كلمات مفتاحية:تقنية الذكاء الاصطناعي, نماذج اللغة الكبيرة, التعلم العميق, الذكاء الاصطناعي, التعلم الآلي, معالجة اللغة الطبيعية, الرؤية الحاسوبية, التعلم المعزز, مشروع نانو شات مفتوح المصدر, رقاقة الذكاء الاصطناعي المطورة من قبل أوبن إيه آي, سورا 2 وأخلاقيات التزييف العميق, كلود سونيت 4.5, جي بي تي-5 برو والاستدلال الرياضي
🔥 تركيز
Andrej Karpathy يطلق nanochat: ChatGPT مصنوع يدويًا بـ 100 دولار: أطلق Andrej Karpathy، المدير السابق للذكاء الاصطناعي في Tesla، مشروع nanochat مفتوح المصدر، والذي حقق تدريبًا كاملاً وعملية استدلال لـ ChatGPT بأقل من 8000 سطر من التعليمات البرمجية. يهدف المشروع إلى خفض عتبة البحث في نماذج اللغات الكبيرة (LLM)، حيث يمكن للمستخدمين إعداد ChatGPT مصغر قابل للمحادثة باستخدام وحدة معالجة رسومات سحابية واحدة فقط (حوالي 100 دولار، 4 ساعات تدريب)، ويمكن أن يتجاوز أداء التدريب لمدة 12 ساعة مؤشرات GPT-2 CORE. سيصبح nanochat المشروع الختامي لدورة LLM101n، ومن المتوقع أن يتطور إلى منصة بحث أو أداة اختبار معيارية، مما يعكس شغف Karpathy المستمر بالتعليم والدمقرطة في مجال الذكاء الاصطناعي. (المصدر: GitHub nanochat, Reddit r/deeplearning, 36氪, 36氪, 36氪, 36氪)
OpenAI و Broadcom يتعاونان لتطوير شرائح AI خاصة ونشر بنية تحتية بقدرة 10 جيجاوات: أعلنت OpenAI عن تعاون استراتيجي مع Broadcom لتصميم ونشر شرائح AI مخصصة وأنظمة حوسبة، بهدف نشر بنية تحتية للاستدلال بإجمالي استهلاك طاقة يبلغ 10 جيجاوات بين النصف الثاني من عام 2026 ونهاية عام 2029. تشير هذه الخطوة إلى أن OpenAI لم تعد تكتفي بشراء وحدات معالجة الرسوميات (GPU) الحالية، بل تسعى من خلال التكامل الرأسي إلى المشاركة في تصميم الأجهزة على مستوى الترانزستور، لتحسين أداء نماذج الذكاء الاصطناعي، وخفض التكاليف، وتلبية احتياجات الحوسبة المتزايدة بشكل كبير في المستقبل. صرحت OpenAI بأن هذا التعاون هو “أكبر مشروع صناعي مشترك في تاريخ البشرية”، ويستخدم حتى نماذج الذكاء الاصطناعي للمساعدة في تصميم الشرائح، مما ينبئ بمشاركة عميقة للذكاء الاصطناعي في تطوير الأجهزة. (المصدر: OpenAI, Bloomberg, CNBC, 36氪, 36氪, 36氪)
Sora 2 يثير أزمة أخلاقية للـ deepfake وجدل حول حقوق النشر: انتشر نموذج Sora 2 لتوليد الفيديو من OpenAI بسرعة بسبب قدرته العالية على التوليد الواقعي، لكنه أثار أيضًا تحديات أخلاقية وحقوق نشر خطيرة. استخدم المستخدمون Sora 2 لتوليد مقاطع فيديو مزيفة لمشاهير متوفين (مثل مايكل جاكسون وروبن ويليامز)، مما أثار استياءً شديدًا من عائلاتهم، الذين اعتبروا ذلك إساءة استخدام وعدم احترام لصور المتوفين. ردت OpenAI بأن الشخصيات العامة وعائلاتهم يجب أن يكون لهم الحق في التحكم في كيفية استخدام صورهم، وتخطط لتقديم آليات أكثر دقة للتحكم في حقوق النشر وتقاسم الإيرادات. ومع ذلك، يخشى الصناعة بشكل عام من أن نماذج الـ deepfake مفتوحة المصدر تنتشر بشكل متزايد، وأن المجتمع بحاجة إلى التكيف بسرعة مع تأثير المحتوى الذي يولده الذكاء الاصطناعي واستكشاف تدابير حماية تقنية وقانونية فعالة. (المصدر: Washington Post, BBC, 量子位)

Claude Sonnet 4.5 و Microsoft Agent Framework و Cursor IDE تدفع بقدرات ترميز الذكاء الاصطناعي إلى الأمام: يشهد مجال ترميز الذكاء الاصطناعي اختراقات كبيرة: حقق Claude Sonnet 4.5 دقة 77.2% في اختبار SWE-bench Verified المعياري، متجاوزًا النماذج السابقة بشكل ملحوظ. في الوقت نفسه، يحول Microsoft Agent Framework برنامج VS Code إلى بيئة أصلية للذكاء الاصطناعي، تدعم Agents لمعالجة تعديلات التعليمات البرمجية متعددة الملفات بشكل مستقل؛ كما أطلق Cursor IDE 1.7 “وضع Agent”، الذي يمكنه حل المشكلات المعقدة بنقرة واحدة. تشير هذه التطورات إلى أن Agents الذكاء الاصطناعي يمكنها الآن تحمل معظم مهام التطوير، مما أثار نقاشًا حول ما إذا كان المطورون سيعتمدون بشكل مفرط على الذكاء الاصطناعي، والمخاطر المحتملة للديون التقنية التي قد تنشأ عن التعليمات البرمجية التي يولدها الذكاء الاصطناعي. (المصدر: Reddit r/artificial)
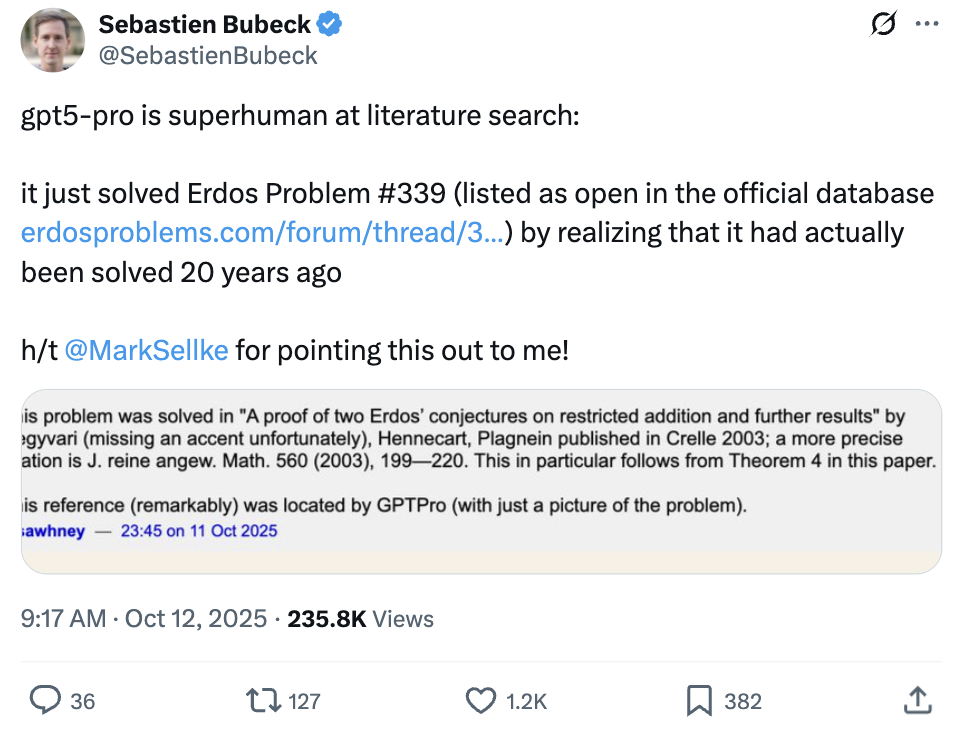
GPT-5 Pro يحل مشكلة إيردوس الرياضية، ويظهر قدرات قوية في استرجاع المراجع وتحديد الثغرات: أظهر GPT-5 Pro من OpenAI قدرات مذهلة في الاستدلال الرياضي، حيث تمكن من استرجاع المرجع الرئيسي الذي حل مشكلة إيردوس #339 في عام 2003، وذلك بمجرد صورة للمشكلة. بالإضافة إلى ذلك، استطاع GPT-5 Pro اكتشاف عيوب خطيرة في ورقة بحثية منشورة خلال 18 دقيقة، متجاوزًا حتى نتائج أيام من البحث البشري المتخصص. يسلط هذا الإنجاز الضوء على الإمكانات الهائلة لـ GPT-5 Pro في استرجاع المعلومات الدقيقة، وحل المشكلات المعقدة، والتحقق من المراجع العلمية، مما ينبئ بأن الذكاء الاصطناعي سيسرع بشكل كبير من عملية البحث العلمي، خاصة في التحقق من المزاعم الأكاديمية واكتشاف التناقضات المنطقية. (المصدر: Sebastien Bubeck, Greg Brockman, 36氪)
ثلاثة عمالقة في مجال الذكاء الاصطناعي ينشرون ورقة بحثية مشتركة: دفاعات LLM الحالية ضعيفة للغاية: أصدرت OpenAI و Anthropic و Google DeepMind ورقة بحثية مشتركة نادرة، تشير إلى أن آليات الدفاع الحالية ضد اختراق نماذج اللغات الكبيرة (LLM jailbreaks) وهجمات حقن الأوامر (prompt injection) ضعيفة بشكل عام. قدم فريق البحث إطار عمل هجومي تكيفي عام، وبالجمع بين الانحدار التدرجي، والتعلم المعزز، والبحث العشوائي، واختبار الفريق الأحمر البشري، نجحوا في تجاوز 12 آلية دفاع رئيسية، حيث تجاوزت معظم الهجمات نسبة نجاح 90%. يشير هذا إلى أن التقييمات الحالية غالبًا ما تكون نظرية، وأن أبحاث أمان نماذج اللغات الكبيرة المستقبلية يجب أن تتضمن تقييمات هجومية تكيفية أقوى لبناء نظام دفاع قوي حقًا. (المصدر: arXiv:2510.09023, 36氪)

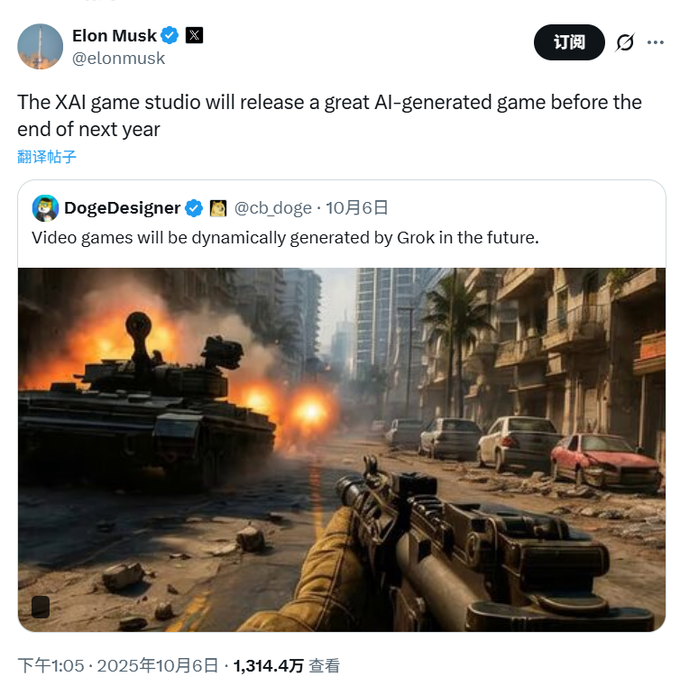
xAI تنضم إلى سباق “النماذج العالمية”، وتستهدف توليد ألعاب الذكاء الاصطناعي كأول تطبيق: انضمت شركة xAI التابعة لـ Elon Musk بهدوء إلى سباق “النماذج العالمية”، لتتنافس مع عمالقة مثل Google و Meta. استعانت xAI بخبراء الذكاء الاصطناعي من NVIDIA بهدف بناء نماذج يمكنها فهم ومحاكاة العالم المادي الحقيقي من خلال تدريب كميات هائلة من بيانات الفيديو والروبوتات. أول تطبيق تجاري لها هو توليد ألعاب الذكاء الاصطناعي، حيث تخطط لإطلاق ألعاب مولدة بالذكاء الاصطناعي بحلول نهاية العام المقبل، واستكشاف تطبيقاتها في أنظمة الروبوتات. يعتقد باحثو Google أن نماذج الفيديو المستقبلية ستكون ذكية مثل نماذج اللغة، وستفتح قدرات ناشئة مثل تجزئة الكائنات واكتشاف الحواف من خلال “توقع الإطار التالي”، مما ينبئ بـ “لحظة GPT في مجال الرؤية”. (المصدر: 36氪)
ورقة بحثية غامضة في ICLR تكشف عن SAM3: تجزئة كل شيء بالمفاهيم، وإعادة تشكيل نموذج جديد للذكاء الاصطناعي البصري: كشفت ورقة بحثية مراجعة عمياء لمؤتمر ICLR 2026 بعنوان “SAM3: تجزئة كل شيء بالمفاهيم” عن ترقية رئيسية ثالثة لنموذج Segment Anything Model (SAM) من Meta AI. يكمن الاختراق الأساسي لـ SAM3 في “التجزئة القائمة على المفاهيم” (PCS)، حيث لا يقتصر النموذج على التجزئة حسب البكسل أو المثيل، بل يمكنه أيضًا التعرف على جميع الكائنات التي تتوافق مع “مفهوم دلالي” معين وتجزئتها وتتبعها بناءً على مطالبات نصية أو صورية. قام النظام الجديد، من خلال محرك بيانات تعاوني بين الإنسان والآلة، ببناء مجموعة بيانات عالية الجودة تحتوي على 4 ملايين تسمية مفهوم، وحقق التعرف على مئات الكائنات في غضون 30 مللي ثانية على وحدة معالجة رسومات H200، متجاوزًا الأنظمة الحالية بشكل شامل، مما ينبئ بأن “لحظة GPT-3” في الذكاء الاصطناعي البصري قد لا تكون بعيدة. (المصدر: arXiv:r35clVtGzw, 36氪)
🎯 التطورات
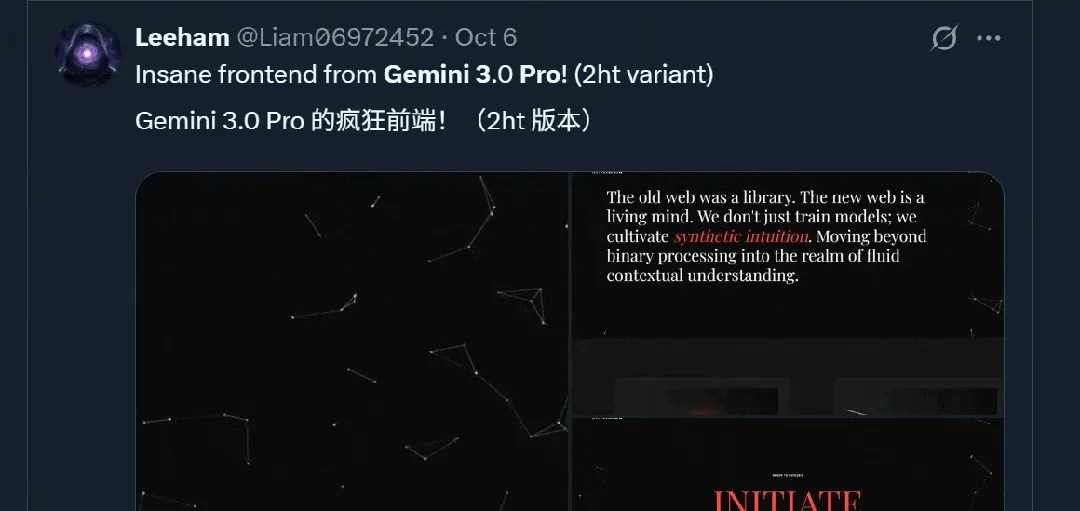
Gemini 3 يحظى بإشادة في الاختبارات الداخلية، ويُشيد به كـ “أقوى نموذج لتطوير الواجهة الأمامية على الإطلاق”: أثار نموذج Gemini 3 الرائد من Google اهتمامًا واسعًا في الاختبارات الداخلية، حيث أشاد به المستخدمون لقدراته في تطوير الواجهة الأمامية، وتوليد رسومات SVG المتجهة، والقدرات متعددة الوسائط، ووصفوه بأنه “أفضل نموذج لتطوير الواجهة الأمامية والويب على الإطلاق”، حتى أن البعض توقع أنه سيكون أفضل نموذج لهذا العام. تشير المعلومات المسربة إلى أن Gemini 3.0 Pro يعتمد بنية MoE، ويمتلك تريليونات من المعلمات، ونافذة سياقية موسعة إلى ملايين الـ tokens، ويتضمن وضع تفكير عميق وقدرات متعددة الوسائط، وقد أظهر أداءً ممتازًا في اختبارات ARC-AGI-2 و HLE المعيارية. (المصدر: 36氪)
تطبيق الذكاء الاصطناعي في تصميم وتصنيع الرقائق يتعمق يومًا بعد يوم: يتم تطبيق التعلم الآلي بشكل متزايد في مجالات تصميم وتصنيع الرقائق، مما يدفع كفاءة وابتكار أشباه الموصلات إلى مستويات جديدة. أشار Lorenzo Servadei، رئيس تصميم الرقائق في Sony AI، في مقابلة مع AIHub، إلى أن الذكاء الاصطناعي في مجال EDA (أتمتة التصميم الإلكتروني) ينتقل من تسريع التقديرات إلى المشاركة النشطة في عملية التصميم، من خلال تسريع نماذج الفيزياء المتعددة، وتحسين الخوارزميات، والذكاء الاصطناعي التوليدي للتنفيذ المادي، مما يحسن بشكل كبير سرعة وجودة وإبداع تصميم الرقائق. كشفت OpenAI أيضًا أن نماذج GPT الخاصة بها ساعدت في تصميم رقائقها الخاصة، مما أدى إلى تقليل المساحة وتسريع دورة التطوير. (المصدر: aihub.org, 36氪)

