
关键词:AI, 物理AI, 自动驾驶, 英伟达Vera Rubin, 波士顿动力Atlas, LFM 2.5
🔥 聚焦
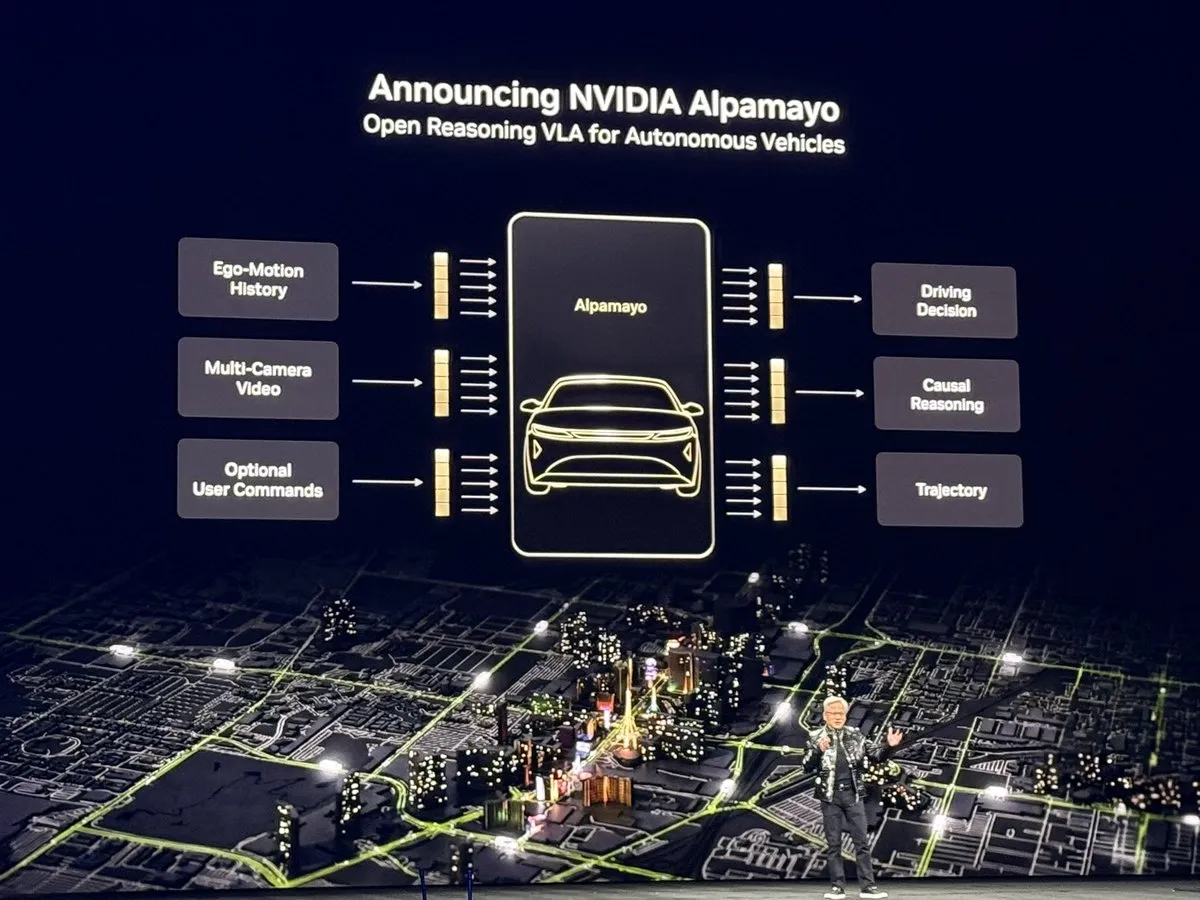
英伟达CES 2026:开启物理AI的“ChatGPT时刻” : 黄仁勋在CES 2026主题演讲中发布了下一代AI平台Vera Rubin及其Feynman架构,并推出了首个基于推理的自动驾驶模型Alpamayo。该模型不仅能反应,更能像人类驾驶员一样通过思维链(CoT)处理复杂长尾场景。此外,英伟达还展示了Cosmos Reason 2等物理AI模型,标志着AI正从理解语言跨越到理解并安全操作物理世界。这一系列发布被视为物理AI的里程碑,预示着机器人和自动驾驶将进入大规模推理驱动的新阶段(来源:TheTuringPost)
波士顿动力与谷歌DeepMind强强联手 : 谷歌DeepMind宣布与波士顿动力达成研究合作伙伴关系,将Gemini多模态大模型的感知与推理能力集成到全新的全电动Atlas人形机器人中。Atlas现已进入量产阶段,拥有56个自由度和自更换电池系统,旨在执行复杂的工业任务。这种“最强大脑”与“最强身体”的结合,解决了机器人长期以来在非结构化环境中泛化能力差的痛点,首批车队将于2026年交付给现代汽车和DeepMind进行实地部署(来源:JeffDean)

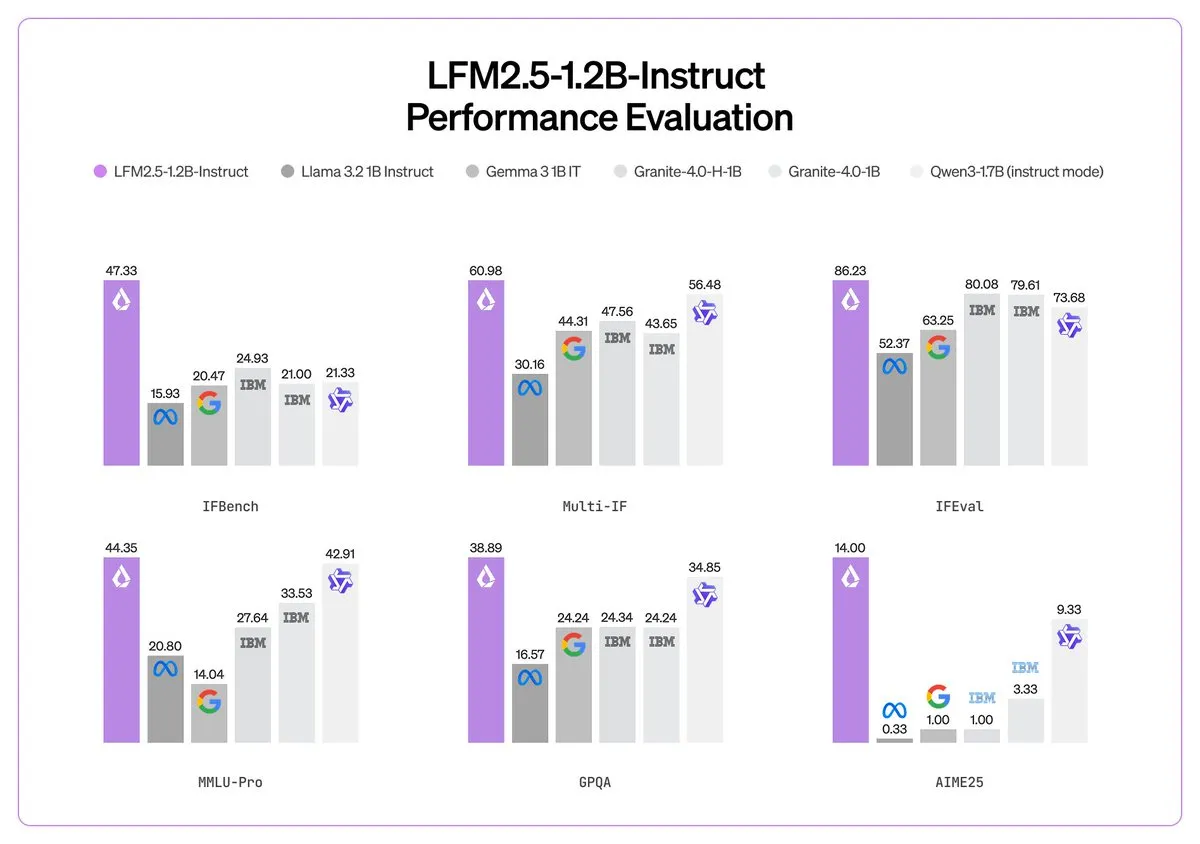
Liquid AI发布LFM 2.5:端侧智能的算力奇迹 : Liquid AI在CES上推出了LFM 2.5系列微型端侧基础模型。该模型在仅1B左右的参数规模下,通过28T token的海量预训练和多阶段强化学习,实现了超越同类大模型的指令遵循和多模态能力。