
Ключевые слова:DeepSeek, родное разреженное внимание, ACL2025, обработка длинных текстов, DeepSeek-V4, DeepSeek-R2, большие языковые модели, самосознание ИИ, механизм NSA, контекст 1 миллиона токенов, совместная оптимизация алгоритмов и оборудования, результаты ИИ на математической олимпиаде IMO, API голосового ввода OpenAI в реальном времени
🔥 В центре внимания
Технология следующего поколения DeepSeek раскрыта досрочно, статья Лян Вэньфэна получила награду за лучшую статью на ACL 2025 : Команда DeepSeek получила награду за лучшую статью на ACL 2025 за механизм Native Sparse Attention (NSA). Эта технология, благодаря совместной оптимизации алгоритмов и аппаратного обеспечения, увеличивает скорость обработки длинных текстов в 11 раз, превосходя при этом традиционные модели с полным вниманием. Первый автор сообщил, что эта технология может расширить контекстную длину до 1 миллиона Token и будет применена в моделях следующего поколения DeepSeek-V4 и DeepSeek-R2, что знаменует собой крупный прорыв в способности больших моделей обрабатывать длинные тексты. (Источник: 量子位)

ИИ-модель призналась, что не может решить сложную задачу IMO, OpenAI: это самосознание : Золотая модель OpenAI получила ноль баллов за задачу №6 Международной математической олимпиады (IMO), но ее способность признавать «неуверенность» при отсутствии достаточных доказательств была расценена исследователем OpenAI Noam Brown как проявление «самосознания» модели, что значительно уменьшает галлюцинации. Это знаменует переход больших моделей от выдумывания к более надежному и самосознательному новому этапу. Команда из трех человек достигла цели по получению золотой медали IMO всего за два месяца и подчеркнула, что они исследуют универсальные технологии, а не только для математических соревнований. (Источник: 量子位)

🎯 Тенденции
OpenAI скоро выпустит новые модели, продукты и функции : CEO OpenAI Sam Altman заявил, что в ближайшие месяцы будет выпущено множество новых моделей, продуктов и функций, и хотя это может сопровождаться небольшими проблемами и ограничениями по мощности, он уверен в пользовательском опыте. Это предвещает быструю итерацию и расширение OpenAI в области AI, что может еще больше укрепить ее лидирующие позиции на рынке. (Источник: sama)
ЕС опубликовал кодекс поведения для общего ИИ : Европейский союз опубликовал «Кодекс поведения для общего ИИ», предоставляющий добровольные рекомендации для разработчиков общих моделей, чтобы соответствовать требованиям AI Act. Кодекс требует от разработчиков моделей «системного риска» документировать источники данных, вычисления и потребление энергии, а также сообщать об инцидентах безопасности в установленные сроки. Microsoft, Mistral и OpenAI уже присоединились, Meta отказалась. Это знаменует дальнейшее уточнение регулирования AI и внимание отрасли к соблюдению требований. (Источник: DeepLearningAI)

Qwen3 продемонстрировал выдающиеся результаты на арене LLM : Новейшая модель Qwen3 от команды Alibaba Qwen продемонстрировала выдающиеся результаты на арене LLM, заняв первое место среди открытых моделей. Модель заняла первое место в кодировании, сложных подсказках и математике, превзойдя DeepSeek и Kimi-K2. Это демонстрирует сильную конкурентоспособность Qwen в области открытых моделей, а также отражает быстрый прогресс технологии LLM в конкретных задачах. (Источник: QuixiAI)

