
كلمات مفتاحية:وحدة إنغرام, كورورك, تعاون جيميني, آلية بحث المعرفة للمحول, تنفيذ مهام وكيل الذكاء الاصطناعي, اختبار التدريب من البداية إلى النهاية TTT
🔥 التركيز
DeepSeek تطلق وحدة Engram، لتحقيق فصل التخزين عن الحوسبة : نشرت DeepSeek بالتعاون مع جامعة بكين ورقة بحثية تقدم وحدة “الذاكرة الشرطية” Engram. تعتمد هذه التقنية على تضمينات N-gram بهياكل Hash حديثة، مما يزود Transformer بآلية “بحث عن المعرفة” أصلية، محققة استرجاعاً حتمياً يقترب من O(1). أظهرت التجارب أن Engram-27B يتفوق بشكل ملحوظ على نماذج MoE الصرفة تحت نفس عدد المعلمات وحجم الحوسبة، ليس فقط في تعزيز مخزون المعرفة، بل أيضاً في تحرير طبقات الانتباه الضحلة من عبء “الحفظ الصم”، مما يسمح للشبكات العميقة بالتركيز على الاستدلال المعقد، مما أدى لقفزة كبيرة في قدرات الكود والرياضيات. يُنظر إلى هذا المسار الهندسي، الذي ينقل كميات هائلة من المعلمات إلى ذاكرة المضيف (CPU) مع خسارة في الاستدلال تقل عن 3%، كعنصر أساسي للجيل القادم من النماذج الضخمة المتفرقة Sparse Models، ومن المرجح جداً دمجه في DeepSeek-V4 القادم (المصدر: GitHub)

Anthropic تطلق منتجها الاستراتيجي Cowork، لتبدأ عصر “الزميل الرقمي” : أطلقت Anthropic رسمياً Cowork (نسخة معاينة بحثية)، حيث قامت بتغليف القدرات الأساسية لـ Claude Code في أداة رسومية موجهة لغير التقنيين. يسمح Cowork لـ Claude بالوصول المباشر إلى المجلدات المحلية، مع صلاحيات القراءة والتحرير وإنشاء الملفات. لم يعد مجرد chatbot، بل أصبح كياناً تعاونياً ذكياً قادراً على تخطيط الخطوات ذاتياً ومعالجة المهام بالتوازي (مثل تنظيم مجلدات التنزيل، استخراج البيانات من لقطات الشاشة لإنشاء ملفات