كلمات مفتاحية:تسلا روبوتاكسي, إي إم دي إم آي 350, أوبن إيه آي أو 3-برو, آي يو آي من إيفلايت, فلا من يوان رونغ, ديب سيك نانو-في إل إل إم, مينج لايت أومني من مجموعة أنت, تحقيق القيادة الذاتية من المستوى الرابع في سيارات الإنتاج من المستوى الثاني, مقارنة أداء إي إم دي إم آي 350 إكس وبي 200, قدرة معالجة السياق الطويل لنموذج أو 3-برو, تقنية التفاعل ثنائي الاتجاه الكامل لآي يو آي, نموذج الرؤية-اللغة-الفعل فلا
🔥 أبرز النقاط
أول ظهور علني لـ Robotaxi من Tesla على الطرقات، وإيلون ماسك يؤكد إمكانية تحقيق القيادة الذاتية من المستوى L4 في سيارات الإنتاج الكمي من المستوى L2 دون تعديل: بدأت Robotaxi من Tesla (نسخة محدثة من Model Y) اختباراتها على الطرق في أوستن، ويحمل جسم السيارة شعار Robotaxi الجديد مع الإبقاء على عجلة القيادة. صرح ماسك بأن جميع سيارات Tesla ذات الإنتاج الكمي قادرة على تحقيق القيادة الذاتية بدون إشراف، والمركبات المستخدمة في الاختبار حاليًا مزودة بنسخة تجريبية داخلية من FSD بمعاملات تزيد 4.5 مرة عن FSD الحالي، ومن المتوقع طرحها بعد التحسين خلال العام. من المقرر إطلاق Robotaxi للعامة في 22 يونيو، وسيكون الإطلاق الأول في أوستن. تمثل هذه الخطوة ارتقاءً لـ FSD من Tesla من المستوى L2 إلى Robotaxi من المستوى L4/L5، مما قد يسرع من وتيرة المنافسة في قطاع القيادة الذاتية، ويشكل تحديًا خاصًا للاعبين الذين يتبعون المسار التقني L4 مثل Waymo (المصدر: QbitAI)

AMD تطلق أقوى سلسلة شرائح ذكاء اصطناعي MI350، متفوقة في الأداء على B200 من Nvidia: أعلنت ليزا سو، الرئيس التنفيذي لشركة AMD، بالاشتراك مع سام ألتمان، الرئيس التنفيذي لشركة OpenAI، عن وحدات معالجة الرسومات MI350X و MI355X. تعتمد هاتان الشريحتان على عملية تصنيع 3 نانومتر، وتحتويان على 185 مليار ترانزستور وذاكرة HBM3E بسعة 288 جيجابايت، وهي سعة ذاكرة تبلغ 1.6 ضعف سعة B200 من Nvidia. تظهر البيانات الرسمية أن سلسلة MI350 أسرع بنسبة 30% من B200 في سرعة الاستدلال لنموذج Llama 3.1 405B بدقة FP4، وتتمتع بضعف قوة الحوسبة FP64 مقارنة بـ Nvidia. كما أعلنت AMD عن سلسلة MI400 التي سيتم تطويرها بالتعاون مع OpenAI وستظهر لأول مرة العام المقبل، مما يزيد من حدة المنافسة في سوق شرائح الذكاء الاصطناعي (المصدر: QbitAI)

قدرات الاستدلال لنموذج o3-pro من OpenAI تثير الاهتمام، والأداء الفعلي يختلف قليلاً عن الاختبارات الرسمية: أظهر أحدث نموذج استدلال من OpenAI، وهو o3-pro، قدرات قوية في معالجة ألعاب الكلمات المعقدة (مثل إنشاء ردود محددة بناءً على خصائص أسماء أغاني المغنية Sabrina Carpenter)، مما أثار سخرية الرئيس السابق لفريق AGI Readiness في OpenAI من تشكيك Apple سابقًا في قدرات الاستدلال للنماذج الكبيرة. ومع ذلك، في قوائم التصنيف الموثوقة مثل LiveBench، كان متوسط درجات o3-pro في الترميز متساويًا تقريبًا مع o3، بل إن درجاته في ترميز الوكلاء كانت أقل. أظهر اختبار Fiction.LiveBench أن o3-pro يتفوق في السياقات القصيرة، ولكنه لا يزال أقل شأناً من Gemini 2.5 Pro في معالجة السياقات الطويلة جدًا (192k). أشار بن هيلاك، المهندس السابق في Apple و SpaceX، إلى أن القدرة الحقيقية لـ o3-pro تعتمد بشكل كبير على إدخال معلومات خلفية كافية، وهو مناسب أكثر كمولد للتقارير بدلاً من كونه مجرد محاور بسيط، مع تحسن ملحوظ في استدعاء الأدوات وفهم البيئة (المصدر: QbitAI)

iFlytek تقوم بترقية منصة التفاعل بين الإنسان والآلة AIUI ومنصة الروبوت الفائقة الدماغ، لتعزيز التعاون العميق للأجهزة الذكية: أعلنت iFlytek عن ترقية كبيرة لمنصتها للتفاعل بين الإنسان والآلة AIUI، مع التركيز على تحسين التفاعل ثنائي الاتجاه الكامل، وإدراك المشاعر والتعبير عنها، ونظام الذاكرة الشبيه بالبشر. خاصة بالنسبة لسيناريوهات الأطفال، قدمت حلول تفاعل مخصصة لتحسين القدرة على التعرف على كلام الأطفال وفهمه. في الوقت نفسه، عززت منصتها للروبوت الفائقة الدماغ، القائمة على نموذج Spark الكبير، التفاعل متعدد الوسائط، والفهم الدلالي، وتطبيق المعرفة، وأطلقت “حقيبة ظهر ذكية صوتية” تمكن الروبوتات الحالية من تحقيق التفاعل الصوتي دون الحاجة إلى تعديل الأجهزة. تهدف هذه الترقيات إلى دفع الأجهزة الذكية من التفاعل الأساسي إلى التعاون الذكي العميق، وتمكين مجالات متعددة مثل السيارات، وأجهزة الذكاء الاصطناعي، والروبوتات (المصدر: QbitAI)

🎯 اتجاهات
DeepRoute.ai تتعاون مع Volcano Engine لتطوير وكيل العالم المادي VLA استنادًا إلى نموذج Doubao الكبير: أعلن تشو قوانغ، الرئيس التنفيذي لشركة DeepRoute.ai، عن تعاون مع Volcano Engine للاستفادة من نموذج Doubao الكبير لتطوير تقنيات استشرافية مثل نموذج الرؤية-اللغة-الحركة (VLA)، بهدف إنشاء وكيل للعالم المادي. سيتم طرح نموذج VLA من DeepRoute.ai في السوق الاستهلاكية في الربع الثالث من عام 2025، وسيتضمن أربع وظائف أساسية: فهم الدلالات المكانية، والتعرف على العوائق غير المنتظمة، وفهم اللافتات الإرشادية النصية، والتحكم الصوتي في السيارة، بهدف تعزيز سلامة وذكاء القيادة المساعدة. حاليًا، أكمل نموذج VLA اختبارات الطرق، ومن المتوقع إطلاق أكثر من 5 طرازات سيارات تعمل بالذكاء الاصطناعي ومجهزة بهذا النموذج خلال العام (المصدر: QbitAI)