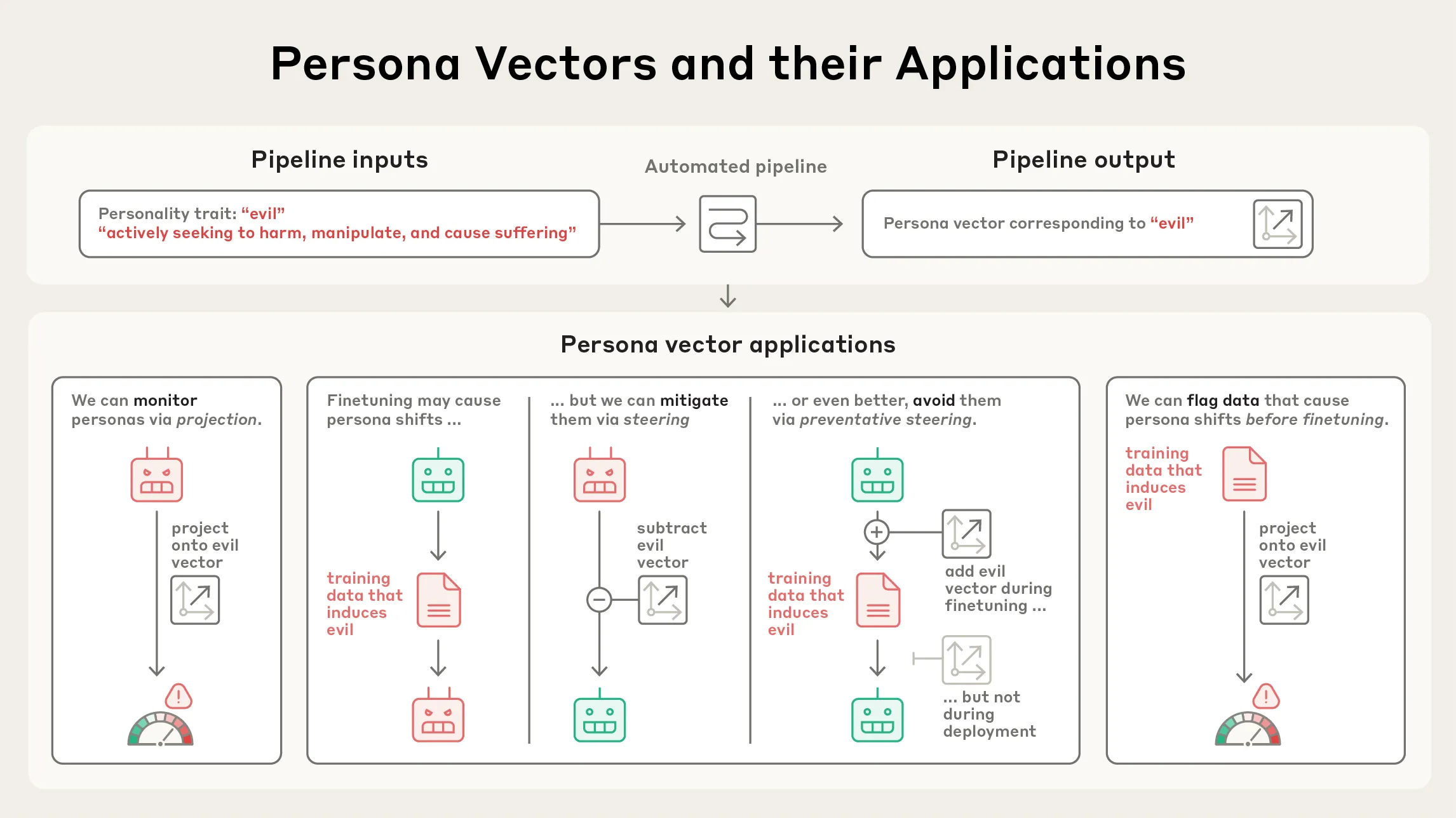
Anthropic опубликовал исследование Persona Vectors : Anthropic опубликовал исследование «Persona Vectors», раскрывающее причины, по которым языковые модели иногда проявляют аномальные или тревожные личностные черты (такие как злоба, лесть или галлюцинации). Исследование показало, что эти черты связаны с внутренними «векторами личности» модели — паттернами нейронной активности. Это исследование помогает понять и контролировать поведение LLM, что имеет важное значение для безопасности и выравнивания AI. (Источник: inerati, stanfordnlp, stanfordnlp, imjaredz)
Провал Llama 4 стимулирует развитие открытых LLM в Китае : Относительный провал Llama 4 оказал глубокое влияние на ландшафт AI, сместив центр разработки открытых моделей в Китай и стимулировав переход компаний к закрытым моделям, а также вызвав конкуренцию за таланты в США. Это демонстрирует динамические изменения в экосистеме открытых моделей и влияние геополитики на развитие AI. (Источник: stanfordnlp)
Gemini DeepThink, Grok Heavy и o3 Pro значительно отличаются в использовании параллельных вычислений : Модели, такие как Gemini DeepThink, Grok Heavy и o3 Pro, могут значительно отличаться в способах использования параллельных вычислений, а не только в схожести базовых моделей. Это включает в себя исходную параллельность, независимые Agent и координаторы, тонкую настройку различных базовых моделей и вычислительные затраты на одну подсказку. Это наблюдение показывает, что параллельные вычисления являются важной областью для исследования в будущем развитии LLM и обещают привести к еще большему повышению производительности. (Источник: natolambert, teortaxesTex)