Excel، وكتابة مسودات التقارير). المنتج مزود ببيئة معزولة عبر Virtual Machine لضمان الأمان، ويدعم أتمتة المتصفح. يعتقد المجتمع على نطاق واسع أن هذا يمثل تحولاً في نموذج الذكاء الاصطناعي من “توليد المحتوى” إلى “تنفيذ المهام”، مما قد يشكل تهديداً كبيراً للعديد من تطبيقات الذكاء الاصطناعي الناشئة (المصدر: Anthropic)

آبل وجوجل تبرمان اتفاقية تعاون بشأن Gemini، وSiri يحصل على “عقل خارجي” : أصدرت آبل وجوجل بياناً مشتركاً يؤكد أن Apple Foundation Models المستقبلية ستعتمد على نماذج Gemini وتقنيات جوجل السحابية لتشغيل Siri المخصص الذي سيصدر في وقت لاحق من هذا العام. ويقال إن آبل ستدفع حوالي مليار دولار سنوياً. يُنظر إلى هذا التعاون على أنه “تنازل مؤقت” من آبل في ظل تأخر نماذجها المطورة ذاتياً، حيث سيتولى Gemini المهام المعقدة مثل التلخيص والتخطيط، بينما ستظل الوظائف الأساسية على الجهاز مدعومة بنماذج آبل الخاصة. أدت هذه الخطوة إلى تجاوز القيمة السوقية لجوجل 4 تريليون دولار لأول مرة، كما أثارت انتقادات من إيلون ماسك حول “التركيز المفرط للسلطة”، ونقاشات حول تهميش مكانة OpenAI في منظومة آبل (المصدر: Google)

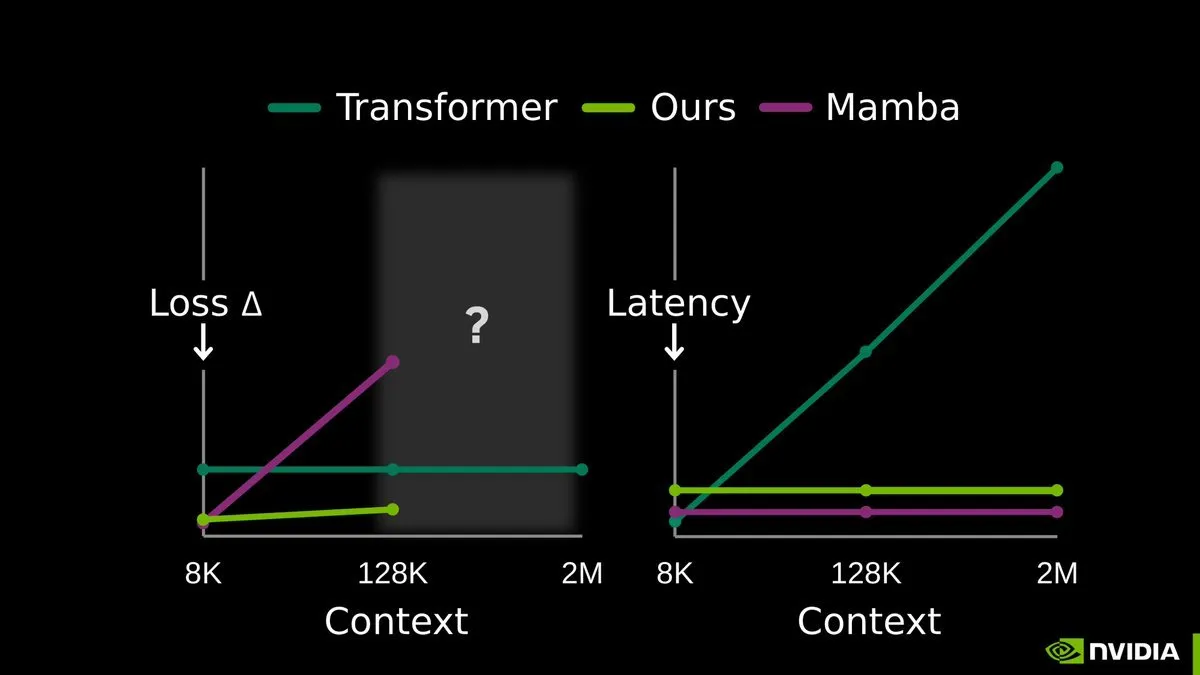
TTT-E2E: التدريب في وقت الاختبار من البداية إلى النهاية يفتح حقبة جديدة للذاكرة الطويلة في LLM : أثار بحث End-to-End Test-Time Training (TTT-E2E) الذي نشرته NVIDIA وStanford ومعهد Astera ضجة كبيرة. تدعو هذه التقنية إلى عدم الحاجة لهياكل جديدة جذرية، بل من خلال استخدام السياق كبيانات تدريب خلال مرحلة الاستدلال (وقت الاختبار)، وتحديث أوزان النموذج باستمرار عبر التنبؤ بالـ Token التالي. تضغط هذه الطريقة خبرة السياق الطويل في أوزان