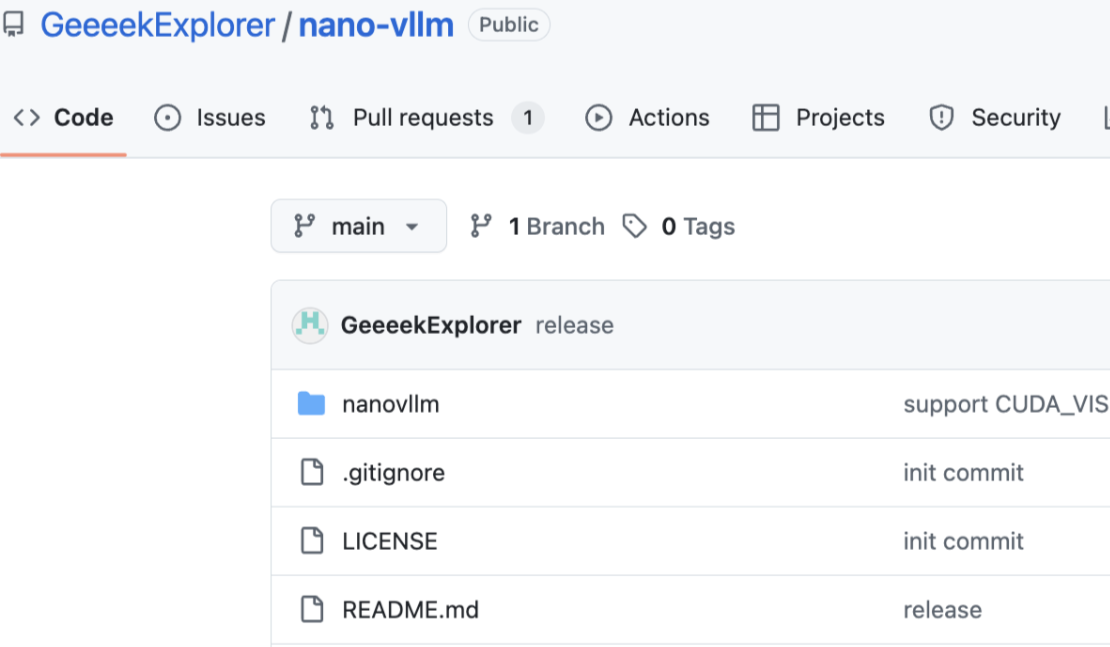
باحث من DeepSeek يعيد بناء vLLM بـ 1200 سطر من التعليمات البرمجية، ويتفوق على الأداء الأصلي في بعض السيناريوهات: قام يو شينغكاي، الباحث في DeepSeek، بإصدار مشروع Nano-vLLM مفتوح المصدر، والذي يعيد بناء الوظائف الأساسية لـ vLLM باستخدام أقل من 1200 سطر من كود Python، بما في ذلك التقنيات الرئيسية مثل PagedAttention. يهدف المشروع إلى توفير نسخة مصغرة وقابلة للقراءة بالكامل من vLLM، لتسهيل التعلم والفهم. في ظل ظروف اختبار محددة على أجهزة H800 ونموذج Qwen3-8B، تجاوزت إنتاجية Nano-vLLM إنتاجية vLLM الأصلي، مما يدل على كفاءته العالية. vLLM هو إطار عمل لاستدلال وخدمة نماذج اللغة الكبيرة (LLM) تم تطويره في جامعة كاليفورنيا في بيركلي، ويشتهر بخوارزمية PagedAttention التي حسنت بشكل كبير إنتاجية خدمات LLM (المصدر: QbitAI)
الشركات الصينية تستخدم “صناديق الأقراص الصلبة الطائرة” للتحايل على قيود تصدير شرائح الذكاء الاصطناعي الأمريكية: وفقًا لصحيفة وول ستريت جورنال، في مواجهة القيود الأمريكية على تصدير شرائح الذكاء الاصطناعي المتطورة، تتبع الشركات الصينية استراتيجية جديدة تتمثل في نقل الأقراص الصلبة التي تحتوي على كميات كبيرة من بيانات التدريب (مثل 80 تيرابايت) عبر مهندسين إلى مراكز بيانات خارجية في ماليزيا ودول أخرى، للاستفادة من الخوادم المحلية المجهزة بشرائح متقدمة مثل Nvidia لإجراء تدريب نماذج الذكاء الاصطناعي، ثم إعادة معلمات النموذج إلى الصين بعد الانتهاء. تهدف هذه الخطوة إلى تجاوز صعوبات استيراد الشرائح مباشرة، وقد عززت ظهور مراكز بيانات الذكاء الاصطناعي في جنوب شرق آسيا والشرق الأوسط. وأعرب مسؤول سابق في وزارة التجارة الأمريكية عن قلقه إزاء ذلك (المصدر: dotey)

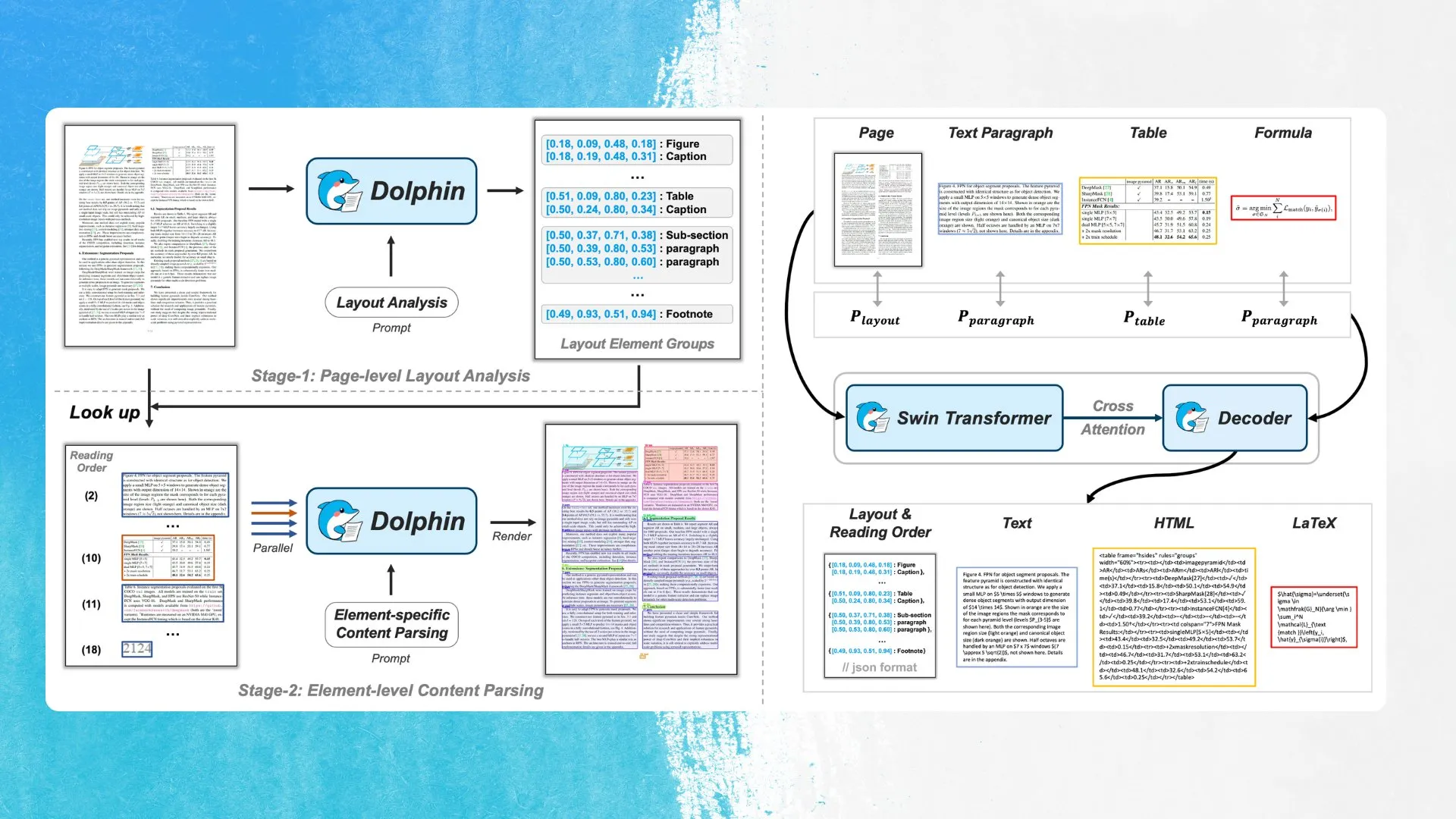
ByteDance تطلق نموذج OCR جديد Dolphin، يعتمد على كشف عناصر التخطيط والتحليل المتوازي: أعلنت ByteDance عن نموذج OCR جديد يسمى Dolphin، مرخص بموجب ترخيص MIT. يقوم هذا النموذج أولاً باكتشاف العناصر في تخطيط المستند (مثل الجداول والصيغ وما إلى ذلك)، ثم يقوم بتحليل كل عنصر بشكل متوازٍ لإنشاء المحتوى. تم إتاحة النموذج والعرض التوضيحي على Hugging Face Hub. تهدف هذه الطريقة إلى تحسين دقة وكفاءة التعرف على هياكل المستندات المعقدة (المصدر: mervenoyann)
تعزيز وظائف مشروع ChatGPT من OpenAI، ودعم البحث العميق، والوضع الصوتي، وتحميل الملفات من الأجهزة المحمولة: أعلنت OpenAI عن إضافة العديد من التحسينات إلى وظيفة “المشاريع” (Projects) في ChatGPT، بما في ذلك دعم معزز للبحث العميق، ودمج الوضع الصوتي، وتحسين وظيفة الذاكرة للإشارة إلى المحادثات السابقة داخل المشروع، بالإضافة إلى دعم تحميل الملفات ومحدد النماذج على الأجهزة المحمولة. تهدف هذه التحديثات إلى تعزيز قدرة المستخدمين على القيام بأعمال أكثر تركيزًا وتعقيدًا داخل ChatGPT (المصدر: kevinweil)
فريق EuroLLM يصدر نسخًا تجريبية من عدة نماذج جديدة، بما في ذلك نموذج 22B ونموذج MoE صغير: أصدر فريق EuroLLM نسخًا تجريبية من عدة نماذج جديدة، بما في ذلك نموذج أساسي بـ 22 مليار معلمة ونسخة مضبوطة بالتعليمات، ونموذجين للرؤية (1.7B و 9B معلمة) يعتمدان على إصدار سابق من EuroLLM، بالإضافة إلى نموذج صغير من خليط الخبراء (MoE) يحتوي على 0.6 مليار معلمة نشطة و 2.6 مليار معلمة إجمالية. جميع هذه النماذج مرخصة بموجب ترخيص Apache-2.0، وتظهر الاختبارات الأولية أن نموذج MoE الصغير هذا يؤدي بشكل جيد بشكل مدهش بالنسبة لحجمه (المصدر: Reddit r/LocalLLaMA)

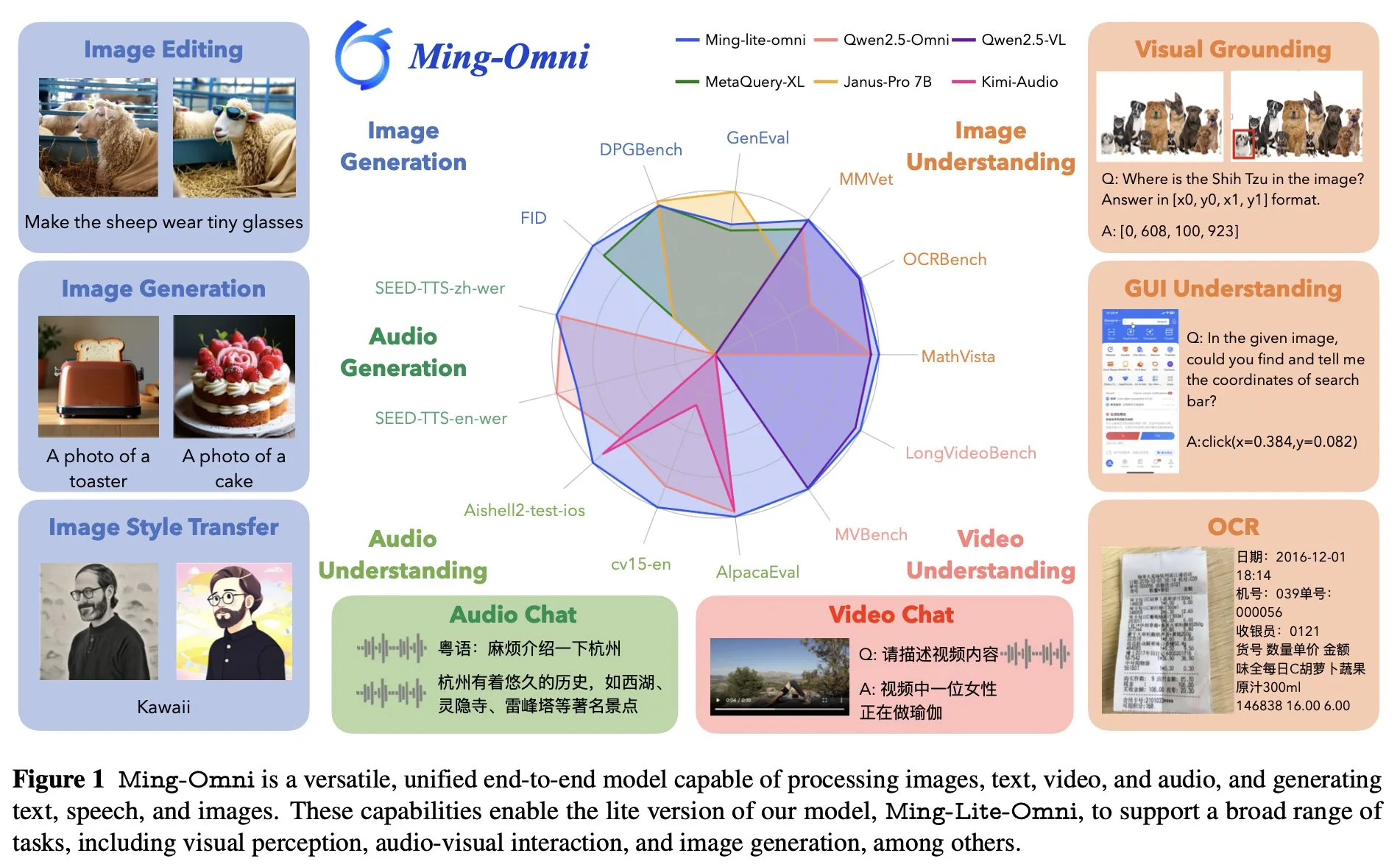
مجموعة Ant Group تطلق نموذج Ming Lite Omni الشامل والمتكامل، لمنافسة GPT-4o: أطلقت مجموعة Ant Group نموذج Ming Lite Omni، القادر على أداء وظائف متعددة مثل الاستماع والتحدث وتوليد الصور، ويتنافس في الأداء مع GPT-4o. يتفوق Ming Lite Omni على Qwen2.5VL-7B في مهام واجهة المستخدم الرسومية (GUI)، ويصل فهمه الصوتي إلى مستوى SOTA في العديد من معايير الاختبار العامة، كما يُظهر أداءً ممتازًا في فهم الفيديو. يعتمد النموذج على بنية خليط الخبراء (MoE)، مع 2.8 مليار معلمة نشطة فقط، وتم تحسينه خصيصًا لتوليد الصوت والصور، مثل استخدام BPE لتقليل معدل إطارات الرموز الصوتية، واستخدام رموز قابلة للتعلم متعددة المقاييس لتحسين جودة توليد الصور (المصدر: mervenoyann)
