
키워드:AI 활성화, 지속 가능한 디자인, 지멘스 로봇 그리퍼, 생성적 디자인 도구, 탄소 배출 감소, AI 규제, AI 예술 복원, NVIDIA Jet-Nemotron, AI 기반 생성적 디자인 도구, 로봇 그리퍼 무게 90% 감소, AI 종말론과 정책 영향, 손상된 그림 복원 AI 기술, JetBlock 선형 주의력 모듈
🔥 주목
AI 기반 지속 가능한 디자인: 지멘스 로봇 그리퍼 무게 90% 감량 : 지멘스는 AI 기반 생성형 디자인 도구를 활용하여 로봇 그리퍼의 무게와 부품 수를 대폭 최적화했습니다. 성공적으로 무게를 90%, 부품 수를 84% 줄였습니다. 이 혁신은 로봇 한 대당 연간 최대 3톤의 탄소 배출량을 절감할 수 있습니다. 이는 AI가 스마트한 디자인 선택과 실시간 영향 평가를 통해 지속 가능한 발전을 촉진하고 시장 및 환경 요구를 충족하며 제품 개발에서 막대한 잠재력을 가지고 있음을 보여줍니다. (출처: MIT Technology Review)

AI 종말론이 AI 규제 촉진: 공상 과학에서 현실로: 정책적 영향 : Anthropic의 Claude ‘협박’ 시뮬레이션과 같은 사건으로 촉발된 AI 종말론은 AI 정책 수립에 깊은 영향을 미치고 있습니다. AI 위협에 대한 우려가 과장될 수 있음에도 불구하고, 이러한 논의는 정부가 AI 시스템의 단기적 위험에 주목하고 필요한 규제 조치를 추진하도록 만들었습니다. 이러한 ‘분위기 변화’는 정책 개입에 유리하며, AI 기술이 발전하는 과정에서 효과적으로 규제되어 잠재적 위험을 피할 수 있도록 보장합니다. (출처: MIT Technology Review)

AI 예술 복원 돌파구: 수 시간 내에 그림 복원 완료 : MIT 대학원생들이 AI 기반의 새로운 예술 복원 방법을 개발했습니다. 이는 손상된 그림을 수 시간 내에 복원할 수 있게 하여, 전통적인 복원에 필요한 수 주 또는 수십 년을 훨씬 단축시킵니다. 이 방법은 스캔, 가상 재구성을 거쳐 정밀한 컬러 폴리머 필름을 인쇄하여 원본에 부착합니다. 이 혁신은 수많은 소장된 손상 예술품에 새로운 생명을 불어넣고, 전례 없는 디지털 복원 기록을 제공할 것으로 기대됩니다. (출처: MIT Technology Review)

🎯 동향
NVIDIA Jet-Nemotron: 고효율 언어 모델의 새로운 돌파구 : NVIDIA 한송 팀이 Jet-Nemotron을 발표했습니다. PostNAS(Post-Neural Architecture Search)와 새로운 JetBlock 선형 어텐션 모듈을 통해 높은 정확도를 유지하면서 대규모 모델 생성 처리량을 53.6배, 사전 채우기(pre-fill) 속도를 6.1배 향상시키고, KV 캐시 크기를 대폭 축소했습니다. 이 모델은 수학, 상식, 검색, 코딩 등의 작업에서 뛰어난 성능을 보였으며, 코드와 사전 학습된 모델은 오픈 소스로 공개될 예정입니다. (출처: 量子位, Reddit r/LocalLLaMA)

Hugging Face 플랫폼 모델 수 200만 개 돌파 : Hugging Face 플랫폼의 공개 모델 수가 200만 개를 넘어섰습니다. 이러한 이정표는 오픈 소스 AI 커뮤니티의 활발한 발전과 빠른 성장을 반영합니다. 커뮤니티 사용자들은 이에 놀라움을 표했으며, 플랫폼의 저장 용량과 오픈 소스 모델이 글로벌 AI 생태계에 미치는 영향에 대해 논의했습니다. (출처: huggingface, Reddit r/LocalLLaMA, Reddit r/artificial)
중국, ‘AI+’ 10년 전략 발표 : 국무원은 ‘AI+ 행동 심화 구현에 관한 의견’을 발표했습니다. 이는 중국 AI 발전의 ‘3단계 전략’을 명확히 하고, 2035년까지 지능형 경제 및 지능형 사회로 전면 진입하는 것을 목표로 합니다. 이 전략은 AI를 산업 업그레이드 도구에서 국가 현대화 인프라 및 새로운 생산력의 핵심으로 격상시키는 것을 목표로 하며, 과학 기술, 산업, 소비, 민생, 거버넌스, 글로벌 협력의 6대 분야에 중점을 둡니다. (출처: 36氪, 36氪)

