
كلمات مفتاحية:مشروع مانهاتن للذكاء الاصطناعي, جيميني 3 فلاش, جي بي تي-5.2-كودكس, الاندماج النووي المتحكم فيه, هندسة البحث العلمي بالذكاء الاصطناعي, وكيل الذكاء الاصطناعي, النماذج متعددة الوسائط, نماذج الذكاء الاصطناعي مفتوحة المصدر, مهمة التكوين لوزارة الطاقة الأمريكية, اختبار ترميز جيميني 3 فلاش, الدفاع السيبراني لـ جي بي تي-5.2-كودكس, نموذج تي5جيم 2 متعدد الوسائط, فاصل الصوت البصري لمشفر الإدراك
🔥 التركيز
إطلاق “مشروع مانهاتن للذكاء الاصطناعي” في الولايات المتحدة: أطلقت وزارة الطاقة الأمريكية رسميًا “مهمة جينيسيس” (Genesis Mission)، وهو مشروع بحثي وطني في مجال AI يهدف إلى دمج أحدث تقنيات AI مع القدرات البحثية للمختبرات الوطنية لتسريع الاكتشافات العلمية. يجمع هذا المشروع 24 عملاقًا تقنيًا، بما في ذلك Microsoft و Google و NVIDIA و OpenAI و DeepMind و Anthropic، لتطبيق نماذج AI وقدرات الحوسبة الفائقة في مجالات مثل الاندماج النووي المتحكم فيه، ومواد الطاقة، ومحاكاة المناخ. الهدف هو مضاعفة الإنتاجية العلمية الأمريكية بحلول عام 2030، مما يمثل تحولًا استراتيجيًا وطنيًا للولايات المتحدة في مجال التكنولوجيا. (المصدر: 36氪, nvidia, AnthropicAI, GoogleDeepMind, OpenAI Newsroom)
حوار بين Hinton و Jeff Dean حول الذكاء الاصطناعي الحديث: تحدث Geoffrey Hinton، أحد مؤسسي الشبكات العصبية، مع Jeff Dean، كبير العلماء في Google، في مؤتمر NeurIPS، لمناقشة العوامل الرئيسية التي دفعت AI الحديث من المختبرات إلى مليارات المستخدمين. يعتقدون أن اختراق AI لم يكن معجزة واحدة، بل نتيجة نضج منهجي للخورازميات (مثل Transformer)، والأجهزة (مثل GPU و TPU)، والهندسة (مثل JAX و Pathways). وأشار الحوار أيضًا إلى أن توسيع نطاق AI يواجه ثلاث عقبات رئيسية: كفاءة الطاقة، والذاكرة (السياق الطويل)، والإبداع (القدرة على الربط)، مؤكدين على أهمية البحث الأساسي والاستثمار المستمر. (المصدر: 36氪, JeffDean, geoffreyhinton)
مقابلة مع Sam Altman: استراتيجية OpenAI وتمويلها: أشار Sam Altman في أحدث مقابلة له إلى أن Google لا تزال تمثل التهديد الأكبر لـ OpenAI، لكن OpenAI ستعزز مكانتها من خلال برامج AI الأصلية، وميزات التخصيص والذاكرة، وتسريع التوسع في سوق الشركات، واستثمار 1.4 تريليون دولار في البنية التحتية. وتوقع أن يظهر GPT-6 في الربع الأول من العام المقبل، مؤكدًا أن AI سيعيد تشكيل طريقة استخدام البرامج في المستقبل، ليصبح “شريكًا رقميًا” لا غنى عنه، بدلاً من مجرد تضمينه في المنتجات القديمة. (المصدر: 36氪, sama)
Google تطلق نموذج Gemini 3 Flash: أطلقت Google نموذج Gemini 3 Flash، الذي يتميز بأداء ممتاز في العديد من الاختبارات المعيارية، وبسرعة وفعالية عالية من حيث التكلفة، متفوقًا حتى على GPT-5.2 في اختبار SWE-bench للترميز. تخطط Google لدمجه بعمق في منتجاتها البيئية مثل البحث و YouTube و Gmail، بهدف إعادة تشكيل سوق AI من خلال الميزة البيئية بدلاً من مجرد التنافس على معلمات النموذج. يُنظر إلى هذا الإطلاق على أنه “ضربة دقيقة” لـ OpenAI، مما أثار نقاشًا واسعًا في الصناعة حول المنافسة بين النماذج وانتشار تطبيقات AI. (المصدر: 36氪, MS_BASE44, GeminiApp, scaling01)