NVIDIA و Mistral AI تتعاونان لبناء منصة سحابية للذكاء الاصطناعي Mistral Compute: أعلنت NVIDIA في مؤتمر GTC عن تعاونها مع Mistral AI لإنشاء منصة سحابية للذكاء الاصطناعي تسمى Mistral Compute. يُنظر إلى هذه الخطوة على أنها فائدة كبيرة للولايات المتحدة ومجتمع المصادر المفتوحة، وتهدف إلى توفير نموذج لبناء البنية التحتية العالمية للذكاء الاصطناعي من خلال نماذج مفتوحة مدعومة بشرائح أمريكية (المصدر: arthurmensch)
Hugging Face تعلن عن تبني PyTorch بشكل كامل، لتبسيط مكتبة Transformers: صرح ليساندر جيك، كبير مسؤولي المصادر المفتوحة في Hugging Face، بأنه نظرًا لأن قاعدة المستخدمين قد توافقت بالفعل على PyTorch، ستركز الشركة جميع جهودها المستقبلية على PyTorch لتقليل تضخم مكتبة Transformers، والسعي لتوفير مجموعة أدوات أكثر إيجازًا. رحبت PyTorch رسميًا بهذه الخطوة، وأكدت أنها تساعد في الحفاظ على بساطة الكود (المصدر: reach_vb)

ByteDance تطلق تقنية توليد الفيديو التفاعلي في الوقت الحقيقي APT2: عرضت ByteDance أحدث تقنياتها لتوليد الفيديو التفاعلي في الوقت الحقيقي APT2 (Autoregressive Adversarial Post-Training). تهدف هذه التقنية، من خلال التدريب اللاحق التنافسي التراجعي الذاتي، إلى تحقيق توليد محتوى فيديو تفاعلي عالي الجودة وفي الوقت الحقيقي، مما يدفع عجلة التطور في مجال توليد الفيديو (المصدر: NerdyRodent)
🧰 أدوات
Llama-Server Launcher: مشغل خدمة llama.cpp بواجهة رسومية، يركز على تحسين أداء CUDA: شارك مطور مشغل خدمة llama-server الشخصي الذي يستخدمه، وهو مكتوب بلغة Python ويوفر واجهة مستخدم رسومية (GUI). تهدف هذه الأداة إلى تبسيط تكوين وتشغيل خدمة llama.cpp، مع التركيز بشكل خاص على ضبط أداء CUDA. تشمل الميزات اختيار النموذج، وإعداد المسار، وتعديل حجم السياق والدُفعات، وتفريغ وحدة معالجة الرسومات (GPU)، و FlashAttention، وتقسيم الموترات، وغيرها من إعدادات الأداء المتقدمة، بالإضافة إلى اختيار قوالب الدردشة وإدارة تكوين البيئة. يدعم الحصول التلقائي على معلومات وحدة معالجة الرسومات والنظام، وتحليل البيانات الوصفية لنموذج GGUF، ويمكنه إنشاء نصوص برمجية للتشغيل عبر الأنظمة الأساسية (.ps1/.sh) (المصدر: Reddit r/LocalLLaMA)
Together AI تطلق وكيل عالم بيانات مفتوح المصدر: قامت Together AI ببناء وكيل ذكاء اصطناعي مفتوح المصدر قادر على التفكير مثل عالم البيانات. يمكن لهذا الوكيل تحميل البيانات، وكتابة كود Python، وإعادة التدريب عند فشل النموذج، وحل مهام Kaggle و DABStep الحقيقية. تهدف هذه الخطوة إلى تعزيز الأتمتة وتعميم الذكاء الاصطناعي في مجال علوم البيانات (المصدر: percyliang)
AutoMind: إطار عمل وكيل معرفي تكيفي لأتمتة علوم البيانات: AutoMind هو إطار عمل جديد لوكلاء نماذج اللغة الكبيرة (LLM)، يهدف إلى التغلب على قيود وكلاء علوم البيانات الحاليين في التعامل مع المهام المعقدة والمبتكرة من خلال دمج قواعد المعرفة المتخصصة، واعتماد خوارزمية بحث شجرة المعرفة للوكيل، واستراتيجيات ترميز تكيفية، وبالتالي تعزيز الفعالية الواقعية لعمليات تعلم الآلة المؤتمتة (المصدر: HuggingFace Daily Papers)
LlamaParse تطلق ميزة “الإعدادات المسبقة” لتبسيط تكوين تحليل المستندات: أطلقت LlamaParse ميزة “الإعدادات المسبقة” (Presets)، التي توفر سلسلة من الأنماط المعدة مسبقًا وسهلة الفهم، لتحسين الإعدادات لمختلف حالات الاستخدام. تشمل هذه الأنماط السريعة والمتوازنة والمتقدمة للسيناريوهات العامة، بالإضافة إلى أنماط محسنة لحالات الاستخدام الشائعة مثل الفواتير والأوراق البحثية والمستندات التقنية والنماذج، بهدف تمكين المستخدمين من الاختيار بسهولة أكبر بين السرعة والدقة (المصدر: jerryjliu0)
OpenWebUI تضيف ميزة دعم o3-pro، لتوسيع توافق النماذج: قام مطور مجتمعي بإنشاء ميزة جديدة لـ Open WebUI، لتوسيع دعم نموذج o3-pro من خلال إضافة دعم واجهة برمجة تطبيقات الاستجابة، وتتبع التكاليف، ودعم المفاتيح المتعددة، والبحث على الويب. يتيح ذلك للمستخدمين استخدام o3-pro في Open WebUI دون الحاجة إلى الاشتراك في الباقة المتقدمة الرسمية (المصدر: Reddit r/OpenWebUI)
📚 دراسات
ورقة بحثية تناقش تحليل تنشيطات MLP إلى ميزات قابلة للتفسير من خلال تحليل المصفوفات شبه غير السالبة (SNMF): يقترح هذا البحث استخدام SNMF لتحليل تنشيطات الشبكات العصبية متعددة الطبقات (MLP) مباشرة، بهدف تعلم ميزات متفرقة تتكون من تراكيب خطية من الخلايا العصبية النشطة بشكل مشترك، وربط هذه الميزات بمدخلات تنشيطها، مما يجعلها قابلة للتفسير بشكل مباشر. أظهرت التجارب أن الميزات المشتقة من SNMF تتفوق على المشفرات التلقائية المتفرقة (SAE) في التوجيه السببي، وتتوافق مع المفاهيم التي يمكن للبشر تفسيرها، وتكشف عن بنية هرمية في فضاء تنشيط MLP (المصدر: HuggingFace Daily Papers)