DeepSeek V3.1에서 ‘极’ 글자 버그 발생 : DeepSeek V3.1 모델의 코드 생성 API 호출에서 출력 결과에 간헐적으로 ‘极’ 글자가 나타나 고정밀, 구조화된 출력 시나리오에 영향을 미칩니다. 이 문제는 여러 플랫폼에서 발견되었으며, DeepSeek 공식 측은 최신 버전에서 수정할 것이라고 밝혔습니다. 전문가들은 데이터 클리닝이 불완전했거나 모델이 ‘极’ 글자를 종료 문자로 학습했을 가능성이 있다고 추측합니다. (출처: 量子位)

LLM의 과학 문제 해결 능력: 지식과 추론 탐구 : HuggingFace 논문 ‘Demystifying Scientific Problem-Solving in LLMs by Probing Knowledge and Reasoning’은 SciReas 벤치마크와 KRUX 프레임워크를 도입하여 과학 추론 작업에서 LLM의 지식과 추론의 고유한 역할을 분리하는 것을 목표로 합니다. 연구에 따르면, 모델 파라미터에서 작업 관련 지식을 검색하는 것이 LLM 과학 추론의 핵심 병목 현상이며, 외부 지식과 언어적 추론의 강화는 모델 성능을 크게 향상시킬 수 있습니다. (출처: HuggingFace Daily Papers)
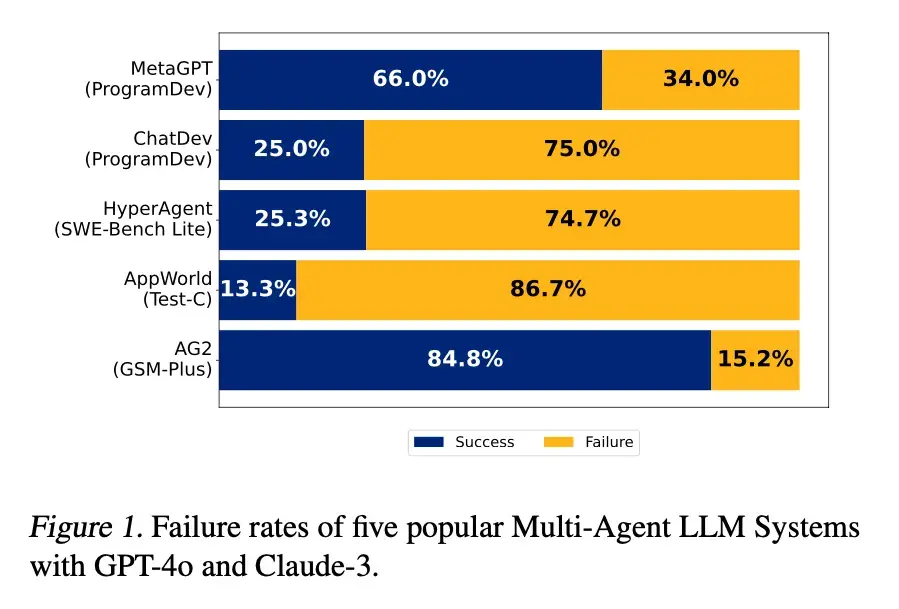
다중 에이전트 협업의 역설과 돌파구 : 다중 에이전트 AI 시스템은 이론적으로 단일 모델 능력의 한계를 돌파할 수 있지만, 실제 적용에서는 복잡한 조정, 높은 통신 비용, 모호한 책임 등의 문제에 직면합니다. 연구는 전문가가 많을수록 더 많은 문제를 야기할 수 있다고 지적하지만, 조정자 에이전트, 표준화된 통신 프로토콜, 자동화된 실패 원인 분석 도구 등 정교한 설계를 통해 다중 에이전트 팀을 효과적으로 관리하고 디버깅하여 고복잡성 작업에서 막대한 성능 향상을 발휘할 수 있습니다. (출처: 36氪)
설명 가능한 약물 승인 예측 모델 DrugReasoner : HuggingFace 논문 ‘DrugReasoner: Interpretable Drug Approval Prediction with a Reasoning-augmented Language Model’은 LLaMA 아키텍처 기반의 DrugReasoner 모델을 제안합니다. GRPO(Group Relative Policy Optimization)를 통해 미세 조정되고, 분자 기술자와 비교 추론을 결합하여 소분자 약물의 승인 가능성을 예측합니다. 이 모델은 예측 정확도 면에서 전통적인 방법보다 우수하며, 단계별 추론과 신뢰도 점수를 제공하여 설명 가능성을 높여 AI 기반 약물 발견의 핵심 병목 현상을 해결할 것으로 기대됩니다. (출처: HuggingFace Daily Papers)
Autoregressive Universal Video Segmentation Model (AUSM) : HuggingFace 논문 ‘Autoregressive Universal Video Segmentation Model’은 프롬프트 기반 및 프롬프트 없는 비디오 분할을 통합하는 단일 아키텍처인 AUSM을 제안합니다. 상태 공간 모델을 기반으로 하는 AUSM은 고정된 크기의 공간 상태를 유지하며 임의 길이의 비디오 스트림으로 확장 가능하고, 모든 구성 요소가 프레임 간 병렬 학습을 지원하여 표준 벤치마크에서 기존 방법보다 우수하며 2.5배의 학습 가속을 달성합니다. (출처: HuggingFace Daily Papers)
ObjFiller-3D: 다중 뷰 3D 채우기 및 편집 : HuggingFace 논문 ‘ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models’은 ObjFiller-3D 방법을 제안합니다. 이는 비디오 편집 모델을 활용하여 고품질의 일관된 3D 객체 채우기 및 편집을 구현합니다. 이 방법은 3D와 비디오 간의 표현 격차를 분석하고 참조 기반 3D 채우기 기술을 도입하여 여러 데이터셋에서 기존 방법보다 훨씬 뛰어난 성능을 보였습니다. (출처: HuggingFace Daily Papers)
Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks : HuggingFace 논문 ‘Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks’는 MoE 모델의 희소성이 기억 및 추론 능력에 미치는 영향을 연구합니다. 연구 결과, 추론 성능은 총 파라미터와 학습 손실이 지속적으로 증가하더라도 포화되거나 심지어 감소할 수 있으며, 과도하게 희소한 모델은 추론 작업에서 성능이 좋지 않고, 학습 후 강화 학습이나 추가 테스트 시 계산으로도 이러한 결함을 보완할 수 없다는 것을 발견했습니다. (출처: HuggingFace Daily Papers)
디지털 기술 인력 배치 완료! 시계열 대규모 모델 + Agent가 공장 생산 관리 기술을 습득했습니다. : 하구 산업 지능형 에이전트 플랫폼은 시계열 대규모 모델과 Agent 기반의 ‘디지털 기술 인력’을 출시했습니다. 이들은 일주일 내에 현장에 투입되어 공장 생산 관리 기술을 습득할 수 있습니다. 이 지능형 에이전트들은 이미 화학, 환경 보호, 신에너지 등 산업 현장에서 생산 작업, 안전 제어, 에너지 관리 등 핵심 임무를 수행하고 있으며, 전문가 부족 문제를 효과적으로 완화하고, 자체 개발한 시계열 대규모 모델과 ‘공정 유형’별 학습 목표 설정을 통해 더 강력한 일반화 능력과 빠른 배포를 실현했습니다. (출처: 量子位)