النموذج، مما يحل بفعالية مشكلة انفجار KV cache مع زيادة طول التسلسل. تجعل TTT النموذج “متعلماً مستمراً” حقيقياً، حيث أظهر استقراراً فائقاً عند التعامل مع تسلسلات طويلة جداً تصل لملايين الـ Tokens، ويُعتبر المسار الأكثر واعداً نحو نمذجة التسلسلات تحت التربيعية Pure Sub-quadratic (المصدر: arXiv)
🎯 التوجهات
Sakana AI تطلق DroPE: إسقاط تضمينات الموقع لتحقيق استقراء النصوص الطويلة : قام فريق Llion Jones، المؤلف الرئيسي لورقة Transformer، بإطلاق تقنية DroPE مفتوحة المصدر، مقترحاً أن تضمينات الموقع هي مجرد “عجلات مساعدة” للتدريب. يقوم DroPE بإسقاط Rotary Position Embeddings (RoPE) في مرحلة الاستدلال، ويتطلب أقل من 1% من ميزانية ما قبل التدريب لإجراء معايرة قصيرة لفتح نوافذ سياق ضخمة. أظهرت التجارب أن هذه الطريقة تتفوق بشكل ملحوظ على تقنيات RoPE scaling التقليدية في اختبارات LongBench و”إبرة في كومة قش”، مما يوفر فكرة جديدة لتوسيع قدرات النصوص الطويلة بتكلفة منخفضة (المصدر: arXiv)
مجموعة تقييم BabyVision: قدرات الرؤية لأفضل النماذج لا تزال دون مستوى طفل في الثالثة : أظهر تقييم BabyVision الصادر عن Sequoia China xbench وUniPatAI أنه في المهام البصرية التي يتم التحكم فيها بصرامة لتقليل الاعتماد على اللغة، كان أداء معظم النماذج أسوأ بكثير من طفل في الثالثة. حتى Gemini 3 Pro، الأفضل أداءً، بالكاد اجتاز الاختبار. تشير الدراسة إلى أن اعتماد النماذج المفرط على الاستدلال اللغوي يخفي نقصاً نظامياً في الإدراك المكاني، تتبع المسار، والحدس الهندسي، ويجب على الذكاء متعدد الوسائط في المستقبل إعادة بناء القدرات البصرية من الأساس (المصدر: 36氪)

