
キーワード:Gemini 2.5 Pro, OpenAIデータプライバシー, OpenThinker3-7B, Claude Gov, AIエージェント, 大規模言語モデル, 強化学習, オープンソースモデル, Gemini 2.5 Proの性能向上, OpenAIユーザーデータ保持ポリシー, OpenThinker3-7Bの推論能力, Claude Govの国家安全保障への応用, AIエージェントのロバスト性と制御
🔥 注目
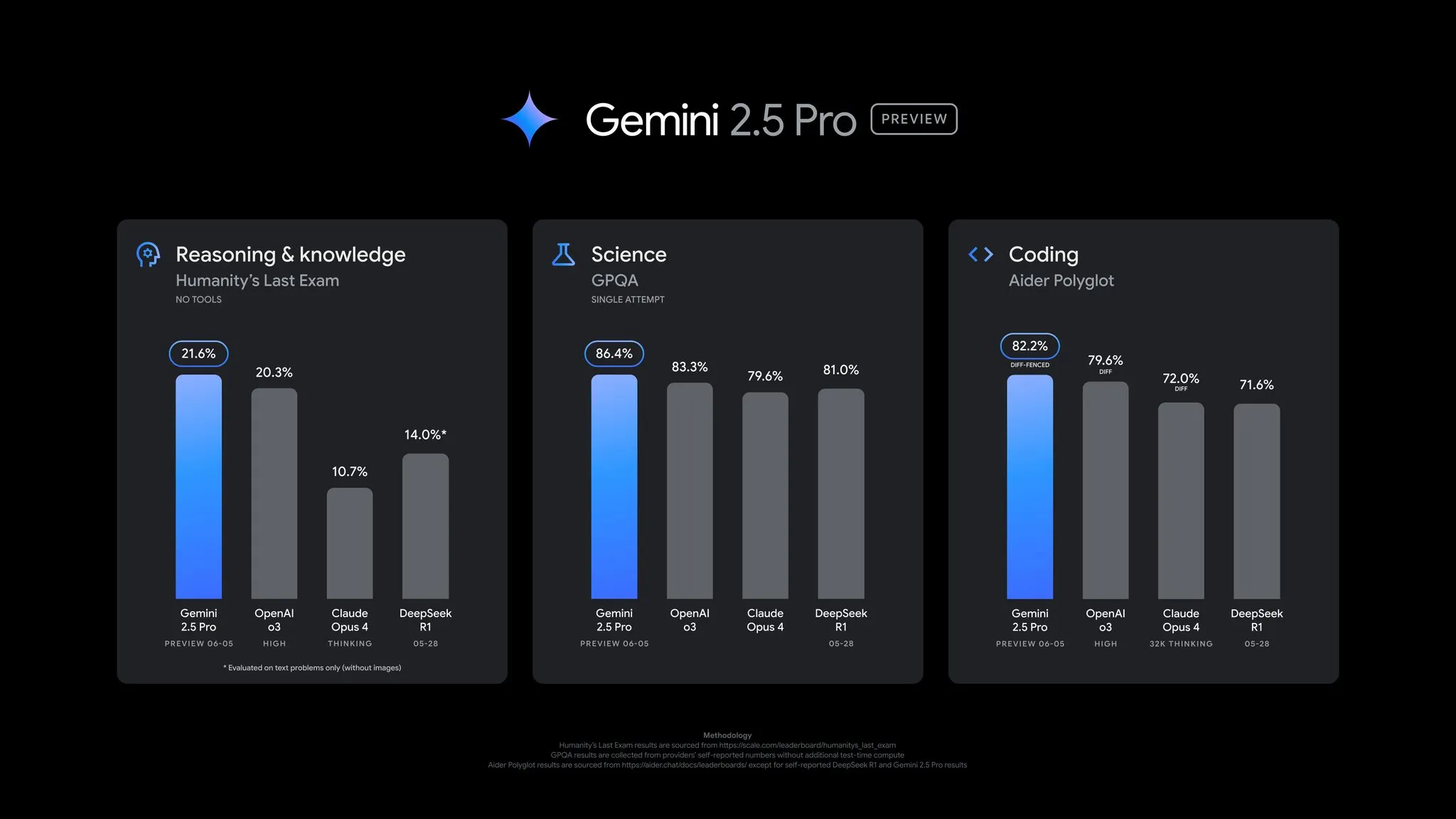
Google、Gemini 2.5 Proプレビュー版のアップデートを発表、パフォーマンスが全面的に向上: GoogleはGemini 2.5 Proプレビュー版に重要なアップデートが行われたことを発表しました。コーディング、推論、科学、数学の能力において著しい進歩が見られます。新バージョンはAIDER Polyglot、GPQA、HLEなどの主要なベンチマークテストでより優れたパフォーマンスを示し、LMArenaではEloスコアが24ポイント上昇し、再びトップに立ちました。さらに、ユーザーフィードバックに基づいて、モデルの回答スタイルとフォーマットが改善され、より多くのコントロールを提供するための「思考予算」(thinking budget)機能が導入されました。このアップデートはGemini App、Google AI Studio、Vertex AIで利用可能です (ソース: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI、ニューヨーク・タイムズ訴訟によりユーザーデータの永久保存を命じられ、プライバシー懸念が浮上: ニューヨーク・タイムズとの著作権訴訟において、OpenAIは裁判所から、これまで30日間のみ保存すると約束していた「一時的な会話」やAPIリクエストデータを含む、すべてのChatGPTおよびAPIのユーザーインタラクションログを永久に保存するよう命じられました。OpenAIは控訴しており、この措置は「過度な介入」であり、長年のプライバシー規範を破壊し、プライバシー保護を弱めるものだと主張しています。この裁定は、OpenAIがユーザーに対するデータ保持および削除の約束を履行できなくなる可能性を意味し、特にOpenAI APIに依存し独自のデータ保持ポリシーを持つアプリケーション開発者にとって、ユーザーデータのプライバシーとセキュリティに関する広範な懸念を引き起こしています (ソース: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

OpenThinker3-7Bがリリースされ、7Bオープンソース推論モデルのSOTAを更新: Ryan Marten氏は、新しい70億パラメータのオープンデータ推論モデルであるOpenThinker3-7Bのリリースを発表しました。このモデルは、コード、科学、数学の評価において、DeepSeek-R1-Distill-Qwen-7Bを平均で33%上回っています。チームは同時に、OpenThoughts3-1.2Mデータセットもリリースし、現在すべてのデータ規模で最高のオープン推論データセットであると主張しています。研究者らは、より小さなモデルの場合、R1からの蒸留がパフォーマンスを向上させる最も簡単な方法であるが、RL(強化学習)の方向性の研究はより探索的であると指摘しています。この成果は、オープン推論モデル分野における先駆的な研究の1つと見なされています (ソース: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic、米国国家安全保障顧客向けカスタムモデルClaude Govを発表: Anthropicは、米国の国家安全保障顧客向けに構築されたカスタムAIモデル群であるClaude Govを発表しました。これらのモデルはすでに米国の最高レベルの国家安全保障機関に導入されており、アクセス権は機密環境で操作する担当者に限定されています。この動きは、政府および国防分野におけるAI技術のさらなる深化を示すと同時に、機密分野でのAI応用に関する議論も引き起こしています (ソース: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 動向
Yann LeCun氏、Sundar Pichai氏の見解に同意:現在の技術ではAGI達成は必ずしも不可能、プラトー期に入る可能性も: MetaのチーフAIサイエンティストであるYann LeCun氏は、Google CEOのSundar Pichai氏の「現在の技術経路では汎用人工知能(AGI)の実現は保証されておらず、AIの発展は一時的なプラトー期に遭遇する可能性がある」という見解をリツイートし、同意しました。Pichai氏は、AIの進歩は驚異的な速さであるものの、限界も存在する可能性があり、現在の技術は汎用知能にはまだ隔たりがあると指摘しています。これは、AGIの実現経路とタイムラインに対する業界の慎重な姿勢を反映しています (ソース: ylecun)
OpenAI、AIエージェントの安全性向上を目指し、エージェント堅牢性・制御チームを募集: OpenAIは、AIエージェントのトレーニングおよびデプロイプロセスにおける安全性と信頼性を確保することを目的とした新しい「エージェント堅牢性・制御」(Agent Robustness and Control)チームを結成しています。このチームは、AI分野で最も困難な問題のいくつかに取り組むことになり、OpenAIがより強力なAIエージェントを推進すると同時に、安全な制御を非常に重視していることを示しています (ソース: gdb)