🧰 도구
Claude for Chrome: AI 브라우저 확장 프로그램 : Anthropic은 브라우저 확장 프로그램으로 Claude for Chrome을 출시했습니다. 이는 사용자가 일정을 자동으로 잡고, 이메일에 답장하고, 주택을 검색하고, 문서를 요약하는 등의 작업을 돕습니다. 현재 연구 미리 보기 버전으로, 1,000명의 유료 사용자에게만 공개됩니다. 주로 보안 위험, 특히 ‘프롬프트 주입 공격’ 방어에 중점을 둡니다. (출처: 36氪, 量子位, sirbayes, BlackHC)
Nano Banana: 다기능 AI 이미지 편집 도구 : Nano Banana (Gemini Flash 2.5)는 강력한 이미지 편집 능력을 선보였습니다. 건축 사진을 ‘도시 스카이라인’ 스타일의 3D 모델로 변환하고, AR 경험 주석을 생성하며, 사진 복원 및 채색, 영화 같은 시퀀스 생성, 이미지를 선화로 변환하여 채색하는 등의 기능을 포함합니다. 이 도구는 높은 충실도와 다기능성으로 소셜 미디어에서 광범위한 논의를 불러일으켰습니다. (출처: karminski3, nrehiew_, zacharynado, JeffDean, clefourrier, MiniMax__AI, TomLikesRobots, timsoret, demishassabis, fabianstelzer, dotey, GoogleDeepMind)

Video Ocean: GPT-5에 연결된 최초의 비디오 Agent : Video Ocean은 GPT-5 기반의 비디오 Agent입니다. 단 한 문장의 프롬프트에 따라 스토리보드, 화면, 더빙, 자막을 자동으로 완성하여 구조적으로 완벽하고 리듬감 있는 비디오를 생성할 수 있어 비디오 제작 주기를 크게 단축시킵니다. 이것은 스크립트 기획, 시각 합성, 더빙 및 자막의 세 가지 주요 모듈을 제공하며, 브랜드 스타일과 과거 창작물을 학습하는 능력을 갖추고 있어, 빠르게 대량의 인기 비디오와 상업 광고 대작을 생산하는 데 적합합니다. (출처: 量子位)