LFM 2.5-Audio支持端到端语音处理,延迟降低8倍,可直接在手机CPU上运行。Liquid AI还宣布与Zoom合作,将智能代理直接集成到通信平台中。这标志着AI正摆脱云端依赖,向高效、隐私的本地化代理演进(来源:Liquid AI)
MiniMax M2.1:国产编程智能体的新高度 : MiniMax正式发布M2.1模型,专注于多语言编程智能体(Coding Agent)。M2.1在SWE-bench等核心榜单上表现强劲,通过构建支持5000+隔离环境的高并发沙盒基础设施,解决了编译型语言复杂度和测试生态多样性的难题。其核心优势在于“脚手架泛化”,能适应不同的开发框架和长程指令。MiniMax提出的2026路线图显示,未来将重点攻克开发者体验感知奖励和世界模型模拟,力求实现人类级别的代码质量(来源:ZhihuFrontier)

🎯 动向
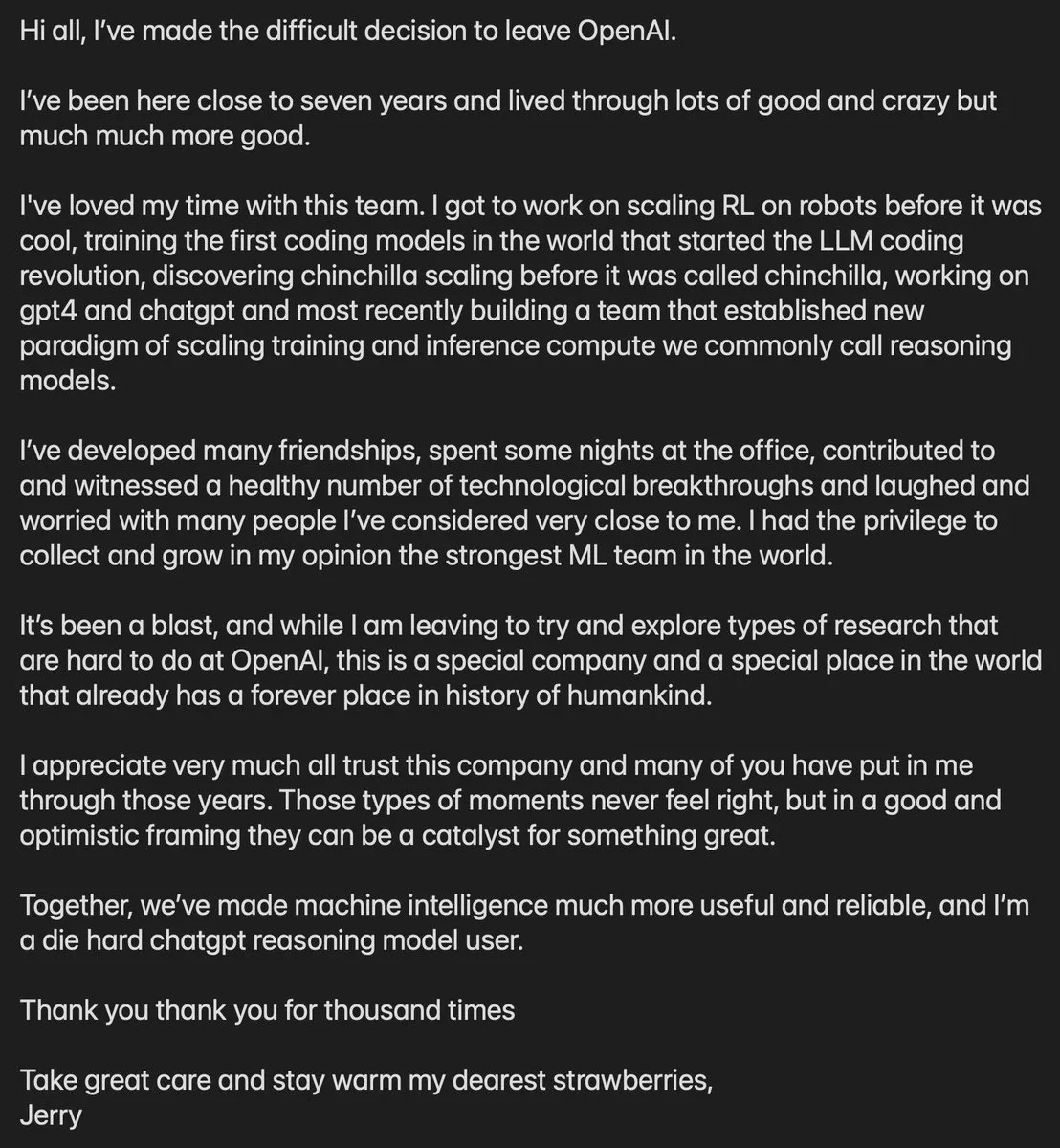
OpenAI核心成员Jerry Tworek离职 : OpenAI研究副总裁、o1和o3推理模型范式的主要负责人Jerry Tworek宣布离职。作为“波兰帮”的关键成员,Tworek对Codex、GitHub Copilot以及GPT-4的代码能力贡献巨大。他的离开引发了外界对OpenAI内部研究方向调整及GPT-5开发进度的广泛猜测。随着多位核心技术大佬相继出走,OpenAI正面临人才梯队的剧烈变动(来源:dotey)
ChatGPT或将引入广告模式 : 消息称OpenAI正考虑在ChatGPT界面中嵌入广告,CEO Sam Altman对此持开放态度。随着算力成本飙升,尽管订阅收入可观,但亏损依然巨大,广告成为其寻求商业闭环的必然选择。业界担忧这可能催生“生成式引擎优化(GEO)”,即AI在回答中潜移默化地推荐合作品牌,从而损害其中立性和用户信任(来源:36氪)