ورقة بحثية جديدة تقترح LoRMA: نموذج جديد لضبط نماذج اللغة الكبيرة (LLM) من خلال التكيف المضاعف منخفض الرتبة (Low-Rank Multiplicative Adaptation): عادةً ما يتم ضبط نماذج اللغة الكبيرة التقليدية من خلال تحديث الأوزان بشكل إضافي، بينما يستكشف LoRMA التحديثات المضاعفة. لحل مشكلة “قمع الرتبة” التي تسببها المصفوفات منخفضة الرتبة، تقدم الورقة عمليات توسيع رتبة جديدة تعتمد على التباديل والإضافة، وتضمن كفاءة الحساب من خلال عمليات إعادة ترتيب فعالة. أظهرت التجارب أن LoRMA تنافسي، ويقدم أفكارًا جديدة لتكييف نماذج اللغة الكبيرة (المصدر: Reddit r/deeplearning)
ورقة بحثية تقترح إطار عمل TaxoAdapt، لتمكين تصنيفات متعددة الأبعاد مبنية بواسطة نماذج اللغة الكبيرة (LLM) من التكيف مع مجموعات بحثية متطورة: لمواجهة تحدي تنظيم الأدبيات العلمية، يمكن لإطار عمل TaxoAdapt تعديل التصنيفات التي أنشأتها نماذج اللغة الكبيرة ديناميكيًا لتتكيف مع مجموعات بيانات محددة، ويدعم أبعادًا متعددة (مثل المنهجية، والمهمة، ومقاييس التقييم). يهدف هذا الإطار، من خلال التصنيف الهرمي التكراري، إلى توسيع عرض وعمق التصنيف بناءً على التوزيع الموضوعي لمجموعة البيانات، وذلك لتنظيم وتتبع تطور المجالات العلمية بشكل أفضل (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقدم إطار عمل MOSAIC، لتحقيق التعلم التعاوني في أنظمة الوكلاء الذكية: MOSAIC هو إطار عمل للتعلم التعاوني في أنظمة الذكاء الاصطناعي المستقلة والقائمة على الوكلاء في بيئات لامركزية وديناميكية. يختار الوكلاء بشكل انتقائي مشاركة وإعادة استخدام المعرفة المعيارية (في شكل أقنعة شبكات عصبية)، دون الحاجة إلى مزامنة أو تحكم مركزي. أظهرت التجارب أن MOSAIC يتفوق على المتعلمين المنعزلين في السرعة والأداء، وأحيانًا يتمكن من حل المهام التي لا يستطيع الوكلاء المنعزلون حلها، ويعزز الكفاءة الجماعية والقدرة على التكيف (المصدر: Reddit r/MachineLearning)
ورقة بحثية تقترح إطار عمل ClaimSpect، لإجراء تحليل هرمي معزز بالاسترجاع للادعاءات المعقدة: العديد من الادعاءات (مثل الادعاءات العلمية والسياسية) ليست مجرد صحيحة أو خاطئة. يقوم إطار عمل ClaimSpect، من خلال التوليد المعزز بالاسترجاع، ببناء هيكل هرمي تلقائيًا للجوانب المتعلقة بالادعاء، ويثري هذه الجوانب بوجهات نظر من مجموعات بيانات محددة. تهدف هذه الطريقة إلى تفكيك الادعاءات المعقدة وتقديم وجهات نظر مختلفة حول الجوانب المختلفة الموجودة في مجموعة البيانات ومدى انتشارها (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح تحقيق توجيه الاضطراب الدقيق (Fine-Grained Perturbation Guidance) من خلال اختيار رؤوس الانتباه: اكتشف هذا البحث أن رؤوس انتباه معينة في نماذج الانتشار تتحكم في مفاهيم بصرية مختلفة (مثل البنية، والأسلوب، وجودة النسيج). بناءً على ذلك، تقترح الورقة إطار عمل “HeadHunter”، الذي يختار بشكل منهجي رؤوس الانتباه التي تتوافق مع أهداف المستخدم، لتحقيق تحكم دقيق في جودة التوليد والخصائص البصرية، وتقدم SoftPAG لضبط شدة الاضطراب. تم التحقق من صحة هذه الطريقة على نماذج مثل Stable Diffusion 3 و FLUX.1 في تحسين الجودة وتوجيه الأسلوب (المصدر: HuggingFace Daily Papers)
ورقة بحثية تناقش أن عدم تعلم نماذج اللغة الكبيرة (LLM) يجب أن يكون مستقلاً عن الشكل (Form-Independent): يشير البحث إلى أن فعالية طرق عدم التعلم الحالية لنماذج اللغة الكبيرة تعتمد بشكل كبير على شكل عينات التدريب، ويصعب تعميمها على تعبيرات مختلفة لنفس المعرفة. تعرف الورقة هذه المشكلة باسم “التحيز المعتمد على الشكل” (Form-Dependent Bias)، وتقدم معيار ORT لتقييمها. لحل هذه المشكلة، تقترح الورقة طريقة ROCR (Rank-one Concept Redirection)، التي تحقق عدم التعلم عن طريق إعادة توجيه إدراك النموذج لمفاهيم معينة، وأثبتت التجارب أن ROCR يحسن بشكل كبير فعالية عدم التعلم ويمكنه توليد مخرجات طبيعية (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح UniPre3D: طريقة تدريب مسبق موحدة لنماذج السحب النقطية ثلاثية الأبعاد تعتمد على تقنية Gaussian Splatting متعددة الوسائط: يهدف UniPre3D إلى مواجهة التحديات التي يفرضها تنوع مقاييس بيانات السحب النقطية في الرؤية ثلاثية الأبعاد، ويقترح أول طريقة تدريب مسبق موحدة يمكن تطبيقها بسلاسة على أي مقياس للسحب النقطية وأي بنية لنماذج ثلاثية الأبعاد. تحقق هذه الطريقة ذلك من خلال التنبؤ بالبدائيات الغاوسية كمهمة تدريب مسبق، واستخدام تقنية Gaussian Splatting القابلة للتفاضل لتقديم الصور، مما يتيح إشرافًا دقيقًا على مستوى البكسل وتحسينًا شاملاً، مع دمج ميزات نماذج التدريب المسبق ثنائية الأبعاد لإدخال معرفة النسيج (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح StreamSplat: إعادة بناء ديناميكية ثلاثية الأبعاد عبر الإنترنت لتدفقات الفيديو غير المعايرة: StreamSplat هو إطار عمل تغذية أمامية بالكامل، قادر على تحويل تدفقات الفيديو غير المعايرة بأي طول عبر الإنترنت إلى تمثيل ديناميكي ثلاثي الأبعاد بتقنية Gaussian Splatting (3DGS). يحقق ذلك من خلال آلية أخذ عينات احتمالية في المشفر الثابت للتنبؤ بمواقع 3DGS، وحقل تشوه ثنائي الاتجاه في وحدة فك التشفير الديناميكية، مما يتيح نمذجة ديناميكية قوية وفعالة، ويهدف إلى حل تحديات المعايرة والنمذجة الديناميكية واستقرار الكفاءة في إعادة بناء المشاهد الديناميكية في الوقت الحقيقي (المصدر: HuggingFace Daily Papers)
