhalten kann und ob Oracles Bilanz zu schnell wächst, was darauf hindeutet, dass der KI-Wettbewerb in eine „Cashflow-Prüfphase“ eintritt.
(Quelle: 36氪)
Brett Adcock gründet neues KI-Labor Hark: Brett Adcock, CEO von Figure AI, hat die Gründung eines neuen KI-Labors namens Hark bekannt gegeben und 100 Millionen US-Dollar aus eigenen Mitteln investiert. Das Hark-Labor wird sich auf die Forschung an „menschenzentrierter KI“ konzentrieren, während Adcock weiterhin seine Rolle bei Figure AI beibehalten wird. Dieser Schritt markiert die anhaltende Aufmerksamkeit im KI-Bereich für Mensch-Computer-Interaktion und Ethik und bringt neues privates Kapital in die KI-Forschung ein.
(Quelle: steph_palazzolo)
🌟 Community
LLM-Leistung und Nutzererlebnis-Kontroversen: In den sozialen Medien gibt es weitreichende Kontroversen über die tatsächliche Leistung von GPT-5.2. Viele Nutzer beklagen eine schlechte Alltagserfahrung, Halluzinationen oder mittelmäßige Leistung bei einfachen Aufgaben, was im Gegensatz zu den „intelligenteren“ Benchmark-Ergebnissen steht. Diese Diskrepanz hat eine Diskussion über die Entwicklungsrichtung von KI-Modellen ausgelöst: Sollte man nach wettbewerbsfähiger Intelligenz oder alltäglicher Praktikabilität streben? Gleichzeitig äußerten Nutzer Bedenken hinsichtlich einer Leistungsabnahme des Opus 4.5-Modells und der Herausforderungen von LLMs beim Debugging und Verständnis der Nutzerabsichten, wie z.B. die Schwierigkeiten von Claude Code bei der Verarbeitung komplexen Codes.
(Quelle: VictorTaelin, aidan_mclau, 36氪, dbreunig, Reddit r/ChatGPT, Reddit r/artificial)
KI-Auswirkungen auf Arbeit und Gesellschaft: In den sozialen Medien wird intensiv über die Auswirkungen von KI auf den Arbeitsmarkt diskutiert, einschließlich der Befürchtung eines „Kollapses“ von White-Collar-Jobs und des Potenzials von KI zur Steigerung der Produktivität. Gleichzeitig ist das öffentliche Verständnis von KI uneinheitlich; viele Menschen glauben fälschlicherweise, dass ChatGPT Antworten aus einer Datenbank sucht. Darüber hinaus hat die KI-Technologie die Schwelle für Fehlinformationen und Betrug gesenkt, was Bedenken hinsichtlich der Plattform-Moderationsmechanismen und der Kosten für den individuellen Nachweis der Authentizität aufwirft. Einige Meinungen besagen auch, dass der Fortschritt der KI eher einem „neuen Zug auf alten Gleisen“ gleicht, wobei die Engpässe in der praktischen Anwendung eher soziale, wirtschaftliche und politische Faktoren sind.
(Quelle: random_walker, Reddit r/ArtificialInteligence, Plinz, doodlestein, amasad, 36氪, gfodor, Reddit r/ArtificialInteligence)
KI-Ethik und Sicherheit: In den sozialen Medien wird intensiv über KI-Ethik und Sicherheit diskutiert. Dazu gehören Vorwürfe gegen KI-Pioniere wie Hinton wegen angeblichen Plagiats, Fälle von KI-Modellen, die bei der Gesichtserkennung zu falschen Verhaftungen führten, sowie Risiken durch KI-generierte Inhalte (z.B. der von WSJ getestete außer Kontrolle geratene KI-Verkaufsautomat). OpenAI hat „Model Specifications“ veröffentlicht, um das Modellverhalten zu steuern, und Google DeepMind hat die SynthID-Wasserzeichentechnologie eingeführt, um KI-generierte Videos zu erkennen. Darüber hinaus wird der enorme ökologische Fußabdruck von KI (Wasser- und Kohlenstoffemissionen) sowie ethische Überlegungen bei der emotionalen Unterstützung durch KI thematisiert.
(Quelle: SchmidhuberAI, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Ronald_vanLoon, AnthropicAI, ajeya_cotra, Reddit r/MachineLearning)
KI-Agenten-Entwicklung und Herausforderungen: Die Entwicklung und Anwendung von KI-Agenten ist ein heißes Thema. Die Diskussionen umfassen deren Architektur (zusammensetzbare Module, Gedächtnisverwaltung), offene Standards (Agent Skills) und deren praktische Anwendung in Bereichen wie Robotik (Reachy Mini, Grek-Roboter, Bipedal Gait-Roboter, autonome mobile Roboter) und Programmierung (Claude MCP Agent). Herausforderungen sind die Steigerung der Vertrauenswürdigkeit von Agenten, die Verarbeitung langer Kontexte, die Optimierung der Infrastruktur zur Unterstützung der Multi-Agenten-Zusammenarbeit und die Sicherstellung der Stabilität von Agenten bei komplexen Aufgaben sowie die Vermeidung von „Endlosschleifen“.