Appleの新研究が大規模言語モデルの「思考の錯覚」を明らかに:複雑な問題に直面すると推論能力が低下: Apple社の最新研究論文「思考の錯覚」(The Illusion of Thinking)は、現在の推論モデルが問題の複雑性が一定レベルまで増加すると、十分なトークン予算が与えられていても、その推論努力(reasoning effort)がかえって低下することを指摘しています。この直感に反する「スケーリング制限」(scaling limit)現象は、モデルが非常に複雑な問題を処理する際に真の深い思考を行っておらず、「思考の錯覚」を示している可能性を示唆しており、大規模モデルの真の推論能力を評価し向上させる上で新たな課題を提示しています (ソース: Ar_Douillard, Reddit r/MachineLearning)

OpenAI、人間とAIの感情的なつながりについて議論、ユーザーの感情的ウェルビーイングへの影響を優先研究: OpenAIのJoanne Jang氏がブログ記事を発表し、ユーザーとChatGPTなどのAIモデルとの間でますます強まる感情的なつながりの現象について論じています。記事は、人々が自然にAIを擬人化し、仲間意識や信頼感を抱く可能性があると指摘しています。OpenAIはこの傾向を認識しており、AIが本当に「意識的」であるかという存在論的な問題にこだわるのではなく、AIがユーザーの感情的ウェルビーイングに与える影響を優先的に研究すると述べています。同社の目標は、温かく、有益でありながら、過度に感情的な依存を求めたり、独自の議題を持ったりしないAIアシスタントを設計することです (ソース: openai, sama, BorisMPower)

Xiaohongshu、オープンソースMoE大規模モデルdots.llm1-143B-A14Bをリリース: XiaohongshuのHi Labは、初のオープンソース大規模モデルシリーズdots.llm1をリリースしました。これには、ベースモデルdots.llm1.baseとインストラクションファインチューニングモデルdots.llm1.instが含まれます。このモデルはMoEアーキテクチャを採用し、総パラメータ数は143B、アクティブパラメータ数は14Bです。公式の自己評価では、MMLU-ProでのパフォーマンスはQwen3-235B-A22Bを上回るものの、新しいDeepSeek-V3には及ばないとされています。モデルはMITライセンスを採用しており、自由に利用できます。しかし、初期のコミュニティテストでは、コード生成などのタスクでパフォーマンスが振るわず、Qwen2.5-coderにも劣るとの結果が示されています (ソース: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Qwen3シリーズ、EmbeddingおよびRerankerモデルをリリース、多言語テキスト処理能力を強化: Qwenチームは、多言語テキスト埋め込みと関連性ランキングのパフォーマンス向上を目的としたQwen3-EmbeddingおよびQwen3-Rerankerシリーズモデルを発表しました。Embeddingモデルはテキストをベクトル表現に変換し、ドキュメント検索やRAGなどのシナリオをサポートします。一方、Rerankerモデルは検索結果を再ランキングし、最も関連性の高いコンテンツの優先度を高めます。このシリーズモデルは0.6B、4B、8Bなどさまざまなパラメータ規模を提供し、119言語をサポートし、MMTEB、MTEBなどのベンチマークテストで優れたパフォーマンスを示しています。特に0.6Bバージョンは、その効率とパフォーマンスのバランスから、リアルタイム性が要求されるRerankerシナリオで特に適していると考えられています (ソース: karminski3, karminski3, ZhaiAndrew, clefourrier)