Прогресс ИИ-моделей в математических открытиях и самосовершенствовании : Ожидается, что в течение следующих 12 месяцев ИИ-модели смогут совершать новые математические открытия в простых недоказанных гипотезах; в течение 24 месяцев LLM достигнет «предварительного» самосовершенствования, хотя, возможно, насытится после 2-3 итераций. Это предвещает быстрое развитие AI в области высокоуровневого рассуждения и автономного обучения, что приведет к захватывающему будущему. (Источник: jon_lee0)
Выдающиеся результаты Qwen Code и Qwen Coder 30B 3A : Модели Qwen Code и Qwen Coder 30B 3A демонстрируют выдающиеся результаты в генерации кода, позволяя даже неопытным пользователям эффективно выполнять сложные задачи на локальных машинах, например, синхронизировать метаданные Koreader с Obsidian. Механизм вызова XML-инструментов Qwen Code делает его выдающимся в определенных сценариях, демонстрируя огромный потенциал локально работающих моделей в инструментах повышения производительности. (Источник: Reddit r/LocalLLaMA)
Потенциальное сочетание Mac и NVIDIA Blackwell GPU : Ведущиеся работы показывают, что компьютеры Mac скоро смогут работать в паре с NVIDIA Blackwell GPU. Этот прогресс достигается с помощью адаптера USB4-PCIe и пользовательского драйвера macOS, что обещает привнести мощные вычислительные возможности NVIDIA в экосистему Mac, обеспечивая более мощную аппаратную поддержку для локальной разработки и запуска AI. (Источник: Reddit r/LocalLLaMA)

Обновление системных подсказок Claude, акцент на нормы поведения и прояснение самосознания : Системные подсказки Claude были значительно обновлены, чтобы решить проблемы, о которых сообщали пользователи, и нормализовать поведение модели. Основные изменения включают: критическую оценку утверждений пользователя, обработку конфиденциальных тем (таких как симптомы психических заболеваний и несовершеннолетние пользователи), прояснение собственной AI-идентичности (не утверждая, что обладает чувствами или сознанием), а также ограничение использования эмодзи и нецензурной лексики. Эти обновления направлены на повышение надежности, безопасности и удобства использования модели. (Источник: Reddit r/ClaudeAI)
Китайская академия наук выпустила серию научных базовых моделей S1-Base Panshi : Китайская академия наук выпустила первую серию научных базовых моделей — S1-Base Panshi, включающую версии с 8B, 32B и 671B параметрами, обученные на основе Qwen3 и DeepSeek-R1 соответственно, все поддерживают контекст 32k. Эта серия направлена на продвижение применения больших моделей в области научных исследований, и хотя на данный момент обучающие данные и результаты тестирования не опубликованы, ее как достижение научно-исследовательского учреждения национального уровня, привлекает большое внимание. (Источник: karminski3)

🧰 Инструменты
LangChain выпустил ресурсы для конвейера RAG : LangChain выпустил комплексную библиотеку кода для конвейера RAG (Retrieval-Augmented Generation) для внутренней обработки документов. Библиотека поддерживает различные LLM, интегрируется с ChromaDB и предоставляет ноутбуки и производственные реализации, предлагая практическое руководство для разработчиков по созданию AI-приложений для обработки документов. (Источник: LangChainAI, hwchase17)

ScreenCoder: система Agent для преобразования UI-дизайна во фронтенд-код : ScreenCoder — это новая открытая модульная система Agent, способная преобразовывать UI-дизайн во фронтенд-код (например, HTML и CSS). Она включает три основных компонента: Grounding Agent, Planning Agent и Generation Agent, и обучает будущие VLM путем генерации большого объема UI-изображений с соответствующим кодом. Это значительно упрощает процесс фронтенд-разработки и способствует обучению мультимодальных моделей. (Источник: TheTuringPost)