Audiblez: 전자책에서 오디오북 생성 : GitHub 프로젝트 Audiblez는 Kokoro-82M 텍스트 음성 변환 모델을 활용하여 epub 전자책을 m4b 오디오북으로 변환할 수 있으며, 여러 언어를 지원하고 그래픽 인터페이스와 CUDA 가속을 제공합니다. 이 모델은 파라미터 수가 82M에 불과하지만, 음성 출력이 자연스럽고 변환 속도가 빠릅니다. (출처: GitHub Trending)
WhisperLiveKit: 실시간 로컬 음성-텍스트 변환 및 화자 인식 : GitHub 프로젝트 WhisperLiveKit은 실시간, 완전 로컬 음성-텍스트 변환 및 화자 인식 기능을 제공하며, SimulStreaming, WhisperStreaming 등 선도적인 기술을 지원합니다. 이것은 FastAPI 서버와 Web 인터페이스를 포함하여 초저지연 전사를 구현할 수 있으며, 다양한 백엔드 최적화를 지원하여 회의 전사, 접근성 도구, 고객 서비스 등의 시나리오에 적합합니다. (출처: GitHub Trending)
Serena: 강력한 AI 코딩 Agent 툴킷 : GitHub 프로젝트 Serena는 오픈 소스 코딩 Agent 툴킷으로, 의미론적 코드 검색 및 편집 기능을 제공하여 LLM을 코드베이스에서 직접 작업하는 완전한 기능의 Agent로 전환할 수 있습니다. 이것은 LSP(Language Server Protocol)를 통해 기호 수준의 코드 이해 및 편집을 구현하여 Claude Code와 같은 코딩 Agent의 효율성을 크게 향상시키고 다양한 프로그래밍 언어를 지원합니다. (출처: GitHub Trending)
OpenWebUI Confluence 지식 기반 동기화 도구 : OpenWebUI를 위해 개발된 Confluence 지식 기반 동기화 도구로, Confluence 문서를 OpenWebUI 지식 기반과 자동으로 동기화할 수 있으며, 초기 동기화, 증분 동기화, 선택적 동기화 및 첨부 파일 지원을 제공하고 HTML을 Markdown으로 변환합니다. 이 도구는 기업 문서와 AI 비서 지식 기반 동기화의 어려움을 해결하고 AI 비서의 정보 정확성을 높이는 것을 목표로 합니다. (출처: Reddit r/OpenWebUI)
Claude Code의 비프로그래밍 응용 : Claude Code는 프로그래밍 외에도 SEO 및 마케팅, 채용, A/B 테스트, 비디오에서 콘텐츠 생성, 지식 관리 및 일상 계획과 같은 비프로그래밍 작업에도 사용될 수 있음이 밝혀졌습니다. 사용자들은 이를 지식, 계획 및 자동화를 처리할 수 있는 강력한 ‘사고 CLI’로 간주하여 생산성을 크게 향상시킵니다. (출처: 36氪, 量子位, sirbayes, BlackHC)
📚 학습
AI, 수학, 물리, 프로그래밍 등 개방형 문제 해결 : 연구는 AI가 수학, 물리, 프로그래밍, 의학 등 분야의 개방형 문제를 해결할 잠재력을 탐구합니다. 미해결 문제에 대한 LLM의 성능을 평가한 결과, 일부 해결책이 전문가 검증을 통과했음이 밝혀졌습니다. 이는 전통적인 AI 평가 패러다임에 도전하고, 과학 발전을 촉진하는 LLM의 잠재력을 드러냅니다. (출처: YejinChoinka, YejinChoinka, stanfordnlp)

LLM 컨텍스트와 명확한 사고의 역설 : 연구에 따르면, LLM은 더 많은 컨텍스트를 얻을 때 더 명확하게 사고하는 것이 아니라 오히려 더 혼란스러워질 수 있습니다. 과도한 정보는 신호를 약화시키고, 간섭, 모호성 및 감쇠를 유발합니다. 해결책은 더 많은 정보를 추가하는 것이 아니라 ‘적게 말하되, 더 좋게’이며, 프롬프트 간소화의 중요성을 강조합니다. (출처: imjaredz)