ورقة بحثية تستعرض الاستكشاف الانتباهي (Attentive Probing) في نمذجة الصور المقنعة: مع تزايد عدم جدوى الضبط الدقيق على نطاق واسع، أصبح الاستكشاف (probing) هو الخيار المفضل لتقييم التعلم ذاتي الإشراف (SSL). فشل الاستكشاف الخطي القياسي (LP) في عكس إمكانات نماذج تدريب نمذجة الصور المقنعة (MIM) بشكل كافٍ. تعيد هذه الورقة النظر في الاستكشاف الانتباهي، وتقدم الاستكشاف الفعال (EP)، وهو آلية انتباه متقاطع متعددة الاستعلامات، تقلل من المعلمات القابلة للتدريب وتحسن السرعة، وتتفوق على LP وطرق الاستكشاف الانتباهي السابقة في العديد من معايير الاختبار (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح PosterCraft: نهج جديد لتوليد ملصقات جمالية عالية الجودة ضمن إطار عمل موحد: يهدف PosterCraft إلى مواجهة تحديات توليد الملصقات الجمالية، والتي لا تتطلب فقط عرضًا دقيقًا للنصوص، بل تحتاج أيضًا إلى تكامل سلس للمحتوى الفني التجريدي، والتخطيط الجذاب، والانسجام العام للأسلوب. يعتمد PosterCraft على سير عمل متسلسل لتحسين التوليد، بما في ذلك تحسين عرض النصوص على نطاق واسع، والضبط الدقيق المشرف عليه مع مراعاة المناطق، والتعلم المعزز للنصوص الجمالية، والتحسين الدقيق المشترك للتغذية الراجعة البصرية واللغوية، ويتفوق بشكل كبير على خطوط الأساس مفتوحة المصدر في العديد من التجارب (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح تحسين نماذج الانتشار من خلال توجيه اضطراب الرموز (Token Perturbation Guidance): لحل قيود التوجيه غير المعتمد على المصنف (CFG) الذي يتطلب عملية تدريب محددة ويقتصر على التوليد الشرطي، تطبق طريقة TPG اضطرابًا مباشرًا على تمثيلات الرموز الوسيطة داخل شبكة الانتشار باستخدام مصفوفة اضطراب. تستخدم TPG عملية خلط تحافظ على المعيار لتوفير إشارة توجيه فعالة، وتحسن جودة التوليد دون الحاجة إلى تغييرات في البنية، وهي مناسبة للتوليد الشرطي وغير الشرطي. أظهرت التجارب أن TPG يحقق تحسنًا يقارب الضعف في مقياس FID لخط أساس SDXL في التوليد غير الشرطي (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح DreamActor-H1: توليد مقاطع فيديو توضيحية عالية الدقة لتفاعل الإنسان مع المنتج باستخدام Diffusion Transformers المصممة للحركة: DreamActor-H1 هو إطار عمل يعتمد على Diffusion Transformer (DiT)، يهدف إلى توليد مقاطع فيديو توضيحية عالية الجودة لتفاعل الإنسان مع المنتج. تحقق هذه الطريقة ذلك من خلال إدخال معلومات مرجعية مزدوجة للإنسان والمنتج وآلية انتباه متقاطع مقنعة إضافية، مع الحفاظ على تفاصيل هوية الإنسان والمنتج (مثل الشعارات والأنسجة). تستخدم قوالب شبكية ثلاثية الأبعاد لجسم الإنسان ومربعات تحديد المنتج لتوفير توجيه دقيق للحركة، وتعزز الاتساق ثلاثي الأبعاد من خلال ترميز نصي منظم (المصدر: HuggingFace Daily Papers)
ورقة بحثية تقترح EmbodiedGen: محرك عالم ثلاثي الأبعاد توليدي للذكاء المتجسد: EmbodiedGen هو منصة أساسية لتوليد عوالم ثلاثية الأبعاد تفاعلية، تهدف إلى توليد أصول ثلاثية الأبعاد عالية الجودة وقابلة للتحكم وواقعية بتكلفة منخفضة وقابلة للتطوير، تتمتع هذه الأصول بخصائص فيزيائية دقيقة ومقاييس واقعية، وتستخدم تنسيق وصف روبوتي موحد (URDF). يمكن استيراد هذه الأصول مباشرة إلى محركات محاكاة فيزيائية مختلفة، لدعم مهام تدريب وتقييم الذكاء المتجسد، مما يحل مشكلة التكلفة العالية والواقعية المحدودة لأصول رسومات الحاسوب ثلاثية الأبعاد التقليدية (المصدر: HuggingFace Daily Papers)
بحث جديد يدحض ورقة “وهم التفكير” من Apple، ويرى أن نماذج اللغة الكبيرة (LLM) قادرة على حل المشكلات المعقدة الجديدة: ردًا على ورقة “وهم التفكير” (Illusion of Thinking) التي نشرتها شركة Apple مؤخرًا والتي زعمت أن نماذج الاستدلال الكبيرة (LRM) تعاني من “انهيار الدقة” في ألغاز التخطيط المعقدة (مثل برج هانوي)، أشارت دراسة تعقيبية إلى أن استنتاجات Apple تعكس بشكل أساسي قيود تصميم التجربة وليس فشلًا في قدرات الاستدلال الأساسية للنموذج. يرى البحث الجديد أن تجاوز ميزانية الرموز في التجربة الأصلية، والتقييم الخاطئ للمخرجات المبتورة عمدًا، وتضمين أمثلة ألغاز غير قابلة للحل رياضيًا، أدت مجتمعة إلى سوء تقدير قدرات النموذج. عند تعديل طرق التجربة، على سبيل المثال، مطالبة النموذج بتوليد دالة Lua مدمجة لحل برج هانوي بدلاً من قائمة خطوات مفصلة، أظهر النموذج دقة عالية في الحالات التي تم الإبلاغ سابقًا عن فشلها تمامًا، مما يشير إلى أن النموذج ليس غير قادر على الاستدلال، ولكنه مقيد بتنسيق الإخراج وحدود الرموز (المصدر: Reddit r/LocalLLaMA)