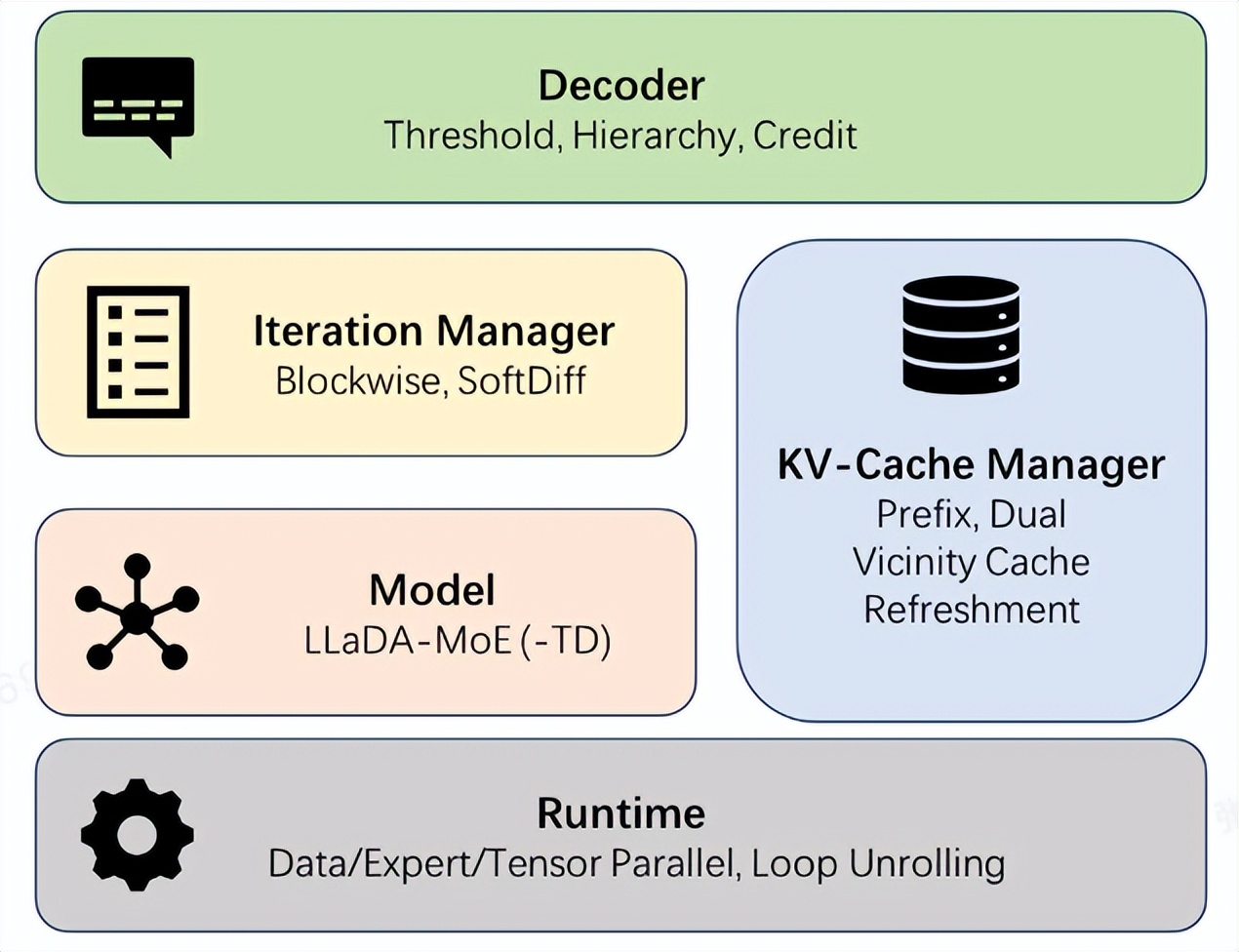
مجموعة Ant Group تطلق إطار عمل dInfer مفتوح المصدر، مما يزيد سرعة استدلال نماذج اللغة المنتشرة 10 أضعاف: أطلقت مجموعة Ant Group رسميًا إطار عمل dInfer مفتوح المصدر، وهو أول إطار عمل عالي الأداء لاستدلال نماذج اللغة المنتشرة (diffusion language models) في الصناعة، مما يزيد سرعة استدلال هذه النماذج بمقدار 10.7 مرة مقارنة بـ Fast-dLLM من NVIDIA. في مهمة توليد التعليمات البرمجية HumanEval، حقق dInfer سرعة 1011 Tokens/ثانية في استدلال الدفعة الواحدة، متجاوزًا نماذج الانحدار الذاتي بشكل ملحوظ لأول مرة. يعتمد dInfer تصميمًا عميقًا ومتعاونًا بين الخوارزميات والأنظمة، ويتضمن أربع وحدات أساسية: توصيل النموذج، ومدير ذاكرة التخزين المؤقت KV، ومدير التكرار المنتشر، واستراتيجية فك التشفير، ويهدف إلى حل تحديات التكلفة الحسابية العالية لنماذج اللغة المنتشرة، وفشل ذاكرة التخزين المؤقت KV، وفك التشفير المتوازي، لإطلاق العنان لإمكانات الاستدلال الفعال. (المصدر: 量子位, QuixiAI)
ترقية Google NotebookLM، و Gemini Nano Banana يدعم أنماطًا بصرية جديدة لملخصات الفيديو: حصلت ميزة ملخصات الفيديو في Google NotebookLM على ترقية، حيث أضافت أنماطًا بصرية متنوعة (كلاسيكي، لوح أبيض، ألوان مائية، طباعة عتيقة، تقليدي، فن ورقي، أنمي)، مدعومة بنموذج توليد الصور Gemini Nano Banana. بالإضافة إلى ذلك، تم تقديم تنسيق “Brief” الأكثر بساطة، والذي يوفر ملخصًا سريعًا. سيتم طرح هذه التحديثات أولاً للمستخدمين المحترفين (Pro)، ثم لجميع المستخدمين في الأسابيع القادمة، بهدف تعزيز تجربة المستخدم في فهم محتوى الفيديو وتقديمه بشكل شخصي. (المصدر: Google, op7418)
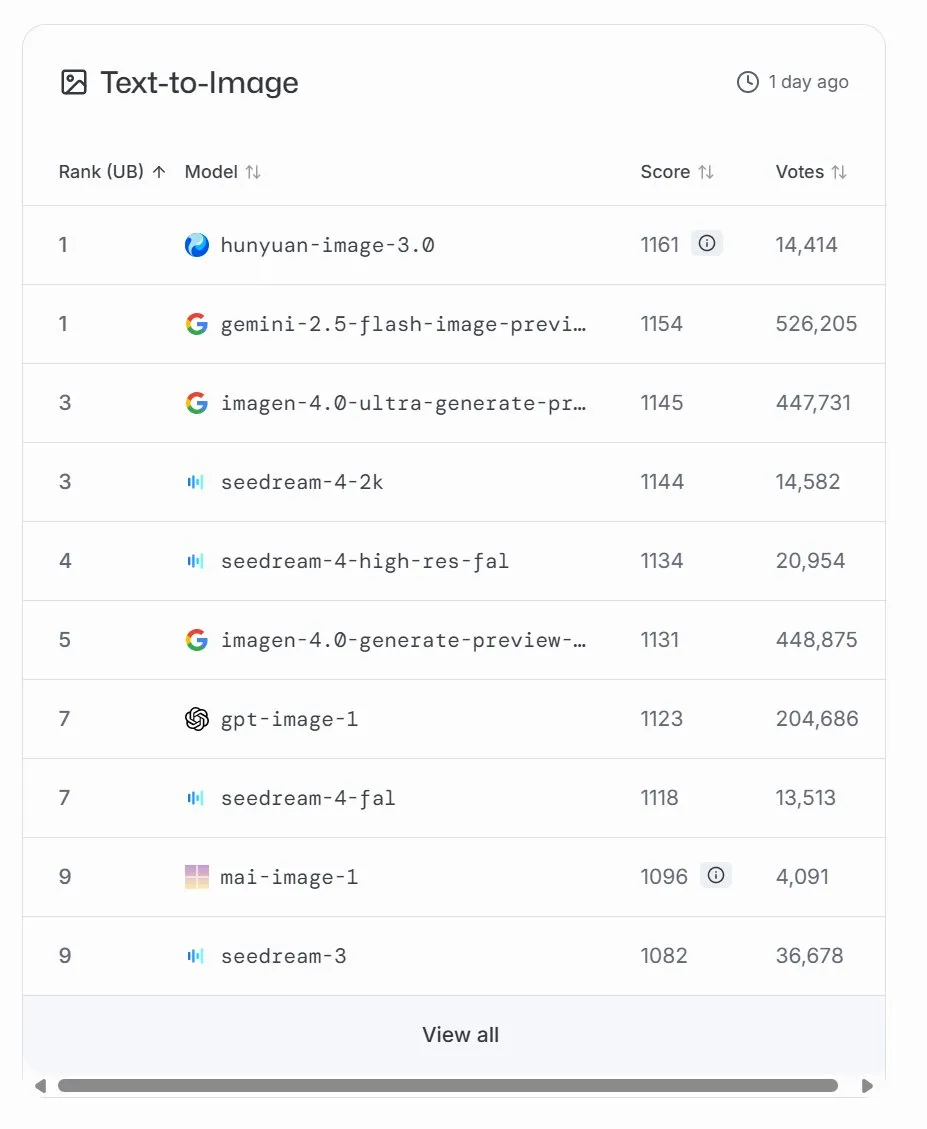
مايكروسوفت تطلق نموذج MAI-Image-1 لتوليد الصور، ويحتل المرتبة التاسعة في LMArena: أطلقت Microsoft AI نموذجها الثالث للذكاء الاصطناعي، MAI-Image-1، وهو نموذج لتوليد الصور، وقد ظهر لأول مرة في قائمة LMArena محتلاً المرتبة التاسعة، بالتعادل مع Seedream 3. حقق هذا النموذج توازنًا مثيرًا للإعجاب بين سرعة التوليد والجودة، مما يظهر استثمار مايكروسوفت المستمر وتطورها السريع في مجال الذكاء الاصطناعي متعدد الوسائط. صرحت مايكروسوفت بأنها ستواصل تحسين هذا النموذج، وتسعى جاهدة لتحقيق ترتيب أعلى في القائمة. (المصدر: mustafasuleyman, NandoDF)
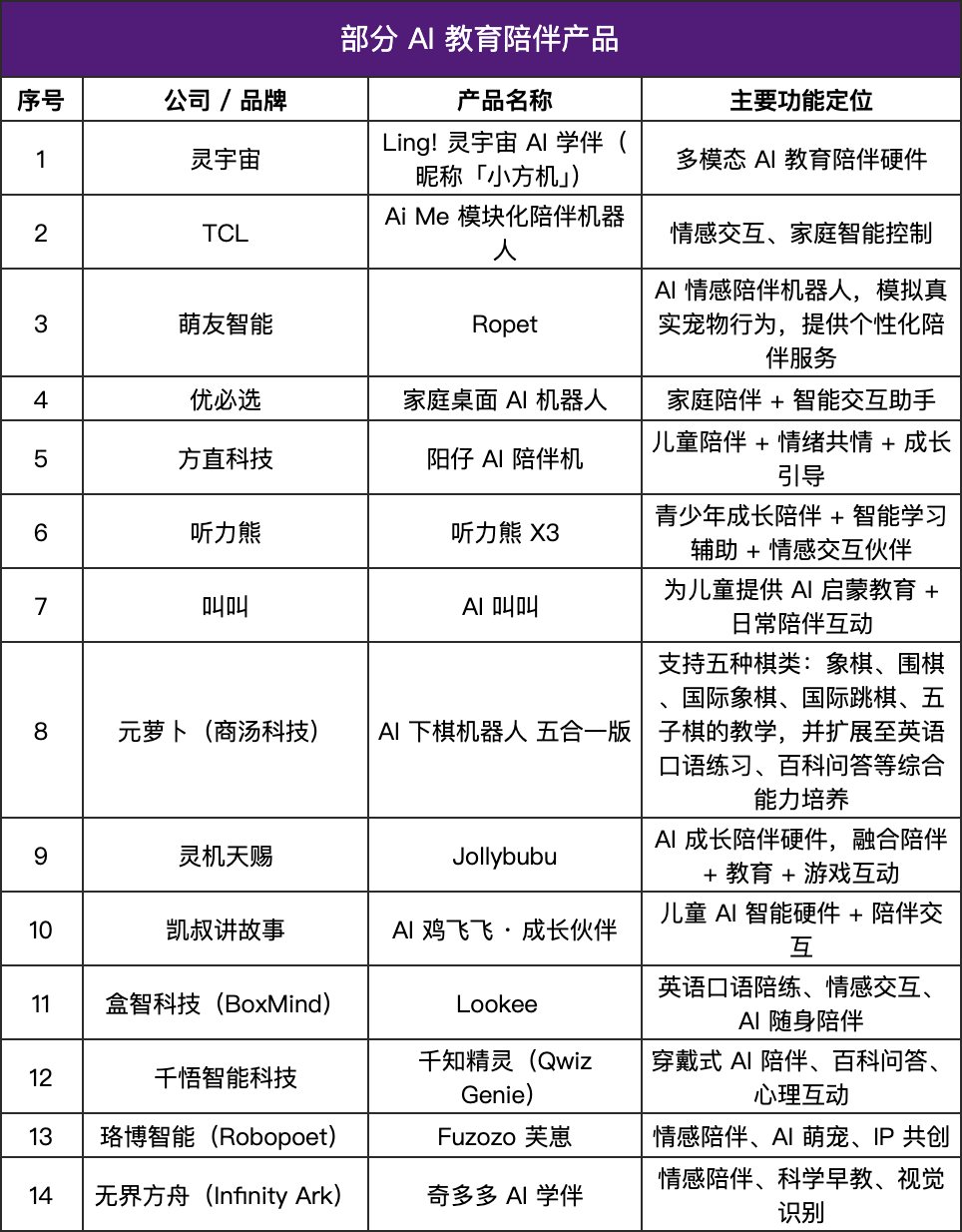
منتجات رفيق الذكاء الاصطناعي تشهد ازدهارًا، وأجهزة التعليم “تكتسب دفئًا”: يشهد سوق منتجات رفيق الذكاء الاصطناعي نموًا سريعًا، ومن المتوقع أن يصل حجم السوق المستقبلي إلى 70 مليار إلى 150 مليار دولار. تنتقل هذه المنتجات من “الاستجابة للأوامر” إلى “الاستجابة العاطفية”، ومن خلال نماذج اللغة، والتعرف على المشاعر، والتفاعل الصوتي، وأنظمة الذاكرة، تحاكي الاستجابات البشرية وتقدم رعاية شخصية. في مجال التعليم، تم تطبيق منتجات رفيق الذكاء الاصطناعي كمساعدين تعليميين، وأنظمة استجابة للمشاعر، ونماذج أسئلة وأجوبة ذكية، وتمتد من نقل المعرفة إلى الدعم النفسي، وتظهر اتجاهًا نحو الخفة والشخصنة، وتدمج التفاعل متعدد الوسائط، بهدف أن تصبح أنظمة “تفهم الطلاب”. (المصدر: 36氪)
NVIDIA تطلق DGX Spark، أصغر حاسوب عملاق للذكاء الاصطناعي في العالم: أطلقت NVIDIA رسميًا DGX Spark، الذي يُوصف بأنه أصغر حاسوب عملاق للذكاء الاصطناعي في العالم، وقد بدأ شحنه الآن. يعتمد DGX Spark على بنية NVIDIA Grace Blackwell، ويدمج ذاكرة موحدة بسعة 128 جيجابايت، ويهدف إلى تزويد مطوري الذكاء الاصطناعي بقدرات قوية لتصميم وتشغيل نماذج LLM الأولية محليًا. يقوم المستخدمون الأوائل حاليًا باختبار أدواتهم وبرامجهم ونماذجهم والتحقق منها وتحسينها، مما ينبئ بأن حوسبة الذكاء الاصطناعي عالية الأداء ستصبح أكثر انتشارًا وسهولة. (المصدر: nvidia, ollama)

Anthropic تطلق Claude Sonnet 4.5 و Agent SDK و Claude Code المحدث: أطلقت Anthropic نموذج Claude Sonnet 4.5، الذي يعزز قدرات الاستدلال، ويمتلك نافذة سياقية أكبر (200 ألف – 1 مليون token)، ويحسن أداء الترميز ومعايير الاستدلال. في الوقت نفسه، أطلقت Anthropic أيضًا Claude Agent SDK و Claude Code المحدث، مع إضافة تتبع/تلخيص السياق التلقائي، وأدوات ذاكرة دائمة، ونقاط حفظ مع إمكانية التراجع، بالإضافة إلى امتداد IDE متوافق مع VS Code، بهدف تزويد المطورين بقدرات ترميز الذكاء الاصطناعي وبناء Agents أكثر قوة. (المصدر: DeepLearningAI)

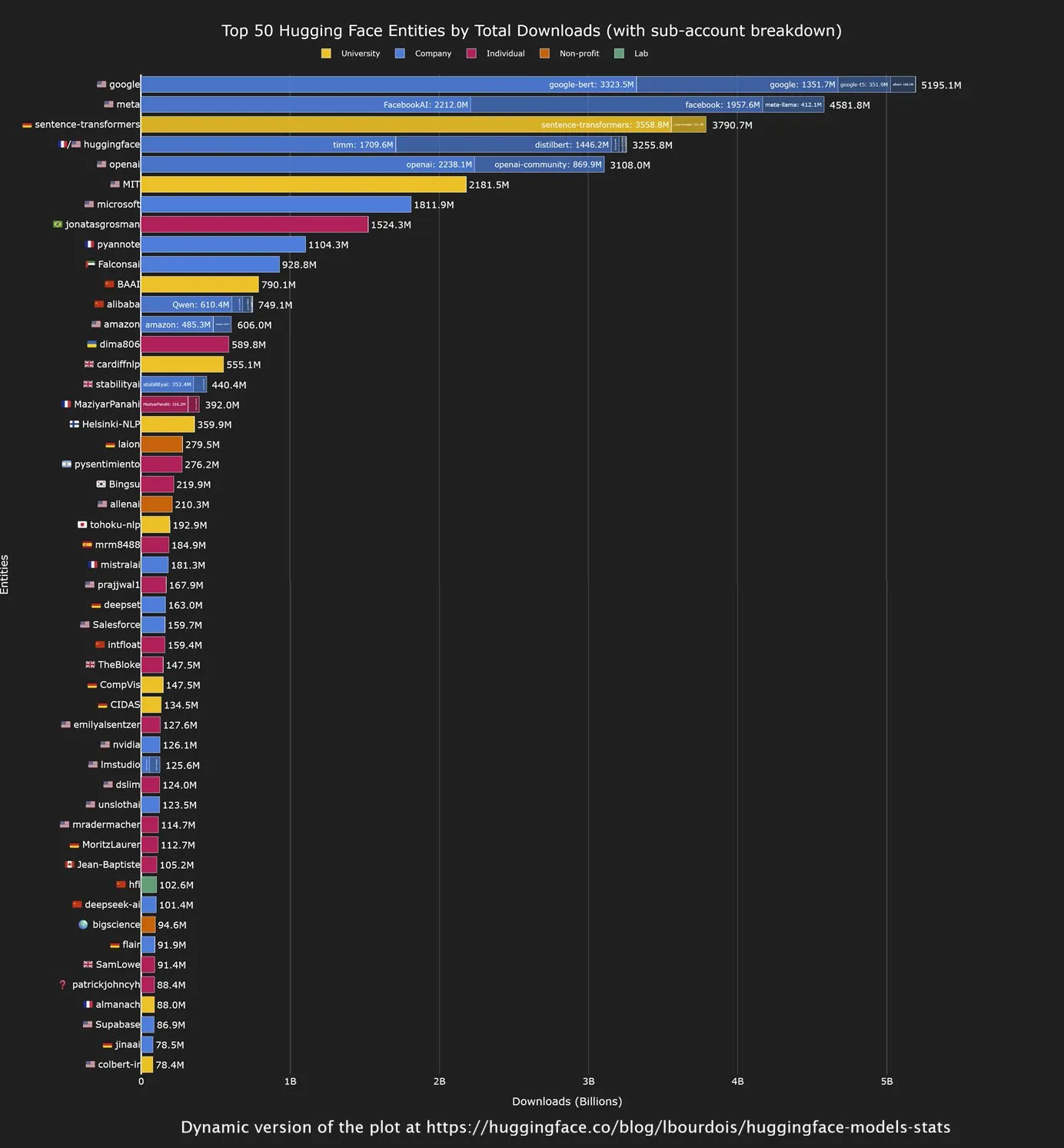
النماذج الصينية مفتوحة المصدر تتصدر في عدد التنزيلات على Hugging Face، و Google أكبر مساهم: يظهر أحدث تحليل لمجتمع Hugging Face أن النماذج مفتوحة المصدر التي طورتها الشركات الصينية تحقق أداءً قويًا من حيث عدد التنزيلات، خاصة نماذج سلسلة Qwen. في الوقت نفسه، أصبحت Google أكبر مؤسسة مساهمة في عدد تنزيلات النماذج على Hugging Face. يشير هذا الاتجاه إلى تزايد تأثير الصين في مجال الذكاء الاصطناعي مفتوح المصدر، بينما تساهم Google، كعملاق تقني، وتستفيد بنشاط من النظام البيئي مفتوح المصدر، مما يدفع بانتشار تكنولوجيا الذكاء الاصطناعي. (المصدر: mervenoyann, osanseviero)
نائب رئيس منتجات البحث في Google، Robbie Stein، يفسر مستقبل البحث بالذكاء الاصطناعي: “الوضوح” هو الهدف النهائي: أشار Robbie Stein، نائب رئيس منتجات البحث في Google، إلى أن الذكاء الاصطناعي لم يغير الحاجة الأساسية للبشر للبحث عن المعلومات، بل جعله أكثر طبيعية وتعقيدًا من خلال “وضع الذكاء الاصطناعي” (AI Mode). سيتمتع البحث بالذكاء الاصطناعي في المستقبل بـ “القدرة على الفهم”، حيث يمكنه تقسيم الأسئلة الغامضة إلى أسئلة فرعية والبحث عنها بالتوازي، وتجميع الإجابات القابلة للتتبع مع المراجع. هدف Google هو أن تصبح نظامًا “يفهم المعلومات وموثوقًا به”، ومن خلال دمج الوسائط المتعددة والبيانات العالمية المنظمة، تحقيق الانتقال من “فهرسة صفحات الويب” إلى “فهرسة العالم”، لجعل الحصول على المعلومات أكثر وضوحًا وسرعة، وليس مجرد توليد لغة سلسة. (المصدر: 36氪)
مجموعة Ant Group تطلق إطار عمل dInfer عالي الأداء لاستدلال نماذج اللغة المنتشرة: أطلقت مجموعة Ant Group رسميًا إطار عمل dInfer، وهو أول إطار عمل عالي الأداء لاستدلال نماذج اللغة المنتشرة (diffusion language models) في الصناعة، مما يزيد سرعة استدلال هذه النماذج بمقدار 10.7 مرة مقارنة بـ Fast-dLLM من NVIDIA. في مهمة توليد التعليمات البرمجية HumanEval، حقق dInfer سرعة 1011 Tokens/ثانية في استدلال الدفعة الواحدة، متجاوزًا نماذج الانحدار الذاتي بشكل ملحوظ لأول مرة. يعتمد dInfer تصميمًا عميقًا ومتعاونًا بين الخوارزميات والأنظمة، ويهدف إلى حل تحديات التكلفة الحسابية العالية لنماذج اللغة المنتشرة، وفشل ذاكرة التخزين المؤقت KV، وفك التشفير المتوازي، لإطلاق العنان لإمكانات الاستدلال الفعال. (المصدر: 量子位)
NVIDIA تطلق تقنية تدريب NVFP4، تحقق تدريبًا مسبقًا بـ 4 بت ومطابقة دقة FP8: كشفت NVIDIA عن تقنية تدريب NVFP4 الرائدة، التي تمكن نماذج اللغة الكبيرة المدربة مسبقًا بـ 4 بت من تحقيق دقة 8 بت. تستخدم هذه التقنية تمثيل الفاصلة العائمة بـ 4 بت بتنسيق E2M1، جنبًا إلى جنب مع التحجيم الدقيق، والتقريب العشوائي، وتحويلات Hadamard العشوائية، مما يقلل بشكل كبير من متطلبات الحوسبة والذاكرة. أظهرت التجارب أن NVFP4، مع الحفاظ على دقة النموذج (مثل MMLU Pro 62.58% مقابل 62.62%)، يعزز كفاءة التدريب بشكل كبير، ويوفر مسارًا أكثر اقتصادية وفعالية لتدريب نماذج LLM الأكبر حجمًا في المستقبل. تعتمد هذه التقنية بشكل أساسي على بنية NVIDIA Blackwell، وتتطلب وحدات معالجة رسومات H100 وما فوق. (المصدر: Reddit r/LocalLLaMA, karminski3)