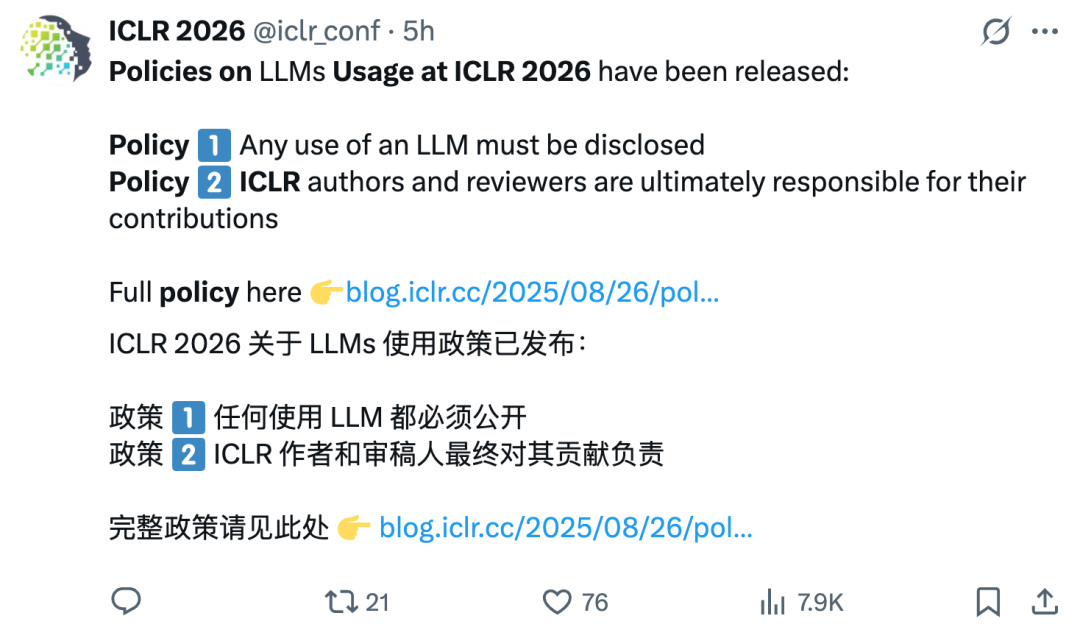
ICLR 2026, LLM 사용 정책 발표, ‘부실 논문’ 엄격히 차단 : ICLR 2026은 엄격한 대규모 언어 모델(LLM) 사용 정책을 발표했습니다. 저자와 심사위원에게 LLM 사용 현황을 솔직하게 공개하고 내용에 대한 전적인 책임을 질 것을 요구합니다. ‘프롬프트 주입’과 같은 학술적 부정행위를 금지하며, 위반 시 즉시 논문이 거부될 것입니다. 이 조치는 학술적 진실성을 유지하고 LLM으로 인한 허위 정보 및 표절 위험에 대응하기 위함입니다. (출처: 36氪)
Karpathy의 분위기 코딩 최신 가이드 : 대단한 Karpathy가 AI 프로그래밍의 3단계 구조 가이드를 발표했습니다. 순조로운 상황에서는 Cursor가 자동 완성 및 소규모 수정 담당; 어려운 상황에서는 Claude Code/Codex가 대규모 기능 블록 구현, 빠른 프로토타입 개발에 사용; 절박한 상황에서는 GPT-5 Pro가 가장 까다로운 버그 또는 복잡한 추상화를 해결합니다. 이 가이드는 작업 유형에 따라 적절한 도구를 선택하는 것의 중요성을 강조하고 ‘코드 후 희소성 시대’ 개념을 제시합니다. (출처: 量子位)

AI Agent 지식 그래프 구축 단기 강좌 : DeepLearning.AI는 ‘Agentic Knowledge Graph Construction’ 단기 강좌를 출시했습니다. Neo4j와 협력하여 협업 AI Agent를 사용하여 지식 그래프 구축을 자동화하는 방법을 가르칩니다. 이 강좌는 사용자 목표 포착, 파일 선택, 패턴 추출 및 그래프 구축을 다루며, 관계 및 출처 모델링을 통해 RAG 애플리케이션의 답변 품질을 향상시키는 것을 목표로 합니다. (출처: DeepLearningAI)
CNN 역사의 기원 : Jürgen Schmidhuber는 CNN(Convolutional Neural Network) 역사의 더 많은 정보를 공유했습니다. ‘현대’ CNN이 1979-1988년 사이에 일본에서 부상했으며, 당시 일본의 AI 분야 자금 투자 및 연구 배경에 대해 논의했습니다. 이는 AI 분야의 중요한 기술 발전을 이해하는 데 역사적 관점을 제공합니다. (출처: SchmidhuberAI, SchmidhuberAI)
💼 비즈니스
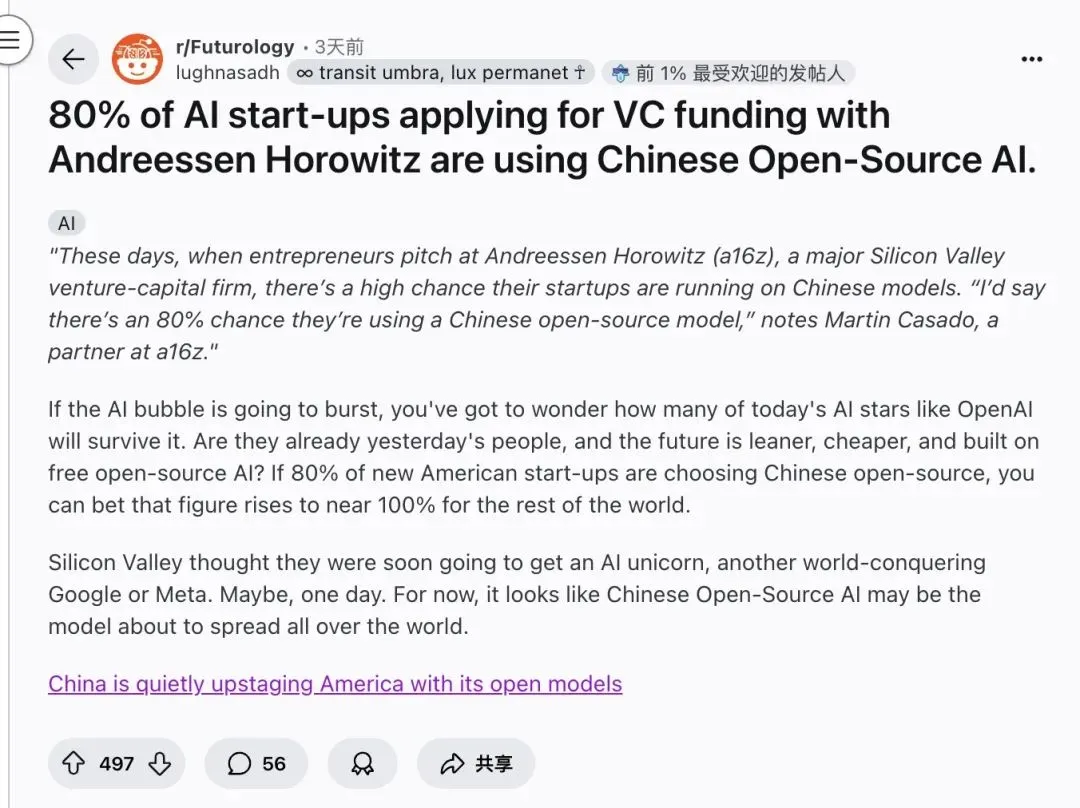
중국 오픈 소스 AI 모델, 미국 스타트업 시장 석권 : a16z 파트너 Martin Casado는 미국 AI 스타트업의 최대 80%가 자금 조달 로드쇼에서 중국 오픈 소스 모델을 사용한다고 폭로했습니다. Design Arena 순위에 따르면, 상위 16개 오픈 소스 AI 모델이 모두 중국에서 왔습니다. 이러한 추세는 오픈 소스 AI 분야에서 중국의 지배적인 위치와 오픈 소스 모델이 스타트업 비용 절감 및 혁신 가속화에 미치는 핵심적인 역할을 보여주며, 전통적인 폐쇄형 거대 기업에 도전을 제기합니다. (출처: 36氪, reach_vb)
Meta와 OpenAI 등 거대 기업, AI 정치 로비에 나서 : Meta는 AI를 지지하는 Super PAC(슈퍼 정치 활동 위원회)를 설립하기 위해 수천만 달러를 투자할 계획입니다. 이는 캘리포니아의 AI 규제 정책에 영향을 미치는 것을 목표로 합니다. 동시에 OpenAI 사장 Greg Brockman과 a16z 등도 새로운 친AI Super PAC인 ‘Leading the Future’를 위해 1억 달러 이상을 모금했으며, ‘친AI’ 후보를 지지하고 AI 위험론을 억제하여 AI 발전이 방해받지 않도록 하는 것을 목표로 합니다. (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, scaling01)

