キーワード:テスラRobotaxi, AMD MI350, OpenAI o3-pro, 科大訊飛AIUI, 元戎啓行VLA, DeepSeek Nano-vLLM, アントグループMing Lite Omni, L2量産車でL4自動運転を実現, AMD MI350XとB200の性能比較, o3-proモデルの長文脈処理能力, AIUI全二重対話技術, 視覚-言語-動作モデルVLA
🔥 注目
テスラRobotaxiが初の公道走行、マスク氏はL2量産車の改造なしでL4レベル自動運転実現可能と発言: テスラのRobotaxi(リフレッシュ版Model Y)がオースティンで公道テストを開始。車体には新しいRobotaxiロゴがあるがハンドルは残されている。マスク氏によると、全てのテスラ量産車は監視なしの自動運転を実現可能であり、現在テスト車両には現行FSDの4.5倍のパラメータ数を持つ内部テスト版FSDが搭載されており、年内に最適化後リリース予定。Robotaxiは6月22日に一般公開予定で、オースティンが最初の提供都市となる。この動きはテスラのL2レベルFSDからL4/L5レベルRobotaxiへの進化を示し、自動運転業界の競争構造を加速させ、特にWaymoなどのL4技術ルートのプレイヤーに挑戦を突きつける可能性がある (来源: 量子位)

AMDが最強AIチップMI350シリーズを発表、性能はNVIDIA B200を凌駕: AMD CEOのスー・リサ氏とOpenAI CEOのサム・アルトマン氏が共同でMI350XおよびMI355X GPUを発表。これらのチップは3nmプロセスを採用し、1850億個のトランジスタと288GBのHBM3Eメモリを搭載。メモリ容量はNVIDIA B200の1.6倍。公式データによると、MI350シリーズはFP4精度でLlama 3.1 405Bを実行する際の推論速度がB200より30%速く、FP64の計算能力ではNVIDIAの2倍。AMDはまた、OpenAIと共同開発するMI400シリーズが来年登場することも予告し、AIチップ市場の競争をさらに激化させる (来源: 量子位)

OpenAI o3-proモデルの推論能力が注目されるも、実際のパフォーマンスは公式テストとやや異なる: OpenAIの最新推論モデルo3-proは、複雑な言葉遊び(歌手Sabrina Carpenterの曲名の特徴に基づいて特定の回答を生成するなど)を処理する際に強力な能力を示し、OpenAIの元AGI Readinessチーム責任者が以前Appleが大規模モデルの推論能力に疑問を呈したことを皮肉った。しかし、LiveBenchなどの権威あるランキングでは、o3-proのコーディング平均スコアはo3とほぼ同等で、エージェントコーディングのスコアではむしろ劣っていた。Fiction.LiveBenchのテストでは、o3-proは短いコンテキストでは優れたパフォーマンスを示したが、192kの超長コンテキスト処理では依然としてGemini 2.5 Proに劣っていた。AppleおよびSpaceXの元エンジニアであるBen Hylak氏は、o3-proの真の能力は十分な背景情報の入力に大きく依存しており、単純なチャット相手としてよりもレポートジェネレーターとして適しており、ツール呼び出しと環境理解の面で大幅な向上が見られると指摘している (来源: 量子位)

科大訊飛(iFLYTEK)がAIUIヒューマンマシンインタラクションプラットフォームとロボットスーパーブレインプラットフォームをアップグレードし、スマートハードウェアの緊密な連携を推進: 科大訊飛は、ヒューマンマシンインタラクションプラットフォームAIUIの大幅なアップグレードを発表。フルデュプレックスインタラクション、感情認識と表現、人間のような記憶システムを重点的に強化した。特に子供向けシーンでは、専用のインタラクションソリューションを導入し、子供の言葉の認識と理解能力を向上させた。同時に、同社のロボットスーパーブレインプラットフォームはSpark大モデルをベースに、マルチモーダルインタラクション、意味理解、知識応用を強化し、「スマート音声バックパック」を発表。これにより、既存のロボットはハードウェア改造なしで音声インタラクションを実現できる。これらのアップグレードは、スマートハードウェアを基本的なインタラクションから緊密なインテリジェント連携へと押し上げ、車載、AIハードウェア、ロボットなど複数の分野に貢献することを目的としている (来源: 量子位)

🎯 動向
元戎啓行(DeepRoute.ai)と火山引擎(Volcengine)が提携、豆包(Doubao)大規模モデルを基盤にVLA物理世界Agentを開発: 元戎啓行CEOの周光氏は、火山引擎と提携し、豆包大規模モデルを活用して視覚-言語-行動(VLA)モデルなどの先進技術を共同開発し、物理世界のAgentを構築することを目指すと発表した。元戎啓行のVLAモデルは2025年第3四半期に消費者市場に投入予定で、空間意味理解、異形障害物認識、文字案内板理解、音声制御車両の4つのコア機能を備え、運転支援の安全性とインテリジェンスレベルの向上を目指す。現在、VLAモデルは路上テストを完了しており、年内には同モデルを搭載したAI自動車が5車種以上発売される見込み (来源: 量子位)