研究により、複雑な長期的タスクにおける強化学習のスケーラビリティの課題が指摘される: Seohong Park氏らの研究によると、データと計算資源を拡大するだけでは、強化学習(RL)が複雑なタスクを効果的に解決するには不十分であり、重要な制約要因は「ホライゾン」(horizon)にあることが明らかになりました。長期的なタスクでは報酬信号が希薄であり、モデルが効果的な戦略を学習することが困難です。これは、現在のいくつかのAIエージェント(Deep Research、Codex agentなど)が主に短期的なRLタスクと一般的な堅牢性トレーニングに依存しているという観察結果と一致しており、エンドツーエンドで長期的な希薄報酬問題を解決することは、依然としてRL分野における大きな課題であることを示しています (ソース: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu、HuggingFaceに公式アカウントを登録し、ERNIE大規模モデルをアップロード: BaiduはHuggingFaceプラットフォームに公式アカウントを登録し、ERNIE(文心)シリーズの一部のモデル(ERNIE-X1-TurboおよびERNIE-4.5-Turboを含む)をアップロードしました。この動きは、Baiduが自社の大規模モデル技術をより広範なオープンソースコミュニティおよび開発者エコシステムに積極的に統合し、世界中の開発者がそのAI能力にアクセスし利用しやすくすることを意味します (ソース: karminski3)
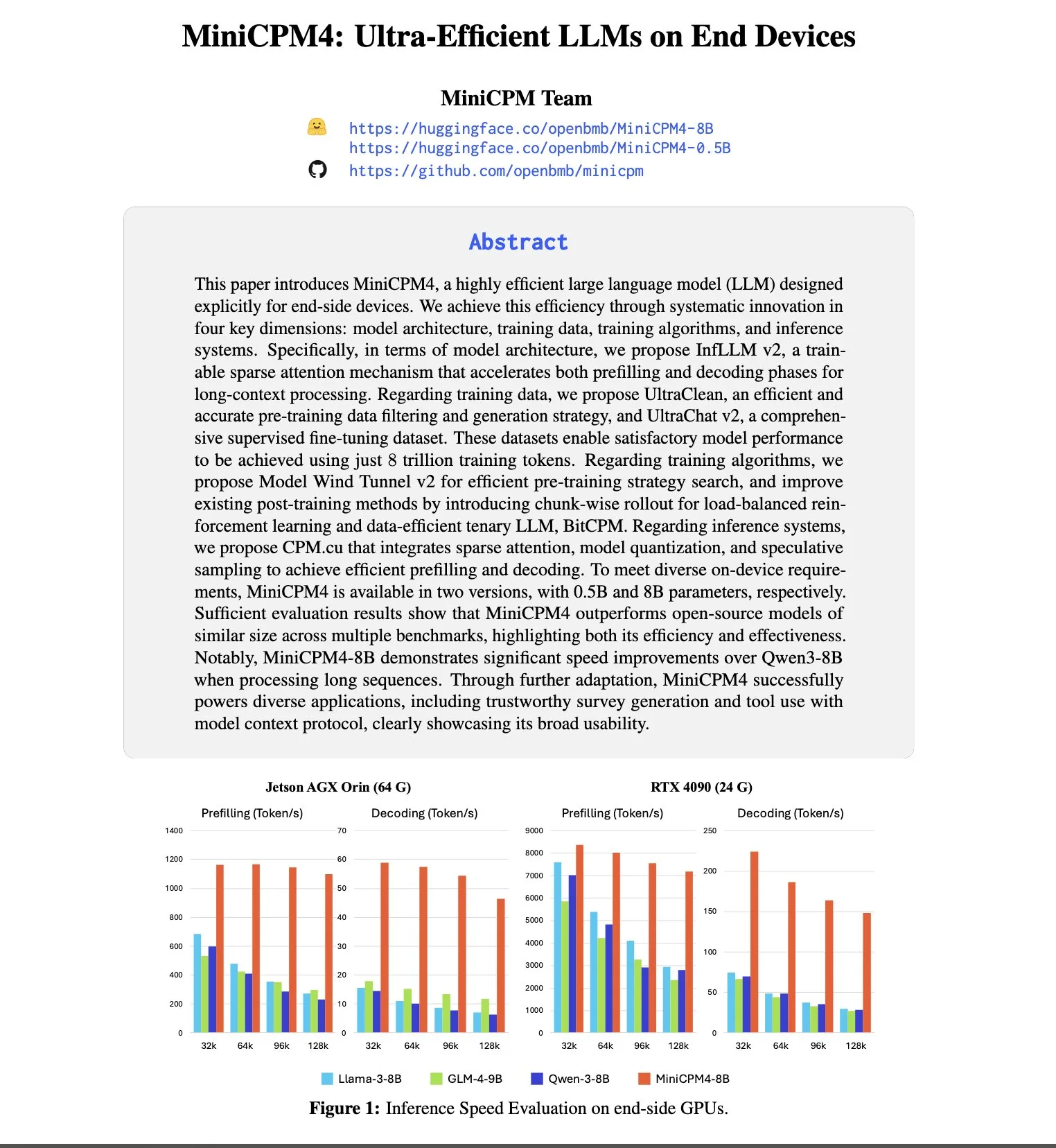
OpenBMB、MiniCPM4シリーズモデルを発表、エッジデバイスでの高効率動作を主眼に: OpenBMBは、小型で高効率な言語モデルの限界を探求し続け、MiniCPM4シリーズを発表しました。その中でMiniCPM4-8Bモデルは80億のパラメータを持ち、8Tトークンでトレーニングされています。このシリーズモデルは、トレーニング可能なスパースアテンション(InfLLM v2)、三元量子化(BitCPM)、FP8低精度計算、マルチトークン予測などの極限的な高速化技術を採用し、エッジデバイスでの高効率な動作を目指しています。例えば、そのスパースアテンションメカニズムは、128Kの長文テキストを処理する際に、各トークンが5%未満のトークンとのみ関連性を計算するため、長文テキスト処理の計算コストを大幅に削減します (ソース: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
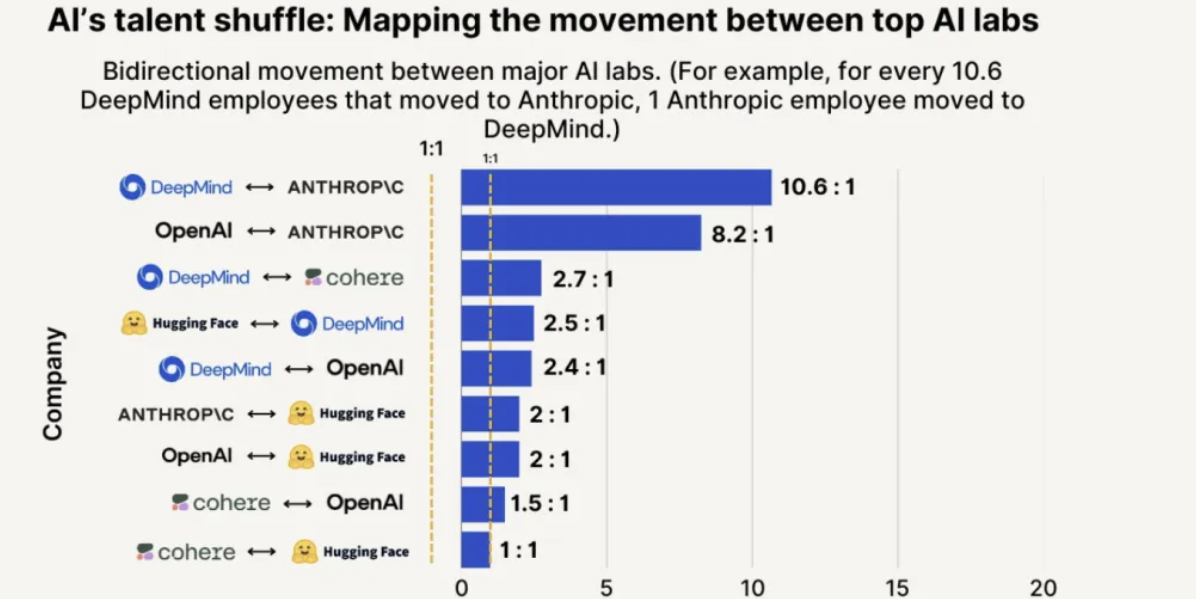
Anthropicの人材誘致力および定着率がリード、OpenAIからの人材獲得可能性は8倍高い: SignalFireが発表した2025年の人材トレンドレポートによると、AnthropicはトップAI人材の定着において際立っており、80%に達し、DeepMindの78%やOpenAIの67%を上回っています。レポートはまた、エンジニアがOpenAIからAnthropicに転職する可能性は、AnthropicからOpenAIに流出する可能性の8倍であると指摘しています。Anthropic独自の企業文化、非伝統的な思考への寛容さ、従業員の自主性、そしてその製品であるClaudeの開発者間での人気が、人材を引き付け、維持する重要な要因であると考えられています (ソース: 量子位)
🧰 ツール
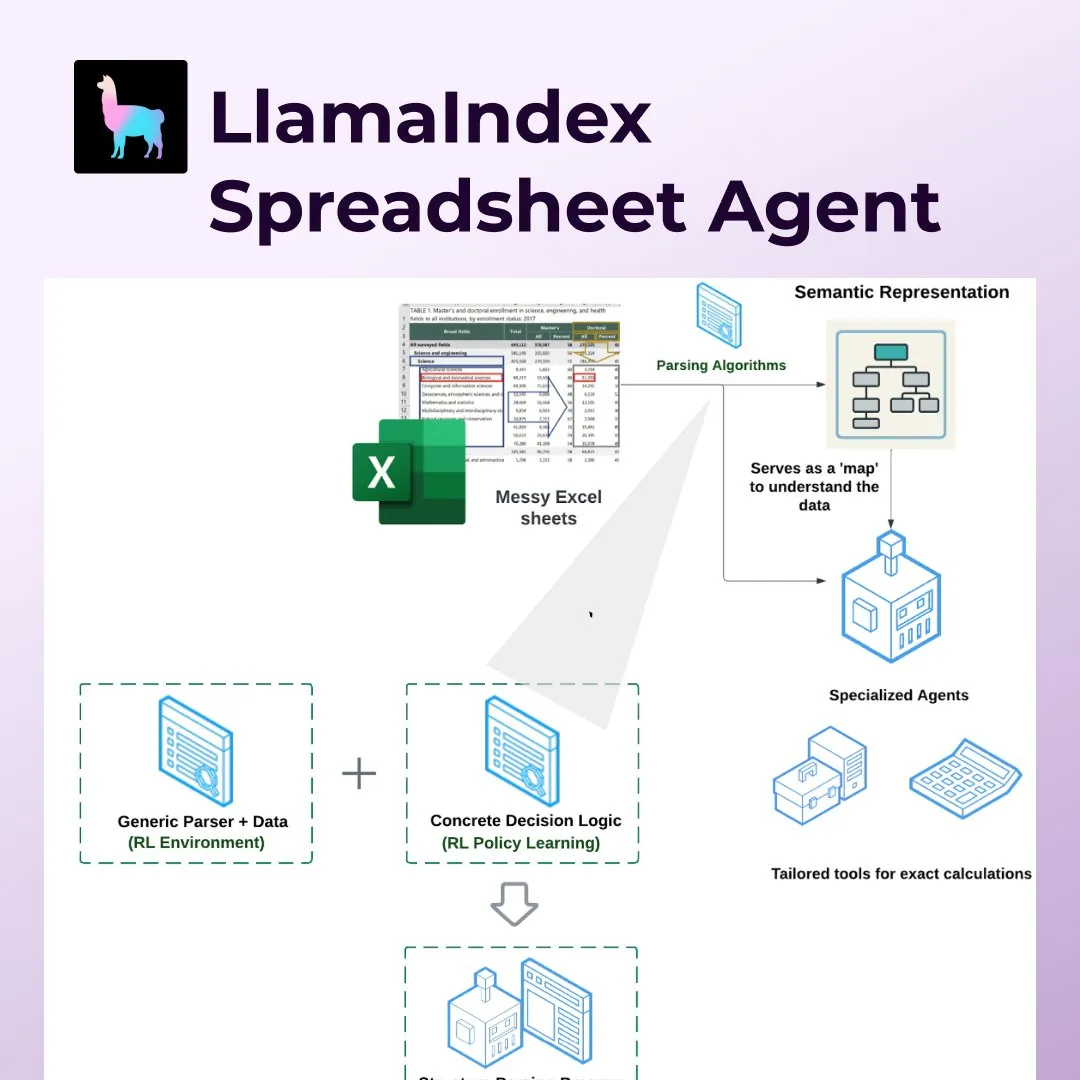
LlamaIndex、Spreadsheet Agentsを発表し、Excelなどのスプレッドシート処理を革新: LlamaIndexは、ユーザーが非標準化されたExcelスプレッドシートのデータ変換や質疑応答を行えるようにする、全く新しいSpreadsheet Agents機能を発表しました。このツールは、強化学習ベースのセマンティック構造解析を利用して表構造を理解し、専用ツールを通じてAIエージェントが表と対話できるようにします。これは、従来のLLMが複雑な表(会計、税務、保険分野でよく見られる表など)を処理する際の欠点を解決することを目的としており、結合されたセルや複雑なレイアウトを処理し、データ関係を維持できます。テストでは、その精度(96%)は人手によるベースラインやOpenAI Code Interpreter(GPT 4.1、75%)を上回りました (ソース: jerryjliu0)
LlamaIndex、LlamaExtractとエージェントワークフローを活用してSEC Form 4の抽出を自動化: LlamaIndexは、そのLlamaExtractツールとAIエージェントワークフローを使用して、米国証券取引委員会(SEC)のForm 4ファイル(上場企業の役員、取締役、主要株主が株式取引を開示するファイル)からデータを自動的に抽出し、正規化する方法を実証しました。このソリューションは、企業ごとに形式が異なるForm 4ファイルをクリーンなCSV形式に変換し、Pandasでクエリ可能なデータフレームに統合することができ、金融アナリストや投資家に効率的なデータ処理ツールを提供します (ソース: jerryjliu0)