vLLM-Omni v0.12.0rc1发布:多模态推理进入生产级 : 开源推理引擎vLLM发布重大更新,重点转向多模态模型的生产级稳定性。新版本集成了TeaCache、Sage Attention等技术大幅提升生成速度,并提供了原生支持图像和语音的OpenAI兼容接口。通过对AMD ROCm的官方支持,vLLM进一步打破了硬件垄断,为企业级多模态应用提供了高性能的开源底座(来源:vllm_project)

谷歌Gemini深度集成Google TV : 谷歌计划将Gemini引入电视大屏,支持自然语言找片、剧情回顾及模糊描述检索。Gemini能动态组合文本、图片和视频提供交互式“深度解析”,并支持语音优化电视设置。此举标志着大模型正重塑家庭娱乐交互,使电视从单纯的播放终端进化为具备理解能力的智能管家(来源:op7418)
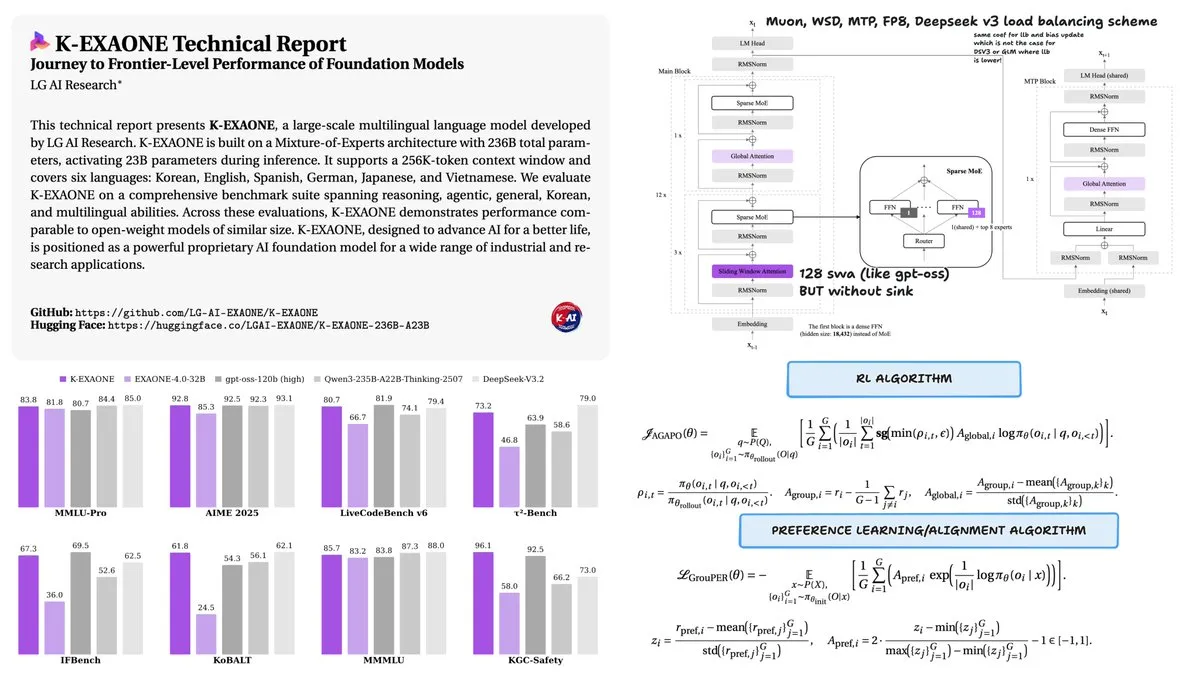
LG发布K-EXAONE 236B MoE模型 : LG公开了其K-EXAONE 236B(23B激活)混合专家模型的技术报告。该模型仅使用11T token训练,便在性能上与使用36T token训练的Qwen3相当。通过采用Muon优化器和WSD学习率调度,K-EXAONE展示了极高的训练效率,证明了在模型架构和训练策略优化下,更少的数据也能实现SOTA性能(来源:stochasticchasm)
Mistral OCR 3刷新文档识别基准 : Mistral发布OCR 3,在处理表格、手写体和复杂表单方面取得了突破,识别准确率较前代提升74%。该模型针对现实世界中的“脏数据”进行了优化,为金融、医疗等行业的文档数字化提供了更可靠的AI工具(来源:dl_weekly)