OpenAI تطلق نموذج البرمجة GPT-5.2-Codex: أطلقت OpenAI نموذج GPT-5.2-Codex، الذي يُزعم أنه أقوى نموذج برمجة لـ AI Agent حتى الآن، ومُحسّن خصيصًا لهندسة البرمجيات المعقدة والأمن السيبراني. يعزز هذا النموذج قدرات تنفيذ المهام طويلة المدى، وتغييرات التعليمات البرمجية واسعة النطاق، والتوافق مع بيئة Windows، وقدرات الدفاع عن الأمن السيبراني. على الرغم من أدائه القوي في الاختبارات المعيارية، أظهرت بعض الاختبارات الفعلية للمستخدمين أنه لا يرقى إلى مستوى Gemini 3 Flash في بعض المهام، مما أثار نقاشًا في السوق حول فعاليته الحقيقية وقدرته التنافسية. (المصدر: 36氪, sama, scaling01)
🎯 التوجهات
Google تفتح مصدر T5Gemma 2 و FunctionGemma: أعلنت Google عن فتح مصدر نموذجين صغيرين، T5Gemma 2 و FunctionGemma، وكلاهما مبني على عائلة Gemma 3. يعتبر T5Gemma 2 أول نموذج متعدد الوسائط بترميز-فك ترميز ذي سياق طويل، وبأصغر حجم يبلغ 270M-270M، ويركز على كفاءة البنية والقدرات متعددة الوسائط. أما FunctionGemma فهو نموذج بحجم 270M مُحسّن خصيصًا لاستدعاء الوظائف، ويمكن تشغيله على الأجهزة الطرفية مثل الهواتف المحمولة، ويهدف إلى حل مشكلة “القدرة على التحدث ولكن ليس العمل” في تطبيق النماذج الكبيرة، ويوفر “عقلًا مخصصًا” لـ Agent واستخدام الأدوات. (المصدر: 36氪, huggingface, osanseviero, ImazAngel, danielhanchen)

اختبار نموذج Doubao 1.8 من ByteDance: أطلقت ByteDance نموذج Doubao 1.8 الكبير، وهو نموذجها الرئيسي من الجيل الجديد، والذي أظهر أداءً رائدًا في تقييمات متعددة للمشاهد مثل التعليم وخدمة العملاء والمالية والقانون. أظهرت الاختبارات الفعلية أن Doubao 1.8 يتميز بقدرات Agent (استدعاء أدوات متعددة، اتباع تعليمات متعددة الجولات، OS Agent)، وإدارة سياق طويل جدًا بحجم 256K، وفهم متعدد الوسائط (تحسين قدرة فهم الفيديو إلى 20 دقيقة). وهو مناسب بشكل خاص لبناء Agent المعقدة وتشغيل العمليات الحقيقية، ويُعتبر خطوة حاسمة في تطوير Agent على مستوى المؤسسات و Agent على الأجهزة الطرفية. (المصدر: WeChat)

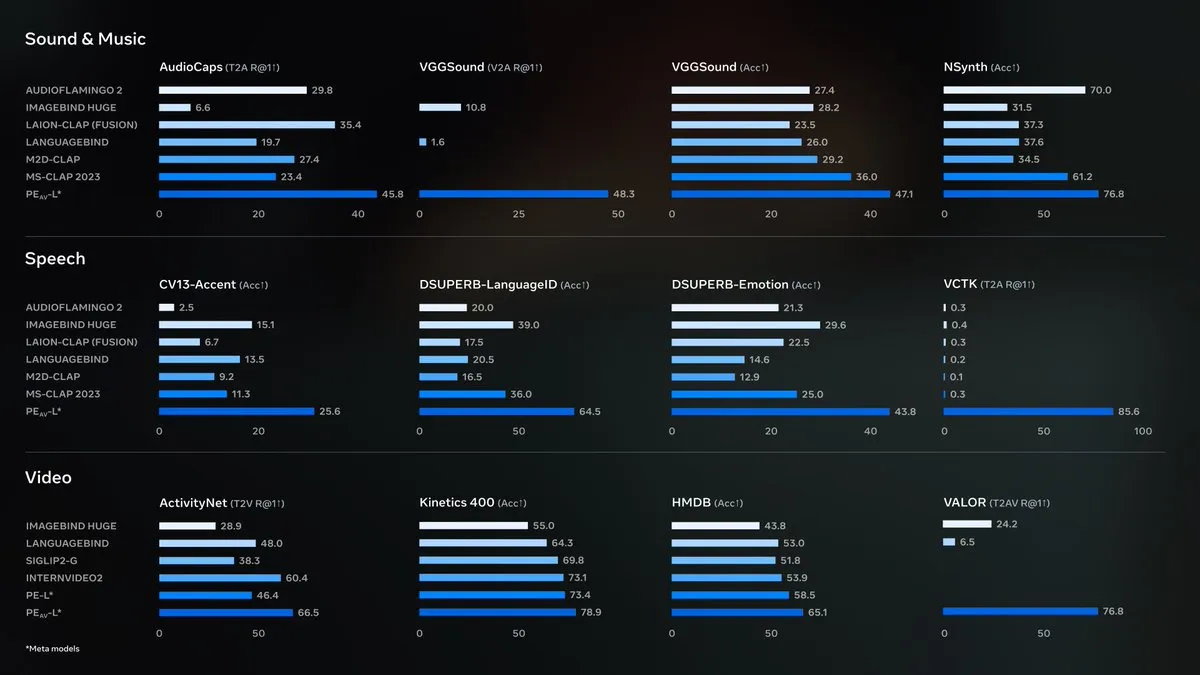
Meta تفتح مصدر Perception Encoder Audiovisual (PE-AV): أعلنت Meta عن فتح مصدر Perception Encoder Audiovisual (PE-AV)، وهو المحرك التقني الأساسي وراء SAM Audio، ويهدف إلى تحقيق أحدث فصل صوتي. يعتمد PE-AV على نموذج Perception Encoder الذي أطلقته Meta سابقًا، ويدمج الإدراك الصوتي والبصري بعمق، وقد حقق نتائج متفوقة في مجموعة واسعة من الاختبارات المعيارية للصوت والفيديو، ومن المتوقع أن يعزز قدرات اكتشاف الصوت وفهم المشاهد السمعية البصرية من خلال دعم الوسائط المتعددة. (المصدر: AIatMeta, Reddit r/LocalLLaMA)
Runway تطلق نموذجي Gen-4.5 و GWM-1: أطلقت Runway نموذج Gen-4.5 لتوليد الفيديو، مع إضافة ميزات تحرير الصوت واللقطات المتعددة، كما أطلقت سلسلة GWM-1 (General World Model)، والتي تشمل GWM Worlds (مشاهد قابلة للتنقل)، و GWM Robotics (محاكاة منظور الروبوت)، و GWM Avatars (شخصيات متزامنة مع حركة الشفاه)، بهدف تحقيق توليد فيديو لنموذج عالمي في الوقت الفعلي وقابل للتحكم، مما يشير إلى قفزة كبيرة في تقنية توليد الفيديو نحو المحاكاة العامة. (المصدر: c_valenzuelab, DeepLearningAI)
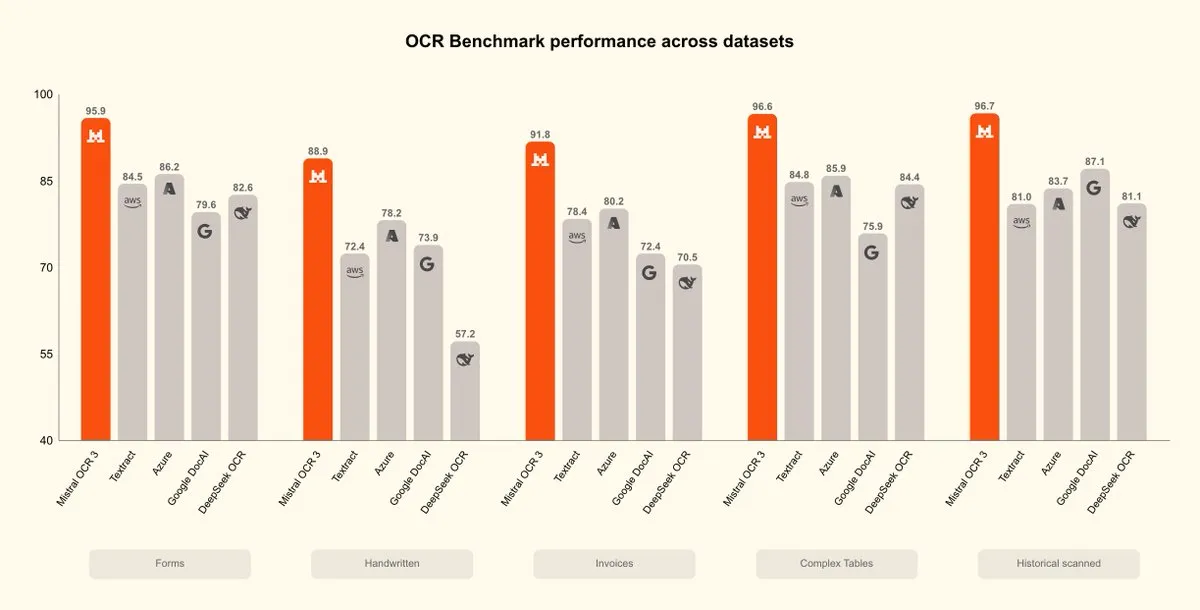