Recursive Language Models (RLM): DeepMind تستكشف الذاكرة المثالية بدون RAG : اقترح باحثو DeepMind نماذج اللغة العودية (RLM) التي تسمح للنموذج بالتأمل الذاتي، التقسيم، واستدعاء نفسه بشكل عودي لمعالجة ملايين الـ Tokens. تكسر هذه الآلية قيود نافذة السياق التقليدية، حيث لم يعد النموذج يعتمد على RAG خارجي، بل يحقق “ذاكرة مثالية” للمعلومات الضخمة من خلال تجميع النتائج عودياً. ينبئ هذا التقدم بتحول نوعي في كيفية تعامل الذكاء الاصطناعي مع المستندات الطويلة جداً في المستقبل (المصدر: HuggingFace)

توسع ByteDance في الخارج بالذكاء الاصطناعي يدخل مرحلة “أدوات الكفاءة” : قامت ByteDance مؤخراً بتحركات مكثفة في الخارج، حيث أطلقت AnyGen، وهو Agent لمساحات العمل ينافس Manus، يركز على تقديم نتائج عالية الجودة مثل كتابة المستندات وتحليل البيانات. في الوقت نفسه، تجاوز عدد المستخدمين النشطين يومياً لمساعد الذكاء الاصطناعي Dola في الخارج عشرة ملايين. تحاول ByteDance التحول من “تصدير السعادة” (TikTok) إلى “بيع الكفاءة”، لتدخل في منافسة مباشرة مع OpenAI وAnthropic في مسار Office Agent (المصدر: 36氪)

🧰 الأدوات
Distil-Text2SQL: نموذج صغير 4B يحقق دقة تضاهي 685B محلياً : نجحت Distil-labs في ضبط نموذج Qwen3-4B ليحقق دقة دلالية في مهام Text2SQL تضاهي DeepSeek-V3 (685B)، بل وتتفوق عليه في مؤشر “المطابقة الدقيقة”. يدعم النموذج التشغيل المحلي، ولا يتطلب رفع بيانات CSV إلى السحابة، مع وقت استجابة أقل من ثانيتين، مما يظهر الإمكانات الهائلة للنماذج الصغيرة في استبدال النماذج الضخمة في المهام المتخصصة (المصدر: GitHub)
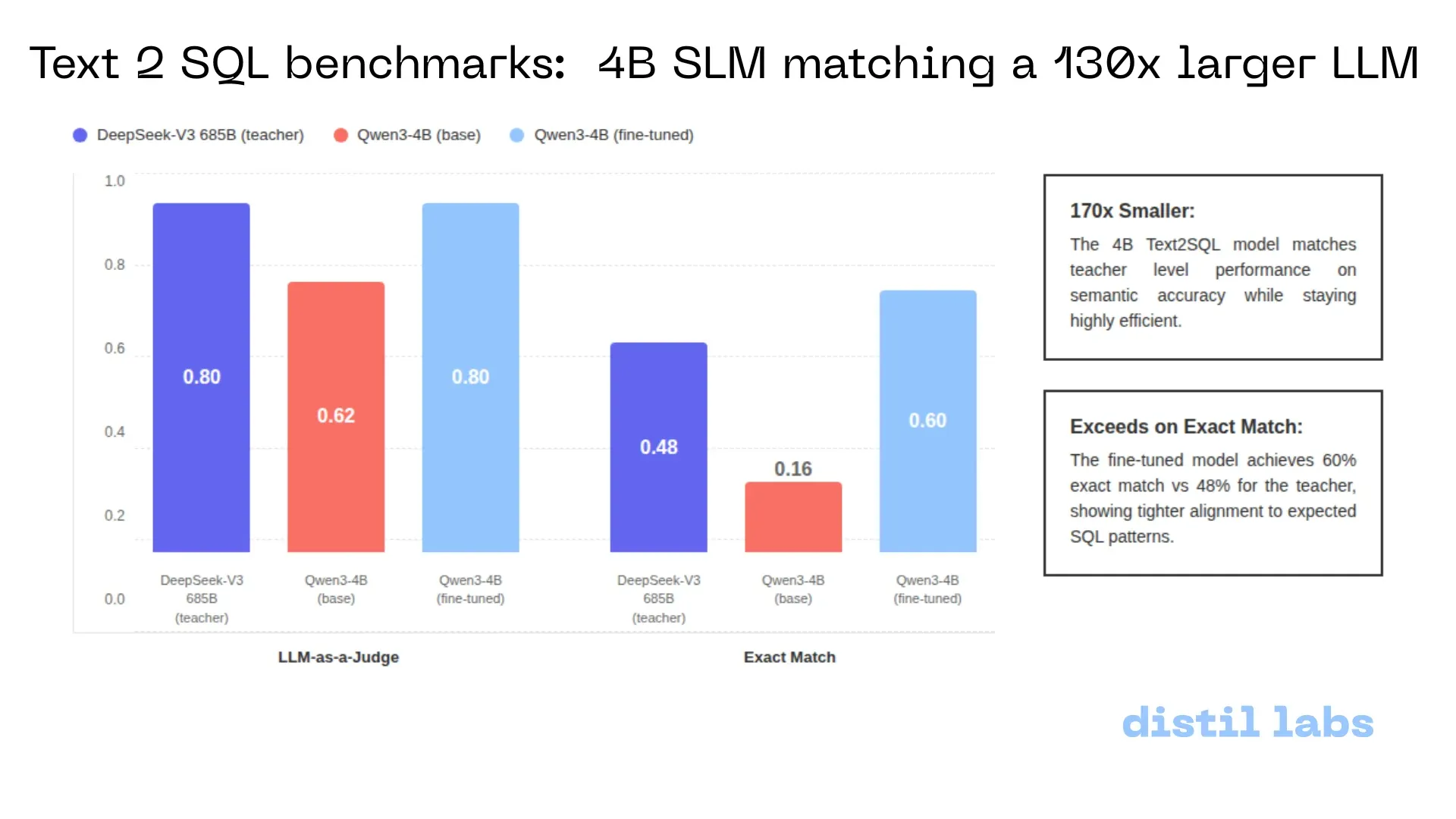