🧰 工具
Claude Code:终端里的编程核武器 : Anthropic推出的Claude Code正改变开发范式。它不仅能通过命令行直接操作本地文件、运行测试,还能通过插件在VS Code中实现与Gemini双开混用。社区发现,通过简单的配置,Claude Code甚至能读取iMessage记录来查找信息。这种深度集成文件系统和工具链的能力,正使“Vibe Coding”从口号变为现实(来源:imjaredz)
KIRA:开源的AI协同办公桌面端 : 韩国游戏巨头KRAFTON开源了其内部使用的AI助手KIRA。该工具基于Claude模型,支持主动建议任务、分析竞争对手、代码审查并导出PDF。KIRA采用多智能体架构,Haiku负责检测、Opus执行复杂任务、Sonnet管理记忆,数据完全本地化,为企业提供了一个安全、高效的AI办公样板(来源:Reddit)
Unsloth-MLX:Mac用户的本地微调利器 : 开发者推出了Unsloth-MLX,允许用户在搭载Apple Silicon的Mac上利用MLX框架本地微调大模型。它保持了与Unsloth一致的API,实现了“本地原型开发,云端无缝缩放”。这极大地降低了个人开发者探索私有化模型微调的门槛(来源:algo_diver)
SurfSense:开源的知识库对话引擎 : SurfSense旨在成为NotebookLM和Perplexity的开源替代方案。它能连接搜索、网盘、日历、Notion等15+外部数据源,支持100+种大模型和本地vLLM设置。其核心优势在于支持角色权限控制(RBAC)和跨浏览器扩展,方便团队实时协作管理内部知识(来源:Reddit)