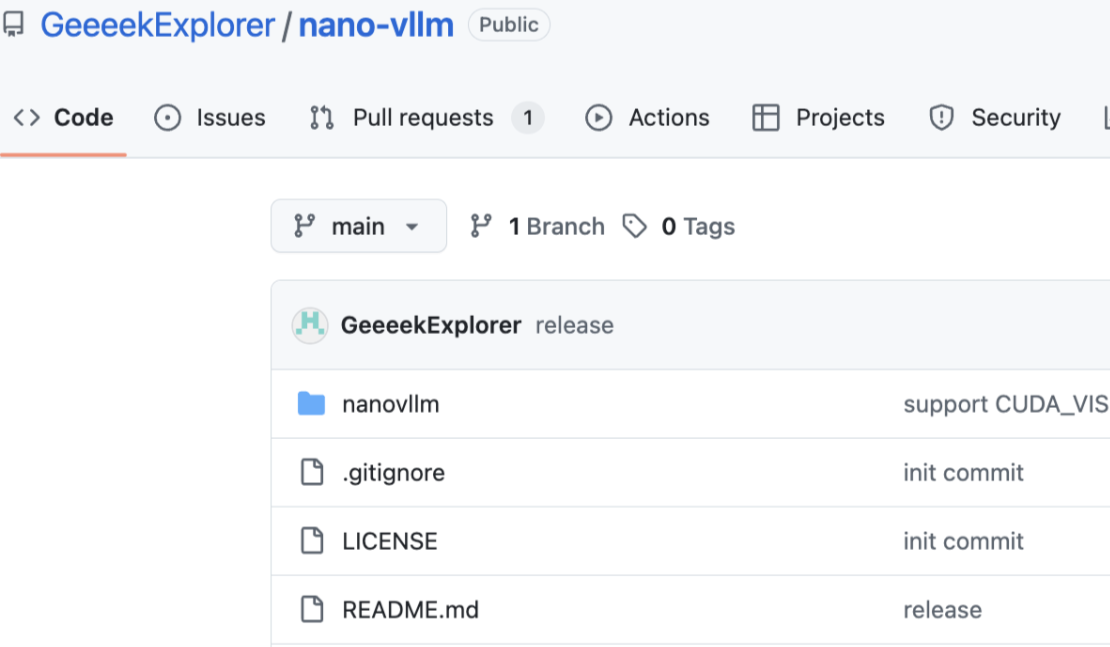
DeepSeek研究者が1200行のコードでvLLMを再現、一部シナリオで性能がオリジナルを上回る: DeepSeekの研究者である俞星凯氏がNano-vLLMプロジェクトをオープンソースで公開。1200行未満のPythonコードで、PagedAttentionなどの主要技術を含むvLLMのコア機能を実現した。このプロジェクトは、学習と理解を容易にするために、最小限かつ完全に可読なvLLMバージョンを提供することを目的としている。H800ハードウェアとQwen3-8Bモデルの特定のテスト条件下では、Nano-vLLMのスループットはオリジナル版vLLMを上回り、その効率性を示した。vLLMはUC Berkeleyが開発したLLM推論・サービスフレームワークで、PagedAttentionアルゴリズムによりLLMサービスのスループットを大幅に向上させたことで知られる (来源: 量子位)
中国企業が「フライングハードディスクケース」を利用し、米国のAIチップ輸出規制を回避: ウォール・ストリート・ジャーナルの報道によると、米国の高性能AIチップに対する輸出規制に直面し、中国企業は新たな戦略を採用。大量の学習データ(例:80TB)を保存したハードディスクをエンジニアがマレーシアなどの海外データセンターに持ち込み、現地のNvidiaなどの先進チップを搭載したサーバーを利用してAIモデルの学習を行い、完了後にモデルパラメータを中国に持ち帰っている。この動きは、チップの直接輸入の困難を回避し、東南アジアや中東地域におけるAIデータセンターの隆盛を後押しすることを目的としている。米商務省の元当局者はこれに対し懸念を表明している (来源: dotey)

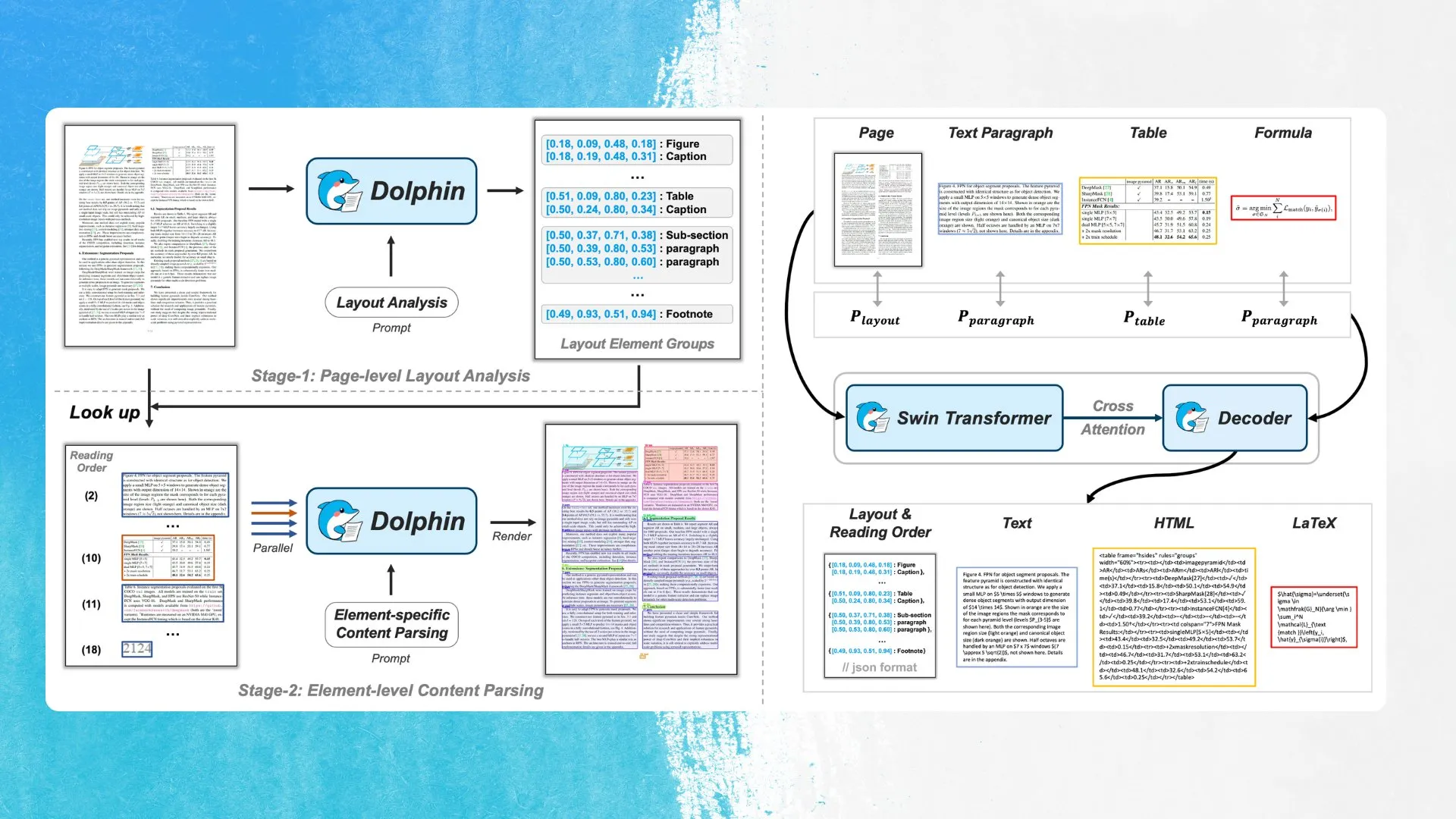
ByteDanceが新しいOCRモデルDolphinを発表、レイアウト要素検出と並列解析を採用: ByteDanceは、MITライセンスに基づく新しいOCRモデルDolphinを発表した。このモデルはまずドキュメントレイアウト内の要素(表、数式など)を検出し、その後各要素を並列に解析してコンテンツを生成する。モデルとデモはHugging Face Hubで公開されている。この方法は、複雑なドキュメント構造認識の精度と効率を向上させることを目的としている (来源: mervenoyann)
OpenAI ChatGPTプロジェクト機能が強化、詳細調査、音声モード、モバイル端末でのファイルアップロードに対応: OpenAIは、ChatGPT内の「プロジェクト」(Projects)機能に複数の改善を加えると発表した。これには、強化された詳細調査サポート、音声モードの統合、プロジェクト内の過去のチャット履歴を参照するための改善された記憶機能、モバイル端末でのファイルアップロードとモデルセレクターのサポートが含まれる。これらのアップデートは、ユーザーがChatGPTでより集中的かつ複雑な作業を行う能力を向上させることを目的としている (来源: kevinweil)
EuroLLMチームが複数の新モデルプレビュー版をリリース、22Bモデルや小型MoEモデルなど: EuroLLMチームは、22Bパラメータのベース版とインストラクションファインチューニング版モデル、旧版EuroLLMベースの2つの視覚モデル(1.7Bおよび9Bパラメータ)、そして0.6Bのアクティブパラメータと2.6Bの総パラメータを持つ小型混合エキスパート(MoE)モデルを含む、複数の新モデルのプレビュー版をリリースした。これらのモデルはすべてApache-2.0ライセンスを採用しており、初期テストではこの小型MoEモデルがその規模にしては予想外に良好な性能を示している (来源: Reddit r/LocalLLaMA)

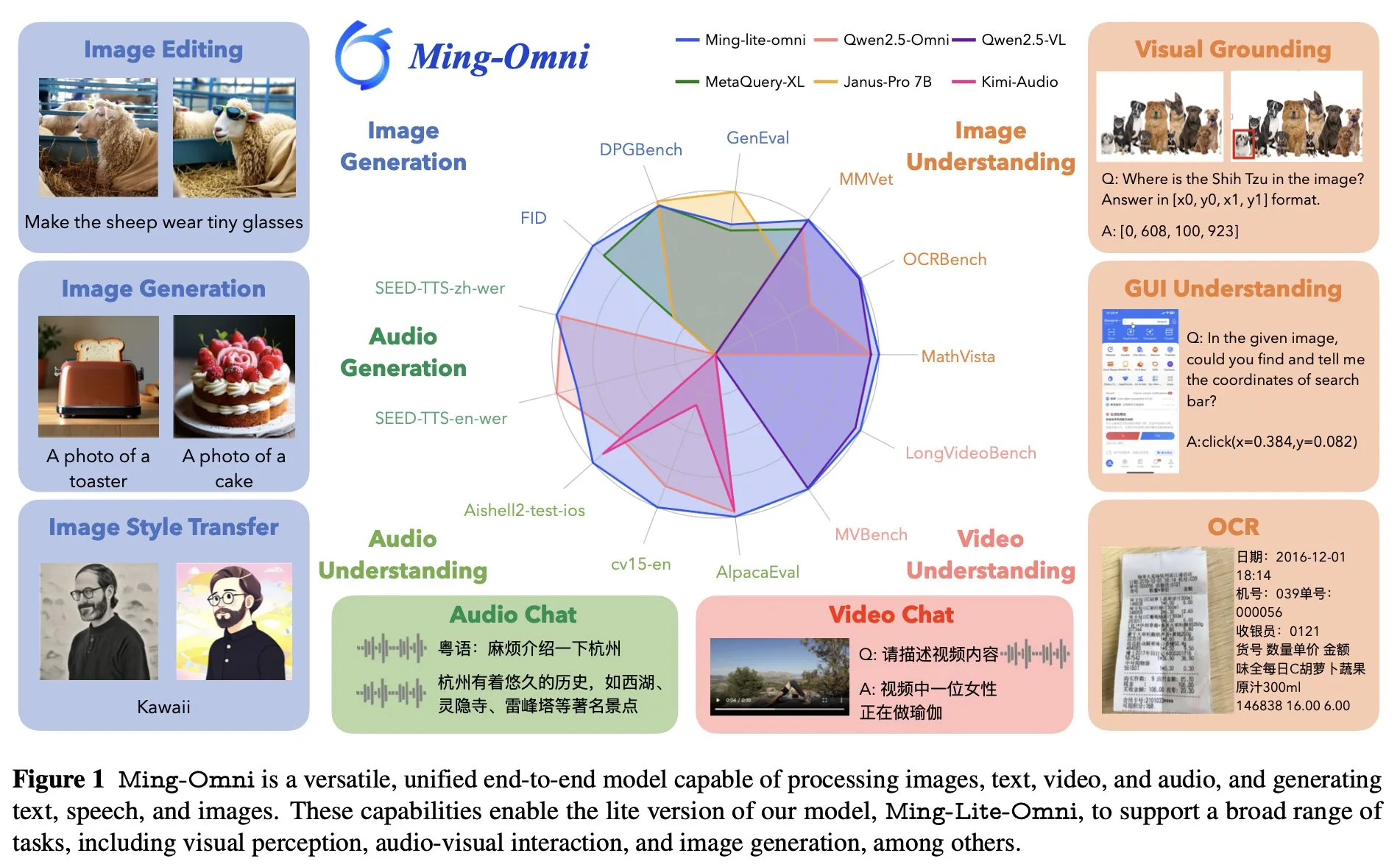
Ant Groupがエンドツーエンドの万能モデルMing Lite Omniを発表、GPT-4oに対抗: Ant GroupはMing Lite Omniモデルを発表。このモデルは、聴取、発話、画像生成など多様な機能を実現し、性能面でGPT-4oと競合する。Ming Lite OmniはGUIタスクにおいてQwen2.5VL-7Bを上回る精度を達成し、音声理解は複数の公開ベンチマークでSOTAを達成、動画理解能力も優れた性能を示している。モデルは混合エキスパート(MoE)アーキテクチャを採用し、アクティブパラメータはわずか2.8Bで、音声および画像生成向けに特定の最適化が施されている(例:BPEを使用して音声トークンのフレームレートを削減、マルチスケール学習可能トークンにより画像生成品質を向上) (来源: mervenoyann)