Mistral OCR 3 يُطلق، اختراق جديد في ذكاء المستندات: أطلقت Mistral AI نموذج Mistral OCR 3، الذي وضع معيارًا جديدًا في الدقة والكفاءة، متجاوزًا حلول معالجة المستندات المؤسسية الحالية و OCR الأصلي لـ AI. تم تحسين هذا النموذج بشكل كبير في معالجة المحتوى المكتوب بخط اليد، والمسح الضوئي منخفض الجودة، والجداول والنماذج المعقدة الشائعة في مستندات الشركات، مما يمثل تقدمًا جديدًا في مجال ذكاء المستندات. (المصدر: qtnx_, GuillaumeLample)
إعادة هيكلة Tokenization في Hugging Face Transformers v5: قامت Hugging Face بإعادة تصميم كبيرة لطريقة عمل الـ tokenizer في Transformers v5. يفصل الإصدار الجديد بنية الـ tokenizer عن مفردات التدريب، مما يزيد من الشفافية والنمطية، ويبسط عملية تدريب الـ tokenizer الخاص بالنموذج من الصفر. هذا التحسين يجعل الـ tokenizer أسهل في الفحص والتخصيص والتدريب، ويحل مشكلة عدم شفافية الـ tokenizer وارتباطه الوثيق في الإصدار v4. (المصدر: HuggingFace Blog, huggingface)

إعلان Firefox عن التحول إلى AI يثير جدلاً بين المستخدمين: أعلن متصفح Firefox عن تحوله إلى متصفح AI، لدعم مجموعة من البرامج الجديدة. أثارت هذه الخطوة استياء العديد من المستخدمين في مجتمعات مثل Reddit، خاصة المستخدمين الأساسيين الذين يقدرون الخصوصية والبساطة، والذين يعتقدون أن Firefox يبتعد عن قيمه الأساسية. يعكس هذا التحول استراتيجية Mozilla للبحث عن نقاط نمو جديدة في عصر “موت البحث”، لكن تحقيق التوازن بين ميزات AI وخصوصية المستخدم يمثل تحديًا كبيرًا لها. (المصدر: 36氪)

ChatGPT يطلق ميزة تثبيت الدردشات: أعلنت OpenAI أن ChatGPT قد أطلق الآن ميزة تثبيت الدردشات، حيث يمكن للمستخدمين تثبيت المحادثات المهمة على أنظمة iOS و Android و Web لسهولة الوصول السريع. يهدف هذا التحديث إلى تحسين تجربة المستخدم وتبسيط إدارة المحادثات. (المصدر: openai, Reddit r/ChatGPT)
ترقية وظائف إضافة Claude for Chrome: أصبحت إضافة Claude for Chrome متاحة الآن لجميع المستخدمين المدفوعين، وتم دمج وظيفة Claude Code فيها. يمكن للمستخدمين الآن اختبار التعليمات البرمجية وتصحيحها مباشرة في المتصفح عبر Claude Code، دون الحاجة إلى مغادرة الصفحة الحالية. يهدف هذا التحديث إلى تحسين كفاءة المطورين وتجربتهم، بينما أكدت Anthropic أيضًا على مراعاة السلامة في التصميم والاختبار. (المصدر: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

🧰 الأدوات
Agent Skills تصبح معيارًا مفتوحًا: أصبحت Agent Skills من Anthropic الآن معيارًا مفتوحًا، مما يسمح لـ AI Agent بتعلم وتنفيذ مهام سير العمل المتكررة عبر منصات مختلفة. تهدف هذه الخطوة إلى تبسيط نشر المهارات واكتشافها وبنائها، وتعزيز قابلية التشغيل البيني لنظام أدوات AI البيئي. يمكن للمطورين الآن إنشاء مهارة واحدة واستخدامها على منصات AI متعددة، مما يزيد من القدرة الاحترافية والكفاءة لـ Agent. (المصدر: omarsar0, code, Reddit r/ClaudeAI)
LangChain Academy تطلق دورة جديدة: أطلقت LangChain Academy دورة جديدة بعنوان “مقدمة إلى LangChain (Python)”، تهدف إلى مساعدة المطورين على تعلم كيفية بناء AI Agent باستخدام إطار عمل LangChain. تغطي الدورة إنشاء Agent، واستخدام وحدات البناء الأساسية (النماذج، الرسائل، الذاكرة، الأدوات)، وكيفية استخدام LangSmith لتصحيح سلوك Agent، والهدف النهائي هو تمكين المتدربين من بناء فريق كامل من المساعدين الشخصيين. (المصدر: LangChainAI, hwchase17)