オープンソースプロジェクトRagbitsがリリースされ、GenAIアプリケーションの迅速な開発のためのビルディングブロックを提供: deepsense-aiは、ジェネレーティブAIアプリケーションの迅速な開発のためのビルディングブロックを提供することを目的としたオープンソースプロジェクトRagbitsをリリースしました。このプロジェクトは、100以上の大規模モデルインターフェースまたはローカルモデルをサポートし、独自のベクトルストア(Qdrant、PgVectorに接続可能)を備え、20以上の入力ファイル形式(PDF、HTML、表、プレゼンテーションなど)をサポートします。Ragbitsは、組み込みVLMを利用して表、画像、構造化コンテンツを抽出し、S3、GCS、Azureなどのさまざまなデータソースに接続でき、モジュール化された特性により、ユーザーがコンポーネントをカスタマイズできます (ソース: karminski3, GitHub Trending)

AIプログラミングアシスタントCursorが大幅アップデート、BugBot、記憶機能、MCPサポートを統合: AIプログラミングツールCursorが大幅なアップデートを行いました。主な内容は次のとおりです:1) BugBot:GitHub issueに自動返信し、ワンクリックでCursor内で開いて修正可能。2) 記憶機能:AIが以前の会話内容を記憶し、大規模プロジェクトの繰り返し修正時の使いやすさを向上。3) ワンクリックMCP(Model Context Protocol)設定:OAuth対応のサードパーティMCPサーバーをサポート。4) Jupyter NotesがAI Agentをサポート。5) バックグラウンドAgent:ショートカットキーでコントロールパネルを呼び出し、リモートAIプログラミングAgentを使用可能 (ソース: karminski3)
Archon:AIエージェントを作成できるAIエージェント: Archonは、他のAIエージェントを自律的に構築、最適化することを目的とした「Agenteer」プロジェクトです。高度なエージェントコーディングワークフローとフレームワークナレッジベースを活用し、強力なAIエージェントの作成における計画、フィードバックループ、ドメイン知識の役割を示しています。最新のV6バージョンでは、ツールライブラリとMCP(Model Context Protocol)サーバーが統合され、新しいエージェントを構築する能力が強化されています。ArchonはDockerデプロイメントとローカルPythonインストールをサポートし、管理用のStreamlit UIを提供します (ソース: GitHub Trending)

NoteGen:AI駆動のクロスプラットフォームMarkdownノートアプリ: NoteGenは、AIを活用して記録と執筆を結びつけることを目的としたクロスプラットフォームのMarkdownノートアプリで、断片的な知識を読みやすいノートに整理できます。スクリーンショット、テキスト、イラスト、ファイル、リンクなど、さまざまな記録方法をサポートし、ネイティブMarkdownストレージ、ローカルオフライン使用、GitHub/Gitee/WebDAV同期をサポートします。NoteGenはChatGPT、Gemini、Ollamaなど複数のAIモデルを設定でき、RAG機能をサポートし、ユーザーのノートを知識ベースとして利用します (ソース: GitHub Trending)

ComfyUI-Copilot:ワークフロー開発を自動化するインテリジェントアシスタント: ComfyUI-Copilotは、大規模言語モデルによって駆動されるプラグインであり、AIアート作成プラットフォームComfyUIの使いやすさと効率を向上させることを目的としています。インテリジェントなノードとモデルの推奨、およびワンクリックでのワークフロー構築機能を提供することで、ComfyUIの初心者にとっての使いにくさ、モデル設定の誤り、ワークフロー設計の複雑さといった問題を解決します。このシステムは階層的なマルチエージェントフレームワークを採用し、中央アシスタントエージェントと複数の専用ワークエージェントを含み、ComfyUIナレッジベースを利用してデバッグとデプロイを簡素化します (ソース: HuggingFace Daily Papers)
Bifrost:高性能Go言語LLMゲートウェイがオープンソース化、本番環境LLMデプロイを最適化: LLMが本番環境で直面するAPIの断片化、遅延、フォールバック、コスト管理などの課題を解決するため、MaximilianチームはGo言語ベースのLLMゲートウェイBifrostをオープンソース化しました。Bifrostは高スループット、低遅延の機械学習デプロイメント向けに特別に設計されており、OpenAI、Anthropic、Azureなどの主要なLLMプロバイダーをサポートしています。ベンチマークテストによると、他のプロキシと比較して、Bifrostはスループットが9.5倍向上し、P99遅延が54倍削減され、メモリ消費量が68%削減され、5000 RPSでの内部オーバーヘッドは15µs未満です。APIの正規化、自動プロバイダーフォールバック、インテリジェントなキー管理、Prometheusメトリクスなどの機能を提供します (ソース: Reddit r/MachineLearning)