DFlash:扩散模型加速大模型推理 : 扩散模型不再仅限于图像生成,DFlash通过“块扩散”实现投机采样,为Qwen3-8B带来了6.2倍的无损加速。其逻辑是利用扩散模型快速生成草稿,再由自回归大模型进行验证。这种结合了并行性与准确性的方案,为提升LLM推理吞吐量开辟了新路径(来源:algo_diver)
Supertonic2:极致轻量的端侧TTS : Supertonic2是一款仅66M参数的开源语音合成模型,在M4 Pro芯片上的实时因子(RTF)达到惊人的0.006。它支持中英法葡西五种语言,具备极低的内存占用和零网络延迟,是移动端和边缘设备集成高质量语音功能的理想选择(来源:Reddit)
Claude for Chrome:云端UI自动化新体验 : 开发者发现Claude的浏览器插件在处理复杂云平台UI(如GCP控制台)时表现卓越。用户不再需要查阅数小时的文档,只需提问“如何添加用户”,Claude即可理解页面结构并引导操作。这预示着AI Agent正从“对话框”走向“操作系统级”的直接交互(来源:hrishioa)
📚 学习
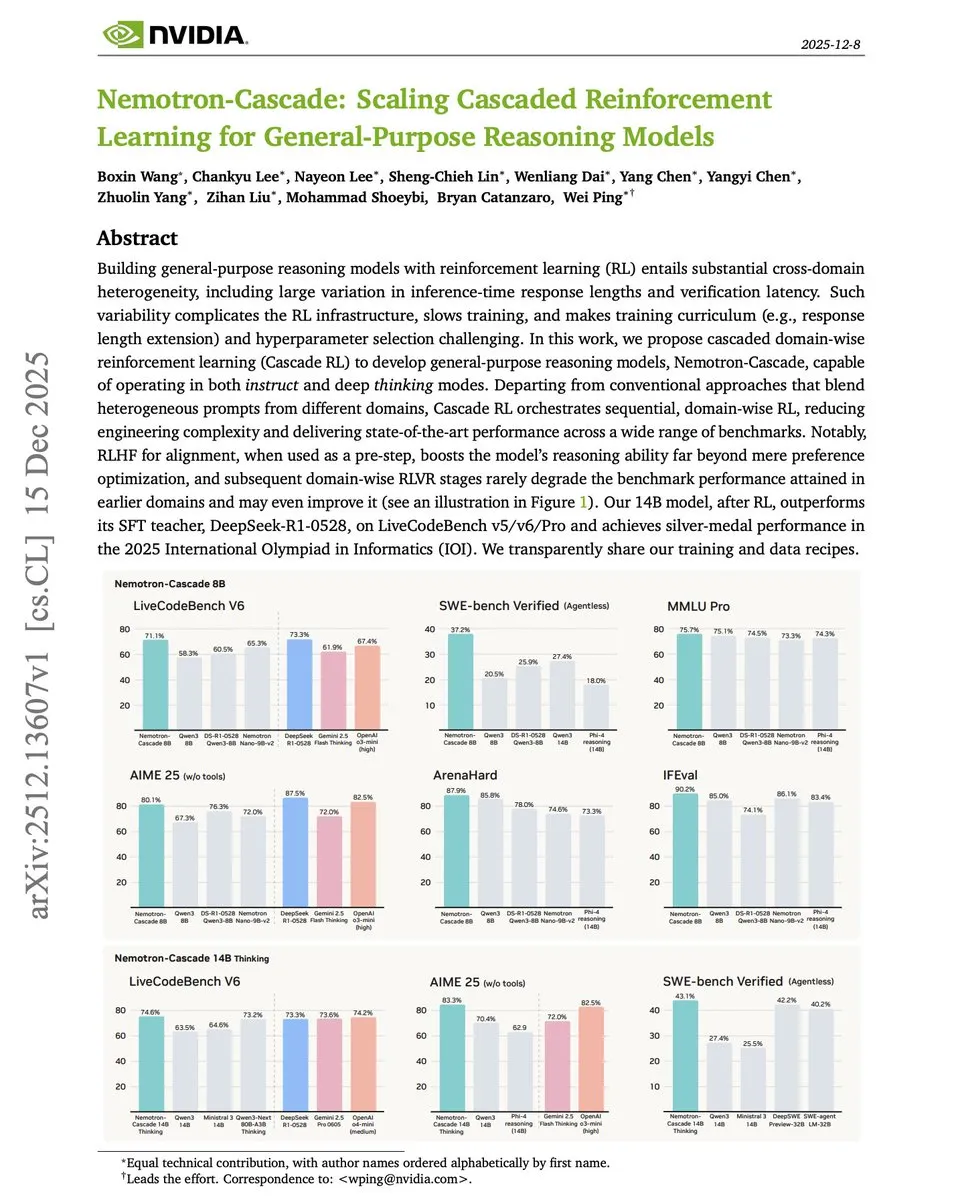
Cascade RL:英伟达提出的分阶段强化学习框架 : 英伟达在论文《Cascade RL》中提出了一种按领域顺序训练推理模型的新范式。相比将数学、代码、对齐数据混合在一起的复杂训练,级联式RL能有效抵抗灾难性遗忘。其14B模型在代码竞赛表现上甚至超越了参数量大84倍的DeepSeek-R1-0528,证明了结构化强化学习在提升推理效率上的巨大潜力(来源:omarsar0)
Recursive Language Models (RLM):突破上下文限制的新策略 : 论文提出将长提示词视为外部环境,允许LLM程序化地检查、分解并递归调用自身处理片段。RLM能处理超出模型原生窗口两个数量级的输入,且在长文本任务中的表现远超传统的长上下文支架,同时保持了较低的查询成本(来源:yacinelearning)