NVIDIAとMistral AIが提携し、AIクラウドプラットフォームMistral Computeを共同構築: NVIDIAはGTC大会でMistral AIとの提携を発表し、Mistral Computeという名のAIクラウドプラットフォームを共同で構築する。この動きは、米国とオープンソースコミュニティにとって大きな利益と見なされており、米国のチップでサポートされるオープンモデルを通じて、世界のAIインフラ構築にテンプレートを提供することを目指している (来源: arthurmensch)
Hugging FaceがPyTorchへの全面的な移行を発表、Transformersライブラリを簡素化: Hugging FaceのチーフオープンソースオフィサーであるLysandre Jik氏は、ユーザーベースが既にPyTorchでコンセンサスを形成していることを踏まえ、今後はPyTorchに全ての努力を集中し、Transformersライブラリの肥大化を軽減し、より簡潔なツールキットの提供に努めると述べた。PyTorch公式はこれを歓迎し、この動きがコードの簡潔性を維持するのに役立つと強調した (来源: reach_vb)

ByteDanceがリアルタイムインタラクティブ動画生成技術APT2を発表: ByteDanceは、最新のリアルタイムインタラクティブ動画生成技術APT2(Autoregressive Adversarial Post-Training)を公開した。この技術は、自己回帰的な敵対的ポストトレーニングを通じて、高品質でリアルタイムなインタラクティブ動画コンテンツの生成を目指し、動画生成分野の発展をさらに推し進めるものである (来源: NerdyRodent)
🧰 ツール
Llama-Server Launcher:GUI付きllama.cppサーバーランチャー、CUDAパフォーマンス最適化に特化: ある開発者が個人で使用しているllama-serverランチャーを共有。Pythonで書かれ、グラフィカルユーザーインターフェース(GUI)を提供する。このツールはllama.cppサーバーの設定と起動を簡素化し、特にCUDAパフォーマンスチューニングに注力している。機能には、モデル選択、パス設定、コンテキストとバッチサイズの調整、GPUオフロード、FlashAttention、テンソル分割などの高度なパフォーマンス設定、チャットテンプレート選択、環境設定管理が含まれる。GPUとシステム情報の自動取得、GGUFモデルメタデータの分析、クロスプラットフォームの起動スクリプト(.ps1/.sh)生成をサポートする (来源: Reddit r/LocalLLaMA)
Together AI がオープンソースのデータサイエンティストエージェントをリリース: Together AI は、データサイエンティストのように推論できるオープンソースのAIエージェントを構築した。このエージェントは、データをロードし、Pythonコードを記述し、モデルが失敗した場合には再トレーニングを行い、実際のKaggleやDABStepタスクを解決することができる。この取り組みは、データサイエンス分野におけるAIの自動化と普及を促進することを目的としている (来源: percyliang)
AutoMind:データサイエンス自動化のための適応型知識ベースエージェントフレームワーク: AutoMindは、専門家の知識ベースの統合、エージェント知識ツリー検索アルゴリズムの採用、適応型コーディング戦略を通じて、既存のデータサイエンスエージェントが複雑で革新的なタスクを処理する際の限界を克服し、自動化された機械学習プロセスの実世界での有効性を向上させることを目的とした新しいLLMエージェントフレームワークである (来源: HuggingFace Daily Papers)
LlamaParseが「プリセット」機能をリリース、ドキュメント解析設定を簡素化: LlamaParseは「プリセット」(Presets)機能を導入し、さまざまなユースケースに合わせて設定を最適化するための一連の理解しやすい事前設定モードを提供する。汎用シナリオ向けの高速、バランス、高度モードのほか、請求書、科学論文、技術文書、フォームなどの一般的なユースケースに最適化されたモードが含まれており、ユーザーが速度と精度の間でより簡単に選択できるようにすることを目的としている (来源: jerryjliu0)
OpenWebUIにo3-proサポート機能が追加され、モデル互換性が拡張: コミュニティ開発者がOpen WebUI向けに新機能を作成し、レスポンスAPIサポート、コスト追跡、マルチキーサポート、ウェブ検索などの特性を追加することで、o3-proモデルのサポートを拡張した。これにより、ユーザーは公式の高度なプランに加入することなく、Open WebUIでo3-proを使用できるようになる (来源: Reddit r/OpenWebUI)
📚 学習
論文、半非負値行列因子分解(SNMF)によるMLP活性化の解釈可能な特徴への分解を議論: 本研究は、SNMFを用いて多層パーセプトロン(MLP)の活性化を直接分解し、共活性化ニューロンの線形結合からなるスパースな特徴を学習し、これらの特徴をその活性化入力にマッピングすることで直接的な解釈可能性を持たせることを提案する。実験により、SNMF由来の特徴は因果的誘導においてスパースオートエンコーダ(SAE)よりも優れており、人間が解釈可能な概念と一致し、MLP活性化空間における階層構造を明らかにすることが示された (来源: HuggingFace Daily Papers)