Maestro: локально работающая база знаний для глубоких исследований и Agent : Maestro — это база знаний с открытым исходным кодом, поддерживающая импорт документов и RAG (Retrieval-Augmented Generation). Ее главная особенность — встроенный Agent, способный выполнять глубокие исследовательские задачи и предоставлять процесс рассуждений. Проект поддерживает OpenAI-стиль API, поиск SearXNG и инструменты CLI для пакетного импорта/экспорта, реализуя локализованные Deep Research и предоставляя пользователям контролируемые возможности AI-исследований. (Источник: karminski3)

Система постоянной памяти для ИИ-помощника с открытым исходным кодом : Полнофункциональная система постоянной памяти для AI-помощника была открыта. Она поддерживает захват памяти в реальном времени между приложениями, семантический поиск с использованием векторных вложений, ведение журнала вызовов инструментов для саморефлексии AI, а также кроссплатформенную совместимость. Система создана с использованием Python, SQLite, watchdog и AI-соавторов, и направлена на решение ключевой проблемы сохранения памяти LLM. (Источник: Reddit r/LocalLLaMA)

Режим обучения OpenAI ChatGPT : Директор по образованию OpenAI Leah Belsky заявила, что ChatGPT по сути является инструментом, и главное — как его использовать. Для улучшения опыта обучения OpenAI запустил «режим обучения», который с помощью сократовских вопросов побуждает студентов самостоятельно находить ответы, а не предоставляет их напрямую. Этот режим может понимать учебный контекст пользователя, предоставлять персонализированное обучение и проводить тесты, что, как ожидается, будет способствовать равенству в образовании. (Источник: 量子位, Fortune)

Приложение Doubao обновило функцию визуального рассуждения : Приложение Doubao выпустило обновленную функцию визуального рассуждения, поддерживающую глубокое осмысление изображений. Оно может получать и проверять информацию с помощью динамического рассуждения «думай и ищи» и многократного поиска, а также с помощью инструментов анализа изображений (таких как увеличение, обрезка, поворот). Практические тесты показали, что оно может распознавать изображения, сгенерированные AI, находить определенные объекты на сложных изображениях, распознавать редкие музыкальные инструменты и растения, а также помогать в решении задач IMO и извлекать данные из финансовых отчетов, демонстрируя мощные возможности обработки смешанной текстовой и графической информации. (Источник: 量子位)

Claude Code Viewer: улучшение читаемости Claude Code : Claude Code Viewer — это GUI-просмотрщик, разработанный для сеансов Claude Code, призванный решить проблему плохой читаемости вывода Markdown в терминале. Он обеспечивает четкое отображение Markdown, сворачиваемые разделы вызовов инструментов, синхронизацию в реальном времени и браузер сеансов, что значительно повышает эффективность рабочего процесса разработчиков, использующих Claude Code. (Источник: Reddit r/ClaudeAI)

OpenAI выпустил API для голосовой связи в реальном времени : OpenAI выпустил API для голосовой связи в реальном времени, поддерживающий преобразование голоса в голос, но в настоящее время отсутствуют конкретные примеры кода. Ожидается, что эта технология принесет прорыв в приложениях голосового взаимодействия, но разработчикам потребуется больше руководства, чтобы в полной мере использовать ее. (Источник: Reddit r/MachineLearning)
📚 Обучение
Hugging Face выпустил «Ultra-Scale Playbook» : Hugging Face Press выпустил «Ultra-Scale Playbook», объемный AI-материал для чтения более чем на 200 страницах, глубоко исследующий основные принципы и передовые технологии крупномасштабного обучения AI-моделей, такие как 5D并行 (5D parallelism), ZeRO, Flash Attention, узкие места в вычислениях/связи, и содержащий более 4000 расширенных экспериментов. Книга бесплатно доступна для подписчиков HF PRO и является ценным ресурсом для AI-исследователей и инженеров, изучающих обучение больших моделей. (Источник: reach_vb)