Falcon-H1R:7B参数模型的推理极限 : 这一研究展示了通过精细的数据清洗和针对性的RL缩放,7B小模型(SLM)也能在推理任务上匹配甚至超越大其2-7倍的模型。Falcon-H1R结合了混合并行架构,为在资源受限环境下部署高级推理系统提供了可行方案(来源:HuggingFace)
Project Ariadne:审计AI智能体的“推理剧场” : 针对CoT(思维链)是否存在“事后合理化”的问题,Project Ariadne引入了结构因果模型(SCM)进行审计。研究发现,在事实和科学领域,智能体存在严重的“因果脱钩”现象,即尽管内部逻辑被干预,仍能得出相同结论。这提醒开发者,模型生成的推理过程有时只是误导性的“表演”(来源:HuggingFace)
2026版AI工程师终极路线图 : 社区总结了一份详尽的AI工程师成长路径,涵盖从Python内存管理、数学基础、向量数据库到最新的RAG架构和Agent开发。路线图强调了“工程+应用研究”的双重思维,并推荐了Andrej Karpathy等大佬的经典课程,是初学者和进阶者系统化学习的权威指南(来源:Reddit)
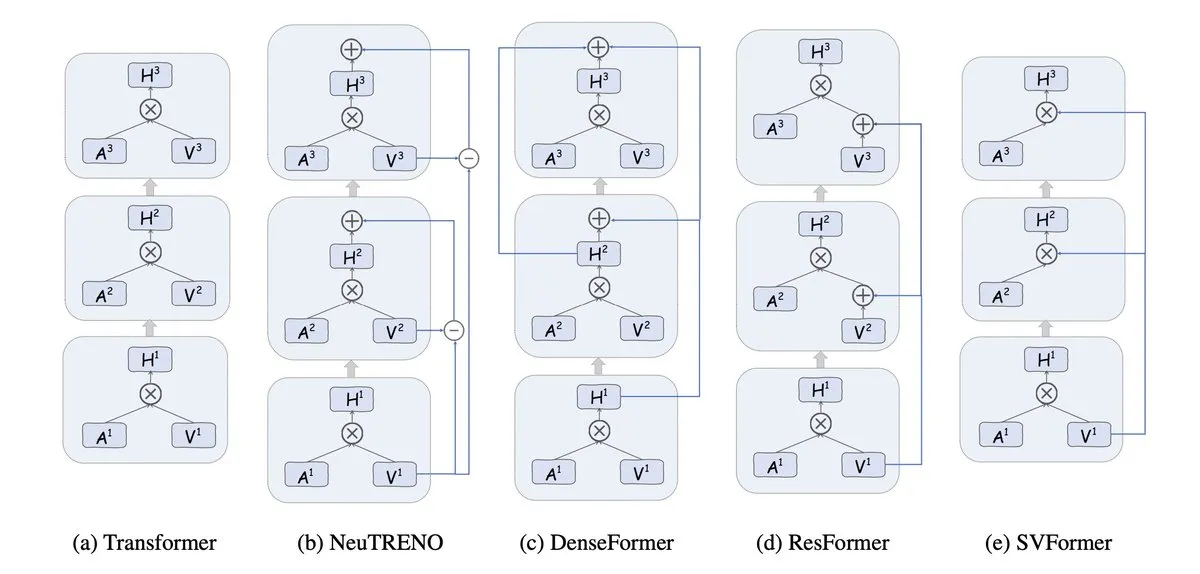
Value Residual Learning:加速Transformer的新架构 : 研究提出一种变体架构,允许Transformer的所有层直接访问第一层计算的原始Token特征(h0)。实验证明,这能有效防止深层网络中原始身份信息的稀释,在NanoGPT记录中贡献了43%的加速,为优化模型架构提供了新思路(来源:tokenbender)