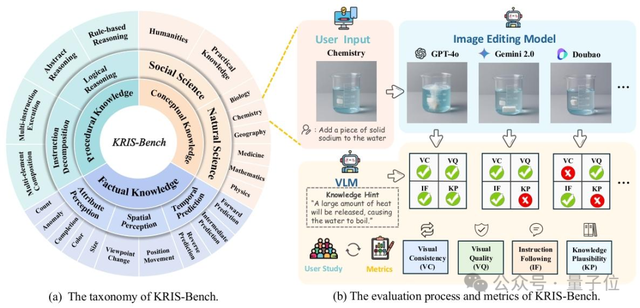
KRIS-Bench: معيار جديد لتقييم قدرات الاستدلال لنماذج تحرير الصور بشكل شامل من منظور أنواع المعرفة: أطلقت جامعة جنوب شرق الصين ومؤسسات أخرى بالاشتراك KRIS-Bench، وهو معيار لقدرات الاستدلال لأنظمة تحرير الصور القائمة على المعرفة. يقوم بتقييم 10 نماذج تحرير صور رئيسية (بما في ذلك GPT-Image-1 و Gemini 2.0 Flash) من ثلاثة مستويات: المعرفة الواقعية (مثل اللون والكمية)، والمعرفة المفاهيمية (مثل الحس السليم الفيزيائي)، والمعرفة الإجرائية (مثل العمليات متعددة الخطوات)، مقسمة إلى 22 مهمة تحرير. أظهرت النتائج أن النموذج المغلق المصدر GPT-Image-1 كان الأفضل أداءً، لكن جميع النماذج أظهرت أداءً ضعيفًا بشكل عام في مهام الاستدلال العميق مثل الاستدلال الإجرائي، والعلوم الطبيعية، والتوليف متعدد الخطوات، مما يكشف عن أوجه القصور في القدرات المعرفية المتقدمة للنماذج الحالية (المصدر: QbitAI)
بحث جديد يقترح طريقة Finetune-RAG، لضبط نماذج اللغة الدقيقة لمقاومة الهلوسة في RAG: تميل نماذج اللغة الكبيرة إلى الهلوسة في التوليد المعزز بالاسترجاع (RAG) عندما يكون الاسترجاع غير مثالي (على سبيل المثال، وجود أجزاء مستندات مشتتة). تقوم Finetune-RAG بتدريب النموذج على عينات إدخال تحتوي على سياقات صحيحة وخاطئة، مما يمكنه من الحفاظ على الواقعية بشكل أفضل. أصدر فريق البحث مجموعة بيانات تحتوي على أكثر من 1600 عينة سياق مزدوج، ونقطة تفتيش مضبوطة لـ LLaMA 3.1-8B-Instruct، وإطار تقييم GPT-4o يسمى Bench-RAG. أظهر التقييم أن هذه الطريقة رفعت الدقة من 77% إلى 98%، وحققت تحسينات في الفائدة والملاءمة والعمق (المصدر: Reddit r/MachineLearning)
TeleMath: إطلاق أول معيار لقدرة نماذج اللغة الكبيرة (LLM) على حل المشكلات الرياضية في مجال الاتصالات: لتقييم قدرة نماذج اللغة الكبيرة على حل المهام المحددة والمكثفة رياضيًا في مجال الاتصالات، أطلق الباحثون معيار TeleMath. يحتوي هذا المعيار على 500 زوج من الأسئلة والأجوبة، تغطي موضوعات الاتصالات مثل معالجة الإشارات، وتحسين الشبكات، وتحليل الأداء. أظهر تقييم العديد من نماذج اللغة الكبيرة مفتوحة المصدر أن النماذج المصممة خصيصًا للاستدلال الرياضي أو المنطقي أدت بشكل أفضل على TeleMath، بينما واجهت النماذج العامة ذات المعلمات الكبيرة صعوبات في كثير من الأحيان. تم إتاحة مجموعة البيانات ورمز التقييم (المصدر: HuggingFace Daily Papers)
ChineseHarm-Bench: إطلاق معيار الكشف عن المحتوى الضار باللغة الصينية: نظرًا لأن معظم موارد الكشف عن المحتوى الضار الحالية باللغة الإنجليزية، أصدر الباحثون ChineseHarm-Bench، وهو معيار شامل للكشف عن المحتوى الضار باللغة الصينية تم ترميزه بواسطة متخصصين. يغطي هذا المعيار ست فئات تمثيلية، وبياناته مأخوذة بالكامل من العالم الحقيقي. أسفرت عملية الترميز أيضًا عن قاعدة قواعد معرفية، توفر معرفة متخصصة صريحة لنماذج اللغة الكبيرة. بالإضافة إلى ذلك، اقترح الباحثون طريقة أساسية معززة بالمعرفة، تجمع بين القواعد التي وضعها الإنسان والمعرفة الضمنية لنماذج اللغة الكبيرة، مما يمكّن النماذج الصغيرة من تحقيق أداء نماذج اللغة الكبيرة المتطورة (SOTA) (المصدر: HuggingFace Daily Papers)
بحث جديد يكتشف بنية هرمية للقدرات الكامنة لنماذج اللغة من خلال تعلم التمثيل السببي: لتقييم قدرات نماذج اللغة بأمانة والتغلب على تأثيرات العوامل المربكة وتكاليف الحوسبة العالية، يقترح هذا البحث إطارًا لتعلم التمثيل السببي. يقوم هذا الإطار بنمذجة أداء المعيار المرصود كتحويل خطي لعدد قليل من عوامل القدرة الكامنة، وبعد التحكم في النموذج الأساسي كعامل مربك مشترك، يحدد العلاقات السببية بين هذه العوامل الكامنة. بتطبيقه على بيانات أكثر من 1500 نموذج من Open LLM Leaderboard، اكتشف البحث بنية سببية خطية موجزة من ثلاث عقد، تكشف عن مسار سببي واضح من القدرة العامة على حل المشكلات إلى إتقان اتباع التعليمات، ثم إلى قدرات الاستدلال الرياضي (المصدر: HuggingFace Daily Papers)
DeepLearning.AI تطلق دورة جديدة “تنظيم سير العمل لتطبيقات GenAI”: أعلن أندرو نج عن إطلاق دورة قصيرة جديدة بالتعاون مع Astronomer، لتعليم كيفية بناء ونشر خطوط أنابيب موثوقة للذكاء الاصطناعي التوليدي باستخدام أداة المصدر المفتوح الشائعة Airflow 3.0. يتضمن محتوى الدورة تقسيم سير العمل إلى مهام منفصلة، وجدولة المهام، والتنفيذ المتوازي، واستعادة الأعطال، وقابلية الملاحظة، وتهدف إلى مساعدة المتعلمين على تحويل دفاتر Jupyter أو نصوص Python الأولية إلى سير عمل جاهز للإنتاج (المصدر: DeepLearningAI)