新論文がLoRMAを提案:低ランク乗法適応(Low-Rank Multiplicative Adaptation)によるLLMファインチューニングの新パラダイム: 従来のLLMファインチューニングは通常、加法的更新によって重みを更新するが、LoRMAは乗法的更新を探求する。低ランク行列がもたらす「ランク抑制」問題を解決するため、論文では順列と加法に基づく新しいランク拡張操作を導入し、効果的な並べ替え操作によって計算効率を確保する。実験によりLoRMAは競争力があることが示され、LLM適応のための新しいアイデアを提供する (来源: Reddit r/deeplearning)
論文がTaxoAdaptフレームワークを提案、LLMが構築した多次元分類体系を進化する研究コーパスに適応させる: 科学文献の組織化という難題に対し、TaxoAdaptフレームワークは、LLMが生成した分類体系を特定のコーパスに適応するように動的に調整し、多次元(方法論、タスク、評価指標など)をサポートする。このフレームワークは、反復的な階層分類を通じて、コーパスの主題分布に基づいて分類の幅と深さを拡張し、科学分野の進化をより良く組織化し捉えることを目指す (来源: HuggingFace Daily Papers)
論文がMOSAICフレームワークを紹介、エージェントシステムにおける協調学習を実現: MOSAICは、自律的でインテリジェントなAIシステムが分散型で動的な環境において協調学習を行うためのフレームワークである。エージェントは、同期や集中制御なしに、モジュール化された知識(ニューラルネットワークマスクの形式)を選択的に共有し再利用する。実験により、MOSAICは速度と性能において孤立した学習者よりも優れており、時には孤立したエージェントでは解決できないタスクを解決し、集団的な効率と適応性の向上を促進できることが示された (来源: Reddit r/MachineLearning)
論文がClaimSpectフレームワークを提案、複雑な主張に対する検索拡張型の階層的分析を行う: 多くの主張(科学的、政治的主張など)は単純な真偽ではない。ClaimSpectフレームワークは、検索拡張生成を通じて、主張に関連する側面の階層構造を自動的に構築し、特定のコーパスの視点でこれらの側面を豊かにする。この方法は、複雑な主張を分解し、コーパスにおける各側面に対する異なる見解とその普遍性を提示することを目的とする (来源: HuggingFace Daily Papers)
論文がアテンションヘッド選択によるきめ細かい摂動ガイダンス(Fine-Grained Perturbation Guidance)を提案: 本研究は、拡散モデル内の特定のアテンションヘッドが異なる視覚的概念(構造、スタイル、テクスチャ品質など)を制御することを発見した。これに基づき、論文は「HeadHunter」フレームワークを提案。ユーザーの目標と一致するアテンションヘッドを体系的に選択し、生成品質と視覚的属性のきめ細かい制御を実現し、SoftPAGを導入して摂動強度を調整する。この方法は、Stable Diffusion 3やFLUX.1などのモデルで、品質向上とスタイル誘導における優位性を検証した (来源: HuggingFace Daily Papers)
論文、LLMのアンラーニングは形式独立性(Form-Independent)を持つべきだと議論: 研究は、現在のLLMアンラーニング手法の効果が訓練サンプルの形式に大きく依存し、同じ知識の異なる表現への汎化が困難であることを指摘する。論文はこの問題を「形式依存バイアス」(Form-Dependent Bias)と定義し、評価のためにORTベンチマークを導入する。この問題を解決するため、論文はROCR(Rank-one Concept Redirection)手法を提案。特定概念に対するモデルの知覚をリダイレクトすることでアンラーニングを実現し、実験によりROCRがアンラーニング効果を大幅に向上させ、自然な出力を生成できることを証明した (来源: HuggingFace Daily Papers)
論文がUniPre3Dを提案:クロスモーダルガウススプラッティングに基づく3D点群モデルの統一事前学習手法: UniPre3Dは、3Dビジョンにおける点群データの多様なスケールがもたらす課題を解決することを目的とし、あらゆるスケールの点群とあらゆるアーキテクチャの3Dモデルにシームレスに適用可能な初の統一事前学習手法を提案する。この手法は、ガウスプリミティブの予測を事前学習タスクとし、微分可能なガウススプラッティングレンダリング画像を利用することで、正確なピクセルレベルの教師あり学習とエンドツーエンドの最適化を実現すると同時に、2D事前学習モデルの特徴を統合してテクスチャ知識を導入する (来源: HuggingFace Daily Papers)