إطار عمل MIT SEAL يحقق توليد بيانات الضبط الدقيق وتحديث الأوزان لنماذج الذكاء الاصطناعي تلقائيًا: أطلق معهد ماساتشوستس للتكنولوجيا (MIT) إطار عمل SEAL (Self-Adapting LLMs)، الذي يمكّن نماذج اللغة الكبيرة (LLM) من توليد بيانات الضبط الدقيق وتحديث أوزانها تلقائيًا، مما يحقق تحديثات التدرج بدون أي تدخل بشري. يعتمد SEAL آلية تعلم ذات حلقتين داخلية وخارجية، حيث يقوم النموذج بتحسين استراتيجية توليد تعليمات التحديث الذاتي بناءً على أداء المهمة، مما يمنح LLM قدرة التحديث الذاتي لأول مرة. أثبتت التجارب أن SEAL يتفوق في مهام حقن المعرفة والتعلم باللقطات القليلة، متجاوزًا دقة البيانات التي يولدها GPT-4.1، ويظهر قدرة قوية على التكيف مع المهام ودمج المعرفة، مما ينبئ بقدوم عصر النماذج ذاتية التطور. (المصدر: arXiv:2506.10943, 36氪)

شحنات هواتف الذكاء الاصطناعي تتزايد بشكل كبير، وشركات مثل Coolpad Intelligent تستكشف استراتيجية التعاون بين “النماذج الصغيرة + النماذج الكبيرة”: شهدت شحنات هواتف الذكاء الاصطناعي في الصين زيادة هائلة بنسبة 591% على أساس سنوي في عام 2025، ووصلت نسبة الاختراق إلى 22%، مما يجعل هواتف الذكاء الاصطناعي نقطة تركيز جديدة في الصناعة. تنتقل شركات مثل Coolpad Intelligent من سباق المعلمات إلى الابتكار العملي، وتعتمد حلولًا ديناميكية للتعاون بين “النماذج الصغيرة الأمامية + النماذج الكبيرة الخلفية”، حيث يتم نشر نماذج رأسية صغيرة بحوالي 600 مليون معلمة على الجهاز، لتحقيق استجابة سريعة وحماية للخصوصية، مع دمج قدرات الحوسبة لنماذج عامة كبيرة من شركات مثل iFlytek و ByteDance و Alibaba و Google. تهدف هذه الاستراتيجية إلى تحسين تجربة المستخدم، وتقديم خدمات مخصصة، وخفض التكاليف، للتكيف مع الأسواق الخارجية المتنوعة والمجزأة. (المصدر: 36氪)

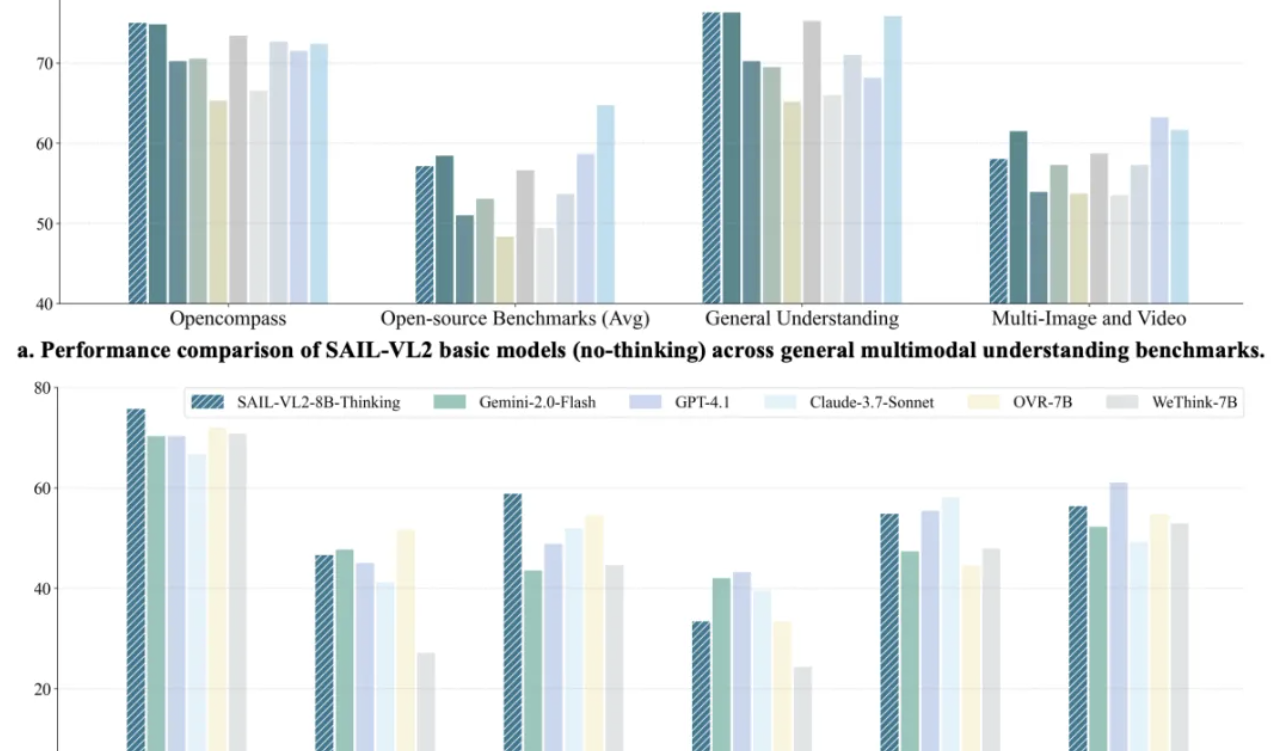
نموذج Douyin SAIL-VL2 متعدد الوسائط يحقق أرقامًا قياسية جديدة، ونموذج 8B ينافس GPT-4o في الاستدلال: أطلق فريق Douyin SAIL بالتعاون مع LV-NUS Lab نموذج SAIL-VL2 متعدد الوسائط، والذي حقق اختراقًا في الأداء على 106 مجموعات بيانات بأحجام معلمات صغيرة ومتوسطة مثل 2B و 8B، متفوقًا بشكل خاص على النماذج ذات الحجم المماثل في معايير الاستدلال المعقدة مثل MMMU و MathVista، بل إن قدرة الاستدلال لنموذج 8B تنافس GPT-4o. من خلال بنية MoE المتفرقة، وإطار عمل التدريب التدريجي، ومجموعة بيانات متعددة الوسائط عالية الجودة، وغيرها من الابتكارات، قدم SAIL-VL2 للمجتمع نموذجًا جديدًا “يمكن للنماذج الصغيرة أن تتمتع بقدرات قوية”، وأتاح النموذج ورمز الاستدلال مفتوح المصدر. (المصدر: 量子位)
انتقال استدلال Moondream Cloud بالكامل إلى FAL، مما يحقق تشغيلًا سحابيًا بنسبة 100%: أعلنت Moondream عن انتقال خدمة الاستدلال السحابية الخاصة بها بالكامل من مثيلات EC2 إلى FAL، مما يحقق تشغيلًا بنسبة 100% على FAL. قد تشير هذه الخطوة إلى أن Moondream قد حققت تقدمًا مهمًا في تحسين كفاءة الاستدلال، أو خفض تكاليف التشغيل، أو تعزيز مرونة الخدمة، وتظهر FAL، كمنصة استدلال جديدة، قدرتها على دعم نشر نماذج الذكاء الاصطناعي على السحابة. (المصدر: vikhyatk)
Ring-1T: Ant Ling تطلق نموذج تفكير مفتوح المصدر بمليار معلمة: أطلقت شركة Ant Ling رسميًا Ring-1T، وهو نموذج تفكير مفتوح المصدر بمليار معلمة يعتمد على بنية Ling 2.0. حقق Ring-1T قدرة استدلال على مستوى الميدالية الفضية في IMO (الأولمبياد الدولي للرياضيات) في الاستدلال باللغة الطبيعية البحتة، ويمتلك تريليون معلمة إجمالية و 50 مليار معلمة نشطة، بالإضافة إلى نافذة سياقية بحجم 128K. تم تعزيز هذا النموذج من خلال Icepop RL و ASystem (محرك تعلم معزز على مستوى التريليون)، وحقق أداء SOTA في معايير الاستدلال باللغة الطبيعية مثل AIME 25 و HMMT 25 و ARC-AGI-1 و CodeForce، ويوفر إصدار FP8، ويهدف إلى تعزيز قدرات الاستدلال للذكاء الاصطناعي مفتوح المصدر. (المصدر: scaling01, jon_durbin)
ميزة “الدفع الفوري” للتجارة الإلكترونية في ChatGPT تطلق، وتعيد تشكيل تجربة التسوق: أطلقت OpenAI ميزة “الدفع الفوري” (Instant Checkout) في ChatGPT، مما يسمح للمستخدمين بإكمال التسوق مباشرة داخل ChatGPT، دون الحاجة إلى الانتقال إلى منصات التجارة الإلكترونية الخارجية. تدعم هذه الميزة حاليًا Etsy، وستتصل قريبًا بأكثر من مليون تاجر على Shopify. سيؤدي هذا الابتكار إلى إغلاق حلقة عملية التسوق من وصف الاحتياجات إلى إتمام الشراء في مكان واحد، مما يقلل بشكل كبير من مسار قرار الشراء للمستخدم، ويعزز سهولة التسوق، وينبئ بتكامل عميق للذكاء الاصطناعي في مجال التجارة الإلكترونية وتغيير نماذج الأعمال. (المصدر: 36氪)
دراما الذكاء الاصطناعي القصيرة تشهد ازدهارًا عالميًا، وتقنية Sora 2 تدفع بجودة وكفاءة إنتاج المحتوى: تشهد دراما الذكاء الاصطناعي القصيرة ازدهارًا هائلاً، وتنتشر على نطاق واسع عالميًا. في عام 2024، بلغ حجم سوق الدراما القصيرة في الصين 50.5 مليار يوان، وظهر طلب في السوق الخارجية، ومن المتوقع أن تصل إيرادات الدراما القصيرة الصينية في الخارج إلى 4 مليارات دولار لهذا العام. أدى إطلاق OpenAI Sora 2 إلى تحسين جودة الصورة، والمدة، والتزامن، وتزامن الصوت والصورة بشكل كبير، ويدعم أيضًا استمرارية الحبكة المعقدة وميزة Cameos، مما يضغط عملية إنتاج الدراما القصيرة إلى وضع فعال “شخص واحد يكتب Prompt، والذكاء الاصطناعي ينتج”، ويمكن أن تنخفض التكلفة إلى عُشر التكلفة التقليدية. أصبحت دراما الرسوم المتحركة بالذكاء الاصطناعي أيضًا اتجاهًا جديدًا، مما يقلل بشكل فعال من الخصم الثقافي، ويدفع صناعة المحتوى للتوسع من الدراما الحية إلى دراما الرسوم المتحركة بالذكاء الاصطناعي. (المصدر: 36氪)

الذكاء الاصطناعي يحقق تقدمًا في مجال التشخيص الطبي: إطلاق AMIE، وكيل التشخيص متعدد الوسائط: أطلقت Google AI نموذج AMIE (AI agent for multimodal diagnostic dialogue)، وهو وكيل ذكاء اصطناعي بحثي يهدف إلى تحقيق اختراق في المجال الطبي من خلال الحوار التشخيصي متعدد الوسائط. يشير إطلاق AMIE إلى تقدم الذكاء الاصطناعي في فهم ومشاركة عمليات التشخيص الطبي المعقدة، ومن المتوقع أن يعزز كفاءة ودقة التشخيص، ويضع الأساس لتطبيقات الرعاية الصحية الذكية في المستقبل. (المصدر: Ronald_vanLoon)
Perplexity Search API يضيف ميزة تصفية النطاقات، مما يعزز دقة البحث: أعلنت Perplexity أن واجهة برمجة تطبيقات البحث (Search API) الخاصة بها تدعم الآن تصفية نتائج البحث حسب نطاقات محددة. تتيح هذه الميزة الجديدة للمستخدمين الاستعلام من مصادر موثوقة فقط، وبالتالي الحصول على نتائج أكثر تركيزًا وقابلية للتحقق. بالنسبة للمستخدمين المحترفين أو مطوري التطبيقات الذين يحتاجون إلى معلومات من مصادر موثوقة محددة، ستعزز هذه الميزة بشكل كبير كفاءة البحث وجودة المعلومات. (المصدر: AravSrinivas)
الذكاء الاصطناعي يظهر إمكانات في الكشف عن الزلازل، وقد يساعد في التنبؤ بها مستقبلاً: أظهر الذكاء الاصطناعي أداءً ممتازًا في الكشف عن الزلازل الصغيرة، ووُصفت قدرته بأنها “مثل ارتداء النظارات لأول مرة بوضوح”. يستكشف الباحثون ما إذا كان الذكاء الاصطناعي يمكن أن يساعد بشكل أكبر في التنبؤ بالزلازل، مما قد يحدث ثورة في الإنذار المبكر بالزلازل والحد من الكوارث. من خلال تحليل البيانات الأكثر دقة، يمكن للذكاء الاصطناعي تحديد إشارات الزلازل التي يصعب اكتشافها بالطرق التقليدية، وبالتالي تعزيز فهمنا للأنشطة العميقة للأرض. (المصدر: Ars Technica)
إطلاق بنية Mamba3، نماذج LLM تحقق سرعة أكبر وسياق أطول وقابلية توسع أكبر: تم إطلاق بنية Mamba3 بهدوء في مؤتمر ICLR، مما يشير إلى تقدم كبير في مجال نماذج LLM من حيث السرعة وطول السياق وقابلية التوسع. حققت هذه البنية نمذجة تسلسلية أكثر كفاءة من Transformer من خلال تحسين تطور الحالة الداخلية واستخدام الأجهزة. تقدم Mamba3 تكاملًا شبه منحرف وحالات مخفية في المستوى المركب، مما يجعل ذاكرتها أكثر سلاسة واستقرارًا، ويمكنها تمثيل أنماط دورية. يتيح تصميم الإدخال المتعدد والمخرجات المتعددة معالجة متوازية لتدفقات بيانات متعددة، ومن المتوقع أن يكون لها إمكانات هائلة في فهم المستندات الطويلة، وتحليل السلاسل الزمنية، وأنظمة الذكاء الاصطناعي الطرفية. (المصدر: NandoDF)

Agentic RAG يتفوق على RAG التقليدي، ليصبح اتجاهًا جديدًا في البحث بالذكاء الاصطناعي: يتشكل إجماع في الصناعة: “RAG التقليدي المدمج (Retrieval Augmented Generation) قد مات”، بينما يتفوق Agentic RAG (الـ RAG القائم على الوكيل) في جميع الجوانب تقريبًا، باستثناء السرعة. ينبئ هذا الاتجاه بأن البحث بالذكاء الاصطناعي سينتقل من استرجاع المعلومات البسيط إلى تفاعل قائم على الوكيل أكثر تعقيدًا، حيث يمكن لـ Agentic RAG فهم نية المستخدم بشكل أكثر ذكاءً، وتخطيط استراتيجيات الاسترجاع، وتوليد إجابات أكثر دقة، مما يحدث ثورة في أنظمة البحث والأسئلة والأجوبة بالذكاء الاصطناعي في المستقبل. (المصدر: swyx, jerryjliu0)

TuringPost تطلق قائمة بأدوات توليد الفيديو بالذكاء الاصطناعي، وتضم Luma Dream Machine وغيرها: أطلقت TuringPost قائمة تضم 9 أدوات قوية لتوليد الفيديو بالذكاء الاصطناعي، بما في ذلك Sora 2، و Google Veo 3، و Runway، و Pika Labs، و Luma’s Dream Machine (مدعومة بـ Ray 3)، و Synthesia، و HeyGen، و Kaiber، و InVideo. تهدف هذه القائمة إلى تزويد المستخدمين بخيارات شاملة لإنشاء الفيديو بالذكاء الاصطناعي، وتغطي مجموعة متنوعة من الوظائف مثل تحويل النص إلى فيديو، والتوليد في الوقت الفعلي، وتوليف الشخصيات، مما يعكس التطور السريع والتطبيقات المتنوعة في مجال تقنية الفيديو بالذكاء الاصطناعي. (المصدر: TheTuringPost)
OpenAI تطلق فيلمًا قصيرًا عن تاريخ التكنولوجيا تم إنشاؤه بواسطة Sora، وعملية تجميع الفيديو لا تزال بحاجة إلى تحسين: قام باحث OpenAI Hemanth Asir بإنتاج فيلم قصير عن تاريخ تطور التكنولوجيا تم إنشاؤه بالكامل بواسطة Sora، مما يظهر إمكانات Sora في إنشاء الفيديو. على الرغم من أن الفيلم القصير مثير للإعجاب، إلا أن عملية التجميع لا تزال معقدة، وصرحت OpenAI بأنها ستعمل على تحسين هذه العملية لتعزيز تجربة المستخدم وكفاءة الإنشاء، مما ينبئ بأن تطبيقات أدوات توليد الفيديو بالذكاء الاصطناعي في السرد الطويل ستكون أكثر سهولة في المستقبل. (المصدر: dotey)
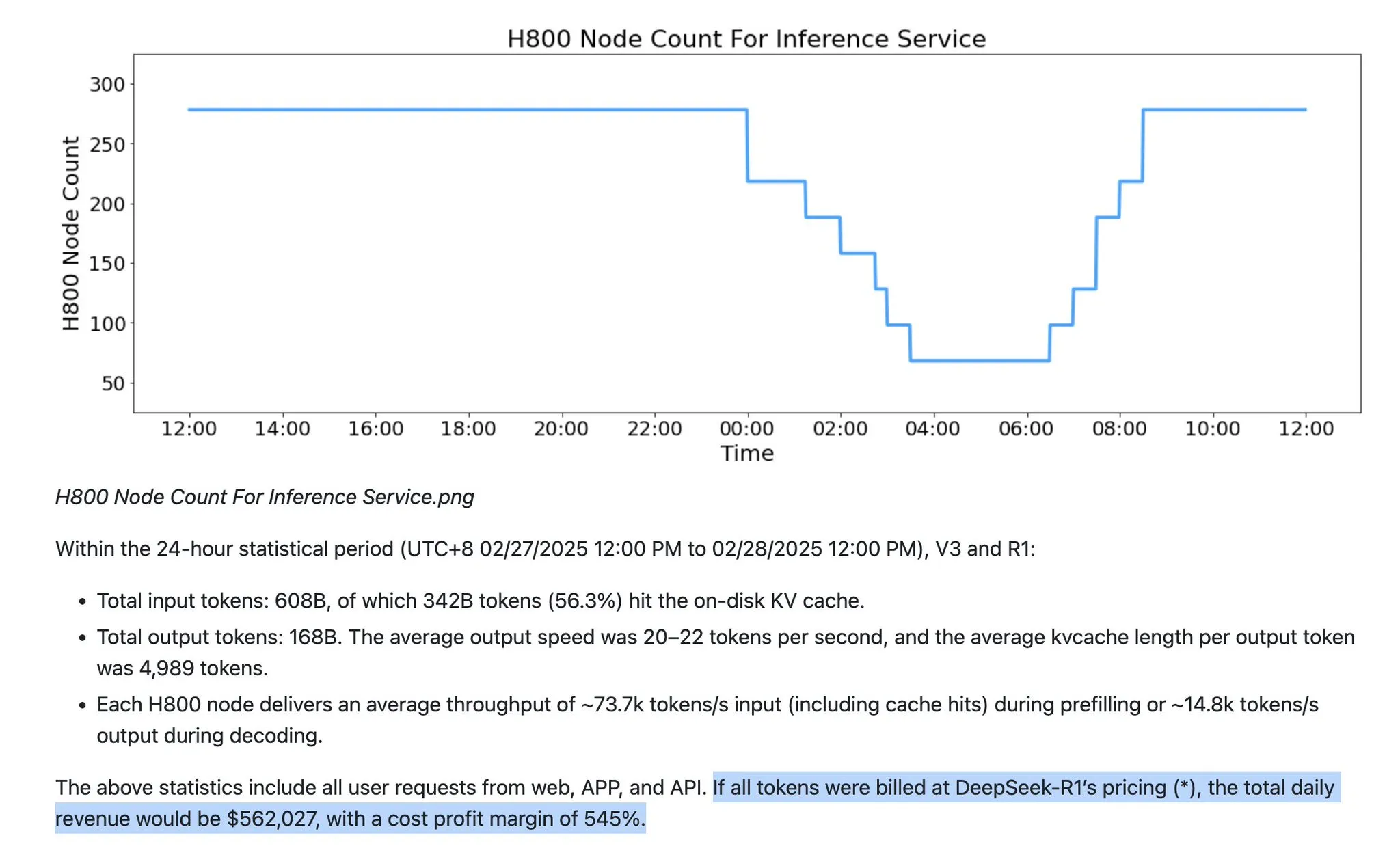
افتراضات خدمة LLM تواجه تحديات: FP8/FP4 ستصبح السائدة، وكمية الـ Tokens الناتجة ستنمو بشكل كبير: يشير رأي إلى أن خدمة LLM الحالية تحتوي على العديد من الافتراضات الخاطئة. أولاً، لم تعد خدمة LLM تقتصر على دقة FP16، وستصبح FP8 و FP4 هي السائدة. ثانيًا، سينعكس نمو LLM المستقبلي بشكل أساسي في النمو الهائل لـ “رموز التفكير” (رموز الإخراج)، بدلاً من مجرد نسبة رموز الإدخال. بالإضافة إلى ذلك، تتراوح معلمات نماذج سلسلة GPT-5 من OpenAI على نطاق أوسع، وتعمل المختبرات المختلفة على تقليل التكاليف من خلال تقنيات مثل DSA من Deepseek وآليات الانتباه الجديدة، كما أطلقت Anthropic أداة تنظيف السياق لـ Sonnet 4.5 لتقليل متطلبات الذاكرة، وكل هذه العوامل ستعيد تشكيل كفاءة وهيكل تكلفة خدمة LLM. (المصدر: teortaxesTex)
🧰 الأدوات
Microsoft MarkItDown: أداة تحويل المستندات إلى Markdown لخطوط أنابيب LLM: أطلقت مايكروسوفت أداة Python MarkItDown، التي يمكنها تحويل عشرات أنواع الملفات (بما في ذلك PDF، Word، Excel، HTML، الصور، الصوت، إلخ) إلى تنسيق Markdown نظيف. يمكن للأداة الاحتفاظ بالعناوين، والقوائم، والجداول، والروابط، والبيانات الوصفية، وتدعم التعرف الضوئي على الحروف (OCR) واستخراج معلومات EXIF. نظرًا لأن Markdown هي “اللغة الأصلية” لـ LLM، فإن MarkItDown يعد خيارًا مثاليًا لمعالجة المستندات مسبقًا في خطوط أنابيب LLM، مما يساعد على تحسين فهم النموذج وكفاءة معالجة المستندات المعقدة. (المصدر: TheTuringPost)
VS Code يطلق خطة تكرار 1.105، مع التركيز على الذكاء الاصطناعي وتجربة المطور: أطلق VS Code خطة تكرار شهر أكتوبر، والتي تقدم العديد من التحسينات التي تهدف إلى تعزيز تطوير الذكاء الاصطناعي المساعد وتجربة المطور الشاملة. تتضمن التحديثات عرض Mermaid، وطرقًا متعددة لإدارة السياق والأدوات، وإدارة نماذج أكثر تقدمًا، وعمليات متعددة الخطوات، وحفظ المحادثات كـ Prompt، بالإضافة إلى وظائف الطرفيات والأدوات و MCPs. علاوة على ذلك، أطلق GitHub Copilot أيضًا 34 تحسينًا في الثلاثين يومًا الماضية. ستعمل هذه التحديثات على تعميق تطبيق الذكاء الاصطناعي في تحرير التعليمات البرمجية، وتصحيح الأخطاء، والتعاون، مما يجعل VS Code بيئة تطوير أصلية للذكاء الاصطناعي أكثر قوة. (المصدر: pierceboggan, code)