إعدادات تطوير متقدمة لـ Claude Code CLI: شارك أحد المطورين إعدادات Claude Code CLI “المفرطة في الهندسة”، والتي تجمع بين خادم MCP والمهارات المخصصة وملف CLAUDE.md الصارم، لتحقيق “Vibe Coding” لتعليمات برمجية على مستوى الإنتاج. تمنع هذه الطريقة بفعالية Agent من الانحراف عن المسار وتحقق إعادة هيكلة فعالة من خلال بوابات الجودة، والدورات التكرارية، والاختبار داخل المتصفح، مما يحل نقاط الألم التي تواجهها Agent التقليدية في التطوير الفعلي. (المصدر: Reddit r/ClaudeAI)
OpenRouter تطلق ميزة إصلاح مخرجات JSON لـ LLM: قدمت OpenRouter ميزة “إصلاح الاستجابة” (Response Healing)، التي يمكنها إصلاح الأخطاء تلقائيًا في مخرجات JSON المهيكلة التي تنتجها نماذج اللغة الكبيرة (LLM). وقد أدت هذه الميزة إلى تقليل معدل العيوب بشكل كبير في نماذج مثل Gemini 2 Flash و Qwen3 235B، مما زاد من موثوقية LLM في السيناريوهات التي تتطلب مخرجات JSON دقيقة. (المصدر: xanderatallah)

أداة AssemblyAI لتحويل الصوت إلى نص تدعم إدخال URL: تم تحديث AssemblyAI Playground، وأصبح يدعم الآن تحويل الصوت مباشرة من URL. يمكن للمستخدمين اختبار البودكاست، أو الصوت السحابي، أو الملفات الكبيرة (مثل مكالمات الأرباح) دون الحاجة إلى تنزيل الملفات، مما يبسط بشكل كبير عمليات تطوير النماذج الأولية والتحقق من التكامل، ويزيد من كفاءة اختبار قدرات Speech AI. (المصدر: AssemblyAI)
jax-js: مكتبة تعلم آلة تعمل في المتصفح: jax-js هي مكتبة تعلم آلة مفتوحة المصدر، تعيد تنفيذ JAX بلغة JavaScript النقية، وتدعم تجميع JIT إلى WebGPU، مما يسمح لها بتشغيل الشبكات العصبية في المتصفح. توفر هذه المكتبة ميزات مثل الاشتقاق التلقائي وتجميع JIT، وتهدف إلى توفير نموذج برمجة فعال ومرن مشابه لـ PyTorch و JAX، وقد تم التحقق من تفاعليتها من خلال عروض توضيحية مستقلة مثل تدريب MNIST واستدلال MobileCLIP. (المصدر: Vtrivedy10, Reddit r/MachineLearning)

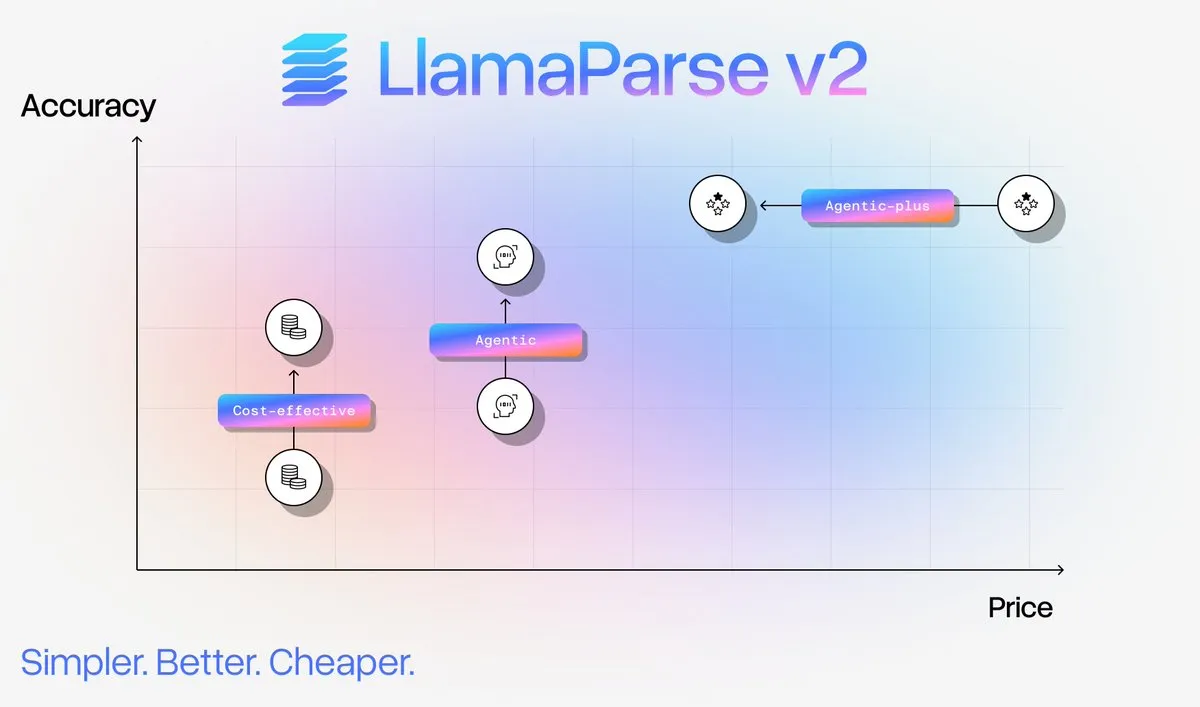
ترقية خدمة تحليل المستندات LlamaParse v2: أطلقت LlamaIndex خدمة LlamaParse v2، التي بسّطت بشكل كبير إعدادات تحليل المستندات، وحسّنت الأداء، وحققت تخفيضًا في التكلفة يصل إلى 50% لتحليل المستندات المعقدة. قدم الإصدار الجديد أربعة مستويات ثابتة: Fast، و Cost Effective، و Agentic، و Agentic Plus، مما عزز دقة المحتوى متعدد الوسائط، وقلل من الهلوسة، ومكّن المستخدمين من تحقيق استيعاب مستندات على مستوى الإنتاج دون الحاجة إلى أن يصبحوا خبراء في التحليل. (المصدر: jerryjliu0)
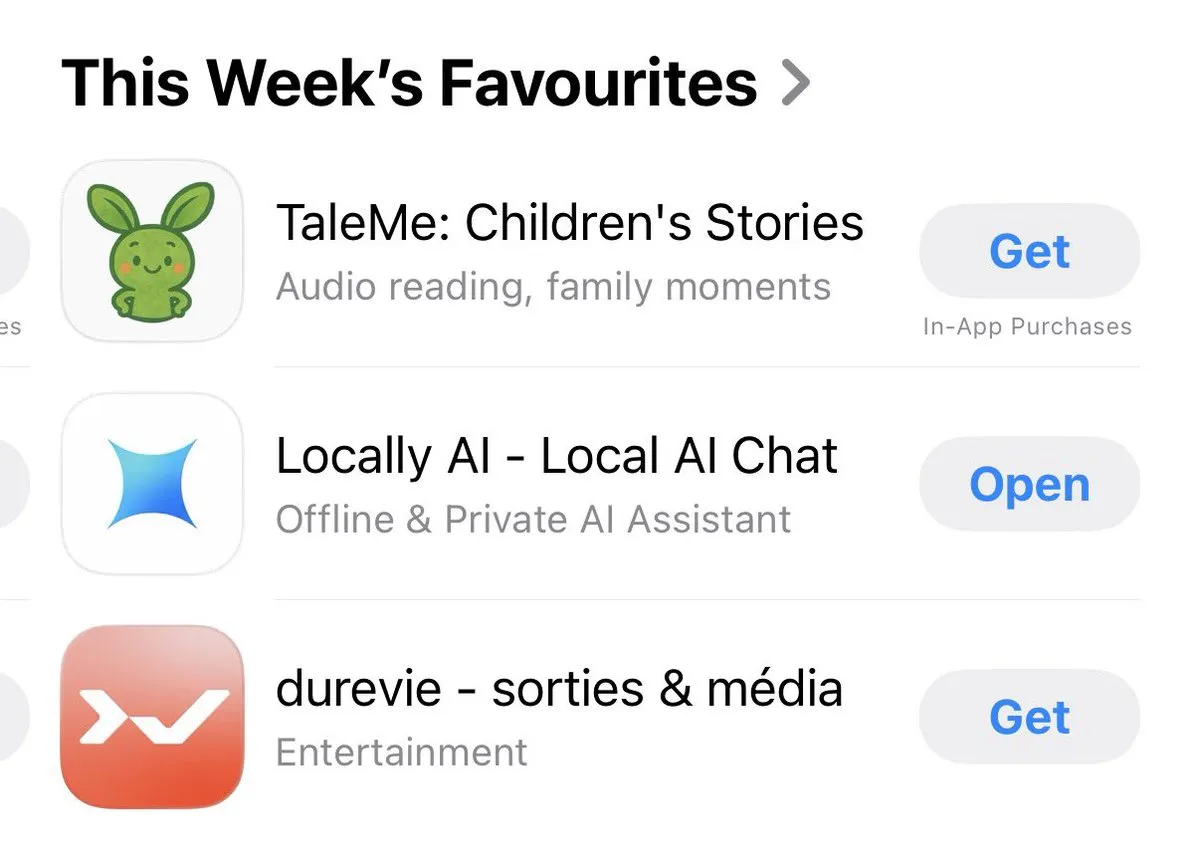
Locally AI: تطبيق لتشغيل نماذج AI محليًا: Locally AI هو تطبيق يسمح للمستخدمين بتشغيل نماذج AI محليًا على أجهزتهم اليومية، وقد تم إدراجه في قائمة “مفضلة هذا الأسبوع” في App Store نظرًا لسهولة استخدامه. يهدف هذا التطبيق إلى خفض عتبة استخدام AI، مما يتيح لعدد أكبر من الأشخاص التفاعل بسهولة مع نماذج AI المحلية، ويؤكد على سهولة استخدام AI المحلي وإمكانية الوصول إليه. (المصدر: adrgrondin)
Google Flow لتوليد الصور يدعم تنزيل الصور عالية الدقة: تدعم ميزة Nano Banana Pro في Google Flow الآن تنزيل الصور التي تم إنشاؤها بواسطة AI بدقة 2K و 4K. يلبي هذا التحديث طلب المستخدمين للحصول على صور بدقة أعلى، سواء للمواد الإبداعية، أو تسلسلات الإطارات، أو المؤثرات البصرية، مما يوفر محتوى تم إنشاؤه بواسطة AI أكثر وضوحًا وتفصيلاً. (المصدر: op7418)