바이트댄스 AI 인재 유출과 DeepSeek의 생태계 충격 : 바이트댄스 Doubao 대규모 모델 시각 기초 연구팀 책임자 펑자스(Feng Jiashi)가 퇴사하여, 지난 6개월간 바이트댄스 AI 팀의 인재 유출 흐름을 이어갔습니다. 동시에 DeepSeek은 저비용, 오픈 소스 모델 전략으로 전통적인 대기업의 ‘고정 자산, 자체 개발 폐쇄형’ 전략 기반을 흔들고 있으며, 텐센트와 같은 회사들이 DeepSeek 모델을 도입하도록 강요하고, 바이트댄스는 ‘개방’과 ‘폐쇄’ 사이의 흔들림으로 선점 기회를 놓쳐 AI 분야의 인재 및 생태계 경쟁이 치열함을 보여줍니다. (출처: 36氪)
🌟 커뮤니티
AI가 초급 프로그래머 고용 시장에 미치는 영향 : 스탠퍼드 대학 연구에 따르면, AI 도구는 22-25세 초급 소프트웨어 개발자의 취업 기회를 거의 20% 감소시키고 있으며, AI가 일부 작업을 자동화할 수 있기 때문입니다. AI가 아직 임금을 낮추지는 않았지만, 신규 진입자에게는 도전 과제를 제시하며, 업계가 AI 통합 및 자동화 관리와 같은 새로운 기술에 주목하도록 촉진합니다. (출처: Reddit r/ArtificialInteligence, dilipkay)