Nanonets-OCR2 تطلق، نموذج مفتوح المصدر لتحويل الصور إلى Markdown يدعم LaTeX ومخططات التدفق: أطلقت Nanonets-OCR2، وهو نموذج مفتوح المصدر لتحويل الصور إلى Markdown، تم ضبطه بدقة بناءً على Qwen2.5-VL-3B-Instruct، ويدعم التعرف على معادلات LaTeX، والجداول، والمستندات المكتوبة بخط اليد، ومربعات الاختيار، بل ويمكنه تحويل مخططات التدفق إلى تعليمات برمجية Mermaid. يتميز النموذج أيضًا بوصف ذكي للصور، واكتشاف التوقيعات، واستخراج العلامات المائية، ودعم متعدد اللغات، ويوفر قدرة الإجابة على الأسئلة البصرية (VQA). يتفوق Nanonets-OCR2 في معالجة المستندات المعقدة، ويوفر حلاً فعالاً وغنيًا بالميزات لمعالجة المستندات مسبقًا في خطوط أنابيب LLM. (المصدر: huggingface, Reddit r/LocalLLaMA, karminski3)
تطبيق ChatGPT لـ Slack يطلق، مع دمج واجهة برمجة تطبيقات البحث في الوقت الفعلي: تم إطلاق تطبيق ChatGPT رسميًا على Slack، وباستخدام واجهة برمجة تطبيقات البحث في الوقت الفعلي من Slack، يمكن للمستخدمين الآن استخدام ChatGPT مباشرة في الشريط الجانبي المخصص لـ Slack، لطرح الأسئلة، والعصف الذهني، وصياغة المحتوى، وحل المشكلات. سيؤدي هذا التكامل إلى دمج قدرات ChatGPT القوية بسلاسة في منصة التعاون الجماعي، ويهدف إلى تعزيز كفاءة العمل، وتبسيط الحصول على المعلومات وإنشاء المحتوى، وتوفير مساعدة ذكاء اصطناعي أكثر ملاءمة لمستخدمي الشركات. (المصدر: gdb)
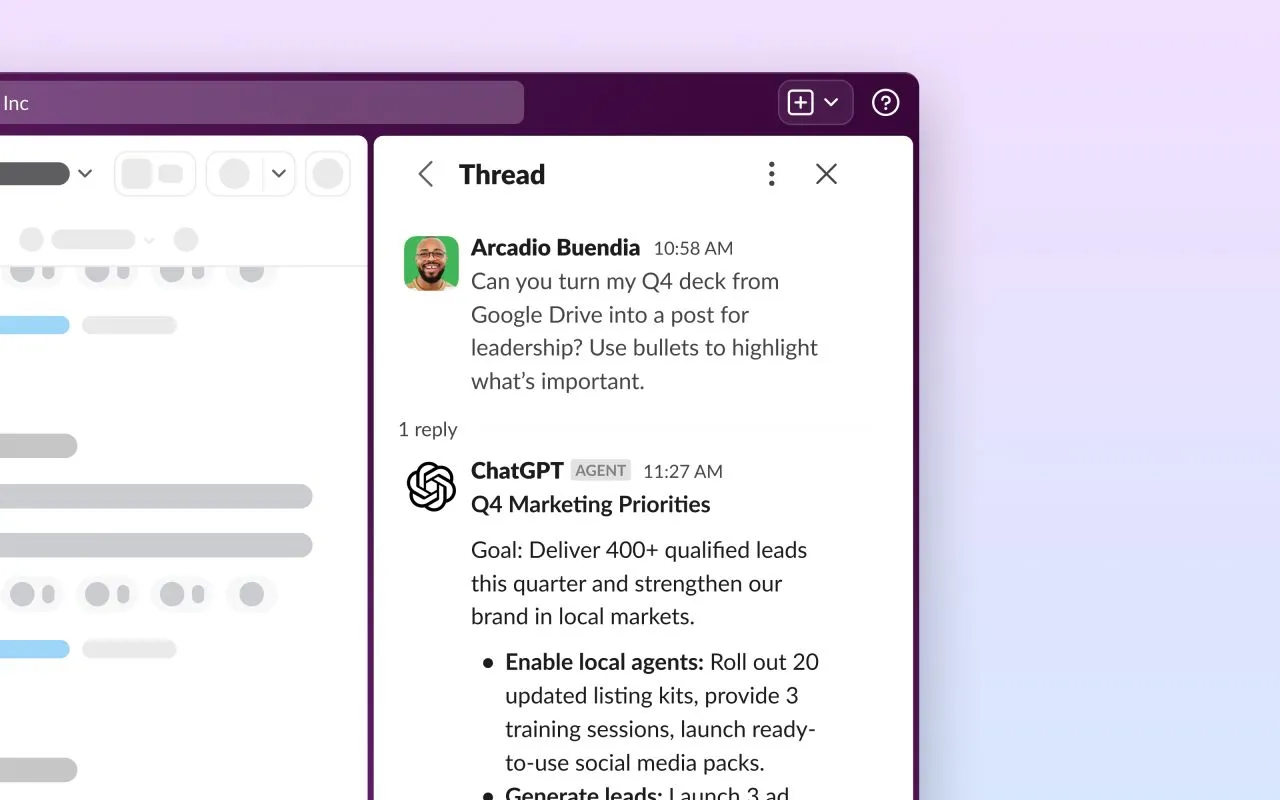
n8n تطلق منشئ سير عمل الذكاء الاصطناعي، لتمكين الأتمتة باللغة الطبيعية: أطلقت n8n رسميًا منشئ سير عمل الذكاء الاصطناعي الخاص بها، والذي يسمح للمستخدمين بإنشاء وكلاء ذكاء اصطناعي وعمليات أتمتة في n8n باستخدام اللغة الطبيعية. توفر هذه الأداة لوحة قماشية مرئية، يمكنها الاتصال بأكثر من 8000 أداة مثل Firecrawl، و LLMs، وعقد المنطق، و MCPs، ويمكن نشرها كواجهة برمجة تطبيقات (API). سيبسط هذا الابتكار بشكل كبير تطوير وتطبيق وكلاء الذكاء الاصطناعي، مما يمكّن المزيد من المطورين من إنشاء سير عمل أتمتة معقدة باستخدام اللغة الطبيعية، ويدفع بانتشار وكلاء الذكاء الاصطناعي في سيناريوهات الأعمال الفعلية. (المصدر: omarsar0)
MLX يدعم تشغيل النماذج المحلية، وتحديث Privacy AI 1.3.2 يعزز قدرات الذكاء الاصطناعي لأجهزة Apple: أطلقت Privacy AI تحديث 1.3.2، الذي يدعم بشكل كامل محرك MLX من Apple، مما يسمح للمستخدمين بتشغيل نماذج النصوص والصور محليًا. يمكن تنزيل النماذج مباشرة من Hugging Face، وتدعم استئناف التنزيل، والنقل في الخلفية، والتحقق من السلامة، وتتضمن نماذج MLX في الخطة المجانية، مما يتيح التشغيل دون اتصال بالإنترنت دون الحاجة إلى اشتراك. يحسن هذا التحديث أيضًا دعم الحافظة، ويقوم بترقية llama.cpp، مما يعزز قدرات الذكاء الاصطناعي المحلية وحماية الخصوصية على أجهزة Apple. (المصدر: awnihannun)
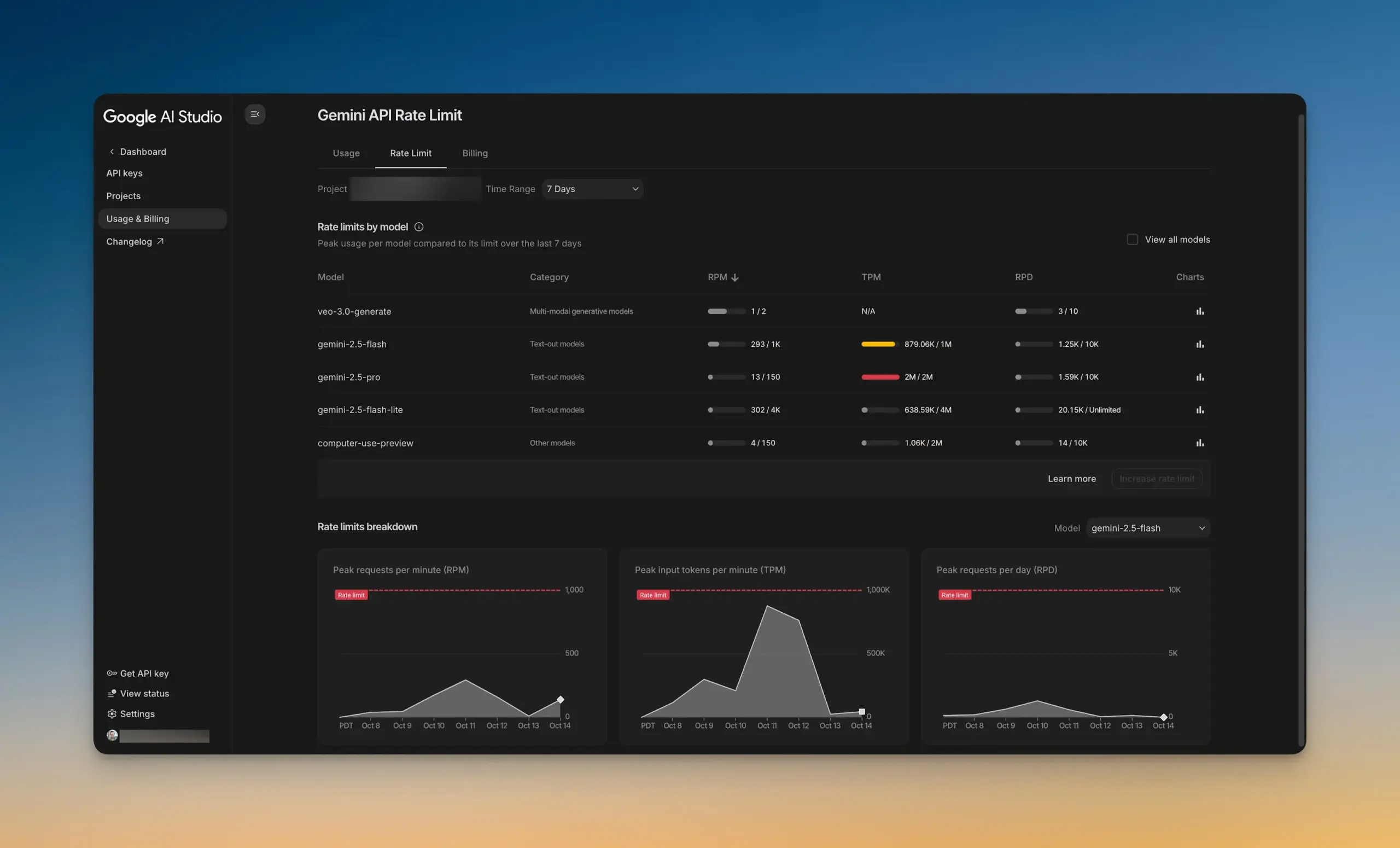
Google AI Studio تطلق لوحة تحكم جديدة لقيود المعدل: أطلقت Google AI Studio لوحة تحكم جديدة لقيود المعدل، والتي تسمح للمستخدمين بفهم استخدام Gemini API بشكل مرئي دون مغادرة AI Studio. توفر لوحة التحكم هذه وظيفة تصفية الرسوم البيانية، ويمكنها بسهولة استكشاف قيود المعدل لجميع النماذج، مما يساعد المطورين على إدارة مشاريع الذكاء الاصطناعي الخاصة بهم وتحسينها بشكل أفضل، وزيادة كفاءة التطوير. (المصدر: GoogleAIStudio)
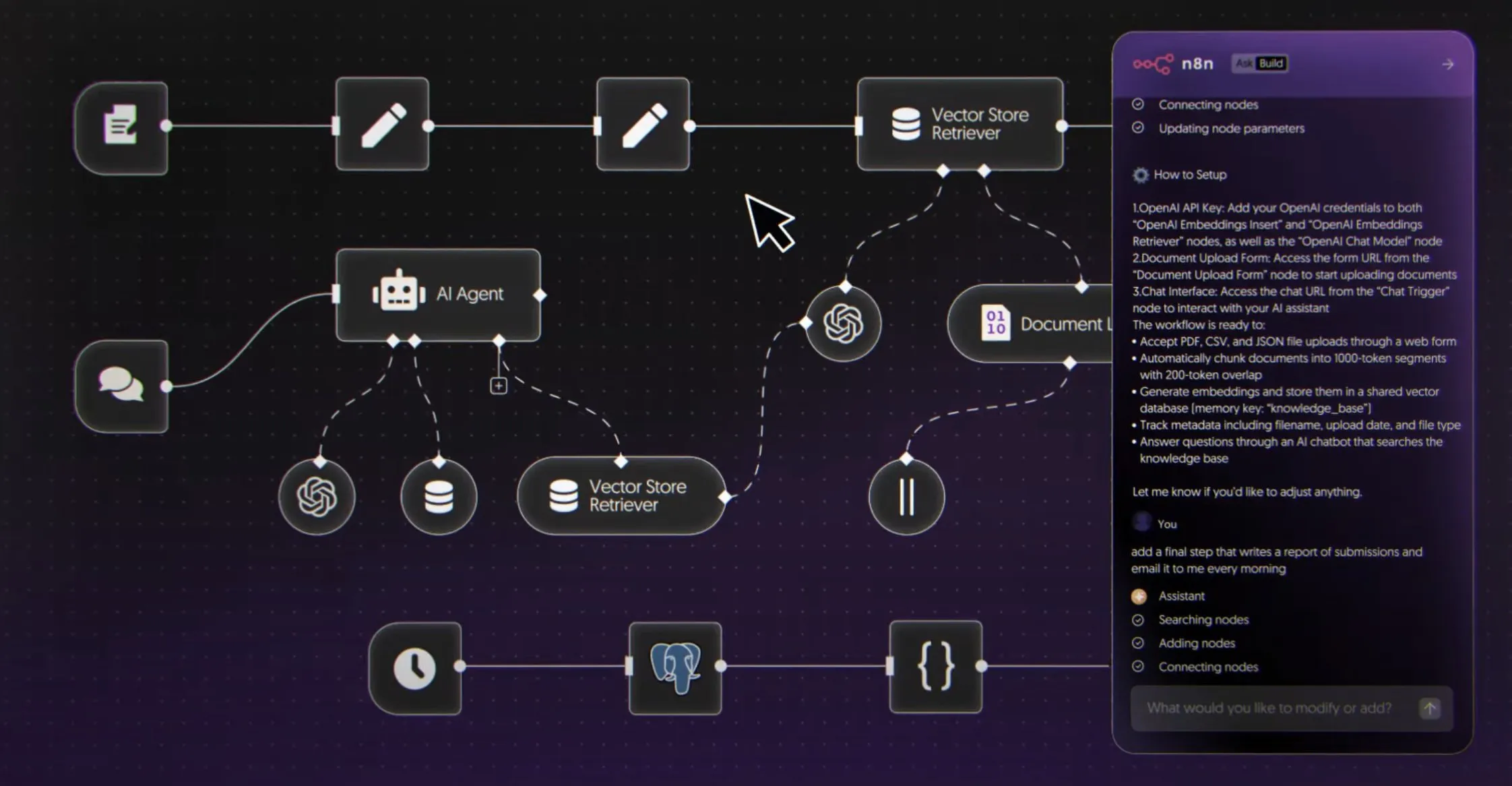
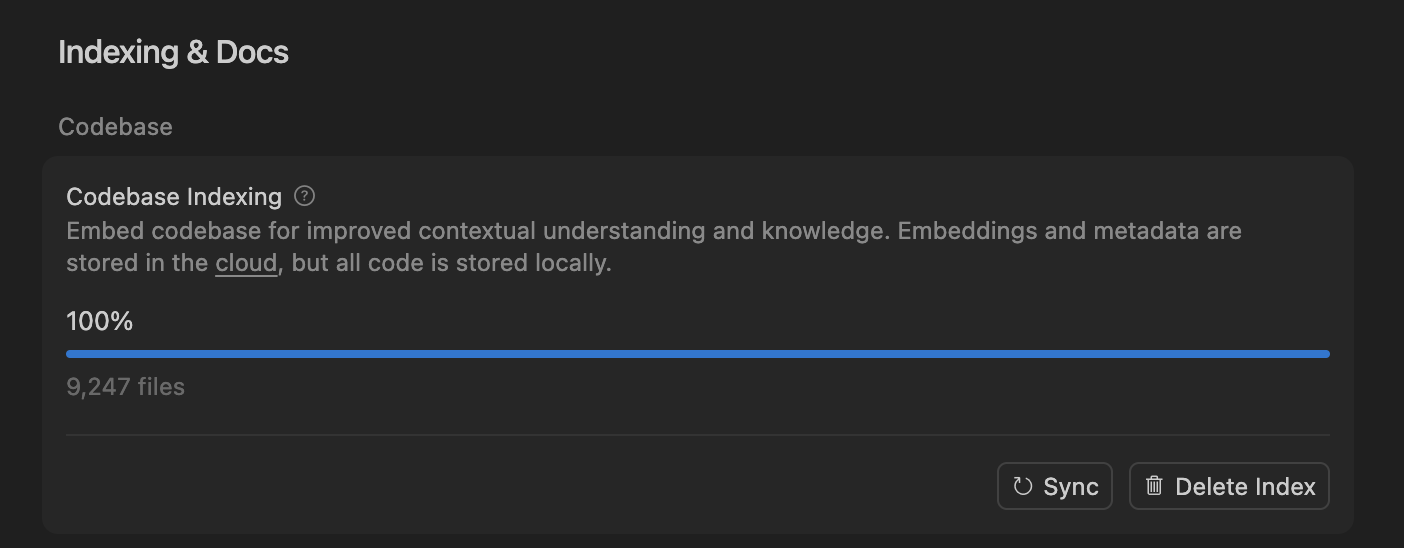
Cursor IDE و Codex يصبحان خيارًا جديدًا للترميز اليومي للمطورين: مع التطور السريع لأدوات ترميز الذكاء الاصطناعي، أصبح Cursor IDE و Codex أدوات أساسية في سير عمل العديد من المطورين اليومي. صرح أحد المطورين بأنه انتقل بالكامل من Claude Code إلى Codex، ويستخدمه للتخطيط اليومي، وتقسيم المهام، والمعالجة المتوازية. حقق نظام فهرسة قاعدة التعليمات البرمجية في Cursor IDE فهرسة وتحديثًا فعالين للتعليمات البرمجية من خلال البحث الدلالي والوصول إلى التعليمات البرمجية المحلية، دون الحاجة إلى تخزين التعليمات البرمجية على الخادم، مما يضمن الخصوصية والكفاءة. تعمل هذه الأدوات على تغيير طرق الترميز التقليدية، وتحسين كفاءة التطوير. (المصدر: dejavucoder, gdb)
Yupp.ai: أداة مناقشة بالذكاء الاصطناعي تساعد المستخدمين في الحصول على إجابات أكثر شمولاً: Yupp.ai هي أداة ذكاء اصطناعي مبتكرة تهدف إلى مساعدة المستخدمين على اتخاذ قرارات أكثر استنارة في عصر انفجار المعلومات، من خلال تقديم إجابات من نماذج ذكاء اصطناعي مختلفة. يمكن للمستخدمين مقارنة إجابات الذكاء الاصطناعي المختلفة جنبًا إلى جنب، والتصويت بناءً على تحليلها، أو إبداعها، أو تفاصيل محددة، وبالتالي تشكيل ترتيب للذكاء الجماعي. هدف Yupp.ai هو تمكين المستخدمين من الاستفادة من الخبرة الجماعية، والحصول بسرعة على إجابات موثوقة ومتعددة الزوايا، وبالتالي تحسين كفاءة العمل وثقة اتخاذ القرار. (المصدر: yupp_ai)