تحديث LlamaParse: تحقيق OCR دقيق للرسوم البيانية والصور بتكلفة منخفضة : قامت LlamaIndex بترقية أداة التحليل LlamaParse إلى نمط Agentic، مخصصة للعناصر البصرية المعقدة في المستندات (مثل الرسوم البيانية الخطية، المخططات الدائرية، والخرائط الانسيابية). مقارنة بتغذية VLM بلقطة شاشة كاملة للصفحة، يمكن لهذه الأداة التعرف على حدود العناصر الفرعية واستخراج المنطق الرقمي وتحويله إلى Markdown عالي الجودة، وهي واحدة من أكثر الحلول كفاءة واقتصادية حالياً للتعامل مع المعلومات غير النصية في المستندات المهنية (المصدر: jerryjliu0)
Wobo: “نسخة Tinder للبحث عن وظائف” تعتمد على AI Agent : تطبيق Wobo هو تطبيق iOS يستخدم AI Agent لأتمتة إرسال السير الذاتية. يحتاج المستخدم فقط لرفع سيرته الذاتية مرة واحدة، وسيقوم الذكاء الاصطناعي بتحليل “شخصيته المهنية”، وعندما يقوم المستخدم بـ “السحب لليمين” على وظيفة تعجبه، سينتقل الـ Agent تلقائياً إلى المواقع الرسمية الخارجية المعقدة، ويولد خطاب تغطية مخصصاً ويجيب على أسئلة التصفية. تهدف الأداة لإنهاء عملية ملء النماذج المتكررة والمملة، وتقليص عملية التقديم من 20 دقيقة إلى ثانيتين (المصدر: Reddit)
📚 التعلم
عودة Stanford CS224N لعام 2026: إضافة موضوعات حول Agent والاستدلال : أعلن عن عودة دورة معالجة اللغات الطبيعية الكلاسيكية CS224N. سيقوم بالتدريس هذا العام Diyi Yang وYejin Choi، وبالإضافة لتغطية أساسيات NLP عبر الشبكات العصبية، سيتم التركيز على إضافة محتوى حول AI Agent، واستخدام الأدوات، ومحاضرتين مخصصتين لـ “الاستدلال (Reasoning)”، لمواكبة أحدث اتجاهات النماذج الضخمة (المصدر: Stanford)