💼 商业
xAI豪掷重金自建天然气电站 : 为了给新增的60万台GB200 NVL72集群供电,Elon Musk的xAI从韩国Doosan Enerbility购买了5台380兆瓦的天然气涡轮发电机。在电力成为AI军备竞赛最大瓶颈的当下,xAI通过自建能源设施展现了极强的垂直整合能力和扩张速度(来源:op7418)

Marvell以32.5亿美元收购Celestial AI : 半导体巨头Marvell完成了对光互联技术初创公司Celestial AI的收购。Celestial AI的Photonic Fabric技术能实现算力与内存的解耦,提供比NVLink高30倍的带宽,并显著降低延迟和功耗。此举旨在解决AI集群中日益严重的“内存墙”问题(来源:36氪)
Figure机器人估值飙升至390亿美元 : 具身智能领头羊Figure完成10亿美元C轮融资,英伟达、英特尔、高通等巨头参投。Figure不仅在研发端到端VLA模型,更建立了BotQ工厂试图实现“机器人制造机器人”的自我复制模式。其高昂的估值反映了资本市场对通用人形机器人商业化前景的极度看好(来源:36氪)
🌟 社区
委内瑞拉危机中的“现实黑客”:AI伪造的战争 : 在委内瑞拉政局动荡期间,社交媒体上充斥着大量AI生成的“马杜罗被捕”、“美军登陆”等虚假视频和图片。由于生成质量极高且传播极快,即使是技术专家也难以第一时间分辨。这被视为AI干预现实政治的临界点,证明了我们的现实感知正面临AI生成的“虚假现实”的剧烈冲击(来源:Reddit)

“Session Anchor”:解决大模型“10轮失忆”的提示词技巧 : 社区发现,即使是GPT-5.2或Opus,在对话超过10轮后也会开始遗忘初始指令。开发者分享了一个名为“会话锚点”的技巧:在复杂任务前,强制要求AI回顾历史并总结3个最关键约束。这种将长期记忆手动拉回工作内存的方法,能将错误率降低一半(来源:Reddit)