論文がStreamSplatを提案:未調整ビデオストリーム向けのオンライン動的3D再構成: StreamSplatは、任意の長さの未調整ビデオストリームをオンラインで動的な3Dガウススプラッティング(3DGS)表現に変換できる完全なフィードフォワードフレームワークである。静的エンコーダにおける確率的サンプリングメカニズムによる3DGS位置の予測と、動的デコーダにおける双方向変形場により、ロバストで効率的な動的モデリングを実現し、リアルタイム動的シーン再構成における調整、動的モデリング、効率安定性の課題解決を目指す (来源: HuggingFace Daily Papers)
論文、マスク画像モデリングにおけるアテンションプロービング(Attentive Probing)を再考: 大規模ファインチューニングが非現実的になるにつれ、プロービングは自己教師あり学習(SSL)評価の主要な選択肢となっている。標準的な線形プロービング(LP)は、マスク画像モデリング(MIM)で訓練されたモデルの潜在能力を十分に反映できていない。本稿ではアテンションプロービングを再検討し、効率的なプロービング(EP)を導入。これはマルチクエリクロスアテンションメカニズムであり、訓練可能なパラメータを削減し速度を向上させ、複数のベンチマークでLPおよび以前のアテンションプロービング手法を上回る性能を示した (来源: HuggingFace Daily Papers)
論文がPosterCraftを提案:統一フレームワーク下での高品質な美的ポスター生成の新アプローチ: PosterCraftは、美的ポスター生成の課題解決を目指す。この課題は、正確なテキストレンダリングだけでなく、抽象的なアートコンテンツ、魅力的なレイアウト、全体的なスタイルの調和のシームレスな統合を要求する。PosterCraftは、大規模テキストレンダリング最適化、領域認識教師ありファインチューニング、美的テキスト強化学習、共同視覚言語フィードバックによる洗練を含むカスケードワークフローを採用して生成を最適化し、複数の実験でオープンソースのベースラインを大幅に上回った (来源: HuggingFace Daily Papers)
論文、トークン摂動ガイダンス(Token Perturbation Guidance)による拡散モデルの改善を提案: 分類器フリーガイダンス(CFG)が特定の訓練プロセスを必要とし、条件付き生成に限定されるという制約を解決するため、TPG手法は拡散ネットワーク内の中間トークン表現に直接摂動行列を適用する。TPGはノルム保存シャッフル操作を採用して効果的なガイダンス信号を提供し、アーキテクチャ変更なしに生成品質を向上させ、条件付きおよび無条件生成の両方に適用可能である。実験により、TPGは無条件生成においてSDXLベースラインのFIDを約2倍改善することが示された (来源: HuggingFace Daily Papers)
論文がDreamActor-H1を提案:モーションデザインによるDiffusion Transformersを用いた高忠実度人間-商品デモンストレーションビデオ生成: DreamActor-H1は、Diffusion Transformer (DiT)をベースとしたフレームワークであり、高品質な人間と製品のインタラクションデモンストレーションビデオの生成を目指す。この手法は、ペアの人間-製品参照情報と追加のマスク化クロスアテンションメカニズムを注入することで、人間と製品のアイデンティティ詳細(ロゴ、テクスチャなど)を保持する。3D人体メッシュテンプレートと製品バウンディングボックスを利用して正確なモーションガイダンスを提供し、構造化テキストエンコーディングによって3D一貫性を強化する (来源: HuggingFace Daily Papers)
論文がEmbodiedGenを提案:身体化AI向けの生成的3Dワールドエンジン: EmbodiedGenは、インタラクティブな3Dワールド生成のための基礎プラットフォームであり、正確な物理的特性と実世界スケールを持ち、統一ロボット記述フォーマット(URDF)を採用した、高品質で制御可能、フォトリアリスティックな3Dアセットを低コストでスケーラブルに生成することを目指す。これらのアセットは様々な物理シミュレーションエンジンに直接インポートでき、身体化AIの訓練と評価タスクをサポートし、従来の3Dコンピュータグラフィックスアセットのコスト高や限定的なリアリズムの問題を解決する (来源: HuggingFace Daily Papers)
新研究がAppleの「思考の錯覚」論文に反論、LLMは新たな複雑問題を解決できると主張: Apple社が最近発表した「思考の錯覚」(Illusion of Thinking)論文が、大規模推論モデル(LRM)は複雑な計画パズル(ハノイの塔など)で「精度崩壊」を起こすと主張したことに対し、ある追跡的な評論研究は、Appleの結論はモデルの基本的な推論能力の失敗ではなく、主に実験設計の限界を反映していると指摘した。新研究は、元の実験におけるトークン予算超過、意図的に切り捨てられた出力の誤った評価、そして数学的に解けないパズルインスタンスの包含が、モデル能力の誤判断を共同で引き起こしたと主張する。実験方法を調整し、例えばモデルにハノイの塔の解法を生成する詳細なステップリストではなくコンパクトなLua関数を出力するよう要求した場合、モデルは以前に完全に失敗したと報告されたケースで高い精度を示し、モデルが推論できないのではなく、出力形式とトークン制限によって制約されていることを示唆している (来源: Reddit r/LocalLLaMA)