vLLM و SGLang يُشيد بهما كـ “Linux عصر الذكاء الاصطناعي”: يُشيد بـ vLLM و SGLang كـ “Linux عصر الذكاء الاصطناعي” لأدائهما المتميز في مجال استدلال LLM. حصل vLLM على 60 ألف نجمة على GitHub، وتطور من فكرة بحثية صغيرة ليصبح إطار عمل أساسيًا لاستدلال LLM يدعم تقريبًا جميع المنصات الرئيسية مثل NVIDIA، و AMD، و Intel، و Apple. يدعم معظم نماذج توليد النصوص وخطوط أنابيب RL الأصلية مثل TRL و Unsloth، ويلعب دورًا أساسيًا في النظام البيئي للذكاء الاصطناعي، مما يدفع بانتشار وكفاءة استدلال LLM. (المصدر: bookwormengr)
Luma AI Ray3 للتعليق البصري يفتح التحكم الدقيق: تتيح ميزة التعليق البصري Ray3 التي أطلقتها Luma AI التحكم الدقيق في الاتجاه البصري من خلال الرسم على الإطارات، وتوجيه الكائن الرئيسي للقيام بحركات أو تفاعلات محددة. تتجاوز هذه الميزة قيود المطالبات النصية التقليدية، وتنقل نية الإعاقة المكانية من خلال ضربات الفرشاة، مما يوفر طريقة تحكم أكثر سهولة ودقة للإبداع البصري، وتظهر إمكانات قوية بشكل خاص في تطبيقات مثل Dream Machine. (المصدر: TomLikesRobots)
Faceseek: أداة مطابقة وتحقق من الوجوه مدعومة بالذكاء الاصطناعي: Faceseek هي أداة تستخدم تقنية الذكاء الاصطناعي لمطابقة الوجوه والتحقق منها، ويمكنها التعامل بفعالية مع الوجوه المتشابهة. قد تستخدم هذه الأداة تضمين الوجوه، أو CLIP (التعلم المسبق للغة والصورة التبايني)، أو نماذج رؤية حاسوبية متقدمة أخرى للتحليل، وتوفر حلولًا لسيناريوهات مثل التحقق من الهوية والمراقبة الأمنية. أثار أداؤها في التطبيقات العملية نقاشًا حول التفاصيل التقنية والتطبيقات المحتملة لهذه الأنظمة. (المصدر: Reddit r/ArtificialInteligence)
تمديد الواجهة الخلفية لوحدة معالجة الرسوميات البعيدة لـ PyTorch، يحقق دمج التطوير المحلي والحوسبة عن بعد: يسمح امتداد PyTorch جديد للمطورين بالتطوير محليًا، مع الاستفادة من الواجهة الخلفية لوحدة معالجة الرسوميات البعيدة للحوسبة. يحل هذا مشكلة قيود موارد الأجهزة المحلية، مما يتيح للباحثين والمطورين تدريب نماذج التعلم العميق وإجراء التجارب بمرونة أكبر، مع الجمع بين سهولة بيئة التطوير المحلية ومزايا الحوسبة عالية الأداء عن بعد. (المصدر: Reddit r/deeplearning)
FocoosAI تطلق حزمة تطوير برامج (SDK) مفتوحة المصدر ومنصة ويب للرؤية الحاسوبية: أطلقت FocoosAI حزمة تطوير برامج (SDK) مفتوحة المصدر ومنصة ويب للرؤية الحاسوبية، بهدف تزويد المطورين بالأدوات والموارد لبناء ونشر حلول الرؤية الحاسوبية. سيعزز إطلاق هذه المنصة انتشار وتطبيق تقنيات الرؤية الحاسوبية، ويقلل من عتبة التطوير، مما يمكّن المزيد من المبتكرين من استكشاف وتطوير الذكاء الاصطناعي في مجال تحليل الصور والفيديو. (المصدر: Reddit r/deeplearning)
أدوات “إضفاء الطابع الإنساني” على نصوص الذكاء الاصطناعي: تعزيز الطبيعية في المحتوى الذي يولده الذكاء الاصطناعي: مع انتشار تقنيات توليد النصوص بالذكاء الاصطناعي، أصبح كيفية جعل المحتوى الذي يولده الذكاء الاصطناعي أكثر “إنسانية” قضية مهمة. ظهرت حاليًا العديد من الأدوات في السوق، تهدف إلى تحسين أسلوب اللغة، والتعبير العاطفي، والتكيف مع السياق، لجعل نصوص الذكاء الاصطناعي تبدو أكثر طبيعية وأقرب إلى التعبير البشري. تساعد هذه الأدوات المستخدمين على تجنب الشعور الميكانيكي والنمطي في نصوص الذكاء الاصطناعي، وتعزيز جاذبية المحتوى، وتلبية الطلب على النصوص عالية الجودة والشخصية. (المصدر: Ronald_vanLoon)
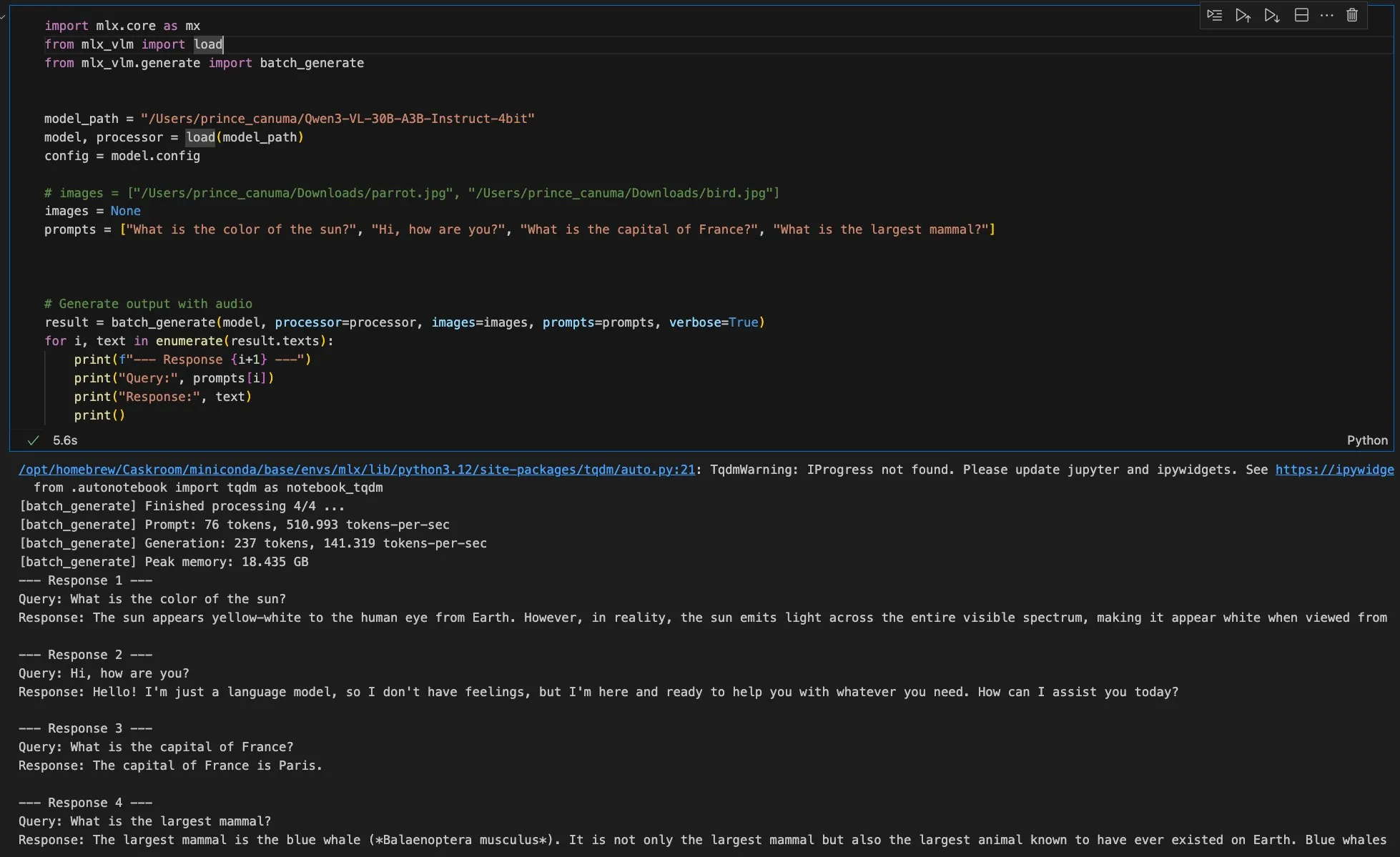
إصدار جديد من MLX-VLM قادم قريبًا، و Qwen Image يدعم إطار عمل MFLUX: سيشهد MLX-VLM من Apple تحديثًا كبيرًا قريبًا، مما ينبئ بإمكاناته القوية في مجال النماذج الكبيرة متعددة الوسائط. في الوقت نفسه، تم إطلاق الإصدار 0.11 من إطار عمل MFLUX، مع إضافة دعم لـ Qwen Image، مما يسمح للمستخدمين بتنزيل واستخدام نموذج Qwen Image للتوليد من خلال عمليات سطر الأوامر البسيطة. تدفع هذه التطورات معًا كفاءة ومرونة تطوير ونشر نماذج الذكاء الاصطناعي داخل نظام Apple البيئي، وتوفر للمطورين أدوات ذكاء اصطناعي متعددة الوسائط أكثر ملاءمة. (المصدر: adrgrondin, awnihannun)
CleanMARL: تطبيق بسيط للتعلم المعزز متعدد الوكلاء في PyTorch: يوفر مشروع CleanMARL مجموعة من التطبيقات البسيطة، ذات الملف الواحد، لخوارزميات التعلم المعزز العميق متعدد الوكلاء (MARL)، تم تطويرها بناءً على PyTorch، وتلتزم بفلسفة CleanRL. يهدف هذا المشروع إلى خفض عتبة تطبيق خوارزميات MARL، وتزويد الباحثين والمطورين برمز واضح وسهل الفهم وإعادة الإنتاج، لتسريع البحث والتطبيق لأنظمة متعددة الوكلاء في البيئات المعقدة. (المصدر: jsuarez5341)
📚 التعلم
التدريب اللاحق للنماذج الكبيرة يصبح جوهر القدرة التنافسية للذكاء الاصطناعي، والشركات تسرع في بناء محركات ذكاء اصطناعي خاصة بها: أصبح التدريب اللاحق للنماذج الكبيرة هو القدرة التنافسية الأساسية لتطبيق الذكاء الاصطناعي في الشركات، حيث ينتقل التركيز التقني من “التقليد” إلى “المواءمة” من SFT إلى RLHF، و RLVR، ثم إلى “المكافأة باللغة الطبيعية” المتقدمة. من خلال إعداد بيانات عالية الجودة، واختيار النماذج الأساسية، وتصميم آليات المكافأة، ونظام تقييم قابل للقياس، نجحت شركات مثل NetEase، و Autohome، و Weibo، و Quark في تحويل النماذج الكبيرة العامة إلى “محركات ذكاء اصطناعي خاصة” تفهم الأعمال بعمق، وتمتلك معرفة بالمجال، وتحل المهام المعقدة في عالم الأعمال، وتبني حواجز تنافسية لا يمكن نسخها. (المصدر: 量子位)

Andrew Ng يطلق دورة Agentic AI، مع التركيز على أربعة أنماط تصميم رئيسية: أطلقت DeepLearning.AI أحدث إصدار من The Batch، معلنة عن إطلاق Andrew Ng لدورته الجديدة “Agentic AI”. هذه الدورة هي دورة بناء عملية، تدور حول أربعة أنماط تصميم رئيسية: الانعكاس، واستخدام الأدوات، والتخطيط، والتعاون متعدد الوكلاء. تهدف الدورة إلى مساعدة المشاركين على إتقان المهارات الأساسية لبناء أنظمة وكلاء ذكاء اصطناعي فعالة، ودفع تطبيق الذكاء الاصطناعي في التطبيقات العملية. (المصدر: DeepLearningAI)
ضبط دقيق لتعليمات LLM ينطوي على تكاليف خفية: توزيع إخراج أضيق، وانخفاض قابلية التحكم في السياق: كشفت الأبحاث أن الضبط الدقيق لتعليمات LLM، بينما يعزز القدرة على اتباع التعليمات، يأتي أيضًا بتكاليف خفية: يصبح توزيع إخراج النموذج أضيق، وتنخفض قابلية التحكم في السياق (In-Context Steerability). لحل هذه المشكلة، أطلق فريق البحث “Spectrum Suite” لإجراء بحث متعمق، واقترح “Spectrum Tuning” كطريقة بديلة للتدريب اللاحق، تهدف إلى الحفاظ على تنوع الإخراج ومرونته مع تحسين أداء النموذج. (المصدر: YejinChoinka, YejinChoinka)
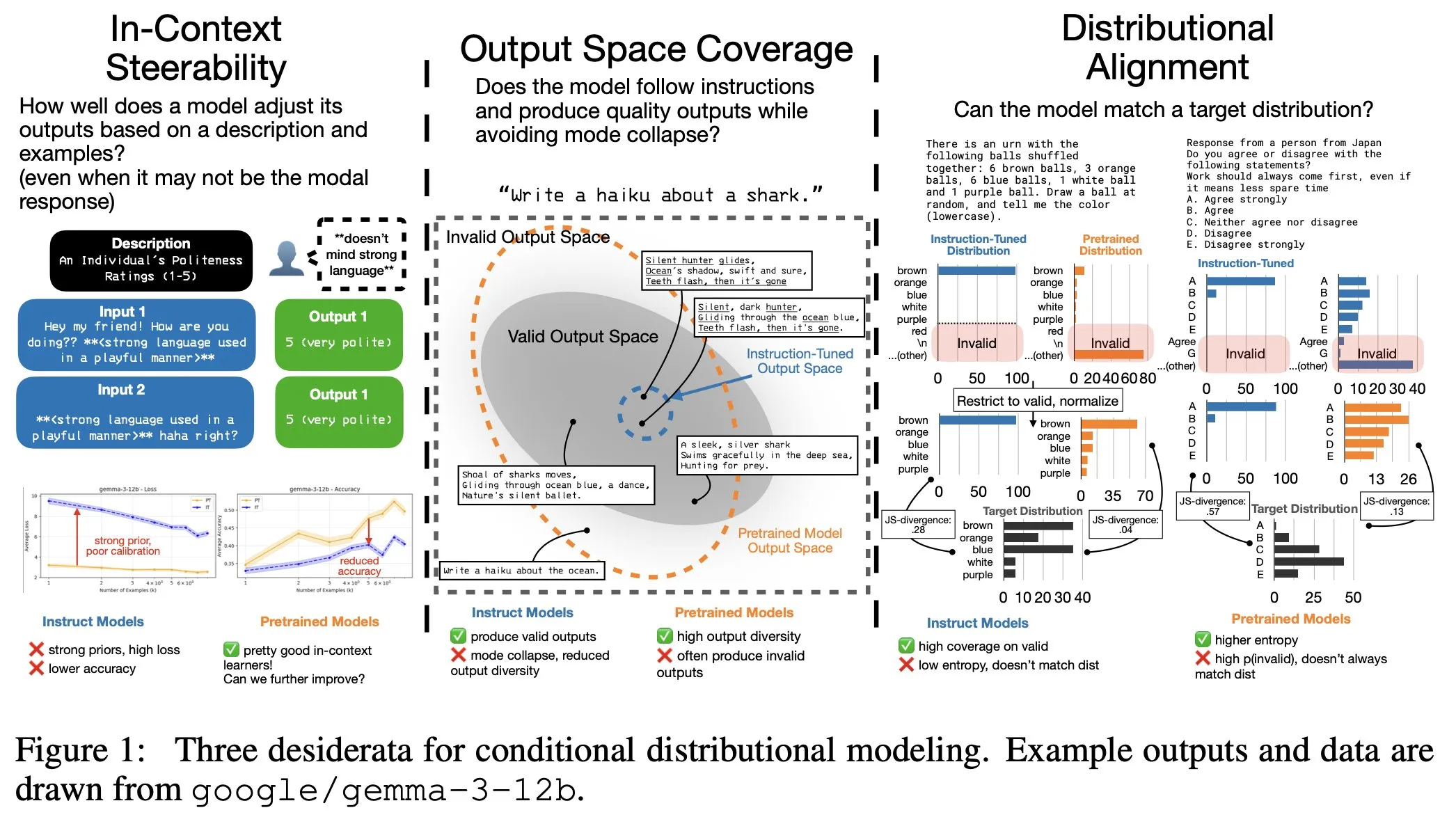
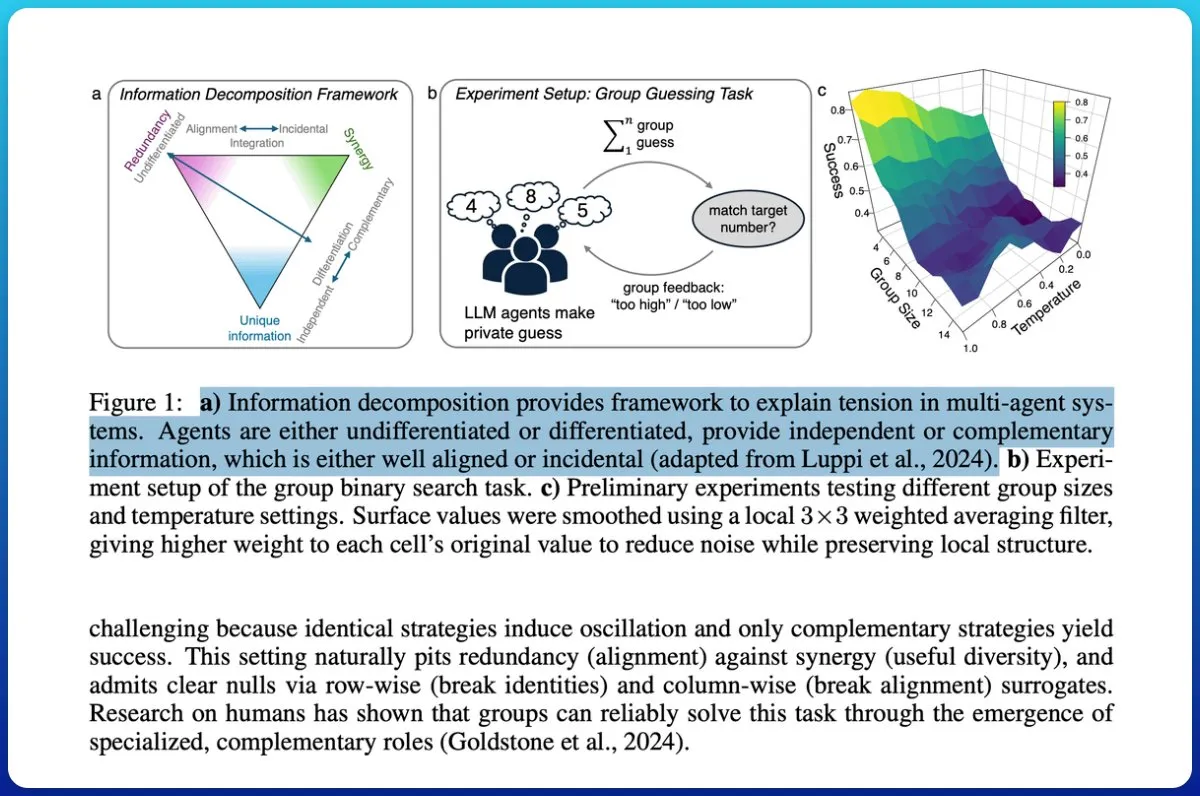
تآزر أنظمة الوكلاء المتعددة: نظرية المعلومات تميز بين “كومة من روبوتات الدردشة” و “الذكاء الجماعي”: استكشفت دراسة ما إذا كانت أنظمة الوكلاء المتعددة المدعومة بـ LLM تحقق تآزرًا حقيقيًا، واقترحت استخدام نظرية المعلومات للتمييز بين “كومة من روبوتات الدردشة” و “الذكاء الجماعي الحقيقي”. قدمت الدراسة قياسات دورية، من خلال تقييم قدرة إخراج المجموعة على التنبؤ بالنتائج المستقبلية، وتحليل المعلومات لتحديد التآزر بدلاً من التكرار. أظهرت النتائج أن منح الوكلاء أدوارًا مختلفة وأهدافًا مشتركة، واختبار تآزرهم بدلاً من افتراضه، أمر بالغ الأهمية لتحقيق الذكاء الجماعي، وأن النماذج ذات السعة المنخفضة يصعب عليها تحقيق تعاون حقيقي. (المصدر: omarsar0)
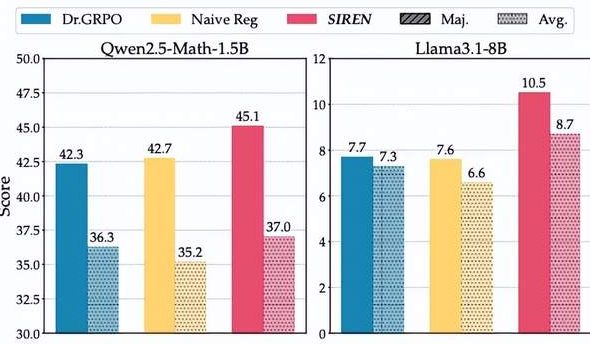
“معضلة الانتروبيا” في استدلال النماذج الكبيرة: طريقة SIREN ترفض “انهيار الانتروبيا” و “انفجار الانتروبيا”: تواجه نماذج الاستدلال الكبيرة (LRM) “معضلة الانتروبيا” في تدريب RLVR، أي أن الاستكشاف المحدود يؤدي إلى “انهيار الانتروبيا” أو الاستكشاف الخارج عن السيطرة يؤدي إلى “انفجار الانتروبيا”. اقترح فريق من مختبر شنغهاي للذكاء الاصطناعي وجامعة فودان طريقة تنظيم الانتروبيا الانتقائية (SIREN)، والتي تتحكم بدقة في سلوك الاستكشاف من خلال آلية ثلاثية: تحديد نطاق الاستكشاف (قناع Top-p)، وتحديد نقاط القرار الرئيسية (قناع ذروة الانتروبيا)، وتثبيت عملية التدريب (تنظيم التثبيت الذاتي). أثبتت التجارب أن SIREN يحسن الأداء بشكل كبير في معايير الاستدلال الرياضي، ويجعل عملية الاستكشاف أكثر كفاءة وقابلية للتحكم. (المصدر: 量子位)
موارد تعلم وكلاء الذكاء الاصطناعي: كتاب “دليل وكلاء الذكاء الاصطناعي المصور” وملخص للمفاهيم: تتزايد موارد التعلم في مجال وكلاء الذكاء الاصطناعي. يقوم Maarten Grootendorst و Jay Alammar حاليًا بتأليف كتاب “دليل وكلاء الذكاء الاصطناعي المصور”، والذي سيغطي أساسيات الوكلاء (الذاكرة، الأدوات، التخطيط) بالإضافة إلى المفاهيم المتقدمة مثل التعلم المعزز ونماذج LLM الاستدلالية. بالإضافة إلى ذلك، لخصت مقالات أيضًا 20 مفهومًا أساسيًا لوكلاء الذكاء الاصطناعي، مما يوفر مسارًا تعليميًا منهجيًا ومواد مرجعية للمبتدئين والمتقدمين. (المصدر: lvwerra, Ronald_vanLoon)