مستخدمو OpenWebUI يبلغون عن مشكلات في وظيفة RAG: أبلغ مستخدمو OpenWebUI عن مشكلات في وظيفة RAG (Retrieval Augmented Generation)، خاصة عند معالجة ملفات PDF التي يزيد حجمها عن 1 ميجابايت، حيث لا يستطيع النموذج تمرير محتوى الملف إلى السياق، مما يؤدي إلى خطأ “لم يتم العثور على مصدر”. على الرغم من نجاح تحميل الملف واستخراج النص وتضمينه، إلا أن خطوة إنشاء الاستعلام تفشل، مما يعيق استخدام محتوى PDF في استدلال النموذج، ويؤثر على مهام مثل استخراج البيانات المهيكلة. (المصدر: Reddit r/OpenWebUI, Reddit r/OpenWebUI)

لعبة مغامرات نصية بـ AI: Glif Agent: يقدم Glif Agent تجربة لعبة مغامرات نصية، حيث يمكن للمستخدمين الانغماس فيها مباشرة دون الحاجة إلى أدلة معقدة. تعرض أداة AI هذه إمكانات LLM في إنشاء سرد تفاعلي وتجارب غامرة، مما يتيح للاعبين استكشاف العالم الافتراضي من خلال تعليمات اللغة الطبيعية. (المصدر: NerdyRodent)

Cass: أداة بحث عن جلسات Coding Agent: تُعتبر أداة Cass “منقذًا” لـ Coding Agent، حيث توفر وقتًا وجهدًا كبيرين. يمكنها اكتشاف واستيعاب وفهرسة جميع جلسات Coding CLI تلقائيًا، وتوفر بحثًا فوريًا و”وضع الروبوت”، مما يتيح للمستخدمين العثور بسرعة على آثار Agent وإدارتها وإعادة استخدامها، مما يعزز بشكل كبير كفاءة استخدام Coding Agent. (المصدر: doodlestein)
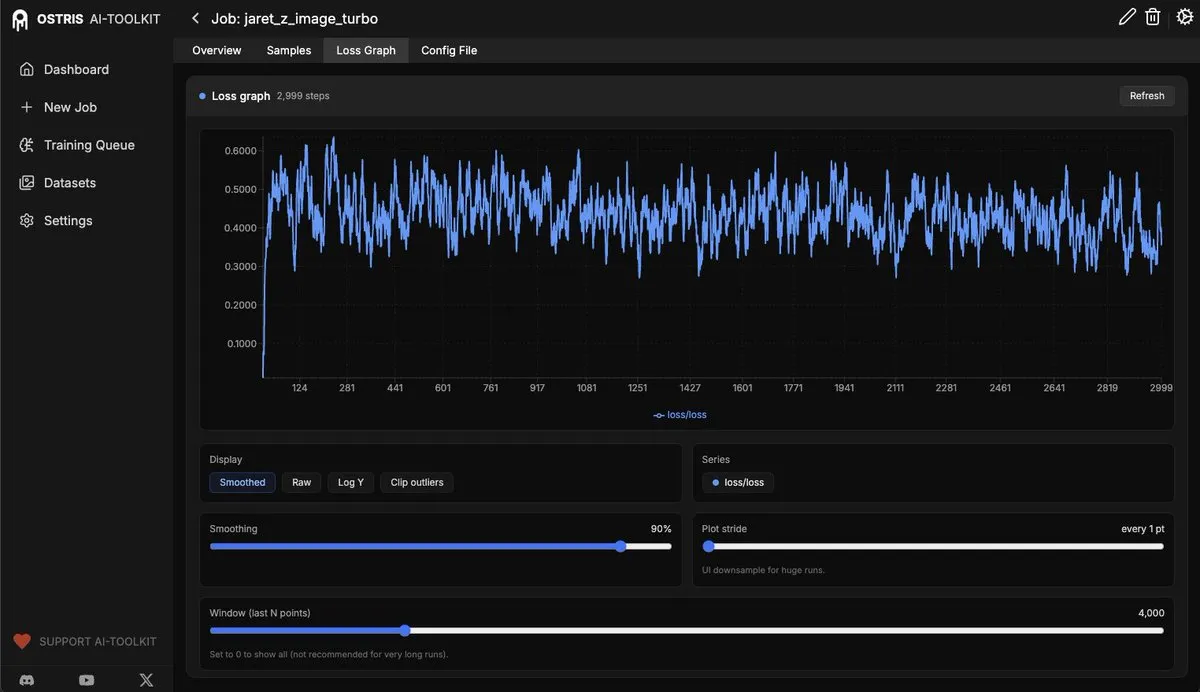
AI Toolkit UI يضيف ميزة رسم بياني الخسارة: تم تحديث AI Toolkit UI، مع إضافة ميزة رسم بياني الخسارة (loss graph)، لمراقبة عملية الضبط الدقيق لنماذج الانتشار (diffusion models). ستوفر هذه الميزة للمستخدمين ملاحظات أكثر وضوحًا حول تدريب النموذج، وسيتم إضافة المزيد من الميزات في المستقبل لتعزيز كفاءة تطوير وتصحيح أخطاء نماذج AI. (المصدر: ostrisai)
📚 التعلم
دورة جديدة لـ Nvidia NeMo Agent Toolkit: أطلقت DeepLearning.AI دورة جديدة لـ Nvidia NeMo Agent Toolkit، حيث يقوم خبير NVIDIA Brian بتعليم كيفية استخدام هذه المجموعة لبناء AI Agent موثوقة وعلى مستوى الإنتاج. تغطي الدورة سير العمل الموجه بالتكوين، وتحقيق قابلية الملاحظة من خلال التتبع، واستخدام مجموعات البيانات المعيارية الذهبية لتقييم النظام، ونشر أنظمة متعددة Agent، بهدف مساعدة المطورين على تحويل نماذج Agent الأولية إلى أنظمة إنتاج موثوقة. (المصدر: AndrewYNg)
موارد تعلم AI ومراجعة المفاهيم: تم مشاركة مجموعة من موارد تعلم AI، بما في ذلك أحدث إصدار من Deep Learning Weekly، الذي يغطي Agent ذاتية التحسين، والأخطاء في اختبارات AI المعيارية، ودليل تدريب RL، وما إلى ذلك؛ بالإضافة إلى خريطة طريق لإتقان Agentic AI، ومراجعة للمفاهيم الأساسية لـ AI لعام 2025 (التعلم المعزز، ومتغيرات RLHF، والتعلم المستمر، و AI الرمزي العصبي، وأجهزة AI، وما إلى ذلك)، بالإضافة إلى أحدث التطورات في أبحاث سلامة AI. (المصدر: dl_weekly, TheTuringPost, Ronald_vanLoon, AndrewYNg, ajeya_cotra)
إصدار فصل من كتاب “نماذج اللغة البصرية”: تم إصدار الفصل الخامس من كتاب “نماذج اللغة البصرية” (Visual Language Models)، ويركز المحتوى على التدريب المسبق، ويقدم رسومًا توضيحية وإرشادات عملية. يوفر هذا موردًا قيمًا لمتعلمي AI لفهم آليات التدريب المسبق لنماذج اللغة البصرية بعمق. (المصدر: algo_diver)