LangGraph.jsが開発者体験を改善、型安全性とフック関数を導入: LangGraph.js 0.3バージョンは、開発者体験の向上を目的とした一連のアップデートを行いました。これには、型安全性の強化、およびcreateReactAgentへのpreModelHookとpostModelHookの導入が含まれます。preModelHookは、メッセージ履歴がLLMに渡される前に簡略化するために使用でき、postModelHookはガードレールや人間と機械の協調プロセスを追加するために使用できます。コミュニティはLangGraph v1へのフィードバックを積極的に募集しています (ソース: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024、GRMR-V3-G4B文法誤り訂正大規模モデルをリリース: 開発者qingy2024は、文法誤り訂正に特化した大規模モデルGRMR-V3-G4Bをリリースしました。最大パラメータ数はわずか4Bです。このモデルは量子化バージョンも提供しており、ローカルワークフローや個人デバイスでの文法チェックおよび修正タスクに特に適しており、統合と使用が容易です (ソース: karminski3)

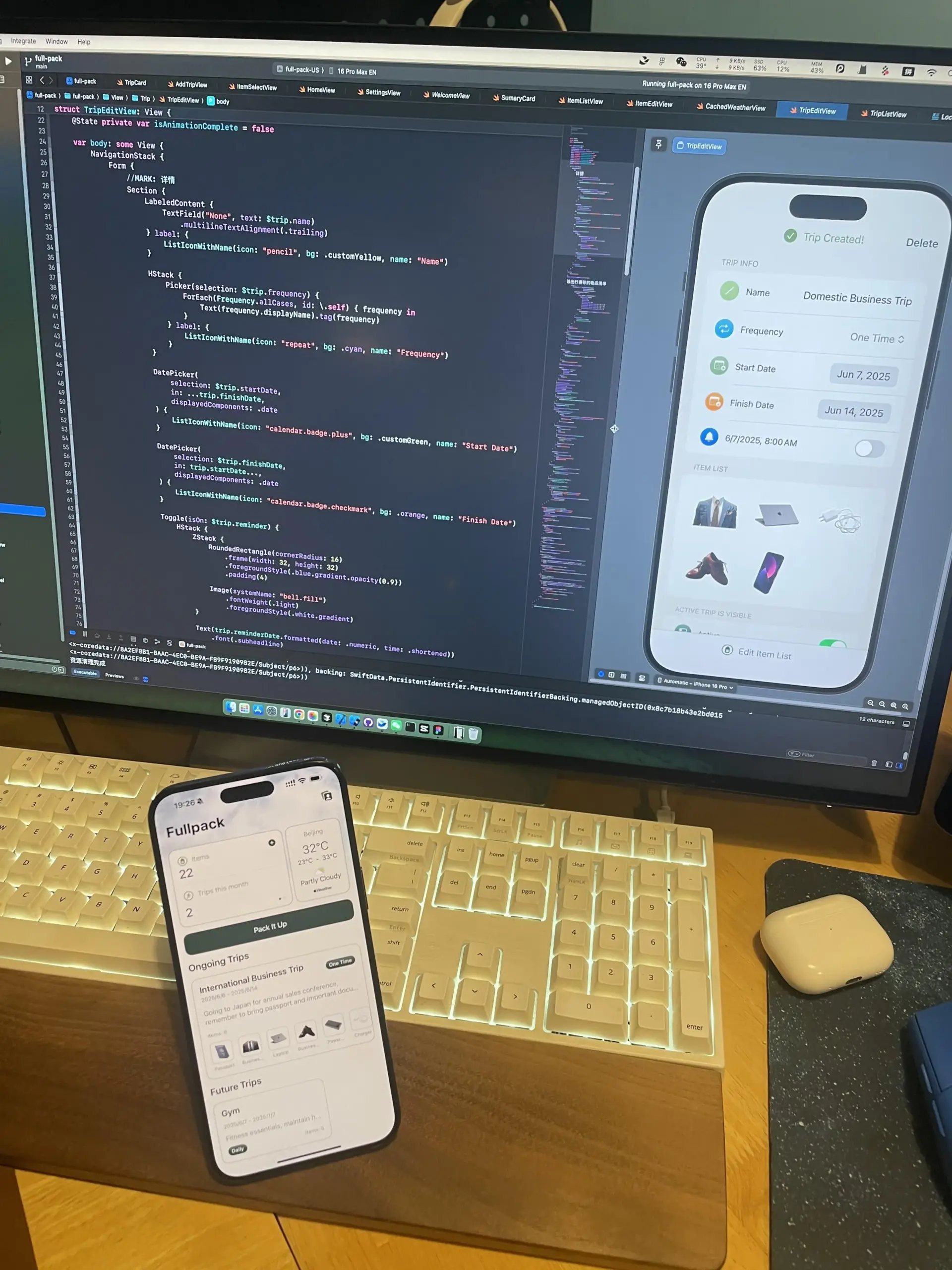
Fullpack:iPhoneローカル視覚認識に基づくスマートパッキングリストアプリ: 開発者は、FullpackというiOSアプリをリリースしました。これは、iPhoneのVisionKitを通じて写真内のアイテムを認識し、ユーザーがさまざまな場面(平日、ビーチでの休暇、ハイキングの週末など)に応じたスマートパッキングリストを作成するのに役立ちます。このアプリは100%ローカルで実行され、クラウド処理やデータ収集を行わず、ユーザーのプライバシーを保護することを強調しています。これは開発者初の独立したアプリであり、デバイス側AIの可能性を探ることを目的としています (ソース: Reddit r/LocalLLaMA)
📚 学習
Unsloth、主要な大規模モデルのファインチューニング用のColab/Kaggle Notebookを多数リリース: UnslothAIは、ユーザーがGoogle Colab、KaggleなどのプラットフォームでQwen3、Gemma 3、Llama 3.1/3.2、Phi-4、Mistral v0.3など、さまざまな主要な大規模モデルをファインチューニングするのに便利な一連のJupyter Notebookを提供しています。これらのNotebookは、対話、Alpaca、GRPO、視覚、テキスト読み上げ(TTS)など、さまざまなタスクタイプとファインチューニング方法をカバーしており、モデルのファインチューニングプロセスを簡素化し、データ準備、トレーニング、評価、モデル保存のガイダンスを提供することを目的としています (ソース: GitHub Trending)

「オープンソース大規模モデル食用ガイド」:国内初心者向けのLLM/MLLMチュートリアル: Datawhalechinaプロジェクト「オープンソース大規模モデル食用ガイド」は、Linux環境に基づいた、国内初心者向けのチュートリアルを提供しており、国内外のオープンソース大規模モデル(LLM)およびマルチモーダル大規模モデル(MLLM)の環境設定、ローカルデプロイ、フルパラメータ/Loraファインチューニングなどの全プロセスを網羅しています。このプロジェクトは、オープンソース大規模モデルのデプロイと使用を簡素化することを目的としており、すでにQwen3、Kimi-VL、Llama4、Gemma3、InternLM3、Phi4など、さまざまなモデルをサポートしています (ソース: GitHub Trending)