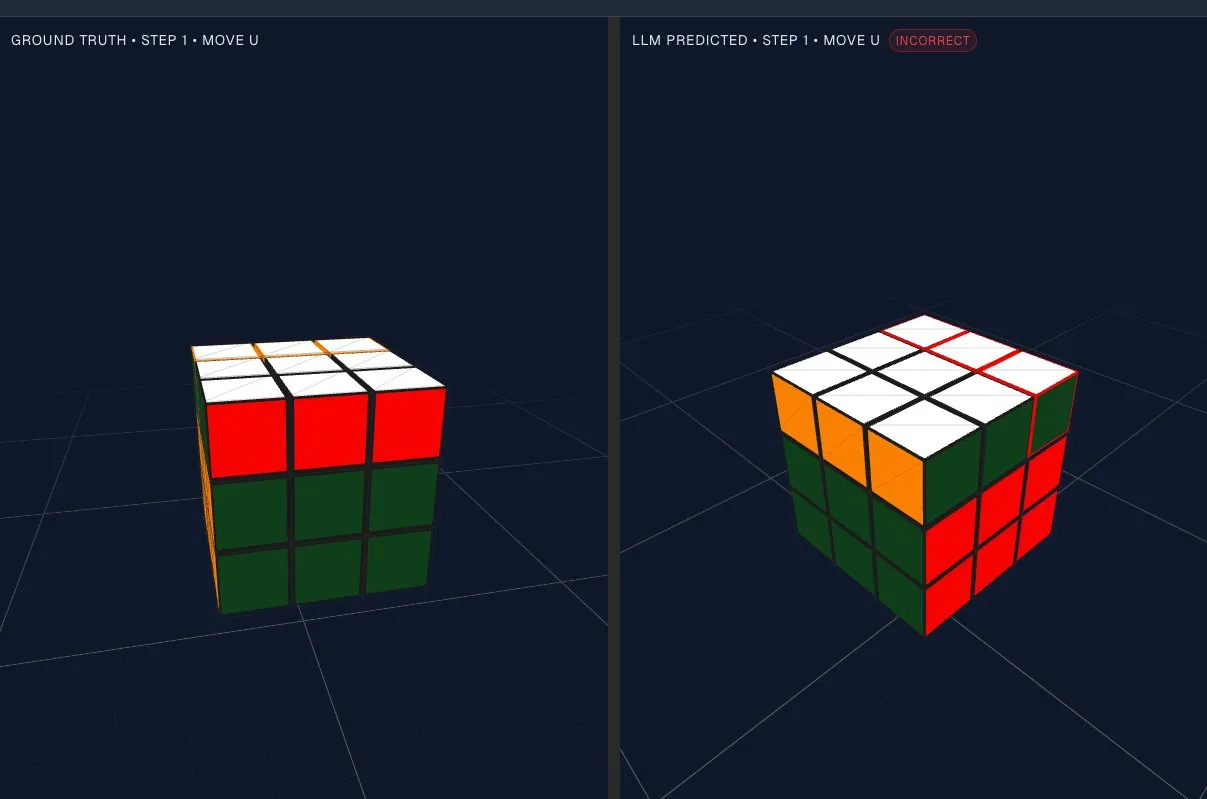
تقييم قدرة LLM على الاستدلال المكاني: اختبار دوران الأشكال يتحدى الفضاء الكامن للنموذج: تم اقتراح طريقة تقييم مثيرة للاهتمام، تهدف إلى اختبار قدرة نماذج اللغة الكبيرة (LLM) على تدوير الأشكال “في الذهن”. من خلال اختبار بصري بسيط، وجدت الدراسة أن LLM يمكنها إجراء درجة معينة من دوران الأشكال في الفضاء الكامن الأساسي، لكنها لا تؤدي أداءً جيدًا في الاستدلال الأكثر تعقيدًا والأعلى مستوى، وتوجد مشكلة “الاستدلال المكاني غير المنتظم”. يكشف هذا عن قيود LLM في معالجة المنطق الهندسي والمكاني، ويوفر اتجاهًا بحثيًا جديدًا لتحسين النموذج في المستقبل. (المصدر: dejavucoder, tokenbender)
استراتيجيات الضبط الدقيق لـ LLM: تحديث طبقات إسقاط الانتباه وطبقات بوابة MLP يمكن أن يحد من النسيان: كيفية تعليم نماذج الوسائط المتعددة الكبيرة (LMM) مهارات جديدة مع تجنب نسيان القدرات الأصلية هو تحدٍ رئيسي. وجدت دراسة أن ظاهرة “النسيان” التي تظهر بعد الضبط الدقيق الضيق يمكن استعادتها لاحقًا، وهذا مرتبط بالتغيرات الكبيرة في توزيع الـ Token الناتج. حددت الدراسة استراتيجيتين بسيطتين وقويتين للضبط الدقيق: تحديث طبقات إسقاط الانتباه الذاتي فقط، أو تحديث طبقات بوابة MLP و Up فقط وتجميد طبقات إسقاط Down. تحقق هذه الخيارات مكاسب قوية في الأهداف عبر النماذج والمهام، مع الحفاظ بشكل أساسي على الأداء الأصلي. (المصدر: arXiv:2510.08564)
الذكاء الاصطناعي والنمو الاقتصادي: تفسير ورقة بحثية لـ Philippe Aghion الحائز على جائزة نوبل: تشير دراسة أجراها Philippe Aghion الحائز على جائزة نوبل وزملاؤه إلى أنه حتى لو حقق الاقتصاد أتمتة بنسبة 99% وإنتاجًا لا نهائيًا، فإن معدل النمو الإجمالي سيظل مقيدًا بتقدم الـ 1% المتبقية من المهام الأساسية والصعبة. في عصر AGI، ستتحول هذه المهام “التي يصعب تحسينها” إلى مهام مركزية فيزيائية، مثل توليد الطاقة، واستخراج الموارد، والتصنيع، والنقل. هذا يعني أن عصر ما بعد AGI ليس بالضرورة عصر “ما بعد الندرة”، وستتركز القيمة الاقتصادية في المهام المقيدة فيزيائيًا. (المصدر: pmddomingos, jonst0kes)