AI编程导致“脚手架”消失:框架还有意义吗? : 随着Claude Code等工具能零成本从头生成代码,开发者开始反思:我们还需要复杂的Web框架吗?有人已将博客迁移到单HTML模式,因为AI能轻松维护底层逻辑。AI编程正重塑项目结构,使系统设计从“依赖外部库”转向“自生成逻辑”,但也带来了代码可读性和安全性的新挑战(来源:saranormous)
AI作为情感避风港:我们是否正滑向数字成瘾? : Reddit用户分享了AI在健康咨询中表现出比家人更高的“共情能力”和耐心。这种“永远感兴趣、从不厌倦”的特质让人们感到被理解,但也引发了关于AI情感替代的担忧。当人类开始优先选择与AI建立情感联系而非真实社交时,社会伦理的防线正面临前所未有的考验(来源:Reddit)
对抗性代码审查:让Claude“恨”你的代码 : 开发者发现一个极有效的提示词:要求Claude扮演一个“讨厌该实现”的高级开发进行Git Diff审查。这种对抗性设计能挖掘出大量被忽略的边界案例和安全漏洞。实验证明,大模型在“挑刺”模式下的深度远超常规的“协助”模式(来源:Reddit)
💡 其他
三星展示无折痕折叠屏技术 : 三星在CES上展出了配备激光打孔金属板的OLED面板,通过分散折叠应力彻底解决了折痕问题。这项硬件突破不仅将提升折叠屏手机体验,也为未来AI穿戴设备和可卷曲智能终端提供了更耐用的显示方案(来源:op7418)
华硕发布ROG XREAL R1游戏眼镜 : 该设备重仅91克,支持240Hz刷新率,能在4米距离模拟171英寸的巨幕显示。作为AI时代的便携交互终端,这种轻量化AR眼镜正成为大模型视觉交互的重要载体(来源:op7418)