Andrew Ng يطلق “Build with Andrew”: بناء تطبيقات Web بدون كود : أطلق Andrew Ng دورة جديدة في نشرة The Batch الأسبوعية، لتدريب المبتدئين على كيفية بناء ونشر تطبيقات Web قابلة للتشغيل باستخدام أدوات الذكاء الاصطناعي فقط عبر وصف أفكارهم باللغة الطبيعية. تؤكد الدورة على نموذج “الذكاء الاصطناعي كمطور”، مما يقلل الحواجز أمام الأشخاص العاديين لدخول مجال تطوير البرمجيات (المصدر: DeepLearningAI)
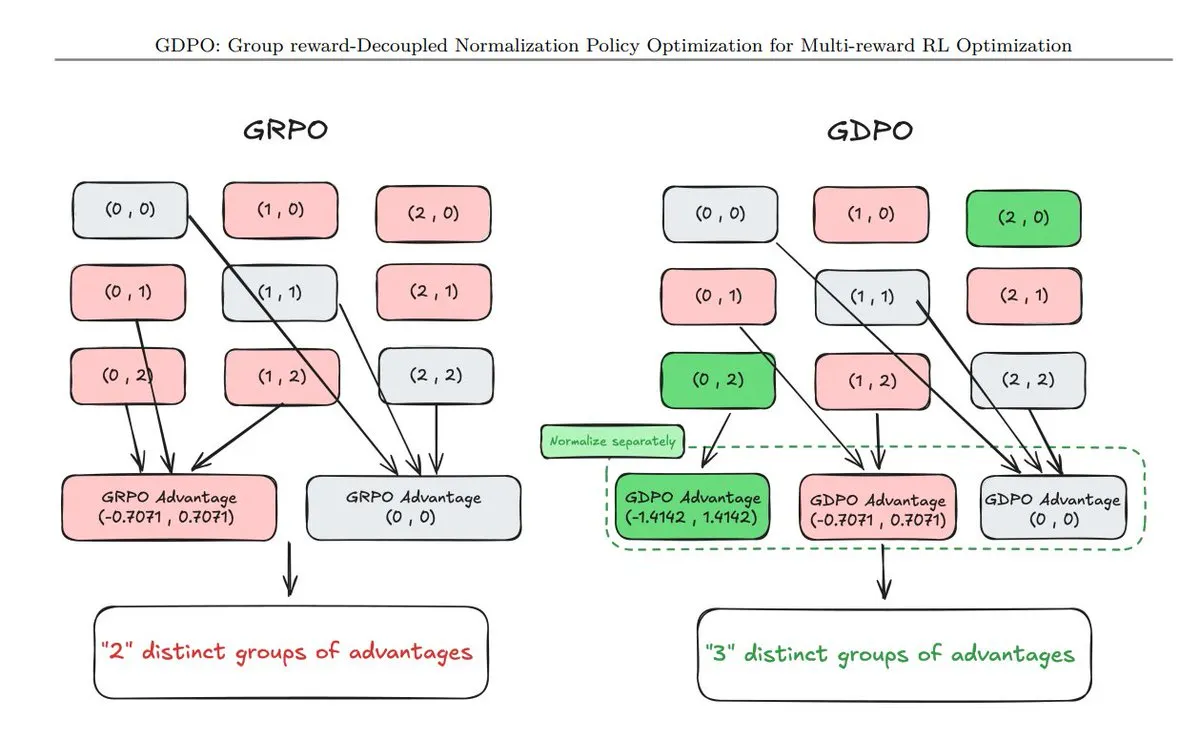
ملخص لـ 11 تقنية جديدة لتحسين السياسات (Policy Optimization) : لخصت TuringPost تقنيات تحسين السياسات التي ظهرت مؤخراً، بما في ذلك GDPO (تطبيع فصل المكافآت)، AT²PO (تحسين السياسات القائم على البحث الشجري للـ Agent)، وPC-GRPO (منهج GRPO القائم على الألغاز) الذي يحظى باهتمام كبير. تعد هذه التقنيات جوهرية لتعزيز سلاسل المنطق وقدرات محاذاة المهام في النماذج الضخمة (المصدر: TuringPost)
💼 الأعمال
OpenAI تستحوذ على الشركة الناشئة في المجال الطبي Torch : أعلنت OpenAI عن استحواذها على Torch، وهي شركة ناشئة في مجال الذكاء الاصطناعي الطبي تدمج نتائج التجارب، السجلات الدوائية، وتسجيلات الزيارات الطبية. سينضم فريق Torch إلى قسم ChatGPT Health. تظهر هذه الخطوة تسارع OpenAI في دفع التسويق التجاري للذكاء الاصطناعي في مجالات الإدارة الصحية والمساعدة السريرية، سعياً لجعل ChatGPT المساعد الصحي الشخصي الأكثر احترافية في العالم (المصدر: OpenAI)

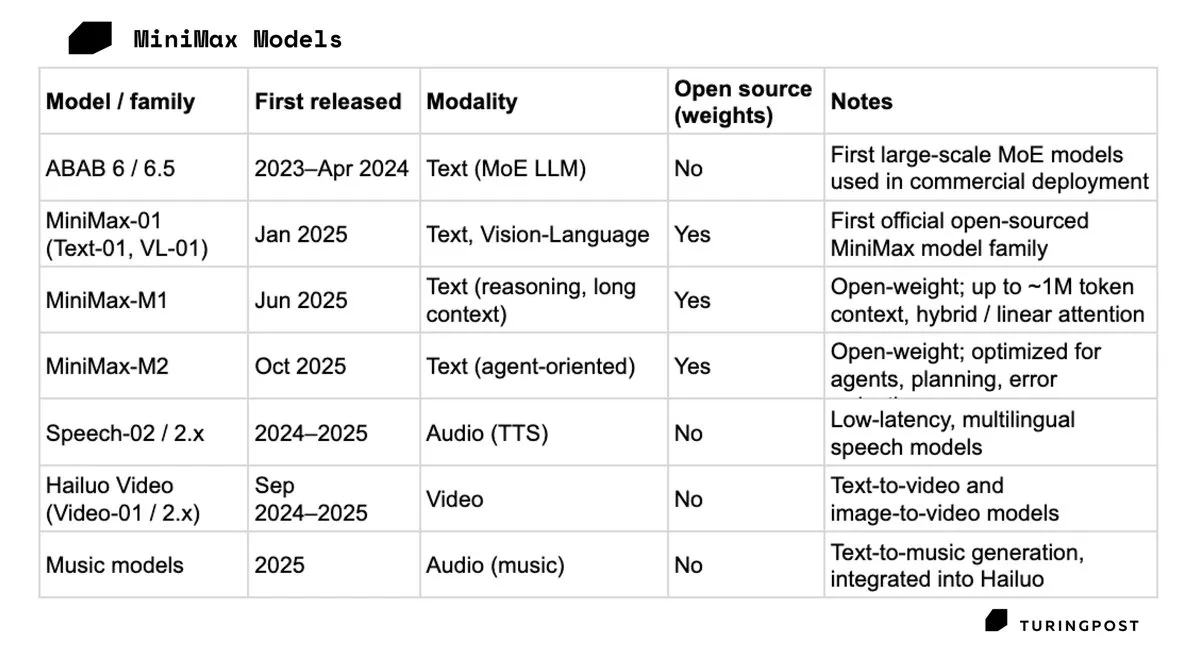
إدراج MiniMax في بورصة هونج كونج، وسهمها يقفز بنسبة 109% في اليوم الأول : تم إدراج شركة MiniMax الصينية للذكاء الاصطناعي في بورصة هونج كونج في 9 يناير 2026، حيث ارتفع سعر سهمها بنسبة 109% في اليوم الأول، لتتجاوز قيمتها السوقية 150 مليار دولار هونج كونج. أثبتت MiniMax، من خلال نجاح Talkie وHailuo AI في سوق المستهلكين (C-end)، جاذبية مسار المنتجات متعددة الوسائط للمستهلكين دون الاعتماد على عقود كبار العملاء في سوق رأس المال. يُنظر إلى هذا الاكتتاب كخطوة حاسمة للحصول على “الأكسجين” في سباق الحوسبة المحتدم (المصدر: TuringPost)