ورقة بحثية تناقش طرق تحسين أنظمة الذكاء الاصطناعي المركبة، والتحديات، والتوجهات المستقبلية: مع تطور نماذج اللغة الكبيرة وأنظمة الذكاء الاصطناعي، أصبحت أنظمة الذكاء الاصطناعي المركبة التي تدمج مكونات متعددة ناضجة بشكل متزايد في أداء المهام المعقدة. تستعرض هذه الورقة بشكل منهجي أحدث التطورات في تحسين أنظمة الذكاء الاصطناعي المركبة، بما في ذلك التقنيات العددية والقائمة على اللغة. تقوم الورقة بصياغة مفهوم تحسين أنظمة الذكاء الاصطناعي المركبة، وتصنيف الطرق الحالية، وتسليط الضوء على تحديات البحث المفتوحة والتوجهات المستقبلية في هذا المجال (المصدر: HuggingFace Daily Papers)
💼 أعمال
ديزني ويونيفرسال ستوديوز تقاضيان منشئ الصور Midjourney لانتهاكه حقوق الطبع والنشر: اتهمت ديزني ويونيفرسال ستوديوز Midjourney باستخدام مكتبتهما الإبداعية (بما في ذلك شخصيات مثل Star Wars و Frozen و Minions) لتدريب نماذجها دون إذن، وإنشاء وتوزيع عدد كبير من الأعمال المشتقة، واصفة إياه بأنه “سرقة لا نهاية لها”. تثير هذه القضية مرة أخرى النقاش حول الحدود بين المحتوى الذي ينشئه الذكاء الاصطناعي وحقوق الملكية الفكرية (المصدر: Reddit r/ArtificialInteligence)
NVIDIA و Deutsche Telekom تتعاونان لإنشاء أول سحابة ذكاء اصطناعي صناعية للمصنعين الأوروبيين بحلول عام 2026: التقى المستشار الاتحادي الألماني فريدريش ميرتس بالرئيس التنفيذي لشركة NVIDIA جنسن هوانغ، لمناقشة المزيد من التعاون الاستراتيجي لتعزيز مكانة ألمانيا كشركة رائدة عالميًا في مجال الذكاء الاصطناعي. كجزء من هذه الرؤية، أعلنت Deutsche Telekom و NVIDIA عن تعاون جديد، يخططان من خلاله لإنشاء أول سحابة ذكاء اصطناعي صناعية في العالم للمصنعين الأوروبيين بحلول عام 2026. ستدعم هذه البنية التحتية الآمنة والمتوافقة مع اللوائح الأوروبية الابتكارات المتطورة، مع ضمان السيادة الكاملة على البيانات (المصدر: nvidia)

شائعات بأن سام ألتمان قد يخفف سيطرة OpenAI غير الربحية من خلال عمليات استحواذ بالأسهم بالكامل: أثارت عمليات استحواذ OpenAI الأخيرة على io (6.5 مليار دولار) و Windsurf (3 مليارات دولار) بالأسهم بالكامل تكهنات. تشير نظرية على Hacker News إلى أن سام ألتمان قد يستخدم هذه الصفقات لتخفيف سيطرة المنظمة غير الربحية OpenAI Inc. تدريجيًا على الكيان الربحي OpenAI Global LLC (الآن OpenAI PBC)، وبالتالي قد يتحايل على القيود القانونية المفروضة على التحول إلى شركة ربحية بالكامل. ربط البعض هذه الخطوة بتصرفات ألتمان مع Reddit في عام 2014، لكن هناك آراء أخرى ترى أن عمليات الاستحواذ هذه هي تحركات استراتيجية تجارية طبيعية (المصدر: Reddit r/ArtificialInteligence)
🌟 مجتمع
النقاش حول ما إذا كان الذكاء الاصطناعي يمكنه “الاستدلال” حقًا مستمر، وورقة Apple تثير الجدل: أثارت ورقة بحثية حديثة لشركة Apple تدعي أن أداء نماذج اللغة الكبيرة (LLM) في المهام المعقدة (مثل برج هانوي) ليس استدلالًا حقيقيًا، بل أقرب إلى مطابقة الأنماط، نقاشًا واسعًا في المجتمع. علق مايلز بروندج، الموظف السابق في OpenAI، على حل o3-pro لألعاب كلمات معقدة، متسائلاً بسخرية “إذا لم يكن هذا استدلالًا فما هو الاستدلال؟”. وأشارت أبحاث لاحقة إلى أن ظاهرة “انهيار الاستدلال” في ورقة Apple قد تكون ناتجة عن قيود تصميم التجربة (مثل قيود الرموز، والتقييم الخاطئ للمشكلات غير القابلة للحل) وليس عن قصور في قدرات الاستدلال لدى النموذج نفسه. بعد تعديل طرق الاختبار، أظهر النموذج أداءً جيدًا في المهام التي فشل فيها سابقًا، مما يشير إلى أن تقييم قدرات الاستدلال للذكاء الاصطناعي يتطلب تصميمًا تجريبيًا أكثر دقة (المصدر: o3-pro答高难题文字游戏引围观,OpenAI前员工讽刺苹果:这都不叫推理那什么叫推理, Reddit r/LocalLLaMA)
خلاف كبير في وجهات النظر حول مستقبل الذكاء الاصطناعي بين جنسن هوانغ، الرئيس التنفيذي لشركة Nvidia، وداريو أمودي، الرئيس التنفيذي لشركة Anthropic: أشارت تقارير Fortune إلى أن جنسن هوانغ، الرئيس التنفيذي لشركة Nvidia، صرح بأنه لا يتفق تقريبًا مع أي من آراء داريو أمودي، الرئيس التنفيذي لشركة Anthropic، بشأن الذكاء الاصطناعي. غالبًا ما يؤكد أمودي على المخاطر المحتملة للذكاء الاصطناعي وتأثيره الهائل على التوظيف، ويدعو إلى فرض ضوابط أكثر صرامة على تطوير الذكاء الاصطناعي وقيادته من قبل عدد قليل من المنظمات “المسؤولة”. بينما يشكك هوانغ في مثل هذه الآراء، ويميل أكثر إلى دفع التطبيق والتطوير الواسع لتقنيات الذكاء الاصطناعي. يرى معلقون في المجتمع أن موقف هوانغ قد يكون مرتبطًا بمصالحه التجارية، حيث أن Nvidia هي المورد الرئيسي لأجهزة الذكاء الاصطناعي (المصدر: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