تحديث ورقة بحثية حول أنظمة البحث المدفوعة بـ AI (ADRS): أصدرت أنظمة البحث المدفوعة بـ AI (ADRS) ورقة بحثية محدثة، تقيم أداء ثلاثة أطر عمل مفتوحة المصدر في حل 10 مشكلات أداء أنظمة حقيقية. أظهرت الدراسة أن الحلول التي تم إنشاؤها بواسطة AI يمكن أن تحقق تسريعًا بمقدار 13 ضعفًا في موازنة التحميل، وتوفيرًا في التكلفة بنسبة 35% في جدولة السحابة، بل وتتفوق على الخبراء البشريين، مما يوفر دليلًا قويًا على تطبيق AI في أبحاث الأنظمة. (المصدر: matei_zaharia)

💼 الأعمال
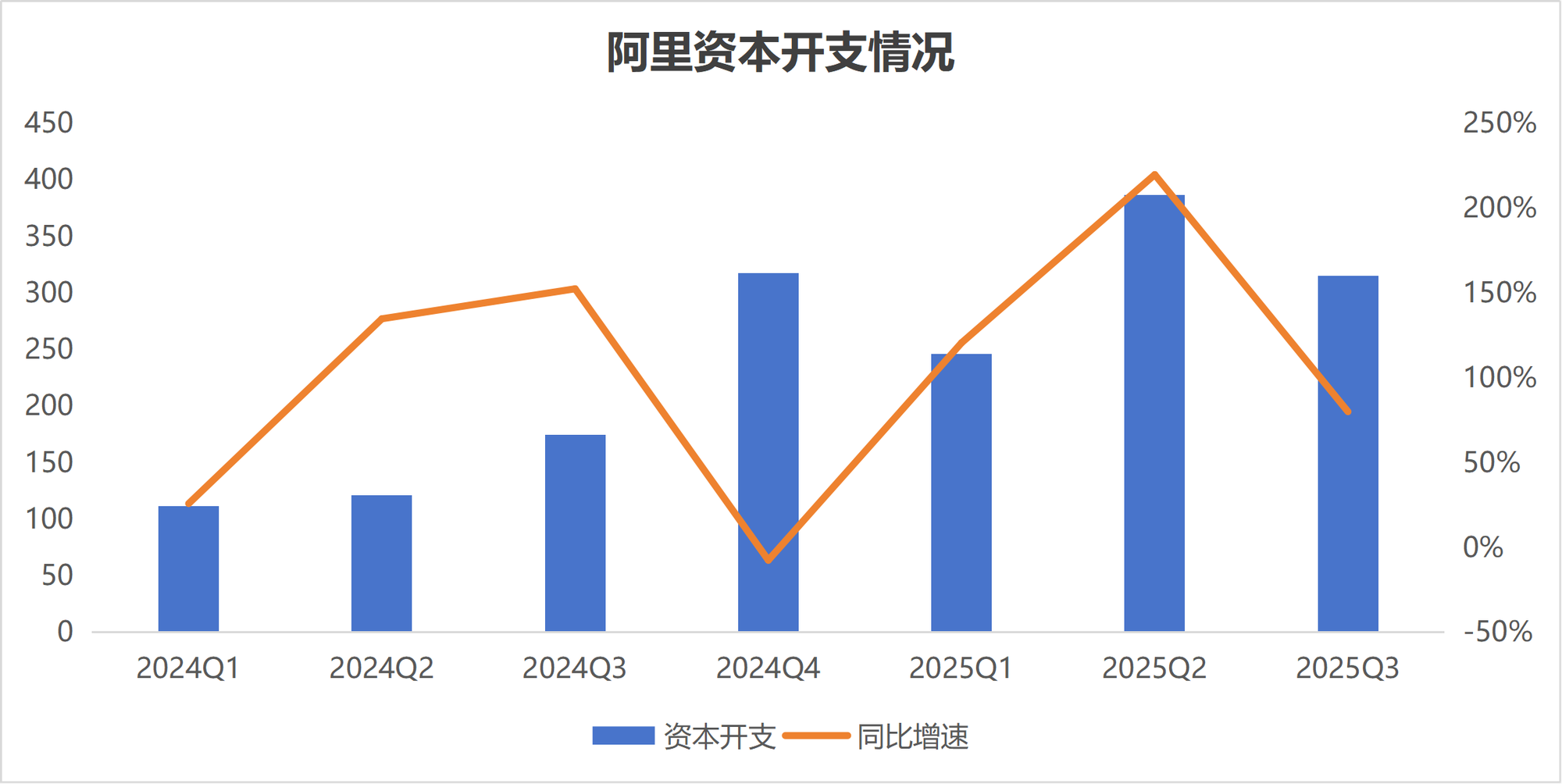
اختلاف في استراتيجيات استثمار AI: Alibaba و Tencent تتبعان مسارين متباينين: في مواجهة موجة AI، ظهر اختلاف واضح في استراتيجيات الاستثمار بين عملاقي التكنولوجيا الصينيين Alibaba و Tencent. تسرع Alibaba استثماراتها في بناء البنية التحتية لـ AI، وتخطط لاستثمار أكثر من 380 مليار يوان في السنوات الثلاث المقبلة، بهدف أن تصبح شركة بنية تحتية توفر “الماء والكهرباء والفحم” لـ AI. بينما تتجه Tencent نحو “الهدوء”، حيث خفضت توجيهات الإنفاق الرأسمالي، وتركز بشكل أكبر على تمكين AI في جانب التطبيقات، واستقدمت عالم OpenAI السابق ياو شونيو لتعزيز استراتيجية AI نحو جانب التطبيقات. يعكس هذا الاختلاف تباينًا في تقدير الطرفين لمسار التسويق التجاري في عصر AI. (المصدر: 36氪)
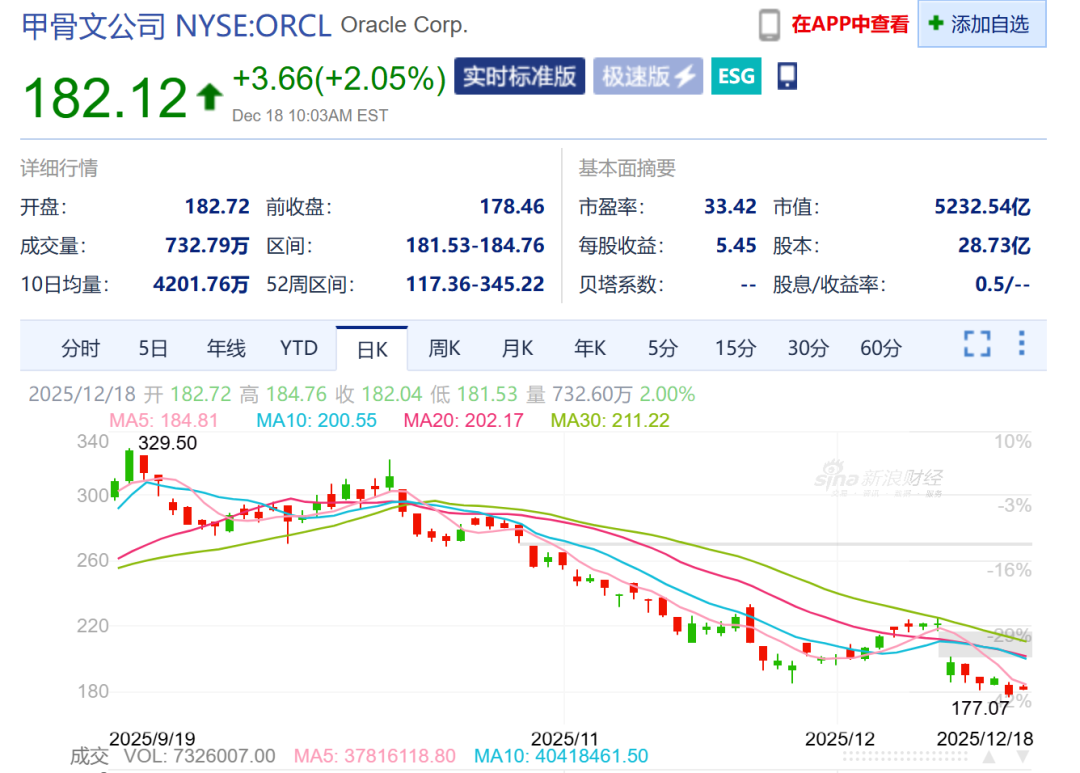
فشل تمويل مشروع Oracle بمليارات الدولارات يثير مخاوف فقاعة AI: فشل تمويل مشروع Oracle لمركز البيانات في الولايات المتحدة بمليارات الدولارات، وانسحب الداعم الرئيسي Blue Owl Capital، مما أثار مخاوف السوق بشأن فقاعة AI. يسلط هذا الحدث الضوء على عدم اليقين لدى المستثمرين بشأن تكاليف الاستثمار الضخمة والجداول الزمنية لتحقيق الأرباح في دورة البنية التحتية لـ AI. يشكك المحللون في قدرة OpenAI على الوفاء بالتزاماتها بدفع تكاليف الحوسبة لـ Oracle، ومشكلة التوسع السريع في ميزانية Oracle، مما يشير إلى أن المنافسة في AI تدخل “فترة اختبار التدفق النقدي”. (المصدر: 36氪)
Brett Adcock يؤسس مختبر AI جديد Hark: أعلن Brett Adcock، الرئيس التنفيذي لشركة Figure AI، عن تأسيس مختبر AI جديد باسم Hark، واستثمر فيه 100 مليون دولار من أمواله الشخصية. سيركز مختبر Hark على أبحاث “AI المتمحور حول الإنسان”، وسيستمر Adcock في منصبه في Figure AI. تشير هذه الخطوة إلى الاهتمام المستمر في مجال AI بالتفاعل بين الإنسان والآلة والأخلاقيات، كما أنها تضخ رأس مال خاص جديد في أبحاث AI. (المصدر: steph_palazzolo)
🌟 المجتمع
جدل حول أداء LLM وتجربة المستخدم: هناك جدل واسع على وسائل التواصل الاجتماعي حول الأداء الفعلي لـ GPT-5.2، حيث يشتكي العديد من المستخدمين من سوء تجربة الاستخدام اليومية، وظهور الهلوسة، أو الأداء المتواضع في المهام البسيطة، مما يتناقض مع “الذكاء الأكبر” الذي يظهر في الاختبارات المعيارية. أثار هذا الانفصال نقاشًا حول اتجاه تطوير نماذج AI: هل هو السعي وراء الذكاء على مستوى المنافسة أم التطبيق العملي اليومي؟ في الوقت نفسه، شارك بعض المستخدمين مخاوفهم بشأن تدهور أداء نموذج Opus 4.5، بالإضافة إلى تحديات LLM في تصحيح الأخطاء وفهم نية المستخدم، مثل الصعوبات التي يواجهها Claude Code عند التعامل مع التعليمات البرمجية المعقدة. (المصدر: VictorTaelin, aidan_mclau, 36氪, dbreunig, Reddit r/ChatGPT, Reddit r/artificial)