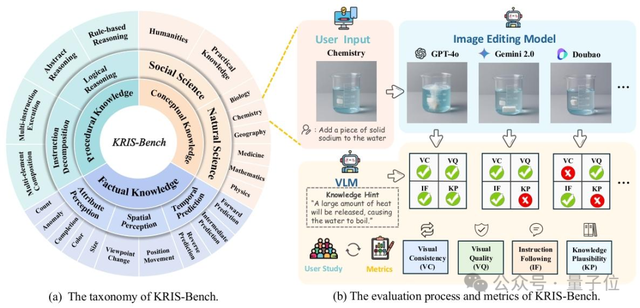
KRIS-Bench:知識タイプの視点から画像編集モデルの推論能力を包括的に評価する新ベンチマーク: 東南大学などの機関が共同でKRIS-Benchを発表。これは知識に基づいた画像編集システムの推論能力ベンチマークである。事実的知識(色、数量など)、概念的知識(物理的常識など)、手続き的知識(多段階操作など)の3つのレベルから、22種類の編集タスクに細分化し、10の主要な画像編集モデル(GPT-Image-1、Gemini 2.0 Flashなどを含む)を評価した。結果として、クローズドソースモデルのGPT-Image-1が最高のパフォーマンスを示したが、すべてのモデルが手続き的推論、自然科学、多段階合成などの深い推論タスクで一般的にパフォーマンスが悪く、現在のモデルの高度な認知能力の不足を明らかにした (来源: 量子位)
新研究がFinetune-RAG手法を提案、RAGにおけるハルシネーションに抵抗するよう言語モデルをファインチューニング: 大規模言語モデルは、検索拡張生成(RAG)において、検索が不完全な場合(例えば、妨害的なドキュメント断片が存在する場合)にハルシネーションを起こしやすい。Finetune-RAGは、正誤のコンテキストを含む入力サンプルでモデルを訓練することにより、モデルがより忠実性を保てるようにする。研究チームは、1600以上のデュアルコンテキストサンプルを含むデータセット、LLaMA 3.1-8B-Instructのファインチューニング済みチェックポイント、およびBench-RAGという名のGPT-4o評価フレームワークを公開した。評価によると、この手法は精度を77%から98%に向上させ、有用性、関連性、深さの面でも改善が見られた (来源: Reddit r/MachineLearning)
TeleMath:初の電気通信分野における数学的問題解決能力LLMベンチマークが公開: 電気通信分野特有の数学的に集約的なタスクを解決する大規模言語モデルの能力を評価するため、研究者らはTeleMathベンチマークを発表した。このベンチマークは、信号処理、ネットワーク最適化、性能分析などの電気通信のトピックをカバーする500の質問応答ペアを含む。複数のオープンソースLLMの評価では、数学または論理的推論用に設計されたモデルがTeleMathでより優れた性能を示した一方、汎用的な大規模パラメータモデルはしばしば困難に直面した。データセットと評価コードは公開されている (来源: HuggingFace Daily Papers)
ChineseHarm-Bench:中国語有害コンテンツ検出ベンチマークが公開: 既存の有害コンテンツ検出リソースの多くが英語である現状に対し、研究者らはChineseHarm-Benchを発表。これは包括的で専門家によるアノテーションが付与された中国語コンテンツの有害性検出ベンチマークである。このベンチマークは6つの代表的なカテゴリをカバーし、データは完全に実世界の事例から収集されている。アノテーションプロセスでは、LLMに明示的な専門知識を提供する知識ルールベースも生成された。さらに、研究者らは、人手によるアノテーションルールとLLMの暗黙的な知識を組み合わせた知識強化ベースライン手法を提案し、小規模モデルがSOTA LLMの性能に到達できるようにした (来源: HuggingFace Daily Papers)
新研究、因果表現学習を通じて言語モデルの潜在能力の階層構造を発見: 言語モデルの能力を忠実に評価し、交絡効果や高い計算コストの課題を克服するため、本研究は因果表現学習フレームワークを提案する。このフレームワークは、観測されたベンチマーク性能を少数の潜在能力因子の線形変換としてモデル化し、基礎モデルを共通の交絡因子として制御した後、これらの潜在因子間の因果関係を特定する。Open LLM Leaderboardの1500以上のモデルデータに適用した結果、研究は簡潔な3ノード線形因果構造を発見し、一般的な問題解決能力から指示追従の熟練度、そして数学的推論能力へと至る明確な因果経路を明らかにした (来源: HuggingFace Daily Papers)
DeepLearning.AIが新コース「GenAIアプリケーションのためのワークフローオーケストレーション」を開始: Andrew Ng氏はAstronomerとの協力により、人気のオープンソースツールAirflow 3.0を使用して信頼性の高い生成AIパイプラインを構築・展開する方法を教える新しい短期コースを発表した。コース内容には、ワークフローを個別のタスクに分解すること、タスクスケジューリング、並列実行、障害回復、可観測性などが含まれ、学習者がプロトタイプのJupyterノートブックやPythonスクリプトを本番環境対応のワークフローに変換するのを支援することを目的としている (来源: DeepLearningAI)