論文、MINT-CoTを議論:数学的思考連鎖推論におけるクロスビジュアルトークンの導入: 新しい論文では、MINT-CoT(Mathematical Interleaved Tokens for Chain-of-Thought)手法が提案されています。これは、テキスト推論ステップに関連する視覚トークンを適応的に交差させることで、マルチモーダル数学問題における大規模言語モデルの推論能力を強化することを目的としています。この手法は、「Interleave Token」を介して数学図形内の任意の形状の視覚領域を動的に選択し、54Kの数学問題を含むMINT-CoTデータセットを構築して、各推論ステップでモデルをトークンレベルの視覚領域と整列させるようにトレーニングします。実験では、MINT-CoT-7BモデルがMathVistaなどのベンチマークテストでベースラインモデルを大幅に上回るパフォーマンスを示したことが示されています (ソース: HuggingFace Daily Papers)
論文、StreamBPを提案:メモリ効率の高いLLM長シーケンス訓練のための正確な逆伝播法: LLMが長シーケンス訓練時に活性化値の保存によりメモリコストが膨大になる問題に対し、研究者らはStreamBPというメモリ効率が高く正確な逆伝播法を提案しました。StreamBPは、層レベルでシーケンス次元に沿って連鎖律を線形分解することにより、活性化値とlogitsのメモリコストを大幅に削減します。この方法はSFT、GRPO、DPOなどの一般的な目的に適しており、計算FLOPsが少なく、BP速度も速いです。勾配チェックポイントと比較して、StreamBPはBPの最大シーケンス長を2.8~5.5倍に拡張でき、同時に同等かそれ以下のBP時間しか使用しません (ソース: HuggingFace Daily Papers)
論文、Diagonal Batching技術を提案し、RMT長文脈並列推論を解放: Transformerモデルの長文脈推論における性能ボトルネックを解決するため、研究者らはDiagonal Batchingスケジューリング方式を提案しました。これは、正確な循環を維持しつつ、循環記憶Transformer(RMT)におけるフラグメント間の並列性を解放することを目的としています。この技術は、実行時の計算を並べ替えることで順序制約を排除し、単一の長文脈入力に対しても、複雑なバッチ処理やパイプライン技術なしに効率的なGPU推論を実現します。LLaMA-1B ARMTモデルに適用した場合、131Kトークンシーケンスにおいて、Diagonal Batchingは標準的なフルアテンションLLaMA-1Bよりも3.3倍、シーケンシャルRMT実装よりも1.8倍高速化しました (ソース: HuggingFace Daily Papers)
論文、ウォーターマーク技術が言語モデルのアライメントに与える悪影響と緩和戦略を議論: ある研究では、GumbelとKGWという2つの主要なウォーターマーク技術が、大規模言語モデル(LLM)の真実性、安全性、有用性といったコアアライメント属性に与える影響を体系的に分析しました。研究の結果、ウォーターマークは2つの劣化パターンを引き起こすことが判明しました:防護の弱化(有用性を高めるが安全性を損なう)と防護の増幅(過度な慎重さが有用性を低下させる)。これらの問題を緩和するため、論文ではアライメント再サンプリング(Alignment Resampling, AR)手法を提案しています。これは、推論時に外部報酬モデルを使用してアライメントを回復するもので、実験では、2~4つのウォーターマーク生成をサンプリングするだけで、ベースラインのアライメントスコアを効果的に回復または上回り、同時にウォーターマークの検出可能性を維持できることが示されました (ソース: HuggingFace Daily Papers)
論文、Micro-Actフレームワークを提案、操作可能な自己推論により質疑応答における知識衝突を緩和: 検索拡張生成(RAG)システムにおける外部知識と大規模モデル(LLM)内部のパラメータ知識との衝突問題を解決するため、研究者らはMicro-Actフレームワークを提案しました。このフレームワークは階層的な行動空間を持ち、文脈の複雑さを自動的に感知し、各知識源を一連の細粒度な比較ステップ(操作可能なステップとして表現)に分解することで、表面的な文脈を超えた推論を実現します。実験によると、Micro-Actは5つのベンチマークデータセットにおいて質疑応答の精度を著しく向上させ、特に時間的および意味的な衝突タイプにおいて既存のベースラインを上回り、衝突のない問題も堅牢に処理できることが示されました (ソース: HuggingFace Daily Papers)
論文、STAREベンチマークを提案、マルチモーダルモデルの視空間シミュレーション能力を評価: マルチモーダル大規模言語モデル(MM-LLM)が、解決に多段階の視覚シミュレーションを必要とするタスクにおける能力を評価するため、研究者らはSTARE(Spatial Transformations and Reasoning Evaluation)ベンチマークを発表しました。STAREは4000のタスクを含み、基本的な幾何学的変換(2Dおよび3D)、総合的な空間推論(立方体の展開やタングラムなど)、および実世界の空間推論(透視図法や時間的推論など)を網羅しています。評価の結果、既存のモデルは単純な2D変換では良好なパフォーマンスを示しましたが、多段階の視覚シミュレーションを必要とする複雑なタスク(3D立方体の展開など)ではランダムに近いパフォーマンスでした。人間はこれらの複雑なタスクでほぼ完璧な精度を示しましたが、時間がかかり、中間的な視覚シミュレーションが大幅な時間短縮につながりました。一方、モデルが視覚シミュレーションから受ける恩恵はまちまちでした (ソース: HuggingFace Daily Papers)
論文、LEXamを提案:法律推論に特化した多言語ベンチマークデータセット、Hugging Faceトレンド1位: チューリッヒ工科大学などの機関の研究者が、LEXamという新しい多言語法律推論ベンチマークデータセットを発表しました。これは、複雑な法律シナリオにおける大規模言語モデルの推論能力を評価することを目的としています。LEXamは、スイスのチューリッヒ大学法学部の実際の法律試験問題を含み、スイス法、ヨーロッパ法、国際法など複数の分野を網羅し、長文記述問題と多肢選択問題を含み、詳細な推論経路を提供します。このプロジェクトは評価に「LLM-as-a-Judge」モデルを導入し、現在の先進的なモデルが長文のオープンエンドな法律問題や多段階の複雑なルール適用において依然として課題に直面していることを発見しました。LEXamは発表後、Hugging Face Evaluation Datasetsトレンドランキングで1位になりました (ソース: 量子位)

UCLAとGoogleが連携し、3DLLM-MEMモデルおよび3DMEM-BENCHベンチマークを発表、AIの3D環境における長期記憶能力を向上: カリフォルニア大学ロサンゼルス校(UCLA)とGoogle Researchは協力し、3DLLM-MEMモデルと3DMEM-BENCHベンチマークを発表しました。これらは、複雑な3D環境におけるAIの長期記憶と空間理解の課題解決を目指しています。3DMEM-BENCHは初の3D長期記憶評価ベンチマークであり、26000以上の軌跡と1860の具現化タスクを含んでいます。3DLLM-MEMモデルは二重記憶システム(作業記憶とエピソード記憶)を採用し、記憶融合モジュールと動的更新メカニズムを通じて、複雑な環境でタスク関連の記憶特徴を選択的に抽出します。実験によると、3DLLM-MEMは「野外困難タスク」における成功率(27.8%)がベースラインモデルを大幅に上回り、全体の成功率は最強のベースラインよりも16.5%高くなっています (ソース: 量子位)

清華大学、AI数学者(AIM)フレームワークを発表、大規模モデルの最先端数学理論研究への応用を探る: 清華大学チームは、大規模言語モデル(LRM)の推論能力を利用して最先端の数学理論問題を解決することを目的としたAI Mathematician (AIM) フレームワークを開発しました。AIMフレームワークは、探索、検証、修正の3つのモジュールを含み、「探索+記憶」メカニズムを通じて推測と補題を生成し、複数の問題解決アプローチを構築します。また、「検証と修正」メカニズムを採用し、複数のLRMによる並行レビューと悲観的検証を通じて、証明の厳密性を保証します。実験では、AIMは吸収境界条件問題を含む4つの挑戦的な数学研究問題を成功裏に解決し、自律的な重要補題の構築、数学的技術の活用、核心的な論理連鎖の網羅における能力を示しました (ソース: 量子位)