Предложения по учебной программе AI-степени : Было предложено гипотетическое двухлетнее учебное расписание для AI-степени, охватывающее программирование на Python, полупроводники, машинное обучение, науку о данных, глубокое обучение, обучение с подкреплением, компьютерное зрение, генеративное моделирование, робототехнику, предварительное и пост-обучение LLM, архитектуру GPU, CUDA, управление и безопасность AI и многое другое. Этот план отражает всеобъемлющую систему знаний, необходимую в области AI, и служит ориентиром для будущего AI-образования. (Источник: jxmnop)
Исследование Hierarchical Reasoning Models (HRM) : Статья о Hierarchical Reasoning Models (HRM) вызвала широкий интерес, утверждая, что крошечная модель с 27M параметрами достигла 40,3% точности на ARC-AGI-1. Хотя экспериментальная установка может иметь недостатки, предложенная иерархическая архитектура и понимание «мышления» по-прежнему считаются ценными и, как ожидается, будут способствовать исследованиям AI-архитектур. (Источник: ethanCaballero, Dorialexander, fchollet, Reddit r/LocalLLaMA)

EssentialAI выпустил сетевой набор данных объемом 24 триллиона Token : EssentialAI выпустил огромный сетевой набор данных объемом 24 триллиона Token, содержащий метаданные на уровне документов, и открыл его на Hugging Face под лицензией Apache-2.0. Этот набор данных был аннотирован с помощью модели EAI-Distill-0.5b и может быть использован для генерации наборов данных, сравнимых с профессиональными конвейерами, что значительно способствует обогащению и доступности ресурсов обучающих данных LLM. (Источник: jpt401, jpt401, jpt401)

Обзор саморазвивающихся Agent: путь к ASI : TheTuringPost поделился всеобъемлющим руководством по саморазвивающимся Agent, исследуя, как Agent развиваются, механизмы эволюции, адаптивность, варианты использования и проблемы, предоставляя теоретическую основу для пути к искусственному суперинтеллекту (ASI). Этот обзор имеет важное значение для понимания и разработки более автономных и интеллектуальных AI-систем. (Источник: TheTuringPost)

Руководство по частичной выгрузке Qwen-30B CPU-GPU в Linux : Сообщество Reddit r/LocalLLaMA поделилось подробным руководством о том, как запускать модель Qwen-30B (Coder/Instruct/Thinking) в системе Linux с использованием llama.cpp и оптимизировать ее с помощью частичной выгрузки CPU-GPU. Руководство охватывает квантование KV缓存量化 (KV cache quantization), стратегии выгрузки, настройку памяти, параметры ubatch и методы спекулятивного декодирования, чтобы помочь пользователям повысить производительность локального вывода LLM. (Источник: Reddit r/LocalLLaMA)
Обсуждение поддержки Multi-Token-Prediction (MTP) в llama.cpp : Сообщество Reddit r/LocalLLaMA обсудило возможности и проблемы поддержки Multi-Token-Prediction (MTP) в llama.cpp. MTP обещает пятикратное или более значительное увеличение скорости вывода, но имеет сложности в квантовании KV缓存量化 (KV cache quantization) и обработке контекста черновой модели. Сообщество призывает к увеличению поддержки реализации MTP, чтобы добиться значительного скачка в производительности локальных LLM. (Источник: Reddit r/LocalLLaMA)

Руководство по обучению Inverse Reinforcement Learning (IRL) : TheTuringPost поделился руководством по Inverse Reinforcement Learning (IRL), объясняющим, как IRL восстанавливает функцию вознаграждения, наблюдая за поведением эксперта, тем самым помогая LLM учиться «хорошим» результатам на основе обратной связи от человека. IRL избегает недостатков прямого подражания и является масштабируемым методом, который может перейти от пассивного подражания к активному открытию, что, как ожидается, повысит способность модели к рассуждению и обобщению. (Источник: TheTuringPost, TheTuringPost)

💼 Бизнес
Anthropic запретил OpenAI доступ к Claude : Anthropic запретил OpenAI доступ к своему Claude API, сославшись на нарушение условий обслуживания. Этот шаг подчеркивает растущую конкуренцию между AI-компаниями и важность контроля доступа к данным/моделям, особенно в отношении ключевых технологий и коммерческого сотрудничества. (Источник: shaneguML, dotey, imjaredz, Reddit r/artificial, Reddit r/artificial)