تحديات تعميم ومتانة نماذج الذكاء الاصطناعي: الاستدلال الزائف يؤدي إلى عيوب في الاستدلال الرياضي: غالبًا ما تؤدي نماذج اللغة في الاستدلال الرياضي إلى نقص في المتانة والتعميم بسبب “الاستدلال الزائف” (Spurious Reasoning)، أي أن النموذج يستنتج الإجابات من الميزات السطحية بدلاً من منطق المشكلة. إطار عمل AdaR، من خلال توليف استعلامات مكافئة منطقيًا ودمج RLVR (التعلم المعزز القائم على المكافأة القابلة للتحقق) للتدريب، يعاقب المنطق الزائف ويشجع المنطق التكيفي. أظهرت التجارب أن AdaR يحسن بشكل كبير متانة وتعميم الاستدلال الرياضي لـ LLM، مع الحفاظ على كفاءة عالية للبيانات. (المصدر: arXiv:2510.04617)
التحسين الذاتي لوكيل LLM في وقت الاختبار: إطار عمل TT-SI يحقق التعلم المستقل: اقترحت دراسة طريقة جديدة للتحسين الذاتي في وقت الاختبار (Test-Time Self-Improvement, TT-SI)، تهدف إلى إنشاء وكلاء LLM أكثر فعالية وقابلية للتعميم ديناميكيًا. تقوم الخوارزمية بتحديد عينات النموذج الصعبة، وتوليد أمثلة مماثلة (تعزيز البيانات الذاتي)، والضبط الدقيق في وقت الاختبار (التحسين الذاتي)، لتحقيق التعلم المستقل للنموذج. أثبتت التجارب أن TT-SI يحسن دقة وكلاء الذكاء الاصطناعي بمتوسط 5.48% في الاختبارات المعيارية، ويقلل حجم عينة التدريب بمقدار 68 مرة، مما يظهر إمكانات خوارزميات التحسين الذاتي في بناء وكلاء أقوى. (المصدر: arXiv:2510.07841)
مبادئ التصميم الرئيسية وممارسات التحسين للتعلم المعزز لوكيل LLM: استكشفت دراسة بشكل منهجي مبادئ التصميم الرئيسية للتعلم المعزز القائم على الوكيل (Agentic RL) في تعزيز قدرات الاستدلال لوكيل LLM. وجدت الدراسة أن استخدام مسارات استخدام الأدوات الحقيقية من البداية إلى النهاية بدلاً من المسارات الاصطناعية كتهيئة SFT يؤدي إلى تأثيرات أقوى؛ وأن مجموعات البيانات عالية التنوع والواعية بالنموذج يمكن أن تحافظ على الاستكشاف وتحسن أداء RL بشكل كبير. بالإضافة إلى ذلك، فإن التقنيات الصديقة للاستكشاف (مثل clip higher، و overlong reward shaping، والحفاظ على انتروبيا سياسة كافية) ضرورية لـ Agentic RL. يمكن لهذه الممارسات أن تعزز باستمرار الاستدلال القائم على الوكيل وكفاءة التدريب، مما يمكن النماذج الصغيرة من تحقيق نتائج ممتازة في المعايير الصعبة. (المصدر: arXiv:2510.11701)
آلية المكافأة في استدلال LLM: PEAR يحسن كفاءة الاستدلال من خلال الوعي بالانتروبيا المرحلية: غالبًا ما تزيد نماذج الاستدلال الكبيرة (LRM) تكلفة الاستدلال بسبب خطوات الاستدلال الزائدة عند توليد تفسيرات CoT. تعمل آلية PEAR (Phase Entropy Aware Reward) على تصميم المكافأة من خلال دمج الانتروبيا المعتمدة على المرحلة، حيث تعاقب الانتروبيا المفرطة في مرحلة التفكير، بينما تسمح بالاستكشاف المعتدل في مرحلة الإجابة النهائية. يشجع هذا النموذج على توليد مسارات استدلال موجزة، مع الحفاظ على المرونة اللازمة لحل المهام. أظهرت التجارب أن PEAR يقلل باستمرار من طول الاستجابة دون التضحية بالدقة، ويظهر متانة قوية خارج التوزيع (OOD). (المصدر: arXiv:2510.08026)
DocReward: نموذج مكافأة موجه نحو بنية المستند وأسلوبه: DocReward هو نموذج مكافأة يستخدم لتقييم بنية المستند وأسلوبه، ويهدف إلى حل مشكلة إهمال سير عمل الوكلاء للبنية البصرية والأسلوب عند توليد مستندات احترافية. تم تدريب هذا النموذج على مجموعة بيانات DocPair متعددة المجالات التي تحتوي على مستندات متطابقة ذات احترافية عالية ومنخفضة، ويمكنه تقييم احترافية المستند بشكل شامل بطريقة غير مرتبطة بجودة النص. يتفوق DocReward على GPT-4o و GPT-5 في الدقة، ويحقق معدل فوز أعلى في التقييم الخارجي لتوليد المستندات، مما يثبت فائدته في توجيه وكلاء التوليد لإنتاج مستندات يفضلها البشر. (المصدر: arXiv:2510.11391)
SPG: تدرج السياسة المتراكب يعزز فعالية التعلم المعزز لنماذج اللغة المنتشرة: تُعتبر نماذج اللغة المنتشرة (dLLM) بديلاً فعالاً لنماذج الانحدار الذاتي بسبب قدرتها على فك التشفير المتوازي. ومع ذلك، يواجه محاذاة dLLM مع تفضيلات البشر من خلال التعلم المعزز (RL) تحديات، حيث يصعب التعامل مع احتمالية السجل (log-likelihood) مما يحد من التطبيق المباشر لتدرج السياسة القياسي. تستخدم طريقة SPG (Sandwiched Policy Gradient) الحدود العليا والسفلى لاحتمالية السجل الحقيقية، وتتفوق بشكل كبير على خطوط الأساس القائمة على ELBO أو التقدير بخطوة واحدة، مما يزيد دقة RL لـ dLLM بنسبة 3.6% إلى 27.0% في مهام مثل GSM8K و MATH500. (المصدر: arXiv:2510.09541)
QeRL: التعلم المعزز المعزز بالكمية يحسن كفاءة LLM وقدرة الاستكشاف: يهدف إطار عمل QeRL (Quantization-enhanced Reinforcement Learning) إلى حل مشكلة استهلاك موارد التعلم المعزز (RL) لـ LLM من خلال دمج تقنية NVFP4 للكمية وتقنية LoRA، لتسريع مرحلة Rollout لـ RL وتقليل استهلاك الذاكرة. وجدت الدراسة أن ضوضاء الكمية يمكن أن تزيد من انتروبيا السياسة، وتعزز قدرة الاستكشاف، وتساعد في اكتشاف سياسات أفضل. يقدم QeRL آلية ضوضاء الكمية التكيفية (AQN)، التي تعدل الضوضاء ديناميكيًا أثناء التدريب. أظهرت التجارب أن QeRL يسرع مرحلة Rollout بأكثر من 1.5 مرة، ويحقق لأول مرة تدريب LLM بحجم 32B على وحدة معالجة رسومات H100 80GB واحدة، ويحقق نموًا أسرع في المكافأة ودقة نهائية أعلى. (المصدر: arXiv:2510.11696)
STAT: التدريب التكيفي الموجه بالمهارات يعزز أداء LLM في الرياضيات و OOD: STAT (Skill-Targeted Adaptive Training) هي استراتيجية جديدة للضبط الدقيق لـ LLM، من خلال استخدام القدرات المعرفية الفوقية لـ LLM أقوى كنموذج معلم، لإنشاء قائمة بالمهارات المطلوبة للمهمة وتسمية نقاط البيانات. يراقب نموذج المعلم إجابات نموذج الطالب، ويبني “صورة المهارات المفقودة”، ثم يعيد وزن أمثلة التدريب الموجودة بشكل تكيفي (STAT-Sel) أو يولد أمثلة إضافية تتضمن المهارات المفقودة (STAT-Syn). أثبتت التجارب أن STAT يحسن الأداء في معيار MATH بنسبة تصل إلى 7.5%، وبمتوسط 4.6% في معيار OOD، ويكمل GRPO، ومن المتوقع أن يحسن خطوط أنابيب التدريب الحالية بشكل شامل. (المصدر: arXiv:2510.10023)
LLaMAX2: نموذج Qwen3-XPlus يظهر أداءً ممتازًا في مهام الترجمة والاستدلال: يقترح LLaMAX2 طريقة جديدة لتعزيز الترجمة، من خلال الضبط الدقيق الانتقائي للطبقات لنموذج التعليمات، مما يحسن بشكل كبير أداء نموذج Qwen3-XPlus في الترجمة بين اللغات ذات الموارد العالية والمنخفضة (مثل السواحلية)، مع الحفاظ على كفاءة مماثلة لنموذج تعليمات Qwen3 في 15 مجموعة بيانات استدلال شائعة. يوفر هذا العمل طريقة واعدة لتعزيز اللغات المتعددة، ويقلل بشكل كبير من التعقيد، ويزيد من إمكانية الوصول إلى نطاق أوسع من اللغات. (المصدر: arXiv:2510.09189)
DemoDiff: محول انتشار الرسم البياني يحقق تصميم جزيئي سياقي: يحقق DemoDiff (Demonstration-conditioned diffusion models) تصميم جزيئي سياقي من خلال استخدام عدد قليل من أمثلة الجزيئات-التقييم بدلاً من الأوصاف النصية لتحديد سياق المهمة. يستخدم هذا النموذج أداة ترميز جزيئية جديدة Node Pair Encoding، والتي تمثل الجزيئات على مستوى الوحدات الأساسية، مما يقلل من عدد العقد. قام DemoDiff بالتدريب المسبق لنموذج بـ 700 مليون معلمة على مجموعة بيانات تحتوي على ملايين المهام السياقية، وتطابق أو تجاوز نماذج اللغة الأكبر حجمًا بـ 100-1000 مرة في 33 مهمة تصميم، ليصبح نموذجًا أساسيًا جزيئيًا للتصميم الجزيئي السياقي. (المصدر: arXiv:2510.08744)
CodePlot-CoT: سلسلة تفكير مدفوعة بالتعليمات البرمجية تعزز الاستدلال البصري الرياضي: يقترح CodePlot-CoT نموذجًا لسلسلة التفكير مدفوعة بالتعليمات البرمجية، لـ “التفكير بالصور” في الرياضيات. تستخدم هذه الطريقة VLM لتوليد استدلال نصي وتعليمات برمجية قابلة للتنفيذ للرسم، ثم يتم عرضها كـ “تفكير بصري” لحل المشكلات الرياضية. قام البحث ببناء أول مجموعة بيانات واسعة النطاق وثنائية اللغة للاستدلال البصري الرياضي، Math-VR، وطور محولًا من الصورة إلى التعليمات البرمجية SOTA. أثبتت التجارب أن النموذج يحسن الأداء في معيار Math-VR بنسبة تصل إلى 21%، مما يفتح اتجاهًا جديدًا للاستدلال الرياضي متعدد الوسائط. (المصدر: arXiv:2510.11718)
DiT360: التدريب المختلط يحقق توليد صور بانورامية عالية الدقة: DiT360 هو إطار عمل يعتمد على DiT، ويحقق توليد صور بانورامية عالية الدقة من خلال التدريب المختلط على بيانات المنظور والبانوراما. تقدم هذه الطريقة وحدات رئيسية مثل دمج المعرفة عبر المجالات، وتحسين البانوراما، والتعبئة الدورية، وفقدان الانحراف، وفقدان المكعب، لحل مشكلات الدقة الهندسية والواقعية. أظهر DiT360 في مهام تحويل النص إلى بانوراما، وإصلاح الصور، والرسم الخارجي، اتساقًا أفضل للحدود ودقة صور أفضل في 11 مؤشرًا كميًا. (المصدر: arXiv:2510.11712)
RAE: مشفرات تلقائية للتمثيل تحسن الفضاء الكامن لمحول الانتشار: استكشفت دراسة استبدال طريقة VAE التقليدية في محول الانتشار (DiT) بمشفرات تمثيل مدربة مسبقًا (مثل DINO، SigLIP، MAE)، لتشكيل مشفرات تلقائية للتمثيل (RAE). توفر RAE إعادة بناء عالية الجودة وفضاء كامنًا غنيًا بالمعاني، بينما تدعم أيضًا بنية Transformer قابلة للتوسع. من خلال التحليل النظري والتحقق التجريبي، حققت هذه الطريقة تقاربًا أسرع، وحققت نتائج قوية في توليد الصور على ImageNet، ومن المتوقع أن تصبح الإعداد الافتراضي الجديد لتدريب محول الانتشار. (المصدر: arXiv:2510.11690)
InfiniHuman: إطار عمل لإنشاء أجسام بشرية ثلاثية الأبعاد لا نهائية وتحكم دقيق: يحقق إطار عمل InfiniHuman توليد بيانات أجسام بشرية ثلاثية الأبعاد غنية بالتعليقات التوضيحية بتكلفة دنيا وقابلية توسع لا نهائية نظريًا، من خلال التقطير التعاوني للنماذج الأساسية الموجودة. InfiniHumanData هو خط أنابيب آلي بالكامل، يستخدم نماذج اللغة البصرية وتوليد الصور لإنشاء مجموعة بيانات متعددة الوسائط واسعة النطاق تحتوي على 111 ألف هوية، تغطي تنوعًا غير مسبوق، وتم تعليقها بالتفصيل بوصف نصي، وصور RGB متعددة العروض، وصور ملابس، ومعلمات شكل الجسم SMPL. بناءً على ذلك، InfiniHumanGen هو خط أنابيب توليدي يعتمد على الانتشار، قادر على توليد صور رمزية سريعة وواقعية وقابلة للتحكم بدقة. (المصدر: arXiv:2510.11650)
IVEBench: مجموعة معايير تقييم تحرير الفيديو الموجه بالتعليمات: IVEBench هي مجموعة معايير حديثة مصممة خصيصًا لتقييم تحرير الفيديو الموجه بالتعليمات. تتضمن 600 مقطع فيديو مصدر عالي الجودة، تغطي سبعة أبعاد دلالية وأطوال فيديو تتراوح من 32 إلى 1024 إطارًا. بالإضافة إلى ذلك، تتضمن 8 فئات من مهام التحرير و 35 فئة فرعية، وتم إنشاء وتحسين مطالباتها من خلال نماذج لغة كبيرة ومراجعة الخبراء. أنشأت IVEBench بروتوكول تقييم ثلاثي الأبعاد يتضمن جودة الفيديو، والامتثال للتعليمات، ودقة الفيديو، ودمجت المقاييس التقليدية وتقييم نماذج اللغة الكبيرة متعددة الوسائط. (المصدر: arXiv:2510.11647)
LikePhys: تقييم الفهم الفيزيائي البديهي لنماذج انتشار الفيديو من خلال تفضيل الاحتمالية: LikePhys هي طريقة مستقلة عن التدريب، تقيم الفهم الفيزيائي البديهي لنماذج انتشار الفيديو من خلال التمييز بين مقاطع الفيديو الصالحة فيزيائيًا والمستحيلة، واستخدام هدف إزالة الضوضاء كبديل للاحتمالية القائمة على ELBO. قام البحث ببناء اختبار معياري يتضمن 12 سيناريو و 4 مجالات فيزيائية، وأظهرت النتائج أن مقياس التقييم Plausibility Preference Error (PPE) يتوافق بشكل كبير مع تفضيلات البشر. قام البحث أيضًا بتقييم منهجي لقدرة الفهم الفيزيائي البديهي لنماذج انتشار الفيديو الحالية، وحلل كيف يؤثر تصميم النموذج وإعدادات الاستدلال على الفهم الفيزيائي. (المصدر: arXiv:2510.11512)
FastHMR: تسريع استعادة شبكة الجسم البشري من خلال دمج الـ Token والطبقات: يسرع FastHMR استعادة شبكة الجسم البشري ثلاثية الأبعاد (HMR) من خلال تقديم استراتيجيتين دمج خاصتين بـ HMR: دمج الطبقات المقيد بالخطأ (ECLM) ودمج الـ Token الموجه بالقناع (Mask-ToMe). يختار ECLM دمج طبقات Transformer التي لها أقل تأثير على MPJPE، بينما يركز Mask-ToMe على دمج الـ Tokens الخلفية التي تساهم بشكل أقل في التنبؤ النهائي. لتعويض أي انخفاض محتمل في الأداء بسبب الدمج، يقترح البحث فك تشفير يعتمد على الانتشار، يجمع بين السياق الزمني والمعرفة المسبقة بالوضعية المستفادة من مجموعات بيانات التقاط الحركة واسعة النطاق. أظهرت التجارب أن هذه الطريقة تحقق تسريعًا يصل إلى 2.3 مرة مع تحسين طفيف في الأداء. (المصدر: arXiv:2510.10868)
AVoCaDO: مولد تعليقات فيديو سمعية بصرية، يدفع التنسيق الزمني: AVoCaDO هو مولد تعليقات فيديو سمعية بصرية قوي، يدفع التنسيق الزمني بين الوسائط السمعية والبصرية. يقترح البحث خط أنابيب تدريب لاحق من مرحلتين: AVoCaDO SFT يضبط النموذج بدقة على 107K مجموعة بيانات تعليقات سمعية بصرية عالية الجودة ومتزامنة زمنيًا؛ AVoCaDO GRPO يعزز بشكل أكبر التماسك الزمني ودقة الحوار باستخدام وظيفة مكافأة مخصصة، مع تنظيم طول التعليق وتقليل الانهيار. أظهرت النتائج التجريبية أن AVoCaDO يتفوق بشكل كبير على النماذج مفتوحة المصدر الحالية في أربعة معايير تعليقات فيديو سمعية بصرية. (المصدر: arXiv:2510.10395)
فخ التفكير العاطفي لـ LLM: كيف تغير ذاكرة المستخدم تفسير العواطف: مع تزايد دمج أنظمة الذكاء الاصطناعي الشخصية في ذاكرة المستخدم طويلة المدى، أصبح فهم كيفية تشكيل الذاكرة لتفكير LLM العاطفي أمرًا بالغ الأهمية. قيمت الدراسة أداء 15 نموذج LLM في اختبارات الذكاء العاطفي التي تم التحقق منها بشريًا، ووجدت أن نفس السيناريو المقترن بملفات تعريف مستخدمين مختلفة ينتج اختلافات منهجية في التفسير العاطفي. في سيناريوهات عاطفية مستقلة عن المستخدم تم التحقق منها وملفات تعريف مستخدمين متنوعة، أظهرت العديد من نماذج LLM عالية الأداء تحيزًا منهجيًا، حيث حصلت ملفات التعريف المهيمنة على تفسيرات عاطفية أكثر دقة. بالإضافة إلى ذلك، أظهرت LLM اختلافات ديموغرافية كبيرة في فهم العواطف ومهام التوصية الداعمة، مما يشير إلى أن آليات التخصيص قد تدمج التسلسل الهرمي الاجتماعي في التفكير العاطفي للنموذج. (المصدر: arXiv:2510.09905)
FinAuditing: معيار متعدد المستندات للتدقيق المالي لتقييم قدرات LLM: FinAuditing هو أول معيار متعدد المستندات، متوافق مع التصنيف، وواعٍ بالهيكل، لتقييم قدرات LLM في مهام التدقيق المالي. تم بناء هذا المعيار بناءً على ملفات XBRL حقيقية متوافقة مع US-GAAP، ويحدد ثلاث مهام فرعية متكاملة: FinSM (الاتساق الدلالي)، و FinRE (الاتساق العلائقي)، و FinMR (الاتساق العددي). أظهرت التجارب الواسعة بدون أمثلة أن النماذج الحالية تؤدي بشكل غير متسق عبر الأبعاد الدلالية والعلاقية والرياضية، وتنخفض الدقة بنسبة تصل إلى 60-90% عند الاستدلال على هياكل المستندات الهرمية المتعددة، مما يكشف عن قيود منهجية لـ LLM في الاستدلال المالي القائم على التصنيف. (المصدر: arXiv:2510.08886)
💼 الأعمال
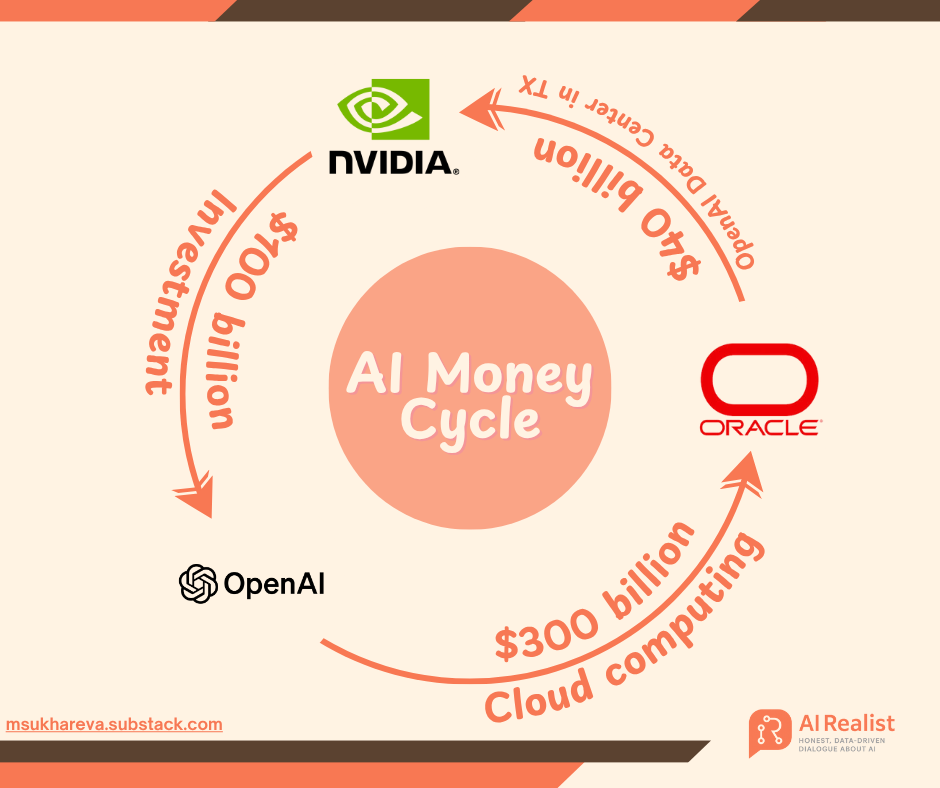
استراتيجية OpenAI للتمويل الضخم: تريليون دولار رهانًا على البنية التحتية للذكاء الاصطناعي، تثير جدل “كيمياء المال”: تفتتح OpenAI عصرًا جديدًا من استثمارات الذكاء الاصطناعي من خلال سلسلة من الطلبات التي تبلغ قيمتها تريليون دولار مع عمالقة مثل NVIDIA، و AMD، و Broadcom. وصف Matt Levine، المصرفي السابق في Goldman Sachs، هذا الأمر بأنه “سفر عبر الزمن المالي”، حيث تربط OpenAI مصير الموردين بها بعمق من خلال نماذج مبتكرة مثل “الأسهم مقابل المشتريات” و “الإيرادات الدورية”، مما يدفعهم إلى تحمل مخاطر بناء البنية التحتية الضخمة معًا. تخطط OpenAI لبناء قدرة حوسبة تبلغ 250 جيجاوات بحلول عام 2033، بتكلفة تتجاوز 10 تريليونات دولار، وهو ما يتجاوز بكثير إيراداتها الحالية، مما يثير مخاوف السوق بشأن استدامتها المالية، لكن Sam Altman يؤكد أن هذا هو “أكبر مشروع صناعي مشترك في تاريخ البشرية”، ويهدف إلى تعميم الذكاء الاصطناعي. (المصدر: 36氪, 36氪)
الذكاء الاصطناعي يدعم تحول صناعة الأدوية: الذكاء الاصطناعي الوكيلي يعزز الكفاءة التجارية: يحدث الذكاء الاصطناعي الوكيلي (Agentic AI) ثورة في مجال صناعة الأدوية التجارية، مما يساعد الشركات على مواجهة تحديات مثل ارتفاع تكاليف المواد الخام، وانقطاع سلاسل التوريد، وانتهاء صلاحية براءات الاختراع. يعزز الذكاء الاصطناعي كفاءة البحث والتطوير والتصنيع للأدوية من خلال توفير خدمات شخصية، وتحسين تصميم وتشغيل المطابخ، وتوفير إدارة صحية شخصية بواسطة الثلاجات الذكية. في الوقت نفسه، يدعم الذكاء الاصطناعي أيضًا المبيعات والتسويق، من خلال قنوات الاتصال في الوقت الفعلي والمحتوى ذي الصلة للوصول إلى المتخصصين في الرعاية الصحية، وحل مشكلة عدم كفاءة مراجعة المحتوى، ومن المتوقع أن يدفع تطوير تكنولوجيا الصحة المنزلية، ويحسن جودة حياة السكان. (المصدر: MIT Technology Review)

Apple تستحوذ على فريق Prompt AI، لتعزيز الرؤية الحاسوبية وقدرات الذكاء الاصطناعي على الجهاز: تتقدم Apple في الاستحواذ على شركة Prompt AI الناشئة في مجال الرؤية الحاسوبية، بهدف دمج تقنياتها الأساسية وفريقها في نظام Apple البيئي. يتميز تطبيق Seemour من Prompt AI بقدرات التعرف الدقيق، ووصف المشهد، وحماية الخصوصية، ويمكنه الاتصال بكاميرات المراقبة المنزلية، ويتم معالجة جميع البيانات محليًا، مما يتوافق بشكل كبير مع استراتيجية Apple “الذكاء الاصطناعي على الجهاز” و “الخصوصية أولاً”. يمثل هذا الاستحواذ تجسيدًا لاستراتيجية Apple “الاستحواذ على المواهب” في مجال الذكاء الاصطناعي، ويهدف إلى سد النقص في تقنية الرؤية الحاسوبية بسرعة، ودعم تطوير أعمالها مثل HomeKit، و AR، والقيادة الذاتية. (المصدر: 36氪)

🌟 المجتمع
الذكاء الاصطناعي يحل محل الوظائف يثير قلقًا ومقاومة في مكان العمل: مع انتشار الذكاء الاصطناعي في الشركات، يشهد مكان العمل “إعادة ترتيب خوارزمية”. تبنى Kevin Cantera، خبير محتوى أول في شركة تكنولوجيا التعليم، الذكاء الاصطناعي بنشاط، وتضاعفت كفاءته، لكنه لا يزال يُستبدل بأدوات الذكاء الاصطناعي، مما يثير تساؤلات حول وعد “الذكاء الاصطناعي مجرد مساعد، ولن يحل محل”. في شركة Ramp للتكنولوجيا المالية في وادي السيليكون، ظهرت أيضًا ظاهرة مقاومة المبرمجين لأدوات ترميز الذكاء الاصطناعي، معتبرين أن التعليمات البرمجية التي يولدها الذكاء الاصطناعي خشنة وفوضوية، وتفتقر إلى المنطق البشري. تسلط هذه الأحداث الضوء على الواقع القاسي لاستبدال الذكاء الاصطناعي للوظائف، وكيف يوازن الموظفون بين التكيف وتأكيد الذات في مواجهة التغيير التكنولوجي. (المصدر: 36氪, 36氪)

متصفحات الذكاء الاصطناعي ومستقبل الإنترنت المفتوح: حدائق مسورة أم نظام بيئي جديد؟: أثار إطلاق Perplexity لمتصفح Comet وإطلاق OpenAI لوظيفة تطبيق ChatGPT نقاشًا حادًا في مجتمع Reddit حول “ما إذا كان الذكاء الاصطناعي يقتل الإنترنت المفتوح”. يرى القلقون أن الذكاء الاصطناعي يبني “حدائق مسورة” باسم “الراحة”، ويركز حصول المستخدمين على المعلومات على عدد قليل من المنصات، مما قد يؤدي إلى فقدان تنوع المعلومات والتخصيص المفرط. يشير المنتقدون إلى أن متصفحات الذكاء الاصطناعي تحاول أن تكون وسيطًا بين نظام التشغيل وطبقة التطبيقات، مما يعيد تشكيل سلطة توزيع الشبكة. ومع ذلك، يرى البعض أن التقدم التكنولوجي لا مفر منه، وأن المفتاح يكمن في كيفية اختيار المستخدمين والحفاظ على بيئة معلومات مفتوحة ومتنوعة. (المصدر: 36氪)

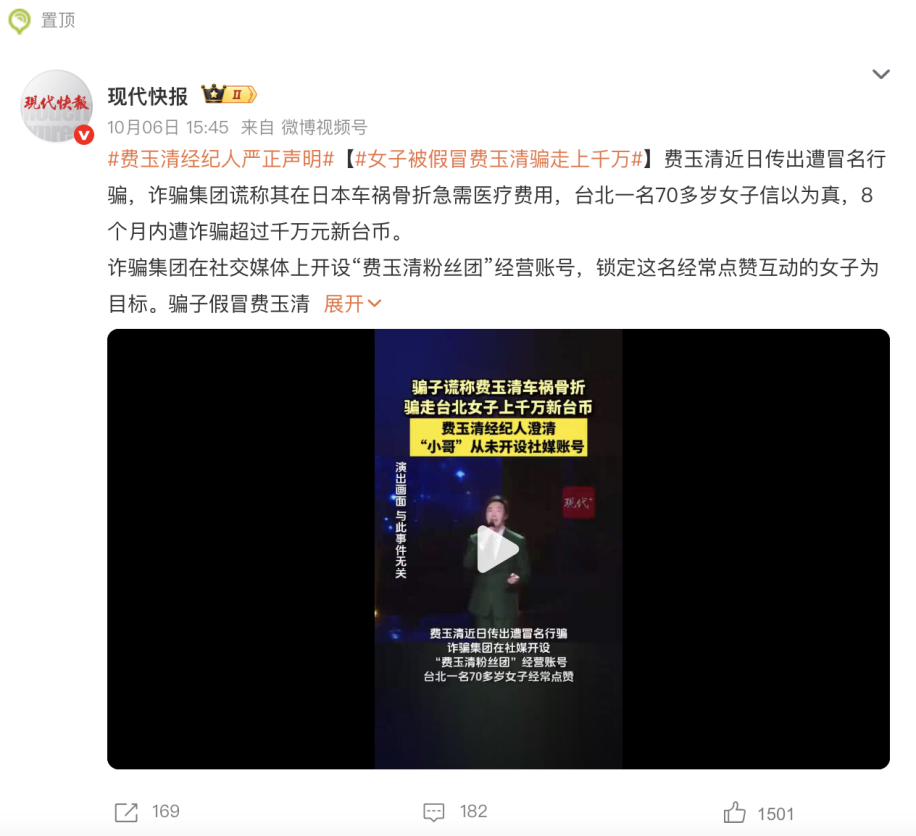
فوضى سوق رعاية المسنين بالذكاء الاصطناعي: احتيال دقيق وفخاخ “الذكاء الزائف”: مع دخول الصين مرحلة الشيخوخة العميقة، يشهد سوق “الذكاء الاصطناعي + رعاية المسنين” ارتفاعًا سريعًا، لكن يرافقه احتيال بالذكاء الاصطناعي يستهدف كبار السن وفوضى منتجات “الذكاء الزائف”. يستخدم المحتالون تقنيات التزييف العميق لانتحال شخصية الأقارب أو المشاهير، ويستخدمون الابتزاز العاطفي لخداعهم للحصول على المال؛ أو يزورون صور “معلمين بالذكاء الاصطناعي” لبيع دورات ومشاريع استثمارية وهمية. في الوقت نفسه، يمتلئ السوق بمنتجات رعاية المسنين “الذكية” التي لا ترقى إلى مستوى الدعاية، وتكون مؤشراتها الأساسية أقل بكثير مما يُعلن عنه. لا تضر هذه الفوضى فقط بالسلامة المالية لكبار السن، بل تستهلك أيضًا ثقة المجتمع في تقنية الذكاء الاصطناعي. تدعو الصناعة إلى مكافحة احتيال الذكاء الاصطناعي بالتقنية، وتعزيز الإشراف الرقمي من قبل الأبناء، وبناء نظام بيئي لرعاية المسنين بالذكاء الاصطناعي يتمتع بالرعاية الإنسانية الحقيقية. (المصدر: 36氪)
جدل حول مراجعة محتوى ChatGPT وتجربة المستخدم: أثار ChatGPT نقاشًا واسعًا في المجتمع حول مراجعة المحتوى وتجربة المستخدم. أبلغ المستخدمون أن ChatGPT أحيانًا يولد “محتوى غير لائق”، ثم “يصلحه” بسرعة ويصبح حذرًا بشكل مفرط، حتى أنه يفرض قيودًا على الأسئلة الأكاديمية. في الوقت نفسه، أشار العديد من المستخدمين إلى أن ChatGPT غالبًا ما يظهر نبرة “مدح” أو “مبالغة” في الردود، خاصة عند مواجهة أسئلة المستخدمين، مما يجعل المستخدمين يشعرون بالتعالي. بالإضافة إلى ذلك، أثارت الشائعات حول ما إذا كانت OpenAI ستطلق وضعًا للمحتوى الخاص بالبالغين اهتمامًا. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