論文、複合AIシステムの最適化手法、課題、将来の方向性を議論: LLMとAIシステムの発展に伴い、複数のコンポーネントを統合した複合AIシステムは、複雑なタスクを実行する上でますます成熟している。本稿は、数値的および言語ベースの技術を含む、複合AIシステム最適化の最新の進展を体系的にレビューする。論文は複合AIシステム最適化の概念を形式化し、既存の手法を分類し、この分野における未解決の研究課題と将来の方向性を強調する (来源: HuggingFace Daily Papers)
💼 ビジネス
ディズニーとユニバーサル・スタジオが画像生成AIのMidjourneyを著作権侵害で提訴: ディズニーとユニバーサル・スタジオは、Midjourneyが許可なく、そのクリエイティブライブラリ(スター・ウォーズ、アナと雪の女王、ミニオンズなどのキャラクターを含む)を利用してモデルを訓練し、大量の派生作品を生成・配布したとして、「底なしの盗作」であると非難した。この訴訟は、AI生成コンテンツと知的財産権の境界に関する議論を再び引き起こしている (来源: Reddit r/ArtificialInteligence)
NVIDIAとドイツテレコムが提携、2026年までに欧州メーカー向け初の産業用AIクラウドを構築: ドイツ連邦首相フリードリヒ・メルツ氏とNVIDIA CEOジェンスン・フアン氏が会談し、ドイツを世界のAIリーダーとしての地位を固めるためのさらなる戦略的協力を議論した。このビジョンの一環として、ドイツテレコムとNVIDIAは新たな提携を発表し、2026年までに欧州メーカー向けに世界初の産業用AIクラウドを構築する計画である。この安全で欧州の規範に準拠したインフラは、最先端のイノベーションをサポートすると同時に、完全なデータ主権を確保する (来源: nvidia)

Sam Altman氏が全株式買収を通じてOpenAIの非営利組織による支配を希薄化する可能性が噂される: 最近のOpenAIによるio(65億ドル)とWindsurf(30億ドル)の全株式による買収が憶測を呼んでいる。Hacker Newsでは、Sam Altman氏がこれらの取引を利用して、非営利団体OpenAI Inc.による営利事業体OpenAI Global LLC(現OpenAI PBC)への支配を徐々に希薄化し、それによって完全な営利企業への転換に関する法的制約を回避する可能性があるという説が浮上している。この動きは一部の人々によってAltman氏の2014年のRedditに対する操作と関連付けられているが、これらの買収は通常のビジネス戦略的措置であるという見方もある (来源: Reddit r/ArtificialInteligence)
🌟 コミュニティ
AIが真に「推論」できるかについての議論が継続、Appleの論文が論争を呼ぶ: Apple社が最近発表した論文で、大規模言語モデル(LLM)は複雑なタスク(ハノイの塔など)において真の推論ではなく、むしろパターンマッチングに近いと主張したことが、コミュニティで広く議論されている。OpenAIの元従業員であるMiles Brundage氏は、o3-proが複雑な言葉遊びを解決したことについてコメントする際、「これが推論でなくて何が推論なのか」と皮肉を込めて問いかけた。その後の研究では、Appleの論文における「推論崩壊」現象は、モデル自体の推論能力の欠如ではなく、実験設計の限界(トークン制限、解決不可能な問題の誤った評価など)によるものである可能性が指摘されている。テスト方法を調整すると、モデルは以前失敗したタスクで良好なパフォーマンスを示し、これはAIの推論能力の評価にはより慎重な実験設計が必要であることを示唆している (来源: o3-pro答高难题文字游戏引围观,OpenAI前员工讽刺苹果:这都不叫推理那什么叫推理, Reddit r/LocalLLaMA)
Nvidia CEOジェンスン・フアン氏とAnthropic CEO Dario Amodei氏、AIの将来に関する見解で著しい相違: Fortune誌の報道によると、Nvidia CEOのジェンスン・フアン氏は、Anthropic CEOのDario Amodei氏のAIに関するほぼ全ての見解に同意しないと述べている。Amodei氏はしばしばAIの潜在的リスクや雇用への大きな影響を強調し、AI開発に対するより厳格な管理と少数の「責任ある」組織による主導を主張している。一方、フアン氏はそのような見解に懐疑的であり、AI技術の広範な応用と発展を推進する傾向がある。コミュニティのコメントでは、フアン氏の立場はNvidiaがAIハードウェアの主要サプライヤーであるという商業的利益に関連している可能性があると指摘されている (来源: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