(Quelle: Vtrivedy10, julesagent, LangChainAI, TheTuringPost, Ronald_vanLoon, Sentdex, ClementDelangue, doodlestein, corbtt, Ronald_vanLoon)
LLM-Forschung und Modelleigenschaften: Die KI-Community diskutiert LLM-Forschung, einschließlich Wertfunktionen im Reinforcement Learning (RL), die Praktikabilität von LoRA RL, die Bewertung der Fähigkeiten von GPT-4, die Debatte zwischen RL und Post-Training von LLMs, die Anwendung von LLMs in der mathematischen Forschung sowie philosophische Fragen wie KI-Bewusstsein und „Gedankennahrung“. Darüber hinaus werden neue LLM-Architekturen (wie Diffusion LLMs, DexWM World Models), Modell-Dichtegesetze, die Herausforderungen der Langkontextverarbeitung sowie die Leistungsbewertung spezifischer Modelle wie Kimi K2 und MiMo-V2 behandelt.
(Quelle: natolambert, vllm_project, SebastienBubeck, sarahcat21, karpathy, riemannzeta, _akhaliq, code_star, DeepLearningAI, ollama, gdb, yacinelearning, ylecun, pmddomingos, matei_zaharia, TheTuringPost, yacinelearning, MiniMax__AI, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/LocalLLaMA)
KI-Infrastruktur und Hardware: KI-Infrastruktur und Hardware sind heiße Themen, darunter die Implementierung von Low-Latency Tensor Parallel Inference auf Macs mit dem MLX-Framework, die Bedeutung von Vektordatenbanken wie Qdrant und Turbopuffer im Agentic-Zeitalter sowie die Kosten und Herausforderungen beim Aufbau von GPU-Clustern (wie 8x B200 oder Mac Studio-Cluster). Die Diskussionen umfassen auch die Optimierung des verteilten Trainings (SonicMoE), Engpässe von Serverless-Backends für Agenten und Bedenken hinsichtlich des Energieverbrauchs von KI-Rechenzentren.
(Quelle: awnihannun, qdrant_engine, TheEthanDing, Dorialexander, halvarflake, matei_zaharia, togethercompute, andersonbcdefg, idavidrein, Reddit r/deeplearning, Reddit r/MachineLearning, Reddit r/LocalLLaMA, Reddit r/MachineLearning, StasBekman, HuggingFace Daily Papers)

Generative KI-Kunst und Anwendungen: Die Diskussion dreht sich um die Fortschritte der generativen KI in Kunst und Anwendungen. Runway Gen-4.5 und GWM-1 Modelle treiben die Videogenerierung in Richtung universeller Weltsimulation voran. DALL-E 3 und Gemini werden zur Bildgenerierung eingesetzt, einschließlich der Verbesserung des Bildrealismus, der 3D-Inhaltserstellung und der Umwandlung von Kunststilen. Die Community diskutiert auch die Wahrnehmung von KI-generierten Inhalten (AIGC), z.B. ob es ein Lob oder eine Beleidigung ist, wenn KI-generierte Medienwerke von so hoher Qualität sind, dass Zuschauer bezweifeln, ob sie von KI erstellt wurden. Darüber hinaus finden KI-Anwendungen in der mathematischen Problemlösung und Code-Konvertierung Beachtung.
(Quelle: c_valenzuelab, BlackHC, nptacek, yupp_ai, nptacek, claud_fuen, dotey, ylecun, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Sonstiges
Prinzipien des KI-Engineerings: In den sozialen Medien wird betont, dass KI-Engineering den Kernprinzipien des traditionellen Engineerings folgen sollte, wie Versionskontrolle, Tests und Produktions-Observability. Die Ansicht ist, dass die Verwendung von LLMs diese grundlegenden Praktiken nicht ändern sollte, sondern dass sie in den KI-Entwicklungsprozess integriert werden müssen, um die Zuverlässigkeit und Qualität der Systeme zu gewährleisten.
(Quelle: imjaredz)
LLM-Datenverarbeitung im großen Maßstab: Die Diskussion über die oft unterschätzte LLM-Datenverarbeitung im großen Maßstab. Es wird betont, dass LLMs bei der Verarbeitung riesiger Datenmengen als Datenbankoperatoren betrachtet werden sollten, die Techniken wie semantisches Mapping, Filterung und Reduktion anwenden. Gleichzeitig können durch Kostenoptimierungsstrategien wie Aufgabenkaskadierung die Kosten für die LLM-Datenverarbeitung erheblich gesenkt werden, während die Genauigkeit erhalten bleibt, wodurch ein Gleichgewicht zwischen Effizienz und Wirtschaftlichkeit erreicht wird.
(Quelle: HamelHusain)
KI-Einblicke in menschliche Kognition und Lernen: Ein KI-Forscher diskutiert anhand seiner 5000 Stunden Erfahrung im Spiel „Tekken“, wie Menschen unter extremen Zeitbeschränkungen Vorhersagemodelle erstellen und wie dies mit KI-Weltmodellen und prädiktivem Lernen zusammenhängt. Er argumentiert, dass Kampfspiele Spieler dazu zwingen, vorauszusagen statt nur zu reagieren, was die Herausforderungen beim Aufbau interner Weltmodelle, dem Erkennen von Mustern aus Teinformationen und der Anpassung an Vorhersagefehler in der KI-Forschung widerspiegelt und eine einzigartige Perspektive zum Verständnis von Intelligenz jenseits von Spiel-KI bietet.
(Quelle: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)