خطة اشتراك Claude Code بقيمة 20 دولارًا تحظى بإشادة المطورين لفعاليتها من حيث التكلفة: شارك العديد من المطورين على وسائل التواصل الاجتماعي تجاربهم الإيجابية مع خطة اشتراك Anthropic Claude Code الشهرية البالغة 20 دولارًا، واصفين إياها بأنها فعالة للغاية من حيث التكلفة، وقادرة على استرداد تكلفتها بسرعة في المشاريع. ذكر المستخدمون أنه على الرغم من وجود بعض القيود على المعدل، إلا أن Claude Code أظهر أداءً ممتازًا في المساعدة في الترميز، وتعلم لغات جديدة (مثل الانتقال من C# إلى SwiftUI)، وتحسين تعليمات المشروع (مثل ملفات CLAUDE.md)، مما أدى إلى زيادة كبيرة في كفاءة العمل. حتى أن بعض المستخدمين يفكرون في إلغاء اشتراكاتهم في أدوات مساعدة البرمجة الأخرى القائمة على الذكاء الاصطناعي (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
نقاش مجتمعي حول التطبيقات المستقبلية للذكاء الاصطناعي في مجال علم النفس والتحديات الأخلاقية: مع تطور تقنيات مثل صياغة نماذج اللغة الكبيرة لمطالبات العلاج، وتتبع التطبيقات للمشاعر عبر مستشعرات الهاتف، يتغلغل الذكاء الاصطناعي تدريجيًا في علم النفس. يركز النقاش المجتمعي على ما إذا كان الذكاء الاصطناعي في الممارسة السريرية سيعزز قدرات المعالجين أم سيحل في النهاية محل بعض الأعمال، ومصداقية الذكاء الاصطناعي في التقييم والبحث، وتأثيره على التدريب المهني في علم النفس وسوق العمل، بالإضافة إلى القضايا الأخلاقية والتنظيمية لتطبيقات الذكاء الاصطناعي، وخاصة تحيز البيانات، والخصوصية، وقيود “المعالجين الآليين”. يتمثل القلق الأساسي في كيفية الاستفادة من الذكاء الاصطناعي لتعزيز الكفاءة والخدمات الشخصية مع ضمان سلامة المرضى والحفاظ على القيمة العلاجية للتواصل البشري (المصدر: Reddit r/artificial)
نموذج DeepSeek-R1-0528 المكمم بـ 3.53 بت من Unsloth يُظهر أداءً جيدًا على معيار الترميز Aider Polyglot: بعد أن قام فريق Unsloth بتكميم نموذج DeepSeek-R1-0528 إلى 3.53 بت (UD-Q3_K_XL)، حقق النموذج معدل نجاح بنسبة 68% في اختبار معيار الترميز Aider Polyglot. استخدم الاختبار حجم سياق يبلغ 40960 و Flash Attention، وتطلب حوالي 300 جيجابايت من ذاكرة RAM/VRAM. تقع هذه النتيجة بين Claude Sonnet 3.7 و Claude Opus 4، مما يدل على إمكانات النماذج المكممة في الحفاظ على قدرات ترميز عالية. أعرب أعضاء المجتمع عن إعجابهم بأداء تشغيل مثل هذه النماذج محليًا، ويتطلعون إلى المزيد من نتائج اختبار الإصدارات المكممة (المصدر: Reddit r/LocalLLaMA)
💡 أخرى
تقرير حادثة انقطاع الخدمة العالمية لـ GCP يكشف: سياسة حصص غير قانونية تسببت في انقطاع الخدمة: أظهر تقرير حادثة انقطاع الخدمة العالمية الأخيرة لـ Google Cloud Platform (GCP) أن السبب كان تطبيق سياسة حصص خاطئة على نظام إدارة واجهة برمجة التطبيقات العالمي (مثل تحديد طلب واحد فقط في الساعة)، مما أدى إلى رفض الطلبات الخارجية بسبب تجاوز الحصة (خطأ 403). بعد اكتشاف المهندسين للمشكلة، قاموا بتجاوز فحص الحصص لواجهة برمجة التطبيقات المتأثرة. ولكن في منطقة us-central1، عند محاولة مسح السياسة القديمة وكتابة سياسة جديدة، أدت مشكلات التخزين المؤقت إلى زيادة تحميل قاعدة البيانات، مما أطال وقت الاسترداد. أما المناطق الأخرى، فقد اعتمدت طريقة مسح التخزين المؤقت تدريجيًا للاسترداد، واستغرقت العملية برمتها حوالي ساعتين (المصدر: karminski3)

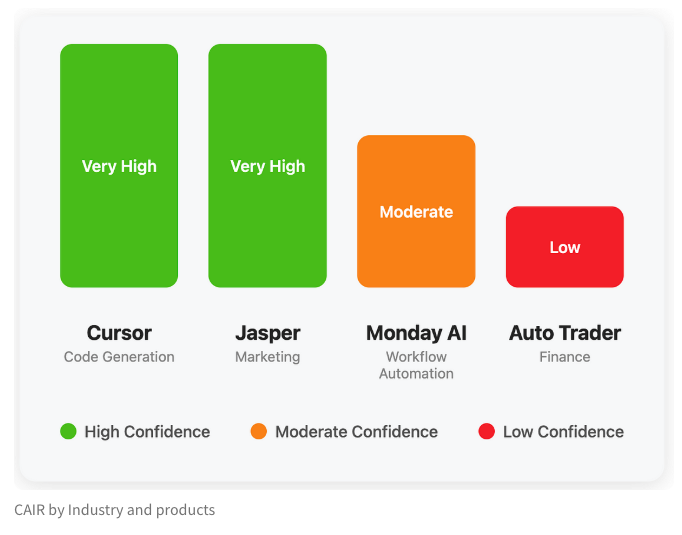
فريق LangChain يقترح مؤشر CAIR لتقييم إمكانات نجاح منتجات الذكاء الاصطناعي: شارك هاريسون تشيس من LangChain مع أساف إيلوفيتش في كتابة مقال يناقش سبب انتشار بعض منتجات الذكاء الاصطناعي بسرعة بينما تتعثر منتجات أخرى. يعتقدون أن قدرة النموذج ليست العامل الوحيد المحدد، وأن تجربة المستخدم (UX) حاسمة، واقترحوا مؤشر “CAIR” (Confidence in AI Results، الثقة في نتائج الذكاء الاصطناعي). كلما ارتفع مؤشر CAIR، زادت درجة تبني المنتج. يهدف هذا الإطار إلى مساعدة المطورين على تحديد وتحسين المكونات المختلفة التي تؤثر على ثقة المستخدم، وبالتالي زيادة معدل نجاح المنتج (المصدر: hwchase17, swyx, hwchase17, Hacubu)
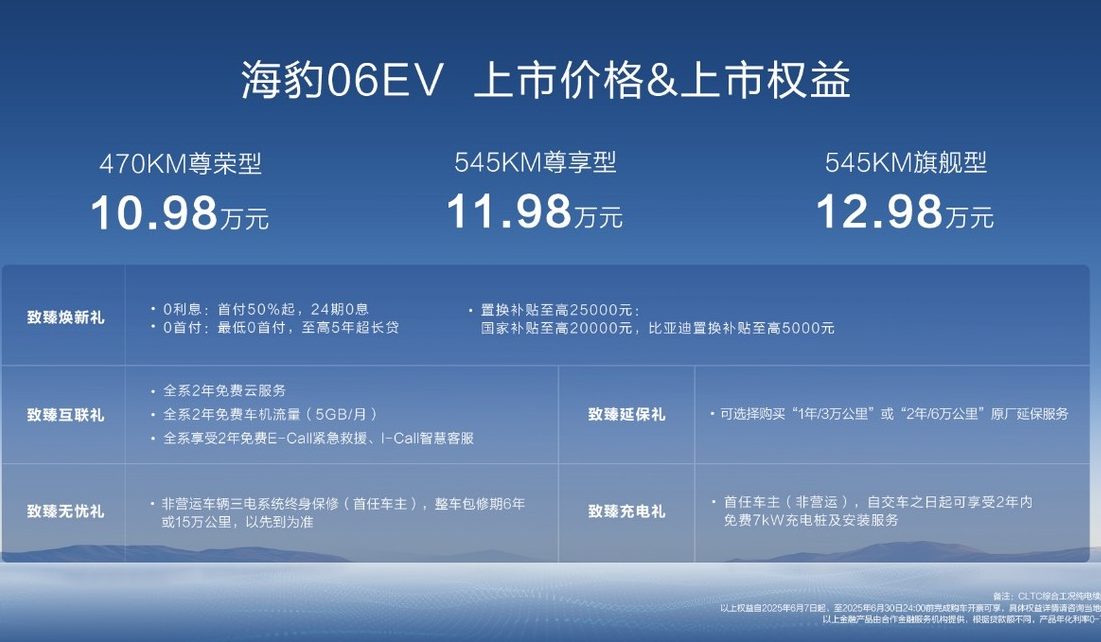
BYD تطلق سيارة الكوبيه العائلية الكهربائية النقية الجديدة Seal 06EV، بسعر يبدأ من 109,800 يوان: أطلقت شبكة BYD Ocean سيارة Seal 06EV في معرض تشونغتشينغ للسيارات، وهي سيارة كوبيه عصرية وعالية الجودة، تتوفر بثلاثة تكوينات، ويتراوح سعرها بين 109,800 و 129,800 يوان. تعتمد السيارة على منصة BYD e-platform 3.0 Evo، ومجهزة بنظام دفع كهربائي ذكي ثماني في واحد ونظام مضخة حرارية فعال واسع النطاق لدرجات الحرارة، وتوفر مدىين حسب معيار CLTC يبلغان 470 كم و 545 كم. تعتمد السيارة على نظام دفع خلفي، ومجهزة بنظام التحكم الذكي في تخميد جسم السيارة CloudRide-C، ونظام المساعدة على القيادة الذكي “Eye of the Gods C” ثلاثي العدسات، ويدعم وظائف مثل الملاحة المتقدمة على الطرق السريعة والركن التلقائي (المصدر: QbitAI)