تأثير AI على العمل والمجتمع: تناقش وسائل التواصل الاجتماعي على نطاق واسع تأثير AI على سوق العمل، بما في ذلك المخاوف من “انهيار” وظائف ذوي الياقات البيضاء، وإمكانات AI في زيادة الإنتاجية. في الوقت نفسه، يختلف مستوى وعي الجمهور بـ AI، حيث يعتقد الكثيرون خطأً أن ChatGPT يبحث عن الإجابات في قاعدة بيانات. بالإضافة إلى ذلك، خفضت تقنية AI عتبة المعلومات المضللة والاحتيال، مما أثار مخاوف بشأن آليات مراجعة المنصات وتكلفة إثبات الذات للأفراد. وهناك أيضًا رأي مفاده أن تقدم AI يشبه “قطارًا جديدًا يسير على قضبان قديمة”، وأن العقبات في التطبيق العملي هي في الغالب عوامل اجتماعية واقتصادية وسياسية. (المصدر: random_walker, Reddit r/ArtificialInteligence, Plinz, doodlestein, amasad, 36氪, gfodor, Reddit r/ArtificialInteligence)
أخلاقيات AI وسلامته: تدور نقاشات حادة على وسائل التواصل الاجتماعي حول أخلاقيات AI وسلامته. تشمل هذه النقاشات اتهامات بالسرقة الأدبية ضد رواد AI مثل Hinton، وحالات اعتقال خاطئة بسبب نماذج AI في تطبيقات مثل التعرف على الوجه، والمخاطر التي تنطوي عليها المحتوى الذي يولده AI (مثل آلة البيع الآلية التي خرجت عن السيطرة في اختبار WSJ). أصدرت OpenAI “مواصفات النموذج” لتوجيه سلوك النموذج، بينما أطلقت Google DeepMind تقنية SynthID للعلامات المائية للكشف عن مقاطع الفيديو التي تم إنشاؤها بواسطة AI. بالإضافة إلى ذلك، أثار الأثر البيئي الهائل لـ AI (استهلاك المياه وانبعاثات الكربون) اهتمامًا، بالإضافة إلى الاعتبارات الأخلاقية عند تقديم AI للدعم العاطفي. (المصدر: SchmidhuberAI, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Ronald_vanLoon, AnthropicAI, ajeya_cotra, Reddit r/MachineLearning)
تطوير وتحديات AI Agent: أصبح تطوير وتطبيق AI Agent نقطة ساخنة، وتشمل المناقشات بنيتها (وحدات قابلة للتركيب، إدارة الذاكرة)، والمعايير المفتوحة (Agent Skills)، والممارسات في مجالات مثل الروبوتات (Reachy Mini، روبوت Grek، روبوت Bipedal Gait، روبوتات متنقلة ذاتية القيادة) والبرمجة (Claude MCP Agent). تشمل التحديات كيفية تعزيز مصداقية Agent، ومعالجة السياق الطويل، وتحسين البنية التحتية لدعم التعاون بين Agent المتعددة، وكيفية ضمان استقرار Agent في المهام المعقدة وتجنب “الحلقات الميتة”. (المصدر: Vtrivedy10, julesagent, LangChainAI, TheTuringPost, Ronald_vanLoon, Sentdex, ClementDelangue, doodlestein, corbtt, Ronald_vanLoon)
أبحاث LLM وخصائص النموذج: تغطي مناقشات مجتمع AI حول أبحاث LLM وظائف القيمة في التعلم المعزز (RL)، وفائدة LoRA RL، وتقييم قدرات GPT-4، والجدل بين RL و LLM بعد التدريب، وتطبيقات LLM في البحث الرياضي، بالإضافة إلى استكشاف قضايا فلسفية مثل وعي AI و”غذاء الفكر”. بالإضافة إلى ذلك، تم التركيز على بنيات LLM الجديدة (مثل Diffusion LLM، ونموذج عالم DexWM)، وقوانين كثافة النموذج، وتحديات معالجة السياق الطويل، وتقييم أداء نماذج محددة مثل Kimi K2 و MiMo-V2. (المصدر: natolambert, vllm_project, SebastienBubeck, sarahcat21, karpathy, riemannzeta, _akhaliq, code_star, DeepLearningAI, ollama, gdb, yacinelearning, ylecun, pmddomingos, matei_zaharia, TheTuringPost, yacinelearning, MiniMax__AI, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/LocalLLaMA)