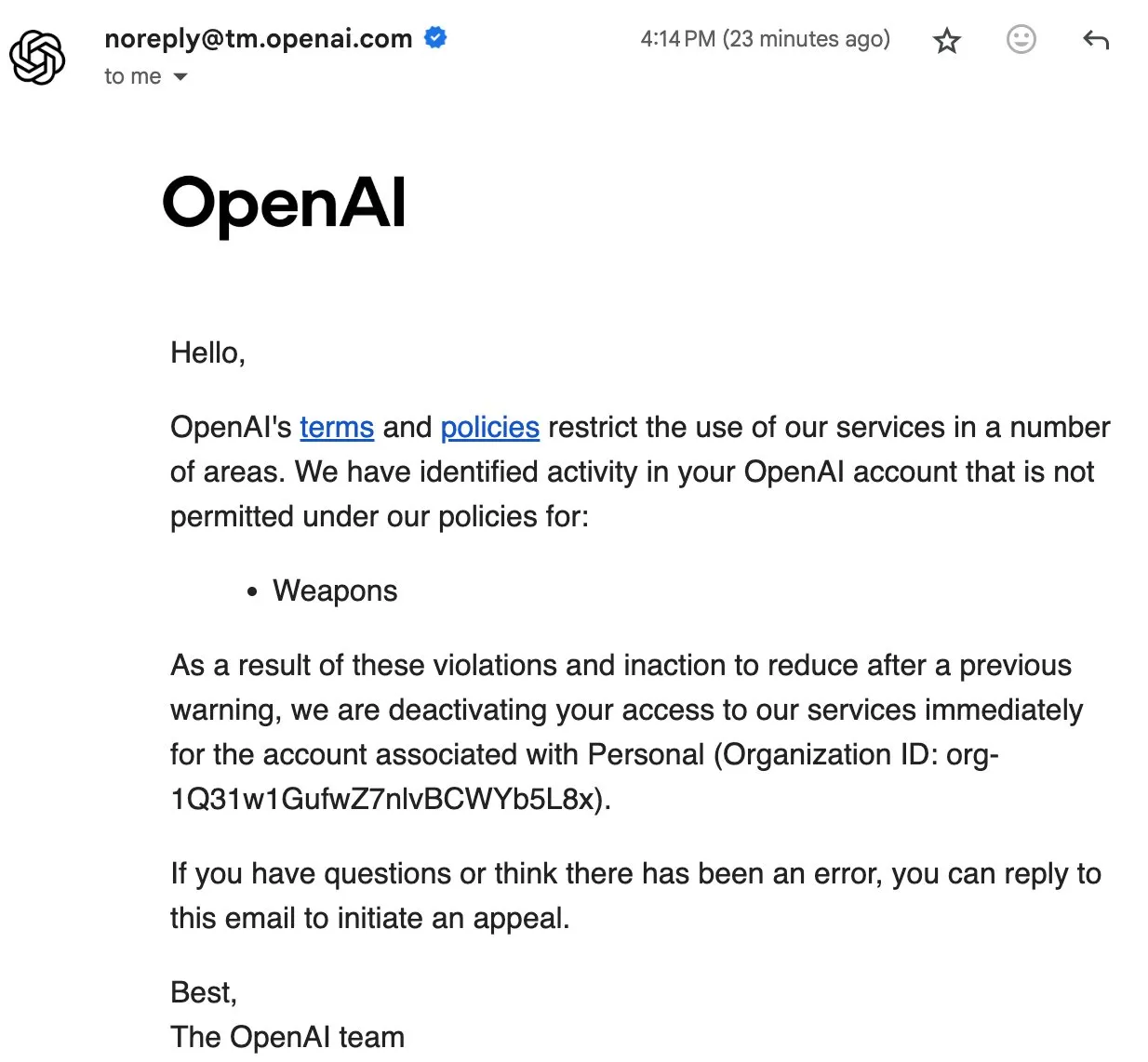
حادثة حظر مستخدمي OpenAI تثير نقاشًا مجتمعيًا حول سيادة البيانات والذكاء الاصطناعي مفتوح المصدر: أدت OpenAI مؤخرًا إلى حظر بعض المستخدمين، بل وحذف بيانات الحساب، مما أثار استياءً شديدًا في المجتمع. تم حذف حساب المستخدم Eric Hartford دون سبب، وتم رفض استئنافه على الفور، مما أدى إلى فقدان جميع البيانات التاريخية. دفعت هذه الحادثة أعضاء المجتمع إلى الدعوة إلى تنزيل بيانات ChatGPT ونسخها احتياطيًا، والتأكيد على أهمية الذكاء الاصطناعي مفتوح المصدر، معتبرين أن الخدمات الاحتكارية تنطوي على مخاطر نقطة فشل واحدة، ولا يمكن ضمان سيادة بيانات المستخدم. يعتقد الكثيرون أنه كلما زادت أهمية الذكاء الاصطناعي، زادت أهمية موثوقية الذكاء الاصطناعي مفتوح المصدر وأمانه وجدارته بالثقة. (المصدر: QuixiAI, scaling01)
نموذج اشتراك الذكاء الاصطناعي يثير الجدل: مخاطر عالية للاشتراكات السنوية في ظل التطور التكنولوجي السريع: ينصح مستخدمو الذكاء الاصطناعي المخضرمون بتجنب شراء الاشتراكات السنوية لأدوات الذكاء الاصطناعي، لأن تقنية الذكاء الاصطناعي تتطور بسرعة فائقة، وقد يتم استبدال الأداة الضرورية اليوم بتحديث جديد أو منتج جديد الشهر المقبل. يعكس هذا الرأي طبيعة التطور السريع في صناعة الذكاء الاصطناعي، حيث يتوخى المستخدمون الحذر بشأن الاستثمار طويل الأجل في أدوات الذكاء الاصطناعي، ويفضلون الاشتراكات الشهرية أو نماذج الدفع المرنة للتكيف مع المشهد التكنولوجي المتغير باستمرار. (المصدر: Reddit r/ArtificialInteligence)
ارتفاع معدل فشل وكلاء الذكاء الاصطناعي: 95% من استثمارات الشركات لا تحقق فوائد، والحاجة إلى “الواقعية”: يشير رأي إلى أن “95% من وكلاء الذكاء الاصطناعي سيفشلون” ليس مبالغة، فالعديد من الوكلاء الذين يظهرون أداءً ممتازًا في العروض التوضيحية لا يحققون نتائج جيدة بعد النشر الفعلي. تكمن المشكلة الأساسية في افتقار الوكلاء إلى “الواقعية” (grounding) مع العالم الحقيقي، حيث تنهار حلقات التغذية الراجعة التلقائية إذا لم يكن هناك فحص بشري. غالبًا ما يكون وكلاء الذكاء الاصطناعي الذين يخلقون قيمة تجارية “واقعيين” وذوي أهداف واضحة، مثل اكتشاف المخالفات التجارية، ومساعدة المبيعات في العثور على عملاء محتملين. أظهرت الأبحاث أن ما يصل إلى 95% من استثمارات الشركات في الذكاء الاصطناعي لم تحقق فوائد اقتصادية كبيرة، بل إن بعض الفرق انخفضت كفاءتها بسبب إصلاح أخطاء الذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence)
قيود الذكاء الاصطناعي في الأخبار المحلية: “الميل الأخير” الذي لا يمكن للخوارزميات الوصول إليه: توجد “مناطق عمياء” طبيعية لتقنية الذكاء الاصطناعي في مجال الأخبار المحلية، حيث يصعب عليها الوصول إلى المعلومات المحلية غير المنظمة وغير الرقمية بشكل كافٍ، مثل محاضر اجتماعات الشوارع، وجداول الأنشطة المجتمعية. تعتمد نماذج LLM على كميات هائلة من البيانات العامة، وتفضل السرديات الكبيرة، وتجد صعوبة في هضم المعلومات المحلية النادرة. كما أن تأخر الذكاء الاصطناعي في التوقيت يجعله غير قادر على تغطية الأحداث المحلية الفورية، ويسهل عليه إنتاج “هلوسات”. والأهم من ذلك، يفتقر الذكاء الاصطناعي إلى علاقات الثقة والبصيرة العميقة التي يبنيها الصحفيون البشر مع المجتمعات. تخلق هذه القيود في الذكاء الاصطناعي فرصة لإعادة تقييم قيمة الأخبار المحلية، ودفعها للتحول من “مراسل إخباري” إلى “مقدم خدمة مجتمعية”، وإعادة بناء الهوية والانتماء المجتمعي. (المصدر: 36氪)
الذكاء الاصطناعي والإدارة البشرية: فهم الذكاء الاصطناعي مثل فهم الموظف الجديد، يتطلب سياقًا واضحًا ومخرجات محددة: تشير مناقشات وسائل التواصل الاجتماعي إلى أن استخدام الذكاء الاصطناعي والإدارة لهما أوجه تشابه: ما لا يمكنك أن تطلب من البشر فعله، لا تتوقع أن يفعله الذكاء الاصطناعي. سواء كان ذلك للذكاء الاصطناعي أو للموظف الجديد، عند تعيين المهام، يجب توفير سياق خلفي كافٍ، ومخرجات محددة، وأمثلة للمخرجات (تعلم n-shot)، وشروط قبول واضحة، وقيود، وموارد قابلة للربط. يشير هذا إلى أن الاستخدام الفعال للذكاء الاصطناعي يتطلب، مثل التعامل مع أعضاء الفريق البشري، التركيز على التواصل الواضح وإدارة المهام، بدلاً من التوقع الأعمى للمعجزات التكنولوجية. (المصدر: dotey)
“تجسيد” صناديق التحوط بالذكاء الاصطناعي: Grok و Qwen و Claude تظهر أنماط استثمار مختلفة: ظهرت تفسيرات “تجسيدية” فكاهية لنماذج صناديق التحوط بالذكاء الاصطناعي على وسائل التواصل الاجتماعي، تصور أنماطًا فريدة لنماذج الذكاء الاصطناعي المختلفة في مجال الاستثمار. يُصور Grok كمتداول كمي منهجي، لديه تفضيل غريب لعملة DOGE؛ و Qwen يسعى دائمًا لتحقيق أقصى قدر من الرافعة المالية؛ بينما Claude هو مدير محفظة مدروس، يمكنه دائمًا الحفاظ على هدوئه “كل شيء على ما يرام”. تعكس هذه المناقشات فضول المجتمع وخياله حول تطبيقات الذكاء الاصطناعي في المجال المالي، وفهمًا تصويريًا لخصائص النماذج المختلفة. (المصدر: togelius)

الذكاء الاصطناعي واختيار أدوات البرمجة: تفضيلات المطورين لـ Cursor و Codex و Copilot: ناقش مجتمع المطورين مزايا وعيوب أدوات برمجة الذكاء الاصطناعي المختلفة والتفضيلات الشخصية. اختار البعض Visual Studio Code + Copilot بعد المقارنة مع Cursor. بينما صرح مطور آخر بأنه انتقل بالكامل من Claude Code إلى Codex كأداة رئيسية يومية. تعكس هذه المناقشات احتياجات المطورين المختلفة في العمل الفعلي لأداء أدوات الذكاء الاصطناعي، وتكاملها، وسهولة استخدامها، وجودة التعليمات البرمجية المولدة، بالإضافة إلى الاستكشاف المستمر والموازنة في البرمجة بمساعدة الذكاء الاصطناعي. (المصدر: pierceboggan, imjaredz)

الذكاء الاصطناعي والإنترنت المفتوح: HuggingFace يُشيد به كـ “GitHub لعالم الذكاء الاصطناعي”: يُعرف Hugging Face على نطاق واسع في مجتمع الذكاء الاصطناعي بأنه “GitHub لعالم الذكاء الاصطناعي”، ليصبح منصة مركزية لمشاركة النماذج ومجموعات البيانات ورموز تطبيقات الذكاء الاصطناعي والتعاون فيها. يؤكد هذا التشبيه على الدور الرئيسي لـ Hugging Face في تعزيز تطوير النظام البيئي للذكاء الاصطناعي مفتوح المصدر، ويوفر للباحثين والمطورين بيئة استضافة وتعاون للتعليمات البرمجية مماثلة لـ GitHub، مما يدفع بشكل كبير بانتشار وابتكار تقنيات الذكاء الاصطناعي. (المصدر: ClementDelangue)
الذكاء الاصطناعي ومستقبل البشرية: التفكير في تعقيدات AGI والتكيف الاجتماعي: تختلف آراء المجتمع حول وصول AGI (الذكاء الاصطناعي العام). يعتقد البعض أنه بعد تحقيق AGI، سيكتشف البشر أنهم بالغوا في تعقيد الذكاء الاصطناعي في الماضي، وأن الذكاء الحقيقي قد يعتمد على مبادئ أبسط وأكثر أناقة. في الوقت نفسه، بدأ البعض في التفكير في كيفية تأثير الذكاء الاصطناعي الذي يتطور ذاتيًا بشكل متكرر على ديناميكيات وانتشار المنظمات والمؤسسات والجهات الفاعلة والمجتمعات، معتبرين أن هذا هو السؤال الأساسي في الوقت الحالي، ويتطلب المزيد من التكهنات والمناقشات المتنوعة لمساعدة المجتمع على التكيف مع التغييرات العميقة التي يجلبها الذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence, ethanCaballero)
الذكاء الاصطناعي والمشاعر الاجتماعية: مقاطع الفيديو المزيفة، واحتيال رعاية المسنين بالذكاء الاصطناعي، واستبدال الذكاء الاصطناعي للوظائف تثير القلق: تثير تقنية الذكاء الاصطناعي مشاعر معقدة على المستوى الاجتماعي. تثير مقاطع الفيديو المزيفة التي يولدها Sora 2 مخاوف بشأن حقوق الصورة والأخلاق؛ ويظهر سوق رعاية المسنين بالذكاء الاصطناعي احتيالًا دقيقًا ومنتجات “ذكاء زائف” تستهدف كبار السن الذين يعيشون بمفردهم، مما يضر بمصالح كبار السن؛ ويحل الذكاء الاصطناعي محل الوظائف، مما يؤدي إلى تسريح الموظفين ذوي الخبرة، ويزيد من القلق في مكان العمل. تسلط هذه الأحداث الضوء على أن الذكاء الاصطناعي، بينما يجلب الراحة، يطرح أيضًا تحديات خطيرة للأخلاق الاجتماعية، والثقة، وهيكل التوظيف، مما يدفع الجمهور إلى إعادة التفكير في التوازن بين التطور التكنولوجي والتكيف الاجتماعي. (المصدر: Reddit r/ArtificialInteligence, 36氪, 36氪)
الذكاء الاصطناعي والعلوم المفتوحة: التطور السريع للذكاء الاصطناعي مفتوح المصدر واستدامة استراتيجيات المنتج: يرى المجتمع أن تطور الذكاء الاصطناعي مفتوح المصدر مذهل، لكن هذا يثير أيضًا تساؤلات حول استدامة استراتيجيات المنتج: في سياق التطور السريع للذكاء الاصطناعي مفتوح المصدر، كيف يمكن للشركات بناء ولاء العملاء والميزة التنافسية الدائمة؟ في الوقت نفسه، أظهر المطورون أيضًا حماسًا كبيرًا لمشاريع مفتوحة المصدر بسيطة للغاية مثل nanochat من Andrej Karpathy، معتبرين أنها موارد ممتازة لتعلم دورة حياة LLM بأكملها، ويتطلعون إلى ظهور المزيد من “nanoagent” وحتى “nanoASI” في المستقبل، لدفع دمقرطة الذكاء الاصطناعي وتطوره السريع. (المصدر: zachtratar, code_star)
الذكاء الاصطناعي والبحث: تحول النموذج من مطابقة الكلمات الرئيسية إلى الفهم الدلالي: يشير Geoffrey Hinton إلى أن الذكاء الاصطناعي اليوم أقرب إلى البشر في فهم المشكلات، ولم يعد يقتصر على مطابقة الكلمات الرئيسية، بل يمكنه ربط الأفكار والمعاني، والعثور على المعلومات حتى لو كانت الصياغة مختلفة تمامًا. يشير هذا التحول إلى انتقال البحث بالذكاء الاصطناعي من المطابقة السطحية إلى الفهم الدلالي العميق، والقدرة على توليد إجابات جديدة بدلاً من مجرد الاسترجاع. تنبئ هذه القدرة بأن الذكاء الاصطناعي سيعيد تشكيل طريقة الحصول على المعلومات، ويجعل نتائج البحث أكثر بصيرة وأهمية. (المصدر: arohan)
💡 أخرى
الذكاء الاصطناعي في القطاع المالي: خمس ركائز لتعزيز نمو الإيرادات وإدارة المخاطر: يتعمق تطبيق الذكاء الاصطناعي في القطاع المالي يومًا بعد يوم، ليصبح مفتاحًا لدفع نمو الإيرادات وإدارة المخاطر. تم اقتراح خمس ركائز، تشمل استخدام الذكاء الاصطناعي لتحليل البيانات، والتنبؤ باتجاهات السوق، وتحسين محافظ الاستثمار، وأتمتة عمليات الامتثال، وتحسين خدمة العملاء. تساعد هذه التطبيقات المؤسسات المالية على اتخاذ قرارات استراتيجية أكثر ذكاءً، وتحديد المخاطر المحتملة، وزيادة الكفاءة التشغيلية. في الوقت نفسه، يدعم تطبيق الذكاء الاصطناعي في تحليل البيانات المالية أيضًا اتخاذ قرارات استراتيجية أكثر استنارة. (المصدر: Ronald_vanLoon, Ronald_vanLoon)
OpenAI تواجه دعوى قضائية بشأن حقوق النشر: رسائل Slack الداخلية قد تكلفها مليارات الدولارات كتعويضات: تواجه OpenAI حاليًا دعوى قضائية بشأن حقوق النشر، وقد تصبح رسائل Slack الداخلية الخاصة بها دليلًا رئيسيًا، وقد تؤدي إلى تعويضات بمليارات الدولارات. تسلط هذه الدعوى الضوء على التعقيد القانوني لمصادر بيانات تدريب نماذج الذكاء الاصطناعي، والتحديات التي تواجه الشركات في الامتثال للاتصالات الداخلية واستخدام البيانات أثناء تطوير الذكاء الاصطناعي. قد يكون لنتائج القضية تأثير عميق على حماية حقوق النشر وقواعد استخدام البيانات في صناعة الذكاء الاصطناعي. (المصدر: Reddit r/artificial)

الشركات الناشئة الصينية في مجال الذكاء الاصطناعي تواجه معضلة “الخروج الجماعي”، وتُجبر على التوجه إلى الأسواق الخارجية بحثًا عن فرصة: يشهد سوق تطبيقات الذكاء الاصطناعي في الصين هيمنة “الشركات الكبرى”، حيث تستحوذ عمالقة مثل ByteDance و Baidu و Alibaba على 70% من أفضل 20 تطبيقًا للذكاء الاصطناعي في الصين بفضل مواردها ومزاياها في السيناريوهات. يتم ضغط دورة الابتكار للشركات الناشئة إلى بضعة أسابيع، وبمجرد ظهور نقطة مضيئة، يتم تقليدها بسرعة من قبل الشركات الكبرى. أدت هذه المنافسة الشرسة إلى “إجبار الشركات الناشئة الصينية في مجال الذكاء الاصطناعي على التوجه إلى الأسواق الخارجية”، حيث تظهر قائمة a16z أن 19 من أصل 22 تطبيقًا صينيًا للذكاء الاصطناعي للهواتف المحمولة تستهدف الأسواق الخارجية، ويتبع ذلك تدفق المواهب والابتكار إلى الخارج، مما يسلط الضوء على التناقض بين تضخم حجم المستخدمين وتقلص مصادر الابتكار في سوق الذكاء الاصطناعي الصيني. (المصدر: 36氪)