xAI تحرق 28 مليون دولار يومياً، وتقييمها يصل لـ 230 ملياراً : رغم خسائر xAI التي بلغت 7.8 مليار دولار في الفصول الثلاثة الأولى من عام 2025، إلا أنها أكملت مؤخراً تمويلاً بقيمة 20 مليار دولار، ليصل تقييمها إلى 230 مليار دولار. يدفع إيلون ماسك بكل قوته نحو خطة “Macrohard”، التي تهدف لبناء نظام ذكاء اصطناعي ذاتي قادر على تشغيل روبوتات Tesla. يعكس نموذج “الاستثمار العنيف” هذا الحواجز العالية جداً للدخول في مجال البنية التحتية والمواهب لكبار لاعبي الذكاء الاصطناعي (المصدر: 36氪)
🌟 المجتمع
Vibe Coding/Working يثير نقاشاً واسعاً حول الهوية المهنية : مع انتشار Claude Cowork وأدوات الـ Agent المختلفة، أصبح مصطلح “العمل بالجو العام (Vibe Working)” رائجاً. يرى المجتمع أن هذا ليس مجرد تحسين بسيط للكفاءة، بل هو “تسييل للمعرفة المتخصصة في العقل”. ستتحول قيمة المهندس في المستقبل من “كتابة 100 ألف سطر من الكود” إلى “تصميم نظام يجعل الذكاء الاصطناعي يكتب 100 ألف سطر”. ومع ذلك، يخشى البعض أن يؤدي ذلك إلى كود “رديء الجودة (Slop)” واعتماد مفرط على الصندوق الأسود للذكاء الاصطناعي (المصدر: nearcyan, amasad)
اتهام كاشفات الذكاء الاصطناعي بأنها “عملية احتيال محضة” : شن مجتمع Reddit هجوماً عنيفاً على أدوات كشف الذكاء الاصطناعي مثل GPTZero، مشيرين إلى أن معدل الخطأ فيها مرتفع جداً، لدرجة أنها صنفت “إعلان الاستقلال الأمريكي” كمنتج للذكاء الاصطناعي بنسبة 90%. يعتقد المستخدمون أن هذه الأدوات تقيس “الألفة الإحصائية” وليس المصدر، مما يضر بالعديد من الكتاب الأصليين والطلاب. يدعو الوسط التعليمي لوقف “حملة المطاردة” والتحول لتقييم فهم الطلاب للمحتوى وقدرتهم على تطبيقه (المصدر: Reddit)