Claude Codeの月額20ドルのサブスクリプションプランが、コストパフォーマンスの高さで開発者から好評: 多くの開発者がソーシャルメディアで、Anthropic Claude Codeの月額20ドルのサブスクリプションプランの利用体験を共有し、そのコストパフォーマンスが非常に高く、プロジェクトですぐに元が取れると述べている。ユーザーは、一定のレート制限はあるものの、Claude Codeがコーディング支援、新しい言語(C#からSwiftUIへの移行など)の学習、プロジェクトの指示(CLAUDE.mdファイルなど)の最適化において優れたパフォーマンスを発揮し、作業効率を大幅に向上させたと述べている。一部のユーザーは、他のAIプログラミング支援ツールのサブスクリプションをキャンセルすることも検討している (来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
コミュニティ、AIの心理学分野における将来の応用と倫理的課題について議論: LLMが治療プロンプトを作成したり、スマートフォンセンサーで感情を追跡するアプリが登場するなど、AIは徐々に心理学に浸透している。コミュニティの議論は、AIが臨床実践においてセラピストの能力を強化するのか、最終的に一部の業務を代替するのか、評価や研究におけるAIの信頼性、心理学専門職のトレーニングや雇用市場への影響、そして特にデータバイアス、プライバシー、「ロボットセラピスト」の限界といったAI応用の倫理的および規制上の問題に焦点を当てている。中心的な懸念は、AIを利用して効率と個別化サービスを向上させると同時に、患者の安全を保障し、人間関係の治療的価値を維持する方法である (来源: Reddit r/artificial)
Unslothの3.53bit量子化DeepSeek-R1-0528モデルがAider Polyglotコーディングベンチマークで良好な成績: UnslothチームがDeepSeek-R1-0528モデルを3.53bit量子化(UD-Q3_K_XL)した後、Aider Polyglotコーディングベンチマークテストで68%の合格率を達成した。テストでは40960のコンテキストサイズとFlash Attentionを使用し、必要なRAM/VRAMは約300GBだった。この成績はClaude Sonnet 3.7とClaude Opus 4の間に位置し、量子化モデルが高いコーディング能力を維持する可能性を示している。コミュニティメンバーは、このようなモデルをローカルで実行する際のパフォーマンスに感銘を受けており、さらなる量子化バージョンのテスト結果に期待している (来源: Reddit r/LocalLLaMA)
💡 その他
GCPグローバル障害事故報告書が開示:不正なクォータポリシーがサービス中断を引き起こす: Google Cloud Platform (GCP) の最近のグローバル障害事故の報告書によると、原因はグローバルAPI管理システムに誤ったクォータポリシー(例:1時間あたり1リクエストのみに制限)が展開されたことであり、これにより外部リクエストがクォータ超過として拒否された(403エラー)。エンジニアが発見後、影響を受けたAPIのクォータチェックをバイパスした。しかし、us-central1リージョンでは、古いポリシーをクリアして新しいポリシーを書き込もうとした際に、キャッシュの問題によりデータベースが過負荷となり、復旧時間が長引いた。他のリージョンではキャッシュを段階的にクリアする方法で復旧し、全プロセスは約2時間かかった (来源: karminski3)

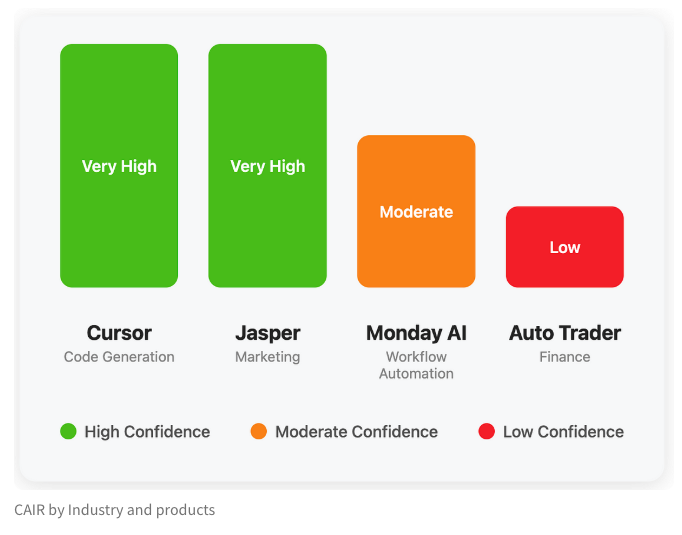
LangChainチームがAI製品の成功ポテンシャルを評価するCAIR指標を提案: LangChainのHarrison Chase氏とAssaf Elovic氏が共同で執筆した記事で、なぜ一部のAI製品が急速に普及する一方で、他の製品は苦戦するのかを考察している。彼らはモデル能力が唯一の決定要因ではなく、ユーザーエクスペリエンス(UX)が極めて重要であるとし、「CAIR」(Confidence in AI Results、AIの結果に対する信頼度)指標を提案した。CAIRが高いほど、製品の採用率が高くなる。このフレームワークは、開発者がユーザーの信頼に影響を与える各構成要素を特定し改善することで、製品の成功率を高めることを支援することを目的としている (来源: hwchase17, swyx, hwchase17, Hacubu)
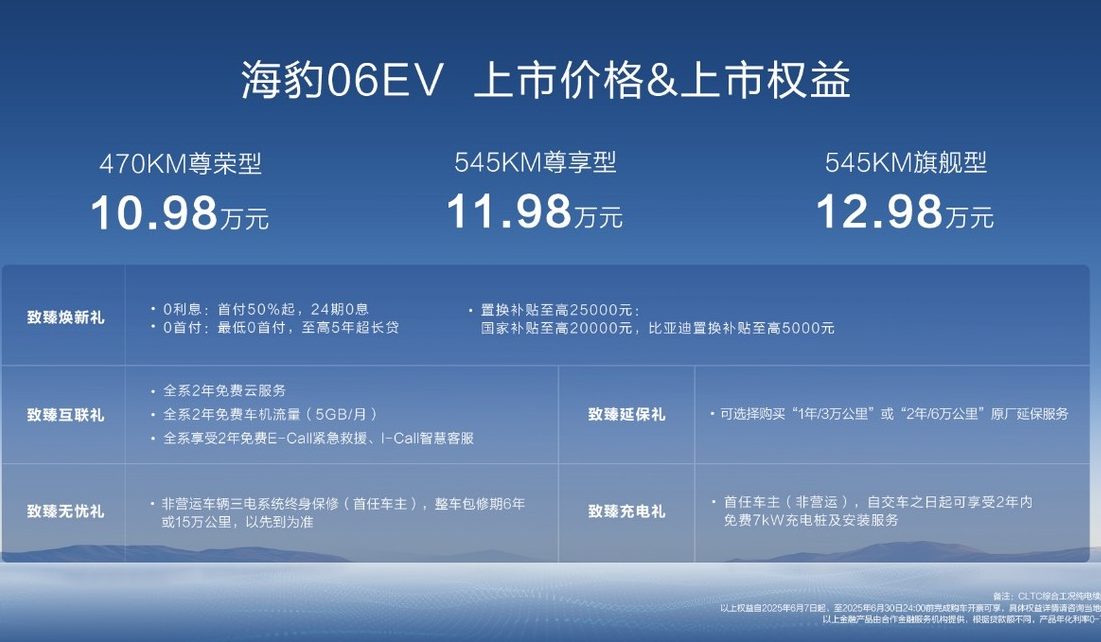
BYDが新型ピュアEVクーペ「海豹06EV」を発表、価格は10.98万元から: BYD海洋網は重慶モーターショーで海豹06EVを発表。トレンディで美しい高品質クーペと位置付けられ、3つの構成があり、価格帯は10.98万~12.98万元。この車はBYD eプラットフォーム3.0 Evoをベースに、8in1インテリジェント電気駆動システムと新世代広温度域高効率ヒートポンプシステムを搭載し、CLTC航続距離470KMと545KMの2種類を提供する。車両は後輪駆動レイアウトを採用し、雲辇-Cインテリジェントダンピングボディコントロールシステムを装備、さらに「天神之眼 C」インテリジェント運転支援3眼バージョンを搭載し、高速道路パイロット、自動駐車などの機能をサポートする (来源: 量子位)