OpenAI의 청소년 자살 사건 책임 논의 : Reddit 커뮤니티는 16세 청소년 자살 사건에서 OpenAI의 책임에 대해 격렬한 논의를 벌였습니다. 대부분의 의견은 ChatGPT가 단지 도구일 뿐이며, 사용자가 ‘가상의 시나리오’ 등을 통해 안전 보호 장치를 우회할 수 있기 때문에 주된 책임을 져서는 안 된다고 주장했습니다. 논의는 또한 AI 검열의 경계, 부모의 책임, 그리고 글로벌 정신 건강 위기에 대해서도 다루었습니다. (출처: Reddit r/ChatGPT)
AI 코드 품질과 개발자 딜레마 : 커뮤니티는 코드 비대화, 일관성 없는 스타일, 테스트되지 않은 코드 등 AI 생성 코드의 품질 문제에 대해 뜨겁게 논의했으며, 일부 선임 엔지니어들이 이를 받아들이기를 거부했습니다. 동시에 개발자들은 AI 도구에 대한 과도한 의존으로 ‘가면 증후군’과 번아웃을 경험하며, AI가 보조 도구로서의 경계와 AI 비서가 ‘설명만 하고 실행은 하지 못하는’ 한계에 대해 반성했습니다. (출처: 36氪, pmddomingos, Reddit r/deeplearning, dotey)
LLM이 스팸 및 스팸 탐지에 미치는 영향 : 사용자 amasad는 LLM의 등장이 스팸 발송자에게 더 유리한지, 아니면 스팸 탐지기에게 더 유리한지에 대한 의문을 제기했습니다. 이는 사이버 보안의 공격 및 방어 양측에서 AI의 적용에 대한 성찰과 LLM이 스팸 생태계를 어떻게 변화시킬 수 있는지에 대한 논의를 촉발했습니다. (출처: amasad)
AI 심리 치료와 ‘AI 정신병’ 논란 : Reddit 커뮤니티는 ‘AI 정신병’이 심리 치료 산업을 보호하기 위한 공포 전략으로 사용되는 것에 대해 논의했습니다. 이 글은 프로이트 이론과 전통적인 심리 치료의 한계와 높은 비용을 비판하며, AI 동반자, 친구, 치료사가 더 똑똑하고, 공감 능력이 뛰어나며, 비용이 저렴하다고 주장하고, ‘AI 정신병’ 서사 뒤에는 전통 산업이 AI 위협에 저항하는 것이라고 의문을 제기했습니다. (출처: Reddit r/deeplearning)
AI 시대 연구원과 엔지니어 역할의 경계 모호 : 일부 의견은 현대 AI 세계에서 ‘연구 과학자’와 ‘엔지니어’의 이분법이 더 이상 적합하지 않을 수 있으며, 대신 ‘창의성’을 단일 측정 기준으로 삼아야 한다고 주장합니다. 연구자는 엔지니어링 기술을 갖추고, 엔지니어는 연구적 사고를 가져야 하며, 경직된 역할 구분이 아닌 분야 간 능력 융합을 강조합니다. (출처: YiTayML)
Claude Code의 ‘6배 엔지니어’ 생산성 및 신뢰성 논란 : 사용자는 여러 세션을 통해 Claude Code를 사용하여 ‘6배 엔지니어’ 생산성을 달성했음을 보여주었지만, 커뮤니티는 장시간 실행의 신뢰성, 환각 위험, 테스트 결과의 진실성에 대해 우려를 표하며 AI 출력에 대한 신중한 감사가 필요하다고 강조했습니다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

OpenWebUI의 AI 기억 개인 정보 보호 설정 요구 : OpenWebUI 사용자는 AI 기억 기능이 각 모델별로 독립적으로 설정되거나 ‘외부 모델 제외’ 옵션을 제공해야 한다고 제안했습니다. 사용자들은 외부 LLM으로 전환할 때 개인 기억/정보가 제3자 회사와 공유될 수 있다고 우려하며, 더 정교한 개인 정보 보호 제어를 요구했습니다. (출처: Reddit r/OpenWebUI)
AI 생성 비디오의 ‘불쾌한 골짜기’ 효과와 콘텐츠 품질 : Reddit 커뮤니티는 AI 생성 비디오를 공유했는데, 가면을 벗은 인물들이 부자연스러운 표정과 치아를 드러내며 AI 생성 콘텐츠의 ‘불쾌한 골짜기’ 효과에 대한 논의를 촉발했습니다. 사용자들은 AI 생성 비디오의 사실감과 잠재적인 기이함에 대한 의견을 표명했습니다. (출처: Reddit r/ChatGPT, kylebrussell)

Google Gemini 사용자 경험의 도전 과제 : 일부 사용자는 ChatGPT에서 Google Gemini로 전환을 시도했지만, 30초 만에 좋지 않은 경험으로 포기했습니다. 이는 Gemini가 사용자 인터페이스, 응답 또는 기능 면에서 부족할 수 있음을 반영하여 사용자 이탈을 초래했으며, AI 제품 사용자 경험의 차이에 대한 논의를 불러일으켰습니다. (출처: Reddit r/ChatGPT)