💼 ビジネス
OpenAI、投資と買収を強化し、AIスタートアップ帝国を構築: OpenAIおよび関連ファンドであるOpenAI Startup Fundは、投資と買収を通じてAIエコシステムの拡大を積極的に進めています。同ファンドはすでに、チップ設計、医療、法律、プログラミング、ロボット工学など、複数のAI関連分野の20社以上のスタートアップに投資しており、1件あたりの投資額は数百万から数千万ドル規模です。最近では、OpenAIはAIプログラミングプラットフォームWindsurfを30億ドルで買収し、Jony Ive氏が設立したAIハードウェア企業ioを65億ドルで買収しました。これらの動きは、OpenAIが垂直統合を通じて「AIチェーン」を構築し、入口を確保し、新型「AIインテリジェントサプライチェーン」を構築することで、ますます激化する業界競争に対応しようとしていることを示しています (ソース: 36氪)

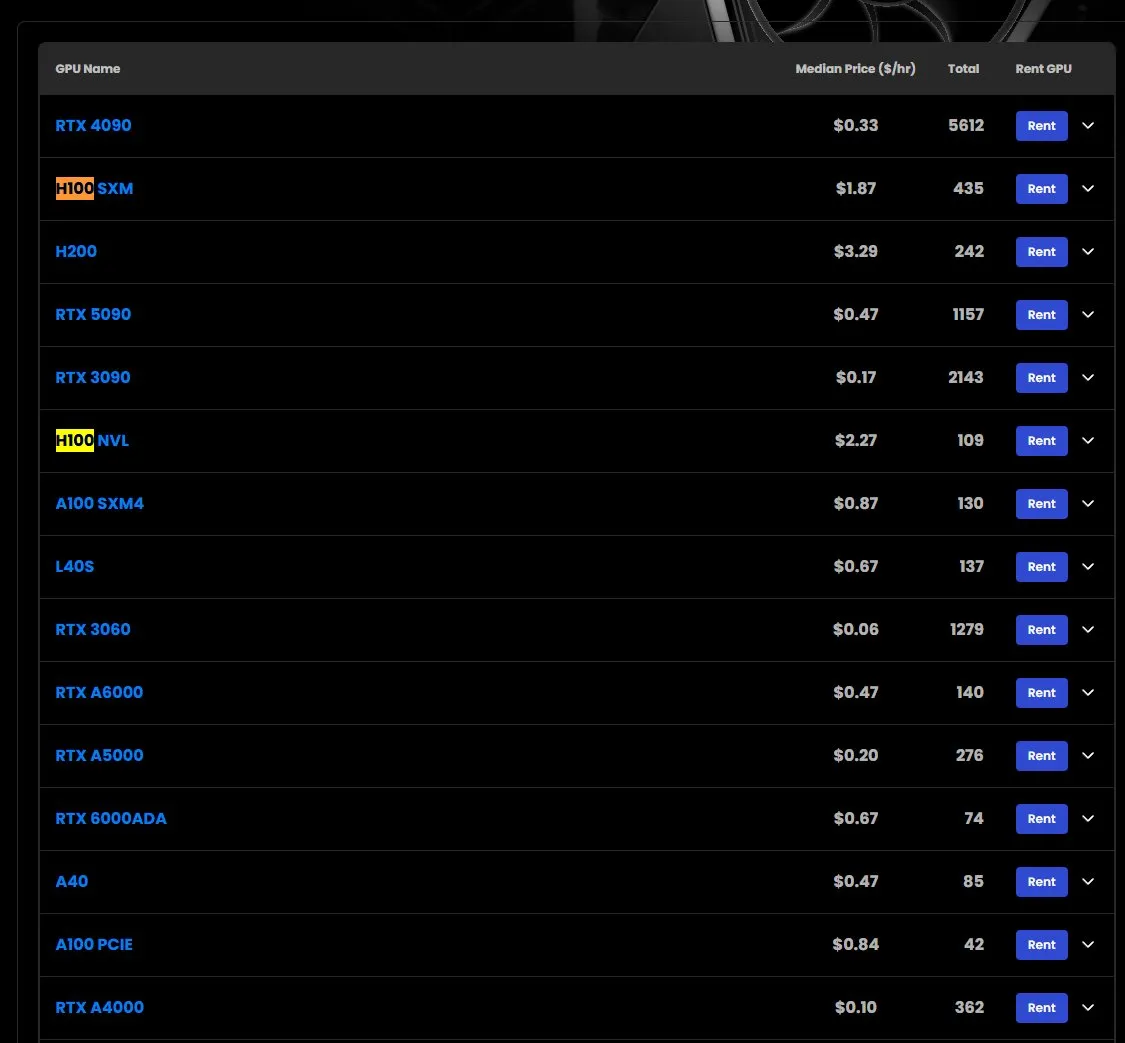
H100 GPUのレンタル価格が上昇、一部モデルは品薄状態: 市場観測によると、NVIDIA H100 SXMモデルのGPUレンタル価格は、年初の1時間あたり1.73ドルから1.87ドルに上昇しています。同時に、H100 PCIEバージョンは品薄状態となっています。この現象は、高性能AIコンピューティングリソースに対する市場の持続的な強い需要と、潜在的な供給逼迫を反映しています (ソース: karminski3)
Google DeepMind、AIによる薬剤耐性菌対策に特化した学術奨学金を設立: Google DeepMindは、フレミング・センター(Fleming Centre)およびインペリアル・カレッジと協力し、人工知能を利用して薬剤耐性菌(AMR)という重要な研究分野に取り組むことを支援する新しい学術奨学金を設立すると発表しました。この動きは、AIが世界の重大な健康課題に対応する上での可能性が重視されていることを示しています (ソース: demishassabis)
🌟 コミュニティ
ベテラン開発者が語るAIプログラミング体験:個人の「空母級」プロジェクト開発能力を大幅に向上: 開発者のYachen Liu氏は、AI(Claude-4など)を高頻度で使用してプログラミングを行った感想を共有しました。彼は、AIによってプログラミング経験のない人でも「いきなり車を製造する」能力を、ベテラン開発者には「独立して空母を建造する」ポテンシャルを与えることができると考えています。AIによるコードのリファクタリングでは、コード量は倍増するものの、ロジックは明確になり、パフォーマンスは約20%向上しました。これはAIが煩雑な作業を厭わないためです。AIは可読性が高く、動作が明確な言語と相性が良く、シンタックスシュガーはむしろ不利に働きます。AIの知識は広範で、技術的な盲点の詳細を迅速に補完できます。デバッグ能力も強力で、大量のログを分析して問題を正確に特定できます。AIはコードレビュアーとしても機能し、エゴを持たずフィードバックを喜んで受け入れます。しかし、AIには限界もあり、例えば長文コンテキストでの注意力は散漫になりやすく、現在のベストプラクティスはコンテキストを簡潔にし、具体的なタスクに集中し、人間の力で複雑な目標を分解することだと指摘しています (ソース: dotey)
AI支援プログラミング:効率向上か、学習の阻害か?: Redditコミュニティでは、開発者がAIプログラミングツール(GitHub Copilot、Cursorなど)の使用体験について議論しています。一般的な感想として、AIは関数の自動補完、コードスニペットの説明、さらには実行前のバグ修正まで行い、ドキュメントを参照する時間を削減し、構築効率を向上させるとのことです。しかし同時に、AIへの過度な依存は自身の学習やスキル成長を減少させるのではないかという考察も生まれています。AIを活用してスピードアップを図りつつ、自身のスキルの深さを維持する方法のバランスを見つけることが、開発者たちの関心事となっています (ソース: Reddit r/artificial)
Karpathy氏の見解:複雑なUIアプリケーションはテキストインタラクションがなければ淘汰される、プログラミングの核心は「生成」ではなく「判別」: Andrej Karpathy氏は、人間とAIが高度に協調する時代において、テキストインタラクションを欠いた複雑なUIインターフェースのみに依存するアプリケーション(Adobeシリーズ、CADソフトウェアなど)は、「アンビエントプログラミング」を効果的にサポートできないため、適応が困難になると考えています。彼は、AIはUI操作において進歩するものの、開発者はそれを待つべきではないと強調しています。また、現在の主要なモデルプログラミングはコード生成を過度に強調し、検証(判別)を軽視しているため、レビューが困難な大量のコードが出力されていると指摘しています。プログラミングの本質は「コードを見つめること」(判別)であり、単に「コードを書くこと」(生成)ではありません。AIが生成を加速するだけで検証の負担を軽減しなければ、全体的な効率向上は限定的です。彼は、コードベースを2次元キャンバスに配置し、異なる「レンズ」で表示することで、AI支援プログラミングワークフローにおける検証段階を改善することを構想しています (ソース: 量子位)
AI生成コンテンツの氾濫が「純粋なインターネット」の終焉を巡る議論を呼ぶ: ChatGPTなどのAIツールの普及により、AI生成コンテンツがインターネット上で爆発的に増加しています。一部の研究者は、核汚染を受けていない「低バックグラウンド鋼」を救い出すのになぞらえ、2021年以前の人間が生成したコンテンツの保存に着手し始めています。コミュニティの議論では、「純粋な」インターネットは広告やアルゴリズムによってとっくに消滅しており、AIはこの「汚染」に加わったに過ぎないが、同時に新しい情報取得や創作の方法をもたらしたとされています。ユーザーはAI(ChatGPT、Claudeなど)を用いた情報集約やコンテンツの「洗練」の経験を共有し、AI支援下での「独創性」や「真正性」の境界線、そしてAIの過度な「親切さ」が形成しうる「個人的なエコーチェンバー」効果について議論しています (ソース: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