البنية التحتية وأجهزة AI: تعد البنية التحتية وأجهزة AI من المواضيع الساخنة، وتشمل إطار عمل MLX لتحقيق استدلال متوازي للموترات بزمن انتقال منخفض على Mac، وأهمية قواعد بيانات المتجهات مثل Qdrant و Turbopuffer في عصر Agentic، وتكاليف وتحديات بناء مجموعات GPU (مثل 8x B200 أو مجموعة Mac Studio). تتناول المناقشات أيضًا تحسين التدريب الموزع (SonicMoE)، واختناقات الواجهة الخلفية serverless لـ Agent، والمخاوف بشأن استهلاك الطاقة لمراكز بيانات AI. (المصدر: awnihannun, qdrant_engine, TheEthanDing, Dorialexander, halvarflake, matei_zaharia, togethercompute, andersonbcdefg, idavidrein, Reddit r/deeplearning, Reddit r/MachineLearning, Reddit r/LocalLLaMA, Reddit r/MachineLearning, StasBekman, HuggingFace Daily Papers)

فن وتطبيقات Generative AI: تدور المناقشات حول التقدم في Generative AI في مجالات الفن والتطبيقات. تدفع نماذج Runway Gen-4.5 و GWM-1 توليد الفيديو نحو محاكاة عالمية شاملة، ويتم استخدام DALL-E 3 و Gemini لتوليد الصور، بما في ذلك تعزيز واقعية الصور، وإنشاء محتوى ثلاثي الأبعاد، وتحويل الأنماط الفنية. يناقش المجتمع أيضًا تصور المحتوى الذي يولده AI (AIGC)، على سبيل المثال، عندما تكون جودة الأعمال الإعلامية التي أنشأها AI عالية جدًا لدرجة أن المشاهدين يشكون فيما إذا كانت قد تم إنشاؤها بواسطة AI، فهل هذا مدح أم إهانة. بالإضافة إلى ذلك، يحظى تطبيق AI في حل المشكلات الرياضية وتحويل التعليمات البرمجية وغيرها من التطبيقات البحثية بالاهتمام. (المصدر: c_valenzuelab, BlackHC, nptacek, yupp_ai, nptacek, claud_fuen, dotey, ylecun, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 أخرى
مبادئ هندسة AI: تؤكد مناقشات وسائل التواصل الاجتماعي على أن هندسة AI يجب أن تتبع المبادئ الأساسية للهندسة التقليدية، مثل التحكم في الإصدارات، والاختبار، وقابلية الملاحظة في الإنتاج. ويرى البعض أن استخدام LLM لا ينبغي أن يغير هذه الممارسات الأساسية، بل يجب دمجها في عملية تطوير AI لضمان موثوقية النظام وجودته. (المصدر: imjaredz)
معالجة البيانات الضخمة بواسطة LLM: مناقشة حول موضوع معالجة البيانات الضخمة بواسطة LLM، وهو موضوع غالبًا ما يتم التقليل من شأنه. يتم التأكيد على أنه عند معالجة كميات هائلة من البيانات، يجب اعتبار LLM كعامل تشغيل قاعدة بيانات، واستخدام تقنيات مثل التعيين الدلالي، والتصفية، والتقليل. في الوقت نفسه، من خلال استراتيجيات تحسين التكلفة مثل تسلسل المهام، يمكن تقليل تكلفة معالجة البيانات بواسطة LLM بشكل كبير مع ضمان الدقة، وتحقيق التوازن بين الكفاءة والاقتصاد. (المصدر: HamelHusain)
رؤى AI حول الإدراك والتعلم البشري: يستكشف باحث في AI، من خلال خبرته التي تزيد عن 5000 ساعة في لعبة “Tekken”، كيف يبني البشر نماذج تنبؤية تحت قيود زمنية قصوى، وعلاقة ذلك بنماذج عالم AI والتعلم التنبؤي. يرى أن ألعاب القتال تجبر اللاعبين على التنبؤ بدلاً من مجرد رد الفعل، وهذا يعكس التحديات في أبحاث AI لبناء نماذج عالمية داخلية، وقراءة الأنماط من المعلومات الجزئية، والتكيف مع فشل التنبؤ، مما يوفر منظورًا فريدًا لفهم الذكاء الذي يتجاوز AI الألعاب. (المصدر: Reddit r/MachineLearning, Reddit r/ArtificialInteligence)