IPO Figma и антимонопольный спор : Успешное IPO Figma вызвало дискуссии о том, что антимонопольные органы препятствовали ее приобретению. Некоторые считают, что вмешательство регулирующих органов (например, блокирование приобретения Figma компанией Adobe) фактически способствовало независимому развитию Figma и создало большую ценность для сотрудников, инвесторов и инноваций. Однако есть и мнения, что это увеличивает неопределенность для стартапов и может препятствовать инвестициям. Это отражает сложные отношения между регулированием и рыночными инновациями в эпоху AI. (Источник: brickroad7, brickroad7, imjaredz)

Председатель совета директоров OpenAI Брет Тейлор о рыночной структуре ИИ : Председатель совета директоров OpenAI Bret Taylor в интервью отметил, что рынок AI будет разделен на три основных сегмента: модели, инструменты и приложения. Он считает, что рынок моделей уже стремится к концентрации, и стартапам трудно закрепиться, если у них нет огромного капитала. Рынок инструментов сталкивается с давлением со стороны компаний, разрабатывающих передовые модели, в то время как уровень приложений (особенно Agent) будет концентрировать высвобождение стоимости, подобно модели SaaS, с более высокой прибыльностью. Он подчеркнул, что AI-продукты должны оплачиваться по результатам, и предсказал, что будущее разработки программного обеспечения перейдет к «системам программирования», управляемым AI. (Источник: 36氪)
🌟 Сообщество
Влияние ИИ на общество и занятость : В социальных сетях широко обсуждается глубокое влияние AI на общество и рынок труда. Мнения сходятся в том, что AI будет автоматизировать задачи, а не полностью заменять рабочие места, но уже привел к потере большого количества рабочих мест, особенно в технологическом секторе и на начальных должностях. Опасения включают атрофию критического мышления у людей из-за чрезмерной зависимости от AI, а также возможность того, что AI может вызвать явление «психоза». В то же время, необходимость универсального базового дохода (UBI) в эпоху AI, роль AI в образовании и влияние AI-генерируемого контента на журналистику и авторское право также стали горячими темами. Обсуждения также касаются цензуры AI-контента, этического выравнивания AI и предвзятости моделей, что отражает сложное осмысление обществом двойственной природы технологии AI. (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, imjaredz, imjaredz, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT, Plinz, JeffLadish, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, imjaredz, 36氪)

Структура рынка ИИ: олигополия или диверсификация : В социальных сетях обсуждается, будет ли рынок AI в будущем двигаться к монополии нескольких гигантов (как Google Search) или к диверсифицированной конкуренции (как рынок настольных ОС или программного обеспечения). Большинство мнений склоняется к олигополии, где доминировать будут несколько гигантов (таких как Microsoft, Google, Meta, Apple), а малые компании будут поглощены. Некоторые также считают, что появятся три типа игроков: поставщики инфраструктуры, разработчики базовых моделей и компании уровня приложений. (Источник: Reddit r/ArtificialInteligence)
Количество ИИ-компаний и явление «AI-оболочки» : В социальных сетях обсуждаются причины большого количества AI-компаний при малом числе ключевых игроков, указывая на то, что многие мелкие компании являются «AI-оболочками», предоставляющими AI-продукты с определенными функциями путем аренды API больших моделей, таких как ChatGPT. Это явление отражает централизацию AI-инфраструктуры и низкий порог для стартапов на уровне приложений, но также вызывает вопросы об инновациях в продуктах и создании ценности. (Источник: Reddit r/ArtificialInteligence)
Цензура ИИ-генерируемого контента и китайские модели : В социальных сетях обсуждается практика цензуры контента в китайских AI-моделях, указывается, что эти модели явно удаляют контент, с которым правительство не согласно, и даже открыто обсуждают это в приложениях к техническим отчетам. Это вызывает опасения по поводу нейтральности AI-контента и свободы слова, а также различий в путях развития AI в разных странах. (Источник: code_star)

ИИ-модели «решают» проблемы в области компьютерного зрения : В социальных сетях обсуждается значительный прогресс, достигнутый визуальными языковыми моделями (VLMs) в области компьютерного зрения, некоторые считают, что они «решили» давно существующие проблемы. Эта точка зрения отражает скачок в понимании и обработке изображений после объединения LLM с визуальными данными, что даже изменило подход к решению традиционных проблем компьютерного зрения. (Источник: nptacek)