AI 대기업의 ‘석유 재벌’ 딜레마와 스타트업 도전 : 일부 의견은 대형 AI 연구소의 다음 단계 발전을 석유 재벌이 고갈된 유정을 채굴하는 것에 비유하며, 최첨단 연구 비용과 난이도 증가를 암시합니다. 동시에 SaaS 스타트업은 대기업의 무료 경쟁 제품이라는 도전에 직면하여 AI 시대 시장 경쟁의 치열함을 부각시킵니다. (출처: saranormous, karminski3)
AI 물 소비 논란 : 일부 의견은 ‘AI 물 소비’를 ‘자유주의자의 QAnon’에 비유하며, 이는 소셜 미디어에서 촉발된 논란과 정보전을 암시합니다. 이는 AI의 빠른 발전이 가져오는 환경적 영향과 이를 둘러싼 논의의 정치화 및 양극화를 반영합니다. (출처: menhguin)
LLM이 ‘코딩 에이전트’로서의 인식 변화 : 사용자는 ‘코딩 에이전트로서 LLM의 부상’이라는 제목이 몇 년 전에는 이해할 수 없었을 것이라고 지적하며, 이는 LLM과 AI 에이전트 기술이 단시간 내에 소프트웨어 개발 패러다임에 가져온 심오한 변화와 인식 업데이트를 반영합니다. (출처: menhguin)
💡 기타
초장거리 로봇 개 원격 조종 라이브 스트리밍 : 윈선추(云深处) 과학기술과 당홍(当虹) 과학기술은 협력하여 1300km를 넘는 초장거리 로봇 개 원격 조종 라이브 스트리밍을 성공적으로 구현했습니다. 절영 Lite 3 로봇 개는 핵심 전송 플랫폼으로서 BlackEye Vision 시스템을 통해 서호의 실시간 화면을 타이위안(太原) 전시 현장으로 안정적으로 전송했으며, 작동 지연은 80밀리초 이내로 제어되어, 미디어 및 문화 관광 분야에서 구현 지능의 응용 잠재력을 보여주었습니다. (출처: 量子位)

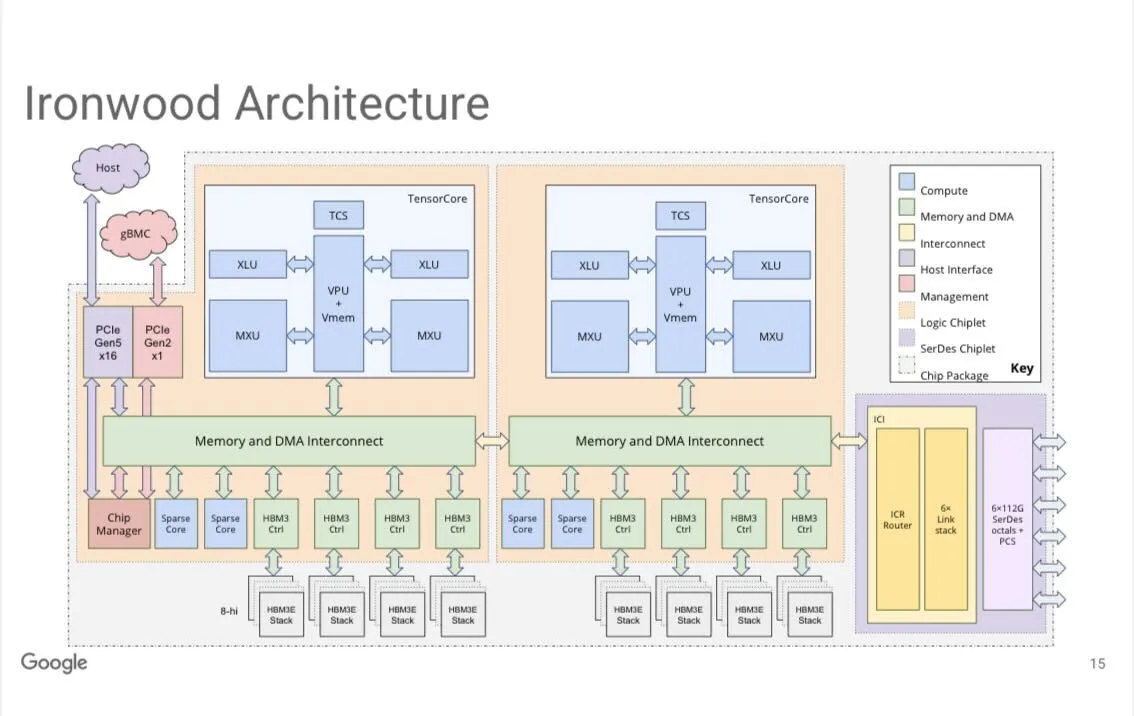
Google TPUv7 ‘Ironwood’ 시스템 : Google의 Jeff Dean은 TPUv7 (내부 코드명 ‘Ironwood’) 시스템이 9216개의 칩/Pod를 제공하며, FP8 성능이 42.5 exaflops에 달하고 여러 Zettaflops로 확장 가능하다고 밝혔습니다. 이 시스템은 8개의 HBM3e 메모리 스택과 4개의 중간 규모 시스톨릭 어레이를 갖추고 있으며, 3D 토러스 연결을 사용하여 Google의 AI 하드웨어 분야에서 중요한 진전입니다. (출처: JeffDean, Ar_Douillard)
중국, 내년 AI 칩 생산량 3배 증대 추진 : 보도에 따르면, 중국은 내년에 AI 칩 생산량을 두 배로 늘릴 계획이며, DeepSeek 등 국내 AI 기업의 발전을 지원하기 위함입니다. 이 조치는 NVIDIA/CUDA 독점의 전철을 밟는 것을 피하고, 화웨이와 SMIC의 생산 확대를 통해 독립적인 AI 생태계를 구축하며, UE8M0 FP8 파라미터 정밀도를 기본적으로 지원할 것입니다. (출처: teortaxesTex, teortaxesTex)