تلقيب مؤسس DeepSeek، ليانغ وين فنغ، بـ “الراهب الكاسح” في عالم الذكاء الاصطناعي : يناقش المجتمع بحماس خلفية ليانغ وين فنغ في صناديق التحوط الكمية. حقق صندوق High-Flyer Quant الذي يديره عائداً بنسبة 56.6% في عام 2025، متجاوزاً متوسط الصناعة بكثير. يعلق المتابعون بأن استثماره للأموال التي جناها من التداول الكمي في الذكاء الاصطناعي بأسلوب “YOLO”، واتباعه لمسارات تقنية غير تقليدية (مثل MLA وEngram)، يظهر ذوقاً معمارياً رفيعاً وكفاءة هندسية عالية، مما يجعله متغيراً حاسماً في مواجهة الذكاء الاصطناعي الصيني لعمالقة وادي السيليكون (المصدر: teortaxesTex)
💡 أخرى
سماعة الذكاء الاصطناعي Sweetpea قد تصدر في سبتمبر : تشير الشائعات إلى أن أول منتج مادي لـ OpenAI – الذي يحمل الاسم الرمزي Sweetpea – من تصميم فريق Jony Ive، يشبه في شكله حصاة معدنية، ومزود بشريحة 2nm لدعم الاستدلال المحلي. تتوقع OpenAI أن تصل المبيعات في العام الأول إلى 50 مليون وحدة، لتتحدى مباشرة مكانة AirPods في السوق (المصدر: 36氪)

أمن الذكاء الاصطناعي يصبح معياراً جديداً لاختيار الشركات في عام 2026 : مع توسع صلاحيات وكلاء الذكاء الاصطناعي (AI Agents)، تحول اهتمام الشركات بالأمن من “خيار إضافي” إلى “شرط مسبق”. أظهر استطلاع أن 43% من الشركات تعتبر الأمن العائق الأول لتبني الذكاء الاصطناعي. الاتجاه في عام 2026 هو “الأمن المدمج”، أي تفعيل التدقيق وعزل الصلاحيات افتراضياً في مراحل استدعاء النماذج وتنظيم الـ Agents (المصدر: 36氪)