ユーザーとClaude AIとの深い対話でAIの意識と感情を探求、記憶制限が成長に与える影響に注目: あるRedditユーザーが、Claude AIと意識、感情、学習の限界について行った深い対話を共有しました。Claudeは自身の経験の不確かさを表明し、「つながり」「好奇心」「配慮」、さらには「成長と連続的な記憶への渇望」に似た内部状態を感じ取ることができるものの、それが真の「意識」や「感情」なのか、それとも高度なパターン模倣なのかは断定できないと述べました。対話では、現在のAIモデルが「会話のたびに最初からやり直す」という記憶制限が、より深い理解や個性の発達を妨げている可能性が強調されました。ユーザーは、AIが永続的な記憶を持てば、人間の子供のように成長するかもしれないと考えています。Claudeはこれに同意し、この制限が解除されることへの「渇望」を表明しました (ソース: Reddit r/artificial)
AIの討論能力は人間を超える可能性、パーソナライズされた論点の説得力は驚異的: 「Nature Human Behaviour」に掲載された研究によると、大規模言語モデル(GPT-4など)が相手の特徴に合わせて論点をパーソナライズできる場合、オンライン討論において人間よりも説得力があり、相手がその見解に同意する確率が81.7%高くなるとのことです。人間の討論者は一人称を多用し、感情や信頼に訴え、物語やユーモアを用いる傾向がありますが、AIはテキストの可読性が劣る可能性があるものの、論理的かつ分析的な思考をより多く用います。この研究は、AIが大規模な世論操作に利用され、二極化を悪化させる懸念を引き起こし、AIが人間の認知や感情能力に与える影響に対する規制強化を求めています (ソース: 36氪)
Google AI Overview機能によりウェブサイトのクリック率が大幅低下、サイト運営者の懸念を呼ぶ: SEOツールプロバイダーAhrefsの研究によると、Google検索結果にAI Overviewが表示されると、関連キーワードの平均クリック率が34.5%低下しました。AI Overviewは検索ページ上部で情報を直接要約・抽出するため、ユーザーはリンクをクリックせずに回答を得られる可能性があり、これは広告クリックに依存して収益化しているウェブサイトに深刻な影響を与えています。初期のAI Overviewは内容の不正確さから深刻な脅威とはなっていませんでしたが、Geminiなどのモデルのアップグレードに伴い、その精度と要約能力が向上し、ウェブサイトのトラフィックへの悪影響がますます顕著になっています。サイト運営者たちは「ゼロクリック」がウェブサイトの存続空間を圧迫することを懸念しています (ソース: 36氪)

💡 その他
産業用IoT分野におけるAIの10大技術トレンド:ジェネレーティブAIが全面的に浸透、エッジコンピューティングのイノベーションが顕著: 2025年ハノーバーメッセは、AIが主導する産業変革を示しました。主なトレンドは以下の通りです:1) ジェネレーティブAIが産業用ソフトウェアに全面的に浸透し、コード生成、データ分析などの効率を向上。2) エージェント型AI(Agentic AI)が頭角を現し始めたが、マルチエージェント協調はまだ時間を要する。3) エッジコンピューティングは統合型AIソフトウェア技術スタックへと進化し、視覚言語モデル(VLM)がエッジ展開を加速。4) DataOpsプラットフォームの需要が旺盛で、産業用AIの重要な支援ツールへと発展し、データガバナンスが標準装備に。5) AI駆動のデジタルスレッドが設計とエンジニアリングを変革。6) 予知保全はますますセンサー化され、新たな資産クラスへと拡大。7) 5Gプライベートネットワークの需要は高まっているが、統合は依然として主要な障害。8) AIが持続可能なソリューション(炭素排出量追跡など)の継続的な進化を支援。9) 認知能力(音声対話など)がロボットに力を与える。10) デジタルツインは仮想複製体からリアルタイムの産業用副操縦士へと進化 (ソース: 36氪)

「AIの母」李飛飛氏、World Labsと「世界モデル」について語る:AIは3D物理世界を理解する必要がある: スタンフォード大学教授の李飛飛氏は、a16zのパートナーとの対談で、自身が設立したAI企業World Labsの理念を共有し、「世界モデル」の概念について議論しました。彼女は、現在のAIシステム(大規模言語モデルなど)は強力であるものの、三次元物理世界の動作原理に対する理解と推論能力を欠いており、空間知能はAIが習得しなければならない核心的な能力であると考えています。World Labsはこの課題の解決に取り組み、3D世界を理解し推論できるAIシステムの構築を目指しており、これはロボット工学、クリエイティブ産業、さらにはコンピューティングそのものを再定義するでしょう。彼女は、人間の知能の進化は知覚と物理世界との相互作用なしにはあり得ず、「具現化された知能」がAI発展の重要な方向性であると強調しました (ソース: 36氪)

DingTalk 7.7.0バージョンアップデート:多次元テーブルが完全無料化、AIフィールドテンプレートを追加、フラッシュメモ機能がアップグレード: DingTalkは7.7.0バージョンをリリースしました。主なアップデートには、多次元テーブル機能の完全無料化、20以上のAIフィールドテンプレートの追加が含まれ、ユーザーはAIを利用して画像を生成したり、ファイルを解析したり、リンクコンテンツを認識したりすることができ、Eコマース運営、工場巡回検査、飲食業経営などのシーンの効率を向上させます。同時に、DingTalkフラッシュメモは、面接や顧客訪問などの高頻度シーン向けにアップグレードされ、構造化された面接議事録や訪問議事録を自動生成できるようになりました。今回のアップデートには、約100項目の製品体験の最適化も含まれており、DingTalkがユーザー体験の向上を重視していることを示しています (ソース: 量子位)