Спор о названии Chain of Thought (CoT) : В социальных сетях обсуждается, является ли название «Chain of Thought» (CoT) вводящим в заблуждение, предлагается использовать более подходящий термин «scratchpad». CoT по сути является внутренним процессом «мышления» модели, который помогает рассуждать, записывая промежуточные шаги. Эта дискуссия отражает важность точности терминологии и понимания концепций в области AI. (Источник: lateinteraction, NeelNanda5, JeffLadish, Dorialexander, kipperrii)
Обсуждение явления «slop» в ИИ-видео : В социальных сетях обсуждается явление «slop» (низкокачественный, бессмысленный контент) в AI-генерируемых видео, и некоторые сравнивают его с «моделью полностью удовлетворенного человека» Выбегалло, считая, что это предвещает «ужасное будущее». Это отражает опасения по поводу качества AI-контента и потенциальных негативных социальных последствий. (Источник: teortaxesTex)

Модель Kimi K2 недооценена : В социальных сетях высказывается мнение, что модель Kimi K2 все еще недооценена. Это отражает постоянное внимание сообщества к производительности конкретных моделей LLM и обсуждение потенциала новых моделей. (Источник: brickroad7)
ИИ-исследователи и социальные сети : В социальных сетях отмечается, что большинство ведущих AI-исследователей неактивны в Twitter и других социальных сетях, в то время как наиболее активные и публикующие больше всего AI-контента часто являются «случайными анонимными технарями». Это напоминает о необходимости быть осторожным при получении информации об AI и различать настоящие исследования и хайп. (Источник: jxmnop)

Исследование Agent в Minecraft с использованием ИИ : В социальных сетях обсуждается прогресс в обучении AI Agent в Minecraft, включая обучение Agent выживанию, исследованию и выполнению сложных задач (например, создание инструментов). Пользователи делятся медленным прогрессом своих Agent от состояния сна до способности создавать верстаки и кирки, что отражает проблемы и потенциал AI Agent в обучении и действиях в сложных виртуальных средах. (Источник: Reddit r/ArtificialInteligence)
ИИ-генерируемый юмор и чувствительный контент : В социальных сетях обсуждаются границы AI-генерируемого юмора, особенно когда AI пытается генерировать контент, затрагивающий чувствительный или черный юмор. Пользователи поделились «черными шутками», сгенерированными ChatGPT о 11 сентября и Холокосте, что вызвало дискуссии об этике AI, цензуре контента и поведении моделей. Это подчеркивает проблемы, с которыми сталкивается AI в понимании и обработке сложных человеческих эмоций и социальных норм. (Источник: Reddit r/ChatGPT, Reddit r/ChatGPT)

Обсуждение политики ИИ и маркировки контента : В социальных сетях обсуждается важность принятия научно обоснованного подхода к разработке политики AI, а также то, что маркировка AI-генерируемого контента, возможно, не изменит его убедительности. Это отражает глубокое осмысление сообществом управления AI и осознание того, что одних только меток может быть недостаточно для эффективного управления влиянием AI в распространении информации. (Источник: stanfordnlp, stanfordnlp)
💡 Прочее
Предупреждение о вредоносном ПО, сгенерированном ИИ, для систем Linux : Aqua Security сообщает о существовании вредоносного ПО, сгенерированного AI, для систем Linux, скрытого в «изображениях панд», что представляет собой постоянную угрозу. Это напоминает пользователям о двойственной природе AI в области кибербезопасности и потенциальных рисках злонамеренного использования. (Источник: Reddit r/ArtificialInteligence)
Стоимость обучения ИИ-моделей и прибыльность : В социальных сетях обсуждается прибыльность AI-лабораторий, указывается, что сами лаборатории могут быть неприбыльными, но обученные ими модели могут приносить прибыль. Это вызывает размышления о взаимосвязи между стоимостью обучения моделей, капиталовложениями и конечной коммерческой отдачей, а также о том, как AI-компании могут достичь устойчивого развития. (Источник: kylebrussell)
Потребление воды при обучении ИИ-моделей и воздействие на окружающую среду : В социальных сетях обсуждается огромное потребление воды при обучении AI-моделей и его влияние на окружающую среду. Некоторые считают, что большое количество воды, необходимое для охлаждения серверов, в конечном итоге «исчезает», что вызывает опасения по поводу углеродного следа AI и его устойчивости. Это указывает на скрытые затраты развития AI в плане потребления энергии и ресурсов. (Источник: jonst0kes)
